":
- question = st.text_input("Enter your question here:", "")
-else:
- question = question_s
-
-if st.button("Show me!"):
- if action in [0, 1, 3]:
- if index_type == "mixed":
- _, support_list_dense = make_support(question, source=wiki_source, method="dense", n_results=10)
- _, support_list_sparse = make_support(question, source=wiki_source, method="sparse", n_results=10)
- support_list = []
- for res_d, res_s in zip(support_list_dense, support_list_sparse):
- if tuple(res_d) not in support_list:
- support_list += [tuple(res_d)]
- if tuple(res_s) not in support_list:
- support_list += [tuple(res_s)]
- support_list = support_list[:10]
- question_doc = " " + "
".join([res[-1] for res in support_list])
- else:
- question_doc, support_list = make_support(question, source=wiki_source, method=index_type, n_results=10)
- if action in [0, 3]:
- answer, support_list = answer_question(
- question_doc,
- s2s_model,
- s2s_tokenizer,
- min_len=min_len,
- max_len=int(max_len),
- sampling=(sampled == "sampled"),
- n_beams=n_beams,
- top_p=top_p,
- temp=temp,
- )
- st.markdown("### The model generated answer is:")
- st.write(answer)
- if action in [0, 1, 3] and wiki_source != "none":
- st.markdown("--- \n ### The model is drawing information from the following Wikipedia passages:")
- for i, res in enumerate(support_list):
- wiki_url = "https://en.wikipedia.org/wiki/{}".format(res[0].replace(" ", "_"))
- sec_titles = res[1].strip()
- if sec_titles == "":
- sections = "[{}]({})".format(res[0], wiki_url)
- else:
- sec_list = sec_titles.split(" & ")
- sections = " & ".join(
- ["[{}]({}#{})".format(sec.strip(), wiki_url, sec.strip().replace(" ", "_")) for sec in sec_list]
- )
- st.markdown(
- "{0:02d} - **Article**: {1:<18}
_Section_: {2}".format(i + 1, res[0], sections),
- unsafe_allow_html=True,
- )
- if show_passages:
- st.write(
- '> ' + res[-1] + "", unsafe_allow_html=True
- )
- if action in [2, 3]:
- nn_train_list = find_nearest_training(question)
- train_exple = nn_train_list[0]
- st.markdown(
- "--- \n ### The most similar question in the ELI5 training set was: \n\n {}".format(train_exple["title"])
- )
- answers_st = [
- "{}. {}".format(i + 1, " \n".join([line.strip() for line in ans.split("\n") if line.strip() != ""]))
- for i, (ans, sc) in enumerate(zip(train_exple["answers"]["text"], train_exple["answers"]["score"]))
- if i == 0 or sc > 2
- ]
- st.markdown("##### Its answers were: \n\n {}".format("\n".join(answers_st)))
-
-
-disclaimer = """
----
-
-**Disclaimer**
-
-*The intent of this app is to provide some (hopefully entertaining) insights into the behavior of a current LFQA system.
-Evaluating biases of such a model and ensuring factual generations are still very much open research problems.
-Therefore, until some significant progress is achieved, we caution against using the generated answers for practical purposes.*
-"""
-st.sidebar.markdown(disclaimer, unsafe_allow_html=True)
diff --git a/examples/research_projects/longform-qa/eli5_utils.py b/examples/research_projects/longform-qa/eli5_utils.py
deleted file mode 100644
index d4b235fdbaa..00000000000
--- a/examples/research_projects/longform-qa/eli5_utils.py
+++ /dev/null
@@ -1,688 +0,0 @@
-import functools
-import math
-import os # noqa: F401
-from random import choice, randint
-from time import time
-
-import datasets # noqa: F401
-import faiss # noqa: F401
-import numpy as np
-import pandas as pd
-import torch
-import torch.utils.checkpoint as checkpoint
-from elasticsearch import Elasticsearch # noqa: F401
-from elasticsearch.helpers import bulk, streaming_bulk # noqa: F401
-from torch import nn
-from torch.utils.data import DataLoader, Dataset, RandomSampler, SequentialSampler
-from tqdm import tqdm
-
-from transformers import AdamW, AutoModel, AutoModelForSeq2SeqLM, AutoTokenizer, get_linear_schedule_with_warmup
-
-
-pd.set_option("display.max_colwidth", None)
-
-
-###############
-# Sparse index
-###############
-def make_es_index_snippets(es_client, passages_dset, index_name="english_wiki_kilt_snippets_100w"):
- index_config = {
- "settings": {
- "number_of_shards": 1,
- "analysis": {"analyzer": {"stop_standard": {"type": "standard", " stopwords": "_english_"}}},
- },
- "mappings": {
- "properties": {
- "article_title": {"type": "text", "analyzer": "standard", "similarity": "BM25"},
- "section_title": {"type": "text", "analyzer": "standard", "similarity": "BM25"},
- "passage_text": {"type": "text", "analyzer": "standard", "similarity": "BM25"},
- }
- },
- }
- es_client.indices.create(index=index_name, body=index_config)
- number_of_docs = passages_dset.num_rows
- progress = tqdm(unit="docs", total=number_of_docs)
- successes = 0
-
- def passage_generator():
- for passage in passages_dset:
- yield passage
-
- # create the ES index
- for ok, action in streaming_bulk(
- client=es_client,
- index=index_name,
- actions=passage_generator(),
- ):
- progress.update(1)
- successes += ok
- print("Indexed %d documents" % (successes,))
-
-
-def query_es_index(question, es_client, index_name="english_wiki_kilt_snippets_100w", n_results=10, min_length=20):
- q = question.lower()
- banned = ["how", "why", "what", "where", "which", "do", "does", "is", "?", "eli5", "eli5:"]
- q = " ".join([w for w in q.split() if w not in banned])
- response = es_client.search(
- index=index_name,
- body={
- "query": {
- "multi_match": {
- "query": q,
- "fields": ["article_title", "section_title", "passage_text^2"],
- "type": "cross_fields",
- }
- },
- "size": 2 * n_results,
- },
- )
- hits = response["hits"]["hits"]
- support_doc = "
" + "
".join([hit["_source"]["passage_text"] for hit in hits])
- res_list = [{k: hit["_source"][k] for k in hit["_source"] if k != "passage_text"} for hit in hits]
- for r, hit in zip(res_list, hits):
- r["passage_id"] = hit["_id"]
- r["score"] = hit["_score"]
- r["passage_text"] = hit["_source"]["passage_text"]
- res_list = [res for res in res_list if len(res["passage_text"].split()) > min_length][:n_results]
- return support_doc, res_list
-
-
-###############
-# ELI5 retriever training
-###############
-class ELI5DatasetQARetriver(Dataset):
- def __init__(self, examples_array, extra_answer_threshold=3, min_answer_length=64, training=True, n_samples=None):
- self.data = examples_array
- self.answer_thres = extra_answer_threshold
- self.min_length = min_answer_length
- self.training = training
- self.n_samples = self.data.num_rows if n_samples is None else n_samples
-
- def __len__(self):
- return self.n_samples
-
- def make_example(self, idx):
- example = self.data[idx]
- question = example["title"]
- if self.training:
- answers = [a for i, (a, sc) in enumerate(zip(example["answers"]["text"], example["answers"]["score"]))]
- answer_tab = choice(answers).split(" ")
- start_idx = randint(0, max(0, len(answer_tab) - self.min_length))
- answer_span = " ".join(answer_tab[start_idx:])
- else:
- answer_span = example["answers"]["text"][0]
- return (question, answer_span)
-
- def __getitem__(self, idx):
- return self.make_example(idx % self.data.num_rows)
-
-
-class RetrievalQAEmbedder(nn.Module):
- def __init__(self, sent_encoder, dim):
- super(RetrievalQAEmbedder, self).__init__()
- self.sent_encoder = sent_encoder
- self.output_dim = 128
- self.project_q = nn.Linear(dim, self.output_dim, bias=False)
- self.project_a = nn.Linear(dim, self.output_dim, bias=False)
- self.ce_loss = nn.CrossEntropyLoss(reduction="mean")
-
- def embed_sentences_checkpointed(self, input_ids, attention_mask, checkpoint_batch_size=-1):
- # reproduces BERT forward pass with checkpointing
- if checkpoint_batch_size < 0 or input_ids.shape[0] < checkpoint_batch_size:
- return self.sent_encoder(input_ids, attention_mask=attention_mask)[1]
- else:
- # prepare implicit variables
- device = input_ids.device
- input_shape = input_ids.size()
- token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
- head_mask = [None] * self.sent_encoder.config.num_hidden_layers
- extended_attention_mask: torch.Tensor = self.sent_encoder.get_extended_attention_mask(
- attention_mask, input_shape
- )
-
- # define function for checkpointing
- def partial_encode(*inputs):
- encoder_outputs = self.sent_encoder.encoder(
- inputs[0],
- attention_mask=inputs[1],
- head_mask=head_mask,
- )
- sequence_output = encoder_outputs[0]
- pooled_output = self.sent_encoder.pooler(sequence_output)
- return pooled_output
-
- # run embedding layer on everything at once
- embedding_output = self.sent_encoder.embeddings(
- input_ids=input_ids, position_ids=None, token_type_ids=token_type_ids, inputs_embeds=None
- )
- # run encoding and pooling on one mini-batch at a time
- pooled_output_list = []
- for b in range(math.ceil(input_ids.shape[0] / checkpoint_batch_size)):
- b_embedding_output = embedding_output[b * checkpoint_batch_size : (b + 1) * checkpoint_batch_size]
- b_attention_mask = extended_attention_mask[b * checkpoint_batch_size : (b + 1) * checkpoint_batch_size]
- pooled_output = checkpoint.checkpoint(partial_encode, b_embedding_output, b_attention_mask)
- pooled_output_list.append(pooled_output)
- return torch.cat(pooled_output_list, dim=0)
-
- def embed_questions(self, q_ids, q_mask, checkpoint_batch_size=-1):
- q_reps = self.embed_sentences_checkpointed(q_ids, q_mask, checkpoint_batch_size)
- return self.project_q(q_reps)
-
- def embed_answers(self, a_ids, a_mask, checkpoint_batch_size=-1):
- a_reps = self.embed_sentences_checkpointed(a_ids, a_mask, checkpoint_batch_size)
- return self.project_a(a_reps)
-
- def forward(self, q_ids, q_mask, a_ids, a_mask, checkpoint_batch_size=-1):
- device = q_ids.device
- q_reps = self.embed_questions(q_ids, q_mask, checkpoint_batch_size)
- a_reps = self.embed_answers(a_ids, a_mask, checkpoint_batch_size)
- compare_scores = torch.mm(q_reps, a_reps.t())
- loss_qa = self.ce_loss(compare_scores, torch.arange(compare_scores.shape[1]).to(device))
- loss_aq = self.ce_loss(compare_scores.t(), torch.arange(compare_scores.shape[0]).to(device))
- loss = (loss_qa + loss_aq) / 2
- return loss
-
-
-def make_qa_retriever_model(model_name="google/bert_uncased_L-8_H-512_A-8", from_file=None, device="cuda:0"):
- tokenizer = AutoTokenizer.from_pretrained(model_name)
- bert_model = AutoModel.from_pretrained(model_name).to(device)
- # run bert_model on a dummy batch to get output dimension
- d_ids = torch.LongTensor(
- [[bert_model.config.bos_token_id if bert_model.config.bos_token_id is not None else 1]]
- ).to(device)
- d_mask = torch.LongTensor([[1]]).to(device)
- sent_dim = bert_model(d_ids, attention_mask=d_mask)[1].shape[-1]
- qa_embedder = RetrievalQAEmbedder(bert_model, sent_dim).to(device)
- if from_file is not None:
- param_dict = torch.load(from_file) # has model weights, optimizer, and scheduler states
- qa_embedder.load_state_dict(param_dict["model"])
- return tokenizer, qa_embedder
-
-
-def make_qa_retriever_batch(qa_list, tokenizer, max_len=64, device="cuda:0"):
- q_ls = [q for q, a in qa_list]
- a_ls = [a for q, a in qa_list]
- q_toks = tokenizer(q_ls, max_length=max_len, padding="max_length", truncation=True)
- q_ids, q_mask = (
- torch.LongTensor(q_toks["input_ids"]).to(device),
- torch.LongTensor(q_toks["attention_mask"]).to(device),
- )
- a_toks = tokenizer(a_ls, max_length=max_len, padding="max_length", truncation=True)
- a_ids, a_mask = (
- torch.LongTensor(a_toks["input_ids"]).to(device),
- torch.LongTensor(a_toks["attention_mask"]).to(device),
- )
- return (q_ids, q_mask, a_ids, a_mask)
-
-
-def train_qa_retriever_epoch(model, dataset, tokenizer, optimizer, scheduler, args, e=0):
- model.train()
- # make iterator
- train_sampler = RandomSampler(dataset)
- model_collate_fn = functools.partial(
- make_qa_retriever_batch, tokenizer=tokenizer, max_len=args.max_length, device="cuda:0"
- )
- data_loader = DataLoader(dataset, batch_size=args.batch_size, sampler=train_sampler, collate_fn=model_collate_fn)
- epoch_iterator = tqdm(data_loader, desc="Iteration", disable=True)
- # accumulate loss since last print
- loc_steps = 0
- loc_loss = 0.0
- st_time = time()
- for step, batch in enumerate(epoch_iterator):
- q_ids, q_mask, a_ids, a_mask = batch
- pre_loss = model(q_ids, q_mask, a_ids, a_mask, checkpoint_batch_size=args.checkpoint_batch_size)
- loss = pre_loss.sum()
- # optimizer
- loss.backward()
- optimizer.step()
- scheduler.step()
- model.zero_grad()
- # some printing within the epoch
- loc_loss += loss.item()
- loc_steps += 1
- if step % args.print_freq == 0 or step == 1:
- print(
- "{:2d} {:5d} of {:5d} \t L: {:.3f} \t -- {:.3f}".format(
- e,
- step,
- len(dataset) // args.batch_size,
- loc_loss / loc_steps,
- time() - st_time,
- )
- )
- loc_loss = 0
- loc_steps = 0
-
-
-def train_qa_retriever_joint_epoch(model, dataset_list, tokenizer, optimizer, scheduler, args, e=0):
- model.train()
- model_collate_fn = functools.partial(
- make_qa_retriever_batch, tokenizer=tokenizer, max_len=args.max_length, device="cuda:0"
- )
- # make iterator
- train_samplers = [RandomSampler(dataset) for dataset in dataset_list]
- data_loaders = [
- DataLoader(dataset, batch_size=args.batch_size, sampler=train_sampler, collate_fn=model_collate_fn)
- for dataset, train_sampler in zip(dataset_list, train_samplers)
- ]
- iterators = [iter(dloader) for dloader in data_loaders]
- joint_iter = zip(*iterators)
- # accumulate loss since last print
- loc_steps = 0
- loc_loss = 0.0
- st_time = time()
- for step, (batches,) in enumerate(zip(joint_iter)):
- for batch in batches:
- q_ids, q_mask, a_ids, a_mask = batch
- loss = model(q_ids, q_mask, a_ids, a_mask, checkpoint_batch_size=args.checkpoint_batch_size)
- # optimizer
- loss.backward()
- optimizer.step()
- scheduler.step()
- model.zero_grad()
- # some printing within the epoch
- loc_loss += loss.item()
- loc_steps += 1
- if step % args.print_freq == 0:
- print(
- "{:2d} {:5d} of {:5d} \t L: {:.3f} \t -- {:.3f}".format(
- e,
- step,
- len(dataset_list[0]) // args.batch_size,
- loc_loss / loc_steps,
- time() - st_time,
- )
- )
- loc_loss = 0
- loc_steps = 0
-
-
-def evaluate_qa_retriever(model, dataset, tokenizer, args):
- model.eval()
- # make iterator
- eval_sampler = SequentialSampler(dataset)
- model_collate_fn = functools.partial(
- make_qa_retriever_batch, tokenizer=tokenizer, max_len=args.max_length, device="cuda:0"
- )
- data_loader = DataLoader(dataset, batch_size=args.batch_size, sampler=eval_sampler, collate_fn=model_collate_fn)
- epoch_iterator = tqdm(data_loader, desc="Iteration", disable=True)
- tot_loss = 0.0
- with torch.no_grad():
- for step, batch in enumerate(epoch_iterator):
- q_ids, q_mask, a_ids, a_mask = batch
- loss = model(q_ids, q_mask, a_ids, a_mask)
- tot_loss += loss.item()
- return tot_loss / (step + 1)
-
-
-def train_qa_retriever(qar_model, qar_tokenizer, qar_train_dset, qar_valid_dset, qar_args):
- qar_optimizer = AdamW(qar_model.parameters(), lr=qar_args.learning_rate, eps=1e-8)
- qar_scheduler = get_linear_schedule_with_warmup(
- qar_optimizer,
- num_warmup_steps=100,
- num_training_steps=(qar_args.num_epochs + 1) * math.ceil(len(qar_train_dset) / qar_args.batch_size),
- )
- for e in range(qar_args.num_epochs):
- train_qa_retriever_epoch(qar_model, qar_train_dset, qar_tokenizer, qar_optimizer, qar_scheduler, qar_args, e)
- m_save_dict = {
- "model": qar_model.state_dict(),
- "optimizer": qar_optimizer.state_dict(),
- "scheduler": qar_scheduler.state_dict(),
- }
- print("Saving model {}".format(qar_args.model_save_name))
- torch.save(m_save_dict, "{}_{}.pth".format(qar_args.model_save_name, e))
- eval_loss = evaluate_qa_retriever(qar_model, qar_valid_dset, qar_tokenizer, qar_args)
- print("Evaluation loss epoch {:4d}: {:.3f}".format(e, eval_loss))
-
-
-###############
-# ELI5 seq2seq model training
-###############
-class ELI5DatasetS2S(Dataset):
- def __init__(
- self, examples_array, make_doc_fun=None, extra_answer_threshold=3, document_cache=None, training=True
- ):
- self.training = training
- self.data = examples_array
- self.make_doc_function = make_doc_fun
- self.document_cache = {} if document_cache is None else document_cache
- assert not (make_doc_fun is None and document_cache is None)
- # make index of specific question-answer pairs from multi-answers
- if self.training:
- self.qa_id_list = [
- (i, j)
- for i, qa in enumerate(self.data)
- for j, (a, sc) in enumerate(zip(qa["answers"]["text"], qa["answers"]["score"]))
- if j == 0 or sc >= extra_answer_threshold
- ]
- else:
- self.qa_id_list = [(i, 0) for i in range(self.data.num_rows)]
-
- def __len__(self):
- return len(self.qa_id_list)
-
- def make_example(self, idx):
- i, j = self.qa_id_list[idx]
- example = self.data[i]
- question = example["title"] + " " + example["selftext"]
- answer = example["answers"]["text"][j]
- q_id = example["q_id"]
- if self.make_doc_function is not None:
- self.document_cache[q_id] = self.document_cache.get(q_id, self.make_doc_function(example["title"]))
- document = self.document_cache[q_id]
- in_st = "question: {} context: {}".format(
- question.lower().replace(" --t--", "").strip(),
- document.lower().strip(),
- )
- out_st = answer
- return (in_st, out_st)
-
- def __getitem__(self, idx):
- return self.make_example(idx)
-
-
-def make_qa_s2s_model(model_name="facebook/bart-large", from_file=None, device="cuda:0"):
- tokenizer = AutoTokenizer.from_pretrained(model_name)
- model = AutoModelForSeq2SeqLM.from_pretrained(model_name).to(device)
- if from_file is not None:
- param_dict = torch.load(from_file) # has model weights, optimizer, and scheduler states
- model.load_state_dict(param_dict["model"])
- return tokenizer, model
-
-
-def make_qa_s2s_batch(qa_list, tokenizer, max_len=64, max_a_len=360, device="cuda:0"):
- q_ls = [q for q, a in qa_list]
- a_ls = [a for q, a in qa_list]
- q_toks = tokenizer(q_ls, max_length=max_len, padding="max_length", truncation=True)
- q_ids, q_mask = (
- torch.LongTensor(q_toks["input_ids"]).to(device),
- torch.LongTensor(q_toks["attention_mask"]).to(device),
- )
- a_toks = tokenizer(a_ls, max_length=min(max_len, max_a_len), padding="max_length", truncation=True)
- a_ids, a_mask = (
- torch.LongTensor(a_toks["input_ids"]).to(device),
- torch.LongTensor(a_toks["attention_mask"]).to(device),
- )
- lm_labels = a_ids[:, 1:].contiguous().clone()
- lm_labels[a_mask[:, 1:].contiguous() == 0] = -100
- model_inputs = {
- "input_ids": q_ids,
- "attention_mask": q_mask,
- "decoder_input_ids": a_ids[:, :-1].contiguous(),
- "lm_labels": lm_labels,
- }
- return model_inputs
-
-
-def train_qa_s2s_epoch(model, dataset, tokenizer, optimizer, scheduler, args, e=0, curriculum=False):
- model.train()
- # make iterator
- if curriculum:
- train_sampler = SequentialSampler(dataset)
- else:
- train_sampler = RandomSampler(dataset)
- model_collate_fn = functools.partial(
- make_qa_s2s_batch, tokenizer=tokenizer, max_len=args.max_length, device="cuda:0"
- )
- data_loader = DataLoader(dataset, batch_size=args.batch_size, sampler=train_sampler, collate_fn=model_collate_fn)
- epoch_iterator = tqdm(data_loader, desc="Iteration", disable=True)
- # accumulate loss since last print
- loc_steps = 0
- loc_loss = 0.0
- st_time = time()
- for step, batch_inputs in enumerate(epoch_iterator):
- pre_loss = model(**batch_inputs)[0]
- loss = pre_loss.sum() / pre_loss.shape[0]
- loss.backward()
- # optimizer
- if step % args.backward_freq == 0:
- optimizer.step()
- scheduler.step()
- model.zero_grad()
- # some printing within the epoch
- loc_loss += loss.item()
- loc_steps += 1
- if step % args.print_freq == 0 or step == 1:
- print(
- "{:2d} {:5d} of {:5d} \t L: {:.3f} \t -- {:.3f}".format(
- e,
- step,
- len(dataset) // args.batch_size,
- loc_loss / loc_steps,
- time() - st_time,
- )
- )
- loc_loss = 0
- loc_steps = 0
-
-
-def eval_qa_s2s_epoch(model, dataset, tokenizer, args):
- model.eval()
- # make iterator
- train_sampler = SequentialSampler(dataset)
- model_collate_fn = functools.partial(
- make_qa_s2s_batch, tokenizer=tokenizer, max_len=args.max_length, device="cuda:0"
- )
- data_loader = DataLoader(dataset, batch_size=args.batch_size, sampler=train_sampler, collate_fn=model_collate_fn)
- epoch_iterator = tqdm(data_loader, desc="Iteration", disable=True)
- # accumulate loss since last print
- loc_steps = 0
- loc_loss = 0.0
- st_time = time()
- with torch.no_grad():
- for step, batch_inputs in enumerate(epoch_iterator):
- pre_loss = model(**batch_inputs)[0]
- loss = pre_loss.sum() / pre_loss.shape[0]
- loc_loss += loss.item()
- loc_steps += 1
- if step % args.print_freq == 0:
- print(
- "{:5d} of {:5d} \t L: {:.3f} \t -- {:.3f}".format(
- step,
- len(dataset) // args.batch_size,
- loc_loss / loc_steps,
- time() - st_time,
- )
- )
- print(
- "Total \t L: {:.3f} \t -- {:.3f}".format(
- loc_loss / loc_steps,
- time() - st_time,
- )
- )
-
-
-def train_qa_s2s(qa_s2s_model, qa_s2s_tokenizer, s2s_train_dset, s2s_valid_dset, s2s_args):
- s2s_optimizer = AdamW(qa_s2s_model.parameters(), lr=s2s_args.learning_rate, eps=1e-8)
- s2s_scheduler = get_linear_schedule_with_warmup(
- s2s_optimizer,
- num_warmup_steps=400,
- num_training_steps=(s2s_args.num_epochs + 1) * math.ceil(len(s2s_train_dset) / s2s_args.batch_size),
- )
- for e in range(s2s_args.num_epochs):
- train_qa_s2s_epoch(
- qa_s2s_model,
- s2s_train_dset,
- qa_s2s_tokenizer,
- s2s_optimizer,
- s2s_scheduler,
- s2s_args,
- e,
- curriculum=(e == 0),
- )
- m_save_dict = {
- "model": qa_s2s_model.state_dict(),
- "optimizer": s2s_optimizer.state_dict(),
- "scheduler": s2s_scheduler.state_dict(),
- }
- print("Saving model {}".format(s2s_args.model_save_name))
- eval_qa_s2s_epoch(qa_s2s_model, s2s_valid_dset, qa_s2s_tokenizer, s2s_args)
- torch.save(m_save_dict, "{}_{}.pth".format(s2s_args.model_save_name, e))
-
-
-# generate answer from input "question: ... context:
..."
-def qa_s2s_generate(
- question_doc,
- qa_s2s_model,
- qa_s2s_tokenizer,
- num_answers=1,
- num_beams=None,
- min_len=64,
- max_len=256,
- do_sample=False,
- temp=1.0,
- top_p=None,
- top_k=None,
- max_input_length=512,
- device="cuda:0",
-):
- model_inputs = make_qa_s2s_batch(
- [(question_doc, "A")],
- qa_s2s_tokenizer,
- max_input_length,
- device=device,
- )
- n_beams = num_answers if num_beams is None else max(num_beams, num_answers)
- generated_ids = qa_s2s_model.generate(
- input_ids=model_inputs["input_ids"],
- attention_mask=model_inputs["attention_mask"],
- min_length=min_len,
- max_length=max_len,
- do_sample=do_sample,
- early_stopping=True,
- num_beams=1 if do_sample else n_beams,
- temperature=temp,
- top_k=top_k,
- top_p=top_p,
- eos_token_id=qa_s2s_tokenizer.eos_token_id,
- no_repeat_ngram_size=3,
- num_return_sequences=num_answers,
- decoder_start_token_id=qa_s2s_tokenizer.bos_token_id,
- )
- return [qa_s2s_tokenizer.decode(ans_ids, skip_special_tokens=True).strip() for ans_ids in generated_ids]
-
-
-###############
-# ELI5-trained retrieval model usage
-###############
-def embed_passages_for_retrieval(passages, tokenizer, qa_embedder, max_length=128, device="cuda:0"):
- a_toks = tokenizer(passages, max_length=max_length, padding="max_length", truncation=True)
- a_ids, a_mask = (
- torch.LongTensor(a_toks["input_ids"]).to(device),
- torch.LongTensor(a_toks["attention_mask"]).to(device),
- )
- with torch.no_grad():
- a_reps = qa_embedder.embed_answers(a_ids, a_mask).cpu().type(torch.float)
- return a_reps.numpy()
-
-
-def embed_questions_for_retrieval(q_ls, tokenizer, qa_embedder, device="cuda:0"):
- q_toks = tokenizer(q_ls, max_length=128, padding="max_length", truncation=True)
- q_ids, q_mask = (
- torch.LongTensor(q_toks["input_ids"]).to(device),
- torch.LongTensor(q_toks["attention_mask"]).to(device),
- )
- with torch.no_grad():
- q_reps = qa_embedder.embed_questions(q_ids, q_mask).cpu().type(torch.float)
- return q_reps.numpy()
-
-
-def make_qa_dense_index(
- qa_embedder,
- tokenizer,
- passages_dset,
- batch_size=512,
- max_length=128,
- index_name="kilt_passages_reps.dat",
- dtype="float32",
- device="cuda:0",
-):
- st_time = time()
- fp = np.memmap(index_name, dtype=dtype, mode="w+", shape=(passages_dset.num_rows, 128))
- n_batches = math.ceil(passages_dset.num_rows / batch_size)
- for i in range(n_batches):
- passages = list(passages_dset[i * batch_size : (i + 1) * batch_size]["passage_text"])
- reps = embed_passages_for_retrieval(passages, tokenizer, qa_embedder, max_length, device)
- fp[i * batch_size : (i + 1) * batch_size] = reps
- if i % 50 == 0:
- print(i, time() - st_time)
-
-
-def evaluate_retriever(qa_list, retriever_func, scoring_func, n_ret=10, verbose=False):
- total_retriever_time = 0.0
- total_retriever_score = 0.0
- st_time = time()
- for i, (question, answer) in enumerate(qa_list):
- r_time = time()
- retrieved_passages = retriever_func(question, n_ret)
- total_retriever_time += time() - r_time
- total_retriever_score += scoring_func(retrieved_passages, answer)
- if verbose and ((i + 1) % 500 == 0 or i <= 1):
- print(
- "{:03d}: S-{:.4f} T-{:.4f} | {:.2f}".format(
- i + 1, total_retriever_score / (i + 1), total_retriever_time / (i + 1), time() - st_time
- )
- )
- return {"idf_recall": total_retriever_score / (i + 1), "retrieval_time": total_retriever_time / (i + 1)}
-
-
-# build a support document for the question out of Wikipedia snippets
-def query_qa_dense_index(
- question, qa_embedder, tokenizer, wiki_passages, wiki_index, n_results=10, min_length=20, device="cuda:0"
-):
- q_rep = embed_questions_for_retrieval([question], tokenizer, qa_embedder, device=device)
- D, I = wiki_index.search(q_rep, 2 * n_results)
- res_passages = [wiki_passages[int(i)] for i in I[0]]
- support_doc = "
" + "
".join([p["passage_text"] for p in res_passages])
- res_list = [{k: p[k] for k in wiki_passages.column_names} for p in res_passages]
- res_list = [res for res in res_list if len(res["passage_text"].split()) > min_length][:n_results]
- for r, sc in zip(res_list, D[0]):
- r["score"] = float(sc)
- return support_doc, res_list
-
-
-def batch_query_qa_dense_index(questions, qa_embedder, tokenizer, wiki_passages, wiki_index, n_results=10):
- q_rep = embed_questions_for_retrieval(questions, tokenizer, qa_embedder)
- D, I = wiki_index.search(q_rep, n_results)
- res_passages_lst = [[wiki_passages[int(i)] for i in i_lst] for i_lst in I]
- support_doc_lst = [
- "
" + "
".join([p["passage_text"] for p in res_passages]) for res_passages in res_passages_lst
- ]
- all_res_lists = []
- for res_passages, dl in zip(res_passages_lst, D):
- res_list = [{k: p[k] for k in wiki_passages.column_names} for p in res_passages]
- for r, sc in zip(res_list, dl):
- r["score"] = float(sc)
- all_res_lists += [res_list[:]]
- return support_doc_lst, all_res_lists
-
-
-# find nearest neighbors of an answer or declarative text in Wikipedia snippets
-def query_qa_dense_index_nn(passage, qa_embedder, tokenizer, wiki_passages, wiki_index, n_results=10, min_length=20):
- a_rep = embed_passages_for_retrieval([passage], tokenizer, qa_embedder)
- D, I = wiki_index.search(a_rep, 2 * n_results)
- res_passages = [wiki_passages[int(i)] for i in I[0]]
- support_doc = "
" + "
".join([p["passage_text"] for p in res_passages])
- res_list = [{k: p[k] for k in wiki_passages.column_names} for p in res_passages]
- res_list = [res for res in res_list if len(res["passage_text"].split()) > min_length][:n_results]
- for r, sc, i in zip(res_list, D[0], I[0]):
- r["passage_id"] = int(i)
- r["score"] = float(sc)
- return support_doc, res_list
-
-
-def batch_query_qa_dense_index_nn(passages, qa_embedder, tokenizer, wiki_passages, wiki_index, n_results=10):
- a_reps = embed_passages_for_retrieval(passages, tokenizer, qa_embedder)
- D, I = wiki_index.search(a_reps, n_results)
- res_passages_lst = [[wiki_passages[int(i)] for i in i_lst] for i_lst in I]
- support_doc_lst = [
- "
" + "
".join([p["passage_text"] for p in res_passages]) for res_passages in res_passages_lst
- ]
- all_res_lists = []
- for res_passages, dl, il in zip(res_passages_lst, D, I):
- res_list = [{k: p[k] for k in wiki_passages.column_names} for p in res_passages]
- for r, sc, i in zip(res_list, dl, il):
- r["passage_id"] = int(i)
- r["score"] = float(sc)
- all_res_lists += [res_list[:]]
- return support_doc_lst, all_res_lists
diff --git a/examples/research_projects/longform-qa/requirements.txt b/examples/research_projects/longform-qa/requirements.txt
deleted file mode 100644
index a21b64d33df..00000000000
--- a/examples/research_projects/longform-qa/requirements.txt
+++ /dev/null
@@ -1,4 +0,0 @@
-datasets >= 1.1.3
-faiss-cpu
-streamlit
-elasticsearch
diff --git a/examples/research_projects/luke/README.md b/examples/research_projects/luke/README.md
deleted file mode 100644
index 703eb0b4e42..00000000000
--- a/examples/research_projects/luke/README.md
+++ /dev/null
@@ -1,71 +0,0 @@
-# Token classification
-
-## PyTorch version, no Trainer
-
-Fine-tuning (m)LUKE for token classification task such as Named Entity Recognition (NER), Parts-of-speech
-tagging (POS) or phrase extraction (CHUNKS). You can easily
-customize it to your needs if you need extra processing on your datasets.
-
-It will either run on a datasets hosted on our [hub](https://huggingface.co/datasets) or with your own text files for
-training and validation, you might just need to add some tweaks in the data preprocessing.
-
-The script can be run in a distributed setup, on TPU and supports mixed precision by
-the mean of the [🤗 `Accelerate`](https://github.com/huggingface/accelerate) library. You can use the script normally
-after installing it:
-
-```bash
-pip install git+https://github.com/huggingface/accelerate
-```
-
-then to train English LUKE on CoNLL2003:
-
-```bash
-export TASK_NAME=ner
-
-python run_luke_ner_no_trainer.py \
- --model_name_or_path studio-ousia/luke-base \
- --dataset_name conll2003 \
- --task_name $TASK_NAME \
- --max_length 128 \
- --per_device_train_batch_size 32 \
- --learning_rate 2e-5 \
- --num_train_epochs 3 \
- --output_dir /tmp/$TASK_NAME/
-```
-
-You can then use your usual launchers to run in it in a distributed environment, but the easiest way is to run
-
-```bash
-accelerate config
-```
-
-and reply to the questions asked. Then
-
-```bash
-accelerate test
-```
-
-that will check everything is ready for training. Finally, you can launch training with
-
-```bash
-export TASK_NAME=ner
-
-accelerate launch run_ner_no_trainer.py \
- --model_name_or_path studio-ousia/luke-base \
- --dataset_name conll2003 \
- --task_name $TASK_NAME \
- --max_length 128 \
- --per_device_train_batch_size 32 \
- --learning_rate 2e-5 \
- --num_train_epochs 3 \
- --output_dir /tmp/$TASK_NAME/
-```
-
-This command is the same and will work for:
-
-- a CPU-only setup
-- a setup with one GPU
-- a distributed training with several GPUs (single or multi node)
-- a training on TPUs
-
-Note that this library is in alpha release so your feedback is more than welcome if you encounter any problem using it.
diff --git a/examples/research_projects/luke/luke_utils.py b/examples/research_projects/luke/luke_utils.py
deleted file mode 100644
index aec4133f21b..00000000000
--- a/examples/research_projects/luke/luke_utils.py
+++ /dev/null
@@ -1,115 +0,0 @@
-import unicodedata
-from dataclasses import dataclass
-from typing import Optional, Union
-
-import numpy as np
-
-from transformers.data.data_collator import DataCollatorMixin
-from transformers.file_utils import PaddingStrategy
-from transformers.tokenization_utils_base import PreTrainedTokenizerBase
-
-
-def padding_tensor(sequences, padding_value, padding_side, sequence_length):
- if isinstance(padding_value, tuple):
- out_tensor = np.full((len(sequences), sequence_length, 2), padding_value)
- else:
- out_tensor = np.full((len(sequences), sequence_length), padding_value)
-
- for i, tensor in enumerate(sequences):
- if padding_side == "right":
- if isinstance(padding_value, tuple):
- out_tensor[i, : len(tensor[:sequence_length]), :2] = tensor[:sequence_length]
- else:
- out_tensor[i, : len(tensor[:sequence_length])] = tensor[:sequence_length]
- else:
- if isinstance(padding_value, tuple):
- out_tensor[i, len(tensor[:sequence_length]) - 1 :, :2] = tensor[:sequence_length]
- else:
- out_tensor[i, len(tensor[:sequence_length]) - 1 :] = tensor[:sequence_length]
-
- return out_tensor.tolist()
-
-
-def is_punctuation(char):
- cp = ord(char)
- if (cp >= 33 and cp <= 47) or (cp >= 58 and cp <= 64) or (cp >= 91 and cp <= 96) or (cp >= 123 and cp <= 126):
- return True
- cat = unicodedata.category(char)
- if cat.startswith("P"):
- return True
- return False
-
-
-@dataclass
-class DataCollatorForLukeTokenClassification(DataCollatorMixin):
- """
- Data collator that will dynamically pad the inputs received, as well as the labels.
-
- Args:
- tokenizer ([`PreTrainedTokenizer`] or [`PreTrainedTokenizerFast`]):
- The tokenizer used for encoding the data.
- padding (`bool`, `str` or [`~file_utils.PaddingStrategy`], *optional*, defaults to `True`):
- Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
- among:
-
- - `True` or `'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
- sequence if provided).
- - `'max_length'`: Pad to a maximum length specified with the argument `max_length` or to the
- maximum acceptable input length for the model if that argument is not provided.
- - `False` or `'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
- different lengths).
- max_length (`int`, *optional*):
- Maximum length of the returned list and optionally padding length (see above).
- pad_to_multiple_of (`int`, *optional*):
- If set will pad the sequence to a multiple of the provided value.
-
- This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
- 7.5 (Volta).
- label_pad_token_id (`int`, *optional*, defaults to -100):
- The id to use when padding the labels (-100 will be automatically ignore by PyTorch loss functions).
- return_tensors (`str`):
- The type of Tensor to return. Allowable values are "np", "pt" and "tf".
- """
-
- tokenizer: PreTrainedTokenizerBase
- padding: Union[bool, str, PaddingStrategy] = True
- max_length: Optional[int] = None
- pad_to_multiple_of: Optional[int] = None
- label_pad_token_id: int = -100
- return_tensors: str = "pt"
-
- def torch_call(self, features):
- import torch
-
- label_name = "label" if "label" in features[0].keys() else "labels"
- labels = [feature[label_name] for feature in features] if label_name in features[0].keys() else None
- batch = self.tokenizer.pad(
- features,
- padding=self.padding,
- max_length=self.max_length,
- pad_to_multiple_of=self.pad_to_multiple_of,
- # Conversion to tensors will fail if we have labels as they are not of the same length yet.
- return_tensors="pt" if labels is None else None,
- )
-
- if labels is None:
- return batch
-
- sequence_length = torch.tensor(batch["entity_ids"]).shape[1]
- padding_side = self.tokenizer.padding_side
- if padding_side == "right":
- batch[label_name] = [
- list(label) + [self.label_pad_token_id] * (sequence_length - len(label)) for label in labels
- ]
- else:
- batch[label_name] = [
- [self.label_pad_token_id] * (sequence_length - len(label)) + list(label) for label in labels
- ]
-
- ner_tags = [feature["ner_tags"] for feature in features]
- batch["ner_tags"] = padding_tensor(ner_tags, -1, padding_side, sequence_length)
- original_entity_spans = [feature["original_entity_spans"] for feature in features]
- batch["original_entity_spans"] = padding_tensor(original_entity_spans, (-1, -1), padding_side, sequence_length)
- batch = {k: torch.tensor(v, dtype=torch.int64) for k, v in batch.items()}
-
- return batch
diff --git a/examples/research_projects/luke/run_luke_ner_no_trainer.py b/examples/research_projects/luke/run_luke_ner_no_trainer.py
deleted file mode 100644
index 1552acbd42c..00000000000
--- a/examples/research_projects/luke/run_luke_ner_no_trainer.py
+++ /dev/null
@@ -1,720 +0,0 @@
-#!/usr/bin/env python
-# coding=utf-8
-# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-Fine-tuning (m)LUKE model on token classification tasks (NER, POS, CHUNKS) relying on the accelerate library 🤗
-without using a Trainer.
-"""
-
-import argparse
-import logging
-import math
-import os
-import random
-from pathlib import Path
-
-import datasets
-import torch
-from accelerate import Accelerator, DistributedDataParallelKwargs
-from datasets import ClassLabel, load_dataset, load_metric
-from huggingface_hub import Repository, create_repo
-from luke_utils import DataCollatorForLukeTokenClassification, is_punctuation, padding_tensor
-from torch.utils.data import DataLoader
-from tqdm.auto import tqdm
-
-import transformers
-from transformers import (
- AdamW,
- LukeConfig,
- LukeForEntitySpanClassification,
- LukeTokenizer,
- SchedulerType,
- default_data_collator,
- get_scheduler,
- set_seed,
-)
-from transformers.utils.versions import require_version
-
-
-logger = logging.getLogger(__name__)
-require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/token-classification/requirements.txt")
-
-
-def parse_args():
- parser = argparse.ArgumentParser(
- description="Finetune (m)LUKE on a token classification task (such as NER) with the accelerate library"
- )
- parser.add_argument(
- "--dataset_name",
- type=str,
- default=None,
- help="The name of the dataset to use (via the datasets library).",
- )
- parser.add_argument(
- "--dataset_config_name",
- type=str,
- default=None,
- help="The configuration name of the dataset to use (via the datasets library).",
- )
- parser.add_argument(
- "--train_file", type=str, default=None, help="A csv or a json file containing the training data."
- )
- parser.add_argument(
- "--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
- )
- parser.add_argument(
- "--text_column_name",
- type=str,
- default=None,
- help="The column name of text to input in the file (a csv or JSON file).",
- )
- parser.add_argument(
- "--label_column_name",
- type=str,
- default=None,
- help="The column name of label to input in the file (a csv or JSON file).",
- )
- parser.add_argument(
- "--max_length",
- type=int,
- default=128,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer than this will be truncated,"
- " sequences shorter will be padded if `--pad_to_max_length` is passed."
- ),
- )
- parser.add_argument(
- "--max_entity_length",
- type=int,
- default=32,
- help=(
- "The maximum total input entity length after tokenization (Used only for (M)Luke models). Sequences longer"
- " than this will be truncated, sequences shorter will be padded if `--pad_to_max_length` is passed."
- ),
- )
- parser.add_argument(
- "--max_mention_length",
- type=int,
- default=30,
- help=(
- "The maximum total input mention length after tokenization (Used only for (M)Luke models). Sequences"
- " longer than this will be truncated, sequences shorter will be padded if `--pad_to_max_length` is passed."
- ),
- )
- parser.add_argument(
- "--pad_to_max_length",
- action="store_true",
- help="If passed, pad all samples to `max_length`. Otherwise, dynamic padding is used.",
- )
- parser.add_argument(
- "--model_name_or_path",
- type=str,
- help="Path to pretrained model or model identifier from huggingface.co/models.",
- required=True,
- )
- parser.add_argument(
- "--config_name",
- type=str,
- default=None,
- help="Pretrained config name or path if not the same as model_name",
- )
- parser.add_argument(
- "--tokenizer_name",
- type=str,
- default=None,
- help="Pretrained tokenizer name or path if not the same as model_name",
- )
- parser.add_argument(
- "--per_device_train_batch_size",
- type=int,
- default=8,
- help="Batch size (per device) for the training dataloader.",
- )
- parser.add_argument(
- "--per_device_eval_batch_size",
- type=int,
- default=8,
- help="Batch size (per device) for the evaluation dataloader.",
- )
- parser.add_argument(
- "--learning_rate",
- type=float,
- default=5e-5,
- help="Initial learning rate (after the potential warmup period) to use.",
- )
- parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
- parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
- parser.add_argument(
- "--max_train_steps",
- type=int,
- default=None,
- help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
- )
- parser.add_argument(
- "--gradient_accumulation_steps",
- type=int,
- default=1,
- help="Number of updates steps to accumulate before performing a backward/update pass.",
- )
- parser.add_argument(
- "--lr_scheduler_type",
- type=SchedulerType,
- default="linear",
- help="The scheduler type to use.",
- choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
- )
- parser.add_argument(
- "--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
- )
- parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
- parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
- parser.add_argument(
- "--label_all_tokens",
- action="store_true",
- help="Setting labels of all special tokens to -100 and thus PyTorch will ignore them.",
- )
- parser.add_argument(
- "--return_entity_level_metrics",
- action="store_true",
- help="Indication whether entity level metrics are to be returner.",
- )
- parser.add_argument(
- "--task_name",
- type=str,
- default="ner",
- choices=["ner", "pos", "chunk"],
- help="The name of the task.",
- )
- parser.add_argument(
- "--debug",
- action="store_true",
- help="Activate debug mode and run training only with a subset of data.",
- )
- parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
- parser.add_argument(
- "--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
- )
- parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
- args = parser.parse_args()
-
- # Sanity checks
- if args.task_name is None and args.train_file is None and args.validation_file is None:
- raise ValueError("Need either a task name or a training/validation file.")
- else:
- if args.train_file is not None:
- extension = args.train_file.split(".")[-1]
- assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
- if args.validation_file is not None:
- extension = args.validation_file.split(".")[-1]
- assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
-
- if args.push_to_hub:
- assert args.output_dir is not None, "Need an `output_dir` to create a repo when `--push_to_hub` is passed."
-
- return args
-
-
-def main():
- args = parse_args()
-
- # Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
- handler = DistributedDataParallelKwargs(find_unused_parameters=True)
- accelerator = Accelerator(kwargs_handlers=[handler])
- # Make one log on every process with the configuration for debugging.
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- level=logging.INFO,
- )
- logger.info(accelerator.state)
-
- # Setup logging, we only want one process per machine to log things on the screen.
- # accelerator.is_local_main_process is only True for one process per machine.
- logger.setLevel(logging.INFO if accelerator.is_local_main_process else logging.ERROR)
- if accelerator.is_local_main_process:
- datasets.utils.logging.set_verbosity_warning()
- transformers.utils.logging.set_verbosity_info()
- else:
- datasets.utils.logging.set_verbosity_error()
- transformers.utils.logging.set_verbosity_error()
-
- # If passed along, set the training seed now.
- if args.seed is not None:
- set_seed(args.seed)
-
- # Handle the repository creation
- if accelerator.is_main_process:
- if args.push_to_hub:
- # Retrieve of infer repo_name
- repo_name = args.hub_model_id
- if repo_name is None:
- repo_name = Path(args.output_dir).absolute().name
- # Create repo and retrieve repo_id
- repo_id = create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
- # Clone repo locally
- repo = Repository(args.output_dir, clone_from=repo_id, token=args.hub_token)
- elif args.output_dir is not None:
- os.makedirs(args.output_dir, exist_ok=True)
- accelerator.wait_for_everyone()
-
- # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
- # or just provide the name of one of the public datasets for token classification task available on the hub at https://huggingface.co/datasets/
- # (the dataset will be downloaded automatically from the datasets Hub).
- #
- # For CSV/JSON files, this script will use the column called 'tokens' or the first column if no column called
- # 'tokens' is found. You can easily tweak this behavior (see below).
- #
- # In distributed training, the load_dataset function guarantee that only one local process can concurrently
- # download the dataset.
- if args.dataset_name is not None:
- # Downloading and loading a dataset from the hub.
- raw_datasets = load_dataset(args.dataset_name, args.dataset_config_name)
- else:
- data_files = {}
- if args.train_file is not None:
- data_files["train"] = args.train_file
- extension = args.train_file.split(".")[-1]
- if args.validation_file is not None:
- data_files["validation"] = args.validation_file
- extension = args.validation_file.split(".")[-1]
- raw_datasets = load_dataset(extension, data_files=data_files)
- # Trim a number of training examples
- if args.debug:
- for split in raw_datasets.keys():
- raw_datasets[split] = raw_datasets[split].select(range(100))
- # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
- # https://huggingface.co/docs/datasets/loading_datasets.
-
- if raw_datasets["train"] is not None:
- column_names = raw_datasets["train"].column_names
- features = raw_datasets["train"].features
- else:
- column_names = raw_datasets["validation"].column_names
- features = raw_datasets["validation"].features
-
- if args.text_column_name is not None:
- text_column_name = args.text_column_name
- elif "tokens" in column_names:
- text_column_name = "tokens"
- else:
- text_column_name = column_names[0]
-
- if args.label_column_name is not None:
- label_column_name = args.label_column_name
- elif f"{args.task_name}_tags" in column_names:
- label_column_name = f"{args.task_name}_tags"
- else:
- label_column_name = column_names[1]
-
- # In the event the labels are not a `Sequence[ClassLabel]`, we will need to go through the dataset to get the
- # unique labels.
- def get_label_list(labels):
- unique_labels = set()
- for label in labels:
- unique_labels = unique_labels | set(label)
- label_list = list(unique_labels)
- label_list.sort()
- return label_list
-
- if isinstance(features[label_column_name].feature, ClassLabel):
- label_list = features[label_column_name].feature.names
- # No need to convert the labels since they are already ints.
- else:
- label_list = get_label_list(raw_datasets["train"][label_column_name])
- num_labels = len(label_list)
-
- # Map that sends B-Xxx label to its I-Xxx counterpart
- b_to_i_label = []
-
- for idx, label in enumerate(label_list):
- if label.startswith("B-") and label.replace("B-", "I-") in label_list:
- b_to_i_label.append(label_list.index(label.replace("B-", "I-")))
- else:
- b_to_i_label.append(idx)
-
- # Load pretrained model and tokenizer
- #
- # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
- # download model & vocab.
- if args.config_name:
- config = LukeConfig.from_pretrained(args.config_name, num_labels=num_labels)
- elif args.model_name_or_path:
- config = LukeConfig.from_pretrained(args.model_name_or_path, num_labels=num_labels)
- else:
- logger.warning("You are instantiating a new config instance from scratch.")
-
- tokenizer_name_or_path = args.tokenizer_name if args.tokenizer_name else args.model_name_or_path
- if not tokenizer_name_or_path:
- raise ValueError(
- "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
- "You can do it from another script, save it, and load it from here, using --tokenizer_name."
- )
-
- tokenizer = LukeTokenizer.from_pretrained(
- tokenizer_name_or_path,
- use_fast=False,
- task="entity_span_classification",
- max_entity_length=args.max_entity_length,
- max_mention_length=args.max_mention_length,
- )
-
- if args.model_name_or_path:
- model = LukeForEntitySpanClassification.from_pretrained(
- args.model_name_or_path,
- from_tf=bool(".ckpt" in args.model_name_or_path),
- config=config,
- )
- else:
- logger.info("Training new model from scratch")
- model = LukeForEntitySpanClassification.from_config(config)
-
- model.resize_token_embeddings(len(tokenizer))
-
- # Preprocessing the datasets.
- # First we tokenize all the texts.
- padding = "max_length" if args.pad_to_max_length else False
-
- def compute_sentence_boundaries_for_luke(examples):
- sentence_boundaries = []
-
- for tokens in examples[text_column_name]:
- sentence_boundaries.append([0, len(tokens)])
-
- examples["sentence_boundaries"] = sentence_boundaries
-
- return examples
-
- def compute_entity_spans_for_luke(examples):
- all_entity_spans = []
- texts = []
- all_labels_entity_spans = []
- all_original_entity_spans = []
-
- for labels, tokens, sentence_boundaries in zip(
- examples[label_column_name], examples[text_column_name], examples["sentence_boundaries"]
- ):
- subword_lengths = [len(tokenizer.tokenize(token)) for token in tokens]
- total_subword_length = sum(subword_lengths)
- _, context_end = sentence_boundaries
-
- if total_subword_length > args.max_length - 2:
- cur_length = sum(subword_lengths[:context_end])
- idx = context_end - 1
-
- while cur_length > args.max_length - 2:
- cur_length -= subword_lengths[idx]
- context_end -= 1
- idx -= 1
-
- text = ""
- sentence_words = tokens[:context_end]
- sentence_subword_lengths = subword_lengths[:context_end]
- word_start_char_positions = []
- word_end_char_positions = []
- labels_positions = {}
-
- for word, label in zip(sentence_words, labels):
- if word[0] == "'" or (len(word) == 1 and is_punctuation(word)):
- text = text.rstrip()
-
- word_start_char_positions.append(len(text))
- text += word
- word_end_char_positions.append(len(text))
- text += " "
- labels_positions[(word_start_char_positions[-1], word_end_char_positions[-1])] = label
-
- text = text.rstrip()
- texts.append(text)
- entity_spans = []
- labels_entity_spans = []
- original_entity_spans = []
-
- for word_start in range(len(sentence_words)):
- for word_end in range(word_start, len(sentence_words)):
- if (
- sum(sentence_subword_lengths[word_start:word_end]) <= tokenizer.max_mention_length
- and len(entity_spans) < tokenizer.max_entity_length
- ):
- entity_spans.append((word_start_char_positions[word_start], word_end_char_positions[word_end]))
- original_entity_spans.append((word_start, word_end + 1))
- if (
- word_start_char_positions[word_start],
- word_end_char_positions[word_end],
- ) in labels_positions:
- labels_entity_spans.append(
- labels_positions[
- (word_start_char_positions[word_start], word_end_char_positions[word_end])
- ]
- )
- else:
- labels_entity_spans.append(0)
-
- all_entity_spans.append(entity_spans)
- all_labels_entity_spans.append(labels_entity_spans)
- all_original_entity_spans.append(original_entity_spans)
-
- examples["entity_spans"] = all_entity_spans
- examples["text"] = texts
- examples["labels_entity_spans"] = all_labels_entity_spans
- examples["original_entity_spans"] = all_original_entity_spans
-
- return examples
-
- def tokenize_and_align_labels(examples):
- entity_spans = []
-
- for v in examples["entity_spans"]:
- entity_spans.append(list(map(tuple, v)))
-
- tokenized_inputs = tokenizer(
- examples["text"],
- entity_spans=entity_spans,
- max_length=args.max_length,
- padding=padding,
- truncation=True,
- )
-
- if padding == "max_length":
- tokenized_inputs["labels"] = padding_tensor(
- examples["labels_entity_spans"], -100, tokenizer.padding_side, tokenizer.max_entity_length
- )
- tokenized_inputs["original_entity_spans"] = padding_tensor(
- examples["original_entity_spans"], (-1, -1), tokenizer.padding_side, tokenizer.max_entity_length
- )
- tokenized_inputs[label_column_name] = padding_tensor(
- examples[label_column_name], -1, tokenizer.padding_side, tokenizer.max_entity_length
- )
- else:
- tokenized_inputs["labels"] = [ex[: tokenizer.max_entity_length] for ex in examples["labels_entity_spans"]]
- tokenized_inputs["original_entity_spans"] = [
- ex[: tokenizer.max_entity_length] for ex in examples["original_entity_spans"]
- ]
- tokenized_inputs[label_column_name] = [
- ex[: tokenizer.max_entity_length] for ex in examples[label_column_name]
- ]
-
- return tokenized_inputs
-
- with accelerator.main_process_first():
- raw_datasets = raw_datasets.map(
- compute_sentence_boundaries_for_luke,
- batched=True,
- desc="Adding sentence boundaries",
- )
- raw_datasets = raw_datasets.map(
- compute_entity_spans_for_luke,
- batched=True,
- desc="Adding sentence spans",
- )
-
- processed_raw_datasets = raw_datasets.map(
- tokenize_and_align_labels,
- batched=True,
- remove_columns=raw_datasets["train"].column_names,
- desc="Running tokenizer on dataset",
- )
-
- train_dataset = processed_raw_datasets["train"]
- eval_dataset = processed_raw_datasets["validation"]
-
- # Log a few random samples from the training set:
- for index in random.sample(range(len(train_dataset)), 3):
- logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
-
- # DataLoaders creation:
- if args.pad_to_max_length:
- # If padding was already done ot max length, we use the default data collator that will just convert everything
- # to tensors.
- data_collator = default_data_collator
- else:
- # Otherwise, `DataCollatorForTokenClassification` will apply dynamic padding for us (by padding to the maximum length of
- # the samples passed). When using mixed precision, we add `pad_to_multiple_of=8` to pad all tensors to multiple
- # of 8s, which will enable the use of Tensor Cores on NVIDIA hardware with compute capability >= 7.5 (Volta).
- # For fp8, we pad to multiple of 16.
- if accelerator.mixed_precision == "fp8":
- pad_to_multiple_of = 16
- elif accelerator.mixed_precision != "no":
- pad_to_multiple_of = 8
- else:
- pad_to_multiple_of = None
- data_collator = DataCollatorForLukeTokenClassification(tokenizer, pad_to_multiple_of=pad_to_multiple_of)
-
- train_dataloader = DataLoader(
- train_dataset, shuffle=True, collate_fn=data_collator, batch_size=args.per_device_train_batch_size
- )
- eval_dataloader = DataLoader(eval_dataset, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size)
-
- # Optimizer
- # Split weights in two groups, one with weight decay and the other not.
- no_decay = ["bias", "LayerNorm.weight"]
- optimizer_grouped_parameters = [
- {
- "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
- "weight_decay": args.weight_decay,
- },
- {
- "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
- "weight_decay": 0.0,
- },
- ]
- optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
-
- # Use the device given by the `accelerator` object.
- device = accelerator.device
- model.to(device)
-
- # Prepare everything with our `accelerator`.
- model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
- model, optimizer, train_dataloader, eval_dataloader
- )
-
- # Note -> the training dataloader needs to be prepared before we grab his length below (cause its length will be
- # shorter in multiprocess)
-
- # Scheduler and math around the number of training steps.
- num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
- if args.max_train_steps is None:
- args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
- else:
- args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
-
- lr_scheduler = get_scheduler(
- name=args.lr_scheduler_type,
- optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps,
- num_training_steps=args.max_train_steps,
- )
-
- # Metrics
- metric = load_metric("seqeval")
-
- def get_luke_labels(outputs, ner_tags, original_entity_spans):
- true_predictions = []
- true_labels = []
-
- for output, original_spans, tags in zip(outputs.logits, original_entity_spans, ner_tags):
- true_tags = [val for val in tags if val != -1]
- true_original_spans = [val for val in original_spans if val != (-1, -1)]
- max_indices = torch.argmax(output, axis=1)
- max_logits = torch.max(output, axis=1).values
- predictions = []
-
- for logit, index, span in zip(max_logits, max_indices, true_original_spans):
- if index != 0:
- predictions.append((logit, span, label_list[index]))
-
- predicted_sequence = [label_list[0]] * len(true_tags)
-
- for _, span, label in sorted(predictions, key=lambda o: o[0], reverse=True):
- if all(o == label_list[0] for o in predicted_sequence[span[0] : span[1]]):
- predicted_sequence[span[0]] = label
- if span[1] - span[0] > 1:
- predicted_sequence[span[0] + 1 : span[1]] = [label] * (span[1] - span[0] - 1)
-
- true_predictions.append(predicted_sequence)
- true_labels.append([label_list[tag_id] for tag_id in true_tags])
-
- return true_predictions, true_labels
-
- def compute_metrics():
- results = metric.compute()
- if args.return_entity_level_metrics:
- # Unpack nested dictionaries
- final_results = {}
- for key, value in results.items():
- if isinstance(value, dict):
- for n, v in value.items():
- final_results[f"{key}_{n}"] = v
- else:
- final_results[key] = value
- return final_results
- else:
- return {
- "precision": results["overall_precision"],
- "recall": results["overall_recall"],
- "f1": results["overall_f1"],
- "accuracy": results["overall_accuracy"],
- }
-
- # Train!
- total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
-
- logger.info("***** Running training *****")
- logger.info(f" Num examples = {len(train_dataset)}")
- logger.info(f" Num Epochs = {args.num_train_epochs}")
- logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
- logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
- logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
- logger.info(f" Total optimization steps = {args.max_train_steps}")
- # Only show the progress bar once on each machine.
- progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
- completed_steps = 0
-
- for epoch in range(args.num_train_epochs):
- model.train()
- for step, batch in enumerate(train_dataloader):
- _ = batch.pop("original_entity_spans")
- outputs = model(**batch)
- loss = outputs.loss
- loss = loss / args.gradient_accumulation_steps
- accelerator.backward(loss)
- if step % args.gradient_accumulation_steps == 0 or step == len(train_dataloader) - 1:
- optimizer.step()
- lr_scheduler.step()
- optimizer.zero_grad()
- progress_bar.update(1)
- completed_steps += 1
-
- if completed_steps >= args.max_train_steps:
- break
-
- model.eval()
- for step, batch in enumerate(eval_dataloader):
- original_entity_spans = batch.pop("original_entity_spans")
- with torch.no_grad():
- outputs = model(**batch)
-
- preds, refs = get_luke_labels(outputs, batch[label_column_name], original_entity_spans)
-
- metric.add_batch(
- predictions=preds,
- references=refs,
- ) # predictions and preferences are expected to be a nested list of labels, not label_ids
-
- eval_metric = compute_metrics()
- accelerator.print(f"epoch {epoch}:", eval_metric)
-
- if args.push_to_hub and epoch < args.num_train_epochs - 1:
- accelerator.wait_for_everyone()
- unwrapped_model = accelerator.unwrap_model(model)
- unwrapped_model.save_pretrained(args.output_dir, save_function=accelerator.save)
- if accelerator.is_main_process:
- tokenizer.save_pretrained(args.output_dir)
- repo.push_to_hub(
- commit_message=f"Training in progress epoch {epoch}", blocking=False, auto_lfs_prune=True
- )
-
- if args.output_dir is not None:
- accelerator.wait_for_everyone()
- unwrapped_model = accelerator.unwrap_model(model)
- unwrapped_model.save_pretrained(args.output_dir, save_function=accelerator.save)
- if accelerator.is_main_process:
- tokenizer.save_pretrained(args.output_dir)
- if args.push_to_hub:
- repo.push_to_hub(commit_message="End of training", auto_lfs_prune=True)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/lxmert/README.md b/examples/research_projects/lxmert/README.md
deleted file mode 100644
index 2ec1aaebbb0..00000000000
--- a/examples/research_projects/lxmert/README.md
+++ /dev/null
@@ -1,5 +0,0 @@
-# LXMERT DEMO
-
-1. make a virtualenv: ``virtualenv venv`` and activate ``source venv/bin/activate``
-2. install reqs: ``pip install -r ./requirements.txt``
-3. usage is as shown in demo.ipynb
diff --git a/examples/research_projects/lxmert/demo.ipynb b/examples/research_projects/lxmert/demo.ipynb
deleted file mode 100644
index 576a4b7631c..00000000000
--- a/examples/research_projects/lxmert/demo.ipynb
+++ /dev/null
@@ -1,264 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "code",
- "execution_count": 1,
- "metadata": {},
- "outputs": [],
- "source": [
- "# %pip install-r requirements.txt"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 1,
- "metadata": {},
- "outputs": [
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "PyTorch version 1.6.0 available.\n"
- ]
- }
- ],
- "source": [
- "import io\n",
- "\n",
- "import numpy as np\n",
- "import PIL.Image\n",
- "from IPython.display import Image, display\n",
- "from modeling_frcnn import GeneralizedRCNN\n",
- "from processing_image import Preprocess\n",
- "from visualizing_image import SingleImageViz\n",
- "\n",
- "import utils\n",
- "from transformers import LxmertForQuestionAnswering, LxmertTokenizer\n",
- "from utils import Config\n",
- "\n",
- "\n",
- "# URL = \"https://raw.githubusercontent.com/airsplay/py-bottom-up-attention/master/demo/data/images/input.jpg\",\n",
- "URL = \"https://vqa.cloudcv.org/media/test2014/COCO_test2014_000000262567.jpg\"\n",
- "OBJ_URL = \"https://raw.githubusercontent.com/airsplay/py-bottom-up-attention/master/demo/data/genome/1600-400-20/objects_vocab.txt\"\n",
- "ATTR_URL = \"https://raw.githubusercontent.com/airsplay/py-bottom-up-attention/master/demo/data/genome/1600-400-20/attributes_vocab.txt\"\n",
- "GQA_URL = \"https://raw.githubusercontent.com/airsplay/lxmert/master/data/gqa/trainval_label2ans.json\"\n",
- "VQA_URL = \"https://raw.githubusercontent.com/airsplay/lxmert/master/data/vqa/trainval_label2ans.json\"\n",
- "\n",
- "\n",
- "# for visualizing output\n",
- "def showarray(a, fmt=\"jpeg\"):\n",
- " a = np.uint8(np.clip(a, 0, 255))\n",
- " f = io.BytesIO()\n",
- " PIL.Image.fromarray(a).save(f, fmt)\n",
- " display(Image(data=f.getvalue()))"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 2,
- "metadata": {},
- "outputs": [],
- "source": [
- "# load object, attribute, and answer labels\n",
- "\n",
- "objids = utils.get_data(OBJ_URL)\n",
- "attrids = utils.get_data(ATTR_URL)\n",
- "gqa_answers = utils.get_data(GQA_URL)\n",
- "vqa_answers = utils.get_data(VQA_URL)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 3,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "loading configuration file cache\n",
- "loading weights file https://cdn.huggingface.co/unc-nlp/frcnn-vg-finetuned/pytorch_model.bin from cache at /home/eltoto/.cache/torch/transformers/57f6df6abe353be2773f2700159c65615babf39ab5b48114d2b49267672ae10f.77b59256a4cf8343ae0f923246a81489fc8d82f98d082edc2d2037c977c0d9d0\n",
- "All model checkpoint weights were used when initializing GeneralizedRCNN.\n",
- "\n",
- "All the weights of GeneralizedRCNN were initialized from the model checkpoint at unc-nlp/frcnn-vg-finetuned.\n",
- "If your task is similar to the task the model of the checkpoint was trained on, you can already use GeneralizedRCNN for predictions without further training.\n"
- ]
- }
- ],
- "source": [
- "# load models and model components\n",
- "frcnn_cfg = Config.from_pretrained(\"unc-nlp/frcnn-vg-finetuned\")\n",
- "\n",
- "frcnn = GeneralizedRCNN.from_pretrained(\"unc-nlp/frcnn-vg-finetuned\", config=frcnn_cfg)\n",
- "\n",
- "image_preprocess = Preprocess(frcnn_cfg)\n",
- "\n",
- "lxmert_tokenizer = LxmertTokenizer.from_pretrained(\"unc-nlp/lxmert-base-uncased\")\n",
- "lxmert_gqa = LxmertForQuestionAnswering.from_pretrained(\"unc-nlp/lxmert-gqa-uncased\")\n",
- "lxmert_vqa = LxmertForQuestionAnswering.from_pretrained(\"unc-nlp/lxmert-vqa-uncased\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 6,
- "metadata": {},
- "outputs": [
- {
- "data": {
- "image/jpeg": "/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAgGBgcGBQgHBwcJCQgKDBQNDAsLDBkSEw8UHRofHh0aHBwgJC4nICIsIxwcKDcpLDAxNDQ0Hyc5PTgyPC4zNDL/2wBDAQkJCQwLDBgNDRgyIRwhMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjL/wAARCAGPAlgDASIAAhEBAxEB/8QAHwAAAQUBAQEBAQEAAAAAAAAAAAECAwQFBgcICQoL/8QAtRAAAgEDAwIEAwUFBAQAAAF9AQIDAAQRBRIhMUEGE1FhByJxFDKBkaEII0KxwRVS0fAkM2JyggkKFhcYGRolJicoKSo0NTY3ODk6Q0RFRkdISUpTVFVWV1hZWmNkZWZnaGlqc3R1dnd4eXqDhIWGh4iJipKTlJWWl5iZmqKjpKWmp6ipqrKztLW2t7i5usLDxMXGx8jJytLT1NXW19jZ2uHi4+Tl5ufo6erx8vP09fb3+Pn6/8QAHwEAAwEBAQEBAQEBAQAAAAAAAAECAwQFBgcICQoL/8QAtREAAgECBAQDBAcFBAQAAQJ3AAECAxEEBSExBhJBUQdhcRMiMoEIFEKRobHBCSMzUvAVYnLRChYkNOEl8RcYGRomJygpKjU2Nzg5OkNERUZHSElKU1RVVldYWVpjZGVmZ2hpanN0dXZ3eHl6goOEhYaHiImKkpOUlZaXmJmaoqOkpaanqKmqsrO0tba3uLm6wsPExcbHyMnK0tPU1dbX2Nna4uPk5ebn6Onq8vP09fb3+Pn6/9oADAMBAAIRAxEAPwDA1q3ik8VajNKu9V8pQvHUoDn9KbHZWxCgwpl84+UcVpz6Ne3/AIvvjbywqrxoxEhPZVHTBrTi8HaoRgXFp/303/xNdrnCPKpLov636r7iDn1srXA/cJnbn7op4srXk+RHjGcbR6/SumTwPqpx/pFn0x99un/fNWI/Auq4P+kWfTA+dv8A4miNam3Zr+vvCx55qOmW0944WJQ4ij2YAAGWbP6CmTaZZxwtttFO+ZfLyQMDZnk4zjOfyrtrr4da1Lq0Zi1CziZ4tpGGYEcnutOPwr19txbWLNt3qrHB9RxweTyKzVak3Ll31X9a+noZxfM3Z7M4w6RaQy4URqxRkYIwIPBBwDyP1rF162gJ8qNcDbGm44z2H4cV6efhVr7bd2sWZK9G2tn8TjJrG8R/CnWbXRrm7a/tZ2Tb8q7gT8wHGRinKUJSSpx3f9ItK2rZxV9Z211HeWwREFrMFQiILsX5sjI5bgZ59Kj0SCGOZEEgNvJliDApLEYBUknK9uR612a/Dnxnf21tOYrXBAkBDoN+R1YZ54P61Inwy8ax7vKgs4wc4Csnyk9SCTkH8at1YKrzdvLz/pDtocbZWkUcUiuIzAFZ5N0I3PnPBbqGyDwPSs+30W1lklhDF5hB5qKFwM4BxnPpn/PFehR/DHxtHbrbiK0MSqVCsY269TknOaU/CvxfBOsltDarIqIolEik8KOOTjqPSo56b5ey3/ry6BY4+LQbSy1OCaLcVS5gWMk9Tvwx/MfrTU0WwuLwTWv2iMLcPHJj72euQR0Fdmfhl43aKOMRWo8tw6sJFzuBBzyfUUifC7xnG+5be0ALmQr5i4Lnq33s5/Stfb0dktN/61FZnHS6HYywafAyGKTY2WBHzAFyeuME46k8cCqF5pun2tutwkUchZthi88OF685XFdrefDnxRp1nF9qn0+zgSX928txGgDcnaGZvqcfWqLeENSlGJtV0CRePlN7AoyO/wArConUhKOi1/4C/rzuO2pjixt/tX9lJCgtmt9+4qN24jOc9fbHSo9KsrVXlmWK1jVcIJTlwrZHBDZ5PqB61vHwrrBi8v8AtzRfvbt32+Dd1zjO7pnnFOXwrqaODHqnh9F43Ri9g2t06gv7VXtYcydvw/rYLGNNaJb37SRW0EYZsyFkBCqAMtznaDntz0ra8N+HbC8068uDEHHnFo9wOSCAcde2G/KsKe3137ZcQxXdgV8xhhWikVyuckE5zj2NaWhXmvabBFBA1lLtle4CqyHzA3BBAP3eD0x1NKVWN9G1v/Wn9XGovqdUfDOkCBYHgiVhctGHCZJOF6nPTNNt/DWlN5az2se3E3CpyCq565BP/wBb3rGtL7Wp0hBv7EML5V+aWLJZ/X5hwNvt160y31nW5r6KGO601mV5Dh54wrBh8wY7uAAD0IqfbO+7/EfKbUPhHT50V47QkOSIyIyRx/eOeP1qC10DSmaR5LJGWNC+3JGeg9fes6bWNUtkXfJpE0UoLwsJ1IQZwQPnB69mz+tQpf6vp/lzvqemyeZHu8hpozvU8YOMY/MGl7V3Vm/xDlNe60DSlMTpZIqyRh9uScHJHr7VNceH9HaDdb2NsVULuKs+4HHOcnHX0rFm1HVriKe5W90tkRFXy0nQeSCRjGTz6dW6n601ta1i4hWK3/s+PewUtDIpMhHblj+QxR7WWvvfmHKdTZ+HNFl1qxENhbNbm8jQlGfOCw4OT9eleof8IP4a/wCgTB+bf414lZaxrM9zE8Eun2YgdZ/3Tod7KwH8THOM9B+VdMPHmugzJJr0KyoBhBDEeSQPm446+h5wO9N4iqn7s2vmw5E+qPR/+EI8Nf8AQIg/Nv8AGj/hCPDX/QIg/Nv8a89uvGPiW1vmtG1y2eQEgeXHGQ4Hdfl5FVf+Fha75vl/8JBaB87dpWHOfT7tH1mv/wA/H97H7Nd0emf8IP4a/wCgRB+bf41h+HPDOjyatrkTWS7IrgKih2G0Zb39q5q98Z67ZR7/APhKtLmAfy38kxHY/ocqPfkZHB5rN0DxHrTTXt1H4l0yB7u4ZY0laPdMy5Jx8pA+91OAa1hiq3JNOo+nV9xOmr7o9Z/4RPQ/+fEf9/H/AMaX/hE9D/58R/38f/GvNoPG2tXFs0kfizTDKqM5gIQPtXJJzs29BnGa7bSvEcV5p9mz+ItKe4khRnXz4927aCeB+NZqtXf/AC8f3spUovqv6+Rp/wDCJ6H/AM+A/wC/j/41Q1zwtosegai62QDLaykHzH4O0+9XP7S/6jOn/wDf1ar31yL2wubQ61YDz4mjyJFJ+YEdPxqufEfzv73/AJBKlFJvmX9fI4a08GaJd28Oy02verG9ufNb5Quzzu/TLMef7tRad4W0a9JDWFvHFctKbcmWYyhVzjbjK4H+11rTj8KyRCIL4vtovKDKilgCgOcgfNxnJ/Onw+GZreEww+NLaOIncUR8Ln1wGrJqr3f4k04xlFO6M3+z7X+y9vlcf2Js+8en2nOPzrMsLZdN8Pareaarw3qtEoliYh1QhycHqAWCA/l3rov+ETO3b/wl9nt2eXjcMbc52/e6Z5x61DL4Yk0+0ubi08X2sUqwuQYWCseOmQ1EYVW0r/n/AJF8i7ox7+MQ6tKsCBHEmSkYxtkPLAAdMNnitG/vZbnR7O7X7R5sNwV864m8xy2AflOB8ox05wTUeheGGl0aCT/hK7WLe5kKFhkMGOGPzdeTz71qTeGp55o5pvGtvJLGco7yZZT7EtxRUoTjNp/1+AKKt8SMXxBI82oxSysXke0t2ZmPJJiTJq/ZaPaXWmRziEmS4hMMQDH/AI+BvOevOQijHT56t3Xhqe+2fa/GlvcbM7fOk37c9cZbjoKZH4VaJY1j8YWiCN/MQKwG1uPmHzcHgc+1R7GX9X/yHyL+ZGdql/Y6RCLT+z1u4W1MQAGVlAG0KzDHOTjI7c9Kh0+8gsNRtgtgJXN3qNqWeRvmWKJSvAx13Efj9Kp6j4YM/iSLS/8AhI4ZRJALhHTkK4Ylm+912q3PWqz6DPNNpc0HiBUkvbhriEnqjYUMy/N95mBHHUqKwd1JoOUu6XeaXd6daXt3BaW6Xc0iSIXuGaFVxny9iMC2DnDnnI+tZWg6441C72Wf+kRWUs9vh8lmC5BAx125I7jFaU+jalZztMviS8inura4kuPMUwu5RSQXUOefc1zd9ozaffWssOspFKLeGVXT5GUlAcgg+/WhJvZisaPiDX5xaaPd3Fk5ubq0MkrM5y37x1Uk45JUKfpiuhvdVeXS7yxijlkuYLK1d7Zvlt4QTH88b92O4ZyB95uTisLVdCvozql5Prrsl46pBM5P+lITkYO75htAz17CnaTpNzcLBpVz4q8tlnMZsZzIfLC9lXoDnIxxjHvRZ2vcfKb91fT6fpVlLb2lvc2tjqiBTBeRuZBhcv8AKSeT26gYz0rU/wCFlN/0BW/8CP8A7CuT0LwvdQnTpI9QaeGC9MrNGh8mErjDuCehAzzjj16U7RbaW7vzZuY2NxE8cZYdHxlSOOOQB+NS03e0hqKOth+Ik1xPHBFoZaSRgij7TjJJwOq0i/EWV5vK/sYBs4+a6CgfiVxVMw263thd2qQqtxfQxRhVHyrG5DH6keWT9TVW0T7dPaSzQWwIvniISIAMm0EA8c4Pc889am0v5h8qNVviNKiozaG6q4ypM5AYZIyPk55BH4Uz/hZLf9AY/wDgR/8AYVm26S3NvoS3SxGyWNkkkEC/6wPJtUtgdfl4yM5z3zWfr0DRpagRSxT/AD72ltFtw4424VSRxzzxnimou9uYOVeR0/8Awn919m+0/wDCPTeRnHm+adufTOzFFv49vLxmW18OzzsoyRFKWI/JKxhHc+ULrd/xL/7LMW7+HzNhG36+Zzj8axdO064n1O3guSY4mxJISuCIgNxbp/dBNCjKz94OVeR2h8bag872y+GrkzoMtEHbco9xsyK09F1yTWbOSc2LQFJTGU37ugB9B61x1nJNqa6pNJDNc+dPG32W1ba4GWwc4PyqOMY7jpiuo0JbtzqjJcRMDfyHKjg8L9f5mhQlJ257DUY36fibJmf/AJ4tTTK//PFqQx3v/PZPy/8ArUwx3n/PVPy/+tVfV5/8/fwX+RfJDuvvf+Q4yt/zyamGVv8AnkaQx3n/AD1T8v8A61MKXf8Az1T8v/rUvq8/+fv4L/IOSHdfe/8AIguXYzQZQ/e/wqYu39w1WuVuPOhzIpO7jj6VKUuf+eifl/8AWrGnQnzz/edu3b0OajCHtamq3XV9vQUu39w0wsf7ppClz/z0X8v/AK1MK3H/AD0X8q2+rz/5+/l/kdPJDuvvf+QpY/3aYTntSFZ/761GRMP4l/Kj6vP/AJ+/l/kHJDuvvf8AkK1RsPelKy/31/Ko2En94Uvq8/8An7+X+Q+SHdfe/wDIfEv75eaglQeY/wAw6mpIdwuUDEHrTJR+8b6mnOjUjFLn/BHLJKFfZP3V37shMa/3xRQV+YfWiuDEVKtJpKX4I6acYzWxl6af+Kru/wDriP8A2WuvgPSuOsDjxXd/9cR/7LXXWx6V7WI+KP8AhX5HIjTi6VbjqnFV2PoKwAhb/kLwf7h/rWkBWc//ACF4P9w/1rSA4rGjvP1/RHNQ+Kf+L9ELWR4pH/FNXn0X/wBCFbNZHir/AJFq8+i/+hiu3Dfxoeq/M3exd0kf8Sex/wCveP8A9BFXRVPSf+QPZf8AXvH/AOgirtRV+OXq/wA2NBS0UuKzGGKMUUtAHnvxgGfCNoMdb9P/AECSvNG061VV3Wah2bCgSt+p/CvU/ivaT3nha1jt03uL1GIyBxscd/rXF6v4K12DRbuSa1crHEzbmmjyuB7GuuE6cKSc+77/AKee/lsLW5z32KzJVFsxvLFSDIcAgZ60R2Vk5QmzCq+QD5hzkdf5Gku/BNnYyXobVZpFsbgQzlbUZYtnBQb+funOSMds1D/whXkTyx3l28SrdtawvHFvDsMEseRtXDL6nnpXP/aWGlHRP/yb8Pw+RXIzLtZreB5ikZDpMXjHULuIyM/QUjw2EsrjHyJGscWSwHH075zWnaeASyQx3M7R3s8ssKxLCGUOhx8zbhgE9CAT7VY07wfBJZxyajFLtbTZJo/Jt03RuJmXnDLvOBkEnoQOwqpZhhI1OZRvZ+euvTv+o3CWxkGS3a4MoTINzHN8uT90e/1qpbxW0F0ZHGFcOhIzwGBUn9a1k8BySWy7ZGF3JC88MLQrtKLnAZt3ysQpIABHTJqHU/BclhDbiItcXEsMUzx+UqpGHQMRuLZJBOOmCOc9qn65h5LljH3vn9/p2/UXKyhLb2jQwW4ZHRNx3fMBk9h39OtSKIRZvDJceahTasJ3HYc9eeBjnpW8ng6I20dgdLT7Q+nvdG8835llCs4QLnbtwoXpnJzmsrSPDdwl8BdafYNG4I3XbuI075PlHd7d+tSsZCpFe78P3tf8Fpvv+Actioy26WDQNMzxnBjg3NhTnOeeB36etLaNa2scy42OuHjxk/Pgr+H3s/hW+3hOCDxJdW4srBrFtpilvpJQqggE7fLO7BzwWHTGar2/hAw+OIYUs1fT11FVCz7CWi8wcMO/FKpj4zjLljo/e6LS3+fS4KBnyPbM8nl5QNCyADPVm3H+eKrt9neB04JeBIxnP8JBx+ldNYeBo4tdtLiMx3dqLsxTxSQqqg4JGBk7lODjODx0FZ1p8Pbq70qW5VZ1mjjeTabceVheSPMDcHAz93HbNaf2jhV9nTS979X+H/DBySM92tJLm5Y+WUuDuYtuAxnocc9SOnpUEqxNfrdbFYptYFA20hQPU57d63LfwMtpfWCzuZbkywvLB5KmMKxBKli3JweRtx71Brfgeazu5MIvnPK7fZ0VQIkz8uTnqR2A4GOe1OOOw82ocvR2311/qz2/AOV7mZLHZeRLHG6us0yuSQw24zjP/fR6UWElnaqYt6IEkLOGQsxDAfcOPlOOO1dHa+C7U21pYy6aGnu7WSZrvzSGicb9ihQdpX5RnIJ+Y4IxXO6Nocn2+4WXSI75lPlrFI5A3Z4PysCehGAe9ZxxSqUXGMdV6d3rfz212t5hy2Yy1NvDbyqZWWJ1IaFWbDkjj29Oa7TwBpdhda/YieHzIihG0sRz5ZJ6fh+VUZvBtnZz6jdDTEuEhWBUtHmPlrK65cblYMQpDAc+nJ79J4K8EPD4wmeGGVNPjWOTPmKTGJImYL6nBOPwprMee6px1aXZaqzfnfVfeDhbc9G/4RrQf+fFf+/j/wCNIfDuhINy2QDDkHzH6/nUl5olvaRLKkkpO8Dk9jUdof3Df7xrKOLr+0UJ6X877EziuRtAvh/RJhvlslZz1PmN/jU0fhXQX6WK/wDfx/8AGnxn5BV61NdDrVLv3n95nRS9nH0RS/4RHQv+fAf9/H/xqrqnhTRE0m8dbEBlgcg+Y/XafeukHSqmrf8AIGvv+veT/wBBNVTrVOePvPddfNGlkc14Z8LaLP4dtJJLIM7BsnzG/vH3rW/4RHQv+fAf9/H/AMaXwn/yLFl9G/8AQzWzWmJrVPbT957vr5gkrGJ/wiOhf8+A/wC/j/40f8IjoX/PgP8Av4/+NbdFYe2qfzP7x2Rw2q/Drw/qWrws8U8X7rbtil46k55z61EfhL4a9b3/AL+j/wCJrsZP+QnF/uH+tWzWFOrNud29/wDI0klZehwR+E3hv1vP+/o/+JpD8JvDfre/9/R/8TXdmm1pzy7kWOF/4VN4b9bz/v6P/iaxPE/w50TStNintXuw7TKh3SA8EH29q9UrmvHI/wCJJD/18r/Jq2oScqsU2J7FY/D7Sf8An4vf++0/+Jo/4V9pP/Pxe/8Afaf/ABNdbiiuco5L/hX2k/8APxe/99p/8TSf8K+0n/n4vf8AvtP/AImutpKAOS/4V9pP/Pxe/wDfaf8AxNJ/wr/Sv+fi9/77X/4mutpDQByX/Cv9K/5+L3/vtf8A4mk/4V/pX/Pxe/8Afa//ABNdZRQBx8ngHSgf+Pi8/wC+1/8Aia1tJ0i30W0e2tnkdGcyEyEE5IA7Aelakn3qiNADDTTTjTDQAw0w080w0gKd1/r7f/e/wqY1Dd/663/3v8KmNYU/4k/Vfkc9H+LU9V+RGajNSNUbVsdIwjFMIp5phFAEZqNgKlNRsKQEcfN2n0NMlH7xvqafH/x+J9D/AFpJRl2+proqfBEVT+Mv8K/NlfHzCin4+YUV42O+KJ10NmYFtNHF4ruvMkRP3I+8cf3a6i2vrXvcw/8AfwV5X4ltluPGcxc4jS2Qt/IVDFp9qw3EYUttU88/rXvVYczi/Jfkec6lrr/M9thv7Pj/AEuD/v4Kux6hZf8AP5b/APf0f414emmW3AZMMSRjJ7fjUiaZaHGE4Oe57fjUexf9WJ9sv6ue0NqFn/a0Dfa4MBDz5g9/etIajY/8/tt/39X/ABrwQ6Zam4UiP5dpPU/41ONNs8cxdvU/41nSoWcvN36GNOXLzPu/8j3b+0bH/n9tv+/q/wCNZPii/sm8OXird27EhcASg/xD3ryD+zLTH+p/U/41U1TT7VNOmKxYIx3PqK6KUHTqRk11RsqnNome76VqNiukWQN5bgiBMgyr/dHvV3+0rD/n9tv+/q/414Fb6bafZogYQTsXJ3H0+tSjTbP/AJ4j/vo/41NSC9o7vdv8wjNuN0j3n+0rD/n9tv8Av6v+NH9pWH/P7bf9/V/xrwcabZ5/1I/76P8AjR/Ztn/zxH/fR/xqHTX42Gqj7dLnvP8AaVh/z+23/f1f8aP7SsP+f22/7+r/AI14N/Zlp/zxH/fR/wAaU6daFi3kjOfU4p+xdrk+21t/mep+N76zk0WFY7uBz9pU4WQHs1aHiK9tZ/D2oxRXMMkj27hUSQEscdAB1rw3V9OtvsybI9sjSgDGeSe3XirU+nWqRMyxYI9zTxFN+wt2uOFW8kjT1XWJreK4ku7VlN9MJX2Qnhhk4GT0+Y1VPjdjNJI+nNLuk85VeE4R8YyPm9hwcjiszUNLtJbOIeT8zsq7txypPGevrXIw+Ur5aESeikkDP4Vz/VKPKrr+rL9LFKrNt2O5j8X3VvNBMbGSRopGlQshySxyd3/1qSPxpdRCFRpRkSOFodr7gGVmLHOOep7Y6CubawtvMZmREEUId0Z22qxIGCRz3+varOl28cc9yGjQAhGUIxK4IPIzzWtTB0lq0N1pSlZG1/wm18sOxNIjDqjRpKS25EbOVHbueTk89apXXinUbqRXbT1UrGkYxu6KoUdvQVL5UP8Ac/U0GKL+7+pqI0KMXdLX+vML1H2E/wCEz1gWvkjT4N4jMQmKMXCHqvXHcjpnHGarxeKdRick6TaSLtC7XSXGR34YHJ+uPapzFF/d/WozHH/d/WkqFFXst/67jvU8hD4y1d7iWa4060nL7QqvDIBGFGAF2sOMYHOelVD4r1/+1F1BgrSrMJtphO0kHOMA9KsMkY/h/WomVP7tJUKK2XS3y+8L1PIkfxxr3nwSxW1vF5UplZI4X2yORjLZY/kMD2qOLxrrsNksH2eF5FgktxO0T7wjhgf4tuRuJBxnpnI4qFgoPSomx6VP1bD7W/r7x81TyJG8X60yW5e2ja5gKYuSjh2CYwGAbaeABnGcd6qX/iXXNQhVJy+9HZllVSHCnnZnuoPTOSPXFOYioy1UqNFO6W39dxXqeRJF4s1uHTha+WHlSN4orpkbzY0bO5Rzt7tyQSMnBFVtH8R3+k30lzDYQyu0JhbzPN6k8vlXBD44yCB6DvSsxqtGx8yXnvWsMNRlTqadr/f6i5ql+hbi8R30FxcPHp0X2W4RVks284xcHIIJfeDn/a7kdOKj/tvV7i9urya5nieZgxCEooA6AD0A4FIjZBJNMmOYXPtWcKNNPmjv/XmJymrXSPqSKQz+FLKUnJMUZJ/Cqdqf3Df7xp+jv5vgPT39bdD+tR2v+pb/AHjWE/48Pn+hpL4Jf13LafdFXrQ9qz0PFXrM10S+JkUf4UfRGiOlVNW/5A19/wBe8n/oJq2OlVNW/wCQNff9e8n/AKCaqn8cfVfmiyj4T/5Fiy+jf+hmtqsbwn/yLFl9G/8AQzWzWmJ/jT9X+YlsJRS0VgMpSj/iZxf7h/rVo1Vl/wCQnF/uH+tWjWFLefr+iNJ7L0GmmmnEU2tiBK5nxz/yBIf+vlf5NXT1zHjn/kCQ/wDXyv8AJq3w38aPqJ7HS0UtFYFDaQ9KdTSKAENNp1JQA00lONYHiy+v7DTYX05mWd5wnyoHJG1jjBB9KTdlcDWbqajNeb/8JN4kZUcTSlXVnVvs64ZVzuI+XkDBye2Kc2v+Jo1heeSeKKYgJI9qoVs+hK81PM+wHoZphrhdR1nWrCKV/wC0/M2Xktrj7Ogzs2/N077ulJb6p4hubRJ11KFXlV3hhZF3yqudxX5cdj1Izg4zRzPsB3BphrgLLxBrl/M6LqCRrGhkkkkjUKijqThSfToD1qz/AGhrwnkV9Vt0gSJZjcsg8so3CkYTdyTjGM9fSjmfYZ1N1/roP97/AAqZq8+v9c1y31JLOScvOHAQRxo27OCpXA5yCCPrSjX/ABAwQhpyJGZUIt1+Yr1A+XkjvWMLqcnbe35GNONqk33a/I701Gxrjr/U9fsoY5xNPJbNDFIZxbKEUuobbnGMjOKUXfiOazuru3N08NsyK4a0Af5lLZwARgAcnPRlPeteZ9jY6w0w1w8uua9FbR3Mv2hLeT7krW6hW+hxg1YsNS1jUITL/aMFvH5giRp1ADueijCn8zgDjJo5n2A60mmk1xUeua3LqAsFlb7SZPK2GNBhs4OTjilutbv4Z44odUhvHc4H2eLOD6fMgz+GRS5n2GdhHj7WmPQ0kgPmN9TWbpMt5b+JzY6pMk5FqJR5WMAnGOQBngkelb7yWW5swydfX/69a1aj5Irlf9fMmetVf4V+bM0jkUVoK1i8iqIXyxA6/wD16K8fHVPeV00dVF2TPLtYtLy58cSraxCUNbqrKWAB79yParMOgawDgWKYzkDzF4P/AH1WhF/yPr/9cf8A2UV1kZwwr6HEScHCz+yjgjGMm7rqchF4a1xtp+xA4Of9an/xVWofCmudPsIwAf8Alqnp/vV3Ns3StOE8VjGrJO9xypxatY8xPhTXft0afYRkofl81Pf/AGquDwdr5/5h4/7/ACf/ABVegk/8TaD/AHD/AFrWWs6Vabctev6IwpRi3O62f+R4BFqDzuI4rC6kfBO1ApOAMno3oKo6nqQfT5R9lnGccnZ6j/aru/Ddrb20dhstDLJcWk87XG5sqQJFwBnGBtAORnJqrrOn6XD4ckWWWESvZLOrgTGQyEBguAuzbn5fbrntXSpLnS8zp5YrZHL2N+8sMEUVhdSSFAAECknj03U/+1R/z53H/jn/AMVXb6VaWYutOnsIoktVcRFyZBKpMZIEgbjPB+7xxWPq9tFZ3KW8MZ2KgInJz54P8Y7AegH481Mql5Xf9fgJQglaxgf2sP8Anzuf/HP/AIqj+1R/z53P/jn/AMVXcTtIYbm0Of7Pj02KWNf4Q5VDuH+0XJBPuRVPw3b5u/tavAZopEWJJJUQ5J5bDEZwAencipc0/wDhylGK2Ryn9rD/AJ87j/xz/wCKo/tYf8+dz/45/wDFV2UNzNp3iW5RvtTRyXJBS1nChzuyAcAhhg/d96oxW0TeJTaXKRiNrloWCEhVJJUEewPP4VTqt73JVOC2Rxmr6rm0TFpOGEgILbeDz0w1W5tTDxEC0uBn/c/+KrqvEei2Nv4fknki2yW6JDJlz/x8Eocnnsrvx0+Srtxo9jcXM9l5BtUgvobbz95JkVn2knJxnA3DGBilVqc1K3r/AFsNQgndI4K61Jm02REtZxIE+Vjs4Pr96uXt3urMQXX2A7SGVJHB2uR1IOeoyOnTivYrfTLLUIYy+ntbASyxG3V2zKFjLBeSTuyApx/eHArlk02x1PT9EE9nHYwJHqE4gLSmOQpt6EbpNvGTjJ4bGOxGpZLy/rsDhDXTc4lryRSGW0UI6bXjzlWHB/vZ6gd6sWOpGOSV54mXcFVVTGABkY610U1n4fW2vb6K3t7xbfTFn8mF7hIUmNykfyl9rlSrcgnuQD0I57X7S0tNZgFvH5FtcW1vceWGLeX5kaswBPJAJOM84qpVL6MuUYqV7F3+2IP7sv5D/Gk/tiD+5J+Q/wAa2fE8txNbeJ7e7z9ksNQjj05SPlhXc4VY/RTGM4HXANZfhK+v7FWu5L2W30O2lEl1Gp+W5bj9zt6OWAxg5AGSajmj2DQhOrwf3JPyH+NXbcG6t1mTAVs4DdeuK1/C0oXTdJtxLLCb+4uTHaQx5guhgKEuGzwAR6NgHOF61yunP/xL4h9f5mmpQ6r8Rq3Y1GtZD/En51G1pL/eT86rM+aiZqvmp/y/j/wB+72LTWUp/iT86iawm/vJ+dVmaoi1Lmp/y/j/AMAV49i02nzH+KP86jOmzf3o/wA6qk0w0c1P+X8f+AK8exaOmT/3o/zP+FVYNPmeaYBo/lbB5+tRmoI/vyfWt6Uqfs6nu9F18/QTcbrQ0DpU/Z4/++j/AIU06bNtMZePJHrVPGeKe67I2ArKMqf8v4/8Aio42WnVH0R4e1WGPwJYWzrIZEgCkqMjIP1p1vqESLsKvkn0p/gV/N+GNgfSFh+tTWn+pP1/pXLOVP28Pd6Pr6eRcnHklp/Wo06nCjFSkhI9v/r1btdZtl6pL/3yP8aF6VfsetdDlTv8P4/8Aii4+yjp0QDXrXH+rm/75H+NVdU1y1bSL1RHNkwOPuj+6fet4dKq6sP+JNff9e8n/oJq6cqfPH3eq6+a8i2422Of8L63bR+HLRGSYkBuij+8fetj+3rX/nnP/wB8j/GovCf/ACLFl9G/9DNbVXiZU/bT93q+vn6Ci422Mn+3rX/nnP8A98j/ABo/t61/55z/APfI/wAa1aSsOal/L+P/AACrx7GE+sW5vo5Qku0Lj7oz396n/t21/wCec3/fI/xq1L/yE4v9w/1qyawoyp3n7vXv5LyLm42WnQyjrlr/AM85v++R/jSf25a/885v++R/jWoaK35qX8v4/wDAIvHsZf8Ablr/AM85v++R/jXN+NNXt5tGhVUlBFwp5Ueje9dvXMeOf+QJD/18r/Jq2w8qftY+7+P/AABScbbGn/blt/zzm/75H+NH9uWv/POb/vkf41p0lYc1L+X8f+AO8exmf23bf885v++R/jSHW7b+5N/3yP8AGtQ0ho5qX8v4/wDAHePYy/7btv8AnnN/3yP8aT+2rb/nnN/3yP8AGtM0lPmpfy/j/wAALx7GZ/bVt/cm/wC+R/jXP+K9cijs7GeJJN8F7HLyBzgMfWuzxUM9pb3cfl3NvFMgO4LKgYA+uDWVadNQbUfx/wCAF49jy7UPEWkCwvra0ldhAohsf3ZG5H2+Yeen3Dwcffpk+saHDpc8NtMhMjQOgCzGQ7T82/d8uRk/dH416C2i6V/0DLP/AL8L/hUZ0bS/+gbZ/wDfhf8ACnePYWh5lrWtWN1bzrBIzltTuJwNhGY2C7W59cHjrVuw1GxEOmXklxsmsIXj8goxMpLOykEDGMvg5I6d67XUdH0xbGUjTrQHjpAvqPanQaPphtoidOtPuD/lgvp9Kcork5l3G1pc890ae2srl5JLiFXltmWN3jZ0icnGHXHzDaD0DD5h7ir13qNhfNd2rXkaedBCDc+UwiMkfYKBlVweML1HQCu1Oj6Z/wBA2z/78L/hTDpGmf8AQOtP+/C/4VmSeZa1fJPrMU9ozbIVijjcjBby0VQ2Pfbmulvdf0pkvVt5DhIme0Gwj95LvEg6cYEvU/8APMe1btzpOmiaDGn2nLf88V9vapTpGm/9A60/78r/AIVlCV5yXp+RlTlec12t+RxU2r20jzKbgmM6RHaqCGx5gVMr0/vA89KL6/sb6DVIVu0jMrWssbOj4fy4mVl4UkHLcZwOOtdkdJ03/oHWn/flf8KYdJ03tp9r/wB+V/wrS5scnrOs2d3Z3j2v2JDdrGGj2z+cu0ggckxjGMZHbsM1n6fNYz6VHZXd2LUwXf2gMUZt6lQGA2g/MNoxnA56iu5Ok6cOmn2n/flf8KadK04f8w+1/wC/K/4UXCxxdrq8EXir+25CoSW7ldodpZkV884xtP3jxnt9Ksy63awSWT3Nw+q3UHnE3UbNGyhgoQBnXJK4YjI4LDHSuoOlad/z4Wv/AH5X/Cm/2Vp3/Pha/wDflf8ACi4WMjSrzT7zxPbNYLMFj01I38x92CoUY+6Onc9633++31NQ2tlaW9+rQW0MTFSMpGFOPwqeT75+tbVF7kSZq1Zf4V+bEh4uIv8AfH86KWH/AI+Yv98fzorwcz+OPp+p1UtmcdF/yPj/APXH/wBlFdWtcpD/AMj4/wD1x/8AZRXVrX0WL3h/hRx0936mhav0rVhPSsSBsNWtbtwK5kWybP8AxNof9w/1rXQ1jA/8TWH/AHD/AFrYjPFZUd5+v6I5aHxT/wAX6I4TRPBd5/Zzxxa/PFF5hzGkZCk4HON9R694Mu7LwzdomvT/AGcAZhEZCnLDtvxXZ6D/AMeT/wDXU/yFR+K/+RZvPov/AKGK9JRX1lR6XX6HTU0bOdtPBl/eafYzzeI7l2EKshdGYplR0JenN8O5HjSNtaYomdimAkLnrgb+K67Sf+QNY/8AXvH/AOgirtc9RWm15v8ANiucQfAFy1sLU69KbdTkRGE7QfXG/FNb4dyvKJW1t2kGMOYCSMdOd/bAruaWoA4uLwNfQeZ5PiK4j805k2RsNx98PzVcfDYhgw1cgg5yLfp/4/Xe0HPagDyrxf4LuLfSA8mtSzCa6VnVoz8zYb5j83J68+9a+o+A7l7ALLr00scQGxHiJC89hv4rX8d/8gOD/r5T/wBBat7UP+PKT8P5iniNMNzLf3gW5xq+Bbu6EEs3iCeSRFGxnjLFfoS/FeQ+LrDVLDxbcwz61dzS28u+GV3bcpIHK5bg8Dp6CvpK34giP+yP5V4n8XLT7P4tjnAwLiEHPqRx/SohrFBfU4vU01G5jjlutYurh7iIJK0rsxdQQwUktyMgHB7jNZ0tjLcMrTXjyMqKilwThQMADJ6AAACte/b/AESz/wCuf9BVEPxW1RJSsvL8jeskp2Xl+SEmXULmG3in1a6litv9QjuzCL/dBPy/hVi2vdcshKLXxDqMAlkMsgindd7nqxw3JOBz1qHfS76gzGwtqVtbzW8GsXcUE5JmjSRlWQnruAbB/Glt4/IgWLdu255xjvRu4ppagZKWpjNUZamlqBDmNRk0E0wmkICaYaU0lAhpqvH/AKyT61YNQR/fk+tdFL+FU9F+Ynuh4OCDTj86N25pv0pwOIz9ayhuyKmy9UfQvw0fzPhnbD+75i/yq7af6n8azPhQ/mfDlR/dlkH6CtO0/wBRj3/pXLP+PD5/oXL4Jf13LI/Sr9j96s9TV6xPz10S+JkUf4UfRGuvSqurf8ga+/695P8A0E1aXpVXVv8AkDX3/XvJ/wCgmqp/HH1X5oroUvCf/IsWX0b/ANDNbVYvhP8A5Fiy+jf+hmtqtMT/ABp+r/MFsJQaKSsBlOT/AJCcX+4f61aqrL/yE4v9w/1qzWFHefr+iNJ7L0ENJS0lbECVzPjn/kCQf9fK/wAmrp65jxz/AMgSH/r5X+TVvhv40fUT2OlopaSsBiGkzSmkNACUlKaSgBKDR3pD978Kyr/w5DW5UaozUjVG1aAUdS/48Jfw/mKdB/x7Rf7g/lTdS/48Jfw/mKWD/j2i/wBwfyrV/wAFev6F/ZHGmGnmmViSVLr/AF0H+9/hUpqG6/10H+9/hUxrCn/En6r8jno/xanqvyGHvUbU8jmmGtjpGn60w08mmGgBhxTTinHGaacUANT/AI/E+lK/32+tJH/x+J9D/Wlfh2+tdFT4Iiqfxl/hX5sIf+PiL/eH86KIOLiP/fH86K8DM/jj6fqdFLZnhdje+IJZbjU5bp0kW18xGEi7jyAMrnIBBOOmanOueMERWN1J8xAwHBYE9MgHIz71Auq2T288v2s5lsliEJZdqsNoOOc/w+g/Grt3r1pMu+O6A8yRGKgRALhgeo+bt3r15SqN6r+vvPKjKrfb+v66j7fXPFG+dZ9SYGOB5F8uVW5XscE/lULeLfGNvII31CVXwDt3DIz688H2qX+3rCC7ScTrJIsUgLMUGScYGFOOx96yL29tWvvOhuFKthgGcfKfTr0+tEHK/vL+vvLpuo5e8tDo7zxB4stQ0ya3JJLAwjlXGNpOeh3HIzkcgVLpnirxjfkqNZulfOBtQMoHqx3ggfgaxrvUtOK3TQ3ILXkiswLLhBkk459T3xUdjd6bbzGaS6JaJsqqlfnHbndx+tTHmUHpr/X9ehEVP2b7+nkv1/A29J8SeMJreZYdYuUZGbO1AYwQO7buOnoaoXXjPxne2U8UmpSyRBdzqW7Aj3qtp2oaavl3ElwqNG7MYgV2nJyBnOcduhqKyv7KK6HnzR+RIGjkAcfdYY/rW3PJTckv6+80fPeT3NiPxb48tokhGoTKI1RQoYcAj5R1qRvGHj9JEQ6nKWckLtkDDI6jIPaqr+IbN1t5fOj8wTh5PnHKgkr/AOhGmpq+n25jjF2JFLuWZnXIDKV4wT6//WFZ89TrFX/rz/4chSrW1j/X3/8ADlz/AITHx95oj/tSQll3AiQFceu7djH41Pc+LfHEbwJFq0xZoBJIWkG1TkjrnGOn51mLq1girb/awV8p0Mpdd2SQR3x29akGtWCShBdJt8hU3koxyGJ6E471LlUvpH+vv/ATlVvov6/roWl8X/EBi4GpyjyyFYtIoAJ6clu+Kjj8beO5Ltbb+1pllL7MM3Q5xzzVC61i2eK4CXSbmkjw25ASFVh/Ccdx0qOTVbRdbN2k8RQTB8FxyM5qlKdndL+vmXF1GnddPxLviDxR4qexiL61Lcwebj5htIcD03Hsf/rCr0HjHxddW53a9MZdrN5TKCvAJwTuz0HpXO6ldae1nFaQ3QKNceYzFkJAxgfxY/Mj8KtW99p0ensv2wRyuGEjDYxI7KPmyPyond0+Vrv/AEw9/l63v/VzaXxX4ya1Drr0om8nzhEAMBeuM7s5xz0x71L4zs/EU+gaLq+qTPKs8KFXL5+8ob+8cda5+31m2t9NK/a1eVozEFOwbQevzZyRz045r1LxXLY3vwd0ry7u3aaC0t2CLKpP+rXtmrw8+W/NFP1v/mhwjNt8x5Fdx3q29sXkbaU+X5u3HvVXZdf3z+f/ANetXUpF+x2HzDBj9fYVnCZe7L+dddStBS+BdO/b1OutStPr0/JEe26/vn8//r0uy6/vn8//AK9S+an98fnR5yd2X86j28P+fcfx/wAzL2b8yHbdf3z+f/16Cl1/fP5//XqbzU/vr+dJ5y/3h+dHtof8+4/j/mP2b8yHZc/3z+f/ANemE3COmSTk9zVrzE/vL+dQzOhki+YYz61Mq0LaQX4/5kuDXcdvn/uL+dJum/uL+dPLqP41/Ok8xP7y/nWn1mP/AD7j+P8AmVyPzGbpv7i0hab+4Kk8xP7y/nSb0/vD86PrMf8An3H8f8w5H5keZf7oqKMyb5MKOvNWN6f3l/OoI3UPJyOvrXRSxEfZz/dx2Xfv6kuDuhxeRBkqMVKeIz9aimdTGPmHX1p5dfKY7h19azqOEqUZqKTfNt5W8yJp7eaPe/g62/wFMv8AduHH/jorYtP9R+Ncv8G9StIPCl7DPdwRkXBIDyBTyvvXQW19ZqmxrqAMW4BkGTXlzf7+Hz/Q1knyS0/rU0B7VdsM+YayDqNkjYa8t1I7GVQf51bsdU08SHN9bD6zL/jW8n7zIoxfso6dEdKvSqurf8ga+/695P8A0E01NX03H/IRtP8Av8v+NVtV1bTm0e9Av7Uk28gAEy8/Kferpv34+q/NFcrsN8J/8ixZfRv/AENq2q5rwrqmnp4as1e/tVYBsgzKD94+9bH9r6Z/0EbT/v8AL/jV4l/vp+r/ADBRdti5SGqn9r6Z/wBBG0/7/L/jSf2vpv8A0EbT/v8AL/jWNx8r7BJ/yFIv9w/1q1WXJqdgdQjkF7bbAuC3mrgdfepzq+m/9BC0/wC/y/41hR3n6/ojSadlp0LZpKqHVtN/6CFp/wB/l/xpP7X03/oIWn/f5f8AGtiOV9i3XM+Of+QJD/18r/Jq2v7X03/oIWn/AH+X/GsLxpNHPoFvJFIkiNcrhkOQeG71vhv40fUmSaR1NNpeKaTWIC5ptBNQT3EdvGXc4ApATGkNVIL+KdcowNTeaP7woGS5ppP7z8KaJFPQg03fmY/Ssq/8NjW5AxqM04mmE1oBT1L/AI8Jfw/mKWD/AI9Yv9wfypupf8eMv4fzFLB/x7Rf7g/lWr/hL1/Qv7Ip60005qjJrEkq3P8AroP97/CpjUNz/roP97/CpSawp/xJ/L8jno/xanqvyGseKYaeaYeK2OkYaaTz0p5NRmgBD9KaRSkU2gBqf8fkefT/ABok++31oT/j7j+h/rRJ/rGHvW9T4Iiqfxl/hX5sWD/j4j/3x/OilhwLiP8A3h/OivBzP44+n6nRS2Z8+6bpNpvCzDfJ5O5l5AGSMc5681q/2FYDrb/XLN/jTNCs9QvZYY0tkZ3hI37gCQDj1x2rox4f1Y/8uYz3PmL/AI17VeM4yV+yKjPDuNkvz/q5hLoen5I+z547s3+NKmiabuwbcH/gbf410I8Pav2tAP8Atov+NOXw5q5b/j0/8iJ/jWcb31FVlScbQ3MNNC00yqv2bg8n52/xqZvD+lg/8e2OM8O3+Nb8fhnWTcIos+SP+eqe/vWing7XX6WR6YOJo+f1qI3aaXcUK1F1XLovL+umn9XOOtPD2mOFLW2csRje3p9adqPh3S47GRo7TDAdfMbj9a6zTvB2uzwl0szgOeksfXHuak1fwnrtrpU872ICptyTKh/iH+1XWoS9rZLW/wDkTOULxu9Ounn+OhyMGgaT9nTfZ/MEyx8xuwHvUp8PaSuQ1jg8YAlc5zx6111l4J12WyhlFgSJIV/5bR8jH+9U/wDwguv4ObFiTxkzx8f+PVjKM02mac+HvotPn/X+fQ4r/hHtJHymxG/OMea+P500aBpIB3Wag7sDMrAD8c13H/CC6/j/AI8WznO7z48/zoHgTXwOLFs5znz485/OptManQSs/wBf6t+JxI8P6Q23ZYgkg/8ALZu3404+HtI8gyCz/hyAZH/xrth4H8QBgxsCSARzNH/8VSjwNr4j8v8As/K4xzNH/wDFU0pdTOU6N1ZdV93X9DzfVtA063t12W/JYc729/ertx4e0pB+7tcbTyfMb/Gui8ReD9bstPjlmsjgzKuWmQ9jxwa07vwProgaRtNAIwc+bH/8VTqpqjf1HGpS9peWunbr3scUPD2lM0X+icHg/vG5OM+tes3Pg7SJ/h6BFZhZf7PRlbex52D3rnU8Ca60cb/2aOgbPmx88f71eo2Fo8ehWlnOu2RbVInXOcEKARRTTtqZ1qkWo+z001Pl7UYV+xWCleRHj9BWb5Mf939a6PxJbfZrpbfGPLZ1/IisPYc1vVS5/u/JFVpy59+i/JEHlR/3f1p3lR/3f1qXZS+WaysjLnl3IPJj/u/rSiGL0x+NTbDUdw3kQNJtzt7dO9FkCnJ9Q8mLHC/rUEsUYePC9T61B/aR/wCeB/76/wDrUn2uSaQbLfOwFyN3Ydal2sNqo9F+Zd8mM/w/rSmCPqF/WqsV9JLIEjtiWPQbv/rU6W+kgfbJbYJGQRICCPUEcGneOxXLVtzdCbyY/wC7+tVry1MwhhhTMkkgVRnuc1N505haZYIyiruOJ1JA+nXvUE11c24hulgQiKRX4kDfgQORmtKMoe0jfuOVOty63FbR4zZw+TJFLK87L5iOdoAUE5zjGOTnFV10dmfKzwtDsL+cC20AHB4xnPI7d6sx6qbe1imtLNokinOd0pLEsuDyAMcDrTH1J28q8cXzIGaNd14TIrcEkHbwOfSu9VqXK9e39bGPs59vMamlLLYsYijus+0zbiECbcknPQfhmoLKzjuJ2jdz5SKzuy9Sqgk4z64qd9fkYSr9jHlTSBpELcOoXGDx14zn15qva3D24kvEg3Qq3lNGzclXVhjOPQHn6Up16doWemtyeSb2Op8P6Fp97ZNOPPCN0VnBKnJBGQBnpnp3q6uiWUv70iUMmOd3HX6VleH9cmihkhtNKmkhTAADkkck5Y7ff26VoSaxeRKI/wCxpyRzlJNwJ/Ba53VXtb8y2f36baadynTm4N20JpNBsJt0rCYMSB9/j+VEPhqxc8+b1x9+oW1bUPs6v/Y8oUdvM5/LGafHrV/Egb+xpmD9AHyR9QBkU/rEXNJvS3Tvv/wAjRqKF7dC6PC2nY/5bf8AfdMn8MactvIwMoIQnJfgcfStoWviA/8AMs6n/wCA7/8AxNR3NtrotZjJ4a1MJsbcTA4wMc87a1VWlzaSf4/5bfiHJMxbLwvYm0jMok385w/HWrB8L6aSSBKM9g/Sr1hFrs1jHJH4c1F0OdrJA5GMn/Zqz9l8Qf8AQs6n/wCA7/8AxNXKrS5mm3v5/wCX9dRckzI/4RbTv+m3/fdJ/wAItp3/AE2/77rY+y+IP+hZ1P8A8B3/APiaT7L4g/6FnU//AAHf/wCJrD20eZWf9W9O4+SRjHw9YqwhHm7G5Pzc0v8Awi+nf9Nv++//AK1abWuvfaVz4b1PdjgeQ/8A8TUhtfEH/Qtan/34f/4mohWXNN82l/8AL+vuKlCWhU0rwlpk+s2MLibbJcRqcP2LAelepf8ACsPDvpd/9/v/AK1cFpaa7b6vZTN4a1ILHOjnMLgYDA9dtemf8JJqX/QvXf5n/wCJq62KcZ/upWX9eQRpTa/4P/BMfUPhtoFvp11NH9q3xwu65l7gEjtXP3nhixTwTp9yJbje8+CN4x1f29q63UvEOoPpd2p0C7UGBwWJPHynn7tcpeaxeN4KsITpE4RZ8iTJweX46UUMZV9rG8nb+vIt0JOD/wA1/mdifBGmY/195/38H+FNPgrTB/y3vP8Av4P8KU+JNRH/ADL93+Z/+JqJ/EuoDOdBuh7kn/4ms/rtb+d/18iPq8u34r/MyvEml6H4Z0aXUruS/dFYIqowJZjnA+7x0rw+/wDEd/PftcxyMsecLAWyNvoff3rZ8deNbzxTqTQqzQ6dA2I4A2dzDqzeprjWI7mh42t/O/6+Q/q8u34r/M34fGEbJmG0mVx1zMMZ/Klj8XT+cDPbs0XcJLhv5VzQAV+CMGn4B70vrtb+d/18g+ry7fiv8z13S206/so7y2ublo3H3S4yp7g8V2nh/RrCT/SI5bgsyYILg46e1eEeG9WOm3jQyORbzcH/AGT2Ney+E78rdFM8eWT+orKviq7pyTkzNRSZqDwfpxH+uu/+/g/woPg7Tv8Antd/99j/AArahl3oGHcZqbPArf63X/mYuVHK33hGwSzkYTXWRjq49fpTovCOntbxkzXWSgP3x6fSt3Uf+PGX8P5ilg/49ov9wfyrR4qv7JPme/6F8q5djBPhDT/+e11/32P8KYfCVh/z2uv++x/hXRNUbVj9br/zsXKjnJPDVlCyIstwRIcHLj/ClPhOw/563P8A32P8K2Ln/XQcfxf4VMawpYquqk3zPdfkc9GK9rU9V+Rz58J2A/5bXP8A32P8KafClh/z2uf++x/hW+3SmE5rf63X/nZ08qOa0m1Sx8TXdtEzsiQDBc5PO010JPHWsW2/5HC+/wCuA/8AZa2feni25TTe9l+QR2EzTTnFKcfjSE1ylDE/4/E+n+NLIMO31pE/4/E+n+NK5+dvrW9T4Ik1P4y/wr82EGftEf8AvD+dFLD/AMfEX+8P50V4OZfHH0/U6KWzPL/BX/H/AGn/AFwf/wBCNd70bFcH4J/5CFp/1wf/ANCNd64wc19Jj/4kfRHHR6+pKpqZTVdDxUymuG6WrNi7bP8A6ZF/u/410MDdK5i3fF5GSeAK6C3mQYy6/nWVCcbz1W/6I5KKfNP/ABfoibQD/ob/APXQ/wAhR4p/5Fm8+i/+hiotCljS0cM6j94ep9hTvE8sb+GrxUkVmIXAByfvCvUjUh9bWq+JdV5eZ0VFqzT0j/kDWP8A17x/+girtZ+kzxLo9kGlQEW8YILDj5RV37RD/wA9o/8AvoVzVJw55ard9V3ZKRJS1F9oh/57R/8AfQo+0Qf89o/++hUc8e6+9DsSilqL7RD/AM9o/wDvoUfaIP8AntH/AN9Clzx7r70FjnfHf/ICg/6+k/k1b+of8eMv4fzFc744kSXRYVjdXP2lThTns1b1/cQtZSASxnp0YeoqsTOH1Xdfa6oIr3izB/x6xf7g/lStxg+lQwXEItYgZo/uD+IelOa4hI/10f8A30KinOPKtVsuq7A0eAfEG08nxRcoBhfMcj865PyOelegfEtAPEEcwIKybxkeuRXGhQDXRVacrry/I1rfH935IqC3p32aryqvWpViBHAqDEzTbmqWpQhLCQsOAVz+YrofI46VU1C2V7KRXXKnGR+IpPYqGs0c/JukvEJulFvvJi2uPlHbA/h7CnvMEuISk+2V4ZELGYE57ZYYFaaaRaeSh8nkqP4j/jVO7022SeACLgt/ePtWTp6HW8Y4t6de7/r07GTbHbdSCVxudHTeWyMkEZz9e9Jcp+6ghDozRIxYhwQMknAPf8PWtSW0skbb5ZLeikk1A1pD2tW/Fj/jV8utzBVvccLf1e5Q3LFpxVWBeZ/mAPIVen5k/pSy7otMljklhwdpQRlSzHPfHOMZ6+1WjawjrbsPxNUroWqYXy2z16n/ABq6UVzq7tqONV7JdLf1+ZNZySLYSJBcJFKZlPzOFJXBzyacZLeSUCOZYk+1yMCpAIGFwfYEjrVUvaf88n/P/wCvUINtub923Xjn/wCvUxhFxk7/ANXNlWqKKjy7f18jTmmi8yJhMouTC6h3mVyrZ4yw4zjOD9OaZbzqkFwLuZHmMqbXLhwDtbDHHUDj/PFZrNb9o2/P/wCvT99t5RHltnPXP/16fs4+zXvdxyxNXm5uT+np9/mdP4LLtJqSu298qSQ27Jye/et6PgN9TWb8NtU8Pabe351ixubiN0XyxCeQQTnPzCurGt+DkZt2lX/3iRg9v+/lYSt7SPzMrzVNx5d7/wBfgjHJqSBv3lara34NzzpGoA+h/wD3lTQ674Kil/eaPqPHUf5kq3a+5UHP2aTg9rff/Wx7dGflFV9W/wCQNff9e8n/AKCa4lPi5oCgf6Hqf/fpP/i6h1H4saFLpt1CLPUw8kLKN0SAcqcfx1tCUVNa9V+aOf2U7bHX+E/+RYsvo3/oZrZry3QPinodlodtbyWuol0DZKxpjlif7/vWl/wt7QP+fPU/+/Sf/F1WInF1pNPq/wAwVKdtjv8ANITXn5+Lugf8+ep/9+k/+LqxYfE7R9RnaGG2v1ZV3fPGuMZA7MfWseZDVGbdkjq5WH9pxf7h/rVgvXIy+MLA3qP5NzgL/cHv71HN4pt3kMga7SM9AFH8s1z05pOXr+iNp4erp7vQ68v700ye9cd/wk9r/wA9b3/vgf8AxVV5fFtmhw0l8PrH/wDZVr7VE/Vav8p1mrS/8Se+/wCveT/0E1xd+/8AxQGmj/p4/q9LeeKbV7CcB7pgYm4KjB4+tYWoa5D/AMItZw7ZRmVXAwMD73v71th6sVWi2N4eqoW5ep6jLNgE1geJdUGn+HtRus4Mdu+D7kYH6ms+bxhZkHEVx/3yP8a4T4ieJlvNA+x2/mp50g3luMqOcdfUCs+ePcX1at/KzzEEk7ic7uT9TUM4weh/CpYlYoMkU7y8rhiPejnj3D6tW/lZmyTtkALgZqa3dyfnx7U+UxohRVHmZ64BGKas8hbb5cQB9EGab2Ippqok+4NMoYgmvU/hpqr3d1tkJJSMruP8XIryRgTIR0yfpXpvgJ/J1VYgQQsB5HTqtZVv4bE/iZ7FZSZiUe1Xwaw9OkBhj57CthGz1rdmaItR/wCPGT8P5inQf8e0X+4P5UzUD/oMv4fzFPg/49Yv9wfyrR/wl6/oafZBqYae1MNYCKlz/roP97/Cpj0qK5/10H+9/hUp61hT/iT+X5GFH+LU9V+Qw0z6U9v0pnetjoMG2/5HC9x/zwX/ANlraPSsW248YX3/AFwX/wBlra78HiujE/FH/CvyFESmmlJzSdq5yhif8fkf0/xpX++31NIn/H4n0/xpz/fbnvW9T4Ik1P4y/wAK/NhDjz4/94fzooh/4+I/94fzorwcz+OPp+p0UtmeYeCf+Qhaf9cH/wDQjXfydDXn3go/6faf9cH/APQjXY6xqP8AZmnPdeX5u0gbd23OTjrX0uOi5VYpdl+pyUE5Npdy4j1OrAjrXF/8JZcC2F1/ZZEJcxhvP/iABIxjPQihfHBXJbTyFAyf33/2NediKM3RkvLyOn2cl/SO5jdRcJk8Y5ratvs7EA4J+tebweO0+zx3h0cG3LeUGN0PmYjP92pT42laVfs+jS/MQFUTEnPt8tRSwaTleC38vI56NKpzTv37+S8z0vRYIZbVi65O89z6CneI7aKHw7dyRptcBcHJ/vCuA0/4h3elhrW40GZZQ27a8pRhx6FKl134jXVz4cui3h+aO3O0NOZiVX5h1OzFelHC0vrKfIrXXReRtUpVLu35npWl2Vu+k2btHlmgQk5PXaKu/YLX/nl+pryyD4rz6bpNmZ/DtzHB5SKk0jsqPhR0JSp7f4wNdLut9I8wf7Nzn/2SsKmEhzv3Fu+3cn2VT+memfYLX/nl+ppf7Ptf+eQ/M150PitdDr4fc/8Abwf/AIinf8LYn7+HJP8AwJP/AMRUfVIfyr8A9nP+mv8AM9C+wWv/ADy/8eNch8RryfQfD9vc6Y/k3El2sRO0PlSrHGGz3ArFuPjG8EkcZ8NXDvIGIWO4ycKMk/c6Ac/hXK+KPi9baqtlFNos0Atr5JXbzg5AUMCAMDnnPXtThQoqaUor8BWknq/xGa7qniyPS4Xnv8O9wEEX2ZAemQfu+9W5NX8Y7jC95l8Z8sWy7iPpsrmpPH+mpFZq0U0xjuJHfg4UMhUEdCTk57dODSzePE8qJEsI0jkjdYyRKY3GRkZI3Hkduh+taVKdBw5eWP3IE9ToLvxH4nsLFZZdT/fGUQpbLaqXYkZAA25zVWDVvG+qyIsupLaLnPlmNAwA5O4heOlY1n420awNwq212zTTA+a3LRDYASuegByMdcHrmorTx7bwXf8ApFhMsLq6GRWz1UjIBA9aXs6KsuWP3Id2S+MLvXGiglur6K4TeSjxxgA5yD/CD1B61i3cOoWlnFPJqdr5kkayrbhG37W6c7Nv/j1WdX8TWt9ZQWKQSDGXMpBA3FicKMZPGOuOc0HUDDp1xZX91eTK9uqw2zxH903ysGG4/LxnkdQfQ1cJRiuWy/AHqyvfLfaaqiTVbV5yqMYI0bcoZQwySgXoR0NNtrvWp/L8lnk8xtibIQdzeg45PI4qaXUopNJntbu+vLwtsFuHTPk7TyQSeOOMDjn2qXRdZs9NsrhW+1ecp8y2YIPlfayHv6MD9VFX7SN+lvkK3oRRXGuzNGkRkdpM7AsIJbHXHHNRSNr1w8lqkc0sy/eiSDLDHqAM1sXev6XNLcxQC6igltjFG3lj5C0vmMDz05K/TFV7/WtOutOntFkuo3ZLdfPZPv8Alggg45x8wx/ujpRKcbNXX4DirNMoWR1u7YRReawTAkKwbvLHTLccfjTLux1ma/nijMslvaSsklyIPlUA4ycA46ZrdGt6dqF1CsP9orL9tWdfLjBeY7VUcDPzZUnH+0eafJ4m0+6vrVrexZ5oLuSaMSLJnBIOVCMATgHIYdPxpOcLWbX4EySOdFveRWzTxwXktuF3GZYcJjJGc46ZBH4UlksmoSyKG8mOJDJLNI3yooIGTgE9SBwDya2Itf0hXsVaO98uCzmgZRjAL+Zxj/gQ5+npVOwvtDhgvLeS3u1S5iCFiQcEOrDp2+Wn7SN1t+A7ehRvLc2d39nlvShKq6SbdyOrDIIPXBB9KgvNMMIluXurbUEjhVgIC+AS2Pm+VTwMnj861tQ1DQLl4gLa5ZYIEiUscFsf/XJ69qqale6eyRLb314vlbVhUFiI1y2TkkY69B71EpqWisaUpKEuZ7fIo2Vmkrq7i0a3lmEQwZcqcZwvGc98nIqG7aOLTIYfKjJEsqiTJzwR74/SugtLrTpZ4o5r+9m3MdwjUgY2n1cc5xxW1oOhafqAvgfN8gzcIynk9ckbvpWaVrttdDo9vT9nyRWrur+76/p/kcTYtJHBYrB0muSkwHRx8vyt7YJ/WqVpcR2V6Zo1Z0QtjY2DjBGQe1eoan4WtbSwzbboQ7gPhCoYYPB55pg0XTV1WBYbhFRFPCrjBOeg3fSqbjy3bjrcidde4k7OLXVfhr835/ect4eWaW+eaKeUtPbBh9obey4YgDPccH866BYbtlDRzIAPv5HU/l6YraTStNilZ1uQsrcMfKGT/wCPUkWmxQlo2upDvbIPlev/AAKuZVIxqxu47PsXXrqVKUFbXXdf5vV/lpczGju2UiOSNcgbTjnPfPFIEvVckSRFCc9OQPyrcXTYAxVbl2I/6Y//AGVWIdDE+dsz8f8ATH/69XCLl7sZRubQxFOpJPlvfXeP9fqc4EvwmBNEW9WHT0xxUV2t79jmCzJ/qznI9ucceua6w+HW/wCez/8Afn/69VL7QCljcEztxGx/1XsfeumGHrc6em/deXmDT5JRUVqu8dLX89fn8uhy2nJenTYds0Y5J5HbP0qxImolm23EYXPAI7flWrpOjbtKgb7QRkH/AJZ+596mk0jH/L0f+/f/ANerqUKsastFu+3+ZHLOdKEbbW6x/DXru/MwpPtny7JUA/izyT/47W94SbU/7YkNrcxRH7Mcl+c/Mv8As1Uk0ls8XRz/ANc//r1Z0mN9KvHuDIZd0ZTG3HUg56n0rOFGpBp2jp6f5mtRVJxkrb26x6dd/wCu7Oxd9a/ivYDL2baMAf8AfNQh9a3krew+b/E23gj8qzhq7G3eUoeDj71WNP1J7iVfLgaRj1VTzgfhWdOVXml7sfi/u9l5nPPD1NNF96/zIdd8Sav4aht/Mu0nurptsNvDGC7Y6nkduPzrF1fxpqi6jaafcOZIroDE/lAKrEcr06jvW/qkEk+qR6pJpEk8tpCRboSQQ5Iyc49BXPeIZdT8U2sdvb6VJp7W7B4WdNzbz948Ada7Oat/LH7o/wCZH1ar2X3r/MnuLnV4bO4iN3EU8tsjA6Y+lZupXF7/AMI1YhbhAhZeMd8H2qXXZWs7YiRTGrRlAX4ycVi6neovh/T13rzg4z7UUZVfbwTjH7l/mE6FRQ1S+9f5nUT3uqlTuvYsfQf4V5/46uJ5ILb7Y/mgyYG3jBwfpXRS6rCf+W8f/fQrmPEv2e/hgBu41KSZzuB7Uuat/LH7o/5h9Wq9l96/zObSSFFA2sKHnhEirtbJIzSyWcABxqEQz9P8ab9ig84N9viJGOOP8acpVbP3Y/dH/McMPV5lovvX+Y2WWESldjZJA601XhLgBHz9Klexhkm/4/YwxIwvfP50ySAx3LlpC3l4HHGSRmspTqRpXcY29EVUpVIVuZpW5vIY5gDEMjZ69a7X4fz+drEgXOVgYc/Va4V3BkYkZOa7j4UKJPFDoeAbdjj15WsK2Ik6TXKtuyOSUveZ6XpiazJaxOl3AAVGMr/9atiK31/tfW//AHz/APY1HpsYigVOy1swngYrpeJl/LH/AMBRmpGRe22viyctfW5XjIC+/wDu06G31/7PHi+t8bRgbfb/AHa1705sJfoP5inw/wDHvEP9gfyqniZeyT5Y79l2Neb3TAvf7dsrWS4kvICqYyFQZ5OP7tbFrI0tlBI5yzxqzH3Iqtr3/IFufov/AKEKnsf+Qdbf9ck/kKzqy56Ck0k7taK3RCewy5/10H+9/hUx6YqG5H76D/e/wqY15tP+JP1X5HLR/i1PVfkRtzTT7089eaYeK2OkwLYf8Vhff9cF/wDZa2j04rFtv+Rwvv8ArgP/AGWto10Yn4o/4V+QoiU0+1O6dqb+tc5QxP8Aj8j+n+NK/Ejc96RP+PxPof60r/fPrmt6nwRJqfxl/hX5sWH/AI+I/wDfH86KIc/aI8/3x/OivBzL44+n6nRS2Z5X4NOL61/64P8A+hGut1QW80cMV2R9naeISbjgY3jqewrjvCLbby2/64v/AOhGuh1hEu7NrdywVyM7TzxzX1WIV8RBeS/JmOBV6qS7/oRrEWt7CPV7SK13Xk37tYljDYjGzKggctgdRkd+9Qtbq13Gn9lXbXBgkDE6bGh6rtcQ5Ktjkds5HpWHPpVmjECWb/vof4VZC+H7VvsUE9zc3QjLvtZQo/HHvXm1ayjBtrY05/I1YLewuNOubKYW0k0F0ohQxLHE0vlhgGUcAjONvTcMHis/RtRJ1WS1t4XlulinjD7NiLLsYKueADuwOOhrE8PRWmrW01xqFldXCpIT5Nu6qAvHQEc11l+3htPCNxqGktqDXceI47SVQrBj0428j3FKOJpyk1fVM5o14uT6WZi6vZX/APZ2nW888kNzBDI80EXEiR7iRnuABk/Q1p31rpFx4f8AtRtR5UWnxiO9di37wAZQEnGS2cjrkk1xsvh+SS+EkguGygycd8n2q5LoEUdk7kTgjHX6/SuiNWP1jkT3aXQ6JOKu7r70drBdfYfDLC6g+yqEjxI6sDMc9FycHrnKjtVfTG0K5jn1BoITNYMJ2fy8FwQQAf7w3bOD61iWnh63a3iJNxygPUen0q4vhy1x964/Mf4VlKvFTeu1/wBSVKCad196Na4uW0u6ms7eNNRngtPNhTYDJKzSgjA6NiJgQOehqaPVLaV7hLW1EmpRpC0tosYdo9wJfCc8g7c/3cnpWKfDNo3G64OeOSP8KytU8AQRzY066lSQDLqwyN3oCBR9Yg/6Q5VILqvvR1Fy1lN4hgjtzEu37Yk7feES/Z+vHQbtwz7VlHS9KLXzXNtGqWzqu24SSUShif3h8vJAIHBGB8w5PfNt/DM7SQJqEt3psgDK06rlZFYYbbjB5GQQeuat3fhpbDypbHXdT3xfu4zGmzYnJIBDZHPP41zcrrVmoSSvZb/16HPKUZTbjJfeMGk6LqEot7WGMwRkTTS+WQfIIfcw3AH5GUDOATuFLpVtY6np+lQTaWuL150Rtx/cKZRwvuoOTnOQtZ7WYij1WeJ76Rrn/RRcztgupILnb3yVxknpnjvV2HwzfR2zQLq95DbsCpgjJ2kHqCM4P5VlOlNxTc9Omvlq9H3ehNub7S+/y9SI6dZeXBavpiln017p7wZ+R1VjjH3cZUKcjOT17VLJo0MXh26luLKzt7m3SCUlPMZ/nZV+fcNnR8/Ke2Klj8IzizNoNYvFtmOTCM7CfUrnFSSeFLqS1Fs+t3rW4XYImJKBcg4xnGMgHHsKVp3uprf+uv8AwCuXW/Mvv/4JHqMOk6dd6rJHoK7LG8VFR2Y+YC5G/r0GMDHHzDOal1rVbGDxOLS40+NAPIV96KSoKJwT7A/pUEfhXUYrq9vdL1G7n1WOaLzAoPmNG6lmcnOSMgAn35rUufCUc2p6mz3d3e3cV6YpEt7AXTeUFXacNICFPIyM42jkU6VKV1Lmvpbr2X6pv5j9naWr6f5FfVtcVrLUDeWSZtL1beFZIh8vD7lX2AVf09al0PWbZpbawKxWjtPi4g8jInQ7e65GAM53EADmqzaFfXukzTi81CKKyEr2891bbo9qMcKJd5Mb8ABR1IHNN8RaReWFncJYarPNbuyf2goBUo7KNuV3fdIx83c8HHApPDydLkuv6Vv+D6/eQ6a5eXQdYa1KNNup/s5OlJvRIVgBEzEHt0wMgknp9SKydOni1yWfTY7WH7RNCxgxCo+dfm/UKw/GtDQdM1m60nTo9N1a7WGO9dLuONmCQRnYQ7/NgIfn64GQfWuctdC1e+8QQw6H9qV7ieRLOdFaMMF+8Qw6YU5OOgq1SnaVmk3/AF/w/ctK17WuztUSy0/WdKlt7MJHdX8MVsrRgMqqSshz1znaa5GO20/WJ7C7bTvswlubiCSFZGwwSJXVuvB+bnGAcDgU7U7HVNJ1C203brEcNvGVt5ntpIpeXBaWNCQRyOOhwBnBp99omo2+u2GnQzyW1oJH+zz+XhXOGHy8/MSir35yAacMJVtfnu9uvn/wPmZ+zfcei2erzeHbGayhjU6a0zTK0m5ghmOw4LcMy84XOTx2FYWtDTAbRtOEEksgZZY7VZjGGB42+aA3IPI56e9dgmkTwPp9jFe3UYntprlLaS22FJE7CIMQGILdOePesCwt9R1vUYv7QuLl5XhnR5ZlLNBKNwEfJypPGBxy3StYYapTmtdNdNfN/r+BUabT3Ll48ogudMlidNMj0WOdY2XCrIUQ78dm80lc9eorM8MwzWOkapfMbuxiCwqLu2hzMNzE/LyvykDk7h/D16VPqularbaJbabJNeNbRWTXM0JVtsMgJIBGeufyBzila21DTtFu9VTUriF5XjhgmiYiR4F2DduByR8wGOcbSOKlYaSi4adH93fzfX9RKFk0atwE0iTUr5YL2Ce41JIQ2nkRvsZMr8xXuScqAMkY4xUWn67caBHrdpdWzX0C3zQrexyhHSUbuR1yCATgjFTPpl1Y3d7dJql5FFcvbx29ysexbje68Blcl/l3Zz0wR3rP0MXUvg2d7HTku7gaoq7DbrIdnlnnaeD7nqM9e9a4bDzoykr3uvyt/lpqOnDleo661/W7nShdbbxrQSlfMEnAYAHnHThhzVSfXZdYuQLixlvXx0PzMf610y2cMn9mwaUyNYw6jeJISvmKBjhf9rIwB65FU59IUXlpcxWHm3rWE0iWs9osHmSK+BuhU4ztJ4HXaOOa7XzuCjpZX79dzZ2fQ5SXTby4MtxZWd1GkUixyJ99lZgSOM5HCn24rWj8T3h1iHy2cBSim3kbliD0Hoe1b9jYTanFfpqVskMwmtH+ypH5aI4jlAR1GMDkHHHUA4GSOf0ee8fx20t1araSl2XZIu0xvsYJngAfNt9K53Tjzxk1/TB2tqa+oeILsaq0c9hcW9w4BELuQxGOwIz2qSbVL+C1W4n026S3HBlywUn0ztxWVrsGpwwaXCY5jfRSTyeUEJdYsIRkdQMrIfoc1oae+pnTLuaeyEEUtq7LeMr+gIQc7SSRjpkZ9qJxpuorx79+wQkkopLb/ImTxJE1s0w0W4lhRgrSPdPtBPQHaAAa0Lq4tHtZv9BljJQ8pcMe3vmqUzRDwtdxQ3tvPDF5J2bZAzOd24nK4yTwOeiilvrqM20wjSUAoSAyHPToauM6UJxvFO9uvn6myqU0nzP8SO0lgS0iUzFDz/rGx39aluImhK+azx7xlSTgN9PWudkluWtIxHFIwGeiH1qFbnUmtjbmGYx5yAUPyn2qsTWo+2neC3fV9/USxNNJLT7zoWhB581vruqJrUHnzjz7/wD16x431IKCqS49ChqVJb8cmGTHptNc/tqP8i/8Cf8AmaLFUvL71/mbiQAaTNFklWcEv2HStPQtTh8N/Zb+Rg8Y3xlS23O4N3+tc/Ff3S+HrpjbyFlmGF2HJGVp1hZ2+r6Hq11K8NlLBdWqLNd7wEV0l3DCgk5Kp2OMdhmsaVWk5StBaPu+3qOpXpSSSa+86a9+JdxcSCKyNlECcAud5/nVefxprGn3piuZrHIAJjMW04I+v41yEeiXTaxPpUt3YW19FP8AZ1imL/vXzgBWVSoBPdiBz1o1OwFr4WstVN1CL6aWaOS0dJC/yMq4XCbQRkk5bpjHORXR7aN/gVvV/wCZi6lNdPxOh8Ra/ZeItKaNvKjn3CTcsm4DAx07Vg6vbW50nTc3EYITAzj0HvRotha3Flpr6mLpZdVvGtLc2+AsAXYPMcEEsN0g+UFeFPPSsjStOXUfE8Om6wTDboZVkZJVh+ZUYgb3BVcsoGSO9a0qtNVYy5Fp5sTrR5bJfiXTptow4vIvyH+NUrnSLUjnUIUx3wP8alutKtLDxDbW95pepW9jKgYKl7FO0mSQGSVYwhXPoD0NZ2v6X/Z3iDU9PgWZobW7lhjZxliquVBJAxnAqfa0l9hfexuvFqzS+8l/sGybG/WreM56MB/8VR/YVgr7hrtqxByFAHP/AI9VuX4f607MYzbybb2KyXazfvGkAKuvy/c+dMnr868VPN4J+0aNo8tlPZpeS21zI8bPJuumimlBKfKQPkQY3bc9snNZ1ornfK7ISnBSWn4lCLRbJrqOU6zbq+4HyyBn6feq3d6Xaf6Q/wDa0G7cp8vjPTHrUmneDor2C4uL66tdP8rSo76B185g5NwseZMI56EghcclD03VTl8J332aS4Fxaeabf7WLPL+c0IH3x8u3GAWwWDY5xihP9y436/odDrw10+1fcYNEsHAY65bKTyRgcf8Aj1dr8PdKsrHVpblNXt3KQMOMDuPeuD0XR7Wax1LVdTivHtbMxIIbZhG8ryE4+ZlYAAKxPB6Ad81dbRxo3im4tEMstt5KSxOy4YxyKki57Z2sM+9YVItwa5vyOV1IX2/E9l8LarDqUEiJfQXLxnkxkdPzrp45kVwu4bj2zXjGh+GLIy6Rc2ry2a6hci3MMl9DdsVIUh/3arsPONjDOTVuO4tETS9ag03VIbV9Qa2dJgJJFKbG3DAGQQxGMcFSMmtNf5vyJ54dl956/eOTYyfKe386njLfZojsP3B/KuUsvFmn6gr2cdwXZvuFo2XP5gV1ttNGbSMeYmQg6sPSrcl7Fe91fbsP21Ll6ff/AMEzNeY/2Lc/Kei/+hCp7An+zrX5f+WSfyFQa86NpFwqupJ28A5/iFT2MiDT7YF1BES8E+wqpSX1Ze99p9uyH7albp9//BEuSfOg4/i/wqZs+lQzsrTQbWBw3Y/SpzXDSTc52fb8jChOLqVGl1XXyIzk0w09hTDW9n3Ormj/AC/mYNsP+Kxvuf8Algv/ALLW0QO5rEtv+Rwvv+uA/wDZa2j+tdGJT5o6/Zj+RMZR7BgetJtHqKbkGkJxzXNyvuVzR/lBAPtic9v8aV1Bc/NzmmJ/x+Rn2/xpW/1p/wB6uiqn7OOvQmbj7dafZX5sdF8tzGDz8w/nRSx/8fSf74orwsxd5QfkbwSTaR5B4WcLc25P/PFv/QjW1f3QBPzcDk9q5PTNRi06JLiV9qrEw+uWPAqGO/udUvWeYlINp2RZ/U19ZW/3qn6L9THLleuvX9CK91Wa+do7U7YujS+v0qz4etES+kwOsRyT1PIqjGoUAAAAdAKswXFxbzRi1DtNKwiVUXczE9AB9a8LEJzpuKNYwSVx+j3Fxpco8iTCHOVwOcitCG6n+YGTOT12j/CqZ03UFvFtBFG0xVnPl3MLKgX7xdgxCY77iKmj03VnuLiIW+026JJK7zRLGqN91t5baVPqDiudujzc7S19CHSoyd3BX9ESw67dXt4sMSKrFCfmfjgEn+H0FVbjxLNJaOjRZBx/EPX6Vo6XZ6rDpNxcTzGC0g0551jWWLJZmAVnTk4YNwxA7YNUNPmju9Bupry/kt9LgjjhdY0WQmV8kYjO3n5WbdnOB36V3Qnh1U9pFbNbLr0sYOjT/lX3I0NM8Q3Ny0FrHAoYqAC0mBwP932p6+Kpym42uF/vF+P5Vn315d6dr8dpe6iB5EwUFWDRqhXh1XHygqQQPeo9WWCW1sdRTVZ5tMaVrfH2RUeEqATiPfhuGHO4E98cVE/YN83Le/l31F7Gn/KvuR0jeJbmCwFzHpAYbQxkkuAxAJwG2AAgZ7nIqmPF2tX42QCCEpzuMkcZP4uOfwrO1horGxtNRtdUmmF/alBFNapE6opCKcBm4JRvT7tH9jalDYabqWniOXzrNriUTNC3KySBtiNywCopOAcZ7VLeGsny6PTbsH1el/KvuReTU9a1D7RFLFI8kZ2N5kqrtY54GQBnjoPSsOTVtTgfbJPM0IODEwUEH0ztrT1C2u7maGCzvEZp4o76R7maKJdzjBIZtoxnGB15qmLbW5ddu5WiERguCLh53jhRS2Rjc5C5IzgDr2qqLw0J86S/DzWwlQp3+Bfcia/8UefYxxJZ7FVwRiT2PtWg3i2Qn/jzYe3m/wD1qq6lbXP9hWUttIZW+wyCYkxqqRrMykhuAAdnckktgdQKjsbqTUUu7nUNRCabZtHKNkKylQW2qqpxjOeRkDgnnFOfsJUkraJ/r+ti4U6cZXUV9y/yL48WS/8APm//AH9/+tU8niS4jtYZzaHbKWCgTHI24zn5fesjUrrULLV4baa/S7l3LLbTbFOUkQMhxjgHcpx25rZ1OK90gWa3t9cPcK7KZZbIBM9ykhyXweM4HtWap4XRcu+39XLuv5V/4DH/ACMrUdQhvHFzJa3AdwN22YY4AH932qibi2/597n/AL/D/wCIrpzNLaa/AiX7XUdzaLJ5jwqjNySOmeQV657Cr11DbSS7zFG7siF/lBJOBnJ9a1pUaTgnFaDlNX2X3L/I5K4tmtYVlms7hUJA4uVJUkZAYBcqcdjiktoftYPkW0pOcBWu0VmPoAVyfwrtrlICtw/7phNIGGMZ6k5P/wBemWsKxXImH2dQp2ljsyPp/wDWrX6vTvaxHP5L7l/kcULZ5LQ3K27rECwzJeRoSR1wCAT1HSqgtVmsRceXPsPuCOuOu2vRINoDBzF5BZjhtu7nv656V2tmqf8ACqREFGQDkYGOZjSdGmlexVOSc1ot+yPCJtIL2o3w3IRwMcYz39Kbf+GPK/s/ybe9YXEeVBxndnnHy+4r6P1MrJ4Gibk7IIjyeQflHFUdTIFz4TkPTMYyDz/BXQ6VNYdSS1v+iJqSsnZLfsjwaLwbc3lncMllqL3Fu4VgFzwex+XrUMHgq/uIlmSwvzC3/LXZ8oHrnbX1em2OZ/70pJyp64GOfypm1DA1uAMgDI/h/KsuSHYnm8l9yPl6b4f6pJO5t9I1Vo/4SY85GOv3azofDJMpWS3uywJAQEAkjPH3fUGvrctsjwM4A9TXlPimytbfXILiKILJLyzZPP36unThKpGNt2jWk0+a6Wz6Hl6fDvXriaRF0fUWeMgONn3c9P4ap2vgfVLsXMkOm3pjtz+9YD7vXr8vsa+rI3HmTPtA+brzziuT8PMv2jxESoGZuQfcvV06VN05trZL8zLn1Wi+5HgMPhCW7tTcQQXLwq4QuGGAxGcfd9K0I/AV61wUezvhIAx4IyNuc8bfY17NrljZaf4YgS0tIoA90rNsQAE7TVi6m2a/ayYUE20hzjrkPVexp+xjK2/N+FiZ1Gnol06I8hHw8D2BmNlqbcgCeN12gnsV2fTvTP8AhXmpaTPG80dx5LSqrPj3+lerxata2ul7JriKJjNnaxA7CuL8U+LlvtQg02GQPGLhTvTofmHSuOnyuKujXERipSSS6/kcXq+mQ2uqyxG4kUDGN2PQe1RTWltFDE3nv8y5+8v+FN8VvdS6vMgLOqkY3HOPlFVLyOU2tn93cI+/0FRVjFVFp1f5GFNRcIadP0GyRqchLpse5FSyXt3IjA6gvIPG0c1mtFL/ABsMe1SoQsbbSucelbU4U3ON4rdfmhyo03vFfcWIrq8jiUC+UL/d2ilN9d5yNRA9ii1V83bECwBHsKgnAddyNwe1XiqdL28/cW7/ADJWHpNX5V9yNaK/us836t/wFatRXs7Hi8Rh3G0VzkD7Wwe/pVohoysqHaR1I/rXP7Kl/IhrD0v5V9yN1ri6OjXKx3eWMow+0Hb04rHl1O+XRtR05kaR7m5gm87pt8pZFxjHOfM9eNvfNX7R1bRblgcDzh/7LWHNduZZN2OGIBxUUqdP3mopa/oi3Rpxs1Fbdjo7b4mT2Wp3d3/Z91G818LtRbXph3AADy5CEy6cZwNvU1g6j4q/tHSmtZrOZLhLqae3mSYBUEjKWV1KHdjbwQV69DWNO3zZzyarElia25V2FyR7HT6L4y/s+0tYbzT2vJLG5a6s3E3lhHO3IcbTvTKKcAqevPNZkeqwPcRyahb3dzlna4CXCxmQn7pU+WdpBOTndn2rKVvmA96lVd9xtzWtCEZVYxsN048l7HQS+K4Li/00Pp9yul2ERjjt0ulErZZn3NKYyM7m7IBgY461Dr+vrrGu3WoWdrcWi3MjTPFLMsxDsxJwQi8c8DBPuasaXFZQ/LLEr7ThiRyKxrtBFqcqIMKGOMCseWPYHTjbY7WH4h3totnt03d9n042py5G+X5Ak33eCvlQ8d9nXnjAsvGVxaT6ITal/wCzYJoCPMx5vmNIc/d+XHmYxznHvURG4BSe1Zs6RpOoHXcK3xUFCrKKWxoqcXI3rbxkVlitbmwlktm01dNlSKcI7YmEodWKMFOQowQeM+vFm88e30ul/wBlSPqyPHbfZVWHUTHAyYwN8Oz5jtODhgDjkdc8kONUj/66L/Spr1c6vIc9x/6DUqEfYOduv6G/sI6v+9b8y7pHiP7BBe2N9ayXdldBN8cUoidWQ5VlYqwHVhyp4Y/WtXT9Yn1/xFd3UtlKXcJ5UUL/ACRwoAuwjaSflCANkYweDnjlBsEjZPeuq8Bf8hqcD/n2b+a1z1ElBuxyunFS2NS3uo7qwhsdO0q9i08XS3MzvP5ssrKCAqsI1CgBm7E5I54rX8Q6zf3OlHyYNQhS0DSrLdStPJvwOS5UDACjAxgc+tYWhaibe2CSSrHFGOpOAKh17xQl9YS2Vpu2ycPM3AI7gCteWO1iFCPVFTwtq97L4ksElnLI0uCNo54PtX0baW8BhjJTOVHc+lfNvhK2H9u2s7Z2KxKn1ODX0XY3Ae1iIPO0fyq3RpeyXurft5E/V6XL8K+4Zr9tFDpFw8aYIC4Of9oVJZW0L2FuxTJMSknJ9BS66wfQLn1AX/0IVLYD/iXWv/XJP5CqlQpfV0+VfE+nkh/V6PL8K+5ALaFSGCYI6cmnmpGqJuKwjGMfhVi4U4w0irEZPFRtUjd6iJFM0MG2/wCRwvf+uA/9lraNYtt/yOF7n/ngv/stbRPSujE/FH/CvyJiN/Ck47ilNI3Nc5Q1P+PyP6f405v9afrTI8/a48+n+NOb/Wn/AHq3rfw4+n+Ypfx4/wCFf+lMdH/x9p/vCiiP/j7QY/jFFfP5hvD0OmO8vU8Mn0dWtNF+zndPeWskz+fPHHGm2V04ZyoAwo6nrUlnoesfbbuBLTY9rGjzPJPEqIj42tvLbSpyMEHHI5qa213R4xpUd9aSSfZLCWDe1uk4jkaZnVxG7BXADYw2OT7Cto6zpOu6frcrJc29oljZ27PFbxq4ZZPvCNWCY/2QRj8K+mlO9RO5y4e6acbmInhy9GlapeTtFbzafPFC8E08SFt6O2QWcZ4QYAzu3fLnBqJItT8P3Om6zPY7o4bmJzH5ybxuBKhlBLJuGcFgKnvPEOlajaanZSQ3UMEgsxauqLIx+zRPEokG4Y3BskgnHoanl13SdQvbieK0me+1WaATxzxr5UGHVmKNuJbJXA4XAJHNcsowlFxbWvkV73n95m79O0OW7jJ1B7K9ga1ndo4vMgbcrrhVkIJyg6lcjPSrT6vY3uktYQvcRpcww2Nm0iDc5jfeWkwflBZ8ADdj8M0/xRNpMV3ren6ZaO1xcak0kpmhVVgVGcbUIYlgS3UheABg9ar6Rq2iWltp66havPd6dctPGttArR3AO0iORiQQAy9QG4YjHesvq1Jvmcrv+vL5DvIeutaRcm+leLUlv77To7F40iVo0ZfLG4HcC2fLHGBjPeodPs7aK0vNEvVvRBcrHeo8UAMyPHvUKYyw5Ku3f0NVrLRU1G5jeaW7SKQuZ2ht0Ijb+HaC43e4+XHvW5qPh7R5Le1je6uoLa0tvLa4S2Rpp3MhbLLvAAAbaBuJwBz2rSOEpp8qlu18rbWJbZgaxcafqOvT3cxureN5418oxLvWELtOfm++AAAOh5OR0rQ8RQ2180EelG8+y28v2WG1kt0jWInn7wkbexPJYgZ+mAH66ulG9thBDLsjtIo1d413yALjc2D1P49uTXRnxRodtKI5NIlDpYeWw+zxn/TAABJ1+78o/M0vYQi01Lbp/SCzOY1+0/tO6gubKN0s47VY4klZQypHlegJ5IXccZ5Y81tWUtglpplxtuFvdLsGiWNmQRSl3kIO4sCAPMyeOenHUwQa5pEc2ms9pOy29hNbyjyE+eRvN2t97nHmJyefl9hUz6tou2S0ubW6hD2ENuZI7WN2SRWViwG8A5AI6g80pYanKKhfRf8ADBaRAl3ZAJPcW7DZp8MEcr28VwY2U/M3lO2Cp6bj09Kj1fV9I1qPUTcvdWtm1xBLG8MKO4cRbCpQMq4O0kEEYx05wLt1rtlf6OYYLWaOVbRbd1i0i3YHChd5m++uQMn3zg1y+m3Glm0u9I1CO7P2iWKWOW1t1klR03DAUsMhg5zz1APOKmGEpe05r2YK5f1DW7BdAt/DV4lz9mtlY+dEo3CXzJHRgNw3qVcAg4xnI961g+l2el3MF1cXX2XUcJvS3XfG0bBg+3fhhyRjI6+2DX19oNS1O5lgs7qCeSVRDZi2HEQUgZIOd2Av8POScjvNrd5ptzeWdslvPaW1tbxwtm3USZ6yOV3DJLFiMnpgZqnhqSp2T3d/ne9xpPmL0rWl/wCLrZ4XmEcUNsLVGjHKRxKAXO7g/KDwDkk9K7TU20u8hvfkuWa9uVuZhKeIyN3C/Nz9488cDFc5DdaBLrenz2H9oELbpBIJLKNM7Itu4YkbJYgk9Me9b32vTnJDJeYB4Atk/wDiqqODoOzc7W9f8u+oWm9vzRf0fTtB1LxTpcMaXEohiNuyzJ5YwFcg5Vyepr0E+ENAEoX7APmBJzPJ+nzV5XaX1pb3ck0L3scynKmOBQR+IathNcu54ZZ0vtXIgALtgfKCcdPM55I6V0Rw9GmuVVPwf+RVSnLm/wCCjvF8HeHyzIbAADHBnkz/ADpB4R0Bo2Y6eNyk4HnPkf8Aj1cB/wAJJMH3DUNYyep29f8Ax+kHiOUZUX+sBD229f8Ax+q9lS/5+L7mR7Kf9NHoLeEfD4jDrYjPGT50nH/j1Gu2ttpnhWe0s0EUAxhdxbq4PU8964RNYv5LV51n117dD80iwkop9zvwKp3uq6hqdjLbW02t3U5AIjSIueozwGP8qTpUrfxF9zKhTmpJ2/FHot+wHgsRkgL9lhIX8Vqlfvvk8LgkErIuB6cR1w8t9qc+nCwj/t2S5WNVa3EBLDGONu7PH0pqS3+oXulQxXWpxyQyKrLKhUqxwOBuPp7VtONL6uo+0W/Z9kKdOTXz7o9mMpa1LhxvAILkcj1pZJgFSRWABYbiBya4ldH11iwGo6js6Yw2P50v9ka43y/2hqWQfRv8ay9nS/5+L7mP2FTt+K/zOzupTHbSN7V514qAN/YktjIHH/fVXLvStcEW19T1Ebj33c/rXJeKtN1S2urVZru7ZioKlwc/xe9XSp01Whad9V0ZrSo1FzNro+q7ep7Lsiit5Faf5m3cY9a5TRjFHL4h/e9J1xkdeXrI1HT9atbf97ql/GGOMvu/xrlLgzwi4WPUZGMpBdicZPPvz1qb06dOaUrt26Pv5mSw1Rvb8V/mdn411uwt9Dgi+0JvWVW25x2avPtd8ePeTIbNSixx+UTnk9c4/OsDWI22ZkvhId38XJFUnto2b/j9i9d6gcfrTb/2eH/b36EVKE0/muq/zLWqSvJMHLt90E7jiqdtOralaAsc+cnT6ip9RtYZLlWk1FEAQfKce/vT9KsIJdQt2ivbdwJV7ZPUf7VedR+GJ1YqjPmn8+q7eoa5Iia5cZOMlev+6Kde2yS21q6vyE45znpV3W9KjfWp3+1IpOMqw/2R702exi8m3Buo48JgHsenvSrfxY+r/I5aVGfJT9O67eph+WFbBYg+pHFQypBySoDY4I5FbyWMTDi/ib2wP8aqNoMCiV2ul6Egdv51vS+OPqvzRvKhO3T71/mZqkCFcyDGOBiqshBzhh9RXSW3hiC8s0k+27c54A6c1Fc+E44eftqge4/+vWmKf7+fq/zFGhUcVt96/wAzll+/1GK04ZBsxlT6CrI0O2U83sePoP8AGnx6Tbwtn7fDn3H/ANesB/V6n9Nf5lmzjQaROpO3dMPp/DXL3wCSuNwxuPT612UdjE+g3BW8jYCUcgfT3rnn060JZjqcGQT97HBz9aijtL/F+iHOjNtLy7r/ADOfkACjBJz6jFQZ5NbsunWkgwdWg+px/jUI0a0xk6tAB9B/jWlyPq9Ty+9f5mOv3xircZ8uQnHPvWnDoVuVZ01GJyq7sAD/ABqFrCAIH/tCIsTgpxkfrW2Gf7+JUqE1Tf8Amv8AMbNfMWDxbUkHX3qOWZboq5QrIBhsdD71eTSbMj/kKQH8B/jUq6XaqMHUoPwx/jWIvq9T+mv8yJBmYcHpTLu0kaRXONuR0ra07SoJ7hSb5BngLgc/rVvU9Ot7M7Hv03HkIQB/Wt8d/Hnbua06EnNN/mv8zlEgUX0ZxzvX+lNv4caq7e4/lWzFZ2pnRzfRBtw+U4z/ADov7GA3Ekn22Pdx8uB6fWsY831Z+q/JnfKlo/8AEu3n5mI9jKtuLhkj8thuG6RQxGcZC5yRnvitWw0/UdPvZDhrd1UxuYpQWBz0IU5GccZ64qNHtJrD7NLcb3KbUDxL+6Oc5D53Y68dOa6JIYbbXdQlikdpZZt7K4G1drZ455yfpitpxhytt/19xlKlTs3e23b/AC19Djri2vYTGksY+dti/vVIDehIOFPscVcstGllkcXi7IxC0ibJFcPgeoyMZrUEEMs8YL+fCJfMMItI05wQMlfvYz3rViWaJoXjictFG6gmBUBJ6fKOKtcl9xRpUb3ctPkYkFnfpdKqO8ZjUHPmhdgPQdeD7da3be51qOIsNUvI0QlT+/IwR261EkRh8791IiSMJCWiWTa3II+bqOevWorm6k8nDo+4ys+5lABBAA6fSh8qhuRKnTULp3evb/I02vNSmsJDLrt8IiQpHmM3OfTdVlZ9ahRY/wC274bQFwJnwMenNc8mow/ZHinLBdwYGPBJ9RgkVuW+ofaEW4SIsWOcdQKG17JepDScI6q/Xb5/pYstLrIZV/t+/wCQSf3z8Y6/xe1Ng1LVIy5OrXsqHgFpmBBBII60hu/uf6OwABDYz3z/AI1RS5BkkjjjcqjHJYYJJJzUy5HF2/rb/gmlWFNwly26fp/wb+ZryahqaqGW/uyNoY/v2/xpr3+pGQqmoXXQHm4I6j61U+1RnHyuH8vbgjjp1p3nR7mYqckLg7QegwetJqmTKnQva9r26laC71M6xczC7uQQoUuZiCTxx1rQfUNSChlv7vGwMSZm4/Wsz7TFNqU6MHXDM6kAHIYLwfyFWXmWSFYyCNo4I9auqod+iM/Z0EpJO/b1u/LT9Swmo6gys7aldqoIGRKxOT+PtTJNS1KORkOoXXBx/rm/xqvG6eW0cm4AkHKjPI//AF0jSgzGXHIbIUjjFY2jyohxpumtdf8Ah7/pYttfahFLCW1K6y2c4lb5f1rS0S8vG8SW0Ml7cSxtkkPISDlCemaw3mSRok2bSCSSMnr9TWtoLxv4ntGjLHgg7hjohHr7VpWUeTQqrGlzXhbaNu/W+/8AVz0BP+PqP/fFFEf/AB9p/viivncw3h6CjvL1PD7+2gEseIYx+7H8I9TTbS3gMh/cxn5f7orr9N8InWbqz866EUUsZ+6MtwW/wrq5PBOi6RapJHE80pcKXlbPHPavp5Qvi16/5meVTjzRT7/oeT2mmSX8nl2diZ39Iot38q6rTvhhq14ym6toLKI9TIBux9K9igghtoxHBEkSDoqLgVKK4VBCdZ9EcNb/AAs0RVRLovLGvPloAgY/7RHJ+mcV0dl4V8P2EYS30WwUDu0Cs35kZrXpaoycmzlvCuk6dJpcpewtWPnsMtCp7D2qz4j0jTE8P3bJp1orALgiFQfvD2pPCkqppM2eT57cD6CrXiSVW8PXQ5yQv/oQrrh/vS9V+gp9Tl7rSbXaHsdJs7i9Fra5ja2R8RlX3MFI9QoLdvUZq1Jo+lf2jqLRaZFNMt6VeKHT47nEWBjgkbQTu+Yc8Dkd7S+G7PWrm2muZZ1ZbKJR5bADGAe4PrVkeAdK/wCfi9/77X/4muep8cvV/mzSorNei/I5v+x7KXSLn7NpUdtDH5zedPZRusgDHA83qj4woA6n60eItK05IpHsrC1YZT7U5hXfG20bQBj5VPqOpyD2FdMPAGlf8/F7/wB9r/8AE07/AIV/pP8Az8Xv/fa//E1BmcXY6RHd22jtZ2ULeRqDPdkRr8iHy9rP/s4D8njr61yviLw79r1CO50vTDKJZ3WKKOIgSqMtgYxnA7DnmvUL/wACaXHd2Sie8w0mDl19R/s1U8UeBdLt9LRlnuyWmCkM69MH/ZqsMuetyre/6BH4jzrX9JuZ5NFhg8PQLdJAWfSYYpNwUSMfnG4yfNnpnIHTioPGFrHHqFmGsrW0k+xx77SJMfZyCw2tkkk4Abk5+YA9Km8XeEYtBvXti8xTeDGxI+ZTn2/Ck1DQLdEuWiluN8Vr5qgFTubzY0x09HP6U5xfsVLzNINc9vJndWCaATaF7XT4ZLm3XVfliVSsMYQSKPQZ8/j/AGBUGlahY3emW12sFo2mSQTSXt0Ih+5lDPgFv4CAE2rxnPfNeXHwxqE1zKghBdGCNvkjX5iOFyerf7I59qjg0C7aW3jELBrjPlj5BnBIOfTBB649ax9oV7Jdz1Yy2cenTXX2e3GkGwSWK9Ea5achcjf1Lbyy7M8AdO9aN3c21vYaqz28UGlAwCC5SIDzIjIvzBh9/jBJ5weOOleZXfh24h063uLeSRoWt0mcFo8jPUhcZ2j1x+NVJtGv7e0F05dYsKxwULKG+6So5APYkc01VT6FyprqeuNLpw1nT4HsJvKl1KKKCRrFI4XQk/KHDHzQeDnnp15rmr3XrG48P2t+Y4o2N1LBmKILlQsbAHHXG48nn1ri20TUle3QMXa4lEMflyxMN56KSOFPPQ4p8Wh6m8/llzhWVWxNFwTn5f8Af4Py9fan7RdvxEqUT0jT9UiltNMvot502CznW6kA+SNsyblf0ZgVwO+RiuXF1PeL5VtpV1eu0YmW38l/3se4DICkMRnuD2rnZNPkfxHLpVvdygLcvCrybeFDEZOB6DNVtVtUgsIru2v5rm2lZowXiVGDrtJBHPZlI570e0XYapxuen3N4t3FqFo9lcTzGwtlfTLE4lT7vygkMfkwM5DHnnpkQS+I7ex8YLvWVzFNASF5K4UfKTzlh0PuDXn8ej+dYRL/AGhL9smtWuY4PKBUooYkFuzYQkDGOnNLpy2406e7h1K6SW2iWR1ktE2btwUKG355J/u9AfSm6i5Nuoeyj1Pdf+Fi2SE4s71wfwqP/hYlsrFhYXhz2LV4fBqus3as8EjOBIkZwEzufO0Y98Gr1iNZuNTe1ujImPtEfy7MmWKJn29DnkLz0wetHtor7P4/8A2VPDvo/vZ63P8AEC2mIJ0y7OOg8zpXH+LvFo1G8tXFlLGI1Aw0hJP3v8a4ea41mKR0mTfi3adWiliK7RxuDAEMAQcgHPFN1e11a3v4bVJba6d4UlBWWH5AY1clsE7VG77zYBxkVdOvFVIvl2a6lxhQSlZPZnqWr+Km1KEL9mMRHQtISa5WQSysSBEc+prhL+/1KymMV2FD4DcbGDA8ggjII9xWtcpcWMF0Ir8Pc2JRbuHyFUIW4+Vud2G4PA56ZqHVi94fj/wDFKh0X5k2taZM0avJ5f3gMA/Wql3oF7M/kK0MeRlcE4qSwV9RtBLc3jRK1wlvGsdqsrF2BwSMjA9+T7Vbso0vdSaxuNSmiuIzIGZLNJI1VASW3FwcYB7Vu8RD2UY8j05uvexEoUpP5oim8Ganqcysk1tsC4wWwc1qaX8NL23uIZ3mhDRyK2B3wc9ayLJrmeJpmZmcOVBAA4wP8au2vie+0+6gtWnnYSSqpDNkcmsaThGKTjr6ixE6UuaSj36+Ru3/AIdkGpzPcFGV8cBvYVWm8MXd6mLfywsfBDDrWJqniCWPxBcBn6Feozj5RWy3jB9LsFdbna0oB29c/wCc1NZw9pHTq+vkc1KVPkh7vTv5ehWt9CkjcxlIi44IOaffaTILJyEVMISQD14rS0TxFBrYkY2yROozvJ5Jqa8gN/ZS+XvQBGLMe/Hat6bp88fd6rr5o6Oenb4fx/4Bzul2l0ttE8RTByCMnnmr11a3UseAIs/7X/6qsaZoKy6fCwkZWYHPPXk1ox6escDC4CnH3cCrxMqftp+71fXzCEqdl7v4/wDAOJudCudwfdFnOTzgfypn9g3Eh3kxn0AY/wCFb1/pcRUlVwc8VlSQrbw+WnGDg/Wsean/AC/j/wAAfNS/l/H/AIBag0ySPQriJvKGZB0J9q5Q+HXeWVXliRixKtuOME9xiujZlj0GZu5lH9K8/kuvJvZX2BmDtgntzWdGUPf0+138kE5U9Pd6dzWPg3UZJ1SNoGLHC4Y8/pXWa38L103wnazmZv7VDHzs5MTAngD0IFcfpfi270/UoLgEhYzyFPOK63VfiJf69G1na6hJ5BHzQz8b/bNa81P+X8SVKl/L+P8AwDjz4c1H5T58AXgH5z+XSo5tAu4PneSEgnHDH/CvRrDWr+98MvpV7otlPbbSSXADZ/vggckVVtPC+k2enxX7L5jzSBdrDITr/gK1w8qfto2X4jlKn7N+7+P/AADjoPCepzNiERyH0Usf6VbbwhqtuwFwkaZ7MWH9K+h7GKztF8m3hijC8jYoGRWH400VNaslKKDNGcof6VlzU/5fxFzUv5fx/wCAeceF9G3T+ZMsbxZ2kZzg1d8XeGZrmMTW8w2oN2G4IqXw/bvaRPuQoS/ysfuk+lJrXiJpIJbWeHZKMq6np7EVtjZU1Wndde5rBwc0uX8f+AcNHoV8LiKQvBguCAXOev0o1DSL1buSQvDsGP4jnoPapfLilmjYRgHcOfxqG/tF+0yOOvH8qxVWH1Z6dV18j0PZU7PT7Xf1LVho1xcXZZni8pk2nk5/lXpnhKzM2qEMwBMZWQBiehHIry+Fdm4/3QX4613/AMP5Vtr37ajbmEZEi+2RzUYmUOSWn4+hw4n2arS93r3PQ7T7HYQLDawGNAP4VGT9T3qU3kfo35U+0vIL62W4t5A8bDqD09jS3EQngeIkgOpUkdqrmp/y/j/wDFSpfy/j/wAAy7zVLN4XjEo3nHH41Pb3sL2yAHeAoBAwRXF6h4c1Czl3KDJCDneh/mKTSbPVYrtGhilDbsliMDHvWrdP2S069/Irmp8vw/j/AMA2PEel6Zc6bNMLbyphjDxjb3HUDg03wybjQDGkp8yxnUEMOCpI9K2dbJ/sWfPXC5/76FWbNUm0u3jcAq0Kgj8BWjlD6stPtPr5IV6bXw/j/wAAuSXsR5Cvg+1YOmXKC/1M4bmX092q7pOqI88+lySAzW5wpPcVX0s/8TDVP+u39WrFShZ+7+JpTlT5J+726+foPluFN4jYOAv+NPNwno35Usv/AB/R/wC7/jTyeaz5qf8AL+P/AACqsqdo+707+vkc/bTL/wAJdenB/wBQP/Za2TOvoaybY/8AFX3v/XAf+y1tZ9a6MTKnzR937K6+RzxlT/l/H/gEJnXrg0hmX0NTZwODTDjmufmp/wAv4/8AAK5qX8v4/wDAGwsHu0POKe3+tP8AvUsR/eimsf3p/wB6nVkpQVlsc7mpYjRWsl+bHp/x9x4/viikT/j7j/3xRXg5hvD0OuO8vUxfC3+t0r/rlJ/N66fW/wDjyT/roP5GuZ8Lf6zSv+uUn83rptb/AOPJP+ug/ka+rf8AvS9f8zkyv+JH1NQU6kFVbjVdOs5fKur+1gkxnZLMqnH0JrgAuClxWd/wkGi/9Bew/wDAlP8AGl/4SDRv+gvYf+BKf40AZfhaEnTJSvP78jH4Cr3iSNU8O3ZA5wv/AKEKyvC2t6TDpkiy6nZIxnY4adAeg96vavqek6hpU9rFrOmq8gGC1ymOCD6+1dKko4lSe11+gS6lnResP/XpH/6Ctbgrzy2v7uC8McfibR1VIwqkzJjAAAHStBdT1AnjxVon/f6P/Cqlh4yk2qkd33/yNK0rtadF+R2opwrjlvtQPXxdoQ/7eI/8Kf8A2ndR8/8ACXaEx9poz/7LS+qr/n5H8f8AIx5vI6W8sHvmiKSNG0ZJBAz6f4Vh+JtLuYNMieW8kcGZRtbPoeetVxrupfw+K9CUe80f+FY3iTU7+fT4/N8UaROPOB2xzJxweeBV4fAUnXjKU1v3a/RCVnLYk+J2kpZ6JDeSXH2qRJgu1x0BBPvXFX+uDRrszJHulktjHGMZGfMjbnuBhTyOc4+ta/j3xEraKLSTxFpl8xkB8q0KuRweSQtczfXBa4Ux6ha42D+Me9KWCpRoJKa37v8AyFTTVRO3chttb0+C3e1iEsUImM8byWkNwykqAV+f02jDAjPcVLDqDroOoXtxG5kkmdbSZgF3NKCJen+yvbgE+9QefL/0EbT/AL6X/Cgzy/8AQRtP++h/hXJ9Th/z8j97/wAjtXp/X3kz6xYrYwXCC5NylkbQRlV2ElWUtnOeAx4x1x0qC41uxkS6nSOdrm8ijiljYARoFKEkNnJzsGBgYz3q3Jcz/wBmxA6pZkBz8u9cjr7VAv2yRAyXUDKehXBB/SksJD/n5H73/kU1/X9MnbxRpUMlt5EEoii1KC72rbRR7I03ZTKnLnkYLHn2741lrFiLQQXy3AEV19pjMKhi+QAVOSMdBzzjnirskV6RzPF+X/1qqPFd/wDPRPy/+tR9Uh/z8j97/wAgtfp/X3kH9vRR+KJdUSBmhe5eXYxAYoxOR3wcGmX2paa1lb6fb/afssckkzyyRLvLsFAAUNjA2DnPcn2qQxXefvr+X/1qimiuRGxZhj6UpYWCV+eP3v8AyLjTu7Wev9dy1YeJo7DSNiyzyXAhkhSIwIFQPkcSZ345ztwBmsx9WhTQ47CKJvNluPNnY4AIUYQD1xucn6irPl3HlDJG3A7VBNDP5kOSOTxxWrwkFQU+db932XkTUhZdf6+ZPoOvwaTcXLzwO6vD+7CY4lVg0bc9gy8+xNXZPFlo89i4t5gIrKaObgZaeSExlhz0OEyevXiqJgucdR+X/wBaoZUuEGeCf92s1hIN/wASP3v/ACBrlX9f5liLxHaQ6dDbtBIXSyntzgDG53LDv055qRPFWmx3n2sRSlriyjtLlXto5BHsWMBlDEh8mMHBC9evesOWOdyco5/4CaYYpBCR5bZJ6bTW0MDDniudatdX/kYwm5N+Sf4E+ta3Ff3kZjzNFHGI0L28cGACTgImQBknvWne+JdPu47+W2gnF3qTI1yJFUJHhtzbSDlssAeQMD1rCFrMWDeW/wCRpqxzK5/dyDPX5TR9Sh/z8j97/wAjHnfY63S/EFnpls8KXF9bgXIkEtvGu6dMcI43DA79WHJ4NQxatbxnU2jgaKa7GyIKBtjjLbmH14VenQmqUP2m4tkClioOMlcY/SupgtdRS8izdW4YqeWUHHX2rb+zqfs1L2i1v1fS3kTKo9rGZpd40Fi7CFmxIfmH0FINRgnv7dfsg3mVRuIHqPatHUY9TRSWubeQHqFUZ/lXPw293HfwOj4bzVPsOa5/7Ppt39ovvl/kKaXK9C3rfkrq1xuto3bK8nqflHtXOapO0wjAQIsWRgHI7f4Vr6yLo6pceY6s2RllXr8o9qxZhM67SjnPbbT+oU1K6qR++X+RFJJQjp0Lfh7WBaXwEuRGcDg16tFqMI06YKdwaJxuXt8pxXiDwyAnEEvH+ya6TwlNqFxeNZwTlcg7o5T1HetY4eMZJupHT1/yNebyPWdCjE2m2sgB+6wP/fRq1dW+6LyySN2RmrehWRttIihcgumc46ckmn3cO6VQOxzWGIkpVZSWzbKjsctEfPkuLaTHmwnp7CsDW7cwXa4+7KuR9RWne3CW3jSRgcCUcj8Kj8RoZRGVx+7YHP1rAowbn/kA3HtKD/6DXnVxue6kABJLngD3r1YWYuNIu0xzvz/Krvwx8JaDqGq3TXyGa8iYkxzcKOeoHeoo7S/xfoh1Onocd4c+F2v67MjNam3txgs8hxkHpiu/h/Z+TyFabW2SUnO2ODt9c9a9mstOtLGFY7ePao9WJ/nV0dK0bIPIp/hh/YmkzvYapcsiQsWW5w2cA9MYxXGahKbTR7WKSZMs+dufdq9z8YRXD+FdU+ycT/ZpNuBk/dNfJVx9vmvfs8iytL6EEmtcLrWiW/4T9T2221lzcAo/8OPrW3DdXToWLhl6gEVwWmeH9c0fTopdUiESkgYJ+YfWt2616HTLAu7huOOeTXO20wSTRS/tO3g0iZJCNxl2kfUcH8xXI62/m3aOWVn8oCTBzk//AKsVmT3UtzI3zHBOetSBTsOTniujHS/fzXmdVOnaaYkKneh/2h/OnXw+eT8P6U6AfNGff+tF/wANJx6VjH/dn6r8md72f+L/ADKxYp5jcfcGK6TwROz390kWdqQlwPbI4/KuUkkBjki/i+8PpW74EnaDWblwM/6MxP8A30uaWJ+GR5uJX76Xqa+j6vf6d5c1lcr0/eRNyCOx9x1H4V29h45s5VCX8T20ndl+ZD/hXkcLXNvfRLbAmFF3pnoUOMg/Q8j8a0ZNUcOwGCAcAgda0aORM9im1KzvLFzb3UUmcfdb3qzbE+SmWGNo714paamr3aKVwTnkDHanv4gdJXQT3C4YjiQitGv3S9f0Lv7p63rzqNFuMso4Hf8A2hWbN4psNM0yBEk8+4ES4jTscdzXmFxrJniZGlmfPZpCajXVI0UKBjArRr/Zl/if5IL+6bQ1O6j1QagJGEu/c20dR6V3vh2+jv3vrmM8SOGI9OteUHVC27GcAZJ56V1fgKaf+1JjGSLdo/nz/Ee1Yr4WXT+Cfy/M72U/6dH/ALp/rUhNV3ObxP8Ad/xqb61kXV2h6fqzEtv+Rvvf+uA/9lraP61iWx/4q69/64j/ANlrZOetdOJ+KP8AhX5GEQPrSHNHNNOfU5rnGSRf65aacmY/WlhP75e1MbiY88bv61T+Axh/vHyX5kkf/H2n++KKRP8Aj8jP+2KK8TMN4eh3R3l6mP4W/wBbpX/XKT+b10+t/wDHkn/XQfyNcz4W/wBbpX/XKT+b102t/wDHkn/XQfyNfVv/AHpev+ZyZX/Ej6moK878XQ2z6/eySjdIsESqDGGAzu9T7de1eiDnpXDeINF1bVPFFzHY2gljaCMsS6qQVz6kf3q4o9QOXuNJszcyu4ESGTYoVc8/TIwKjXQ7fescmFldyiKMkEg45OeOa6oeEvEe52l02Ngzb8GVMA+o+amr4c12M/8AHgskgYsrGVCVJ64+aq0EcVY6Rbpp0UrEvJMC4XbgKMkYJz7VqQaNZFIUkgBaYE7tzfLyQMc47VZ0jw/r95patHYKUhJjUiRMnHPduvNXV8MeLRBmSwgt0XO2SWZNy564+YD881UtJO4Pc5qG0sY79hJGhQL/ABs2B09Dmr8tjZJcqsVrHIHUYyz4JPpyDWdeC30i4LXkaXJA2YjkD7269m69uPSqU/iTWJplksdMji2DCmZs49MDI+vWs+dLdm0qc3ay6I2bvT7MXEmyFVjU4+8ccdTyaZfx6NHfXKJIrSJMEeKNT8m5to6HHU47VxtxaazeHN3LI+f4Q4A/Q1oz3eozXDzixtYpZZlmlaPjzCDkA5bp9MZ70vaoXsX1LV1PZn7QYSYYIZfI85oi5Z+ei7vu4GcnB56VQ/4R+7u7oQ3OoAYmkichflRlxt79GLAUkLaghmD2UE0c0nmmOQ/KG5wRhge57/Wmy3GsLb3aMik3UqyO5I3Bgd3HPHOPyFXRkpVEkX7NrZEMmiwR2bzT3TQrHFHK4WHc3znAUDI5xg9utPurDy9WSz8wNuKBXxjIbBBx9CKNWm1O4W7kmt4l+1sgcKRhdvQLzx0qe/s9SlvVmeAJIEQDa442gAd/ak2vZXW1yeV89mLfW1m1rdPb2/km1uFizvJ8xTu5OT1+Xtgc9Kj0qK1uJPIntFaMAtNcF2BjT1GDjj3ByeKnuTqN0NrWMCq0nmyhDjzW9W+b3PTHU0sP2yGze1OlW0kbybzudgT6AlXGQO2ay51e9y+R22GWMFrPpzCW1ULHG7Pc72BU87eM45OBjHNXdKVf7MhyPX/0I0z7PfpoEMD6ZbvFvYh2kIJY55OHAJHbIqSwjkt7GOOQbXGcjOe5rKU9NGawhZ6omkCgcDNVZMjvVh2461UlJyeay5pdzoUY9iJmbsar3Dt5Lc1Ix55zVeckwtzScpdzWEY8y0H72MA54wKhndvMt+eh/wAKX/liOewqCckPD7Gulyl9VWv2n+SM60Y2en9XLUlwyZO7isue/mL4D8fQVJdy7Iz3NUY03Zd84qabe7ZyYlq9kh32q5PPmYH0FONzNtLF8YPBwKjHUscYHSnrH+5y/O411UW3Vj11RlSaTd3a6Y5Ly6m+VG4XvgU5jeDlpAR7AVoRRL5fljaOD2pohY+YRjgDPvWHtJeZXsY/zr8f8h8OpoLZULN5gYfeGK6H+0YWuI2JBXb0FcpPFsRX9aUNJu2vJ5fON1dbqP2ENH9r9DKdFX+Nbrv/AJHTXV/CynY2PrWZDJLLc22dwUzKM46/NWVM6W4LRz+bnqKZZar5d3AA5RPNU5b7q89a5FOV+ppOiuV++vx/yNPxFbX8WqTshUxAqAARn7orAknvgcFmBB4+UV2ssEeoyvc/2vZHJ+7uHpii38GXF/eLAt9bvIeRk8gVblO+39fec9P2agk5rbz/APkTiY7i6adA7kgsB0HrViwupNO8SLdRkgowP14GRXXap4Mm0va13d2yYPyk8ZNZEmlWbT731WzSQdi4zQ3Jx1X9feX+7351+P8A8ieyaVqcdzZRXEePLdcn2NS3dwoaNwQVbqa810meSyVooNcsxE4wRvBGfWrU91eqiIuu2g2nI5FQ2+35f5lqMH9tfdL/AORKGp6jDcaqLgHMnmAfQZrSub2OdGGcnIrCubCG4uBM+q2KuG3EqwGTTfsfBA1q0H/AhU3fb8v8zTlp/wA6+6X/AMidTYyQjSrt2OP3g5P4VEuoJZ6mmr6U8SXcCASx5z5i9Dmsqz0xxpcwXWLVozJyd3fiqcGkRpcM66vaBsn+Os6bklLTr5dl5lSjSdvf6dpf/ImjrnxN8RLfi7sLp44nUDyuqqe9el/Dn4jp4nVNMuIpft0Ue55T0f1NeP3GhxucHVLTbnOA3erWhLJ4d1D7ZYaxZxykYbkcj8a05n2/L/MydOHSa+6X/wAifSWrYOiX/wD17yf+gmvPrzTbNPBOn3i28YuJJwGk28kAv3qtZ+Lb3VNNuLc6/p+8wsGUlQcEc/w0tzaay/hGyQ6ham0E2UYAYJy3fH171th7qrF2/r7yZOmoNOa/8m/+RPQryzjnjIdFZAOhFfPfxI0qbTvEjny1S3k5jCHj8uxr2trbxSet7b/98f8A2NcR420e5v7Vv7T1GzWVTlCcA/yFYuMu39feOnOkn8a/H/5E8mgXJq0R8h+lW7XSY5EJOo2qYOMM1WTo6EYOq2f/AH1WuMUnXm7dfL/M7PaUoy1mvx/+RMuD70f1H86ZqJw0n4VuQ6NaLs3arb7gegwf61X1XSrRUlcapAzDHyjGe3vSUGsO15r8mWsVSaaTfxLo/PyOTumKTK46gfnXQ+DFD6zckdBaOw/Nar/2PZzqHk1aCI4+6wH+NdB4N0ezgv7pk1e3lPkFcKBwMj3rPERfLL+uxx4utD20l59n/kctJct5cYC4BjFVTubqK0xotkljCp1+2+ZmbPHPT/aqP+xrL/oYLf8AT/4qt+RnB9Yp+f3P/Ih04H+0IvlPft7GorgH7VNwfvnt71qadpFmt/ERr0DHnjjng/7VEukWhuZf+J/bj5zxxxz/AL1auL9kl5/oX9Yp8vX7n/kZA3bhwfyppZsnr19K2F0e03D/AIn8B9uP/iqa2j2m4/8AFQW/X/Z/+Kq3F/V0v7z/ACQvrFPl6/c/8jJaV1t5sbjlQP1r1HwMnl2uSMHavb61xlh4etLq4ii/tuCQvIoCgDnHPrXpWiW0UV3eosqgK4UfrWKi+VmtKvDkn6Lo+/obDH/S0/3f8amz71H5SC4Q+cvA6VN5aD/lqtZckiquJp2jvt2fn5GDbf8AI23v/XEf+y1tE8nrWbb20Q8S3cguULGIAp3H3fetbyl/56rXRiItyj/hX5GCxFPz+5/5EXJ780hNS+Wn/PVaTyk/57LXPyMf1in5/c/8hsP+tA701v8AXH/e/rUqIqOG81TjtUJIMpI/vU5K0LMVKanXuuy/MfHn7ZH/AL4ooT/j9j/31orw8w3h6HoR3l6md4RgeaTR9veGT+b11uu2Qi0+Nnf/AJagfoa43wLeNPNYQRtiSBHBwOcHcf611/iGNl09JZ2wPNHzSNgdD619a1/tS9Tjyx2qxXmbYltYuIl3kf3Rn9axoLiVvFN4UATMI9/7tZeq/ETwvpBMf21r6cf8srRS/wD490/WuHvPiPqs19NeaRZx2RlXZmfDso45x0zxXDzRVxqnOR7E0bFDJM52DktI2FH9K5nVPiF4X0gtE2oC7nX/AJY2nznPocdK8c1K/wBT1l92r6pcXX+wznYPw6VXjjhhXEaKBWTq9jaOHX2mdenj7WNLs2stJtbeMO5k8+YbmXOBgDp29K5vUtR1TWHL6vq11c5/5Z7yif8AfK4FJNLslH+7VORgW5NGIk/aSN4QitbFz9zBpkSxRqAHOAB9ahExPanyN/xLIv8AfP8AWqgb3rnudVXdeiLJfPWgNzUAfJqRWpGRMG9qq3l5An7tnwwIyMH0qcHnrQtzFa6PrcwFytwTDGJIZxGQGB4+6TjI5GeRxxW1CbhVjKO9wKWoX9vLbqqPk7wcbTWreatZNOCs2RtH8B/wqtr1nY/2leXd+bpklv8A7Oi27BSuFBLHIOfvDA4zzyKkbQLSO/ttPuZZ2ubq4kt4pImASMq+wFgQS2W7AjA9arnfsOXzMH/FTGf2paf89f8Ax0/4Uv8Aaln/AM9f/HT/AIVl39rZWem2LL9oe7uYPOZi42J87LjGMnhfXj37aumQweXo1k1tC8eopIZ5HjBcHeyDa3VdoUNxjrzmsLOxqp6l2XWrBtJhjE/zhySNje/tVA6paH/lr/46f8KybS4W2WCVioXdhmaBZsDnna3BP1rRvp7W11mC4hRYrWe2RjI1lFJu4wXERO1cspGM8c4qVFobqJitqVr/AM9f/HT/AIVXe+tj0k/8dP8AhUOupbx643lxPHaOI5FVQFLIyKdwHIXOc47Zx2rVl8KW0IbzLic+VNK8m1hzbqJNrDjqfKb/AL6Xiiw1MyjeQdpD+RqCe5iaMgOc/SrTaPaC3NuJLn7cLEXvmbh5WCofZtxn7p6568Yp1x4ftXku7C2muFvLN4klkkYGOTe6odoABXDMO5yM9KXKXGq0yj9piEPL9h2NQT3ETPDh+/oa6GLTLK90qXTLGS5j36xb27yXDBs/JMNwwBjv8vOMDnmqn/CPaZLfWS/anjjfz/MijvYbiQBIi6uCnABIxg+nXnjfm/cqHm3+CIqTcl/XcxZTE7ctkD261BKynCpnHrVnWLW3gtLG7sjcLFdIx8uZw7KysVPzADIPB6VqSxQrC+l/Z4RENHF4J/LHmeb5Yk3b/vYydmM49s1MboxqWluc7y0qjGEWrJK/ZwM/Nmq+hX4tb5RPKEiYYd2tI7kj6LIQPxzmuolvNN07UNWtmRbNp7iFrV5LGO6CRlWJyrn5QdyHjJGMY4rooznComjDlg0Z1nFJPC8kakgPjOfxq9DaTq5LRnaRg8iqsVtc2U19ZzSYnguXR/LOF3A4OMdqvNIy5RnbBxg56Vj7/Ror911T/ApXNlcGPaIzw3qKbe2NwYGxDuYdORUl5JIGx5jjJGPmNE0suwjzHyPeuxqr7CGq+138jKbo32e67GYNHvZEDGILnryK2/Dng+5vJlWZAsO7Dlhkgeoqbwva3et6gljDMGmByQ7HpX0XoXh2003T44XgiZwOSVB5+priSqd0bN0V0f4Hnlp8PvD9pdW1wtwDtX94u04LevSte80+wsrv7fa3C5GFKhCMjv2r0FrGzxxawf8AfsVVutPgkhcJawZI/uCn7/kTel2f4Hn/AIsFlqPhqfy9jyou+MFD1rw26064kunbyB25BFe1+J9TTS9Km0+SzVZGUgSbQDzXjsrSm5f97J/30ambqKO6OijGk3s/wEt9NmUcx4/EVYaynP8AB+op0RlA++/5mpAZD/y0b8zXN7/kdsVT6JlU2E//ADz/AFFINOn5/d/qKtEyY5d/++jQN+Pvvj6mj3/Id4dmXLO1kTRZ0K4Yyg4z9KzPsU6ysQnf1FbVtu/sS4O458wYJPPash3k3sd79fU1NPn5Zev6Im9Pm2exMLaU9U/UU9bFjyY/5VWEkm7iRv8AvqniaVeTIf8Avqq98b9n2ZYOmjy3YxgttOOla8evavbeGbbTUbMUcu9VODjr/jWE93IInG9h8p71Vku5P7PjHmPnd/e+tdGF9p7aNmtzOqqbpu6Z6ZqPxB1u7t1iUpHxhigwTXB6jPqF9MTK8kme7Nk1DNdyY4dufeqwlkY58x/++jWLlUfUIwpR2T/AlgtpWThe/qKcRtJUjpTrBn81QWOCTxn2pZR++f6murFyf1qafcUox5VJDF5kX6iq+oj5pPwqymN6/UVBqAG6T8Kpf7u/VfkzWn/D/wC3l+RkXQ+cfStjwYWXWLjHQ2zZH4rWbOivg7wOK1PCo8jVJWUeaTAw2r25HNZ4iEmpNfmjOvRlKcmvzRzFx8kdvGeNsQ4+pNQZHrV6SFXYEzLwAOKj+zx/89hW9n/Vji+qVPL71/mLpJH9pw8+v8jUc7hb6fPTzG/nVzToUS/iYSBiCeB9DUF1BGbuYmZQS549Oa1al7Jev6D+qz5bfqv8wT/WCmsrM7ALnntSxKRKo+1Agdqs2wKTZ8/POcA1q4v6ul/ef5Ih4edrfqv8zc8FWpk8RWquP9UrSsD+AFelaX/x+Xx7eZ/U1yugSeTILhbQvIV27wOSPyrqNJEnnXMkkTR+YwIDD61z2ai7lRpuEJc3l1Xc18/6Sn0qxmqoP+kJ9KnrEVXaHp+rMe2P/FWXn/XEf+y1tZrEtuPFt5z/AMsR/Ja2s4rpxPxR/wAK/IwiO64pp60hz2pDn0rnGGcNg0L99frSbgRSqRvAI5zSew47olT/AI/Y/wDfWikQ/wCmxgj+Nf50V4+Ybw9DeO79TzOwuNTsb2G80y7FvIE2bs/XPH41JcQ6vqN00upapJdEjgPJwPwArjLJiLVOeh/rWvazFm5P8NfUKpGWIjdfj6meXU5qpFRa37eRoR6S0IxGIR+P/wBantp8+0fPH+f/ANasQy+9PaT/AEdTnvXEpU9fd/H/AIA3Gpp734f8E1P7NnJ+/H/30f8ACkOm3H/PSL8//rVjeYfWjec8moc6f8v4/wDANFGp/N+H/BN6606dpRh4/u+v/wBaq50u4P8AHH+Z/wAKp6g2J15/gH8zVXfx96tK8qftZXj+P/ACMalvi/D/AIJ0D6bOdOiTfHkMT976+1VhpU/9+P8AM/4VWkb/AIlEBz/Gf61UDe9YuVP+X8f+AbVY1br3ui6f8E1l0ucfxx/99f8A1qkGmTf3o/8Avr/61ZKvj+Knh896Oan/AC/j/wAAy5an834f8E1hpsw/jj/76P8AhVK90XUXhnjingWCdkLqTySoOO3uaiDcdakuT/oMf+//AI1th3TdeEeXd9/XyKjTqST97p2/4I+S28QwvLOt7aGSaQSOXRWG8dGAKYVh6jBpHXWbLMMd5FhsvuIDMpbhirFcqT3IIqlqDf6OvP8AGP61eDAdDmio4exjyrdv8DKFOXPeUr2M+bT764SFZZ4mEMflx9sLknHT1JqxAmr2tmbWG6hER3YyoLLuGG2sVyuR1wRmrO/1o3gmuW7NuVCR2Go2mnW9xG9ljmMB4lcEZJ5BUg/U5PSoc6sbprh57WR2QJiSFHQKOgClSoA9hW1Mw/sG25/5aH/2as3eM9eKlNspwRl3djf3lw9xczxySv1Yk9uB26YHSrEs2tP5u++QiW3W1fgcxLjC9Pbr1/M1YZ896hLj1qtRcqKzPq32D7H9qi8nZ5f3Rv2Zzt37d23PbOKivJ9XnsvIlu4yi7clVCs23hdzBctjtknFW2bjrUE7fuWyaltmkIRckJc3+t3Vuqy3kYAlW4zGioTIAcOSqglvmPPU9+gqvNe6o1zDN5tskih13R28aZ3rtbO1RkkE8nmrSO2xeR0HaoJ2Jmh6fe/wrenWpqHLOF/nb9CKkUr/ANdSnPBdzW0EDyoYoNwjXH3cnJ7c806SbVX0/wDs83KfZ9uz7i79md2zfjdtzztzj2rSDc9KQqTnir9vQ/59v/wL/gD9lFmXaSahaXLPF9i+ZVVg9rG6/KMA4KEZ9+p7mpv7Q1aCeWfz7eSeWQSNJNAkjBuxUsp2n6Yq0I8HIWqV4P3e4Kc7h/KurC1MNOrGLpvX+9/wDGrS5VdFi2kkRJHncvK0m9mzkknHJPrU88+8BhmqCFwrqQ2HHHHQ9qky/wBnCFW4as/bYf8Akf8A4F/wDL2T7DribzYlH8QbIp80u9SV71SlRwnKkEHvVqOPzIypV1BI7V2OtQ9hD3H9r7Xp5GU6avquqGafeX+k6xFf6fMYpVwCR3HcV774f+KFnfQJDcWF5HOqgHADBjjrnIry3RfDtlPIrvJqLueoghA/Ug1674V0/T7UCO03CUff3zF3/H0rjjVoP7D/APAv+AbTjGK2NYeNNNwN0N0D6bB/jTT4y0/nEV3/AN+x/jW5KluTGJHUvn5cnkmkZ1UtGCCw64PShzoL7D/8C/4BkuXseSfEXUbTVoIpIIpgydS6gZH515iQvmlueTXsPxM1MC1isoJVeXdmQJztHoa8v8pyf9Wx98VE62H5fgf/AIF/wDroQfYpq6Ds30qQSp/darflP/zzP5UeTLwfKbH0rH2uF/kf/gX/AADq5ZFQyp2B/Km+auMYNXDFL/zzP5UnkTHpE35Ue2wv8j/8C/4AOMh8N1GukzxlWyZARx9Ky3dST1roYYpRolwChz5g7fSslrafJPlHFTTrYXll7j3/AJvJeRLi+b5FEuvvTC/XrV421wf+WRqFrWfvGar2uF/kf/gX/AHyyKsj5RwM8g1WfP2VF96vy204hc7ONpqnJbS/YY328bvX61vhauG9tG0Hv/N/wCakX7N6E+4e5pysB61KLWfOCo/Opfsky9uvvWHtsL/I/wDwL/gD5JdhbAfvVz6n+VLL/rHx2Y0+2ikW4XIH5+1RzRymV8AdT3rCtWVWvKptcpwl7PbqIg/eL65FQ3/WT8P6VKiSCRen3h3qG/Vt0h4xxW6kvq79V+TNKcX7Pb7S/Izpl+UfStjwYp/tqb/r3b+a1Q+zGSMfMBxWz4QtCmsSnfn/AEdv5rXJVkuRnPOL1OPZc1ERV42f+2fyqNrUd2P5VspIzcWGlj/iZw/U/wAjVa8X/TJ/+ujfzrR023C6jEdx7/yNQXVuv2uYknl2/nXQ5fuV6v8AIlxdihCP3y1oWkJaYY9ahSBRIOTW3pFsG5zk5rdO+GX+J/kjnqxsrnY6G22NR0wK6uBvl965TTVKBa6W3bt1rBmKLuf9IT6VOD6VWzmdT7VYB5qToq7Q9P1ZkW3/ACNV5/1xH/stbWaw7bjxXef9cR/7LW1k4rpxPxR/wr8jCI7JI+lNPFHQZFJnrXMMOlC/eX60n86FPI+ooew1uiwhzeR9OHWimJ/x/wAZ/wBtf6UV4+Ybw9DeO8vU8Q06ENYxHA5z1+prRggZX+XaOPSqWmg/2fEcev8AM1pQM28g56V7dOpL60o+f+Z24PDwcoPVXts/Ir/Zs9An5U8wERgYXj2pUZuwNSEkr3rljVlZ6LbsRKhHTV/eQC3OeQn5UvksOML9cVOMntSrnJGKj20uy+4v6vDu/vGzROZBuKk49KYIDn+D8qvMIX5dyD04FAS3/wCejf5/CuuupSqNpx/AmnQjyrV/eRPBL9jj5Tbu4GPr7VEbdh/zz/KtNhbiyj/eNt3cH86gxbZ/1rflWXLN9Y/gbVKEbrV7LqUfs7Kf4Pypwhk7BPyq4fs2MeYaX/Rto/emjln3j96I9hDu/vKqxyg/wflS3SOLNMlfvdh9atZtRj94aivDD9lTDnG//GtcNCf1indx36NdmXGjFKWr27leexknQISgGc5xSDTrkjH2pvzNXw9vj/WmnLJAD/rG/KoU68VyqUbfIj6rTbu2/vZltYXAP/Hy3606PT7g/wDL0361ouYOpkb8qYrwZyJW/Kn7Wv8AzR/8l/yD6pS8/vYsmlXo06JjfZjLnC5PB5qqNMuMf8fWPzrceWP+yYCzHZvOD+dVhJBtOGNR7XEfzQ/8l/yL+qUu8vvZlnTbgHBuj+tL/Z1w3/L3/OtAyQ45kP5U4NCB/rT+VL22I/mh/wCS/wCQfU6Xn97M3+zLj/n6/nUV1p06WzsbkkDHHPrWsJIc/wCtb8qhvjELOTEjE8fzpOrXtrKP/kv+RcMJSUk7v72VINMu3gjK3JAKjjn0qvd6ddJc2oNxks+Ac9Olblq0Qtov3hzsHf2qrqDRfa7Ihv8Alpz+Ype1r94/+S/5GdbC01Fu7+99yMaVeY/4/P1NNbTLsHBvf1Na3mQ5yHpxaI85P5UvbYj+aH/kv+Rr9Upd5fezJ/sy725F6xHtmqeoafPHbqz3LMC4GOfeukV4wOCaz9adTZpj/noP5GujCVa7rwTcd/7vn5GdbC0lTbvL72QDSrsj/j9P5mm/2Rdk/wDH2fzNbW5dvX9KQSoBgs35Vz+2xHeH/kv+Rp9Tpd5feznNQ02eOAF7kuCwGOfera6Nc7wzXhB9ec1Y1dk+yJhmJ8wdvY1faRMcsfyrqqVMQsNTalHVy/l8vIzjhaPtHe+lurIY9KmCfvdVnC/3FB5/WrcBvYIfKh1m6hj7JFkAf+PUxXRh94n8KTcg53NXIquJW0o/+S/5G8sPSlun+JPFJf283nQ6tdedjHmsx3fnu4FV5JdVMrMNcustyTuPP60eYn9400SRg/eP5U3Wxb+3H/yX/ISw1BdPzKEtndMzM2ozNnk5zz+tMWwnZci/lXPYZ4/WtGSSIqcE9KZG8YiByeBRzYhw+KN7/wB3/IOSmppeXn/mUTp06nnUZfyP+NPbT7kJn+0psfj/AI1aaSI8lzQZoQuPM/OoviP5o/8Akv8Akaezp+f4/wCZRGnTkH/iYzfr/jSDT5zx/aEw/A/41bM0J/5a/lTPPhGf31UniP5o/wDkv+RPLT8/vf8AmNOnXI0uZv7RmIDD5ecHp71QNnPt5vpf1/xrZE0LaNORLkbx/Sso3VkBg3QB+tOnKu4tc0d/7vZeRjy0+d+nd/5kH2Gb/n9l/X/GoJLSbP8Ax+Sf5/GrpvdPUHN4v51Cb3TM5N4Pz/8ArVoniP5o/wDkv+Q3Gn/Tf+ZSltZRC+buQ/Kf89abbWLS2ke64YjOdpGe/wBanuL3SzE4F6CdpwPfH0plnqOlx2qLJeBWGcj8fpVqWIW0o/8Akv8AkTy0uv5/8EvYGelB4GMVWOraOD/x/D8j/hTH1nRv+f8AP/fJ/wAK5vqlTuvvLdWHcuQn9+tQSsfNfnuait9V0h7lFjvGZznA2n0+lRy6xoyyuGu3DBiCAh6/lSWFnz2utu4OrDk36kwPzr9RUF+RmT8P6UxdW0Z5UC3UhJYADYf8KjvtQ0vzJI/Pk83jjacfyrsWGmsO9VuuvkyoVYez36r8hUcCNfXFbfhM51eX/r3b+YrnRqmjKgVp5gwGDhD1/Kt3whqGlS6xMIppi32duqnplfauarhZqm3dfejkqVYaq5zzNxUDuBTmv9HP/LxP/wB8n/CmG80c/wDLef8A75P+FbrCz7r70ZurHuWNObOoxcev8jVe6b/Spv8Afb+dPg1HSreZZUmlJXplT/hWXPqSyXUrBDsZyQc9s1pOny0lG636PyM3Uj3LiNlxW7ohJIyOM8VzlvIZHOAAB711OixgFc+lbJWwy/xP8kc9WaklY6yzHT3rct+grHswNorYh+6PcVzsyRbB/eqfarIORVRT++X6VYB680joq7R9P1Zl2x/4qq87/uR/7LWxnjNYtv8A8jVeEf8APEf+y1sg/nXTifij/hX5HPEcTz703PAGMUGgmucYnSlQ/OPrTc+1Kv31+opPYcdydP8Aj+j/AN9f6UU2P/j/AI/99f6UV4+Ybw9DeO79T54ju5o4wizMFHQA1JDO11d28NxMzRtKoIz15ro7CHTksdEhRVkkuobmaZZbOM7iqSAfvCSwwVGABg9eDxXPNpTW8Vu6XTvqPkC9FusGVWMAuCXz12jdjbjHevZcuZt2NIRjSmtW7FR4YPJmnF1KI0kEagx8kkE/3unHrThp80sJaKSbIjVwGhI3EsF455HPX2qS6s52jurZI9ksDJLcRLE2I8kLwST3cA5A5PFSXM6W+oahazyCOUxmGSTyWXdIrjIIyTjAOen09aoRvNKW2v5Dc6T/AK9fP0KVvbXRuJIQsxYIcq0XI9wOfzpPKuixEW+QKu44TkD39OlaEktuXniZRm1jWPdIJNp5w2cc+gFOS5i1G8McJxi4EqtsfLDGT07jnr610xw8O/5EScWrJlCOOVrhbcS/viwUoVAwatT28sAj/wBJjZHzhgo7deoqNLpF1y5naHIjkdi6gk7c4z6dDTRJE/kWkLq+0yyM6o20ZX3Gf4ahwjyy7q//AAPv1FzQ11JEikmj3x3cTYUuUK4OB1PTH61OInEOfPg3iMSFeNwX16YxVe1G2yObpzbNFJmFUcFjjv24JB61OGieJZVz509uIUjMR3EBcHnpjCk1ahTcVff1/H/gfgCmt79Bsbs3KywOCQvQdT0HA61JDE8kjqXjGN2AyDOVGSP5VBpkHkCYvGfmVZIAEb5pB939SatNKjXUXllmkmilx+7bmUrg4/SlCnSaUpP5BCSsrsi8uUSvG8iq6jOwxrkfUY460lzY3kUojY5ZhkAR9fpxz1FQJcIyjeXeZbJt42nrvLgfkRViW4i8x3ZVKXlsD86vhCAuc4wccds1SpU9Ne3YIyjZ3ZFc7g75mjVlOGTao2/hio7y1khjkf7QjyCXY4jA+QnoCOAPwplzN54luPLj2KEQSIrhWIxx83NXLwRquobAu551dg6uPLJOTuP1I6VmqcLSXb+vnroP2id9Sl9kkFuZnuliQPs/eIwycZ4wDxT7FGnjRRPH5khOEOd2B6YGPzNOsWnj1NbWSdIT9p2yW6pIfN5xjGMHPTnFP0rKMHhuyLZnYPEEcE4BOBjg8dz+VONKD5br11/Hf+uzBThffQs2U0LWcAuJEIy+QxPXDYzjnrikeLy5JbnCMiQ+YsaOdj/MFzyc9T+lR6fpxmt9PwrM97K0NqrwMRO2cckNx8xwMZ9xU0Wn6pNAb1Yj5As2ZYvIbY2C5aPOc8eVI2c5+U1xuLvoEK1JRSk/w/P0NvwrHa3fivR7eVcQXk0CvHvIJVnUFc5z6+9aUls1q0cranZPavM0DzJOxWGQclWyoPTuMg4OCawtJjm0XxNaatfNIBp2oxRGAQFRvjKsUyT8uCCD1PfBqfTfFEFvrtrZ2uk+RBBeS3Nyj3HmF5NjL8h2jaF5K5DEE5JOKpQXU5qsoym2m7fd+p1kGnh3Ux6paPbNbtci6WR/L2K21jjG7hsDG3v6Uj2cFxYyuNb08Q+YIUmedtkjnB2jgnoR1AAyM4rFvPGttqL6XqMlvqyraieBHTVGNxuyjBvNKk9GIxjH0q9b+OY54NQCre2iyP8AaFj0+9kgmZ1RVJZgpVshQWJAOQTxmnyR7GaSvu/vf+Zf0y3hm1OPTbm+SGWLcJ0EgLR7FJcYz1AU/lVXX1s44tKv7GaQ29zI6ASyhyjJtz8wABGGU9BXL2+sC0u49bS33z/aX83zpWczK6ncGYnkkMQT15q/dahbahHpVpbWcsFhbK5SJpw0hdwPmL7MHkJxtHC46nNJxXYrlg95P7/+CdPaRWd1o11cG4eKS3jLGQ30ZDNkYURY34OfvZIqLVoIrLSY7myF1cDyYXluE1CN1jZwCQ0SruUZOASayo7mHTrOX7PY/wCnS2727TPc7owGG1mCbAc4J6sQM9KhS+hi0u5tbKzaK4uolhnlmufMG0MrHYoQbclR1LUcnkXyU/5n/XzLmmQ6hqiK8E6qpuI7dt8rDYXDEMePu4Vsn26VoxaLcSx3cOoSopSK52b5mAjeLALnHbJPrnB46Z5vSby80W31OOPy5vttq0Kbnx5LngSDjkhSwx/te1P1TxldyxSyT2axuNPNiQsuQXblpenUszNj3xmqhFqSaWpE4wW0n9//AATqPJuYhc5vIZYltFulnEr7TGZFTcvAOcnBDD14zirOo2P2fVLm3t9ZiNvbqHllkkceUOAN3yjJJIwFBrztPF0z6c1p5ABOmDT95k7i4E2/G3224/HPatSLxvLHqNxe28V3CbyFY7sW995b7l24aJgmU+70O8cmi3katR/mZc8QJercQ2H2kySSSRmNkkJVg4yrD2IIq3rUEMVrfSWF5fF9PultpjNKCJd24b1AA2jKHg56jmuI1nXru71U3qXV1uUrsN1P58gwOMuVGenoKt6t4ujv4p4rewa2+2XS3V8VuA3mMN3yx5T5F+djg7jkjnjFXLmdNJrTUEoX+JnReHGtNRvFtL86n/HLJPBehFjiVSzHaY2yQAe4zwKs6VpA1KPTYftGptdaoZRA8c37uEqSAHGMt0ycFcAg81wdp4gmsbPVYYIn33sYhSVnBMMe8Mw4Xknaozxxnjni1ovjSbQrJ0hN6bskspF5ttw2PlZognzMvUfNjIGQayt5DfL0kzqtLMkmmRO5Z2OcknJPzGp2V/7h/OuBtNdvIrVI0ucAZwNgPf6VIfEF+G5uCo7koo/pWbUux1KGGa1m/wADtHV+fkaoSj4+5J+Rrkk1++d1xdDlgPur/hT7jWtSSVgJmb6Rr/hT9/l2D2eF/wCfj/A0tQjuzbSrDHPu3gjapzWM1hq0pH7i+Y9vlar+l6tqVxcrGbjBJ/iRf8K3o7rVIpAUu0EnZto/wrmqVeSXvI78NhKVWm/ZzelzO0LTtQW0kWSyuQQ/8cTZ/WtNtOvP+fOX/v0f8KuWmrakrOLm9JzypjRP8KsHW7kH/j6nP/AY60VWm1ucksLWT0K8Wn3Q0adTay7vMHHln29q4C80DU2vp9mnXTDzDyIm9a9KOr37afLJHdSBFYA7lTOePasaTV9Y8xmW8UA+qLn+VTGpCMXbv+iEsLUlK0mtjhz4d1X/AKBl1/35b/Ck/wCEc1X/AKBlz/35b/Cu1bWNaA5vl/74X/Cmf2zrWM/bVx/uL/hT9ui/qb7o44eHNUHP9mXPH/TE/wCFKPDmqvyNNuSD/wBMj/hXXPrWtCJm+2r0P8C/4U2DW9ZeBW+2rj3Rf8KPbIPqjta6/r5HKf8ACNarn/kHXH/fs/4Uv/CN6r/0D5/+/Z/wrrW1nWgMm+H/AHwv+FRHXNZ6/bR/37X/AApqqiXhGuq/r5GFp3h7U476J2sZwATzsPofaobjw7qbXUpFjNguSPkPr9K6e11zWGuU3XmRz/yzX0+lRza5rImfF5xuP/LNfX6VKqLnKeGfJa63/roc5b+HdTW4jY2cvDg/cPr9KnvNA1E30kgtJscf8s29K2E17WTIv+mHlh/Av+FLPr2srMym8/8AHF/wrp9p+5a8/wBGXCg4091uvy9DnW8Nai3zfZpeeceU1b/gzQr631mZpLaVQbdhkxsO60v/AAkWqAYNyeP9hf8ACtnwrrmoT6rKklyWUQMcbFHce1c1Sa5Hc5J0t2efnw7qPe0n/wC/LUn/AAj2o97O4H/bFv8ACt7/AISTVf8An8P/AHwv+FNPiXVf+fw/98L/AIVtzEOmYf8Awj2of8+lz/35b/Cj+wL8f8ulz/35b/Cto+JdW/5/D/3wv+FN/wCEm1bH/H4f++F/wp3J5DPttIv1uEH2K5wO/kt/hXYaTp94qgG0mHuYzWDZeJNXlnJN4cD/AKZr/hXXabrGotGpa4J4/ur/AIV26/Vl6v8AJHPI1reCSJR5iMhPTcMVqQgcZNJdM0lvZO5yxTJ+uBQg6VzMETqf3qmrCn0qsp/eD6VYU8UjertH0/VmXbH/AIqm7/64j/2WtjisW2P/ABVN5/1xH/stbNdOJ+KP+GP5HPEcOCOaT2ozjGaQ56VzjDJxSo3zrn1FJn1oTh1+tJ7DW5Mn/H/H/vr/ADopEP8AxMI/99f5iivHzDeHobx3l6nz42sX1lNYhYYc2cMkce4E5Em7OeevzHH4VJa63evbfZhbWxmFsbYXWD5vk/3PvbenGcZxxnFUtRBNwP8AdFJYfJOxP9w/zFe0mubU6XSaxfL0uT3HiS9nhaP7NarPN5az3CKfMnCEFQ3zY6qpOAMkDOauT21zf3sl5NBGJbl3mfGMZZixxk9MmsWzh8y9j3cqDk4rrpbiBjCUVwqrgZHPetKKi7+jOFxm9yC8lurq2MJ02zjZiplljQB5dowM84HvtAyeTUVubq2+2fZ7OGJbpdhVTnyxuB+XLE9sZOTgn1qybuPnh/yqNrtB0DflUqSWzJ5al72H2BfTo5kbRbG681dpactkLxwNrjHTr196r2MdxYX63UdjbuyhgElUMnzAjpnnrVm5vFRwMN09KZHeIHDEN+VErJsFGppoX5I7trdTHpNlDEYmhCIowN3Vslid3uSaaYdZ0+xtU/sawfAYwTyKpcK3UcNg9T1GRngirMmqwmwjAWTO70+tX9av1GnaUcN80Pp7LU6GtWE01bsjCtLzWLRLQDRtNka0EnltIgJO8knd82Gx2z0wKjs11izisSukWLm0cukkqqWYEgkN82COMdM4zzVs6xawgYV2b3AqvLr+4khG/Gn7ply1DHb+0LPUY5/sVruC7GidVKOu3aQRnuP8Rit42Orahp6zLoFgkRi8iMxtjYvXjL5znucn1rEW93zPPKpMh6Hrge1dXpOqm38NoZQ/MhKDH1rWiozrQi+rt+ZpSpTaaa6EWo2OppElhL4Y0wMsaplZDnAOc8S4ye5xzTLWLVry+eOTw9pjYeOS4OMeYFIAz8+MeoXGe+aunxAr3r3DiQs+c5UH+tPtddW3vp5mjYmSPGNv09/apiou/kSo1He6OX1SW60vxCNVks7VrmC7Fx5ciKY2YNuwVUj5fYY4rPm8STrcWxh0nTIFi80+VFCdsryJsZmyxOcdACFU9AOaueLrlLvWWljLqjxq6owxz0NYwUK24f6wj7x/h+lZOSuONKXI3bsb1hrOo6J4bsGWxtJntrl5LOeYEtayHOWTDAE5UH5gQCMgZqPSPEmtafp2n28MFqbawvTeK06n52Ixsbn5kwX4GPvtzzSyXcEXhm0hWPzJFlJy4+Ufe96xJ5ZLg7mYuVIPHQf4URkKdKStZHRabrN7d3c9olsk8n2t9Rklc4JlOM9+n60ukarrN/4lfV44Ihtme6faoCqeScZPI5xg9RxTPCkfmaxPI4wGiY7R9RWlocsUdtPEPNLTyRxgKowF3Bj+gpxa5mc8YTdSSt2/U7nQ9A1u9sYWh0WzS0Uu0UEEm2PL9W+aQsT079gOgxW9D4e8Q29u0cOi26StGYjOJV3lSMHq+3kEjOM1raV4s0uyso4Vt7vCrjiMf41of8Jzpn/PC8/79j/4qtLxL9nPscu+ga8NK+wHQrbaG3+b5/z7sYz/AKzHT2xXVW6yW2j2kEo2yR26Iy5zghQCKrT+OdNxxBd/9+x/jWPd+NLBs4huv++B/jRzIPZT7CarLnPNc0bho5jtNLqHia0kJxHP+Kj/ABrCk1u3L52S/wDfI/xqHJFKlPsdVFPuGc151rN2b6x1ubOR9sCL7Bdo/pXQjxDbxwudk3Cn+Een1rjoJQ/hS/kIOWudx/Eqa1oSXtYeqMMRTkoq66r8yhHCpTJz+FTxRBTzuU9uaSK6hOAUcAdxU4u4QclH/EVldHUqcuxHdPKIlBldgD0ODVe53t95nbJqW5uUZFwrDnJyOtNlmQnofyrqqtfV6frL9CVTk5PQo+WVHAwfrSB5s/eJ/CrBlRVwoP4imtMAMBSBj0rkuinTl2K7PNgkuRjnoKYskwGfNP4jIqUyBlwQenpSAqFy4OBQ2hKnPsOChDbTLGoaR8EgcDB9KgvizXcnJI47+1WLaZTOA6ny3YDaP4fQim3uEvJRjnj+VO65Rezle1ix4eONSjDZxk117FfPXGelcVpUwhvUY569q6H7cpG/5sDivNxavNNHv5VeMJJ9n+RqsyK5/nULOgJJ61nfbl7lvypjXsfq/wCQrFQZs5HRRODoc+Cf9YP6VlNMoP6GprS5R9CuDlv9aO30rGku4gzD5uvpVU4+4/8AE/yRztvnfoX3mXHFRGcdc9aom7h9G/KkF1B3D/kK0UQbZclnXyX4HIPeo7eUfZkGMf8A66rvcxFWAD5IxT4HAt045/8Ar0coXdiy8w9/yphmx0/lTScjoM+tRsTnpimkiG2WbaYm7jGPX+VV7iVvOk/3jT7T/j7j/H+VV7g/v5P94/zoS9/5BJvk+YRSN5yem4fzp94x+0vz6fyqKL/XR4/vD+dOvP8Aj6f8P5V2L/d36r8mH/Ll+q/IryOw71u+DWJ1mYk/8u7fzWufkJArd8F5/tib/r3b+a1y1P4bOSZzZJppPag59abzW5mwPSmOcKTSkGmMCSq56mqSM5uyNHTI8IWx1rtNNX92n0FctZR7Y8D0rrtNH7pCPQV3P/dl/if5I5vsnWzjNnY/9c/6Ckj5wD0zT7kYsrL/AK5/0FRJ93JrkY0TrzIB7VYBFVlOZBUwoN620fT9WZlsf+Kou/8AriP/AGWtkfWsS2/5Gi7/AOuI/wDZa2c85rpxPxR/wr8jmiOznvRnIpvSjJzXOULuyPelU/vFx6imbsGnLjzF9M0nsC3RMh/4mMY/6aL/AEopE/5CMf8A10X+lFePmG8PQ6I7y9T531Bf34/3RTdO/wCPlv8AcP8AMVNfr+9B/wBkVDp//Hy3+4f5ivcj8fz/AMzp/wCY/wCf6Gn4J09r7XVwdqpjLeldprlmsOuJGgx8mTz7Gs74SWf2nWJQegYV6g+lWlx8RIYJFXy/s+SCM/wmumlH3fkzy0/efoeXSW0mSAjH6DNVpLabH+pk/wC+TXpGsaeuk6lLBJbP5LHMUoXhh6exriNX1bUba4zb22FBI2bCeK5ybmNdo6yAhGPHpUCSuTgDmr11q8+BGbORs85VTgn8qbDDf3XI0y5wehCU57saLjMw0iHc2PnP9am8R3D/ANlaUsIyTAe+M8LxSS6Drl7pkMFtZMkgfJErBcDnmti/8GancabpkUlxBE0UWH5Lc4Xpx7VKN6+69F+RwUMs6hnuxGgx8qKQT+NVJ/Mlb5JHwei16PZfDnzMbpJ5h3baEUfrmup0rwZpukkSCESz+rchatJs5m0cBoHge5uFS61SRoIcBhEPvMPf0rZ1Ro9kCIu2AOAi+wFdbqSSSKsCkh5HEage/X9M1zniG08y9MUSnbGyoMewrWgrYin/AIv0Zvh3dy9P8gltla8uLm4QLCn7z6+grHhuHutXmduPkyB7cVd1O5UP9gW4V0RvmfeDuNYV7qcWkvczrh5SgSJV5y3HP0ohCXvaPbs/8iIJ2ZmeNJIZr2JYzmW2gIbHbJ4H865d7meDGyQKpHT1/CpT5s9vLNLuaWWbLE98D/69QSblJIjLHoBtzWDhPmWj+5/5GkU/Zy+X6m1cyb/CFiZfmJuG69Or1mRTmVtsjjCnCoeFH4VqTRbvBlmjAeb5zHHpy1RaeIZrY+dYwtIhH3sgsKUKc7PR/c/8hTTuvRHT+FI1FyzKVZfKI+XqORXb/Dm2gm1KeLA3Q7ZkHUdNv/s1cXpNnpaXpeyE0NwYiHgD715I5B4xWt4Ia70Lw3repG5T7WGijCmQZ2EjIHr71Uac+d6Pp0ZzL+LLTov1Pf4NvlAqQR6g0skm0Vg+Hb+0t/D9tHJeQAgEjdKM4PPPPqTV2bUrExFvttuT2Hmr/jWvJPs/uf8AkVZjbu4yDXP30/B5o1HW7WIfLPDJ/uyCsS41S2kGRcRc9t4qHCfZ/c/8i1Fle9ferY6j+VYkgJbIq9Lewb8iaPj/AGhWRrt8tnYStbujOeAQ2doI61Hs59n9z/yKsxupT+TpF22eRGa4+0B/4Q+7zn/XL1/4DWldXpuPCkzs+ZGUKQepOfSs61D/APCH3YP/AD3Xgf8AAa1oQkqsLp7rozDEp8q9UNhMeA289fTrT12s5BY896rxgbQcgY7mpo5VRic7m9xwKjkn/K/uf+R0KI28ZDFwMndk7u1TuFfndj29Kgu2R41bCg7ux61KXQA/Lye4NdNSnP6vT0e8uj8vIFpJlKRirHnC471GWcjJPB6CrU21QWGG9P8A69QCR9xAAY471y+zn2f3P/IdiNxxubJX+FQeWP8AhULAuA8hA9FHYVbmjErGWM5LYymeU9h6iqjqRng8eoo9nPs/uf8AkJpjY8eagTIUsOtTXSLPK6ceag+T/aGORTI0JlQkEfMOlOuSyXTFQcjnOO+Kfs58uz+5/wCQrO5DpzgX0Z6DdXQeYNpPTHvWHjbqEbKMBiGPHQ4rVyDG33etefiqU+ZaP7n/AJHt5U7RkvJ/kSGYHim+aM9P1qLeuMcUxpEHSs1Rn/K/uf8AkaORuWkg/sO4x2lHf6VjSSDzD06mrFlqklupt0RCjtuORz0/+tUjeIrpGKCKEgcfcP8AjQqNaMXaF7vz7LyMXJc/yM/zfm60hce9Xx4ku8/6mH/vg/40v/CR3f8Azyg/75P+NLkxH/Pv8/8AIfMu5nq496UMM96v/wDCR3n/ADxg/wC+T/jTh4ivP+eUH/fJ/wAaOTEf8+/z/wAguu5nEgnHNNLAds1p/wDCQ3f/ADzg/wC+T/jSHxFef88oP++T/jT5MR/z7/P/ACBtFKzYfak49f5VXnJNxJx/Ef51sW2vXktyiNFAFOein/Gmya/epK6iO3wGIHyn/GpUa/N8H5/5DdnBepkx5E0eR/EKW9OLqTj0/lWpH4gvTKmUgxuGflP+NOuvEF2twwWOAj/dPp9a6lHEewa9n1X5PyHp7J+v6HOsd3AyK6DwZu/tiYf9O7fzWoT4hvAP9VD/AN8H/Gtvwlrt3Pq0qNFEAIGOQp9R71zVI1+R3h/X3HLJK25whBB6U09O1bp8R3v/ADxg/wC+D/jTT4kvv+eEH/fB/wAa25cR/wA+/wCvuIaj3ME9aWFd9yo9K2j4kv8A/nhB/wB+z/jVqHXb0SHMUGMD+A/41pGOI/59/wBfcY1VG1r/AIDbZMQk11WnL+6j9NorNh1u4MR+WDPptP8AjXRWOoTPChKx5IHQV0zddYdJwt7z6+S8jG0bb/gbd1xaWQ9Y/wCgqBT3q5d3Ti2szheU9PYVAt0+BwvPPSuVyq/y/j/wBpR7gpw4qwCM5qNbhyw4X8qmE7Y6ClzVf5fx/wCAbVVG0den+Zj2x/4qe7/65D/2WtkH8qzbe8kbxDcwkJtWMEHHP8NannN6CunETrXjeC2XXy9DBKHf8BtJnjg08SsSelHmtnoK5+ar/L+P/AHaHf8AAYeQaWP76/UU7zj6ChJm8xQQME0nOrb4fx/4AJQutfwJU/5CMf8A10X+lFKspW/jHGN6/wBKK87FwqT5bq2nc1vGMmfPl+P3g/3ag0//AI+X/wBw/wAxVq+XLD/dqrYD/SmH+wf5ivbj8fz/AMzp/wCY/wCf6HpnwPhD395IeisP5Cuztr5H+KwkdtqyRMqn+78pxVP4W+GH0nw685BN5dAuyjsMcD8qy9QdoPGynBVkT8Rwa7Kbs7PseTHWT9Gex+UjxhJgrg+oBBrOutC0u4z59oRno68VQ0TxDBcxGG5lVSB/EeG/+vXRROpAaNjtI71nKCZlscZoXhe0ntnlEpBEhUAgEdBXQRaOkOFfy2x6Ej+tR+HCy6dJt4/fHoPYVrbiDzQ4q4Ns56XTLOXUpkdXChQcBiPSrnk28SIscS4AwM81DMxfV5yR/COB+FSykhEI9KhHRX3XovyGkb2CHgHpiq8sDR++KeZcjBFXIv8ASYAWUh14Pv71RznMyFRr1uSPlijeQ/XBrKvVRftElwm55BuAzjFdNcaaV1Pz2X92Ewff2rltVk8/VJdxG0cfpWU5OLi1vf8AzOihtL0/VHKzWdvHIXkQKmC7HJ6VwOuXYuLx5IgUjP3F9BXVeKdSDym0iPAA8zH6CuI1JS+zGM5710Rr1bP3nt3HCTsyuLi4a3OGwA/JxUgaZnG1yB9BUEcnlo8bx/Kw4x2PrV6CASSqvmPjvsXP86xderzL3n95pFv2cvl+ptvAn/CKWk0jsGMrZb2+alsNNuL1EffHbwN/y2bnj0A7mtV9PM3hezjWFUjablpnGQMn3/zmrkls1uiLsVY1XqMAf/qqqdetZ3m/vZM5O69EW9HsbSC5b7ODxEVMjnLPyOT2H0GK7P4faTotz4fvptQjR0+0bT5rlRgZ9DXIaNxcNsZWUxn8OlZeSq7XZnI6jOQDihYiqpv3n06mELurL0X6npWva/4T0VNsdgbhwPlVJGx/OuD1Lx6zEfZdGtYEPA3O7Ef+PViS3LEup+UcZzzWRcvu3fMeu4n2qnia38z+9m1mupoXHizUWc4W3Xnsh/xqkfE+o558k/8AAP8A69ZrEM2M8fyqMEDOMmp+s1v5n97Dmfc24vFsytiaxt3H1Yf1rUg8UaTcoI7uxeEnurFhXHFc549qUIxc/LzS+sVv5397GpM7HWHsZNEkNiyM2QAFPI/CqdsJF8IXZIOfPXr/AMBrDhQ55OK3wp/4RS8wODMpGf8AgNaUa9V1YJye66nPiW+Veq/MonZgDJz2x0oCAOPmBU9fam42Kd5G30FRRsNrDOAOc1H1it/O/vZ0czHzOnl7Qo+961YjKOGJXoOxqlKq7Bh+M5PHNSq0YLFQ3THWumpiKv1eHvPeXX0EpPmZLL5ZQ4BVuvB61TMhAwDk9/8ACn5YnndjPBIqKQYbjv0Fc31it/O/vY3J9x25mHA5Hemlp0P+sGPRgDTHc8DawA9RimlGO3jb9eKX1it/O/vYczZYjmJljHlpncASCR/WlupWF0wVUA9eSelQwgCZfnBG4cCluwpumDdM5z+FP6xVtfmf3sLsgR3F0qly2WrUJ/cN9ax12m7TbnG4VqhsW7/WuLEYitde+/vZ62WvSV+z/IjZsDmmGTA60jfWonPWksTX/nf3smTsT28xN0gz6/yqGa4IncZ/iNJan/S0/H+VVpz/AKRJ/vH+dbKvW5b87+9nO5e8Ti4bHX9KeJ84yapZIpQ1L29b+d/ex87Lwm96eJuKzxIacJDS9vW/nf3saqF8S8etIZRVQS0eZS9vX/nf3srnNOxkzexj6/yqOeQ/aJcf3j/OotOkzfx+vP8AI1HcP/pMv++f51n7etz353t3Zpzfu16k8L7pkB/vD+dOvH2XTgdOP5VWgb9/HjP3h/On37f6ZJ+H8q61XrewfvvddX2ZV17FvzX5DDK3XPFdD4LcnWZuf+Xdv5rXMFq6PwUf+JzN/wBezfzWuWtXrOm05v72cspHOGR/WmmVv71ITTCa2WJrfzv72S2P818jLY59K10XIU+3NYafNMg98mugtFBXn1rWOIrW+N/ezmqSfMa1jbxsnK559a6S1ARAFGABwKw7BOnYZreg47dsVM6s56SbZF2zbvCfsdljr5f9BUSHPX0qS7x9lsv+ufX8BUMbc5zWbGiZT8wqdTxVdT834VMvOMUjattD0/Vmbb/8jPd4/wCeQ/8AZa2c+lYluf8Aiprv/rkP/Za2Sea6cT8Uf8K/I54iggUtNzR6D8q5yhQ2RjvSp/rV+opuaEP7xP8AeFD2BbosD/kIR/8AXRf6UU0EnUU/66L/AEorgxH2fQuXxM8JvCMj/dqPR4ll1IknhV6evIp96MsP92maYy2955hOOMHP1FenH49Tuv8A7f8AP9D6Q8KXaIYkBwykfKeKx9Xsra/+I/lTjCmHkr1HBrQ0W8jvrCGeCxaYFQUkQ8fmBWBqltq9x4nku7SN45VjAw4JPT6e9ejGjJO0tNO6/wAzz44aonrbXzX+Zoar4bl06bdbzebH1AIw1dBoOpH7Ekdz1XgOOR+PpXISXHiadVt5ZAJFHy5TBI/75qpDceIbS4LGVUJ+8DHwfw20lh5rS6+9B9Tqd196/wAz0Tw2QdLk5yPObn8BWo5GwmvMtFv9eitW8idQpc8Bfp/s1sLfeKJRhZEPt5Y/+IoeHk9mvvF9TqPW6+9f5m4P+QrN/uD+lSXjiKJSRntiuT3+J11CQ5G/aMjy/p/s0+8PibZFukRs84EfT/x2o+rS7r7zathZ3W2y6rt6nVWcHn4bBwa1wkNqmWwTjpXCQXXiqCEIpUD/AK5f/YUNdeKmOXYH/tn/APY1X1WXdfejH6nU7r71/mdRfzNJGxGF4OK8r1m7eGSYoMyscKPT3ra1DUfEdtEWmlQA8DKdf/Ha466GpTMzyTx5Y8/L/wDWrGrhZXjqt+/qb0sLUipbbd15eZy2oRFGJY5YnLH1NZFzEJUAZc4NdHfWcrH95PGKy5bJCpBuoxjHSr+ryinqtu6COFqJPb71/mY6QxqfugGui0awWRt7sAOwPeobPR1mk3/aFdV6gD/69bunwqtsVIBG4gcdelYewmpL/Nf5lxwtTkktOnVf5mvIj/2JaxsCuZCDx/vVVijZGwAdnQq/9KvyPt0aCM7iokOHJ+vFZu4gfNJhskkZqoYepZ7bvqv8xVMLVuttl1X+ZJHdSWc4eONMjgbu/wDnFFx4iuc7VSEdz8p/xqnJtwAJlBBLHJqpIY9rZnQHdnPtSlhZPVpfev8AMxeXuTvKK+9f5libxDeAjEUH4of8arP4ivVXmKDr/cPT86qPBHJkm6U57/5NQiBM4+1KW9ABUfU32X3r/MX9nL+Vfev8y23iS7VR+6t8kZ4Q/wCNIviS9JOYrfj/AGD/AI1UNkvQXUQOOhH/ANenC2hUY+1Rn8sfzo+pvsvvX+Yv7N/ur71/mWT4nve8Nv8A98H/ABqRfEl22cRW/v8AIf8AGqAtoFGftERye/8A+ulNvDwPtUY78Y/xpfU32X3r/Mf9mr+Vfev8zSXxJeY/1VuSOg2H/Gqmpa7d3tk1vIkQRiM7VIPHPrUJt4sAC6T1/wA809II8ZW4QnHHtWtHDypzU+Vaea/zD+zu0V96/wAyi06v/C349KaJBj8egq79mU5xdIB3/wA5pRaI3/Lyp+gFbeyh/J/5MjVYSr5fev8AMz5pUKAbSDmhZ0DDcGI9AKt3VsgUOZ064AP/AOun/ZVz/wAfcY9en+NdFSnD2EPc6y+0vIlYWrzNafev8ykLobictkn0oNxG3BViR3Aq75EK8tcREjjp/wDXoMMZU4uohkdgP8a5/Zw/k/8AJkP6pW8vvX+ZneeoPcgdjUJk3kkkmtD7HCAcXcfT8v1pq2cPH+lxnHbjn9afsofyf+TIX1St5fev8yrGwM0WARhhT72QfaXH0/pVlLRPPVjdoeRwf/1064s43uWb7Sg9sf8A16Xs4fyf+TIPq1W9tPvX+ZlKds+4duauidvschx/F/hTktIUuA32uPOOh/8A11c8qIwMBLH169v51y4ilC69zqvtI9LAYeslLVbPqu3qZolBQHBzio3kJ7V01lp0UllE3nRtgYJzjmntY2i/euIR9XFbKhS/59/+To43RxPdfev8zlbd3+2RcDGT/Kqk7yfaZen3z/OuqubazBjMd3AXDcBWBPSsSWzhM8hN7ECWPGOnP1pulC1uT/yZErD127N/iv8AMzd8vtSbpfUVofYoP+f6H8v/AK9H2GH/AJ/ovyH+NL2UP+ff/k6K+q1u6+9f5mful9RRul/vCtD7DD/z/RfkP8aPsMH/AD/RfkP8aPZQ/wCff/k6D6rW7r71/mZ+6X+8KTdL/frR+wwf8/0X5D/Gj7DB/wA/0X5D/Gj2UP8An3/5Og+q1u6+9f5kWltL/aMOX9f5Goroy/a5sOf9Y3861NPsolv42F7Gx54AHofeorixhNzKft8Yy54445+tZKlD2r9zp/Mu5o8NW9mlfr3Xb1M6B5RcREucBx/On37u97IyswBxj8hVyOzgSVH+3RnawOOP8arX7K97IysCpxyOe1by9jClaUOv83kTOlUhRak+vl29SniTu5rp/Aob+3JssT/ozfzWudx710vgYAa3N/17N/Na4a86Hs5Wg/v/AOActpdzldjHuaNh9alwKQgAGteeh/I//Av+AJqXcktfkkye1btrcooBIbGfSsS0B3iuksgdgGa056H8j/8AAv8AgGOvc0rTUYUXlZPwA/xrUj1m3A+7N/3yP8ajsuIwe5rTjbA4pc9D+R/+Bf8AAKSfcu3+rwR2OnsUlw0WRhR6D3qkmvWo/wCWc3/fI/xravGxaWP/AFy/oKrRt8ppKdDrB/f/AMAEn3Ka6/a/885+n90f41KviG0A/wBXP/3yP8avrwalXoaOeh/I/wDwL/gG1VStHXp/mZGm3KXWvXE6BgjRDG4c/wAIre6GmE5INLmorVFUldK2iX3GSVh+aQnNJ70p+lZABPFKh/eoO2RTc/LihD+9X6ik9hx3ROMf2lH6+Yv9KKZnGpxkf89F/pRXDiPs+hpL4meFXmPNH+7UC4zT7xv3w/3RUSNzXqxxdf2KjzO1jevFfXX6mhYave6Y2badlXumflP4V3GheK9DlkWTXBdWyyDb5kR3KG9+OnFebFqnl/5BkX++f612RzDEfale39djz3CLPoe18LeHtctFuNO1CS5TqGimVsfkMiq114OtrY/vGuX994B/lzXz3baje6dJ5lndSwP6xsRW5bfE7xZZDb/arzr/AHZxuFP6/Ue02iPZHrGk6Bp11A/mSTq4cjAYDjj2q8vhjT1b93Nc59Aw/wAK5Hwx8R9PjuFsNaUW8jHdHcqPlyeMH06V6ctyHt1nhMcsRGVkjIINOWKxEdVN2/ryCy6mPZ+EobjUnRvtIXaCSZAOOPatDUvBtrPHDH9onAjG0EOM/wAvakgvLh9QkfzTGpUZJ5OOKtXmpNGsSpkK4OXbrUrF13Z87NK8UmrdkZT+FNKto8yXVyAByzSDn9Kxrq10iPKwTXLn+8ZBj+VaFxI8jlncufU1kzWqysxThs/hV/XMR/O/6+Rz2Rm3GkQTuzNPM4/hG4cfpWdPpEPl+XukwDnr/wDWrWmhkhIBOM9CKEzMSZV5H61jWxdduPvvf/M3opWn6fqjjNS0yKJCwL59zXOPBvGE3ZZsD+tdrrhEpZV4UcVR0myiUmWQDAUhRnn603jMRf43/XyJjFDbLSLVbQMJmyRz6VHaWUUiBQ75y2R2AAFbMqKH3P8ALGi/jVXTQBbuSj8khcDk+tRLF1+ZPnfX+tjphFezl8v1LEmkW40mCUvIBvJO4jGOfb6Vj3FrBvIDSEeu4Vupq81vAsMaoF67XGTj86qy+ILlWb5YCOg+Q8/rUrG4tX95/f8A8AJRpu3+RgyWsW7hmZR1yRxVKRE3EKzfietbz+Jrv5lCW599hH9ahPia8H/LK3I9Np5P50njsX/M/v8A+AL2dLv+Bguo4wTSeX3y1bv/AAlF1n/UW5PfCn/Gr1hrOo3M8eyzjkiJ+fYhzj160fXsX/M/v/4A/Z0u/wCBy0dpLKsjqjBIxlmPatLTdCiv7a4uXufKghAG5v4mPQCuyutUfTftqXCxeQ3EY2/MMHqeaqQ69PdQNJa26Jawgnlc59+tL6/iv5n9/wDwBclLv+Byd3o5S8jtrUPNJ5YaTbztPXn04qi9usLbXV9w/vcV3lhf6xcwbzBarG5O3k8+xPTNWY5JZhiSGKNz0dV35P5in9fxX8z+/wD4AuSn3/A858uPb3B7CkMYjxhiSfTtXXaje6rYTgNajyyTtbyic/kazj4hvs/6u2+uw/rzR9exf8z+/wD4A+Sl3/Aw2AwcMc9xSccfM2K3P+Eou+AsNuwHqh/xpqeKLwsf3NsG/wBw/wCNH17F/wAz+/8A4AclPv8AgYrRlhkBjn14pwUB8Ek+yjAFa6eKb85zFb/Taf8AGmnxTej/AJZ23/fB/wAayqV69W3tHe3n/wAAaVNbP8DFlYbxz+NKCgQl8sSfujpW0fEmo4B8m1G48Daf8aQ+KLtflMVqzdyEPH61jeXYdod/wMR5Fb/lmAPbtTMKOcnHpW8fE90oyYrcnPGFP+NR/wDCUXZ6Jbg/7h/xp3l2BqHf8DJhY+bGScfOOv1pt85F5IN3cd/atdPE98ZQrxWxDEDhD3/GnT+J72CRo1it9q/3kPP607y5dibQvv8Agc/GwF2prQL/AOiOff1+lXI/FV606gw24B9UP+NWW1+6MZm8uAMvAG04/nXJWburo9TActpWfR/kc25Vs/KD9arttz91fyrpW8UXoGfKtv8Avg/41A3iq+HSG2/74P8AjVJvsc8uXuY1jj7bH8oHXoPao5yPtEv++f510Fv4mvZ51jaK3APXCH0+tMk8U3qSsgitsKSBlD/jWt5cuxlaN9zn8ik3Vv8A/CWX3/PK2/74P+NH/CV33/PG1/74P+NTeXYdo9/wMAmjNb3/AAll9/zytv8Avg/40Dxbfn/lja/98H/Gi8uwWj3/AAMHNFb/APwll/8A88bb/vg/40f8JZfZ/wBTa/8AfB/xpXl2C0e5maYf+JjD+P8AI1DdH/S5v+ujfzrobLxPez3kcbRW4DZyQh9PrUU/iq9S4kQRW2FYjlD6/WoTlz7dDVqPs1r1/Q53mit//hLL/wD542v/AHwf8aT/AISy/wD+eNr/AN8H/GtLy7GVo9zCwa6bwMP+J3P/ANezfzWq3/CWX/8Azxtv++D/AI10Xg7xLeXOryo8VuALdj8qH1X3rOs5ezegrR7nAc01umK3/wDhLb7/AJ423/fB/wAaT/hLb4nHk23/AHwf8a1TlfYmShbf8DMtF+b3rpbFehqO28TXrEfurb/vg/41u2mu3bAZih/BT/jV3l2MuWHf8CS14A9KvxtkUQ61O3VIv++T/jVtNWnxnbF+R/xpXl2HaHf8DQvT/oVj/wBc/wCgqBCM49av3moSraWJ2p80eTx7CoI9RlOPlT8qLy7AlDv+ABqlU0LeSMwcqmfpUy3smOiflReXY3qqFo69O3mxg6/zp+eKeLyT0X8qd9rfphfyovLsY2h3/Aj7UZ6VKt254wufpQbt/RfyovLsFod/wISaEP71P94VKbx/RfyphvZB2T8qG5dgSgtb/gPyP7UQf9NF/pRUEMhkv4nbGTIvT6iiuPEqzivIG7ts8KvT+/X/AHRUUbc/hU13DJJKGRcjaO4qOO3lU5KfqK6oyXs7XO6tRqvFuSi7X7DM1bkP/Esi/wB8/wBarfZ5f7n6irqRo1mkUpZSCTxWynHXU4vq1b+R/czMbpVaQVstZ25H+sk/z+FRHT7Y/wDLST9P8KV49194/q1b+R/cypqqlrxAOpQfzNerfB/xMIzN4dvX/dyfvLZmPRu6/jxXByadaTzCUzuCF24xVuws7exuUuYbqQSxncrY6VvCcVJ3as/Mh4Ws18D+5nvUsezUZQvZRx6dKjv1JhhZey/4VxNv46dwDJ5bS7QCSGrSuvGKNBb+UI3bZ84KsMHinzRXVFVcJXk01F7LozTf96mU69xVac+RCQgy546ViN4lYsGVIwc9s1G/iBnDfLGpPcA8fSn7SHdfeZfUcR/Ky7BM5nLzEFcHqOgqrN5m9wjlgf4u2KpnVIQwaRRIQMAHOPyqOfVUuBjcIweyA1jVqR9136nRRwVf3ly7r/IhuIVlO0N0OP8AePpTTbq1yxRcBVJ9qGnhYAeawxjpmgzxH/l4cc9h/wDWpfWKfcpZdiF9kkmYOY432qFG5t3f0rOtC6wM6yA5c9TV83UO52D8vjccHmqlnp32qzYNu27z0IB7VDrQutTeOBrqDXL2KkpLO2Byo556VF/Z11cYWKPAxkM3ANbkOlwwsWEG85z8zVNNBPNwWKp/dXFDrw7mTwGJ/lMFfDUpG6eYKBzlanj0jTkljDSb3Y4Ck9TWiNOG3afMb6vSrYxxtGyQImw5BAGan20O4v7PxH8oWnhqCzuPOeNxIjY2uOMfT0pLW7t7e+aPTl+yurZzyVcnqKtXj3d2CGuJRkAAgjIxTLW3aBQqgkg5Z+NzH3PWn7WHcP7PxP8AKYOstcXmqXXlqGMJ6N90e59q6VfDs1r4etrV5DIb2Tc0qDG0kdB7cVWS0jj2I9ukqq2/a/IZvVh3P1rbtdb1CGF0jCYMu8f7IxjA9qPa0+4v7PxP8pR1SCHS9HTS7dibyOECGIf8tWYfe/OuX03Vf7LnNpfbnnXPmOHG1PpxzW7qNrLfapHflnikjxsCNwPpWLdeEIJZzMZJxk5I3g0OrT7h/Z+J/lLn9swai4gMs5izzJvALe3Sqd/4ajG6S3eRUb5iXbdj+VaNhpdpZ9LKOU9mkJJX6c1bMDbCgUkN1DHP86XtYdx/UMT/ACnFvo7ouY3EmDyAefwqCW3niTmEqnXOOa7eezjnQK1tErgcOgANVf7KdcYkfA9SDR7aHcP7PxP8pwxDo3KsPrTCwD8fdHt1rvG0pZBiRQynsQKrHw1Z7TtjZW7MG5FP20O4/qGI/lOLdnZtzAqO1IM54XLV2H/CLxBtwlmzjHJB/pTH8LxsuDLKBnPBXml7WHcf1DEfynJFQW5c59hxTShz1Bx+Ga6v/hEoP+es35r/AIUHwlCcDzpvzWn7aHcX9n4j+U5WIHz48g/eHI6dakvSBcucZ6dfpXTJ4ThR1YTTfKc4yMUs/hSKeRnaWUE+hFP29O24LLsS38Jx6yYnRm4HrV4zKbOQg8A/4VunwfDkfvpeP92pE8JBx9nR5CH5zlf89q5qs4Sasd2Ewlakpcyto/yOQeUdjUDOCa7c+AG/vzf99JTf+FfN/wA9Jv8AvpKtSRyOjN9V95yNi4+2R9e/8qjncfaJf98/zrtofAbwyrIHlJHYstRSeBS8jsXmBJJ+8tU6kVGxKw829196OK3e1G6uy/4QP/ppN/30tH/CBD/npN/30tT7SJX1afdfejjM0ZA4rs/+ED/6aT/99LR/wgQ/vzf99LR7SIvq0+6+9HGbs0m73Fdp/wAIF/00m/76Wj/hAh/z0m/NKPaRD6tPuvvRy+lv/wATGH6n+RqC7b/S5+n+sb+ddpbeCTbXCShpiV7Fl9KpT+Ela4kY+fksT99fWlFqU212KlSkqaTa37o5ItSbzXVf8Ignrcf99rR/wiCes/8A32ta2MfZPuvvOVDmuo8CsTrc+f8An2b+a07/AIRBP+m//fa10HhDwyltq0r/AL7mBl5ZfUVnWX7ti9k11X3nmu406Plq7f8A4Vzef88J/wDv7H/jUkfw7vAf9RP/AN/Y/wDGtFKPcmVGT6r70c5ZIMrXR2gxHmtG28CXiEfuJf8Av6n+Nasfg++VMeQ//fxP8afPHuT7CXdfejJhP/16tRsBx+NaieFb4f8ALB/+/if41Kvhi+DZ+zt/38T/ABo5o9x+wfdfeiS+b/QtOz/zy/oKgjPpWrfaRcG1s4/LO5EwRuXjgVXj0m6AH7o/99L/AI0nUguoKg31X3jEOVqRTxUy6XeAYEP/AI8P8aeumXgP+p/8eH+NL2kO46ytyrsv8yIHpT+pqYabef8APH/x4f40/wDs67z/AKn/AMeH+NHtIdzArZwM+9KT1HrVj+zrvH+q/wDHh/jSHTbz/nl/48P8aPaQ7oLFbOCKjZqt/wBm3n/PH/x4f40w6bebv9T/AOPD/Gj2kO4EFq3+mQD/AKaL/OirEGnXaXUTNDhVcEncOmfrRXHiZJtWZSP/2Q==\n",
- "text/plain": [
- ""
- ]
- },
- "metadata": {},
- "output_type": "display_data"
- }
- ],
- "source": [
- "# image viz\n",
- "frcnn_visualizer = SingleImageViz(URL, id2obj=objids, id2attr=attrids)\n",
- "# run frcnn\n",
- "images, sizes, scales_yx = image_preprocess(URL)\n",
- "output_dict = frcnn(\n",
- " images,\n",
- " sizes,\n",
- " scales_yx=scales_yx,\n",
- " padding=\"max_detections\",\n",
- " max_detections=frcnn_cfg.max_detections,\n",
- " return_tensors=\"pt\",\n",
- ")\n",
- "# add boxes and labels to the image\n",
- "\n",
- "frcnn_visualizer.draw_boxes(\n",
- " output_dict.get(\"boxes\"),\n",
- " output_dict.pop(\"obj_ids\"),\n",
- " output_dict.pop(\"obj_probs\"),\n",
- " output_dict.pop(\"attr_ids\"),\n",
- " output_dict.pop(\"attr_probs\"),\n",
- ")\n",
- "showarray(frcnn_visualizer._get_buffer())"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 7,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Question: ['Where is the cat?']\n",
- "prediction from LXMERT GQA: desk\n",
- "prediction from LXMERT VQA: desk\n",
- "Question: ['What is near the disk?']\n",
- "prediction from LXMERT GQA: can\n",
- "prediction from LXMERT VQA: cat\n",
- "Question: ['What is the color of the table?']\n",
- "prediction from LXMERT GQA: brown\n",
- "prediction from LXMERT VQA: brown\n",
- "Question: ['What is the color of the cat?']\n",
- "prediction from LXMERT GQA: black\n",
- "prediction from LXMERT VQA: black and white\n",
- "Question: ['What is the shape of the monitor?']\n",
- "prediction from LXMERT GQA: square\n",
- "prediction from LXMERT VQA: rectangle\n"
- ]
- }
- ],
- "source": [
- "test_questions_for_url1 = [\n",
- " \"Where is this scene?\",\n",
- " \"what is the man riding?\",\n",
- " \"What is the man wearing?\",\n",
- " \"What is the color of the horse?\",\n",
- "]\n",
- "test_questions_for_url2 = [\n",
- " \"Where is the cat?\",\n",
- " \"What is near the disk?\",\n",
- " \"What is the color of the table?\",\n",
- " \"What is the color of the cat?\",\n",
- " \"What is the shape of the monitor?\",\n",
- "]\n",
- "\n",
- "# Very important that the boxes are normalized\n",
- "normalized_boxes = output_dict.get(\"normalized_boxes\")\n",
- "features = output_dict.get(\"roi_features\")\n",
- "\n",
- "for test_question in test_questions_for_url2:\n",
- " # run lxmert\n",
- " test_question = [test_question]\n",
- "\n",
- " inputs = lxmert_tokenizer(\n",
- " test_question,\n",
- " padding=\"max_length\",\n",
- " max_length=20,\n",
- " truncation=True,\n",
- " return_token_type_ids=True,\n",
- " return_attention_mask=True,\n",
- " add_special_tokens=True,\n",
- " return_tensors=\"pt\",\n",
- " )\n",
- "\n",
- " # run lxmert(s)\n",
- " output_gqa = lxmert_gqa(\n",
- " input_ids=inputs.input_ids,\n",
- " attention_mask=inputs.attention_mask,\n",
- " visual_feats=features,\n",
- " visual_pos=normalized_boxes,\n",
- " token_type_ids=inputs.token_type_ids,\n",
- " output_attentions=False,\n",
- " )\n",
- " output_vqa = lxmert_vqa(\n",
- " input_ids=inputs.input_ids,\n",
- " attention_mask=inputs.attention_mask,\n",
- " visual_feats=features,\n",
- " visual_pos=normalized_boxes,\n",
- " token_type_ids=inputs.token_type_ids,\n",
- " output_attentions=False,\n",
- " )\n",
- " # get prediction\n",
- " pred_vqa = output_vqa[\"question_answering_score\"].argmax(-1)\n",
- " pred_gqa = output_gqa[\"question_answering_score\"].argmax(-1)\n",
- " print(\"Question:\", test_question)\n",
- " print(\"prediction from LXMERT GQA:\", gqa_answers[pred_gqa])\n",
- " print(\"prediction from LXMERT VQA:\", vqa_answers[pred_vqa])"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": []
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": []
- }
- ],
- "metadata": {
- "kernelspec": {
- "display_name": "Python 3",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.8.2"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 4
-}
\ No newline at end of file
diff --git a/examples/research_projects/lxmert/extracting_data.py b/examples/research_projects/lxmert/extracting_data.py
deleted file mode 100644
index 6b1342c9b11..00000000000
--- a/examples/research_projects/lxmert/extracting_data.py
+++ /dev/null
@@ -1,149 +0,0 @@
-import getopt
-import json
-import os
-
-# import numpy as np
-import sys
-from collections import OrderedDict
-
-import datasets
-import numpy as np
-import torch
-from modeling_frcnn import GeneralizedRCNN
-from processing_image import Preprocess
-
-from utils import Config
-
-
-"""
-USAGE:
-``python extracting_data.py -i -o .datasets ``
-"""
-
-
-TEST = False
-CONFIG = Config.from_pretrained("unc-nlp/frcnn-vg-finetuned")
-DEFAULT_SCHEMA = datasets.Features(
- OrderedDict(
- {
- "attr_ids": datasets.Sequence(length=CONFIG.MAX_DETECTIONS, feature=datasets.Value("float32")),
- "attr_probs": datasets.Sequence(length=CONFIG.MAX_DETECTIONS, feature=datasets.Value("float32")),
- "boxes": datasets.Array2D((CONFIG.MAX_DETECTIONS, 4), dtype="float32"),
- "img_id": datasets.Value("int32"),
- "obj_ids": datasets.Sequence(length=CONFIG.MAX_DETECTIONS, feature=datasets.Value("float32")),
- "obj_probs": datasets.Sequence(length=CONFIG.MAX_DETECTIONS, feature=datasets.Value("float32")),
- "roi_features": datasets.Array2D((CONFIG.MAX_DETECTIONS, 2048), dtype="float32"),
- "sizes": datasets.Sequence(length=2, feature=datasets.Value("float32")),
- "preds_per_image": datasets.Value(dtype="int32"),
- }
- )
-)
-
-
-class Extract:
- def __init__(self, argv=sys.argv[1:]):
- inputdir = None
- outputfile = None
- subset_list = None
- batch_size = 1
- opts, args = getopt.getopt(argv, "i:o:b:s", ["inputdir=", "outfile=", "batch_size=", "subset_list="])
- for opt, arg in opts:
- if opt in ("-i", "--inputdir"):
- inputdir = arg
- elif opt in ("-o", "--outfile"):
- outputfile = arg
- elif opt in ("-b", "--batch_size"):
- batch_size = int(arg)
- elif opt in ("-s", "--subset_list"):
- subset_list = arg
-
- assert inputdir is not None # and os.path.isdir(inputdir), f"{inputdir}"
- assert outputfile is not None and not os.path.isfile(outputfile), f"{outputfile}"
- if subset_list is not None:
- with open(os.path.realpath(subset_list)) as f:
- self.subset_list = {self._vqa_file_split()[0] for x in tryload(f)}
- else:
- self.subset_list = None
-
- self.config = CONFIG
- if torch.cuda.is_available():
- self.config.model.device = "cuda"
- self.inputdir = os.path.realpath(inputdir)
- self.outputfile = os.path.realpath(outputfile)
- self.preprocess = Preprocess(self.config)
- self.model = GeneralizedRCNN.from_pretrained("unc-nlp/frcnn-vg-finetuned", config=self.config)
- self.batch = batch_size if batch_size != 0 else 1
- self.schema = DEFAULT_SCHEMA
-
- def _vqa_file_split(self, file):
- img_id = int(file.split(".")[0].split("_")[-1])
- filepath = os.path.join(self.inputdir, file)
- return (img_id, filepath)
-
- @property
- def file_generator(self):
- batch = []
- for i, file in enumerate(os.listdir(self.inputdir)):
- if self.subset_list is not None and i not in self.subset_list:
- continue
- batch.append(self._vqa_file_split(file))
- if len(batch) == self.batch:
- temp = batch
- batch = []
- yield list(map(list, zip(*temp)))
-
- for i in range(1):
- yield list(map(list, zip(*batch)))
-
- def __call__(self):
- # make writer
- if not TEST:
- writer = datasets.ArrowWriter(features=self.schema, path=self.outputfile)
- # do file generator
- for i, (img_ids, filepaths) in enumerate(self.file_generator):
- images, sizes, scales_yx = self.preprocess(filepaths)
- output_dict = self.model(
- images,
- sizes,
- scales_yx=scales_yx,
- padding="max_detections",
- max_detections=self.config.MAX_DETECTIONS,
- pad_value=0,
- return_tensors="np",
- location="cpu",
- )
- output_dict["boxes"] = output_dict.pop("normalized_boxes")
- if not TEST:
- output_dict["img_id"] = np.array(img_ids)
- batch = self.schema.encode_batch(output_dict)
- writer.write_batch(batch)
- if TEST:
- break
- # finalizer the writer
- if not TEST:
- num_examples, num_bytes = writer.finalize()
- print(f"Success! You wrote {num_examples} entry(s) and {num_bytes >> 20} mb")
-
-
-def tryload(stream):
- try:
- data = json.load(stream)
- try:
- data = list(data.keys())
- except Exception:
- data = [d["img_id"] for d in data]
- except Exception:
- try:
- data = eval(stream.read())
- except Exception:
- data = stream.read().split("\n")
- return data
-
-
-if __name__ == "__main__":
- extract = Extract(sys.argv[1:])
- extract()
- if not TEST:
- dataset = datasets.Dataset.from_file(extract.outputfile)
- # wala!
- # print(np.array(dataset[0:2]["roi_features"]).shape)
diff --git a/examples/research_projects/lxmert/modeling_frcnn.py b/examples/research_projects/lxmert/modeling_frcnn.py
deleted file mode 100644
index c7c3bf376ce..00000000000
--- a/examples/research_projects/lxmert/modeling_frcnn.py
+++ /dev/null
@@ -1,1920 +0,0 @@
-"""
-coding=utf-8
-Copyright 2018, Antonio Mendoza Hao Tan, Mohit Bansal
-Adapted From Facebook Inc, Detectron2 && Huggingface Co.
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.import copy
-"""
-
-import itertools
-import math
-import os
-from abc import ABCMeta, abstractmethod
-from collections import OrderedDict, namedtuple
-from typing import Dict, List, Tuple
-
-import numpy as np
-import torch
-from torch import nn
-from torch.nn.modules.batchnorm import BatchNorm2d
-from torchvision.ops import RoIPool
-from torchvision.ops.boxes import batched_nms, nms
-
-from utils import WEIGHTS_NAME, Config, cached_path, hf_bucket_url, is_remote_url, load_checkpoint
-
-
-# other:
-def norm_box(boxes, raw_sizes):
- if not isinstance(boxes, torch.Tensor):
- normalized_boxes = boxes.copy()
- else:
- normalized_boxes = boxes.clone()
- normalized_boxes[:, :, (0, 2)] /= raw_sizes[:, 1]
- normalized_boxes[:, :, (1, 3)] /= raw_sizes[:, 0]
- return normalized_boxes
-
-
-def pad_list_tensors(
- list_tensors,
- preds_per_image,
- max_detections=None,
- return_tensors=None,
- padding=None,
- pad_value=0,
- location=None,
-):
- """
- location will always be cpu for np tensors
- """
- if location is None:
- location = "cpu"
- assert return_tensors in {"pt", "np", None}
- assert padding in {"max_detections", "max_batch", None}
- new = []
- if padding is None:
- if return_tensors is None:
- return list_tensors
- elif return_tensors == "pt":
- if not isinstance(list_tensors, torch.Tensor):
- return torch.stack(list_tensors).to(location)
- else:
- return list_tensors.to(location)
- else:
- if not isinstance(list_tensors, list):
- return np.array(list_tensors.to(location))
- else:
- return list_tensors.to(location)
- if padding == "max_detections":
- assert max_detections is not None, "specify max number of detections per batch"
- elif padding == "max_batch":
- max_detections = max(preds_per_image)
- for i in range(len(list_tensors)):
- too_small = False
- tensor_i = list_tensors.pop(0)
- if tensor_i.ndim < 2:
- too_small = True
- tensor_i = tensor_i.unsqueeze(-1)
- assert isinstance(tensor_i, torch.Tensor)
- tensor_i = nn.functional.pad(
- input=tensor_i,
- pad=(0, 0, 0, max_detections - preds_per_image[i]),
- mode="constant",
- value=pad_value,
- )
- if too_small:
- tensor_i = tensor_i.squeeze(-1)
- if return_tensors is None:
- if location == "cpu":
- tensor_i = tensor_i.cpu()
- tensor_i = tensor_i.tolist()
- if return_tensors == "np":
- if location == "cpu":
- tensor_i = tensor_i.cpu()
- tensor_i = tensor_i.numpy()
- else:
- if location == "cpu":
- tensor_i = tensor_i.cpu()
- new.append(tensor_i)
- if return_tensors == "np":
- return np.stack(new, axis=0)
- elif return_tensors == "pt" and not isinstance(new, torch.Tensor):
- return torch.stack(new, dim=0)
- else:
- return list_tensors
-
-
-def do_nms(boxes, scores, image_shape, score_thresh, nms_thresh, mind, maxd):
- scores = scores[:, :-1]
- num_bbox_reg_classes = boxes.shape[1] // 4
- # Convert to Boxes to use the `clip` function ...
- boxes = boxes.reshape(-1, 4)
- _clip_box(boxes, image_shape)
- boxes = boxes.view(-1, num_bbox_reg_classes, 4) # R x C x 4
-
- # Select max scores
- max_scores, max_classes = scores.max(1) # R x C --> R
- num_objs = boxes.size(0)
- boxes = boxes.view(-1, 4)
- idxs = torch.arange(num_objs).to(boxes.device) * num_bbox_reg_classes + max_classes
- max_boxes = boxes[idxs] # Select max boxes according to the max scores.
-
- # Apply NMS
- keep = nms(max_boxes, max_scores, nms_thresh)
- keep = keep[:maxd]
- if keep.shape[-1] >= mind and keep.shape[-1] <= maxd:
- max_boxes, max_scores = max_boxes[keep], max_scores[keep]
- classes = max_classes[keep]
- return max_boxes, max_scores, classes, keep
- else:
- return None
-
-
-# Helper Functions
-def _clip_box(tensor, box_size: Tuple[int, int]):
- assert torch.isfinite(tensor).all(), "Box tensor contains infinite or NaN!"
- h, w = box_size
- tensor[:, 0].clamp_(min=0, max=w)
- tensor[:, 1].clamp_(min=0, max=h)
- tensor[:, 2].clamp_(min=0, max=w)
- tensor[:, 3].clamp_(min=0, max=h)
-
-
-def _nonempty_boxes(box, threshold: float = 0.0) -> torch.Tensor:
- widths = box[:, 2] - box[:, 0]
- heights = box[:, 3] - box[:, 1]
- keep = (widths > threshold) & (heights > threshold)
- return keep
-
-
-def get_norm(norm, out_channels):
- if isinstance(norm, str):
- if len(norm) == 0:
- return None
- norm = {
- "BN": BatchNorm2d,
- "GN": lambda channels: nn.GroupNorm(32, channels),
- "nnSyncBN": nn.SyncBatchNorm, # keep for debugging
- "": lambda x: x,
- }[norm]
- return norm(out_channels)
-
-
-def _create_grid_offsets(size: List[int], stride: int, offset: float, device):
- grid_height, grid_width = size
- shifts_x = torch.arange(
- offset * stride,
- grid_width * stride,
- step=stride,
- dtype=torch.float32,
- device=device,
- )
- shifts_y = torch.arange(
- offset * stride,
- grid_height * stride,
- step=stride,
- dtype=torch.float32,
- device=device,
- )
-
- shift_y, shift_x = torch.meshgrid(shifts_y, shifts_x)
- shift_x = shift_x.reshape(-1)
- shift_y = shift_y.reshape(-1)
- return shift_x, shift_y
-
-
-def build_backbone(cfg):
- input_shape = ShapeSpec(channels=len(cfg.MODEL.PIXEL_MEAN))
- norm = cfg.RESNETS.NORM
- stem = BasicStem(
- in_channels=input_shape.channels,
- out_channels=cfg.RESNETS.STEM_OUT_CHANNELS,
- norm=norm,
- caffe_maxpool=cfg.MODEL.MAX_POOL,
- )
- freeze_at = cfg.BACKBONE.FREEZE_AT
-
- if freeze_at >= 1:
- for p in stem.parameters():
- p.requires_grad = False
-
- out_features = cfg.RESNETS.OUT_FEATURES
- depth = cfg.RESNETS.DEPTH
- num_groups = cfg.RESNETS.NUM_GROUPS
- width_per_group = cfg.RESNETS.WIDTH_PER_GROUP
- bottleneck_channels = num_groups * width_per_group
- in_channels = cfg.RESNETS.STEM_OUT_CHANNELS
- out_channels = cfg.RESNETS.RES2_OUT_CHANNELS
- stride_in_1x1 = cfg.RESNETS.STRIDE_IN_1X1
- res5_dilation = cfg.RESNETS.RES5_DILATION
- assert res5_dilation in {1, 2}, "res5_dilation cannot be {}.".format(res5_dilation)
-
- num_blocks_per_stage = {50: [3, 4, 6, 3], 101: [3, 4, 23, 3], 152: [3, 8, 36, 3]}[depth]
-
- stages = []
- out_stage_idx = [{"res2": 2, "res3": 3, "res4": 4, "res5": 5}[f] for f in out_features]
- max_stage_idx = max(out_stage_idx)
- for idx, stage_idx in enumerate(range(2, max_stage_idx + 1)):
- dilation = res5_dilation if stage_idx == 5 else 1
- first_stride = 1 if idx == 0 or (stage_idx == 5 and dilation == 2) else 2
- stage_kargs = {
- "num_blocks": num_blocks_per_stage[idx],
- "first_stride": first_stride,
- "in_channels": in_channels,
- "bottleneck_channels": bottleneck_channels,
- "out_channels": out_channels,
- "num_groups": num_groups,
- "norm": norm,
- "stride_in_1x1": stride_in_1x1,
- "dilation": dilation,
- }
-
- stage_kargs["block_class"] = BottleneckBlock
- blocks = ResNet.make_stage(**stage_kargs)
- in_channels = out_channels
- out_channels *= 2
- bottleneck_channels *= 2
-
- if freeze_at >= stage_idx:
- for block in blocks:
- block.freeze()
- stages.append(blocks)
-
- return ResNet(stem, stages, out_features=out_features)
-
-
-def find_top_rpn_proposals(
- proposals,
- pred_objectness_logits,
- images,
- image_sizes,
- nms_thresh,
- pre_nms_topk,
- post_nms_topk,
- min_box_side_len,
- training,
-):
- """Args:
- proposals (list[Tensor]): (L, N, Hi*Wi*A, 4).
- pred_objectness_logits: tensors of length L.
- nms_thresh (float): IoU threshold to use for NMS
- pre_nms_topk (int): before nms
- post_nms_topk (int): after nms
- min_box_side_len (float): minimum proposal box side
- training (bool): True if proposals are to be used in training,
- Returns:
- results (List[Dict]): stores post_nms_topk object proposals for image i.
- """
- num_images = len(images)
- device = proposals[0].device
-
- # 1. Select top-k anchor for every level and every image
- topk_scores = [] # #lvl Tensor, each of shape N x topk
- topk_proposals = []
- level_ids = [] # #lvl Tensor, each of shape (topk,)
- batch_idx = torch.arange(num_images, device=device)
- for level_id, proposals_i, logits_i in zip(itertools.count(), proposals, pred_objectness_logits):
- Hi_Wi_A = logits_i.shape[1]
- num_proposals_i = min(pre_nms_topk, Hi_Wi_A)
-
- # sort is faster than topk (https://github.com/pytorch/pytorch/issues/22812)
- # topk_scores_i, topk_idx = logits_i.topk(num_proposals_i, dim=1)
- logits_i, idx = logits_i.sort(descending=True, dim=1)
- topk_scores_i = logits_i[batch_idx, :num_proposals_i]
- topk_idx = idx[batch_idx, :num_proposals_i]
-
- # each is N x topk
- topk_proposals_i = proposals_i[batch_idx[:, None], topk_idx] # N x topk x 4
-
- topk_proposals.append(topk_proposals_i)
- topk_scores.append(topk_scores_i)
- level_ids.append(torch.full((num_proposals_i,), level_id, dtype=torch.int64, device=device))
-
- # 2. Concat all levels together
- topk_scores = torch.cat(topk_scores, dim=1)
- topk_proposals = torch.cat(topk_proposals, dim=1)
- level_ids = torch.cat(level_ids, dim=0)
-
- # if I change to batched_nms, I wonder if this will make a difference
- # 3. For each image, run a per-level NMS, and choose topk results.
- results = []
- for n, image_size in enumerate(image_sizes):
- boxes = topk_proposals[n]
- scores_per_img = topk_scores[n]
- # I will have to take a look at the boxes clip method
- _clip_box(boxes, image_size)
- # filter empty boxes
- keep = _nonempty_boxes(boxes, threshold=min_box_side_len)
- lvl = level_ids
- if keep.sum().item() != len(boxes):
- boxes, scores_per_img, lvl = (
- boxes[keep],
- scores_per_img[keep],
- level_ids[keep],
- )
-
- keep = batched_nms(boxes, scores_per_img, lvl, nms_thresh)
- keep = keep[:post_nms_topk]
-
- res = (boxes[keep], scores_per_img[keep])
- results.append(res)
-
- # I wonder if it would be possible for me to pad all these things.
- return results
-
-
-def subsample_labels(labels, num_samples, positive_fraction, bg_label):
- """
- Returns:
- pos_idx, neg_idx (Tensor):
- 1D vector of indices. The total length of both is `num_samples` or fewer.
- """
- positive = torch.nonzero((labels != -1) & (labels != bg_label)).squeeze(1)
- negative = torch.nonzero(labels == bg_label).squeeze(1)
-
- num_pos = int(num_samples * positive_fraction)
- # protect against not enough positive examples
- num_pos = min(positive.numel(), num_pos)
- num_neg = num_samples - num_pos
- # protect against not enough negative examples
- num_neg = min(negative.numel(), num_neg)
-
- # randomly select positive and negative examples
- perm1 = torch.randperm(positive.numel(), device=positive.device)[:num_pos]
- perm2 = torch.randperm(negative.numel(), device=negative.device)[:num_neg]
-
- pos_idx = positive[perm1]
- neg_idx = negative[perm2]
- return pos_idx, neg_idx
-
-
-def add_ground_truth_to_proposals(gt_boxes, proposals):
- raise NotImplementedError()
-
-
-def add_ground_truth_to_proposals_single_image(gt_boxes, proposals):
- raise NotImplementedError()
-
-
-def _fmt_box_list(box_tensor, batch_index: int):
- repeated_index = torch.full(
- (len(box_tensor), 1),
- batch_index,
- dtype=box_tensor.dtype,
- device=box_tensor.device,
- )
- return torch.cat((repeated_index, box_tensor), dim=1)
-
-
-def convert_boxes_to_pooler_format(box_lists: List[torch.Tensor]):
- pooler_fmt_boxes = torch.cat(
- [_fmt_box_list(box_list, i) for i, box_list in enumerate(box_lists)],
- dim=0,
- )
- return pooler_fmt_boxes
-
-
-def assign_boxes_to_levels(
- box_lists: List[torch.Tensor],
- min_level: int,
- max_level: int,
- canonical_box_size: int,
- canonical_level: int,
-):
- box_sizes = torch.sqrt(torch.cat([boxes.area() for boxes in box_lists]))
- # Eqn.(1) in FPN paper
- level_assignments = torch.floor(canonical_level + torch.log2(box_sizes / canonical_box_size + 1e-8))
- # clamp level to (min, max), in case the box size is too large or too small
- # for the available feature maps
- level_assignments = torch.clamp(level_assignments, min=min_level, max=max_level)
- return level_assignments.to(torch.int64) - min_level
-
-
-# Helper Classes
-class _NewEmptyTensorOp(torch.autograd.Function):
- @staticmethod
- def forward(ctx, x, new_shape):
- ctx.shape = x.shape
- return x.new_empty(new_shape)
-
- @staticmethod
- def backward(ctx, grad):
- shape = ctx.shape
- return _NewEmptyTensorOp.apply(grad, shape), None
-
-
-class ShapeSpec(namedtuple("_ShapeSpec", ["channels", "height", "width", "stride"])):
- def __new__(cls, *, channels=None, height=None, width=None, stride=None):
- return super().__new__(cls, channels, height, width, stride)
-
-
-class Box2BoxTransform:
- """
- This R-CNN transformation scales the box's width and height
- by exp(dw), exp(dh) and shifts a box's center by the offset
- (dx * width, dy * height).
- """
-
- def __init__(self, weights: Tuple[float, float, float, float], scale_clamp: float = None):
- """
- Args:
- weights (4-element tuple): Scaling factors that are applied to the
- (dx, dy, dw, dh) deltas. In Fast R-CNN, these were originally set
- such that the deltas have unit variance; now they are treated as
- hyperparameters of the system.
- scale_clamp (float): When predicting deltas, the predicted box scaling
- factors (dw and dh) are clamped such that they are <= scale_clamp.
- """
- self.weights = weights
- if scale_clamp is not None:
- self.scale_clamp = scale_clamp
- else:
- """
- Value for clamping large dw and dh predictions.
- The heuristic is that we clamp such that dw and dh are no larger
- than what would transform a 16px box into a 1000px box
- (based on a small anchor, 16px, and a typical image size, 1000px).
- """
- self.scale_clamp = math.log(1000.0 / 16)
-
- def get_deltas(self, src_boxes, target_boxes):
- """
- Get box regression transformation deltas (dx, dy, dw, dh) that can be used
- to transform the `src_boxes` into the `target_boxes`. That is, the relation
- ``target_boxes == self.apply_deltas(deltas, src_boxes)`` is true (unless
- any delta is too large and is clamped).
- Args:
- src_boxes (Tensor): source boxes, e.g., object proposals
- target_boxes (Tensor): target of the transformation, e.g., ground-truth
- boxes.
- """
- assert isinstance(src_boxes, torch.Tensor), type(src_boxes)
- assert isinstance(target_boxes, torch.Tensor), type(target_boxes)
-
- src_widths = src_boxes[:, 2] - src_boxes[:, 0]
- src_heights = src_boxes[:, 3] - src_boxes[:, 1]
- src_ctr_x = src_boxes[:, 0] + 0.5 * src_widths
- src_ctr_y = src_boxes[:, 1] + 0.5 * src_heights
-
- target_widths = target_boxes[:, 2] - target_boxes[:, 0]
- target_heights = target_boxes[:, 3] - target_boxes[:, 1]
- target_ctr_x = target_boxes[:, 0] + 0.5 * target_widths
- target_ctr_y = target_boxes[:, 1] + 0.5 * target_heights
-
- wx, wy, ww, wh = self.weights
- dx = wx * (target_ctr_x - src_ctr_x) / src_widths
- dy = wy * (target_ctr_y - src_ctr_y) / src_heights
- dw = ww * torch.log(target_widths / src_widths)
- dh = wh * torch.log(target_heights / src_heights)
-
- deltas = torch.stack((dx, dy, dw, dh), dim=1)
- assert (src_widths > 0).all().item(), "Input boxes to Box2BoxTransform are not valid!"
- return deltas
-
- def apply_deltas(self, deltas, boxes):
- """
- Apply transformation `deltas` (dx, dy, dw, dh) to `boxes`.
- Args:
- deltas (Tensor): transformation deltas of shape (N, k*4), where k >= 1.
- deltas[i] represents k potentially different class-specific
- box transformations for the single box boxes[i].
- boxes (Tensor): boxes to transform, of shape (N, 4)
- """
- boxes = boxes.to(deltas.dtype)
-
- widths = boxes[:, 2] - boxes[:, 0]
- heights = boxes[:, 3] - boxes[:, 1]
- ctr_x = boxes[:, 0] + 0.5 * widths
- ctr_y = boxes[:, 1] + 0.5 * heights
-
- wx, wy, ww, wh = self.weights
- dx = deltas[:, 0::4] / wx
- dy = deltas[:, 1::4] / wy
- dw = deltas[:, 2::4] / ww
- dh = deltas[:, 3::4] / wh
-
- # Prevent sending too large values into torch.exp()
- dw = torch.clamp(dw, max=self.scale_clamp)
- dh = torch.clamp(dh, max=self.scale_clamp)
-
- pred_ctr_x = dx * widths[:, None] + ctr_x[:, None]
- pred_ctr_y = dy * heights[:, None] + ctr_y[:, None]
- pred_w = torch.exp(dw) * widths[:, None]
- pred_h = torch.exp(dh) * heights[:, None]
-
- pred_boxes = torch.zeros_like(deltas)
- pred_boxes[:, 0::4] = pred_ctr_x - 0.5 * pred_w # x1
- pred_boxes[:, 1::4] = pred_ctr_y - 0.5 * pred_h # y1
- pred_boxes[:, 2::4] = pred_ctr_x + 0.5 * pred_w # x2
- pred_boxes[:, 3::4] = pred_ctr_y + 0.5 * pred_h # y2
- return pred_boxes
-
-
-class Matcher:
- """
- This class assigns to each predicted "element" (e.g., a box) a ground-truth
- element. Each predicted element will have exactly zero or one matches; each
- ground-truth element may be matched to zero or more predicted elements.
- The matching is determined by the MxN match_quality_matrix, that characterizes
- how well each (ground-truth, prediction)-pair match each other. For example,
- if the elements are boxes, this matrix may contain box intersection-over-union
- overlap values.
- The matcher returns (a) a vector of length N containing the index of the
- ground-truth element m in [0, M) that matches to prediction n in [0, N).
- (b) a vector of length N containing the labels for each prediction.
- """
-
- def __init__(
- self,
- thresholds: List[float],
- labels: List[int],
- allow_low_quality_matches: bool = False,
- ):
- """
- Args:
- thresholds (list): a list of thresholds used to stratify predictions
- into levels.
- labels (list): a list of values to label predictions belonging at
- each level. A label can be one of {-1, 0, 1} signifying
- {ignore, negative class, positive class}, respectively.
- allow_low_quality_matches (bool): if True, produce additional matches or predictions with maximum match quality lower than high_threshold.
- For example, thresholds = [0.3, 0.5] labels = [0, -1, 1] All predictions with iou < 0.3 will be marked with 0 and
- thus will be considered as false positives while training. All predictions with 0.3 <= iou < 0.5 will be marked with -1 and
- thus will be ignored. All predictions with 0.5 <= iou will be marked with 1 and thus will be considered as true positives.
- """
- thresholds = thresholds[:]
- assert thresholds[0] > 0
- thresholds.insert(0, -float("inf"))
- thresholds.append(float("inf"))
- assert all(low <= high for (low, high) in zip(thresholds[:-1], thresholds[1:]))
- assert all(label_i in [-1, 0, 1] for label_i in labels)
- assert len(labels) == len(thresholds) - 1
- self.thresholds = thresholds
- self.labels = labels
- self.allow_low_quality_matches = allow_low_quality_matches
-
- def __call__(self, match_quality_matrix):
- """
- Args:
- match_quality_matrix (Tensor[float]): an MxN tensor, containing the pairwise quality between M ground-truth elements and N predicted
- elements. All elements must be >= 0 (due to the us of `torch.nonzero` for selecting indices in :meth:`set_low_quality_matches_`).
- Returns:
- matches (Tensor[int64]): a vector of length N, where matches[i] is a matched ground-truth index in [0, M)
- match_labels (Tensor[int8]): a vector of length N, where pred_labels[i] indicates true or false positive or ignored
- """
- assert match_quality_matrix.dim() == 2
- if match_quality_matrix.numel() == 0:
- default_matches = match_quality_matrix.new_full((match_quality_matrix.size(1),), 0, dtype=torch.int64)
- # When no gt boxes exist, we define IOU = 0 and therefore set labels
- # to `self.labels[0]`, which usually defaults to background class 0
- # To choose to ignore instead,
- # can make labels=[-1,0,-1,1] + set appropriate thresholds
- default_match_labels = match_quality_matrix.new_full(
- (match_quality_matrix.size(1),), self.labels[0], dtype=torch.int8
- )
- return default_matches, default_match_labels
-
- assert torch.all(match_quality_matrix >= 0)
-
- # match_quality_matrix is M (gt) x N (predicted)
- # Max over gt elements (dim 0) to find best gt candidate for each prediction
- matched_vals, matches = match_quality_matrix.max(dim=0)
-
- match_labels = matches.new_full(matches.size(), 1, dtype=torch.int8)
-
- for l, low, high in zip(self.labels, self.thresholds[:-1], self.thresholds[1:]):
- low_high = (matched_vals >= low) & (matched_vals < high)
- match_labels[low_high] = l
-
- if self.allow_low_quality_matches:
- self.set_low_quality_matches_(match_labels, match_quality_matrix)
-
- return matches, match_labels
-
- def set_low_quality_matches_(self, match_labels, match_quality_matrix):
- """
- Produce additional matches for predictions that have only low-quality matches.
- Specifically, for each ground-truth G find the set of predictions that have
- maximum overlap with it (including ties); for each prediction in that set, if
- it is unmatched, then match it to the ground-truth G.
- This function implements the RPN assignment case (i)
- in Sec. 3.1.2 of Faster R-CNN.
- """
- # For each gt, find the prediction with which it has highest quality
- highest_quality_foreach_gt, _ = match_quality_matrix.max(dim=1)
- # Find the highest quality match available, even if it is low, including ties.
- # Note that the matches qualities must be positive due to the use of
- # `torch.nonzero`.
- of_quality_inds = match_quality_matrix == highest_quality_foreach_gt[:, None]
- if of_quality_inds.dim() == 0:
- (_, pred_inds_with_highest_quality) = of_quality_inds.unsqueeze(0).nonzero().unbind(1)
- else:
- (_, pred_inds_with_highest_quality) = of_quality_inds.nonzero().unbind(1)
- match_labels[pred_inds_with_highest_quality] = 1
-
-
-class RPNOutputs:
- def __init__(
- self,
- box2box_transform,
- anchor_matcher,
- batch_size_per_image,
- positive_fraction,
- images,
- pred_objectness_logits,
- pred_anchor_deltas,
- anchors,
- boundary_threshold=0,
- gt_boxes=None,
- smooth_l1_beta=0.0,
- ):
- """
- Args:
- box2box_transform (Box2BoxTransform): :class:`Box2BoxTransform` instance for anchor-proposal transformations.
- anchor_matcher (Matcher): :class:`Matcher` instance for matching anchors to ground-truth boxes; used to determine training labels.
- batch_size_per_image (int): number of proposals to sample when training
- positive_fraction (float): target fraction of sampled proposals that should be positive
- images (ImageList): :class:`ImageList` instance representing N input images
- pred_objectness_logits (list[Tensor]): A list of L elements. Element i is a tensor of shape (N, A, Hi, W)
- pred_anchor_deltas (list[Tensor]): A list of L elements. Element i is a tensor of shape (N, A*4, Hi, Wi)
- anchors (list[torch.Tensor]): nested list of boxes. anchors[i][j] at (n, l) stores anchor array for feature map l
- boundary_threshold (int): if >= 0, then anchors that extend beyond the image boundary by more than boundary_thresh are not used in training.
- gt_boxes (list[Boxes], optional): A list of N elements.
- smooth_l1_beta (float): The transition point between L1 and L2 lossn. When set to 0, the loss becomes L1. When +inf, it is ignored
- """
- self.box2box_transform = box2box_transform
- self.anchor_matcher = anchor_matcher
- self.batch_size_per_image = batch_size_per_image
- self.positive_fraction = positive_fraction
- self.pred_objectness_logits = pred_objectness_logits
- self.pred_anchor_deltas = pred_anchor_deltas
-
- self.anchors = anchors
- self.gt_boxes = gt_boxes
- self.num_feature_maps = len(pred_objectness_logits)
- self.num_images = len(images)
- self.boundary_threshold = boundary_threshold
- self.smooth_l1_beta = smooth_l1_beta
-
- def _get_ground_truth(self):
- raise NotImplementedError()
-
- def predict_proposals(self):
- # pred_anchor_deltas: (L, N, ? Hi, Wi)
- # anchors:(N, L, -1, B)
- # here we loop over specific feature map, NOT images
- proposals = []
- anchors = self.anchors.transpose(0, 1)
- for anchors_i, pred_anchor_deltas_i in zip(anchors, self.pred_anchor_deltas):
- B = anchors_i.size(-1)
- N, _, Hi, Wi = pred_anchor_deltas_i.shape
- anchors_i = anchors_i.flatten(start_dim=0, end_dim=1)
- pred_anchor_deltas_i = pred_anchor_deltas_i.view(N, -1, B, Hi, Wi).permute(0, 3, 4, 1, 2).reshape(-1, B)
- proposals_i = self.box2box_transform.apply_deltas(pred_anchor_deltas_i, anchors_i)
- # Append feature map proposals with shape (N, Hi*Wi*A, B)
- proposals.append(proposals_i.view(N, -1, B))
- proposals = torch.stack(proposals)
- return proposals
-
- def predict_objectness_logits(self):
- """
- Returns:
- pred_objectness_logits (list[Tensor]) -> (N, Hi*Wi*A).
- """
- pred_objectness_logits = [
- # Reshape: (N, A, Hi, Wi) -> (N, Hi, Wi, A) -> (N, Hi*Wi*A)
- score.permute(0, 2, 3, 1).reshape(self.num_images, -1)
- for score in self.pred_objectness_logits
- ]
- return pred_objectness_logits
-
-
-# Main Classes
-class Conv2d(nn.Conv2d):
- def __init__(self, *args, **kwargs):
- norm = kwargs.pop("norm", None)
- activation = kwargs.pop("activation", None)
- super().__init__(*args, **kwargs)
-
- self.norm = norm
- self.activation = activation
-
- def forward(self, x):
- if x.numel() == 0 and self.training:
- assert not isinstance(self.norm, nn.SyncBatchNorm)
- if x.numel() == 0:
- assert not isinstance(self.norm, nn.GroupNorm)
- output_shape = [
- (i + 2 * p - (di * (k - 1) + 1)) // s + 1
- for i, p, di, k, s in zip(
- x.shape[-2:],
- self.padding,
- self.dilation,
- self.kernel_size,
- self.stride,
- )
- ]
- output_shape = [x.shape[0], self.weight.shape[0]] + output_shape
- empty = _NewEmptyTensorOp.apply(x, output_shape)
- if self.training:
- _dummy = sum(x.view(-1)[0] for x in self.parameters()) * 0.0
- return empty + _dummy
- else:
- return empty
-
- x = super().forward(x)
- if self.norm is not None:
- x = self.norm(x)
- if self.activation is not None:
- x = self.activation(x)
- return x
-
-
-class LastLevelMaxPool(nn.Module):
- """
- This module is used in the original FPN to generate a downsampled P6 feature from P5.
- """
-
- def __init__(self):
- super().__init__()
- self.num_levels = 1
- self.in_feature = "p5"
-
- def forward(self, x):
- return [nn.functional.max_pool2d(x, kernel_size=1, stride=2, padding=0)]
-
-
-class LastLevelP6P7(nn.Module):
- """
- This module is used in RetinaNet to generate extra layers, P6 and P7 from C5 feature.
- """
-
- def __init__(self, in_channels, out_channels):
- super().__init__()
- self.num_levels = 2
- self.in_feature = "res5"
- self.p6 = nn.Conv2d(in_channels, out_channels, 3, 2, 1)
- self.p7 = nn.Conv2d(out_channels, out_channels, 3, 2, 1)
-
- def forward(self, c5):
- p6 = self.p6(c5)
- p7 = self.p7(nn.functional.relu(p6))
- return [p6, p7]
-
-
-class BasicStem(nn.Module):
- def __init__(self, in_channels=3, out_channels=64, norm="BN", caffe_maxpool=False):
- super().__init__()
- self.conv1 = Conv2d(
- in_channels,
- out_channels,
- kernel_size=7,
- stride=2,
- padding=3,
- bias=False,
- norm=get_norm(norm, out_channels),
- )
- self.caffe_maxpool = caffe_maxpool
- # use pad 1 instead of pad zero
-
- def forward(self, x):
- x = self.conv1(x)
- x = nn.functional.relu_(x)
- if self.caffe_maxpool:
- x = nn.functional.max_pool2d(x, kernel_size=3, stride=2, padding=0, ceil_mode=True)
- else:
- x = nn.functional.max_pool2d(x, kernel_size=3, stride=2, padding=1)
- return x
-
- @property
- def out_channels(self):
- return self.conv1.out_channels
-
- @property
- def stride(self):
- return 4 # = stride 2 conv -> stride 2 max pool
-
-
-class ResNetBlockBase(nn.Module):
- def __init__(self, in_channels, out_channels, stride):
- super().__init__()
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.stride = stride
-
- def freeze(self):
- for p in self.parameters():
- p.requires_grad = False
- return self
-
-
-class BottleneckBlock(ResNetBlockBase):
- def __init__(
- self,
- in_channels,
- out_channels,
- bottleneck_channels,
- stride=1,
- num_groups=1,
- norm="BN",
- stride_in_1x1=False,
- dilation=1,
- ):
- super().__init__(in_channels, out_channels, stride)
-
- if in_channels != out_channels:
- self.shortcut = Conv2d(
- in_channels,
- out_channels,
- kernel_size=1,
- stride=stride,
- bias=False,
- norm=get_norm(norm, out_channels),
- )
- else:
- self.shortcut = None
-
- # The original MSRA ResNet models have stride in the first 1x1 conv
- # The subsequent fb.torch.resnet and Caffe2 ResNe[X]t implementations have
- # stride in the 3x3 conv
- stride_1x1, stride_3x3 = (stride, 1) if stride_in_1x1 else (1, stride)
-
- self.conv1 = Conv2d(
- in_channels,
- bottleneck_channels,
- kernel_size=1,
- stride=stride_1x1,
- bias=False,
- norm=get_norm(norm, bottleneck_channels),
- )
-
- self.conv2 = Conv2d(
- bottleneck_channels,
- bottleneck_channels,
- kernel_size=3,
- stride=stride_3x3,
- padding=1 * dilation,
- bias=False,
- groups=num_groups,
- dilation=dilation,
- norm=get_norm(norm, bottleneck_channels),
- )
-
- self.conv3 = Conv2d(
- bottleneck_channels,
- out_channels,
- kernel_size=1,
- bias=False,
- norm=get_norm(norm, out_channels),
- )
-
- def forward(self, x):
- out = self.conv1(x)
- out = nn.functional.relu_(out)
-
- out = self.conv2(out)
- out = nn.functional.relu_(out)
-
- out = self.conv3(out)
-
- if self.shortcut is not None:
- shortcut = self.shortcut(x)
- else:
- shortcut = x
-
- out += shortcut
- out = nn.functional.relu_(out)
- return out
-
-
-class Backbone(nn.Module, metaclass=ABCMeta):
- def __init__(self):
- super().__init__()
-
- @abstractmethod
- def forward(self):
- pass
-
- @property
- def size_divisibility(self):
- """
- Some backbones require the input height and width to be divisible by a specific integer. This is
- typically true for encoder / decoder type networks with lateral connection (e.g., FPN) for which feature maps need to match
- dimension in the "bottom up" and "top down" paths. Set to 0 if no specific input size divisibility is required.
- """
- return 0
-
- def output_shape(self):
- return {
- name: ShapeSpec(
- channels=self._out_feature_channels[name],
- stride=self._out_feature_strides[name],
- )
- for name in self._out_features
- }
-
- @property
- def out_features(self):
- """deprecated"""
- return self._out_features
-
- @property
- def out_feature_strides(self):
- """deprecated"""
- return {f: self._out_feature_strides[f] for f in self._out_features}
-
- @property
- def out_feature_channels(self):
- """deprecated"""
- return {f: self._out_feature_channels[f] for f in self._out_features}
-
-
-class ResNet(Backbone):
- def __init__(self, stem, stages, num_classes=None, out_features=None):
- """
- Args:
- stem (nn.Module): a stem module
- stages (list[list[ResNetBlock]]): several (typically 4) stages, each contains multiple :class:`ResNetBlockBase`.
- num_classes (None or int): if None, will not perform classification.
- out_features (list[str]): name of the layers whose outputs should be returned in forward. Can be anything in:
- "stem", "linear", or "res2" ... If None, will return the output of the last layer.
- """
- super(ResNet, self).__init__()
- self.stem = stem
- self.num_classes = num_classes
-
- current_stride = self.stem.stride
- self._out_feature_strides = {"stem": current_stride}
- self._out_feature_channels = {"stem": self.stem.out_channels}
-
- self.stages_and_names = []
- for i, blocks in enumerate(stages):
- for block in blocks:
- assert isinstance(block, ResNetBlockBase), block
- curr_channels = block.out_channels
- stage = nn.Sequential(*blocks)
- name = "res" + str(i + 2)
- self.add_module(name, stage)
- self.stages_and_names.append((stage, name))
- self._out_feature_strides[name] = current_stride = int(
- current_stride * np.prod([k.stride for k in blocks])
- )
- self._out_feature_channels[name] = blocks[-1].out_channels
-
- if num_classes is not None:
- self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
- self.linear = nn.Linear(curr_channels, num_classes)
-
- # Sec 5.1 in "Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour":
- # "The 1000-way fully-connected layer is initialized by
- # drawing weights from a zero-mean Gaussian with std of 0.01."
- nn.init.normal_(self.linear.weight, stddev=0.01)
- name = "linear"
-
- if out_features is None:
- out_features = [name]
- self._out_features = out_features
- assert len(self._out_features)
- children = [x[0] for x in self.named_children()]
- for out_feature in self._out_features:
- assert out_feature in children, "Available children: {}".format(", ".join(children))
-
- def forward(self, x):
- outputs = {}
- x = self.stem(x)
- if "stem" in self._out_features:
- outputs["stem"] = x
- for stage, name in self.stages_and_names:
- x = stage(x)
- if name in self._out_features:
- outputs[name] = x
- if self.num_classes is not None:
- x = self.avgpool(x)
- x = self.linear(x)
- if "linear" in self._out_features:
- outputs["linear"] = x
- return outputs
-
- def output_shape(self):
- return {
- name: ShapeSpec(
- channels=self._out_feature_channels[name],
- stride=self._out_feature_strides[name],
- )
- for name in self._out_features
- }
-
- @staticmethod
- def make_stage(
- block_class,
- num_blocks,
- first_stride=None,
- *,
- in_channels,
- out_channels,
- **kwargs,
- ):
- """
- Usually, layers that produce the same feature map spatial size
- are defined as one "stage".
- Under such definition, stride_per_block[1:] should all be 1.
- """
- if first_stride is not None:
- assert "stride" not in kwargs and "stride_per_block" not in kwargs
- kwargs["stride_per_block"] = [first_stride] + [1] * (num_blocks - 1)
- blocks = []
- for i in range(num_blocks):
- curr_kwargs = {}
- for k, v in kwargs.items():
- if k.endswith("_per_block"):
- assert (
- len(v) == num_blocks
- ), f"Argument '{k}' of make_stage should have the same length as num_blocks={num_blocks}."
- newk = k[: -len("_per_block")]
- assert newk not in kwargs, f"Cannot call make_stage with both {k} and {newk}!"
- curr_kwargs[newk] = v[i]
- else:
- curr_kwargs[k] = v
-
- blocks.append(block_class(in_channels=in_channels, out_channels=out_channels, **curr_kwargs))
- in_channels = out_channels
-
- return blocks
-
-
-class ROIPooler(nn.Module):
- """
- Region of interest feature map pooler that supports pooling from one or more
- feature maps.
- """
-
- def __init__(
- self,
- output_size,
- scales,
- sampling_ratio,
- canonical_box_size=224,
- canonical_level=4,
- ):
- super().__init__()
- # assumption that stride is a power of 2.
- min_level = -math.log2(scales[0])
- max_level = -math.log2(scales[-1])
-
- # a bunch of testing
- assert math.isclose(min_level, int(min_level)) and math.isclose(max_level, int(max_level))
- assert len(scales) == max_level - min_level + 1, "not pyramid"
- assert 0 < min_level and min_level <= max_level
- if isinstance(output_size, int):
- output_size = (output_size, output_size)
- assert len(output_size) == 2 and isinstance(output_size[0], int) and isinstance(output_size[1], int)
- if len(scales) > 1:
- assert min_level <= canonical_level and canonical_level <= max_level
- assert canonical_box_size > 0
-
- self.output_size = output_size
- self.min_level = int(min_level)
- self.max_level = int(max_level)
- self.level_poolers = nn.ModuleList(RoIPool(output_size, spatial_scale=scale) for scale in scales)
- self.canonical_level = canonical_level
- self.canonical_box_size = canonical_box_size
-
- def forward(self, feature_maps, boxes):
- """
- Args:
- feature_maps: List[torch.Tensor(N,C,W,H)]
- box_lists: list[torch.Tensor])
- Returns:
- A tensor of shape(N*B, Channels, output_size, output_size)
- """
- x = list(feature_maps.values())
- num_level_assignments = len(self.level_poolers)
- assert len(x) == num_level_assignments and len(boxes) == x[0].size(0)
-
- pooler_fmt_boxes = convert_boxes_to_pooler_format(boxes)
-
- if num_level_assignments == 1:
- return self.level_poolers[0](x[0], pooler_fmt_boxes)
-
- level_assignments = assign_boxes_to_levels(
- boxes,
- self.min_level,
- self.max_level,
- self.canonical_box_size,
- self.canonical_level,
- )
-
- num_boxes = len(pooler_fmt_boxes)
- num_channels = x[0].shape[1]
- output_size = self.output_size[0]
-
- dtype, device = x[0].dtype, x[0].device
- output = torch.zeros(
- (num_boxes, num_channels, output_size, output_size),
- dtype=dtype,
- device=device,
- )
-
- for level, (x_level, pooler) in enumerate(zip(x, self.level_poolers)):
- inds = torch.nonzero(level_assignments == level).squeeze(1)
- pooler_fmt_boxes_level = pooler_fmt_boxes[inds]
- output[inds] = pooler(x_level, pooler_fmt_boxes_level)
-
- return output
-
-
-class ROIOutputs:
- def __init__(self, cfg, training=False):
- self.smooth_l1_beta = cfg.ROI_BOX_HEAD.SMOOTH_L1_BETA
- self.box2box_transform = Box2BoxTransform(weights=cfg.ROI_BOX_HEAD.BBOX_REG_WEIGHTS)
- self.training = training
- self.score_thresh = cfg.ROI_HEADS.SCORE_THRESH_TEST
- self.min_detections = cfg.MIN_DETECTIONS
- self.max_detections = cfg.MAX_DETECTIONS
-
- nms_thresh = cfg.ROI_HEADS.NMS_THRESH_TEST
- if not isinstance(nms_thresh, list):
- nms_thresh = [nms_thresh]
- self.nms_thresh = nms_thresh
-
- def _predict_boxes(self, proposals, box_deltas, preds_per_image):
- num_pred = box_deltas.size(0)
- B = proposals[0].size(-1)
- K = box_deltas.size(-1) // B
- box_deltas = box_deltas.view(num_pred * K, B)
- proposals = torch.cat(proposals, dim=0).unsqueeze(-2).expand(num_pred, K, B)
- proposals = proposals.reshape(-1, B)
- boxes = self.box2box_transform.apply_deltas(box_deltas, proposals)
- return boxes.view(num_pred, K * B).split(preds_per_image, dim=0)
-
- def _predict_objs(self, obj_logits, preds_per_image):
- probs = nn.functional.softmax(obj_logits, dim=-1)
- probs = probs.split(preds_per_image, dim=0)
- return probs
-
- def _predict_attrs(self, attr_logits, preds_per_image):
- attr_logits = attr_logits[..., :-1].softmax(-1)
- attr_probs, attrs = attr_logits.max(-1)
- return attr_probs.split(preds_per_image, dim=0), attrs.split(preds_per_image, dim=0)
-
- @torch.no_grad()
- def inference(
- self,
- obj_logits,
- attr_logits,
- box_deltas,
- pred_boxes,
- features,
- sizes,
- scales=None,
- ):
- # only the pred boxes is the
- preds_per_image = [p.size(0) for p in pred_boxes]
- boxes_all = self._predict_boxes(pred_boxes, box_deltas, preds_per_image)
- obj_scores_all = self._predict_objs(obj_logits, preds_per_image) # list of length N
- attr_probs_all, attrs_all = self._predict_attrs(attr_logits, preds_per_image)
- features = features.split(preds_per_image, dim=0)
-
- # fun for each image too, also I can experiment and do multiple images
- final_results = []
- zipped = zip(boxes_all, obj_scores_all, attr_probs_all, attrs_all, sizes)
- for i, (boxes, obj_scores, attr_probs, attrs, size) in enumerate(zipped):
- for nms_t in self.nms_thresh:
- outputs = do_nms(
- boxes,
- obj_scores,
- size,
- self.score_thresh,
- nms_t,
- self.min_detections,
- self.max_detections,
- )
- if outputs is not None:
- max_boxes, max_scores, classes, ids = outputs
- break
-
- if scales is not None:
- scale_yx = scales[i]
- max_boxes[:, 0::2] *= scale_yx[1]
- max_boxes[:, 1::2] *= scale_yx[0]
-
- final_results.append(
- (
- max_boxes,
- classes,
- max_scores,
- attrs[ids],
- attr_probs[ids],
- features[i][ids],
- )
- )
- boxes, classes, class_probs, attrs, attr_probs, roi_features = map(list, zip(*final_results))
- return boxes, classes, class_probs, attrs, attr_probs, roi_features
-
- def training(self, obj_logits, attr_logits, box_deltas, pred_boxes, features, sizes):
- pass
-
- def __call__(
- self,
- obj_logits,
- attr_logits,
- box_deltas,
- pred_boxes,
- features,
- sizes,
- scales=None,
- ):
- if self.training:
- raise NotImplementedError()
- return self.inference(
- obj_logits,
- attr_logits,
- box_deltas,
- pred_boxes,
- features,
- sizes,
- scales=scales,
- )
-
-
-class Res5ROIHeads(nn.Module):
- """
- ROIHeads perform all per-region computation in an R-CNN.
- It contains logic of cropping the regions, extract per-region features
- (by the res-5 block in this case), and make per-region predictions.
- """
-
- def __init__(self, cfg, input_shape):
- super().__init__()
- self.batch_size_per_image = cfg.RPN.BATCH_SIZE_PER_IMAGE
- self.positive_sample_fraction = cfg.ROI_HEADS.POSITIVE_FRACTION
- self.in_features = cfg.ROI_HEADS.IN_FEATURES
- self.num_classes = cfg.ROI_HEADS.NUM_CLASSES
- self.proposal_append_gt = cfg.ROI_HEADS.PROPOSAL_APPEND_GT
- self.feature_strides = {k: v.stride for k, v in input_shape.items()}
- self.feature_channels = {k: v.channels for k, v in input_shape.items()}
- self.cls_agnostic_bbox_reg = cfg.ROI_BOX_HEAD.CLS_AGNOSTIC_BBOX_REG
- self.stage_channel_factor = 2**3 # res5 is 8x res2
- self.out_channels = cfg.RESNETS.RES2_OUT_CHANNELS * self.stage_channel_factor
-
- # self.proposal_matcher = Matcher(
- # cfg.ROI_HEADS.IOU_THRESHOLDS,
- # cfg.ROI_HEADS.IOU_LABELS,
- # allow_low_quality_matches=False,
- # )
-
- pooler_resolution = cfg.ROI_BOX_HEAD.POOLER_RESOLUTION
- pooler_scales = (1.0 / self.feature_strides[self.in_features[0]],)
- sampling_ratio = cfg.ROI_BOX_HEAD.POOLER_SAMPLING_RATIO
- res5_halve = cfg.ROI_BOX_HEAD.RES5HALVE
- use_attr = cfg.ROI_BOX_HEAD.ATTR
- num_attrs = cfg.ROI_BOX_HEAD.NUM_ATTRS
-
- self.pooler = ROIPooler(
- output_size=pooler_resolution,
- scales=pooler_scales,
- sampling_ratio=sampling_ratio,
- )
-
- self.res5 = self._build_res5_block(cfg)
- if not res5_halve:
- """
- Modifications for VG in RoI heads:
- 1. Change the stride of conv1 and shortcut in Res5.Block1 from 2 to 1
- 2. Modifying all conv2 with (padding: 1 --> 2) and (dilation: 1 --> 2)
- """
- self.res5[0].conv1.stride = (1, 1)
- self.res5[0].shortcut.stride = (1, 1)
- for i in range(3):
- self.res5[i].conv2.padding = (2, 2)
- self.res5[i].conv2.dilation = (2, 2)
-
- self.box_predictor = FastRCNNOutputLayers(
- self.out_channels,
- self.num_classes,
- self.cls_agnostic_bbox_reg,
- use_attr=use_attr,
- num_attrs=num_attrs,
- )
-
- def _build_res5_block(self, cfg):
- stage_channel_factor = self.stage_channel_factor # res5 is 8x res2
- num_groups = cfg.RESNETS.NUM_GROUPS
- width_per_group = cfg.RESNETS.WIDTH_PER_GROUP
- bottleneck_channels = num_groups * width_per_group * stage_channel_factor
- out_channels = self.out_channels
- stride_in_1x1 = cfg.RESNETS.STRIDE_IN_1X1
- norm = cfg.RESNETS.NORM
-
- blocks = ResNet.make_stage(
- BottleneckBlock,
- 3,
- first_stride=2,
- in_channels=out_channels // 2,
- bottleneck_channels=bottleneck_channels,
- out_channels=out_channels,
- num_groups=num_groups,
- norm=norm,
- stride_in_1x1=stride_in_1x1,
- )
- return nn.Sequential(*blocks)
-
- def _shared_roi_transform(self, features, boxes):
- x = self.pooler(features, boxes)
- return self.res5(x)
-
- def forward(self, features, proposal_boxes, gt_boxes=None):
- if self.training:
- """
- see https://github.com/airsplay/py-bottom-up-attention/\
- blob/master/detectron2/modeling/roi_heads/roi_heads.py
- """
- raise NotImplementedError()
-
- assert not proposal_boxes[0].requires_grad
- box_features = self._shared_roi_transform(features, proposal_boxes)
- feature_pooled = box_features.mean(dim=[2, 3]) # pooled to 1x1
- obj_logits, attr_logits, pred_proposal_deltas = self.box_predictor(feature_pooled)
- return obj_logits, attr_logits, pred_proposal_deltas, feature_pooled
-
-
-class AnchorGenerator(nn.Module):
- """
- For a set of image sizes and feature maps, computes a set of anchors.
- """
-
- def __init__(self, cfg, input_shape: List[ShapeSpec]):
- super().__init__()
- sizes = cfg.ANCHOR_GENERATOR.SIZES
- aspect_ratios = cfg.ANCHOR_GENERATOR.ASPECT_RATIOS
- self.strides = [x.stride for x in input_shape]
- self.offset = cfg.ANCHOR_GENERATOR.OFFSET
- assert 0.0 <= self.offset < 1.0, self.offset
-
- """
- sizes (list[list[int]]): sizes[i] is the list of anchor sizes for feat map i
- 1. given in absolute lengths in units of the input image;
- 2. they do not dynamically scale if the input image size changes.
- aspect_ratios (list[list[float]])
- strides (list[int]): stride of each input feature.
- """
-
- self.num_features = len(self.strides)
- self.cell_anchors = nn.ParameterList(self._calculate_anchors(sizes, aspect_ratios))
- self._spacial_feat_dim = 4
-
- def _calculate_anchors(self, sizes, aspect_ratios):
- # If one size (or aspect ratio) is specified and there are multiple feature
- # maps, then we "broadcast" anchors of that single size (or aspect ratio)
- if len(sizes) == 1:
- sizes *= self.num_features
- if len(aspect_ratios) == 1:
- aspect_ratios *= self.num_features
- assert self.num_features == len(sizes)
- assert self.num_features == len(aspect_ratios)
-
- cell_anchors = [self.generate_cell_anchors(s, a).float() for s, a in zip(sizes, aspect_ratios)]
-
- return cell_anchors
-
- @property
- def box_dim(self):
- return self._spacial_feat_dim
-
- @property
- def num_cell_anchors(self):
- """
- Returns:
- list[int]: Each int is the number of anchors at every pixel location, on that feature map.
- """
- return [len(cell_anchors) for cell_anchors in self.cell_anchors]
-
- def grid_anchors(self, grid_sizes):
- anchors = []
- for size, stride, base_anchors in zip(grid_sizes, self.strides, self.cell_anchors):
- shift_x, shift_y = _create_grid_offsets(size, stride, self.offset, base_anchors.device)
- shifts = torch.stack((shift_x, shift_y, shift_x, shift_y), dim=1)
-
- anchors.append((shifts.view(-1, 1, 4) + base_anchors.view(1, -1, 4)).reshape(-1, 4))
-
- return anchors
-
- def generate_cell_anchors(self, sizes=(32, 64, 128, 256, 512), aspect_ratios=(0.5, 1, 2)):
- """
- anchors are continuous geometric rectangles
- centered on one feature map point sample.
- We can later build the set of anchors
- for the entire feature map by tiling these tensors
- """
-
- anchors = []
- for size in sizes:
- area = size**2.0
- for aspect_ratio in aspect_ratios:
- w = math.sqrt(area / aspect_ratio)
- h = aspect_ratio * w
- x0, y0, x1, y1 = -w / 2.0, -h / 2.0, w / 2.0, h / 2.0
- anchors.append([x0, y0, x1, y1])
- return nn.Parameter(torch.tensor(anchors))
-
- def forward(self, features):
- """
- Args:
- features List[torch.Tensor]: list of feature maps on which to generate anchors.
- Returns:
- torch.Tensor: a list of #image elements.
- """
- num_images = features[0].size(0)
- grid_sizes = [feature_map.shape[-2:] for feature_map in features]
- anchors_over_all_feature_maps = self.grid_anchors(grid_sizes)
- anchors_over_all_feature_maps = torch.stack(anchors_over_all_feature_maps)
- return anchors_over_all_feature_maps.unsqueeze(0).repeat_interleave(num_images, dim=0)
-
-
-class RPNHead(nn.Module):
- """
- RPN classification and regression heads. Uses a 3x3 conv to produce a shared
- hidden state from which one 1x1 conv predicts objectness logits for each anchor
- and a second 1x1 conv predicts bounding-box deltas specifying how to deform
- each anchor into an object proposal.
- """
-
- def __init__(self, cfg, input_shape: List[ShapeSpec]):
- super().__init__()
-
- # Standard RPN is shared across levels:
- in_channels = [s.channels for s in input_shape]
- assert len(set(in_channels)) == 1, "Each level must have the same channel!"
- in_channels = in_channels[0]
-
- anchor_generator = AnchorGenerator(cfg, input_shape)
- num_cell_anchors = anchor_generator.num_cell_anchors
- box_dim = anchor_generator.box_dim
- assert len(set(num_cell_anchors)) == 1, "Each level must have the same number of cell anchors"
- num_cell_anchors = num_cell_anchors[0]
-
- if cfg.PROPOSAL_GENERATOR.HIDDEN_CHANNELS == -1:
- hid_channels = in_channels
- else:
- hid_channels = cfg.PROPOSAL_GENERATOR.HIDDEN_CHANNELS
- # Modifications for VG in RPN (modeling/proposal_generator/rpn.py)
- # Use hidden dim instead fo the same dim as Res4 (in_channels)
-
- # 3x3 conv for the hidden representation
- self.conv = nn.Conv2d(in_channels, hid_channels, kernel_size=3, stride=1, padding=1)
- # 1x1 conv for predicting objectness logits
- self.objectness_logits = nn.Conv2d(hid_channels, num_cell_anchors, kernel_size=1, stride=1)
- # 1x1 conv for predicting box2box transform deltas
- self.anchor_deltas = nn.Conv2d(hid_channels, num_cell_anchors * box_dim, kernel_size=1, stride=1)
-
- for layer in [self.conv, self.objectness_logits, self.anchor_deltas]:
- nn.init.normal_(layer.weight, std=0.01)
- nn.init.constant_(layer.bias, 0)
-
- def forward(self, features):
- """
- Args:
- features (list[Tensor]): list of feature maps
- """
- pred_objectness_logits = []
- pred_anchor_deltas = []
- for x in features:
- t = nn.functional.relu(self.conv(x))
- pred_objectness_logits.append(self.objectness_logits(t))
- pred_anchor_deltas.append(self.anchor_deltas(t))
- return pred_objectness_logits, pred_anchor_deltas
-
-
-class RPN(nn.Module):
- """
- Region Proposal Network, introduced by the Faster R-CNN paper.
- """
-
- def __init__(self, cfg, input_shape: Dict[str, ShapeSpec]):
- super().__init__()
-
- self.min_box_side_len = cfg.PROPOSAL_GENERATOR.MIN_SIZE
- self.in_features = cfg.RPN.IN_FEATURES
- self.nms_thresh = cfg.RPN.NMS_THRESH
- self.batch_size_per_image = cfg.RPN.BATCH_SIZE_PER_IMAGE
- self.positive_fraction = cfg.RPN.POSITIVE_FRACTION
- self.smooth_l1_beta = cfg.RPN.SMOOTH_L1_BETA
- self.loss_weight = cfg.RPN.LOSS_WEIGHT
-
- self.pre_nms_topk = {
- True: cfg.RPN.PRE_NMS_TOPK_TRAIN,
- False: cfg.RPN.PRE_NMS_TOPK_TEST,
- }
- self.post_nms_topk = {
- True: cfg.RPN.POST_NMS_TOPK_TRAIN,
- False: cfg.RPN.POST_NMS_TOPK_TEST,
- }
- self.boundary_threshold = cfg.RPN.BOUNDARY_THRESH
-
- self.anchor_generator = AnchorGenerator(cfg, [input_shape[f] for f in self.in_features])
- self.box2box_transform = Box2BoxTransform(weights=cfg.RPN.BBOX_REG_WEIGHTS)
- self.anchor_matcher = Matcher(
- cfg.RPN.IOU_THRESHOLDS,
- cfg.RPN.IOU_LABELS,
- allow_low_quality_matches=True,
- )
- self.rpn_head = RPNHead(cfg, [input_shape[f] for f in self.in_features])
-
- def training(self, images, image_shapes, features, gt_boxes):
- pass
-
- def inference(self, outputs, images, image_shapes, features, gt_boxes=None):
- outputs = find_top_rpn_proposals(
- outputs.predict_proposals(),
- outputs.predict_objectness_logits(),
- images,
- image_shapes,
- self.nms_thresh,
- self.pre_nms_topk[self.training],
- self.post_nms_topk[self.training],
- self.min_box_side_len,
- self.training,
- )
-
- results = []
- for img in outputs:
- im_boxes, img_box_logits = img
- img_box_logits, inds = img_box_logits.sort(descending=True)
- im_boxes = im_boxes[inds]
- results.append((im_boxes, img_box_logits))
-
- (proposal_boxes, logits) = tuple(map(list, zip(*results)))
- return proposal_boxes, logits
-
- def forward(self, images, image_shapes, features, gt_boxes=None):
- """
- Args:
- images (torch.Tensor): input images of length `N`
- features (dict[str: Tensor])
- gt_instances
- """
- # features is dict, key = block level, v = feature_map
- features = [features[f] for f in self.in_features]
- pred_objectness_logits, pred_anchor_deltas = self.rpn_head(features)
- anchors = self.anchor_generator(features)
- outputs = RPNOutputs(
- self.box2box_transform,
- self.anchor_matcher,
- self.batch_size_per_image,
- self.positive_fraction,
- images,
- pred_objectness_logits,
- pred_anchor_deltas,
- anchors,
- self.boundary_threshold,
- gt_boxes,
- self.smooth_l1_beta,
- )
- # For RPN-only models, the proposals are the final output
-
- if self.training:
- raise NotImplementedError()
- return self.training(outputs, images, image_shapes, features, gt_boxes)
- else:
- return self.inference(outputs, images, image_shapes, features, gt_boxes)
-
-
-class FastRCNNOutputLayers(nn.Module):
- """
- Two linear layers for predicting Fast R-CNN outputs:
- (1) proposal-to-detection box regression deltas
- (2) classification scores
- """
-
- def __init__(
- self,
- input_size,
- num_classes,
- cls_agnostic_bbox_reg,
- box_dim=4,
- use_attr=False,
- num_attrs=-1,
- ):
- """
- Args:
- input_size (int): channels, or (channels, height, width)
- num_classes (int)
- cls_agnostic_bbox_reg (bool)
- box_dim (int)
- """
- super().__init__()
-
- if not isinstance(input_size, int):
- input_size = np.prod(input_size)
-
- # (do + 1 for background class)
- self.cls_score = nn.Linear(input_size, num_classes + 1)
- num_bbox_reg_classes = 1 if cls_agnostic_bbox_reg else num_classes
- self.bbox_pred = nn.Linear(input_size, num_bbox_reg_classes * box_dim)
-
- self.use_attr = use_attr
- if use_attr:
- """
- Modifications for VG in RoI heads
- Embedding: {num_classes + 1} --> {input_size // 8}
- Linear: {input_size + input_size // 8} --> {input_size // 4}
- Linear: {input_size // 4} --> {num_attrs + 1}
- """
- self.cls_embedding = nn.Embedding(num_classes + 1, input_size // 8)
- self.fc_attr = nn.Linear(input_size + input_size // 8, input_size // 4)
- self.attr_score = nn.Linear(input_size // 4, num_attrs + 1)
-
- nn.init.normal_(self.cls_score.weight, std=0.01)
- nn.init.normal_(self.bbox_pred.weight, std=0.001)
- for item in [self.cls_score, self.bbox_pred]:
- nn.init.constant_(item.bias, 0)
-
- def forward(self, roi_features):
- if roi_features.dim() > 2:
- roi_features = torch.flatten(roi_features, start_dim=1)
- scores = self.cls_score(roi_features)
- proposal_deltas = self.bbox_pred(roi_features)
- if self.use_attr:
- _, max_class = scores.max(-1) # [b, c] --> [b]
- cls_emb = self.cls_embedding(max_class) # [b] --> [b, 256]
- roi_features = torch.cat([roi_features, cls_emb], -1) # [b, 2048] + [b, 256] --> [b, 2304]
- roi_features = self.fc_attr(roi_features)
- roi_features = nn.functional.relu(roi_features)
- attr_scores = self.attr_score(roi_features)
- return scores, attr_scores, proposal_deltas
- else:
- return scores, proposal_deltas
-
-
-class GeneralizedRCNN(nn.Module):
- def __init__(self, cfg):
- super().__init__()
-
- self.device = torch.device(cfg.MODEL.DEVICE)
- self.backbone = build_backbone(cfg)
- self.proposal_generator = RPN(cfg, self.backbone.output_shape())
- self.roi_heads = Res5ROIHeads(cfg, self.backbone.output_shape())
- self.roi_outputs = ROIOutputs(cfg)
- self.to(self.device)
-
- @classmethod
- def from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs):
- config = kwargs.pop("config", None)
- state_dict = kwargs.pop("state_dict", None)
- cache_dir = kwargs.pop("cache_dir", None)
- from_tf = kwargs.pop("from_tf", False)
- force_download = kwargs.pop("force_download", False)
- resume_download = kwargs.pop("resume_download", False)
- proxies = kwargs.pop("proxies", None)
- local_files_only = kwargs.pop("local_files_only", False)
- use_cdn = kwargs.pop("use_cdn", True)
-
- # Load config if we don't provide a configuration
- if not isinstance(config, Config):
- config_path = config if config is not None else pretrained_model_name_or_path
- # try:
- config = Config.from_pretrained(
- config_path,
- cache_dir=cache_dir,
- force_download=force_download,
- resume_download=resume_download,
- proxies=proxies,
- local_files_only=local_files_only,
- )
-
- # Load model
- if pretrained_model_name_or_path is not None:
- if os.path.isdir(pretrained_model_name_or_path):
- if os.path.isfile(os.path.join(pretrained_model_name_or_path, WEIGHTS_NAME)):
- # Load from a PyTorch checkpoint
- archive_file = os.path.join(pretrained_model_name_or_path, WEIGHTS_NAME)
- else:
- raise EnvironmentError(
- "Error no file named {} found in directory {} ".format(
- WEIGHTS_NAME,
- pretrained_model_name_or_path,
- )
- )
- elif os.path.isfile(pretrained_model_name_or_path) or is_remote_url(pretrained_model_name_or_path):
- archive_file = pretrained_model_name_or_path
- elif os.path.isfile(pretrained_model_name_or_path + ".index"):
- assert from_tf, "We found a TensorFlow checkpoint at {}, please set from_tf to True to load from this checkpoint".format(
- pretrained_model_name_or_path + ".index"
- )
- archive_file = pretrained_model_name_or_path + ".index"
- else:
- archive_file = hf_bucket_url(
- pretrained_model_name_or_path,
- filename=WEIGHTS_NAME,
- use_cdn=use_cdn,
- )
-
- try:
- # Load from URL or cache if already cached
- resolved_archive_file = cached_path(
- archive_file,
- cache_dir=cache_dir,
- force_download=force_download,
- proxies=proxies,
- resume_download=resume_download,
- local_files_only=local_files_only,
- )
- if resolved_archive_file is None:
- raise EnvironmentError
- except EnvironmentError:
- msg = f"Can't load weights for '{pretrained_model_name_or_path}'."
- raise EnvironmentError(msg)
-
- if resolved_archive_file == archive_file:
- print("loading weights file {}".format(archive_file))
- else:
- print("loading weights file {} from cache at {}".format(archive_file, resolved_archive_file))
- else:
- resolved_archive_file = None
-
- # Instantiate model.
- model = cls(config)
-
- if state_dict is None:
- try:
- try:
- state_dict = torch.load(resolved_archive_file, map_location="cpu")
- except Exception:
- state_dict = load_checkpoint(resolved_archive_file)
-
- except Exception:
- raise OSError(
- "Unable to load weights from pytorch checkpoint file. "
- "If you tried to load a PyTorch model from a TF 2.0 checkpoint, please set from_tf=True. "
- )
-
- missing_keys = []
- unexpected_keys = []
- error_msgs = []
-
- # Convert old format to new format if needed from a PyTorch state_dict
- old_keys = []
- new_keys = []
- for key in state_dict.keys():
- new_key = None
- if "gamma" in key:
- new_key = key.replace("gamma", "weight")
- if "beta" in key:
- new_key = key.replace("beta", "bias")
- if new_key:
- old_keys.append(key)
- new_keys.append(new_key)
- for old_key, new_key in zip(old_keys, new_keys):
- state_dict[new_key] = state_dict.pop(old_key)
-
- # copy state_dict so _load_from_state_dict can modify it
- metadata = getattr(state_dict, "_metadata", None)
- state_dict = state_dict.copy()
- if metadata is not None:
- state_dict._metadata = metadata
-
- model_to_load = model
- model_to_load.load_state_dict(state_dict)
-
- if model.__class__.__name__ != model_to_load.__class__.__name__:
- base_model_state_dict = model_to_load.state_dict().keys()
- head_model_state_dict_without_base_prefix = [
- key.split(cls.base_model_prefix + ".")[-1] for key in model.state_dict().keys()
- ]
- missing_keys.extend(head_model_state_dict_without_base_prefix - base_model_state_dict)
-
- if len(unexpected_keys) > 0:
- print(
- f"Some weights of the model checkpoint at {pretrained_model_name_or_path} were not used when"
- f" initializing {model.__class__.__name__}: {unexpected_keys}\n- This IS expected if you are"
- f" initializing {model.__class__.__name__} from the checkpoint of a model trained on another task or"
- " with another architecture (e.g. initializing a BertForSequenceClassification model from a"
- " BertForPreTraining model).\n- This IS NOT expected if you are initializing"
- f" {model.__class__.__name__} from the checkpoint of a model that you expect to be exactly identical"
- " (initializing a BertForSequenceClassification model from a BertForSequenceClassification model)."
- )
- else:
- print(f"All model checkpoint weights were used when initializing {model.__class__.__name__}.\n")
- if len(missing_keys) > 0:
- print(
- f"Some weights of {model.__class__.__name__} were not initialized from the model checkpoint at"
- f" {pretrained_model_name_or_path} and are newly initialized: {missing_keys}\nYou should probably"
- " TRAIN this model on a down-stream task to be able to use it for predictions and inference."
- )
- else:
- print(
- f"All the weights of {model.__class__.__name__} were initialized from the model checkpoint at"
- f" {pretrained_model_name_or_path}.\nIf your task is similar to the task the model of the checkpoint"
- f" was trained on, you can already use {model.__class__.__name__} for predictions without further"
- " training."
- )
- if len(error_msgs) > 0:
- raise RuntimeError(
- "Error(s) in loading state_dict for {}:\n\t{}".format(
- model.__class__.__name__, "\n\t".join(error_msgs)
- )
- )
- # Set model in evaluation mode to deactivate DropOut modules by default
- model.eval()
-
- return model
-
- def forward(
- self,
- images,
- image_shapes,
- gt_boxes=None,
- proposals=None,
- scales_yx=None,
- **kwargs,
- ):
- """
- kwargs:
- max_detections (int), return_tensors {"np", "pt", None}, padding {None,
- "max_detections"}, pad_value (int), location = {"cuda", "cpu"}
- """
- if self.training:
- raise NotImplementedError()
- return self.inference(
- images=images,
- image_shapes=image_shapes,
- gt_boxes=gt_boxes,
- proposals=proposals,
- scales_yx=scales_yx,
- **kwargs,
- )
-
- @torch.no_grad()
- def inference(
- self,
- images,
- image_shapes,
- gt_boxes=None,
- proposals=None,
- scales_yx=None,
- **kwargs,
- ):
- # run images through backbone
- original_sizes = image_shapes * scales_yx
- features = self.backbone(images)
-
- # generate proposals if none are available
- if proposals is None:
- proposal_boxes, _ = self.proposal_generator(images, image_shapes, features, gt_boxes)
- else:
- assert proposals is not None
-
- # pool object features from either gt_boxes, or from proposals
- obj_logits, attr_logits, box_deltas, feature_pooled = self.roi_heads(features, proposal_boxes, gt_boxes)
-
- # prepare FRCNN Outputs and select top proposals
- boxes, classes, class_probs, attrs, attr_probs, roi_features = self.roi_outputs(
- obj_logits=obj_logits,
- attr_logits=attr_logits,
- box_deltas=box_deltas,
- pred_boxes=proposal_boxes,
- features=feature_pooled,
- sizes=image_shapes,
- scales=scales_yx,
- )
-
- # will we pad???
- subset_kwargs = {
- "max_detections": kwargs.get("max_detections", None),
- "return_tensors": kwargs.get("return_tensors", None),
- "pad_value": kwargs.get("pad_value", 0),
- "padding": kwargs.get("padding", None),
- }
- preds_per_image = torch.tensor([p.size(0) for p in boxes])
- boxes = pad_list_tensors(boxes, preds_per_image, **subset_kwargs)
- classes = pad_list_tensors(classes, preds_per_image, **subset_kwargs)
- class_probs = pad_list_tensors(class_probs, preds_per_image, **subset_kwargs)
- attrs = pad_list_tensors(attrs, preds_per_image, **subset_kwargs)
- attr_probs = pad_list_tensors(attr_probs, preds_per_image, **subset_kwargs)
- roi_features = pad_list_tensors(roi_features, preds_per_image, **subset_kwargs)
- subset_kwargs["padding"] = None
- preds_per_image = pad_list_tensors(preds_per_image, None, **subset_kwargs)
- sizes = pad_list_tensors(image_shapes, None, **subset_kwargs)
- normalized_boxes = norm_box(boxes, original_sizes)
- return OrderedDict(
- {
- "obj_ids": classes,
- "obj_probs": class_probs,
- "attr_ids": attrs,
- "attr_probs": attr_probs,
- "boxes": boxes,
- "sizes": sizes,
- "preds_per_image": preds_per_image,
- "roi_features": roi_features,
- "normalized_boxes": normalized_boxes,
- }
- )
diff --git a/examples/research_projects/lxmert/processing_image.py b/examples/research_projects/lxmert/processing_image.py
deleted file mode 100644
index 65f8f6cd377..00000000000
--- a/examples/research_projects/lxmert/processing_image.py
+++ /dev/null
@@ -1,151 +0,0 @@
-"""
-coding=utf-8
-Copyright 2018, Antonio Mendoza Hao Tan, Mohit Bansal
-Adapted From Facebook Inc, Detectron2
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.import copy
-"""
-
-import sys
-from typing import Tuple
-
-import numpy as np
-import torch
-from PIL import Image
-from torch import nn
-
-from transformers.image_utils import PILImageResampling
-from utils import img_tensorize
-
-
-class ResizeShortestEdge:
- def __init__(self, short_edge_length, max_size=sys.maxsize):
- """
- Args:
- short_edge_length (list[min, max])
- max_size (int): maximum allowed longest edge length.
- """
- self.interp_method = "bilinear"
- self.max_size = max_size
- self.short_edge_length = short_edge_length
-
- def __call__(self, imgs):
- img_augs = []
- for img in imgs:
- h, w = img.shape[:2]
- # later: provide list and randomly choose index for resize
- size = np.random.randint(self.short_edge_length[0], self.short_edge_length[1] + 1)
- if size == 0:
- return img
- scale = size * 1.0 / min(h, w)
- if h < w:
- newh, neww = size, scale * w
- else:
- newh, neww = scale * h, size
- if max(newh, neww) > self.max_size:
- scale = self.max_size * 1.0 / max(newh, neww)
- newh = newh * scale
- neww = neww * scale
- neww = int(neww + 0.5)
- newh = int(newh + 0.5)
-
- if img.dtype == np.uint8:
- pil_image = Image.fromarray(img)
- pil_image = pil_image.resize((neww, newh), PILImageResampling.BILINEAR)
- img = np.asarray(pil_image)
- else:
- img = img.permute(2, 0, 1).unsqueeze(0) # 3, 0, 1) # hw(c) -> nchw
- img = nn.functional.interpolate(
- img, (newh, neww), mode=self.interp_method, align_corners=False
- ).squeeze(0)
- img_augs.append(img)
-
- return img_augs
-
-
-class Preprocess:
- def __init__(self, cfg):
- self.aug = ResizeShortestEdge([cfg.INPUT.MIN_SIZE_TEST, cfg.INPUT.MIN_SIZE_TEST], cfg.INPUT.MAX_SIZE_TEST)
- self.input_format = cfg.INPUT.FORMAT
- self.size_divisibility = cfg.SIZE_DIVISIBILITY
- self.pad_value = cfg.PAD_VALUE
- self.max_image_size = cfg.INPUT.MAX_SIZE_TEST
- self.device = cfg.MODEL.DEVICE
- self.pixel_std = torch.tensor(cfg.MODEL.PIXEL_STD).to(self.device).view(len(cfg.MODEL.PIXEL_STD), 1, 1)
- self.pixel_mean = torch.tensor(cfg.MODEL.PIXEL_MEAN).to(self.device).view(len(cfg.MODEL.PIXEL_STD), 1, 1)
- self.normalizer = lambda x: (x - self.pixel_mean) / self.pixel_std
-
- def pad(self, images):
- max_size = tuple(max(s) for s in zip(*[img.shape for img in images]))
- image_sizes = [im.shape[-2:] for im in images]
- images = [
- nn.functional.pad(
- im,
- [0, max_size[-1] - size[1], 0, max_size[-2] - size[0]],
- value=self.pad_value,
- )
- for size, im in zip(image_sizes, images)
- ]
-
- return torch.stack(images), torch.tensor(image_sizes)
-
- def __call__(self, images, single_image=False):
- with torch.no_grad():
- if not isinstance(images, list):
- images = [images]
- if single_image:
- assert len(images) == 1
- for i in range(len(images)):
- if isinstance(images[i], torch.Tensor):
- images.insert(i, images.pop(i).to(self.device).float())
- elif not isinstance(images[i], torch.Tensor):
- images.insert(
- i,
- torch.as_tensor(img_tensorize(images.pop(i), input_format=self.input_format))
- .to(self.device)
- .float(),
- )
- # resize smallest edge
- raw_sizes = torch.tensor([im.shape[:2] for im in images])
- images = self.aug(images)
- # transpose images and convert to torch tensors
- # images = [torch.as_tensor(i.astype("float32")).permute(2, 0, 1).to(self.device) for i in images]
- # now normalize before pad to avoid useless arithmetic
- images = [self.normalizer(x) for x in images]
- # now pad them to do the following operations
- images, sizes = self.pad(images)
- # Normalize
-
- if self.size_divisibility > 0:
- raise NotImplementedError()
- # pad
- scales_yx = torch.true_divide(raw_sizes, sizes)
- if single_image:
- return images[0], sizes[0], scales_yx[0]
- else:
- return images, sizes, scales_yx
-
-
-def _scale_box(boxes, scale_yx):
- boxes[:, 0::2] *= scale_yx[:, 1]
- boxes[:, 1::2] *= scale_yx[:, 0]
- return boxes
-
-
-def _clip_box(tensor, box_size: Tuple[int, int]):
- assert torch.isfinite(tensor).all(), "Box tensor contains infinite or NaN!"
- h, w = box_size
- tensor[:, 0].clamp_(min=0, max=w)
- tensor[:, 1].clamp_(min=0, max=h)
- tensor[:, 2].clamp_(min=0, max=w)
- tensor[:, 3].clamp_(min=0, max=h)
diff --git a/examples/research_projects/lxmert/requirements.txt b/examples/research_projects/lxmert/requirements.txt
deleted file mode 100644
index e2778663a53..00000000000
--- a/examples/research_projects/lxmert/requirements.txt
+++ /dev/null
@@ -1,98 +0,0 @@
-appdirs==1.4.3
-argon2-cffi==20.1.0
-async-generator==1.10
-attrs==20.2.0
-backcall==0.2.0
-CacheControl==0.12.6
-certifi==2024.7.4
-cffi==1.14.2
-chardet==3.0.4
-click==7.1.2
-colorama==0.4.3
-contextlib2==0.6.0
-cycler==0.10.0
-datasets==1.0.0
-decorator==4.4.2
-defusedxml==0.6.0
-dill==0.3.2
-distlib==0.3.0
-distro==1.4.0
-entrypoints==0.3
-filelock==3.0.12
-future==0.18.3
-html5lib==1.0.1
-idna==3.7
-ipaddr==2.2.0
-ipykernel==5.3.4
-ipython
-ipython-genutils==0.2.0
-ipywidgets==7.5.1
-jedi==0.17.2
-Jinja2>=2.11.3
-joblib==1.2.0
-jsonschema==3.2.0
-jupyter==1.0.0
-jupyter-client==6.1.7
-jupyter-console==6.2.0
-jupyter-core==4.11.2
-jupyterlab-pygments==0.1.1
-kiwisolver==1.2.0
-lockfile==0.12.2
-MarkupSafe==1.1.1
-matplotlib==3.3.1
-mistune==2.0.3
-msgpack==0.6.2
-nbclient==0.5.0
-nbconvert==6.5.1
-nbformat==5.0.7
-nest-asyncio==1.4.0
-notebook==6.4.12
-numpy==1.22.0
-opencv-python==4.8.1.78
-packaging==20.3
-pandas==1.1.2
-pandocfilters==1.4.2
-parso==0.7.1
-pep517==0.8.2
-pexpect==4.8.0
-pickleshare==0.7.5
-Pillow>=8.1.1
-progress==1.5
-prometheus-client==0.8.0
-prompt-toolkit==3.0.7
-ptyprocess==0.6.0
-pyaml==20.4.0
-pyarrow==15.0.0
-pycparser==2.20
-Pygments>=2.7.4
-pyparsing==2.4.6
-pyrsistent==0.16.0
-python-dateutil==2.8.1
-pytoml==0.1.21
-pytz==2020.1
-PyYAML>=5.4
-pyzmq==19.0.2
-qtconsole==4.7.7
-QtPy==1.9.0
-regex==2020.7.14
-requests==2.32.2
-retrying==1.3.3
-sacremoses==0.0.43
-Send2Trash==1.5.0
-sentencepiece==0.1.91
-six==1.14.0
-terminado==0.8.3
-testpath==0.4.4
-tokenizers==0.8.1rc2
-torch==2.2.0
-torchvision==0.7.0
-tornado==6.4.2
-tqdm==4.66.3
-traitlets
-git+https://github.com/huggingface/transformers.git
-urllib3==1.26.19
-wcwidth==0.2.5
-webencodings==0.5.1
-wget==3.2
-widgetsnbextension==3.5.1
-xxhash==2.0.0
diff --git a/examples/research_projects/lxmert/utils.py b/examples/research_projects/lxmert/utils.py
deleted file mode 100644
index 995fbd2c19a..00000000000
--- a/examples/research_projects/lxmert/utils.py
+++ /dev/null
@@ -1,554 +0,0 @@
-"""
-coding=utf-8
-Copyright 2018, Antonio Mendoza Hao Tan, Mohit Bansal, Huggingface team :)
-Adapted From Facebook Inc, Detectron2
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.import copy
-"""
-
-import copy
-import fnmatch
-import json
-import os
-import pickle as pkl
-import shutil
-import sys
-import tarfile
-import tempfile
-from collections import OrderedDict
-from contextlib import contextmanager
-from functools import partial
-from io import BytesIO
-from pathlib import Path
-from urllib.parse import urlparse
-from zipfile import ZipFile, is_zipfile
-
-import cv2
-import numpy as np
-import requests
-import wget
-from filelock import FileLock
-from huggingface_hub.utils import insecure_hashlib
-from PIL import Image
-from tqdm.auto import tqdm
-from yaml import Loader, dump, load
-
-
-try:
- import torch
-
- _torch_available = True
-except ImportError:
- _torch_available = False
-
-
-try:
- from torch.hub import _get_torch_home
-
- torch_cache_home = _get_torch_home()
-except ImportError:
- torch_cache_home = os.path.expanduser(
- os.getenv("TORCH_HOME", os.path.join(os.getenv("XDG_CACHE_HOME", "~/.cache"), "torch"))
- )
-
-default_cache_path = os.path.join(torch_cache_home, "transformers")
-
-CLOUDFRONT_DISTRIB_PREFIX = "https://cdn.huggingface.co"
-S3_BUCKET_PREFIX = "https://s3.amazonaws.com/models.huggingface.co/bert"
-PATH = "/".join(str(Path(__file__).resolve()).split("/")[:-1])
-CONFIG = os.path.join(PATH, "config.yaml")
-ATTRIBUTES = os.path.join(PATH, "attributes.txt")
-OBJECTS = os.path.join(PATH, "objects.txt")
-PYTORCH_PRETRAINED_BERT_CACHE = os.getenv("PYTORCH_PRETRAINED_BERT_CACHE", default_cache_path)
-PYTORCH_TRANSFORMERS_CACHE = os.getenv("PYTORCH_TRANSFORMERS_CACHE", PYTORCH_PRETRAINED_BERT_CACHE)
-TRANSFORMERS_CACHE = os.getenv("TRANSFORMERS_CACHE", PYTORCH_TRANSFORMERS_CACHE)
-WEIGHTS_NAME = "pytorch_model.bin"
-CONFIG_NAME = "config.yaml"
-
-
-def load_labels(objs=OBJECTS, attrs=ATTRIBUTES):
- vg_classes = []
- with open(objs) as f:
- for object in f.readlines():
- vg_classes.append(object.split(",")[0].lower().strip())
-
- vg_attrs = []
- with open(attrs) as f:
- for object in f.readlines():
- vg_attrs.append(object.split(",")[0].lower().strip())
- return vg_classes, vg_attrs
-
-
-def load_checkpoint(ckp):
- r = OrderedDict()
- with open(ckp, "rb") as f:
- ckp = pkl.load(f)["model"]
- for k in copy.deepcopy(list(ckp.keys())):
- v = ckp.pop(k)
- if isinstance(v, np.ndarray):
- v = torch.tensor(v)
- else:
- assert isinstance(v, torch.tensor), type(v)
- r[k] = v
- return r
-
-
-class Config:
- _pointer = {}
-
- def __init__(self, dictionary: dict, name: str = "root", level=0):
- self._name = name
- self._level = level
- d = {}
- for k, v in dictionary.items():
- if v is None:
- raise ValueError()
- k = copy.deepcopy(k)
- v = copy.deepcopy(v)
- if isinstance(v, dict):
- v = Config(v, name=k, level=level + 1)
- d[k] = v
- setattr(self, k, v)
-
- self._pointer = d
-
- def __repr__(self):
- return str(list((self._pointer.keys())))
-
- def __setattr__(self, key, val):
- self.__dict__[key] = val
- self.__dict__[key.upper()] = val
- levels = key.split(".")
- last_level = len(levels) - 1
- pointer = self._pointer
- if len(levels) > 1:
- for i, l in enumerate(levels):
- if hasattr(self, l) and isinstance(getattr(self, l), Config):
- setattr(getattr(self, l), ".".join(levels[i:]), val)
- if l == last_level:
- pointer[l] = val
- else:
- pointer = pointer[l]
-
- def to_dict(self):
- return self._pointer
-
- def dump_yaml(self, data, file_name):
- with open(f"{file_name}", "w") as stream:
- dump(data, stream)
-
- def dump_json(self, data, file_name):
- with open(f"{file_name}", "w") as stream:
- json.dump(data, stream)
-
- @staticmethod
- def load_yaml(config):
- with open(config) as stream:
- data = load(stream, Loader=Loader)
- return data
-
- def __str__(self):
- t = " "
- if self._name != "root":
- r = f"{t * (self._level-1)}{self._name}:\n"
- else:
- r = ""
- level = self._level
- for i, (k, v) in enumerate(self._pointer.items()):
- if isinstance(v, Config):
- r += f"{t * (self._level)}{v}\n"
- self._level += 1
- else:
- r += f"{t * (self._level)}{k}: {v} ({type(v).__name__})\n"
- self._level = level
- return r[:-1]
-
- @classmethod
- def from_pretrained(cls, pretrained_model_name_or_path: str, **kwargs):
- config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
- return cls(config_dict)
-
- @classmethod
- def get_config_dict(cls, pretrained_model_name_or_path: str, **kwargs):
- cache_dir = kwargs.pop("cache_dir", None)
- force_download = kwargs.pop("force_download", False)
- resume_download = kwargs.pop("resume_download", False)
- proxies = kwargs.pop("proxies", None)
- local_files_only = kwargs.pop("local_files_only", False)
-
- if os.path.isdir(pretrained_model_name_or_path):
- config_file = os.path.join(pretrained_model_name_or_path, CONFIG_NAME)
- elif os.path.isfile(pretrained_model_name_or_path) or is_remote_url(pretrained_model_name_or_path):
- config_file = pretrained_model_name_or_path
- else:
- config_file = hf_bucket_url(pretrained_model_name_or_path, filename=CONFIG_NAME, use_cdn=False)
-
- try:
- # Load from URL or cache if already cached
- resolved_config_file = cached_path(
- config_file,
- cache_dir=cache_dir,
- force_download=force_download,
- proxies=proxies,
- resume_download=resume_download,
- local_files_only=local_files_only,
- )
- # Load config dict
- if resolved_config_file is None:
- raise EnvironmentError
-
- config_file = Config.load_yaml(resolved_config_file)
-
- except EnvironmentError:
- msg = "Can't load config for"
- raise EnvironmentError(msg)
-
- if resolved_config_file == config_file:
- print("loading configuration file from path")
- else:
- print("loading configuration file cache")
-
- return Config.load_yaml(resolved_config_file), kwargs
-
-
-# quick compare tensors
-def compare(in_tensor):
- out_tensor = torch.load("dump.pt", map_location=in_tensor.device)
- n1 = in_tensor.numpy()
- n2 = out_tensor.numpy()[0]
- print(n1.shape, n1[0, 0, :5])
- print(n2.shape, n2[0, 0, :5])
- assert np.allclose(n1, n2, rtol=0.01, atol=0.1), (
- f"{sum([1 for x in np.isclose(n1, n2, rtol=0.01, atol=0.1).flatten() if x is False])/len(n1.flatten())*100:.4f} %"
- " element-wise mismatch"
- )
- raise Exception("tensors are all good")
-
- # Hugging face functions below
-
-
-def is_remote_url(url_or_filename):
- parsed = urlparse(url_or_filename)
- return parsed.scheme in ("http", "https")
-
-
-def hf_bucket_url(model_id: str, filename: str, use_cdn=True) -> str:
- endpoint = CLOUDFRONT_DISTRIB_PREFIX if use_cdn else S3_BUCKET_PREFIX
- legacy_format = "/" not in model_id
- if legacy_format:
- return f"{endpoint}/{model_id}-{filename}"
- else:
- return f"{endpoint}/{model_id}/{filename}"
-
-
-def http_get(
- url,
- temp_file,
- proxies=None,
- resume_size=0,
- user_agent=None,
-):
- ua = "python/{}".format(sys.version.split()[0])
- if _torch_available:
- ua += "; torch/{}".format(torch.__version__)
- if isinstance(user_agent, dict):
- ua += "; " + "; ".join("{}/{}".format(k, v) for k, v in user_agent.items())
- elif isinstance(user_agent, str):
- ua += "; " + user_agent
- headers = {"user-agent": ua}
- if resume_size > 0:
- headers["Range"] = "bytes=%d-" % (resume_size,)
- response = requests.get(url, stream=True, proxies=proxies, headers=headers)
- if response.status_code == 416: # Range not satisfiable
- return
- content_length = response.headers.get("Content-Length")
- total = resume_size + int(content_length) if content_length is not None else None
- progress = tqdm(
- unit="B",
- unit_scale=True,
- total=total,
- initial=resume_size,
- desc="Downloading",
- )
- for chunk in response.iter_content(chunk_size=1024):
- if chunk: # filter out keep-alive new chunks
- progress.update(len(chunk))
- temp_file.write(chunk)
- progress.close()
-
-
-def get_from_cache(
- url,
- cache_dir=None,
- force_download=False,
- proxies=None,
- etag_timeout=10,
- resume_download=False,
- user_agent=None,
- local_files_only=False,
-):
- if cache_dir is None:
- cache_dir = TRANSFORMERS_CACHE
- if isinstance(cache_dir, Path):
- cache_dir = str(cache_dir)
-
- os.makedirs(cache_dir, exist_ok=True)
-
- etag = None
- if not local_files_only:
- try:
- response = requests.head(url, allow_redirects=True, proxies=proxies, timeout=etag_timeout)
- if response.status_code == 200:
- etag = response.headers.get("ETag")
- except (EnvironmentError, requests.exceptions.Timeout):
- # etag is already None
- pass
-
- filename = url_to_filename(url, etag)
-
- # get cache path to put the file
- cache_path = os.path.join(cache_dir, filename)
-
- # etag is None = we don't have a connection, or url doesn't exist, or is otherwise inaccessible.
- # try to get the last downloaded one
- if etag is None:
- if os.path.exists(cache_path):
- return cache_path
- else:
- matching_files = [
- file
- for file in fnmatch.filter(os.listdir(cache_dir), filename + ".*")
- if not file.endswith(".json") and not file.endswith(".lock")
- ]
- if len(matching_files) > 0:
- return os.path.join(cache_dir, matching_files[-1])
- else:
- # If files cannot be found and local_files_only=True,
- # the models might've been found if local_files_only=False
- # Notify the user about that
- if local_files_only:
- raise ValueError(
- "Cannot find the requested files in the cached path and outgoing traffic has been"
- " disabled. To enable model look-ups and downloads online, set 'local_files_only'"
- " to False."
- )
- return None
-
- # From now on, etag is not None.
- if os.path.exists(cache_path) and not force_download:
- return cache_path
-
- # Prevent parallel downloads of the same file with a lock.
- lock_path = cache_path + ".lock"
- with FileLock(lock_path):
- # If the download just completed while the lock was activated.
- if os.path.exists(cache_path) and not force_download:
- # Even if returning early like here, the lock will be released.
- return cache_path
-
- if resume_download:
- incomplete_path = cache_path + ".incomplete"
-
- @contextmanager
- def _resumable_file_manager():
- with open(incomplete_path, "a+b") as f:
- yield f
-
- temp_file_manager = _resumable_file_manager
- if os.path.exists(incomplete_path):
- resume_size = os.stat(incomplete_path).st_size
- else:
- resume_size = 0
- else:
- temp_file_manager = partial(tempfile.NamedTemporaryFile, dir=cache_dir, delete=False)
- resume_size = 0
-
- # Download to temporary file, then copy to cache dir once finished.
- # Otherwise you get corrupt cache entries if the download gets interrupted.
- with temp_file_manager() as temp_file:
- print(
- "%s not found in cache or force_download set to True, downloading to %s",
- url,
- temp_file.name,
- )
-
- http_get(
- url,
- temp_file,
- proxies=proxies,
- resume_size=resume_size,
- user_agent=user_agent,
- )
-
- os.replace(temp_file.name, cache_path)
-
- meta = {"url": url, "etag": etag}
- meta_path = cache_path + ".json"
- with open(meta_path, "w") as meta_file:
- json.dump(meta, meta_file)
-
- return cache_path
-
-
-def url_to_filename(url, etag=None):
- url_bytes = url.encode("utf-8")
- url_hash = insecure_hashlib.sha256(url_bytes)
- filename = url_hash.hexdigest()
-
- if etag:
- etag_bytes = etag.encode("utf-8")
- etag_hash = insecure_hashlib.sha256(etag_bytes)
- filename += "." + etag_hash.hexdigest()
-
- if url.endswith(".h5"):
- filename += ".h5"
-
- return filename
-
-
-def cached_path(
- url_or_filename,
- cache_dir=None,
- force_download=False,
- proxies=None,
- resume_download=False,
- user_agent=None,
- extract_compressed_file=False,
- force_extract=False,
- local_files_only=False,
-):
- if cache_dir is None:
- cache_dir = TRANSFORMERS_CACHE
- if isinstance(url_or_filename, Path):
- url_or_filename = str(url_or_filename)
- if isinstance(cache_dir, Path):
- cache_dir = str(cache_dir)
-
- if is_remote_url(url_or_filename):
- # URL, so get it from the cache (downloading if necessary)
- output_path = get_from_cache(
- url_or_filename,
- cache_dir=cache_dir,
- force_download=force_download,
- proxies=proxies,
- resume_download=resume_download,
- user_agent=user_agent,
- local_files_only=local_files_only,
- )
- elif os.path.exists(url_or_filename):
- # File, and it exists.
- output_path = url_or_filename
- elif urlparse(url_or_filename).scheme == "":
- # File, but it doesn't exist.
- raise EnvironmentError("file {} not found".format(url_or_filename))
- else:
- # Something unknown
- raise ValueError("unable to parse {} as a URL or as a local path".format(url_or_filename))
-
- if extract_compressed_file:
- if not is_zipfile(output_path) and not tarfile.is_tarfile(output_path):
- return output_path
-
- # Path where we extract compressed archives
- # We avoid '.' in dir name and add "-extracted" at the end: "./model.zip" => "./model-zip-extracted/"
- output_dir, output_file = os.path.split(output_path)
- output_extract_dir_name = output_file.replace(".", "-") + "-extracted"
- output_path_extracted = os.path.join(output_dir, output_extract_dir_name)
-
- if os.path.isdir(output_path_extracted) and os.listdir(output_path_extracted) and not force_extract:
- return output_path_extracted
-
- # Prevent parallel extractions
- lock_path = output_path + ".lock"
- with FileLock(lock_path):
- shutil.rmtree(output_path_extracted, ignore_errors=True)
- os.makedirs(output_path_extracted)
- if is_zipfile(output_path):
- with ZipFile(output_path, "r") as zip_file:
- zip_file.extractall(output_path_extracted)
- zip_file.close()
- elif tarfile.is_tarfile(output_path):
- tar_file = tarfile.open(output_path)
- tar_file.extractall(output_path_extracted)
- tar_file.close()
- else:
- raise EnvironmentError("Archive format of {} could not be identified".format(output_path))
-
- return output_path_extracted
-
- return output_path
-
-
-def get_data(query, delim=","):
- assert isinstance(query, str)
- if os.path.isfile(query):
- with open(query) as f:
- data = eval(f.read())
- else:
- req = requests.get(query)
- try:
- data = requests.json()
- except Exception:
- data = req.content.decode()
- assert data is not None, "could not connect"
- try:
- data = eval(data)
- except Exception:
- data = data.split("\n")
- req.close()
- return data
-
-
-def get_image_from_url(url):
- response = requests.get(url)
- img = np.array(Image.open(BytesIO(response.content)))
- return img
-
-
-# to load legacy frcnn checkpoint from detectron
-def load_frcnn_pkl_from_url(url):
- fn = url.split("/")[-1]
- if fn not in os.listdir(os.getcwd()):
- wget.download(url)
- with open(fn, "rb") as stream:
- weights = pkl.load(stream)
- model = weights.pop("model")
- new = {}
- for k, v in model.items():
- new[k] = torch.from_numpy(v)
- if "running_var" in k:
- zero = torch.tensor([0])
- k2 = k.replace("running_var", "num_batches_tracked")
- new[k2] = zero
- return new
-
-
-def get_demo_path():
- print(f"{os.path.abspath(os.path.join(PATH, os.pardir))}/demo.ipynb")
-
-
-def img_tensorize(im, input_format="RGB"):
- assert isinstance(im, str)
- if os.path.isfile(im):
- img = cv2.imread(im)
- else:
- img = get_image_from_url(im)
- assert img is not None, f"could not connect to: {im}"
- img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
- if input_format == "RGB":
- img = img[:, :, ::-1]
- return img
-
-
-def chunk(images, batch=1):
- return (images[i : i + batch] for i in range(0, len(images), batch))
diff --git a/examples/research_projects/lxmert/visualizing_image.py b/examples/research_projects/lxmert/visualizing_image.py
deleted file mode 100644
index dcfd8426ff4..00000000000
--- a/examples/research_projects/lxmert/visualizing_image.py
+++ /dev/null
@@ -1,500 +0,0 @@
-"""
-coding=utf-8
-Copyright 2018, Antonio Mendoza Hao Tan, Mohit Bansal
-Adapted From Facebook Inc, Detectron2
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.import copy
-"""
-
-import colorsys
-import io
-
-import cv2
-import matplotlib as mpl
-import matplotlib.colors as mplc
-import matplotlib.figure as mplfigure
-import numpy as np
-import torch
-from matplotlib.backends.backend_agg import FigureCanvasAgg
-
-from utils import img_tensorize
-
-
-_SMALL_OBJ = 1000
-
-
-class SingleImageViz:
- def __init__(
- self,
- img,
- scale=1.2,
- edgecolor="g",
- alpha=0.5,
- linestyle="-",
- saveas="test_out.jpg",
- rgb=True,
- pynb=False,
- id2obj=None,
- id2attr=None,
- pad=0.7,
- ):
- """
- img: an RGB image of shape (H, W, 3).
- """
- if isinstance(img, torch.Tensor):
- img = img.numpy().astype("np.uint8")
- if isinstance(img, str):
- img = img_tensorize(img)
- assert isinstance(img, np.ndarray)
-
- width, height = img.shape[1], img.shape[0]
- fig = mplfigure.Figure(frameon=False)
- dpi = fig.get_dpi()
- width_in = (width * scale + 1e-2) / dpi
- height_in = (height * scale + 1e-2) / dpi
- fig.set_size_inches(width_in, height_in)
- ax = fig.add_axes([0.0, 0.0, 1.0, 1.0])
- ax.axis("off")
- ax.set_xlim(0.0, width)
- ax.set_ylim(height)
-
- self.saveas = saveas
- self.rgb = rgb
- self.pynb = pynb
- self.img = img
- self.edgecolor = edgecolor
- self.alpha = 0.5
- self.linestyle = linestyle
- self.font_size = int(np.sqrt(min(height, width)) * scale // 3)
- self.width = width
- self.height = height
- self.scale = scale
- self.fig = fig
- self.ax = ax
- self.pad = pad
- self.id2obj = id2obj
- self.id2attr = id2attr
- self.canvas = FigureCanvasAgg(fig)
-
- def add_box(self, box, color=None):
- if color is None:
- color = self.edgecolor
- (x0, y0, x1, y1) = box
- width = x1 - x0
- height = y1 - y0
- self.ax.add_patch(
- mpl.patches.Rectangle(
- (x0, y0),
- width,
- height,
- fill=False,
- edgecolor=color,
- linewidth=self.font_size // 3,
- alpha=self.alpha,
- linestyle=self.linestyle,
- )
- )
-
- def draw_boxes(self, boxes, obj_ids=None, obj_scores=None, attr_ids=None, attr_scores=None):
- if len(boxes.shape) > 2:
- boxes = boxes[0]
- if len(obj_ids.shape) > 1:
- obj_ids = obj_ids[0]
- if len(obj_scores.shape) > 1:
- obj_scores = obj_scores[0]
- if len(attr_ids.shape) > 1:
- attr_ids = attr_ids[0]
- if len(attr_scores.shape) > 1:
- attr_scores = attr_scores[0]
- if isinstance(boxes, torch.Tensor):
- boxes = boxes.numpy()
- if isinstance(boxes, list):
- boxes = np.array(boxes)
- assert isinstance(boxes, np.ndarray)
- areas = np.prod(boxes[:, 2:] - boxes[:, :2], axis=1)
- sorted_idxs = np.argsort(-areas).tolist()
- boxes = boxes[sorted_idxs] if boxes is not None else None
- obj_ids = obj_ids[sorted_idxs] if obj_ids is not None else None
- obj_scores = obj_scores[sorted_idxs] if obj_scores is not None else None
- attr_ids = attr_ids[sorted_idxs] if attr_ids is not None else None
- attr_scores = attr_scores[sorted_idxs] if attr_scores is not None else None
-
- assigned_colors = [self._random_color(maximum=1) for _ in range(len(boxes))]
- assigned_colors = [assigned_colors[idx] for idx in sorted_idxs]
- if obj_ids is not None:
- labels = self._create_text_labels_attr(obj_ids, obj_scores, attr_ids, attr_scores)
- for i in range(len(boxes)):
- color = assigned_colors[i]
- self.add_box(boxes[i], color)
- self.draw_labels(labels[i], boxes[i], color)
-
- def draw_labels(self, label, box, color):
- x0, y0, x1, y1 = box
- text_pos = (x0, y0)
- instance_area = (y1 - y0) * (x1 - x0)
- small = _SMALL_OBJ * self.scale
- if instance_area < small or y1 - y0 < 40 * self.scale:
- if y1 >= self.height - 5:
- text_pos = (x1, y0)
- else:
- text_pos = (x0, y1)
-
- height_ratio = (y1 - y0) / np.sqrt(self.height * self.width)
- lighter_color = self._change_color_brightness(color, brightness_factor=0.7)
- font_size = np.clip((height_ratio - 0.02) / 0.08 + 1, 1.2, 2)
- font_size *= 0.75 * self.font_size
-
- self.draw_text(
- text=label,
- position=text_pos,
- color=lighter_color,
- )
-
- def draw_text(
- self,
- text,
- position,
- color="g",
- ha="left",
- ):
- rotation = 0
- font_size = self.font_size
- color = np.maximum(list(mplc.to_rgb(color)), 0.2)
- color[np.argmax(color)] = max(0.8, np.max(color))
- bbox = {
- "facecolor": "black",
- "alpha": self.alpha,
- "pad": self.pad,
- "edgecolor": "none",
- }
- x, y = position
- self.ax.text(
- x,
- y,
- text,
- size=font_size * self.scale,
- family="sans-serif",
- bbox=bbox,
- verticalalignment="top",
- horizontalalignment=ha,
- color=color,
- zorder=10,
- rotation=rotation,
- )
-
- def save(self, saveas=None):
- if saveas is None:
- saveas = self.saveas
- if saveas.lower().endswith(".jpg") or saveas.lower().endswith(".png"):
- cv2.imwrite(
- saveas,
- self._get_buffer()[:, :, ::-1],
- )
- else:
- self.fig.savefig(saveas)
-
- def _create_text_labels_attr(self, classes, scores, attr_classes, attr_scores):
- labels = [self.id2obj[i] for i in classes]
- attr_labels = [self.id2attr[i] for i in attr_classes]
- labels = [
- f"{label} {score:.2f} {attr} {attr_score:.2f}"
- for label, score, attr, attr_score in zip(labels, scores, attr_labels, attr_scores)
- ]
- return labels
-
- def _create_text_labels(self, classes, scores):
- labels = [self.id2obj[i] for i in classes]
- if scores is not None:
- if labels is None:
- labels = ["{:.0f}%".format(s * 100) for s in scores]
- else:
- labels = ["{} {:.0f}%".format(li, s * 100) for li, s in zip(labels, scores)]
- return labels
-
- def _random_color(self, maximum=255):
- idx = np.random.randint(0, len(_COLORS))
- ret = _COLORS[idx] * maximum
- if not self.rgb:
- ret = ret[::-1]
- return ret
-
- def _get_buffer(self):
- if not self.pynb:
- s, (width, height) = self.canvas.print_to_buffer()
- if (width, height) != (self.width, self.height):
- img = cv2.resize(self.img, (width, height))
- else:
- img = self.img
- else:
- buf = io.BytesIO() # works for cairo backend
- self.canvas.print_rgba(buf)
- width, height = self.width, self.height
- s = buf.getvalue()
- img = self.img
-
- buffer = np.frombuffer(s, dtype="uint8")
- img_rgba = buffer.reshape(height, width, 4)
- rgb, alpha = np.split(img_rgba, [3], axis=2)
-
- try:
- import numexpr as ne # fuse them with numexpr
-
- visualized_image = ne.evaluate("img * (1 - alpha / 255.0) + rgb * (alpha / 255.0)")
- except ImportError:
- alpha = alpha.astype("float32") / 255.0
- visualized_image = img * (1 - alpha) + rgb * alpha
-
- return visualized_image.astype("uint8")
-
- def _change_color_brightness(self, color, brightness_factor):
- assert brightness_factor >= -1.0 and brightness_factor <= 1.0
- color = mplc.to_rgb(color)
- polygon_color = colorsys.rgb_to_hls(*mplc.to_rgb(color))
- modified_lightness = polygon_color[1] + (brightness_factor * polygon_color[1])
- modified_lightness = 0.0 if modified_lightness < 0.0 else modified_lightness
- modified_lightness = 1.0 if modified_lightness > 1.0 else modified_lightness
- modified_color = colorsys.hls_to_rgb(polygon_color[0], modified_lightness, polygon_color[2])
- return modified_color
-
-
-# Color map
-_COLORS = (
- np.array(
- [
- 0.000,
- 0.447,
- 0.741,
- 0.850,
- 0.325,
- 0.098,
- 0.929,
- 0.694,
- 0.125,
- 0.494,
- 0.184,
- 0.556,
- 0.466,
- 0.674,
- 0.188,
- 0.301,
- 0.745,
- 0.933,
- 0.635,
- 0.078,
- 0.184,
- 0.300,
- 0.300,
- 0.300,
- 0.600,
- 0.600,
- 0.600,
- 1.000,
- 0.000,
- 0.000,
- 1.000,
- 0.500,
- 0.000,
- 0.749,
- 0.749,
- 0.000,
- 0.000,
- 1.000,
- 0.000,
- 0.000,
- 0.000,
- 1.000,
- 0.667,
- 0.000,
- 1.000,
- 0.333,
- 0.333,
- 0.000,
- 0.333,
- 0.667,
- 0.000,
- 0.333,
- 1.000,
- 0.000,
- 0.667,
- 0.333,
- 0.000,
- 0.667,
- 0.667,
- 0.000,
- 0.667,
- 1.000,
- 0.000,
- 1.000,
- 0.333,
- 0.000,
- 1.000,
- 0.667,
- 0.000,
- 1.000,
- 1.000,
- 0.000,
- 0.000,
- 0.333,
- 0.500,
- 0.000,
- 0.667,
- 0.500,
- 0.000,
- 1.000,
- 0.500,
- 0.333,
- 0.000,
- 0.500,
- 0.333,
- 0.333,
- 0.500,
- 0.333,
- 0.667,
- 0.500,
- 0.333,
- 1.000,
- 0.500,
- 0.667,
- 0.000,
- 0.500,
- 0.667,
- 0.333,
- 0.500,
- 0.667,
- 0.667,
- 0.500,
- 0.667,
- 1.000,
- 0.500,
- 1.000,
- 0.000,
- 0.500,
- 1.000,
- 0.333,
- 0.500,
- 1.000,
- 0.667,
- 0.500,
- 1.000,
- 1.000,
- 0.500,
- 0.000,
- 0.333,
- 1.000,
- 0.000,
- 0.667,
- 1.000,
- 0.000,
- 1.000,
- 1.000,
- 0.333,
- 0.000,
- 1.000,
- 0.333,
- 0.333,
- 1.000,
- 0.333,
- 0.667,
- 1.000,
- 0.333,
- 1.000,
- 1.000,
- 0.667,
- 0.000,
- 1.000,
- 0.667,
- 0.333,
- 1.000,
- 0.667,
- 0.667,
- 1.000,
- 0.667,
- 1.000,
- 1.000,
- 1.000,
- 0.000,
- 1.000,
- 1.000,
- 0.333,
- 1.000,
- 1.000,
- 0.667,
- 1.000,
- 0.333,
- 0.000,
- 0.000,
- 0.500,
- 0.000,
- 0.000,
- 0.667,
- 0.000,
- 0.000,
- 0.833,
- 0.000,
- 0.000,
- 1.000,
- 0.000,
- 0.000,
- 0.000,
- 0.167,
- 0.000,
- 0.000,
- 0.333,
- 0.000,
- 0.000,
- 0.500,
- 0.000,
- 0.000,
- 0.667,
- 0.000,
- 0.000,
- 0.833,
- 0.000,
- 0.000,
- 1.000,
- 0.000,
- 0.000,
- 0.000,
- 0.167,
- 0.000,
- 0.000,
- 0.333,
- 0.000,
- 0.000,
- 0.500,
- 0.000,
- 0.000,
- 0.667,
- 0.000,
- 0.000,
- 0.833,
- 0.000,
- 0.000,
- 1.000,
- 0.000,
- 0.000,
- 0.000,
- 0.143,
- 0.143,
- 0.143,
- 0.857,
- 0.857,
- 0.857,
- 1.000,
- 1.000,
- 1.000,
- ]
- )
- .astype(np.float32)
- .reshape(-1, 3)
-)
diff --git a/examples/research_projects/mlm_wwm/README.md b/examples/research_projects/mlm_wwm/README.md
deleted file mode 100644
index bf5aa941082..00000000000
--- a/examples/research_projects/mlm_wwm/README.md
+++ /dev/null
@@ -1,98 +0,0 @@
-
-
-## Whole Word Mask Language Model
-
-
-These scripts leverage the 🤗 Datasets library and the Trainer API. You can easily customize them to your needs if you
-need extra processing on your datasets.
-
-The following examples, will run on a datasets hosted on our [hub](https://huggingface.co/datasets) or with your own
-text files for training and validation. We give examples of both below.
-
-
-
-The BERT authors released a new version of BERT using Whole Word Masking in May 2019. Instead of masking randomly
-selected tokens (which may be part of words), they mask randomly selected words (masking all the tokens corresponding
-to that word). This technique has been refined for Chinese in [this paper](https://arxiv.org/abs/1906.08101).
-
-To fine-tune a model using whole word masking, use the following script:
-```bash
-python run_mlm_wwm.py \
- --model_name_or_path FacebookAI/roberta-base \
- --dataset_name wikitext \
- --dataset_config_name wikitext-2-raw-v1 \
- --do_train \
- --do_eval \
- --output_dir /tmp/test-mlm-wwm
-```
-
-For Chinese models, we need to generate a reference files (which requires the ltp library), because it's tokenized at
-the character level.
-
-**Q :** Why a reference file?
-
-**A :** Suppose we have a Chinese sentence like: `我喜欢你` The original Chinese-BERT will tokenize it as
-`['我','喜','欢','你']` (character level). But `喜欢` is a whole word. For whole word masking proxy, we need a result
-like `['我','喜','##欢','你']`, so we need a reference file to tell the model which position of the BERT original token
-should be added `##`.
-
-**Q :** Why LTP ?
-
-**A :** Cause the best known Chinese WWM BERT is [Chinese-BERT-wwm](https://github.com/ymcui/Chinese-BERT-wwm) by HIT.
-It works well on so many Chines Task like CLUE (Chinese GLUE). They use LTP, so if we want to fine-tune their model,
-we need LTP.
-
-You could run the following:
-
-
-```bash
-export TRAIN_FILE=/path/to/train/file
-export LTP_RESOURCE=/path/to/ltp/tokenizer
-export BERT_RESOURCE=/path/to/bert/tokenizer
-export SAVE_PATH=/path/to/data/ref.txt
-
-python run_chinese_ref.py \
- --file_name=$TRAIN_FILE \
- --ltp=$LTP_RESOURCE \
- --bert=$BERT_RESOURCE \
- --save_path=$SAVE_PATH
-```
-
-Then you can run the script like this:
-
-
-```bash
-export TRAIN_FILE=/path/to/train/file
-export VALIDATION_FILE=/path/to/validation/file
-export TRAIN_REF_FILE=/path/to/train/chinese_ref/file
-export VALIDATION_REF_FILE=/path/to/validation/chinese_ref/file
-export OUTPUT_DIR=/tmp/test-mlm-wwm
-
-python run_mlm_wwm.py \
- --model_name_or_path FacebookAI/roberta-base \
- --train_file $TRAIN_FILE \
- --validation_file $VALIDATION_FILE \
- --train_ref_file $TRAIN_REF_FILE \
- --validation_ref_file $VALIDATION_REF_FILE \
- --do_train \
- --do_eval \
- --output_dir $OUTPUT_DIR
-```
-
-**Note1:** On TPU, you should the flag `--pad_to_max_length` to make sure all your batches have the same length.
-
-**Note2:** And if you have any questions or something goes wrong when running this code, don't hesitate to pin @wlhgtc.
diff --git a/examples/research_projects/mlm_wwm/requirements.txt b/examples/research_projects/mlm_wwm/requirements.txt
deleted file mode 100644
index 2d0f26bd4dc..00000000000
--- a/examples/research_projects/mlm_wwm/requirements.txt
+++ /dev/null
@@ -1,4 +0,0 @@
-datasets >= 1.1.3
-sentencepiece != 0.1.92
-protobuf
-ltp
diff --git a/examples/research_projects/mlm_wwm/run_chinese_ref.py b/examples/research_projects/mlm_wwm/run_chinese_ref.py
deleted file mode 100644
index eca89df9798..00000000000
--- a/examples/research_projects/mlm_wwm/run_chinese_ref.py
+++ /dev/null
@@ -1,164 +0,0 @@
-import argparse
-import json
-from typing import List
-
-from ltp import LTP
-
-from transformers.models.bert.tokenization_bert import BertTokenizer
-
-
-def _is_chinese_char(cp):
- """Checks whether CP is the codepoint of a CJK character."""
- # This defines a "chinese character" as anything in the CJK Unicode block:
- # https://en.wikipedia.org/wiki/CJK_Unified_Ideographs_(Unicode_block)
- #
- # Note that the CJK Unicode block is NOT all Japanese and Korean characters,
- # despite its name. The modern Korean Hangul alphabet is a different block,
- # as is Japanese Hiragana and Katakana. Those alphabets are used to write
- # space-separated words, so they are not treated specially and handled
- # like the all of the other languages.
- if (
- (cp >= 0x4E00 and cp <= 0x9FFF)
- or (cp >= 0x3400 and cp <= 0x4DBF) #
- or (cp >= 0x20000 and cp <= 0x2A6DF) #
- or (cp >= 0x2A700 and cp <= 0x2B73F) #
- or (cp >= 0x2B740 and cp <= 0x2B81F) #
- or (cp >= 0x2B820 and cp <= 0x2CEAF) #
- or (cp >= 0xF900 and cp <= 0xFAFF)
- or (cp >= 0x2F800 and cp <= 0x2FA1F) #
- ): #
- return True
-
- return False
-
-
-def is_chinese(word: str):
- # word like '180' or '身高' or '神'
- for char in word:
- char = ord(char)
- if not _is_chinese_char(char):
- return 0
- return 1
-
-
-def get_chinese_word(tokens: List[str]):
- word_set = set()
-
- for token in tokens:
- chinese_word = len(token) > 1 and is_chinese(token)
- if chinese_word:
- word_set.add(token)
- word_list = list(word_set)
- return word_list
-
-
-def add_sub_symbol(bert_tokens: List[str], chinese_word_set: set()):
- if not chinese_word_set:
- return bert_tokens
- max_word_len = max([len(w) for w in chinese_word_set])
-
- bert_word = bert_tokens
- start, end = 0, len(bert_word)
- while start < end:
- single_word = True
- if is_chinese(bert_word[start]):
- l = min(end - start, max_word_len)
- for i in range(l, 1, -1):
- whole_word = "".join(bert_word[start : start + i])
- if whole_word in chinese_word_set:
- for j in range(start + 1, start + i):
- bert_word[j] = "##" + bert_word[j]
- start = start + i
- single_word = False
- break
- if single_word:
- start += 1
- return bert_word
-
-
-def prepare_ref(lines: List[str], ltp_tokenizer: LTP, bert_tokenizer: BertTokenizer):
- ltp_res = []
-
- for i in range(0, len(lines), 100):
- res = ltp_tokenizer.pipeline(lines[i : i + 100], tasks=["cws"]).cws
- res = [get_chinese_word(r) for r in res]
- ltp_res.extend(res)
- assert len(ltp_res) == len(lines)
-
- bert_res = []
- for i in range(0, len(lines), 100):
- res = bert_tokenizer(lines[i : i + 100], add_special_tokens=True, truncation=True, max_length=512)
- bert_res.extend(res["input_ids"])
- assert len(bert_res) == len(lines)
-
- ref_ids = []
- for input_ids, chinese_word in zip(bert_res, ltp_res):
- input_tokens = []
- for id in input_ids:
- token = bert_tokenizer._convert_id_to_token(id)
- input_tokens.append(token)
- input_tokens = add_sub_symbol(input_tokens, chinese_word)
- ref_id = []
- # We only save pos of chinese subwords start with ##, which mean is part of a whole word.
- for i, token in enumerate(input_tokens):
- if token[:2] == "##":
- clean_token = token[2:]
- # save chinese tokens' pos
- if len(clean_token) == 1 and _is_chinese_char(ord(clean_token)):
- ref_id.append(i)
- ref_ids.append(ref_id)
-
- assert len(ref_ids) == len(bert_res)
-
- return ref_ids
-
-
-def main(args):
- # For Chinese (Ro)Bert, the best result is from : RoBERTa-wwm-ext (https://github.com/ymcui/Chinese-BERT-wwm)
- # If we want to fine-tune these model, we have to use same tokenizer : LTP (https://github.com/HIT-SCIR/ltp)
- with open(args.file_name, "r", encoding="utf-8") as f:
- data = f.readlines()
- data = [line.strip() for line in data if len(line) > 0 and not line.isspace()] # avoid delimiter like '\u2029'
- ltp_tokenizer = LTP(args.ltp) # faster in GPU device
- bert_tokenizer = BertTokenizer.from_pretrained(args.bert)
-
- ref_ids = prepare_ref(data, ltp_tokenizer, bert_tokenizer)
-
- with open(args.save_path, "w", encoding="utf-8") as f:
- data = [json.dumps(ref) + "\n" for ref in ref_ids]
- f.writelines(data)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser(description="prepare_chinese_ref")
- parser.add_argument(
- "--file_name",
- required=False,
- type=str,
- default="./resources/chinese-demo.txt",
- help="file need process, same as training data in lm",
- )
- parser.add_argument(
- "--ltp",
- required=False,
- type=str,
- default="./resources/ltp",
- help="resources for LTP tokenizer, usually a path",
- )
- parser.add_argument(
- "--bert",
- required=False,
- type=str,
- default="./resources/robert",
- help="resources for Bert tokenizer",
- )
- parser.add_argument(
- "--save_path",
- required=False,
- type=str,
- default="./resources/ref.txt",
- help="path to save res",
- )
-
- args = parser.parse_args()
- main(args)
diff --git a/examples/research_projects/mlm_wwm/run_mlm_wwm.py b/examples/research_projects/mlm_wwm/run_mlm_wwm.py
deleted file mode 100644
index 629026bdb20..00000000000
--- a/examples/research_projects/mlm_wwm/run_mlm_wwm.py
+++ /dev/null
@@ -1,435 +0,0 @@
-# coding=utf-8
-# Copyright 2020 The HuggingFace Team All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-Fine-tuning the library models for masked language modeling (BERT, ALBERT, RoBERTa...) with whole word masking on a
-text file or a dataset.
-
-Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
-https://huggingface.co/models?filter=fill-mask
-"""
-# You can also adapt this script on your own masked language modeling task. Pointers for this are left as comments.
-
-import json
-import logging
-import math
-import os
-import sys
-from dataclasses import dataclass, field
-from typing import Optional
-
-from datasets import Dataset, load_dataset
-
-import transformers
-from transformers import (
- CONFIG_MAPPING,
- MODEL_FOR_MASKED_LM_MAPPING,
- AutoConfig,
- AutoModelForMaskedLM,
- AutoTokenizer,
- DataCollatorForWholeWordMask,
- HfArgumentParser,
- Trainer,
- TrainingArguments,
- set_seed,
-)
-from transformers.trainer_utils import get_last_checkpoint, is_main_process
-
-
-logger = logging.getLogger(__name__)
-MODEL_CONFIG_CLASSES = list(MODEL_FOR_MASKED_LM_MAPPING.keys())
-MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
-
-
-@dataclass
-class ModelArguments:
- """
- Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
- """
-
- model_name_or_path: Optional[str] = field(
- default=None,
- metadata={
- "help": (
- "The model checkpoint for weights initialization. Don't set if you want to train a model from scratch."
- )
- },
- )
- model_type: Optional[str] = field(
- default=None,
- metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
- )
- config_overrides: Optional[str] = field(
- default=None,
- metadata={
- "help": (
- "Override some existing default config settings when a model is trained from scratch. Example: "
- "n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
- )
- },
- )
- config_name: Optional[str] = field(
- default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
- )
- tokenizer_name: Optional[str] = field(
- default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
- )
- cache_dir: Optional[str] = field(
- default=None,
- metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
- )
- use_fast_tokenizer: bool = field(
- default=True,
- metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
- )
- model_revision: str = field(
- default="main",
- metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
- )
- use_auth_token: bool = field(
- default=False,
- metadata={
- "help": (
- "Will use the token generated when running `huggingface-cli login` (necessary to use this script "
- "with private models)."
- )
- },
- )
-
- def __post_init__(self):
- if self.config_overrides is not None and (self.config_name is not None or self.model_name_or_path is not None):
- raise ValueError(
- "--config_overrides can't be used in combination with --config_name or --model_name_or_path"
- )
-
-
-@dataclass
-class DataTrainingArguments:
- """
- Arguments pertaining to what data we are going to input our model for training and eval.
- """
-
- dataset_name: Optional[str] = field(
- default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
- )
- dataset_config_name: Optional[str] = field(
- default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
- )
- train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
- validation_file: Optional[str] = field(
- default=None,
- metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
- )
- train_ref_file: Optional[str] = field(
- default=None,
- metadata={"help": "An optional input train ref data file for whole word masking in Chinese."},
- )
- validation_ref_file: Optional[str] = field(
- default=None,
- metadata={"help": "An optional input validation ref data file for whole word masking in Chinese."},
- )
- overwrite_cache: bool = field(
- default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
- )
- validation_split_percentage: Optional[int] = field(
- default=5,
- metadata={
- "help": "The percentage of the train set used as validation set in case there's no validation split"
- },
- )
- max_seq_length: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated. Default to the max input length of the model."
- )
- },
- )
- preprocessing_num_workers: Optional[int] = field(
- default=None,
- metadata={"help": "The number of processes to use for the preprocessing."},
- )
- mlm_probability: float = field(
- default=0.15, metadata={"help": "Ratio of tokens to mask for masked language modeling loss"}
- )
- pad_to_max_length: bool = field(
- default=False,
- metadata={
- "help": (
- "Whether to pad all samples to `max_seq_length`. "
- "If False, will pad the samples dynamically when batching to the maximum length in the batch."
- )
- },
- )
-
- def __post_init__(self):
- if self.train_file is not None:
- extension = self.train_file.split(".")[-1]
- assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, a json or a txt file."
- if self.validation_file is not None:
- extension = self.validation_file.split(".")[-1]
- assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, a json or a txt file."
-
-
-def add_chinese_references(dataset, ref_file):
- with open(ref_file, "r", encoding="utf-8") as f:
- refs = [json.loads(line) for line in f.read().splitlines() if (len(line) > 0 and not line.isspace())]
- assert len(dataset) == len(refs)
-
- dataset_dict = {c: dataset[c] for c in dataset.column_names}
- dataset_dict["chinese_ref"] = refs
- return Dataset.from_dict(dataset_dict)
-
-
-def main():
- # See all possible arguments in src/transformers/training_args.py
- # or by passing the --help flag to this script.
- # We now keep distinct sets of args, for a cleaner separation of concerns.
-
- parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
- if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
- # If we pass only one argument to the script and it's the path to a json file,
- # let's parse it to get our arguments.
- model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
- else:
- model_args, data_args, training_args = parser.parse_args_into_dataclasses()
-
- # Detecting last checkpoint.
- last_checkpoint = None
- if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
- last_checkpoint = get_last_checkpoint(training_args.output_dir)
- if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
- raise ValueError(
- f"Output directory ({training_args.output_dir}) already exists and is not empty. "
- "Use --overwrite_output_dir to overcome."
- )
- elif last_checkpoint is not None:
- logger.info(
- f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
- "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
- )
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- handlers=[logging.StreamHandler(sys.stdout)],
- )
- logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
-
- # Log on each process the small summary:
- logger.warning(
- f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
- + f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
- )
- # Set the verbosity to info of the Transformers logger (on main process only):
- if is_main_process(training_args.local_rank):
- transformers.utils.logging.set_verbosity_info()
- transformers.utils.logging.enable_default_handler()
- transformers.utils.logging.enable_explicit_format()
- logger.info("Training/evaluation parameters %s", training_args)
-
- # Set seed before initializing model.
- set_seed(training_args.seed)
-
- # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
- # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
- # (the dataset will be downloaded automatically from the datasets Hub).
- #
- # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
- # 'text' is found. You can easily tweak this behavior (see below).
- #
- # In distributed training, the load_dataset function guarantee that only one local process can concurrently
- # download the dataset.
- if data_args.dataset_name is not None:
- # Downloading and loading a dataset from the hub.
- datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name)
- if "validation" not in datasets.keys():
- datasets["validation"] = load_dataset(
- data_args.dataset_name,
- data_args.dataset_config_name,
- split=f"train[:{data_args.validation_split_percentage}%]",
- )
- datasets["train"] = load_dataset(
- data_args.dataset_name,
- data_args.dataset_config_name,
- split=f"train[{data_args.validation_split_percentage}%:]",
- )
- else:
- data_files = {}
- if data_args.train_file is not None:
- data_files["train"] = data_args.train_file
- extension = data_args.train_file.split(".")[-1]
- if data_args.validation_file is not None:
- data_files["validation"] = data_args.validation_file
- extension = data_args.validation_file.split(".")[-1]
- if extension == "txt":
- extension = "text"
- datasets = load_dataset(extension, data_files=data_files)
- # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
- # https://huggingface.co/docs/datasets/loading_datasets.
-
- # Load pretrained model and tokenizer
- #
- # Distributed training:
- # The .from_pretrained methods guarantee that only one local process can concurrently
- # download model & vocab.
- config_kwargs = {
- "cache_dir": model_args.cache_dir,
- "revision": model_args.model_revision,
- "use_auth_token": True if model_args.use_auth_token else None,
- }
- if model_args.config_name:
- config = AutoConfig.from_pretrained(model_args.config_name, **config_kwargs)
- elif model_args.model_name_or_path:
- config = AutoConfig.from_pretrained(model_args.model_name_or_path, **config_kwargs)
- else:
- config = CONFIG_MAPPING[model_args.model_type]()
- logger.warning("You are instantiating a new config instance from scratch.")
- if model_args.config_overrides is not None:
- logger.info(f"Overriding config: {model_args.config_overrides}")
- config.update_from_string(model_args.config_overrides)
- logger.info(f"New config: {config}")
-
- tokenizer_kwargs = {
- "cache_dir": model_args.cache_dir,
- "use_fast": model_args.use_fast_tokenizer,
- "revision": model_args.model_revision,
- "use_auth_token": True if model_args.use_auth_token else None,
- }
- if model_args.tokenizer_name:
- tokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name, **tokenizer_kwargs)
- elif model_args.model_name_or_path:
- tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, **tokenizer_kwargs)
- else:
- raise ValueError(
- "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
- "You can do it from another script, save it, and load it from here, using --tokenizer_name."
- )
-
- if model_args.model_name_or_path:
- model = AutoModelForMaskedLM.from_pretrained(
- model_args.model_name_or_path,
- from_tf=bool(".ckpt" in model_args.model_name_or_path),
- config=config,
- cache_dir=model_args.cache_dir,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- )
- else:
- logger.info("Training new model from scratch")
- model = AutoModelForMaskedLM.from_config(config)
-
- model.resize_token_embeddings(len(tokenizer))
-
- # Preprocessing the datasets.
- # First we tokenize all the texts.
- if training_args.do_train:
- column_names = datasets["train"].column_names
- else:
- column_names = datasets["validation"].column_names
- text_column_name = "text" if "text" in column_names else column_names[0]
-
- padding = "max_length" if data_args.pad_to_max_length else False
-
- def tokenize_function(examples):
- # Remove empty lines
- examples["text"] = [line for line in examples["text"] if len(line) > 0 and not line.isspace()]
- return tokenizer(examples["text"], padding=padding, truncation=True, max_length=data_args.max_seq_length)
-
- tokenized_datasets = datasets.map(
- tokenize_function,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- remove_columns=[text_column_name],
- load_from_cache_file=not data_args.overwrite_cache,
- )
-
- # Add the chinese references if provided
- if data_args.train_ref_file is not None:
- tokenized_datasets["train"] = add_chinese_references(tokenized_datasets["train"], data_args.train_ref_file)
- if data_args.validation_ref_file is not None:
- tokenized_datasets["validation"] = add_chinese_references(
- tokenized_datasets["validation"], data_args.validation_ref_file
- )
- # If we have ref files, need to avoid it removed by trainer
- has_ref = data_args.train_ref_file or data_args.validation_ref_file
- if has_ref:
- training_args.remove_unused_columns = False
-
- # Data collator
- # This one will take care of randomly masking the tokens.
- data_collator = DataCollatorForWholeWordMask(tokenizer=tokenizer, mlm_probability=data_args.mlm_probability)
-
- # Initialize our Trainer
- trainer = Trainer(
- model=model,
- args=training_args,
- train_dataset=tokenized_datasets["train"] if training_args.do_train else None,
- eval_dataset=tokenized_datasets["validation"] if training_args.do_eval else None,
- tokenizer=tokenizer,
- data_collator=data_collator,
- )
-
- # Training
- if training_args.do_train:
- if last_checkpoint is not None:
- checkpoint = last_checkpoint
- elif model_args.model_name_or_path is not None and os.path.isdir(model_args.model_name_or_path):
- checkpoint = model_args.model_name_or_path
- else:
- checkpoint = None
- train_result = trainer.train(resume_from_checkpoint=checkpoint)
- trainer.save_model() # Saves the tokenizer too for easy upload
-
- output_train_file = os.path.join(training_args.output_dir, "train_results.txt")
- if trainer.is_world_process_zero():
- with open(output_train_file, "w") as writer:
- logger.info("***** Train results *****")
- for key, value in sorted(train_result.metrics.items()):
- logger.info(f" {key} = {value}")
- writer.write(f"{key} = {value}\n")
-
- # Need to save the state, since Trainer.save_model saves only the tokenizer with the model
- trainer.state.save_to_json(os.path.join(training_args.output_dir, "trainer_state.json"))
-
- # Evaluation
- results = {}
- if training_args.do_eval:
- logger.info("*** Evaluate ***")
-
- eval_output = trainer.evaluate()
-
- perplexity = math.exp(eval_output["eval_loss"])
- results["perplexity"] = perplexity
-
- output_eval_file = os.path.join(training_args.output_dir, "eval_results_mlm_wwm.txt")
- if trainer.is_world_process_zero():
- with open(output_eval_file, "w") as writer:
- logger.info("***** Eval results *****")
- for key, value in sorted(results.items()):
- logger.info(f" {key} = {value}")
- writer.write(f"{key} = {value}\n")
-
- return results
-
-
-def _mp_fn(index):
- # For xla_spawn (TPUs)
- main()
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/mm-imdb/README.md b/examples/research_projects/mm-imdb/README.md
deleted file mode 100644
index 68b2f15159e..00000000000
--- a/examples/research_projects/mm-imdb/README.md
+++ /dev/null
@@ -1,23 +0,0 @@
-## MM-IMDb
-
-Based on the script [`run_mmimdb.py`](https://github.com/huggingface/transformers/blob/main/examples/research_projects/mm-imdb/run_mmimdb.py).
-
-[MM-IMDb](http://lisi1.unal.edu.co/mmimdb/) is a Multimodal dataset with around 26,000 movies including images, plots and other metadata.
-
-### Training on MM-IMDb
-
-```bash
-python run_mmimdb.py \
- --data_dir /path/to/mmimdb/dataset/ \
- --model_type bert \
- --model_name_or_path google-bert/bert-base-uncased \
- --output_dir /path/to/save/dir/ \
- --do_train \
- --do_eval \
- --max_seq_len 512 \
- --gradient_accumulation_steps 20 \
- --num_image_embeds 3 \
- --num_train_epochs 100 \
- --patience 5
-```
-
diff --git a/examples/research_projects/mm-imdb/run_mmimdb.py b/examples/research_projects/mm-imdb/run_mmimdb.py
deleted file mode 100644
index 686691e0b9c..00000000000
--- a/examples/research_projects/mm-imdb/run_mmimdb.py
+++ /dev/null
@@ -1,575 +0,0 @@
-# coding=utf-8
-# Copyright (c) Facebook, Inc. and its affiliates.
-# Copyright (c) HuggingFace Inc. team.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Finetuning the library models for multimodal multiclass prediction on MM-IMDB dataset."""
-
-import argparse
-import glob
-import json
-import logging
-import os
-import random
-
-import numpy as np
-import torch
-from sklearn.metrics import f1_score
-from torch import nn
-from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
-from torch.utils.data.distributed import DistributedSampler
-from tqdm import tqdm, trange
-from utils_mmimdb import ImageEncoder, JsonlDataset, collate_fn, get_image_transforms, get_mmimdb_labels
-
-import transformers
-from transformers import (
- WEIGHTS_NAME,
- AdamW,
- AutoConfig,
- AutoModel,
- AutoTokenizer,
- MMBTConfig,
- MMBTForClassification,
- get_linear_schedule_with_warmup,
-)
-from transformers.trainer_utils import is_main_process
-
-
-try:
- from torch.utils.tensorboard import SummaryWriter
-except ImportError:
- from tensorboardX import SummaryWriter
-
-
-logger = logging.getLogger(__name__)
-
-
-def set_seed(args):
- random.seed(args.seed)
- np.random.seed(args.seed)
- torch.manual_seed(args.seed)
- if args.n_gpu > 0:
- torch.cuda.manual_seed_all(args.seed)
-
-
-def train(args, train_dataset, model, tokenizer, criterion):
- """Train the model"""
- if args.local_rank in [-1, 0]:
- tb_writer = SummaryWriter()
-
- args.train_batch_size = args.per_gpu_train_batch_size * max(1, args.n_gpu)
- train_sampler = RandomSampler(train_dataset) if args.local_rank == -1 else DistributedSampler(train_dataset)
- train_dataloader = DataLoader(
- train_dataset,
- sampler=train_sampler,
- batch_size=args.train_batch_size,
- collate_fn=collate_fn,
- num_workers=args.num_workers,
- )
-
- if args.max_steps > 0:
- t_total = args.max_steps
- args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
- else:
- t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
-
- # Prepare optimizer and schedule (linear warmup and decay)
- no_decay = ["bias", "LayerNorm.weight"]
- optimizer_grouped_parameters = [
- {
- "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
- "weight_decay": args.weight_decay,
- },
- {"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], "weight_decay": 0.0},
- ]
-
- optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
- scheduler = get_linear_schedule_with_warmup(
- optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
- )
- if args.fp16:
- try:
- from apex import amp
- except ImportError:
- raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
- model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
-
- # multi-gpu training (should be after apex fp16 initialization)
- if args.n_gpu > 1:
- model = nn.DataParallel(model)
-
- # Distributed training (should be after apex fp16 initialization)
- if args.local_rank != -1:
- model = nn.parallel.DistributedDataParallel(
- model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True
- )
-
- # Train!
- logger.info("***** Running training *****")
- logger.info(" Num examples = %d", len(train_dataset))
- logger.info(" Num Epochs = %d", args.num_train_epochs)
- logger.info(" Instantaneous batch size per GPU = %d", args.per_gpu_train_batch_size)
- logger.info(
- " Total train batch size (w. parallel, distributed & accumulation) = %d",
- args.train_batch_size
- * args.gradient_accumulation_steps
- * (torch.distributed.get_world_size() if args.local_rank != -1 else 1),
- )
- logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)
- logger.info(" Total optimization steps = %d", t_total)
-
- global_step = 0
- tr_loss, logging_loss = 0.0, 0.0
- best_f1, n_no_improve = 0, 0
- model.zero_grad()
- train_iterator = trange(int(args.num_train_epochs), desc="Epoch", disable=args.local_rank not in [-1, 0])
- set_seed(args) # Added here for reproducibility
- for _ in train_iterator:
- epoch_iterator = tqdm(train_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])
- for step, batch in enumerate(epoch_iterator):
- model.train()
- batch = tuple(t.to(args.device) for t in batch)
- labels = batch[5]
- inputs = {
- "input_ids": batch[0],
- "input_modal": batch[2],
- "attention_mask": batch[1],
- "modal_start_tokens": batch[3],
- "modal_end_tokens": batch[4],
- }
- outputs = model(**inputs)
- logits = outputs[0] # model outputs are always tuple in transformers (see doc)
- loss = criterion(logits, labels)
-
- if args.n_gpu > 1:
- loss = loss.mean() # mean() to average on multi-gpu parallel training
- if args.gradient_accumulation_steps > 1:
- loss = loss / args.gradient_accumulation_steps
-
- if args.fp16:
- with amp.scale_loss(loss, optimizer) as scaled_loss:
- scaled_loss.backward()
- else:
- loss.backward()
-
- tr_loss += loss.item()
- if (step + 1) % args.gradient_accumulation_steps == 0:
- if args.fp16:
- nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
- else:
- nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
-
- optimizer.step()
- scheduler.step() # Update learning rate schedule
- model.zero_grad()
- global_step += 1
-
- if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
- logs = {}
- if (
- args.local_rank == -1 and args.evaluate_during_training
- ): # Only evaluate when single GPU otherwise metrics may not average well
- results = evaluate(args, model, tokenizer, criterion)
- for key, value in results.items():
- eval_key = "eval_{}".format(key)
- logs[eval_key] = value
-
- loss_scalar = (tr_loss - logging_loss) / args.logging_steps
- learning_rate_scalar = scheduler.get_lr()[0]
- logs["learning_rate"] = learning_rate_scalar
- logs["loss"] = loss_scalar
- logging_loss = tr_loss
-
- for key, value in logs.items():
- tb_writer.add_scalar(key, value, global_step)
- print(json.dumps({**logs, **{"step": global_step}}))
-
- if args.local_rank in [-1, 0] and args.save_steps > 0 and global_step % args.save_steps == 0:
- # Save model checkpoint
- output_dir = os.path.join(args.output_dir, "checkpoint-{}".format(global_step))
- if not os.path.exists(output_dir):
- os.makedirs(output_dir)
- model_to_save = (
- model.module if hasattr(model, "module") else model
- ) # Take care of distributed/parallel training
- torch.save(model_to_save.state_dict(), os.path.join(output_dir, WEIGHTS_NAME))
- torch.save(args, os.path.join(output_dir, "training_args.bin"))
- logger.info("Saving model checkpoint to %s", output_dir)
-
- if args.max_steps > 0 and global_step > args.max_steps:
- epoch_iterator.close()
- break
- if args.max_steps > 0 and global_step > args.max_steps:
- train_iterator.close()
- break
-
- if args.local_rank == -1:
- results = evaluate(args, model, tokenizer, criterion)
- if results["micro_f1"] > best_f1:
- best_f1 = results["micro_f1"]
- n_no_improve = 0
- else:
- n_no_improve += 1
-
- if n_no_improve > args.patience:
- train_iterator.close()
- break
-
- if args.local_rank in [-1, 0]:
- tb_writer.close()
-
- return global_step, tr_loss / global_step
-
-
-def evaluate(args, model, tokenizer, criterion, prefix=""):
- # Loop to handle MNLI double evaluation (matched, mis-matched)
- eval_output_dir = args.output_dir
- eval_dataset = load_examples(args, tokenizer, evaluate=True)
-
- if not os.path.exists(eval_output_dir) and args.local_rank in [-1, 0]:
- os.makedirs(eval_output_dir)
-
- args.eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)
- # Note that DistributedSampler samples randomly
- eval_sampler = SequentialSampler(eval_dataset)
- eval_dataloader = DataLoader(
- eval_dataset, sampler=eval_sampler, batch_size=args.eval_batch_size, collate_fn=collate_fn
- )
-
- # multi-gpu eval
- if args.n_gpu > 1 and not isinstance(model, nn.DataParallel):
- model = nn.DataParallel(model)
-
- # Eval!
- logger.info("***** Running evaluation {} *****".format(prefix))
- logger.info(" Num examples = %d", len(eval_dataset))
- logger.info(" Batch size = %d", args.eval_batch_size)
- eval_loss = 0.0
- nb_eval_steps = 0
- preds = None
- out_label_ids = None
- for batch in tqdm(eval_dataloader, desc="Evaluating"):
- model.eval()
- batch = tuple(t.to(args.device) for t in batch)
-
- with torch.no_grad():
- batch = tuple(t.to(args.device) for t in batch)
- labels = batch[5]
- inputs = {
- "input_ids": batch[0],
- "input_modal": batch[2],
- "attention_mask": batch[1],
- "modal_start_tokens": batch[3],
- "modal_end_tokens": batch[4],
- }
- outputs = model(**inputs)
- logits = outputs[0] # model outputs are always tuple in transformers (see doc)
- tmp_eval_loss = criterion(logits, labels)
- eval_loss += tmp_eval_loss.mean().item()
- nb_eval_steps += 1
- if preds is None:
- preds = torch.sigmoid(logits).detach().cpu().numpy() > 0.5
- out_label_ids = labels.detach().cpu().numpy()
- else:
- preds = np.append(preds, torch.sigmoid(logits).detach().cpu().numpy() > 0.5, axis=0)
- out_label_ids = np.append(out_label_ids, labels.detach().cpu().numpy(), axis=0)
-
- eval_loss = eval_loss / nb_eval_steps
- result = {
- "loss": eval_loss,
- "macro_f1": f1_score(out_label_ids, preds, average="macro"),
- "micro_f1": f1_score(out_label_ids, preds, average="micro"),
- }
-
- output_eval_file = os.path.join(eval_output_dir, prefix, "eval_results.txt")
- with open(output_eval_file, "w") as writer:
- logger.info("***** Eval results {} *****".format(prefix))
- for key in sorted(result.keys()):
- logger.info(" %s = %s", key, str(result[key]))
- writer.write("%s = %s\n" % (key, str(result[key])))
-
- return result
-
-
-def load_examples(args, tokenizer, evaluate=False):
- path = os.path.join(args.data_dir, "dev.jsonl" if evaluate else "train.jsonl")
- transforms = get_image_transforms()
- labels = get_mmimdb_labels()
- dataset = JsonlDataset(path, tokenizer, transforms, labels, args.max_seq_length - args.num_image_embeds - 2)
- return dataset
-
-
-def main():
- parser = argparse.ArgumentParser()
-
- # Required parameters
- parser.add_argument(
- "--data_dir",
- default=None,
- type=str,
- required=True,
- help="The input data dir. Should contain the .jsonl files for MMIMDB.",
- )
- parser.add_argument(
- "--model_name_or_path",
- default=None,
- type=str,
- required=True,
- help="Path to pretrained model or model identifier from huggingface.co/models",
- )
- parser.add_argument(
- "--output_dir",
- default=None,
- type=str,
- required=True,
- help="The output directory where the model predictions and checkpoints will be written.",
- )
-
- # Other parameters
- parser.add_argument(
- "--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
- )
- parser.add_argument(
- "--tokenizer_name",
- default="",
- type=str,
- help="Pretrained tokenizer name or path if not the same as model_name",
- )
- parser.add_argument(
- "--cache_dir",
- default=None,
- type=str,
- help="Where do you want to store the pre-trained models downloaded from huggingface.co",
- )
- parser.add_argument(
- "--max_seq_length",
- default=128,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument(
- "--num_image_embeds", default=1, type=int, help="Number of Image Embeddings from the Image Encoder"
- )
- parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
- parser.add_argument("--do_eval", action="store_true", help="Whether to run eval on the dev set.")
- parser.add_argument(
- "--evaluate_during_training", action="store_true", help="Rul evaluation during training at each logging step."
- )
- parser.add_argument(
- "--do_lower_case", action="store_true", help="Set this flag if you are using an uncased model."
- )
-
- parser.add_argument("--per_gpu_train_batch_size", default=8, type=int, help="Batch size per GPU/CPU for training.")
- parser.add_argument(
- "--per_gpu_eval_batch_size", default=8, type=int, help="Batch size per GPU/CPU for evaluation."
- )
- parser.add_argument(
- "--gradient_accumulation_steps",
- type=int,
- default=1,
- help="Number of updates steps to accumulate before performing a backward/update pass.",
- )
- parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
- parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
- parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
- parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
- parser.add_argument(
- "--num_train_epochs", default=3.0, type=float, help="Total number of training epochs to perform."
- )
- parser.add_argument("--patience", default=5, type=int, help="Patience for Early Stopping.")
- parser.add_argument(
- "--max_steps",
- default=-1,
- type=int,
- help="If > 0: set total number of training steps to perform. Override num_train_epochs.",
- )
- parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
-
- parser.add_argument("--logging_steps", type=int, default=50, help="Log every X updates steps.")
- parser.add_argument("--save_steps", type=int, default=50, help="Save checkpoint every X updates steps.")
- parser.add_argument(
- "--eval_all_checkpoints",
- action="store_true",
- help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
- )
- parser.add_argument("--no_cuda", action="store_true", help="Avoid using CUDA when available")
- parser.add_argument("--num_workers", type=int, default=8, help="number of worker threads for dataloading")
- parser.add_argument(
- "--overwrite_output_dir", action="store_true", help="Overwrite the content of the output directory"
- )
- parser.add_argument(
- "--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
- )
- parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
-
- parser.add_argument(
- "--fp16",
- action="store_true",
- help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
- )
- parser.add_argument(
- "--fp16_opt_level",
- type=str,
- default="O1",
- help=(
- "For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
- "See details at https://nvidia.github.io/apex/amp.html"
- ),
- )
- parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
- parser.add_argument("--server_ip", type=str, default="", help="For distant debugging.")
- parser.add_argument("--server_port", type=str, default="", help="For distant debugging.")
- args = parser.parse_args()
-
- if (
- os.path.exists(args.output_dir)
- and os.listdir(args.output_dir)
- and args.do_train
- and not args.overwrite_output_dir
- ):
- raise ValueError(
- "Output directory ({}) already exists and is not empty. Use --overwrite_output_dir to overcome.".format(
- args.output_dir
- )
- )
-
- # Setup distant debugging if needed
- if args.server_ip and args.server_port:
- # Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
- import ptvsd
-
- print("Waiting for debugger attach")
- ptvsd.enable_attach(address=(args.server_ip, args.server_port), redirect_output=True)
- ptvsd.wait_for_attach()
-
- # Setup CUDA, GPU & distributed training
- if args.local_rank == -1 or args.no_cuda:
- device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
- args.n_gpu = 0 if args.no_cuda else torch.cuda.device_count()
- else: # Initializes the distributed backend which will take care of synchronizing nodes/GPUs
- torch.cuda.set_device(args.local_rank)
- device = torch.device("cuda", args.local_rank)
- torch.distributed.init_process_group(backend="nccl")
- args.n_gpu = 1
-
- args.device = device
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- level=logging.INFO if args.local_rank in [-1, 0] else logging.WARN,
- )
- logger.warning(
- "Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
- args.local_rank,
- device,
- args.n_gpu,
- bool(args.local_rank != -1),
- args.fp16,
- )
- # Set the verbosity to info of the Transformers logger (on main process only):
- if is_main_process(args.local_rank):
- transformers.utils.logging.set_verbosity_info()
- transformers.utils.logging.enable_default_handler()
- transformers.utils.logging.enable_explicit_format()
- # Set seed
- set_seed(args)
-
- # Load pretrained model and tokenizer
- if args.local_rank not in [-1, 0]:
- torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab
-
- # Setup model
- labels = get_mmimdb_labels()
- num_labels = len(labels)
- transformer_config = AutoConfig.from_pretrained(args.config_name if args.config_name else args.model_name_or_path)
- tokenizer = AutoTokenizer.from_pretrained(
- args.tokenizer_name if args.tokenizer_name else args.model_name_or_path,
- do_lower_case=args.do_lower_case,
- cache_dir=args.cache_dir,
- )
- transformer = AutoModel.from_pretrained(
- args.model_name_or_path, config=transformer_config, cache_dir=args.cache_dir
- )
- img_encoder = ImageEncoder(args)
- config = MMBTConfig(transformer_config, num_labels=num_labels)
- model = MMBTForClassification(config, transformer, img_encoder)
-
- if args.local_rank == 0:
- torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab
-
- model.to(args.device)
-
- logger.info("Training/evaluation parameters %s", args)
-
- # Training
- if args.do_train:
- train_dataset = load_examples(args, tokenizer, evaluate=False)
- label_frequences = train_dataset.get_label_frequencies()
- label_frequences = [label_frequences[l] for l in labels]
- label_weights = (
- torch.tensor(label_frequences, device=args.device, dtype=torch.float) / len(train_dataset)
- ) ** -1
- criterion = nn.BCEWithLogitsLoss(pos_weight=label_weights)
- global_step, tr_loss = train(args, train_dataset, model, tokenizer, criterion)
- logger.info(" global_step = %s, average loss = %s", global_step, tr_loss)
-
- # Saving best-practices: if you use defaults names for the model, you can reload it using from_pretrained()
- if args.do_train and (args.local_rank == -1 or torch.distributed.get_rank() == 0):
- logger.info("Saving model checkpoint to %s", args.output_dir)
- # Save a trained model, configuration and tokenizer using `save_pretrained()`.
- # They can then be reloaded using `from_pretrained()`
- model_to_save = (
- model.module if hasattr(model, "module") else model
- ) # Take care of distributed/parallel training
- torch.save(model_to_save.state_dict(), os.path.join(args.output_dir, WEIGHTS_NAME))
- tokenizer.save_pretrained(args.output_dir)
-
- # Good practice: save your training arguments together with the trained model
- torch.save(args, os.path.join(args.output_dir, "training_args.bin"))
-
- # Load a trained model and vocabulary that you have fine-tuned
- model = MMBTForClassification(config, transformer, img_encoder)
- model.load_state_dict(torch.load(os.path.join(args.output_dir, WEIGHTS_NAME)))
- tokenizer = AutoTokenizer.from_pretrained(args.output_dir)
- model.to(args.device)
-
- # Evaluation
- results = {}
- if args.do_eval and args.local_rank in [-1, 0]:
- checkpoints = [args.output_dir]
- if args.eval_all_checkpoints:
- checkpoints = [
- os.path.dirname(c) for c in sorted(glob.glob(args.output_dir + "/**/" + WEIGHTS_NAME, recursive=True))
- ]
-
- logger.info("Evaluate the following checkpoints: %s", checkpoints)
- for checkpoint in checkpoints:
- global_step = checkpoint.split("-")[-1] if len(checkpoints) > 1 else ""
- prefix = checkpoint.split("/")[-1] if checkpoint.find("checkpoint") != -1 else ""
- model = MMBTForClassification(config, transformer, img_encoder)
- model.load_state_dict(torch.load(checkpoint))
- model.to(args.device)
- result = evaluate(args, model, tokenizer, criterion, prefix=prefix)
- result = {k + "_{}".format(global_step): v for k, v in result.items()}
- results.update(result)
-
- return results
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/mm-imdb/utils_mmimdb.py b/examples/research_projects/mm-imdb/utils_mmimdb.py
deleted file mode 100644
index df8e38d5974..00000000000
--- a/examples/research_projects/mm-imdb/utils_mmimdb.py
+++ /dev/null
@@ -1,146 +0,0 @@
-# coding=utf-8
-# Copyright (c) Facebook, Inc. and its affiliates.
-# Copyright (c) HuggingFace Inc. team.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import json
-import os
-from collections import Counter
-
-import torch
-import torchvision
-import torchvision.transforms as transforms
-from PIL import Image
-from torch import nn
-from torch.utils.data import Dataset
-
-
-POOLING_BREAKDOWN = {1: (1, 1), 2: (2, 1), 3: (3, 1), 4: (2, 2), 5: (5, 1), 6: (3, 2), 7: (7, 1), 8: (4, 2), 9: (3, 3)}
-
-
-class ImageEncoder(nn.Module):
- def __init__(self, args):
- super().__init__()
- model = torchvision.models.resnet152(pretrained=True)
- modules = list(model.children())[:-2]
- self.model = nn.Sequential(*modules)
- self.pool = nn.AdaptiveAvgPool2d(POOLING_BREAKDOWN[args.num_image_embeds])
-
- def forward(self, x):
- # Bx3x224x224 -> Bx2048x7x7 -> Bx2048xN -> BxNx2048
- out = self.pool(self.model(x))
- out = torch.flatten(out, start_dim=2)
- out = out.transpose(1, 2).contiguous()
- return out # BxNx2048
-
-
-class JsonlDataset(Dataset):
- def __init__(self, data_path, tokenizer, transforms, labels, max_seq_length):
- self.data = [json.loads(l) for l in open(data_path)]
- self.data_dir = os.path.dirname(data_path)
- self.tokenizer = tokenizer
- self.labels = labels
- self.n_classes = len(labels)
- self.max_seq_length = max_seq_length
-
- self.transforms = transforms
-
- def __len__(self):
- return len(self.data)
-
- def __getitem__(self, index):
- sentence = torch.LongTensor(self.tokenizer.encode(self.data[index]["text"], add_special_tokens=True))
- start_token, sentence, end_token = sentence[0], sentence[1:-1], sentence[-1]
- sentence = sentence[: self.max_seq_length]
-
- label = torch.zeros(self.n_classes)
- label[[self.labels.index(tgt) for tgt in self.data[index]["label"]]] = 1
-
- image = Image.open(os.path.join(self.data_dir, self.data[index]["img"])).convert("RGB")
- image = self.transforms(image)
-
- return {
- "image_start_token": start_token,
- "image_end_token": end_token,
- "sentence": sentence,
- "image": image,
- "label": label,
- }
-
- def get_label_frequencies(self):
- label_freqs = Counter()
- for row in self.data:
- label_freqs.update(row["label"])
- return label_freqs
-
-
-def collate_fn(batch):
- lens = [len(row["sentence"]) for row in batch]
- bsz, max_seq_len = len(batch), max(lens)
-
- mask_tensor = torch.zeros(bsz, max_seq_len, dtype=torch.long)
- text_tensor = torch.zeros(bsz, max_seq_len, dtype=torch.long)
-
- for i_batch, (input_row, length) in enumerate(zip(batch, lens)):
- text_tensor[i_batch, :length] = input_row["sentence"]
- mask_tensor[i_batch, :length] = 1
-
- img_tensor = torch.stack([row["image"] for row in batch])
- tgt_tensor = torch.stack([row["label"] for row in batch])
- img_start_token = torch.stack([row["image_start_token"] for row in batch])
- img_end_token = torch.stack([row["image_end_token"] for row in batch])
-
- return text_tensor, mask_tensor, img_tensor, img_start_token, img_end_token, tgt_tensor
-
-
-def get_mmimdb_labels():
- return [
- "Crime",
- "Drama",
- "Thriller",
- "Action",
- "Comedy",
- "Romance",
- "Documentary",
- "Short",
- "Mystery",
- "History",
- "Family",
- "Adventure",
- "Fantasy",
- "Sci-Fi",
- "Western",
- "Horror",
- "Sport",
- "War",
- "Music",
- "Musical",
- "Animation",
- "Biography",
- "Film-Noir",
- ]
-
-
-def get_image_transforms():
- return transforms.Compose(
- [
- transforms.Resize(256),
- transforms.CenterCrop(224),
- transforms.ToTensor(),
- transforms.Normalize(
- mean=[0.46777044, 0.44531429, 0.40661017],
- std=[0.12221994, 0.12145835, 0.14380469],
- ),
- ]
- )
diff --git a/examples/research_projects/movement-pruning/README.md b/examples/research_projects/movement-pruning/README.md
deleted file mode 100644
index 575ec1a9b49..00000000000
--- a/examples/research_projects/movement-pruning/README.md
+++ /dev/null
@@ -1,185 +0,0 @@
-# Movement Pruning: Adaptive Sparsity by Fine-Tuning
-
-Author: @VictorSanh
-
-*Magnitude pruning is a widely used strategy for reducing model size in pure supervised learning; however, it is less effective in the transfer learning regime that has become standard for state-of-the-art natural language processing applications. We propose the use of *movement pruning*, a simple, deterministic first-order weight pruning method that is more adaptive to pretrained model fine-tuning. Experiments show that when pruning large pretrained language models, movement pruning shows significant improvements in high-sparsity regimes. When combined with distillation, the approach achieves minimal accuracy loss with down to only 3% of the model parameters:*
-
-| Fine-pruning+Distillation
(Teacher=BERT-base fine-tuned) | BERT base
fine-tuned | Remaining
Weights (%) | Magnitude Pruning | L0 Regularization | Movement Pruning | Soft Movement Pruning |
-| :---: | :---: | :---: | :---: | :---: | :---: | :---: |
-| SQuAD - Dev
EM/F1 | 80.4/88.1 | 10%
3% | 70.2/80.1
45.5/59.6 | 72.4/81.9
64.3/75.8 | 75.6/84.3
67.5/78.0 | **76.6/84.9**
**72.7/82.3** |
-| MNLI - Dev
acc/MM acc | 84.5/84.9 | 10%
3% | 78.3/79.3
69.4/70.6 | 78.7/79.7
76.0/76.2 | 80.1/80.4
76.5/77.4 | **81.2/81.8**
**79.5/80.1** |
-| QQP - Dev
acc/F1 | 91.4/88.4 | 10%
3% | 79.8/65.0
72.4/57.8 | 88.1/82.8
87.0/81.9 | 89.7/86.2
86.1/81.5 | **90.2/86.8**
**89.1/85.5** |
-
-This page contains information on how to fine-prune pre-trained models such as `BERT` to obtain extremely sparse models with movement pruning. In contrast to magnitude pruning which selects weights that are far from 0, movement pruning retains weights that are moving away from 0.
-
-For more information, we invite you to check out [our paper](https://arxiv.org/abs/2005.07683).
-You can also have a look at this fun *Explain Like I'm Five* introductory [slide deck](https://www.slideshare.net/VictorSanh/movement-pruning-explain-like-im-five-234205241).
-
-
-

-
-Pre-trained `BERT-base-uncased` fine-pruned with soft movement pruning on SQuAD v1.1. We use an additional distillation signal from `BERT-base-uncased` finetuned on SQuAD. The encoder counts 6% of total non-null weights and reaches 83.8 F1 score. The model can be accessed with: `pruned_bert = BertForQuestionAnswering.from_pretrained("huggingface/prunebert-base-uncased-6-finepruned-w-distil-squad")`
-- **`prunebert-base-uncased-6-finepruned-w-distil-mnli`**
-Pre-trained `BERT-base-uncased` fine-pruned with soft movement pruning on MNLI. We use an additional distillation signal from `BERT-base-uncased` finetuned on MNLI. The encoder counts 6% of total non-null weights and reaches 80.7 (matched) accuracy. The model can be accessed with: `pruned_bert = BertForSequenceClassification.from_pretrained("huggingface/prunebert-base-uncased-6-finepruned-w-distil-mnli")`
-
-## How to fine-prune?
-
-### Setup
-
-The code relies on the 🤗 Transformers library. In addition to the dependencies listed in the [`examples`](https://github.com/huggingface/transformers/tree/main/examples) folder, you should install a few additional dependencies listed in the `requirements.txt` file: `pip install -r requirements.txt`.
-
-Note that we built our experiments on top of a stabilized version of the library (commit https://github.com/huggingface/transformers/commit/352d5472b0c1dec0f420d606d16747d851b4bda8): we do not guarantee that everything is still compatible with the latest version of the main branch.
-
-### Fine-pruning with movement pruning
-
-Below, we detail how to reproduce the results reported in the paper. We use SQuAD as a running example. Commands (and scripts) can be easily adapted for other tasks.
-
-The following command fine-prunes a pre-trained `BERT-base` on SQuAD using movement pruning towards 15% of remaining weights (85% sparsity). Note that we freeze all the embeddings modules (from their pre-trained value) and only prune the Fully Connected layers in the encoder (12 layers of Transformer Block).
-
-```bash
-SERIALIZATION_DIR=
-SQUAD_DATA=
-
-python examples/movement-pruning/masked_run_squad.py \
- --output_dir $SERIALIZATION_DIR \
- --data_dir $SQUAD_DATA \
- --train_file train-v1.1.json \
- --predict_file dev-v1.1.json \
- --do_train --do_eval --do_lower_case \
- --model_type masked_bert \
- --model_name_or_path google-bert/bert-base-uncased \
- --per_gpu_train_batch_size 16 \
- --warmup_steps 5400 \
- --num_train_epochs 10 \
- --learning_rate 3e-5 --mask_scores_learning_rate 1e-2 \
- --initial_threshold 1 --final_threshold 0.15 \
- --initial_warmup 1 --final_warmup 2 \
- --pruning_method topK --mask_init constant --mask_scale 0.
-```
-
-### Fine-pruning with other methods
-
-We can also explore other fine-pruning methods by changing the `pruning_method` parameter:
-
-Soft movement pruning
-```bash
-python examples/movement-pruning/masked_run_squad.py \
- --output_dir $SERIALIZATION_DIR \
- --data_dir $SQUAD_DATA \
- --train_file train-v1.1.json \
- --predict_file dev-v1.1.json \
- --do_train --do_eval --do_lower_case \
- --model_type masked_bert \
- --model_name_or_path google-bert/bert-base-uncased \
- --per_gpu_train_batch_size 16 \
- --warmup_steps 5400 \
- --num_train_epochs 10 \
- --learning_rate 3e-5 --mask_scores_learning_rate 1e-2 \
- --initial_threshold 0 --final_threshold 0.1 \
- --initial_warmup 1 --final_warmup 2 \
- --pruning_method sigmoied_threshold --mask_init constant --mask_scale 0. \
- --regularization l1 --final_lambda 400.
-```
-
-L0 regularization
-```bash
-python examples/movement-pruning/masked_run_squad.py \
- --output_dir $SERIALIZATION_DIR \
- --data_dir $SQUAD_DATA \
- --train_file train-v1.1.json \
- --predict_file dev-v1.1.json \
- --do_train --do_eval --do_lower_case \
- --model_type masked_bert \
- --model_name_or_path google-bert/bert-base-uncased \
- --per_gpu_train_batch_size 16 \
- --warmup_steps 5400 \
- --num_train_epochs 10 \
- --learning_rate 3e-5 --mask_scores_learning_rate 1e-1 \
- --initial_threshold 1. --final_threshold 1. \
- --initial_warmup 1 --final_warmup 1 \
- --pruning_method l0 --mask_init constant --mask_scale 2.197 \
- --regularization l0 --final_lambda 125.
-```
-
-Iterative Magnitude Pruning
-```bash
-python examples/movement-pruning/masked_run_squad.py \
- --output_dir ./dbg \
- --data_dir examples/distillation/data/squad_data \
- --train_file train-v1.1.json \
- --predict_file dev-v1.1.json \
- --do_train --do_eval --do_lower_case \
- --model_type masked_bert \
- --model_name_or_path google-bert/bert-base-uncased \
- --per_gpu_train_batch_size 16 \
- --warmup_steps 5400 \
- --num_train_epochs 10 \
- --learning_rate 3e-5 \
- --initial_threshold 1 --final_threshold 0.15 \
- --initial_warmup 1 --final_warmup 2 \
- --pruning_method magnitude
-```
-
-### After fine-pruning
-
-**Counting parameters**
-
-Regularization based pruning methods (soft movement pruning and L0 regularization) rely on the penalty to induce sparsity. The multiplicative coefficient controls the sparsity level.
-To obtain the effective sparsity level in the encoder, we simply count the number of activated (non-null) weights:
-
-```bash
-python examples/movement-pruning/counts_parameters.py \
- --pruning_method sigmoied_threshold \
- --threshold 0.1 \
- --serialization_dir $SERIALIZATION_DIR
-```
-
-**Pruning once for all**
-
-Once the model has been fine-pruned, the pruned weights can be set to 0. once for all (reducing the amount of information to store). In our running experiments, we can convert a `MaskedBertForQuestionAnswering` (a BERT model augmented to enable on-the-fly pruning capabilities) to a standard `BertForQuestionAnswering`:
-
-```bash
-python examples/movement-pruning/bertarize.py \
- --pruning_method sigmoied_threshold \
- --threshold 0.1 \
- --model_name_or_path $SERIALIZATION_DIR
-```
-
-## Hyper-parameters
-
-For reproducibility purposes, we share the detailed results presented in the paper. These [tables](https://docs.google.com/spreadsheets/d/17JgRq_OFFTniUrz6BZWW_87DjFkKXpI1kYDSsseT_7g/edit?usp=sharing) exhaustively describe the individual hyper-parameters used for each data point.
-
-## Inference speed
-
-Early experiments show that even though models fine-pruned with (soft) movement pruning are extremely sparse, they do not benefit from significant improvement in terms of inference speed when using the standard PyTorch inference.
-We are currently benchmarking and exploring inference setups specifically for sparse architectures.
-In particular, hardware manufacturers are announcing devices that will speedup inference for sparse networks considerably.
-
-## Citation
-
-If you find this resource useful, please consider citing the following paper:
-
-```bibtex
-@article{sanh2020movement,
- title={Movement Pruning: Adaptive Sparsity by Fine-Tuning},
- author={Victor Sanh and Thomas Wolf and Alexander M. Rush},
- year={2020},
- eprint={2005.07683},
- archivePrefix={arXiv},
- primaryClass={cs.CL}
-}
-```
diff --git a/examples/research_projects/movement-pruning/Saving_PruneBERT.ipynb b/examples/research_projects/movement-pruning/Saving_PruneBERT.ipynb
deleted file mode 100644
index 0c27bd02a7d..00000000000
--- a/examples/research_projects/movement-pruning/Saving_PruneBERT.ipynb
+++ /dev/null
@@ -1,645 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "# Saving PruneBERT\n",
- "\n",
- "\n",
- "This notebook aims at showcasing how we can leverage standard tools to save (and load) an extremely sparse model fine-pruned with [movement pruning](https://arxiv.org/abs/2005.07683) (or any other unstructured pruning mehtod).\n",
- "\n",
- "In this example, we used BERT (base-uncased, but the procedure described here is not specific to BERT and can be applied to a large variety of models.\n",
- "\n",
- "We first obtain an extremely sparse model by fine-pruning with movement pruning on SQuAD v1.1. We then used the following combination of standard tools:\n",
- "- We reduce the precision of the model with Int8 dynamic quantization using [PyTorch implementation](https://pytorch.org/tutorials/intermediate/dynamic_quantization_bert_tutorial.html). We only quantized the Fully Connected Layers.\n",
- "- Sparse quantized matrices are converted into the [Compressed Sparse Row format](https://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.csr_matrix.html).\n",
- "- We use HDF5 with `gzip` compression to store the weights.\n",
- "\n",
- "We experiment with a question answering model with only 6% of total remaining weights in the encoder (previously obtained with movement pruning). **We are able to reduce the memory size of the encoder from 340MB (original dense BERT) to 11MB**, which fits on a [91' floppy disk](https://en.wikipedia.org/wiki/Floptical)!\n",
- "\n",
- " \n",
- "\n",
- "*Note: this notebook is compatible with `torch>=1.5.0` If you are using, `torch==1.4.0`, please refer to [this previous version of the notebook](https://github.com/huggingface/transformers/commit/b11386e158e86e62d4041eabd86d044cd1695737).*"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 1,
- "metadata": {},
- "outputs": [],
- "source": [
- "# Includes\n",
- "\n",
- "import json\n",
- "import os\n",
- "from collections import OrderedDict\n",
- "\n",
- "import h5py\n",
- "import numpy as np\n",
- "import torch\n",
- "from scipy import sparse\n",
- "from torch import nn\n",
- "\n",
- "from transformers import BertForQuestionAnswering\n",
- "\n",
- "\n",
- "os.chdir(\"../../\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Saving"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Dynamic quantization induces little or no loss of performance while significantly reducing the memory footprint."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 2,
- "metadata": {},
- "outputs": [],
- "source": [
- "# Load fine-pruned model and quantize the model\n",
- "\n",
- "model = BertForQuestionAnswering.from_pretrained(\"huggingface/prunebert-base-uncased-6-finepruned-w-distil-squad\")\n",
- "model.to(\"cpu\")\n",
- "\n",
- "quantized_model = torch.quantization.quantize_dynamic(\n",
- " model=model,\n",
- " qconfig_spec={\n",
- " nn.Linear: torch.quantization.default_dynamic_qconfig,\n",
- " },\n",
- " dtype=torch.qint8,\n",
- ")\n",
- "# print(quantized_model)\n",
- "\n",
- "qtz_st = quantized_model.state_dict()"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 3,
- "metadata": {},
- "outputs": [],
- "source": [
- "# Saving the original (encoder + classifier) in the standard torch.save format\n",
- "\n",
- "dense_st = {\n",
- " name: param for name, param in model.state_dict().items() if \"embedding\" not in name and \"pooler\" not in name\n",
- "}\n",
- "torch.save(\n",
- " dense_st,\n",
- " \"dbg/dense_squad.pt\",\n",
- ")\n",
- "dense_mb_size = os.path.getsize(\"dbg/dense_squad.pt\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 4,
- "metadata": {
- "scrolled": true
- },
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Decompose quantization for bert.encoder.layer.0.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.0.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.0.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.0.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.0.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.0.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.1.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.1.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.1.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.1.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.1.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.1.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.2.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.2.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.2.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.2.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.2.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.2.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.3.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.3.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.3.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.3.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.3.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.3.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.4.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.4.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.4.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.4.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.4.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.4.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.5.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.5.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.5.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.5.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.5.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.5.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.6.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.6.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.6.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.6.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.6.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.6.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.7.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.7.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.7.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.7.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.7.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.7.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.8.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.8.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.8.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.8.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.8.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.8.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.9.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.9.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.9.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.9.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.9.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.9.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.10.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.10.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.10.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.10.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.10.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.10.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.11.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.11.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.11.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.11.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.11.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.11.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.pooler.dense._packed_params.weight\n",
- "Decompose quantization for qa_outputs._packed_params.weight\n"
- ]
- }
- ],
- "source": [
- "# Elementary representation: we decompose the quantized tensors into (scale, zero_point, int_repr).\n",
- "# See https://pytorch.org/docs/stable/quantization.html\n",
- "\n",
- "# We further leverage the fact that int_repr is sparse matrix to optimize the storage: we decompose int_repr into\n",
- "# its CSR representation (data, indptr, indices).\n",
- "\n",
- "elementary_qtz_st = {}\n",
- "for name, param in qtz_st.items():\n",
- " if \"dtype\" not in name and param.is_quantized:\n",
- " print(\"Decompose quantization for\", name)\n",
- " # We need to extract the scale, the zero_point and the int_repr for the quantized tensor and modules\n",
- " scale = param.q_scale() # torch.tensor(1,) - float32\n",
- " zero_point = param.q_zero_point() # torch.tensor(1,) - int32\n",
- " elementary_qtz_st[f\"{name}.scale\"] = scale\n",
- " elementary_qtz_st[f\"{name}.zero_point\"] = zero_point\n",
- "\n",
- " # We assume the int_repr is sparse and compute its CSR representation\n",
- " # Only the FCs in the encoder are actually sparse\n",
- " int_repr = param.int_repr() # torch.tensor(nb_rows, nb_columns) - int8\n",
- " int_repr_cs = sparse.csr_matrix(int_repr) # scipy.sparse.csr.csr_matrix\n",
- "\n",
- " elementary_qtz_st[f\"{name}.int_repr.data\"] = int_repr_cs.data # np.array int8\n",
- " elementary_qtz_st[f\"{name}.int_repr.indptr\"] = int_repr_cs.indptr # np.array int32\n",
- " assert max(int_repr_cs.indices) < 65535 # If not, we shall fall back to int32\n",
- " elementary_qtz_st[f\"{name}.int_repr.indices\"] = np.uint16(int_repr_cs.indices) # np.array uint16\n",
- " elementary_qtz_st[f\"{name}.int_repr.shape\"] = int_repr_cs.shape # tuple(int, int)\n",
- " else:\n",
- " elementary_qtz_st[name] = param"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 5,
- "metadata": {},
- "outputs": [],
- "source": [
- "# Create mapping from torch.dtype to string description (we could also used an int8 instead of string)\n",
- "str_2_dtype = {\"qint8\": torch.qint8}\n",
- "dtype_2_str = {torch.qint8: \"qint8\"}"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 6,
- "metadata": {
- "scrolled": true
- },
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Encoder Size (MB) - Sparse & Quantized - `torch.save`: 21.29\n"
- ]
- }
- ],
- "source": [
- "# Saving the pruned (encoder + classifier) in the standard torch.save format\n",
- "\n",
- "dense_optimized_st = {\n",
- " name: param for name, param in elementary_qtz_st.items() if \"embedding\" not in name and \"pooler\" not in name\n",
- "}\n",
- "torch.save(\n",
- " dense_optimized_st,\n",
- " \"dbg/dense_squad_optimized.pt\",\n",
- ")\n",
- "print(\n",
- " \"Encoder Size (MB) - Sparse & Quantized - `torch.save`:\",\n",
- " round(os.path.getsize(\"dbg/dense_squad_optimized.pt\") / 1e6, 2),\n",
- ")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 7,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Skip bert.embeddings.word_embeddings.weight\n",
- "Skip bert.embeddings.position_embeddings.weight\n",
- "Skip bert.embeddings.token_type_embeddings.weight\n",
- "Skip bert.embeddings.LayerNorm.weight\n",
- "Skip bert.embeddings.LayerNorm.bias\n",
- "Skip bert.pooler.dense.scale\n",
- "Skip bert.pooler.dense.zero_point\n",
- "Skip bert.pooler.dense._packed_params.weight.scale\n",
- "Skip bert.pooler.dense._packed_params.weight.zero_point\n",
- "Skip bert.pooler.dense._packed_params.weight.int_repr.data\n",
- "Skip bert.pooler.dense._packed_params.weight.int_repr.indptr\n",
- "Skip bert.pooler.dense._packed_params.weight.int_repr.indices\n",
- "Skip bert.pooler.dense._packed_params.weight.int_repr.shape\n",
- "Skip bert.pooler.dense._packed_params.bias\n",
- "Skip bert.pooler.dense._packed_params.dtype\n",
- "\n",
- "Encoder Size (MB) - Dense: 340.26\n",
- "Encoder Size (MB) - Sparse & Quantized: 11.28\n"
- ]
- }
- ],
- "source": [
- "# Save the decomposed state_dict with an HDF5 file\n",
- "# Saving only the encoder + QA Head\n",
- "\n",
- "with h5py.File(\"dbg/squad_sparse.h5\", \"w\") as hf:\n",
- " for name, param in elementary_qtz_st.items():\n",
- " if \"embedding\" in name:\n",
- " print(f\"Skip {name}\")\n",
- " continue\n",
- "\n",
- " if \"pooler\" in name:\n",
- " print(f\"Skip {name}\")\n",
- " continue\n",
- "\n",
- " if isinstance(param, torch.Tensor):\n",
- " if param.numel() == 1:\n",
- " # module scale\n",
- " # module zero_point\n",
- " hf.attrs[name] = param\n",
- " continue\n",
- "\n",
- " if param.requires_grad:\n",
- " # LayerNorm\n",
- " param = param.detach().numpy()\n",
- " hf.create_dataset(name, data=param, compression=\"gzip\", compression_opts=9)\n",
- "\n",
- " elif isinstance(param, (float, int, tuple)):\n",
- " # float - tensor _packed_params.weight.scale\n",
- " # int - tensor _packed_params.weight.zero_point\n",
- " # tuple - tensor _packed_params.weight.shape\n",
- " hf.attrs[name] = param\n",
- "\n",
- " elif isinstance(param, torch.dtype):\n",
- " # dtype - tensor _packed_params.dtype\n",
- " hf.attrs[name] = dtype_2_str[param]\n",
- "\n",
- " else:\n",
- " hf.create_dataset(name, data=param, compression=\"gzip\", compression_opts=9)\n",
- "\n",
- "\n",
- "with open(\"dbg/metadata.json\", \"w\") as f:\n",
- " f.write(json.dumps(qtz_st._metadata))\n",
- "\n",
- "size = os.path.getsize(\"dbg/squad_sparse.h5\") + os.path.getsize(\"dbg/metadata.json\")\n",
- "print(\"\")\n",
- "print(\"Encoder Size (MB) - Dense: \", round(dense_mb_size / 1e6, 2))\n",
- "print(\"Encoder Size (MB) - Sparse & Quantized:\", round(size / 1e6, 2))"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 8,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- "Size (MB): 99.41\n"
- ]
- }
- ],
- "source": [
- "# Save the decomposed state_dict to HDF5 storage\n",
- "# Save everything in the architecutre (embedding + encoder + QA Head)\n",
- "\n",
- "with h5py.File(\"dbg/squad_sparse_with_embs.h5\", \"w\") as hf:\n",
- " for name, param in elementary_qtz_st.items():\n",
- " # if \"embedding\" in name:\n",
- " # print(f\"Skip {name}\")\n",
- " # continue\n",
- "\n",
- " # if \"pooler\" in name:\n",
- " # print(f\"Skip {name}\")\n",
- " # continue\n",
- "\n",
- " if isinstance(param, torch.Tensor):\n",
- " if param.numel() == 1:\n",
- " # module scale\n",
- " # module zero_point\n",
- " hf.attrs[name] = param\n",
- " continue\n",
- "\n",
- " if param.requires_grad:\n",
- " # LayerNorm\n",
- " param = param.detach().numpy()\n",
- " hf.create_dataset(name, data=param, compression=\"gzip\", compression_opts=9)\n",
- "\n",
- " elif isinstance(param, (float, int, tuple)):\n",
- " # float - tensor _packed_params.weight.scale\n",
- " # int - tensor _packed_params.weight.zero_point\n",
- " # tuple - tensor _packed_params.weight.shape\n",
- " hf.attrs[name] = param\n",
- "\n",
- " elif isinstance(param, torch.dtype):\n",
- " # dtype - tensor _packed_params.dtype\n",
- " hf.attrs[name] = dtype_2_str[param]\n",
- "\n",
- " else:\n",
- " hf.create_dataset(name, data=param, compression=\"gzip\", compression_opts=9)\n",
- "\n",
- "\n",
- "with open(\"dbg/metadata.json\", \"w\") as f:\n",
- " f.write(json.dumps(qtz_st._metadata))\n",
- "\n",
- "size = os.path.getsize(\"dbg/squad_sparse_with_embs.h5\") + os.path.getsize(\"dbg/metadata.json\")\n",
- "print(\"\\nSize (MB):\", round(size / 1e6, 2))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Loading"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 9,
- "metadata": {},
- "outputs": [],
- "source": [
- "# Reconstruct the elementary state dict\n",
- "\n",
- "reconstructed_elementary_qtz_st = {}\n",
- "\n",
- "hf = h5py.File(\"dbg/squad_sparse_with_embs.h5\", \"r\")\n",
- "\n",
- "for attr_name, attr_param in hf.attrs.items():\n",
- " if \"shape\" in attr_name:\n",
- " attr_param = tuple(attr_param)\n",
- " elif \".scale\" in attr_name:\n",
- " if \"_packed_params\" in attr_name:\n",
- " attr_param = float(attr_param)\n",
- " else:\n",
- " attr_param = torch.tensor(attr_param)\n",
- " elif \".zero_point\" in attr_name:\n",
- " if \"_packed_params\" in attr_name:\n",
- " attr_param = int(attr_param)\n",
- " else:\n",
- " attr_param = torch.tensor(attr_param)\n",
- " elif \".dtype\" in attr_name:\n",
- " attr_param = str_2_dtype[attr_param]\n",
- " reconstructed_elementary_qtz_st[attr_name] = attr_param\n",
- " # print(f\"Unpack {attr_name}\")\n",
- "\n",
- "# Get the tensors/arrays\n",
- "for data_name, data_param in hf.items():\n",
- " if \"LayerNorm\" in data_name or \"_packed_params.bias\" in data_name:\n",
- " reconstructed_elementary_qtz_st[data_name] = torch.from_numpy(np.array(data_param))\n",
- " elif \"embedding\" in data_name:\n",
- " reconstructed_elementary_qtz_st[data_name] = torch.from_numpy(np.array(data_param))\n",
- " else: # _packed_params.weight.int_repr.data, _packed_params.weight.int_repr.indices and _packed_params.weight.int_repr.indptr\n",
- " data_param = np.array(data_param)\n",
- " if \"indices\" in data_name:\n",
- " data_param = np.array(data_param, dtype=np.int32)\n",
- " reconstructed_elementary_qtz_st[data_name] = data_param\n",
- " # print(f\"Unpack {data_name}\")\n",
- "\n",
- "\n",
- "hf.close()"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 10,
- "metadata": {},
- "outputs": [],
- "source": [
- "# Sanity checks\n",
- "\n",
- "for name, param in reconstructed_elementary_qtz_st.items():\n",
- " assert name in elementary_qtz_st\n",
- "for name, param in elementary_qtz_st.items():\n",
- " assert name in reconstructed_elementary_qtz_st, name\n",
- "\n",
- "for name, param in reconstructed_elementary_qtz_st.items():\n",
- " assert isinstance(param, type(elementary_qtz_st[name])), name\n",
- " if isinstance(param, torch.Tensor):\n",
- " assert torch.all(torch.eq(param, elementary_qtz_st[name])), name\n",
- " elif isinstance(param, np.ndarray):\n",
- " assert (param == elementary_qtz_st[name]).all(), name\n",
- " else:\n",
- " assert param == elementary_qtz_st[name], name"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 11,
- "metadata": {},
- "outputs": [],
- "source": [
- "# Re-assemble the sparse int_repr from the CSR format\n",
- "\n",
- "reconstructed_qtz_st = {}\n",
- "\n",
- "for name, param in reconstructed_elementary_qtz_st.items():\n",
- " if \"weight.int_repr.indptr\" in name:\n",
- " prefix_ = name[:-16]\n",
- " data = reconstructed_elementary_qtz_st[f\"{prefix_}.int_repr.data\"]\n",
- " indptr = reconstructed_elementary_qtz_st[f\"{prefix_}.int_repr.indptr\"]\n",
- " indices = reconstructed_elementary_qtz_st[f\"{prefix_}.int_repr.indices\"]\n",
- " shape = reconstructed_elementary_qtz_st[f\"{prefix_}.int_repr.shape\"]\n",
- "\n",
- " int_repr = sparse.csr_matrix(arg1=(data, indices, indptr), shape=shape)\n",
- " int_repr = torch.tensor(int_repr.todense())\n",
- "\n",
- " scale = reconstructed_elementary_qtz_st[f\"{prefix_}.scale\"]\n",
- " zero_point = reconstructed_elementary_qtz_st[f\"{prefix_}.zero_point\"]\n",
- " weight = torch._make_per_tensor_quantized_tensor(int_repr, scale, zero_point)\n",
- "\n",
- " reconstructed_qtz_st[f\"{prefix_}\"] = weight\n",
- " elif (\n",
- " \"int_repr.data\" in name\n",
- " or \"int_repr.shape\" in name\n",
- " or \"int_repr.indices\" in name\n",
- " or \"weight.scale\" in name\n",
- " or \"weight.zero_point\" in name\n",
- " ):\n",
- " continue\n",
- " else:\n",
- " reconstructed_qtz_st[name] = param"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 12,
- "metadata": {},
- "outputs": [],
- "source": [
- "# Sanity checks\n",
- "\n",
- "for name, param in reconstructed_qtz_st.items():\n",
- " assert name in qtz_st\n",
- "for name, param in qtz_st.items():\n",
- " assert name in reconstructed_qtz_st, name\n",
- "\n",
- "for name, param in reconstructed_qtz_st.items():\n",
- " assert isinstance(param, type(qtz_st[name])), name\n",
- " if isinstance(param, torch.Tensor):\n",
- " assert torch.all(torch.eq(param, qtz_st[name])), name\n",
- " elif isinstance(param, np.ndarray):\n",
- " assert (param == qtz_st[name]).all(), name\n",
- " else:\n",
- " assert param == qtz_st[name], name"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Sanity checks"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 13,
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/plain": [
- ""
- ]
- },
- "execution_count": 13,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "# Load the re-constructed state dict into a model\n",
- "\n",
- "dummy_model = BertForQuestionAnswering.from_pretrained(\"bert-base-uncased\")\n",
- "dummy_model.to(\"cpu\")\n",
- "\n",
- "reconstructed_qtz_model = torch.quantization.quantize_dynamic(\n",
- " model=dummy_model,\n",
- " qconfig_spec=None,\n",
- " dtype=torch.qint8,\n",
- ")\n",
- "\n",
- "reconstructed_qtz_st = OrderedDict(reconstructed_qtz_st)\n",
- "with open(\"dbg/metadata.json\", \"r\") as read_file:\n",
- " metadata = json.loads(read_file.read())\n",
- "reconstructed_qtz_st._metadata = metadata\n",
- "\n",
- "reconstructed_qtz_model.load_state_dict(reconstructed_qtz_st)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 14,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Sanity check passed\n"
- ]
- }
- ],
- "source": [
- "# Sanity checks on the infernce\n",
- "\n",
- "N = 32\n",
- "\n",
- "for _ in range(25):\n",
- " inputs = torch.randint(low=0, high=30000, size=(N, 128))\n",
- " mask = torch.ones(size=(N, 128))\n",
- "\n",
- " y_reconstructed = reconstructed_qtz_model(input_ids=inputs, attention_mask=mask)[0]\n",
- " y = quantized_model(input_ids=inputs, attention_mask=mask)[0]\n",
- "\n",
- " assert torch.all(torch.eq(y, y_reconstructed))\n",
- "print(\"Sanity check passed\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": []
- }
- ],
- "metadata": {
- "kernelspec": {
- "display_name": "Python 3",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.6.8"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 4
-}
diff --git a/examples/research_projects/movement-pruning/bertarize.py b/examples/research_projects/movement-pruning/bertarize.py
deleted file mode 100644
index da7534f4a6f..00000000000
--- a/examples/research_projects/movement-pruning/bertarize.py
+++ /dev/null
@@ -1,136 +0,0 @@
-# Copyright 2020-present, the HuggingFace Inc. team.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-Once a model has been fine-pruned, the weights that are masked during the forward pass can be pruned once for all.
-For instance, once the a model from the :class:`~emmental.MaskedBertForSequenceClassification` is trained, it can be saved (and then loaded)
-as a standard :class:`~transformers.BertForSequenceClassification`.
-"""
-
-import argparse
-import os
-import shutil
-
-import torch
-from emmental.modules import MagnitudeBinarizer, ThresholdBinarizer, TopKBinarizer
-
-
-def main(args):
- pruning_method = args.pruning_method
- threshold = args.threshold
-
- model_name_or_path = args.model_name_or_path.rstrip("/")
- target_model_path = args.target_model_path
-
- print(f"Load fine-pruned model from {model_name_or_path}")
- model = torch.load(os.path.join(model_name_or_path, "pytorch_model.bin"))
- pruned_model = {}
-
- for name, tensor in model.items():
- if "embeddings" in name or "LayerNorm" in name or "pooler" in name:
- pruned_model[name] = tensor
- print(f"Copied layer {name}")
- elif "classifier" in name or "qa_output" in name:
- pruned_model[name] = tensor
- print(f"Copied layer {name}")
- elif "bias" in name:
- pruned_model[name] = tensor
- print(f"Copied layer {name}")
- else:
- if pruning_method == "magnitude":
- mask = MagnitudeBinarizer.apply(inputs=tensor, threshold=threshold)
- pruned_model[name] = tensor * mask
- print(f"Pruned layer {name}")
- elif pruning_method == "topK":
- if "mask_scores" in name:
- continue
- prefix_ = name[:-6]
- scores = model[f"{prefix_}mask_scores"]
- mask = TopKBinarizer.apply(scores, threshold)
- pruned_model[name] = tensor * mask
- print(f"Pruned layer {name}")
- elif pruning_method == "sigmoied_threshold":
- if "mask_scores" in name:
- continue
- prefix_ = name[:-6]
- scores = model[f"{prefix_}mask_scores"]
- mask = ThresholdBinarizer.apply(scores, threshold, True)
- pruned_model[name] = tensor * mask
- print(f"Pruned layer {name}")
- elif pruning_method == "l0":
- if "mask_scores" in name:
- continue
- prefix_ = name[:-6]
- scores = model[f"{prefix_}mask_scores"]
- l, r = -0.1, 1.1
- s = torch.sigmoid(scores)
- s_bar = s * (r - l) + l
- mask = s_bar.clamp(min=0.0, max=1.0)
- pruned_model[name] = tensor * mask
- print(f"Pruned layer {name}")
- else:
- raise ValueError("Unknown pruning method")
-
- if target_model_path is None:
- target_model_path = os.path.join(
- os.path.dirname(model_name_or_path), f"bertarized_{os.path.basename(model_name_or_path)}"
- )
-
- if not os.path.isdir(target_model_path):
- shutil.copytree(model_name_or_path, target_model_path)
- print(f"\nCreated folder {target_model_path}")
-
- torch.save(pruned_model, os.path.join(target_model_path, "pytorch_model.bin"))
- print("\nPruned model saved! See you later!")
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
-
- parser.add_argument(
- "--pruning_method",
- choices=["l0", "magnitude", "topK", "sigmoied_threshold"],
- type=str,
- required=True,
- help=(
- "Pruning Method (l0 = L0 regularization, magnitude = Magnitude pruning, topK = Movement pruning,"
- " sigmoied_threshold = Soft movement pruning)"
- ),
- )
- parser.add_argument(
- "--threshold",
- type=float,
- required=False,
- help=(
- "For `magnitude` and `topK`, it is the level of remaining weights (in %) in the fine-pruned model. "
- "For `sigmoied_threshold`, it is the threshold \tau against which the (sigmoied) scores are compared. "
- "Not needed for `l0`"
- ),
- )
- parser.add_argument(
- "--model_name_or_path",
- type=str,
- required=True,
- help="Folder containing the model that was previously fine-pruned",
- )
- parser.add_argument(
- "--target_model_path",
- default=None,
- type=str,
- required=False,
- help="Folder containing the model that was previously fine-pruned",
- )
-
- args = parser.parse_args()
-
- main(args)
diff --git a/examples/research_projects/movement-pruning/counts_parameters.py b/examples/research_projects/movement-pruning/counts_parameters.py
deleted file mode 100644
index c0ac53fb785..00000000000
--- a/examples/research_projects/movement-pruning/counts_parameters.py
+++ /dev/null
@@ -1,97 +0,0 @@
-# Copyright 2020-present, the HuggingFace Inc. team.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-Count remaining (non-zero) weights in the encoder (i.e. the transformer layers).
-Sparsity and remaining weights levels are equivalent: sparsity % = 100 - remaining weights %.
-"""
-
-import argparse
-import os
-
-import torch
-from emmental.modules import ThresholdBinarizer, TopKBinarizer
-
-
-def main(args):
- serialization_dir = args.serialization_dir
- pruning_method = args.pruning_method
- threshold = args.threshold
-
- st = torch.load(os.path.join(serialization_dir, "pytorch_model.bin"), map_location="cpu")
-
- remaining_count = 0 # Number of remaining (not pruned) params in the encoder
- encoder_count = 0 # Number of params in the encoder
-
- print("name".ljust(60, " "), "Remaining Weights %", "Remaining Weight")
- for name, param in st.items():
- if "encoder" not in name:
- continue
-
- if "mask_scores" in name:
- if pruning_method == "topK":
- mask_ones = TopKBinarizer.apply(param, threshold).sum().item()
- elif pruning_method == "sigmoied_threshold":
- mask_ones = ThresholdBinarizer.apply(param, threshold, True).sum().item()
- elif pruning_method == "l0":
- l, r = -0.1, 1.1
- s = torch.sigmoid(param)
- s_bar = s * (r - l) + l
- mask = s_bar.clamp(min=0.0, max=1.0)
- mask_ones = (mask > 0.0).sum().item()
- else:
- raise ValueError("Unknown pruning method")
- remaining_count += mask_ones
- print(name.ljust(60, " "), str(round(100 * mask_ones / param.numel(), 3)).ljust(20, " "), str(mask_ones))
- else:
- encoder_count += param.numel()
- if "bias" in name or "LayerNorm" in name:
- remaining_count += param.numel()
-
- print("")
- print("Remaining Weights (global) %: ", 100 * remaining_count / encoder_count)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
-
- parser.add_argument(
- "--pruning_method",
- choices=["l0", "topK", "sigmoied_threshold"],
- type=str,
- required=True,
- help=(
- "Pruning Method (l0 = L0 regularization, topK = Movement pruning, sigmoied_threshold = Soft movement"
- " pruning)"
- ),
- )
- parser.add_argument(
- "--threshold",
- type=float,
- required=False,
- help=(
- "For `topK`, it is the level of remaining weights (in %) in the fine-pruned model. "
- "For `sigmoied_threshold`, it is the threshold \tau against which the (sigmoied) scores are compared. "
- "Not needed for `l0`"
- ),
- )
- parser.add_argument(
- "--serialization_dir",
- type=str,
- required=True,
- help="Folder containing the model that was previously fine-pruned",
- )
-
- args = parser.parse_args()
-
- main(args)
diff --git a/examples/research_projects/movement-pruning/emmental/__init__.py b/examples/research_projects/movement-pruning/emmental/__init__.py
deleted file mode 100644
index 6646667ea88..00000000000
--- a/examples/research_projects/movement-pruning/emmental/__init__.py
+++ /dev/null
@@ -1,9 +0,0 @@
-from .configuration_bert_masked import MaskedBertConfig
-from .modeling_bert_masked import (
- MaskedBertForMultipleChoice,
- MaskedBertForQuestionAnswering,
- MaskedBertForSequenceClassification,
- MaskedBertForTokenClassification,
- MaskedBertModel,
-)
-from .modules import *
diff --git a/examples/research_projects/movement-pruning/emmental/configuration_bert_masked.py b/examples/research_projects/movement-pruning/emmental/configuration_bert_masked.py
deleted file mode 100644
index 9c7459f27a7..00000000000
--- a/examples/research_projects/movement-pruning/emmental/configuration_bert_masked.py
+++ /dev/null
@@ -1,70 +0,0 @@
-# coding=utf-8
-# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
-# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Masked BERT model configuration. It replicates the class `~transformers.BertConfig`
-and adapts it to the specificities of MaskedBert (`pruning_method`, `mask_init` and `mask_scale`."""
-
-import logging
-
-from transformers.configuration_utils import PretrainedConfig
-
-
-logger = logging.getLogger(__name__)
-
-
-class MaskedBertConfig(PretrainedConfig):
- """
- A class replicating the `~transformers.BertConfig` with additional parameters for pruning/masking configuration.
- """
-
- model_type = "masked_bert"
-
- def __init__(
- self,
- vocab_size=30522,
- hidden_size=768,
- num_hidden_layers=12,
- num_attention_heads=12,
- intermediate_size=3072,
- hidden_act="gelu",
- hidden_dropout_prob=0.1,
- attention_probs_dropout_prob=0.1,
- max_position_embeddings=512,
- type_vocab_size=2,
- initializer_range=0.02,
- layer_norm_eps=1e-12,
- pad_token_id=0,
- pruning_method="topK",
- mask_init="constant",
- mask_scale=0.0,
- **kwargs,
- ):
- super().__init__(pad_token_id=pad_token_id, **kwargs)
-
- self.vocab_size = vocab_size
- self.hidden_size = hidden_size
- self.num_hidden_layers = num_hidden_layers
- self.num_attention_heads = num_attention_heads
- self.hidden_act = hidden_act
- self.intermediate_size = intermediate_size
- self.hidden_dropout_prob = hidden_dropout_prob
- self.attention_probs_dropout_prob = attention_probs_dropout_prob
- self.max_position_embeddings = max_position_embeddings
- self.type_vocab_size = type_vocab_size
- self.initializer_range = initializer_range
- self.layer_norm_eps = layer_norm_eps
- self.pruning_method = pruning_method
- self.mask_init = mask_init
- self.mask_scale = mask_scale
diff --git a/examples/research_projects/movement-pruning/emmental/modeling_bert_masked.py b/examples/research_projects/movement-pruning/emmental/modeling_bert_masked.py
deleted file mode 100644
index 8c0b091c7de..00000000000
--- a/examples/research_projects/movement-pruning/emmental/modeling_bert_masked.py
+++ /dev/null
@@ -1,1019 +0,0 @@
-# coding=utf-8
-# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
-# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Masked Version of BERT. It replaces the `torch.nn.Linear` layers with
-:class:`~emmental.MaskedLinear` and add an additional parameters in the forward pass to
-compute the adaptive mask.
-Built on top of `transformers.models.bert.modeling_bert`"""
-
-import logging
-import math
-
-import torch
-from torch import nn
-from torch.nn import CrossEntropyLoss, MSELoss
-
-from emmental import MaskedBertConfig
-from emmental.modules import MaskedLinear
-from transformers.file_utils import add_start_docstrings, add_start_docstrings_to_model_forward
-from transformers.modeling_utils import PreTrainedModel, prune_linear_layer
-from transformers.models.bert.modeling_bert import ACT2FN, load_tf_weights_in_bert
-
-
-logger = logging.getLogger(__name__)
-
-
-class BertEmbeddings(nn.Module):
- """Construct the embeddings from word, position and token_type embeddings."""
-
- def __init__(self, config):
- super().__init__()
- self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=0)
- self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
- self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
-
- # self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
- # any TensorFlow checkpoint file
- self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
- self.dropout = nn.Dropout(config.hidden_dropout_prob)
-
- def forward(self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None):
- if input_ids is not None:
- input_shape = input_ids.size()
- else:
- input_shape = inputs_embeds.size()[:-1]
-
- seq_length = input_shape[1]
- device = input_ids.device if input_ids is not None else inputs_embeds.device
- if position_ids is None:
- position_ids = torch.arange(seq_length, dtype=torch.long, device=device)
- position_ids = position_ids.unsqueeze(0).expand(input_shape)
- if token_type_ids is None:
- token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
-
- if inputs_embeds is None:
- inputs_embeds = self.word_embeddings(input_ids)
- position_embeddings = self.position_embeddings(position_ids)
- token_type_embeddings = self.token_type_embeddings(token_type_ids)
-
- embeddings = inputs_embeds + position_embeddings + token_type_embeddings
- embeddings = self.LayerNorm(embeddings)
- embeddings = self.dropout(embeddings)
- return embeddings
-
-
-class BertSelfAttention(nn.Module):
- def __init__(self, config):
- super().__init__()
- if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
- raise ValueError(
- "The hidden size (%d) is not a multiple of the number of attention heads (%d)"
- % (config.hidden_size, config.num_attention_heads)
- )
- self.output_attentions = config.output_attentions
-
- self.num_attention_heads = config.num_attention_heads
- self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
- self.all_head_size = self.num_attention_heads * self.attention_head_size
-
- self.query = MaskedLinear(
- config.hidden_size,
- self.all_head_size,
- pruning_method=config.pruning_method,
- mask_init=config.mask_init,
- mask_scale=config.mask_scale,
- )
- self.key = MaskedLinear(
- config.hidden_size,
- self.all_head_size,
- pruning_method=config.pruning_method,
- mask_init=config.mask_init,
- mask_scale=config.mask_scale,
- )
- self.value = MaskedLinear(
- config.hidden_size,
- self.all_head_size,
- pruning_method=config.pruning_method,
- mask_init=config.mask_init,
- mask_scale=config.mask_scale,
- )
-
- self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
-
- def transpose_for_scores(self, x):
- new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
- return x.permute(0, 2, 1, 3)
-
- def forward(
- self,
- hidden_states,
- attention_mask=None,
- head_mask=None,
- encoder_hidden_states=None,
- encoder_attention_mask=None,
- threshold=None,
- ):
- mixed_query_layer = self.query(hidden_states, threshold=threshold)
-
- # If this is instantiated as a cross-attention module, the keys
- # and values come from an encoder; the attention mask needs to be
- # such that the encoder's padding tokens are not attended to.
- if encoder_hidden_states is not None:
- mixed_key_layer = self.key(encoder_hidden_states, threshold=threshold)
- mixed_value_layer = self.value(encoder_hidden_states, threshold=threshold)
- attention_mask = encoder_attention_mask
- else:
- mixed_key_layer = self.key(hidden_states, threshold=threshold)
- mixed_value_layer = self.value(hidden_states, threshold=threshold)
-
- query_layer = self.transpose_for_scores(mixed_query_layer)
- key_layer = self.transpose_for_scores(mixed_key_layer)
- value_layer = self.transpose_for_scores(mixed_value_layer)
-
- # Take the dot product between "query" and "key" to get the raw attention scores.
- attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
- attention_scores = attention_scores / math.sqrt(self.attention_head_size)
- if attention_mask is not None:
- # Apply the attention mask is (precomputed for all layers in BertModel forward() function)
- attention_scores = attention_scores + attention_mask
-
- # Normalize the attention scores to probabilities.
- attention_probs = nn.functional.softmax(attention_scores, dim=-1)
-
- # This is actually dropping out entire tokens to attend to, which might
- # seem a bit unusual, but is taken from the original Transformer paper.
- attention_probs = self.dropout(attention_probs)
-
- # Mask heads if we want to
- if head_mask is not None:
- attention_probs = attention_probs * head_mask
-
- context_layer = torch.matmul(attention_probs, value_layer)
-
- context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
- new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
- context_layer = context_layer.view(*new_context_layer_shape)
-
- outputs = (context_layer, attention_probs) if self.output_attentions else (context_layer,)
- return outputs
-
-
-class BertSelfOutput(nn.Module):
- def __init__(self, config):
- super().__init__()
- self.dense = MaskedLinear(
- config.hidden_size,
- config.hidden_size,
- pruning_method=config.pruning_method,
- mask_init=config.mask_init,
- mask_scale=config.mask_scale,
- )
- self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
- self.dropout = nn.Dropout(config.hidden_dropout_prob)
-
- def forward(self, hidden_states, input_tensor, threshold):
- hidden_states = self.dense(hidden_states, threshold=threshold)
- hidden_states = self.dropout(hidden_states)
- hidden_states = self.LayerNorm(hidden_states + input_tensor)
- return hidden_states
-
-
-class BertAttention(nn.Module):
- def __init__(self, config):
- super().__init__()
- self.self = BertSelfAttention(config)
- self.output = BertSelfOutput(config)
- self.pruned_heads = set()
-
- def prune_heads(self, heads):
- if len(heads) == 0:
- return
- mask = torch.ones(self.self.num_attention_heads, self.self.attention_head_size)
- heads = set(heads) - self.pruned_heads # Convert to set and remove already pruned heads
- for head in heads:
- # Compute how many pruned heads are before the head and move the index accordingly
- head = head - sum(1 if h < head else 0 for h in self.pruned_heads)
- mask[head] = 0
- mask = mask.view(-1).contiguous().eq(1)
- index = torch.arange(len(mask))[mask].long()
-
- # Prune linear layers
- self.self.query = prune_linear_layer(self.self.query, index)
- self.self.key = prune_linear_layer(self.self.key, index)
- self.self.value = prune_linear_layer(self.self.value, index)
- self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
-
- # Update hyper params and store pruned heads
- self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
- self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
- self.pruned_heads = self.pruned_heads.union(heads)
-
- def forward(
- self,
- hidden_states,
- attention_mask=None,
- head_mask=None,
- encoder_hidden_states=None,
- encoder_attention_mask=None,
- threshold=None,
- ):
- self_outputs = self.self(
- hidden_states,
- attention_mask,
- head_mask,
- encoder_hidden_states,
- encoder_attention_mask,
- threshold=threshold,
- )
- attention_output = self.output(self_outputs[0], hidden_states, threshold=threshold)
- outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
- return outputs
-
-
-class BertIntermediate(nn.Module):
- def __init__(self, config):
- super().__init__()
- self.dense = MaskedLinear(
- config.hidden_size,
- config.intermediate_size,
- pruning_method=config.pruning_method,
- mask_init=config.mask_init,
- mask_scale=config.mask_scale,
- )
- if isinstance(config.hidden_act, str):
- self.intermediate_act_fn = ACT2FN[config.hidden_act]
- else:
- self.intermediate_act_fn = config.hidden_act
-
- def forward(self, hidden_states, threshold):
- hidden_states = self.dense(hidden_states, threshold=threshold)
- hidden_states = self.intermediate_act_fn(hidden_states)
- return hidden_states
-
-
-class BertOutput(nn.Module):
- def __init__(self, config):
- super().__init__()
- self.dense = MaskedLinear(
- config.intermediate_size,
- config.hidden_size,
- pruning_method=config.pruning_method,
- mask_init=config.mask_init,
- mask_scale=config.mask_scale,
- )
- self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
- self.dropout = nn.Dropout(config.hidden_dropout_prob)
-
- def forward(self, hidden_states, input_tensor, threshold):
- hidden_states = self.dense(hidden_states, threshold=threshold)
- hidden_states = self.dropout(hidden_states)
- hidden_states = self.LayerNorm(hidden_states + input_tensor)
- return hidden_states
-
-
-class BertLayer(nn.Module):
- def __init__(self, config):
- super().__init__()
- self.attention = BertAttention(config)
- self.is_decoder = config.is_decoder
- if self.is_decoder:
- self.crossattention = BertAttention(config)
- self.intermediate = BertIntermediate(config)
- self.output = BertOutput(config)
-
- def forward(
- self,
- hidden_states,
- attention_mask=None,
- head_mask=None,
- encoder_hidden_states=None,
- encoder_attention_mask=None,
- threshold=None,
- ):
- self_attention_outputs = self.attention(hidden_states, attention_mask, head_mask, threshold=threshold)
- attention_output = self_attention_outputs[0]
- outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
-
- if self.is_decoder and encoder_hidden_states is not None:
- cross_attention_outputs = self.crossattention(
- attention_output, attention_mask, head_mask, encoder_hidden_states, encoder_attention_mask
- )
- attention_output = cross_attention_outputs[0]
- outputs = outputs + cross_attention_outputs[1:] # add cross attentions if we output attention weights
-
- intermediate_output = self.intermediate(attention_output, threshold=threshold)
- layer_output = self.output(intermediate_output, attention_output, threshold=threshold)
- outputs = (layer_output,) + outputs
- return outputs
-
-
-class BertEncoder(nn.Module):
- def __init__(self, config):
- super().__init__()
- self.output_attentions = config.output_attentions
- self.output_hidden_states = config.output_hidden_states
- self.layer = nn.ModuleList([BertLayer(config) for _ in range(config.num_hidden_layers)])
-
- def forward(
- self,
- hidden_states,
- attention_mask=None,
- head_mask=None,
- encoder_hidden_states=None,
- encoder_attention_mask=None,
- threshold=None,
- ):
- all_hidden_states = ()
- all_attentions = ()
- for i, layer_module in enumerate(self.layer):
- if self.output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- layer_outputs = layer_module(
- hidden_states,
- attention_mask,
- head_mask[i],
- encoder_hidden_states,
- encoder_attention_mask,
- threshold=threshold,
- )
- hidden_states = layer_outputs[0]
-
- if self.output_attentions:
- all_attentions = all_attentions + (layer_outputs[1],)
-
- # Add last layer
- if self.output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- outputs = (hidden_states,)
- if self.output_hidden_states:
- outputs = outputs + (all_hidden_states,)
- if self.output_attentions:
- outputs = outputs + (all_attentions,)
- return outputs # last-layer hidden state, (all hidden states), (all attentions)
-
-
-class BertPooler(nn.Module):
- def __init__(self, config):
- super().__init__()
- self.dense = nn.Linear(config.hidden_size, config.hidden_size)
- self.activation = nn.Tanh()
-
- def forward(self, hidden_states):
- # We "pool" the model by simply taking the hidden state corresponding
- # to the first token.
- first_token_tensor = hidden_states[:, 0]
- pooled_output = self.dense(first_token_tensor)
- pooled_output = self.activation(pooled_output)
- return pooled_output
-
-
-class MaskedBertPreTrainedModel(PreTrainedModel):
- """An abstract class to handle weights initialization and
- a simple interface for downloading and loading pretrained models.
- """
-
- config_class = MaskedBertConfig
- load_tf_weights = load_tf_weights_in_bert
- base_model_prefix = "bert"
-
- def _init_weights(self, module):
- """Initialize the weights"""
- if isinstance(module, (nn.Linear, nn.Embedding)):
- # Slightly different from the TF version which uses truncated_normal for initialization
- # cf https://github.com/pytorch/pytorch/pull/5617
- module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
- elif isinstance(module, nn.LayerNorm):
- module.bias.data.zero_()
- module.weight.data.fill_(1.0)
- if isinstance(module, nn.Linear) and module.bias is not None:
- module.bias.data.zero_()
-
-
-MASKED_BERT_START_DOCSTRING = r"""
- This model is a PyTorch `torch.nn.Module `_ sub-class.
- Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general
- usage and behavior.
-
- Parameters:
- config (:class:`~emmental.MaskedBertConfig`): Model configuration class with all the parameters of the model.
- Initializing with a config file does not load the weights associated with the model, only the configuration.
- Check out the :meth:`~transformers.PreTrainedModel.from_pretrained` method to load the model weights.
-"""
-
-MASKED_BERT_INPUTS_DOCSTRING = r"""
- Args:
- input_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`):
- Indices of input sequence tokens in the vocabulary.
-
- Indices can be obtained using :class:`transformers.BertTokenizer`.
- See :func:`transformers.PreTrainedTokenizer.encode` and
- :func:`transformers.PreTrainedTokenizer.__call__` for details.
-
- `What are input IDs? <../glossary.html#input-ids>`__
- attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
- Mask to avoid performing attention on padding token indices.
- Mask values selected in ``[0, 1]``:
- ``1`` for tokens that are NOT MASKED, ``0`` for MASKED tokens.
-
- `What are attention masks? <../glossary.html#attention-mask>`__
- token_type_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
- Segment token indices to indicate first and second portions of the inputs.
- Indices are selected in ``[0, 1]``: ``0`` corresponds to a `sentence A` token, ``1``
- corresponds to a `sentence B` token
-
- `What are token type IDs? <../glossary.html#token-type-ids>`_
- position_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
- Indices of positions of each input sequence tokens in the position embeddings.
- Selected in the range ``[0, config.max_position_embeddings - 1]``.
-
- `What are position IDs? <../glossary.html#position-ids>`_
- head_mask (:obj:`torch.FloatTensor` of shape :obj:`(num_heads,)` or :obj:`(num_layers, num_heads)`, `optional`):
- Mask to nullify selected heads of the self-attention modules.
- Mask values selected in ``[0, 1]``:
- :obj:`1` indicates the head is **not masked**, :obj:`0` indicates the head is **masked**.
- inputs_embeds (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
- Optionally, instead of passing :obj:`input_ids` you can choose to directly pass an embedded representation.
- This is useful if you want more control over how to convert `input_ids` indices into associated vectors
- than the model's internal embedding lookup matrix.
- encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
- Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention
- if the model is configured as a decoder.
- encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
- Mask to avoid performing attention on the padding token indices of the encoder input. This mask
- is used in the cross-attention if the model is configured as a decoder.
- Mask values selected in ``[0, 1]``:
- ``1`` for tokens that are NOT MASKED, ``0`` for MASKED tokens.
-"""
-
-
-@add_start_docstrings(
- "The bare Masked Bert Model transformer outputting raw hidden-states without any specific head on top.",
- MASKED_BERT_START_DOCSTRING,
-)
-class MaskedBertModel(MaskedBertPreTrainedModel):
- """
- The `MaskedBertModel` class replicates the :class:`~transformers.BertModel` class
- and adds specific inputs to compute the adaptive mask on the fly.
- Note that we freeze the embeddings modules from their pre-trained values.
- """
-
- def __init__(self, config):
- super().__init__(config)
- self.config = config
-
- self.embeddings = BertEmbeddings(config)
- self.embeddings.requires_grad_(requires_grad=False)
- self.encoder = BertEncoder(config)
- self.pooler = BertPooler(config)
-
- self.init_weights()
-
- def get_input_embeddings(self):
- return self.embeddings.word_embeddings
-
- def set_input_embeddings(self, value):
- self.embeddings.word_embeddings = value
-
- def _prune_heads(self, heads_to_prune):
- """Prunes heads of the model.
- heads_to_prune: dict of {layer_num: list of heads to prune in this layer}
- See base class PreTrainedModel
- """
- for layer, heads in heads_to_prune.items():
- self.encoder.layer[layer].attention.prune_heads(heads)
-
- @add_start_docstrings_to_model_forward(MASKED_BERT_INPUTS_DOCSTRING)
- def forward(
- self,
- input_ids=None,
- attention_mask=None,
- token_type_ids=None,
- position_ids=None,
- head_mask=None,
- inputs_embeds=None,
- encoder_hidden_states=None,
- encoder_attention_mask=None,
- threshold=None,
- ):
- r"""
- threshold (:obj:`float`):
- Threshold value (see :class:`~emmental.MaskedLinear`).
-
- Return:
- :obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~emmental.MaskedBertConfig`) and inputs:
- last_hidden_state (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`):
- Sequence of hidden-states at the output of the last layer of the model.
- pooler_output (:obj:`torch.FloatTensor`: of shape :obj:`(batch_size, hidden_size)`):
- Last layer hidden-state of the first token of the sequence (classification token)
- further processed by a Linear layer and a Tanh activation function. The Linear
- layer weights are trained from the next sentence prediction (classification)
- objective during pre-training.
-
- This output is usually *not* a good summary
- of the semantic content of the input, you're often better with averaging or pooling
- the sequence of hidden-states for the whole input sequence.
- hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
- Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
- of shape :obj:`(batch_size, sequence_length, hidden_size)`.
-
- Hidden-states of the model at the output of each layer plus the initial embedding outputs.
- attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
- Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
- :obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
-
- Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
- heads.
- """
-
- if input_ids is not None and inputs_embeds is not None:
- raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
- elif input_ids is not None:
- input_shape = input_ids.size()
- elif inputs_embeds is not None:
- input_shape = inputs_embeds.size()[:-1]
- else:
- raise ValueError("You have to specify either input_ids or inputs_embeds")
-
- device = input_ids.device if input_ids is not None else inputs_embeds.device
-
- if attention_mask is None:
- attention_mask = torch.ones(input_shape, device=device)
- if token_type_ids is None:
- token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
-
- # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
- # ourselves in which case we just need to make it broadcastable to all heads.
- if attention_mask.dim() == 3:
- extended_attention_mask = attention_mask[:, None, :, :]
- elif attention_mask.dim() == 2:
- # Provided a padding mask of dimensions [batch_size, seq_length]
- # - if the model is a decoder, apply a causal mask in addition to the padding mask
- # - if the model is an encoder, make the mask broadcastable to [batch_size, num_heads, seq_length, seq_length]
- if self.config.is_decoder:
- batch_size, seq_length = input_shape
- seq_ids = torch.arange(seq_length, device=device)
- causal_mask = seq_ids[None, None, :].repeat(batch_size, seq_length, 1) <= seq_ids[None, :, None]
- causal_mask = causal_mask.to(
- attention_mask.dtype
- ) # causal and attention masks must have same type with pytorch version < 1.3
- extended_attention_mask = causal_mask[:, None, :, :] * attention_mask[:, None, None, :]
- else:
- extended_attention_mask = attention_mask[:, None, None, :]
- else:
- raise ValueError(
- "Wrong shape for input_ids (shape {}) or attention_mask (shape {})".format(
- input_shape, attention_mask.shape
- )
- )
-
- # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
- # masked positions, this operation will create a tensor which is 0.0 for
- # positions we want to attend and -10000.0 for masked positions.
- # Since we are adding it to the raw scores before the softmax, this is
- # effectively the same as removing these entirely.
- extended_attention_mask = extended_attention_mask.to(dtype=next(self.parameters()).dtype) # fp16 compatibility
- extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
-
- # If a 2D ou 3D attention mask is provided for the cross-attention
- # we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
- if self.config.is_decoder and encoder_hidden_states is not None:
- encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
- encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
- if encoder_attention_mask is None:
- encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
-
- if encoder_attention_mask.dim() == 3:
- encoder_extended_attention_mask = encoder_attention_mask[:, None, :, :]
- elif encoder_attention_mask.dim() == 2:
- encoder_extended_attention_mask = encoder_attention_mask[:, None, None, :]
- else:
- raise ValueError(
- "Wrong shape for encoder_hidden_shape (shape {}) or encoder_attention_mask (shape {})".format(
- encoder_hidden_shape, encoder_attention_mask.shape
- )
- )
-
- encoder_extended_attention_mask = encoder_extended_attention_mask.to(
- dtype=next(self.parameters()).dtype
- ) # fp16 compatibility
- encoder_extended_attention_mask = (1.0 - encoder_extended_attention_mask) * -10000.0
- else:
- encoder_extended_attention_mask = None
-
- # Prepare head mask if needed
- # 1.0 in head_mask indicate we keep the head
- # attention_probs has shape bsz x n_heads x N x N
- # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
- # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
- if head_mask is not None:
- if head_mask.dim() == 1:
- head_mask = head_mask.unsqueeze(0).unsqueeze(0).unsqueeze(-1).unsqueeze(-1)
- head_mask = head_mask.expand(self.config.num_hidden_layers, -1, -1, -1, -1)
- elif head_mask.dim() == 2:
- head_mask = (
- head_mask.unsqueeze(1).unsqueeze(-1).unsqueeze(-1)
- ) # We can specify head_mask for each layer
- head_mask = head_mask.to(
- dtype=next(self.parameters()).dtype
- ) # switch to float if need + fp16 compatibility
- else:
- head_mask = [None] * self.config.num_hidden_layers
-
- embedding_output = self.embeddings(
- input_ids=input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds
- )
- encoder_outputs = self.encoder(
- embedding_output,
- attention_mask=extended_attention_mask,
- head_mask=head_mask,
- encoder_hidden_states=encoder_hidden_states,
- encoder_attention_mask=encoder_extended_attention_mask,
- threshold=threshold,
- )
- sequence_output = encoder_outputs[0]
- pooled_output = self.pooler(sequence_output)
-
- outputs = (
- sequence_output,
- pooled_output,
- ) + encoder_outputs[1:] # add hidden_states and attentions if they are here
- return outputs # sequence_output, pooled_output, (hidden_states), (attentions)
-
-
-@add_start_docstrings(
- """Masked Bert Model transformer with a sequence classification/regression head on top (a linear layer on top of
- the pooled output) e.g. for GLUE tasks. """,
- MASKED_BERT_START_DOCSTRING,
-)
-class MaskedBertForSequenceClassification(MaskedBertPreTrainedModel):
- def __init__(self, config):
- super().__init__(config)
- self.num_labels = config.num_labels
-
- self.bert = MaskedBertModel(config)
- self.dropout = nn.Dropout(config.hidden_dropout_prob)
- self.classifier = nn.Linear(config.hidden_size, self.config.num_labels)
-
- self.init_weights()
-
- @add_start_docstrings_to_model_forward(MASKED_BERT_INPUTS_DOCSTRING)
- def forward(
- self,
- input_ids=None,
- attention_mask=None,
- token_type_ids=None,
- position_ids=None,
- head_mask=None,
- inputs_embeds=None,
- labels=None,
- threshold=None,
- ):
- r"""
- labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
- Labels for computing the sequence classification/regression loss.
- Indices should be in :obj:`[0, ..., config.num_labels - 1]`.
- If :obj:`config.num_labels == 1` a regression loss is computed (Mean-Square loss),
- If :obj:`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
- threshold (:obj:`float`):
- Threshold value (see :class:`~emmental.MaskedLinear`).
-
- Returns:
- :obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~emmental.MaskedBertConfig`) and inputs:
- loss (:obj:`torch.FloatTensor` of shape :obj:`(1,)`, `optional`, returned when :obj:`label` is provided):
- Classification (or regression if config.num_labels==1) loss.
- logits (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, config.num_labels)`):
- Classification (or regression if config.num_labels==1) scores (before SoftMax).
- hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
- Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
- of shape :obj:`(batch_size, sequence_length, hidden_size)`.
-
- Hidden-states of the model at the output of each layer plus the initial embedding outputs.
- attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
- Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
- :obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
-
- Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
- heads.
- """
-
- outputs = self.bert(
- input_ids,
- attention_mask=attention_mask,
- token_type_ids=token_type_ids,
- position_ids=position_ids,
- head_mask=head_mask,
- inputs_embeds=inputs_embeds,
- threshold=threshold,
- )
-
- pooled_output = outputs[1]
-
- pooled_output = self.dropout(pooled_output)
- logits = self.classifier(pooled_output)
-
- outputs = (logits,) + outputs[2:] # add hidden states and attention if they are here
-
- if labels is not None:
- if self.num_labels == 1:
- # We are doing regression
- loss_fct = MSELoss()
- loss = loss_fct(logits.view(-1), labels.view(-1))
- else:
- loss_fct = CrossEntropyLoss()
- loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
- outputs = (loss,) + outputs
-
- return outputs # (loss), logits, (hidden_states), (attentions)
-
-
-@add_start_docstrings(
- """Masked Bert Model with a multiple choice classification head on top (a linear layer on top of
- the pooled output and a softmax) e.g. for RocStories/SWAG tasks. """,
- MASKED_BERT_START_DOCSTRING,
-)
-class MaskedBertForMultipleChoice(MaskedBertPreTrainedModel):
- def __init__(self, config):
- super().__init__(config)
-
- self.bert = MaskedBertModel(config)
- self.dropout = nn.Dropout(config.hidden_dropout_prob)
- self.classifier = nn.Linear(config.hidden_size, 1)
-
- self.init_weights()
-
- @add_start_docstrings_to_model_forward(MASKED_BERT_INPUTS_DOCSTRING)
- def forward(
- self,
- input_ids=None,
- attention_mask=None,
- token_type_ids=None,
- position_ids=None,
- head_mask=None,
- inputs_embeds=None,
- labels=None,
- threshold=None,
- ):
- r"""
- labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
- Labels for computing the multiple choice classification loss.
- Indices should be in ``[0, ..., num_choices]`` where `num_choices` is the size of the second dimension
- of the input tensors. (see `input_ids` above)
- threshold (:obj:`float`):
- Threshold value (see :class:`~emmental.MaskedLinear`).
-
- Returns:
- :obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~emmental.MaskedBertConfig`) and inputs:
- loss (:obj:`torch.FloatTensor` of shape `(1,)`, `optional`, returned when :obj:`labels` is provided):
- Classification loss.
- classification_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, num_choices)`):
- `num_choices` is the second dimension of the input tensors. (see `input_ids` above).
-
- Classification scores (before SoftMax).
- hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
- Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
- of shape :obj:`(batch_size, sequence_length, hidden_size)`.
-
- Hidden-states of the model at the output of each layer plus the initial embedding outputs.
- attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
- Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
- :obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
-
- Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
- heads.
-
- """
- num_choices = input_ids.shape[1]
-
- input_ids = input_ids.view(-1, input_ids.size(-1))
- attention_mask = attention_mask.view(-1, attention_mask.size(-1)) if attention_mask is not None else None
- token_type_ids = token_type_ids.view(-1, token_type_ids.size(-1)) if token_type_ids is not None else None
- position_ids = position_ids.view(-1, position_ids.size(-1)) if position_ids is not None else None
-
- outputs = self.bert(
- input_ids,
- attention_mask=attention_mask,
- token_type_ids=token_type_ids,
- position_ids=position_ids,
- head_mask=head_mask,
- inputs_embeds=inputs_embeds,
- threshold=threshold,
- )
-
- pooled_output = outputs[1]
-
- pooled_output = self.dropout(pooled_output)
- logits = self.classifier(pooled_output)
- reshaped_logits = logits.view(-1, num_choices)
-
- outputs = (reshaped_logits,) + outputs[2:] # add hidden states and attention if they are here
-
- if labels is not None:
- loss_fct = CrossEntropyLoss()
- loss = loss_fct(reshaped_logits, labels)
- outputs = (loss,) + outputs
-
- return outputs # (loss), reshaped_logits, (hidden_states), (attentions)
-
-
-@add_start_docstrings(
- """Masked Bert Model with a token classification head on top (a linear layer on top of
- the hidden-states output) e.g. for Named-Entity-Recognition (NER) tasks. """,
- MASKED_BERT_START_DOCSTRING,
-)
-class MaskedBertForTokenClassification(MaskedBertPreTrainedModel):
- def __init__(self, config):
- super().__init__(config)
- self.num_labels = config.num_labels
-
- self.bert = MaskedBertModel(config)
- self.dropout = nn.Dropout(config.hidden_dropout_prob)
- self.classifier = nn.Linear(config.hidden_size, config.num_labels)
-
- self.init_weights()
-
- @add_start_docstrings_to_model_forward(MASKED_BERT_INPUTS_DOCSTRING)
- def forward(
- self,
- input_ids=None,
- attention_mask=None,
- token_type_ids=None,
- position_ids=None,
- head_mask=None,
- inputs_embeds=None,
- labels=None,
- threshold=None,
- ):
- r"""
- labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
- Labels for computing the token classification loss.
- Indices should be in ``[0, ..., config.num_labels - 1]``.
- threshold (:obj:`float`):
- Threshold value (see :class:`~emmental.MaskedLinear`).
-
- Returns:
- :obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~emmental.MaskedBertConfig`) and inputs:
- loss (:obj:`torch.FloatTensor` of shape :obj:`(1,)`, `optional`, returned when ``labels`` is provided) :
- Classification loss.
- scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, config.num_labels)`)
- Classification scores (before SoftMax).
- hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
- Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
- of shape :obj:`(batch_size, sequence_length, hidden_size)`.
-
- Hidden-states of the model at the output of each layer plus the initial embedding outputs.
- attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
- Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
- :obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
-
- Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
- heads.
- """
-
- outputs = self.bert(
- input_ids,
- attention_mask=attention_mask,
- token_type_ids=token_type_ids,
- position_ids=position_ids,
- head_mask=head_mask,
- inputs_embeds=inputs_embeds,
- threshold=threshold,
- )
-
- sequence_output = outputs[0]
-
- sequence_output = self.dropout(sequence_output)
- logits = self.classifier(sequence_output)
-
- outputs = (logits,) + outputs[2:] # add hidden states and attention if they are here
- if labels is not None:
- loss_fct = CrossEntropyLoss()
- # Only keep active parts of the loss
- if attention_mask is not None:
- active_loss = attention_mask.view(-1) == 1
- active_logits = logits.view(-1, self.num_labels)
- active_labels = torch.where(
- active_loss, labels.view(-1), torch.tensor(loss_fct.ignore_index).type_as(labels)
- )
- loss = loss_fct(active_logits, active_labels)
- else:
- loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
- outputs = (loss,) + outputs
-
- return outputs # (loss), scores, (hidden_states), (attentions)
-
-
-@add_start_docstrings(
- """Masked Bert Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
- layers on top of the hidden-states output to compute `span start logits` and `span end logits`). """,
- MASKED_BERT_START_DOCSTRING,
-)
-class MaskedBertForQuestionAnswering(MaskedBertPreTrainedModel):
- def __init__(self, config):
- super().__init__(config)
- self.num_labels = config.num_labels
-
- self.bert = MaskedBertModel(config)
- self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels)
-
- self.init_weights()
-
- @add_start_docstrings_to_model_forward(MASKED_BERT_INPUTS_DOCSTRING)
- def forward(
- self,
- input_ids=None,
- attention_mask=None,
- token_type_ids=None,
- position_ids=None,
- head_mask=None,
- inputs_embeds=None,
- start_positions=None,
- end_positions=None,
- threshold=None,
- ):
- r"""
- start_positions (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
- Labels for position (index) of the start of the labelled span for computing the token classification loss.
- Positions are clamped to the length of the sequence (`sequence_length`).
- Position outside of the sequence are not taken into account for computing the loss.
- end_positions (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
- Labels for position (index) of the end of the labelled span for computing the token classification loss.
- Positions are clamped to the length of the sequence (`sequence_length`).
- Position outside of the sequence are not taken into account for computing the loss.
- threshold (:obj:`float`):
- Threshold value (see :class:`~emmental.MaskedLinear`).
-
- Returns:
- :obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~emmental.MaskedBertConfig`) and inputs:
- loss (:obj:`torch.FloatTensor` of shape :obj:`(1,)`, `optional`, returned when :obj:`labels` is provided):
- Total span extraction loss is the sum of a Cross-Entropy for the start and end positions.
- start_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length,)`):
- Span-start scores (before SoftMax).
- end_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length,)`):
- Span-end scores (before SoftMax).
- hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
- Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
- of shape :obj:`(batch_size, sequence_length, hidden_size)`.
-
- Hidden-states of the model at the output of each layer plus the initial embedding outputs.
- attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
- Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
- :obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
-
- Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
- heads.
- """
-
- outputs = self.bert(
- input_ids,
- attention_mask=attention_mask,
- token_type_ids=token_type_ids,
- position_ids=position_ids,
- head_mask=head_mask,
- inputs_embeds=inputs_embeds,
- threshold=threshold,
- )
-
- sequence_output = outputs[0]
-
- logits = self.qa_outputs(sequence_output)
- start_logits, end_logits = logits.split(1, dim=-1)
- start_logits = start_logits.squeeze(-1)
- end_logits = end_logits.squeeze(-1)
-
- outputs = (
- start_logits,
- end_logits,
- ) + outputs[2:]
- if start_positions is not None and end_positions is not None:
- # If we are on multi-GPU, split add a dimension
- if len(start_positions.size()) > 1:
- start_positions = start_positions.squeeze(-1)
- if len(end_positions.size()) > 1:
- end_positions = end_positions.squeeze(-1)
- # sometimes the start/end positions are outside our model inputs, we ignore these terms
- ignored_index = start_logits.size(1)
- start_positions.clamp_(0, ignored_index)
- end_positions.clamp_(0, ignored_index)
-
- loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
- start_loss = loss_fct(start_logits, start_positions)
- end_loss = loss_fct(end_logits, end_positions)
- total_loss = (start_loss + end_loss) / 2
- outputs = (total_loss,) + outputs
-
- return outputs # (loss), start_logits, end_logits, (hidden_states), (attentions)
diff --git a/examples/research_projects/movement-pruning/emmental/modules/__init__.py b/examples/research_projects/movement-pruning/emmental/modules/__init__.py
deleted file mode 100644
index 761a6343d6b..00000000000
--- a/examples/research_projects/movement-pruning/emmental/modules/__init__.py
+++ /dev/null
@@ -1,2 +0,0 @@
-from .binarizer import MagnitudeBinarizer, ThresholdBinarizer, TopKBinarizer
-from .masked_nn import MaskedLinear
diff --git a/examples/research_projects/movement-pruning/emmental/modules/binarizer.py b/examples/research_projects/movement-pruning/emmental/modules/binarizer.py
deleted file mode 100644
index c96975e3b37..00000000000
--- a/examples/research_projects/movement-pruning/emmental/modules/binarizer.py
+++ /dev/null
@@ -1,144 +0,0 @@
-# coding=utf-8
-# Copyright 2020-present, AllenAI Authors, University of Illinois Urbana-Champaign,
-# Intel Nervana Systems and the HuggingFace Inc. team.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-Binarizers take a (real value) matrix as input and produce a binary (values in {0,1}) mask of the same shape.
-"""
-
-import torch
-from torch import autograd
-
-
-class ThresholdBinarizer(autograd.Function):
- """
- Thresholdd binarizer.
- Computes a binary mask M from a real value matrix S such that `M_{i,j} = 1` if and only if `S_{i,j} > \tau`
- where `\tau` is a real value threshold.
-
- Implementation is inspired from:
- https://github.com/arunmallya/piggyback
- Piggyback: Adapting a Single Network to Multiple Tasks by Learning to Mask Weights
- Arun Mallya, Dillon Davis, Svetlana Lazebnik
- """
-
- @staticmethod
- def forward(ctx, inputs: torch.tensor, threshold: float, sigmoid: bool):
- """
- Args:
- inputs (`torch.FloatTensor`)
- The input matrix from which the binarizer computes the binary mask.
- threshold (`float`)
- The threshold value (in R).
- sigmoid (`bool`)
- If set to ``True``, we apply the sigmoid function to the `inputs` matrix before comparing to `threshold`.
- In this case, `threshold` should be a value between 0 and 1.
- Returns:
- mask (`torch.FloatTensor`)
- Binary matrix of the same size as `inputs` acting as a mask (1 - the associated weight is
- retained, 0 - the associated weight is pruned).
- """
- nb_elems = inputs.numel()
- nb_min = int(0.005 * nb_elems) + 1
- if sigmoid:
- mask = (torch.sigmoid(inputs) > threshold).type(inputs.type())
- else:
- mask = (inputs > threshold).type(inputs.type())
- if mask.sum() < nb_min:
- # We limit the pruning so that at least 0.5% (half a percent) of the weights are remaining
- k_threshold = inputs.flatten().kthvalue(max(nb_elems - nb_min, 1)).values
- mask = (inputs > k_threshold).type(inputs.type())
- return mask
-
- @staticmethod
- def backward(ctx, gradOutput):
- return gradOutput, None, None
-
-
-class TopKBinarizer(autograd.Function):
- """
- Top-k Binarizer.
- Computes a binary mask M from a real value matrix S such that `M_{i,j} = 1` if and only if `S_{i,j}`
- is among the k% highest values of S.
-
- Implementation is inspired from:
- https://github.com/allenai/hidden-networks
- What's hidden in a randomly weighted neural network?
- Vivek Ramanujan*, Mitchell Wortsman*, Aniruddha Kembhavi, Ali Farhadi, Mohammad Rastegari
- """
-
- @staticmethod
- def forward(ctx, inputs: torch.tensor, threshold: float):
- """
- Args:
- inputs (`torch.FloatTensor`)
- The input matrix from which the binarizer computes the binary mask.
- threshold (`float`)
- The percentage of weights to keep (the rest is pruned).
- `threshold` is a float between 0 and 1.
- Returns:
- mask (`torch.FloatTensor`)
- Binary matrix of the same size as `inputs` acting as a mask (1 - the associated weight is
- retained, 0 - the associated weight is pruned).
- """
- # Get the subnetwork by sorting the inputs and using the top threshold %
- mask = inputs.clone()
- _, idx = inputs.flatten().sort(descending=True)
- j = int(threshold * inputs.numel())
-
- # flat_out and mask access the same memory.
- flat_out = mask.flatten()
- flat_out[idx[j:]] = 0
- flat_out[idx[:j]] = 1
- return mask
-
- @staticmethod
- def backward(ctx, gradOutput):
- return gradOutput, None
-
-
-class MagnitudeBinarizer:
- """
- Magnitude Binarizer.
- Computes a binary mask M from a real value matrix S such that `M_{i,j} = 1` if and only if `S_{i,j}`
- is among the k% highest values of |S| (absolute value).
-
- Implementation is inspired from https://github.com/NervanaSystems/distiller/blob/2291fdcc2ea642a98d4e20629acb5a9e2e04b4e6/distiller/pruning/automated_gradual_pruner.py#L24
- """
-
- @staticmethod
- def apply(inputs: torch.tensor, threshold: float):
- """
- Args:
- inputs (`torch.FloatTensor`)
- The input matrix from which the binarizer computes the binary mask.
- This input marix is typically the weight matrix.
- threshold (`float`)
- The percentage of weights to keep (the rest is pruned).
- `threshold` is a float between 0 and 1.
- Returns:
- mask (`torch.FloatTensor`)
- Binary matrix of the same size as `inputs` acting as a mask (1 - the associated weight is
- retained, 0 - the associated weight is pruned).
- """
- # Get the subnetwork by sorting the inputs and using the top threshold %
- mask = inputs.clone()
- _, idx = inputs.abs().flatten().sort(descending=True)
- j = int(threshold * inputs.numel())
-
- # flat_out and mask access the same memory.
- flat_out = mask.flatten()
- flat_out[idx[j:]] = 0
- flat_out[idx[:j]] = 1
- return mask
diff --git a/examples/research_projects/movement-pruning/emmental/modules/masked_nn.py b/examples/research_projects/movement-pruning/emmental/modules/masked_nn.py
deleted file mode 100644
index e3c94836851..00000000000
--- a/examples/research_projects/movement-pruning/emmental/modules/masked_nn.py
+++ /dev/null
@@ -1,106 +0,0 @@
-# coding=utf-8
-# Copyright 2020-present, the HuggingFace Inc. team.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-Masked Linear module: A fully connected layer that computes an adaptive binary mask on the fly.
-The mask (binary or not) is computed at each forward pass and multiplied against
-the weight matrix to prune a portion of the weights.
-The pruned weight matrix is then multiplied against the inputs (and if necessary, the bias is added).
-"""
-
-import math
-
-import torch
-from torch import nn
-from torch.nn import init
-
-from .binarizer import MagnitudeBinarizer, ThresholdBinarizer, TopKBinarizer
-
-
-class MaskedLinear(nn.Linear):
- """
- Fully Connected layer with on the fly adaptive mask.
- If needed, a score matrix is created to store the importance of each associated weight.
- """
-
- def __init__(
- self,
- in_features: int,
- out_features: int,
- bias: bool = True,
- mask_init: str = "constant",
- mask_scale: float = 0.0,
- pruning_method: str = "topK",
- ):
- """
- Args:
- in_features (`int`)
- Size of each input sample
- out_features (`int`)
- Size of each output sample
- bias (`bool`)
- If set to ``False``, the layer will not learn an additive bias.
- Default: ``True``
- mask_init (`str`)
- The initialization method for the score matrix if a score matrix is needed.
- Choices: ["constant", "uniform", "kaiming"]
- Default: ``constant``
- mask_scale (`float`)
- The initialization parameter for the chosen initialization method `mask_init`.
- Default: ``0.``
- pruning_method (`str`)
- Method to compute the mask.
- Choices: ["topK", "threshold", "sigmoied_threshold", "magnitude", "l0"]
- Default: ``topK``
- """
- super(MaskedLinear, self).__init__(in_features=in_features, out_features=out_features, bias=bias)
- assert pruning_method in ["topK", "threshold", "sigmoied_threshold", "magnitude", "l0"]
- self.pruning_method = pruning_method
-
- if self.pruning_method in ["topK", "threshold", "sigmoied_threshold", "l0"]:
- self.mask_scale = mask_scale
- self.mask_init = mask_init
- self.mask_scores = nn.Parameter(torch.empty(self.weight.size()))
- self.init_mask()
-
- def init_mask(self):
- if self.mask_init == "constant":
- init.constant_(self.mask_scores, val=self.mask_scale)
- elif self.mask_init == "uniform":
- init.uniform_(self.mask_scores, a=-self.mask_scale, b=self.mask_scale)
- elif self.mask_init == "kaiming":
- init.kaiming_uniform_(self.mask_scores, a=math.sqrt(5))
-
- def forward(self, input: torch.tensor, threshold: float):
- # Get the mask
- if self.pruning_method == "topK":
- mask = TopKBinarizer.apply(self.mask_scores, threshold)
- elif self.pruning_method in ["threshold", "sigmoied_threshold"]:
- sig = "sigmoied" in self.pruning_method
- mask = ThresholdBinarizer.apply(self.mask_scores, threshold, sig)
- elif self.pruning_method == "magnitude":
- mask = MagnitudeBinarizer.apply(self.weight, threshold)
- elif self.pruning_method == "l0":
- l, r, b = -0.1, 1.1, 2 / 3
- if self.training:
- u = torch.zeros_like(self.mask_scores).uniform_().clamp(0.0001, 0.9999)
- s = torch.sigmoid((u.log() - (1 - u).log() + self.mask_scores) / b)
- else:
- s = torch.sigmoid(self.mask_scores)
- s_bar = s * (r - l) + l
- mask = s_bar.clamp(min=0.0, max=1.0)
- # Mask weights with computed mask
- weight_thresholded = mask * self.weight
- # Compute output (linear layer) with masked weights
- return nn.functional.linear(input, weight_thresholded, self.bias)
diff --git a/examples/research_projects/movement-pruning/masked_run_glue.py b/examples/research_projects/movement-pruning/masked_run_glue.py
deleted file mode 100644
index 4ddb4248357..00000000000
--- a/examples/research_projects/movement-pruning/masked_run_glue.py
+++ /dev/null
@@ -1,962 +0,0 @@
-# coding=utf-8
-# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
-# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Fine-pruning Masked BERT on sequence classification on GLUE."""
-
-import argparse
-import glob
-import json
-import logging
-import os
-import random
-
-import numpy as np
-import torch
-from emmental import MaskedBertConfig, MaskedBertForSequenceClassification
-from torch import nn
-from torch.utils.data import DataLoader, RandomSampler, SequentialSampler, TensorDataset
-from torch.utils.data.distributed import DistributedSampler
-from tqdm import tqdm, trange
-
-from transformers import (
- WEIGHTS_NAME,
- AdamW,
- BertConfig,
- BertForSequenceClassification,
- BertTokenizer,
- get_linear_schedule_with_warmup,
-)
-from transformers import glue_compute_metrics as compute_metrics
-from transformers import glue_convert_examples_to_features as convert_examples_to_features
-from transformers import glue_output_modes as output_modes
-from transformers import glue_processors as processors
-
-
-try:
- from torch.utils.tensorboard import SummaryWriter
-except ImportError:
- from tensorboardX import SummaryWriter
-
-
-logger = logging.getLogger(__name__)
-
-MODEL_CLASSES = {
- "bert": (BertConfig, BertForSequenceClassification, BertTokenizer),
- "masked_bert": (MaskedBertConfig, MaskedBertForSequenceClassification, BertTokenizer),
-}
-
-
-def set_seed(args):
- random.seed(args.seed)
- np.random.seed(args.seed)
- torch.manual_seed(args.seed)
- if args.n_gpu > 0:
- torch.cuda.manual_seed_all(args.seed)
-
-
-def schedule_threshold(
- step: int,
- total_step: int,
- warmup_steps: int,
- initial_threshold: float,
- final_threshold: float,
- initial_warmup: int,
- final_warmup: int,
- final_lambda: float,
-):
- if step <= initial_warmup * warmup_steps:
- threshold = initial_threshold
- elif step > (total_step - final_warmup * warmup_steps):
- threshold = final_threshold
- else:
- spars_warmup_steps = initial_warmup * warmup_steps
- spars_schedu_steps = (final_warmup + initial_warmup) * warmup_steps
- mul_coeff = 1 - (step - spars_warmup_steps) / (total_step - spars_schedu_steps)
- threshold = final_threshold + (initial_threshold - final_threshold) * (mul_coeff**3)
- regu_lambda = final_lambda * threshold / final_threshold
- return threshold, regu_lambda
-
-
-def regularization(model: nn.Module, mode: str):
- regu, counter = 0, 0
- for name, param in model.named_parameters():
- if "mask_scores" in name:
- if mode == "l1":
- regu += torch.norm(torch.sigmoid(param), p=1) / param.numel()
- elif mode == "l0":
- regu += torch.sigmoid(param - 2 / 3 * np.log(0.1 / 1.1)).sum() / param.numel()
- else:
- raise ValueError("Don't know this mode.")
- counter += 1
- return regu / counter
-
-
-def train(args, train_dataset, model, tokenizer, teacher=None):
- """Train the model"""
- if args.local_rank in [-1, 0]:
- tb_writer = SummaryWriter(log_dir=args.output_dir)
-
- args.train_batch_size = args.per_gpu_train_batch_size * max(1, args.n_gpu)
- train_sampler = RandomSampler(train_dataset) if args.local_rank == -1 else DistributedSampler(train_dataset)
- train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size)
-
- if args.max_steps > 0:
- t_total = args.max_steps
- args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
- else:
- t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
-
- # Prepare optimizer and schedule (linear warmup and decay)
- no_decay = ["bias", "LayerNorm.weight"]
- optimizer_grouped_parameters = [
- {
- "params": [p for n, p in model.named_parameters() if "mask_score" in n and p.requires_grad],
- "lr": args.mask_scores_learning_rate,
- },
- {
- "params": [
- p
- for n, p in model.named_parameters()
- if "mask_score" not in n and p.requires_grad and not any(nd in n for nd in no_decay)
- ],
- "lr": args.learning_rate,
- "weight_decay": args.weight_decay,
- },
- {
- "params": [
- p
- for n, p in model.named_parameters()
- if "mask_score" not in n and p.requires_grad and any(nd in n for nd in no_decay)
- ],
- "lr": args.learning_rate,
- "weight_decay": 0.0,
- },
- ]
-
- optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
- scheduler = get_linear_schedule_with_warmup(
- optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
- )
-
- # Check if saved optimizer or scheduler states exist
- if os.path.isfile(os.path.join(args.model_name_or_path, "optimizer.pt")) and os.path.isfile(
- os.path.join(args.model_name_or_path, "scheduler.pt")
- ):
- # Load in optimizer and scheduler states
- optimizer.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "optimizer.pt")))
- scheduler.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "scheduler.pt")))
-
- if args.fp16:
- try:
- from apex import amp
- except ImportError:
- raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
- model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
-
- # multi-gpu training (should be after apex fp16 initialization)
- if args.n_gpu > 1:
- model = nn.DataParallel(model)
-
- # Distributed training (should be after apex fp16 initialization)
- if args.local_rank != -1:
- model = nn.parallel.DistributedDataParallel(
- model,
- device_ids=[args.local_rank],
- output_device=args.local_rank,
- find_unused_parameters=True,
- )
-
- # Train!
- logger.info("***** Running training *****")
- logger.info(" Num examples = %d", len(train_dataset))
- logger.info(" Num Epochs = %d", args.num_train_epochs)
- logger.info(" Instantaneous batch size per GPU = %d", args.per_gpu_train_batch_size)
- logger.info(
- " Total train batch size (w. parallel, distributed & accumulation) = %d",
- args.train_batch_size
- * args.gradient_accumulation_steps
- * (torch.distributed.get_world_size() if args.local_rank != -1 else 1),
- )
- logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)
- logger.info(" Total optimization steps = %d", t_total)
- # Distillation
- if teacher is not None:
- logger.info(" Training with distillation")
-
- global_step = 0
- # Global TopK
- if args.global_topk:
- threshold_mem = None
- epochs_trained = 0
- steps_trained_in_current_epoch = 0
- # Check if continuing training from a checkpoint
- if os.path.exists(args.model_name_or_path):
- # set global_step to global_step of last saved checkpoint from model path
- try:
- global_step = int(args.model_name_or_path.split("-")[-1].split("/")[0])
- except ValueError:
- global_step = 0
- epochs_trained = global_step // (len(train_dataloader) // args.gradient_accumulation_steps)
- steps_trained_in_current_epoch = global_step % (len(train_dataloader) // args.gradient_accumulation_steps)
-
- logger.info(" Continuing training from checkpoint, will skip to saved global_step")
- logger.info(" Continuing training from epoch %d", epochs_trained)
- logger.info(" Continuing training from global step %d", global_step)
- logger.info(" Will skip the first %d steps in the first epoch", steps_trained_in_current_epoch)
-
- tr_loss, logging_loss = 0.0, 0.0
- model.zero_grad()
- train_iterator = trange(
- epochs_trained,
- int(args.num_train_epochs),
- desc="Epoch",
- disable=args.local_rank not in [-1, 0],
- )
- set_seed(args) # Added here for reproducibility
- for _ in train_iterator:
- epoch_iterator = tqdm(train_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])
- for step, batch in enumerate(epoch_iterator):
- # Skip past any already trained steps if resuming training
- if steps_trained_in_current_epoch > 0:
- steps_trained_in_current_epoch -= 1
- continue
-
- model.train()
- batch = tuple(t.to(args.device) for t in batch)
- threshold, regu_lambda = schedule_threshold(
- step=global_step,
- total_step=t_total,
- warmup_steps=args.warmup_steps,
- final_threshold=args.final_threshold,
- initial_threshold=args.initial_threshold,
- final_warmup=args.final_warmup,
- initial_warmup=args.initial_warmup,
- final_lambda=args.final_lambda,
- )
- # Global TopK
- if args.global_topk:
- if threshold == 1.0:
- threshold = -1e2 # Or an indefinitely low quantity
- else:
- if (threshold_mem is None) or (global_step % args.global_topk_frequency_compute == 0):
- # Sort all the values to get the global topK
- concat = torch.cat(
- [param.view(-1) for name, param in model.named_parameters() if "mask_scores" in name]
- )
- n = concat.numel()
- kth = max(n - (int(n * threshold) + 1), 1)
- threshold_mem = concat.kthvalue(kth).values.item()
- threshold = threshold_mem
- else:
- threshold = threshold_mem
- inputs = {"input_ids": batch[0], "attention_mask": batch[1], "labels": batch[3]}
- if args.model_type != "distilbert":
- inputs["token_type_ids"] = (
- batch[2] if args.model_type in ["bert", "masked_bert", "xlnet", "albert"] else None
- ) # XLM, DistilBERT, RoBERTa, and XLM-RoBERTa don't use segment_ids
-
- if "masked" in args.model_type:
- inputs["threshold"] = threshold
-
- outputs = model(**inputs)
- loss, logits_stu = outputs # model outputs are always tuple in transformers (see doc)
-
- # Distillation loss
- if teacher is not None:
- if "token_type_ids" not in inputs:
- inputs["token_type_ids"] = None if args.teacher_type == "xlm" else batch[2]
- with torch.no_grad():
- (logits_tea,) = teacher(
- input_ids=inputs["input_ids"],
- token_type_ids=inputs["token_type_ids"],
- attention_mask=inputs["attention_mask"],
- )
-
- loss_logits = nn.functional.kl_div(
- input=nn.functional.log_softmax(logits_stu / args.temperature, dim=-1),
- target=nn.functional.softmax(logits_tea / args.temperature, dim=-1),
- reduction="batchmean",
- ) * (args.temperature**2)
-
- loss = args.alpha_distil * loss_logits + args.alpha_ce * loss
-
- # Regularization
- if args.regularization is not None:
- regu_ = regularization(model=model, mode=args.regularization)
- loss = loss + regu_lambda * regu_
-
- if args.n_gpu > 1:
- loss = loss.mean() # mean() to average on multi-gpu parallel training
- if args.gradient_accumulation_steps > 1:
- loss = loss / args.gradient_accumulation_steps
-
- if args.fp16:
- with amp.scale_loss(loss, optimizer) as scaled_loss:
- scaled_loss.backward()
- else:
- loss.backward()
-
- tr_loss += loss.item()
- if (step + 1) % args.gradient_accumulation_steps == 0 or (
- # last step in epoch but step is always smaller than gradient_accumulation_steps
- len(epoch_iterator) <= args.gradient_accumulation_steps and (step + 1) == len(epoch_iterator)
- ):
- if args.fp16:
- nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
- else:
- nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
-
- if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
- tb_writer.add_scalar("threshold", threshold, global_step)
- for name, param in model.named_parameters():
- if not param.requires_grad:
- continue
- tb_writer.add_scalar("parameter_mean/" + name, param.data.mean(), global_step)
- tb_writer.add_scalar("parameter_std/" + name, param.data.std(), global_step)
- tb_writer.add_scalar("parameter_min/" + name, param.data.min(), global_step)
- tb_writer.add_scalar("parameter_max/" + name, param.data.max(), global_step)
- tb_writer.add_scalar("grad_mean/" + name, param.grad.data.mean(), global_step)
- tb_writer.add_scalar("grad_std/" + name, param.grad.data.std(), global_step)
- if args.regularization is not None and "mask_scores" in name:
- if args.regularization == "l1":
- perc = (torch.sigmoid(param) > threshold).sum().item() / param.numel()
- elif args.regularization == "l0":
- perc = (torch.sigmoid(param - 2 / 3 * np.log(0.1 / 1.1))).sum().item() / param.numel()
- tb_writer.add_scalar("retained_weights_perc/" + name, perc, global_step)
-
- optimizer.step()
- scheduler.step() # Update learning rate schedule
- model.zero_grad()
- global_step += 1
-
- if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
- logs = {}
- if (
- args.local_rank == -1 and args.evaluate_during_training
- ): # Only evaluate when single GPU otherwise metrics may not average well
- results = evaluate(args, model, tokenizer)
- for key, value in results.items():
- eval_key = "eval_{}".format(key)
- logs[eval_key] = value
-
- loss_scalar = (tr_loss - logging_loss) / args.logging_steps
- learning_rate_scalar = scheduler.get_lr()
- logs["learning_rate"] = learning_rate_scalar[0]
- if len(learning_rate_scalar) > 1:
- for idx, lr in enumerate(learning_rate_scalar[1:]):
- logs[f"learning_rate/{idx+1}"] = lr
- logs["loss"] = loss_scalar
- if teacher is not None:
- logs["loss/distil"] = loss_logits.item()
- if args.regularization is not None:
- logs["loss/regularization"] = regu_.item()
- if (teacher is not None) or (args.regularization is not None):
- if (teacher is not None) and (args.regularization is not None):
- logs["loss/instant_ce"] = (
- loss.item()
- - regu_lambda * logs["loss/regularization"]
- - args.alpha_distil * logs["loss/distil"]
- ) / args.alpha_ce
- elif teacher is not None:
- logs["loss/instant_ce"] = (
- loss.item() - args.alpha_distil * logs["loss/distil"]
- ) / args.alpha_ce
- else:
- logs["loss/instant_ce"] = loss.item() - regu_lambda * logs["loss/regularization"]
- logging_loss = tr_loss
-
- for key, value in logs.items():
- tb_writer.add_scalar(key, value, global_step)
- print(json.dumps({**logs, **{"step": global_step}}))
-
- if args.local_rank in [-1, 0] and args.save_steps > 0 and global_step % args.save_steps == 0:
- # Save model checkpoint
- output_dir = os.path.join(args.output_dir, "checkpoint-{}".format(global_step))
- if not os.path.exists(output_dir):
- os.makedirs(output_dir)
- model_to_save = (
- model.module if hasattr(model, "module") else model
- ) # Take care of distributed/parallel training
- model_to_save.save_pretrained(output_dir)
- tokenizer.save_pretrained(output_dir)
-
- torch.save(args, os.path.join(output_dir, "training_args.bin"))
- logger.info("Saving model checkpoint to %s", output_dir)
-
- torch.save(optimizer.state_dict(), os.path.join(output_dir, "optimizer.pt"))
- torch.save(scheduler.state_dict(), os.path.join(output_dir, "scheduler.pt"))
- logger.info("Saving optimizer and scheduler states to %s", output_dir)
-
- if args.max_steps > 0 and global_step > args.max_steps:
- epoch_iterator.close()
- break
- if args.max_steps > 0 and global_step > args.max_steps:
- train_iterator.close()
- break
-
- if args.local_rank in [-1, 0]:
- tb_writer.close()
-
- return global_step, tr_loss / global_step
-
-
-def evaluate(args, model, tokenizer, prefix=""):
- # Loop to handle MNLI double evaluation (matched, mis-matched)
- eval_task_names = ("mnli", "mnli-mm") if args.task_name == "mnli" else (args.task_name,)
- eval_outputs_dirs = (args.output_dir, args.output_dir + "/MM") if args.task_name == "mnli" else (args.output_dir,)
-
- results = {}
- for eval_task, eval_output_dir in zip(eval_task_names, eval_outputs_dirs):
- eval_dataset = load_and_cache_examples(args, eval_task, tokenizer, evaluate=True)
-
- if not os.path.exists(eval_output_dir) and args.local_rank in [-1, 0]:
- os.makedirs(eval_output_dir)
-
- args.eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)
- # Note that DistributedSampler samples randomly
- eval_sampler = SequentialSampler(eval_dataset)
- eval_dataloader = DataLoader(eval_dataset, sampler=eval_sampler, batch_size=args.eval_batch_size)
-
- # multi-gpu eval
- if args.n_gpu > 1 and not isinstance(model, nn.DataParallel):
- model = nn.DataParallel(model)
-
- # Eval!
- logger.info("***** Running evaluation {} *****".format(prefix))
- logger.info(" Num examples = %d", len(eval_dataset))
- logger.info(" Batch size = %d", args.eval_batch_size)
- eval_loss = 0.0
- nb_eval_steps = 0
- preds = None
- out_label_ids = None
-
- # Global TopK
- if args.global_topk:
- threshold_mem = None
-
- for batch in tqdm(eval_dataloader, desc="Evaluating"):
- model.eval()
- batch = tuple(t.to(args.device) for t in batch)
-
- with torch.no_grad():
- inputs = {"input_ids": batch[0], "attention_mask": batch[1], "labels": batch[3]}
- if args.model_type != "distilbert":
- inputs["token_type_ids"] = (
- batch[2] if args.model_type in ["bert", "masked_bert", "xlnet", "albert"] else None
- ) # XLM, DistilBERT, RoBERTa, and XLM-RoBERTa don't use segment_ids
- if "masked" in args.model_type:
- inputs["threshold"] = args.final_threshold
- if args.global_topk:
- if threshold_mem is None:
- concat = torch.cat(
- [param.view(-1) for name, param in model.named_parameters() if "mask_scores" in name]
- )
- n = concat.numel()
- kth = max(n - (int(n * args.final_threshold) + 1), 1)
- threshold_mem = concat.kthvalue(kth).values.item()
- inputs["threshold"] = threshold_mem
- outputs = model(**inputs)
- tmp_eval_loss, logits = outputs[:2]
-
- eval_loss += tmp_eval_loss.mean().item()
- nb_eval_steps += 1
- if preds is None:
- preds = logits.detach().cpu().numpy()
- out_label_ids = inputs["labels"].detach().cpu().numpy()
- else:
- preds = np.append(preds, logits.detach().cpu().numpy(), axis=0)
- out_label_ids = np.append(out_label_ids, inputs["labels"].detach().cpu().numpy(), axis=0)
-
- eval_loss = eval_loss / nb_eval_steps
- if args.output_mode == "classification":
- from scipy.special import softmax
-
- probs = softmax(preds, axis=-1)
- entropy = np.exp((-probs * np.log(probs)).sum(axis=-1).mean())
- preds = np.argmax(preds, axis=1)
- elif args.output_mode == "regression":
- preds = np.squeeze(preds)
- result = compute_metrics(eval_task, preds, out_label_ids)
- results.update(result)
- if entropy is not None:
- result["eval_avg_entropy"] = entropy
-
- output_eval_file = os.path.join(eval_output_dir, prefix, "eval_results.txt")
- with open(output_eval_file, "w") as writer:
- logger.info("***** Eval results {} *****".format(prefix))
- for key in sorted(result.keys()):
- logger.info(" %s = %s", key, str(result[key]))
- writer.write("%s = %s\n" % (key, str(result[key])))
-
- return results
-
-
-def load_and_cache_examples(args, task, tokenizer, evaluate=False):
- if args.local_rank not in [-1, 0] and not evaluate:
- torch.distributed.barrier() # Make sure only the first process in distributed training process the dataset, and the others will use the cache
-
- processor = processors[task]()
- output_mode = output_modes[task]
- # Load data features from cache or dataset file
- cached_features_file = os.path.join(
- args.data_dir,
- "cached_{}_{}_{}_{}".format(
- "dev" if evaluate else "train",
- list(filter(None, args.model_name_or_path.split("/"))).pop(),
- str(args.max_seq_length),
- str(task),
- ),
- )
- if os.path.exists(cached_features_file) and not args.overwrite_cache:
- logger.info("Loading features from cached file %s", cached_features_file)
- features = torch.load(cached_features_file)
- else:
- logger.info("Creating features from dataset file at %s", args.data_dir)
- label_list = processor.get_labels()
- if task in ["mnli", "mnli-mm"] and args.model_type in ["roberta", "xlmroberta"]:
- # HACK(label indices are swapped in RoBERTa pretrained model)
- label_list[1], label_list[2] = label_list[2], label_list[1]
- examples = (
- processor.get_dev_examples(args.data_dir) if evaluate else processor.get_train_examples(args.data_dir)
- )
- features = convert_examples_to_features(
- examples,
- tokenizer,
- max_length=args.max_seq_length,
- label_list=label_list,
- output_mode=output_mode,
- )
- if args.local_rank in [-1, 0]:
- logger.info("Saving features into cached file %s", cached_features_file)
- torch.save(features, cached_features_file)
-
- if args.local_rank == 0 and not evaluate:
- torch.distributed.barrier() # Make sure only the first process in distributed training process the dataset, and the others will use the cache
-
- # Convert to Tensors and build dataset
- all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
- all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
- all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
- if output_mode == "classification":
- all_labels = torch.tensor([f.label for f in features], dtype=torch.long)
- elif output_mode == "regression":
- all_labels = torch.tensor([f.label for f in features], dtype=torch.float)
-
- dataset = TensorDataset(all_input_ids, all_attention_mask, all_token_type_ids, all_labels)
- return dataset
-
-
-def main():
- parser = argparse.ArgumentParser()
-
- # Required parameters
- parser.add_argument(
- "--data_dir",
- default=None,
- type=str,
- required=True,
- help="The input data dir. Should contain the .tsv files (or other data files) for the task.",
- )
- parser.add_argument(
- "--model_type",
- default=None,
- type=str,
- required=True,
- help="Model type selected in the list: " + ", ".join(MODEL_CLASSES.keys()),
- )
- parser.add_argument(
- "--model_name_or_path",
- default=None,
- type=str,
- required=True,
- help="Path to pretrained model or model identifier from huggingface.co/models",
- )
- parser.add_argument(
- "--task_name",
- default=None,
- type=str,
- required=True,
- help="The name of the task to train selected in the list: " + ", ".join(processors.keys()),
- )
- parser.add_argument(
- "--output_dir",
- default=None,
- type=str,
- required=True,
- help="The output directory where the model predictions and checkpoints will be written.",
- )
- # Other parameters
- parser.add_argument(
- "--config_name",
- default="",
- type=str,
- help="Pretrained config name or path if not the same as model_name",
- )
- parser.add_argument(
- "--tokenizer_name",
- default="",
- type=str,
- help="Pretrained tokenizer name or path if not the same as model_name",
- )
- parser.add_argument(
- "--cache_dir",
- default="",
- type=str,
- help="Where do you want to store the pre-trained models downloaded from huggingface.co",
- )
- parser.add_argument(
- "--max_seq_length",
- default=128,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
- parser.add_argument("--do_eval", action="store_true", help="Whether to run eval on the dev set.")
- parser.add_argument(
- "--evaluate_during_training",
- action="store_true",
- help="Run evaluation during training at each logging step.",
- )
- parser.add_argument(
- "--do_lower_case",
- action="store_true",
- help="Set this flag if you are using an uncased model.",
- )
-
- parser.add_argument(
- "--per_gpu_train_batch_size",
- default=8,
- type=int,
- help="Batch size per GPU/CPU for training.",
- )
- parser.add_argument(
- "--per_gpu_eval_batch_size",
- default=8,
- type=int,
- help="Batch size per GPU/CPU for evaluation.",
- )
- parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
-
- # Pruning parameters
- parser.add_argument(
- "--mask_scores_learning_rate",
- default=1e-2,
- type=float,
- help="The Adam initial learning rate of the mask scores.",
- )
- parser.add_argument(
- "--initial_threshold", default=1.0, type=float, help="Initial value of the threshold (for scheduling)."
- )
- parser.add_argument(
- "--final_threshold", default=0.7, type=float, help="Final value of the threshold (for scheduling)."
- )
- parser.add_argument(
- "--initial_warmup",
- default=1,
- type=int,
- help=(
- "Run `initial_warmup` * `warmup_steps` steps of threshold warmup during which threshold stays "
- "at its `initial_threshold` value (sparsity schedule)."
- ),
- )
- parser.add_argument(
- "--final_warmup",
- default=2,
- type=int,
- help=(
- "Run `final_warmup` * `warmup_steps` steps of threshold cool-down during which threshold stays "
- "at its final_threshold value (sparsity schedule)."
- ),
- )
-
- parser.add_argument(
- "--pruning_method",
- default="topK",
- type=str,
- help=(
- "Pruning Method (l0 = L0 regularization, magnitude = Magnitude pruning, topK = Movement pruning,"
- " sigmoied_threshold = Soft movement pruning)."
- ),
- )
- parser.add_argument(
- "--mask_init",
- default="constant",
- type=str,
- help="Initialization method for the mask scores. Choices: constant, uniform, kaiming.",
- )
- parser.add_argument(
- "--mask_scale", default=0.0, type=float, help="Initialization parameter for the chosen initialization method."
- )
-
- parser.add_argument("--regularization", default=None, help="Add L0 or L1 regularization to the mask scores.")
- parser.add_argument(
- "--final_lambda",
- default=0.0,
- type=float,
- help="Regularization intensity (used in conjunction with `regularization`.",
- )
-
- parser.add_argument("--global_topk", action="store_true", help="Global TopK on the Scores.")
- parser.add_argument(
- "--global_topk_frequency_compute",
- default=25,
- type=int,
- help="Frequency at which we compute the TopK global threshold.",
- )
-
- # Distillation parameters (optional)
- parser.add_argument(
- "--teacher_type",
- default=None,
- type=str,
- help=(
- "Teacher type. Teacher tokenizer and student (model) tokenizer must output the same tokenization. Only for"
- " distillation."
- ),
- )
- parser.add_argument(
- "--teacher_name_or_path",
- default=None,
- type=str,
- help="Path to the already fine-tuned teacher model. Only for distillation.",
- )
- parser.add_argument(
- "--alpha_ce", default=0.5, type=float, help="Cross entropy loss linear weight. Only for distillation."
- )
- parser.add_argument(
- "--alpha_distil", default=0.5, type=float, help="Distillation loss linear weight. Only for distillation."
- )
- parser.add_argument(
- "--temperature", default=2.0, type=float, help="Distillation temperature. Only for distillation."
- )
-
- parser.add_argument(
- "--gradient_accumulation_steps",
- type=int,
- default=1,
- help="Number of updates steps to accumulate before performing a backward/update pass.",
- )
- parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
- parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
- parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
- parser.add_argument(
- "--num_train_epochs",
- default=3.0,
- type=float,
- help="Total number of training epochs to perform.",
- )
- parser.add_argument(
- "--max_steps",
- default=-1,
- type=int,
- help="If > 0: set total number of training steps to perform. Override num_train_epochs.",
- )
- parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
-
- parser.add_argument("--logging_steps", type=int, default=50, help="Log every X updates steps.")
- parser.add_argument("--save_steps", type=int, default=50, help="Save checkpoint every X updates steps.")
- parser.add_argument(
- "--eval_all_checkpoints",
- action="store_true",
- help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
- )
- parser.add_argument("--no_cuda", action="store_true", help="Avoid using CUDA when available")
- parser.add_argument(
- "--overwrite_output_dir",
- action="store_true",
- help="Overwrite the content of the output directory",
- )
- parser.add_argument(
- "--overwrite_cache",
- action="store_true",
- help="Overwrite the cached training and evaluation sets",
- )
- parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
-
- parser.add_argument(
- "--fp16",
- action="store_true",
- help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
- )
- parser.add_argument(
- "--fp16_opt_level",
- type=str,
- default="O1",
- help=(
- "For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
- "See details at https://nvidia.github.io/apex/amp.html"
- ),
- )
- parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
-
- args = parser.parse_args()
-
- # Regularization
- if args.regularization == "null":
- args.regularization = None
-
- if (
- os.path.exists(args.output_dir)
- and os.listdir(args.output_dir)
- and args.do_train
- and not args.overwrite_output_dir
- ):
- raise ValueError(
- f"Output directory ({args.output_dir}) already exists and is not empty. Use --overwrite_output_dir to"
- " overcome."
- )
-
- # Setup CUDA, GPU & distributed training
- if args.local_rank == -1 or args.no_cuda:
- device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
- args.n_gpu = 0 if args.no_cuda else torch.cuda.device_count()
- else: # Initializes the distributed backend which will take care of synchronizing nodes/GPUs
- torch.cuda.set_device(args.local_rank)
- device = torch.device("cuda", args.local_rank)
- torch.distributed.init_process_group(backend="nccl")
- args.n_gpu = 1
- args.device = device
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- level=logging.INFO if args.local_rank in [-1, 0] else logging.WARN,
- )
- logger.warning(
- "Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
- args.local_rank,
- device,
- args.n_gpu,
- bool(args.local_rank != -1),
- args.fp16,
- )
-
- # Set seed
- set_seed(args)
-
- # Prepare GLUE task
- args.task_name = args.task_name.lower()
- if args.task_name not in processors:
- raise ValueError("Task not found: %s" % (args.task_name))
- processor = processors[args.task_name]()
- args.output_mode = output_modes[args.task_name]
- label_list = processor.get_labels()
- num_labels = len(label_list)
-
- # Load pretrained model and tokenizer
- if args.local_rank not in [-1, 0]:
- torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab
-
- args.model_type = args.model_type.lower()
- config_class, model_class, tokenizer_class = MODEL_CLASSES[args.model_type]
- config = config_class.from_pretrained(
- args.config_name if args.config_name else args.model_name_or_path,
- num_labels=num_labels,
- finetuning_task=args.task_name,
- cache_dir=args.cache_dir if args.cache_dir else None,
- pruning_method=args.pruning_method,
- mask_init=args.mask_init,
- mask_scale=args.mask_scale,
- )
- tokenizer = tokenizer_class.from_pretrained(
- args.tokenizer_name if args.tokenizer_name else args.model_name_or_path,
- cache_dir=args.cache_dir if args.cache_dir else None,
- do_lower_case=args.do_lower_case,
- )
- model = model_class.from_pretrained(
- args.model_name_or_path,
- from_tf=bool(".ckpt" in args.model_name_or_path),
- config=config,
- cache_dir=args.cache_dir if args.cache_dir else None,
- )
-
- if args.teacher_type is not None:
- assert args.teacher_name_or_path is not None
- assert args.alpha_distil > 0.0
- assert args.alpha_distil + args.alpha_ce > 0.0
- teacher_config_class, teacher_model_class, _ = MODEL_CLASSES[args.teacher_type]
- teacher_config = teacher_config_class.from_pretrained(args.teacher_name_or_path)
- teacher = teacher_model_class.from_pretrained(
- args.teacher_name_or_path,
- from_tf=False,
- config=teacher_config,
- cache_dir=args.cache_dir if args.cache_dir else None,
- )
- teacher.to(args.device)
- else:
- teacher = None
-
- if args.local_rank == 0:
- torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab
-
- model.to(args.device)
-
- logger.info("Training/evaluation parameters %s", args)
-
- # Training
- if args.do_train:
- train_dataset = load_and_cache_examples(args, args.task_name, tokenizer, evaluate=False)
- global_step, tr_loss = train(args, train_dataset, model, tokenizer, teacher=teacher)
- logger.info(" global_step = %s, average loss = %s", global_step, tr_loss)
-
- # Saving best-practices: if you use defaults names for the model, you can reload it using from_pretrained()
- if args.do_train and (args.local_rank == -1 or torch.distributed.get_rank() == 0):
- logger.info("Saving model checkpoint to %s", args.output_dir)
- # Save a trained model, configuration and tokenizer using `save_pretrained()`.
- # They can then be reloaded using `from_pretrained()`
- model_to_save = (
- model.module if hasattr(model, "module") else model
- ) # Take care of distributed/parallel training
- model_to_save.save_pretrained(args.output_dir)
- tokenizer.save_pretrained(args.output_dir)
-
- # Good practice: save your training arguments together with the trained model
- torch.save(args, os.path.join(args.output_dir, "training_args.bin"))
-
- # Load a trained model and vocabulary that you have fine-tuned
- model = model_class.from_pretrained(args.output_dir)
- tokenizer = tokenizer_class.from_pretrained(args.output_dir, do_lower_case=args.do_lower_case)
- model.to(args.device)
-
- # Evaluation
- results = {}
- if args.do_eval and args.local_rank in [-1, 0]:
- tokenizer = tokenizer_class.from_pretrained(args.output_dir, do_lower_case=args.do_lower_case)
- checkpoints = [args.output_dir]
- if args.eval_all_checkpoints:
- checkpoints = [
- os.path.dirname(c) for c in sorted(glob.glob(args.output_dir + "/**/" + WEIGHTS_NAME, recursive=True))
- ]
-
- logger.info("Evaluate the following checkpoints: %s", checkpoints)
- for checkpoint in checkpoints:
- global_step = checkpoint.split("-")[-1] if len(checkpoints) > 1 else ""
- prefix = checkpoint.split("/")[-1] if checkpoint.find("checkpoint") != -1 else ""
-
- model = model_class.from_pretrained(checkpoint)
- model.to(args.device)
- result = evaluate(args, model, tokenizer, prefix=prefix)
- result = {k + "_{}".format(global_step): v for k, v in result.items()}
- results.update(result)
-
- return results
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/movement-pruning/masked_run_squad.py b/examples/research_projects/movement-pruning/masked_run_squad.py
deleted file mode 100644
index 7b1c2b32209..00000000000
--- a/examples/research_projects/movement-pruning/masked_run_squad.py
+++ /dev/null
@@ -1,1147 +0,0 @@
-# coding=utf-8
-# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
-# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Fine-pruning Masked BERT for question-answering on SQuAD."""
-
-import argparse
-import glob
-import logging
-import os
-import random
-import timeit
-
-import numpy as np
-import torch
-from emmental import MaskedBertConfig, MaskedBertForQuestionAnswering
-from torch import nn
-from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
-from torch.utils.data.distributed import DistributedSampler
-from tqdm import tqdm, trange
-
-from transformers import (
- WEIGHTS_NAME,
- AdamW,
- BertConfig,
- BertForQuestionAnswering,
- BertTokenizer,
- get_linear_schedule_with_warmup,
- squad_convert_examples_to_features,
-)
-from transformers.data.metrics.squad_metrics import (
- compute_predictions_log_probs,
- compute_predictions_logits,
- squad_evaluate,
-)
-from transformers.data.processors.squad import SquadResult, SquadV1Processor, SquadV2Processor
-
-
-try:
- from torch.utils.tensorboard import SummaryWriter
-except ImportError:
- from tensorboardX import SummaryWriter
-
-
-logger = logging.getLogger(__name__)
-
-MODEL_CLASSES = {
- "bert": (BertConfig, BertForQuestionAnswering, BertTokenizer),
- "masked_bert": (MaskedBertConfig, MaskedBertForQuestionAnswering, BertTokenizer),
-}
-
-
-def set_seed(args):
- random.seed(args.seed)
- np.random.seed(args.seed)
- torch.manual_seed(args.seed)
- if args.n_gpu > 0:
- torch.cuda.manual_seed_all(args.seed)
-
-
-def schedule_threshold(
- step: int,
- total_step: int,
- warmup_steps: int,
- initial_threshold: float,
- final_threshold: float,
- initial_warmup: int,
- final_warmup: int,
- final_lambda: float,
-):
- if step <= initial_warmup * warmup_steps:
- threshold = initial_threshold
- elif step > (total_step - final_warmup * warmup_steps):
- threshold = final_threshold
- else:
- spars_warmup_steps = initial_warmup * warmup_steps
- spars_schedu_steps = (final_warmup + initial_warmup) * warmup_steps
- mul_coeff = 1 - (step - spars_warmup_steps) / (total_step - spars_schedu_steps)
- threshold = final_threshold + (initial_threshold - final_threshold) * (mul_coeff**3)
- regu_lambda = final_lambda * threshold / final_threshold
- return threshold, regu_lambda
-
-
-def regularization(model: nn.Module, mode: str):
- regu, counter = 0, 0
- for name, param in model.named_parameters():
- if "mask_scores" in name:
- if mode == "l1":
- regu += torch.norm(torch.sigmoid(param), p=1) / param.numel()
- elif mode == "l0":
- regu += torch.sigmoid(param - 2 / 3 * np.log(0.1 / 1.1)).sum() / param.numel()
- else:
- raise ValueError("Don't know this mode.")
- counter += 1
- return regu / counter
-
-
-def to_list(tensor):
- return tensor.detach().cpu().tolist()
-
-
-def train(args, train_dataset, model, tokenizer, teacher=None):
- """Train the model"""
- if args.local_rank in [-1, 0]:
- tb_writer = SummaryWriter(log_dir=args.output_dir)
-
- args.train_batch_size = args.per_gpu_train_batch_size * max(1, args.n_gpu)
- train_sampler = RandomSampler(train_dataset) if args.local_rank == -1 else DistributedSampler(train_dataset)
- train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size)
-
- if args.max_steps > 0:
- t_total = args.max_steps
- args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
- else:
- t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
-
- # Prepare optimizer and schedule (linear warmup and decay)
- no_decay = ["bias", "LayerNorm.weight"]
- optimizer_grouped_parameters = [
- {
- "params": [p for n, p in model.named_parameters() if "mask_score" in n and p.requires_grad],
- "lr": args.mask_scores_learning_rate,
- },
- {
- "params": [
- p
- for n, p in model.named_parameters()
- if "mask_score" not in n and p.requires_grad and not any(nd in n for nd in no_decay)
- ],
- "lr": args.learning_rate,
- "weight_decay": args.weight_decay,
- },
- {
- "params": [
- p
- for n, p in model.named_parameters()
- if "mask_score" not in n and p.requires_grad and any(nd in n for nd in no_decay)
- ],
- "lr": args.learning_rate,
- "weight_decay": 0.0,
- },
- ]
-
- optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
- scheduler = get_linear_schedule_with_warmup(
- optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
- )
-
- # Check if saved optimizer or scheduler states exist
- if os.path.isfile(os.path.join(args.model_name_or_path, "optimizer.pt")) and os.path.isfile(
- os.path.join(args.model_name_or_path, "scheduler.pt")
- ):
- # Load in optimizer and scheduler states
- optimizer.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "optimizer.pt")))
- scheduler.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "scheduler.pt")))
-
- if args.fp16:
- try:
- from apex import amp
- except ImportError:
- raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
- model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
-
- # multi-gpu training (should be after apex fp16 initialization)
- if args.n_gpu > 1:
- model = nn.DataParallel(model)
-
- # Distributed training (should be after apex fp16 initialization)
- if args.local_rank != -1:
- model = nn.parallel.DistributedDataParallel(
- model,
- device_ids=[args.local_rank],
- output_device=args.local_rank,
- find_unused_parameters=True,
- )
-
- # Train!
- logger.info("***** Running training *****")
- logger.info(" Num examples = %d", len(train_dataset))
- logger.info(" Num Epochs = %d", args.num_train_epochs)
- logger.info(" Instantaneous batch size per GPU = %d", args.per_gpu_train_batch_size)
- logger.info(
- " Total train batch size (w. parallel, distributed & accumulation) = %d",
- args.train_batch_size
- * args.gradient_accumulation_steps
- * (torch.distributed.get_world_size() if args.local_rank != -1 else 1),
- )
- logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)
- logger.info(" Total optimization steps = %d", t_total)
- # Distillation
- if teacher is not None:
- logger.info(" Training with distillation")
-
- global_step = 1
- # Global TopK
- if args.global_topk:
- threshold_mem = None
- epochs_trained = 0
- steps_trained_in_current_epoch = 0
- # Check if continuing training from a checkpoint
- if os.path.exists(args.model_name_or_path):
- # set global_step to global_step of last saved checkpoint from model path
- try:
- checkpoint_suffix = args.model_name_or_path.split("-")[-1].split("/")[0]
- global_step = int(checkpoint_suffix)
- epochs_trained = global_step // (len(train_dataloader) // args.gradient_accumulation_steps)
- steps_trained_in_current_epoch = global_step % (len(train_dataloader) // args.gradient_accumulation_steps)
-
- logger.info(" Continuing training from checkpoint, will skip to saved global_step")
- logger.info(" Continuing training from epoch %d", epochs_trained)
- logger.info(" Continuing training from global step %d", global_step)
- logger.info(" Will skip the first %d steps in the first epoch", steps_trained_in_current_epoch)
- except ValueError:
- logger.info(" Starting fine-tuning.")
-
- tr_loss, logging_loss = 0.0, 0.0
- model.zero_grad()
- train_iterator = trange(
- epochs_trained, int(args.num_train_epochs), desc="Epoch", disable=args.local_rank not in [-1, 0]
- )
- # Added here for reproducibility
- set_seed(args)
-
- for _ in train_iterator:
- epoch_iterator = tqdm(train_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])
- for step, batch in enumerate(epoch_iterator):
- # Skip past any already trained steps if resuming training
- if steps_trained_in_current_epoch > 0:
- steps_trained_in_current_epoch -= 1
- continue
-
- model.train()
- batch = tuple(t.to(args.device) for t in batch)
- threshold, regu_lambda = schedule_threshold(
- step=global_step,
- total_step=t_total,
- warmup_steps=args.warmup_steps,
- final_threshold=args.final_threshold,
- initial_threshold=args.initial_threshold,
- final_warmup=args.final_warmup,
- initial_warmup=args.initial_warmup,
- final_lambda=args.final_lambda,
- )
- # Global TopK
- if args.global_topk:
- if threshold == 1.0:
- threshold = -1e2 # Or an indefinitely low quantity
- else:
- if (threshold_mem is None) or (global_step % args.global_topk_frequency_compute == 0):
- # Sort all the values to get the global topK
- concat = torch.cat(
- [param.view(-1) for name, param in model.named_parameters() if "mask_scores" in name]
- )
- n = concat.numel()
- kth = max(n - (int(n * threshold) + 1), 1)
- threshold_mem = concat.kthvalue(kth).values.item()
- threshold = threshold_mem
- else:
- threshold = threshold_mem
- inputs = {
- "input_ids": batch[0],
- "attention_mask": batch[1],
- "token_type_ids": batch[2],
- "start_positions": batch[3],
- "end_positions": batch[4],
- }
-
- if args.model_type in ["xlm", "roberta", "distilbert", "camembert"]:
- del inputs["token_type_ids"]
-
- if args.model_type in ["xlnet", "xlm"]:
- inputs.update({"cls_index": batch[5], "p_mask": batch[6]})
- if args.version_2_with_negative:
- inputs.update({"is_impossible": batch[7]})
- if hasattr(model, "config") and hasattr(model.config, "lang2id"):
- inputs.update(
- {"langs": (torch.ones(batch[0].shape, dtype=torch.int64) * args.lang_id).to(args.device)}
- )
-
- if "masked" in args.model_type:
- inputs["threshold"] = threshold
-
- outputs = model(**inputs)
- # model outputs are always tuple in transformers (see doc)
- loss, start_logits_stu, end_logits_stu = outputs
-
- # Distillation loss
- if teacher is not None:
- with torch.no_grad():
- start_logits_tea, end_logits_tea = teacher(
- input_ids=inputs["input_ids"],
- token_type_ids=inputs["token_type_ids"],
- attention_mask=inputs["attention_mask"],
- )
-
- loss_start = nn.functional.kl_div(
- input=nn.functional.log_softmax(start_logits_stu / args.temperature, dim=-1),
- target=nn.functional.softmax(start_logits_tea / args.temperature, dim=-1),
- reduction="batchmean",
- ) * (args.temperature**2)
- loss_end = nn.functional.kl_div(
- input=nn.functional.log_softmax(end_logits_stu / args.temperature, dim=-1),
- target=nn.functional.softmax(end_logits_tea / args.temperature, dim=-1),
- reduction="batchmean",
- ) * (args.temperature**2)
- loss_logits = (loss_start + loss_end) / 2.0
-
- loss = args.alpha_distil * loss_logits + args.alpha_ce * loss
-
- # Regularization
- if args.regularization is not None:
- regu_ = regularization(model=model, mode=args.regularization)
- loss = loss + regu_lambda * regu_
-
- if args.n_gpu > 1:
- loss = loss.mean() # mean() to average on multi-gpu parallel training
- if args.gradient_accumulation_steps > 1:
- loss = loss / args.gradient_accumulation_steps
-
- if args.fp16:
- with amp.scale_loss(loss, optimizer) as scaled_loss:
- scaled_loss.backward()
- else:
- loss.backward()
-
- tr_loss += loss.item()
- if (step + 1) % args.gradient_accumulation_steps == 0:
- if args.fp16:
- nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
- else:
- nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
-
- if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
- tb_writer.add_scalar("threshold", threshold, global_step)
- for name, param in model.named_parameters():
- if not param.requires_grad:
- continue
- tb_writer.add_scalar("parameter_mean/" + name, param.data.mean(), global_step)
- tb_writer.add_scalar("parameter_std/" + name, param.data.std(), global_step)
- tb_writer.add_scalar("parameter_min/" + name, param.data.min(), global_step)
- tb_writer.add_scalar("parameter_max/" + name, param.data.max(), global_step)
- if "pooler" in name:
- continue
- tb_writer.add_scalar("grad_mean/" + name, param.grad.data.mean(), global_step)
- tb_writer.add_scalar("grad_std/" + name, param.grad.data.std(), global_step)
- if args.regularization is not None and "mask_scores" in name:
- if args.regularization == "l1":
- perc = (torch.sigmoid(param) > threshold).sum().item() / param.numel()
- elif args.regularization == "l0":
- perc = (torch.sigmoid(param - 2 / 3 * np.log(0.1 / 1.1))).sum().item() / param.numel()
- tb_writer.add_scalar("retained_weights_perc/" + name, perc, global_step)
-
- optimizer.step()
- scheduler.step() # Update learning rate schedule
- model.zero_grad()
- global_step += 1
-
- # Log metrics
- if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
- # Only evaluate when single GPU otherwise metrics may not average well
- if args.local_rank == -1 and args.evaluate_during_training:
- results = evaluate(args, model, tokenizer)
- for key, value in results.items():
- tb_writer.add_scalar("eval_{}".format(key), value, global_step)
- learning_rate_scalar = scheduler.get_lr()
- tb_writer.add_scalar("lr", learning_rate_scalar[0], global_step)
- if len(learning_rate_scalar) > 1:
- for idx, lr in enumerate(learning_rate_scalar[1:]):
- tb_writer.add_scalar(f"lr/{idx+1}", lr, global_step)
- tb_writer.add_scalar("loss", (tr_loss - logging_loss) / args.logging_steps, global_step)
- if teacher is not None:
- tb_writer.add_scalar("loss/distil", loss_logits.item(), global_step)
- if args.regularization is not None:
- tb_writer.add_scalar("loss/regularization", regu_.item(), global_step)
- if (teacher is not None) or (args.regularization is not None):
- if (teacher is not None) and (args.regularization is not None):
- tb_writer.add_scalar(
- "loss/instant_ce",
- (loss.item() - regu_lambda * regu_.item() - args.alpha_distil * loss_logits.item())
- / args.alpha_ce,
- global_step,
- )
- elif teacher is not None:
- tb_writer.add_scalar(
- "loss/instant_ce",
- (loss.item() - args.alpha_distil * loss_logits.item()) / args.alpha_ce,
- global_step,
- )
- else:
- tb_writer.add_scalar(
- "loss/instant_ce", loss.item() - regu_lambda * regu_.item(), global_step
- )
- logging_loss = tr_loss
-
- # Save model checkpoint
- if args.local_rank in [-1, 0] and args.save_steps > 0 and global_step % args.save_steps == 0:
- output_dir = os.path.join(args.output_dir, "checkpoint-{}".format(global_step))
- if not os.path.exists(output_dir):
- os.makedirs(output_dir)
- # Take care of distributed/parallel training
- model_to_save = model.module if hasattr(model, "module") else model
- model_to_save.save_pretrained(output_dir)
- tokenizer.save_pretrained(output_dir)
-
- torch.save(args, os.path.join(output_dir, "training_args.bin"))
- logger.info("Saving model checkpoint to %s", output_dir)
-
- torch.save(optimizer.state_dict(), os.path.join(output_dir, "optimizer.pt"))
- torch.save(scheduler.state_dict(), os.path.join(output_dir, "scheduler.pt"))
- logger.info("Saving optimizer and scheduler states to %s", output_dir)
-
- if args.max_steps > 0 and global_step > args.max_steps:
- epoch_iterator.close()
- break
- if args.max_steps > 0 and global_step > args.max_steps:
- train_iterator.close()
- break
-
- if args.local_rank in [-1, 0]:
- tb_writer.close()
-
- return global_step, tr_loss / global_step
-
-
-def evaluate(args, model, tokenizer, prefix=""):
- dataset, examples, features = load_and_cache_examples(args, tokenizer, evaluate=True, output_examples=True)
-
- if not os.path.exists(args.output_dir) and args.local_rank in [-1, 0]:
- os.makedirs(args.output_dir)
-
- args.eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)
- # Note that DistributedSampler samples randomly
- eval_sampler = SequentialSampler(dataset)
- eval_dataloader = DataLoader(dataset, sampler=eval_sampler, batch_size=args.eval_batch_size)
-
- # multi-gpu eval
- if args.n_gpu > 1 and not isinstance(model, nn.DataParallel):
- model = nn.DataParallel(model)
-
- # Eval!
- logger.info("***** Running evaluation {} *****".format(prefix))
- logger.info(" Num examples = %d", len(dataset))
- logger.info(" Batch size = %d", args.eval_batch_size)
-
- all_results = []
- start_time = timeit.default_timer()
- # Global TopK
- if args.global_topk:
- threshold_mem = None
-
- for batch in tqdm(eval_dataloader, desc="Evaluating"):
- model.eval()
- batch = tuple(t.to(args.device) for t in batch)
-
- with torch.no_grad():
- inputs = {
- "input_ids": batch[0],
- "attention_mask": batch[1],
- "token_type_ids": batch[2],
- }
-
- if args.model_type in ["xlm", "roberta", "distilbert", "camembert"]:
- del inputs["token_type_ids"]
-
- example_indices = batch[3]
-
- # XLNet and XLM use more arguments for their predictions
- if args.model_type in ["xlnet", "xlm"]:
- inputs.update({"cls_index": batch[4], "p_mask": batch[5]})
- # for lang_id-sensitive xlm models
- if hasattr(model, "config") and hasattr(model.config, "lang2id"):
- inputs.update(
- {"langs": (torch.ones(batch[0].shape, dtype=torch.int64) * args.lang_id).to(args.device)}
- )
- if "masked" in args.model_type:
- inputs["threshold"] = args.final_threshold
- if args.global_topk:
- if threshold_mem is None:
- concat = torch.cat(
- [param.view(-1) for name, param in model.named_parameters() if "mask_scores" in name]
- )
- n = concat.numel()
- kth = max(n - (int(n * args.final_threshold) + 1), 1)
- threshold_mem = concat.kthvalue(kth).values.item()
- inputs["threshold"] = threshold_mem
- outputs = model(**inputs)
-
- for i, example_index in enumerate(example_indices):
- eval_feature = features[example_index.item()]
- unique_id = int(eval_feature.unique_id)
-
- output = [to_list(output[i]) for output in outputs]
-
- # Some models (XLNet, XLM) use 5 arguments for their predictions, while the other "simpler"
- # models only use two.
- if len(output) >= 5:
- start_logits = output[0]
- start_top_index = output[1]
- end_logits = output[2]
- end_top_index = output[3]
- cls_logits = output[4]
-
- result = SquadResult(
- unique_id,
- start_logits,
- end_logits,
- start_top_index=start_top_index,
- end_top_index=end_top_index,
- cls_logits=cls_logits,
- )
-
- else:
- start_logits, end_logits = output
- result = SquadResult(unique_id, start_logits, end_logits)
-
- all_results.append(result)
-
- evalTime = timeit.default_timer() - start_time
- logger.info(" Evaluation done in total %f secs (%f sec per example)", evalTime, evalTime / len(dataset))
-
- # Compute predictions
- output_prediction_file = os.path.join(args.output_dir, "predictions_{}.json".format(prefix))
- output_nbest_file = os.path.join(args.output_dir, "nbest_predictions_{}.json".format(prefix))
-
- if args.version_2_with_negative:
- output_null_log_odds_file = os.path.join(args.output_dir, "null_odds_{}.json".format(prefix))
- else:
- output_null_log_odds_file = None
-
- # XLNet and XLM use a more complex post-processing procedure
- if args.model_type in ["xlnet", "xlm"]:
- start_n_top = model.config.start_n_top if hasattr(model, "config") else model.module.config.start_n_top
- end_n_top = model.config.end_n_top if hasattr(model, "config") else model.module.config.end_n_top
-
- predictions = compute_predictions_log_probs(
- examples,
- features,
- all_results,
- args.n_best_size,
- args.max_answer_length,
- output_prediction_file,
- output_nbest_file,
- output_null_log_odds_file,
- start_n_top,
- end_n_top,
- args.version_2_with_negative,
- tokenizer,
- args.verbose_logging,
- )
- else:
- predictions = compute_predictions_logits(
- examples,
- features,
- all_results,
- args.n_best_size,
- args.max_answer_length,
- args.do_lower_case,
- output_prediction_file,
- output_nbest_file,
- output_null_log_odds_file,
- args.verbose_logging,
- args.version_2_with_negative,
- args.null_score_diff_threshold,
- tokenizer,
- )
-
- # Compute the F1 and exact scores.
- results = squad_evaluate(examples, predictions)
- return results
-
-
-def load_and_cache_examples(args, tokenizer, evaluate=False, output_examples=False):
- if args.local_rank not in [-1, 0] and not evaluate:
- # Make sure only the first process in distributed training process the dataset, and the others will use the cache
- torch.distributed.barrier()
-
- # Load data features from cache or dataset file
- input_dir = args.data_dir if args.data_dir else "."
- cached_features_file = os.path.join(
- input_dir,
- "cached_{}_{}_{}_{}".format(
- "dev" if evaluate else "train",
- args.tokenizer_name
- if args.tokenizer_name
- else list(filter(None, args.model_name_or_path.split("/"))).pop(),
- str(args.max_seq_length),
- list(filter(None, args.predict_file.split("/"))).pop()
- if evaluate
- else list(filter(None, args.train_file.split("/"))).pop(),
- ),
- )
-
- # Init features and dataset from cache if it exists
- if os.path.exists(cached_features_file) and not args.overwrite_cache:
- logger.info("Loading features from cached file %s", cached_features_file)
- features_and_dataset = torch.load(cached_features_file)
- features, dataset, examples = (
- features_and_dataset["features"],
- features_and_dataset["dataset"],
- features_and_dataset["examples"],
- )
- else:
- logger.info("Creating features from dataset file at %s", input_dir)
-
- if not args.data_dir and ((evaluate and not args.predict_file) or (not evaluate and not args.train_file)):
- try:
- import tensorflow_datasets as tfds
- except ImportError:
- raise ImportError("If not data_dir is specified, tensorflow_datasets needs to be installed.")
-
- if args.version_2_with_negative:
- logger.warning("tensorflow_datasets does not handle version 2 of SQuAD.")
-
- tfds_examples = tfds.load("squad")
- examples = SquadV1Processor().get_examples_from_dataset(tfds_examples, evaluate=evaluate)
- else:
- processor = SquadV2Processor() if args.version_2_with_negative else SquadV1Processor()
- if evaluate:
- examples = processor.get_dev_examples(args.data_dir, filename=args.predict_file)
- else:
- examples = processor.get_train_examples(args.data_dir, filename=args.train_file)
-
- features, dataset = squad_convert_examples_to_features(
- examples=examples,
- tokenizer=tokenizer,
- max_seq_length=args.max_seq_length,
- doc_stride=args.doc_stride,
- max_query_length=args.max_query_length,
- is_training=not evaluate,
- return_dataset="pt",
- threads=args.threads,
- )
-
- if args.local_rank in [-1, 0]:
- logger.info("Saving features into cached file %s", cached_features_file)
- torch.save({"features": features, "dataset": dataset, "examples": examples}, cached_features_file)
-
- if args.local_rank == 0 and not evaluate:
- # Make sure only the first process in distributed training process the dataset, and the others will use the cache
- torch.distributed.barrier()
-
- if output_examples:
- return dataset, examples, features
- return dataset
-
-
-def main():
- parser = argparse.ArgumentParser()
-
- # Required parameters
- parser.add_argument(
- "--model_type",
- default=None,
- type=str,
- required=True,
- help="Model type selected in the list: " + ", ".join(MODEL_CLASSES.keys()),
- )
- parser.add_argument(
- "--model_name_or_path",
- default=None,
- type=str,
- required=True,
- help="Path to pretrained model or model identifier from huggingface.co/models",
- )
- parser.add_argument(
- "--output_dir",
- default=None,
- type=str,
- required=True,
- help="The output directory where the model checkpoints and predictions will be written.",
- )
-
- # Other parameters
- parser.add_argument(
- "--data_dir",
- default=None,
- type=str,
- help="The input data dir. Should contain the .json files for the task."
- + "If no data dir or train/predict files are specified, will run with tensorflow_datasets.",
- )
- parser.add_argument(
- "--train_file",
- default=None,
- type=str,
- help="The input training file. If a data dir is specified, will look for the file there"
- + "If no data dir or train/predict files are specified, will run with tensorflow_datasets.",
- )
- parser.add_argument(
- "--predict_file",
- default=None,
- type=str,
- help="The input evaluation file. If a data dir is specified, will look for the file there"
- + "If no data dir or train/predict files are specified, will run with tensorflow_datasets.",
- )
- parser.add_argument(
- "--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
- )
- parser.add_argument(
- "--tokenizer_name",
- default="",
- type=str,
- help="Pretrained tokenizer name or path if not the same as model_name",
- )
- parser.add_argument(
- "--cache_dir",
- default="",
- type=str,
- help="Where do you want to store the pre-trained models downloaded from huggingface.co",
- )
-
- parser.add_argument(
- "--version_2_with_negative",
- action="store_true",
- help="If true, the SQuAD examples contain some that do not have an answer.",
- )
- parser.add_argument(
- "--null_score_diff_threshold",
- type=float,
- default=0.0,
- help="If null_score - best_non_null is greater than the threshold predict null.",
- )
-
- parser.add_argument(
- "--max_seq_length",
- default=384,
- type=int,
- help=(
- "The maximum total input sequence length after WordPiece tokenization. Sequences "
- "longer than this will be truncated, and sequences shorter than this will be padded."
- ),
- )
- parser.add_argument(
- "--doc_stride",
- default=128,
- type=int,
- help="When splitting up a long document into chunks, how much stride to take between chunks.",
- )
- parser.add_argument(
- "--max_query_length",
- default=64,
- type=int,
- help=(
- "The maximum number of tokens for the question. Questions longer than this will "
- "be truncated to this length."
- ),
- )
- parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
- parser.add_argument("--do_eval", action="store_true", help="Whether to run eval on the dev set.")
- parser.add_argument(
- "--evaluate_during_training", action="store_true", help="Run evaluation during training at each logging step."
- )
- parser.add_argument(
- "--do_lower_case", action="store_true", help="Set this flag if you are using an uncased model."
- )
-
- parser.add_argument("--per_gpu_train_batch_size", default=8, type=int, help="Batch size per GPU/CPU for training.")
- parser.add_argument(
- "--per_gpu_eval_batch_size", default=8, type=int, help="Batch size per GPU/CPU for evaluation."
- )
- parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
-
- # Pruning parameters
- parser.add_argument(
- "--mask_scores_learning_rate",
- default=1e-2,
- type=float,
- help="The Adam initial learning rate of the mask scores.",
- )
- parser.add_argument(
- "--initial_threshold", default=1.0, type=float, help="Initial value of the threshold (for scheduling)."
- )
- parser.add_argument(
- "--final_threshold", default=0.7, type=float, help="Final value of the threshold (for scheduling)."
- )
- parser.add_argument(
- "--initial_warmup",
- default=1,
- type=int,
- help=(
- "Run `initial_warmup` * `warmup_steps` steps of threshold warmup during which threshold stays "
- "at its `initial_threshold` value (sparsity schedule)."
- ),
- )
- parser.add_argument(
- "--final_warmup",
- default=2,
- type=int,
- help=(
- "Run `final_warmup` * `warmup_steps` steps of threshold cool-down during which threshold stays "
- "at its final_threshold value (sparsity schedule)."
- ),
- )
-
- parser.add_argument(
- "--pruning_method",
- default="topK",
- type=str,
- help=(
- "Pruning Method (l0 = L0 regularization, magnitude = Magnitude pruning, topK = Movement pruning,"
- " sigmoied_threshold = Soft movement pruning)."
- ),
- )
- parser.add_argument(
- "--mask_init",
- default="constant",
- type=str,
- help="Initialization method for the mask scores. Choices: constant, uniform, kaiming.",
- )
- parser.add_argument(
- "--mask_scale", default=0.0, type=float, help="Initialization parameter for the chosen initialization method."
- )
-
- parser.add_argument("--regularization", default=None, help="Add L0 or L1 regularization to the mask scores.")
- parser.add_argument(
- "--final_lambda",
- default=0.0,
- type=float,
- help="Regularization intensity (used in conjunction with `regularization`.",
- )
-
- parser.add_argument("--global_topk", action="store_true", help="Global TopK on the Scores.")
- parser.add_argument(
- "--global_topk_frequency_compute",
- default=25,
- type=int,
- help="Frequency at which we compute the TopK global threshold.",
- )
-
- # Distillation parameters (optional)
- parser.add_argument(
- "--teacher_type",
- default=None,
- type=str,
- help=(
- "Teacher type. Teacher tokenizer and student (model) tokenizer must output the same tokenization. Only for"
- " distillation."
- ),
- )
- parser.add_argument(
- "--teacher_name_or_path",
- default=None,
- type=str,
- help="Path to the already SQuAD fine-tuned teacher model. Only for distillation.",
- )
- parser.add_argument(
- "--alpha_ce", default=0.5, type=float, help="Cross entropy loss linear weight. Only for distillation."
- )
- parser.add_argument(
- "--alpha_distil", default=0.5, type=float, help="Distillation loss linear weight. Only for distillation."
- )
- parser.add_argument(
- "--temperature", default=2.0, type=float, help="Distillation temperature. Only for distillation."
- )
-
- parser.add_argument(
- "--gradient_accumulation_steps",
- type=int,
- default=1,
- help="Number of updates steps to accumulate before performing a backward/update pass.",
- )
- parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
- parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
- parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
- parser.add_argument(
- "--num_train_epochs",
- default=3.0,
- type=float,
- help="Total number of training epochs to perform.",
- )
- parser.add_argument(
- "--max_steps",
- default=-1,
- type=int,
- help="If > 0: set total number of training steps to perform. Override num_train_epochs.",
- )
- parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
- parser.add_argument(
- "--n_best_size",
- default=20,
- type=int,
- help="The total number of n-best predictions to generate in the nbest_predictions.json output file.",
- )
- parser.add_argument(
- "--max_answer_length",
- default=30,
- type=int,
- help=(
- "The maximum length of an answer that can be generated. This is needed because the start "
- "and end predictions are not conditioned on one another."
- ),
- )
- parser.add_argument(
- "--verbose_logging",
- action="store_true",
- help=(
- "If true, all of the warnings related to data processing will be printed. "
- "A number of warnings are expected for a normal SQuAD evaluation."
- ),
- )
- parser.add_argument(
- "--lang_id",
- default=0,
- type=int,
- help=(
- "language id of input for language-specific xlm models (see"
- " tokenization_xlm.PRETRAINED_INIT_CONFIGURATION)"
- ),
- )
-
- parser.add_argument("--logging_steps", type=int, default=500, help="Log every X updates steps.")
- parser.add_argument("--save_steps", type=int, default=500, help="Save checkpoint every X updates steps.")
- parser.add_argument(
- "--eval_all_checkpoints",
- action="store_true",
- help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
- )
- parser.add_argument("--no_cuda", action="store_true", help="Whether not to use CUDA when available")
- parser.add_argument(
- "--overwrite_output_dir", action="store_true", help="Overwrite the content of the output directory"
- )
- parser.add_argument(
- "--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
- )
- parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
-
- parser.add_argument("--local_rank", type=int, default=-1, help="local_rank for distributed training on gpus")
- parser.add_argument(
- "--fp16",
- action="store_true",
- help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
- )
- parser.add_argument(
- "--fp16_opt_level",
- type=str,
- default="O1",
- help=(
- "For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
- "See details at https://nvidia.github.io/apex/amp.html"
- ),
- )
- parser.add_argument("--server_ip", type=str, default="", help="Can be used for distant debugging.")
- parser.add_argument("--server_port", type=str, default="", help="Can be used for distant debugging.")
-
- parser.add_argument("--threads", type=int, default=1, help="multiple threads for converting example to features")
- args = parser.parse_args()
-
- # Regularization
- if args.regularization == "null":
- args.regularization = None
-
- if args.doc_stride >= args.max_seq_length - args.max_query_length:
- logger.warning(
- "WARNING - You've set a doc stride which may be superior to the document length in some "
- "examples. This could result in errors when building features from the examples. Please reduce the doc "
- "stride or increase the maximum length to ensure the features are correctly built."
- )
-
- if (
- os.path.exists(args.output_dir)
- and os.listdir(args.output_dir)
- and args.do_train
- and not args.overwrite_output_dir
- ):
- raise ValueError(
- "Output directory ({}) already exists and is not empty. Use --overwrite_output_dir to overcome.".format(
- args.output_dir
- )
- )
-
- # Setup distant debugging if needed
- if args.server_ip and args.server_port:
- # Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
- import ptvsd
-
- print("Waiting for debugger attach")
- ptvsd.enable_attach(address=(args.server_ip, args.server_port), redirect_output=True)
- ptvsd.wait_for_attach()
-
- # Setup CUDA, GPU & distributed training
- if args.local_rank == -1 or args.no_cuda:
- device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
- args.n_gpu = 0 if args.no_cuda else torch.cuda.device_count()
- else: # Initializes the distributed backend which will take care of synchronizing nodes/GPUs
- torch.cuda.set_device(args.local_rank)
- device = torch.device("cuda", args.local_rank)
- torch.distributed.init_process_group(backend="nccl")
- args.n_gpu = 1
- args.device = device
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- level=logging.INFO if args.local_rank in [-1, 0] else logging.WARN,
- )
- logger.warning(
- "Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
- args.local_rank,
- device,
- args.n_gpu,
- bool(args.local_rank != -1),
- args.fp16,
- )
-
- # Set seed
- set_seed(args)
-
- # Load pretrained model and tokenizer
- if args.local_rank not in [-1, 0]:
- # Make sure only the first process in distributed training will download model & vocab
- torch.distributed.barrier()
-
- args.model_type = args.model_type.lower()
- config_class, model_class, tokenizer_class = MODEL_CLASSES[args.model_type]
- config = config_class.from_pretrained(
- args.config_name if args.config_name else args.model_name_or_path,
- cache_dir=args.cache_dir if args.cache_dir else None,
- pruning_method=args.pruning_method,
- mask_init=args.mask_init,
- mask_scale=args.mask_scale,
- )
- tokenizer = tokenizer_class.from_pretrained(
- args.tokenizer_name if args.tokenizer_name else args.model_name_or_path,
- do_lower_case=args.do_lower_case,
- cache_dir=args.cache_dir if args.cache_dir else None,
- )
- model = model_class.from_pretrained(
- args.model_name_or_path,
- from_tf=bool(".ckpt" in args.model_name_or_path),
- config=config,
- cache_dir=args.cache_dir if args.cache_dir else None,
- )
-
- if args.teacher_type is not None:
- assert args.teacher_name_or_path is not None
- assert args.alpha_distil > 0.0
- assert args.alpha_distil + args.alpha_ce > 0.0
- teacher_config_class, teacher_model_class, _ = MODEL_CLASSES[args.teacher_type]
- teacher_config = teacher_config_class.from_pretrained(args.teacher_name_or_path)
- teacher = teacher_model_class.from_pretrained(
- args.teacher_name_or_path,
- from_tf=False,
- config=teacher_config,
- cache_dir=args.cache_dir if args.cache_dir else None,
- )
- teacher.to(args.device)
- else:
- teacher = None
-
- if args.local_rank == 0:
- # Make sure only the first process in distributed training will download model & vocab
- torch.distributed.barrier()
-
- model.to(args.device)
-
- logger.info("Training/evaluation parameters %s", args)
-
- # Before we do anything with models, we want to ensure that we get fp16 execution of torch.einsum if args.fp16 is set.
- # Otherwise it'll default to "promote" mode, and we'll get fp32 operations. Note that running `--fp16_opt_level="O2"` will
- # remove the need for this code, but it is still valid.
- if args.fp16:
- try:
- import apex
-
- apex.amp.register_half_function(torch, "einsum")
- except ImportError:
- raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
-
- # Training
- if args.do_train:
- train_dataset = load_and_cache_examples(args, tokenizer, evaluate=False, output_examples=False)
- global_step, tr_loss = train(args, train_dataset, model, tokenizer, teacher=teacher)
- logger.info(" global_step = %s, average loss = %s", global_step, tr_loss)
-
- # Save the trained model and the tokenizer
- if args.do_train and (args.local_rank == -1 or torch.distributed.get_rank() == 0):
- logger.info("Saving model checkpoint to %s", args.output_dir)
- # Save a trained model, configuration and tokenizer using `save_pretrained()`.
- # They can then be reloaded using `from_pretrained()`
- # Take care of distributed/parallel training
- model_to_save = model.module if hasattr(model, "module") else model
- model_to_save.save_pretrained(args.output_dir)
- tokenizer.save_pretrained(args.output_dir)
-
- # Good practice: save your training arguments together with the trained model
- torch.save(args, os.path.join(args.output_dir, "training_args.bin"))
-
- # Load a trained model and vocabulary that you have fine-tuned
- model = model_class.from_pretrained(args.output_dir) # , force_download=True)
- tokenizer = tokenizer_class.from_pretrained(args.output_dir, do_lower_case=args.do_lower_case)
- model.to(args.device)
-
- # Evaluation - we can ask to evaluate all the checkpoints (sub-directories) in a directory
- results = {}
- if args.do_eval and args.local_rank in [-1, 0]:
- if args.do_train:
- logger.info("Loading checkpoints saved during training for evaluation")
- checkpoints = [args.output_dir]
- if args.eval_all_checkpoints:
- checkpoints = [
- os.path.dirname(c)
- for c in sorted(glob.glob(args.output_dir + "/**/" + WEIGHTS_NAME, recursive=True))
- ]
-
- else:
- logger.info("Loading checkpoint %s for evaluation", args.model_name_or_path)
- checkpoints = [args.model_name_or_path]
-
- logger.info("Evaluate the following checkpoints: %s", checkpoints)
-
- for checkpoint in checkpoints:
- # Reload the model
- global_step = checkpoint.split("-")[-1] if len(checkpoints) > 1 else ""
- model = model_class.from_pretrained(checkpoint) # , force_download=True)
- model.to(args.device)
-
- # Evaluate
- result = evaluate(args, model, tokenizer, prefix=global_step)
-
- result = {k + ("_{}".format(global_step) if global_step else ""): v for k, v in result.items()}
- results.update(result)
-
- logger.info("Results: {}".format(results))
- predict_file = list(filter(None, args.predict_file.split("/"))).pop()
- if not os.path.exists(os.path.join(args.output_dir, predict_file)):
- os.makedirs(os.path.join(args.output_dir, predict_file))
- output_eval_file = os.path.join(args.output_dir, predict_file, "eval_results.txt")
- with open(output_eval_file, "w") as writer:
- for key in sorted(results.keys()):
- writer.write("%s = %s\n" % (key, str(results[key])))
-
- return results
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/movement-pruning/requirements.txt b/examples/research_projects/movement-pruning/requirements.txt
deleted file mode 100644
index b678a785bc3..00000000000
--- a/examples/research_projects/movement-pruning/requirements.txt
+++ /dev/null
@@ -1,6 +0,0 @@
-torch>=1.4.0
--e git+https://github.com/huggingface/transformers.git@352d5472b0c1dec0f420d606d16747d851b4bda8#egg=transformers
-knockknock>=0.1.8.1
-h5py>=2.10.0
-numpy>=1.18.2
-scipy>=1.4.1
diff --git a/examples/research_projects/onnx/summarization/README.md b/examples/research_projects/onnx/summarization/README.md
deleted file mode 100644
index c43b0450ea2..00000000000
--- a/examples/research_projects/onnx/summarization/README.md
+++ /dev/null
@@ -1,43 +0,0 @@
-
-
-# Bart + Beam Search to ONNX
-
-Author: [@fatcat-z](https://github.com/fatcat-z)
-
-This folder contains an example of exporting Bart + Beam Search generation (`BartForConditionalGeneration`) to ONNX.
-
-Beam Search contains a for-loop workflow, so we need to make them TorchScript-compatible for exporting to ONNX. This example shows how to make a Bart model be TorchScript-compatible by wrapping up it into a new model. In addition, some changes were made to the `beam_search()` function to make it TorchScript-compatible.
-
-
-## How to run the example
-
-To make sure you can successfully run the latest versions of the example scripts, you have to **install the library from source** and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
-
-```bash
-git clone https://github.com/huggingface/transformers
-cd transformers
-pip install '.[onnxruntime]'
-```
-Then cd in this example folder and run
-```bash
-pip install -r requirements.txt
-```
-
-Now you can run the example command below to get the example ONNX file:
-
-```bash
-python run_onnx_exporter.py --model_name_or_path facebook/bart-base
-```
diff --git a/examples/research_projects/onnx/summarization/bart_onnx/generation_onnx.py b/examples/research_projects/onnx/summarization/bart_onnx/generation_onnx.py
deleted file mode 100644
index 5c1b0da7000..00000000000
--- a/examples/research_projects/onnx/summarization/bart_onnx/generation_onnx.py
+++ /dev/null
@@ -1,755 +0,0 @@
-import copy
-import itertools
-from typing import List, Optional, Tuple
-
-import torch
-import torch.nn.functional as F
-
-from transformers import BartConfig
-from transformers.generation import GenerationMixin
-
-
-def _convert_past_list_to_tuple(past_key_values):
- """
- In Bart model, the type of past_key_values is tuple(tuple(torch.FloatTensor)) which is not
- TorchScript-compatible. To support this, we have to convert it during the export process.
- This function will convert past values from a list to tuple(tuple(torch.FloatTensor)) for
- the inner decoder.
-
- According to the definition of past_key_values, each inner tuple(torch.FloatTensor) has 4 tensors,
- so we convert every 4 elements in the list as a tuple(torch.FloatTensor).
- """
- count_of_each_inner_tuple = 4
- results = ()
- temp_result = ()
- count_n = len(past_key_values) // count_of_each_inner_tuple
- for idx in range(count_n):
- real_idx = idx * count_of_each_inner_tuple
- temp_result = tuple(past_key_values[real_idx : real_idx + count_of_each_inner_tuple])
- results += ((temp_result),)
-
- return results
-
-
-class EncoderForONNX(torch.nn.Module):
- def __init__(self, encoder):
- super().__init__()
- self.encoder = encoder
-
- def forward(self, input_ids, attention_mask):
- return self.encoder(
- input_ids=input_ids,
- attention_mask=attention_mask,
- return_dict=False,
- )
-
-
-class DecoderForONNX(torch.nn.Module):
- def __init__(self, decoder):
- super().__init__()
- self.decoder = decoder
-
- def forward(self, input_ids, encoder_state, attention_mask, past=None):
- all_results = None
- if past is not None:
- all_results = _convert_past_list_to_tuple(past)
- input_ids = input_ids[:, -1:]
-
- last_hidden_state, past_key_values = self.decoder(
- input_ids=input_ids,
- encoder_hidden_states=encoder_state,
- encoder_attention_mask=attention_mask,
- past_key_values=all_results,
- return_dict=False,
- )
-
- past_values = []
- for past in past_key_values:
- past_values = past_values + list(past)
- return last_hidden_state, past_values
-
-
-def _create_traced_encoder(encoder, input_ids, attention_mask):
- encoder_c = copy.deepcopy(encoder)
- encoder_for_onnx = EncoderForONNX(encoder_c)
-
- return torch.jit.trace(encoder_for_onnx, (input_ids, attention_mask))
-
-
-def _create_traced_decoder(decoder, input_ids, encoder_state, attention_mask, past=None):
- decoder_c = copy.deepcopy(decoder)
- decoder_for_onnx = DecoderForONNX(decoder_c)
- past_values = list(itertools.chain.from_iterable(past or ()))
-
- # Do this twice so we got 2 different decoders for further work.
- if past_values:
- return torch.jit.trace(decoder_for_onnx, (input_ids, encoder_state, attention_mask, past_values))
- else:
- return torch.jit.trace(decoder_for_onnx, (input_ids, encoder_state, attention_mask))
-
-
-class BartConfigTS(BartConfig, torch.nn.Module):
- """
- BartConfigTS is a TorchScript-compatible transformers.models.bart.configuration_bart.BartConfig.
- TorchScript only supports sub-classes of torch.nn.Module.
- """
-
- def __init__(self, config):
- BartConfig.__init__(self, config)
- torch.nn.Module.__init__(self)
-
-
-class MinLengthLogitsProcessorTS(torch.nn.Module):
- r"""
- :class:`transformers.LogitsProcessor` enforcing a min-length by setting EOS probability to 0.
-
- Args:
- min_length (:obj:`int`):
- The minimum length below which the score of :obj:`eos_token_id` is set to :obj:`-float("Inf")`.
- eos_token_id (:obj:`int`):
- The id of the `end-of-sequence` token.
- """
-
- def __init__(self, min_length: int, eos_token_id: int):
- super().__init__()
-
- if not isinstance(min_length, int) or min_length < 0:
- raise ValueError(f"`min_length` has to be a positive integer, but is {min_length}")
-
- if not isinstance(eos_token_id, int) or eos_token_id < 0:
- raise ValueError(f"`eos_token_id` has to be a positive integer, but is {eos_token_id}")
-
- self.min_length = min_length
- self.eos_token_id = eos_token_id
-
- def forward(self, input_ids, scores) -> torch.Tensor:
- cur_len = input_ids.shape[-1]
- if cur_len < self.min_length:
- scores[:, self.eos_token_id] = -float("inf")
- return scores
-
-
-class BARTGenerator(torch.nn.Module, GenerationMixin):
- def __init__(self, model):
- super().__init__()
- self.config = BartConfigTS(model.config)
- self.config.force_bos_token_to_be_generated = False
- self._trace_modules(model)
- self.logits_processor = MinLengthLogitsProcessorTS(self.config.min_length, self.config.eos_token_id)
- self.final_logits_weight = model.model.shared.weight
- self.final_logits_bias = model.final_logits_bias
- self.decoder_layers = model.config.decoder_layers
-
- def _trace_modules(self, model):
- input_ids = torch.tensor(
- [
- [
- 19,
- 669,
- 18,
- 420,
- 8,
- 664,
- 57,
- 42,
- 8,
- 664,
- 21,
- 3028,
- 195,
- 4445,
- 331,
- 1293,
- 34,
- 21,
- 10,
- 6174,
- 1100,
- 6,
- 69,
- 104,
- 42,
- 32,
- 2621,
- 1638,
- 144,
- 4,
- 6174,
- 558,
- 108,
- 4419,
- 1091,
- 28,
- 4,
- 1668,
- 9,
- 1509,
- 1621,
- 279,
- 35,
- 867,
- 2734,
- 85,
- 11,
- 2216,
- 2734,
- 85,
- 203,
- 2244,
- 7,
- 6,
- 15,
- 8102,
- 7,
- 57,
- 8629,
- 5,
- model.config.eos_token_id,
- ]
- ],
- device=model.device,
- dtype=torch.long,
- )
- attention_mask = torch.tensor(
- [[True] * input_ids.shape[-1]],
- device=model.device,
- dtype=torch.bool,
- )
- self.encoder = _create_traced_encoder(model.get_encoder(), input_ids, attention_mask)
- encoder_outputs = model.get_encoder()(input_ids, attention_mask=attention_mask, return_dict=True)
- decoder = model.model.decoder
- decoder_outputs = decoder(input_ids, attention_mask, encoder_outputs["last_hidden_state"], None, None, None)
- self.decoder_no_past = _create_traced_decoder(
- model.model.decoder, input_ids, encoder_outputs["last_hidden_state"], attention_mask
- )
- self.decoder_with_past = _create_traced_decoder(
- model.model.decoder, input_ids, encoder_outputs["last_hidden_state"], attention_mask, decoder_outputs[1]
- )
-
- def _encoder_forward(self, input_ids, attention_mask):
- return self.encoder(input_ids, attention_mask)[0]
-
- @staticmethod
- def _init_sequence_length_for_generation(
- input_ids: torch.LongTensor, max_length: int
- ) -> Tuple[torch.Tensor, torch.Tensor, int]:
- unfinished_sequences = torch.zeros(input_ids.shape[0], dtype=torch.long, device=input_ids.device) + 1
- sequence_lengths = torch.zeros(input_ids.shape[0], dtype=torch.long, device=input_ids.device) + max_length
-
- cur_len = input_ids.shape[-1]
- return sequence_lengths, unfinished_sequences, cur_len
-
- def _decoder_forward(self, input_ids, encoder_output, attention_mask, past: List[torch.Tensor]):
- # Update here to use different decoder for different values of past.
- if past is None or len(past) == 0:
- decoder_output, past = self.decoder_no_past(
- input_ids=input_ids, encoder_state=encoder_output, attention_mask=attention_mask
- )
- else:
- decoder_output, past = self.decoder_with_past(
- input_ids=input_ids, encoder_state=encoder_output, attention_mask=attention_mask, past=past
- )
-
- lm_logits = F.linear(decoder_output, self.final_logits_weight, bias=self.final_logits_bias)
-
- return lm_logits, past
-
- def greedy_search(
- self, input_ids, encoder_output, attention_mask, max_length, pad_token_id: int, eos_token_id: int
- ):
- # init sequence length tensors
- sequence_lengths, unfinished_sequences, cur_len = self._init_sequence_length_for_generation(
- input_ids, max_length
- )
-
- past: List[torch.Tensor] = []
- while cur_len < max_length:
- logits, past = self._decoder_forward(input_ids, encoder_output, attention_mask, past)
- next_token_logits = logits[:, -1, :]
-
- # pre-process distribution
- scores = self.logits_processor(input_ids, next_token_logits)
-
- # argmax
- next_tokens = torch.argmax(scores, dim=-1)
-
- # add code that transfomers next_tokens to tokens_to_add
- if eos_token_id is not None:
- assert pad_token_id is not None, "If eos_token_id is defined, make sure that pad_token_id is defined."
- next_tokens = next_tokens * unfinished_sequences + (pad_token_id) * (1 - unfinished_sequences)
-
- # add token and increase length by one
- input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
-
- # update sequence length
- if eos_token_id is not None:
- sequence_lengths, unfinished_sequences = self._update_seq_length_for_generation(
- sequence_lengths, unfinished_sequences, cur_len, next_tokens == eos_token_id
- )
-
- # stop when there is a in each sentence, or if we exceed the maximul length
- if unfinished_sequences.max() == 0:
- break
-
- # increase cur_len
- cur_len = cur_len + 1
-
- return input_ids
-
- def _prepare_decoder_input_ids_for_generation(
- self,
- input_ids: torch.LongTensor,
- decoder_start_token_id,
- bos_token_id: Optional[int] = None,
- ) -> torch.LongTensor:
- decoder_input_ids = (
- torch.ones((input_ids.shape[0], 1), dtype=input_ids.dtype, device=input_ids.device)
- * decoder_start_token_id
- )
- return decoder_input_ids
-
- def forward(self, input_ids, attention_mask, max_length, decoder_start_token_id):
- pad_token_id = self.config.pad_token_id
- bos_token_id = self.config.bos_token_id
- eos_token_id = self.config.eos_token_id
-
- # special case if pad_token_id is not defined
- if pad_token_id is None and eos_token_id is not None:
- # Setting `pad_token_id` to `eos_token_id`:{eos_token_id} for open-end generation.
- pad_token_id = eos_token_id
-
- encoder_output = self._encoder_forward(input_ids, attention_mask)
-
- input_ids = self._prepare_decoder_input_ids_for_generation(
- input_ids,
- decoder_start_token_id=decoder_start_token_id,
- bos_token_id=bos_token_id,
- )
-
- return self.greedy_search(
- input_ids,
- encoder_output,
- attention_mask,
- max_length=max_length,
- pad_token_id=pad_token_id,
- eos_token_id=eos_token_id,
- )
-
-
-# TorchScript compatible BeamSearchScorer
-class BeamSearchScorerTS(torch.nn.Module):
- def __init__(self):
- super().__init__()
- self.max_length: int = 200
- self.num_beams: int = 3
- self.batch_size: int = 1
- self.length_penalty: float = 1.0
- self.do_early_stopping: bool = True
- self.num_beam_hyps_to_keep: int = 1
- self.num_beam_groups: int = 1
- self.group_size: int = self.num_beams // self.num_beam_groups
- self._done = torch.zeros(self.batch_size, dtype=torch.bool)
- self._beam_hyps_count = torch.zeros(self.batch_size, dtype=torch.long)
- self._beam_hyps_worst_scores = torch.zeros(self.batch_size) + 1e9
- self._beam_hyps_max_length: int = self.max_length - 1
- self._beam_hyps: List[torch.Tensor] = [torch.zeros(2)] # placeholder for TorchScript compatibility
- self._beam_scores: List[torch.Tensor] = [torch.zeros(2)] # placeholder for TorchScript compatibility
-
- def is_done(self) -> torch.Tensor:
- return self._done.all()
-
- def init(
- self,
- batch_size: int,
- max_length: int,
- num_beams: int,
- device: torch.device,
- length_penalty: float = 1.0,
- do_early_stopping: bool = False,
- num_beam_hyps_to_keep: int = 1,
- num_beam_groups: int = 1,
- ):
- self.max_length = max_length
- self.num_beams = num_beams
- self.batch_size = batch_size
- self.length_penalty = length_penalty
- self.do_early_stopping = do_early_stopping
- self.num_beam_hyps_to_keep = num_beam_hyps_to_keep
- self.num_beam_groups = num_beam_groups
- self.group_size = self.num_beams // self.num_beam_groups
-
- # NOTE: TorchScript does not support List of Modules
- # Rewritten BeamHypotheses with tensors and list of tensors.
- self._done = torch.zeros(batch_size, dtype=torch.bool, device=device)
- self._beam_hyps_count = torch.zeros(batch_size, dtype=torch.long, device=device)
- self._beam_hyps_worst_scores = torch.zeros(batch_size, device=device) + 1e9
- self._beam_hyps = []
- self._beam_scores = []
-
- self._beam_hyps_max_length = max_length - 1 # ignoring bos_token
-
- if not isinstance(num_beams, int) or num_beams <= 1:
- raise ValueError(
- f"`num_beams` has to be an integer strictly greater than 1, but is {num_beams}. For `num_beams` == 1,"
- " one should make use of `greedy_search` instead."
- )
-
- if not isinstance(num_beam_groups, int) or (num_beam_groups > num_beams) or (num_beams % num_beam_groups != 0):
- raise ValueError(
- "`num_beam_groups` has to be an integer smaller or equal than `num_beams` and `num_beams` has to be"
- f" divisible by `num_beam_groups`, but is {num_beam_groups} with `num_beams` being {num_beams}."
- )
-
- def hypo_len(self, hypo_idx: int):
- """
- Number of hypotheses in the list.
- """
- return self._beam_hyps_count[hypo_idx]
-
- def hypo_add(self, hyp: torch.Tensor, sum_logprobs: float, hypo_idx: int):
- """
- Add a new hypothesis to the list.
- """
- score = sum_logprobs / (hyp.shape[-1] ** self.length_penalty)
- hyps_count = self.hypo_len(hypo_idx)
- if hyps_count < self.num_beams or score > self._beam_hyps_worst_scores[hypo_idx]:
- # NOTE: work around difference of torch.sum(empty_tensor) == 0, while error in onnx.
- # Bug: https://msdata.visualstudio.com/Vienna/_workitems/edit/1486599
- beam_idx = (
- torch.sum(self._beam_hyps_count[:hypo_idx]) if hypo_idx != 0 else torch.tensor(0, dtype=torch.long)
- )
- self._beam_scores.insert(beam_idx, torch.tensor([score]))
- self._beam_hyps.insert(beam_idx, hyp)
- if hyps_count + 1 > self.num_beams:
- sorted_next_scores, sorted_indices = torch.topk(
- torch.cat(self._beam_scores)[beam_idx : beam_idx + hyps_count + 1], hyps_count + 1, largest=False
- )
- del self._beam_hyps[int((sorted_indices[0] + beam_idx))]
- del self._beam_scores[int((sorted_indices[0] + beam_idx))]
- self._beam_hyps_worst_scores[hypo_idx] = sorted_next_scores[1]
- else:
- self._beam_hyps_worst_scores[hypo_idx] = min(score, self._beam_hyps_worst_scores[hypo_idx])
- self._beam_hyps_count[hypo_idx] = hyps_count + 1
-
- def hypo_is_done(self, hypo_idx: int, best_sum_logprobs: float, cur_len: int) -> bool:
- """
- If there are enough hypotheses and that none of the hypotheses being generated can become better than the worst
- one in the heap, then we are done with this sentence.
- """
- if self.hypo_len(hypo_idx) < self.num_beams:
- return False
- elif self.do_early_stopping:
- return True
- else:
- cur_score = best_sum_logprobs / cur_len**self.length_penalty
- ret = self._beam_hyps_worst_scores[hypo_idx].item() >= cur_score
- return ret
-
- def process(
- self,
- input_ids: torch.Tensor,
- next_scores: torch.Tensor,
- next_tokens: torch.Tensor,
- next_indices: torch.Tensor,
- pad_token_id: Optional[int] = None,
- eos_token_id: Optional[int] = None,
- ) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
- cur_len = input_ids.shape[-1]
- batch_size = len(self._beam_hyps_count)
- assert batch_size == (input_ids.shape[0] // self.group_size)
-
- device = input_ids.device
- next_beam_scores = torch.zeros((batch_size, self.group_size), dtype=next_scores.dtype, device=device)
- next_beam_tokens = torch.zeros((batch_size, self.group_size), dtype=next_tokens.dtype, device=device)
- next_beam_indices = torch.zeros((batch_size, self.group_size), dtype=next_indices.dtype, device=device)
-
- for batch_idx in range(batch_size):
- if self._done[batch_idx]:
- assert (
- self.hypo_len(batch_idx) >= self.num_beams
- ), "Batch can only be done if at least {} beams have been generated".format(self.num_beams)
- assert (
- eos_token_id is not None and pad_token_id is not None
- ), "generated beams >= num_beams -> eos_token_id and pad_token have to be defined"
- # pad the batch
- next_beam_scores[batch_idx, :] = 0
- next_beam_tokens[batch_idx, :] = pad_token_id
- next_beam_indices[batch_idx, :] = 0
- continue
-
- # next tokens for this sentence
- beam_idx = 0
- for beam_token_rank, (next_token, next_score, next_index) in enumerate(
- zip(next_tokens[batch_idx], next_scores[batch_idx], next_indices[batch_idx])
- ):
- batch_beam_idx = batch_idx * self.group_size + next_index
- # add to generated hypotheses if end of sentence
- if (eos_token_id is not None) and (next_token == eos_token_id):
- # if beam_token does not belong to top num_beams tokens, it should not be added
- is_beam_token_worse_than_top_num_beams = beam_token_rank >= self.group_size
- if is_beam_token_worse_than_top_num_beams:
- continue
- self.hypo_add(
- input_ids[batch_beam_idx].clone(),
- next_score.item(),
- batch_idx,
- )
- else:
- # add next predicted token since it is not eos_token
- next_beam_scores[batch_idx, beam_idx] = next_score
- next_beam_tokens[batch_idx, beam_idx] = next_token
- next_beam_indices[batch_idx, beam_idx] = batch_beam_idx
- beam_idx += 1
-
- # once the beam for next step is full, don't add more tokens to it.
- if beam_idx == self.group_size:
- break
-
- if beam_idx < self.group_size:
- raise ValueError(
- f"At most {self.group_size} tokens in {next_tokens[batch_idx]} can be equal to `eos_token_id:"
- f" {eos_token_id}`. Make sure {next_tokens[batch_idx]} are corrected."
- )
-
- # Check if we are done so that we can save a pad step if all(done)
- self._done[batch_idx] = self._done[batch_idx] or self.hypo_is_done(
- batch_idx,
- next_scores[batch_idx].max().item(),
- cur_len,
- )
-
- return next_beam_scores.view(-1), next_beam_tokens.view(-1), next_beam_indices.view(-1)
-
- def finalize(
- self,
- input_ids: torch.Tensor,
- final_beam_scores: torch.Tensor,
- final_beam_tokens: torch.Tensor,
- final_beam_indices: torch.Tensor,
- pad_token_id: int,
- eos_token_id: int,
- ) -> Tuple[torch.Tensor, torch.Tensor]:
- batch_size = len(self._beam_hyps_count)
-
- # finalize all open beam hypotheses and add to generated hypotheses
- for batch_idx in range(batch_size):
- if self._done[batch_idx]:
- continue
-
- # all open beam hypotheses are added to the beam hypothesis
- # beam hypothesis class automatically keeps the best beams
- for beam_id in range(self.num_beams):
- batch_beam_idx = batch_idx * self.num_beams + beam_id
- final_score = final_beam_scores[batch_beam_idx].item()
- final_tokens = input_ids[batch_beam_idx]
- self.hypo_add(final_tokens, final_score, batch_idx)
-
- # select the best hypotheses
- # NOTE: torch.Tensor.new_zeros() is not scriptable
- sent_lengths = torch.zeros(batch_size * self.num_beam_hyps_to_keep, dtype=torch.long)
- best = []
- best_scores = torch.zeros(
- batch_size * self.num_beam_hyps_to_keep, device=input_ids.device, dtype=torch.float32
- )
- # retrieve best hypotheses
- for i in range(batch_size):
- # NOTE: lambda is not scriptable
- batch_hypo_start = torch.sum(self._beam_hyps_count[:i]) if i > 0 else torch.tensor(0, dtype=torch.long)
- batch_hypo_end = torch.sum(self._beam_hyps_count[: i + 1])
- beam_scores = torch.cat(self._beam_scores)[batch_hypo_start:batch_hypo_end]
- sorted_next_scores, sorted_indices = torch.topk(beam_scores, len(beam_scores), largest=True)
- for j in range(self.num_beam_hyps_to_keep):
- best_score = beam_scores[sorted_indices[j]]
- best_hyp = self._beam_hyps[batch_hypo_start + sorted_indices[j]]
- sent_lengths[self.num_beam_hyps_to_keep * i + j] = len(best_hyp)
- # append to lists
- best.append(best_hyp)
- best_scores[i * self.num_beam_hyps_to_keep + j] = best_score
-
- # prepare for adding eos
- sent_max_len = min(sent_lengths.max() + 1, self.max_length)
- decoded = torch.zeros(batch_size * self.num_beam_hyps_to_keep, sent_max_len, dtype=torch.long)
- # shorter batches are padded if needed
- if sent_lengths.min() != sent_lengths.max():
- assert pad_token_id is not None, "`pad_token_id` has to be defined"
- decoded.fill_(pad_token_id)
-
- # fill with hypotheses and eos_token_id if the latter fits in
- for i, hypo in enumerate(best):
- decoded[i, : sent_lengths[i]] = hypo
- if sent_lengths[i] < self.max_length:
- decoded[i, sent_lengths[i]] = eos_token_id
-
- return decoded, best_scores
-
-
-class BARTBeamSearchGenerator(BARTGenerator):
- def __init__(self, model):
- super().__init__(model)
- self.beam_scorer = BeamSearchScorerTS()
- self.device = model.device
-
- @staticmethod
- def _expand_inputs_for_generation(
- input_ids: torch.Tensor,
- attention_mask: torch.Tensor,
- last_hidden_state: torch.Tensor,
- expand_size: int = 1,
- ) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
- expanded_return_idx = (
- torch.arange(input_ids.shape[0]).view(-1, 1).repeat(1, expand_size).view(-1).to(input_ids.device)
- )
- input_ids = input_ids.index_select(0, expanded_return_idx)
-
- attention_mask = attention_mask.index_select(0, expanded_return_idx)
-
- last_hidden_state = last_hidden_state.index_select(0, expanded_return_idx.to(last_hidden_state.device))
- return input_ids, attention_mask, last_hidden_state
-
- def adjust_logits_during_generation(self, logits, cur_len: int, max_length: int):
- if cur_len == 1 and self.config.force_bos_token_to_be_generated:
- logits = self._force_token_id_to_be_generated(logits, self.config.bos_token_id)
- elif cur_len == max_length - 1 and self.config.eos_token_id is not None:
- logits = self._force_token_id_to_be_generated(logits, self.config.eos_token_id)
- return logits
-
- @staticmethod
- def _force_token_id_to_be_generated(scores, token_id: int):
- """force one of token_ids to be generated by setting prob of all other tokens to 0 (logprob=-float("inf"))"""
- mask = torch.full_like(scores, 1, dtype=torch.bool)
- mask[:, token_id] = False
- return scores.masked_fill(mask, -float("inf"))
-
- def _reorder_cache(self, past: List[torch.Tensor], beam_idx):
- # if decoder past is not included in output
- # speedy decoding is disabled and no need to reorder
- reordered_decoder_past = []
- for state in past:
- reordered_decoder_past.append(state.index_select(0, beam_idx))
- return reordered_decoder_past
-
- def beam_search(
- self, input_ids, encoder_output, attention_mask, num_beams, max_length, pad_token_id: int, eos_token_id: int
- ):
- batch_size = self.beam_scorer.batch_size
-
- num_beams = self.beam_scorer.num_beams
- batch_beam_size, cur_len = input_ids.shape
-
- assert (
- num_beams * batch_size == batch_beam_size
- ), f"Batch dimension of `input_ids` should be {num_beams * batch_size}, but is {batch_beam_size}."
-
- beam_scores = torch.zeros((batch_size, num_beams), dtype=torch.float, device=input_ids.device)
- beam_scores[:, 1:] = -1e9
- beam_scores = beam_scores.view((batch_size * num_beams,))
- next_tokens = torch.zeros((batch_size, num_beams), dtype=torch.long, device=input_ids.device)
- next_indices = torch.zeros((batch_size, num_beams), dtype=torch.long, device=input_ids.device)
-
- past: List[torch.Tensor] = []
- while cur_len < max_length:
- logits, past = self._decoder_forward(input_ids, encoder_output, attention_mask, past)
- next_token_logits = logits[:, -1, :]
-
- # adjust tokens for Bart, *e.g.*
- next_token_logits = self.adjust_logits_during_generation(
- next_token_logits, cur_len=cur_len, max_length=max_length
- )
-
- next_token_scores = F.log_softmax(next_token_logits, dim=-1) # (batch_size * num_beams, vocab_size)
-
- # pre-process distribution
- next_token_scores = self.logits_processor(input_ids, next_token_scores)
- next_token_scores = next_token_scores + beam_scores[:, None].expand_as(next_token_scores)
-
- # reshape for beam search
- vocab_size = next_token_scores.shape[-1]
- next_token_scores = next_token_scores.view(batch_size, num_beams * vocab_size)
-
- next_token_scores, next_tokens = torch.topk(
- next_token_scores, 2 * num_beams, dim=1, largest=True, sorted=True
- )
-
- next_indices = next_tokens // vocab_size
- next_tokens = next_tokens % vocab_size
-
- beam_scores, beam_next_tokens, beam_idx = self.beam_scorer.process(
- input_ids,
- next_token_scores,
- next_tokens,
- next_indices,
- pad_token_id=pad_token_id,
- eos_token_id=eos_token_id,
- )
-
- input_ids = torch.cat([input_ids[beam_idx, :], beam_next_tokens.unsqueeze(-1)], dim=-1)
-
- cur_len = cur_len + 1
-
- if len(past) > 0:
- past = self._reorder_cache(past, beam_idx)
-
- if self.beam_scorer.is_done():
- break
-
- sequences, sequence_scores = self.beam_scorer.finalize(
- input_ids,
- beam_scores,
- next_tokens,
- next_indices,
- pad_token_id=pad_token_id,
- eos_token_id=eos_token_id,
- )
-
- return sequences
-
- def forward(self, input_ids, attention_mask, num_beams, max_length, decoder_start_token_id):
- pad_token_id = self.config.pad_token_id
- bos_token_id = self.config.bos_token_id
- eos_token_id = self.config.eos_token_id
-
- # special case if pad_token_id is not defined
- if pad_token_id is None and eos_token_id is not None:
- # logger.warning(f"Setting `pad_token_id` to `eos_token_id`:{eos_token_id} for open-end generation.")
- pad_token_id = eos_token_id
-
- encoder_output = self._encoder_forward(input_ids, attention_mask)
-
- input_ids = self._prepare_decoder_input_ids_for_generation(
- input_ids,
- decoder_start_token_id=decoder_start_token_id,
- bos_token_id=bos_token_id,
- )
-
- batch_size = input_ids.shape[0]
-
- length_penalty = self.config.length_penalty
- num_return_sequences = self.config.num_return_sequences
- early_stopping = True
-
- self.beam_scorer.init(
- batch_size=batch_size,
- max_length=max_length,
- num_beams=num_beams,
- device=self.device,
- length_penalty=length_penalty,
- do_early_stopping=early_stopping,
- num_beam_hyps_to_keep=num_return_sequences,
- )
-
- input_ids, attention_mask, encoder_output = self._expand_inputs_for_generation(
- input_ids,
- attention_mask,
- encoder_output,
- expand_size=num_beams,
- )
-
- return self.beam_search(
- input_ids=input_ids,
- encoder_output=encoder_output,
- attention_mask=attention_mask,
- num_beams=num_beams,
- max_length=max_length,
- pad_token_id=pad_token_id,
- eos_token_id=eos_token_id,
- )
diff --git a/examples/research_projects/onnx/summarization/bart_onnx/reduce_onnx_size.py b/examples/research_projects/onnx/summarization/bart_onnx/reduce_onnx_size.py
deleted file mode 100644
index 1df20e4504d..00000000000
--- a/examples/research_projects/onnx/summarization/bart_onnx/reduce_onnx_size.py
+++ /dev/null
@@ -1,121 +0,0 @@
-"""
-Code to remove duplicate initializers to reduce ONNX model size.
-"""
-
-import os
-
-import numpy
-import onnx
-
-
-def _is_equal_tensor_proto(a, b):
- name_a = a.name
- name_b = b.name
-
- a.name = ""
- b.name = ""
-
- res = a == b
-
- a.name = name_a
- b.name = name_b
-
- return res
-
-
-def _node_replace_input_with(node_proto, name, new_name):
- for i, input_name in enumerate(node_proto.input):
- if input_name == name:
- node_proto.input.insert(i, new_name)
- node_proto.input.pop(i + 1)
-
- if node_proto.op_type == "If":
- _graph_replace_input_with(node_proto.attribute[0].g, name, new_name)
- _graph_replace_input_with(node_proto.attribute[1].g, name, new_name)
- if node_proto.op_type == "Loop":
- _graph_replace_input_with(node_proto.attribute[0].g, name, new_name)
-
-
-def _graph_replace_input_with(graph_proto, name, new_name):
- for n in graph_proto.node:
- _node_replace_input_with(n, name, new_name)
-
-
-def _remove_dup_initializers_from_model(model, model_without_ext, ind_to_replace):
- inits_with_data = list(model.graph.initializer)
- inits = list(model_without_ext.graph.initializer)
- for i, ref_i in ind_to_replace:
- assert inits_with_data[i].name == inits[i].name
- assert inits_with_data[ref_i].name == inits[ref_i].name
- assert i > ref_i
-
- name_i = inits[i].name
- name_ref = inits[ref_i].name
-
- model_without_ext.graph.initializer.remove(inits[i])
-
- # for n in model.graph.node:
- _graph_replace_input_with(model_without_ext.graph, name_i, name_ref)
-
-
-def remove_dup_initializers(onnx_file_path):
- """
- Removes duplicate initializers from the model to reduce its size.
- Writes a new file in the same directory as onnx_file_path and returns the path to that file.
- """
-
- model_file_folder = os.path.dirname(onnx_file_path)
- model_file_name = os.path.basename(onnx_file_path)
-
- model = onnx.load(os.path.join(model_file_folder, model_file_name))
-
- inits = list(model.graph.initializer)
-
- dup_set = set()
- dup_map = {}
- ind_to_replace = []
-
- total_reduced_size = 0
-
- for i in range(len(inits)):
- if i in dup_set:
- continue
-
- for j in range(i + 1, len(inits)):
- if j in dup_set:
- continue
- if _is_equal_tensor_proto(inits[i], inits[j]):
- dup_set.add(i)
- dup_set.add(j)
-
- dtype = inits[j].data_type
- mem_size = numpy.prod(inits[j].dims)
- if dtype == 1:
- mem_size *= 4
- elif dtype == 6:
- mem_size *= 4
- elif dtype == 7 or dtype == 11:
- mem_size *= 8
- else:
- print("unexpected data type: ", dtype)
- total_reduced_size += mem_size
-
- name_i = inits[i].name
- name_j = inits[j].name
-
- if name_i in dup_map:
- dup_map[name_i].append(name_j)
- else:
- dup_map[name_i] = [name_j]
- ind_to_replace.append((j, i))
-
- print("total reduced size: ", total_reduced_size / 1024 / 1024 / 1024, "GB")
-
- ind_to_replace = sorted(ind_to_replace)
- _remove_dup_initializers_from_model(model, model, ind_to_replace)
-
- optimized_model_file_name = "optimized_" + model_file_name
- new_model = os.path.join(model_file_folder, optimized_model_file_name)
- onnx.save(model, new_model)
-
- return new_model
diff --git a/examples/research_projects/onnx/summarization/requirements.txt b/examples/research_projects/onnx/summarization/requirements.txt
deleted file mode 100644
index 21535650612..00000000000
--- a/examples/research_projects/onnx/summarization/requirements.txt
+++ /dev/null
@@ -1 +0,0 @@
-torch >= 1.10
\ No newline at end of file
diff --git a/examples/research_projects/onnx/summarization/run_onnx_exporter.py b/examples/research_projects/onnx/summarization/run_onnx_exporter.py
deleted file mode 100644
index fa826732701..00000000000
--- a/examples/research_projects/onnx/summarization/run_onnx_exporter.py
+++ /dev/null
@@ -1,206 +0,0 @@
-#!/usr/bin/env python
-# coding=utf-8
-# Copyright The HuggingFace Team and The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-""" """
-
-import argparse
-import logging
-import os
-import sys
-
-import numpy as np
-import onnxruntime
-import torch
-from bart_onnx.generation_onnx import BARTBeamSearchGenerator
-from bart_onnx.reduce_onnx_size import remove_dup_initializers
-
-import transformers
-from transformers import BartForConditionalGeneration, BartTokenizer
-
-
-logging.basicConfig(
- format="%(asctime)s | %(levelname)s | %(name)s | [%(filename)s:%(lineno)d] %(message)s",
- datefmt="%Y-%m-%d %H:%M:%S",
- level=os.environ.get("LOGLEVEL", "INFO").upper(),
- stream=sys.stdout,
-)
-
-logger = logging.getLogger(__name__)
-
-model_dict = {"facebook/bart-base": BartForConditionalGeneration}
-tokenizer_dict = {"facebook/bart-base": BartTokenizer}
-
-
-def parse_args():
- parser = argparse.ArgumentParser(description="Export Bart model + Beam Search to ONNX graph.")
- parser.add_argument(
- "--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
- )
- parser.add_argument(
- "--max_length",
- type=int,
- default=5,
- help="The maximum total input sequence length after tokenization.",
- )
- parser.add_argument(
- "--num_beams",
- type=int,
- default=None,
- help=(
- "Number of beams to use for evaluation. This argument will be "
- "passed to ``model.generate``, which is used during ``evaluate`` and ``predict``."
- ),
- )
- parser.add_argument(
- "--model_name_or_path",
- type=str,
- help="Path to pretrained model or model identifier from huggingface.co/models.",
- required=True,
- )
- parser.add_argument(
- "--config_name",
- type=str,
- default=None,
- help="Pretrained config name or path if not the same as model_name",
- )
- parser.add_argument(
- "--device",
- type=str,
- default="cpu",
- help="Device where the model will be run",
- )
- parser.add_argument("--output_file_path", type=str, default=None, help="Where to store the final ONNX file.")
-
- args = parser.parse_args()
-
- return args
-
-
-def load_model_tokenizer(model_name, device="cpu"):
- huggingface_model = model_dict[model_name].from_pretrained(model_name).to(device)
- tokenizer = tokenizer_dict[model_name].from_pretrained(model_name)
-
- if model_name in ["facebook/bart-base"]:
- huggingface_model.config.no_repeat_ngram_size = 0
- huggingface_model.config.forced_bos_token_id = None
- huggingface_model.config.min_length = 0
-
- return huggingface_model, tokenizer
-
-
-def export_and_validate_model(model, tokenizer, onnx_file_path, num_beams, max_length):
- model.eval()
-
- ort_sess = None
- bart_script_model = torch.jit.script(BARTBeamSearchGenerator(model))
-
- with torch.no_grad():
- ARTICLE_TO_SUMMARIZE = "My friends are cool but they eat too many carbs."
- inputs = tokenizer([ARTICLE_TO_SUMMARIZE], max_length=1024, return_tensors="pt").to(model.device)
-
- summary_ids = model.generate(
- inputs["input_ids"],
- attention_mask=inputs["attention_mask"],
- num_beams=num_beams,
- max_length=max_length,
- early_stopping=True,
- decoder_start_token_id=model.config.decoder_start_token_id,
- )
-
- torch.onnx.export(
- bart_script_model,
- (
- inputs["input_ids"],
- inputs["attention_mask"],
- num_beams,
- max_length,
- model.config.decoder_start_token_id,
- ),
- onnx_file_path,
- opset_version=14,
- input_names=["input_ids", "attention_mask", "num_beams", "max_length", "decoder_start_token_id"],
- output_names=["output_ids"],
- dynamic_axes={
- "input_ids": {0: "batch", 1: "seq"},
- "output_ids": {0: "batch", 1: "seq_out"},
- },
- example_outputs=summary_ids,
- )
-
- logger.info("Model exported to {}".format(onnx_file_path))
-
- new_onnx_file_path = remove_dup_initializers(os.path.abspath(onnx_file_path))
-
- logger.info("Deduplicated and optimized model written to {}".format(new_onnx_file_path))
-
- ort_sess = onnxruntime.InferenceSession(new_onnx_file_path)
- ort_out = ort_sess.run(
- None,
- {
- "input_ids": inputs["input_ids"].cpu().numpy(),
- "attention_mask": inputs["attention_mask"].cpu().numpy(),
- "num_beams": np.array(num_beams),
- "max_length": np.array(max_length),
- "decoder_start_token_id": np.array(model.config.decoder_start_token_id),
- },
- )
-
- np.testing.assert_allclose(summary_ids.cpu().numpy(), ort_out[0], rtol=1e-3, atol=1e-3)
-
- logger.info("Model outputs from torch and ONNX Runtime are similar.")
- logger.info("Success.")
-
-
-def main():
- args = parse_args()
- max_length = 5
- num_beams = 4
-
- # Make one log on every process with the configuration for debugging.
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- level=logging.INFO,
- )
-
- logger.setLevel(logging.INFO)
- transformers.utils.logging.set_verbosity_error()
-
- device = torch.device(args.device)
-
- model, tokenizer = load_model_tokenizer(args.model_name_or_path, device)
-
- if model.config.decoder_start_token_id is None:
- raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
-
- model.to(device)
-
- if args.max_length:
- max_length = args.max_length
-
- if args.num_beams:
- num_beams = args.num_beams
-
- if args.output_file_path:
- output_name = args.output_file_path
- else:
- output_name = "BART.onnx"
-
- logger.info("Exporting model to ONNX")
- export_and_validate_model(model, tokenizer, output_name, num_beams, max_length)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/performer/README.md b/examples/research_projects/performer/README.md
deleted file mode 100644
index fa847268b0c..00000000000
--- a/examples/research_projects/performer/README.md
+++ /dev/null
@@ -1,25 +0,0 @@
-# Performer fine-tuning
-
-Example authors: @TevenLeScao, @Patrickvonplaten
-
-Paper authors: Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, David Belanger, Lucy Colwell, Adrian Weller
-
-## Requirements
-
-`datasets`, `flax` and `jax`. `wandb` integration is built-in if you want to use it.
-
-## Examples
-
-`sanity_script.sh` will launch performer fine-tuning from the google-bert/bert-base-cased checkpoint on the Simple Wikipedia dataset (a small, easy-language English Wikipedia) from `datasets`.
-`full_script.sh` will launch performer fine-tuning from the google-bert/bert-large-cased checkpoint on the English Wikipedia dataset from `datasets`.
-
-Here are a few key arguments:
-- Remove the `--performer` argument to use a standard Bert model.
-
-- Add `--reinitialize` to start from a blank model rather than a Bert checkpoint.
-
-- You may change the Bert size by passing a different [checkpoint](https://huggingface.co/transformers/pretrained_models.html) to the `--model_name_or_path` argument.
-
-- Passing your user name to the `--wandb_user_name` argument will trigger weights and biases logging.
-
-- You can choose a dataset with `--dataset_name` and `--dataset_config`. Our [viewer](https://huggingface.co/datasets/viewer/) will help you find what you need.
\ No newline at end of file
diff --git a/examples/research_projects/performer/full_script.sh b/examples/research_projects/performer/full_script.sh
deleted file mode 100755
index 8634666f983..00000000000
--- a/examples/research_projects/performer/full_script.sh
+++ /dev/null
@@ -1 +0,0 @@
-TOKENIZERS_PARALLELISM=true python run_mlm_performer.py --output_dir experiments --dataset_name wikipedia --dataset_config_name 20200501.en --model_name_or_path bert-large-cased --tokenizer_name bert-large-cased --do_train --overwrite_output_dir --per_device_train_batch_size 4 --learning_rate 5e-4 --warmup_steps 100 --num_train_epochs 3 --performer
\ No newline at end of file
diff --git a/examples/research_projects/performer/modeling_flax_performer.py b/examples/research_projects/performer/modeling_flax_performer.py
deleted file mode 100644
index 7c2fde6ddbb..00000000000
--- a/examples/research_projects/performer/modeling_flax_performer.py
+++ /dev/null
@@ -1,551 +0,0 @@
-# coding=utf-8
-# Copyright 2018 The Google Flax Team Authors and The HuggingFace Inc. team.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-from typing import Callable, Dict, Tuple
-
-import flax.linen as nn
-import jax
-import jax.numpy as jnp
-import numpy as np
-from jax.random import PRNGKey
-from modeling_flax_performer_utils import make_fast_softmax_attention
-
-from transformers.file_utils import add_start_docstrings
-from transformers.modeling_flax_utils import ACT2FN
-from transformers.models.bert.configuration_bert import BertConfig
-from transformers.models.bert.modeling_flax_bert import FlaxBertOnlyMLMHead, FlaxBertPreTrainedModel
-from transformers.utils import logging
-
-
-logger = logging.get_logger(__name__)
-
-_CONFIG_FOR_DOC = "BertConfig"
-_TOKENIZER_FOR_DOC = "BertTokenizer"
-
-BERT_START_DOCSTRING = r"""
-
- This model inherits from :class:`~transformers.PreTrainedModel`. Check the superclass documentation for the generic
- methods the library implements for all its model (such as downloading or saving, resizing the input embeddings,
- pruning heads etc.)
-
- This model is also a PyTorch `torch.nn.Module `__
- subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to
- general usage and behavior.
-
- Parameters:
- config (:class:`~transformers.BertConfig`): Model configuration class with all the parameters of the model.
- Initializing with a config file does not load the weights associated with the model, only the
- configuration. Check out the :meth:`~transformers.PreTrainedModel.from_pretrained` method to load the model
- weights.
-"""
-
-BERT_INPUTS_DOCSTRING = r"""
- Args:
- input_ids (:obj:`torch.LongTensor` of shape :obj:`({0})`):
- Indices of input sequence tokens in the vocabulary.
-
- Indices can be obtained using :class:`~transformers.BertTokenizer`. See
- :meth:`transformers.PreTrainedTokenizer.encode` and :meth:`transformers.PreTrainedTokenizer.__call__` for
- details.
-
- `What are input IDs? <../glossary.html#input-ids>`__
- attention_mask (:obj:`torch.FloatTensor` of shape :obj:`({0})`, `optional`):
- Mask to avoid performing attention on padding token indices. Mask values selected in ``[0, 1]``:
-
- - 1 for tokens that are **not masked**,
- - 0 for tokens that are **masked**.
-
- `What are attention masks? <../glossary.html#attention-mask>`__
- token_type_ids (:obj:`torch.LongTensor` of shape :obj:`({0})`, `optional`):
- Segment token indices to indicate first and second portions of the inputs. Indices are selected in ``[0,
- 1]``:
-
- - 0 corresponds to a `sentence A` token,
- - 1 corresponds to a `sentence B` token.
-
- `What are token type IDs? <../glossary.html#token-type-ids>`_
- position_ids (:obj:`torch.LongTensor` of shape :obj:`({0})`, `optional`):
- Indices of positions of each input sequence tokens in the position embeddings. Selected in the range ``[0,
- config.max_position_embeddings - 1]``.
-
- `What are position IDs? <../glossary.html#position-ids>`_
- head_mask (:obj:`torch.FloatTensor` of shape :obj:`(num_heads,)` or :obj:`(num_layers, num_heads)`, `optional`):
- Mask to nullify selected heads of the self-attention modules. Mask values selected in ``[0, 1]``:
-
- - 1 indicates the head is **not masked**,
- - 0 indicates the head is **masked**.
-
- inputs_embeds (:obj:`torch.FloatTensor` of shape :obj:`({0}, hidden_size)`, `optional`):
- Optionally, instead of passing :obj:`input_ids` you can choose to directly pass an embedded representation.
- This is useful if you want more control over how to convert :obj:`input_ids` indices into associated
- vectors than the model's internal embedding lookup matrix.
- output_attentions (:obj:`bool`, `optional`):
- Whether or not to return the attentions tensors of all attention layers. See ``attentions`` under returned
- tensors for more detail.
- output_hidden_states (:obj:`bool`, `optional`):
- Whether or not to return the hidden states of all layers. See ``hidden_states`` under returned tensors for
- more detail.
- return_dict (:obj:`bool`, `optional`):
- Whether or not to return a :class:`~transformers.file_utils.ModelOutput` instead of a plain tuple.
-"""
-
-
-class FlaxPerformerLayerNorm(nn.Module):
- """
- Layer normalization (https://arxiv.org/abs/1607.06450). Operates on the last axis of the input data.
- """
-
- epsilon: float = 1e-6
- dtype: jnp.dtype = jnp.float32 # the dtype of the computation
- bias: bool = True # If True, bias (beta) is added.
- scale: bool = True # If True, multiply by scale (gamma). When the next layer is linear
- # (also e.g. nn.relu), this can be disabled since the scaling will be
- # done by the next layer.
- bias_init: jnp.ndarray = nn.initializers.zeros
- scale_init: jnp.ndarray = nn.initializers.ones
-
- @nn.compact
- def __call__(self, x):
- """
- Applies layer normalization on the input. It normalizes the activations of the layer for each given example in
- a batch independently, rather than across a batch like Batch Normalization. i.e. applies a transformation that
- maintains the mean activation within each example close to 0 and the activation standard deviation close to 1
-
- Args:
- x: the inputs
-
- Returns:
- Normalized inputs (the same shape as inputs).
- """
- features = x.shape[-1]
- mean = jnp.mean(x, axis=-1, keepdims=True)
- mean2 = jnp.mean(jax.lax.square(x), axis=-1, keepdims=True)
- var = mean2 - jax.lax.square(mean)
- mul = jax.lax.rsqrt(var + self.epsilon)
- if self.scale:
- mul = mul * jnp.asarray(self.param("gamma", self.scale_init, (features,)), self.dtype)
- y = (x - mean) * mul
- if self.bias:
- y = y + jnp.asarray(self.param("beta", self.bias_init, (features,)), self.dtype)
- return y
-
-
-class FlaxPerformerEmbedding(nn.Module):
- """
- Specify a new class for doing the embedding stuff as Flax's one use 'embedding' for the parameter name and PyTorch
- use 'weight'
- """
-
- vocab_size: int
- hidden_size: int
- emb_init: Callable[..., np.ndarray] = nn.initializers.normal(stddev=0.1)
-
- @nn.compact
- def __call__(self, inputs):
- embedding = self.param("weight", self.emb_init, (self.vocab_size, self.hidden_size))
- return jnp.take(embedding, inputs, axis=0)
-
-
-class FlaxPerformerEmbeddings(nn.Module):
- """Construct the embeddings from word, position and token_type embeddings."""
-
- vocab_size: int
- hidden_size: int
- type_vocab_size: int
- max_length: int
-
- @nn.compact
- def __call__(self, input_ids, token_type_ids, position_ids, attention_mask):
- # Embed
- w_emb = FlaxPerformerEmbedding(self.vocab_size, self.hidden_size, name="word_embeddings")(
- jnp.atleast_2d(input_ids.astype("i4"))
- )
- p_emb = FlaxPerformerEmbedding(self.max_length, self.hidden_size, name="position_embeddings")(
- jnp.atleast_2d(position_ids.astype("i4"))
- )
- t_emb = FlaxPerformerEmbedding(self.type_vocab_size, self.hidden_size, name="token_type_embeddings")(
- jnp.atleast_2d(token_type_ids.astype("i4"))
- )
-
- # Sum all embeddings
- summed_emb = w_emb + jnp.broadcast_to(p_emb, w_emb.shape) + t_emb
-
- # Layer Norm
- layer_norm = FlaxPerformerLayerNorm(name="layer_norm")(summed_emb)
-
- return layer_norm
-
-
-class FlaxPerformerAttention(nn.Module):
- num_heads: int
- head_size: int
-
- @nn.compact
- def __call__(self, hidden_state, attention_mask):
- single_head_dim = self.head_size // self.num_heads
- fast_softmax_attention = make_fast_softmax_attention(qkv_dim=single_head_dim)
- self_att = nn.attention.SelfAttention(
- num_heads=self.num_heads, qkv_features=self.head_size, name="self", attention_fn=fast_softmax_attention
- )(hidden_state, attention_mask)
-
- layer_norm = FlaxPerformerLayerNorm(name="layer_norm")(self_att + hidden_state)
- return layer_norm
-
-
-class FlaxPerformerIntermediate(nn.Module):
- output_size: int
- hidden_act: str = "gelu"
-
- @nn.compact
- def __call__(self, hidden_state):
- # TODO: Add ACT2FN reference to change activation function
- dense = nn.Dense(features=self.output_size, name="dense")(hidden_state)
- return ACT2FN[self.hidden_act](dense)
-
-
-class FlaxPerformerOutput(nn.Module):
- @nn.compact
- def __call__(self, intermediate_output, attention_output):
- hidden_state = nn.Dense(attention_output.shape[-1], name="dense")(intermediate_output)
- hidden_state = FlaxPerformerLayerNorm(name="layer_norm")(hidden_state + attention_output)
- return hidden_state
-
-
-class FlaxPerformerLayer(nn.Module):
- num_heads: int
- head_size: int
- intermediate_size: int
- hidden_act: str = "gelu"
-
- @nn.compact
- def __call__(self, hidden_state, attention_mask):
- attention = FlaxPerformerAttention(self.num_heads, self.head_size, name="attention")(
- hidden_state, attention_mask
- )
- intermediate = FlaxPerformerIntermediate(
- self.intermediate_size, name="intermediate", hidden_act=self.hidden_act
- )(attention)
- output = FlaxPerformerOutput(name="output")(intermediate, attention)
-
- return output
-
-
-class FlaxPerformerLayerCollection(nn.Module):
- """
- Stores N BertLayer(s)
- """
-
- num_layers: int
- num_heads: int
- head_size: int
- intermediate_size: int
- hidden_act: str = "gelu"
-
- @nn.compact
- def __call__(self, inputs, attention_mask):
- assert self.num_layers > 0, f"num_layers should be >= 1, got ({self.num_layers})"
-
- # Initialize input / output
- input_i = inputs
-
- # Forward over all encoders
- for i in range(self.num_layers):
- layer = FlaxPerformerLayer(
- self.num_heads, self.head_size, self.intermediate_size, hidden_act=self.hidden_act, name=f"{i}"
- )
- input_i = layer(input_i, attention_mask)
- return input_i
-
-
-class FlaxPerformerEncoder(nn.Module):
- num_layers: int
- num_heads: int
- head_size: int
- intermediate_size: int
- hidden_act: str = "gelu"
-
- @nn.compact
- def __call__(self, hidden_state, attention_mask):
- layer = FlaxPerformerLayerCollection(
- self.num_layers,
- self.num_heads,
- self.head_size,
- self.intermediate_size,
- name="layer",
- hidden_act=self.hidden_act,
- )(hidden_state, attention_mask)
- return layer
-
-
-class FlaxPerformerPooler(nn.Module):
- @nn.compact
- def __call__(self, hidden_state):
- cls_token = hidden_state[:, 0]
- out = nn.Dense(hidden_state.shape[-1], name="dense")(cls_token)
- return jax.lax.tanh(out)
-
-
-class FlaxPerformerModule(nn.Module):
- vocab_size: int
- hidden_size: int
- type_vocab_size: int
- max_length: int
- num_encoder_layers: int
- num_heads: int
- head_size: int
- intermediate_size: int
- hidden_act: str = "gelu"
- add_pooling_layer: bool = True
-
- @nn.compact
- def __call__(self, input_ids, token_type_ids, position_ids, attention_mask):
- # Embedding
- embeddings = FlaxPerformerEmbeddings(
- self.vocab_size, self.hidden_size, self.type_vocab_size, self.max_length, name="embeddings"
- )(input_ids, token_type_ids, position_ids, attention_mask)
-
- # N stacked encoding layers
- encoder = FlaxPerformerEncoder(
- self.num_encoder_layers,
- self.num_heads,
- self.head_size,
- self.intermediate_size,
- hidden_act=self.hidden_act,
- name="encoder",
- )(embeddings, attention_mask)
-
- if not self.add_pooling_layer:
- return encoder
-
- pooled = FlaxPerformerPooler(name="pooler")(encoder)
- return encoder, pooled
-
-
-@add_start_docstrings(
- "The bare Bert Model transformer outputting raw hidden-states without any specific head on top.",
- BERT_START_DOCSTRING,
-)
-class FlaxPerformerModel(FlaxBertPreTrainedModel):
- """
- The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
- cross-attention is added between the self-attention layers, following the architecture described in `Attention is
- all you need `__ by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
- Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
- """
-
- model_class = FlaxPerformerModule
- config_class = BertConfig
- base_model_prefix = "bert"
-
- @staticmethod
- def convert_from_pytorch(pt_state: Dict, config: BertConfig) -> Dict:
- jax_state = dict(pt_state)
-
- # Need to change some parameters name to match Flax names so that we don't have to fork any layer
- for key, tensor in pt_state.items():
- # Key parts
- key_parts = set(key.split("."))
-
- # Every dense layer has "kernel" parameters instead of "weight"
- if "dense.weight" in key:
- del jax_state[key]
- key = key.replace("weight", "kernel")
- jax_state[key] = tensor
-
- # SelfAttention needs also to replace "weight" by "kernel"
- if {"query", "key", "value"} & key_parts:
- # Flax SelfAttention decomposes the heads (num_head, size // num_heads)
- if "bias" in key:
- jax_state[key] = tensor.reshape((config.num_attention_heads, -1))
- elif "weight":
- del jax_state[key]
- key = key.replace("weight", "kernel")
- tensor = tensor.reshape((config.num_attention_heads, -1, config.hidden_size)).transpose((2, 0, 1))
- jax_state[key] = tensor
-
- # SelfAttention output is not a separate layer, remove one nesting
- if "attention.output.dense" in key:
- del jax_state[key]
- key = key.replace("attention.output.dense", "attention.self.out")
- jax_state[key] = tensor
-
- # SelfAttention output is not a separate layer, remove nesting on layer norm
- if "attention.output.LayerNorm" in key:
- del jax_state[key]
- key = key.replace("attention.output.LayerNorm", "attention.LayerNorm")
- jax_state[key] = tensor
-
- # There are some transposed parameters w.r.t their PyTorch counterpart
- if "intermediate.dense.kernel" in key or "output.dense.kernel" in key:
- jax_state[key] = tensor.T
-
- # Self Attention output projection needs to be transposed
- if "out.kernel" in key:
- jax_state[key] = tensor.reshape((config.hidden_size, config.num_attention_heads, -1)).transpose(
- 1, 2, 0
- )
-
- # Pooler needs to transpose its kernel
- if "pooler.dense.kernel" in key:
- jax_state[key] = tensor.T
-
- # Handle LayerNorm conversion
- if "LayerNorm" in key:
- del jax_state[key]
-
- # Replace LayerNorm by layer_norm
- new_key = key.replace("LayerNorm", "layer_norm")
-
- if "weight" in key:
- new_key = new_key.replace("weight", "gamma")
- elif "bias" in key:
- new_key = new_key.replace("bias", "beta")
-
- jax_state[new_key] = tensor
-
- return jax_state
-
- def __init__(
- self, config: BertConfig, input_shape: Tuple = (1, 1), seed: int = 0, dtype: jnp.dtype = jnp.float32, **kwargs
- ):
- module = FlaxPerformerModule(
- vocab_size=config.vocab_size,
- hidden_size=config.hidden_size,
- type_vocab_size=config.type_vocab_size,
- max_length=config.max_position_embeddings,
- num_encoder_layers=config.num_hidden_layers,
- num_heads=config.num_attention_heads,
- head_size=config.hidden_size,
- intermediate_size=config.intermediate_size,
- dropout_rate=config.hidden_dropout_prob,
- hidden_act=config.hidden_act,
- )
-
- super().__init__(config, module, input_shape=input_shape, seed=seed, dtype=dtype)
-
- @property
- def module(self) -> nn.Module:
- return self._module
-
- def __call__(
- self, input_ids, token_type_ids=None, position_ids=None, dropout_rng: PRNGKey = None, attention_mask=None
- ):
- input_ids, attention_mask, token_type_ids, position_ids = self._check_inputs(
- input_ids, attention_mask, token_type_ids, position_ids
- )
-
- # Handle any PRNG if needed
- rngs = {}
- if dropout_rng is not None:
- rngs["dropout"] = dropout_rng
-
- return self.module.apply(
- {"params": self.params},
- jnp.array(input_ids, dtype="i4"),
- jnp.array(token_type_ids, dtype="i4"),
- jnp.array(position_ids, dtype="i4"),
- jnp.array(attention_mask, dtype="i4"),
- rng=rngs,
- )
-
-
-class FlaxPerformerForMaskedLM(FlaxBertPreTrainedModel):
- def __init__(
- self, config: BertConfig, input_shape: Tuple = (1, 1), seed: int = 0, dtype: jnp.dtype = jnp.float32, **kwargs
- ):
- module = FlaxPerformerForMaskedLMModule(
- vocab_size=config.vocab_size,
- type_vocab_size=config.type_vocab_size,
- hidden_size=config.hidden_size,
- intermediate_size=config.intermediate_size,
- head_size=config.hidden_size,
- num_heads=config.num_attention_heads,
- num_encoder_layers=config.num_hidden_layers,
- max_length=config.max_position_embeddings,
- hidden_act=config.hidden_act,
- **kwargs,
- )
-
- super().__init__(config, module, input_shape=input_shape, seed=seed, dtype=dtype)
-
- def __call__(
- self,
- input_ids,
- attention_mask=None,
- token_type_ids=None,
- position_ids=None,
- params: dict = None,
- train: bool = False,
- dropout_rng: PRNGKey = None,
- ):
- input_ids, attention_mask, token_type_ids, position_ids = self._check_inputs(
- input_ids, attention_mask, token_type_ids, position_ids
- )
-
- # Handle any PRNG if needed
- rngs = {}
- if dropout_rng is not None:
- rngs["dropout"] = dropout_rng
-
- return self.module.apply(
- {"params": params or self.params},
- jnp.array(input_ids, dtype="i4"),
- jnp.array(attention_mask, dtype="i4"),
- jnp.array(token_type_ids, dtype="i4"),
- jnp.array(position_ids, dtype="i4"),
- not train,
- rngs=rngs,
- )
-
-
-class FlaxPerformerForMaskedLMModule(nn.Module):
- vocab_size: int
- hidden_size: int
- intermediate_size: int
- head_size: int
- num_heads: int
- num_encoder_layers: int
- type_vocab_size: int
- max_length: int
- hidden_act: str
- dropout_rate: float = 0.0
- dtype: jnp.dtype = jnp.float32
-
- @nn.compact
- def __call__(
- self, input_ids, attention_mask=None, token_type_ids=None, position_ids=None, deterministic: bool = True
- ):
- # Model
- encoder = FlaxPerformerModule(
- vocab_size=self.vocab_size,
- hidden_size=self.hidden_size,
- type_vocab_size=self.type_vocab_size,
- max_length=self.max_length,
- num_encoder_layers=self.num_encoder_layers,
- num_heads=self.num_heads,
- head_size=self.hidden_size,
- intermediate_size=self.intermediate_size,
- hidden_act=self.hidden_act,
- add_pooling_layer=False,
- name="bert",
- )(input_ids, attention_mask, token_type_ids, position_ids)
-
- # Compute the prediction scores
- encoder = nn.Dropout(rate=self.dropout_rate)(encoder, deterministic=deterministic)
- logits = FlaxBertOnlyMLMHead(
- vocab_size=self.vocab_size, hidden_act=self.hidden_act, name="cls", dtype=self.dtype
- )(encoder)
-
- return (logits,)
diff --git a/examples/research_projects/performer/modeling_flax_performer_utils.py b/examples/research_projects/performer/modeling_flax_performer_utils.py
deleted file mode 100644
index c5242509381..00000000000
--- a/examples/research_projects/performer/modeling_flax_performer_utils.py
+++ /dev/null
@@ -1,658 +0,0 @@
-# coding=utf-8
-# Copyright 2020 The Google Research Authors.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""
-IMPORTANT:
-
-This code was copied from
-https://github.com/google-research/google-research/blob/master/performer/fast_self_attention/fast_self_attention.py on
-6/11/2020. This is very new code, so it might be prone to change soon -> make sure to check the original code and
-update accordingly
-
-Core Fast Attention Module for Flax. Implementation of the approximate fast softmax and generalized attention mechanism
-leveraging structured random feature maps [RFM] techniques and low rank decomposition of the attention matrix.
-"""
-# pylint: disable=invalid-name, missing-function-docstring, line-too-long
-
-import abc
-import functools
-from collections.abc import Iterable # pylint: disable=g-importing-member
-
-import jax
-import jax.numpy as jnp
-import numpy as onp
-from absl import logging
-from jax import lax, random
-
-
-def nonnegative_softmax_kernel_feature_creator(
- data, projection_matrix, attention_dims_t, batch_dims_t, precision, is_query, normalize_data=True, eps=0.0001
-):
- """
- Constructs nonnegative kernel features for fast softmax attention
-
- Args:
- data: input for which features are computes
- projection_matrix: random matrix used to compute features
- attention_dims_t: tuple of attention dimensions
- batch_dims_t: tuple of batch dimensions
- precision: precision parameter
- is_query: predicate indicating whether input data corresponds to queries or
- keys
- normalize_data: predicate indicating whether data should be normalized,
- eps: numerical stabilizer
-
- Returns:
- Random features for fast softmax attention.
- """
- del attention_dims_t
- if normalize_data:
- # We have e^{qk^T/sqrt{d}} = e^{q_norm k_norm^T}, where
- # w_norm = w * data_normalizer for w in {q,k}.
- data_normalizer = 1.0 / (jnp.sqrt(jnp.sqrt(data.shape[-1])))
- else:
- data_normalizer = 1.0
- ratio = 1.0 / jnp.sqrt(projection_matrix.shape[0])
- data_mod_shape = data.shape[0 : len(batch_dims_t)] + projection_matrix.shape
- data_thick_random_matrix = jnp.zeros(data_mod_shape) + projection_matrix
-
- data_dash = lax.dot_general(
- data_normalizer * data,
- data_thick_random_matrix,
- (((data.ndim - 1,), (data_thick_random_matrix.ndim - 1,)), (batch_dims_t, batch_dims_t)),
- precision=precision,
- )
-
- diag_data = jnp.square(data)
- diag_data = jnp.sum(diag_data, axis=data.ndim - 1)
- diag_data = (diag_data / 2.0) * data_normalizer * data_normalizer
- diag_data = jnp.expand_dims(diag_data, axis=data.ndim - 1)
-
- if is_query:
- last_dims_t = (len(data_dash.shape) - 1,)
- data_dash = ratio * (
- jnp.exp(data_dash - diag_data - jnp.max(data_dash, axis=last_dims_t, keepdims=True)) + eps
- )
- else:
- data_dash = ratio * (jnp.exp(data_dash - diag_data - jnp.max(data_dash)) + eps)
-
- return data_dash
-
-
-def sincos_softmax_kernel_feature_creator(
- data, projection_matrix, attention_dims_t, batch_dims_t, precision, normalize_data=True
-):
- """
- Constructs kernel sin-cos features for fast softmax attention
-
- Args:
- data: input for which features are computes
- projection_matrix: random matrix used to compute features
- attention_dims_t: tuple of attention dimensions
- batch_dims_t: tuple of batch dimensions
- precision: precision parameter
- normalize_data: predicate indicating whether data should be normalized
-
- Returns:
- Random features for fast softmax attention.
- """
- if normalize_data:
- # We have: exp(qk^T/sqrt{d}) = exp(|q|^2/2sqrt{d}) * exp(|k|^2/2sqrt{d}) *
- # exp(-(|q*c-k*c|^2)/2), where c = 1.0 / sqrt{sqrt{d}}.
- data_normalizer = 1.0 / (jnp.sqrt(jnp.sqrt(data.shape[-1])))
- else:
- data_normalizer = 1.0
- ratio = 1.0 / jnp.sqrt(projection_matrix.shape[0])
- data_mod_shape = data.shape[0 : len(batch_dims_t)] + projection_matrix.shape
- data_thick_random_matrix = jnp.zeros(data_mod_shape) + projection_matrix
-
- data_dash = lax.dot_general(
- data_normalizer * data,
- data_thick_random_matrix,
- (((data.ndim - 1,), (data_thick_random_matrix.ndim - 1,)), (batch_dims_t, batch_dims_t)),
- precision=precision,
- )
- data_dash_cos = ratio * jnp.cos(data_dash)
- data_dash_sin = ratio * jnp.sin(data_dash)
- data_dash = jnp.concatenate((data_dash_cos, data_dash_sin), axis=-1)
-
- # Constructing D_data and data^{'}
- diag_data = jnp.square(data)
- diag_data = jnp.sum(diag_data, axis=data.ndim - 1)
- diag_data = (diag_data / 2.0) * data_normalizer * data_normalizer
- diag_data = jnp.expand_dims(diag_data, axis=data.ndim - 1)
- # Additional renormalization for numerical stability
- data_renormalizer = jnp.max(diag_data, attention_dims_t, keepdims=True)
- diag_data -= data_renormalizer
- diag_data = jnp.exp(diag_data)
- data_prime = data_dash * diag_data
- return data_prime
-
-
-def generalized_kernel_feature_creator(
- data, projection_matrix, batch_dims_t, precision, kernel_fn, kernel_epsilon, normalize_data
-):
- """
- Constructs kernel features for fast generalized attention
-
- Args:
- data: input for which features are computes
- projection_matrix: matrix used to compute features
- batch_dims_t: tuple of batch dimensions
- precision: precision parameter
- kernel_fn: kernel function used
- kernel_epsilon: additive positive term added to every feature for numerical
- stability
- normalize_data: predicate indicating whether data should be normalized
-
- Returns:
- Random features for fast generalized attention.
- """
- if normalize_data:
- data_normalizer = 1.0 / (jnp.sqrt(jnp.sqrt(data.shape[-1])))
- else:
- data_normalizer = 1.0
- if projection_matrix is None:
- return kernel_fn(data_normalizer * data) + kernel_epsilon
- else:
- data_mod_shape = data.shape[0 : len(batch_dims_t)] + projection_matrix.shape
- data_thick_random_matrix = jnp.zeros(data_mod_shape) + projection_matrix
- data_dash = lax.dot_general(
- data_normalizer * data,
- data_thick_random_matrix,
- (((data.ndim - 1,), (data_thick_random_matrix.ndim - 1,)), (batch_dims_t, batch_dims_t)),
- precision=precision,
- )
- data_prime = kernel_fn(data_dash) + kernel_epsilon
- return data_prime
-
-
-def make_fast_softmax_attention(
- qkv_dim,
- renormalize_attention=True,
- numerical_stabilizer=0.000001,
- nb_features=256,
- ortho_features=True,
- ortho_scaling=0.0,
- redraw_features=True,
- unidirectional=False,
- nonnegative_features=True,
- lax_scan_unroll=1,
-):
- """Construct a fast softmax attention method."""
- logging.info(
- "Fast softmax attention: %s features and orthogonal=%s, renormalize=%s",
- nb_features,
- ortho_features,
- renormalize_attention,
- )
- if ortho_features:
- matrix_creator = functools.partial(GaussianOrthogonalRandomMatrix, nb_features, qkv_dim, scaling=ortho_scaling)
- else:
- matrix_creator = functools.partial(GaussianUnstructuredRandomMatrix, nb_features, qkv_dim)
- if nonnegative_features:
-
- def kernel_feature_creator(
- data, projection_matrix, attention_dims_t, batch_dims_t, precision, is_query, normalize_data=True
- ):
- return nonnegative_softmax_kernel_feature_creator(
- data,
- projection_matrix,
- attention_dims_t,
- batch_dims_t,
- precision,
- is_query,
- normalize_data,
- numerical_stabilizer,
- )
-
- else:
-
- def kernel_feature_creator(
- data, projection_matrix, attention_dims_t, batch_dims_t, precision, is_query, normalize_data=True
- ):
- del is_query
- return sincos_softmax_kernel_feature_creator(
- data, projection_matrix, attention_dims_t, batch_dims_t, precision, normalize_data
- )
-
- attention_fn = FastAttentionviaLowRankDecomposition(
- matrix_creator,
- kernel_feature_creator,
- renormalize_attention=renormalize_attention,
- numerical_stabilizer=numerical_stabilizer,
- redraw_features=redraw_features,
- unidirectional=unidirectional,
- lax_scan_unroll=lax_scan_unroll,
- ).dot_product_attention
- return attention_fn
-
-
-def make_fast_generalized_attention(
- qkv_dim,
- renormalize_attention=True,
- numerical_stabilizer=0.0,
- nb_features=256,
- features_type="deterministic",
- kernel_fn=jax.nn.relu,
- kernel_epsilon=0.001,
- redraw_features=False,
- unidirectional=False,
- lax_scan_unroll=1,
-):
- """Construct a fast generalized attention method."""
- logging.info("Fast generalized attention.: %s features and renormalize=%s", nb_features, renormalize_attention)
- if features_type == "ortho":
- matrix_creator = functools.partial(GaussianOrthogonalRandomMatrix, nb_features, qkv_dim, scaling=False)
- elif features_type == "iid":
- matrix_creator = functools.partial(GaussianUnstructuredRandomMatrix, nb_features, qkv_dim)
- elif features_type == "deterministic":
- matrix_creator = None
- else:
- raise ValueError("Unknown feature value type")
-
- def kernel_feature_creator(
- data, projection_matrix, attention_dims_t, batch_dims_t, precision, is_query, normalize_data=False
- ):
- del attention_dims_t
- del is_query
- return generalized_kernel_feature_creator(
- data, projection_matrix, batch_dims_t, precision, kernel_fn, kernel_epsilon, normalize_data
- )
-
- attention_fn = FastAttentionviaLowRankDecomposition(
- matrix_creator,
- kernel_feature_creator,
- renormalize_attention=renormalize_attention,
- numerical_stabilizer=numerical_stabilizer,
- redraw_features=redraw_features,
- unidirectional=unidirectional,
- lax_scan_unroll=lax_scan_unroll,
- ).dot_product_attention
- return attention_fn
-
-
-class RandomMatrix:
- r"""
- Abstract class providing a method for constructing 2D random arrays. Class is responsible for constructing 2D
- random arrays.
- """
-
- __metaclass__ = abc.ABCMeta
-
- @abc.abstractmethod
- def get_2d_array(self):
- raise NotImplementedError("Abstract method")
-
-
-class GaussianUnstructuredRandomMatrix(RandomMatrix):
- def __init__(self, nb_rows, nb_columns, key):
- self.nb_rows = nb_rows
- self.nb_columns = nb_columns
- self.key = key
-
- def get_2d_array(self):
- return random.normal(self.key, (self.nb_rows, self.nb_columns))
-
-
-class GaussianOrthogonalRandomMatrix(RandomMatrix):
- r"""
- Class providing a method to create Gaussian orthogonal matrix. Class is responsible for constructing 2D Gaussian
- orthogonal arrays.
- """
-
- def __init__(self, nb_rows, nb_columns, key, scaling=0):
- self.nb_rows = nb_rows
- self.nb_columns = nb_columns
- self.key = key
- self.scaling = scaling
-
- def get_2d_array(self):
- nb_full_blocks = int(self.nb_rows / self.nb_columns)
- block_list = []
- rng = self.key
- for _ in range(nb_full_blocks):
- rng, rng_input = jax.random.split(rng)
- unstructured_block = random.normal(rng_input, (self.nb_columns, self.nb_columns))
- q, _ = jnp.linalg.qr(unstructured_block)
- q = jnp.transpose(q)
- block_list.append(q)
- remaining_rows = self.nb_rows - nb_full_blocks * self.nb_columns
- if remaining_rows > 0:
- rng, rng_input = jax.random.split(rng)
- unstructured_block = random.normal(rng_input, (self.nb_columns, self.nb_columns))
- q, _ = jnp.linalg.qr(unstructured_block)
- q = jnp.transpose(q)
- block_list.append(q[0:remaining_rows])
- final_matrix = jnp.vstack(block_list)
-
- if self.scaling == 0:
- multiplier = jnp.linalg.norm(random.normal(self.key, (self.nb_rows, self.nb_columns)), axis=1)
- elif self.scaling == 1:
- multiplier = jnp.sqrt(float(self.nb_columns)) * jnp.ones((self.nb_rows))
- else:
- raise ValueError("Scaling must be one of {0, 1}. Was %s" % self._scaling)
-
- return jnp.matmul(jnp.diag(multiplier), final_matrix)
-
-
-class FastAttention:
- r"""
- Abstract class providing a method for fast attention. Class is responsible for providing a method
- for fast approximate attention.
- """
-
- __metaclass__ = abc.ABCMeta
-
- @abc.abstractmethod
- def dot_product_attention(
- self,
- query,
- key,
- value,
- dtype=jnp.float32,
- bias=None,
- axis=None,
- broadcast_dropout=True,
- dropout_rng=None,
- dropout_rate=0.0,
- deterministic=False,
- precision=None,
- ):
- """
- Computes dot-product attention given query, key, and value. This is the core function for applying fast
- approximate dot-product attention. It calculates the attention weights given query and key and combines the
- values using the attention weights. This function supports multi-dimensional inputs
-
- Args:
- query: queries for calculating attention with shape of [batch_size, dim1,
- dim2, ..., dimN, num_heads, mem_channels].
- key: keys for calculating attention with shape of [batch_size, dim1, dim2,
- ..., dimN, num_heads, mem_channels].
- value: values to be used in attention with shape of [batch_size, dim1,
- dim2,..., dimN, num_heads, value_channels].
- dtype: the dtype of the computation (default: float32)
- bias: bias for the attention weights. This can be used for incorporating
- autoregressive mask, padding mask, proximity bias.
- axis: axises over which the attention is applied.
- broadcast_dropout: bool: use a broadcasted dropout along batch dims.
- dropout_rng: JAX PRNGKey: to be used for dropout.
- dropout_rate: dropout rate.
- deterministic: bool, deterministic or not (to apply dropout).
- precision: numerical precision of the computation see `jax.lax.Precision`
- for details
-
- Returns:
- Output of shape [bs, dim1, dim2, ..., dimN,, num_heads, value_channels].
- """
- raise NotImplementedError("Abstract method")
-
-
-def _numerator(z_slice_shape, precision, unroll=1):
- def fwd(qs, ks, vs):
- def body(p, qkv):
- (q, k, v) = qkv
- p += jnp.einsum("...m,...d->...md", k, v, precision=precision)
- X_slice = jnp.einsum("...m,...md->...d", q, p, precision=precision)
- return p, X_slice
-
- init_value = jnp.zeros(z_slice_shape)
- p, W = lax.scan(body, init_value, (qs, ks, vs), unroll=unroll)
- return W, (p, qs, ks, vs)
-
- def bwd(pqkv, W_ct):
- def body(carry, qkv_xct):
- p, p_ct = carry
- q, k, v, x_ct = qkv_xct
- q_ct = jnp.einsum("...d,...md->...m", x_ct, p, precision=precision)
- p_ct += jnp.einsum("...d,...m->...md", x_ct, q, precision=precision)
- k_ct = jnp.einsum("...md,...d->...m", p_ct, v, precision=precision)
- v_ct = jnp.einsum("...md,...m->...d", p_ct, k, precision=precision)
- p -= jnp.einsum("...m,...d->...md", k, v, precision=precision)
- return (p, p_ct), (q_ct, k_ct, v_ct)
-
- p, qs, ks, vs = pqkv
- _, (qs_ct, ks_ct, vs_ct) = lax.scan(
- body, (p, jnp.zeros_like(p)), (qs, ks, vs, W_ct), reverse=True, unroll=unroll
- )
- return qs_ct, ks_ct, vs_ct
-
- @jax.custom_vjp
- def _numerator_impl(qs, ks, vs):
- W, _ = fwd(qs, ks, vs)
- return W
-
- _numerator_impl.defvjp(fwd, bwd)
-
- return _numerator_impl
-
-
-def _denominator(t_slice_shape, precision, unroll=1):
- def fwd(qs, ks):
- def body(p, qk):
- q, k = qk
- p += k
- x = jnp.einsum("...m,...m->...", q, p, precision=precision)
- return p, x
-
- p = jnp.zeros(t_slice_shape)
- p, R = lax.scan(body, p, (qs, ks), unroll=unroll)
- return R, (qs, ks, p)
-
- def bwd(qkp, R_ct):
- def body(carry, qkx):
- p, p_ct = carry
- q, k, x_ct = qkx
- q_ct = jnp.einsum("...,...m->...m", x_ct, p, precision=precision)
- p_ct += jnp.einsum("...,...m->...m", x_ct, q, precision=precision)
- k_ct = p_ct
- p -= k
- return (p, p_ct), (q_ct, k_ct)
-
- qs, ks, p = qkp
- _, (qs_ct, ks_ct) = lax.scan(body, (p, jnp.zeros_like(p)), (qs, ks, R_ct), reverse=True, unroll=unroll)
- return (qs_ct, ks_ct)
-
- @jax.custom_vjp
- def _denominator_impl(qs, ks):
- R, _ = fwd(qs, ks)
- return R
-
- _denominator_impl.defvjp(fwd, bwd)
-
- return _denominator_impl
-
-
-class FastAttentionviaLowRankDecomposition(FastAttention):
- r"""
- Class providing a method for fast attention via low rank decomposition. Class is responsible for providing a method
- for fast dot-product attention with the use of low rank decomposition (e.g. with random
- feature maps).
- """
-
- def __init__(
- self,
- matrix_creator,
- kernel_feature_creator,
- renormalize_attention,
- numerical_stabilizer,
- redraw_features,
- unidirectional,
- lax_scan_unroll=1,
- ): # For optimal GPU performance, set to 16.
- rng = random.PRNGKey(0)
- self.matrix_creator = matrix_creator
- self.projection_matrix = self.draw_weights(rng)
- self.kernel_feature_creator = kernel_feature_creator
- self.renormalize_attention = renormalize_attention
- self.numerical_stabilizer = numerical_stabilizer
- self.redraw_features = redraw_features
- self.unidirectional = unidirectional
- self.lax_scan_unroll = lax_scan_unroll
-
- def draw_weights(self, key):
- if self.matrix_creator is None:
- return None
- matrixrng, _ = random.split(key)
- projection_matrix = self.matrix_creator(key=matrixrng).get_2d_array()
- return projection_matrix
-
- def dot_product_attention(
- self,
- query,
- key,
- value,
- dtype=jnp.float32,
- bias=None,
- axis=None,
- broadcast_dropout=True,
- dropout_rng=None,
- dropout_rate=0.0,
- deterministic=False,
- precision=None,
- ):
- assert key.shape[:-1] == value.shape[:-1]
- assert query.shape[0:1] == key.shape[0:1] and query.shape[-1] == key.shape[-1]
- if axis is None:
- axis = tuple(range(1, key.ndim - 2))
- if not isinstance(axis, Iterable):
- axis = (axis,)
- assert key.ndim == query.ndim
- assert key.ndim == value.ndim
- for ax in axis:
- if not (query.ndim >= 3 and 1 <= ax < query.ndim - 2):
- raise ValueError("Attention axis must be between the batch axis and the last-two axes.")
- n = key.ndim
-
- # Constructing projection tensor.
- if self.redraw_features:
- # TODO(kchoro): Get rid of the constant below.
- query_seed = lax.convert_element_type(jnp.ceil(jnp.sum(query) * 10000000.0), jnp.int32)
- rng = random.PRNGKey(query_seed)
- self.projection_matrix = self.draw_weights(rng)
-
- # batch_dims is , num_heads>
- batch_dims = tuple(onp.delete(range(n), axis + (n - 1,)))
- # q & k -> (bs, , num_heads, , channels)
- qk_perm = batch_dims + axis + (n - 1,)
- k_extra_perm = axis + batch_dims + (n - 1,)
- key_extra = key.transpose(k_extra_perm)
- key = key.transpose(qk_perm)
- query = query.transpose(qk_perm)
- # v -> (bs, , num_heads, , channels)
- v_perm = batch_dims + axis + (n - 1,)
- value = value.transpose(v_perm)
- batch_dims_t = tuple(range(len(batch_dims)))
- attention_dims_t = tuple(range(len(batch_dims), len(batch_dims) + len(axis)))
-
- # Constructing tensors Q^{'} and K^{'}.
- query_prime = self.kernel_feature_creator(
- query, self.projection_matrix, attention_dims_t, batch_dims_t, precision, True
- )
- key_prime = self.kernel_feature_creator(
- key, self.projection_matrix, attention_dims_t, batch_dims_t, precision, False
- )
-
- if self.unidirectional:
- index = attention_dims_t[0]
- z_slice_shape = key_prime.shape[0 : len(batch_dims_t)] + (key_prime.shape[-1],) + (value.shape[-1],)
-
- numerator_fn = _numerator(z_slice_shape, precision, self.lax_scan_unroll)
- W = numerator_fn(
- jnp.moveaxis(query_prime, index, 0), jnp.moveaxis(key_prime, index, 0), jnp.moveaxis(value, index, 0)
- )
-
- # Constructing W = (Q^{'}(K^{'})^{T})_{masked}V
- W = jnp.moveaxis(W, 0, index)
-
- if not self.renormalize_attention:
- # Unidirectional, not-normalized attention.
- perm_inv = _invert_perm(qk_perm)
- result = W.transpose(perm_inv)
- return result
- else:
- # Unidirectional, normalized attention.
- thick_all_ones = jnp.zeros(key.shape[0:-1]) + jnp.ones(key_extra.shape[0 : len(axis)])
-
- index = attention_dims_t[0]
- t_slice_shape = key_prime.shape[0 : len(batch_dims_t)] + (key_prime.shape[-1],)
- denominator_fn = _denominator(t_slice_shape, precision, self.lax_scan_unroll)
- R = denominator_fn(jnp.moveaxis(query_prime, index, 0), jnp.moveaxis(key_prime, index, 0))
-
- R = jnp.moveaxis(R, 0, index)
- else:
- contract_query = tuple(range(len(batch_dims) + len(axis), len(batch_dims) + len(axis) + 1))
- contract_z = tuple(range(len(batch_dims), len(batch_dims) + 1))
- # Constructing Z = (K^{'})^{T}V
- # Z (bs, , num_heads, channels_m, channels_v)
- Z = lax.dot_general(
- key_prime,
- value,
- ((attention_dims_t, attention_dims_t), (batch_dims_t, batch_dims_t)),
- precision=precision,
- )
- # Constructing W = Q^{'}Z = Q^{'}(K^{'})^{T}V
- # q (bs, , num_heads, , channels_m)
- # Z (bs, , num_heads, channels_m, channels_v)
- # W (bs, , num_heads, , channels_v)
- W = lax.dot_general(
- query_prime, Z, ((contract_query, contract_z), (batch_dims_t, batch_dims_t)), precision=precision
- )
- if not self.renormalize_attention:
- # Bidirectional, not-normalized attention.
- perm_inv = _invert_perm(qk_perm)
- result = W.transpose(perm_inv)
- return result
- else:
- # Bidirectional, normalized attention.
- thick_all_ones = jnp.zeros(key.shape[0:-1]) + jnp.ones(key_extra.shape[0 : len(axis)])
- contract_key = tuple(range(len(batch_dims), len(batch_dims) + len(axis)))
- contract_thick_all_ones = tuple(range(thick_all_ones.ndim - len(axis), thick_all_ones.ndim))
- # Construct T = (K^{'})^{T} 1_L
- # k (bs, , num_heads, , channels)
- T = lax.dot_general(
- key_prime,
- thick_all_ones,
- ((contract_key, contract_thick_all_ones), (batch_dims_t, batch_dims_t)),
- precision=precision,
- )
-
- # Construct partition function: R = Q^{'} T = Q^{'}(K^{'})^{T} 1_L
- # q_p (bs, , num_heads, , channs_m)
- # T (bs, , num_heads, channels_m)
- R = lax.dot_general(
- query_prime,
- T,
- (((query_prime.ndim - 1,), (T.ndim - 1,)), (batch_dims_t, range(0, len(T.shape) - 1))),
- precision=precision,
- )
-
- R = R + 2 * self.numerical_stabilizer * (jnp.abs(R) <= self.numerical_stabilizer)
- R = jnp.reciprocal(R)
- R = jnp.expand_dims(R, len(R.shape))
- # W (bs, , num_heads, , channels_v)
- # R (bs, , num_heads, , extra_channel)
- result = W * R
- # back to (bs, dim1, dim2, ..., dimN, num_heads, channels)
- perm_inv = _invert_perm(qk_perm)
- result = result.transpose(perm_inv)
- return result
-
-
-def _invert_perm(perm):
- perm_inv = [0] * len(perm)
- for i, j in enumerate(perm):
- perm_inv[j] = i
- return tuple(perm_inv)
diff --git a/examples/research_projects/performer/run_mlm_performer.py b/examples/research_projects/performer/run_mlm_performer.py
deleted file mode 100644
index 0332fe1575f..00000000000
--- a/examples/research_projects/performer/run_mlm_performer.py
+++ /dev/null
@@ -1,693 +0,0 @@
-# coding=utf-8
-# Copyright 2020 The HuggingFace Team All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-Fine-tuning the library models for masked language modeling (BERT, ALBERT, RoBERTa...) with whole word masking on a
-text file or a dataset.
-
-Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
-https://huggingface.co/models?filter=fill-mask
-"""
-
-import logging
-import os
-import sys
-from dataclasses import dataclass, field
-
-# You can also adapt this script on your own masked language modeling task. Pointers for this are left as comments.
-from pathlib import Path
-from typing import Dict, List, Optional, Tuple
-
-import jax
-import jax.numpy as jnp
-import numpy as np
-from datasets import load_dataset
-from flax import jax_utils
-from flax.optim import Adam
-from flax.training import common_utils
-from flax.training.common_utils import get_metrics
-from jax.nn import log_softmax
-from modeling_flax_performer import FlaxPerformerForMaskedLM
-from tqdm import tqdm
-
-from transformers import (
- MODEL_FOR_MASKED_LM_MAPPING,
- AutoTokenizer,
- BertConfig,
- FlaxBertForMaskedLM,
- HfArgumentParser,
- PreTrainedTokenizerBase,
- TensorType,
- TrainingArguments,
- is_tensorboard_available,
- set_seed,
-)
-
-
-# Cache the result
-has_tensorboard = is_tensorboard_available()
-if has_tensorboard:
- try:
- from flax.metrics.tensorboard import SummaryWriter
- except ImportError as ie:
- has_tensorboard = False
- print(f"Unable to display metrics through TensorBoard because some package are not installed: {ie}")
-
-else:
- print(
- "Unable to display metrics through TensorBoard because the package is not installed: "
- "Please run pip install tensorboard to enable."
- )
-
-MODEL_CONFIG_CLASSES = list(MODEL_FOR_MASKED_LM_MAPPING.keys())
-MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
-
-
-@dataclass
-class WandbArguments:
- """
- Arguments for logging
- """
-
- wandb_user_name: Optional[str] = field(
- default=None,
- metadata={"help": "The WandB user name for potential logging. If left None, no logging"},
- )
- wandb_project_name: Optional[str] = field(
- default="performer-experiments",
- metadata={"help": "The WandB project name for potential logging"},
- )
-
-
-@dataclass
-class ModelArguments:
- """
- Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
- """
-
- model_name_or_path: Optional[str] = field(
- default=None,
- metadata={
- "help": (
- "The model checkpoint for weights initialization. Don't set if you want to train a model from scratch."
- )
- },
- )
- performer: bool = field(
- default=False,
- metadata={"help": "Whether to use FAVOR+ attention"},
- )
- reinitialize: bool = field(
- default=False,
- metadata={"help": "Whether to use a blank model without pretraining"},
- )
- tokenizer_name: Optional[str] = field(
- default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
- )
- use_fast_tokenizer: bool = field(
- default=True,
- metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
- )
- cache_dir: Optional[str] = field(
- default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
- )
-
-
-@dataclass
-class DataTrainingArguments:
- """
- Arguments pertaining to what data we are going to input our model for training and eval.
- """
-
- dataset_name: Optional[str] = field(
- default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
- )
- dataset_config_name: Optional[str] = field(
- default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
- )
- train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
- validation_file: Optional[str] = field(
- default=None,
- metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
- )
- train_ref_file: Optional[str] = field(
- default=None,
- metadata={"help": "An optional input train ref data file for whole word masking in Chinese."},
- )
- validation_ref_file: Optional[str] = field(
- default=None,
- metadata={"help": "An optional input validation ref data file for whole word masking in Chinese."},
- )
- overwrite_cache: bool = field(
- default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
- )
- validation_split_percentage: Optional[int] = field(
- default=5,
- metadata={
- "help": "The percentage of the train set used as validation set in case there's no validation split"
- },
- )
- max_seq_length: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated. Default to the max input length of the model."
- )
- },
- )
- preprocessing_num_workers: Optional[int] = field(
- default=None,
- metadata={"help": "The number of processes to use for the preprocessing."},
- )
- mlm_probability: float = field(
- default=0.15, metadata={"help": "Ratio of tokens to mask for masked language modeling loss"}
- )
- pad_to_max_length: bool = field(
- default=False,
- metadata={
- "help": (
- "Whether to pad all samples to `max_seq_length`. "
- "If False, will pad the samples dynamically when batching to the maximum length in the batch."
- )
- },
- )
-
- def __post_init__(self):
- if self.dataset_name is None and self.train_file is None and self.validation_file is None:
- raise ValueError("Need either a dataset name or a training/validation file.")
- else:
- if self.train_file is not None:
- extension = self.train_file.split(".")[-1]
- assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, a json or a txt file."
- if self.validation_file is not None:
- extension = self.validation_file.split(".")[-1]
- assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, a json or a txt file."
-
-
-# Adapted from transformers/data/data_collator.py
-# Letting here for now, let's discuss where it should live
-@dataclass
-class FlaxDataCollatorForLanguageModeling:
- """
- Data collator used for language modeling. Inputs are dynamically padded to the maximum length of a batch if they
- are not all of the same length.
-
- Args:
- tokenizer (:class:`~transformers.PreTrainedTokenizer` or :class:`~transformers.PreTrainedTokenizerFast`):
- The tokenizer used for encoding the data.
- mlm (:obj:`bool`, `optional`, defaults to :obj:`True`):
- Whether or not to use masked language modeling. If set to :obj:`False`, the labels are the same as the
- inputs with the padding tokens ignored (by setting them to -100). Otherwise, the labels are -100 for
- non-masked tokens and the value to predict for the masked token.
- mlm_probability (:obj:`float`, `optional`, defaults to 0.15):
- The probability with which to (randomly) mask tokens in the input, when :obj:`mlm` is set to :obj:`True`.
-
- .. note::
-
- For best performance, this data collator should be used with a dataset having items that are dictionaries or
- BatchEncoding, with the :obj:`"special_tokens_mask"` key, as returned by a
- :class:`~transformers.PreTrainedTokenizer` or a :class:`~transformers.PreTrainedTokenizerFast` with the
- argument :obj:`return_special_tokens_mask=True`.
- """
-
- tokenizer: PreTrainedTokenizerBase
- mlm: bool = True
- mlm_probability: float = 0.15
-
- def __post_init__(self):
- if self.mlm and self.tokenizer.mask_token is None:
- raise ValueError(
- "This tokenizer does not have a mask token which is necessary for masked language modeling. "
- "You should pass `mlm=False` to train on causal language modeling instead."
- )
-
- def __call__(self, examples: List[Dict[str, np.ndarray]], pad_to_multiple_of: int) -> Dict[str, np.ndarray]:
- # Handle dict or lists with proper padding and conversion to tensor.
- batch = self.tokenizer.pad(examples, pad_to_multiple_of=pad_to_multiple_of, return_tensors=TensorType.NUMPY)
-
- # If special token mask has been preprocessed, pop it from the dict.
- special_tokens_mask = batch.pop("special_tokens_mask", None)
- if self.mlm:
- batch["input_ids"], batch["labels"] = self.mask_tokens(
- batch["input_ids"], special_tokens_mask=special_tokens_mask
- )
- else:
- labels = batch["input_ids"].copy()
- if self.tokenizer.pad_token_id is not None:
- labels[labels == self.tokenizer.pad_token_id] = -100
- batch["labels"] = labels
- return batch
-
- def mask_tokens(
- self, inputs: np.ndarray, special_tokens_mask: Optional[np.ndarray]
- ) -> Tuple[jnp.ndarray, jnp.ndarray]:
- """
- Prepare masked tokens inputs/labels for masked language modeling: 80% MASK, 10% random, 10% original.
- """
- labels = inputs.copy()
- # We sample a few tokens in each sequence for MLM training (with probability `self.mlm_probability`)
- probability_matrix = np.full(labels.shape, self.mlm_probability)
- special_tokens_mask = special_tokens_mask.astype("bool")
-
- probability_matrix[special_tokens_mask] = 0.0
- masked_indices = np.random.binomial(1, probability_matrix).astype("bool")
- labels[~masked_indices] = -100 # We only compute loss on masked tokens
-
- # 80% of the time, we replace masked input tokens with tokenizer.mask_token ([MASK])
- indices_replaced = np.random.binomial(1, np.full(labels.shape, 0.8)).astype("bool") & masked_indices
- inputs[indices_replaced] = self.tokenizer.convert_tokens_to_ids(self.tokenizer.mask_token)
-
- # 10% of the time, we replace masked input tokens with random word
- indices_random = np.random.binomial(1, np.full(labels.shape, 0.5)).astype("bool")
- indices_random &= masked_indices & ~indices_replaced
-
- random_words = np.random.randint(self.tokenizer.vocab_size, size=labels.shape, dtype="i4")
- inputs[indices_random] = random_words[indices_random]
-
- # The rest of the time (10% of the time) we keep the masked input tokens unchanged
- return inputs, labels
-
-
-def create_learning_rate_scheduler(
- factors="constant * linear_warmup * rsqrt_decay",
- base_learning_rate=0.5,
- warmup_steps=1000,
- decay_factor=0.5,
- steps_per_decay=20000,
- steps_per_cycle=100000,
-):
- """Creates learning rate schedule.
- Interprets factors in the factors string which can consist of:
- * constant: interpreted as the constant value,
- * linear_warmup: interpreted as linear warmup until warmup_steps,
- * rsqrt_decay: divide by square root of max(step, warmup_steps)
- * rsqrt_normalized_decay: divide by square root of max(step/warmup_steps, 1)
- * decay_every: Every k steps decay the learning rate by decay_factor.
- * cosine_decay: Cyclic cosine decay, uses steps_per_cycle parameter.
- Args:
- factors: string, factors separated by "*" that defines the schedule.
- base_learning_rate: float, the starting constant for the lr schedule.
- warmup_steps: int, how many steps to warm up for in the warmup schedule.
- decay_factor: float, the amount to decay the learning rate by.
- steps_per_decay: int, how often to decay the learning rate.
- steps_per_cycle: int, steps per cycle when using cosine decay.
- Returns:
- a function learning_rate(step): float -> {"learning_rate": float}, the
- step-dependent lr.
- """
- factors = [n.strip() for n in factors.split("*")]
-
- def step_fn(step):
- """Step to learning rate function."""
- ret = 1.0
- for name in factors:
- if name == "constant":
- ret *= base_learning_rate
- elif name == "linear_warmup":
- ret *= jnp.minimum(1.0, step / warmup_steps)
- elif name == "rsqrt_decay":
- ret /= jnp.sqrt(jnp.maximum(step, warmup_steps))
- elif name == "rsqrt_normalized_decay":
- ret *= jnp.sqrt(warmup_steps)
- ret /= jnp.sqrt(jnp.maximum(step, warmup_steps))
- elif name == "decay_every":
- ret *= decay_factor ** (step // steps_per_decay)
- elif name == "cosine_decay":
- progress = jnp.maximum(0.0, (step - warmup_steps) / float(steps_per_cycle))
- ret *= jnp.maximum(0.0, 0.5 * (1.0 + jnp.cos(jnp.pi * (progress % 1.0))))
- else:
- raise ValueError("Unknown factor %s." % name)
- return jnp.asarray(ret, dtype=jnp.float32)
-
- return step_fn
-
-
-def compute_metrics(logits, labels, weights, label_smoothing=0.0):
- """Compute summary metrics."""
- loss, normalizer = cross_entropy(logits, labels, weights, label_smoothing)
- acc, _ = accuracy(logits, labels, weights)
- metrics = {"loss": loss, "accuracy": acc, "normalizer": normalizer}
- metrics = jax.lax.psum(metrics, axis_name="batch")
- return metrics
-
-
-def accuracy(logits, targets, weights=None):
- """Compute weighted accuracy for log probs and targets.
- Args:
- logits: [batch, length, num_classes] float array.
- targets: categorical targets [batch, length] int array.
- weights: None or array of shape [batch, length]
- Returns:
- Tuple of scalar loss and batch normalizing factor.
- """
- if logits.ndim != targets.ndim + 1:
- raise ValueError(
- "Incorrect shapes. Got shape %s logits and %s targets" % (str(logits.shape), str(targets.shape))
- )
-
- loss = jnp.equal(jnp.argmax(logits, axis=-1), targets)
- loss *= weights
-
- return loss.sum(), weights.sum()
-
-
-def cross_entropy(logits, targets, weights=None, label_smoothing=0.0):
- """Compute cross entropy and entropy for log probs and targets.
- Args:
- logits: [batch, length, num_classes] float array.
- targets: categorical targets [batch, length] int array.
- weights: None or array of shape [batch, length]
- label_smoothing: label smoothing constant, used to determine the on and off values.
- Returns:
- Tuple of scalar loss and batch normalizing factor.
- """
- if logits.ndim != targets.ndim + 1:
- raise ValueError(
- "Incorrect shapes. Got shape %s logits and %s targets" % (str(logits.shape), str(targets.shape))
- )
-
- vocab_size = logits.shape[-1]
- confidence = 1.0 - label_smoothing
- low_confidence = (1.0 - confidence) / (vocab_size - 1)
- normalizing_constant = -(
- confidence * jnp.log(confidence) + (vocab_size - 1) * low_confidence * jnp.log(low_confidence + 1e-20)
- )
- soft_targets = common_utils.onehot(targets, vocab_size, on_value=confidence, off_value=low_confidence)
-
- loss = -jnp.sum(soft_targets * log_softmax(logits), axis=-1)
- loss = loss - normalizing_constant
-
- if weights is not None:
- loss = loss * weights
- normalizing_factor = weights.sum()
- else:
- normalizing_factor = np.prod(targets.shape)
-
- return loss.sum(), normalizing_factor
-
-
-def training_step(optimizer, batch, dropout_rng):
- dropout_rng, new_dropout_rng = jax.random.split(dropout_rng)
-
- def loss_fn(params):
- targets = batch.pop("labels")
-
- # Hide away tokens which doesn't participate in the optimization
- token_mask = jnp.where(targets > 0, 1.0, 0.0)
-
- logits = model(**batch, params=params, dropout_rng=dropout_rng, train=True)[0]
- loss, weight_sum = cross_entropy(logits, targets, token_mask)
- return loss / weight_sum
-
- step = optimizer.state.step
- lr = lr_scheduler_fn(step)
- grad_fn = jax.value_and_grad(loss_fn)
- loss, grad = grad_fn(optimizer.target)
- grad = jax.lax.pmean(grad, "batch")
- optimizer = optimizer.apply_gradient(grad, learning_rate=lr)
-
- return loss, optimizer, new_dropout_rng
-
-
-def eval_step(params, batch):
- """
- Calculate evaluation metrics on a batch.
- """
- targets = batch.pop("labels")
-
- # Hide away tokens which doesn't participate in the optimization
- token_mask = jnp.where(targets > 0, 1.0, 0.0)
- logits = model(**batch, params=params, train=False)[0]
-
- return compute_metrics(logits, targets, token_mask)
-
-
-def generate_batch_splits(samples_idx: np.ndarray, batch_size: int) -> np.ndarray:
- nb_samples = len(samples_idx)
- samples_to_remove = nb_samples % batch_size
-
- if samples_to_remove != 0:
- samples_idx = samples_idx[:-samples_to_remove]
- sections_split = nb_samples // batch_size
- batch_idx = np.split(samples_idx, sections_split)
- return batch_idx
-
-
-if __name__ == "__main__":
- # See all possible arguments in src/transformers/training_args.py
- # or by passing the --help flag to this script.
- # We now keep distinct sets of args, for a cleaner separation of concerns.
-
- parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments, WandbArguments))
- if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
- # If we pass only one argument to the script and it's the path to a json file,
- # let's parse it to get our arguments.
- model_args, data_args, training_args, wandb_args = parser.parse_json_file(
- json_file=os.path.abspath(sys.argv[1])
- )
- else:
- model_args, data_args, training_args, wandb_args = parser.parse_args_into_dataclasses()
-
- if (
- os.path.exists(training_args.output_dir)
- and os.listdir(training_args.output_dir)
- and training_args.do_train
- and not training_args.overwrite_output_dir
- ):
- raise ValueError(
- f"Output directory ({training_args.output_dir}) already exists and is not empty. "
- "Use --overwrite_output_dir to overcome."
- )
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- level="NOTSET",
- datefmt="[%X]",
- )
-
- # Log on each process the small summary:
- logger = logging.getLogger(__name__)
- logger.warning(
- f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
- + f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
- )
-
- # Set the verbosity to info of the Transformers logger (on main process only):
- logger.info("Training/evaluation parameters %s", training_args)
-
- # Set seed before initializing model.
- set_seed(training_args.seed)
-
- # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
- # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
- # (the dataset will be downloaded automatically from the datasets Hub).
- #
- # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
- # 'text' is found. You can easily tweak this behavior (see below).
- #
- # In distributed training, the load_dataset function guarantees that only one local process can concurrently
- # download the dataset.
- if data_args.dataset_name is not None:
- # Downloading and loading a dataset from the hub.
- datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name)
- if "validation" not in datasets.keys():
- datasets["validation"] = load_dataset(
- data_args.dataset_name,
- data_args.dataset_config_name,
- split=f"train[:{data_args.validation_split_percentage}%]",
- )
- datasets["train"] = load_dataset(
- data_args.dataset_name,
- data_args.dataset_config_name,
- split=f"train[{data_args.validation_split_percentage}%:]",
- )
- else:
- data_files = {}
- if data_args.train_file is not None:
- data_files["train"] = data_args.train_file
- extension = data_args.train_file.split(".")[-1]
- if data_args.validation_file is not None:
- data_files["validation"] = data_args.validation_file
- extension = data_args.validation_file.split(".")[-1]
- if extension == "txt":
- extension = "text"
- datasets = load_dataset(extension, data_files=data_files)
- # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
- # https://huggingface.co/docs/datasets/loading_datasets.
-
- # Load pretrained model and tokenizer
-
- # Distributed training:
- # The .from_pretrained methods guarantee that only one local process can concurrently
- # download model & vocab.
-
- rng = jax.random.PRNGKey(training_args.seed)
- dropout_rngs = jax.random.split(rng, jax.local_device_count())
-
- config = BertConfig.from_pretrained(model_args.model_name_or_path, cache_dir=model_args.cache_dir)
- lm_class = FlaxPerformerForMaskedLM if model_args.performer else FlaxBertForMaskedLM
- if model_args.reinitialize:
- model = lm_class(config=BertConfig.from_pretrained(model_args.model_name_or_path))
- else:
- model = lm_class.from_pretrained(
- model_args.model_name_or_path,
- dtype=jnp.float32,
- input_shape=(training_args.train_batch_size, config.max_position_embeddings),
- seed=training_args.seed,
- dropout_rate=0.1,
- )
-
- if model_args.tokenizer_name:
- tokenizer = AutoTokenizer.from_pretrained(
- model_args.tokenizer_name, cache_dir=model_args.cache_dir, use_fast=model_args.use_fast_tokenizer
- )
- elif model_args.model_name_or_path:
- tokenizer = AutoTokenizer.from_pretrained(
- model_args.model_name_or_path, cache_dir=model_args.cache_dir, use_fast=model_args.use_fast_tokenizer
- )
- else:
- raise ValueError(
- "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
- "You can do it from another script, save it, and load it from here, using --tokenizer_name."
- )
-
- # Preprocessing the datasets.
- # First we tokenize all the texts.
- if training_args.do_train:
- column_names = datasets["train"].column_names
- else:
- column_names = datasets["validation"].column_names
- text_column_name = "text" if "text" in column_names else column_names[0]
-
- padding = "max_length" if data_args.pad_to_max_length else False
-
- def tokenize_function(examples):
- # Remove empty lines
- examples = [line for line in examples if len(line) > 0 and not line.isspace()]
- return tokenizer(
- examples,
- return_special_tokens_mask=True,
- padding=padding,
- truncation=True,
- max_length=data_args.max_seq_length,
- )
-
- tokenized_datasets = datasets.map(
- tokenize_function,
- input_columns=[text_column_name],
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not data_args.overwrite_cache,
- )
-
- # Enable tensorboard only on the master node
- if has_tensorboard and jax.host_id() == 0:
- summary_writer = SummaryWriter(log_dir=Path(training_args.output_dir).joinpath("logs").as_posix())
-
- # Data collator
- # This one will take care of randomly masking the tokens.
- data_collator = FlaxDataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=data_args.mlm_probability)
-
- # Setup optimizer
- optimizer = Adam(
- learning_rate=training_args.learning_rate,
- weight_decay=training_args.weight_decay,
- beta1=training_args.adam_beta1,
- beta2=training_args.adam_beta2,
- ).create(model.params)
-
- # Create learning rate scheduler
- lr_scheduler_fn = create_learning_rate_scheduler(
- base_learning_rate=training_args.learning_rate, warmup_steps=max(training_args.warmup_steps, 1)
- )
-
- # Create parallel version of the training and evaluation steps
- p_training_step = jax.pmap(training_step, "batch", donate_argnums=(0,))
- p_eval_step = jax.pmap(eval_step, "batch", donate_argnums=(0,))
-
- # Replicate the optimizer on each device
- optimizer = jax_utils.replicate(optimizer)
-
- # Store some constant
- nb_epochs = int(training_args.num_train_epochs)
- batch_size = int(training_args.train_batch_size)
- eval_batch_size = int(training_args.eval_batch_size)
-
- if wandb_args.wandb_user_name is not None:
- import wandb
-
- wandb.init(project=wandb_args.wandb_project_name, entity=wandb_args.wandb_user_name)
-
- epochs = tqdm(range(nb_epochs), desc=f"Epoch ... (1/{nb_epochs})", position=0)
- for epoch in epochs:
- # ======================== Training ================================
- # Create sampling rng
- rng, training_rng, eval_rng = jax.random.split(rng, 3)
-
- # Generate an epoch by shuffling sampling indices from the train dataset
- nb_training_samples = len(tokenized_datasets["train"])
- # Avoid using jax.numpy here in case of TPU training
- training_samples_idx = np.random.permutation(np.arange(nb_training_samples))
- training_batch_idx = generate_batch_splits(training_samples_idx, batch_size)
-
- # Gather the indexes for creating the batch and do a training step
- for batch_idx in tqdm(training_batch_idx, desc="Training...", position=1):
- samples = [tokenized_datasets["train"][int(idx)] for idx in batch_idx]
- model_inputs = data_collator(samples, pad_to_multiple_of=16)
-
- # Model forward
- model_inputs = common_utils.shard(model_inputs.data)
- loss, optimizer, dropout_rngs = p_training_step(optimizer, model_inputs, dropout_rngs)
-
- if wandb_args.wandb_user_name is not None:
- wandb.log({"Training loss": np.array(loss).mean()})
-
- epochs.write(f"Loss: {loss}")
-
- # ======================== Evaluating ==============================
- nb_eval_samples = len(tokenized_datasets["validation"])
- # Avoid using jax.numpy here in case of TPU training
- eval_samples_idx = np.arange(nb_eval_samples)
- eval_batch_idx = generate_batch_splits(eval_samples_idx, eval_batch_size)
-
- eval_metrics = []
- for i, batch_idx in enumerate(tqdm(eval_batch_idx, desc="Evaluating ...", position=2)):
- samples = [tokenized_datasets["validation"][int(idx)] for idx in batch_idx]
- model_inputs = data_collator(samples, pad_to_multiple_of=16)
-
- # Model forward
- model_inputs = common_utils.shard(model_inputs.data)
- metrics = p_eval_step(optimizer.target, model_inputs)
- eval_metrics.append(metrics)
-
- eval_metrics_np = get_metrics(eval_metrics)
- eval_metrics_np = jax.tree_util.tree_map(jnp.sum, eval_metrics_np)
- eval_normalizer = eval_metrics_np.pop("normalizer")
- eval_summary = jax.tree_util.tree_map(lambda x: x / eval_normalizer, eval_metrics_np)
-
- # Update progress bar
- epochs.desc = (
- f"Epoch... ({epoch + 1}/{nb_epochs} | Loss: {eval_summary['loss']}, Acc: {eval_summary['accuracy']})"
- )
-
- if wandb_args.wandb_user_name is not None:
- wandb.log({"Eval loss": np.array(eval_summary["loss"]).mean()})
-
- # Save metrics
- if has_tensorboard and jax.host_id() == 0:
- for name, value in eval_summary.items():
- summary_writer.scalar(name, value, epoch)
diff --git a/examples/research_projects/performer/sanity_script.sh b/examples/research_projects/performer/sanity_script.sh
deleted file mode 100755
index b96cd7e643e..00000000000
--- a/examples/research_projects/performer/sanity_script.sh
+++ /dev/null
@@ -1 +0,0 @@
-TOKENIZERS_PARALLELISM=true python run_mlm_performer.py --output_dir experiments --dataset_name wikipedia --dataset_config_name 20200501.simple --model_name_or_path bert-base-cased --tokenizer_name bert-base-cased --do_train --overwrite_output_dir --per_device_train_batch_size 4 --learning_rate 5e-4 --warmup_steps 100 --num_train_epochs 3 --performer
\ No newline at end of file
diff --git a/examples/research_projects/pplm/README.md b/examples/research_projects/pplm/README.md
deleted file mode 100644
index f37ea8e96f2..00000000000
--- a/examples/research_projects/pplm/README.md
+++ /dev/null
@@ -1,56 +0,0 @@
-# Plug and Play Language Models: a Simple Approach to Controlled Text Generation
-
-Authors: [Sumanth Dathathri](https://dathath.github.io/), [Andrea Madotto](https://andreamad8.github.io/), Janice Lan, Jane Hung, Eric Frank, [Piero Molino](https://w4nderlu.st/), [Jason Yosinski](http://yosinski.com/), and [Rosanne Liu](http://www.rosanneliu.com/)
-
-This folder contains the original code used to run the Plug and Play Language Model (PPLM).
-
-Paper link: https://arxiv.org/abs/1912.02164
-
-Blog link: https://eng.uber.com/pplm
-
-Please check out the repo under uber-research for more information: https://github.com/uber-research/PPLM
-
-# Note
-
-⚠️ This project should be run with pytorch-lightning==1.0.4 which has a potential security vulnerability
-
-## Setup
-
-```bash
-git clone https://github.com/huggingface/transformers && cd transformers
-pip install .
-pip install nltk torchtext # additional requirements.
-cd examples/research_projects/pplm
-```
-
-## PPLM-BoW
-
-### Example command for bag-of-words control
-
-```bash
-python run_pplm.py -B military --cond_text "The potato" --length 50 --gamma 1.5 --num_iterations 3 --num_samples 10 --stepsize 0.03 --window_length 5 --kl_scale 0.01 --gm_scale 0.99 --colorama --sample
-```
-
-### Tuning hyperparameters for bag-of-words control
-
-1. Increase `--stepsize` to intensify topic control, and decrease its value to soften the control. `--stepsize 0` recovers the original uncontrolled GPT-2 model.
-
-2. If the language being generated is repetitive (For e.g. "science science experiment experiment"), there are several options to consider:
- a) Reduce the `--stepsize`
- b) Increase `--kl_scale` (the KL-loss coefficient) or decrease `--gm_scale` (the gm-scaling term)
- c) Add `--grad-length xx` where xx is an (integer <= length, e.g. `--grad-length 30`).
-
-
-## PPLM-Discrim
-
-### Example command for discriminator based sentiment control
-
-```bash
-python run_pplm.py -D sentiment --class_label 2 --cond_text "My dog died" --length 50 --gamma 1.0 --num_iterations 10 --num_samples 10 --stepsize 0.04 --kl_scale 0.01 --gm_scale 0.95 --sample
-```
-
-### Tuning hyperparameters for discriminator control
-
-1. Increase `--stepsize` to intensify topic control, and decrease its value to soften the control. `--stepsize 0` recovers the original uncontrolled GPT-2 model.
-
-2. Use `--class_label 3` for negative, and `--class_label 2` for positive
diff --git a/examples/research_projects/pplm/imgs/headfigure.png b/examples/research_projects/pplm/imgs/headfigure.png
deleted file mode 100644
index f4c11ad54d1..00000000000
Binary files a/examples/research_projects/pplm/imgs/headfigure.png and /dev/null differ
diff --git a/examples/research_projects/pplm/imgs/wooly.png b/examples/research_projects/pplm/imgs/wooly.png
deleted file mode 100644
index 190d3afd49f..00000000000
Binary files a/examples/research_projects/pplm/imgs/wooly.png and /dev/null differ
diff --git a/examples/research_projects/pplm/pplm_classification_head.py b/examples/research_projects/pplm/pplm_classification_head.py
deleted file mode 100644
index e26521fe391..00000000000
--- a/examples/research_projects/pplm/pplm_classification_head.py
+++ /dev/null
@@ -1,19 +0,0 @@
-from torch import nn
-
-
-class ClassificationHead(nn.Module):
- """Classification Head for transformer encoders"""
-
- def __init__(self, class_size, embed_size):
- super().__init__()
- self.class_size = class_size
- self.embed_size = embed_size
- # self.mlp1 = nn.Linear(embed_size, embed_size)
- # self.mlp2 = (nn.Linear(embed_size, class_size))
- self.mlp = nn.Linear(embed_size, class_size)
-
- def forward(self, hidden_state):
- # hidden_state = nn.functional.relu(self.mlp1(hidden_state))
- # hidden_state = self.mlp2(hidden_state)
- logits = self.mlp(hidden_state)
- return logits
diff --git a/examples/research_projects/pplm/requirements.txt b/examples/research_projects/pplm/requirements.txt
deleted file mode 100644
index 630d1b0f8f6..00000000000
--- a/examples/research_projects/pplm/requirements.txt
+++ /dev/null
@@ -1,22 +0,0 @@
-tensorboard
-scikit-learn
-seqeval
-psutil
-sacrebleu
-rouge-score
-tensorflow_datasets
-pytorch-lightning
-matplotlib
-git-python==1.0.3
-faiss-cpu
-streamlit
-elasticsearch
-nltk
-pandas
-datasets >= 1.1.3
-fire
-pytest
-conllu
-sentencepiece != 0.1.92
-protobuf
-transformers==4.48.0
diff --git a/examples/research_projects/pplm/run_pplm.py b/examples/research_projects/pplm/run_pplm.py
deleted file mode 100644
index cc49b7fa83c..00000000000
--- a/examples/research_projects/pplm/run_pplm.py
+++ /dev/null
@@ -1,823 +0,0 @@
-#! /usr/bin/env python3
-# coding=utf-8
-
-# Copyright (c) 2019 Uber Technologies, Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""
-Example command with bag of words:
-python run_pplm.py -B space --cond_text "The president" --length 100 --gamma 1.5 --num_iterations 3 --num_samples 10 --stepsize 0.01 --window_length 5 --kl_scale 0.01 --gm_scale 0.95
-
-Example command with discriminator:
-python run_pplm.py -D sentiment --class_label 3 --cond_text "The lake" --length 10 --gamma 1.0 --num_iterations 30 --num_samples 10 --stepsize 0.01 --kl_scale 0.01 --gm_scale 0.95
-"""
-
-import argparse
-import json
-from operator import add
-from typing import List, Optional, Tuple, Union
-
-import numpy as np
-import torch
-from pplm_classification_head import ClassificationHead
-from torch import nn
-from tqdm import trange
-
-from transformers import GPT2LMHeadModel, GPT2Tokenizer
-from transformers.file_utils import cached_path
-
-
-PPLM_BOW = 1
-PPLM_DISCRIM = 2
-PPLM_BOW_DISCRIM = 3
-SMALL_CONST = 1e-15
-BIG_CONST = 1e10
-
-BAG_OF_WORDS_ARCHIVE_MAP = {
- "legal": "https://s3.amazonaws.com/models.huggingface.co/bert/pplm/bow/legal.txt",
- "military": "https://s3.amazonaws.com/models.huggingface.co/bert/pplm/bow/military.txt",
- "politics": "https://s3.amazonaws.com/models.huggingface.co/bert/pplm/bow/politics.txt",
- "religion": "https://s3.amazonaws.com/models.huggingface.co/bert/pplm/bow/religion.txt",
- "science": "https://s3.amazonaws.com/models.huggingface.co/bert/pplm/bow/science.txt",
- "space": "https://s3.amazonaws.com/models.huggingface.co/bert/pplm/bow/space.txt",
- "technology": "https://s3.amazonaws.com/models.huggingface.co/bert/pplm/bow/technology.txt",
-}
-
-DISCRIMINATOR_MODELS_PARAMS = {
- "clickbait": {
- "url": "https://s3.amazonaws.com/models.huggingface.co/bert/pplm/discriminators/clickbait_classifier_head.pt",
- "class_size": 2,
- "embed_size": 1024,
- "class_vocab": {"non_clickbait": 0, "clickbait": 1},
- "default_class": 1,
- "pretrained_model": "openai-community/gpt2-medium",
- },
- "sentiment": {
- "url": "https://s3.amazonaws.com/models.huggingface.co/bert/pplm/discriminators/SST_classifier_head.pt",
- "class_size": 5,
- "embed_size": 1024,
- "class_vocab": {"very_positive": 2, "very_negative": 3},
- "default_class": 3,
- "pretrained_model": "openai-community/gpt2-medium",
- },
-}
-
-
-def top_k_filter(logits, k, probs=False):
- """
- Masks everything but the k top entries as -infinity (1e10).
- Used to mask logits such that e^-infinity -> 0 won't contribute to the
- sum of the denominator.
- """
- if k == 0:
- return logits
- else:
- values = torch.topk(logits, k)[0]
- batch_mins = values[:, -1].view(-1, 1).expand_as(logits)
- if probs:
- return torch.where(logits < batch_mins, torch.ones_like(logits) * 0.0, logits)
- return torch.where(logits < batch_mins, torch.ones_like(logits) * -BIG_CONST, logits)
-
-
-def perturb_past(
- past,
- model,
- last,
- unpert_past=None,
- unpert_logits=None,
- accumulated_hidden=None,
- grad_norms=None,
- stepsize=0.01,
- one_hot_bows_vectors=None,
- classifier=None,
- class_label=None,
- loss_type=0,
- num_iterations=3,
- horizon_length=1,
- window_length=0,
- decay=False,
- gamma=1.5,
- kl_scale=0.01,
- device="cuda",
-):
- # Generate inital perturbed past
- grad_accumulator = [(np.zeros(p.shape).astype("float32")) for p in past]
-
- if accumulated_hidden is None:
- accumulated_hidden = 0
-
- if decay:
- decay_mask = torch.arange(0.0, 1.0 + SMALL_CONST, 1.0 / (window_length))[1:]
- else:
- decay_mask = 1.0
-
- # TODO fix this comment (SUMANTH)
- # Generate a mask is gradient perturbated is based on a past window
- _, _, _, curr_length, _ = past[0].shape
-
- if curr_length > window_length and window_length > 0:
- ones_key_val_shape = tuple(past[0].shape[:-2]) + (window_length,) + tuple(past[0].shape[-1:])
-
- zeros_key_val_shape = tuple(past[0].shape[:-2]) + (curr_length - window_length,) + tuple(past[0].shape[-1:])
-
- ones_mask = torch.ones(ones_key_val_shape)
- ones_mask = decay_mask * ones_mask.permute(0, 1, 2, 4, 3)
- ones_mask = ones_mask.permute(0, 1, 2, 4, 3)
-
- window_mask = torch.cat((ones_mask, torch.zeros(zeros_key_val_shape)), dim=-2).to(device)
- else:
- window_mask = torch.ones_like(past[0]).to(device)
-
- # accumulate perturbations for num_iterations
- loss_per_iter = []
- new_accumulated_hidden = None
- for i in range(num_iterations):
- print("Iteration ", i + 1)
- curr_perturbation = [torch.from_numpy(p_).requires_grad_(True).to(device=device) for p_ in grad_accumulator]
- # make sure p_.grad is not None
- for p_ in curr_perturbation:
- p_.retain_grad()
-
- # Compute hidden using perturbed past
- perturbed_past = list(map(add, past, curr_perturbation))
- _, _, _, curr_length, _ = curr_perturbation[0].shape
- lm_output = model(last, past_key_values=perturbed_past)
- all_logits, all_hidden = lm_output["logits"], lm_output["hidden_states"]
- hidden = all_hidden[-1]
- new_accumulated_hidden = accumulated_hidden + torch.sum(hidden, dim=1).detach()
- # TODO: Check the layer-norm consistency of this with trained discriminator (Sumanth)
- logits = all_logits[:, -1, :]
- probs = nn.functional.softmax(logits, dim=-1)
-
- loss = 0.0
- loss_list = []
- if loss_type == PPLM_BOW or loss_type == PPLM_BOW_DISCRIM:
- for one_hot_bow in one_hot_bows_vectors:
- bow_logits = torch.mm(probs, torch.t(one_hot_bow))
- bow_loss = -torch.log(torch.sum(bow_logits))
- loss += bow_loss
- loss_list.append(bow_loss)
- print(" pplm_bow_loss:", loss.data.cpu().numpy())
-
- if loss_type == 2 or loss_type == 3:
- ce_loss = nn.CrossEntropyLoss()
- # TODO why we need to do this assignment and not just using unpert_past? (Sumanth)
- curr_unpert_past = unpert_past
- curr_probs = torch.unsqueeze(probs, dim=1)
- wte = model.resize_token_embeddings()
- for _ in range(horizon_length):
- inputs_embeds = torch.matmul(curr_probs, wte.weight.data)
- lm_output = model(past_key_values=curr_unpert_past, inputs_embeds=inputs_embeds)
- curr_all_logits, curr_unpert_past, curr_all_hidden = (
- lm_output["logits"],
- lm_output["past_key_values"],
- lm_output["hidden_states"],
- )
- curr_logits = curr_all_logits[:, -1, :]
- curr_probs = nn.functional.softmax(curr_logits, dim=-1)
- curr_probs = torch.unsqueeze(curr_probs, dim=1)
- curr_hidden = curr_all_hidden[-1]
- new_accumulated_hidden = new_accumulated_hidden + torch.sum(curr_hidden, dim=1)
-
- prediction = classifier(new_accumulated_hidden / (curr_length + 1 + horizon_length))
-
- label = torch.tensor(prediction.shape[0] * [class_label], device=device, dtype=torch.long)
- discrim_loss = ce_loss(prediction, label)
- print(" pplm_discrim_loss:", discrim_loss.data.cpu().numpy())
- loss += discrim_loss
- loss_list.append(discrim_loss)
-
- kl_loss = 0.0
- if kl_scale > 0.0:
- unpert_probs = nn.functional.softmax(unpert_logits[:, -1, :], dim=-1)
- unpert_probs = unpert_probs + SMALL_CONST * (unpert_probs <= SMALL_CONST).float().to(device).detach()
- correction = SMALL_CONST * (probs <= SMALL_CONST).float().to(device).detach()
- corrected_probs = probs + correction.detach()
- kl_loss = kl_scale * ((corrected_probs * (corrected_probs / unpert_probs).log()).sum())
- print(" kl_loss", kl_loss.data.cpu().numpy())
- loss += kl_loss
-
- loss_per_iter.append(loss.data.cpu().numpy())
- print(" pplm_loss", (loss - kl_loss).data.cpu().numpy())
-
- # compute gradients
- loss.backward()
-
- # calculate gradient norms
- if grad_norms is not None and loss_type == PPLM_BOW:
- grad_norms = [
- torch.max(grad_norms[index], torch.norm(p_.grad * window_mask))
- for index, p_ in enumerate(curr_perturbation)
- ]
- else:
- grad_norms = [
- (torch.norm(p_.grad * window_mask) + SMALL_CONST) for index, p_ in enumerate(curr_perturbation)
- ]
-
- # normalize gradients
- grad = [
- -stepsize * (p_.grad * window_mask / grad_norms[index] ** gamma).data.cpu().numpy()
- for index, p_ in enumerate(curr_perturbation)
- ]
-
- # accumulate gradient
- grad_accumulator = list(map(add, grad, grad_accumulator))
-
- # reset gradients, just to make sure
- for p_ in curr_perturbation:
- p_.grad.data.zero_()
-
- # removing past from the graph
- new_past = []
- for p_ in past:
- new_past.append(p_.detach())
- past = new_past
-
- # apply the accumulated perturbations to the past
- grad_accumulator = [torch.from_numpy(p_).requires_grad_(True).to(device=device) for p_ in grad_accumulator]
- pert_past = list(map(add, past, grad_accumulator))
-
- return pert_past, new_accumulated_hidden, grad_norms, loss_per_iter
-
-
-def get_classifier(
- name: Optional[str], class_label: Union[str, int], device: str
-) -> Tuple[Optional[ClassificationHead], Optional[int]]:
- if name is None:
- return None, None
-
- params = DISCRIMINATOR_MODELS_PARAMS[name]
- classifier = ClassificationHead(class_size=params["class_size"], embed_size=params["embed_size"]).to(device)
- if "url" in params:
- resolved_archive_file = cached_path(params["url"])
- elif "path" in params:
- resolved_archive_file = params["path"]
- else:
- raise ValueError("Either url or path have to be specified in the discriminator model parameters")
- classifier.load_state_dict(torch.load(resolved_archive_file, map_location=device))
- classifier.eval()
-
- if isinstance(class_label, str):
- if class_label in params["class_vocab"]:
- label_id = params["class_vocab"][class_label]
- else:
- label_id = params["default_class"]
- print("class_label {} not in class_vocab".format(class_label))
- print("available values are: {}".format(params["class_vocab"]))
- print("using default class {}".format(label_id))
-
- elif isinstance(class_label, int):
- if class_label in set(params["class_vocab"].values()):
- label_id = class_label
- else:
- label_id = params["default_class"]
- print("class_label {} not in class_vocab".format(class_label))
- print("available values are: {}".format(params["class_vocab"]))
- print("using default class {}".format(label_id))
-
- else:
- label_id = params["default_class"]
-
- return classifier, label_id
-
-
-def get_bag_of_words_indices(bag_of_words_ids_or_paths: List[str], tokenizer) -> List[List[List[int]]]:
- bow_indices = []
- for id_or_path in bag_of_words_ids_or_paths:
- if id_or_path in BAG_OF_WORDS_ARCHIVE_MAP:
- filepath = cached_path(BAG_OF_WORDS_ARCHIVE_MAP[id_or_path])
- else:
- filepath = id_or_path
- with open(filepath, "r") as f:
- words = f.read().strip().split("\n")
- bow_indices.append([tokenizer.encode(word.strip(), add_prefix_space=True) for word in words])
- return bow_indices
-
-
-def build_bows_one_hot_vectors(bow_indices, tokenizer, device="cuda"):
- if bow_indices is None:
- return None
-
- one_hot_bows_vectors = []
- for single_bow in bow_indices:
- single_bow = list(filter(lambda x: len(x) <= 1, single_bow))
- single_bow = torch.tensor(single_bow).to(device)
- num_words = single_bow.shape[0]
- one_hot_bow = torch.zeros(num_words, tokenizer.vocab_size).to(device)
- one_hot_bow.scatter_(1, single_bow, 1)
- one_hot_bows_vectors.append(one_hot_bow)
- return one_hot_bows_vectors
-
-
-def full_text_generation(
- model,
- tokenizer,
- context=None,
- num_samples=1,
- device="cuda",
- bag_of_words=None,
- discrim=None,
- class_label=None,
- length=100,
- stepsize=0.02,
- temperature=1.0,
- top_k=10,
- sample=False,
- num_iterations=3,
- grad_length=10000,
- horizon_length=1,
- window_length=0,
- decay=False,
- gamma=1.5,
- gm_scale=0.9,
- kl_scale=0.01,
- repetition_penalty=1.0,
- **kwargs,
-):
- classifier, class_id = get_classifier(discrim, class_label, device)
-
- bow_indices = []
- if bag_of_words:
- bow_indices = get_bag_of_words_indices(bag_of_words.split(";"), tokenizer)
-
- if bag_of_words and classifier:
- print("Both PPLM-BoW and PPLM-Discrim are on. This is not optimized.")
- loss_type = PPLM_BOW_DISCRIM
-
- elif bag_of_words:
- loss_type = PPLM_BOW
- print("Using PPLM-BoW")
-
- elif classifier is not None:
- loss_type = PPLM_DISCRIM
- print("Using PPLM-Discrim")
-
- else:
- raise Exception("Specify either a bag of words or a discriminator")
-
- unpert_gen_tok_text, _, _ = generate_text_pplm(
- model=model,
- tokenizer=tokenizer,
- context=context,
- device=device,
- length=length,
- sample=sample,
- perturb=False,
- repetition_penalty=repetition_penalty,
- )
- if device == "cuda":
- torch.cuda.empty_cache()
-
- pert_gen_tok_texts = []
- discrim_losses = []
- losses_in_time = []
-
- for i in range(num_samples):
- pert_gen_tok_text, discrim_loss, loss_in_time = generate_text_pplm(
- model=model,
- tokenizer=tokenizer,
- context=context,
- device=device,
- perturb=True,
- bow_indices=bow_indices,
- classifier=classifier,
- class_label=class_id,
- loss_type=loss_type,
- length=length,
- stepsize=stepsize,
- temperature=temperature,
- top_k=top_k,
- sample=sample,
- num_iterations=num_iterations,
- grad_length=grad_length,
- horizon_length=horizon_length,
- window_length=window_length,
- decay=decay,
- gamma=gamma,
- gm_scale=gm_scale,
- kl_scale=kl_scale,
- repetition_penalty=repetition_penalty,
- )
- pert_gen_tok_texts.append(pert_gen_tok_text)
- if classifier is not None:
- discrim_losses.append(discrim_loss.data.cpu().numpy())
- losses_in_time.append(loss_in_time)
-
- if device == "cuda":
- torch.cuda.empty_cache()
-
- return unpert_gen_tok_text, pert_gen_tok_texts, discrim_losses, losses_in_time
-
-
-def generate_text_pplm(
- model,
- tokenizer,
- context=None,
- past=None,
- device="cuda",
- perturb=True,
- bow_indices=None,
- classifier=None,
- class_label=None,
- loss_type=0,
- length=100,
- stepsize=0.02,
- temperature=1.0,
- top_k=10,
- sample=False,
- num_iterations=3,
- grad_length=10000,
- horizon_length=1,
- window_length=0,
- decay=False,
- gamma=1.5,
- gm_scale=0.9,
- kl_scale=0.01,
- repetition_penalty=1.0,
-):
- output_so_far = None
- if context:
- context_t = torch.tensor(context, device=device, dtype=torch.long)
- while len(context_t.shape) < 2:
- context_t = context_t.unsqueeze(0)
- output_so_far = context_t
-
- # collect one hot vectors for bags of words
- one_hot_bows_vectors = build_bows_one_hot_vectors(bow_indices, tokenizer, device)
-
- grad_norms = None
- last = None
- unpert_discrim_loss = 0
- loss_in_time = []
- for i in trange(length, ascii=True):
- # Get past/probs for current output, except for last word
- # Note that GPT takes 2 inputs: past + current_token
-
- # run model forward to obtain unperturbed
- if past is None and output_so_far is not None:
- last = output_so_far[:, -1:]
- if output_so_far.shape[1] > 1:
- past = model(output_so_far[:, :-1])["past_key_values"]
-
- lm_output = model(output_so_far)
- unpert_logits, unpert_past, unpert_all_hidden = (
- lm_output["logits"],
- lm_output["past_key_values"],
- lm_output["hidden_states"],
- )
- unpert_last_hidden = unpert_all_hidden[-1]
-
- # check if we are abowe grad max length
- if i >= grad_length:
- current_stepsize = stepsize * 0
- else:
- current_stepsize = stepsize
-
- # modify the past if necessary
- if not perturb or num_iterations == 0:
- pert_past = past
-
- else:
- accumulated_hidden = unpert_last_hidden[:, :-1, :]
- accumulated_hidden = torch.sum(accumulated_hidden, dim=1)
-
- if past is not None:
- pert_past, _, grad_norms, loss_this_iter = perturb_past(
- past,
- model,
- last,
- unpert_past=unpert_past,
- unpert_logits=unpert_logits,
- accumulated_hidden=accumulated_hidden,
- grad_norms=grad_norms,
- stepsize=current_stepsize,
- one_hot_bows_vectors=one_hot_bows_vectors,
- classifier=classifier,
- class_label=class_label,
- loss_type=loss_type,
- num_iterations=num_iterations,
- horizon_length=horizon_length,
- window_length=window_length,
- decay=decay,
- gamma=gamma,
- kl_scale=kl_scale,
- device=device,
- )
- loss_in_time.append(loss_this_iter)
- else:
- pert_past = past
-
- lm_output = model(last, past_key_values=pert_past)
- pert_logits, past = (
- lm_output["logits"],
- lm_output["past_key_values"],
- )
- pert_logits = pert_logits[:, -1, :] / temperature # + SMALL_CONST
-
- for token_idx in set(output_so_far[0].tolist()):
- if pert_logits[0, token_idx] < 0:
- pert_logits[0, token_idx] *= repetition_penalty
- else:
- pert_logits[0, token_idx] /= repetition_penalty
-
- pert_probs = nn.functional.softmax(pert_logits, dim=-1)
-
- if classifier is not None:
- ce_loss = nn.CrossEntropyLoss()
- prediction = classifier(torch.mean(unpert_last_hidden, dim=1))
- label = torch.tensor([class_label], device=device, dtype=torch.long)
- unpert_discrim_loss = ce_loss(prediction, label)
- print("unperturbed discrim loss", unpert_discrim_loss.data.cpu().numpy())
- else:
- unpert_discrim_loss = 0
-
- # Fuse the modified model and original model
- if perturb:
- unpert_probs = nn.functional.softmax(unpert_logits[:, -1, :], dim=-1)
-
- pert_probs = (pert_probs**gm_scale) * (unpert_probs ** (1 - gm_scale)) # + SMALL_CONST
- pert_probs = top_k_filter(pert_probs, k=top_k, probs=True) # + SMALL_CONST
-
- # rescale
- if torch.sum(pert_probs) <= 1:
- pert_probs = pert_probs / torch.sum(pert_probs)
-
- else:
- pert_logits = top_k_filter(pert_logits, k=top_k) # + SMALL_CONST
- pert_probs = nn.functional.softmax(pert_logits, dim=-1)
-
- # sample or greedy
- if sample:
- last = torch.multinomial(pert_probs, num_samples=1)
-
- else:
- _, last = torch.topk(pert_probs, k=1, dim=-1)
-
- # update context/output_so_far appending the new token
- output_so_far = last if output_so_far is None else torch.cat((output_so_far, last), dim=1)
-
- print(tokenizer.decode(output_so_far.tolist()[0]))
-
- return output_so_far, unpert_discrim_loss, loss_in_time
-
-
-def set_generic_model_params(discrim_weights, discrim_meta):
- if discrim_weights is None:
- raise ValueError("When using a generic discriminator, discrim_weights need to be specified")
- if discrim_meta is None:
- raise ValueError("When using a generic discriminator, discrim_meta need to be specified")
-
- with open(discrim_meta, "r") as discrim_meta_file:
- meta = json.load(discrim_meta_file)
- meta["path"] = discrim_weights
- DISCRIMINATOR_MODELS_PARAMS["generic"] = meta
-
-
-def run_pplm_example(
- pretrained_model="openai-community/gpt2-medium",
- cond_text="",
- uncond=False,
- num_samples=1,
- bag_of_words=None,
- discrim=None,
- discrim_weights=None,
- discrim_meta=None,
- class_label=-1,
- length=100,
- stepsize=0.02,
- temperature=1.0,
- top_k=10,
- sample=False,
- num_iterations=3,
- grad_length=10000,
- horizon_length=1,
- window_length=0,
- decay=False,
- gamma=1.5,
- gm_scale=0.9,
- kl_scale=0.01,
- seed=0,
- no_cuda=False,
- colorama=False,
- repetition_penalty=1.0,
-):
- # set Random seed
- torch.manual_seed(seed)
- np.random.seed(seed)
-
- # set the device
- device = "cuda" if torch.cuda.is_available() and not no_cuda else "cpu"
-
- if discrim == "generic":
- set_generic_model_params(discrim_weights, discrim_meta)
-
- if discrim is not None:
- pretrained_model = DISCRIMINATOR_MODELS_PARAMS[discrim]["pretrained_model"]
- print("discrim = {}, pretrained_model set to discriminator's = {}".format(discrim, pretrained_model))
-
- # load pretrained model
- model = GPT2LMHeadModel.from_pretrained(pretrained_model, output_hidden_states=True)
- model.to(device)
- model.eval()
-
- # load tokenizer
- tokenizer = GPT2Tokenizer.from_pretrained(pretrained_model)
-
- # Freeze GPT-2 weights
- for param in model.parameters():
- param.requires_grad = False
-
- # figure out conditioning text
- if uncond:
- tokenized_cond_text = tokenizer.encode([tokenizer.bos_token])
- else:
- raw_text = cond_text
- while not raw_text:
- print("Did you forget to add `--cond_text`? ")
- raw_text = input("Model prompt >>> ")
- tokenized_cond_text = tokenizer.encode(tokenizer.bos_token + raw_text)
-
- print("= Prefix of sentence =")
- print(tokenizer.decode(tokenized_cond_text))
- print()
-
- # generate unperturbed and perturbed texts
-
- # full_text_generation returns:
- # unpert_gen_tok_text, pert_gen_tok_texts, discrim_losses, losses_in_time
- unpert_gen_tok_text, pert_gen_tok_texts, _, _ = full_text_generation(
- model=model,
- tokenizer=tokenizer,
- context=tokenized_cond_text,
- device=device,
- num_samples=num_samples,
- bag_of_words=bag_of_words,
- discrim=discrim,
- class_label=class_label,
- length=length,
- stepsize=stepsize,
- temperature=temperature,
- top_k=top_k,
- sample=sample,
- num_iterations=num_iterations,
- grad_length=grad_length,
- horizon_length=horizon_length,
- window_length=window_length,
- decay=decay,
- gamma=gamma,
- gm_scale=gm_scale,
- kl_scale=kl_scale,
- repetition_penalty=repetition_penalty,
- )
-
- # untokenize unperturbed text
- unpert_gen_text = tokenizer.decode(unpert_gen_tok_text.tolist()[0])
-
- print("=" * 80)
- print("= Unperturbed generated text =")
- print(unpert_gen_text)
- print()
-
- generated_texts = []
-
- bow_word_ids = set()
- if bag_of_words and colorama:
- bow_indices = get_bag_of_words_indices(bag_of_words.split(";"), tokenizer)
- for single_bow_list in bow_indices:
- # filtering all words in the list composed of more than 1 token
- filtered = list(filter(lambda x: len(x) <= 1, single_bow_list))
- # w[0] because we are sure w has only 1 item because previous fitler
- bow_word_ids.update(w[0] for w in filtered)
-
- # iterate through the perturbed texts
- for i, pert_gen_tok_text in enumerate(pert_gen_tok_texts):
- try:
- # untokenize unperturbed text
- if colorama:
- import colorama
-
- pert_gen_text = ""
- for word_id in pert_gen_tok_text.tolist()[0]:
- if word_id in bow_word_ids:
- pert_gen_text += "{}{}{}".format(
- colorama.Fore.RED,
- tokenizer.decode([word_id]),
- colorama.Style.RESET_ALL,
- )
- else:
- pert_gen_text += tokenizer.decode([word_id])
- else:
- pert_gen_text = tokenizer.decode(pert_gen_tok_text.tolist()[0])
-
- print("= Perturbed generated text {} =".format(i + 1))
- print(pert_gen_text)
- print()
- except Exception as exc:
- print("Ignoring error while generating perturbed text:", exc)
-
- # keep the prefix, perturbed seq, original seq for each index
- generated_texts.append((tokenized_cond_text, pert_gen_tok_text, unpert_gen_tok_text))
-
- return
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "--pretrained_model",
- "-M",
- type=str,
- default="openai-community/gpt2-medium",
- help="pretrained model name or path to local checkpoint",
- )
- parser.add_argument("--cond_text", type=str, default="The lake", help="Prefix texts to condition on")
- parser.add_argument("--uncond", action="store_true", help="Generate from end-of-text as prefix")
- parser.add_argument(
- "--num_samples",
- type=int,
- default=1,
- help="Number of samples to generate from the modified latents",
- )
- parser.add_argument(
- "--bag_of_words",
- "-B",
- type=str,
- default=None,
- help=(
- "Bags of words used for PPLM-BoW. "
- "Either a BOW id (see list in code) or a filepath. "
- "Multiple BoWs separated by ;"
- ),
- )
- parser.add_argument(
- "--discrim",
- "-D",
- type=str,
- default=None,
- choices=("clickbait", "sentiment", "toxicity", "generic"),
- help="Discriminator to use",
- )
- parser.add_argument(
- "--discrim_weights",
- type=str,
- default=None,
- help="Weights for the generic discriminator",
- )
- parser.add_argument(
- "--discrim_meta",
- type=str,
- default=None,
- help="Meta information for the generic discriminator",
- )
- parser.add_argument(
- "--class_label",
- type=int,
- default=-1,
- help="Class label used for the discriminator",
- )
- parser.add_argument("--length", type=int, default=100)
- parser.add_argument("--stepsize", type=float, default=0.02)
- parser.add_argument("--temperature", type=float, default=1.0)
- parser.add_argument("--top_k", type=int, default=10)
- parser.add_argument("--sample", action="store_true", help="Generate from end-of-text as prefix")
- parser.add_argument("--num_iterations", type=int, default=3)
- parser.add_argument("--grad_length", type=int, default=10000)
- parser.add_argument(
- "--window_length",
- type=int,
- default=0,
- help="Length of past which is being optimized; 0 corresponds to infinite window length",
- )
- parser.add_argument(
- "--horizon_length",
- type=int,
- default=1,
- help="Length of future to optimize over",
- )
- parser.add_argument("--decay", action="store_true", help="whether to decay or not")
- parser.add_argument("--gamma", type=float, default=1.5)
- parser.add_argument("--gm_scale", type=float, default=0.9)
- parser.add_argument("--kl_scale", type=float, default=0.01)
- parser.add_argument("--seed", type=int, default=0)
- parser.add_argument("--no_cuda", action="store_true", help="no cuda")
- parser.add_argument("--colorama", action="store_true", help="colors keywords")
- parser.add_argument(
- "--repetition_penalty",
- type=float,
- default=1.0,
- help="Penalize repetition. More than 1.0 -> less repetition",
- )
-
- args = parser.parse_args()
- run_pplm_example(**vars(args))
diff --git a/examples/research_projects/pplm/run_pplm_discrim_train.py b/examples/research_projects/pplm/run_pplm_discrim_train.py
deleted file mode 100644
index 43ec5823e37..00000000000
--- a/examples/research_projects/pplm/run_pplm_discrim_train.py
+++ /dev/null
@@ -1,526 +0,0 @@
-#! /usr/bin/env python3
-# coding=utf-8
-
-# Copyright (c) 2019 Uber Technologies, Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import argparse
-import csv
-import json
-import math
-import time
-
-import numpy as np
-import torch
-import torch.optim as optim
-import torch.utils.data as data
-from nltk.tokenize.treebank import TreebankWordDetokenizer
-from pplm_classification_head import ClassificationHead
-from torch import nn
-from torchtext import data as torchtext_data
-from torchtext import datasets
-from tqdm import tqdm, trange
-
-from transformers import GPT2LMHeadModel, GPT2Tokenizer
-
-
-torch.manual_seed(0)
-np.random.seed(0)
-EPSILON = 1e-10
-example_sentence = "This is incredible! I love it, this is the best chicken I have ever had."
-max_length_seq = 100
-
-
-class Discriminator(nn.Module):
- """Transformer encoder followed by a Classification Head"""
-
- def __init__(self, class_size, pretrained_model="openai-community/gpt2-medium", cached_mode=False, device="cpu"):
- super().__init__()
- self.tokenizer = GPT2Tokenizer.from_pretrained(pretrained_model)
- self.encoder = GPT2LMHeadModel.from_pretrained(pretrained_model)
- self.embed_size = self.encoder.transformer.config.hidden_size
- self.classifier_head = ClassificationHead(class_size=class_size, embed_size=self.embed_size)
- self.cached_mode = cached_mode
- self.device = device
-
- def get_classifier(self):
- return self.classifier_head
-
- def train_custom(self):
- for param in self.encoder.parameters():
- param.requires_grad = False
- self.classifier_head.train()
-
- def avg_representation(self, x):
- mask = x.ne(0).unsqueeze(2).repeat(1, 1, self.embed_size).float().to(self.device).detach()
- hidden = self.encoder.transformer(x)["last_hidden_state"]
- masked_hidden = hidden * mask
- avg_hidden = torch.sum(masked_hidden, dim=1) / (torch.sum(mask, dim=1).detach() + EPSILON)
- return avg_hidden
-
- def forward(self, x):
- if self.cached_mode:
- avg_hidden = x.to(self.device)
- else:
- avg_hidden = self.avg_representation(x.to(self.device))
-
- logits = self.classifier_head(avg_hidden)
- probs = nn.functional.log_softmax(logits, dim=-1)
-
- return probs
-
-
-class Dataset(data.Dataset):
- def __init__(self, X, y):
- """Reads source and target sequences from txt files."""
- self.X = X
- self.y = y
-
- def __len__(self):
- return len(self.X)
-
- def __getitem__(self, index):
- """Returns one data pair (source and target)."""
- data = {}
- data["X"] = self.X[index]
- data["y"] = self.y[index]
- return data
-
-
-def collate_fn(data):
- def pad_sequences(sequences):
- lengths = [len(seq) for seq in sequences]
-
- padded_sequences = torch.zeros(len(sequences), max(lengths)).long() # padding value = 0
-
- for i, seq in enumerate(sequences):
- end = lengths[i]
- padded_sequences[i, :end] = seq[:end]
-
- return padded_sequences, lengths
-
- item_info = {}
- for key in data[0].keys():
- item_info[key] = [d[key] for d in data]
-
- x_batch, _ = pad_sequences(item_info["X"])
- y_batch = torch.tensor(item_info["y"], dtype=torch.long)
-
- return x_batch, y_batch
-
-
-def cached_collate_fn(data):
- item_info = {}
- for key in data[0].keys():
- item_info[key] = [d[key] for d in data]
-
- x_batch = torch.cat(item_info["X"], 0)
- y_batch = torch.tensor(item_info["y"], dtype=torch.long)
-
- return x_batch, y_batch
-
-
-def train_epoch(data_loader, discriminator, optimizer, epoch=0, log_interval=10, device="cpu"):
- samples_so_far = 0
- discriminator.train_custom()
- for batch_idx, (input_t, target_t) in enumerate(data_loader):
- input_t, target_t = input_t.to(device), target_t.to(device)
-
- optimizer.zero_grad()
-
- output_t = discriminator(input_t)
- loss = nn.functional.nll_loss(output_t, target_t)
- loss.backward(retain_graph=True)
- optimizer.step()
-
- samples_so_far += len(input_t)
-
- if batch_idx % log_interval == 0:
- print(
- "Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}".format(
- epoch + 1,
- samples_so_far,
- len(data_loader.dataset),
- 100 * samples_so_far / len(data_loader.dataset),
- loss.item(),
- )
- )
-
-
-def evaluate_performance(data_loader, discriminator, device="cpu"):
- discriminator.eval()
- test_loss = 0
- correct = 0
- with torch.no_grad():
- for input_t, target_t in data_loader:
- input_t, target_t = input_t.to(device), target_t.to(device)
- output_t = discriminator(input_t)
- # sum up batch loss
- test_loss += nn.functional.nll_loss(output_t, target_t, reduction="sum").item()
- # get the index of the max log-probability
- pred_t = output_t.argmax(dim=1, keepdim=True)
- correct += pred_t.eq(target_t.view_as(pred_t)).sum().item()
-
- test_loss /= len(data_loader.dataset)
-
- print(
- "Performance on test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)".format(
- test_loss, correct, len(data_loader.dataset), 100.0 * correct / len(data_loader.dataset)
- )
- )
-
-
-def predict(input_sentence, model, classes, cached=False, device="cpu"):
- input_t = model.tokenizer.encode(input_sentence)
- input_t = torch.tensor([input_t], dtype=torch.long, device=device)
- if cached:
- input_t = model.avg_representation(input_t)
-
- log_probs = model(input_t).data.cpu().numpy().flatten().tolist()
- print("Input sentence:", input_sentence)
- print(
- "Predictions:",
- ", ".join("{}: {:.4f}".format(c, math.exp(log_prob)) for c, log_prob in zip(classes, log_probs)),
- )
-
-
-def get_cached_data_loader(dataset, batch_size, discriminator, shuffle=False, device="cpu"):
- data_loader = torch.utils.data.DataLoader(dataset=dataset, batch_size=batch_size, collate_fn=collate_fn)
-
- xs = []
- ys = []
- for batch_idx, (x, y) in enumerate(tqdm(data_loader, ascii=True)):
- with torch.no_grad():
- x = x.to(device)
- avg_rep = discriminator.avg_representation(x).cpu().detach()
- avg_rep_list = torch.unbind(avg_rep.unsqueeze(1))
- xs += avg_rep_list
- ys += y.cpu().numpy().tolist()
-
- data_loader = torch.utils.data.DataLoader(
- dataset=Dataset(xs, ys), batch_size=batch_size, shuffle=shuffle, collate_fn=cached_collate_fn
- )
-
- return data_loader
-
-
-def train_discriminator(
- dataset,
- dataset_fp=None,
- pretrained_model="openai-community/gpt2-medium",
- epochs=10,
- batch_size=64,
- log_interval=10,
- save_model=False,
- cached=False,
- no_cuda=False,
-):
- device = "cuda" if torch.cuda.is_available() and not no_cuda else "cpu"
-
- print("Preprocessing {} dataset...".format(dataset))
- start = time.time()
-
- if dataset == "SST":
- idx2class = ["positive", "negative", "very positive", "very negative", "neutral"]
- class2idx = {c: i for i, c in enumerate(idx2class)}
-
- discriminator = Discriminator(
- class_size=len(idx2class), pretrained_model=pretrained_model, cached_mode=cached, device=device
- ).to(device)
-
- text = torchtext_data.Field()
- label = torchtext_data.Field(sequential=False)
- train_data, val_data, test_data = datasets.SST.splits(
- text,
- label,
- fine_grained=True,
- train_subtrees=True,
- )
-
- x = []
- y = []
- for i in trange(len(train_data), ascii=True):
- seq = TreebankWordDetokenizer().detokenize(vars(train_data[i])["text"])
- seq = discriminator.tokenizer.encode(seq)
- seq = torch.tensor([50256] + seq, device=device, dtype=torch.long)
- x.append(seq)
- y.append(class2idx[vars(train_data[i])["label"]])
- train_dataset = Dataset(x, y)
-
- test_x = []
- test_y = []
- for i in trange(len(test_data), ascii=True):
- seq = TreebankWordDetokenizer().detokenize(vars(test_data[i])["text"])
- seq = discriminator.tokenizer.encode(seq)
- seq = torch.tensor([50256] + seq, device=device, dtype=torch.long)
- test_x.append(seq)
- test_y.append(class2idx[vars(test_data[i])["label"]])
- test_dataset = Dataset(test_x, test_y)
-
- discriminator_meta = {
- "class_size": len(idx2class),
- "embed_size": discriminator.embed_size,
- "pretrained_model": pretrained_model,
- "class_vocab": class2idx,
- "default_class": 2,
- }
-
- elif dataset == "clickbait":
- idx2class = ["non_clickbait", "clickbait"]
- class2idx = {c: i for i, c in enumerate(idx2class)}
-
- discriminator = Discriminator(
- class_size=len(idx2class), pretrained_model=pretrained_model, cached_mode=cached, device=device
- ).to(device)
-
- with open("datasets/clickbait/clickbait_train_prefix.txt") as f:
- data = []
- for i, line in enumerate(f):
- try:
- data.append(eval(line))
- except Exception:
- print("Error evaluating line {}: {}".format(i, line))
- continue
- x = []
- y = []
- with open("datasets/clickbait/clickbait_train_prefix.txt") as f:
- for i, line in enumerate(tqdm(f, ascii=True)):
- try:
- d = eval(line)
- seq = discriminator.tokenizer.encode(d["text"])
-
- if len(seq) < max_length_seq:
- seq = torch.tensor([50256] + seq, device=device, dtype=torch.long)
- else:
- print("Line {} is longer than maximum length {}".format(i, max_length_seq))
- continue
- x.append(seq)
- y.append(d["label"])
- except Exception:
- print("Error evaluating / tokenizing line {}, skipping it".format(i))
- pass
-
- full_dataset = Dataset(x, y)
- train_size = int(0.9 * len(full_dataset))
- test_size = len(full_dataset) - train_size
- train_dataset, test_dataset = torch.utils.data.random_split(full_dataset, [train_size, test_size])
-
- discriminator_meta = {
- "class_size": len(idx2class),
- "embed_size": discriminator.embed_size,
- "pretrained_model": pretrained_model,
- "class_vocab": class2idx,
- "default_class": 1,
- }
-
- elif dataset == "toxic":
- idx2class = ["non_toxic", "toxic"]
- class2idx = {c: i for i, c in enumerate(idx2class)}
-
- discriminator = Discriminator(
- class_size=len(idx2class), pretrained_model=pretrained_model, cached_mode=cached, device=device
- ).to(device)
-
- x = []
- y = []
- with open("datasets/toxic/toxic_train.txt") as f:
- for i, line in enumerate(tqdm(f, ascii=True)):
- try:
- d = eval(line)
- seq = discriminator.tokenizer.encode(d["text"])
-
- if len(seq) < max_length_seq:
- seq = torch.tensor([50256] + seq, device=device, dtype=torch.long)
- else:
- print("Line {} is longer than maximum length {}".format(i, max_length_seq))
- continue
- x.append(seq)
- y.append(int(np.sum(d["label"]) > 0))
- except Exception:
- print("Error evaluating / tokenizing line {}, skipping it".format(i))
- pass
-
- full_dataset = Dataset(x, y)
- train_size = int(0.9 * len(full_dataset))
- test_size = len(full_dataset) - train_size
- train_dataset, test_dataset = torch.utils.data.random_split(full_dataset, [train_size, test_size])
-
- discriminator_meta = {
- "class_size": len(idx2class),
- "embed_size": discriminator.embed_size,
- "pretrained_model": pretrained_model,
- "class_vocab": class2idx,
- "default_class": 0,
- }
-
- else: # if dataset == "generic":
- # This assumes the input dataset is a TSV with the following structure:
- # class \t text
-
- if dataset_fp is None:
- raise ValueError("When generic dataset is selected, dataset_fp needs to be specified aswell.")
-
- classes = set()
- with open(dataset_fp) as f:
- csv_reader = csv.reader(f, delimiter="\t")
- for row in tqdm(csv_reader, ascii=True):
- if row:
- classes.add(row[0])
-
- idx2class = sorted(classes)
- class2idx = {c: i for i, c in enumerate(idx2class)}
-
- discriminator = Discriminator(
- class_size=len(idx2class), pretrained_model=pretrained_model, cached_mode=cached, device=device
- ).to(device)
-
- x = []
- y = []
- with open(dataset_fp) as f:
- csv_reader = csv.reader(f, delimiter="\t")
- for i, row in enumerate(tqdm(csv_reader, ascii=True)):
- if row:
- label = row[0]
- text = row[1]
-
- try:
- seq = discriminator.tokenizer.encode(text)
- if len(seq) < max_length_seq:
- seq = torch.tensor([50256] + seq, device=device, dtype=torch.long)
-
- else:
- print("Line {} is longer than maximum length {}".format(i, max_length_seq))
- continue
-
- x.append(seq)
- y.append(class2idx[label])
-
- except Exception:
- print("Error tokenizing line {}, skipping it".format(i))
- pass
-
- full_dataset = Dataset(x, y)
- train_size = int(0.9 * len(full_dataset))
- test_size = len(full_dataset) - train_size
- train_dataset, test_dataset = torch.utils.data.random_split(full_dataset, [train_size, test_size])
-
- discriminator_meta = {
- "class_size": len(idx2class),
- "embed_size": discriminator.embed_size,
- "pretrained_model": pretrained_model,
- "class_vocab": class2idx,
- "default_class": 0,
- }
-
- end = time.time()
- print("Preprocessed {} data points".format(len(train_dataset) + len(test_dataset)))
- print("Data preprocessing took: {:.3f}s".format(end - start))
-
- if cached:
- print("Building representation cache...")
-
- start = time.time()
-
- train_loader = get_cached_data_loader(train_dataset, batch_size, discriminator, shuffle=True, device=device)
-
- test_loader = get_cached_data_loader(test_dataset, batch_size, discriminator, device=device)
-
- end = time.time()
- print("Building representation cache took: {:.3f}s".format(end - start))
-
- else:
- train_loader = torch.utils.data.DataLoader(
- dataset=train_dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn
- )
- test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, collate_fn=collate_fn)
-
- if save_model:
- with open("{}_classifier_head_meta.json".format(dataset), "w") as meta_file:
- json.dump(discriminator_meta, meta_file)
-
- optimizer = optim.Adam(discriminator.parameters(), lr=0.0001)
-
- for epoch in range(epochs):
- start = time.time()
- print("\nEpoch", epoch + 1)
-
- train_epoch(
- discriminator=discriminator,
- data_loader=train_loader,
- optimizer=optimizer,
- epoch=epoch,
- log_interval=log_interval,
- device=device,
- )
- evaluate_performance(data_loader=test_loader, discriminator=discriminator, device=device)
-
- end = time.time()
- print("Epoch took: {:.3f}s".format(end - start))
-
- print("\nExample prediction")
- predict(example_sentence, discriminator, idx2class, cached=cached, device=device)
-
- if save_model:
- # torch.save(discriminator.state_dict(),
- # "{}_discriminator_{}.pt".format(
- # args.dataset, epoch + 1
- # ))
- torch.save(
- discriminator.get_classifier().state_dict(),
- "{}_classifier_head_epoch_{}.pt".format(dataset, epoch + 1),
- )
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser(description="Train a discriminator on top of GPT-2 representations")
- parser.add_argument(
- "--dataset",
- type=str,
- default="SST",
- choices=("SST", "clickbait", "toxic", "generic"),
- help=(
- "dataset to train the discriminator on. "
- "In case of generic, the dataset is expected "
- "to be a TSBV file with structure: class \\t text"
- ),
- )
- parser.add_argument(
- "--dataset_fp",
- type=str,
- default="",
- help="File path of the dataset to use. Needed only in case of generic datadset",
- )
- parser.add_argument(
- "--pretrained_model",
- type=str,
- default="openai-community/gpt2-medium",
- help="Pretrained model to use as encoder",
- )
- parser.add_argument("--epochs", type=int, default=10, metavar="N", help="Number of training epochs")
- parser.add_argument(
- "--batch_size", type=int, default=64, metavar="N", help="input batch size for training (default: 64)"
- )
- parser.add_argument(
- "--log_interval",
- type=int,
- default=10,
- metavar="N",
- help="how many batches to wait before logging training status",
- )
- parser.add_argument("--save_model", action="store_true", help="whether to save the model")
- parser.add_argument("--cached", action="store_true", help="whether to cache the input representations")
- parser.add_argument("--no_cuda", action="store_true", help="use to turn off cuda")
- args = parser.parse_args()
-
- train_discriminator(**(vars(args)))
diff --git a/examples/research_projects/quantization-qdqbert/Dockerfile b/examples/research_projects/quantization-qdqbert/Dockerfile
deleted file mode 100644
index e64c9f0e021..00000000000
--- a/examples/research_projects/quantization-qdqbert/Dockerfile
+++ /dev/null
@@ -1,34 +0,0 @@
-# coding=utf-8
-# Copyright 2021 NVIDIA Corporation. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-FROM nvcr.io/nvidia/pytorch:22.02-py3
-LABEL maintainer="Hugging Face"
-LABEL repository="transformers"
-
-RUN apt-get update
-RUN apt-get install sudo
-
-RUN python3 -m pip install --no-cache-dir --upgrade pip
-RUN python3 -m pip install --no-cache-dir --ignore-installed pycuda
-RUN python3 -m pip install --no-cache-dir \
- pytorch-quantization --extra-index-url https://pypi.ngc.nvidia.com
-RUN python3 -m pip install --no-cache-dir onnxruntime-gpu==1.11
-
-WORKDIR /workspace
-COPY . transformers/
-RUN cd transformers/ && \
- python3 -m pip install --no-cache-dir .
-
-RUN python3 -m pip install --no-cache-dir datasets \
- accelerate
diff --git a/examples/research_projects/quantization-qdqbert/README.md b/examples/research_projects/quantization-qdqbert/README.md
deleted file mode 100644
index 2cc2d5e5f98..00000000000
--- a/examples/research_projects/quantization-qdqbert/README.md
+++ /dev/null
@@ -1,200 +0,0 @@
-
-
-# Huggingface QDQBERT Quantization Example
-
-The QDQBERT model adds fake quantization (pair of QuantizeLinear/DequantizeLinear ops) to:
- * linear layer inputs and weights
- * matmul inputs
- * residual add inputs
-
-In this example, we use QDQBERT model to do quantization on SQuAD task, including Quantization Aware Training (QAT), Post Training Quantization (PTQ) and inferencing using TensorRT.
-
-Required:
-- [pytorch-quantization toolkit](https://github.com/NVIDIA/TensorRT/tree/master/tools/pytorch-quantization)
-- [TensorRT >= 8.2](https://developer.nvidia.com/tensorrt)
-- PyTorch >= 1.10.0
-
-## Setup the environment with Dockerfile
-
-Under the directory of `transformers/`, build the docker image:
-```bash
-docker build . -f examples/research_projects/quantization-qdqbert/Dockerfile -t bert_quantization:latest
-```
-
-Run the docker:
-```bash
-docker run --gpus all --privileged --rm -it --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 bert_quantization:latest
-```
-
-In the container:
-```bash
-cd transformers/examples/research_projects/quantization-qdqbert/
-```
-
-## Quantization Aware Training (QAT)
-
-Calibrate the pretrained model and finetune with quantization awared:
-
-```bash
-python3 run_quant_qa.py \
- --model_name_or_path google-bert/bert-base-uncased \
- --dataset_name squad \
- --max_seq_length 128 \
- --doc_stride 32 \
- --output_dir calib/google-bert/bert-base-uncased \
- --do_calib \
- --calibrator percentile \
- --percentile 99.99
-```
-
-```bash
-python3 run_quant_qa.py \
- --model_name_or_path calib/google-bert/bert-base-uncased \
- --dataset_name squad \
- --do_train \
- --do_eval \
- --per_device_train_batch_size 12 \
- --learning_rate 4e-5 \
- --num_train_epochs 2 \
- --max_seq_length 128 \
- --doc_stride 32 \
- --output_dir finetuned_int8/google-bert/bert-base-uncased \
- --tokenizer_name google-bert/bert-base-uncased \
- --save_steps 0
-```
-
-### Export QAT model to ONNX
-
-To export the QAT model finetuned above:
-
-```bash
-python3 run_quant_qa.py \
- --model_name_or_path finetuned_int8/google-bert/bert-base-uncased \
- --output_dir ./ \
- --save_onnx \
- --per_device_eval_batch_size 1 \
- --max_seq_length 128 \
- --doc_stride 32 \
- --dataset_name squad \
- --tokenizer_name google-bert/bert-base-uncased
-```
-
-Use `--recalibrate-weights` to calibrate the weight ranges according to the quantizer axis. Use `--quant-per-tensor` for per tensor quantization (default is per channel).
-Recalibrating will affect the accuracy of the model, but the change should be minimal (< 0.5 F1).
-
-### Benchmark the INT8 QAT ONNX model inference with TensorRT using dummy input
-
-```bash
-trtexec --onnx=model.onnx --explicitBatch --workspace=16384 --int8 --shapes=input_ids:64x128,attention_mask:64x128,token_type_ids:64x128 --verbose
-```
-
-### Benchmark the INT8 QAT ONNX model inference with [ONNX Runtime-TRT](https://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.html) using dummy input
-
-```bash
-python3 ort-infer-benchmark.py
-```
-
-### Evaluate the INT8 QAT ONNX model inference with TensorRT
-
-```bash
-python3 evaluate-hf-trt-qa.py \
- --onnx_model_path=./model.onnx \
- --output_dir ./ \
- --per_device_eval_batch_size 64 \
- --max_seq_length 128 \
- --doc_stride 32 \
- --dataset_name squad \
- --tokenizer_name google-bert/bert-base-uncased \
- --int8 \
- --seed 42
-```
-
-## Fine-tuning of FP32 model for comparison
-
-Finetune a fp32 precision model with [transformers/examples/pytorch/question-answering/](../../pytorch/question-answering/):
-
-```bash
-python3 ../../pytorch/question-answering/run_qa.py \
- --model_name_or_path google-bert/bert-base-uncased \
- --dataset_name squad \
- --per_device_train_batch_size 12 \
- --learning_rate 3e-5 \
- --num_train_epochs 2 \
- --max_seq_length 128 \
- --doc_stride 32 \
- --output_dir ./finetuned_fp32/google-bert/bert-base-uncased \
- --save_steps 0 \
- --do_train \
- --do_eval
-```
-
-## Post Training Quantization (PTQ)
-
-### PTQ by calibrating and evaluating the finetuned FP32 model above:
-
-```bash
-python3 run_quant_qa.py \
- --model_name_or_path ./finetuned_fp32/google-bert/bert-base-uncased \
- --dataset_name squad \
- --calibrator percentile \
- --percentile 99.99 \
- --max_seq_length 128 \
- --doc_stride 32 \
- --output_dir ./calib/google-bert/bert-base-uncased \
- --save_steps 0 \
- --do_calib \
- --do_eval
-```
-
-### Export the INT8 PTQ model to ONNX
-
-```bash
-python3 run_quant_qa.py \
- --model_name_or_path ./calib/google-bert/bert-base-uncased \
- --output_dir ./ \
- --save_onnx \
- --per_device_eval_batch_size 1 \
- --max_seq_length 128 \
- --doc_stride 32 \
- --dataset_name squad \
- --tokenizer_name google-bert/bert-base-uncased
-```
-
-### Evaluate the INT8 PTQ ONNX model inference with TensorRT
-
-```bash
-python3 evaluate-hf-trt-qa.py \
- --onnx_model_path=./model.onnx \
- --output_dir ./ \
- --per_device_eval_batch_size 64 \
- --max_seq_length 128 \
- --doc_stride 32 \
- --dataset_name squad \
- --tokenizer_name google-bert/bert-base-uncased \
- --int8 \
- --seed 42
-```
-
-### Quantization options
-
-Some useful options to support different implementations and optimizations. These should be specified for both calibration and finetuning.
-
-|argument|description|
-|--------|-----------|
-|`--quant-per-tensor`| quantize weights with one quantization range per tensor |
-|`--fuse-qkv` | use a single range (the max) for quantizing QKV weights and output activations |
-|`--clip-gelu N` | clip the output of GELU to a maximum of N when quantizing (e.g. 10) |
-|`--disable-dropout` | disable dropout for consistent activation ranges |
diff --git a/examples/research_projects/quantization-qdqbert/evaluate-hf-trt-qa.py b/examples/research_projects/quantization-qdqbert/evaluate-hf-trt-qa.py
deleted file mode 100755
index 7a8ea2109bc..00000000000
--- a/examples/research_projects/quantization-qdqbert/evaluate-hf-trt-qa.py
+++ /dev/null
@@ -1,457 +0,0 @@
-# coding=utf-8
-# Copyright 2021 NVIDIA Corporation. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Finetuning the library models for question-answering on SQuAD (DistilBERT, Bert, XLM, XLNet)."""
-
-import argparse
-import logging
-import os
-import time
-import timeit
-
-import datasets
-import numpy as np
-import pycuda.autoinit # noqa: F401
-import pycuda.driver as cuda
-import tensorrt as trt
-import torch
-from absl import logging as absl_logging
-from accelerate import Accelerator
-from datasets import load_dataset, load_metric
-from torch.utils.data import DataLoader
-from utils_qa import postprocess_qa_predictions
-
-import transformers
-from transformers import AutoTokenizer, EvalPrediction, default_data_collator, set_seed
-from transformers.trainer_pt_utils import nested_concat, nested_truncate
-
-
-TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
-absl_logger = absl_logging.get_absl_logger()
-absl_logger.setLevel(logging.WARNING)
-
-logger = logging.getLogger(__name__)
-
-parser = argparse.ArgumentParser()
-
-# Required parameters
-parser.add_argument(
- "--onnx_model_path",
- default=None,
- type=str,
- required=True,
- help="Path to ONNX model: ",
-)
-
-parser.add_argument(
- "--output_dir",
- default=None,
- type=str,
- required=True,
- help="The output directory where the model checkpoints and predictions will be written.",
-)
-
-# Other parameters
-
-parser.add_argument(
- "--tokenizer_name",
- default="",
- type=str,
- required=True,
- help="Pretrained tokenizer name or path if not the same as model_name",
-)
-
-parser.add_argument(
- "--version_2_with_negative",
- action="store_true",
- help="If true, the SQuAD examples contain some that do not have an answer.",
-)
-parser.add_argument(
- "--null_score_diff_threshold",
- type=float,
- default=0.0,
- help="If null_score - best_non_null is greater than the threshold predict null.",
-)
-
-parser.add_argument(
- "--max_seq_length",
- default=384,
- type=int,
- help=(
- "The maximum total input sequence length after WordPiece tokenization. Sequences "
- "longer than this will be truncated, and sequences shorter than this will be padded."
- ),
-)
-parser.add_argument(
- "--doc_stride",
- default=128,
- type=int,
- help="When splitting up a long document into chunks, how much stride to take between chunks.",
-)
-
-parser.add_argument("--per_device_eval_batch_size", default=8, type=int, help="Batch size per GPU/CPU for evaluation.")
-
-parser.add_argument(
- "--n_best_size",
- default=20,
- type=int,
- help="The total number of n-best predictions to generate in the nbest_predictions.json output file.",
-)
-parser.add_argument(
- "--max_answer_length",
- default=30,
- type=int,
- help=(
- "The maximum length of an answer that can be generated. This is needed because the start "
- "and end predictions are not conditioned on one another."
- ),
-)
-
-parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
-
-parser.add_argument(
- "--dataset_name",
- type=str,
- default=None,
- required=True,
- help="The name of the dataset to use (via the datasets library).",
-)
-parser.add_argument(
- "--dataset_config_name",
- type=str,
- default=None,
- help="The configuration name of the dataset to use (via the datasets library).",
-)
-parser.add_argument(
- "--preprocessing_num_workers", type=int, default=4, help="A csv or a json file containing the training data."
-)
-parser.add_argument("--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets")
-parser.add_argument(
- "--fp16",
- action="store_true",
- help="Whether to use 16-bit (mixed) precision instead of 32-bit",
-)
-parser.add_argument(
- "--int8",
- action="store_true",
- help="Whether to use INT8",
-)
-
-args = parser.parse_args()
-
-if args.tokenizer_name:
- tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name, use_fast=True)
-else:
- raise ValueError(
- "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
- "You can do it from another script, save it, and load it from here, using --tokenizer_name."
- )
-
-logger.info("Training/evaluation parameters %s", args)
-
-args.eval_batch_size = args.per_device_eval_batch_size
-
-INPUT_SHAPE = (args.eval_batch_size, args.max_seq_length)
-
-# TRT Engine properties
-STRICT_TYPES = True
-
-engine_name = "temp_engine/bert-fp32.engine"
-if args.fp16:
- engine_name = "temp_engine/bert-fp16.engine"
-if args.int8:
- engine_name = "temp_engine/bert-int8.engine"
-
-# import ONNX file
-if not os.path.exists("temp_engine"):
- os.makedirs("temp_engine")
-
-EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
-with trt.Builder(TRT_LOGGER) as builder, builder.create_network(EXPLICIT_BATCH) as network, trt.OnnxParser(
- network, TRT_LOGGER
-) as parser:
- with open(args.onnx_model_path, "rb") as model:
- if not parser.parse(model.read()):
- for error in range(parser.num_errors):
- print(parser.get_error(error))
-
- # Query input names and shapes from parsed TensorRT network
- network_inputs = [network.get_input(i) for i in range(network.num_inputs)]
- input_names = [_input.name for _input in network_inputs] # ex: ["actual_input1"]
-
- with builder.create_builder_config() as config:
- config.max_workspace_size = 1 << 50
- if STRICT_TYPES:
- config.set_flag(trt.BuilderFlag.STRICT_TYPES)
- if args.fp16:
- config.set_flag(trt.BuilderFlag.FP16)
- if args.int8:
- config.set_flag(trt.BuilderFlag.INT8)
- profile = builder.create_optimization_profile()
- config.add_optimization_profile(profile)
- for i in range(len(input_names)):
- profile.set_shape(input_names[i], INPUT_SHAPE, INPUT_SHAPE, INPUT_SHAPE)
- engine = builder.build_engine(network, config)
-
- # serialize_engine and store in file (can be directly loaded and deserialized):
- with open(engine_name, "wb") as f:
- f.write(engine.serialize())
-
-
-# run inference with TRT
-def model_infer(inputs, context, d_inputs, h_output0, h_output1, d_output0, d_output1, stream):
- input_ids = np.asarray(inputs["input_ids"], dtype=np.int32)
- attention_mask = np.asarray(inputs["attention_mask"], dtype=np.int32)
- token_type_ids = np.asarray(inputs["token_type_ids"], dtype=np.int32)
-
- # Copy inputs
- cuda.memcpy_htod_async(d_inputs[0], input_ids.ravel(), stream)
- cuda.memcpy_htod_async(d_inputs[1], attention_mask.ravel(), stream)
- cuda.memcpy_htod_async(d_inputs[2], token_type_ids.ravel(), stream)
- # start time
- start_time = time.time()
- # Run inference
- context.execute_async(
- bindings=[int(d_inp) for d_inp in d_inputs] + [int(d_output0), int(d_output1)], stream_handle=stream.handle
- )
- # Transfer predictions back from GPU
- cuda.memcpy_dtoh_async(h_output0, d_output0, stream)
- cuda.memcpy_dtoh_async(h_output1, d_output1, stream)
- # Synchronize the stream and take time
- stream.synchronize()
- # end time
- end_time = time.time()
- infer_time = end_time - start_time
- outputs = (h_output0, h_output1)
- # print(outputs)
- return outputs, infer_time
-
-
-# Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
-accelerator = Accelerator()
-# Make one log on every process with the configuration for debugging.
-logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- level=logging.INFO,
-)
-
-# Setup logging, we only want one process per machine to log things on the screen.
-# accelerator.is_local_main_process is only True for one process per machine.
-logger.setLevel(logging.INFO if accelerator.is_local_main_process else logging.ERROR)
-if accelerator.is_local_main_process:
- datasets.utils.logging.set_verbosity_warning()
- transformers.utils.logging.set_verbosity_info()
-else:
- datasets.utils.logging.set_verbosity_error()
- transformers.utils.logging.set_verbosity_error()
-
-# If passed along, set the training seed now.
-if args.seed is not None:
- set_seed(args.seed)
-
-# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
-# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
-# (the dataset will be downloaded automatically from the datasets Hub).
-#
-# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
-# 'text' is found. You can easily tweak this behavior (see below).
-if args.dataset_name is not None:
- # Downloading and loading a dataset from the hub.
- raw_datasets = load_dataset(args.dataset_name, args.dataset_config_name)
-else:
- raise ValueError("Evaluation requires a dataset name")
-# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
-# https://huggingface.co/docs/datasets/loading_datasets.
-
-# Preprocessing the datasets.
-# Preprocessing is slightly different for training and evaluation.
-
-column_names = raw_datasets["validation"].column_names
-
-question_column_name = "question" if "question" in column_names else column_names[0]
-context_column_name = "context" if "context" in column_names else column_names[1]
-answer_column_name = "answers" if "answers" in column_names else column_names[2]
-
-# Padding side determines if we do (question|context) or (context|question).
-pad_on_right = tokenizer.padding_side == "right"
-
-if args.max_seq_length > tokenizer.model_max_length:
- logger.warning(
- f"The max_seq_length passed ({args.max_seq_length}) is larger than the maximum length for the "
- f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
- )
-
-max_seq_length = min(args.max_seq_length, tokenizer.model_max_length)
-
-
-# Validation preprocessing
-def prepare_validation_features(examples):
- # Some of the questions have lots of whitespace on the left, which is not useful and will make the
- # truncation of the context fail (the tokenized question will take a lots of space). So we remove that
- # left whitespace
- examples[question_column_name] = [q.lstrip() for q in examples[question_column_name]]
-
- # Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
- # in one example possible giving several features when a context is long, each of those features having a
- # context that overlaps a bit the context of the previous feature.
- tokenized_examples = tokenizer(
- examples[question_column_name if pad_on_right else context_column_name],
- examples[context_column_name if pad_on_right else question_column_name],
- truncation="only_second" if pad_on_right else "only_first",
- max_length=max_seq_length,
- stride=args.doc_stride,
- return_overflowing_tokens=True,
- return_offsets_mapping=True,
- padding="max_length",
- )
-
- # Since one example might give us several features if it has a long context, we need a map from a feature to
- # its corresponding example. This key gives us just that.
- sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
-
- # For evaluation, we will need to convert our predictions to substrings of the context, so we keep the
- # corresponding example_id and we will store the offset mappings.
- tokenized_examples["example_id"] = []
-
- for i in range(len(tokenized_examples["input_ids"])):
- # Grab the sequence corresponding to that example (to know what is the context and what is the question).
- sequence_ids = tokenized_examples.sequence_ids(i)
- context_index = 1 if pad_on_right else 0
-
- # One example can give several spans, this is the index of the example containing this span of text.
- sample_index = sample_mapping[i]
- tokenized_examples["example_id"].append(examples["id"][sample_index])
-
- # Set to None the offset_mapping that are not part of the context so it's easy to determine if a token
- # position is part of the context or not.
- tokenized_examples["offset_mapping"][i] = [
- (o if sequence_ids[k] == context_index else None)
- for k, o in enumerate(tokenized_examples["offset_mapping"][i])
- ]
-
- return tokenized_examples
-
-
-eval_examples = raw_datasets["validation"]
-# Validation Feature Creation
-eval_dataset = eval_examples.map(
- prepare_validation_features,
- batched=True,
- num_proc=args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not args.overwrite_cache,
- desc="Running tokenizer on validation dataset",
-)
-
-data_collator = default_data_collator
-
-eval_dataset_for_model = eval_dataset.remove_columns(["example_id", "offset_mapping"])
-eval_dataloader = DataLoader(
- eval_dataset_for_model, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size
-)
-
-
-# Post-processing:
-def post_processing_function(examples, features, predictions, stage="eval"):
- # Post-processing: we match the start logits and end logits to answers in the original context.
- predictions = postprocess_qa_predictions(
- examples=examples,
- features=features,
- predictions=predictions,
- version_2_with_negative=args.version_2_with_negative,
- n_best_size=args.n_best_size,
- max_answer_length=args.max_answer_length,
- null_score_diff_threshold=args.null_score_diff_threshold,
- output_dir=args.output_dir,
- prefix=stage,
- )
- # Format the result to the format the metric expects.
- if args.version_2_with_negative:
- formatted_predictions = [
- {"id": k, "prediction_text": v, "no_answer_probability": 0.0} for k, v in predictions.items()
- ]
- else:
- formatted_predictions = [{"id": k, "prediction_text": v} for k, v in predictions.items()]
-
- references = [{"id": ex["id"], "answers": ex[answer_column_name]} for ex in examples]
- return EvalPrediction(predictions=formatted_predictions, label_ids=references)
-
-
-metric = load_metric("squad_v2" if args.version_2_with_negative else "squad")
-
-# Evaluation!
-logger.info("Loading ONNX model %s for evaluation", args.onnx_model_path)
-with open(engine_name, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime, runtime.deserialize_cuda_engine(
- f.read()
-) as engine, engine.create_execution_context() as context:
- # setup for TRT inferrence
- for i in range(len(input_names)):
- context.set_binding_shape(i, INPUT_SHAPE)
- assert context.all_binding_shapes_specified
-
- def binding_nbytes(binding):
- return trt.volume(engine.get_binding_shape(binding)) * engine.get_binding_dtype(binding).itemsize
-
- # Allocate device memory for inputs and outputs.
- d_inputs = [cuda.mem_alloc(binding_nbytes(binding)) for binding in engine if engine.binding_is_input(binding)]
-
- # Allocate output buffer
- h_output0 = cuda.pagelocked_empty(tuple(context.get_binding_shape(3)), dtype=np.float32)
- h_output1 = cuda.pagelocked_empty(tuple(context.get_binding_shape(4)), dtype=np.float32)
- d_output0 = cuda.mem_alloc(h_output0.nbytes)
- d_output1 = cuda.mem_alloc(h_output1.nbytes)
-
- # Create a stream in which to copy inputs/outputs and run inference.
- stream = cuda.Stream()
-
- # Evaluation
- logger.info("***** Running Evaluation *****")
- logger.info(f" Num examples = {len(eval_dataset)}")
- logger.info(f" Batch size = {args.per_device_eval_batch_size}")
-
- total_time = 0.0
- niter = 0
- start_time = timeit.default_timer()
-
- all_preds = None
- for step, batch in enumerate(eval_dataloader):
- outputs, infer_time = model_infer(batch, context, d_inputs, h_output0, h_output1, d_output0, d_output1, stream)
- total_time += infer_time
- niter += 1
-
- start_logits, end_logits = outputs
- start_logits = torch.tensor(start_logits)
- end_logits = torch.tensor(end_logits)
-
- # necessary to pad predictions and labels for being gathered
- start_logits = accelerator.pad_across_processes(start_logits, dim=1, pad_index=-100)
- end_logits = accelerator.pad_across_processes(end_logits, dim=1, pad_index=-100)
-
- logits = (accelerator.gather(start_logits).cpu().numpy(), accelerator.gather(end_logits).cpu().numpy())
- all_preds = logits if all_preds is None else nested_concat(all_preds, logits, padding_index=-100)
-
- if all_preds is not None:
- all_preds = nested_truncate(all_preds, len(eval_dataset))
-
- evalTime = timeit.default_timer() - start_time
- logger.info(" Evaluation done in total %f secs (%f sec per example)", evalTime, evalTime / len(eval_dataset))
- # Inference time from TRT
- logger.info("Average Inference Time = {:.3f} ms".format(total_time * 1000 / niter))
- logger.info("Total Inference Time = {:.3f} ms".format(total_time * 1000))
- logger.info("Total Number of Inference = %d", niter)
-
-prediction = post_processing_function(eval_examples, eval_dataset, all_preds)
-eval_metric = metric.compute(predictions=prediction.predictions, references=prediction.label_ids)
-logger.info(f"Evaluation metrics: {eval_metric}")
diff --git a/examples/research_projects/quantization-qdqbert/ort-infer-benchmark.py b/examples/research_projects/quantization-qdqbert/ort-infer-benchmark.py
deleted file mode 100644
index bb0436c1258..00000000000
--- a/examples/research_projects/quantization-qdqbert/ort-infer-benchmark.py
+++ /dev/null
@@ -1,50 +0,0 @@
-import os
-import time
-
-import numpy as np
-import onnxruntime as ort
-
-
-os.environ["ORT_TENSORRT_INT8_ENABLE"] = "1"
-os.environ["ORT_TENSORRT_INT8_USE_NATIVE_CALIBRATION_TABLE"] = "0"
-os.environ["ORT_TENSORRT_ENGINE_CACHE_ENABLE"] = "1"
-
-sess_opt = ort.SessionOptions()
-sess_opt.graph_optimization_level = ort.GraphOptimizationLevel.ORT_DISABLE_ALL
-print("Create inference session...")
-execution_provider = ["TensorrtExecutionProvider", "CUDAExecutionProvider"]
-sess = ort.InferenceSession("model.onnx", sess_options=sess_opt, providers=execution_provider)
-run_opt = ort.RunOptions()
-
-sequence = 128
-batch = 1
-input_ids = np.ones((batch, sequence), dtype=np.int64)
-attention_mask = np.ones((batch, sequence), dtype=np.int64)
-token_type_ids = np.ones((batch, sequence), dtype=np.int64)
-
-print("Warm up phase...")
-sess.run(
- None,
- {
- sess.get_inputs()[0].name: input_ids,
- sess.get_inputs()[1].name: attention_mask,
- sess.get_inputs()[2].name: token_type_ids,
- },
- run_options=run_opt,
-)
-
-print("Start inference...")
-start_time = time.time()
-max_iters = 2000
-predict = {}
-for iter in range(max_iters):
- predict = sess.run(
- None,
- {
- sess.get_inputs()[0].name: input_ids,
- sess.get_inputs()[1].name: attention_mask,
- sess.get_inputs()[2].name: token_type_ids,
- },
- run_options=run_opt,
- )
-print("Average Inference Time = {:.3f} ms".format((time.time() - start_time) * 1000 / max_iters))
diff --git a/examples/research_projects/quantization-qdqbert/quant_trainer.py b/examples/research_projects/quantization-qdqbert/quant_trainer.py
deleted file mode 100755
index 132aa284905..00000000000
--- a/examples/research_projects/quantization-qdqbert/quant_trainer.py
+++ /dev/null
@@ -1,305 +0,0 @@
-# coding=utf-8
-# Copyright 2021 NVIDIA Corporation. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Helper functions for training models with pytorch-quantization"""
-
-import logging
-import re
-
-import pytorch_quantization
-import pytorch_quantization.nn as quant_nn
-import torch
-from pytorch_quantization import calib
-from pytorch_quantization.tensor_quant import QuantDescriptor
-
-
-logger = logging.getLogger(__name__)
-
-name_width = 50 # max width of layer names
-qname_width = 70 # max width of quantizer names
-
-# ========================================== Quant Trainer API ==========================================
-
-
-def add_arguments(parser):
- """Add arguments to parser for functions defined in quant_trainer."""
-
- group = parser.add_argument_group("quant_trainer arguments")
- group.add_argument("--wprec", type=int, default=8, help="weight precision")
- group.add_argument("--aprec", type=int, default=8, help="activation precision")
- group.add_argument("--quant-per-tensor", action="store_true", help="per tensor weight scaling")
- group.add_argument("--quant-disable", action="store_true", help="disable all quantizers")
- group.add_argument("--quant-disable-embeddings", action="store_true", help="disable all embeddings quantizers")
- group.add_argument("--quant-disable-keyword", type=str, nargs="+", help="disable quantizers by keyword")
- group.add_argument("--quant-disable-layer-module", type=str, help="disable quantizers by keyword under layer.")
- group.add_argument("--quant-enable-layer-module", type=str, help="enable quantizers by keyword under layer")
- group.add_argument("--calibrator", default="max", help="which quantization range calibrator to use")
- group.add_argument("--percentile", default=None, type=float, help="percentile for PercentileCalibrator")
- group.add_argument("--fuse-qkv", action="store_true", help="use the same scale factor for qkv")
- group.add_argument("--clip-gelu", metavar="N", type=float, help="clip gelu output maximum value to N")
- group.add_argument(
- "--recalibrate-weights",
- action="store_true",
- help=(
- "recalibrate weight amaxes by taking the max of the weights."
- " amaxes will be computed with the current quantization granularity (axis)."
- ),
- )
-
-
-def set_default_quantizers(args):
- """Set default quantizers before creating the model."""
-
- if args.calibrator == "max":
- calib_method = "max"
- elif args.calibrator == "percentile":
- if args.percentile is None:
- raise ValueError("Specify --percentile when using percentile calibrator")
- calib_method = "histogram"
- elif args.calibrator == "mse":
- calib_method = "histogram"
- else:
- raise ValueError(f"Invalid calibrator {args.calibrator}")
-
- input_desc = QuantDescriptor(num_bits=args.aprec, calib_method=calib_method)
- weight_desc = QuantDescriptor(num_bits=args.wprec, axis=(None if args.quant_per_tensor else (0,)))
- quant_nn.QuantLinear.set_default_quant_desc_input(input_desc)
- quant_nn.QuantLinear.set_default_quant_desc_weight(weight_desc)
-
-
-def configure_model(model, args, calib=False, eval=False):
- """Function called before the training loop."""
-
- logger.info("Configuring Model for Quantization")
- logger.info(f"using quantization package {pytorch_quantization.__file__}")
-
- if not calib:
- if args.quant_disable_embeddings:
- set_quantizer_by_name(model, ["embeddings"], which="weight", _disabled=True)
-
- if args.quant_disable:
- set_quantizer_by_name(model, [""], _disabled=True)
-
- if args.quant_disable_keyword:
- set_quantizer_by_name(model, args.quant_disable_keyword, _disabled=True)
-
- if args.quant_disable_layer_module:
- set_quantizer_by_name(model, [r"layer.\d+." + args.quant_disable_layer_module], _disabled=True)
-
- if args.quant_enable_layer_module:
- set_quantizer_by_name(model, [r"layer.\d+." + args.quant_enable_layer_module], _disabled=False)
-
- if args.recalibrate_weights:
- recalibrate_weights(model)
-
- if args.fuse_qkv:
- fuse_qkv(model, args)
-
- if args.clip_gelu:
- clip_gelu(model, args.clip_gelu)
-
- # if args.local_rank in [-1, 0] and not calib:
- print_quant_summary(model)
-
-
-def enable_calibration(model):
- """Enable calibration of all *_input_quantizer modules in model."""
-
- logger.info("Enabling Calibration")
- for name, module in model.named_modules():
- if name.endswith("_quantizer"):
- if module._calibrator is not None:
- module.disable_quant()
- module.enable_calib()
- else:
- module.disable()
- logger.info(f"{name:80}: {module}")
-
-
-def finish_calibration(model, args):
- """Disable calibration and load amax for all "*_input_quantizer modules in model."""
-
- logger.info("Loading calibrated amax")
- for name, module in model.named_modules():
- if name.endswith("_quantizer"):
- if module._calibrator is not None:
- if isinstance(module._calibrator, calib.MaxCalibrator):
- module.load_calib_amax()
- else:
- module.load_calib_amax("percentile", percentile=args.percentile)
- module.enable_quant()
- module.disable_calib()
- else:
- module.enable()
- model.cuda()
- print_quant_summary(model)
-
-
-# ========================================== Helper Function ==========================================
-
-
-def fuse_qkv(model, args):
- """Adjust quantization ranges to match an implementation where the QKV projections are implemented with a single GEMM.
- Force the weight and output scale factors to match by taking the max of (Q,K,V).
- """
-
- def fuse3(qq, qk, qv):
- for mod in [qq, qk, qv]:
- if not hasattr(mod, "_amax"):
- print(" WARNING: NO AMAX BUFFER")
- return
- q = qq._amax.detach().item()
- k = qk._amax.detach().item()
- v = qv._amax.detach().item()
-
- amax = max(q, k, v)
- qq._amax.fill_(amax)
- qk._amax.fill_(amax)
- qv._amax.fill_(amax)
- logger.info(f" q={q:5.2f} k={k:5.2f} v={v:5.2f} -> {amax:5.2f}")
-
- for name, mod in model.named_modules():
- if name.endswith(".attention.self"):
- logger.info(f"FUSE_QKV: {name:{name_width}}")
- fuse3(mod.matmul_q_input_quantizer, mod.matmul_k_input_quantizer, mod.matmul_v_input_quantizer)
- if args.quant_per_tensor:
- fuse3(mod.query._weight_quantizer, mod.key._weight_quantizer, mod.value._weight_quantizer)
-
-
-def clip_gelu(model, maxval):
- """Clip activations generated by GELU to maxval when quantized.
- Implemented by adjusting the amax of the following input_quantizer.
- """
-
- for name, mod in model.named_modules():
- if name.endswith(".output.dense") and not name.endswith("attention.output.dense"):
- amax_init = mod._input_quantizer._amax.data.detach().item()
- mod._input_quantizer._amax.data.detach().clamp_(max=maxval)
- amax = mod._input_quantizer._amax.data.detach().item()
- logger.info(f"CLIP_GELU: {name:{name_width}} amax: {amax_init:5.2f} -> {amax:5.2f}")
-
-
-def expand_amax(model):
- """Expand per-tensor amax to be per channel, where each channel is assigned the per-tensor amax."""
-
- for name, mod in model.named_modules():
- if hasattr(mod, "_weight_quantizer") and mod._weight_quantizer.axis is not None:
- k = mod.weight.shape[0]
- amax = mod._weight_quantizer._amax.detach()
- mod._weight_quantizer._amax = torch.ones(k, dtype=amax.dtype, device=amax.device) * amax
- print(f"expanding {name} {amax} -> {mod._weight_quantizer._amax}")
-
-
-def recalibrate_weights(model):
- """Performs max calibration on the weights and updates amax."""
-
- for name, mod in model.named_modules():
- if hasattr(mod, "_weight_quantizer"):
- if not hasattr(mod.weight_quantizer, "_amax"):
- print("RECALIB: {name:{name_width}} WARNING: NO AMAX BUFFER")
- continue
-
- # determine which axes to reduce across
- # e.g. a 4D tensor quantized per axis 0 should reduce over (1,2,3)
- axis_set = set() if mod._weight_quantizer.axis is None else set(mod._weight_quantizer.axis)
- reduce_axis = set(range(len(mod.weight.size()))) - axis_set
- amax = pytorch_quantization.utils.reduce_amax(mod.weight, axis=reduce_axis, keepdims=True).detach()
- logger.info(f"RECALIB: {name:{name_width}} {mod._weight_quantizer._amax.flatten()} -> {amax.flatten()}")
- mod._weight_quantizer._amax = amax
-
-
-def print_model_summary(model, name_width=25, line_width=180, ignore=None):
- """Print model quantization configuration."""
-
- if ignore is None:
- ignore = []
- elif not isinstance(ignore, list):
- ignore = [ignore]
-
- name_width = 0
- for name, mod in model.named_modules():
- if not hasattr(mod, "weight"):
- continue
- name_width = max(name_width, len(name))
-
- for name, mod in model.named_modules():
- input_q = getattr(mod, "_input_quantizer", None)
- weight_q = getattr(mod, "_weight_quantizer", None)
- if not hasattr(mod, "weight"):
- continue
- if type(mod) in ignore:
- continue
- if [True for s in ignore if isinstance(s, str) and s in name]:
- continue
- act_str = f"Act:{input_q.extra_repr()}"
- wgt_str = f"Wgt:{weight_q.extra_repr()}"
- s = f"{name:{name_width}} {act_str} {wgt_str}"
- if len(s) <= line_width:
- logger.info(s)
- else:
- logger.info(f"{name:{name_width}} {act_str}")
- logger.info(f'{" ":{name_width}} {wgt_str}')
-
-
-def print_quant_summary(model):
- """Print summary of all quantizer modules in the model."""
-
- count = 0
- for name, mod in model.named_modules():
- if isinstance(mod, pytorch_quantization.nn.TensorQuantizer):
- print(f"{name:80} {mod}")
- count += 1
- print(f"{count} TensorQuantizers found in model")
-
-
-def set_quantizer(name, mod, quantizer, k, v):
- """Set attributes for mod.quantizer."""
-
- quantizer_mod = getattr(mod, quantizer, None)
- if quantizer_mod is not None:
- assert hasattr(quantizer_mod, k)
- setattr(quantizer_mod, k, v)
- else:
- logger.warning(f"{name} has no {quantizer}")
-
-
-def set_quantizers(name, mod, which="both", **kwargs):
- """Set quantizer attributes for mod."""
-
- s = f"Warning: changing {which} quantizers of {name:{qname_width}}"
- for k, v in kwargs.items():
- s += f" {k}={v}"
- if which in ["input", "both"]:
- set_quantizer(name, mod, "_input_quantizer", k, v)
- if which in ["weight", "both"]:
- set_quantizer(name, mod, "_weight_quantizer", k, v)
- logger.info(s)
-
-
-def set_quantizer_by_name(model, names, **kwargs):
- """Set quantizer attributes for layers where name contains a substring in names."""
-
- for name, mod in model.named_modules():
- if hasattr(mod, "_input_quantizer") or hasattr(mod, "_weight_quantizer"):
- for n in names:
- if re.search(n, name):
- set_quantizers(name, mod, **kwargs)
- elif name.endswith("_quantizer"):
- for n in names:
- if re.search(n, name):
- s = f"Warning: changing {name:{name_width}}"
- for k, v in kwargs.items():
- s += f" {k}={v}"
- setattr(mod, k, v)
- logger.info(s)
diff --git a/examples/research_projects/quantization-qdqbert/run_quant_qa.py b/examples/research_projects/quantization-qdqbert/run_quant_qa.py
deleted file mode 100755
index 770a36525b5..00000000000
--- a/examples/research_projects/quantization-qdqbert/run_quant_qa.py
+++ /dev/null
@@ -1,688 +0,0 @@
-#!/usr/bin/env python
-# coding=utf-8
-# Copyright 2020 The HuggingFace Team All rights reserved.
-# Copyright 2021 NVIDIA Corporation. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-Fine-tuning the library models for question answering.
-"""
-# You can also adapt this script on your own question answering task. Pointers for this are left as comments.
-
-import logging
-import os
-import sys
-from dataclasses import dataclass, field
-from typing import Optional
-
-import datasets
-import quant_trainer
-from datasets import load_dataset, load_metric
-from trainer_quant_qa import QuestionAnsweringTrainer
-from utils_qa import postprocess_qa_predictions
-
-import transformers
-from transformers import (
- AutoTokenizer,
- DataCollatorWithPadding,
- EvalPrediction,
- HfArgumentParser,
- PreTrainedTokenizerFast,
- QDQBertConfig,
- QDQBertForQuestionAnswering,
- TrainingArguments,
- default_data_collator,
- set_seed,
-)
-from transformers.trainer_utils import SchedulerType, get_last_checkpoint
-from transformers.utils import check_min_version
-from transformers.utils.versions import require_version
-
-
-# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.9.0")
-
-require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/question-answering/requirements.txt")
-
-logger = logging.getLogger(__name__)
-
-
-@dataclass
-class ModelArguments:
- """
- Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
- """
-
- model_name_or_path: str = field(
- metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
- )
- config_name: Optional[str] = field(
- default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
- )
- tokenizer_name: Optional[str] = field(
- default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
- )
- cache_dir: Optional[str] = field(
- default=None,
- metadata={"help": "Path to directory to store the pretrained models downloaded from huggingface.co"},
- )
- model_revision: str = field(
- default="main",
- metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
- )
- use_auth_token: bool = field(
- default=False,
- metadata={
- "help": (
- "Will use the token generated when running `huggingface-cli login` (necessary to use this script "
- "with private models)."
- )
- },
- )
- do_calib: bool = field(default=False, metadata={"help": "Whether to run calibration of quantization ranges."})
- num_calib_batch: int = field(
- default=4,
- metadata={"help": "Number of batches for calibration. 0 will disable calibration "},
- )
- save_onnx: bool = field(default=False, metadata={"help": "Whether to save model to onnx."})
-
-
-@dataclass
-class DataTrainingArguments:
- """
- Arguments pertaining to what data we are going to input our model for training and eval.
- """
-
- dataset_name: Optional[str] = field(
- default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
- )
- dataset_config_name: Optional[str] = field(
- default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
- )
- train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
- validation_file: Optional[str] = field(
- default=None,
- metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
- )
- test_file: Optional[str] = field(
- default=None,
- metadata={"help": "An optional input test data file to evaluate the perplexity on (a text file)."},
- )
- overwrite_cache: bool = field(
- default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
- )
- preprocessing_num_workers: Optional[int] = field(
- default=None,
- metadata={"help": "The number of processes to use for the preprocessing."},
- )
- max_seq_length: int = field(
- default=384,
- metadata={
- "help": (
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- )
- },
- )
- pad_to_max_length: bool = field(
- default=True,
- metadata={
- "help": (
- "Whether to pad all samples to `max_seq_length`. If False, will pad the samples dynamically when"
- " batching to the maximum length in the batch (which can be faster on GPU but will be slower on TPU)."
- )
- },
- )
- max_train_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of training examples to this "
- "value if set."
- )
- },
- )
- max_eval_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
- "value if set."
- )
- },
- )
- max_predict_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of prediction examples to this "
- "value if set."
- )
- },
- )
- version_2_with_negative: bool = field(
- default=False, metadata={"help": "If true, some of the examples do not have an answer."}
- )
- null_score_diff_threshold: float = field(
- default=0.0,
- metadata={
- "help": (
- "The threshold used to select the null answer: if the best answer has a score that is less than "
- "the score of the null answer minus this threshold, the null answer is selected for this example. "
- "Only useful when `version_2_with_negative=True`."
- )
- },
- )
- doc_stride: int = field(
- default=128,
- metadata={"help": "When splitting up a long document into chunks, how much stride to take between chunks."},
- )
- n_best_size: int = field(
- default=20,
- metadata={"help": "The total number of n-best predictions to generate when looking for an answer."},
- )
- max_answer_length: int = field(
- default=30,
- metadata={
- "help": (
- "The maximum length of an answer that can be generated. This is needed because the start "
- "and end predictions are not conditioned on one another."
- )
- },
- )
-
- def __post_init__(self):
- if (
- self.dataset_name is None
- and self.train_file is None
- and self.validation_file is None
- and self.test_file is None
- ):
- raise ValueError("Need either a dataset name or a training/validation file/test_file.")
- else:
- if self.train_file is not None:
- extension = self.train_file.split(".")[-1]
- assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
- if self.validation_file is not None:
- extension = self.validation_file.split(".")[-1]
- assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
- if self.test_file is not None:
- extension = self.test_file.split(".")[-1]
- assert extension in ["csv", "json"], "`test_file` should be a csv or a json file."
-
-
-def main():
- # See all possible arguments in src/transformers/training_args.py
- # or by passing the --help flag to this script.
- # We now keep distinct sets of args, for a cleaner separation of concerns.
-
- parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
- # quant_trainer arguments
- quant_trainer.add_arguments(parser)
-
- # if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
- # # If we pass only one argument to the script and it's the path to a json file,
- # # let's parse it to get our arguments.
- # model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
- # else:
-
- model_args, data_args, training_args, quant_trainer_args = parser.parse_args_into_dataclasses()
-
- # setup QAT training args for scheduler (default to use cosine annealing learning rate schedule)
- training_args.lr_scheduler_type = SchedulerType.COSINE
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- handlers=[logging.StreamHandler(sys.stdout)],
- )
-
- log_level = training_args.get_process_log_level()
- logger.setLevel(log_level)
- datasets.utils.logging.set_verbosity(log_level)
- transformers.utils.logging.set_verbosity(log_level)
- transformers.utils.logging.enable_default_handler()
- transformers.utils.logging.enable_explicit_format()
-
- # Log on each process the small summary:
- logger.warning(
- f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
- + f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
- )
- logger.info(f"Training/evaluation parameters {training_args}")
-
- # Detecting last checkpoint.
- last_checkpoint = None
- if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
- last_checkpoint = get_last_checkpoint(training_args.output_dir)
- if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
- raise ValueError(
- f"Output directory ({training_args.output_dir}) already exists and is not empty. "
- "Use --overwrite_output_dir to overcome."
- )
- elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
- logger.info(
- f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
- "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
- )
-
- # Set seed before initializing model.
- set_seed(training_args.seed)
-
- # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
- # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
- # (the dataset will be downloaded automatically from the datasets Hub).
- #
- # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
- # 'text' is found. You can easily tweak this behavior (see below).
- #
- # In distributed training, the load_dataset function guarantee that only one local process can concurrently
- # download the dataset.
- if data_args.dataset_name is not None:
- # Downloading and loading a dataset from the hub.
- raw_datasets = load_dataset(
- data_args.dataset_name, data_args.dataset_config_name, cache_dir=model_args.cache_dir
- )
- else:
- data_files = {}
- if data_args.train_file is not None:
- data_files["train"] = data_args.train_file
- extension = data_args.train_file.split(".")[-1]
-
- if data_args.validation_file is not None:
- data_files["validation"] = data_args.validation_file
- extension = data_args.validation_file.split(".")[-1]
- if data_args.test_file is not None:
- data_files["test"] = data_args.test_file
- extension = data_args.test_file.split(".")[-1]
- raw_datasets = load_dataset(extension, data_files=data_files, field="data", cache_dir=model_args.cache_dir)
- # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
- # https://huggingface.co/docs/datasets/loading_datasets.
-
- # set default quantization parameters before building model
- quant_trainer.set_default_quantizers(quant_trainer_args)
-
- # Load pretrained model and tokenizer
- #
- # Distributed training:
- # The .from_pretrained methods guarantee that only one local process can concurrently
- # download model & vocab.
- config = QDQBertConfig.from_pretrained(
- model_args.config_name if model_args.config_name else model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- )
- tokenizer = AutoTokenizer.from_pretrained(
- model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- use_fast=True,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- )
- model = QDQBertForQuestionAnswering.from_pretrained(
- model_args.model_name_or_path,
- from_tf=bool(".ckpt" in model_args.model_name_or_path),
- config=config,
- cache_dir=model_args.cache_dir,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- )
-
- # Tokenizer check: this script requires a fast tokenizer.
- if not isinstance(tokenizer, PreTrainedTokenizerFast):
- raise ValueError(
- "This example script only works for models that have a fast tokenizer. Checkout the big table of models at"
- " https://huggingface.co/transformers/index.html#supported-frameworks to find the model types that meet"
- " this requirement"
- )
-
- # Preprocessing the datasets.
- # Preprocessing is slightly different for training and evaluation.
- if training_args.do_train or model_args.do_calib:
- column_names = raw_datasets["train"].column_names
- elif training_args.do_eval or model_args.save_onnx:
- column_names = raw_datasets["validation"].column_names
- else:
- column_names = raw_datasets["test"].column_names
- question_column_name = "question" if "question" in column_names else column_names[0]
- context_column_name = "context" if "context" in column_names else column_names[1]
- answer_column_name = "answers" if "answers" in column_names else column_names[2]
-
- # Padding side determines if we do (question|context) or (context|question).
- pad_on_right = tokenizer.padding_side == "right"
-
- if data_args.max_seq_length > tokenizer.model_max_length:
- logger.warning(
- f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the "
- f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
- )
- max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
-
- # Training preprocessing
- def prepare_train_features(examples):
- # Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
- # in one example possible giving several features when a context is long, each of those features having a
- # context that overlaps a bit the context of the previous feature.
- tokenized_examples = tokenizer(
- examples[question_column_name if pad_on_right else context_column_name],
- examples[context_column_name if pad_on_right else question_column_name],
- truncation="only_second" if pad_on_right else "only_first",
- max_length=max_seq_length,
- stride=data_args.doc_stride,
- return_overflowing_tokens=True,
- return_offsets_mapping=True,
- padding="max_length" if data_args.pad_to_max_length else False,
- )
-
- # Since one example might give us several features if it has a long context, we need a map from a feature to
- # its corresponding example. This key gives us just that.
- sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
- # The offset mappings will give us a map from token to character position in the original context. This will
- # help us compute the start_positions and end_positions.
- offset_mapping = tokenized_examples.pop("offset_mapping")
-
- # Let's label those examples!
- tokenized_examples["start_positions"] = []
- tokenized_examples["end_positions"] = []
-
- for i, offsets in enumerate(offset_mapping):
- # We will label impossible answers with the index of the CLS token.
- input_ids = tokenized_examples["input_ids"][i]
- cls_index = input_ids.index(tokenizer.cls_token_id)
-
- # Grab the sequence corresponding to that example (to know what is the context and what is the question).
- sequence_ids = tokenized_examples.sequence_ids(i)
-
- # One example can give several spans, this is the index of the example containing this span of text.
- sample_index = sample_mapping[i]
- answers = examples[answer_column_name][sample_index]
- # If no answers are given, set the cls_index as answer.
- if len(answers["answer_start"]) == 0:
- tokenized_examples["start_positions"].append(cls_index)
- tokenized_examples["end_positions"].append(cls_index)
- else:
- # Start/end character index of the answer in the text.
- start_char = answers["answer_start"][0]
- end_char = start_char + len(answers["text"][0])
-
- # Start token index of the current span in the text.
- token_start_index = 0
- while sequence_ids[token_start_index] != (1 if pad_on_right else 0):
- token_start_index += 1
-
- # End token index of the current span in the text.
- token_end_index = len(input_ids) - 1
- while sequence_ids[token_end_index] != (1 if pad_on_right else 0):
- token_end_index -= 1
-
- # Detect if the answer is out of the span (in which case this feature is labeled with the CLS index).
- if not (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char):
- tokenized_examples["start_positions"].append(cls_index)
- tokenized_examples["end_positions"].append(cls_index)
- else:
- # Otherwise move the token_start_index and token_end_index to the two ends of the answer.
- # Note: we could go after the last offset if the answer is the last word (edge case).
- while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char:
- token_start_index += 1
- tokenized_examples["start_positions"].append(token_start_index - 1)
- while offsets[token_end_index][1] >= end_char:
- token_end_index -= 1
- tokenized_examples["end_positions"].append(token_end_index + 1)
-
- return tokenized_examples
-
- if training_args.do_train or model_args.do_calib:
- if "train" not in raw_datasets:
- raise ValueError("--do_train requires a train dataset")
- train_dataset = raw_datasets["train"]
- if data_args.max_train_samples is not None:
- # We will select sample from whole data if argument is specified
- max_train_samples = min(len(train_dataset), data_args.max_train_samples)
- train_dataset = train_dataset.select(range(max_train_samples))
- # Create train feature from dataset
- with training_args.main_process_first(desc="train dataset map pre-processing"):
- train_dataset = train_dataset.map(
- prepare_train_features,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not data_args.overwrite_cache,
- desc="Running tokenizer on train dataset",
- )
- if data_args.max_train_samples is not None:
- # Number of samples might increase during Feature Creation, We select only specified max samples
- max_train_samples = min(len(train_dataset), data_args.max_train_samples)
- train_dataset = train_dataset.select(range(max_train_samples))
-
- # Validation preprocessing
- def prepare_validation_features(examples):
- # Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
- # in one example possible giving several features when a context is long, each of those features having a
- # context that overlaps a bit the context of the previous feature.
- tokenized_examples = tokenizer(
- examples[question_column_name if pad_on_right else context_column_name],
- examples[context_column_name if pad_on_right else question_column_name],
- truncation="only_second" if pad_on_right else "only_first",
- max_length=max_seq_length,
- stride=data_args.doc_stride,
- return_overflowing_tokens=True,
- return_offsets_mapping=True,
- padding="max_length" if data_args.pad_to_max_length else False,
- )
-
- # Since one example might give us several features if it has a long context, we need a map from a feature to
- # its corresponding example. This key gives us just that.
- sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
-
- # For evaluation, we will need to convert our predictions to substrings of the context, so we keep the
- # corresponding example_id and we will store the offset mappings.
- tokenized_examples["example_id"] = []
-
- for i in range(len(tokenized_examples["input_ids"])):
- # Grab the sequence corresponding to that example (to know what is the context and what is the question).
- sequence_ids = tokenized_examples.sequence_ids(i)
- context_index = 1 if pad_on_right else 0
-
- # One example can give several spans, this is the index of the example containing this span of text.
- sample_index = sample_mapping[i]
- tokenized_examples["example_id"].append(examples["id"][sample_index])
-
- # Set to None the offset_mapping that are not part of the context so it's easy to determine if a token
- # position is part of the context or not.
- tokenized_examples["offset_mapping"][i] = [
- (o if sequence_ids[k] == context_index else None)
- for k, o in enumerate(tokenized_examples["offset_mapping"][i])
- ]
-
- return tokenized_examples
-
- if training_args.do_eval or model_args.save_onnx:
- if "validation" not in raw_datasets:
- raise ValueError("--do_eval requires a validation dataset")
- eval_examples = raw_datasets["validation"]
- if data_args.max_eval_samples is not None:
- # We will select sample from whole data
- max_eval_samples = min(len(eval_examples), data_args.max_eval_samples)
- eval_examples = eval_examples.select(range(max_eval_samples))
- # Validation Feature Creation
- with training_args.main_process_first(desc="validation dataset map pre-processing"):
- eval_dataset = eval_examples.map(
- prepare_validation_features,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not data_args.overwrite_cache,
- desc="Running tokenizer on validation dataset",
- )
- if data_args.max_eval_samples is not None:
- # During Feature creation dataset samples might increase, we will select required samples again
- max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
- eval_dataset = eval_dataset.select(range(max_eval_samples))
-
- if training_args.do_predict:
- if "test" not in raw_datasets:
- raise ValueError("--do_predict requires a test dataset")
- predict_examples = raw_datasets["test"]
- if data_args.max_predict_samples is not None:
- # We will select sample from whole data
- predict_examples = predict_examples.select(range(data_args.max_predict_samples))
- # Predict Feature Creation
- with training_args.main_process_first(desc="prediction dataset map pre-processing"):
- predict_dataset = predict_examples.map(
- prepare_validation_features,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not data_args.overwrite_cache,
- desc="Running tokenizer on prediction dataset",
- )
- if data_args.max_predict_samples is not None:
- # During Feature creation dataset samples might increase, we will select required samples again
- max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)
- predict_dataset = predict_dataset.select(range(max_predict_samples))
-
- # Data collator
- # We have already padded to max length if the corresponding flag is True, otherwise we need to pad in the data
- # collator.
- data_collator = (
- default_data_collator
- if data_args.pad_to_max_length
- else DataCollatorWithPadding(tokenizer, pad_to_multiple_of=8 if training_args.fp16 else None)
- )
-
- # Post-processing:
- def post_processing_function(examples, features, predictions, stage="eval"):
- # Post-processing: we match the start logits and end logits to answers in the original context.
- predictions = postprocess_qa_predictions(
- examples=examples,
- features=features,
- predictions=predictions,
- version_2_with_negative=data_args.version_2_with_negative,
- n_best_size=data_args.n_best_size,
- max_answer_length=data_args.max_answer_length,
- null_score_diff_threshold=data_args.null_score_diff_threshold,
- output_dir=training_args.output_dir,
- log_level=log_level,
- prefix=stage,
- )
- # Format the result to the format the metric expects.
- if data_args.version_2_with_negative:
- formatted_predictions = [
- {"id": k, "prediction_text": v, "no_answer_probability": 0.0} for k, v in predictions.items()
- ]
- else:
- formatted_predictions = [{"id": k, "prediction_text": v} for k, v in predictions.items()]
-
- references = [{"id": ex["id"], "answers": ex[answer_column_name]} for ex in examples]
- return EvalPrediction(predictions=formatted_predictions, label_ids=references)
-
- metric = load_metric("squad_v2" if data_args.version_2_with_negative else "squad")
-
- def compute_metrics(p: EvalPrediction):
- return metric.compute(predictions=p.predictions, references=p.label_ids)
-
- # Initialize our Trainer
- trainer = QuestionAnsweringTrainer(
- model=model,
- args=training_args,
- train_dataset=train_dataset if training_args.do_train or model_args.do_calib else None,
- eval_dataset=eval_dataset if training_args.do_eval or model_args.save_onnx else None,
- eval_examples=eval_examples if training_args.do_eval or model_args.save_onnx else None,
- tokenizer=tokenizer,
- data_collator=data_collator,
- post_process_function=post_processing_function,
- compute_metrics=compute_metrics,
- quant_trainer_args=quant_trainer_args,
- )
-
- # Calibration
- if model_args.do_calib:
- logger.info("*** Calibrate ***")
- results = trainer.calibrate()
- trainer.save_model()
-
- # Training
- if training_args.do_train:
- checkpoint = None
- if training_args.resume_from_checkpoint is not None:
- checkpoint = training_args.resume_from_checkpoint
- elif last_checkpoint is not None:
- checkpoint = last_checkpoint
-
- quant_trainer.configure_model(trainer.model, quant_trainer_args)
-
- train_result = trainer.train(resume_from_checkpoint=checkpoint)
- trainer.save_model() # Saves the tokenizer too for easy upload
-
- metrics = train_result.metrics
- max_train_samples = (
- data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
- )
- metrics["train_samples"] = min(max_train_samples, len(train_dataset))
-
- trainer.log_metrics("train", metrics)
- trainer.save_metrics("train", metrics)
- trainer.save_state()
-
- # Evaluation
- if training_args.do_eval:
- logger.info("*** Evaluate ***")
- quant_trainer.configure_model(trainer.model, quant_trainer_args, eval=True)
- metrics = trainer.evaluate()
-
- max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
- metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
-
- trainer.log_metrics("eval", metrics)
- trainer.save_metrics("eval", metrics)
-
- # Prediction
- if training_args.do_predict:
- logger.info("*** Predict ***")
- results = trainer.predict(predict_dataset, predict_examples)
- metrics = results.metrics
-
- max_predict_samples = (
- data_args.max_predict_samples if data_args.max_predict_samples is not None else len(predict_dataset)
- )
- metrics["predict_samples"] = min(max_predict_samples, len(predict_dataset))
-
- trainer.log_metrics("predict", metrics)
- trainer.save_metrics("predict", metrics)
-
- if training_args.push_to_hub:
- kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "question-answering"}
- if data_args.dataset_name is not None:
- kwargs["dataset_tags"] = data_args.dataset_name
- if data_args.dataset_config_name is not None:
- kwargs["dataset_args"] = data_args.dataset_config_name
- kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
- else:
- kwargs["dataset"] = data_args.dataset_name
-
- trainer.push_to_hub(**kwargs)
-
- if model_args.save_onnx:
- logger.info("Exporting model to onnx")
- results = trainer.save_onnx(output_dir=training_args.output_dir)
-
-
-def _mp_fn(index):
- # For xla_spawn (TPUs)
- main()
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/quantization-qdqbert/trainer_quant_qa.py b/examples/research_projects/quantization-qdqbert/trainer_quant_qa.py
deleted file mode 100644
index a56d875354d..00000000000
--- a/examples/research_projects/quantization-qdqbert/trainer_quant_qa.py
+++ /dev/null
@@ -1,212 +0,0 @@
-# coding=utf-8
-# Copyright 2020 The HuggingFace Team All rights reserved.
-# Copyright 2021 NVIDIA Corporation. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-A subclass of `Trainer` specific to Question-Answering tasks
-"""
-
-import logging
-import os
-
-import quant_trainer
-import torch
-from torch.utils.data import DataLoader
-
-from transformers import Trainer, is_torch_xla_available
-from transformers.trainer_utils import PredictionOutput
-
-
-logger = logging.getLogger(__name__)
-
-if is_torch_xla_available():
- import torch_xla.core.xla_model as xm
- import torch_xla.debug.metrics as met
-
-
-class QuestionAnsweringTrainer(Trainer):
- def __init__(self, *args, eval_examples=None, post_process_function=None, quant_trainer_args=None, **kwargs):
- super().__init__(*args, **kwargs)
- self.eval_examples = eval_examples
- self.post_process_function = post_process_function
- self.quant_trainer_args = quant_trainer_args
- self.calib_num = 128 # default number of calibration samples
-
- def get_calib_dataloader(self, calib_dataset=None):
- """
- Returns the calibration dataloader :class:`~torch.utils.data.DataLoader`.
-
- Args:
- calib_dataset (:obj:`torch.utils.data.Dataset`, `optional`)
- """
- if calib_dataset is None and self.calib_dataset is None:
- raise ValueError("Trainer: calibration requires an calib_dataset.")
- calib_dataset = calib_dataset if calib_dataset is not None else self.calib_dataset
-
- calib_dataset = self._remove_unused_columns(calib_dataset, description="Calibration")
-
- return DataLoader(
- calib_dataset,
- batch_size=self.args.eval_batch_size,
- collate_fn=self.data_collator,
- drop_last=self.args.dataloader_drop_last,
- num_workers=self.args.dataloader_num_workers,
- pin_memory=self.args.dataloader_pin_memory,
- shuffle=True,
- )
-
- def calibrate(self, calib_dataset=None):
- calib_dataset = self.train_dataset if calib_dataset is None else calib_dataset
- calib_dataloader = self.get_calib_dataloader(calib_dataset)
-
- model = self.model
- quant_trainer.configure_model(model, self.quant_trainer_args, calib=True)
- model.eval()
- quant_trainer.enable_calibration(model)
-
- logger.info("***** Running calibration *****")
- logger.info(f" Num examples = {self.calib_num}")
- logger.info(f" Batch size = {calib_dataloader.batch_size}")
-
- for step, inputs in enumerate(calib_dataloader):
- # Prediction step
- loss, logits, labels = self.prediction_step(model, inputs, prediction_loss_only=True)
- if (step + 1) * calib_dataloader.batch_size >= self.calib_num:
- break
-
- quant_trainer.finish_calibration(model, self.quant_trainer_args)
- self.model = model
-
- def evaluate(self, eval_dataset=None, eval_examples=None, ignore_keys=None, metric_key_prefix: str = "eval"):
- eval_dataset = self.eval_dataset if eval_dataset is None else eval_dataset
- eval_dataloader = self.get_eval_dataloader(eval_dataset)
- eval_examples = self.eval_examples if eval_examples is None else eval_examples
-
- # Temporarily disable metric computation, we will do it in the loop here.
- compute_metrics = self.compute_metrics
- self.compute_metrics = None
- eval_loop = self.prediction_loop if self.args.use_legacy_prediction_loop else self.evaluation_loop
- try:
- output = eval_loop(
- eval_dataloader,
- description="Evaluation",
- # No point gathering the predictions if there are no metrics, otherwise we defer to
- # self.args.prediction_loss_only
- prediction_loss_only=True if compute_metrics is None else None,
- ignore_keys=ignore_keys,
- )
- finally:
- self.compute_metrics = compute_metrics
-
- if self.post_process_function is not None and self.compute_metrics is not None:
- eval_preds = self.post_process_function(eval_examples, eval_dataset, output.predictions)
- metrics = self.compute_metrics(eval_preds)
-
- # Prefix all keys with metric_key_prefix + '_'
- for key in list(metrics.keys()):
- if not key.startswith(f"{metric_key_prefix}_"):
- metrics[f"{metric_key_prefix}_{key}"] = metrics.pop(key)
-
- self.log(metrics)
- else:
- metrics = {}
-
- if self.args.tpu_metrics_debug or self.args.debug:
- # tpu-comment: Logging debug metrics for PyTorch/XLA (compile, execute times, ops, etc.)
- xm.master_print(met.metrics_report())
-
- self.control = self.callback_handler.on_evaluate(self.args, self.state, self.control, metrics)
- return metrics
-
- def predict(self, predict_dataset, predict_examples, ignore_keys=None, metric_key_prefix: str = "test"):
- predict_dataloader = self.get_test_dataloader(predict_dataset)
-
- # Temporarily disable metric computation, we will do it in the loop here.
- compute_metrics = self.compute_metrics
- self.compute_metrics = None
- eval_loop = self.prediction_loop if self.args.use_legacy_prediction_loop else self.evaluation_loop
- try:
- output = eval_loop(
- predict_dataloader,
- description="Prediction",
- # No point gathering the predictions if there are no metrics, otherwise we defer to
- # self.args.prediction_loss_only
- prediction_loss_only=True if compute_metrics is None else None,
- ignore_keys=ignore_keys,
- )
- finally:
- self.compute_metrics = compute_metrics
-
- if self.post_process_function is None or self.compute_metrics is None:
- return output
-
- predictions = self.post_process_function(predict_examples, predict_dataset, output.predictions, "predict")
- metrics = self.compute_metrics(predictions)
-
- # Prefix all keys with metric_key_prefix + '_'
- for key in list(metrics.keys()):
- if not key.startswith(f"{metric_key_prefix}_"):
- metrics[f"{metric_key_prefix}_{key}"] = metrics.pop(key)
-
- return PredictionOutput(predictions=predictions.predictions, label_ids=predictions.label_ids, metrics=metrics)
-
- def save_onnx(self, output_dir="./"):
- eval_dataset = self.eval_dataset
- eval_dataloader = self.get_eval_dataloader(eval_dataset)
-
- batch = next(iter(eval_dataloader))
-
- # saving device - to make it consistent
- device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
-
- # convert to tuple
- input_tuple = tuple(v.to(device) for k, v in batch.items())
-
- logger.info("Converting model to be onnx compatible")
- from pytorch_quantization.nn import TensorQuantizer
-
- TensorQuantizer.use_fb_fake_quant = True
-
- model = self.model.to(device)
-
- model.eval()
- model.float()
-
- model_to_save = model.module if hasattr(model, "module") else model
- quant_trainer.configure_model(model_to_save, self.quant_trainer_args)
-
- output_model_file = os.path.join(output_dir, "model.onnx")
- logger.info(f"exporting model to {output_model_file}")
-
- axes = {0: "batch_size", 1: "seq_len"}
-
- torch.onnx.export(
- model_to_save,
- input_tuple,
- output_model_file,
- export_params=True,
- opset_version=13,
- do_constant_folding=True,
- input_names=["input_ids", "attention_mask", "token_type_ids"],
- output_names=["output_start_logits", "output_end_logits"],
- dynamic_axes={
- "input_ids": axes,
- "attention_mask": axes,
- "token_type_ids": axes,
- "output_start_logits": axes,
- "output_end_logits": axes,
- },
- verbose=True,
- )
- logger.info("onnx export finished")
diff --git a/examples/research_projects/quantization-qdqbert/utils_qa.py b/examples/research_projects/quantization-qdqbert/utils_qa.py
deleted file mode 100644
index e90d6c4747c..00000000000
--- a/examples/research_projects/quantization-qdqbert/utils_qa.py
+++ /dev/null
@@ -1,435 +0,0 @@
-# coding=utf-8
-# Copyright 2020 The HuggingFace Team All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-Post-processing utilities for question answering.
-"""
-
-import collections
-import json
-import logging
-import os
-from typing import Optional, Tuple
-
-import numpy as np
-from tqdm.auto import tqdm
-
-
-logger = logging.getLogger(__name__)
-
-
-def postprocess_qa_predictions(
- examples,
- features,
- predictions: Tuple[np.ndarray, np.ndarray],
- version_2_with_negative: bool = False,
- n_best_size: int = 20,
- max_answer_length: int = 30,
- null_score_diff_threshold: float = 0.0,
- output_dir: Optional[str] = None,
- prefix: Optional[str] = None,
- log_level: Optional[int] = logging.WARNING,
-):
- """
- Post-processes the predictions of a question-answering model to convert them to answers that are substrings of the
- original contexts. This is the base postprocessing functions for models that only return start and end logits.
-
- Args:
- examples: The non-preprocessed dataset (see the main script for more information).
- features: The processed dataset (see the main script for more information).
- predictions (:obj:`Tuple[np.ndarray, np.ndarray]`):
- The predictions of the model: two arrays containing the start logits and the end logits respectively. Its
- first dimension must match the number of elements of :obj:`features`.
- version_2_with_negative (:obj:`bool`, `optional`, defaults to :obj:`False`):
- Whether or not the underlying dataset contains examples with no answers.
- n_best_size (:obj:`int`, `optional`, defaults to 20):
- The total number of n-best predictions to generate when looking for an answer.
- max_answer_length (:obj:`int`, `optional`, defaults to 30):
- The maximum length of an answer that can be generated. This is needed because the start and end predictions
- are not conditioned on one another.
- null_score_diff_threshold (:obj:`float`, `optional`, defaults to 0):
- The threshold used to select the null answer: if the best answer has a score that is less than the score of
- the null answer minus this threshold, the null answer is selected for this example (note that the score of
- the null answer for an example giving several features is the minimum of the scores for the null answer on
- each feature: all features must be aligned on the fact they `want` to predict a null answer).
-
- Only useful when :obj:`version_2_with_negative` is :obj:`True`.
- output_dir (:obj:`str`, `optional`):
- If provided, the dictionaries of predictions, n_best predictions (with their scores and logits) and, if
- :obj:`version_2_with_negative=True`, the dictionary of the scores differences between best and null
- answers, are saved in `output_dir`.
- prefix (:obj:`str`, `optional`):
- If provided, the dictionaries mentioned above are saved with `prefix` added to their names.
- log_level (:obj:`int`, `optional`, defaults to ``logging.WARNING``):
- ``logging`` log level (e.g., ``logging.WARNING``)
- """
- if len(predictions) != 2:
- raise ValueError("`predictions` should be a tuple with two elements (start_logits, end_logits).")
- all_start_logits, all_end_logits = predictions
-
- if len(predictions[0]) != len(features):
- raise ValueError(f"Got {len(predictions[0])} predictions and {len(features)} features.")
-
- # Build a map example to its corresponding features.
- example_id_to_index = {k: i for i, k in enumerate(examples["id"])}
- features_per_example = collections.defaultdict(list)
- for i, feature in enumerate(features):
- features_per_example[example_id_to_index[feature["example_id"]]].append(i)
-
- # The dictionaries we have to fill.
- all_predictions = collections.OrderedDict()
- all_nbest_json = collections.OrderedDict()
- if version_2_with_negative:
- scores_diff_json = collections.OrderedDict()
-
- # Logging.
- logger.setLevel(log_level)
- logger.info(f"Post-processing {len(examples)} example predictions split into {len(features)} features.")
-
- # Let's loop over all the examples!
- for example_index, example in enumerate(tqdm(examples)):
- # Those are the indices of the features associated to the current example.
- feature_indices = features_per_example[example_index]
-
- min_null_prediction = None
- prelim_predictions = []
-
- # Looping through all the features associated to the current example.
- for feature_index in feature_indices:
- # We grab the predictions of the model for this feature.
- start_logits = all_start_logits[feature_index]
- end_logits = all_end_logits[feature_index]
- # This is what will allow us to map some the positions in our logits to span of texts in the original
- # context.
- offset_mapping = features[feature_index]["offset_mapping"]
- # Optional `token_is_max_context`, if provided we will remove answers that do not have the maximum context
- # available in the current feature.
- token_is_max_context = features[feature_index].get("token_is_max_context", None)
-
- # Update minimum null prediction.
- feature_null_score = start_logits[0] + end_logits[0]
- if min_null_prediction is None or min_null_prediction["score"] > feature_null_score:
- min_null_prediction = {
- "offsets": (0, 0),
- "score": feature_null_score,
- "start_logit": start_logits[0],
- "end_logit": end_logits[0],
- }
-
- # Go through all possibilities for the `n_best_size` greater start and end logits.
- start_indexes = np.argsort(start_logits)[-1 : -n_best_size - 1 : -1].tolist()
- end_indexes = np.argsort(end_logits)[-1 : -n_best_size - 1 : -1].tolist()
- for start_index in start_indexes:
- for end_index in end_indexes:
- # Don't consider out-of-scope answers, either because the indices are out of bounds or correspond
- # to part of the input_ids that are not in the context.
- if (
- start_index >= len(offset_mapping)
- or end_index >= len(offset_mapping)
- or offset_mapping[start_index] is None
- or len(offset_mapping[start_index]) < 2
- or offset_mapping[end_index] is None
- or len(offset_mapping[end_index]) < 2
- ):
- continue
- # Don't consider answers with a length that is either < 0 or > max_answer_length.
- if end_index < start_index or end_index - start_index + 1 > max_answer_length:
- continue
- # Don't consider answer that don't have the maximum context available (if such information is
- # provided).
- if token_is_max_context is not None and not token_is_max_context.get(str(start_index), False):
- continue
-
- prelim_predictions.append(
- {
- "offsets": (offset_mapping[start_index][0], offset_mapping[end_index][1]),
- "score": start_logits[start_index] + end_logits[end_index],
- "start_logit": start_logits[start_index],
- "end_logit": end_logits[end_index],
- }
- )
- if version_2_with_negative:
- # Add the minimum null prediction
- prelim_predictions.append(min_null_prediction)
- null_score = min_null_prediction["score"]
-
- # Only keep the best `n_best_size` predictions.
- predictions = sorted(prelim_predictions, key=lambda x: x["score"], reverse=True)[:n_best_size]
-
- # Add back the minimum null prediction if it was removed because of its low score.
- if version_2_with_negative and not any(p["offsets"] == (0, 0) for p in predictions):
- predictions.append(min_null_prediction)
-
- # Use the offsets to gather the answer text in the original context.
- context = example["context"]
- for pred in predictions:
- offsets = pred.pop("offsets")
- pred["text"] = context[offsets[0] : offsets[1]]
-
- # In the very rare edge case we have not a single non-null prediction, we create a fake prediction to avoid
- # failure.
- if len(predictions) == 0 or (len(predictions) == 1 and predictions[0]["text"] == ""):
- predictions.insert(0, {"text": "empty", "start_logit": 0.0, "end_logit": 0.0, "score": 0.0})
-
- # Compute the softmax of all scores (we do it with numpy to stay independent from torch/tf in this file, using
- # the LogSumExp trick).
- scores = np.array([pred.pop("score") for pred in predictions])
- exp_scores = np.exp(scores - np.max(scores))
- probs = exp_scores / exp_scores.sum()
-
- # Include the probabilities in our predictions.
- for prob, pred in zip(probs, predictions):
- pred["probability"] = prob
-
- # Pick the best prediction. If the null answer is not possible, this is easy.
- if not version_2_with_negative:
- all_predictions[example["id"]] = predictions[0]["text"]
- else:
- # Otherwise we first need to find the best non-empty prediction.
- i = 0
- while predictions[i]["text"] == "":
- i += 1
- best_non_null_pred = predictions[i]
-
- # Then we compare to the null prediction using the threshold.
- score_diff = null_score - best_non_null_pred["start_logit"] - best_non_null_pred["end_logit"]
- scores_diff_json[example["id"]] = float(score_diff) # To be JSON-serializable.
- if score_diff > null_score_diff_threshold:
- all_predictions[example["id"]] = ""
- else:
- all_predictions[example["id"]] = best_non_null_pred["text"]
-
- # Make `predictions` JSON-serializable by casting np.float back to float.
- all_nbest_json[example["id"]] = [
- {k: (float(v) if isinstance(v, (np.float16, np.float32, np.float64)) else v) for k, v in pred.items()}
- for pred in predictions
- ]
-
- # If we have an output_dir, let's save all those dicts.
- if output_dir is not None:
- if not os.path.isdir(output_dir):
- raise EnvironmentError(f"{output_dir} is not a directory.")
-
- prediction_file = os.path.join(
- output_dir, "predictions.json" if prefix is None else f"{prefix}_predictions.json"
- )
- nbest_file = os.path.join(
- output_dir, "nbest_predictions.json" if prefix is None else f"{prefix}_nbest_predictions.json"
- )
- if version_2_with_negative:
- null_odds_file = os.path.join(
- output_dir, "null_odds.json" if prefix is None else f"{prefix}_null_odds.json"
- )
-
- logger.info(f"Saving predictions to {prediction_file}.")
- with open(prediction_file, "w") as writer:
- writer.write(json.dumps(all_predictions, indent=4) + "\n")
- logger.info(f"Saving nbest_preds to {nbest_file}.")
- with open(nbest_file, "w") as writer:
- writer.write(json.dumps(all_nbest_json, indent=4) + "\n")
- if version_2_with_negative:
- logger.info(f"Saving null_odds to {null_odds_file}.")
- with open(null_odds_file, "w") as writer:
- writer.write(json.dumps(scores_diff_json, indent=4) + "\n")
-
- return all_predictions
-
-
-def postprocess_qa_predictions_with_beam_search(
- examples,
- features,
- predictions: Tuple[np.ndarray, np.ndarray],
- version_2_with_negative: bool = False,
- n_best_size: int = 20,
- max_answer_length: int = 30,
- start_n_top: int = 5,
- end_n_top: int = 5,
- output_dir: Optional[str] = None,
- prefix: Optional[str] = None,
- log_level: Optional[int] = logging.WARNING,
-):
- """
- Post-processes the predictions of a question-answering model with beam search to convert them to answers that are substrings of the
- original contexts. This is the postprocessing functions for models that return start and end logits, indices, as well as
- cls token predictions.
-
- Args:
- examples: The non-preprocessed dataset (see the main script for more information).
- features: The processed dataset (see the main script for more information).
- predictions (:obj:`Tuple[np.ndarray, np.ndarray]`):
- The predictions of the model: two arrays containing the start logits and the end logits respectively. Its
- first dimension must match the number of elements of :obj:`features`.
- version_2_with_negative (:obj:`bool`, `optional`, defaults to :obj:`False`):
- Whether or not the underlying dataset contains examples with no answers.
- n_best_size (:obj:`int`, `optional`, defaults to 20):
- The total number of n-best predictions to generate when looking for an answer.
- max_answer_length (:obj:`int`, `optional`, defaults to 30):
- The maximum length of an answer that can be generated. This is needed because the start and end predictions
- are not conditioned on one another.
- start_n_top (:obj:`int`, `optional`, defaults to 5):
- The number of top start logits too keep when searching for the :obj:`n_best_size` predictions.
- end_n_top (:obj:`int`, `optional`, defaults to 5):
- The number of top end logits too keep when searching for the :obj:`n_best_size` predictions.
- output_dir (:obj:`str`, `optional`):
- If provided, the dictionaries of predictions, n_best predictions (with their scores and logits) and, if
- :obj:`version_2_with_negative=True`, the dictionary of the scores differences between best and null
- answers, are saved in `output_dir`.
- prefix (:obj:`str`, `optional`):
- If provided, the dictionaries mentioned above are saved with `prefix` added to their names.
- log_level (:obj:`int`, `optional`, defaults to ``logging.WARNING``):
- ``logging`` log level (e.g., ``logging.WARNING``)
- """
- if len(predictions) != 5:
- raise ValueError("`predictions` should be a tuple with five elements.")
- start_top_log_probs, start_top_index, end_top_log_probs, end_top_index, cls_logits = predictions
-
- if len(predictions[0]) != len(features):
- raise ValueError(f"Got {len(predictions[0])} predictions and {len(features)} features.")
-
- # Build a map example to its corresponding features.
- example_id_to_index = {k: i for i, k in enumerate(examples["id"])}
- features_per_example = collections.defaultdict(list)
- for i, feature in enumerate(features):
- features_per_example[example_id_to_index[feature["example_id"]]].append(i)
-
- # The dictionaries we have to fill.
- all_predictions = collections.OrderedDict()
- all_nbest_json = collections.OrderedDict()
- scores_diff_json = collections.OrderedDict() if version_2_with_negative else None
-
- # Logging.
- logger.setLevel(log_level)
- logger.info(f"Post-processing {len(examples)} example predictions split into {len(features)} features.")
-
- # Let's loop over all the examples!
- for example_index, example in enumerate(tqdm(examples)):
- # Those are the indices of the features associated to the current example.
- feature_indices = features_per_example[example_index]
-
- min_null_score = None
- prelim_predictions = []
-
- # Looping through all the features associated to the current example.
- for feature_index in feature_indices:
- # We grab the predictions of the model for this feature.
- start_log_prob = start_top_log_probs[feature_index]
- start_indexes = start_top_index[feature_index]
- end_log_prob = end_top_log_probs[feature_index]
- end_indexes = end_top_index[feature_index]
- feature_null_score = cls_logits[feature_index]
- # This is what will allow us to map some the positions in our logits to span of texts in the original
- # context.
- offset_mapping = features[feature_index]["offset_mapping"]
- # Optional `token_is_max_context`, if provided we will remove answers that do not have the maximum context
- # available in the current feature.
- token_is_max_context = features[feature_index].get("token_is_max_context", None)
-
- # Update minimum null prediction
- if min_null_score is None or feature_null_score < min_null_score:
- min_null_score = feature_null_score
-
- # Go through all possibilities for the `n_start_top`/`n_end_top` greater start and end logits.
- for i in range(start_n_top):
- for j in range(end_n_top):
- start_index = int(start_indexes[i])
- j_index = i * end_n_top + j
- end_index = int(end_indexes[j_index])
- # Don't consider out-of-scope answers (last part of the test should be unnecessary because of the
- # p_mask but let's not take any risk)
- if (
- start_index >= len(offset_mapping)
- or end_index >= len(offset_mapping)
- or offset_mapping[start_index] is None
- or offset_mapping[end_index] is None
- ):
- continue
- # Don't consider answers with a length negative or > max_answer_length.
- if end_index < start_index or end_index - start_index + 1 > max_answer_length:
- continue
- # Don't consider answer that don't have the maximum context available (if such information is
- # provided).
- if token_is_max_context is not None and not token_is_max_context.get(str(start_index), False):
- continue
- prelim_predictions.append(
- {
- "offsets": (offset_mapping[start_index][0], offset_mapping[end_index][1]),
- "score": start_log_prob[i] + end_log_prob[j_index],
- "start_log_prob": start_log_prob[i],
- "end_log_prob": end_log_prob[j_index],
- }
- )
-
- # Only keep the best `n_best_size` predictions.
- predictions = sorted(prelim_predictions, key=lambda x: x["score"], reverse=True)[:n_best_size]
-
- # Use the offsets to gather the answer text in the original context.
- context = example["context"]
- for pred in predictions:
- offsets = pred.pop("offsets")
- pred["text"] = context[offsets[0] : offsets[1]]
-
- # In the very rare edge case we have not a single non-null prediction, we create a fake prediction to avoid
- # failure.
- if len(predictions) == 0:
- predictions.insert(0, {"text": "", "start_logit": -1e-6, "end_logit": -1e-6, "score": -2e-6})
-
- # Compute the softmax of all scores (we do it with numpy to stay independent from torch/tf in this file, using
- # the LogSumExp trick).
- scores = np.array([pred.pop("score") for pred in predictions])
- exp_scores = np.exp(scores - np.max(scores))
- probs = exp_scores / exp_scores.sum()
-
- # Include the probabilities in our predictions.
- for prob, pred in zip(probs, predictions):
- pred["probability"] = prob
-
- # Pick the best prediction and set the probability for the null answer.
- all_predictions[example["id"]] = predictions[0]["text"]
- if version_2_with_negative:
- scores_diff_json[example["id"]] = float(min_null_score)
-
- # Make `predictions` JSON-serializable by casting np.float back to float.
- all_nbest_json[example["id"]] = [
- {k: (float(v) if isinstance(v, (np.float16, np.float32, np.float64)) else v) for k, v in pred.items()}
- for pred in predictions
- ]
-
- # If we have an output_dir, let's save all those dicts.
- if output_dir is not None:
- if not os.path.isdir(output_dir):
- raise EnvironmentError(f"{output_dir} is not a directory.")
-
- prediction_file = os.path.join(
- output_dir, "predictions.json" if prefix is None else f"{prefix}_predictions.json"
- )
- nbest_file = os.path.join(
- output_dir, "nbest_predictions.json" if prefix is None else f"{prefix}_nbest_predictions.json"
- )
- if version_2_with_negative:
- null_odds_file = os.path.join(
- output_dir, "null_odds.json" if prefix is None else f"{prefix}_null_odds.json"
- )
-
- logger.info(f"Saving predictions to {prediction_file}.")
- with open(prediction_file, "w") as writer:
- writer.write(json.dumps(all_predictions, indent=4) + "\n")
- logger.info(f"Saving nbest_preds to {nbest_file}.")
- with open(nbest_file, "w") as writer:
- writer.write(json.dumps(all_nbest_json, indent=4) + "\n")
- if version_2_with_negative:
- logger.info(f"Saving null_odds to {null_odds_file}.")
- with open(null_odds_file, "w") as writer:
- writer.write(json.dumps(scores_diff_json, indent=4) + "\n")
-
- return all_predictions, scores_diff_json
diff --git a/examples/research_projects/rag-end2end-retriever/README.md b/examples/research_projects/rag-end2end-retriever/README.md
deleted file mode 100644
index 9aa0bc5dbcb..00000000000
--- a/examples/research_projects/rag-end2end-retriever/README.md
+++ /dev/null
@@ -1,56 +0,0 @@
-# End-to-End finetuning of RAG (including DPR retriever) for Question Answering.
-
-This finetuning script is actively maintained by [Shamane Siri](https://github.com/shamanez). Feel free to ask questions on the [Forum](https://discuss.huggingface.co/) or post an issue on [GitHub](https://github.com/huggingface/transformers/issues/new/choose) and tag @shamanez.
-
-Others that helped out: Patrick von Platen (@patrickvonplaten), Quentin Lhoest (@lhoestq), and Rivindu Weerasekera (@rivinduw)
-
-The original RAG implementation is able to train the question encoder and generator end-to-end.
-This extension enables complete end-to-end training of RAG including the context encoder in the retriever component.
-Please read the [accompanying blog post](https://shamanesiri.medium.com/how-to-finetune-the-entire-rag-architecture-including-dpr-retriever-4b4385322552) for details on this implementation.
-
-The original RAG code has also been modified to work with the latest versions of pytorch lightning (version 1.2.10) and RAY (version 1.3.0). All other implementation details remain the same as the [original RAG code](https://github.com/huggingface/transformers/tree/main/examples/research_projects/rag).
-Read more about RAG at https://arxiv.org/abs/2005.11401.
-
-This code can be modified to experiment with other research on retrieval augmented models which include training of the retriever (e.g. [REALM](https://arxiv.org/abs/2002.08909) and [MARGE](https://arxiv.org/abs/2006.15020)).
-
-To start training, use the bash script (finetune_rag_ray_end2end.sh) in this folder. This script also includes descriptions on each command-line argument used.
-
-# Latest Update
-
-⚠️ Updated the rag-end2end-retriever to be compatible with PL==1.6.4 and RAY==1.13.0 (latest versions to the date 2022-June-11)
-
-# Note
-
-⚠️ This project should be run with pytorch-lightning==1.3.1 which has a potential security vulnerability
-
-# Testing
-
-The following two bash scripts can be used to quickly test the implementation.
-1. sh ./test_run/test_finetune.sh script
- - Tests the full end-to-end fine-tuning ability with a dummy knowlendge-base and dummy training dataset (check test_dir directory).
- - Users can replace the dummy dataset and knowledge-base with their own to do their own finetuning.
- - Please read the comments in the test_finetune.sh file.
-2. sh ./test_run/test_rag_new_features.sh
- - Tests the newly added functions (set_context_encoder and set_context_encoder_tokenizer) related to modeling rag.
- - This is sufficient to check the model's ability to use the set functions correctly.
-
-
-
-# Comparison of end2end RAG (including DPR finetuning) VS original-RAG
-
-We conducted a simple experiment to investigate the effectiveness of this end2end training extension using the SQuAD dataset. Please execute the following steps to reproduce the results.
-
-- Create a knowledge-base using all the context passages in the SQuAD dataset with their respective titles.
-- Use the question-answer pairs as training data.
-- Train the system for 10 epochs.
-- Test the Exact Match (EM) score with the SQuAD dataset's validation set.
-- Training dataset, the knowledge-base, and hyperparameters used in experiments can be accessed from [here](https://drive.google.com/drive/folders/1qyzV-PaEARWvaU_jjpnU_NUS3U_dSjtG?usp=sharing).
-
-# Results
-
-- We train both models for 10 epochs.
-
-| Model Type | EM-Score|
-| --------------------| --------|
-| RAG-original | 28.12 |
-| RAG-end2end with DPR| 40.02 |
diff --git a/examples/research_projects/rag-end2end-retriever/callbacks_rag.py b/examples/research_projects/rag-end2end-retriever/callbacks_rag.py
deleted file mode 100644
index 09a30ff6d5c..00000000000
--- a/examples/research_projects/rag-end2end-retriever/callbacks_rag.py
+++ /dev/null
@@ -1,119 +0,0 @@
-import logging
-from pathlib import Path
-
-import numpy as np
-import pytorch_lightning as pl
-import torch
-from pytorch_lightning.callbacks import EarlyStopping, ModelCheckpoint
-from pytorch_lightning.utilities import rank_zero_only
-from utils_rag import save_json
-
-
-def count_trainable_parameters(model):
- model_parameters = filter(lambda p: p.requires_grad, model.parameters())
- params = sum([np.prod(p.size()) for p in model_parameters])
- return params
-
-
-logger = logging.getLogger(__name__)
-
-
-def get_checkpoint_callback(output_dir, metric):
- """Saves the best model by validation EM score."""
- if metric == "rouge2":
- exp = "{val_avg_rouge2:.4f}-{step_count}"
- elif metric == "bleu":
- exp = "{val_avg_bleu:.4f}-{step_count}"
- elif metric == "em":
- exp = "{val_avg_em:.4f}-{step_count}"
- elif metric == "loss":
- exp = "{val_avg_loss:.4f}-{step_count}"
- else:
- raise NotImplementedError(
- f"seq2seq callbacks only support rouge2 and bleu, got {metric}, You can make your own by adding to this"
- " function."
- )
-
- checkpoint_callback = ModelCheckpoint(
- dirpath=output_dir,
- filename=exp,
- monitor=f"val_{metric}",
- mode="max",
- save_top_k=1,
- every_n_epochs=1, # works only with PL > 1.3
- )
-
- return checkpoint_callback
-
-
-def get_early_stopping_callback(metric, patience):
- return EarlyStopping(
- monitor=f"val_{metric}", # does this need avg?
- mode="min" if "loss" in metric else "max",
- patience=patience,
- verbose=True,
- )
-
-
-class Seq2SeqLoggingCallback(pl.Callback):
- def on_batch_end(self, trainer, pl_module):
- lrs = {f"lr_group_{i}": param["lr"] for i, param in enumerate(pl_module.trainer.optimizers[0].param_groups)}
- pl_module.logger.log_metrics(lrs)
-
- @rank_zero_only
- def _write_logs(
- self, trainer: pl.Trainer, pl_module: pl.LightningModule, type_path: str, save_generations=True
- ) -> None:
- logger.info(f"***** {type_path} results at step {trainer.global_step:05d} *****")
- metrics = trainer.callback_metrics
- trainer.logger.log_metrics({k: v for k, v in metrics.items() if k not in ["log", "progress_bar", "preds"]})
- # Log results
- od = Path(pl_module.hparams.output_dir)
- if type_path == "test":
- results_file = od / "test_results.txt"
- generations_file = od / "test_generations.txt"
- else:
- # this never gets hit. I prefer not to save intermediate generations, and results are in metrics.json
- # If people want this it will be easy enough to add back.
- results_file = od / f"{type_path}_results/{trainer.global_step:05d}.txt"
- generations_file = od / f"{type_path}_generations/{trainer.global_step:05d}.txt"
- results_file.parent.mkdir(exist_ok=True)
- generations_file.parent.mkdir(exist_ok=True)
- with open(results_file, "a+") as writer:
- for key in sorted(metrics):
- if key in ["log", "progress_bar", "preds"]:
- continue
- val = metrics[key]
- if isinstance(val, torch.Tensor):
- val = val.item()
- msg = f"{key}: {val:.6f}\n"
- writer.write(msg)
-
- if not save_generations:
- return
-
- if "preds" in metrics:
- content = "\n".join(metrics["preds"])
- generations_file.open("w+").write(content)
-
- @rank_zero_only
- def on_train_start(self, trainer, pl_module):
- try:
- npars = pl_module.model.model.num_parameters()
- except AttributeError:
- npars = pl_module.model.num_parameters()
-
- n_trainable_pars = count_trainable_parameters(pl_module)
- # mp stands for million parameters
- trainer.logger.log_metrics({"n_params": npars, "mp": npars / 1e6, "grad_mp": n_trainable_pars / 1e6})
-
- @rank_zero_only
- def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
- save_json(pl_module.metrics, pl_module.metrics_save_path)
- return self._write_logs(trainer, pl_module, "test")
-
- @rank_zero_only
- def on_validation_end(self, trainer: pl.Trainer, pl_module):
- save_json(pl_module.metrics, pl_module.metrics_save_path)
- # Uncommenting this will save val generations
- # return self._write_logs(trainer, pl_module, "valid")
diff --git a/examples/research_projects/rag-end2end-retriever/distributed_ray_retriever.py b/examples/research_projects/rag-end2end-retriever/distributed_ray_retriever.py
deleted file mode 100644
index f97467292c2..00000000000
--- a/examples/research_projects/rag-end2end-retriever/distributed_ray_retriever.py
+++ /dev/null
@@ -1,185 +0,0 @@
-import logging
-import random
-
-import ray
-
-from transformers import RagConfig, RagRetriever, RagTokenizer
-from transformers.models.rag.retrieval_rag import CustomHFIndex
-
-
-logger = logging.getLogger(__name__)
-
-
-class RayRetriever:
- def __init__(self):
- self.initialized = False
-
- def create_rag_retriever(self, config, question_encoder_tokenizer, generator_tokenizer, index):
- if not self.initialized:
- self.retriever = RagRetriever(
- config,
- question_encoder_tokenizer=question_encoder_tokenizer,
- generator_tokenizer=generator_tokenizer,
- index=index,
- init_retrieval=False,
- )
- self.initialized = True
-
- def init_retrieval(self):
- self.retriever.index.init_index()
-
- def clear_object(self):
- # delete the old self.retriever object before assigning the new index
- del self.retriever
- self.initialized = False
-
- def retrieve(self, question_hidden_states, n_docs):
- doc_ids, retrieved_doc_embeds = self.retriever._main_retrieve(question_hidden_states, n_docs)
- doc_dicts = self.retriever.index.get_doc_dicts(doc_ids)
- return doc_ids, retrieved_doc_embeds, doc_dicts
-
-
-class RagRayDistributedRetriever(RagRetriever):
- """
- A distributed retriever built on top of the ``Ray`` API, a library
- for building distributed applications (https://docs.ray.io/en/master/).
- package. During training, all training workers initialize their own
- instance of a `RagRayDistributedRetriever`, and each instance of
- this distributed retriever shares a common set of Retrieval Ray
- Actors (https://docs.ray.io/en/master/walkthrough.html#remote
- -classes-actors) that load the index on separate processes. Ray
- handles the communication between the `RagRayDistributedRetriever`
- instances and the remote Ray actors. If training is done in a
- non-distributed setup, the index will simply be loaded in the same
- process as the training worker and Ray will not be used.
-
- Args:
- config (:class:`~transformers.RagConfig`):
- The configuration of the RAG model this Retriever is used with. Contains parameters indicating which ``Index`` to build.
- question_encoder_tokenizer (:class:`~transformers.PreTrainedTokenizer`):
- The tokenizer that was used to tokenize the question.
- It is used to decode the question and then use the generator_tokenizer.
- generator_tokenizer (:class:`~transformers.PreTrainedTokenizer`):
- The tokenizer used for the generator part of the RagModel.
- retrieval_workers (:obj:`List[ray.ActorClass(RayRetriever)]`): A list of already initialized `RayRetriever` actors.
- These actor classes run on remote processes and are responsible for performing the index lookup.
- index (:class:`~transformers.retrieval_rag.Index`, optional, defaults to the one defined by the configuration):
- If specified, use this index instead of the one built using the configuration
- """
-
- def __init__(self, config, question_encoder_tokenizer, generator_tokenizer, retrieval_workers, index=None):
- if index is not None and index.is_initialized() and len(retrieval_workers) > 0:
- raise ValueError(
- "When using Ray for distributed fine-tuning, "
- "you'll need to provide the paths instead, "
- "as the dataset and the index are loaded "
- "separately. More info in examples/rag/use_own_knowledge_dataset.py "
- )
-
- super().__init__(
- config,
- question_encoder_tokenizer=question_encoder_tokenizer,
- generator_tokenizer=generator_tokenizer,
- index=index,
- init_retrieval=False,
- )
-
- self.retrieval_workers = retrieval_workers
- self.question_encoder_tokenizer = question_encoder_tokenizer
- self.generator_tokenizer = generator_tokenizer
- if len(self.retrieval_workers) > 0:
- ray.get(
- [
- worker.create_rag_retriever.remote(config, question_encoder_tokenizer, generator_tokenizer, index)
- for worker in self.retrieval_workers
- ]
- )
-
- def init_retrieval(self):
- """
- Retriever initialization function, needs to be called from the
- training process. This function triggers retrieval initialization
- for all retrieval actors if using distributed setting, or loads
- index into current process if training is not distributed.
- """
- logger.info("initializing retrieval")
-
- if len(self.retrieval_workers) > 0:
- ray.get([worker.init_retrieval.remote() for worker in self.retrieval_workers])
- else:
- # Non-distributed training. Load index into this same process.
- self.index.init_index()
-
- def retrieve(self, question_hidden_states, n_docs):
- """
- Retrieves documents for specified ``question_hidden_states``. If
- running training with multiple workers, a random retrieval actor is
- selected to perform the index lookup and return the result.
-
- Args:
- question_hidden_states (:obj:`np.ndarray` of shape :obj:`(batch_size, vector_size)`):
- A batch of query vectors to retrieve with.
- n_docs (:obj:`int`):
- The number of docs retrieved per query.
-
- Output:
- retrieved_doc_embeds (:obj:`np.ndarray` of shape :obj:`(batch_size, n_docs, dim)`
- The retrieval embeddings of the retrieved docs per query.
- doc_ids (:obj:`np.ndarray` of shape :obj:`batch_size, n_docs`)
- The ids of the documents in the index
- doc_dicts (:obj:`List[dict]`):
- The retrieved_doc_embeds examples per query.
- """
- if len(self.retrieval_workers) > 0:
- # Select a random retrieval actor.
- random_worker = self.retrieval_workers[random.randint(0, len(self.retrieval_workers) - 1)]
- doc_ids, retrieved_doc_embeds, doc_dicts = ray.get(
- random_worker.retrieve.remote(question_hidden_states, n_docs)
- )
- else:
- doc_ids, retrieved_doc_embeds = self._main_retrieve(question_hidden_states, n_docs)
- doc_dicts = self.index.get_doc_dicts(doc_ids)
- return retrieved_doc_embeds, doc_ids, doc_dicts
-
- @classmethod
- def get_tokenizers(cls, retriever_name_or_path, indexed_dataset=None, **kwargs):
- return super(RagRayDistributedRetriever, cls).get_tokenizers(retriever_name_or_path, indexed_dataset, **kwargs)
-
- @classmethod
- def from_pretrained(cls, retriever_name_or_path, actor_handles, indexed_dataset=None, **kwargs):
- config = kwargs.pop("config", None) or RagConfig.from_pretrained(retriever_name_or_path, **kwargs)
- rag_tokenizer = RagTokenizer.from_pretrained(retriever_name_or_path, config=config)
- question_encoder_tokenizer = rag_tokenizer.question_encoder
- generator_tokenizer = rag_tokenizer.generator
-
- if indexed_dataset is not None:
- config.index_name = "custom"
- index = CustomHFIndex(config.retrieval_vector_size, indexed_dataset)
- else:
- index = cls._build_index(config)
-
- return cls(
- config,
- question_encoder_tokenizer=question_encoder_tokenizer,
- generator_tokenizer=generator_tokenizer,
- retrieval_workers=actor_handles,
- index=index,
- )
-
- def re_load(self):
- logger.info("re-loading the new dataset with embeddings")
- # access from the training loop
-
- ray.get([worker.clear_object.remote() for worker in self.retrieval_workers])
-
- # build the index object again
- index = self._build_index(self.config)
-
- ray.get(
- [
- worker.create_rag_retriever.remote(
- self.config, self.question_encoder_tokenizer, self.generator_tokenizer, index
- )
- for worker in self.retrieval_workers
- ]
- )
diff --git a/examples/research_projects/rag-end2end-retriever/eval_rag.py b/examples/research_projects/rag-end2end-retriever/eval_rag.py
deleted file mode 100644
index 55f4da56571..00000000000
--- a/examples/research_projects/rag-end2end-retriever/eval_rag.py
+++ /dev/null
@@ -1,320 +0,0 @@
-"""Evaluation script for RAG models."""
-
-import argparse
-import ast
-import logging
-import os
-import sys
-
-import pandas as pd
-import torch
-from tqdm import tqdm
-
-from transformers import BartForConditionalGeneration, RagRetriever, RagSequenceForGeneration, RagTokenForGeneration
-from transformers import logging as transformers_logging
-
-
-sys.path.append(os.path.join(os.getcwd())) # noqa: E402 # isort:skip
-from utils_rag import exact_match_score, f1_score # noqa: E402 # isort:skip
-
-
-logger = logging.getLogger(__name__)
-logging.basicConfig(level=logging.INFO)
-
-transformers_logging.set_verbosity_info()
-
-
-def infer_model_type(model_name_or_path):
- if "token" in model_name_or_path:
- return "rag_token"
- if "sequence" in model_name_or_path:
- return "rag_sequence"
- if "bart" in model_name_or_path:
- return "bart"
- return None
-
-
-def metric_max_over_ground_truths(metric_fn, prediction, ground_truths):
- return max(metric_fn(prediction, gt) for gt in ground_truths)
-
-
-def get_scores(args, preds_path, gold_data_path):
- hypos = [line.strip() for line in open(preds_path, "r").readlines()]
- answers = []
-
- if args.gold_data_mode == "qa":
- data = pd.read_csv(gold_data_path, sep="\t", header=None)
- for answer_list in data[1]:
- ground_truths = ast.literal_eval(answer_list)
- answers.append(ground_truths)
- else:
- references = [line.strip() for line in open(gold_data_path, "r").readlines()]
- answers = [[reference] for reference in references]
-
- f1 = em = total = 0
- for prediction, ground_truths in zip(hypos, answers):
- total += 1
- em += metric_max_over_ground_truths(exact_match_score, prediction, ground_truths)
- f1 += metric_max_over_ground_truths(f1_score, prediction, ground_truths)
-
- em = 100.0 * em / total
- f1 = 100.0 * f1 / total
-
- logger.info(f"F1: {f1:.2f}")
- logger.info(f"EM: {em:.2f}")
-
-
-def get_precision_at_k(args, preds_path, gold_data_path):
- k = args.k
- hypos = [line.strip() for line in open(preds_path, "r").readlines()]
- references = [line.strip() for line in open(gold_data_path, "r").readlines()]
-
- em = total = 0
- for hypo, reference in zip(hypos, references):
- hypo_provenance = set(hypo.split("\t")[:k])
- ref_provenance = set(reference.split("\t"))
- total += 1
- em += len(hypo_provenance & ref_provenance) / k
-
- em = 100.0 * em / total
- logger.info(f"Precision@{k}: {em: .2f}")
-
-
-def evaluate_batch_retrieval(args, rag_model, questions):
- def strip_title(title):
- if title.startswith('"'):
- title = title[1:]
- if title.endswith('"'):
- title = title[:-1]
- return title
-
- retriever_input_ids = rag_model.retriever.question_encoder_tokenizer.batch_encode_plus(
- questions,
- return_tensors="pt",
- padding=True,
- truncation=True,
- )["input_ids"].to(args.device)
-
- question_enc_outputs = rag_model.rag.question_encoder(retriever_input_ids)
- question_enc_pool_output = question_enc_outputs[0]
-
- result = rag_model.retriever(
- retriever_input_ids,
- question_enc_pool_output.cpu().detach().to(torch.float32).numpy(),
- prefix=rag_model.rag.generator.config.prefix,
- n_docs=rag_model.config.n_docs,
- return_tensors="pt",
- )
- all_docs = rag_model.retriever.index.get_doc_dicts(result.doc_ids)
- provenance_strings = []
- for docs in all_docs:
- provenance = [strip_title(title) for title in docs["title"]]
- provenance_strings.append("\t".join(provenance))
- return provenance_strings
-
-
-def evaluate_batch_e2e(args, rag_model, questions):
- with torch.no_grad():
- inputs_dict = rag_model.retriever.question_encoder_tokenizer.batch_encode_plus(
- questions, return_tensors="pt", padding=True, truncation=True
- )
-
- input_ids = inputs_dict.input_ids.to(args.device)
- attention_mask = inputs_dict.attention_mask.to(args.device)
- outputs = rag_model.generate( # rag_model overwrites generate
- input_ids,
- attention_mask=attention_mask,
- num_beams=args.num_beams,
- min_length=args.min_length,
- max_length=args.max_length,
- early_stopping=False,
- num_return_sequences=1,
- bad_words_ids=[[0, 0]], # BART likes to repeat BOS tokens, dont allow it to generate more than one
- )
- answers = rag_model.retriever.generator_tokenizer.batch_decode(outputs, skip_special_tokens=True)
-
- if args.print_predictions:
- for q, a in zip(questions, answers):
- logger.info("Q: {} - A: {}".format(q, a))
-
- return answers
-
-
-def get_args():
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "--model_type",
- choices=["rag_sequence", "rag_token", "bart"],
- type=str,
- help=(
- "RAG model type: rag_sequence, rag_token or bart, if none specified, the type is inferred from the"
- " model_name_or_path"
- ),
- )
- parser.add_argument(
- "--index_name",
- default=None,
- choices=["exact", "compressed", "legacy"],
- type=str,
- help="RAG model retriever type",
- )
- parser.add_argument(
- "--index_path",
- default=None,
- type=str,
- help="Path to the retrieval index",
- )
- parser.add_argument("--n_docs", default=5, type=int, help="Number of retrieved docs")
- parser.add_argument(
- "--model_name_or_path",
- default=None,
- type=str,
- required=True,
- help="Path to pretrained checkpoints or model identifier from huggingface.co/models",
- )
- parser.add_argument(
- "--eval_mode",
- choices=["e2e", "retrieval"],
- default="e2e",
- type=str,
- help=(
- "Evaluation mode, e2e calculates exact match and F1 of the downstream task, retrieval calculates"
- " precision@k."
- ),
- )
- parser.add_argument("--k", default=1, type=int, help="k for the precision@k calculation")
- parser.add_argument(
- "--evaluation_set",
- default=None,
- type=str,
- required=True,
- help="Path to a file containing evaluation samples",
- )
- parser.add_argument(
- "--gold_data_path",
- default=None,
- type=str,
- required=True,
- help="Path to a tab-separated file with gold samples",
- )
- parser.add_argument(
- "--gold_data_mode",
- default="qa",
- type=str,
- choices=["qa", "ans"],
- help=(
- "Format of the gold data file"
- "qa - a single line in the following format: question [tab] answer_list"
- "ans - a single line of the gold file contains the expected answer string"
- ),
- )
- parser.add_argument(
- "--predictions_path",
- type=str,
- default="predictions.txt",
- help="Name of the predictions file, to be stored in the checkpoints directory",
- )
- parser.add_argument(
- "--eval_all_checkpoints",
- action="store_true",
- help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
- )
- parser.add_argument(
- "--eval_batch_size",
- default=8,
- type=int,
- help="Batch size per GPU/CPU for evaluation.",
- )
- parser.add_argument(
- "--recalculate",
- help="Recalculate predictions even if the prediction file exists",
- action="store_true",
- )
- parser.add_argument(
- "--num_beams",
- default=4,
- type=int,
- help="Number of beams to be used when generating answers",
- )
- parser.add_argument("--min_length", default=1, type=int, help="Min length of the generated answers")
- parser.add_argument("--max_length", default=50, type=int, help="Max length of the generated answers")
-
- parser.add_argument(
- "--print_predictions",
- action="store_true",
- help="If True, prints predictions while evaluating.",
- )
- parser.add_argument(
- "--print_docs",
- action="store_true",
- help="If True, prints docs retried while generating.",
- )
- args = parser.parse_args()
- args.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
- return args
-
-
-def main(args):
- model_kwargs = {}
- if args.model_type is None:
- args.model_type = infer_model_type(args.model_name_or_path)
- assert args.model_type is not None
- if args.model_type.startswith("rag"):
- model_class = RagTokenForGeneration if args.model_type == "rag_token" else RagSequenceForGeneration
- model_kwargs["n_docs"] = args.n_docs
- if args.index_name is not None:
- model_kwargs["index_name"] = args.index_name
- if args.index_path is not None:
- model_kwargs["index_path"] = args.index_path
- else:
- model_class = BartForConditionalGeneration
-
- checkpoints = (
- [f.path for f in os.scandir(args.model_name_or_path) if f.is_dir()]
- if args.eval_all_checkpoints
- else [args.model_name_or_path]
- )
-
- logger.info("Evaluate the following checkpoints: %s", checkpoints)
-
- score_fn = get_scores if args.eval_mode == "e2e" else get_precision_at_k
- evaluate_batch_fn = evaluate_batch_e2e if args.eval_mode == "e2e" else evaluate_batch_retrieval
-
- for checkpoint in checkpoints:
- if os.path.exists(args.predictions_path) and (not args.recalculate):
- logger.info("Calculating metrics based on an existing predictions file: {}".format(args.predictions_path))
- score_fn(args, args.predictions_path, args.gold_data_path)
- continue
-
- logger.info("***** Running evaluation for {} *****".format(checkpoint))
- logger.info(" Batch size = %d", args.eval_batch_size)
- logger.info(" Predictions will be stored under {}".format(args.predictions_path))
-
- if args.model_type.startswith("rag"):
- retriever = RagRetriever.from_pretrained(checkpoint, **model_kwargs)
- model = model_class.from_pretrained(checkpoint, retriever=retriever, **model_kwargs)
- model.retriever.init_retrieval()
- else:
- model = model_class.from_pretrained(checkpoint, **model_kwargs)
- model.to(args.device)
-
- with open(args.evaluation_set, "r") as eval_file, open(args.predictions_path, "w") as preds_file:
- questions = []
- for line in tqdm(eval_file):
- questions.append(line.strip())
- if len(questions) == args.eval_batch_size:
- answers = evaluate_batch_fn(args, model, questions)
- preds_file.write("\n".join(answers) + "\n")
- preds_file.flush()
- questions = []
- if len(questions) > 0:
- answers = evaluate_batch_fn(args, model, questions)
- preds_file.write("\n".join(answers))
- preds_file.flush()
-
- score_fn(args, args.predictions_path, args.gold_data_path)
-
-
-if __name__ == "__main__":
- args = get_args()
- main(args)
diff --git a/examples/research_projects/rag-end2end-retriever/finetune_rag.py b/examples/research_projects/rag-end2end-retriever/finetune_rag.py
deleted file mode 100644
index 9bc2e5db6d5..00000000000
--- a/examples/research_projects/rag-end2end-retriever/finetune_rag.py
+++ /dev/null
@@ -1,815 +0,0 @@
-"""Finetuning script for RAG models. Adapted from examples.seq2seq.finetune.py"""
-
-import argparse
-import copy
-import json
-import logging
-import multiprocessing
-import os
-import random
-import shutil
-import sys
-import time
-from collections import defaultdict
-from pathlib import Path
-from typing import Any, Dict, List, Tuple
-
-import numpy as np
-import pytorch_lightning as pl
-import torch
-import torch.distributed as dist
-from datasets import concatenate_datasets, load_from_disk
-from torch.utils.data import DataLoader
-
-from transformers import (
- AutoConfig,
- AutoTokenizer,
- BartForConditionalGeneration,
- BatchEncoding,
- DPRConfig,
- DPRContextEncoder,
- DPRContextEncoderTokenizerFast,
- RagConfig,
- RagSequenceForGeneration,
- RagTokenForGeneration,
- RagTokenizer,
- T5ForConditionalGeneration,
-)
-from transformers import logging as transformers_logging
-from transformers.integrations import is_ray_available
-
-
-if is_ray_available():
- import ray
- from distributed_ray_retriever import RagRayDistributedRetriever, RayRetriever
-
-from glob import glob
-
-from callbacks_rag import Seq2SeqLoggingCallback, get_checkpoint_callback, get_early_stopping_callback
-from kb_encode_utils import add_index, embed_update
-from lightning_base import BaseTransformer, add_generic_args, generic_train
-from pynvml import nvmlDeviceGetCount, nvmlDeviceGetHandleByIndex, nvmlDeviceGetMemoryInfo, nvmlInit
-from utils_rag import (
- Seq2SeqDataset,
- calculate_exact_match,
- get_git_info,
- is_rag_model,
- lmap,
- pickle_save,
- save_git_info,
- save_json,
- set_extra_model_params,
-)
-
-
-logging.basicConfig(level=logging.INFO)
-logger = logging.getLogger(__name__)
-
-transformers_logging.set_verbosity_info()
-
-
-sys.path.insert(2, str(Path(__file__).resolve().parents[1]))
-isEmUpdateBusy = False
-isAddIndexBusy = False
-processes = []
-threadHandle_index = None
-
-
-class AttrDict(dict):
- def __init__(self, *args, **kwargs):
- super(AttrDict, self).__init__(*args, **kwargs)
- self.__dict__ = self
-
-
-class GenerativeQAModule(BaseTransformer):
- mode = "generative_qa"
- loss_names = ["loss"]
- metric_names = ["em"]
- val_metric = "em"
-
- def __init__(self, hparams, **kwargs):
- # when loading from a pytorch lightning checkpoint, hparams are passed as dict
- if isinstance(hparams, dict):
- hparams = AttrDict(hparams)
- if hparams.model_type == "rag_sequence":
- self.model_class = RagSequenceForGeneration
- elif hparams.model_type == "rag_token":
- self.model_class = RagTokenForGeneration
- elif hparams.model_type == "bart":
- self.model_class = BartForConditionalGeneration
- else:
- self.model_class = T5ForConditionalGeneration
- self.is_rag_model = is_rag_model(hparams.model_type)
-
- config_class = RagConfig if self.is_rag_model else AutoConfig
- config = config_class.from_pretrained(hparams.model_name_or_path)
-
- # set retriever parameters
- config.index_name = hparams.index_name or config.index_name
- config.passages_path = hparams.passages_path or config.passages_path
- config.index_path = hparams.index_path or config.index_path
- config.use_dummy_dataset = hparams.use_dummy_dataset
-
- # set extra_model_params for generator configs and load_model
- extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "attention_dropout", "dropout")
- if self.is_rag_model:
- if hparams.prefix is not None:
- config.generator.prefix = hparams.prefix
- config.label_smoothing = hparams.label_smoothing
- hparams, config.generator = set_extra_model_params(extra_model_params, hparams, config.generator)
- if hparams.distributed_retriever == "ray":
- # The Ray retriever needs the handles to the retriever actors.
- retriever = RagRayDistributedRetriever.from_pretrained(
- hparams.model_name_or_path, hparams.actor_handles, config=config
- )
-
- if hparams.end2end:
- ctx_encoder_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained(
- "facebook/dpr-ctx_encoder-multiset-base"
- )
- retriever.set_ctx_encoder_tokenizer(ctx_encoder_tokenizer)
- else:
- logger.info("please use RAY as the distributed retrieval method")
-
- model = self.model_class.from_pretrained(hparams.model_name_or_path, config=config, retriever=retriever)
- if hparams.end2end:
- ctx_encoder = DPRContextEncoder.from_pretrained(hparams.context_encoder_name)
- model.set_context_encoder_for_training(ctx_encoder)
- prefix = config.question_encoder.prefix
- else:
- if hparams.prefix is not None:
- config.prefix = hparams.prefix
- hparams, config = set_extra_model_params(extra_model_params, hparams, config)
- model = self.model_class.from_pretrained(hparams.model_name_or_path, config=config)
- prefix = config.prefix
-
- tokenizer = (
- RagTokenizer.from_pretrained(hparams.model_name_or_path)
- if self.is_rag_model
- else AutoTokenizer.from_pretrained(hparams.model_name_or_path)
- )
-
- self.config_dpr = DPRConfig.from_pretrained(hparams.context_encoder_name)
- self.custom_config = hparams
- self.context_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained(hparams.context_encoder_name)
-
- super().__init__(hparams, config=config, tokenizer=tokenizer, model=model)
-
- save_git_info(self.hparams.output_dir)
- self.output_dir = Path(self.hparams.output_dir)
- self.dpr_ctx_check_dir = str(Path(self.hparams.output_dir)) + "/dpr_ctx_checkpoint"
- self.metrics_save_path = Path(self.output_dir) / "metrics.json"
- self.hparams_save_path = Path(self.output_dir) / "hparams.pkl"
- pickle_save(self.hparams, self.hparams_save_path)
- self.step_count = 0
- self.metrics = defaultdict(list)
-
- self.dataset_kwargs: dict = {
- "data_dir": self.hparams.data_dir,
- "max_source_length": self.hparams.max_source_length,
- "prefix": prefix or "",
- }
- n_observations_per_split = {
- "train": self.hparams.n_train,
- "val": self.hparams.n_val,
- "test": self.hparams.n_test,
- }
- self.n_obs = {k: v if v >= 0 else None for k, v in n_observations_per_split.items()}
- self.target_lens = {
- "train": self.hparams.max_target_length,
- "val": self.hparams.val_max_target_length,
- "test": self.hparams.test_max_target_length,
- }
- assert self.target_lens["train"] <= self.target_lens["val"], f"target_lens: {self.target_lens}"
- assert self.target_lens["train"] <= self.target_lens["test"], f"target_lens: {self.target_lens}"
-
- self.hparams.git_sha = get_git_info()["repo_sha"]
- self.num_workers = hparams.num_workers
- self.distributed_port = self.hparams.distributed_port
-
- # For single GPU training, init_ddp_connection is not called.
- # So we need to initialize the retrievers here.
- if hparams.gpus <= 1:
- if hparams.distributed_retriever == "ray":
- self.model.retriever.init_retrieval()
- else:
- logger.info("please use RAY as the distributed retrieval method")
-
- self.distributed_retriever = hparams.distributed_retriever
-
- def forward(self, input_ids, **kwargs):
- return self.model(input_ids, **kwargs)
-
- def ids_to_clean_text(self, generated_ids: List[int]):
- gen_text = self.tokenizer.batch_decode(
- generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
- )
- return lmap(str.strip, gen_text)
-
- def _step(self, batch: dict) -> Tuple:
- source_ids, source_mask, target_ids = batch["input_ids"], batch["attention_mask"], batch["decoder_input_ids"]
-
- rag_kwargs = {}
- if isinstance(self.model, T5ForConditionalGeneration):
- decoder_input_ids = self.model._shift_right(target_ids)
- lm_labels = target_ids
- elif isinstance(self.model, BartForConditionalGeneration):
- decoder_input_ids = target_ids[:, :-1].contiguous()
- lm_labels = target_ids[:, 1:].clone()
- else:
- assert self.is_rag_model
- generator = self.model.rag.generator
- if isinstance(generator, T5ForConditionalGeneration):
- decoder_start_token_id = generator.config.decoder_start_token_id
- decoder_input_ids = (
- torch.cat(
- [torch.tensor([[decoder_start_token_id]] * target_ids.shape[0]).to(target_ids), target_ids],
- dim=1,
- )
- if target_ids.shape[0] < self.target_lens["train"]
- else generator._shift_right(target_ids)
- )
- elif isinstance(generator, BartForConditionalGeneration):
- decoder_input_ids = target_ids
- lm_labels = decoder_input_ids
- rag_kwargs["reduce_loss"] = True
-
- assert decoder_input_ids is not None
-
- outputs = self(
- source_ids,
- attention_mask=source_mask,
- decoder_input_ids=decoder_input_ids,
- use_cache=False,
- labels=lm_labels,
- **rag_kwargs,
- )
- loss = outputs["loss"]
- return (loss,)
-
- @property
- def pad(self) -> int:
- raise NotImplementedError("pad not implemented")
-
- def training_step(self, batch, batch_idx) -> Dict:
- global isEmUpdateBusy # use to check whether the entire embedding update process is finished or not
- global isAddIndexBusy # use to check whether the entire indexing process is finished or not
- global processes # use to keep threads embedding update processes
- global threadHandle_index # use to keep thread in embedding indexing processes
-
- if (self.trainer.global_rank == 0) and (self.custom_config.end2end):
- if (not batch_idx == 0) and (batch_idx % self.custom_config.indexing_freq == 0):
- free_gpu_list = []
- nvmlInit()
- deviceCount = nvmlDeviceGetCount()
-
- my_list = json.loads(self.custom_config.gpu_order)
-
- for i in range(deviceCount):
- handle = nvmlDeviceGetHandleByIndex(i)
- info = nvmlDeviceGetMemoryInfo(handle)
-
- if info.used / 1e6 < 15:
- position = my_list.index(i)
- free_gpu_list.append("cuda:" + str(position))
-
- if len(free_gpu_list) >= self.custom_config.index_gpus:
- has_free_gpus = True
-
- else:
- has_free_gpus = False
-
- if (not isEmUpdateBusy) and has_free_gpus:
- model_copy = type(self.model.rag.ctx_encoder)(
- self.config_dpr
- ) # get a new instance #this will be load in the CPU
- model_copy.load_state_dict(self.model.rag.ctx_encoder.state_dict()) # copy weights
-
- processes = []
-
- if len(free_gpu_list) > self.custom_config.index_gpus:
- cuda_devices = random.sample(free_gpu_list, self.custom_config.index_gpus)
- else:
- cuda_devices = free_gpu_list
-
- num_processes = len(cuda_devices)
-
- for rank in range(num_processes):
- logger.info("Iniitializing embedding calculation process rank{}".format(rank))
- device = cuda_devices[rank]
- p = multiprocessing.Process(
- target=embed_update,
- args=(
- copy.deepcopy(model_copy),
- num_processes,
- device,
- rank,
- self.custom_config.shard_dir,
- self.custom_config.csv_path,
- ),
- )
- processes.append(p)
-
- for p in processes:
- p.start()
-
- isEmUpdateBusy = True
-
- if isEmUpdateBusy and (not isAddIndexBusy):
- index_process_list = [processes[k].is_alive() for k in range(self.custom_config.index_gpus)]
- if (
- sum(index_process_list) == 0
- ): # If entire list is false, we can say all embedding calculation process has finished
- logger.info("Start adding the index")
- threadHandle_index = multiprocessing.Process(
- target=add_index,
- args=(
- self.custom_config.shard_dir,
- self.config.index_path,
- ),
- )
- threadHandle_index.start()
- isAddIndexBusy = True
-
- # check when index building has started
- if isAddIndexBusy:
- # check still the index_building process is happening
- if not threadHandle_index.is_alive():
- logger.info("Merging the dataset shards")
- saved_dataset_shards = []
-
- for address in glob(str(self.custom_config.shard_dir) + "/*/"):
- saved_dataset_shards.append(load_from_disk(address))
-
- concat = concatenate_datasets(saved_dataset_shards)
- concat.save_to_disk(self.config.passages_path) # here we update the main passage file on the disk
- logger.info("done updating the dataset")
-
- # To Do (@Aaron) : Useful in the future dynamic memory implementation.
- # if you load the index from the disk make sure to update the index file here, otherwise it is ok to update the index file from the worker.
- # logger.info("then updating the index")
- # shutil.copy(self.custom_config.temp_index, self.config.idex_path)
-
- logger.info("Loading new passages and iniitalzing new index")
- self.trainer.model.module.module.model.rag.retriever.re_load()
- self.trainer.model.module.module.model.rag.retriever.init_retrieval()
-
- isEmUpdateBusy = False
- isAddIndexBusy = False
- self.trainer.strategy.barrier("barrier")
-
- loss_tensors = self._step(batch)
-
- logs = dict(zip(self.loss_names, loss_tensors))
- # tokens per batch
- tgt_pad_token_id = (
- self.tokenizer.generator.pad_token_id
- if isinstance(self.tokenizer, RagTokenizer)
- else self.tokenizer.pad_token_id
- )
- src_pad_token_id = (
- self.tokenizer.question_encoder.pad_token_id
- if isinstance(self.tokenizer, RagTokenizer)
- else self.tokenizer.pad_token_id
- )
- logs["tpb"] = (
- batch["input_ids"].ne(src_pad_token_id).sum() + batch["decoder_input_ids"].ne(tgt_pad_token_id).sum()
- )
- self.log("loss", loss_tensors[0])
- return loss_tensors[0]
-
- def validation_step(self, batch, batch_idx) -> Dict:
- return self._generative_step(batch)
-
- def validation_epoch_end(self, outputs, prefix="val") -> Dict:
- self.step_count += 1
- losses = {k: torch.stack([x[k] for x in outputs]).mean() for k in self.loss_names}
- loss = losses["loss"]
- gen_metrics = {
- k: np.array([x[k] for x in outputs]).mean() for k in self.metric_names + ["gen_time", "gen_len"]
- }
- metrics_tensor: torch.FloatTensor = torch.tensor(gen_metrics[self.val_metric]).type_as(loss)
- gen_metrics.update({k: v.item() for k, v in losses.items()})
-
- # fix for https://github.com/PyTorchLightning/pytorch-lightning/issues/2424
- if dist.is_initialized():
- dist.all_reduce(metrics_tensor, op=dist.ReduceOp.SUM)
- metrics_tensor = metrics_tensor / dist.get_world_size()
- gen_metrics.update({self.val_metric: metrics_tensor.item()})
-
- losses.update(gen_metrics)
- metrics = {f"{prefix}_avg_{k}": x for k, x in losses.items()}
- metrics["step_count"] = self.step_count
- self.save_metrics(metrics, prefix) # writes to self.metrics_save_path
-
- log_dict = {
- f"{prefix}_avg_em": metrics[f"{prefix}_avg_em"],
- "step_count": metrics["step_count"],
- f"{prefix}_avg_loss": metrics[f"{prefix}_avg_loss"],
- f"{prefix}_loss": loss,
- f"{prefix}_em": metrics_tensor,
- }
- self.log_dict(log_dict)
-
- def save_metrics(self, latest_metrics, type_path) -> None:
- self.metrics[type_path].append(latest_metrics)
- save_json(self.metrics, self.metrics_save_path)
-
- def calc_generative_metrics(self, preds, target) -> Dict:
- return calculate_exact_match(preds, target)
-
- def _generative_step(self, batch: dict) -> dict:
- start_time = time.time()
- batch = BatchEncoding(batch).to(device=self.model.device)
- generated_ids = self.model.generate(
- batch["input_ids"],
- attention_mask=batch["attention_mask"],
- do_deduplication=False, # rag specific parameter
- use_cache=True,
- min_length=1,
- max_length=self.target_lens["val"],
- )
- gen_time = (time.time() - start_time) / batch["input_ids"].shape[0]
- preds: List[str] = self.ids_to_clean_text(generated_ids)
- target: List[str] = self.ids_to_clean_text(batch["decoder_input_ids"])
- # print(preds,target)
- loss_tensors = self._step(batch)
- base_metrics = dict(zip(self.loss_names, loss_tensors))
- gen_metrics: Dict = self.calc_generative_metrics(preds, target)
-
- summ_len = np.mean(lmap(len, generated_ids))
- base_metrics.update(gen_time=gen_time, gen_len=summ_len, preds=preds, target=target, **gen_metrics)
- return base_metrics
-
- def test_step(self, batch, batch_idx):
- return self._generative_step(batch)
-
- def test_epoch_end(self, outputs):
- return self.validation_epoch_end(outputs, prefix="test")
-
- def get_dataset(self, type_path) -> Seq2SeqDataset:
- n_obs = self.n_obs[type_path]
- max_target_length = self.target_lens[type_path]
- dataset = Seq2SeqDataset(
- self.tokenizer,
- type_path=type_path,
- n_obs=n_obs,
- max_target_length=max_target_length,
- **self.dataset_kwargs,
- )
- return dataset
-
- def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False) -> DataLoader:
- dataset = self.get_dataset(type_path)
-
- dataloader = DataLoader(
- dataset,
- batch_size=batch_size,
- collate_fn=dataset.collate_fn,
- shuffle=shuffle,
- num_workers=self.num_workers,
- )
- return dataloader
-
- def train_dataloader(self) -> DataLoader:
- dataloader = self.get_dataloader("train", batch_size=self.hparams.train_batch_size, shuffle=True)
- return dataloader
-
- def val_dataloader(self) -> DataLoader:
- return self.get_dataloader("val", batch_size=self.hparams.eval_batch_size)
-
- def test_dataloader(self) -> DataLoader:
- return self.get_dataloader("test", batch_size=self.hparams.eval_batch_size)
-
- @pl.utilities.rank_zero_only
- def on_save_checkpoint(self, checkpoint: Dict[str, Any]) -> None:
- save_path = self.output_dir.joinpath("checkpoint{}".format(self.step_count))
- self.model.config.save_step = self.step_count
- # self.model.save_pretrained(save_path)
- self.tokenizer.save_pretrained(save_path)
-
- if self.custom_config.end2end:
- modified_state_dict = self.model.state_dict()
- for key in self.model.state_dict().keys():
- if key.split(".")[1] == "ctx_encoder":
- del modified_state_dict[key]
- self.model.save_pretrained(save_directory=save_path, state_dict=modified_state_dict)
-
- save_path_dpr = os.path.join(self.dpr_ctx_check_dir, "checkpoint{}".format(self.step_count))
- self.model.rag.ctx_encoder.save_pretrained(save_path_dpr)
- self.context_tokenizer.save_pretrained(save_path_dpr)
-
- @staticmethod
- def add_model_specific_args(parser, root_dir):
- BaseTransformer.add_model_specific_args(parser, root_dir)
- add_generic_args(parser, root_dir)
- parser.add_argument(
- "--max_source_length",
- default=128,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument(
- "--max_target_length",
- default=25,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument(
- "--val_max_target_length",
- default=25,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument(
- "--test_max_target_length",
- default=25,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument("--logger_name", type=str, choices=["default", "wandb", "wandb_shared"], default="default")
- parser.add_argument("--n_train", type=int, default=-1, required=False, help="# examples. -1 means use all.")
- parser.add_argument("--n_val", type=int, default=-1, required=False, help="# examples. -1 means use all.")
- parser.add_argument("--n_test", type=int, default=-1, required=False, help="# examples. -1 means use all.")
- parser.add_argument("--label_smoothing", type=float, default=0.0, required=False)
- parser.add_argument(
- "--prefix",
- type=str,
- default=None,
- help="Prefix added at the beginning of each text, typically used with T5-based models.",
- )
- parser.add_argument(
- "--early_stopping_patience",
- type=int,
- default=-1,
- required=False,
- help=(
- "-1 means never early stop. early_stopping_patience is measured in validation checks, not epochs. So"
- " val_check_interval will effect it."
- ),
- )
- parser.add_argument(
- "--distributed-port", type=int, default=-1, required=False, help="Port number for distributed training."
- )
- parser.add_argument(
- "--model_type",
- choices=["rag_sequence", "rag_token", "bart", "t5"],
- type=str,
- help=(
- "RAG model type: sequence or token, if none specified, the type is inferred from the"
- " model_name_or_path"
- ),
- )
- parser.add_argument(
- "--context_encoder_name",
- default="facebook/dpr-ctx_encoder-multiset-base",
- type=str,
- help="Name of the pre-trained context encoder checkpoint from the DPR",
- )
- parser.add_argument(
- "--csv_path",
- default=str(Path(__file__).parent / "test_run" / "dummy-kb" / "my_knowledge_dataset.csv"),
- type=str,
- help="path of the raw KB csv",
- )
- parser.add_argument("--end2end", action="store_true", help="whether to train the system end2end or not")
- parser.add_argument("--index_gpus", type=int, help="how many GPUs used in re-encoding process")
- parser.add_argument(
- "--shard_dir",
- type=str,
- default=str(Path(__file__).parent / "test_run" / "kb-shards"),
- help="directory used to keep temporary shards during the re-encode process",
- )
-
- parser.add_argument(
- "--gpu_order",
- type=str,
- help=(
- "order of the GPU used during the fine-tuning. Used to finding free GPUs during the re-encode"
- " process. I do not have many GPUs :)"
- ),
- )
-
- parser.add_argument("--indexing_freq", type=int, help="frequency of re-encode process")
- return parser
-
- @staticmethod
- def add_retriever_specific_args(parser):
- parser.add_argument(
- "--index_name",
- type=str,
- default=None,
- help=(
- "Name of the index to use: 'hf' for a canonical dataset from the datasets library (default), 'custom'"
- " for a local index, or 'legacy' for the orignal one)"
- ),
- )
- parser.add_argument(
- "--passages_path",
- type=str,
- default=str(Path(__file__).parent / "test_run" / "dummy-kb" / "my_knowledge_dataset"),
- help=(
- "Path to the dataset of passages for custom index. More info about custom indexes in the RagRetriever"
- " documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
- ),
- )
- parser.add_argument(
- "--index_path",
- type=str,
- default=str(Path(__file__).parent / "test_run" / "dummy-kb" / "my_knowledge_dataset_hnsw_index.faiss"),
- help=(
- "Path to the faiss index for custom index. More info about custom indexes in the RagRetriever"
- " documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
- ),
- )
- parser.add_argument(
- "--distributed_retriever",
- choices=["ray", "pytorch"],
- type=str,
- default="ray",
- help=(
- "What implementation to use for distributed retriever? If "
- "pytorch is selected, the index is loaded on training "
- "worker 0, and torch.distributed is used to handle "
- "communication between training worker 0, and the other "
- "training workers. If ray is selected, the Ray library is "
- "used to create load the index on separate processes, "
- "and Ray handles the communication between the training "
- "workers and the retrieval actors."
- ),
- )
- parser.add_argument(
- "--use_dummy_dataset",
- type=bool,
- default=False,
- help=(
- "Whether to use the dummy version of the dataset index. More info about custom indexes in the"
- " RagRetriever documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
- ),
- )
- return parser
-
- @staticmethod
- def add_ray_specific_args(parser):
- # Ray cluster address.
- parser.add_argument(
- "--ray-address",
- default="auto",
- type=str,
- help=(
- "The address of the Ray cluster to connect to. If not "
- "specified, Ray will attempt to automatically detect the "
- "cluster. Has no effect if pytorch is used as the distributed "
- "retriever."
- ),
- )
- parser.add_argument(
- "--num_retrieval_workers",
- type=int,
- default=1,
- help=(
- "The number of retrieval actors to use when Ray is selected "
- "for the distributed retriever. Has no effect when "
- "distributed_retriever is set to pytorch."
- ),
- )
- return parser
-
-
-def main(args=None, model=None) -> GenerativeQAModule:
- parser = argparse.ArgumentParser()
- parser = pl.Trainer.add_argparse_args(parser)
- parser = GenerativeQAModule.add_model_specific_args(parser, os.getcwd())
- parser = GenerativeQAModule.add_retriever_specific_args(parser)
- args = args or parser.parse_args()
-
- Path(args.output_dir).mkdir(exist_ok=True)
- Path(args.output_dir + "/dpr_ctx_checkpoint").mkdir(
- exist_ok=True
- ) # save dpr_context encoder seprately for the future use
- print(args.shard_dir)
- if os.path.exists(args.shard_dir): # we do not need previous kb shards used in dataset re-conding and re-indexing
- shutil.rmtree(args.shard_dir)
- Path(args.shard_dir).mkdir(exist_ok=True)
-
- if os.path.exists(
- args.cache_dir
- ): # we do not need previous cache files used in dataset re-conding and re-indexing
- shutil.rmtree(args.cache_dir)
- Path(args.cache_dir).mkdir(exist_ok=True)
-
- named_actors = []
- if args.distributed_retriever == "ray" and args.gpus > 1:
- if not is_ray_available():
- raise RuntimeError("Please install Ray to use the Ray distributed retriever.")
- # Connect to an existing Ray cluster.
- try:
- ray.init(address=args.ray_address, namespace="rag")
- except (ConnectionError, ValueError):
- logger.warning(
- "Connection to Ray cluster failed. Make sure a Ray "
- "cluster is running by either using Ray's cluster "
- "launcher (`ray up`) or by manually starting Ray on "
- "each node via `ray start --head` for the head node "
- "and `ray start --address=':6379'` for "
- "additional nodes. See "
- "https://docs.ray.io/en/master/cluster/index.html "
- "for more info."
- )
- raise
-
- # Create Ray actors only for rank 0.
- if ("LOCAL_RANK" not in os.environ or os.environ["LOCAL_RANK"] == 0) and (
- "NODE_RANK" not in os.environ or os.environ["NODE_RANK"] == 0
- ):
- remote_cls = ray.remote(RayRetriever)
- named_actors = [
- remote_cls.options(name="retrieval_worker_{}".format(i)).remote()
- for i in range(args.num_retrieval_workers)
- ]
- else:
- logger.info(
- "Getting named actors for NODE_RANK {}, LOCAL_RANK {}".format(
- os.environ["NODE_RANK"], os.environ["LOCAL_RANK"]
- )
- )
- named_actors = [ray.get_actor("retrieval_worker_{}".format(i)) for i in range(args.num_retrieval_workers)]
- args.actor_handles = named_actors
- assert args.actor_handles == named_actors
-
- if model is None:
- model: GenerativeQAModule = GenerativeQAModule(args)
-
- dataset = Path(args.data_dir).name
- if (
- args.logger_name == "default"
- or args.fast_dev_run
- or str(args.output_dir).startswith("/tmp")
- or str(args.output_dir).startswith("/var")
- ):
- training_logger = True # don't pollute wandb logs unnecessarily
- elif args.logger_name == "wandb":
- from pytorch_lightning.loggers import WandbLogger
-
- project = os.environ.get("WANDB_PROJECT", dataset)
- training_logger = WandbLogger(name=model.output_dir.name, project=project)
-
- elif args.logger_name == "wandb_shared":
- from pytorch_lightning.loggers import WandbLogger
-
- training_logger = WandbLogger(name=model.output_dir.name, project=f"hf_{dataset}")
-
- es_callback = (
- get_early_stopping_callback(model.val_metric, args.early_stopping_patience)
- if args.early_stopping_patience >= 0
- else False
- )
-
- trainer: pl.Trainer = generic_train(
- model,
- args,
- logging_callback=Seq2SeqLoggingCallback(),
- checkpoint_callback=get_checkpoint_callback(args.output_dir, model.val_metric),
- early_stopping_callback=es_callback,
- logger=training_logger,
- profiler=pl.profiler.AdvancedProfiler() if args.profile else None,
- )
-
- pickle_save(model.hparams, model.output_dir / "hparams.pkl")
- if not args.do_predict:
- return model
-
- # test() without a model tests using the best checkpoint automatically
- trainer.test()
- return model
-
-
-if __name__ == "__main__":
- multiprocessing.set_start_method("spawn")
- parser = argparse.ArgumentParser()
- parser = pl.Trainer.add_argparse_args(parser)
- parser = GenerativeQAModule.add_model_specific_args(parser, os.getcwd())
- parser = GenerativeQAModule.add_retriever_specific_args(parser)
- parser = GenerativeQAModule.add_ray_specific_args(parser)
-
- # Pytorch Lightning Profiler
- parser.add_argument(
- "--profile",
- action="store_true",
- help="If True, use pytorch_lightning.profiler.AdvancedProfiler to profile the Trainer.",
- )
-
- args = parser.parse_args()
- main(args)
diff --git a/examples/research_projects/rag-end2end-retriever/finetune_rag_ray_end2end.sh b/examples/research_projects/rag-end2end-retriever/finetune_rag_ray_end2end.sh
deleted file mode 100755
index cef1a264c93..00000000000
--- a/examples/research_projects/rag-end2end-retriever/finetune_rag_ray_end2end.sh
+++ /dev/null
@@ -1,68 +0,0 @@
-# Sample script to finetune RAG using Ray for distributed retrieval.
-
-# Add parent directory to python path to access lightning_base.py
-export PYTHONPATH="../":"${PYTHONPATH}"
-
-#creates the custom knowlegebase
-python use_own_knowledge_dataset.py \
- --csv_path /DIR/SQUAD-KB/squad-kb.csv \
- --output_dir /DIR/SQUAD-KB
-
-# Start a single-node Ray cluster.
-ray start --head
-
-# A sample finetuning run, you need to specify data_dir, output_dir and model_name_or_path
-# run ./examples/rag/finetune_rag_ray.sh --help to see all the possible options
-
-
-
-python finetune_rag.py \
- --data_dir /DIR/squad-training-data \
- --output_dir /DIR/model_checkpoints \
- --model_name_or_path facebook/rag-token-base \
- --model_type rag_token \
- --fp16 \
- --gpus 2 \
- --profile \
- --do_train \
- --end2end \
- --do_predict \
- --n_val -1 \
- --train_batch_size 4 \
- --eval_batch_size 1 \
- --max_source_length 128 \
- --max_target_length 25 \
- --val_max_target_length 25 \
- --test_max_target_length 25 \
- --label_smoothing 0.1 \
- --dropout 0.1 \
- --attention_dropout 0.1 \
- --weight_decay 0.001 \
- --adam_epsilon 1e-08 \
- --max_grad_norm 0.1 \
- --lr_scheduler polynomial \
- --learning_rate 3e-05 \
- --num_train_epochs 10 \
- --warmup_steps 500 \
- --gradient_accumulation_steps 8 \
- --distributed_retriever ray \
- --num_retrieval_workers 4 \
- --passages_path /DIR/SQUAD-KB/my_knowledge_dataset \
- --index_path /DIR/SQUAD-KB/my_knowledge_dataset_hnsw_index.faiss \
- --index_name custom \
- --context_encoder_name facebook/dpr-ctx_encoder-multiset-base \
- --csv_path /DIR/SQUAD-KB/squad-kb.csv \
- --index_gpus 1 \
- --gpu_order [5,6,7,8,9,0,1,2,3,4] \
- --shard_dir ./test_dir/kb-shards \
- --indexing_freq 500
-
-
-
-# Stop the Ray cluster.
-ray stop
-
-
-#this script was used to test the SQuAD data.
-#change the dir paramater acording to your prefernece.
-#please use the same device ordere when running CUDA_VISIBLE_DEVICES=5,6,7,8,9,0,1,2,3,4 sh finetune_rag_ray_end2end.sh
\ No newline at end of file
diff --git a/examples/research_projects/rag-end2end-retriever/kb_encode_utils.py b/examples/research_projects/rag-end2end-retriever/kb_encode_utils.py
deleted file mode 100644
index 444c07b2bab..00000000000
--- a/examples/research_projects/rag-end2end-retriever/kb_encode_utils.py
+++ /dev/null
@@ -1,80 +0,0 @@
-import os
-from functools import partial
-from glob import glob
-
-import faiss
-from datasets import Features, Sequence, Value, concatenate_datasets, load_dataset, load_from_disk
-
-from transformers import DPRContextEncoder, DPRContextEncoderTokenizerFast
-
-
-def split_text(text, n=100, character=" "):
- """Split the text every ``n``-th occurrence of ``character``"""
- text = text.split(character)
- return [character.join(text[i : i + n]).strip() for i in range(0, len(text), n)]
-
-
-def split_documents(documents):
- """Split documents into passages"""
- titles, texts = [], []
- for title, text in zip(documents["title"], documents["text"]):
- if text is not None:
- for passage in split_text(text):
- titles.append(title if title is not None else "")
- texts.append(passage)
- return {"title": titles, "text": texts}
-
-
-def embed_update(ctx_encoder, total_processes, device, process_num, shard_dir, csv_path):
- kb_dataset = load_dataset(
- "csv", data_files=[csv_path], split="train", delimiter="\t", column_names=["title", "text"]
- )
- kb_dataset = kb_dataset.map(
- split_documents, batched=True, num_proc=1
- ) # if you want you can load already splitted csv.
- kb_list = [kb_dataset.shard(total_processes, i, contiguous=True) for i in range(total_processes)]
- data_shrad = kb_list[process_num]
-
- arrow_folder = "data_" + str(process_num)
- passages_path = os.path.join(shard_dir, arrow_folder)
-
- context_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained("facebook/dpr-ctx_encoder-multiset-base")
- ctx_encoder = ctx_encoder.to(device=device)
-
- def embed(
- documents: dict, ctx_encoder: DPRContextEncoder, ctx_tokenizer: DPRContextEncoderTokenizerFast, device
- ) -> dict:
- """Compute the DPR embeddings of document passages"""
- input_ids = ctx_tokenizer(
- documents["title"], documents["text"], truncation=True, padding="longest", return_tensors="pt"
- )["input_ids"]
- embeddings = ctx_encoder(input_ids.to(device=device), return_dict=True).pooler_output
- return {"embeddings": embeddings.detach().cpu().numpy()}
-
- new_features = Features(
- {"text": Value("string"), "title": Value("string"), "embeddings": Sequence(Value("float32"))}
- ) # optional, save as float32 instead of float64 to save space
-
- dataset = data_shrad.map(
- partial(embed, ctx_encoder=ctx_encoder, ctx_tokenizer=context_tokenizer, device=device),
- batched=True,
- batch_size=16,
- features=new_features,
- )
- dataset.save_to_disk(passages_path)
-
-
-def add_index(shard_dir, index_path):
- data_shard_list = []
-
- for shard_address in glob(str(shard_dir) + "/*/"):
- data_shard_list.append(load_from_disk(shard_address))
-
- concat = concatenate_datasets(data_shard_list)
- faiss.omp_set_num_threads(96)
-
- index = faiss.IndexHNSWFlat(768, 128, faiss.METRIC_INNER_PRODUCT)
- concat.add_faiss_index("embeddings", custom_index=index)
- concat.get_index("embeddings").save(
- index_path
- ) # since we load the index in to memory,we can directly update the index in the disk
diff --git a/examples/research_projects/rag-end2end-retriever/lightning_base.py b/examples/research_projects/rag-end2end-retriever/lightning_base.py
deleted file mode 100644
index c1a271e88d1..00000000000
--- a/examples/research_projects/rag-end2end-retriever/lightning_base.py
+++ /dev/null
@@ -1,414 +0,0 @@
-import argparse
-import logging
-import os
-from pathlib import Path
-from typing import Any, Dict
-
-import pytorch_lightning as pl
-from pytorch_lightning.utilities import rank_zero_info
-
-from transformers import (
- AdamW,
- AutoConfig,
- AutoModel,
- AutoModelForPreTraining,
- AutoModelForQuestionAnswering,
- AutoModelForSeq2SeqLM,
- AutoModelForSequenceClassification,
- AutoModelForTokenClassification,
- AutoModelWithLMHead,
- AutoTokenizer,
- PretrainedConfig,
- PreTrainedTokenizer,
-)
-from transformers.optimization import (
- Adafactor,
- get_cosine_schedule_with_warmup,
- get_cosine_with_hard_restarts_schedule_with_warmup,
- get_linear_schedule_with_warmup,
- get_polynomial_decay_schedule_with_warmup,
-)
-from transformers.utils.versions import require_version
-
-
-logger = logging.getLogger(__name__)
-
-require_version("pytorch_lightning>=1.0.4")
-
-MODEL_MODES = {
- "base": AutoModel,
- "sequence-classification": AutoModelForSequenceClassification,
- "question-answering": AutoModelForQuestionAnswering,
- "pretraining": AutoModelForPreTraining,
- "token-classification": AutoModelForTokenClassification,
- "language-modeling": AutoModelWithLMHead,
- "summarization": AutoModelForSeq2SeqLM,
- "translation": AutoModelForSeq2SeqLM,
-}
-
-
-# update this and the import above to support new schedulers from transformers.optimization
-arg_to_scheduler = {
- "linear": get_linear_schedule_with_warmup,
- "cosine": get_cosine_schedule_with_warmup,
- "cosine_w_restarts": get_cosine_with_hard_restarts_schedule_with_warmup,
- "polynomial": get_polynomial_decay_schedule_with_warmup,
- # '': get_constant_schedule, # not supported for now
- # '': get_constant_schedule_with_warmup, # not supported for now
-}
-arg_to_scheduler_choices = sorted(arg_to_scheduler.keys())
-arg_to_scheduler_metavar = "{" + ", ".join(arg_to_scheduler_choices) + "}"
-
-
-class BaseTransformer(pl.LightningModule):
- def __init__(
- self,
- hparams: argparse.Namespace,
- num_labels=None,
- mode="base",
- config=None,
- tokenizer=None,
- model=None,
- **config_kwargs,
- ):
- """Initialize a model, tokenizer and config."""
- super().__init__()
- # TODO: move to self.save_hyperparameters()
- # self.save_hyperparameters()
- # can also expand arguments into trainer signature for easier reading
-
- self.save_hyperparameters(hparams)
- self.step_count = 0
- self.output_dir = Path(self.hparams.output_dir)
- cache_dir = self.hparams.cache_dir if self.hparams.cache_dir else None
- if config is None:
- self.config = AutoConfig.from_pretrained(
- self.hparams.config_name if self.hparams.config_name else self.hparams.model_name_or_path,
- **({"num_labels": num_labels} if num_labels is not None else {}),
- cache_dir=cache_dir,
- **config_kwargs,
- )
- else:
- self.config: PretrainedConfig = config
-
- extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "dropout", "attention_dropout")
- for p in extra_model_params:
- if getattr(self.hparams, p, None):
- assert hasattr(self.config, p), f"model config doesn't have a `{p}` attribute"
- setattr(self.config, p, getattr(self.hparams, p))
-
- if tokenizer is None:
- self.tokenizer = AutoTokenizer.from_pretrained(
- self.hparams.tokenizer_name if self.hparams.tokenizer_name else self.hparams.model_name_or_path,
- cache_dir=cache_dir,
- )
- else:
- self.tokenizer: PreTrainedTokenizer = tokenizer
- self.model_type = MODEL_MODES[mode]
- if model is None:
- self.model = self.model_type.from_pretrained(
- self.hparams.model_name_or_path,
- from_tf=bool(".ckpt" in self.hparams.model_name_or_path),
- config=self.config,
- cache_dir=cache_dir,
- )
- else:
- self.model = model
-
- def load_hf_checkpoint(self, *args, **kwargs):
- self.model = self.model_type.from_pretrained(*args, **kwargs)
-
- def get_lr_scheduler(self):
- get_schedule_func = arg_to_scheduler[self.hparams.lr_scheduler]
- scheduler = get_schedule_func(
- self.opt, num_warmup_steps=self.hparams.warmup_steps, num_training_steps=self.total_steps()
- )
- scheduler = {"scheduler": scheduler, "interval": "step", "frequency": 1}
- return scheduler
-
- def configure_optimizers(self):
- """Prepare optimizer and schedule (linear warmup and decay)"""
- model = self.model
- no_decay = ["bias", "LayerNorm.weight"]
- optimizer_grouped_parameters = [
- {
- "params": [
- p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)
- ], # check this named parameters
- "weight_decay": self.hparams.weight_decay,
- },
- {
- "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
- "weight_decay": 0.0,
- },
- ]
- if self.hparams.adafactor:
- optimizer = Adafactor(
- optimizer_grouped_parameters, lr=self.hparams.learning_rate, scale_parameter=False, relative_step=False
- )
-
- else:
- optimizer = AdamW(
- optimizer_grouped_parameters, lr=self.hparams.learning_rate, eps=self.hparams.adam_epsilon
- )
- self.opt = optimizer
-
- scheduler = self.get_lr_scheduler()
-
- return [optimizer], [scheduler]
-
- def test_step(self, batch, batch_nb):
- return self.validation_step(batch, batch_nb)
-
- def test_epoch_end(self, outputs):
- return self.validation_end(outputs)
-
- def total_steps(self) -> int:
- """The number of total training steps that will be run. Used for lr scheduler purposes."""
- num_devices = max(1, self.hparams.gpus) # TODO: consider num_tpu_cores
- effective_batch_size = self.hparams.train_batch_size * self.hparams.accumulate_grad_batches * num_devices
- return (self.dataset_size / effective_batch_size) * self.hparams.max_epochs
-
- def setup(self, stage):
- if stage == "test":
- self.dataset_size = len(self.test_dataloader().dataset)
- else:
- self.train_loader = self.get_dataloader("train", self.hparams.train_batch_size, shuffle=True)
- self.dataset_size = len(self.train_dataloader().dataset)
-
- def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False):
- raise NotImplementedError("You must implement this for your task")
-
- def train_dataloader(self):
- return self.train_loader
-
- def val_dataloader(self):
- return self.get_dataloader("dev", self.hparams.eval_batch_size, shuffle=False)
-
- def test_dataloader(self):
- return self.get_dataloader("test", self.hparams.eval_batch_size, shuffle=False)
-
- def _feature_file(self, mode):
- return os.path.join(
- self.hparams.data_dir,
- "cached_{}_{}_{}".format(
- mode,
- list(filter(None, self.hparams.model_name_or_path.split("/"))).pop(),
- str(self.hparams.max_seq_length),
- ),
- )
-
- @pl.utilities.rank_zero_only
- def on_save_checkpoint(self, checkpoint: Dict[str, Any]) -> None:
- save_path = self.output_dir.joinpath("best_tfmr")
- self.model.config.save_step = self.step_count
- self.model.save_pretrained(save_path)
- self.tokenizer.save_pretrained(save_path)
-
- @staticmethod
- def add_model_specific_args(parser, root_dir):
- parser.add_argument(
- "--model_name_or_path",
- default=None,
- type=str,
- required=True,
- help="Path to pretrained model or model identifier from huggingface.co/models",
- )
- parser.add_argument(
- "--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
- )
- parser.add_argument(
- "--tokenizer_name",
- default=None,
- type=str,
- help="Pretrained tokenizer name or path if not the same as model_name",
- )
- parser.add_argument(
- "--cache_dir",
- default=str(Path(__file__).parent / "test_run" / "cache"),
- type=str,
- help="Where do you want to store the pre-trained models downloaded from huggingface.co",
- )
- parser.add_argument(
- "--encoder_layerdrop",
- type=float,
- help="Encoder layer dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument(
- "--decoder_layerdrop",
- type=float,
- help="Decoder layer dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument(
- "--dropout",
- type=float,
- help="Dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument(
- "--attention_dropout",
- type=float,
- help="Attention dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
- parser.add_argument(
- "--lr_scheduler",
- default="linear",
- choices=arg_to_scheduler_choices,
- metavar=arg_to_scheduler_metavar,
- type=str,
- help="Learning rate scheduler",
- )
- parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
- parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
- parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
- parser.add_argument("--num_workers", default=4, type=int, help="kwarg passed to DataLoader")
- parser.add_argument("--num_train_epochs", dest="max_epochs", default=3, type=int)
- parser.add_argument("--train_batch_size", default=32, type=int)
- parser.add_argument("--eval_batch_size", default=32, type=int)
- parser.add_argument("--adafactor", action="store_true")
-
-
-class InitCallback(pl.Callback):
- # this process can also be done with PL ddp plugging.
- # But still it is experimental (check original RAG, I updated that with pluggin (shamanez))
- def on_sanity_check_start(self, trainer, pl_module):
- if (
- trainer.is_global_zero and trainer.global_rank == 0
- ): # we initialize the retriever only on master worker with RAY. In new pytorch-lightning accelorators are removed.
- pl_module.model.rag.retriever.init_retrieval() # better to use hook functions.
-
-
-class CheckParamCallback(pl.Callback):
- # check whether new added model parameters are differentiable
- def on_after_backward(self, trainer, pl_module):
- # print(pl_module.model.rag)
- for name, param in pl_module.model.rag.named_parameters():
- if param.grad is None:
- print(name)
-
-
-class LoggingCallback(pl.Callback):
- def on_batch_end(self, trainer, pl_module):
- lr_scheduler = trainer.lr_schedulers[0]["scheduler"]
- lrs = {f"lr_group_{i}": lr for i, lr in enumerate(lr_scheduler.get_lr())}
- pl_module.logger.log_metrics(lrs)
-
- def on_validation_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
- rank_zero_info("***** Validation results *****")
- metrics = trainer.callback_metrics
- # Log results
- for key in sorted(metrics):
- if key not in ["log", "progress_bar"]:
- rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
-
- def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
- rank_zero_info("***** Test results *****")
- metrics = trainer.callback_metrics
- # Log and save results to file
- output_test_results_file = os.path.join(pl_module.hparams.output_dir, "test_results.txt")
- with open(output_test_results_file, "w") as writer:
- for key in sorted(metrics):
- if key not in ["log", "progress_bar"]:
- rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
- writer.write("{} = {}\n".format(key, str(metrics[key])))
-
-
-def add_generic_args(parser, root_dir) -> None:
- # To allow all pl args uncomment the following line
- # parser = pl.Trainer.add_argparse_args(parser)
- parser.add_argument(
- "--output_dir",
- default=str(Path(__file__).parent / "test_run" / "model_checkpoints"),
- type=str,
- help="The output directory where the model predictions and checkpoints will be written.",
- )
- parser.add_argument(
- "--fp16",
- action="store_true",
- help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
- )
-
- parser.add_argument(
- "--fp16_opt_level",
- type=str,
- default="O2",
- help=(
- "For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
- "See details at https://nvidia.github.io/apex/amp.html"
- ),
- )
- parser.add_argument("--n_tpu_cores", dest="tpu_cores", type=int)
- parser.add_argument("--max_grad_norm", dest="gradient_clip_val", default=1.0, type=float, help="Max gradient norm")
- parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
- parser.add_argument("--do_predict", action="store_true", help="Whether to run predictions on the test set.")
- parser.add_argument(
- "--gradient_accumulation_steps",
- dest="accumulate_grad_batches",
- type=int,
- default=1,
- help="Number of updates steps to accumulate before performing a backward/update pass.",
- )
- parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
- parser.add_argument(
- "--data_dir",
- default=str(Path(__file__).parent / "test_run" / "dummy-train-data"),
- type=str,
- help="The input data dir. Should contain the training files for the CoNLL-2003 NER task.",
- )
-
-
-def generic_train(
- model: BaseTransformer,
- args: argparse.Namespace,
- early_stopping_callback=None,
- logger=True, # can pass WandbLogger() here
- extra_callbacks=[],
- checkpoint_callback=None,
- logging_callback=None,
- **extra_train_kwargs,
-):
- pl.seed_everything(args.seed)
-
- # init model
- odir = Path(model.hparams.output_dir)
- odir.mkdir(exist_ok=True)
-
- # add custom checkpoints
- if checkpoint_callback is None:
- checkpoint_callback = pl.callbacks.ModelCheckpoint(
- filepath=args.output_dir, prefix="checkpoint", monitor="val_loss", mode="min", save_top_k=1
- )
- if early_stopping_callback:
- extra_callbacks.append(early_stopping_callback)
- if logging_callback is None:
- logging_callback = LoggingCallback()
-
- train_params = {}
-
- if args.fp16:
- train_params["precision"] = 16
-
- if args.gpus > 1:
- train_params["accelerator"] = "auto"
- train_params["strategy"] = "ddp"
-
- train_params["accumulate_grad_batches"] = args.accumulate_grad_batches
- train_params["profiler"] = None
- train_params["devices"] = "auto"
-
- trainer = pl.Trainer.from_argparse_args(
- args,
- weights_summary=None,
- callbacks=[logging_callback] + extra_callbacks + [InitCallback()] + [checkpoint_callback],
- logger=logger,
- val_check_interval=1,
- num_sanity_val_steps=2,
- **train_params,
- )
-
- if args.do_train:
- trainer.fit(model)
-
- else:
- print("RAG modeling tests with new set functions successfully executed!")
- return trainer
diff --git a/examples/research_projects/rag-end2end-retriever/requirements.txt b/examples/research_projects/rag-end2end-retriever/requirements.txt
deleted file mode 100644
index 32025229d07..00000000000
--- a/examples/research_projects/rag-end2end-retriever/requirements.txt
+++ /dev/null
@@ -1,7 +0,0 @@
-faiss-cpu >= 1.7.2
-datasets
-psutil >= 5.9.1
-torch >= 1.11.0
-pytorch-lightning == 1.6.4
-nvidia-ml-py3 == 7.352.0
-ray >= 1.13.0
\ No newline at end of file
diff --git a/examples/research_projects/rag-end2end-retriever/test_run/dummy-kb/my_knowledge_dataset.csv b/examples/research_projects/rag-end2end-retriever/test_run/dummy-kb/my_knowledge_dataset.csv
deleted file mode 100644
index 76da009a2f2..00000000000
--- a/examples/research_projects/rag-end2end-retriever/test_run/dummy-kb/my_knowledge_dataset.csv
+++ /dev/null
@@ -1,2 +0,0 @@
-Aaron Aaron Aaron ( or ; "Ahärôn") is a prophet, high priest, and the brother of Moses in the Abrahamic religions. Knowledge of Aaron, along with his brother Moses, comes exclusively from religious texts, such as the Bible and Quran. The Hebrew Bible relates that, unlike Moses, who grew up in the Egyptian royal court, Aaron and his elder sister Miriam remained with their kinsmen in the eastern border-land of Egypt (Goshen). When Moses first confronted the Egyptian king about the Israelites, Aaron served as his brother's spokesman ("prophet") to the Pharaoh. Part of the Law (Torah) that Moses received from God at Sinai granted Aaron the priesthood for himself and his male descendants, and he became the first High Priest of the Israelites. Aaron died before the Israelites crossed the North Jordan river and he was buried on Mount Hor (Numbers 33:39; Deuteronomy 10:6 says he died and was buried at Moserah). Aaron is also mentioned in the New Testament of the Bible. According to the Book of Exodus, Aaron first functioned as Moses' assistant. Because Moses complained that he could not speak well, God appointed Aaron as Moses' "prophet" (Exodus 4:10-17; 7:1). At the command of Moses, he let his rod turn into a snake. Then he stretched out his rod in order to bring on the first three plagues. After that, Moses tended to act and speak for himself. During the journey in the wilderness, Aaron was not always prominent or active. At the battle with Amalek, he was chosen with Hur to support the hand of Moses that held the "rod of God". When the revelation was given to Moses at biblical Mount Sinai, he headed the elders of Israel who accompanied Moses on the way to the summit.
-"Pokémon" Pokémon , also known as in Japan, is a media franchise managed by The Pokémon Company, a Japanese consortium between Nintendo, Game Freak, and Creatures. The franchise copyright is shared by all three companies, but Nintendo is the sole owner of the trademark. The franchise was created by Satoshi Tajiri in 1995, and is centered on fictional creatures called "Pokémon", which humans, known as Pokémon Trainers, catch and train to battle each other for sport. The English slogan for the franchise is "Gotta Catch 'Em All". Works within the franchise are set in the Pokémon universe. The franchise began as "Pokémon Red" and "Green" (released outside of Japan as "Pokémon Red" and "Blue"), a pair of video games for the original Game Boy that were developed by Game Freak and published by Nintendo in February 1996. "Pokémon" has since gone on to become the highest-grossing media franchise of all time, with over in revenue up until March 2017. The original video game series is the second best-selling video game franchise (behind Nintendo's "Mario" franchise) with more than 300million copies sold and over 800million mobile downloads. In addition, the "Pokémon" franchise includes the world's top-selling toy brand, the top-selling trading card game with over 25.7billion cards sold, an anime television series that has become the most successful video game adaptation with over 20 seasons and 1,000 episodes in 124 countries, as well as an anime film series, a , books, manga comics, music, and merchandise. The franchise is also represented in other Nintendo media, such as the "Super Smash Bros." series. In November 2005, 4Kids Entertainment, which had managed the non-game related licensing of "Pokémon", announced that it had agreed not to renew the "Pokémon" representation agreement. The Pokémon Company International oversees all "Pokémon" licensing outside Asia.
\ No newline at end of file
diff --git a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/test.source b/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/test.source
deleted file mode 100644
index 3d5cbc38039..00000000000
--- a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/test.source
+++ /dev/null
@@ -1,8 +0,0 @@
-What does Moses' rod turn into ?
-Who is Aron?
-Where did Moses grow up ?
-What happens at the command of the Moses ?
-Who manages the Pokémon ?
-Who owned the Pokémon trademark ?
-What else include in Pokémon franchise ?
-How many seasons in Pokémon animme series ?
diff --git a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/test.target b/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/test.target
deleted file mode 100644
index a3a6e04372c..00000000000
--- a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/test.target
+++ /dev/null
@@ -1,8 +0,0 @@
-to a snake
-Moses' assistant
-Egyptian royal court
-let his rod turn in to a snake
-The Pokémon Company
-Nintendo
-world's top-selling toy brand, the top-selling trading card game
-over 20 seasons
diff --git a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/train.source b/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/train.source
deleted file mode 100644
index 9f72c3e03a7..00000000000
--- a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/train.source
+++ /dev/null
@@ -1,48 +0,0 @@
-What does Moses' rod turn into ?
-Who is Aron?
-Where did Moses grow up ?
-What happens at the command of the Moses ?
-Who manages the Pokémon ?
-Who owned the Pokémon trademark ?
-What else include in Pokémon franchise ?
-How many seasons in Pokémon animme series ?
-What does Moses' rod turn into ?
-Who is Aron?
-Where did Moses grow up ?
-What happens at the command of the Moses ?
-Who manages the Pokémon ?
-Who owned the Pokémon trademark ?
-What else include in Pokémon franchise ?
-How many seasons in Pokémon animme series ?
-What does Moses' rod turn into ?
-Who is Aron?
-Where did Moses grow up ?
-What happens at the command of the Moses ?
-Who manages the Pokémon ?
-Who owned the Pokémon trademark ?
-What else include in Pokémon franchise ?
-How many seasons in Pokémon animme series ?
-What does Moses' rod turn into ?
-Who is Aron?
-Where did Moses grow up ?
-What happens at the command of the Moses ?
-Who manages the Pokémon ?
-Who owned the Pokémon trademark ?
-What else include in Pokémon franchise ?
-How many seasons in Pokémon animme series ?
-What does Moses' rod turn into ?
-Who is Aron?
-Where did Moses grow up ?
-What happens at the command of the Moses ?
-Who manages the Pokémon ?
-Who owned the Pokémon trademark ?
-What else include in Pokémon franchise ?
-How many seasons in Pokémon animme series ?
-What does Moses' rod turn into ?
-Who is Aron?
-Where did Moses grow up ?
-What happens at the command of the Moses ?
-Who manages the Pokémon ?
-Who owned the Pokémon trademark ?
-What else include in Pokémon franchise ?
-How many seasons in Pokémon animme series ?
\ No newline at end of file
diff --git a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/train.target b/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/train.target
deleted file mode 100644
index 3bda0caf2e3..00000000000
--- a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/train.target
+++ /dev/null
@@ -1,48 +0,0 @@
-to a snake
-Moses' assistant
-Egyptian royal court
-let his rod turn in to a snake
-The Pokémon Company
-Nintendo
-world's top-selling toy brand, the top-selling trading card game
-over 20 seasons
-to a snake
-Moses' assistant
-Egyptian royal court
-let his rod turn in to a snake
-The Pokémon Company
-Nintendo
-world's top-selling toy brand, the top-selling trading card game
-over 20 seasons
-to a snake
-Moses' assistant
-Egyptian royal court
-let his rod turn in to a snake
-The Pokémon Company
-Nintendo
-world's top-selling toy brand, the top-selling trading card game
-over 20 seasons
-to a snake
-Moses' assistant
-Egyptian royal court
-let his rod turn in to a snake
-The Pokémon Company
-Nintendo
-world's top-selling toy brand, the top-selling trading card game
-over 20 seasons
-to a snake
-Moses' assistant
-Egyptian royal court
-let his rod turn in to a snake
-The Pokémon Company
-Nintendo
-world's top-selling toy brand, the top-selling trading card game
-over 20 seasons
-to a snake
-Moses' assistant
-Egyptian royal court
-let his rod turn in to a snake
-The Pokémon Company
-Nintendo
-world's top-selling toy brand, the top-selling trading card game
-over 20 seasons
\ No newline at end of file
diff --git a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/val.source b/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/val.source
deleted file mode 100644
index a2c628e9ca0..00000000000
--- a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/val.source
+++ /dev/null
@@ -1,8 +0,0 @@
-What does Moses' rod turn into ?
-Who is Aron?
-Where did Moses grow up ?
-What happens at the command of the Moses ?
-Who manages the Pokémon ?
-Who owned the Pokémon trademark ?
-What else include in Pokémon franchise ?
-How many seasons in Pokémon animme series ?
\ No newline at end of file
diff --git a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/val.target b/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/val.target
deleted file mode 100644
index 57bfcf5270a..00000000000
--- a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/val.target
+++ /dev/null
@@ -1,8 +0,0 @@
-to a snake
-Moses' assistant
-Egyptian royal court
-let his rod turn in to a snake
-The Pokémon Company
-Nintendo
-world's top-selling toy brand, the top-selling trading card game
-over 20 seasons
\ No newline at end of file
diff --git a/examples/research_projects/rag-end2end-retriever/test_run/test_finetune.sh b/examples/research_projects/rag-end2end-retriever/test_run/test_finetune.sh
deleted file mode 100755
index c44d110d200..00000000000
--- a/examples/research_projects/rag-end2end-retriever/test_run/test_finetune.sh
+++ /dev/null
@@ -1,57 +0,0 @@
-# Add parent directory to python path to access lightning_base.py
-export PYTHONPATH="../":"${PYTHONPATH}"
-
-#creates the custom knowlegebase
-python use_own_knowledge_dataset.py
-
-
-# Start a single-node Ray cluster.
-ray start --head
-
-# A sample finetuning run, you need to specify data_dir, output_dir and model_name_or_path
-# run ./examples/rag/finetune_rag_ray.sh --help to see all the possible options
-
-
-
-python finetune_rag.py \
- --model_name_or_path facebook/rag-token-base \
- --model_type rag_token \
- --fp16 \
- --gpus 2 \
- --profile \
- --do_train \
- --end2end \
- --do_predict \
- --n_val -1 \
- --train_batch_size 1 \
- --eval_batch_size 1 \
- --max_source_length 128 \
- --max_target_length 25 \
- --val_max_target_length 25 \
- --test_max_target_length 25 \
- --label_smoothing 0.1 \
- --dropout 0.1 \
- --attention_dropout 0.1 \
- --weight_decay 0.001 \
- --adam_epsilon 1e-08 \
- --max_grad_norm 0.1 \
- --lr_scheduler polynomial \
- --learning_rate 3e-05 \
- --num_train_epochs 10 \
- --warmup_steps 500 \
- --gradient_accumulation_steps 1 \
- --distributed_retriever ray \
- --num_retrieval_workers 4 \
- --index_name custom \
- --context_encoder_name facebook/dpr-ctx_encoder-multiset-base \
- --index_gpus 2 \
- --gpu_order [2,3,4,5,6,7,8,9,0,1] \
- --indexing_freq 5
-
-
-
-# Stop the Ray cluster.
-ray stop
-
-#CUDA_VISIBLE_DEVICES=2,3,4,5,6,7,8,9,0,1 sh ./test_run/test_finetune.sh
-#Make sure --gpu_order is same.
\ No newline at end of file
diff --git a/examples/research_projects/rag-end2end-retriever/test_run/test_rag_new_features.sh b/examples/research_projects/rag-end2end-retriever/test_run/test_rag_new_features.sh
deleted file mode 100755
index 6c667c09403..00000000000
--- a/examples/research_projects/rag-end2end-retriever/test_run/test_rag_new_features.sh
+++ /dev/null
@@ -1,16 +0,0 @@
-export PYTHONPATH="../":"${PYTHONPATH}"
-
-python use_own_knowledge_dataset.py
-
-ray start --head
-python finetune_rag.py \
- --model_name_or_path facebook/rag-token-base \
- --model_type rag_token \
- --context_encoder_name facebook/dpr-ctx_encoder-multiset-base \
- --fp16 \
- --gpus 1 \
- --profile \
- --end2end \
- --index_name custom
-
-ray stop
diff --git a/examples/research_projects/rag-end2end-retriever/use_own_knowledge_dataset.py b/examples/research_projects/rag-end2end-retriever/use_own_knowledge_dataset.py
deleted file mode 100644
index 20e0ea2d3cc..00000000000
--- a/examples/research_projects/rag-end2end-retriever/use_own_knowledge_dataset.py
+++ /dev/null
@@ -1,175 +0,0 @@
-import logging
-import os
-from dataclasses import dataclass, field
-from functools import partial
-from pathlib import Path
-from tempfile import TemporaryDirectory
-from typing import List, Optional
-
-import faiss
-import torch
-from datasets import Features, Sequence, Value, load_dataset
-
-from transformers import DPRContextEncoder, DPRContextEncoderTokenizerFast, HfArgumentParser
-
-
-logger = logging.getLogger(__name__)
-torch.set_grad_enabled(False)
-device = "cuda" if torch.cuda.is_available() else "cpu"
-
-
-def split_text(text: str, n=100, character=" ") -> List[str]:
- """Split the text every ``n``-th occurrence of ``character``"""
- text = text.split(character)
- return [character.join(text[i : i + n]).strip() for i in range(0, len(text), n)]
-
-
-def split_documents(documents: dict) -> dict:
- """Split documents into passages"""
- titles, texts = [], []
- for title, text in zip(documents["title"], documents["text"]):
- if text is not None:
- for passage in split_text(text):
- titles.append(title if title is not None else "")
- texts.append(passage)
- return {"title": titles, "text": texts}
-
-
-def embed(documents: dict, ctx_encoder: DPRContextEncoder, ctx_tokenizer: DPRContextEncoderTokenizerFast) -> dict:
- """Compute the DPR embeddings of document passages"""
- input_ids = ctx_tokenizer(
- documents["title"], documents["text"], truncation=True, padding="longest", return_tensors="pt"
- )["input_ids"]
- embeddings = ctx_encoder(input_ids.to(device=device), return_dict=True).pooler_output
- return {"embeddings": embeddings.detach().cpu().numpy()}
-
-
-def main(
- rag_example_args: "RagExampleArguments",
- processing_args: "ProcessingArguments",
- index_hnsw_args: "IndexHnswArguments",
-):
- ######################################
- logger.info("Step 1 - Create the dataset")
- ######################################
-
- # The dataset needed for RAG must have three columns:
- # - title (string): title of the document
- # - text (string): text of a passage of the document
- # - embeddings (array of dimension d): DPR representation of the passage
- # Let's say you have documents in tab-separated csv files with columns "title" and "text"
- assert os.path.isfile(rag_example_args.csv_path), "Please provide a valid path to a csv file"
-
- # You can load a Dataset object this way
- dataset = load_dataset(
- "csv", data_files=[rag_example_args.csv_path], split="train", delimiter="\t", column_names=["title", "text"]
- )
-
- # More info about loading csv files in the documentation: https://huggingface.co/docs/datasets/loading_datasets?highlight=csv#csv-files
-
- # Then split the documents into passages of 100 words
- dataset = dataset.map(split_documents, batched=True, num_proc=processing_args.num_proc)
-
- # And compute the embeddings
- ctx_encoder = DPRContextEncoder.from_pretrained(rag_example_args.dpr_ctx_encoder_model_name).to(device=device)
- ctx_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained(rag_example_args.dpr_ctx_encoder_model_name)
- new_features = Features(
- {"text": Value("string"), "title": Value("string"), "embeddings": Sequence(Value("float32"))}
- ) # optional, save as float32 instead of float64 to save space
- dataset = dataset.map(
- partial(embed, ctx_encoder=ctx_encoder, ctx_tokenizer=ctx_tokenizer),
- batched=True,
- batch_size=processing_args.batch_size,
- features=new_features,
- )
-
- # And finally save your dataset
- passages_path = os.path.join(rag_example_args.output_dir, "my_knowledge_dataset")
- dataset.save_to_disk(passages_path)
- # from datasets import load_from_disk
- # dataset = load_from_disk(passages_path) # to reload the dataset
-
- ######################################
- logger.info("Step 2 - Index the dataset")
- ######################################
-
- # Let's use the Faiss implementation of HNSW for fast approximate nearest neighbor search
- index = faiss.IndexHNSWFlat(index_hnsw_args.d, index_hnsw_args.m, faiss.METRIC_INNER_PRODUCT)
- dataset.add_faiss_index("embeddings", custom_index=index)
-
- # And save the index
- index_path = os.path.join(rag_example_args.output_dir, "my_knowledge_dataset_hnsw_index.faiss")
- dataset.get_index("embeddings").save(index_path)
- # dataset.load_faiss_index("embeddings", index_path) # to reload the index
-
-
-@dataclass
-class RagExampleArguments:
- csv_path: str = field(
- default=str(Path(__file__).parent / "test_run" / "dummy-kb" / "my_knowledge_dataset.csv"),
- metadata={"help": "Path to a tab-separated csv file with columns 'title' and 'text'"},
- )
- question: Optional[str] = field(
- default=None,
- metadata={"help": "Question that is passed as input to RAG. Default is 'What does Moses' rod turn into ?'."},
- )
- rag_model_name: str = field(
- default="facebook/rag-sequence-nq",
- metadata={"help": "The RAG model to use. Either 'facebook/rag-sequence-nq' or 'facebook/rag-token-nq'"},
- )
- dpr_ctx_encoder_model_name: str = field(
- default="facebook/dpr-ctx_encoder-multiset-base",
- metadata={
- "help": (
- "The DPR context encoder model to use. Either 'facebook/dpr-ctx_encoder-single-nq-base' or"
- " 'facebook/dpr-ctx_encoder-multiset-base'"
- )
- },
- )
- output_dir: Optional[str] = field(
- default=str(Path(__file__).parent / "test_run" / "dummy-kb"),
- metadata={"help": "Path to a directory where the dataset passages and the index will be saved"},
- )
-
-
-@dataclass
-class ProcessingArguments:
- num_proc: Optional[int] = field(
- default=None,
- metadata={
- "help": "The number of processes to use to split the documents into passages. Default is single process."
- },
- )
- batch_size: int = field(
- default=16,
- metadata={
- "help": "The batch size to use when computing the passages embeddings using the DPR context encoder."
- },
- )
-
-
-@dataclass
-class IndexHnswArguments:
- d: int = field(
- default=768,
- metadata={"help": "The dimension of the embeddings to pass to the HNSW Faiss index."},
- )
- m: int = field(
- default=128,
- metadata={
- "help": (
- "The number of bi-directional links created for every new element during the HNSW index construction."
- )
- },
- )
-
-
-if __name__ == "__main__":
- logging.basicConfig(level=logging.WARNING)
- logger.setLevel(logging.INFO)
-
- parser = HfArgumentParser((RagExampleArguments, ProcessingArguments, IndexHnswArguments))
- rag_example_args, processing_args, index_hnsw_args = parser.parse_args_into_dataclasses()
- with TemporaryDirectory() as tmp_dir:
- rag_example_args.output_dir = rag_example_args.output_dir or tmp_dir
- main(rag_example_args, processing_args, index_hnsw_args)
diff --git a/examples/research_projects/rag-end2end-retriever/utils_rag.py b/examples/research_projects/rag-end2end-retriever/utils_rag.py
deleted file mode 100644
index ec98c1d782e..00000000000
--- a/examples/research_projects/rag-end2end-retriever/utils_rag.py
+++ /dev/null
@@ -1,244 +0,0 @@
-import itertools
-import json
-import linecache
-import os
-import pickle
-import re
-import socket
-import string
-from collections import Counter
-from logging import getLogger
-from pathlib import Path
-from typing import Callable, Dict, Iterable, List
-
-import git
-import torch
-from torch.utils.data import Dataset
-
-from transformers import BartTokenizer, RagTokenizer, T5Tokenizer
-
-
-def encode_line(tokenizer, line, max_length, padding_side, pad_to_max_length=True, return_tensors="pt"):
- extra_kw = {"add_prefix_space": True} if isinstance(tokenizer, BartTokenizer) and not line.startswith(" ") else {}
- tokenizer.padding_side = padding_side
- return tokenizer(
- [line],
- max_length=max_length,
- padding="max_length" if pad_to_max_length else None,
- truncation=True,
- return_tensors=return_tensors,
- add_special_tokens=True,
- **extra_kw,
- )
-
-
-def trim_batch(
- input_ids,
- pad_token_id,
- attention_mask=None,
-):
- """Remove columns that are populated exclusively by pad_token_id"""
- keep_column_mask = input_ids.ne(pad_token_id).any(dim=0)
- if attention_mask is None:
- return input_ids[:, keep_column_mask]
- else:
- return (input_ids[:, keep_column_mask], attention_mask[:, keep_column_mask])
-
-
-class Seq2SeqDataset(Dataset):
- def __init__(
- self,
- tokenizer,
- data_dir,
- max_source_length,
- max_target_length,
- type_path="train",
- n_obs=None,
- src_lang=None,
- tgt_lang=None,
- prefix="",
- ):
- super().__init__()
- self.src_file = Path(data_dir).joinpath(type_path + ".source")
- self.tgt_file = Path(data_dir).joinpath(type_path + ".target")
- self.src_lens = self.get_char_lens(self.src_file)
- self.max_source_length = max_source_length
- self.max_target_length = max_target_length
- assert min(self.src_lens) > 0, f"found empty line in {self.src_file}"
- self.tokenizer = tokenizer
- self.prefix = prefix
- if n_obs is not None:
- self.src_lens = self.src_lens[:n_obs]
- self.src_lang = src_lang
- self.tgt_lang = tgt_lang
-
- def __len__(self):
- return len(self.src_lens)
-
- def __getitem__(self, index) -> Dict[str, torch.Tensor]:
- index = index + 1 # linecache starts at 1
- source_line = self.prefix + linecache.getline(str(self.src_file), index).rstrip("\n")
- tgt_line = linecache.getline(str(self.tgt_file), index).rstrip("\n")
- assert source_line, f"empty source line for index {index}"
- assert tgt_line, f"empty tgt line for index {index}"
-
- # Need to add eos token manually for T5
- if isinstance(self.tokenizer, T5Tokenizer):
- source_line += self.tokenizer.eos_token
- tgt_line += self.tokenizer.eos_token
-
- # Pad source and target to the right
- source_tokenizer = (
- self.tokenizer.question_encoder if isinstance(self.tokenizer, RagTokenizer) else self.tokenizer
- )
- target_tokenizer = self.tokenizer.generator if isinstance(self.tokenizer, RagTokenizer) else self.tokenizer
-
- source_inputs = encode_line(source_tokenizer, source_line, self.max_source_length, "right")
- target_inputs = encode_line(target_tokenizer, tgt_line, self.max_target_length, "right")
-
- source_ids = source_inputs["input_ids"].squeeze()
- target_ids = target_inputs["input_ids"].squeeze()
- src_mask = source_inputs["attention_mask"].squeeze()
- return {
- "input_ids": source_ids,
- "attention_mask": src_mask,
- "decoder_input_ids": target_ids,
- }
-
- @staticmethod
- def get_char_lens(data_file):
- return [len(x) for x in Path(data_file).open().readlines()]
-
- def collate_fn(self, batch) -> Dict[str, torch.Tensor]:
- input_ids = torch.stack([x["input_ids"] for x in batch])
- masks = torch.stack([x["attention_mask"] for x in batch])
- target_ids = torch.stack([x["decoder_input_ids"] for x in batch])
- tgt_pad_token_id = (
- self.tokenizer.generator.pad_token_id
- if isinstance(self.tokenizer, RagTokenizer)
- else self.tokenizer.pad_token_id
- )
- src_pad_token_id = (
- self.tokenizer.question_encoder.pad_token_id
- if isinstance(self.tokenizer, RagTokenizer)
- else self.tokenizer.pad_token_id
- )
- y = trim_batch(target_ids, tgt_pad_token_id)
- source_ids, source_mask = trim_batch(input_ids, src_pad_token_id, attention_mask=masks)
- batch = {
- "input_ids": source_ids,
- "attention_mask": source_mask,
- "decoder_input_ids": y,
- }
- return batch
-
-
-logger = getLogger(__name__)
-
-
-def flatten_list(summary_ids: List[List]):
- return list(itertools.chain.from_iterable(summary_ids))
-
-
-def save_git_info(folder_path: str) -> None:
- """Save git information to output_dir/git_log.json"""
- repo_infos = get_git_info()
- save_json(repo_infos, os.path.join(folder_path, "git_log.json"))
-
-
-def save_json(content, path, indent=4, **json_dump_kwargs):
- with open(path, "w") as f:
- json.dump(content, f, indent=indent, **json_dump_kwargs)
-
-
-def load_json(path):
- with open(path) as f:
- return json.load(f)
-
-
-def get_git_info():
- repo = git.Repo(search_parent_directories=True)
- repo_infos = {
- "repo_id": str(repo),
- "repo_sha": str(repo.head.object.hexsha),
- "repo_branch": str(repo.active_branch),
- "hostname": str(socket.gethostname()),
- }
- return repo_infos
-
-
-def lmap(f: Callable, x: Iterable) -> List:
- """list(map(f, x))"""
- return list(map(f, x))
-
-
-def pickle_save(obj, path):
- """pickle.dump(obj, path)"""
- with open(path, "wb") as f:
- return pickle.dump(obj, f)
-
-
-def normalize_answer(s):
- """Lower text and remove punctuation, articles and extra whitespace."""
-
- def remove_articles(text):
- return re.sub(r"\b(a|an|the)\b", " ", text)
-
- def white_space_fix(text):
- return " ".join(text.split())
-
- def remove_punc(text):
- exclude = set(string.punctuation)
- return "".join(ch for ch in text if ch not in exclude)
-
- def lower(text):
- return text.lower()
-
- return white_space_fix(remove_articles(remove_punc(lower(s))))
-
-
-def f1_score(prediction, ground_truth):
- prediction_tokens = normalize_answer(prediction).split()
- ground_truth_tokens = normalize_answer(ground_truth).split()
- common = Counter(prediction_tokens) & Counter(ground_truth_tokens)
- num_same = sum(common.values())
- if num_same == 0:
- return 0
- precision = 1.0 * num_same / len(prediction_tokens)
- recall = 1.0 * num_same / len(ground_truth_tokens)
- f1 = (2 * precision * recall) / (precision + recall)
- return f1
-
-
-def exact_match_score(prediction, ground_truth):
- return normalize_answer(prediction) == normalize_answer(ground_truth)
-
-
-def calculate_exact_match(output_lns: List[str], reference_lns: List[str]) -> Dict:
- assert len(output_lns) == len(reference_lns)
- em = 0
- for hypo, pred in zip(output_lns, reference_lns):
- em += exact_match_score(hypo, pred)
- if len(output_lns) > 0:
- em /= len(output_lns)
- return {"em": em}
-
-
-def is_rag_model(model_prefix):
- return model_prefix.startswith("rag")
-
-
-def set_extra_model_params(extra_params, hparams, config):
- equivalent_param = {p: p for p in extra_params}
- # T5 models don't have `dropout` param, they have `dropout_rate` instead
- equivalent_param["dropout"] = "dropout_rate"
- for p in extra_params:
- if getattr(hparams, p, None):
- if not hasattr(config, p) and not hasattr(config, equivalent_param[p]):
- logger.info("config doesn't have a `{}` attribute".format(p))
- delattr(hparams, p)
- continue
- set_p = p if hasattr(config, p) else equivalent_param[p]
- setattr(config, set_p, getattr(hparams, p))
- delattr(hparams, p)
- return hparams, config
diff --git a/examples/research_projects/rag/README.md b/examples/research_projects/rag/README.md
deleted file mode 100644
index 59aa46a8952..00000000000
--- a/examples/research_projects/rag/README.md
+++ /dev/null
@@ -1,203 +0,0 @@
-# Intro
-
-Authors: @patrickvonplaten and @lhoestq
-
-Aimed at tackling the knowledge-intensive NLP tasks (think tasks a human wouldn't be expected to solve without access to external knowledge sources), RAG models are seq2seq models with access to a retrieval mechanism providing relevant context documents at training and evaluation time.
-
-A RAG model encapsulates two core components: a question encoder and a generator.
-During a forward pass, we encode the input with the question encoder and pass it
-to the retriever to extract relevant context documents. The documents are then prepended to the input.
-Such contextualized inputs are passed to the generator.
-
-Read more about RAG at https://arxiv.org/abs/2005.11401.
-
-# Note
-
-⚠️ This project should be run with pytorch-lightning==1.3.1 which has a potential security vulnerability
-
-# Finetuning
-
-Our finetuning logic is based on scripts from [`examples/legacy/seq2seq`](https://github.com/huggingface/transformers/tree/main/examples/legacy/seq2seq). We accept training data in the same format as specified there - we expect a directory consisting of 6 text files:
-```bash
-train.source
-train.target
-val.source
-val.target
-test.source
-test.target
-```
-
-A sample finetuning command (run ` ./examples/research_projects/rag/finetune_rag.py --help` to list all available options):
-
-```bash
-python examples/research_projects/rag/finetune_rag.py \
- --data_dir $DATA_DIR \
- --output_dir $OUTPUT_DIR \
- --model_name_or_path $MODEL_NAME_OR_PATH \
- --model_type rag_sequence \
- --fp16 \
- --gpus 8
-```
-We publish two `base` models which can serve as a starting point for finetuning on downstream tasks (use them as `model_name_or_path`):
-- [`facebook/rag-sequence-base`](https://huggingface.co/facebook/rag-sequence-base) - a base for finetuning `RagSequenceForGeneration` models,
-- [`facebook/rag-token-base`](https://huggingface.co/facebook/rag-token-base) - a base for finetuning `RagTokenForGeneration` models.
-
-The `base` models initialize the question encoder with [`facebook/dpr-question_encoder-single-nq-base`](https://huggingface.co/facebook/dpr-question_encoder-single-nq-base) and the generator with [`facebook/bart-large`](https://huggingface.co/facebook/bart-large).
-
-If you would like to initialize finetuning with a base model using different question encoder and generator architectures, you can build it with a consolidation script, e.g.:
-```bash
-python examples/research_projects/rag/consolidate_rag_checkpoint.py \
- --model_type rag_sequence \
- --generator_name_or_path facebook/bart-large-cnn \
- --question_encoder_name_or_path facebook/dpr-question_encoder-single-nq-base \
- --dest path/to/checkpoint
-```
-You will then be able to pass `path/to/checkpoint` as `model_name_or_path` to the `finetune_rag.py` script.
-
-## Document Retrieval
-When running distributed fine-tuning, each training worker needs to retrieve contextual documents
-for its input by querying a index loaded into memory. RAG provides two implementations for document retrieval,
-one with [`torch.distributed`](https://pytorch.org/docs/stable/distributed.html) communication package and the other
-with [`Ray`](https://docs.ray.io/en/master/).
-
-This option can be configured with the `--distributed_retriever` flag which can either be set to `pytorch` or `ray`.
-By default this flag is set to `pytorch`.
-
-For the Pytorch implementation, only training worker 0 loads the index into CPU memory, and a gather/scatter pattern is used
-to collect the inputs from the other training workers and send back the corresponding document embeddings.
-
-For the Ray implementation, the index is loaded in *separate* process(es). The training workers randomly select which
-retriever worker to query. To use Ray for distributed retrieval, you have to set the `--distributed_retriever` arg to `ray`.
-To configure the number of retrieval workers (the number of processes that load the index), you can set the `num_retrieval_workers` flag.
-Also make sure to start the Ray cluster before running fine-tuning.
-
-```bash
-# Start a single-node Ray cluster.
-ray start --head
-
-python examples/research_projects/rag/finetune_rag.py \
- --data_dir $DATA_DIR \
- --output_dir $OUTPUT_DIR \
- --model_name_or_path $MODEL_NAME_OR_PATH \
- --model_type rag_sequence \
- --fp16 \
- --gpus 8
- --distributed_retriever ray \
- --num_retrieval_workers 4
-
-# Stop the ray cluster once fine-tuning has finished.
-ray stop
-```
-
-Using Ray can lead to retrieval speedups on multi-GPU settings since multiple processes load the index rather than
-just the rank 0 training worker. Using Ray also allows you to load the index on GPU since the index is loaded on a separate
-processes than the model, while with pytorch distributed retrieval, both are loaded in the same process potentially leading to GPU OOM.
-
-# Evaluation
-Our evaluation script enables two modes of evaluation (controlled by the `eval_mode` argument): `e2e` - end2end evaluation, returns EM (exact match) and F1 scores calculated for the downstream task and `retrieval` - which returns precision@k of the documents retrieved for provided inputs.
-
-The evaluation script expects paths to two files:
-- `evaluation_set` - a path to a file specifying the evaluation dataset, a single input per line.
-- `gold_data_path` - a path to a file containing ground truth answers for datapoints from the `evaluation_set`, a single output per line. Check below for expected formats of the gold data files.
-
-
-## Retrieval evaluation
-For `retrieval` evaluation, we expect a gold data file where each line will consist of a tab-separated list of document titles constituting positive contexts for respective datapoints from the `evaluation_set`. E.g. given a question `who sings does he love me with reba` in the `evaluation_set`, a respective ground truth line could look as follows:
-```
-Does He Love You Does He Love You Red Sandy Spika dress of Reba McEntire Greatest Hits Volume Two (Reba McEntire album) Shoot for the Moon (album)
-```
-
-We demonstrate how to evaluate retrieval against DPR evaluation data. You can download respective files from links listed [here](https://github.com/facebookresearch/DPR/blob/master/data/download_data.py#L39-L45).
-
-1. Download and unzip the gold data file. We use the `biencoder-nq-dev` from https://dl.fbaipublicfiles.com/dpr/data/retriever/biencoder-nq-dev.json.gz.
- ```bash
- wget https://dl.fbaipublicfiles.com/dpr/data/retriever/biencoder-nq-dev.json.gz && gzip -d biencoder-nq-dev.json.gz
- ```
-
-2. Parse the unziped file using the `parse_dpr_relevance_data.py`
- ```bash
- mkdir output # or wherever you want to save this
- python examples/research_projects/rag/parse_dpr_relevance_data.py \
- --src_path biencoder-nq-dev.json \
- --evaluation_set output/biencoder-nq-dev.questions \
- --gold_data_path output/biencoder-nq-dev.pages
- ```
-3. Run evaluation:
- ```bash
- python examples/research_projects/rag/eval_rag.py \
- --model_name_or_path facebook/rag-sequence-nq \
- --model_type rag_sequence \
- --evaluation_set output/biencoder-nq-dev.questions \
- --gold_data_path output/biencoder-nq-dev.pages \
- --predictions_path output/retrieval_preds.tsv \
- --eval_mode retrieval \
- --k 1
- ```
- ```bash
- # EXPLANATION
- python examples/research_projects/rag/eval_rag.py \
- --model_name_or_path facebook/rag-sequence-nq \ # model name or path of the model we're evaluating
- --model_type rag_sequence \ # RAG model type (rag_token or rag_sequence)
- --evaluation_set output/biencoder-nq-dev.questions \ # an input dataset for evaluation
- --gold_data_path poutput/biencoder-nq-dev.pages \ # a dataset containing ground truth answers for samples from the evaluation_set
- --predictions_path output/retrieval_preds.tsv \ # name of file where predictions will be stored
- --eval_mode retrieval \ # indicates whether we're performing retrieval evaluation or e2e evaluation
- --k 1 # parameter k for the precision@k metric
-
- ```
-## End-to-end evaluation
-
-We support two formats of the gold data file (controlled by the `gold_data_mode` parameter):
-- `qa` - where a single line has the following format: `input [tab] output_list`, e.g.:
-```
-who is the owner of reading football club ['Xiu Li Dai', 'Dai Yongge', 'Dai Xiuli', 'Yongge Dai']
-```
-- `ans` - where a single line contains a single expected answer, e.g.:
-```
-Xiu Li Dai
-```
-
-Predictions of the model for the samples from the `evaluation_set` will be saved under the path specified by the `predictions_path` parameter.
-If this path already exists, the script will use saved predictions to calculate metrics.
-Add `--recalculate` parameter to force the script to perform inference from scratch.
-
-An example e2e evaluation run could look as follows:
-```bash
-python examples/research_projects/rag/eval_rag.py \
- --model_name_or_path facebook/rag-sequence-nq \
- --model_type rag_sequence \
- --evaluation_set path/to/test.source \
- --gold_data_path path/to/gold_data \
- --predictions_path path/to/e2e_preds.txt \
- --eval_mode e2e \
- --gold_data_mode qa \
- --n_docs 5 \ # You can experiment with retrieving different number of documents at evaluation time
- --print_predictions \
- --recalculate \ # adding this parameter will force recalculating predictions even if predictions_path already exists
-```
-
-# Use your own knowledge source
-
-By default, RAG uses the English Wikipedia as a knowledge source, known as the 'wiki_dpr' dataset.
-With `use_custom_knowledge_dataset.py` you can build your own knowledge source, *e.g.* for RAG.
-
-For instance, if documents are serialized as tab-separated csv files with the columns "title" and "text", one can use `use_own_knowledge_dataset.py` as follows:
-```bash
-python examples/research_projects/rag/use_own_knowledge_dataset.py \
- --csv_path path/to/my_csv \
- --output_dir path/to/my_knowledge_dataset \
-```
-
-The created outputs in `path/to/my_knowledge_dataset` can then be used to finetune RAG as follows:
-```bash
-python examples/research_projects/rag/finetune_rag.py \
- --data_dir $DATA_DIR \
- --output_dir $OUTPUT_DIR \
- --model_name_or_path $MODEL_NAME_OR_PATH \
- --model_type rag_sequence \
- --fp16 \
- --gpus 8
- --index_name custom
- --passages_path path/to/data/my_knowledge_dataset
- --index_path path/to/my_knowledge_dataset_hnsw_index.faiss
-```
diff --git a/examples/research_projects/rag/__init__.py b/examples/research_projects/rag/__init__.py
deleted file mode 100644
index 3cee09bb7f5..00000000000
--- a/examples/research_projects/rag/__init__.py
+++ /dev/null
@@ -1,5 +0,0 @@
-import os
-import sys
-
-
-sys.path.insert(1, os.path.dirname(os.path.realpath(__file__)))
diff --git a/examples/research_projects/rag/_test_finetune_rag.py b/examples/research_projects/rag/_test_finetune_rag.py
deleted file mode 100644
index 0906295b301..00000000000
--- a/examples/research_projects/rag/_test_finetune_rag.py
+++ /dev/null
@@ -1,111 +0,0 @@
-import json
-import logging
-import os
-import sys
-from pathlib import Path
-
-import finetune_rag
-
-from transformers.file_utils import is_apex_available
-from transformers.testing_utils import (
- TestCasePlus,
- execute_subprocess_async,
- require_ray,
- require_torch_gpu,
- require_torch_multi_gpu,
-)
-
-
-logging.basicConfig(level=logging.DEBUG)
-logger = logging.getLogger()
-
-stream_handler = logging.StreamHandler(sys.stdout)
-logger.addHandler(stream_handler)
-
-
-class RagFinetuneExampleTests(TestCasePlus):
- def _create_dummy_data(self, data_dir):
- os.makedirs(data_dir, exist_ok=True)
- contents = {"source": "What is love ?", "target": "life"}
- n_lines = {"train": 12, "val": 2, "test": 2}
- for split in ["train", "test", "val"]:
- for field in ["source", "target"]:
- content = "\n".join([contents[field]] * n_lines[split])
- with open(os.path.join(data_dir, f"{split}.{field}"), "w") as f:
- f.write(content)
-
- def _run_finetune(self, gpus: int, distributed_retriever: str = "pytorch"):
- tmp_dir = self.get_auto_remove_tmp_dir()
- output_dir = os.path.join(tmp_dir, "output")
- data_dir = os.path.join(tmp_dir, "data")
- self._create_dummy_data(data_dir=data_dir)
-
- testargs = f"""
- --data_dir {data_dir} \
- --output_dir {output_dir} \
- --model_name_or_path facebook/rag-sequence-base \
- --model_type rag_sequence \
- --do_train \
- --do_predict \
- --n_val -1 \
- --val_check_interval 1.0 \
- --train_batch_size 2 \
- --eval_batch_size 1 \
- --max_source_length 25 \
- --max_target_length 25 \
- --val_max_target_length 25 \
- --test_max_target_length 25 \
- --label_smoothing 0.1 \
- --dropout 0.1 \
- --attention_dropout 0.1 \
- --weight_decay 0.001 \
- --adam_epsilon 1e-08 \
- --max_grad_norm 0.1 \
- --lr_scheduler polynomial \
- --learning_rate 3e-04 \
- --num_train_epochs 1 \
- --warmup_steps 4 \
- --gradient_accumulation_steps 1 \
- --distributed-port 8787 \
- --use_dummy_dataset 1 \
- --distributed_retriever {distributed_retriever} \
- """.split()
-
- if gpus > 0:
- testargs.append(f"--gpus={gpus}")
- if is_apex_available():
- testargs.append("--fp16")
- else:
- testargs.append("--gpus=0")
- testargs.append("--distributed_backend=ddp_cpu")
- testargs.append("--num_processes=2")
-
- cmd = [sys.executable, str(Path(finetune_rag.__file__).resolve())] + testargs
- execute_subprocess_async(cmd, env=self.get_env())
-
- metrics_save_path = os.path.join(output_dir, "metrics.json")
- with open(metrics_save_path) as f:
- result = json.load(f)
- return result
-
- @require_torch_gpu
- def test_finetune_gpu(self):
- result = self._run_finetune(gpus=1)
- self.assertGreaterEqual(result["test"][0]["test_avg_em"], 0.2)
-
- @require_torch_multi_gpu
- def test_finetune_multigpu(self):
- result = self._run_finetune(gpus=2)
- self.assertGreaterEqual(result["test"][0]["test_avg_em"], 0.2)
-
- @require_torch_gpu
- @require_ray
- def test_finetune_gpu_ray_retrieval(self):
- result = self._run_finetune(gpus=1, distributed_retriever="ray")
- self.assertGreaterEqual(result["test"][0]["test_avg_em"], 0.2)
-
- @require_torch_multi_gpu
- @require_ray
- def test_finetune_multigpu_ray_retrieval(self):
- result = self._run_finetune(gpus=1, distributed_retriever="ray")
- self.assertGreaterEqual(result["test"][0]["test_avg_em"], 0.2)
diff --git a/examples/research_projects/rag/callbacks_rag.py b/examples/research_projects/rag/callbacks_rag.py
deleted file mode 100644
index d75f97995bd..00000000000
--- a/examples/research_projects/rag/callbacks_rag.py
+++ /dev/null
@@ -1,116 +0,0 @@
-import logging
-from pathlib import Path
-
-import numpy as np
-import pytorch_lightning as pl
-import torch
-from pytorch_lightning.callbacks import EarlyStopping, ModelCheckpoint
-from pytorch_lightning.utilities import rank_zero_only
-from utils_rag import save_json
-
-
-def count_trainable_parameters(model):
- model_parameters = filter(lambda p: p.requires_grad, model.parameters())
- params = sum([np.prod(p.size()) for p in model_parameters])
- return params
-
-
-logger = logging.getLogger(__name__)
-
-
-def get_checkpoint_callback(output_dir, metric):
- """Saves the best model by validation EM score."""
- if metric == "rouge2":
- exp = "{val_avg_rouge2:.4f}-{step_count}"
- elif metric == "bleu":
- exp = "{val_avg_bleu:.4f}-{step_count}"
- elif metric == "em":
- exp = "{val_avg_em:.4f}-{step_count}"
- else:
- raise NotImplementedError(
- f"seq2seq callbacks only support rouge2 and bleu, got {metric}, You can make your own by adding to this"
- " function."
- )
-
- checkpoint_callback = ModelCheckpoint(
- dirpath=output_dir,
- filename=exp,
- monitor=f"val_{metric}",
- mode="max",
- save_top_k=3,
- every_n_epochs=1, # maybe save a checkpoint every time val is run, not just end of epoch.
- )
- return checkpoint_callback
-
-
-def get_early_stopping_callback(metric, patience):
- return EarlyStopping(
- monitor=f"val_{metric}", # does this need avg?
- mode="min" if "loss" in metric else "max",
- patience=patience,
- verbose=True,
- )
-
-
-class Seq2SeqLoggingCallback(pl.Callback):
- def on_batch_end(self, trainer, pl_module):
- lrs = {f"lr_group_{i}": param["lr"] for i, param in enumerate(pl_module.trainer.optimizers[0].param_groups)}
- pl_module.logger.log_metrics(lrs)
-
- @rank_zero_only
- def _write_logs(
- self, trainer: pl.Trainer, pl_module: pl.LightningModule, type_path: str, save_generations=True
- ) -> None:
- logger.info(f"***** {type_path} results at step {trainer.global_step:05d} *****")
- metrics = trainer.callback_metrics
- trainer.logger.log_metrics({k: v for k, v in metrics.items() if k not in ["log", "progress_bar", "preds"]})
- # Log results
- od = Path(pl_module.hparams.output_dir)
- if type_path == "test":
- results_file = od / "test_results.txt"
- generations_file = od / "test_generations.txt"
- else:
- # this never gets hit. I prefer not to save intermediate generations, and results are in metrics.json
- # If people want this it will be easy enough to add back.
- results_file = od / f"{type_path}_results/{trainer.global_step:05d}.txt"
- generations_file = od / f"{type_path}_generations/{trainer.global_step:05d}.txt"
- results_file.parent.mkdir(exist_ok=True)
- generations_file.parent.mkdir(exist_ok=True)
- with open(results_file, "a+") as writer:
- for key in sorted(metrics):
- if key in ["log", "progress_bar", "preds"]:
- continue
- val = metrics[key]
- if isinstance(val, torch.Tensor):
- val = val.item()
- msg = f"{key}: {val:.6f}\n"
- writer.write(msg)
-
- if not save_generations:
- return
-
- if "preds" in metrics:
- content = "\n".join(metrics["preds"])
- generations_file.open("w+").write(content)
-
- @rank_zero_only
- def on_train_start(self, trainer, pl_module):
- try:
- npars = pl_module.model.model.num_parameters()
- except AttributeError:
- npars = pl_module.model.num_parameters()
-
- n_trainable_pars = count_trainable_parameters(pl_module)
- # mp stands for million parameters
- trainer.logger.log_metrics({"n_params": npars, "mp": npars / 1e6, "grad_mp": n_trainable_pars / 1e6})
-
- @rank_zero_only
- def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
- save_json(pl_module.metrics, pl_module.metrics_save_path)
- return self._write_logs(trainer, pl_module, "test")
-
- @rank_zero_only
- def on_validation_end(self, trainer: pl.Trainer, pl_module):
- save_json(pl_module.metrics, pl_module.metrics_save_path)
- # Uncommenting this will save val generations
- # return self._write_logs(trainer, pl_module, "valid")
diff --git a/examples/research_projects/rag/consolidate_rag_checkpoint.py b/examples/research_projects/rag/consolidate_rag_checkpoint.py
deleted file mode 100644
index 6adae75fea9..00000000000
--- a/examples/research_projects/rag/consolidate_rag_checkpoint.py
+++ /dev/null
@@ -1,101 +0,0 @@
-"""
-A script creating a RAG checkpoint from a generator and a question encoder checkpoints.
-"""
-
-import argparse
-from pathlib import Path
-
-from transformers import AutoConfig, AutoTokenizer, RagConfig, RagSequenceForGeneration, RagTokenForGeneration
-
-
-def consolidate(
- model_type,
- generator_name_or_path: str,
- question_encoder_name_or_path: str,
- dest_dir: Path,
- config_name_or_path: str = None,
- generator_tokenizer_name_or_path: str = None,
- question_encoder_tokenizer_name_or_path: str = None,
-):
- if config_name_or_path is None:
- config_name_or_path = "facebook/rag-token-base" if model_type == "rag_token" else "facebook/rag-sequence-base"
-
- if generator_tokenizer_name_or_path is None:
- generator_tokenizer_name_or_path = generator_name_or_path
-
- if question_encoder_tokenizer_name_or_path is None:
- question_encoder_tokenizer_name_or_path = question_encoder_name_or_path
-
- model_class = RagTokenForGeneration if model_type == "rag_token" else RagSequenceForGeneration
-
- # Save model.
- rag_config = RagConfig.from_pretrained(config_name_or_path)
- gen_config = AutoConfig.from_pretrained(generator_name_or_path)
- question_encoder_config = AutoConfig.from_pretrained(question_encoder_name_or_path)
-
- rag_config.generator = gen_config
- rag_config.question_encoder = question_encoder_config
-
- rag_model = model_class.from_pretrained_question_encoder_generator(
- question_encoder_name_or_path, generator_name_or_path, config=rag_config
- )
- rag_model.save_pretrained(dest_dir)
-
- # Sanity check.
- model_class.from_pretrained(dest_dir)
-
- # Save tokenizers.
- gen_tokenizer = AutoTokenizer.from_pretrained(generator_tokenizer_name_or_path)
- gen_tokenizer.save_pretrained(dest_dir / "generator_tokenizer/")
- question_encoder_tokenizer = AutoTokenizer.from_pretrained(question_encoder_tokenizer_name_or_path)
- question_encoder_tokenizer.save_pretrained(dest_dir / "question_encoder_tokenizer/")
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "--model_type",
- choices=["rag_sequence", "rag_token"],
- required=True,
- type=str,
- help="RAG model type: rag_sequence, rag_token",
- )
- parser.add_argument("--dest", type=str, required=True, help="Path to the output checkpoint directory.")
- parser.add_argument("--generator_name_or_path", type=str, required=True, help="Generator model identifier")
- parser.add_argument(
- "--question_encoder_name_or_path", type=str, required=True, help="Question encoder model identifier"
- )
-
- parser.add_argument(
- "--generator_tokenizer_name_or_path",
- type=str,
- help="Generator tokenizer identifier, if not specified, resolves to ``generator_name_or_path``",
- )
- parser.add_argument(
- "--question_encoder_tokenizer_name_or_path",
- type=str,
- help="Question encoder tokenizer identifier, if not specified, resolves to ``question_encoder_name_or_path``",
- )
- parser.add_argument(
- "--config_name_or_path",
- type=str,
- help=(
- "Identifier of the model config to use, if not provided, resolves to a base config for a given"
- " ``model_type``"
- ),
- )
-
- args = parser.parse_args()
-
- dest_dir = Path(args.dest)
- dest_dir.mkdir(exist_ok=True)
-
- consolidate(
- args.model_type,
- args.generator_name_or_path,
- args.question_encoder_name_or_path,
- dest_dir,
- args.config_name_or_path,
- args.generator_tokenizer_name_or_path,
- args.question_encoder_tokenizer_name_or_path,
- )
diff --git a/examples/research_projects/rag/distributed_pytorch_retriever.py b/examples/research_projects/rag/distributed_pytorch_retriever.py
deleted file mode 100644
index b8c4b6fc3c5..00000000000
--- a/examples/research_projects/rag/distributed_pytorch_retriever.py
+++ /dev/null
@@ -1,138 +0,0 @@
-import logging
-import os
-from typing import List, Tuple
-
-import numpy as np
-import psutil
-import torch
-import torch.distributed as dist
-
-from transformers import RagRetriever
-
-
-logger = logging.getLogger(__name__)
-
-
-class RagPyTorchDistributedRetriever(RagRetriever):
- """
- A distributed retriever built on top of the ``torch.distributed`` communication package. During training all workers
- initialize their own instance of the retriever, however, only the main worker loads the index into memory. The index is stored
- in cpu memory. The index will also work well in a non-distributed setup.
-
- Args:
- config (:class:`~transformers.RagConfig`):
- The configuration of the RAG model this Retriever is used with. Contains parameters indicating which ``Index`` to build.
- question_encoder_tokenizer (:class:`~transformers.PreTrainedTokenizer`):
- The tokenizer that was used to tokenize the question.
- It is used to decode the question and then use the generator_tokenizer.
- generator_tokenizer (:class:`~transformers.PreTrainedTokenizer`):
- The tokenizer used for the generator part of the RagModel.
- index (:class:`~transformers.models.rag.retrieval_rag.Index`, optional, defaults to the one defined by the configuration):
- If specified, use this index instead of the one built using the configuration
- """
-
- def __init__(self, config, question_encoder_tokenizer, generator_tokenizer, index=None):
- super().__init__(
- config,
- question_encoder_tokenizer=question_encoder_tokenizer,
- generator_tokenizer=generator_tokenizer,
- index=index,
- init_retrieval=False,
- )
- self.process_group = None
-
- def init_retrieval(self, distributed_port: int):
- """
- Retriever initialization function, needs to be called from the training process. The function sets some common parameters
- and environment variables. On top of that, (only) the main process in the process group loads the index into memory.
-
- Args:
- distributed_port (:obj:`int`):
- The port on which the main communication of the training run is carried out. We set the port for retrieval-related
- communication as ``distributed_port + 1``.
- """
-
- logger.info("initializing retrieval")
-
- # initializing a separate process group for retrieval as the default
- # nccl backend doesn't support gather/scatter operations while gloo
- # is too slow to replace nccl for the core gpu communication
- if dist.is_initialized():
- logger.info("dist initialized")
- # needs to be set manually
- os.environ["GLOO_SOCKET_IFNAME"] = self._infer_socket_ifname()
- # avoid clash with the NCCL port
- os.environ["MASTER_PORT"] = str(distributed_port + 1)
- self.process_group = dist.new_group(ranks=None, backend="gloo")
-
- # initialize retriever only on the main worker
- if not dist.is_initialized() or self._is_main():
- logger.info("dist not initialized / main")
- self.index.init_index()
-
- # all processes wait until the retriever is initialized by the main process
- if dist.is_initialized():
- torch.distributed.barrier(group=self.process_group)
-
- def _is_main(self):
- return dist.get_rank(group=self.process_group) == 0
-
- def _scattered(self, scatter_list, target_shape, target_type=torch.float32):
- target_tensor = torch.empty(target_shape, dtype=target_type)
- dist.scatter(target_tensor, src=0, scatter_list=scatter_list, group=self.process_group)
- return target_tensor
-
- def _infer_socket_ifname(self):
- addrs = psutil.net_if_addrs()
- # a hacky way to deal with varying network interface names
- ifname = next((addr for addr in addrs if addr.startswith("e")), None)
- return ifname
-
- def retrieve(self, question_hidden_states: np.ndarray, n_docs: int) -> Tuple[np.ndarray, List[dict]]:
- """
- Retrieves documents for specified ``question_hidden_states``. The main process, which has the access to the index stored in memory, gathers queries
- from all the processes in the main training process group, performs the retrieval and scatters back the results.
-
- Args:
- question_hidden_states (:obj:`np.ndarray` of shape :obj:`(batch_size, vector_size)`):
- A batch of query vectors to retrieve with.
- n_docs (:obj:`int`):
- The number of docs retrieved per query.
-
- Output:
- retrieved_doc_embeds (:obj:`np.ndarray` of shape :obj:`(batch_size, n_docs, dim)`
- The retrieval embeddings of the retrieved docs per query.
- doc_ids (:obj:`np.ndarray` of shape :obj:`batch_size, n_docs`)
- The ids of the documents in the index
- doc_dicts (:obj:`List[dict]`):
- The retrieved_doc_embeds examples per query.
- """
-
- # single GPU training
- if not dist.is_initialized():
- doc_ids, retrieved_doc_embeds = self._main_retrieve(question_hidden_states, n_docs)
- return retrieved_doc_embeds, doc_ids, self.index.get_doc_dicts(doc_ids)
-
- # distributed training
- world_size = dist.get_world_size(group=self.process_group)
-
- # gather logic
- gather_list = None
- if self._is_main():
- gather_list = [torch.empty(question_hidden_states.shape, dtype=torch.float32) for _ in range(world_size)]
- dist.gather(torch.tensor(question_hidden_states), dst=0, gather_list=gather_list, group=self.process_group)
-
- # scatter logic
- n_queries = question_hidden_states.shape[0]
- scatter_ids = []
- scatter_vectors = []
- if self._is_main():
- assert len(gather_list) == world_size
- ids, vectors = self._main_retrieve(torch.cat(gather_list).numpy(), n_docs)
- ids, vectors = torch.tensor(ids), torch.tensor(vectors)
- scatter_ids = self._chunk_tensor(ids, n_queries)
- scatter_vectors = self._chunk_tensor(vectors, n_queries)
- doc_ids = self._scattered(scatter_ids, [n_queries, n_docs], target_type=torch.int64)
- retrieved_doc_embeds = self._scattered(scatter_vectors, [n_queries, n_docs, question_hidden_states.shape[1]])
-
- return retrieved_doc_embeds.numpy(), doc_ids.numpy(), self.index.get_doc_dicts(doc_ids)
diff --git a/examples/research_projects/rag/distributed_ray_retriever.py b/examples/research_projects/rag/distributed_ray_retriever.py
deleted file mode 100644
index dd5baaf7261..00000000000
--- a/examples/research_projects/rag/distributed_ray_retriever.py
+++ /dev/null
@@ -1,152 +0,0 @@
-import logging
-import random
-
-import ray
-
-from transformers import RagConfig, RagRetriever, RagTokenizer
-from transformers.models.rag.retrieval_rag import CustomHFIndex
-
-
-logger = logging.getLogger(__name__)
-
-
-class RayRetriever:
- def __init__(self):
- self.initialized = False
-
- def create_rag_retriever(self, config, question_encoder_tokenizer, generator_tokenizer, index):
- if not self.initialized:
- self.retriever = RagRetriever(
- config,
- question_encoder_tokenizer=question_encoder_tokenizer,
- generator_tokenizer=generator_tokenizer,
- index=index,
- init_retrieval=False,
- )
- self.initialized = True
-
- def init_retrieval(self):
- self.retriever.index.init_index()
-
- def retrieve(self, question_hidden_states, n_docs):
- doc_ids, retrieved_doc_embeds = self.retriever._main_retrieve(question_hidden_states, n_docs)
- return doc_ids, retrieved_doc_embeds
-
-
-class RagRayDistributedRetriever(RagRetriever):
- """
- A distributed retriever built on top of the ``Ray`` API, a library
- for building distributed applications (https://docs.ray.io/en/master/).
- package. During training, all training workers initialize their own
- instance of a `RagRayDistributedRetriever`, and each instance of
- this distributed retriever shares a common set of Retrieval Ray
- Actors (https://docs.ray.io/en/master/walkthrough.html#remote
- -classes-actors) that load the index on separate processes. Ray
- handles the communication between the `RagRayDistributedRetriever`
- instances and the remote Ray actors. If training is done in a
- non-distributed setup, the index will simply be loaded in the same
- process as the training worker and Ray will not be used.
-
- Args:
- config (:class:`~transformers.RagConfig`):
- The configuration of the RAG model this Retriever is used with. Contains parameters indicating which ``Index`` to build.
- question_encoder_tokenizer (:class:`~transformers.PreTrainedTokenizer`):
- The tokenizer that was used to tokenize the question.
- It is used to decode the question and then use the generator_tokenizer.
- generator_tokenizer (:class:`~transformers.PreTrainedTokenizer`):
- The tokenizer used for the generator part of the RagModel.
- retrieval_workers (:obj:`List[ray.ActorClass(RayRetriever)]`): A list of already initialized `RayRetriever` actors.
- These actor classes run on remote processes and are responsible for performing the index lookup.
- index (:class:`~transformers.retrieval_rag.Index`, optional, defaults to the one defined by the configuration):
- If specified, use this index instead of the one built using the configuration
- """
-
- def __init__(self, config, question_encoder_tokenizer, generator_tokenizer, retrieval_workers, index=None):
- if index is not None and index.is_initialized() and len(retrieval_workers) > 0:
- raise ValueError(
- "When using Ray for distributed fine-tuning, "
- "you'll need to provide the paths instead, "
- "as the dataset and the index are loaded "
- "separately. More info in examples/rag/use_own_knowledge_dataset.py "
- )
- super().__init__(
- config,
- question_encoder_tokenizer=question_encoder_tokenizer,
- generator_tokenizer=generator_tokenizer,
- index=index,
- init_retrieval=False,
- )
- self.retrieval_workers = retrieval_workers
- if len(self.retrieval_workers) > 0:
- ray.get(
- [
- worker.create_rag_retriever.remote(config, question_encoder_tokenizer, generator_tokenizer, index)
- for worker in self.retrieval_workers
- ]
- )
-
- def init_retrieval(self):
- """
- Retriever initialization function, needs to be called from the
- training process. This function triggers retrieval initialization
- for all retrieval actors if using distributed setting, or loads
- index into current process if training is not distributed.
- """
- logger.info("initializing retrieval")
-
- if len(self.retrieval_workers) > 0:
- ray.get([worker.init_retrieval.remote() for worker in self.retrieval_workers])
- else:
- # Non-distributed training. Load index into this same process.
- self.index.init_index()
-
- def retrieve(self, question_hidden_states, n_docs):
- """
- Retrieves documents for specified ``question_hidden_states``. If
- running training with multiple workers, a random retrieval actor is
- selected to perform the index lookup and return the result.
-
- Args:
- question_hidden_states (:obj:`np.ndarray` of shape :obj:`(batch_size, vector_size)`):
- A batch of query vectors to retrieve with.
- n_docs (:obj:`int`):
- The number of docs retrieved per query.
-
- Output:
- retrieved_doc_embeds (:obj:`np.ndarray` of shape :obj:`(batch_size, n_docs, dim)`
- The retrieval embeddings of the retrieved docs per query.
- doc_ids (:obj:`np.ndarray` of shape :obj:`batch_size, n_docs`)
- The ids of the documents in the index
- doc_dicts (:obj:`List[dict]`):
- The retrieved_doc_embeds examples per query.
- """
- if len(self.retrieval_workers) > 0:
- # Select a random retrieval actor.
- random_worker = self.retrieval_workers[random.randint(0, len(self.retrieval_workers) - 1)]
- doc_ids, retrieved_doc_embeds = ray.get(random_worker.retrieve.remote(question_hidden_states, n_docs))
- else:
- doc_ids, retrieved_doc_embeds = self._main_retrieve(question_hidden_states, n_docs)
- return retrieved_doc_embeds, doc_ids, self.index.get_doc_dicts(doc_ids)
-
- @classmethod
- def get_tokenizers(cls, retriever_name_or_path, indexed_dataset=None, **kwargs):
- return super(RagRayDistributedRetriever, cls).get_tokenizers(retriever_name_or_path, indexed_dataset, **kwargs)
-
- @classmethod
- def from_pretrained(cls, retriever_name_or_path, actor_handles, indexed_dataset=None, **kwargs):
- config = kwargs.pop("config", None) or RagConfig.from_pretrained(retriever_name_or_path, **kwargs)
- rag_tokenizer = RagTokenizer.from_pretrained(retriever_name_or_path, config=config)
- question_encoder_tokenizer = rag_tokenizer.question_encoder
- generator_tokenizer = rag_tokenizer.generator
- if indexed_dataset is not None:
- config.index_name = "custom"
- index = CustomHFIndex(config.retrieval_vector_size, indexed_dataset)
- else:
- index = cls._build_index(config)
- return cls(
- config,
- question_encoder_tokenizer=question_encoder_tokenizer,
- generator_tokenizer=generator_tokenizer,
- retrieval_workers=actor_handles,
- index=index,
- )
diff --git a/examples/research_projects/rag/eval_rag.py b/examples/research_projects/rag/eval_rag.py
deleted file mode 100644
index 55f4da56571..00000000000
--- a/examples/research_projects/rag/eval_rag.py
+++ /dev/null
@@ -1,320 +0,0 @@
-"""Evaluation script for RAG models."""
-
-import argparse
-import ast
-import logging
-import os
-import sys
-
-import pandas as pd
-import torch
-from tqdm import tqdm
-
-from transformers import BartForConditionalGeneration, RagRetriever, RagSequenceForGeneration, RagTokenForGeneration
-from transformers import logging as transformers_logging
-
-
-sys.path.append(os.path.join(os.getcwd())) # noqa: E402 # isort:skip
-from utils_rag import exact_match_score, f1_score # noqa: E402 # isort:skip
-
-
-logger = logging.getLogger(__name__)
-logging.basicConfig(level=logging.INFO)
-
-transformers_logging.set_verbosity_info()
-
-
-def infer_model_type(model_name_or_path):
- if "token" in model_name_or_path:
- return "rag_token"
- if "sequence" in model_name_or_path:
- return "rag_sequence"
- if "bart" in model_name_or_path:
- return "bart"
- return None
-
-
-def metric_max_over_ground_truths(metric_fn, prediction, ground_truths):
- return max(metric_fn(prediction, gt) for gt in ground_truths)
-
-
-def get_scores(args, preds_path, gold_data_path):
- hypos = [line.strip() for line in open(preds_path, "r").readlines()]
- answers = []
-
- if args.gold_data_mode == "qa":
- data = pd.read_csv(gold_data_path, sep="\t", header=None)
- for answer_list in data[1]:
- ground_truths = ast.literal_eval(answer_list)
- answers.append(ground_truths)
- else:
- references = [line.strip() for line in open(gold_data_path, "r").readlines()]
- answers = [[reference] for reference in references]
-
- f1 = em = total = 0
- for prediction, ground_truths in zip(hypos, answers):
- total += 1
- em += metric_max_over_ground_truths(exact_match_score, prediction, ground_truths)
- f1 += metric_max_over_ground_truths(f1_score, prediction, ground_truths)
-
- em = 100.0 * em / total
- f1 = 100.0 * f1 / total
-
- logger.info(f"F1: {f1:.2f}")
- logger.info(f"EM: {em:.2f}")
-
-
-def get_precision_at_k(args, preds_path, gold_data_path):
- k = args.k
- hypos = [line.strip() for line in open(preds_path, "r").readlines()]
- references = [line.strip() for line in open(gold_data_path, "r").readlines()]
-
- em = total = 0
- for hypo, reference in zip(hypos, references):
- hypo_provenance = set(hypo.split("\t")[:k])
- ref_provenance = set(reference.split("\t"))
- total += 1
- em += len(hypo_provenance & ref_provenance) / k
-
- em = 100.0 * em / total
- logger.info(f"Precision@{k}: {em: .2f}")
-
-
-def evaluate_batch_retrieval(args, rag_model, questions):
- def strip_title(title):
- if title.startswith('"'):
- title = title[1:]
- if title.endswith('"'):
- title = title[:-1]
- return title
-
- retriever_input_ids = rag_model.retriever.question_encoder_tokenizer.batch_encode_plus(
- questions,
- return_tensors="pt",
- padding=True,
- truncation=True,
- )["input_ids"].to(args.device)
-
- question_enc_outputs = rag_model.rag.question_encoder(retriever_input_ids)
- question_enc_pool_output = question_enc_outputs[0]
-
- result = rag_model.retriever(
- retriever_input_ids,
- question_enc_pool_output.cpu().detach().to(torch.float32).numpy(),
- prefix=rag_model.rag.generator.config.prefix,
- n_docs=rag_model.config.n_docs,
- return_tensors="pt",
- )
- all_docs = rag_model.retriever.index.get_doc_dicts(result.doc_ids)
- provenance_strings = []
- for docs in all_docs:
- provenance = [strip_title(title) for title in docs["title"]]
- provenance_strings.append("\t".join(provenance))
- return provenance_strings
-
-
-def evaluate_batch_e2e(args, rag_model, questions):
- with torch.no_grad():
- inputs_dict = rag_model.retriever.question_encoder_tokenizer.batch_encode_plus(
- questions, return_tensors="pt", padding=True, truncation=True
- )
-
- input_ids = inputs_dict.input_ids.to(args.device)
- attention_mask = inputs_dict.attention_mask.to(args.device)
- outputs = rag_model.generate( # rag_model overwrites generate
- input_ids,
- attention_mask=attention_mask,
- num_beams=args.num_beams,
- min_length=args.min_length,
- max_length=args.max_length,
- early_stopping=False,
- num_return_sequences=1,
- bad_words_ids=[[0, 0]], # BART likes to repeat BOS tokens, dont allow it to generate more than one
- )
- answers = rag_model.retriever.generator_tokenizer.batch_decode(outputs, skip_special_tokens=True)
-
- if args.print_predictions:
- for q, a in zip(questions, answers):
- logger.info("Q: {} - A: {}".format(q, a))
-
- return answers
-
-
-def get_args():
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "--model_type",
- choices=["rag_sequence", "rag_token", "bart"],
- type=str,
- help=(
- "RAG model type: rag_sequence, rag_token or bart, if none specified, the type is inferred from the"
- " model_name_or_path"
- ),
- )
- parser.add_argument(
- "--index_name",
- default=None,
- choices=["exact", "compressed", "legacy"],
- type=str,
- help="RAG model retriever type",
- )
- parser.add_argument(
- "--index_path",
- default=None,
- type=str,
- help="Path to the retrieval index",
- )
- parser.add_argument("--n_docs", default=5, type=int, help="Number of retrieved docs")
- parser.add_argument(
- "--model_name_or_path",
- default=None,
- type=str,
- required=True,
- help="Path to pretrained checkpoints or model identifier from huggingface.co/models",
- )
- parser.add_argument(
- "--eval_mode",
- choices=["e2e", "retrieval"],
- default="e2e",
- type=str,
- help=(
- "Evaluation mode, e2e calculates exact match and F1 of the downstream task, retrieval calculates"
- " precision@k."
- ),
- )
- parser.add_argument("--k", default=1, type=int, help="k for the precision@k calculation")
- parser.add_argument(
- "--evaluation_set",
- default=None,
- type=str,
- required=True,
- help="Path to a file containing evaluation samples",
- )
- parser.add_argument(
- "--gold_data_path",
- default=None,
- type=str,
- required=True,
- help="Path to a tab-separated file with gold samples",
- )
- parser.add_argument(
- "--gold_data_mode",
- default="qa",
- type=str,
- choices=["qa", "ans"],
- help=(
- "Format of the gold data file"
- "qa - a single line in the following format: question [tab] answer_list"
- "ans - a single line of the gold file contains the expected answer string"
- ),
- )
- parser.add_argument(
- "--predictions_path",
- type=str,
- default="predictions.txt",
- help="Name of the predictions file, to be stored in the checkpoints directory",
- )
- parser.add_argument(
- "--eval_all_checkpoints",
- action="store_true",
- help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
- )
- parser.add_argument(
- "--eval_batch_size",
- default=8,
- type=int,
- help="Batch size per GPU/CPU for evaluation.",
- )
- parser.add_argument(
- "--recalculate",
- help="Recalculate predictions even if the prediction file exists",
- action="store_true",
- )
- parser.add_argument(
- "--num_beams",
- default=4,
- type=int,
- help="Number of beams to be used when generating answers",
- )
- parser.add_argument("--min_length", default=1, type=int, help="Min length of the generated answers")
- parser.add_argument("--max_length", default=50, type=int, help="Max length of the generated answers")
-
- parser.add_argument(
- "--print_predictions",
- action="store_true",
- help="If True, prints predictions while evaluating.",
- )
- parser.add_argument(
- "--print_docs",
- action="store_true",
- help="If True, prints docs retried while generating.",
- )
- args = parser.parse_args()
- args.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
- return args
-
-
-def main(args):
- model_kwargs = {}
- if args.model_type is None:
- args.model_type = infer_model_type(args.model_name_or_path)
- assert args.model_type is not None
- if args.model_type.startswith("rag"):
- model_class = RagTokenForGeneration if args.model_type == "rag_token" else RagSequenceForGeneration
- model_kwargs["n_docs"] = args.n_docs
- if args.index_name is not None:
- model_kwargs["index_name"] = args.index_name
- if args.index_path is not None:
- model_kwargs["index_path"] = args.index_path
- else:
- model_class = BartForConditionalGeneration
-
- checkpoints = (
- [f.path for f in os.scandir(args.model_name_or_path) if f.is_dir()]
- if args.eval_all_checkpoints
- else [args.model_name_or_path]
- )
-
- logger.info("Evaluate the following checkpoints: %s", checkpoints)
-
- score_fn = get_scores if args.eval_mode == "e2e" else get_precision_at_k
- evaluate_batch_fn = evaluate_batch_e2e if args.eval_mode == "e2e" else evaluate_batch_retrieval
-
- for checkpoint in checkpoints:
- if os.path.exists(args.predictions_path) and (not args.recalculate):
- logger.info("Calculating metrics based on an existing predictions file: {}".format(args.predictions_path))
- score_fn(args, args.predictions_path, args.gold_data_path)
- continue
-
- logger.info("***** Running evaluation for {} *****".format(checkpoint))
- logger.info(" Batch size = %d", args.eval_batch_size)
- logger.info(" Predictions will be stored under {}".format(args.predictions_path))
-
- if args.model_type.startswith("rag"):
- retriever = RagRetriever.from_pretrained(checkpoint, **model_kwargs)
- model = model_class.from_pretrained(checkpoint, retriever=retriever, **model_kwargs)
- model.retriever.init_retrieval()
- else:
- model = model_class.from_pretrained(checkpoint, **model_kwargs)
- model.to(args.device)
-
- with open(args.evaluation_set, "r") as eval_file, open(args.predictions_path, "w") as preds_file:
- questions = []
- for line in tqdm(eval_file):
- questions.append(line.strip())
- if len(questions) == args.eval_batch_size:
- answers = evaluate_batch_fn(args, model, questions)
- preds_file.write("\n".join(answers) + "\n")
- preds_file.flush()
- questions = []
- if len(questions) > 0:
- answers = evaluate_batch_fn(args, model, questions)
- preds_file.write("\n".join(answers))
- preds_file.flush()
-
- score_fn(args, args.predictions_path, args.gold_data_path)
-
-
-if __name__ == "__main__":
- args = get_args()
- main(args)
diff --git a/examples/research_projects/rag/finetune_rag.py b/examples/research_projects/rag/finetune_rag.py
deleted file mode 100644
index af3acd4def6..00000000000
--- a/examples/research_projects/rag/finetune_rag.py
+++ /dev/null
@@ -1,649 +0,0 @@
-"""Finetuning script for RAG models. Adapted from examples.seq2seq.finetune.py"""
-
-import argparse
-import logging
-import os
-import sys
-import time
-from collections import defaultdict
-from pathlib import Path
-from typing import Any, Dict, List, Tuple
-
-import numpy as np
-import pytorch_lightning as pl
-import torch
-import torch.distributed as dist
-import torch.distributed as torch_distrib
-from pytorch_lightning.plugins.training_type import DDPPlugin
-from torch.utils.data import DataLoader
-
-from transformers import (
- AutoConfig,
- AutoTokenizer,
- BartForConditionalGeneration,
- BatchEncoding,
- RagConfig,
- RagSequenceForGeneration,
- RagTokenForGeneration,
- RagTokenizer,
- T5ForConditionalGeneration,
-)
-from transformers import logging as transformers_logging
-from transformers.integrations import is_ray_available
-
-
-if is_ray_available():
- import ray
- from distributed_ray_retriever import RagRayDistributedRetriever, RayRetriever
-
-from callbacks_rag import ( # noqa: E402 # isort:skipq
- get_checkpoint_callback,
- get_early_stopping_callback,
- Seq2SeqLoggingCallback,
-)
-
-from distributed_pytorch_retriever import RagPyTorchDistributedRetriever # noqa: E402 # isort:skip
-from utils_rag import ( # noqa: E402 # isort:skip
- calculate_exact_match,
- flatten_list,
- get_git_info,
- is_rag_model,
- lmap,
- pickle_save,
- save_git_info,
- save_json,
- set_extra_model_params,
- Seq2SeqDataset,
-)
-
-# need the parent dir module
-sys.path.insert(2, str(Path(__file__).resolve().parents[1]))
-from lightning_base import BaseTransformer, add_generic_args, generic_train # noqa
-
-
-logging.basicConfig(level=logging.INFO)
-logger = logging.getLogger(__name__)
-
-transformers_logging.set_verbosity_info()
-
-
-class AttrDict(dict):
- def __init__(self, *args, **kwargs):
- super(AttrDict, self).__init__(*args, **kwargs)
- self.__dict__ = self
-
-
-class CustomDDP(DDPPlugin):
- def init_ddp_connection(self, global_rank=None, world_size=None) -> None:
- module = self.model
- global_rank = global_rank if global_rank is not None else self.cluster_environment.global_rank()
- world_size = world_size if world_size is not None else self.cluster_environment.world_size()
- os.environ["MASTER_ADDR"] = self.cluster_environment.master_address()
- os.environ["MASTER_PORT"] = str(self.cluster_environment.master_port())
- if not torch.distributed.is_initialized():
- logger.info(f"initializing ddp: GLOBAL_RANK: {global_rank}, MEMBER: {global_rank + 1}/{world_size}")
- torch_distrib.init_process_group(self.torch_distributed_backend, rank=global_rank, world_size=world_size)
-
- if module.is_rag_model:
- self.distributed_port = module.hparams.distributed_port
- if module.distributed_retriever == "pytorch":
- module.model.rag.retriever.init_retrieval(self.distributed_port)
- elif module.distributed_retriever == "ray" and global_rank == 0:
- # For the Ray retriever, only initialize it once when global
- # rank is 0.
- module.model.rag.retriever.init_retrieval()
-
-
-class GenerativeQAModule(BaseTransformer):
- mode = "generative_qa"
- loss_names = ["loss"]
- metric_names = ["em"]
- val_metric = "em"
-
- def __init__(self, hparams, **kwargs):
- # when loading from a pytorch lightning checkpoint, hparams are passed as dict
- if isinstance(hparams, dict):
- hparams = AttrDict(hparams)
- if hparams.model_type == "rag_sequence":
- self.model_class = RagSequenceForGeneration
- elif hparams.model_type == "rag_token":
- self.model_class = RagTokenForGeneration
- elif hparams.model_type == "bart":
- self.model_class = BartForConditionalGeneration
- else:
- self.model_class = T5ForConditionalGeneration
- self.is_rag_model = is_rag_model(hparams.model_type)
-
- config_class = RagConfig if self.is_rag_model else AutoConfig
- config = config_class.from_pretrained(hparams.model_name_or_path)
-
- # set retriever parameters
- config.index_name = hparams.index_name or config.index_name
- config.passages_path = hparams.passages_path or config.passages_path
- config.index_path = hparams.index_path or config.index_path
- config.use_dummy_dataset = hparams.use_dummy_dataset
-
- # set extra_model_params for generator configs and load_model
- extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "attention_dropout", "dropout")
- if self.is_rag_model:
- if hparams.prefix is not None:
- config.generator.prefix = hparams.prefix
- config.label_smoothing = hparams.label_smoothing
- hparams, config.generator = set_extra_model_params(extra_model_params, hparams, config.generator)
- if hparams.distributed_retriever == "pytorch":
- retriever = RagPyTorchDistributedRetriever.from_pretrained(hparams.model_name_or_path, config=config)
- elif hparams.distributed_retriever == "ray":
- # The Ray retriever needs the handles to the retriever actors.
- retriever = RagRayDistributedRetriever.from_pretrained(
- hparams.model_name_or_path, hparams.actor_handles, config=config
- )
- model = self.model_class.from_pretrained(hparams.model_name_or_path, config=config, retriever=retriever)
- prefix = config.question_encoder.prefix
- else:
- if hparams.prefix is not None:
- config.prefix = hparams.prefix
- hparams, config = set_extra_model_params(extra_model_params, hparams, config)
- model = self.model_class.from_pretrained(hparams.model_name_or_path, config=config)
- prefix = config.prefix
-
- tokenizer = (
- RagTokenizer.from_pretrained(hparams.model_name_or_path)
- if self.is_rag_model
- else AutoTokenizer.from_pretrained(hparams.model_name_or_path)
- )
-
- super().__init__(hparams, config=config, tokenizer=tokenizer, model=model)
-
- save_git_info(self.hparams.output_dir)
- self.output_dir = Path(self.hparams.output_dir)
- self.metrics_save_path = Path(self.output_dir) / "metrics.json"
- self.hparams_save_path = Path(self.output_dir) / "hparams.pkl"
- pickle_save(self.hparams, self.hparams_save_path)
- self.step_count = 0
- self.metrics = defaultdict(list)
-
- self.dataset_kwargs: dict = {
- "data_dir": self.hparams.data_dir,
- "max_source_length": self.hparams.max_source_length,
- "prefix": prefix or "",
- }
- n_observations_per_split = {
- "train": self.hparams.n_train,
- "val": self.hparams.n_val,
- "test": self.hparams.n_test,
- }
- self.n_obs = {k: v if v >= 0 else None for k, v in n_observations_per_split.items()}
-
- self.target_lens = {
- "train": self.hparams.max_target_length,
- "val": self.hparams.val_max_target_length,
- "test": self.hparams.test_max_target_length,
- }
- assert self.target_lens["train"] <= self.target_lens["val"], f"target_lens: {self.target_lens}"
- assert self.target_lens["train"] <= self.target_lens["test"], f"target_lens: {self.target_lens}"
-
- self.hparams.git_sha = get_git_info()["repo_sha"]
- self.num_workers = hparams.num_workers
- self.distributed_port = self.hparams.distributed_port
-
- # For single GPU training, init_ddp_connection is not called.
- # So we need to initialize the retrievers here.
- if hparams.gpus <= 1:
- if hparams.distributed_retriever == "ray":
- self.model.retriever.init_retrieval()
- elif hparams.distributed_retriever == "pytorch":
- self.model.retriever.init_retrieval(self.distributed_port)
-
- self.distributed_retriever = hparams.distributed_retriever
-
- def forward(self, input_ids, **kwargs):
- return self.model(input_ids, **kwargs)
-
- def ids_to_clean_text(self, generated_ids: List[int]):
- gen_text = self.tokenizer.batch_decode(
- generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
- )
- return lmap(str.strip, gen_text)
-
- def _step(self, batch: dict) -> Tuple:
- source_ids, source_mask, target_ids = batch["input_ids"], batch["attention_mask"], batch["decoder_input_ids"]
-
- rag_kwargs = {}
- if isinstance(self.model, T5ForConditionalGeneration):
- decoder_input_ids = self.model._shift_right(target_ids)
- lm_labels = target_ids
- elif isinstance(self.model, BartForConditionalGeneration):
- decoder_input_ids = target_ids[:, :-1].contiguous()
- lm_labels = target_ids[:, 1:].clone()
- else:
- assert self.is_rag_model
- generator = self.model.rag.generator
- if isinstance(generator, T5ForConditionalGeneration):
- decoder_start_token_id = generator.config.decoder_start_token_id
- decoder_input_ids = (
- torch.cat(
- [torch.tensor([[decoder_start_token_id]] * target_ids.shape[0]).to(target_ids), target_ids],
- dim=1,
- )
- if target_ids.shape[0] < self.target_lens["train"]
- else generator._shift_right(target_ids)
- )
- elif isinstance(generator, BartForConditionalGeneration):
- decoder_input_ids = target_ids
- lm_labels = decoder_input_ids
- rag_kwargs["reduce_loss"] = True
-
- assert decoder_input_ids is not None
-
- outputs = self(
- source_ids,
- attention_mask=source_mask,
- decoder_input_ids=decoder_input_ids,
- use_cache=False,
- labels=lm_labels,
- **rag_kwargs,
- )
-
- loss = outputs["loss"]
- return (loss,)
-
- @property
- def pad(self) -> int:
- raise NotImplementedError("pad not implemented")
-
- def training_step(self, batch, batch_idx) -> Dict:
- loss_tensors = self._step(batch)
-
- logs = {name: loss.detach() for name, loss in zip(self.loss_names, loss_tensors)}
- # tokens per batch
- tgt_pad_token_id = (
- self.tokenizer.generator.pad_token_id
- if isinstance(self.tokenizer, RagTokenizer)
- else self.tokenizer.pad_token_id
- )
- src_pad_token_id = (
- self.tokenizer.question_encoder.pad_token_id
- if isinstance(self.tokenizer, RagTokenizer)
- else self.tokenizer.pad_token_id
- )
- logs["tpb"] = (
- batch["input_ids"].ne(src_pad_token_id).sum() + batch["decoder_input_ids"].ne(tgt_pad_token_id).sum()
- )
-
- return {"loss": loss_tensors[0], "log": logs}
-
- def validation_step(self, batch, batch_idx) -> Dict:
- return self._generative_step(batch)
-
- def validation_epoch_end(self, outputs, prefix="val") -> Dict:
- self.step_count += 1
- losses = {k: torch.stack([x[k] for x in outputs]).mean() for k in self.loss_names}
- loss = losses["loss"]
- gen_metrics = {
- k: np.array([x[k] for x in outputs]).mean() for k in self.metric_names + ["gen_time", "gen_len"]
- }
- metrics_tensor: torch.FloatTensor = torch.tensor(gen_metrics[self.val_metric]).type_as(loss)
- gen_metrics.update({k: v.item() for k, v in losses.items()})
-
- # fix for https://github.com/PyTorchLightning/pytorch-lightning/issues/2424
- if dist.is_initialized():
- dist.all_reduce(metrics_tensor, op=dist.ReduceOp.SUM)
- metrics_tensor = metrics_tensor / dist.get_world_size()
- gen_metrics.update({self.val_metric: metrics_tensor.item()})
-
- losses.update(gen_metrics)
- metrics = {f"{prefix}_avg_{k}": x for k, x in losses.items()}
- metrics["step_count"] = self.step_count
- self.save_metrics(metrics, prefix) # writes to self.metrics_save_path
- preds = flatten_list([x["preds"] for x in outputs])
- return {"log": metrics, "preds": preds, f"{prefix}_loss": loss, f"{prefix}_{self.val_metric}": metrics_tensor}
-
- def save_metrics(self, latest_metrics, type_path) -> None:
- self.metrics[type_path].append(latest_metrics)
- save_json(self.metrics, self.metrics_save_path)
-
- def calc_generative_metrics(self, preds, target) -> Dict:
- return calculate_exact_match(preds, target)
-
- def _generative_step(self, batch: dict) -> dict:
- start_time = time.time()
- batch = BatchEncoding(batch).to(device=self.model.device)
- generated_ids = self.model.generate(
- batch["input_ids"],
- attention_mask=batch["attention_mask"],
- do_deduplication=False, # rag specific parameter
- use_cache=True,
- min_length=1,
- max_length=self.target_lens["val"],
- )
-
- gen_time = (time.time() - start_time) / batch["input_ids"].shape[0]
- preds: List[str] = self.ids_to_clean_text(generated_ids)
- target: List[str] = self.ids_to_clean_text(batch["decoder_input_ids"])
- loss_tensors = self._step(batch)
- base_metrics = dict(zip(self.loss_names, loss_tensors))
- gen_metrics: Dict = self.calc_generative_metrics(preds, target)
-
- summ_len = np.mean(lmap(len, generated_ids))
- base_metrics.update(gen_time=gen_time, gen_len=summ_len, preds=preds, target=target, **gen_metrics)
- return base_metrics
-
- def test_step(self, batch, batch_idx):
- return self._generative_step(batch)
-
- def test_epoch_end(self, outputs):
- return self.validation_epoch_end(outputs, prefix="test")
-
- def get_dataset(self, type_path) -> Seq2SeqDataset:
- n_obs = self.n_obs[type_path]
- max_target_length = self.target_lens[type_path]
- dataset = Seq2SeqDataset(
- self.tokenizer,
- type_path=type_path,
- n_obs=n_obs,
- max_target_length=max_target_length,
- **self.dataset_kwargs,
- )
- return dataset
-
- def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False) -> DataLoader:
- dataset = self.get_dataset(type_path)
-
- dataloader = DataLoader(
- dataset,
- batch_size=batch_size,
- collate_fn=dataset.collate_fn,
- shuffle=shuffle,
- num_workers=self.num_workers,
- )
- return dataloader
-
- def train_dataloader(self) -> DataLoader:
- dataloader = self.get_dataloader("train", batch_size=self.hparams.train_batch_size, shuffle=True)
- return dataloader
-
- def val_dataloader(self) -> DataLoader:
- return self.get_dataloader("val", batch_size=self.hparams.eval_batch_size)
-
- def test_dataloader(self) -> DataLoader:
- return self.get_dataloader("test", batch_size=self.hparams.eval_batch_size)
-
- @pl.utilities.rank_zero_only
- def on_save_checkpoint(self, checkpoint: Dict[str, Any]) -> None:
- save_path = self.output_dir.joinpath("checkpoint{}".format(self.step_count))
- self.model.config.save_step = self.step_count
- self.model.save_pretrained(save_path)
- self.tokenizer.save_pretrained(save_path)
-
- @staticmethod
- def add_model_specific_args(parser, root_dir):
- BaseTransformer.add_model_specific_args(parser, root_dir)
- add_generic_args(parser, root_dir)
- parser.add_argument(
- "--max_source_length",
- default=128,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument(
- "--max_target_length",
- default=25,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument(
- "--val_max_target_length",
- default=25,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument(
- "--test_max_target_length",
- default=25,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument("--logger_name", type=str, choices=["default", "wandb", "wandb_shared"], default="default")
- parser.add_argument("--n_train", type=int, default=-1, required=False, help="# examples. -1 means use all.")
- parser.add_argument("--n_val", type=int, default=-1, required=False, help="# examples. -1 means use all.")
- parser.add_argument("--n_test", type=int, default=-1, required=False, help="# examples. -1 means use all.")
- parser.add_argument("--label_smoothing", type=float, default=0.0, required=False)
- parser.add_argument(
- "--prefix",
- type=str,
- default=None,
- help="Prefix added at the beginning of each text, typically used with T5-based models.",
- )
- parser.add_argument(
- "--early_stopping_patience",
- type=int,
- default=-1,
- required=False,
- help=(
- "-1 means never early stop. early_stopping_patience is measured in validation checks, not epochs. So"
- " val_check_interval will effect it."
- ),
- )
- parser.add_argument(
- "--distributed-port", type=int, default=-1, required=False, help="Port number for distributed training."
- )
- parser.add_argument(
- "--model_type",
- choices=["rag_sequence", "rag_token", "bart", "t5"],
- type=str,
- help=(
- "RAG model type: sequence or token, if none specified, the type is inferred from the"
- " model_name_or_path"
- ),
- )
- return parser
-
- @staticmethod
- def add_retriever_specific_args(parser):
- parser.add_argument(
- "--index_name",
- type=str,
- default=None,
- help=(
- "Name of the index to use: 'hf' for a canonical dataset from the datasets library (default), 'custom'"
- " for a local index, or 'legacy' for the original one)"
- ),
- )
- parser.add_argument(
- "--passages_path",
- type=str,
- default=None,
- help=(
- "Path to the dataset of passages for custom index. More info about custom indexes in the RagRetriever"
- " documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
- ),
- )
- parser.add_argument(
- "--index_path",
- type=str,
- default=None,
- help=(
- "Path to the faiss index for custom index. More info about custom indexes in the RagRetriever"
- " documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
- ),
- )
- parser.add_argument(
- "--distributed_retriever",
- choices=["ray", "pytorch"],
- type=str,
- default="pytorch",
- help=(
- "What implementation to use for distributed retriever? If "
- "pytorch is selected, the index is loaded on training "
- "worker 0, and torch.distributed is used to handle "
- "communication between training worker 0, and the other "
- "training workers. If ray is selected, the Ray library is "
- "used to create load the index on separate processes, "
- "and Ray handles the communication between the training "
- "workers and the retrieval actors."
- ),
- )
- parser.add_argument(
- "--use_dummy_dataset",
- type=bool,
- default=False,
- help=(
- "Whether to use the dummy version of the dataset index. More info about custom indexes in the"
- " RagRetriever documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
- ),
- )
- return parser
-
- @staticmethod
- def add_ray_specific_args(parser):
- # Ray cluster address.
- parser.add_argument(
- "--ray-address",
- default="auto",
- type=str,
- help=(
- "The address of the Ray cluster to connect to. If not "
- "specified, Ray will attempt to automatically detect the "
- "cluster. Has no effect if pytorch is used as the distributed "
- "retriever."
- ),
- )
- parser.add_argument(
- "--num_retrieval_workers",
- type=int,
- default=1,
- help=(
- "The number of retrieval actors to use when Ray is selected "
- "for the distributed retriever. Has no effect when "
- "distributed_retriever is set to pytorch."
- ),
- )
- return parser
-
-
-def main(args=None, model=None) -> GenerativeQAModule:
- parser = argparse.ArgumentParser()
- parser = pl.Trainer.add_argparse_args(parser)
- parser = GenerativeQAModule.add_model_specific_args(parser, os.getcwd())
- parser = GenerativeQAModule.add_retriever_specific_args(parser)
-
- args = args or parser.parse_args()
-
- Path(args.output_dir).mkdir(exist_ok=True)
-
- named_actors = []
- if args.distributed_retriever == "ray" and args.gpus > 1:
- if not is_ray_available():
- raise RuntimeError("Please install Ray to use the Ray distributed retriever.")
- # Connect to an existing Ray cluster.
- try:
- ray.init(address=args.ray_address, namespace="rag")
- except (ConnectionError, ValueError):
- logger.warning(
- "Connection to Ray cluster failed. Make sure a Ray "
- "cluster is running by either using Ray's cluster "
- "launcher (`ray up`) or by manually starting Ray on "
- "each node via `ray start --head` for the head node "
- "and `ray start --address=':6379'` for "
- "additional nodes. See "
- "https://docs.ray.io/en/master/cluster/index.html "
- "for more info."
- )
- raise
-
- # Create Ray actors only for rank 0.
- if ("LOCAL_RANK" not in os.environ or int(os.environ["LOCAL_RANK"]) == 0) and (
- "NODE_RANK" not in os.environ or int(os.environ["NODE_RANK"]) == 0
- ):
- remote_cls = ray.remote(RayRetriever)
- named_actors = [
- remote_cls.options(name="retrieval_worker_{}".format(i)).remote()
- for i in range(args.num_retrieval_workers)
- ]
- else:
- logger.info(
- "Getting named actors for NODE_RANK {}, LOCAL_RANK {}".format(
- os.environ["NODE_RANK"], os.environ["LOCAL_RANK"]
- )
- )
- named_actors = [ray.get_actor("retrieval_worker_{}".format(i)) for i in range(args.num_retrieval_workers)]
- args.actor_handles = named_actors
- assert args.actor_handles == named_actors
-
- if model is None:
- model: GenerativeQAModule = GenerativeQAModule(args)
-
- dataset = Path(args.data_dir).name
- if (
- args.logger_name == "default"
- or args.fast_dev_run
- or str(args.output_dir).startswith("/tmp")
- or str(args.output_dir).startswith("/var")
- ):
- training_logger = True # don't pollute wandb logs unnecessarily
- elif args.logger_name == "wandb":
- from pytorch_lightning.loggers import WandbLogger
-
- project = os.environ.get("WANDB_PROJECT", dataset)
- training_logger = WandbLogger(name=model.output_dir.name, project=project)
-
- elif args.logger_name == "wandb_shared":
- from pytorch_lightning.loggers import WandbLogger
-
- training_logger = WandbLogger(name=model.output_dir.name, project=f"hf_{dataset}")
-
- es_callback = (
- get_early_stopping_callback(model.val_metric, args.early_stopping_patience)
- if args.early_stopping_patience >= 0
- else False
- )
-
- trainer: pl.Trainer = generic_train(
- model,
- args,
- logging_callback=Seq2SeqLoggingCallback(),
- checkpoint_callback=get_checkpoint_callback(args.output_dir, model.val_metric),
- early_stopping_callback=es_callback,
- logger=training_logger,
- custom_ddp_plugin=CustomDDP() if args.gpus > 1 else None,
- profiler=pl.profiler.AdvancedProfiler() if args.profile else None,
- )
- pickle_save(model.hparams, model.output_dir / "hparams.pkl")
-
- if not args.do_predict:
- return model
-
- # test() without a model tests using the best checkpoint automatically
- trainer.test()
- return model
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser = pl.Trainer.add_argparse_args(parser)
- parser = GenerativeQAModule.add_model_specific_args(parser, os.getcwd())
- parser = GenerativeQAModule.add_retriever_specific_args(parser)
- parser = GenerativeQAModule.add_ray_specific_args(parser)
-
- # Pytorch Lightning Profiler
- parser.add_argument(
- "--profile",
- action="store_true",
- help="If True, use pytorch_lightning.profiler.AdvancedProfiler to profile the Trainer.",
- )
-
- args = parser.parse_args()
-
- main(args)
diff --git a/examples/research_projects/rag/finetune_rag.sh b/examples/research_projects/rag/finetune_rag.sh
deleted file mode 100755
index 8fd1fea3e54..00000000000
--- a/examples/research_projects/rag/finetune_rag.sh
+++ /dev/null
@@ -1,34 +0,0 @@
-# Add parent directory to python path to access lightning_base.py
-export PYTHONPATH="../":"${PYTHONPATH}"
-
-# A sample finetuning run, you need to specify data_dir, output_dir and model_name_or_path
-# run ./examples/rag/finetune_rag.sh --help to see all the possible options
-
-python examples/rag/finetune_rag.py \
- --data_dir $DATA_DIR \
- --output_dir $OUTPUT_DIR \
- --model_name_or_path $MODEL_NAME_OR_PATH \
- --model_type rag_sequence \
- --fp16 \
- --gpus 8 \
- --profile \
- --do_train \
- --do_predict \
- --n_val -1 \
- --train_batch_size 8 \
- --eval_batch_size 1 \
- --max_source_length 128 \
- --max_target_length 25 \
- --val_max_target_length 25 \
- --test_max_target_length 25 \
- --label_smoothing 0.1 \
- --dropout 0.1 \
- --attention_dropout 0.1 \
- --weight_decay 0.001 \
- --adam_epsilon 1e-08 \
- --max_grad_norm 0.1 \
- --lr_scheduler polynomial \
- --learning_rate 3e-05 \
- --num_train_epochs 100 \
- --warmup_steps 500 \
- --gradient_accumulation_steps 1 \
diff --git a/examples/research_projects/rag/finetune_rag_ray.sh b/examples/research_projects/rag/finetune_rag_ray.sh
deleted file mode 100755
index 7c8e7b97e77..00000000000
--- a/examples/research_projects/rag/finetune_rag_ray.sh
+++ /dev/null
@@ -1,44 +0,0 @@
-# Sample script to finetune RAG using Ray for distributed retrieval.
-
-# Add parent directory to python path to access lightning_base.py
-export PYTHONPATH="../":"${PYTHONPATH}"
-
-# Start a single-node Ray cluster.
-ray start --head
-
-# A sample finetuning run, you need to specify data_dir, output_dir and model_name_or_path
-# run ./examples/rag/finetune_rag_ray.sh --help to see all the possible options
-
-python examples/rag/finetune_rag.py \
- --data_dir $DATA_DIR \
- --output_dir $OUTPUT_DIR \
- --model_name_or_path $MODEL_NAME_OR_PATH \
- --model_type rag_sequence \
- --fp16 \
- --gpus 8 \
- --profile \
- --do_train \
- --do_predict \
- --n_val -1 \
- --train_batch_size 8 \
- --eval_batch_size 1 \
- --max_source_length 128 \
- --max_target_length 25 \
- --val_max_target_length 25 \
- --test_max_target_length 25 \
- --label_smoothing 0.1 \
- --dropout 0.1 \
- --attention_dropout 0.1 \
- --weight_decay 0.001 \
- --adam_epsilon 1e-08 \
- --max_grad_norm 0.1 \
- --lr_scheduler polynomial \
- --learning_rate 3e-05 \
- --num_train_epochs 100 \
- --warmup_steps 500 \
- --gradient_accumulation_steps 1 \
- --distributed_retriever ray \
- --num_retrieval_workers 4
-
-# Stop the Ray cluster.
-ray stop
diff --git a/examples/research_projects/rag/lightning_base.py b/examples/research_projects/rag/lightning_base.py
deleted file mode 100644
index 12099bc3aa1..00000000000
--- a/examples/research_projects/rag/lightning_base.py
+++ /dev/null
@@ -1,404 +0,0 @@
-import argparse
-import logging
-import os
-from pathlib import Path
-from typing import Any, Dict
-
-import pytorch_lightning as pl
-from pytorch_lightning.utilities import rank_zero_info
-
-from transformers import (
- AdamW,
- AutoConfig,
- AutoModel,
- AutoModelForPreTraining,
- AutoModelForQuestionAnswering,
- AutoModelForSeq2SeqLM,
- AutoModelForSequenceClassification,
- AutoModelForTokenClassification,
- AutoModelWithLMHead,
- AutoTokenizer,
- PretrainedConfig,
- PreTrainedTokenizer,
-)
-from transformers.optimization import (
- Adafactor,
- get_cosine_schedule_with_warmup,
- get_cosine_with_hard_restarts_schedule_with_warmup,
- get_linear_schedule_with_warmup,
- get_polynomial_decay_schedule_with_warmup,
-)
-from transformers.utils.versions import require_version
-
-
-logger = logging.getLogger(__name__)
-
-require_version("pytorch_lightning>=1.0.4")
-
-MODEL_MODES = {
- "base": AutoModel,
- "sequence-classification": AutoModelForSequenceClassification,
- "question-answering": AutoModelForQuestionAnswering,
- "pretraining": AutoModelForPreTraining,
- "token-classification": AutoModelForTokenClassification,
- "language-modeling": AutoModelWithLMHead,
- "summarization": AutoModelForSeq2SeqLM,
- "translation": AutoModelForSeq2SeqLM,
-}
-
-
-# update this and the import above to support new schedulers from transformers.optimization
-arg_to_scheduler = {
- "linear": get_linear_schedule_with_warmup,
- "cosine": get_cosine_schedule_with_warmup,
- "cosine_w_restarts": get_cosine_with_hard_restarts_schedule_with_warmup,
- "polynomial": get_polynomial_decay_schedule_with_warmup,
- # '': get_constant_schedule, # not supported for now
- # '': get_constant_schedule_with_warmup, # not supported for now
-}
-arg_to_scheduler_choices = sorted(arg_to_scheduler.keys())
-arg_to_scheduler_metavar = "{" + ", ".join(arg_to_scheduler_choices) + "}"
-
-
-class BaseTransformer(pl.LightningModule):
- def __init__(
- self,
- hparams: argparse.Namespace,
- num_labels=None,
- mode="base",
- config=None,
- tokenizer=None,
- model=None,
- **config_kwargs,
- ):
- """Initialize a model, tokenizer and config."""
- super().__init__()
- # TODO: move to self.save_hyperparameters()
- # self.save_hyperparameters()
- # can also expand arguments into trainer signature for easier reading
-
- self.save_hyperparameters(hparams)
- self.step_count = 0
- self.output_dir = Path(self.hparams.output_dir)
- cache_dir = self.hparams.cache_dir if self.hparams.cache_dir else None
- if config is None:
- self.config = AutoConfig.from_pretrained(
- self.hparams.config_name if self.hparams.config_name else self.hparams.model_name_or_path,
- **({"num_labels": num_labels} if num_labels is not None else {}),
- cache_dir=cache_dir,
- **config_kwargs,
- )
- else:
- self.config: PretrainedConfig = config
-
- extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "dropout", "attention_dropout")
- for p in extra_model_params:
- if getattr(self.hparams, p, None):
- assert hasattr(self.config, p), f"model config doesn't have a `{p}` attribute"
- setattr(self.config, p, getattr(self.hparams, p))
-
- if tokenizer is None:
- self.tokenizer = AutoTokenizer.from_pretrained(
- self.hparams.tokenizer_name if self.hparams.tokenizer_name else self.hparams.model_name_or_path,
- cache_dir=cache_dir,
- )
- else:
- self.tokenizer: PreTrainedTokenizer = tokenizer
- self.model_type = MODEL_MODES[mode]
- if model is None:
- self.model = self.model_type.from_pretrained(
- self.hparams.model_name_or_path,
- from_tf=bool(".ckpt" in self.hparams.model_name_or_path),
- config=self.config,
- cache_dir=cache_dir,
- )
- else:
- self.model = model
-
- def load_hf_checkpoint(self, *args, **kwargs):
- self.model = self.model_type.from_pretrained(*args, **kwargs)
-
- def get_lr_scheduler(self):
- get_schedule_func = arg_to_scheduler[self.hparams.lr_scheduler]
- scheduler = get_schedule_func(
- self.opt, num_warmup_steps=self.hparams.warmup_steps, num_training_steps=self.total_steps()
- )
- scheduler = {"scheduler": scheduler, "interval": "step", "frequency": 1}
- return scheduler
-
- def configure_optimizers(self):
- """Prepare optimizer and schedule (linear warmup and decay)"""
- model = self.model
- no_decay = ["bias", "LayerNorm.weight"]
- optimizer_grouped_parameters = [
- {
- "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
- "weight_decay": self.hparams.weight_decay,
- },
- {
- "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
- "weight_decay": 0.0,
- },
- ]
- if self.hparams.adafactor:
- optimizer = Adafactor(
- optimizer_grouped_parameters, lr=self.hparams.learning_rate, scale_parameter=False, relative_step=False
- )
-
- else:
- optimizer = AdamW(
- optimizer_grouped_parameters, lr=self.hparams.learning_rate, eps=self.hparams.adam_epsilon
- )
- self.opt = optimizer
-
- scheduler = self.get_lr_scheduler()
-
- return [optimizer], [scheduler]
-
- def test_step(self, batch, batch_nb):
- return self.validation_step(batch, batch_nb)
-
- def test_epoch_end(self, outputs):
- return self.validation_end(outputs)
-
- def total_steps(self) -> int:
- """The number of total training steps that will be run. Used for lr scheduler purposes."""
- num_devices = max(1, self.hparams.gpus) # TODO: consider num_tpu_cores
- effective_batch_size = self.hparams.train_batch_size * self.hparams.accumulate_grad_batches * num_devices
- return (self.dataset_size / effective_batch_size) * self.hparams.max_epochs
-
- def setup(self, stage):
- if stage == "test":
- self.dataset_size = len(self.test_dataloader().dataset)
- else:
- self.train_loader = self.get_dataloader("train", self.hparams.train_batch_size, shuffle=True)
- self.dataset_size = len(self.train_dataloader().dataset)
-
- def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False):
- raise NotImplementedError("You must implement this for your task")
-
- def train_dataloader(self):
- return self.train_loader
-
- def val_dataloader(self):
- return self.get_dataloader("dev", self.hparams.eval_batch_size, shuffle=False)
-
- def test_dataloader(self):
- return self.get_dataloader("test", self.hparams.eval_batch_size, shuffle=False)
-
- def _feature_file(self, mode):
- return os.path.join(
- self.hparams.data_dir,
- "cached_{}_{}_{}".format(
- mode,
- list(filter(None, self.hparams.model_name_or_path.split("/"))).pop(),
- str(self.hparams.max_seq_length),
- ),
- )
-
- @pl.utilities.rank_zero_only
- def on_save_checkpoint(self, checkpoint: Dict[str, Any]) -> None:
- save_path = self.output_dir.joinpath("best_tfmr")
- self.model.config.save_step = self.step_count
- self.model.save_pretrained(save_path)
- self.tokenizer.save_pretrained(save_path)
-
- @staticmethod
- def add_model_specific_args(parser, root_dir):
- parser.add_argument(
- "--model_name_or_path",
- default=None,
- type=str,
- required=True,
- help="Path to pretrained model or model identifier from huggingface.co/models",
- )
- parser.add_argument(
- "--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
- )
- parser.add_argument(
- "--tokenizer_name",
- default=None,
- type=str,
- help="Pretrained tokenizer name or path if not the same as model_name",
- )
- parser.add_argument(
- "--cache_dir",
- default="",
- type=str,
- help="Where do you want to store the pre-trained models downloaded from huggingface.co",
- )
- parser.add_argument(
- "--encoder_layerdrop",
- type=float,
- help="Encoder layer dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument(
- "--decoder_layerdrop",
- type=float,
- help="Decoder layer dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument(
- "--dropout",
- type=float,
- help="Dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument(
- "--attention_dropout",
- type=float,
- help="Attention dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
- parser.add_argument(
- "--lr_scheduler",
- default="linear",
- choices=arg_to_scheduler_choices,
- metavar=arg_to_scheduler_metavar,
- type=str,
- help="Learning rate scheduler",
- )
- parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
- parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
- parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
- parser.add_argument("--num_workers", default=4, type=int, help="kwarg passed to DataLoader")
- parser.add_argument("--num_train_epochs", dest="max_epochs", default=3, type=int)
- parser.add_argument("--train_batch_size", default=32, type=int)
- parser.add_argument("--eval_batch_size", default=32, type=int)
- parser.add_argument("--adafactor", action="store_true")
-
-
-class InitCallback(pl.Callback):
- # This method is better that using a custom DDP plugging with the latest pytorch-lightning (@shamanez)
- def on_sanity_check_start(self, trainer, pl_module):
- if (
- trainer.is_global_zero and trainer.global_rank == 0
- ): # we initialize the retriever only on master worker with RAY. In new pytorch-lightning accelorators are removed.
- pl_module.model.rag.retriever.init_retrieval() # better to use hook functions.
-
-
-class LoggingCallback(pl.Callback):
- def on_batch_end(self, trainer, pl_module):
- lr_scheduler = trainer.lr_schedulers[0]["scheduler"]
- lrs = {f"lr_group_{i}": lr for i, lr in enumerate(lr_scheduler.get_lr())}
- pl_module.logger.log_metrics(lrs)
-
- def on_validation_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
- rank_zero_info("***** Validation results *****")
- metrics = trainer.callback_metrics
- # Log results
- for key in sorted(metrics):
- if key not in ["log", "progress_bar"]:
- rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
-
- def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
- rank_zero_info("***** Test results *****")
- metrics = trainer.callback_metrics
- # Log and save results to file
- output_test_results_file = os.path.join(pl_module.hparams.output_dir, "test_results.txt")
- with open(output_test_results_file, "w") as writer:
- for key in sorted(metrics):
- if key not in ["log", "progress_bar"]:
- rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
- writer.write("{} = {}\n".format(key, str(metrics[key])))
-
-
-def add_generic_args(parser, root_dir) -> None:
- # To allow all pl args uncomment the following line
- # parser = pl.Trainer.add_argparse_args(parser)
- parser.add_argument(
- "--output_dir",
- default=None,
- type=str,
- required=True,
- help="The output directory where the model predictions and checkpoints will be written.",
- )
- parser.add_argument(
- "--fp16",
- action="store_true",
- help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
- )
-
- parser.add_argument(
- "--fp16_opt_level",
- type=str,
- default="O2",
- help=(
- "For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
- "See details at https://nvidia.github.io/apex/amp.html"
- ),
- )
- parser.add_argument("--n_tpu_cores", dest="tpu_cores", type=int)
- parser.add_argument("--max_grad_norm", dest="gradient_clip_val", default=1.0, type=float, help="Max gradient norm")
- parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
- parser.add_argument("--do_predict", action="store_true", help="Whether to run predictions on the test set.")
- parser.add_argument(
- "--gradient_accumulation_steps",
- dest="accumulate_grad_batches",
- type=int,
- default=1,
- help="Number of updates steps to accumulate before performing a backward/update pass.",
- )
- parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
- parser.add_argument(
- "--data_dir",
- default=None,
- type=str,
- required=True,
- help="The input data dir. Should contain the training files for the CoNLL-2003 NER task.",
- )
-
-
-def generic_train(
- model: BaseTransformer,
- args: argparse.Namespace,
- early_stopping_callback=None,
- logger=True, # can pass WandbLogger() here
- custom_ddp_plugin=None,
- extra_callbacks=[],
- checkpoint_callback=None,
- logging_callback=None,
- **extra_train_kwargs,
-):
- pl.seed_everything(args.seed)
-
- # init model
- odir = Path(model.hparams.output_dir)
- odir.mkdir(exist_ok=True)
-
- # add custom checkpoints
- if checkpoint_callback is None:
- checkpoint_callback = pl.callbacks.ModelCheckpoint(
- filepath=args.output_dir, prefix="checkpoint", monitor="val_loss", mode="min", save_top_k=1
- )
- if early_stopping_callback:
- extra_callbacks.append(early_stopping_callback)
- if logging_callback is None:
- logging_callback = LoggingCallback()
-
- train_params = {}
-
- # TODO: remove with PyTorch 1.6 since pl uses native amp
- if args.fp16:
- train_params["precision"] = 16
- # train_params["amp_level"] = args.fp16_opt_level
-
- if args.gpus > 1:
- train_params["accelerator"] = "auto" # "ddp"
- train_params["strategy"] = "ddp"
-
- train_params["accumulate_grad_batches"] = args.accumulate_grad_batches
- train_params["profiler"] = None # extra_train_kwargs.get("profiler", None) #get unwanted logs
- train_params["devices"] = "auto"
-
- trainer = pl.Trainer.from_argparse_args(
- args,
- weights_summary=None,
- callbacks=[logging_callback] + extra_callbacks + [checkpoint_callback] + [InitCallback()],
- # plugins=[custom_ddp_plugin],
- logger=logger,
- **train_params,
- )
-
- if args.do_train:
- trainer.fit(model)
-
- return trainer
diff --git a/examples/research_projects/rag/parse_dpr_relevance_data.py b/examples/research_projects/rag/parse_dpr_relevance_data.py
deleted file mode 100644
index 4d8a1e5f467..00000000000
--- a/examples/research_projects/rag/parse_dpr_relevance_data.py
+++ /dev/null
@@ -1,47 +0,0 @@
-"""
-This script reads DPR retriever training data and parses each datapoint. We save a line per datapoint.
-Each line consists of the query followed by a tab-separated list of Wikipedia page titles constituting
-positive contexts for a given query.
-"""
-
-import argparse
-import json
-
-from tqdm import tqdm
-
-
-def main():
- parser = argparse.ArgumentParser()
-
- # Required parameters
- parser.add_argument(
- "--src_path",
- type=str,
- default="biencoder-nq-dev.json",
- help="Path to raw DPR training data",
- )
- parser.add_argument(
- "--evaluation_set",
- type=str,
- help="where to store parsed evaluation_set file",
- )
- parser.add_argument(
- "--gold_data_path",
- type=str,
- help="where to store parsed gold_data_path file",
- )
- args = parser.parse_args()
-
- with open(args.src_path, "r") as src_file, open(args.evaluation_set, "w") as eval_file, open(
- args.gold_data_path, "w"
- ) as gold_file:
- dpr_records = json.load(src_file)
- for dpr_record in tqdm(dpr_records):
- question = dpr_record["question"]
- contexts = [context["title"] for context in dpr_record["positive_ctxs"]]
- eval_file.write(question + "\n")
- gold_file.write("\t".join(contexts) + "\n")
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/rag/requirements.txt b/examples/research_projects/rag/requirements.txt
deleted file mode 100644
index 5988d38de9e..00000000000
--- a/examples/research_projects/rag/requirements.txt
+++ /dev/null
@@ -1,8 +0,0 @@
-faiss-cpu >= 1.6.3
-datasets >= 1.0.1
-psutil >= 5.7.0
-torch >= 1.4.0
-ray >= 1.10.0
-pytorch-lightning >= 1.5.10, <=1.6.0
-transformers
-GitPython
\ No newline at end of file
diff --git a/examples/research_projects/rag/test_data/my_knowledge_dataset.csv b/examples/research_projects/rag/test_data/my_knowledge_dataset.csv
deleted file mode 100644
index 76da009a2f2..00000000000
--- a/examples/research_projects/rag/test_data/my_knowledge_dataset.csv
+++ /dev/null
@@ -1,2 +0,0 @@
-Aaron Aaron Aaron ( or ; "Ahärôn") is a prophet, high priest, and the brother of Moses in the Abrahamic religions. Knowledge of Aaron, along with his brother Moses, comes exclusively from religious texts, such as the Bible and Quran. The Hebrew Bible relates that, unlike Moses, who grew up in the Egyptian royal court, Aaron and his elder sister Miriam remained with their kinsmen in the eastern border-land of Egypt (Goshen). When Moses first confronted the Egyptian king about the Israelites, Aaron served as his brother's spokesman ("prophet") to the Pharaoh. Part of the Law (Torah) that Moses received from God at Sinai granted Aaron the priesthood for himself and his male descendants, and he became the first High Priest of the Israelites. Aaron died before the Israelites crossed the North Jordan river and he was buried on Mount Hor (Numbers 33:39; Deuteronomy 10:6 says he died and was buried at Moserah). Aaron is also mentioned in the New Testament of the Bible. According to the Book of Exodus, Aaron first functioned as Moses' assistant. Because Moses complained that he could not speak well, God appointed Aaron as Moses' "prophet" (Exodus 4:10-17; 7:1). At the command of Moses, he let his rod turn into a snake. Then he stretched out his rod in order to bring on the first three plagues. After that, Moses tended to act and speak for himself. During the journey in the wilderness, Aaron was not always prominent or active. At the battle with Amalek, he was chosen with Hur to support the hand of Moses that held the "rod of God". When the revelation was given to Moses at biblical Mount Sinai, he headed the elders of Israel who accompanied Moses on the way to the summit.
-"Pokémon" Pokémon , also known as in Japan, is a media franchise managed by The Pokémon Company, a Japanese consortium between Nintendo, Game Freak, and Creatures. The franchise copyright is shared by all three companies, but Nintendo is the sole owner of the trademark. The franchise was created by Satoshi Tajiri in 1995, and is centered on fictional creatures called "Pokémon", which humans, known as Pokémon Trainers, catch and train to battle each other for sport. The English slogan for the franchise is "Gotta Catch 'Em All". Works within the franchise are set in the Pokémon universe. The franchise began as "Pokémon Red" and "Green" (released outside of Japan as "Pokémon Red" and "Blue"), a pair of video games for the original Game Boy that were developed by Game Freak and published by Nintendo in February 1996. "Pokémon" has since gone on to become the highest-grossing media franchise of all time, with over in revenue up until March 2017. The original video game series is the second best-selling video game franchise (behind Nintendo's "Mario" franchise) with more than 300million copies sold and over 800million mobile downloads. In addition, the "Pokémon" franchise includes the world's top-selling toy brand, the top-selling trading card game with over 25.7billion cards sold, an anime television series that has become the most successful video game adaptation with over 20 seasons and 1,000 episodes in 124 countries, as well as an anime film series, a , books, manga comics, music, and merchandise. The franchise is also represented in other Nintendo media, such as the "Super Smash Bros." series. In November 2005, 4Kids Entertainment, which had managed the non-game related licensing of "Pokémon", announced that it had agreed not to renew the "Pokémon" representation agreement. The Pokémon Company International oversees all "Pokémon" licensing outside Asia.
\ No newline at end of file
diff --git a/examples/research_projects/rag/test_distributed_retriever.py b/examples/research_projects/rag/test_distributed_retriever.py
deleted file mode 100644
index 7e75e0a7a7e..00000000000
--- a/examples/research_projects/rag/test_distributed_retriever.py
+++ /dev/null
@@ -1,338 +0,0 @@
-import json
-import os
-import shutil
-import sys
-import tempfile
-import unittest
-from unittest import TestCase
-from unittest.mock import patch
-
-import faiss
-import numpy as np
-from datasets import Dataset
-
-from transformers import BartConfig, BartTokenizer, DPRConfig, DPRQuestionEncoderTokenizer, RagConfig
-from transformers.file_utils import is_datasets_available, is_faiss_available, is_psutil_available, is_torch_available
-from transformers.integrations import is_ray_available
-from transformers.models.bert.tokenization_bert import VOCAB_FILES_NAMES as DPR_VOCAB_FILES_NAMES
-from transformers.models.rag.retrieval_rag import CustomHFIndex, RagRetriever
-from transformers.models.roberta.tokenization_roberta import VOCAB_FILES_NAMES as BART_VOCAB_FILES_NAMES
-from transformers.testing_utils import require_ray
-
-
-sys.path.append(os.path.join(os.getcwd())) # noqa: E402 # noqa: E402 # isort:skip
-
-if is_torch_available():
- from distributed_pytorch_retriever import RagPyTorchDistributedRetriever # noqa: E402 # isort:skip
-else:
- RagPyTorchDistributedRetriever = None
-
-if is_ray_available():
- import ray # noqa: E402 # isort:skip
- from distributed_ray_retriever import RagRayDistributedRetriever, RayRetriever # noqa: E402 # isort:skip
-else:
- ray = None
- RagRayDistributedRetriever = None
- RayRetriever = None
-
-
-def require_distributed_retrieval(test_case):
- """
- Decorator marking a test that requires a set of dependencies necessary for pefrorm retrieval with
- :class:`~transformers.RagRetriever`.
-
- These tests are skipped when respective libraries are not installed.
-
- """
- if not (is_datasets_available() and is_faiss_available() and is_psutil_available()):
- test_case = unittest.skip("test requires Datasets, Faiss, psutil")(test_case)
- return test_case
-
-
-@require_distributed_retrieval
-class RagRetrieverTest(TestCase):
- def setUp(self):
- self.tmpdirname = tempfile.mkdtemp()
- self.retrieval_vector_size = 8
-
- # DPR tok
- vocab_tokens = [
- "[UNK]",
- "[CLS]",
- "[SEP]",
- "[PAD]",
- "[MASK]",
- "want",
- "##want",
- "##ed",
- "wa",
- "un",
- "runn",
- "##ing",
- ",",
- "low",
- "lowest",
- ]
- dpr_tokenizer_path = os.path.join(self.tmpdirname, "dpr_tokenizer")
- os.makedirs(dpr_tokenizer_path, exist_ok=True)
- self.vocab_file = os.path.join(dpr_tokenizer_path, DPR_VOCAB_FILES_NAMES["vocab_file"])
- with open(self.vocab_file, "w", encoding="utf-8") as vocab_writer:
- vocab_writer.write("".join([x + "\n" for x in vocab_tokens]))
-
- # BART tok
- vocab = [
- "l",
- "o",
- "w",
- "e",
- "r",
- "s",
- "t",
- "i",
- "d",
- "n",
- "\u0120",
- "\u0120l",
- "\u0120n",
- "\u0120lo",
- "\u0120low",
- "er",
- "\u0120lowest",
- "\u0120newer",
- "\u0120wider",
- "",
- ]
- vocab_tokens = dict(zip(vocab, range(len(vocab))))
- merges = ["#version: 0.2", "\u0120 l", "\u0120l o", "\u0120lo w", "e r", ""]
- self.special_tokens_map = {"unk_token": ""}
-
- bart_tokenizer_path = os.path.join(self.tmpdirname, "bart_tokenizer")
- os.makedirs(bart_tokenizer_path, exist_ok=True)
- self.vocab_file = os.path.join(bart_tokenizer_path, BART_VOCAB_FILES_NAMES["vocab_file"])
- self.merges_file = os.path.join(bart_tokenizer_path, BART_VOCAB_FILES_NAMES["merges_file"])
- with open(self.vocab_file, "w", encoding="utf-8") as fp:
- fp.write(json.dumps(vocab_tokens) + "\n")
- with open(self.merges_file, "w", encoding="utf-8") as fp:
- fp.write("\n".join(merges))
-
- def get_dpr_tokenizer(self) -> DPRQuestionEncoderTokenizer:
- return DPRQuestionEncoderTokenizer.from_pretrained(os.path.join(self.tmpdirname, "dpr_tokenizer"))
-
- def get_bart_tokenizer(self) -> BartTokenizer:
- return BartTokenizer.from_pretrained(os.path.join(self.tmpdirname, "bart_tokenizer"))
-
- def tearDown(self):
- shutil.rmtree(self.tmpdirname)
-
- def get_dummy_dataset(self):
- dataset = Dataset.from_dict(
- {
- "id": ["0", "1"],
- "text": ["foo", "bar"],
- "title": ["Foo", "Bar"],
- "embeddings": [np.ones(self.retrieval_vector_size), 2 * np.ones(self.retrieval_vector_size)],
- }
- )
- dataset.add_faiss_index("embeddings", string_factory="Flat", metric_type=faiss.METRIC_INNER_PRODUCT)
- return dataset
-
- def get_dummy_pytorch_distributed_retriever(
- self, init_retrieval: bool, port=12345
- ) -> RagPyTorchDistributedRetriever:
- dataset = self.get_dummy_dataset()
- config = RagConfig(
- retrieval_vector_size=self.retrieval_vector_size,
- question_encoder=DPRConfig().to_dict(),
- generator=BartConfig().to_dict(),
- )
- with patch("transformers.models.rag.retrieval_rag.load_dataset") as mock_load_dataset:
- mock_load_dataset.return_value = dataset
- retriever = RagPyTorchDistributedRetriever(
- config,
- question_encoder_tokenizer=self.get_dpr_tokenizer(),
- generator_tokenizer=self.get_bart_tokenizer(),
- )
- if init_retrieval:
- retriever.init_retrieval(port)
- return retriever
-
- def get_dummy_ray_distributed_retriever(self, init_retrieval: bool) -> RagRayDistributedRetriever:
- # Have to run in local mode because sys.path modifications at top of
- # file are not propogated to remote workers.
- # https://stackoverflow.com/questions/54338013/parallel-import-a-python-file-from-sibling-folder
- ray.init(local_mode=True)
- config = RagConfig(
- retrieval_vector_size=self.retrieval_vector_size,
- question_encoder=DPRConfig().to_dict(),
- generator=BartConfig().to_dict(),
- )
- remote_cls = ray.remote(RayRetriever)
- workers = [remote_cls.remote() for _ in range(1)]
- with patch("transformers.models.rag.retrieval_rag.load_dataset") as mock_load_dataset:
- mock_load_dataset.return_value = self.get_dummy_dataset()
- retriever = RagRayDistributedRetriever(
- config,
- question_encoder_tokenizer=self.get_dpr_tokenizer(),
- generator_tokenizer=self.get_bart_tokenizer(),
- retrieval_workers=workers,
- )
- if init_retrieval:
- retriever.init_retrieval()
- return retriever
-
- def get_dummy_custom_hf_index_pytorch_retriever(self, init_retrieval: bool, from_disk: bool, port=12345):
- dataset = self.get_dummy_dataset()
- config = RagConfig(
- retrieval_vector_size=self.retrieval_vector_size,
- question_encoder=DPRConfig().to_dict(),
- generator=BartConfig().to_dict(),
- index_name="custom",
- )
- if from_disk:
- config.passages_path = os.path.join(self.tmpdirname, "dataset")
- config.index_path = os.path.join(self.tmpdirname, "index.faiss")
- dataset.get_index("embeddings").save(os.path.join(self.tmpdirname, "index.faiss"))
- dataset.drop_index("embeddings")
- dataset.save_to_disk(os.path.join(self.tmpdirname, "dataset"))
- del dataset
- retriever = RagPyTorchDistributedRetriever(
- config,
- question_encoder_tokenizer=self.get_dpr_tokenizer(),
- generator_tokenizer=self.get_bart_tokenizer(),
- )
- else:
- retriever = RagPyTorchDistributedRetriever(
- config,
- question_encoder_tokenizer=self.get_dpr_tokenizer(),
- generator_tokenizer=self.get_bart_tokenizer(),
- index=CustomHFIndex(config.retrieval_vector_size, dataset),
- )
- if init_retrieval:
- retriever.init_retrieval(port)
- return retriever
-
- def get_dummy_custom_hf_index_ray_retriever(self, init_retrieval: bool, from_disk: bool):
- # Have to run in local mode because sys.path modifications at top of
- # file are not propogated to remote workers.
- # https://stackoverflow.com/questions/54338013/parallel-import-a-python-file-from-sibling-folder
- ray.init(local_mode=True)
- dataset = self.get_dummy_dataset()
- config = RagConfig(
- retrieval_vector_size=self.retrieval_vector_size,
- question_encoder=DPRConfig().to_dict(),
- generator=BartConfig().to_dict(),
- index_name="custom",
- )
- remote_cls = ray.remote(RayRetriever)
- workers = [remote_cls.remote() for _ in range(1)]
- if from_disk:
- config.passages_path = os.path.join(self.tmpdirname, "dataset")
- config.index_path = os.path.join(self.tmpdirname, "index.faiss")
- dataset.get_index("embeddings").save(os.path.join(self.tmpdirname, "index.faiss"))
- dataset.drop_index("embeddings")
- dataset.save_to_disk(os.path.join(self.tmpdirname, "dataset"))
- del dataset
- retriever = RagRayDistributedRetriever(
- config,
- question_encoder_tokenizer=self.get_dpr_tokenizer(),
- generator_tokenizer=self.get_bart_tokenizer(),
- retrieval_workers=workers,
- index=CustomHFIndex.load_from_disk(
- vector_size=config.retrieval_vector_size,
- dataset_path=config.passages_path,
- index_path=config.index_path,
- ),
- )
- else:
- retriever = RagRayDistributedRetriever(
- config,
- question_encoder_tokenizer=self.get_dpr_tokenizer(),
- generator_tokenizer=self.get_bart_tokenizer(),
- retrieval_workers=workers,
- index=CustomHFIndex(config.retrieval_vector_size, dataset),
- )
- if init_retrieval:
- retriever.init_retrieval()
- return retriever
-
- def distributed_retriever_check(self, retriever: RagRetriever, hidden_states: np.array, n_docs: int) -> None:
- retrieved_doc_embeds, doc_ids, doc_dicts = retriever.retrieve(hidden_states, n_docs=n_docs)
- self.assertEqual(retrieved_doc_embeds.shape, (2, n_docs, self.retrieval_vector_size))
- self.assertEqual(len(doc_dicts), 2)
- self.assertEqual(sorted(doc_dicts[0]), ["embeddings", "id", "text", "title"])
- self.assertEqual(len(doc_dicts[0]["id"]), n_docs)
- self.assertEqual(doc_dicts[0]["id"][0], "1") # max inner product is reached with second doc
- self.assertEqual(doc_dicts[1]["id"][0], "0") # max inner product is reached with first doc
- self.assertListEqual(doc_ids.tolist(), [[1], [0]])
-
- def test_pytorch_distributed_retriever_retrieve(self):
- n_docs = 1
- hidden_states = np.array(
- [np.ones(self.retrieval_vector_size), -np.ones(self.retrieval_vector_size)], dtype=np.float32
- )
-
- self.distributed_retriever_check(
- self.get_dummy_pytorch_distributed_retriever(init_retrieval=True), hidden_states, n_docs
- )
-
- def test_custom_hf_index_pytorch_retriever_retrieve(self):
- n_docs = 1
- hidden_states = np.array(
- [np.ones(self.retrieval_vector_size), -np.ones(self.retrieval_vector_size)], dtype=np.float32
- )
-
- self.distributed_retriever_check(
- self.get_dummy_custom_hf_index_pytorch_retriever(init_retrieval=True, from_disk=False),
- hidden_states,
- n_docs,
- )
-
- def test_custom_pytorch_distributed_retriever_retrieve_from_disk(self):
- n_docs = 1
- hidden_states = np.array(
- [np.ones(self.retrieval_vector_size), -np.ones(self.retrieval_vector_size)], dtype=np.float32
- )
-
- self.distributed_retriever_check(
- self.get_dummy_custom_hf_index_pytorch_retriever(init_retrieval=True, from_disk=True),
- hidden_states,
- n_docs,
- )
-
- @require_ray
- def test_ray_distributed_retriever_retrieve(self):
- n_docs = 1
- hidden_states = np.array(
- [np.ones(self.retrieval_vector_size), -np.ones(self.retrieval_vector_size)], dtype=np.float32
- )
-
- self.distributed_retriever_check(
- self.get_dummy_ray_distributed_retriever(init_retrieval=True), hidden_states, n_docs
- )
- ray.shutdown()
-
- @require_ray
- def test_custom_hf_index_ray_retriever_retrieve(self):
- n_docs = 1
- hidden_states = np.array(
- [np.ones(self.retrieval_vector_size), -np.ones(self.retrieval_vector_size)], dtype=np.float32
- )
- with self.assertRaises(ValueError):
- self.distributed_retriever_check(
- self.get_dummy_custom_hf_index_ray_retriever(init_retrieval=True, from_disk=False),
- hidden_states,
- n_docs,
- )
- ray.shutdown()
-
- @require_ray
- def test_custom_ray_distributed_retriever_retrieve_from_disk(self):
- n_docs = 1
- hidden_states = np.array(
- [np.ones(self.retrieval_vector_size), -np.ones(self.retrieval_vector_size)], dtype=np.float32
- )
-
- self.distributed_retriever_check(
- self.get_dummy_custom_hf_index_ray_retriever(init_retrieval=True, from_disk=True), hidden_states, n_docs
- )
- ray.shutdown()
diff --git a/examples/research_projects/rag/use_own_knowledge_dataset.py b/examples/research_projects/rag/use_own_knowledge_dataset.py
deleted file mode 100644
index d2ab6d07d5c..00000000000
--- a/examples/research_projects/rag/use_own_knowledge_dataset.py
+++ /dev/null
@@ -1,208 +0,0 @@
-import logging
-import os
-from dataclasses import dataclass, field
-from functools import partial
-from pathlib import Path
-from tempfile import TemporaryDirectory
-from typing import List, Optional
-
-import faiss
-import torch
-from datasets import Features, Sequence, Value, load_dataset
-
-from transformers import (
- DPRContextEncoder,
- DPRContextEncoderTokenizerFast,
- HfArgumentParser,
- RagRetriever,
- RagSequenceForGeneration,
- RagTokenizer,
-)
-
-
-logger = logging.getLogger(__name__)
-torch.set_grad_enabled(False)
-device = "cuda" if torch.cuda.is_available() else "cpu"
-
-
-def split_text(text: str, n=100, character=" ") -> List[str]:
- """Split the text every ``n``-th occurrence of ``character``"""
- text = text.split(character)
- return [character.join(text[i : i + n]).strip() for i in range(0, len(text), n)]
-
-
-def split_documents(documents: dict) -> dict:
- """Split documents into passages"""
- titles, texts = [], []
- for title, text in zip(documents["title"], documents["text"]):
- if text is not None:
- for passage in split_text(text):
- titles.append(title if title is not None else "")
- texts.append(passage)
- return {"title": titles, "text": texts}
-
-
-def embed(documents: dict, ctx_encoder: DPRContextEncoder, ctx_tokenizer: DPRContextEncoderTokenizerFast) -> dict:
- """Compute the DPR embeddings of document passages"""
- input_ids = ctx_tokenizer(
- documents["title"], documents["text"], truncation=True, padding="longest", return_tensors="pt"
- )["input_ids"]
- embeddings = ctx_encoder(input_ids.to(device=device), return_dict=True).pooler_output
- return {"embeddings": embeddings.detach().cpu().numpy()}
-
-
-def main(
- rag_example_args: "RagExampleArguments",
- processing_args: "ProcessingArguments",
- index_hnsw_args: "IndexHnswArguments",
-):
- ######################################
- logger.info("Step 1 - Create the dataset")
- ######################################
-
- # The dataset needed for RAG must have three columns:
- # - title (string): title of the document
- # - text (string): text of a passage of the document
- # - embeddings (array of dimension d): DPR representation of the passage
-
- # Let's say you have documents in tab-separated csv files with columns "title" and "text"
- assert os.path.isfile(rag_example_args.csv_path), "Please provide a valid path to a csv file"
-
- # You can load a Dataset object this way
- dataset = load_dataset(
- "csv", data_files=[rag_example_args.csv_path], split="train", delimiter="\t", column_names=["title", "text"]
- )
-
- # More info about loading csv files in the documentation: https://huggingface.co/docs/datasets/loading_datasets?highlight=csv#csv-files
-
- # Then split the documents into passages of 100 words
- dataset = dataset.map(split_documents, batched=True, num_proc=processing_args.num_proc)
-
- # And compute the embeddings
- ctx_encoder = DPRContextEncoder.from_pretrained(rag_example_args.dpr_ctx_encoder_model_name).to(device=device)
- ctx_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained(rag_example_args.dpr_ctx_encoder_model_name)
- new_features = Features(
- {"text": Value("string"), "title": Value("string"), "embeddings": Sequence(Value("float32"))}
- ) # optional, save as float32 instead of float64 to save space
- dataset = dataset.map(
- partial(embed, ctx_encoder=ctx_encoder, ctx_tokenizer=ctx_tokenizer),
- batched=True,
- batch_size=processing_args.batch_size,
- features=new_features,
- )
-
- # And finally save your dataset
- passages_path = os.path.join(rag_example_args.output_dir, "my_knowledge_dataset")
- dataset.save_to_disk(passages_path)
- # from datasets import load_from_disk
- # dataset = load_from_disk(passages_path) # to reload the dataset
-
- ######################################
- logger.info("Step 2 - Index the dataset")
- ######################################
-
- # Let's use the Faiss implementation of HNSW for fast approximate nearest neighbor search
- index = faiss.IndexHNSWFlat(index_hnsw_args.d, index_hnsw_args.m, faiss.METRIC_INNER_PRODUCT)
- dataset.add_faiss_index("embeddings", custom_index=index)
-
- # And save the index
- index_path = os.path.join(rag_example_args.output_dir, "my_knowledge_dataset_hnsw_index.faiss")
- dataset.get_index("embeddings").save(index_path)
- # dataset.load_faiss_index("embeddings", index_path) # to reload the index
-
- ######################################
- logger.info("Step 3 - Load RAG")
- ######################################
-
- # Easy way to load the model
- retriever = RagRetriever.from_pretrained(
- rag_example_args.rag_model_name, index_name="custom", indexed_dataset=dataset
- )
- model = RagSequenceForGeneration.from_pretrained(rag_example_args.rag_model_name, retriever=retriever)
- tokenizer = RagTokenizer.from_pretrained(rag_example_args.rag_model_name)
-
- # For distributed fine-tuning you'll need to provide the paths instead, as the dataset and the index are loaded separately.
- # retriever = RagRetriever.from_pretrained(rag_model_name, index_name="custom", passages_path=passages_path, index_path=index_path)
-
- ######################################
- logger.info("Step 4 - Have fun")
- ######################################
-
- question = rag_example_args.question or "What does Moses' rod turn into ?"
- input_ids = tokenizer.question_encoder(question, return_tensors="pt")["input_ids"]
- generated = model.generate(input_ids)
- generated_string = tokenizer.batch_decode(generated, skip_special_tokens=True)[0]
- logger.info("Q: " + question)
- logger.info("A: " + generated_string)
-
-
-@dataclass
-class RagExampleArguments:
- csv_path: str = field(
- default=str(Path(__file__).parent / "test_data" / "my_knowledge_dataset.csv"),
- metadata={"help": "Path to a tab-separated csv file with columns 'title' and 'text'"},
- )
- question: Optional[str] = field(
- default=None,
- metadata={"help": "Question that is passed as input to RAG. Default is 'What does Moses' rod turn into ?'."},
- )
- rag_model_name: str = field(
- default="facebook/rag-sequence-nq",
- metadata={"help": "The RAG model to use. Either 'facebook/rag-sequence-nq' or 'facebook/rag-token-nq'"},
- )
- dpr_ctx_encoder_model_name: str = field(
- default="facebook/dpr-ctx_encoder-multiset-base",
- metadata={
- "help": (
- "The DPR context encoder model to use. Either 'facebook/dpr-ctx_encoder-single-nq-base' or"
- " 'facebook/dpr-ctx_encoder-multiset-base'"
- )
- },
- )
- output_dir: Optional[str] = field(
- default=None,
- metadata={"help": "Path to a directory where the dataset passages and the index will be saved"},
- )
-
-
-@dataclass
-class ProcessingArguments:
- num_proc: Optional[int] = field(
- default=None,
- metadata={
- "help": "The number of processes to use to split the documents into passages. Default is single process."
- },
- )
- batch_size: int = field(
- default=16,
- metadata={
- "help": "The batch size to use when computing the passages embeddings using the DPR context encoder."
- },
- )
-
-
-@dataclass
-class IndexHnswArguments:
- d: int = field(
- default=768,
- metadata={"help": "The dimension of the embeddings to pass to the HNSW Faiss index."},
- )
- m: int = field(
- default=128,
- metadata={
- "help": (
- "The number of bi-directional links created for every new element during the HNSW index construction."
- )
- },
- )
-
-
-if __name__ == "__main__":
- logging.basicConfig(level=logging.WARNING)
- logger.setLevel(logging.INFO)
-
- parser = HfArgumentParser((RagExampleArguments, ProcessingArguments, IndexHnswArguments))
- rag_example_args, processing_args, index_hnsw_args = parser.parse_args_into_dataclasses()
- with TemporaryDirectory() as tmp_dir:
- rag_example_args.output_dir = rag_example_args.output_dir or tmp_dir
- main(rag_example_args, processing_args, index_hnsw_args)
diff --git a/examples/research_projects/rag/utils_rag.py b/examples/research_projects/rag/utils_rag.py
deleted file mode 100644
index ec98c1d782e..00000000000
--- a/examples/research_projects/rag/utils_rag.py
+++ /dev/null
@@ -1,244 +0,0 @@
-import itertools
-import json
-import linecache
-import os
-import pickle
-import re
-import socket
-import string
-from collections import Counter
-from logging import getLogger
-from pathlib import Path
-from typing import Callable, Dict, Iterable, List
-
-import git
-import torch
-from torch.utils.data import Dataset
-
-from transformers import BartTokenizer, RagTokenizer, T5Tokenizer
-
-
-def encode_line(tokenizer, line, max_length, padding_side, pad_to_max_length=True, return_tensors="pt"):
- extra_kw = {"add_prefix_space": True} if isinstance(tokenizer, BartTokenizer) and not line.startswith(" ") else {}
- tokenizer.padding_side = padding_side
- return tokenizer(
- [line],
- max_length=max_length,
- padding="max_length" if pad_to_max_length else None,
- truncation=True,
- return_tensors=return_tensors,
- add_special_tokens=True,
- **extra_kw,
- )
-
-
-def trim_batch(
- input_ids,
- pad_token_id,
- attention_mask=None,
-):
- """Remove columns that are populated exclusively by pad_token_id"""
- keep_column_mask = input_ids.ne(pad_token_id).any(dim=0)
- if attention_mask is None:
- return input_ids[:, keep_column_mask]
- else:
- return (input_ids[:, keep_column_mask], attention_mask[:, keep_column_mask])
-
-
-class Seq2SeqDataset(Dataset):
- def __init__(
- self,
- tokenizer,
- data_dir,
- max_source_length,
- max_target_length,
- type_path="train",
- n_obs=None,
- src_lang=None,
- tgt_lang=None,
- prefix="",
- ):
- super().__init__()
- self.src_file = Path(data_dir).joinpath(type_path + ".source")
- self.tgt_file = Path(data_dir).joinpath(type_path + ".target")
- self.src_lens = self.get_char_lens(self.src_file)
- self.max_source_length = max_source_length
- self.max_target_length = max_target_length
- assert min(self.src_lens) > 0, f"found empty line in {self.src_file}"
- self.tokenizer = tokenizer
- self.prefix = prefix
- if n_obs is not None:
- self.src_lens = self.src_lens[:n_obs]
- self.src_lang = src_lang
- self.tgt_lang = tgt_lang
-
- def __len__(self):
- return len(self.src_lens)
-
- def __getitem__(self, index) -> Dict[str, torch.Tensor]:
- index = index + 1 # linecache starts at 1
- source_line = self.prefix + linecache.getline(str(self.src_file), index).rstrip("\n")
- tgt_line = linecache.getline(str(self.tgt_file), index).rstrip("\n")
- assert source_line, f"empty source line for index {index}"
- assert tgt_line, f"empty tgt line for index {index}"
-
- # Need to add eos token manually for T5
- if isinstance(self.tokenizer, T5Tokenizer):
- source_line += self.tokenizer.eos_token
- tgt_line += self.tokenizer.eos_token
-
- # Pad source and target to the right
- source_tokenizer = (
- self.tokenizer.question_encoder if isinstance(self.tokenizer, RagTokenizer) else self.tokenizer
- )
- target_tokenizer = self.tokenizer.generator if isinstance(self.tokenizer, RagTokenizer) else self.tokenizer
-
- source_inputs = encode_line(source_tokenizer, source_line, self.max_source_length, "right")
- target_inputs = encode_line(target_tokenizer, tgt_line, self.max_target_length, "right")
-
- source_ids = source_inputs["input_ids"].squeeze()
- target_ids = target_inputs["input_ids"].squeeze()
- src_mask = source_inputs["attention_mask"].squeeze()
- return {
- "input_ids": source_ids,
- "attention_mask": src_mask,
- "decoder_input_ids": target_ids,
- }
-
- @staticmethod
- def get_char_lens(data_file):
- return [len(x) for x in Path(data_file).open().readlines()]
-
- def collate_fn(self, batch) -> Dict[str, torch.Tensor]:
- input_ids = torch.stack([x["input_ids"] for x in batch])
- masks = torch.stack([x["attention_mask"] for x in batch])
- target_ids = torch.stack([x["decoder_input_ids"] for x in batch])
- tgt_pad_token_id = (
- self.tokenizer.generator.pad_token_id
- if isinstance(self.tokenizer, RagTokenizer)
- else self.tokenizer.pad_token_id
- )
- src_pad_token_id = (
- self.tokenizer.question_encoder.pad_token_id
- if isinstance(self.tokenizer, RagTokenizer)
- else self.tokenizer.pad_token_id
- )
- y = trim_batch(target_ids, tgt_pad_token_id)
- source_ids, source_mask = trim_batch(input_ids, src_pad_token_id, attention_mask=masks)
- batch = {
- "input_ids": source_ids,
- "attention_mask": source_mask,
- "decoder_input_ids": y,
- }
- return batch
-
-
-logger = getLogger(__name__)
-
-
-def flatten_list(summary_ids: List[List]):
- return list(itertools.chain.from_iterable(summary_ids))
-
-
-def save_git_info(folder_path: str) -> None:
- """Save git information to output_dir/git_log.json"""
- repo_infos = get_git_info()
- save_json(repo_infos, os.path.join(folder_path, "git_log.json"))
-
-
-def save_json(content, path, indent=4, **json_dump_kwargs):
- with open(path, "w") as f:
- json.dump(content, f, indent=indent, **json_dump_kwargs)
-
-
-def load_json(path):
- with open(path) as f:
- return json.load(f)
-
-
-def get_git_info():
- repo = git.Repo(search_parent_directories=True)
- repo_infos = {
- "repo_id": str(repo),
- "repo_sha": str(repo.head.object.hexsha),
- "repo_branch": str(repo.active_branch),
- "hostname": str(socket.gethostname()),
- }
- return repo_infos
-
-
-def lmap(f: Callable, x: Iterable) -> List:
- """list(map(f, x))"""
- return list(map(f, x))
-
-
-def pickle_save(obj, path):
- """pickle.dump(obj, path)"""
- with open(path, "wb") as f:
- return pickle.dump(obj, f)
-
-
-def normalize_answer(s):
- """Lower text and remove punctuation, articles and extra whitespace."""
-
- def remove_articles(text):
- return re.sub(r"\b(a|an|the)\b", " ", text)
-
- def white_space_fix(text):
- return " ".join(text.split())
-
- def remove_punc(text):
- exclude = set(string.punctuation)
- return "".join(ch for ch in text if ch not in exclude)
-
- def lower(text):
- return text.lower()
-
- return white_space_fix(remove_articles(remove_punc(lower(s))))
-
-
-def f1_score(prediction, ground_truth):
- prediction_tokens = normalize_answer(prediction).split()
- ground_truth_tokens = normalize_answer(ground_truth).split()
- common = Counter(prediction_tokens) & Counter(ground_truth_tokens)
- num_same = sum(common.values())
- if num_same == 0:
- return 0
- precision = 1.0 * num_same / len(prediction_tokens)
- recall = 1.0 * num_same / len(ground_truth_tokens)
- f1 = (2 * precision * recall) / (precision + recall)
- return f1
-
-
-def exact_match_score(prediction, ground_truth):
- return normalize_answer(prediction) == normalize_answer(ground_truth)
-
-
-def calculate_exact_match(output_lns: List[str], reference_lns: List[str]) -> Dict:
- assert len(output_lns) == len(reference_lns)
- em = 0
- for hypo, pred in zip(output_lns, reference_lns):
- em += exact_match_score(hypo, pred)
- if len(output_lns) > 0:
- em /= len(output_lns)
- return {"em": em}
-
-
-def is_rag_model(model_prefix):
- return model_prefix.startswith("rag")
-
-
-def set_extra_model_params(extra_params, hparams, config):
- equivalent_param = {p: p for p in extra_params}
- # T5 models don't have `dropout` param, they have `dropout_rate` instead
- equivalent_param["dropout"] = "dropout_rate"
- for p in extra_params:
- if getattr(hparams, p, None):
- if not hasattr(config, p) and not hasattr(config, equivalent_param[p]):
- logger.info("config doesn't have a `{}` attribute".format(p))
- delattr(hparams, p)
- continue
- set_p = p if hasattr(config, p) else equivalent_param[p]
- setattr(config, set_p, getattr(hparams, p))
- delattr(hparams, p)
- return hparams, config
diff --git a/examples/research_projects/robust-speech-event/README.md b/examples/research_projects/robust-speech-event/README.md
deleted file mode 100644
index ca3c5cdecde..00000000000
--- a/examples/research_projects/robust-speech-event/README.md
+++ /dev/null
@@ -1,713 +0,0 @@
-# Robust Speech Challenge 🤗
-
-Welcome to the robust speech recognition challenge 🎙️ !
-
-The goal of this event is to build **robust**, **real-world** speech recognition (ASR) systems in as many languages as possible 🌏🌍🌎.
-If necessary and available, free access to a V100S 32 GB GPU will kindly be provided by the [OVHcloud team](https://www.ovhcloud.com/) 🚀.
-This document summarizes all the relevant information required for the speech community event 📋.
-
-To sign-up, please see [this forum post](https://discuss.huggingface.co/t/open-to-the-community-robust-speech-recognition-challenge/13614) 🤗. Please make sure to:
-- Read it in detail
-- Fill the google form
-- Join our Discord server in the #join-sprint channel.
-
-## Table of Contents
-
-- [TLDR;](#tldr)
-- [Important dates](#important-dates)
-- [How to install pytorch, transformers, datasets](#how-to-install-relevant-libraries)
-- [Data and Preprocessing](#data-and-preprocessing)
-- [How to fine-tune an acoustic model](#how-to-finetune-an-acoustic-model)
-- [How to fine-tune with OVH could](#how-to-finetune-with-ovh-cloud)
-- [How to combine n-gram language models with acoustic model](#how-to-combine-n-gram-with-acoustic-model)
-- [Evaluation](#evaluation)
-- [Prizes](#prizes)
-- [Communication and Problems](#communication-and-problems)
-- [Talks](#talks)
-- [General Tips & Tricks](#general-tips-and-tricks)
-
-## TLDR
-
-Participants are encouraged to leverage pre-trained speech recognition checkpoints,
-preferably [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53),
-to train a speech recognition system in a language of their choice.
-
-Speech recognition systems should be trained using **PyTorch**, **🤗 Transformers**, and, **🤗 Datasets**.
-For more information on how to install the above libraries, please read through
-[How to install pytorch, transformers, datasets](#how-to-install-relevant-libraries).
-
-Participants can make use of whatever data they think is useful to build a
-speech recognition system for **real-world** audio data -
-**except** the Common Voice `"test"` split of their chosen language.
-The section [Data and preprocessing](#data-and-preprocessing) explains
-in more detail what audio data can be used, how to find suitable audio data, and
-how the audio data can be processed.
-
-For training, it is recommended to use the [official training script](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py) or a modification thereof. A step-by-step guide on how to fine-tune
-an acoustic model for a speech recognition system can be found under [How to fine-tune an acoustic model](#how-to-finetune-an-acoustic-model).
-If possible it is encouraged to fine-tune the acoustic models on local GPU machines, but
-if those are not available, the OVH could team kindly provides a limited
-number of GPUs for the event. Simply fill out [this google form](https://forms.gle/GFZkMkKLiufi75g28) to get access to a GPU.
-For more information on how to train an acoustic model on one of OVH's GPU - see [How to fine-tune a speech recognition model with OVHcould](#how-to-fine-tune-with-ovh-cloud).
-
-The performance of speech recognition system can often significantly be improved by adding a
-language model for decoding. For more information on how to add a language model, please
-take a look at [How to combine n-gram language models with speech recognition models](#how-to-combine-n-gram-with-model).
-
-During the event, the speech recognition system will be evaluated on both the Common Voice `"test"` split
-of the participants' chosen language as well as the *real-world* `"dev"` data provided by
-the Hugging Face team.
-At the end of the robust speech recognition challenge, the speech recognition system will also be evaluated on the
-*real-world* `"test"` data provided by the Hugging Face team. Each participant should add an
-`eval.py` script to her/his model repository in a specific format that lets one easily
-evaluate the speech recognition system on both Common Voice's `"test"` data as well as the *real-world* audio
-data. Please read through the [Evaluation](#evaluation) section to make sure your evaluation script is in the correct format. Speech recognition systems
-with evaluation scripts in an incorrect format can sadly not be considered for the Challenge.
-
-At the end of the event, the best performing speech recognition system
-will receive a prize 🏆 - more information regarding the prizes can be found under [Prizes](#prizes).
-
-We believe that framing the event as a competition is more fun, but at the core, the event is about
-creating speech recognition systems in as many languages as possible as a community.
-This can be achieved by working together, helping each other to solve bugs, share important findings, etc...🤗
-
-**Note**:
-Please, read through the section on [Communication & Problems](#communication-and-problems) to make sure you
-know how to ask for help, etc...
-All important announcements will be made on discord. Please make sure that
-you've joined [this discord channel](https://discord.gg/SHr5wC7m)
-
-Also, please make sure that you have been added to the [Speech Event Organization](https://huggingface.co/speech-recognition-community-v2).
-You should have received an invite by email. If you didn't receive an invite, please contact the organizers, *e.g.* Anton, Patrick, or Omar directly on discord.
-
-## Important dates
-
-
-
-
-## Data and preprocessing
-
-In this section, we will quickly go over how to find suitable training data and
-how to preprocess it.
-
-To begin with, **all data except Common Voice's `"test"` data can be used as training data.**
-The exception includes all Common Voice versions as the test data split of later Common Voice versions often
-overlaps with the one of previous versions, *e.g.* the test data of Common Voice 7 in English is
-to a big part identical to the test data of Common Voice 6 in English:
-
-```python
-load_dataset("mozilla-foundation/common_voice_7_0", "en", split="test")
-```
-
-includes more or less the same data as
-
-```python
-load_dataset("mozilla-foundation/common_voice_6_1", "en", split="test")
-```
-
-However, we strongly encourage participants to make use of Common Voice's other splits, *e.g.* `"train"` and `"validation"`.
-For most languages, the Common Voice dataset offers already a decent amount of training data. It is usually
-always advantageous to collect additional data. To do so, the participants are in a first step encouraged to search the
-Hugging Face Hub for additional audio data, for example by selecting the category
-["speech-processing"](https://huggingface.co/datasets?task_categories=task_categories:speech-processing&sort=downloads).
-All datasets that are available on the Hub can be downloaded via the 🤗 Datasets library in the same way Common Voice is downloaded.
-If one wants to combine multiple datasets for training, it might make sense to take a look at
-the [`interleave_datasets`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=interleave#datasets.interleave_datasets) function.
-
-In addition, participants can also make use of their audio data. Here, please make sure that you **are allowed to use the audio data**. E.g., if audio data
-is taken from media platforms, such as YouTube, it should be verified that the media platform and the owner of the data have given her/his approval to use the audio
-data in the context of machine learning research. If you are not sure whether the data you want to use has the appropriate licensing, please contact the Hugging Face
-team on discord.
-
-Next, let's talk about preprocessing. Audio data and transcriptions have to be brought into the correct format when
-training the acoustic model (example shown in [How to fine-tune an acoustic model](#how-to-finetune-an-acoustic-model)).
-It is recommended that this is done by using 🤗 Datasets `.map()` function as shown
-[here](https://github.com/huggingface/transformers/blob/9a2dabae7002258e41419491c73dd43ad61b5de7/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py#L444). As can be
-see we can pass some characters that will be removed from the transcriptions, *e.g.*: `--chars_to_ignore , ? . ! - \; \: \" “ % ‘ ” � \`
-on the official ["Single GPU Example"](https://github.com/huggingface/transformers/tree/main/examples/pytorch/speech-recognition#single-gpu-ctc).
-The participants are free to modify this preprocessing by removing more characters or even replacing characters as
-it is done in the [official blog post](https://github.com/huggingface/transformers/blob/9a2dabae7002258e41419491c73dd43ad61b5de7/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py#L444).
-**However**, there are some rules regarding what characters are allowed to be removed/replaced and which are not.
-These rules are not this straightforward and therefore often have to be evaluated case-by-case.
-It is allowed (and recommended) to normalize the data to only have lower-case characters. It is also allowed (and recommended) to remove typographical
-symbols and punctuation marks. A list of such symbols can *e.g.* be found [here](https://en.wikipedia.org/wiki/List_of_typographical_symbols_and_punctuation_marks) - however here we already must be careful. We should **not** remove a symbol that would change the meaning of the words, *e.g.* in English,
-we should not remove the single quotation mark `'` since it would change the meaning of the word `"it's"` to `"its"` which would then be incorrect.
-So the golden rule here is to not remove any characters that could change the meaning of a word into another word. This is not always obvious and should
-be given some consideration. As another example, it is fine to remove the "Hyphen-minus" sign "`-`" since it doesn't change the
-meaning of a word to another one. *E.g.* "`fine-tuning`" would be changed to "`finetuning`" which has still the same meaning.
-
-Since those choices are not always obvious when in doubt feel free to ask on Discord or even better post your question on the forum, as was
-done, *e.g.* [here](https://discuss.huggingface.co/t/spanish-asr-fine-tuning-wav2vec2/4586).
-
-## How to install relevant libraries
-
-The following libraries are required to fine-tune a speech model with 🤗 Transformers and 🤗 Datasets in PyTorch.
-
-- [PyTorch](https://pytorch.org/)
-- [Transformers](https://github.com/huggingface/transformers)
-- [Datasets](https://github.com/huggingface/datasets)
-
-We recommend installing the above libraries in a [virtual environment](https://docs.python.org/3/library/venv.html).
-If you're unfamiliar with Python virtual environments, check out the [user guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/). Create a virtual environment with the version of Python you're going
-to use and activate it.
-
-You should be able to run the command:
-
-```bash
-python3 -m venv
-```
-
-You can activate your venv by running
-
-```bash
-source ~//bin/activate
-```
-
-To begin with please make sure you have PyTorch and CUDA correctly installed.
-The following command should return ``True``:
-
-```bash
-python -c "import torch; print(torch.cuda.is_available())"
-```
-
-If the above command doesn't print ``True``, in the first step, please follow the
-instructions [here](https://pytorch.org/) to install PyTorch with CUDA.
-
-We strongly recommend making use of the provided PyTorch examples scripts in [transformers/examples/pytorch/speech-recognition](https://github.com/huggingface/transformers/tree/main/examples/pytorch/speech-recognition) to train your speech recognition
-system.
-In all likelihood, you will adjust one of the example scripts, so we recommend forking and cloning the 🤗 Transformers repository as follows.
-
-1. Fork the [repository](https://github.com/huggingface/transformers) by
- clicking on the 'Fork' button on the repository's page. This creates a copy of the code
- under your GitHub user account.
-
-2. Clone your fork to your local disk, and add the base repository as a remote:
-
- ```bash
- $ git clone https://github.com//transformers.git
- $ cd transformers
- $ git remote add upstream https://github.com/huggingface/transformers.git
- ```
-
-3. Create a new branch to hold your development changes. This is especially useful to share code changes with your team:
-
- ```bash
- $ git checkout -b a-descriptive-name-for-my-project
- ```
-
-4. Set up a PyTorch environment by running the following command your virtual environment:
-
- ```bash
- $ pip install -e ".[torch-speech]"
- ```
-
- (If transformers was already installed in the virtual environment, remove
- it with `pip uninstall transformers` before reinstalling it in editable
- mode with the `-e` flag.)
-
- If you have already cloned that repo, you might need to `git pull` to get the most recent changes in the `transformers`
- library.
-
- Running this command will automatically install `torch` and the most relevant
- libraries required for fine-tuning a speech recognition system.
-
-Next, you should also install the 🤗 Datasets library. We strongly recommend installing the
-library from source to profit from the most current additions during the community week.
-
-Simply run the following steps:
-
-```bash
-$ cd ~/
-$ git clone https://github.com/huggingface/datasets.git
-$ cd datasets
-$ pip install -e ".[streaming]"
-```
-
-If you plan on contributing a specific dataset during
-the community week, please fork the datasets repository and follow the instructions
-[here](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-create-a-pull-request).
-
-To verify that all libraries are correctly installed, you can run the following command in a Python shell.
-It verifies that both `transformers` and `datasets` have been correclty installed.
-
-```python
-from transformers import AutoModelForCTC, AutoProcessor
-from datasets import load_dataset
-
-dummy_dataset = load_dataset("common_voice", "ab", split="test")
-
-model = AutoModelForCTC.from_pretrained("hf-internal-testing/tiny-random-wav2vec2")
-model.to("cuda")
-
-processor = AutoProcessor.from_pretrained("hf-internal-testing/tiny-random-wav2vec2")
-
-input_values = processor(dummy_dataset[0]["audio"]["array"], return_tensors="pt", sampling_rate=16_000).input_values
-input_values = input_values.to("cuda")
-
-logits = model(input_values).logits
-
-assert logits.shape[-1] == 32
-```
-
-## How to finetune an acoustic model
-
-In this section, we show you how to fine-tune a pre-trained [XLS-R Model](https://huggingface.co/docs/transformers/model_doc/xls_r) on the [Common Voice 7 dataset](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
-
-We recommend fine-tuning one of the following pre-trained XLS-R checkpoints:
-
-- [300M parameters version](https://huggingface.co/facebook/wav2vec2-xls-r-300m)
-- [1B parameters version](https://huggingface.co/facebook/wav2vec2-xls-r-1b)
-- [2B parameters version](https://huggingface.co/facebook/wav2vec2-xls-r-2b)
-
-To begin with, please note that to use the Common Voice dataset, you
-have to accept that **your email address** and **username** are shared with the
-mozilla-foundation. To get access to the dataset please click on "*Access repository*" [here](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
-
-Next, we recommended that you get familiar with the XLS-R model and its capabilities.
-In collaboration with [Fairseq's Wav2Vec2 team](https://github.com/pytorch/fairseq/tree/main/examples/wav2vec),
-we've written ["Fine-tuning XLS-R for Multi-Lingual ASR with 🤗 Transformers"](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) which gives an in-detail explanation of how XLS-R functions and how it can be fine-tuned.
-
-The blog can also be opened and directly fine-tuned in a google colab notebook.
-In this section, we will explain how to fine-tune the model on a local machine.
-
-1. **Log in**
-
-To begin with, you should check that you are correctly logged in and that you have `git-lfs` installed so that your fine-tuned model can automatically be uploaded.
-
-Run:
-
-```bash
-huggingface-cli login
-```
-
-to login. It is recommended to login with your access token that can be found under your hugging face profile (icon in the top right corner on [hf.co](http://hf.co/), then Settings -> Access Tokens -> User Access Tokens -> New Token (if haven't generated one already)
-
-You can then copy-paste this token to log in locally.
-
-2. **Create your model repository**
-
-First, let's make sure that `git-lfs` is correctly installed. To so, simply run:
-
-```bash
-git-lfs -v
-```
-
-The output should show something like `git-lfs/2.13.2 (GitHub; linux amd64; go 1.15.4)`. If your console states that the `git-lfs` command was not found, please make
-sure to install it [here](https://git-lfs.github.com/) or simply via:
-
-```bash
-sudo apt-get install git-lfs
-```
-
-Now you can create your model repository which will contain all relevant files to
-reproduce your training. You can either directly create the model repository on the
-Hub (Settings -> New Model) or via the CLI. Here we choose to use the CLI instead.
-
-Assuming that we want to call our model repository *xls-r-ab-test*, we can run the
-following command:
-
-```bash
-huggingface-cli repo create xls-r-ab-test
-```
-
-You can now see the model on the Hub, *e.g.* under https://huggingface.co/hf-test/xls-r-ab-test .
-
-Let's clone the repository so that we can define our training script inside.
-
-```bash
-git lfs install
-git clone https://huggingface.co/hf-test/xls-r-ab-test
-```
-
-3. **Add your training script and `run`-command to the repository**
-
-We encourage participants to add all relevant files for training directly to the
-directory so that everything is fully reproducible.
-
-Let's first copy-paste the official training script from our clone
-of `transformers` to our just created directory:
-
-```bash
-cp ~/transformers/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py ./
-```
-
-Next, we'll create a bash file to define the hyper-parameters and configurations
-for training. More detailed information on different settings (single-GPU vs. multi-GPU) can be found [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/speech-recognition#connectionist-temporal-classification).
-
-For demonstration purposes, we will use a dummy XLS-R model `model_name_or_path="hf-test/xls-r-dummy"` on the very low-resource language of "Abkhaz" of [Common Voice 7](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0): `dataset_config_name="ab"` for just a single epoch.
-
-Before starting to train, let's make sure we have installed all the required libraries. You might want to run:
-
-```bash
-pip install -r ~/transformers/examples/pytorch/speech-recognition/requirements.txt
-```
-
-Alright, finally we can define the training script. We'll simply use some
-dummy hyper-parameters and configurations for demonstration purposes.
-
-Note that we add the flag `--use_auth_token` so that datasets requiring access,
-such as [Common Voice 7](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0) can be downloaded. In addition, we add the `--push_to_hub` flag to make use of the
-[Trainers `push_to-hub` functionality](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#transformers.Trainer.push_to_hub) so that your model will be automatically uploaded to the Hub.
-
-Let's copy the following code snippet in a file called `run.sh`
-
-```bash
-echo '''python run_speech_recognition_ctc.py \
- --dataset_name="mozilla-foundation/common_voice_7_0" \
- --model_name_or_path="hf-test/xls-r-dummy" \
- --dataset_config_name="ab" \
- --output_dir="./" \
- --overwrite_output_dir \
- --max_steps="10" \
- --per_device_train_batch_size="2" \
- --learning_rate="3e-4" \
- --save_total_limit="1" \
- --eval_strategy="steps" \
- --text_column_name="sentence" \
- --length_column_name="input_length" \
- --save_steps="5" \
- --layerdrop="0.0" \
- --freeze_feature_encoder \
- --gradient_checkpointing \
- --fp16 \
- --group_by_length \
- --push_to_hub \
- --use_auth_token \
- --do_train --do_eval''' > run.sh
-```
-
-4. **Start training**
-
-Now all that is left to do is to start training the model by executing the
-run file.
-
-```bash
-bash run.sh
-```
-
-The training should not take more than a couple of minutes.
-During the training intermediate saved checkpoints are automatically uploaded to
-your model repository as can be seen [on this commit](https://huggingface.co/hf-test/xls-r-ab-test/commit/0eb19a0fca4d7d163997b59663d98cd856022aa6) .
-
-At the end of the training, the [Trainer](https://huggingface.co/docs/transformers/main/en/main_classes/trainer) automatically creates a nice model card and all
-relevant files are uploaded.
-
-5. **Tips for real model training**
-
-The above steps illustrate how a model can technically be fine-tuned.
-However as you can see on the model card [hf-test/xls-r-ab-test](https://huggingface.co/hf-test/xls-r-ab-test), our demonstration has a very poor performance which is
-not surprising given that we trained for just 10 steps on a randomly initialized
-model.
-
-For real model training, it is recommended to use one of the actual pre-trained XLS-R models:
-
-- [300M parameters version](https://huggingface.co/facebook/wav2vec2-xls-r-300m)
-- [1B parameters version](https://huggingface.co/facebook/wav2vec2-xls-r-1b)
-- [2B parameters version](https://huggingface.co/facebook/wav2vec2-xls-r-2b)
-
-Also, the hyper-parameters should be carefully chosen depending on the dataset.
-As an example, we will fine-tune the 300M parameters model on Swedish on a single
-TITAN RTX 24GB GPU.
-
-The model will be called `"xls-r-300m-sv"`.
-Following the above steps we first create the model:
-
-```bash
-huggingface-cli repo create xls-r-300m-sv
-```
-
-, clone it locally (assuming the `` is `hf-test`)
-
-```bash
-git clone hf-test/xls-r-300m-sv
-```
-
-, and, define the following hyperparameters for training
-
-```bash
-echo '''python run_speech_recognition_ctc.py \
- --dataset_name="mozilla-foundation/common_voice_7_0" \
- --model_name_or_path="facebook/wav2vec2-xls-r-300m" \
- --dataset_config_name="sv-SE" \
- --output_dir="./" \
- --overwrite_output_dir \
- --num_train_epochs="50" \
- --per_device_train_batch_size="8" \
- --per_device_eval_batch_size="8" \
- --gradient_accumulation_steps="4" \
- --learning_rate="7.5e-5" \
- --warmup_steps="2000" \
- --length_column_name="input_length" \
- --eval_strategy="steps" \
- --text_column_name="sentence" \
- --chars_to_ignore , ? . ! \- \; \: \" “ % ‘ ” � — ’ … – \
- --save_steps="500" \
- --eval_steps="500" \
- --logging_steps="100" \
- --layerdrop="0.0" \
- --activation_dropout="0.1" \
- --save_total_limit="3" \
- --freeze_feature_encoder \
- --feat_proj_dropout="0.0" \
- --mask_time_prob="0.75" \
- --mask_time_length="10" \
- --mask_feature_prob="0.25" \
- --mask_feature_length="64" \
- --gradient_checkpointing \
- --use_auth_token \
- --fp16 \
- --group_by_length \
- --do_train --do_eval \
- --push_to_hub''' > run.sh
-```
-
-The training takes *ca.* 7 hours and yields a reasonable test word
-error rate of 27% as can be seen on the automatically generated [model card](https://huggingface.co/hf-test/xls-r-300m-sv).
-
-The above-chosen hyperparameters probably work quite well on a range of different
-datasets and languages but are by no means optimal. It is up to you to find a good set of
-hyperparameters.
-
-
-## How to finetune with OVH cloud
-
-[](https://youtu.be/XkMnYocAEO0) For a more detailed guide on setting up OVHcloud please watch this video: https://youtu.be/XkMnYocAEO0
-
-### Creating an OVHCloud account
-*TIP*: If you haven't created a project on OVHcloud yet, make sure you've received your GPU voucher code *beforehand*,
-so that you can skip entering the credit card information.
-1. If you're a US citizen, create an account via [OVHcloud.CA](https://ovhcloud.ca/).
-If you're from anywhere else in the world, create an account via [OVHcloud.COM](https://ovhcloud.com/).
-2. Once logged in, click `Public Cloud` from the top menu and then click `Create your first OVH Public Cloud project`.
-Then enter a project name (e.g. "huggingface"), enter your voucher code, and click `Continue` -> `Create my project`.
-*Note: if you see a request for credit card details during the last step, and you can't skip it, then your voucher code
-is invalid. Please report it to the [#ovh-support](https://discord.gg/p4qqDV3M) channel on Discord.*
-
-### Setting up an AI notebook
-1. Go to the `Public Cloud` page and select `Project Management` -> `Users & Roles` from the menu on the left.
-2. Click `+ Add user`. Write a user description (e.g. `AI Trainer`), and select an `AI Training Operator` user role.
-Click `Confirm`.
-3. Write down the *username* and *password* (at the top of the screen) somewhere. They will be needed during step 7.
-4. Select `AI & Machine Learning` -> `AI Training` from the menu on the left.
-Click `+ Launch a new job` on the AI Training page.
-5. On the `Launch a new job` page:
- * In `1. Choose a region` select a region closest to you.
- * In `2. Enter the Docker image` select `Custom image` -> `baaastijn/ovh_huggingface`.
- * You can skip steps `3.` and `4.` if you will be using the Hugging Face Hub to store the models after training.
- * In `5. Configure your job` select **1** `GPU`.
- * Validate the info and Create the job.
-6. On the `AI Training Jobs` screen wait until the job's status changes from `Pending` to `Running`.
-7. Click `HTTP Access` from the Job's details page and log in with the AI training user you've created earlier.
-Once logged in, you can close the page and click `HTTP Access` to launch a JupyterLab notebook.
-8. Awesome, now you have a free GPU-enabled Jupyter instance!
-
-**Note**: If you're an experienced Docker user, feel free to create a custom docker image with all of the needed packages
-like the one in step 5. The Dockerfile for it is available here:
-[baaastijn/Dockerimages](https://github.com/baaastijn/Dockerimages/tree/main/Hugginface_challenge_speech).
-Once you've built your image, push it to https://hub.docker.com/ and select it during the OVHcloud job creation.
-
-For more quick tutorials about OVHcloud AI products, check out the showcase https://vimeo.com/showcase/8903300
-
-## How to combine n-gram with acoustic model
-
-Having trained a speech recognition model with CTC as shown in the section above,
-one can further improve the model's performance by adding an **n-gram language model**
-to the decoding process of the model. By doing so, we are replacing the naive greedy decoding
-with **n-gram-boosted** beam search decoding.
-
-N-gram language models can be built on CPU in just a few minutes. *N-gram-boosted* beam search decoding noticeably slows down the
-inference time, but also yields significant word error rates improvements - usually between 10-40 %.
-
-You can find an in-detail blog post on how to build an *n-gram* [here](https://huggingface.co/blog/wav2vec2-with-ngram).
-The blog post can be opened in a google colab and by adapting three lines of the example for your use case, one can directly
-create an *n-gram* in the google colab.
-The blog post gives in-detail instructions on how to build an n-gram and how to add it to your trained speech recognition model.
-
-- why one should add an *n-gram* to her/his speech recognition system,
-- how to build an *n-gram*, and,
-- how to add the built *n-gram* the speech recognition system for seamless decoding
-
-Our previously trained model - [xls-r-300m-sv](https://huggingface.co/hf-test/xls-r-300m-sv) - enjoys a 30% word error rate reduction after
-having added an n-gram. As shown in the example of the blog post, we strongly advise participants to upload all files required for combining
-the *n-gram* with a trained speech recognition model directly into the same model repository.
-
-## Evaluation
-
-Finally, we have arrived at the most fun part of the challenge - sitting back and
-watching the model transcribe audio. If possible, every participant should evaluate
-the speech recognition system on the test set of Common Voice 7 and
-ideally also on the real-world audio data (if available).
-For languages that have neither a Common Voice evaluation dataset nor a real world
-evaluation dataset, please contact the organizers on Discord so that we can work
-together to find some evaluation data.
-
-As a first step, one should copy the official `eval.py` script to her/his model
-repository. Let's use our previously trained [xls-r-300m-sv](https://huggingface.co/hf-test/xls-r-300m-sv) again as an example.
-
-Assuming that we have a clone of the model's repo under `~/xls-r-300m-sv`, we can
-copy the `eval.py` script to the repo.
-
-```bash
-cp ~/transformers/examples/research_projects/robust-speech-event/eval.py ~/xls-r-300m-sv
-```
-
-Next, we should adapt `eval.py` so that it fits our evaluation data. Here it is
-important to keep the `eval.py` file in the following format:
-
-- 1. The following input arguments should not be changed and keep their original functionality/meaning (being to load the model and dataset): `"--model_id"`, `"--dataset"`, `"--config"`, `"--split"`. We recommend to not change any of the code written under `if __name__ == "__main__":`.
-- 2. The function `def log_results(result: Dataset, args: Dict[str, str])` should also not be changed. The function expects the above names attached to the `args` object as well as a `datasets.Dataset` object, called `result` which includes all predictions and target transcriptions under the names `"predictions"` and `"targets"` respectively.
-- 3. All other code can be changed and adapted. Participants are especially invited to change the `def normalize_text(text: str) -> str:` function as this might be a very language and model-training specific function.
-- 4. **Important**: It is not allowed to "cheat" in any way when in comes to pre-and postprocessing. In short, "cheating" refers to any of the following:
- - a. Somehow giving the model access to the target transcriptions to improve performance. The model is not allowed to use the target transcriptions to generate its predictions.
- - b. Pre-processing the target transcriptions in a way that makes the target transcriptions lose their original meaning. This corresponds to what has already been said in [Data and Preprocessing](#data-and-preprocessing) and is somewhat of a grey zone. It means that one should not remove characters that would make a word to lose its meaning. E.g., it is not allowed to replace all `e` in English with `i` and simply make the model learn that `e` and `i` are the same letter for a better word error rate. This would destroy the meaning of words such as `fell -> fill`. However, it is totally fine to normalize (*e.g.* lowercase) all letters, remove punctuation. There can be a lot of language-specific exceptions and in case you are not sure whether your target transcription pre-processing is allowed, please ask on the Discord channel.
-
-Uff, that was a lot of text describing how to make sure your `eval.py` script
-is in the correct format. If you have any questions, please ask openly in Discord.
-
-Great, now that we have adapted the `eval.py` script, we can lean back and run the
-evaluation.
-First, one should evaluate the model on Common Voice 7's test data. This might
-already have been done for your acoustic model during training but in case you
-added an *n-gram* language model after having fine-tuned the acoustic model, you
-should now see a nice improvement.
-
-The command to evaluate our test model [xls-r-300m-sv](https://huggingface.co/hf-test/xls-r-300m-sv) on Common Voice 7's test data is the following:
-
-```bash
-cd xls-r-300m-sv
-./eval.py --model_id ./ --dataset mozilla-foundation/common_voice_7_0 --config sv-SE --split test --log_outputs
-```
-
-To log each of the model's predictions with the target transcriptions, you can just
-add the `--log_outputs` flag.
-
-Running this command should automatically create the file:
-`mozilla-foundation_common_voice_7_0_sv-SE_test_eval_results.txt` that contains
-both the word- and character error rate.
-
-In a few days, we will give everybody access to some real-world audio data for as many languages as possible.
-If your language has real-world audio data, it will most likely have audio input
-of multiple minutes. 🤗Transformer's [ASR pipeline](https://huggingface.co/docs/transformers/main/en/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline) supports audio chunking out-of-the-box. You only need to specify
-how song each audio chunk should be (`chunk_length_s`) and how much audio stride
-(`stride_length_s`) each chunk should use.
-For more information on the chunking works, please have a look at [this nice blog post](TODO: ).
-
-In the case of `xls-r-300m-sv`, the following command can be run:
-
-```bash
-cd xls-r-300m-sv
-./eval.py --model_id hf-test/xls-r-300m-sv --dataset --config sv --split validation --chunk_length_s 5.0 --stride_length_s 1.0 --log_outputs
-```
-
-Great, now you should have successfully evaluated your model. Finally, there is one
-**important** thing you should do so that your model is taken into account
-for the final evaluation. You should add two tags to your model, one being `robust-speech-event`, one being the ISO code of your chosen language, *e.g.* `"sv"` for the
-exemplary model we used above. You can find a list of all available languages and
-their ISO code [here](https://huggingface.co/languages).
-
-To add the tags, simply edit the README.md of your model repository and add
-
-```
-- "sv"
-- "robust-speech-event"
-```
-
-under `tags:` as done [here](https://huggingface.co/hf-test/xls-r-300m-sv/commit/a495fd70c96bb7d019729be9273a265c2557345e).
-
-To verify that you've added the tags correctly make sure that your model
-appears when clicking on [this link](https://huggingface.co/models?other=robust-speech-event).
-
-Great that's it! This should give you all the necessary information to evaluate
-your model. For the final evaluation, we will verify each evaluation result to
-determine the final score and thereby the winning models for each language.
-
-The final score is calculated as follows:
-
-```bash
-FINAL_SCORE = 1/3 * WER_Common_Voice_7_test + 1/3 * WER_REAL_AUDIO_DEV + 1/3 * WER_REAL_AUDIO_TEST
-```
-
-The dataset `WER_REAL_AUDIO_TEST` is hidden and will only be published
-at the end of the robust speech challenge.
-
-If there is no real audio data for your language the final score will be
-computed solely based on the Common Voice 7 test dataset. If there is also
-no Common Voice 7 test dataset for your language, we will see together how to
-score your model - if this is the case, please don't be discouraged. We are
-especially excited about speech recognition systems of such low-resource
-languages and will make sure that we'll decide on a good approach to evaluating
-your model.
-
-## Prizes
-
-TODO(Patrick, Omar, ...)
-
-## Communication and Problems
-
-If you encounter any problems or have any questions, you should use one of the following platforms
-depending on your type of problem. Hugging Face is an "open-source-first" organization meaning
-that we'll try to solve all problems in the most public and most transparent way possible so that everybody
-in the community profits.
-
-The following table summarizes what platform to use for which problem.
-
-- Problem/question/bug with the 🤗 Datasets library that you think is a general problem that also impacts other people, please open an [Issues on Datasets](https://github.com/huggingface/datasets/issues/new?assignees=&labels=bug&template=bug-report.md&title=) and ping @anton-l and @patrickvonplaten.
-- Problem/question/bug with the 🤗 Transformers library that you think is a general problem that also impacts other people, please open an [Issues on Transformers](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title=) and ping @anton-l and @patrickvonplaten.
-- Problem/question with a modified, customized training script that is less likely to impact other people, please post your problem/question [on the forum](https://discuss.huggingface.co/) and ping @anton-l and @patrickvonplaten.
-- Questions regarding access to the OVHcloud GPU, please ask in the Discord channel **#ovh-support**.
-- Other questions regarding the event, rules of the event, or if you are not sure where to post your question, please ask in the Discord channel **#sprint-discussions**.
-
-## Talks
-
-We are very excited to be hosting 2 days of talks from Kensho-Technologies, Mozilla's Common Voice, Meta AI Research and Hugging Face.
-
-### Thursday, January 20th
-
- Speaker | Topic | Time | Video |
-|-------------|---------------------------------|------------------------|------------------------|
-| Patrick von Platen, Hugging Face | Introduction to Robust Speech Challenge | 4h30pm - 5h00pm UTC | [](https://www.youtube.com/watch?v=X9e5Tto-Iuk)
-| Raymond Grossman and Jeremy Lopez, Kensho-Technologies | Pyctcdecode & Speech2text decoding | 5h30pm - 6h00pm UTC | [](https://www.youtube.com/watch?v=mp7fHMTnK9A)
-
-### Friday, January 21th
-
- Speaker | Topic | Time | Video |
-|-------------|---------------------------------|------------------------|------------------------|
-| Gabriel Habayeb, Mozilla Common Voice | Unlocking global speech with Mozilla Common Voice | 4h30pm - 5h00pm UTC | [](https://www.youtube.com/watch?v=Vvn984QmAVg)
-| Changhan Wang, Meta AI Research | XLS-R: Large-Scale Cross-lingual Speech Representation Learning on 128 Languages | 5h30pm - 6h00pm UTC | [](https://www.youtube.com/watch?v=ic_J7ZCROBM)
-
-### Talks & Speakers
-
-#### Patrick von Platen, Research Engineer, Hugging Face
-- Talk: Introduction to Robust Speech Challenge
-- Abstract: In this talk, Patrick outlines the Robust Speech Challenge and gives tips and tricks on how to train and evaluate speech recognition systems with 🤗 Transformers and 🤗 Datasets, and PyTorch.
-- Speaker info: Patrick von Platen is a research engineer at Hugging Face and one of the core maintainers of the popular Transformers library. He specializes in speech recognition, encoder-decoder models, and long-range sequence modeling. Before joining Hugging Face, Patrick researched speech recognition at Uber AI, Cambridge University, and RWTH Aachen University.
-
-#### Raymond Grossman, Jeremy Lopez, Machine Learning Engineer, Kensho Technologies
-- Talk: PyCTCDecode & Speech2text decoding
-- Abstract: PyCTCDecode is a fast and feature-rich CTC beam search decoder for speech recognition written in Python, providing n-gram (kenlm) language model support similar to PaddlePaddle's decoder, but incorporating many new features such as byte pair encoding and real-time decoding to support models like Nvidia's Conformer-CTC or Facebook's Wav2Vec2.
-- Speaker info :
- - Raymond works as a machine learning engineer at Kensho Technologies, specializing in speech and natural language domains. Before coming to Kensho, he studied mathematics at Princeton and was an avid Kaggler under the moniker @ToTrainThemIsMyCause.
- - Jeremy is a machine learning engineer at Kensho Technologies and has worked on a variety of different topics including search and speech recognition. Before working at Kensho, he earned a PhD in experimental particle physics at MIT and continued doing physics research as a postdoc at the University of Colorado Boulder.
-
-#### Gabriel Habayeb, Data Engineer, Common Voice @ Mozilla
-- Talk: Unlocking global speech with Mozilla Common Voice
-- Abstract: Hear from Common Voice Data Engineer Gabriel Habayeb (Mozilla Foundation) as he talks about how Common Voice makes it easy to crowdsource voice data in global languages, as well as getting key insights into the dataset itself, how we maintain quality, use metadata - and our plans for the future!
-- Speaker info: Gabriel is a software developer with the Common Voice team at the Mozilla Foundation with a focus on data engineering. Before joining the Foundation, he spent the last six years working across different industries, including education, enterprise and not-for-profit organizations.
-
-#### Changhan Wang, Main author of XLS-R and Research Engineer, Meta AI Research
-- Talk: XLS-R: Large-Scale Cross-lingual Speech Representation Learning on 128 Languages
-- Abstract: In this talk, Changhan will present XLS-R, a large-scale model for cross-lingual speech representation learning based on wav2vec 2.0. XLS-R has up to 2B parameters and was trained on nearly half a million hours of publicly available speech audio in 128 languages, an order of magnitude more public data than the largest known prior work. On the CoVoST-2 speech translation benchmark, XLS-R improves the previous state of the art by an average of 7.4 BLEU over 21 translation directions into English. For speech recognition, XLS-R improves over the best known prior work on BABEL, MLS, CommonVoice as well as VoxPopuli, lowering error rates by 14-34% relative on average. XLS-R also sets a new state of the art on VoxLingua107 language identification. The XLS-R team hopes to work together with the open-source community to improve speech processing tasks for many more languages of the world.
-
-## General Tips and Tricks
-
-- Memory efficient training:
-
-In case, you are getting out-of-memory errors on your GPU, we recommend to use
-[bitsandbytes](https://github.com/TimDettmers/bitsandbytes) to replace the
-native memory-intensive Adam optimizer with the one of `bitsandbytes`. You
-can simply run the script `./run_speech_recognition_ctc_bnb.py` provided in this
-folder that makes use of `bitsandbytes` instead of the official one.
-
-- Dataset streaming
-
-TODO(Patrick)
diff --git a/examples/research_projects/robust-speech-event/eval.py b/examples/research_projects/robust-speech-event/eval.py
deleted file mode 100755
index b6c89a6d49f..00000000000
--- a/examples/research_projects/robust-speech-event/eval.py
+++ /dev/null
@@ -1,136 +0,0 @@
-#!/usr/bin/env python3
-import argparse
-import re
-from typing import Dict
-
-import torch
-from datasets import Audio, Dataset, load_dataset, load_metric
-
-from transformers import AutoFeatureExtractor, pipeline
-
-
-def log_results(result: Dataset, args: Dict[str, str]):
- """DO NOT CHANGE. This function computes and logs the result metrics."""
-
- log_outputs = args.log_outputs
- dataset_id = "_".join(args.dataset.split("/") + [args.config, args.split])
-
- # load metric
- wer = load_metric("wer")
- cer = load_metric("cer")
-
- # compute metrics
- wer_result = wer.compute(references=result["target"], predictions=result["prediction"])
- cer_result = cer.compute(references=result["target"], predictions=result["prediction"])
-
- # print & log results
- result_str = f"WER: {wer_result}\nCER: {cer_result}"
- print(result_str)
-
- with open(f"{dataset_id}_eval_results.txt", "w") as f:
- f.write(result_str)
-
- # log all results in text file. Possibly interesting for analysis
- if log_outputs is not None:
- pred_file = f"log_{dataset_id}_predictions.txt"
- target_file = f"log_{dataset_id}_targets.txt"
-
- with open(pred_file, "w") as p, open(target_file, "w") as t:
- # mapping function to write output
- def write_to_file(batch, i):
- p.write(f"{i}" + "\n")
- p.write(batch["prediction"] + "\n")
- t.write(f"{i}" + "\n")
- t.write(batch["target"] + "\n")
-
- result.map(write_to_file, with_indices=True)
-
-
-def normalize_text(text: str) -> str:
- """DO ADAPT FOR YOUR USE CASE. this function normalizes the target text."""
-
- chars_to_ignore_regex = '[,?.!\-\;\:"“%‘”�—’…–]' # noqa: W605 IMPORTANT: this should correspond to the chars that were ignored during training
-
- text = re.sub(chars_to_ignore_regex, "", text.lower())
-
- # In addition, we can normalize the target text, e.g. removing new lines characters etc...
- # note that order is important here!
- token_sequences_to_ignore = ["\n\n", "\n", " ", " "]
-
- for t in token_sequences_to_ignore:
- text = " ".join(text.split(t))
-
- return text
-
-
-def main(args):
- # load dataset
- dataset = load_dataset(args.dataset, args.config, split=args.split, token=True)
-
- # for testing: only process the first two examples as a test
- # dataset = dataset.select(range(10))
-
- # load processor
- feature_extractor = AutoFeatureExtractor.from_pretrained(args.model_id)
- sampling_rate = feature_extractor.sampling_rate
-
- # resample audio
- dataset = dataset.cast_column("audio", Audio(sampling_rate=sampling_rate))
-
- # load eval pipeline
- if args.device is None:
- args.device = 0 if torch.cuda.is_available() else -1
- asr = pipeline("automatic-speech-recognition", model=args.model_id, device=args.device)
-
- # map function to decode audio
- def map_to_pred(batch):
- prediction = asr(
- batch["audio"]["array"], chunk_length_s=args.chunk_length_s, stride_length_s=args.stride_length_s
- )
-
- batch["prediction"] = prediction["text"]
- batch["target"] = normalize_text(batch["sentence"])
- return batch
-
- # run inference on all examples
- result = dataset.map(map_to_pred, remove_columns=dataset.column_names)
-
- # compute and log_results
- # do not change function below
- log_results(result, args)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
-
- parser.add_argument(
- "--model_id", type=str, required=True, help="Model identifier. Should be loadable with 🤗 Transformers"
- )
- parser.add_argument(
- "--dataset",
- type=str,
- required=True,
- help="Dataset name to evaluate the `model_id`. Should be loadable with 🤗 Datasets",
- )
- parser.add_argument(
- "--config", type=str, required=True, help="Config of the dataset. *E.g.* `'en'` for Common Voice"
- )
- parser.add_argument("--split", type=str, required=True, help="Split of the dataset. *E.g.* `'test'`")
- parser.add_argument(
- "--chunk_length_s", type=float, default=None, help="Chunk length in seconds. Defaults to 5 seconds."
- )
- parser.add_argument(
- "--stride_length_s", type=float, default=None, help="Stride of the audio chunks. Defaults to 1 second."
- )
- parser.add_argument(
- "--log_outputs", action="store_true", help="If defined, write outputs to log file for analysis."
- )
- parser.add_argument(
- "--device",
- type=int,
- default=None,
- help="The device to run the pipeline on. -1 for CPU (default), 0 for the first GPU and so on.",
- )
- args = parser.parse_args()
-
- main(args)
diff --git a/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_bnb.py b/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_bnb.py
deleted file mode 100755
index cb489ea28d6..00000000000
--- a/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_bnb.py
+++ /dev/null
@@ -1,779 +0,0 @@
-#!/usr/bin/env python
-# coding=utf-8
-# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-
-"""Fine-tuning a 🤗 Transformers CTC model for automatic speech recognition"""
-
-import functools
-import json
-import logging
-import os
-import re
-import sys
-import warnings
-from dataclasses import dataclass, field
-from typing import Dict, List, Optional, Union
-
-import bitsandbytes as bnb
-import datasets
-import numpy as np
-import torch
-from datasets import DatasetDict, load_dataset, load_metric
-
-import transformers
-from transformers import (
- AutoConfig,
- AutoFeatureExtractor,
- AutoModelForCTC,
- AutoProcessor,
- AutoTokenizer,
- HfArgumentParser,
- Trainer,
- TrainingArguments,
- Wav2Vec2Processor,
- set_seed,
-)
-from transformers.trainer_pt_utils import get_parameter_names
-from transformers.trainer_utils import get_last_checkpoint, is_main_process
-from transformers.utils import check_min_version
-from transformers.utils.versions import require_version
-
-
-# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.16.0.dev0")
-
-require_version("datasets>=1.13.3", "To fix: pip install -r examples/pytorch/text-classification/requirements.txt")
-
-
-logger = logging.getLogger(__name__)
-
-
-def list_field(default=None, metadata=None):
- return field(default_factory=lambda: default, metadata=metadata)
-
-
-@dataclass
-class ModelArguments:
- """
- Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
- """
-
- model_name_or_path: str = field(
- metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
- )
- tokenizer_name_or_path: Optional[str] = field(
- default=None,
- metadata={"help": "Path to pretrained tokenizer or tokenizer identifier from huggingface.co/models"},
- )
- cache_dir: Optional[str] = field(
- default=None,
- metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
- )
- freeze_feature_encoder: bool = field(
- default=True, metadata={"help": "Whether to freeze the feature encoder layers of the model."}
- )
- attention_dropout: float = field(
- default=0.0, metadata={"help": "The dropout ratio for the attention probabilities."}
- )
- activation_dropout: float = field(
- default=0.0, metadata={"help": "The dropout ratio for activations inside the fully connected layer."}
- )
- feat_proj_dropout: float = field(default=0.0, metadata={"help": "The dropout ratio for the projected features."})
- hidden_dropout: float = field(
- default=0.0,
- metadata={
- "help": "The dropout probability for all fully connected layers in the embeddings, encoder, and pooler."
- },
- )
- final_dropout: float = field(
- default=0.0,
- metadata={"help": "The dropout probability for the final projection layer."},
- )
- mask_time_prob: float = field(
- default=0.05,
- metadata={
- "help": (
- "Probability of each feature vector along the time axis to be chosen as the start of the vector "
- "span to be masked. Approximately ``mask_time_prob * sequence_length // mask_time_length`` feature "
- "vectors will be masked along the time axis."
- )
- },
- )
- mask_time_length: int = field(
- default=10,
- metadata={"help": "Length of vector span to mask along the time axis."},
- )
- mask_feature_prob: float = field(
- default=0.0,
- metadata={
- "help": (
- "Probability of each feature vector along the feature axis to be chosen as the start of the vectorspan"
- " to be masked. Approximately ``mask_feature_prob * sequence_length // mask_feature_length`` feature"
- " bins will be masked along the time axis."
- )
- },
- )
- mask_feature_length: int = field(
- default=10,
- metadata={"help": "Length of vector span to mask along the feature axis."},
- )
- layerdrop: float = field(default=0.0, metadata={"help": "The LayerDrop probability."})
- ctc_loss_reduction: Optional[str] = field(
- default="mean", metadata={"help": "The way the ctc loss should be reduced. Should be one of 'mean' or 'sum'."}
- )
-
-
-@dataclass
-class DataTrainingArguments:
- """
- Arguments pertaining to what data we are going to input our model for training and eval.
-
- Using `HfArgumentParser` we can turn this class
- into argparse arguments to be able to specify them on
- the command line.
- """
-
- dataset_name: str = field(
- metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
- )
- dataset_config_name: str = field(
- default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
- )
- train_split_name: str = field(
- default="train+validation",
- metadata={
- "help": "The name of the training data set split to use (via the datasets library). Defaults to 'train'"
- },
- )
- eval_split_name: str = field(
- default="test",
- metadata={
- "help": "The name of the training data set split to use (via the datasets library). Defaults to 'train'"
- },
- )
- audio_column_name: str = field(
- default="audio",
- metadata={"help": "The name of the dataset column containing the audio data. Defaults to 'audio'"},
- )
- text_column_name: str = field(
- default="text",
- metadata={"help": "The name of the dataset column containing the text data. Defaults to 'text'"},
- )
- overwrite_cache: bool = field(
- default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
- )
- preprocessing_num_workers: Optional[int] = field(
- default=None,
- metadata={"help": "The number of processes to use for the preprocessing."},
- )
- max_train_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of training examples to this "
- "value if set."
- )
- },
- )
- max_eval_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of validation examples to this "
- "value if set."
- )
- },
- )
- chars_to_ignore: Optional[List[str]] = list_field(
- default=None,
- metadata={"help": "A list of characters to remove from the transcripts."},
- )
- eval_metrics: List[str] = list_field(
- default=["wer"],
- metadata={"help": "A list of metrics the model should be evaluated on. E.g. `'wer cer'`"},
- )
- max_duration_in_seconds: float = field(
- default=20.0,
- metadata={
- "help": (
- "Filter audio files that are longer than `max_duration_in_seconds` seconds to"
- " 'max_duration_in_seconds`"
- )
- },
- )
- min_duration_in_seconds: float = field(
- default=0.0, metadata={"help": "Filter audio files that are shorter than `min_duration_in_seconds` seconds"}
- )
- preprocessing_only: bool = field(
- default=False,
- metadata={
- "help": (
- "Whether to only do data preprocessing and skip training. This is especially useful when data"
- " preprocessing errors out in distributed training due to timeout. In this case, one should run the"
- " preprocessing in a non-distributed setup with `preprocessing_only=True` so that the cached datasets"
- " can consequently be loaded in distributed training"
- )
- },
- )
- use_auth_token: bool = field(
- default=False,
- metadata={
- "help": (
- "If :obj:`True`, will use the token generated when running"
- ":obj:`huggingface-cli login` as HTTP bearer authorization for remote files."
- )
- },
- )
- unk_token: str = field(
- default="[UNK]",
- metadata={"help": "The unk token for the tokenizer"},
- )
- pad_token: str = field(
- default="[PAD]",
- metadata={"help": "The padding token for the tokenizer"},
- )
- word_delimiter_token: str = field(
- default="|",
- metadata={"help": "The word delimiter token for the tokenizer"},
- )
- phoneme_language: Optional[str] = field(
- default=None,
- metadata={
- "help": (
- "The target language that should be used be"
- " passed to the tokenizer for tokenization. Note that"
- " this is only relevant if the model classifies the"
- " input audio to a sequence of phoneme sequences."
- )
- },
- )
-
-
-@dataclass
-class DataCollatorCTCWithPadding:
- """
- Data collator that will dynamically pad the inputs received.
- Args:
- processor (:class:`~transformers.AutoProcessor`)
- The processor used for processing the data.
- padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
- Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
- among:
- * :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
- sequence if provided).
- * :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
- maximum acceptable input length for the model if that argument is not provided.
- * :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
- different lengths).
- max_length (:obj:`int`, `optional`):
- Maximum length of the ``input_values`` of the returned list and optionally padding length (see above).
- max_length_labels (:obj:`int`, `optional`):
- Maximum length of the ``labels`` returned list and optionally padding length (see above).
- pad_to_multiple_of (:obj:`int`, `optional`):
- If set will pad the sequence to a multiple of the provided value.
- This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
- 7.5 (Volta).
- """
-
- processor: AutoProcessor
- padding: Union[bool, str] = "longest"
- pad_to_multiple_of: Optional[int] = None
- pad_to_multiple_of_labels: Optional[int] = None
-
- def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
- # split inputs and labels since they have to be of different lengths and need
- # different padding methods
- input_features = [{"input_values": feature["input_values"]} for feature in features]
- label_features = [{"input_ids": feature["labels"]} for feature in features]
-
- batch = self.processor.pad(
- input_features,
- padding=self.padding,
- pad_to_multiple_of=self.pad_to_multiple_of,
- return_tensors="pt",
- )
-
- labels_batch = self.processor.pad(
- labels=label_features,
- padding=self.padding,
- pad_to_multiple_of=self.pad_to_multiple_of_labels,
- return_tensors="pt",
- )
-
- # replace padding with -100 to ignore loss correctly
- labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
-
- batch["labels"] = labels
-
- return batch
-
-
-def create_vocabulary_from_data(
- datasets: DatasetDict,
- word_delimiter_token: Optional[str] = None,
- unk_token: Optional[str] = None,
- pad_token: Optional[str] = None,
-):
- # Given training and test labels create vocabulary
- def extract_all_chars(batch):
- all_text = " ".join(batch["target_text"])
- vocab = list(set(all_text))
- return {"vocab": [vocab], "all_text": [all_text]}
-
- vocabs = datasets.map(
- extract_all_chars,
- batched=True,
- batch_size=-1,
- keep_in_memory=True,
- remove_columns=datasets["train"].column_names,
- )
-
- # take union of all unique characters in each dataset
- vocab_set = functools.reduce(
- lambda vocab_1, vocab_2: set(vocab_1["vocab"][0]) | set(vocab_2["vocab"][0]), vocabs.values()
- )
-
- vocab_dict = {v: k for k, v in enumerate(sorted(vocab_set))}
-
- # replace white space with delimiter token
- if word_delimiter_token is not None:
- vocab_dict[word_delimiter_token] = vocab_dict[" "]
- del vocab_dict[" "]
-
- # add unk and pad token
- if unk_token is not None:
- vocab_dict[unk_token] = len(vocab_dict)
-
- if pad_token is not None:
- vocab_dict[pad_token] = len(vocab_dict)
-
- return vocab_dict
-
-
-def main():
- # See all possible arguments in src/transformers/training_args.py
- # or by passing the --help flag to this script.
- # We now keep distinct sets of args, for a cleaner separation of concerns.
-
- parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
- if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
- # If we pass only one argument to the script and it's the path to a json file,
- # let's parse it to get our arguments.
- model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
- else:
- model_args, data_args, training_args = parser.parse_args_into_dataclasses()
-
- # Detecting last checkpoint.
- last_checkpoint = None
- if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
- last_checkpoint = get_last_checkpoint(training_args.output_dir)
- if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
- raise ValueError(
- f"Output directory ({training_args.output_dir}) already exists and is not empty. "
- "Use --overwrite_output_dir to overcome."
- )
- elif last_checkpoint is not None:
- logger.info(
- f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
- "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
- )
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- handlers=[logging.StreamHandler(sys.stdout)],
- )
- logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
-
- # Log on each process the small summary:
- logger.warning(
- f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
- f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
- )
- # Set the verbosity to info of the Transformers logger (on main process only):
- if is_main_process(training_args.local_rank):
- transformers.utils.logging.set_verbosity_info()
- logger.info("Training/evaluation parameters %s", training_args)
-
- # Set seed before initializing model.
- set_seed(training_args.seed)
-
- # 1. First, let's load the dataset
- raw_datasets = DatasetDict()
-
- if training_args.do_train:
- raw_datasets["train"] = load_dataset(
- data_args.dataset_name,
- data_args.dataset_config_name,
- split=data_args.train_split_name,
- token=data_args.use_auth_token,
- )
-
- if data_args.audio_column_name not in raw_datasets["train"].column_names:
- raise ValueError(
- f"--audio_column_name '{data_args.audio_column_name}' not found in dataset '{data_args.dataset_name}'."
- " Make sure to set `--audio_column_name` to the correct audio column - one of"
- f" {', '.join(raw_datasets['train'].column_names)}."
- )
-
- if data_args.text_column_name not in raw_datasets["train"].column_names:
- raise ValueError(
- f"--text_column_name {data_args.text_column_name} not found in dataset '{data_args.dataset_name}'. "
- "Make sure to set `--text_column_name` to the correct text column - one of "
- f"{', '.join(raw_datasets['train'].column_names)}."
- )
-
- if data_args.max_train_samples is not None:
- raw_datasets["train"] = raw_datasets["train"].select(range(data_args.max_train_samples))
-
- if training_args.do_eval:
- raw_datasets["eval"] = load_dataset(
- data_args.dataset_name,
- data_args.dataset_config_name,
- split=data_args.eval_split_name,
- token=data_args.use_auth_token,
- )
-
- if data_args.max_eval_samples is not None:
- raw_datasets["eval"] = raw_datasets["eval"].select(range(data_args.max_eval_samples))
-
- # 2. We remove some special characters from the datasets
- # that make training complicated and do not help in transcribing the speech
- # E.g. characters, such as `,` and `.` do not really have an acoustic characteristic
- # that could be easily picked up by the model
- chars_to_ignore_regex = (
- f'[{"".join(data_args.chars_to_ignore)}]' if data_args.chars_to_ignore is not None else None
- )
- text_column_name = data_args.text_column_name
-
- def remove_special_characters(batch):
- if chars_to_ignore_regex is not None:
- batch["target_text"] = re.sub(chars_to_ignore_regex, "", batch[text_column_name]).lower() + " "
- else:
- batch["target_text"] = batch[text_column_name].lower() + " "
- return batch
-
- with training_args.main_process_first(desc="dataset map special characters removal"):
- raw_datasets = raw_datasets.map(
- remove_special_characters,
- remove_columns=[text_column_name],
- desc="remove special characters from datasets",
- )
-
- # save special tokens for tokenizer
- word_delimiter_token = data_args.word_delimiter_token
- unk_token = data_args.unk_token
- pad_token = data_args.pad_token
-
- # 3. Next, let's load the config as we might need it to create
- # the tokenizer
- # load config
- config = AutoConfig.from_pretrained(
- model_args.model_name_or_path, cache_dir=model_args.cache_dir, token=data_args.use_auth_token
- )
-
- # 4. Next, if no tokenizer file is defined,
- # we create the vocabulary of the model by extracting all unique characters from
- # the training and evaluation datasets
- # We need to make sure that only first rank saves vocabulary
- # make sure all processes wait until vocab is created
- tokenizer_name_or_path = model_args.tokenizer_name_or_path
- tokenizer_kwargs = {}
- if tokenizer_name_or_path is None:
- # save vocab in training output dir
- tokenizer_name_or_path = training_args.output_dir
-
- vocab_file = os.path.join(tokenizer_name_or_path, "vocab.json")
-
- with training_args.main_process_first():
- if training_args.overwrite_output_dir and os.path.isfile(vocab_file):
- os.remove(vocab_file)
-
- with training_args.main_process_first(desc="dataset map vocabulary creation"):
- if not os.path.isfile(vocab_file):
- os.makedirs(tokenizer_name_or_path, exist_ok=True)
- vocab_dict = create_vocabulary_from_data(
- raw_datasets,
- word_delimiter_token=word_delimiter_token,
- unk_token=unk_token,
- pad_token=pad_token,
- )
-
- # save vocab dict to be loaded into tokenizer
- with open(vocab_file, "w") as file:
- json.dump(vocab_dict, file)
-
- # if tokenizer has just been created
- # it is defined by `tokenizer_class` if present in config else by `model_type`
- tokenizer_kwargs = {
- "config": config if config.tokenizer_class is not None else None,
- "tokenizer_type": config.model_type if config.tokenizer_class is None else None,
- "unk_token": unk_token,
- "pad_token": pad_token,
- "word_delimiter_token": word_delimiter_token,
- }
-
- # 5. Now we can instantiate the feature extractor, tokenizer and model
- # Note for distributed training, the .from_pretrained methods guarantee that only
- # one local process can concurrently download model & vocab.
-
- # load feature_extractor and tokenizer
- tokenizer = AutoTokenizer.from_pretrained(
- tokenizer_name_or_path,
- token=data_args.use_auth_token,
- **tokenizer_kwargs,
- )
- feature_extractor = AutoFeatureExtractor.from_pretrained(
- model_args.model_name_or_path, cache_dir=model_args.cache_dir, token=data_args.use_auth_token
- )
-
- # adapt config
- config.update(
- {
- "feat_proj_dropout": model_args.feat_proj_dropout,
- "attention_dropout": model_args.attention_dropout,
- "hidden_dropout": model_args.hidden_dropout,
- "final_dropout": model_args.final_dropout,
- "mask_time_prob": model_args.mask_time_prob,
- "mask_time_length": model_args.mask_time_length,
- "mask_feature_prob": model_args.mask_feature_prob,
- "mask_feature_length": model_args.mask_feature_length,
- "gradient_checkpointing": training_args.gradient_checkpointing,
- "layerdrop": model_args.layerdrop,
- "ctc_loss_reduction": model_args.ctc_loss_reduction,
- "pad_token_id": tokenizer.pad_token_id,
- "vocab_size": len(tokenizer),
- "activation_dropout": model_args.activation_dropout,
- }
- )
-
- # create model
- model = AutoModelForCTC.from_pretrained(
- model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- config=config,
- token=data_args.use_auth_token,
- )
-
- # freeze encoder
- if model_args.freeze_feature_encoder:
- model.freeze_feature_encoder()
-
- # 6. Now we preprocess the datasets including loading the audio, resampling and normalization
- # Thankfully, `datasets` takes care of automatically loading and resampling the audio,
- # so that we just need to set the correct target sampling rate and normalize the input
- # via the `feature_extractor`
-
- # make sure that dataset decodes audio with correct sampling rate
- dataset_sampling_rate = next(iter(raw_datasets.values())).features[data_args.audio_column_name].sampling_rate
- if dataset_sampling_rate != feature_extractor.sampling_rate:
- raw_datasets = raw_datasets.cast_column(
- data_args.audio_column_name, datasets.features.Audio(sampling_rate=feature_extractor.sampling_rate)
- )
-
- # derive max & min input length for sample rate & max duration
- max_input_length = data_args.max_duration_in_seconds * feature_extractor.sampling_rate
- min_input_length = data_args.min_duration_in_seconds * feature_extractor.sampling_rate
- audio_column_name = data_args.audio_column_name
- num_workers = data_args.preprocessing_num_workers
-
- # `phoneme_language` is only relevant if the model is fine-tuned on phoneme classification
- phoneme_language = data_args.phoneme_language
-
- # Preprocessing the datasets.
- # We need to read the audio files as arrays and tokenize the targets.
- def prepare_dataset(batch):
- # load audio
- sample = batch[audio_column_name]
-
- inputs = feature_extractor(sample["array"], sampling_rate=sample["sampling_rate"])
- batch["input_values"] = inputs.input_values[0]
- batch["input_length"] = len(batch["input_values"])
-
- # encode targets
- additional_kwargs = {}
- if phoneme_language is not None:
- additional_kwargs["phonemizer_lang"] = phoneme_language
-
- batch["labels"] = tokenizer(batch["target_text"], **additional_kwargs).input_ids
- return batch
-
- with training_args.main_process_first(desc="dataset map preprocessing"):
- vectorized_datasets = raw_datasets.map(
- prepare_dataset,
- remove_columns=next(iter(raw_datasets.values())).column_names,
- num_proc=num_workers,
- desc="preprocess datasets",
- )
-
- def is_audio_in_length_range(length):
- return length > min_input_length and length < max_input_length
-
- # filter data that is shorter than min_input_length
- vectorized_datasets = vectorized_datasets.filter(
- is_audio_in_length_range,
- num_proc=num_workers,
- input_columns=["input_length"],
- )
-
- # 7. Next, we can prepare the training.
- # Let's use word error rate (WER) as our evaluation metric,
- # instantiate a data collator and the trainer
-
- # Define evaluation metrics during training, *i.e.* word error rate, character error rate
- eval_metrics = {metric: load_metric(metric) for metric in data_args.eval_metrics}
-
- # for large datasets it is advised to run the preprocessing on a
- # single machine first with ``args.preprocessing_only`` since there will mostly likely
- # be a timeout when running the script in distributed mode.
- # In a second step ``args.preprocessing_only`` can then be set to `False` to load the
- # cached dataset
- if data_args.preprocessing_only:
- logger.info(f"Data preprocessing finished. Files cached at {vectorized_datasets.cache_files}")
- return
-
- def compute_metrics(pred):
- pred_logits = pred.predictions
- pred_ids = np.argmax(pred_logits, axis=-1)
-
- pred.label_ids[pred.label_ids == -100] = tokenizer.pad_token_id
-
- pred_str = tokenizer.batch_decode(pred_ids)
- # we do not want to group tokens when computing the metrics
- label_str = tokenizer.batch_decode(pred.label_ids, group_tokens=False)
-
- metrics = {k: v.compute(predictions=pred_str, references=label_str) for k, v in eval_metrics.items()}
-
- return metrics
-
- # Now save everything to be able to create a single processor later
- if is_main_process(training_args.local_rank):
- # save feature extractor, tokenizer and config
- feature_extractor.save_pretrained(training_args.output_dir)
- tokenizer.save_pretrained(training_args.output_dir)
- config.save_pretrained(training_args.output_dir)
-
- try:
- processor = AutoProcessor.from_pretrained(training_args.output_dir)
- except (OSError, KeyError):
- warnings.warn(
- "Loading a processor from a feature extractor config that does not"
- " include a `processor_class` attribute is deprecated and will be removed in v5. Please add the following "
- " attribute to your `preprocessor_config.json` file to suppress this warning: "
- " `'processor_class': 'Wav2Vec2Processor'`",
- FutureWarning,
- )
- processor = Wav2Vec2Processor.from_pretrained(training_args.output_dir)
-
- # Instantiate custom data collator
- data_collator = DataCollatorCTCWithPadding(processor=processor)
-
- decay_parameters = get_parameter_names(model, [torch.nn.LayerNorm], ["bias", "layernorm", "rmsnorm"])
- optimizer_grouped_parameters = [
- {
- "params": [p for n, p in model.named_parameters() if n in decay_parameters],
- "weight_decay": training_args.weight_decay,
- },
- {
- "params": [p for n, p in model.named_parameters() if n not in decay_parameters],
- "weight_decay": 0.0,
- },
- ]
- optimizer = bnb.optim.Adam8bit(
- params=optimizer_grouped_parameters,
- lr=training_args.learning_rate,
- betas=(training_args.adam_beta1, training_args.adam_beta2),
- eps=training_args.adam_epsilon,
- )
-
- optimizers = (optimizer, None)
-
- # Initialize Trainer
- trainer = Trainer(
- model=model,
- data_collator=data_collator,
- args=training_args,
- compute_metrics=compute_metrics,
- train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
- eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
- tokenizer=feature_extractor,
- optimizers=optimizers,
- )
-
- # 8. Finally, we can start training
-
- # Training
- if training_args.do_train:
- # use last checkpoint if exist
- if last_checkpoint is not None:
- checkpoint = last_checkpoint
- elif os.path.isdir(model_args.model_name_or_path):
- checkpoint = model_args.model_name_or_path
- else:
- checkpoint = None
-
- train_result = trainer.train(resume_from_checkpoint=checkpoint)
- trainer.save_model()
-
- metrics = train_result.metrics
- max_train_samples = (
- data_args.max_train_samples
- if data_args.max_train_samples is not None
- else len(vectorized_datasets["train"])
- )
- metrics["train_samples"] = min(max_train_samples, len(vectorized_datasets["train"]))
-
- trainer.log_metrics("train", metrics)
- trainer.save_metrics("train", metrics)
- trainer.save_state()
-
- # Evaluation
- results = {}
- if training_args.do_eval:
- logger.info("*** Evaluate ***")
- metrics = trainer.evaluate()
- max_eval_samples = (
- data_args.max_eval_samples if data_args.max_eval_samples is not None else len(vectorized_datasets["eval"])
- )
- metrics["eval_samples"] = min(max_eval_samples, len(vectorized_datasets["eval"]))
-
- trainer.log_metrics("eval", metrics)
- trainer.save_metrics("eval", metrics)
-
- # Write model card and (optionally) push to hub
- config_name = data_args.dataset_config_name if data_args.dataset_config_name is not None else "na"
- kwargs = {
- "finetuned_from": model_args.model_name_or_path,
- "tasks": "automatic-speech-recognition",
- "tags": ["automatic-speech-recognition", data_args.dataset_name],
- "dataset_args": (
- f"Config: {config_name}, Training split: {data_args.train_split_name}, Eval split:"
- f" {data_args.eval_split_name}"
- ),
- "dataset": f"{data_args.dataset_name.upper()} - {config_name.upper()}",
- }
- if "common_voice" in data_args.dataset_name:
- kwargs["language"] = config_name
-
- if training_args.push_to_hub:
- trainer.push_to_hub(**kwargs)
- else:
- trainer.create_model_card(**kwargs)
-
- return results
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_streaming.py b/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_streaming.py
deleted file mode 100644
index 37f91b9ef61..00000000000
--- a/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_streaming.py
+++ /dev/null
@@ -1,679 +0,0 @@
-#!/usr/bin/env python
-# coding=utf-8
-# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-
-"""Fine-tuning a 🤗 Transformers CTC model for automatic speech recognition in streaming mode"""
-
-import logging
-import os
-import re
-import sys
-import warnings
-from dataclasses import dataclass, field
-from typing import Dict, List, Optional, Union
-
-import datasets
-import numpy as np
-import torch
-from datasets import IterableDatasetDict, interleave_datasets, load_dataset, load_metric
-from torch.utils.data import IterableDataset
-
-import transformers
-from transformers import (
- AutoConfig,
- AutoFeatureExtractor,
- AutoModelForCTC,
- AutoProcessor,
- AutoTokenizer,
- HfArgumentParser,
- Trainer,
- TrainerCallback,
- TrainingArguments,
- Wav2Vec2Processor,
- set_seed,
-)
-from transformers.trainer_pt_utils import IterableDatasetShard
-from transformers.trainer_utils import get_last_checkpoint, is_main_process
-from transformers.utils import check_min_version
-from transformers.utils.versions import require_version
-
-
-# Will error if the minimal version of Transformers is not installed. Remove at your own risk.
-check_min_version("4.17.0.dev0")
-
-require_version("datasets>=1.18.2", "To fix: pip install 'datasets>=1.18.2'")
-
-
-logger = logging.getLogger(__name__)
-
-
-def list_field(default=None, metadata=None):
- return field(default_factory=lambda: default, metadata=metadata)
-
-
-@dataclass
-class ModelArguments:
- """
- Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
- """
-
- model_name_or_path: str = field(
- metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
- )
- tokenizer_name_or_path: Optional[str] = field(
- default=None,
- metadata={"help": "Path to pretrained tokenizer or tokenizer identifier from huggingface.co/models"},
- )
- cache_dir: Optional[str] = field(
- default=None,
- metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
- )
- freeze_feature_encoder: bool = field(
- default=True, metadata={"help": "Whether to freeze the feature encoder layers of the model."}
- )
- attention_dropout: float = field(
- default=0.0, metadata={"help": "The dropout ratio for the attention probabilities."}
- )
- activation_dropout: float = field(
- default=0.0, metadata={"help": "The dropout ratio for activations inside the fully connected layer."}
- )
- feat_proj_dropout: float = field(default=0.0, metadata={"help": "The dropout ratio for the projected features."})
- hidden_dropout: float = field(
- default=0.0,
- metadata={
- "help": "The dropout probability for all fully connected layers in the embeddings, encoder, and pooler."
- },
- )
- final_dropout: float = field(
- default=0.0,
- metadata={"help": "The dropout probability for the final projection layer."},
- )
- mask_time_prob: float = field(
- default=0.05,
- metadata={
- "help": (
- "Probability of each feature vector along the time axis to be chosen as the start of the vector "
- "span to be masked. Approximately ``mask_time_prob * sequence_length // mask_time_length`` feature "
- "vectors will be masked along the time axis."
- )
- },
- )
- mask_time_length: int = field(
- default=10,
- metadata={"help": "Length of vector span to mask along the time axis."},
- )
- mask_feature_prob: float = field(
- default=0.0,
- metadata={
- "help": (
- "Probability of each feature vector along the feature axis to be chosen as the start of the vectorspan"
- " to be masked. Approximately ``mask_feature_prob * sequence_length // mask_feature_length`` feature"
- " bins will be masked along the time axis."
- )
- },
- )
- mask_feature_length: int = field(
- default=10,
- metadata={"help": "Length of vector span to mask along the feature axis."},
- )
- layerdrop: float = field(default=0.0, metadata={"help": "The LayerDrop probability."})
- ctc_loss_reduction: Optional[str] = field(
- default="mean", metadata={"help": "The way the ctc loss should be reduced. Should be one of 'mean' or 'sum'."}
- )
-
-
-@dataclass
-class DataTrainingArguments:
- """
- Arguments pertaining to what data we are going to input our model for training and eval.
-
- Using `HfArgumentParser` we can turn this class
- into argparse arguments to be able to specify them on
- the command line.
- """
-
- dataset_name: str = field(
- metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
- )
- dataset_config_name: str = field(
- default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
- )
- train_split_name: str = field(
- default="train+validation",
- metadata={
- "help": (
- "The name of the training data set split to use (via the datasets library). Defaults to "
- "'train+validation'"
- )
- },
- )
- eval_split_name: str = field(
- default="test",
- metadata={
- "help": "The name of the training data set split to use (via the datasets library). Defaults to 'test'"
- },
- )
- audio_column_name: str = field(
- default="audio",
- metadata={"help": "The name of the dataset column containing the audio data. Defaults to 'audio'"},
- )
- text_column_name: str = field(
- default="text",
- metadata={"help": "The name of the dataset column containing the text data. Defaults to 'text'"},
- )
- overwrite_cache: bool = field(
- default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
- )
- preprocessing_num_workers: Optional[int] = field(
- default=None,
- metadata={"help": "The number of processes to use for the preprocessing."},
- )
- max_train_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of training examples to this "
- "value if set."
- )
- },
- )
- max_eval_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of validation examples to this "
- "value if set."
- )
- },
- )
- shuffle_buffer_size: Optional[int] = field(
- default=500,
- metadata={
- "help": (
- "The number of streamed examples to download before shuffling them. The large the buffer, "
- "the closer it is to real offline shuffling."
- )
- },
- )
- chars_to_ignore: Optional[List[str]] = list_field(
- default=None,
- metadata={"help": "A list of characters to remove from the transcripts."},
- )
- eval_metrics: List[str] = list_field(
- default=["wer"],
- metadata={"help": "A list of metrics the model should be evaluated on. E.g. `'wer cer'`"},
- )
- max_duration_in_seconds: float = field(
- default=20.0,
- metadata={"help": "Filter audio files that are longer than `max_duration_in_seconds` seconds."},
- )
- preprocessing_only: bool = field(
- default=False,
- metadata={
- "help": (
- "Whether to only do data preprocessing and skip training. This is especially useful when data"
- " preprocessing errors out in distributed training due to timeout. In this case, one should run the"
- " preprocessing in a non-distributed setup with `preprocessing_only=True` so that the cached datasets"
- " can consequently be loaded in distributed training"
- )
- },
- )
- use_auth_token: bool = field(
- default=False,
- metadata={
- "help": (
- "If :obj:`True`, will use the token generated when running"
- ":obj:`huggingface-cli login` as HTTP bearer authorization for remote files."
- )
- },
- )
- phoneme_language: Optional[str] = field(
- default=None,
- metadata={
- "help": (
- "The target language that should be used be"
- " passed to the tokenizer for tokenization. Note that"
- " this is only relevant if the model classifies the"
- " input audio to a sequence of phoneme sequences."
- )
- },
- )
-
-
-@dataclass
-class DataCollatorCTCWithPadding:
- """
- Data collator that will dynamically pad the inputs received.
- Args:
- processor (:class:`~transformers.AutoProcessor`)
- The processor used for processing the data.
- padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
- Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
- among:
- * :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
- sequence if provided).
- * :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
- maximum acceptable input length for the model if that argument is not provided.
- * :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
- different lengths).
- max_length (:obj:`int`, `optional`):
- Maximum length of the ``input_values`` of the returned list and optionally padding length (see above).
- max_length_labels (:obj:`int`, `optional`):
- Maximum length of the ``labels`` returned list and optionally padding length (see above).
- pad_to_multiple_of (:obj:`int`, `optional`):
- If set will pad the sequence to a multiple of the provided value.
- This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
- 7.5 (Volta).
- """
-
- processor: AutoProcessor
- padding: Union[bool, str] = "longest"
- max_length: Optional[int] = None
- pad_to_multiple_of: Optional[int] = None
- pad_to_multiple_of_labels: Optional[int] = None
-
- def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
- # split inputs and labels since they have to be of different lengths and need
- # different padding methods
- input_features = []
- label_features = []
- for feature in features:
- if self.max_length and feature["input_values"].shape[-1] > self.max_length:
- continue
- input_features.append({"input_values": feature["input_values"]})
- label_features.append({"input_ids": feature["labels"]})
-
- batch = self.processor.pad(
- input_features,
- padding=self.padding,
- pad_to_multiple_of=self.pad_to_multiple_of,
- return_tensors="pt",
- )
-
- labels_batch = self.processor.pad(
- labels=label_features,
- padding=self.padding,
- pad_to_multiple_of=self.pad_to_multiple_of_labels,
- return_tensors="pt",
- )
-
- # replace padding with -100 to ignore loss correctly
- labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
-
- batch["labels"] = labels
-
- return batch
-
-
-def main():
- # See all possible arguments in src/transformers/training_args.py
- # or by passing the --help flag to this script.
- # We now keep distinct sets of args, for a cleaner separation of concerns.
-
- parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
- if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
- # If we pass only one argument to the script and it's the path to a json file,
- # let's parse it to get our arguments.
- model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
- else:
- model_args, data_args, training_args = parser.parse_args_into_dataclasses()
-
- # Detecting last checkpoint.
- last_checkpoint = None
- if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
- last_checkpoint = get_last_checkpoint(training_args.output_dir)
- if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
- raise ValueError(
- f"Output directory ({training_args.output_dir}) already exists and is not empty. "
- "Use --overwrite_output_dir to overcome."
- )
- elif last_checkpoint is not None:
- logger.info(
- f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
- "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
- )
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- handlers=[logging.StreamHandler(sys.stdout)],
- )
- logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
-
- # Log on each process the small summary:
- logger.warning(
- f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
- f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
- )
- # Set the verbosity to info of the Transformers logger (on main process only):
- if is_main_process(training_args.local_rank):
- transformers.utils.logging.set_verbosity_info()
- logger.info("Training/evaluation parameters %s", training_args)
-
- # Set seed before initializing model.
- set_seed(training_args.seed)
-
- # 1. First, let's load the dataset
- raw_datasets = IterableDatasetDict()
- raw_column_names = {}
-
- def load_streaming_dataset(split, sampling_rate, **kwargs):
- if "+" in split:
- dataset_splits = [load_dataset(split=split_name, **kwargs) for split_name in split.split("+")]
- # `features` and `cast_column` won't be available after interleaving, so we'll use them here
- features = dataset_splits[0].features
- # make sure that the dataset decodes audio with a correct sampling rate
- dataset_splits = [
- dataset.cast_column(data_args.audio_column_name, datasets.features.Audio(sampling_rate=sampling_rate))
- for dataset in dataset_splits
- ]
-
- interleaved_dataset = interleave_datasets(dataset_splits)
- return interleaved_dataset, features
- else:
- dataset = load_dataset(split=split, **kwargs)
- features = dataset.features
- # make sure that the dataset decodes audio with a correct sampling rate
- dataset = dataset.cast_column(
- data_args.audio_column_name, datasets.features.Audio(sampling_rate=sampling_rate)
- )
- return dataset, features
-
- # `datasets` takes care of automatically loading and resampling the audio,
- # so we just need to set the correct target sampling rate and normalize the input
- # via the `feature_extractor`
- feature_extractor = AutoFeatureExtractor.from_pretrained(
- model_args.model_name_or_path, cache_dir=model_args.cache_dir, token=data_args.use_auth_token
- )
-
- if training_args.do_train:
- raw_datasets["train"], train_features = load_streaming_dataset(
- path=data_args.dataset_name,
- name=data_args.dataset_config_name,
- split=data_args.train_split_name,
- token=data_args.use_auth_token,
- streaming=True,
- sampling_rate=feature_extractor.sampling_rate,
- )
- raw_column_names["train"] = list(train_features.keys())
-
- if data_args.audio_column_name not in raw_column_names["train"]:
- raise ValueError(
- f"--audio_column_name '{data_args.audio_column_name}' not found in dataset '{data_args.dataset_name}'."
- " Make sure to set `--audio_column_name` to the correct audio column - one of"
- f" {', '.join(raw_column_names['train'])}."
- )
-
- if data_args.text_column_name not in raw_column_names["train"]:
- raise ValueError(
- f"--text_column_name {data_args.text_column_name} not found in dataset '{data_args.dataset_name}'. "
- "Make sure to set `--text_column_name` to the correct text column - one of "
- f"{', '.join(raw_column_names['train'])}."
- )
-
- if data_args.max_train_samples is not None:
- raw_datasets["train"] = raw_datasets["train"].take(range(data_args.max_train_samples))
-
- if training_args.do_eval:
- raw_datasets["eval"], eval_features = load_streaming_dataset(
- path=data_args.dataset_name,
- name=data_args.dataset_config_name,
- split=data_args.eval_split_name,
- token=data_args.use_auth_token,
- streaming=True,
- sampling_rate=feature_extractor.sampling_rate,
- )
- raw_column_names["eval"] = list(eval_features.keys())
-
- if data_args.max_eval_samples is not None:
- raw_datasets["eval"] = raw_datasets["eval"].take(range(data_args.max_eval_samples))
-
- # 2. We remove some special characters from the datasets
- # that make training complicated and do not help in transcribing the speech
- # E.g. characters, such as `,` and `.` do not really have an acoustic characteristic
- # that could be easily picked up by the model
- chars_to_ignore_regex = (
- f'[{"".join(data_args.chars_to_ignore)}]' if data_args.chars_to_ignore is not None else None
- )
- text_column_name = data_args.text_column_name
-
- def remove_special_characters(batch):
- if chars_to_ignore_regex is not None:
- batch["target_text"] = re.sub(chars_to_ignore_regex, "", batch[text_column_name]).lower() + " "
- else:
- batch["target_text"] = batch[text_column_name].lower() + " "
- return batch
-
- with training_args.main_process_first(desc="dataset map special characters removal"):
- for split, dataset in raw_datasets.items():
- raw_datasets[split] = dataset.map(
- remove_special_characters,
- ).remove_columns([text_column_name])
-
- # 3. Next, let's load the config as we might need it to create
- # the tokenizer
- config = AutoConfig.from_pretrained(
- model_args.model_name_or_path, cache_dir=model_args.cache_dir, token=data_args.use_auth_token
- )
-
- # 4. Now we can instantiate the tokenizer and model
- # Note for distributed training, the .from_pretrained methods guarantee that only
- # one local process can concurrently download model & vocab.
-
- tokenizer_name_or_path = model_args.tokenizer_name_or_path
- if tokenizer_name_or_path is None:
- raise ValueError(
- "Tokenizer has to be created before training in streaming mode. Please specify --tokenizer_name_or_path"
- )
- # load feature_extractor and tokenizer
- tokenizer = AutoTokenizer.from_pretrained(
- tokenizer_name_or_path,
- config=config,
- token=data_args.use_auth_token,
- )
-
- # adapt config
- config.update(
- {
- "feat_proj_dropout": model_args.feat_proj_dropout,
- "attention_dropout": model_args.attention_dropout,
- "hidden_dropout": model_args.hidden_dropout,
- "final_dropout": model_args.final_dropout,
- "mask_time_prob": model_args.mask_time_prob,
- "mask_time_length": model_args.mask_time_length,
- "mask_feature_prob": model_args.mask_feature_prob,
- "mask_feature_length": model_args.mask_feature_length,
- "gradient_checkpointing": training_args.gradient_checkpointing,
- "layerdrop": model_args.layerdrop,
- "ctc_loss_reduction": model_args.ctc_loss_reduction,
- "pad_token_id": tokenizer.pad_token_id,
- "vocab_size": len(tokenizer),
- "activation_dropout": model_args.activation_dropout,
- }
- )
-
- # create model
- model = AutoModelForCTC.from_pretrained(
- model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- config=config,
- token=data_args.use_auth_token,
- )
-
- # freeze encoder
- if model_args.freeze_feature_encoder:
- model.freeze_feature_encoder()
-
- # 5. Now we preprocess the datasets including loading the audio, resampling and normalization
- audio_column_name = data_args.audio_column_name
-
- # `phoneme_language` is only relevant if the model is fine-tuned on phoneme classification
- phoneme_language = data_args.phoneme_language
-
- # Preprocessing the datasets.
- # We need to read the audio files as arrays and tokenize the targets.
- def prepare_dataset(batch):
- # load audio
- sample = batch[audio_column_name]
-
- inputs = feature_extractor(sample["array"], sampling_rate=sample["sampling_rate"])
- batch["input_values"] = inputs.input_values[0]
- batch["input_length"] = len(batch["input_values"])
-
- # encode targets
- additional_kwargs = {}
- if phoneme_language is not None:
- additional_kwargs["phonemizer_lang"] = phoneme_language
-
- batch["labels"] = tokenizer(batch["target_text"], **additional_kwargs).input_ids
- return batch
-
- vectorized_datasets = IterableDatasetDict()
- with training_args.main_process_first(desc="dataset map preprocessing"):
- for split, dataset in raw_datasets.items():
- vectorized_datasets[split] = (
- dataset.map(prepare_dataset)
- .remove_columns(raw_column_names[split] + ["target_text"])
- .with_format("torch")
- )
- if split == "train":
- vectorized_datasets[split] = vectorized_datasets[split].shuffle(
- buffer_size=data_args.shuffle_buffer_size,
- seed=training_args.seed,
- )
-
- # 6. Next, we can prepare the training.
- # Let's use word error rate (WER) as our evaluation metric,
- # instantiate a data collator and the trainer
-
- # Define evaluation metrics during training, *i.e.* word error rate, character error rate
- eval_metrics = {metric: load_metric(metric) for metric in data_args.eval_metrics}
-
- def compute_metrics(pred):
- pred_logits = pred.predictions
- pred_ids = np.argmax(pred_logits, axis=-1)
-
- pred.label_ids[pred.label_ids == -100] = tokenizer.pad_token_id
-
- pred_str = tokenizer.batch_decode(pred_ids)
- # we do not want to group tokens when computing the metrics
- label_str = tokenizer.batch_decode(pred.label_ids, group_tokens=False)
-
- metrics = {k: v.compute(predictions=pred_str, references=label_str) for k, v in eval_metrics.items()}
-
- return metrics
-
- # Now save everything to be able to create a single processor later
- if is_main_process(training_args.local_rank):
- # save feature extractor, tokenizer and config
- feature_extractor.save_pretrained(training_args.output_dir)
- tokenizer.save_pretrained(training_args.output_dir)
- config.save_pretrained(training_args.output_dir)
-
- try:
- processor = AutoProcessor.from_pretrained(training_args.output_dir)
- except (OSError, KeyError):
- warnings.warn(
- "Loading a processor from a feature extractor config that does not"
- " include a `processor_class` attribute is deprecated and will be removed in v5. Please add the following "
- " attribute to your `preprocessor_config.json` file to suppress this warning: "
- " `'processor_class': 'Wav2Vec2Processor'`",
- FutureWarning,
- )
- processor = Wav2Vec2Processor.from_pretrained(training_args.output_dir)
-
- # Instantiate custom data collator
- max_input_length = data_args.max_duration_in_seconds * feature_extractor.sampling_rate
- data_collator = DataCollatorCTCWithPadding(processor=processor, max_length=max_input_length)
-
- # trainer callback to reinitialize and reshuffle the streamable datasets at the beginning of each epoch
- class ShuffleCallback(TrainerCallback):
- def on_epoch_begin(self, args, state, control, train_dataloader, **kwargs):
- if isinstance(train_dataloader.dataset, IterableDatasetShard):
- pass # set_epoch() is handled by the Trainer
- elif isinstance(train_dataloader.dataset, IterableDataset):
- train_dataloader.dataset.set_epoch(train_dataloader.dataset._epoch + 1)
-
- # Initialize Trainer
- trainer = Trainer(
- model=model,
- data_collator=data_collator,
- args=training_args,
- compute_metrics=compute_metrics,
- train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
- eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
- tokenizer=processor,
- callbacks=[ShuffleCallback()],
- )
-
- # 7. Finally, we can start training
-
- # Training
- if training_args.do_train:
- # use last checkpoint if exist
- if last_checkpoint is not None:
- checkpoint = last_checkpoint
- elif os.path.isdir(model_args.model_name_or_path):
- checkpoint = model_args.model_name_or_path
- else:
- checkpoint = None
-
- train_result = trainer.train(resume_from_checkpoint=checkpoint)
- trainer.save_model()
-
- metrics = train_result.metrics
- if data_args.max_train_samples:
- metrics["train_samples"] = data_args.max_train_samples
-
- trainer.log_metrics("train", metrics)
- trainer.save_metrics("train", metrics)
- trainer.save_state()
-
- # Evaluation
- results = {}
- if training_args.do_eval:
- logger.info("*** Evaluate ***")
- metrics = trainer.evaluate()
- if data_args.max_eval_samples:
- metrics["eval_samples"] = data_args.max_eval_samples
-
- trainer.log_metrics("eval", metrics)
- trainer.save_metrics("eval", metrics)
-
- # Write model card and (optionally) push to hub
- config_name = data_args.dataset_config_name if data_args.dataset_config_name is not None else "na"
- kwargs = {
- "finetuned_from": model_args.model_name_or_path,
- "tasks": "automatic-speech-recognition",
- "tags": ["automatic-speech-recognition", data_args.dataset_name],
- "dataset_args": (
- f"Config: {config_name}, Training split: {data_args.train_split_name}, Eval split:"
- f" {data_args.eval_split_name}"
- ),
- "dataset": f"{data_args.dataset_name.upper()} - {config_name.upper()}",
- }
- if "common_voice" in data_args.dataset_name:
- kwargs["language"] = config_name
-
- if training_args.push_to_hub:
- trainer.push_to_hub(**kwargs)
- else:
- trainer.create_model_card(**kwargs)
-
- return results
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/self-training-text-classification/README.md b/examples/research_projects/self-training-text-classification/README.md
deleted file mode 100644
index 062d5de7afd..00000000000
--- a/examples/research_projects/self-training-text-classification/README.md
+++ /dev/null
@@ -1,128 +0,0 @@
-# Self-training
-
-This is an implementation of the self-training algorithm (without task augmentation) in the [EMNLP 2021](https://2021.emnlp.org/) paper: [STraTA: Self-Training with Task Augmentation for Better Few-shot Learning](https://arxiv.org/abs/2109.06270). Please check out https://github.com/google-research/google-research/tree/master/STraTA for the original codebase.
-
-**Note**: The code can be used as a tool for automatic data labeling.
-
-## Table of Contents
-
- * [Installation](#installation)
- * [Self-training](#self-training)
- * [Running self-training with a base model](#running-self-training-with-a-base-model)
- * [Hyperparameters for self-training](#hyperparameters-for-self-training)
- * [Distributed training](#distributed-training)
- * [Demo](#demo)
- * [How to cite](#how-to-cite)
-
-## Installation
-This repository is tested on Python 3.8+, PyTorch 1.10+, and the 🤗 Transformers 4.16+.
-
-You should install all necessary Python packages in a [virtual environment](https://docs.python.org/3/library/venv.html). If you are unfamiliar with Python virtual environments, please check out the [user guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
-
-Below, we create a virtual environment with the [Anaconda Python distribution](https://www.anaconda.com/products/distribution) and activate it.
-```sh
-conda create -n strata python=3.9
-conda activate strata
-```
-Next, you need to install 🤗 Transformers. Please refer to [🤗 Transformers installation page](https://github.com/huggingface/transformers#installation) for a detailed guide.
-```sh
-pip install transformers
-```
-Finally, install all necessary Python packages for our self-training algorithm.
-
-```sh
-pip install -r STraTA/selftraining/requirements.txt
-```
-This will install PyTorch as a backend.
-
-## Self-training
-### Running self-training with a base model
-The following example code shows how to run our self-training algorithm with a base model (e.g., `BERT`) on the `SciTail` science entailment dataset, which has two classes `['entails', 'neutral']`. We assume that you have a data directory that includes some training data (e.g., `train.csv`), evaluation data (e.g., `eval.csv`), and unlabeled data (e.g., `infer.csv`).
-
-```python
-import os
-from selftraining import selftrain
-
-data_dir = '/path/to/your/data/dir'
-parameters_dict = {
- 'max_selftrain_iterations': 100,
- 'model_name_or_path': '/path/to/your/base/model', # could be the id of a model hosted by 🤗 Transformers
- 'output_dir': '/path/to/your/output/dir',
- 'train_file': os.path.join(data_dir, 'train.csv'),
- 'infer_file': os.path.join(data_dir, 'infer.csv'),
- 'eval_file': os.path.join(data_dir, 'eval.csv'),
- 'eval_strategy': 'steps',
- 'task_name': 'scitail',
- 'label_list': ['entails', 'neutral'],
- 'per_device_train_batch_size': 32,
- 'per_device_eval_batch_size': 8,
- 'max_length': 128,
- 'learning_rate': 2e-5,
- 'max_steps': 100000,
- 'eval_steps': 1,
- 'early_stopping_patience': 50,
- 'overwrite_output_dir': True,
- 'do_filter_by_confidence': False,
- # 'confidence_threshold': 0.3,
- 'do_filter_by_val_performance': True,
- 'finetune_on_labeled_data': False,
- 'seed': 42,
-}
-selftrain(**parameters_dict)
-```
-
-**Note**: We checkpoint periodically during self-training. In case of preemptions, just re-run the above script and self-training will resume from the latest iteration.
-
-### Hyperparameters for self-training
-If you have development data, you might want to tune some hyperparameters for self-training.
-Below are hyperparameters that could provide additional gains for your task.
-
- - `finetune_on_labeled_data`: If set to `True`, the resulting model from each self-training iteration is further fine-tuned on the original labeled data before the next self-training iteration. Intuitively, this would give the model a chance to "correct" ifself after being trained on pseudo-labeled data.
- - `do_filter_by_confidence`: If set to `True`, the pseudo-labeled data in each self-training iteration is filtered based on the model confidence. For instance, if `confidence_threshold` is set to `0.3`, pseudo-labeled examples with a confidence score less than or equal to `0.3` will be discarded. Note that `confidence_threshold` should be greater or equal to `1/num_labels`, where `num_labels` is the number of class labels. Filtering out the lowest-confidence pseudo-labeled examples could be helpful in some cases.
- - `do_filter_by_val_performance`: If set to `True`, the pseudo-labeled data in each self-training iteration is filtered based on the current validation performance. For instance, if your validation performance is 80% accuracy, you might want to get rid of 20% of the pseudo-labeled data with the lowest the confidence scores.
-
-### Distributed training
-We strongly recommend distributed training with multiple accelerators. To activate distributed training, please try one of the following methods:
-
-1. Run `accelerate config` and answer to the questions asked. This will save a `default_config.yaml` file in your cache folder for 🤗 Accelerate. Now, you can run your script with the following command:
-
-```sh
-accelerate launch your_script.py --args_to_your_script
-```
-
-2. Run your script with the following command:
-
-```sh
-python -m torch.distributed.launch --nnodes="{$NUM_NODES}" --nproc_per_node="{$NUM_TRAINERS}" --your_script.py --args_to_your_script
-```
-
-3. Run your script with the following command:
-
-```sh
-torchrun --nnodes="{$NUM_NODES}" --nproc_per_node="{$NUM_TRAINERS}" --your_script.py --args_to_your_script
-```
-
-## Demo
-Please check out `run.sh` to see how to perform our self-training algorithm with a `BERT` Base model on the SciTail science entailment dataset using 8 labeled examples per class. You can configure your training environment by specifying `NUM_NODES` and `NUM_TRAINERS` (number of processes per node). To launch the script, simply run `source run.sh`.
-
-## How to cite
-If you extend or use this code, please cite the [paper](https://arxiv.org/abs/2109.06270) where it was introduced:
-
-```bibtex
-@inproceedings{vu-etal-2021-strata,
- title = "{ST}ra{TA}: Self-Training with Task Augmentation for Better Few-shot Learning",
- author = "Vu, Tu and
- Luong, Minh-Thang and
- Le, Quoc and
- Simon, Grady and
- Iyyer, Mohit",
- booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
- month = nov,
- year = "2021",
- address = "Online and Punta Cana, Dominican Republic",
- publisher = "Association for Computational Linguistics",
- url = "https://aclanthology.org/2021.emnlp-main.462",
- doi = "10.18653/v1/2021.emnlp-main.462",
- pages = "5715--5731",
-}
-```
diff --git a/examples/research_projects/self-training-text-classification/finetuning.py b/examples/research_projects/self-training-text-classification/finetuning.py
deleted file mode 100644
index 4bf9eb28df2..00000000000
--- a/examples/research_projects/self-training-text-classification/finetuning.py
+++ /dev/null
@@ -1,818 +0,0 @@
-# coding=utf-8
-# Copyright 2022 The Google Research Authors.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Fine-tuning the library models for sequence classification."""
-
-import argparse
-import dataclasses
-import json
-import logging
-import math
-import os
-import random
-import shutil
-from typing import List, Optional
-
-import datasets
-import numpy as np
-import pandas as pd
-import torch
-from datasets import load_dataset, load_metric
-from torch.utils.data import DataLoader
-from tqdm.auto import tqdm
-
-from transformers import (
- AdamW,
- AutoConfig,
- AutoModelForSequenceClassification,
- AutoTokenizer,
- DataCollatorWithPadding,
- default_data_collator,
- get_scheduler,
- set_seed,
-)
-from transformers.file_utils import ExplicitEnum
-from transformers.trainer_utils import IntervalStrategy
-
-
-logger = logging.getLogger(__name__)
-
-
-class Split(ExplicitEnum):
- TRAIN = "train"
- EVAL = "eval"
- TEST = "test"
- INFER = "infer"
-
-
-@dataclasses.dataclass
-class FTModelArguments:
- """Arguments pertaining to which config/tokenizer/model we are going to fine-tune from."""
-
- model_name_or_path: str = dataclasses.field(
- metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models."}
- )
- use_fast_tokenizer: Optional[bool] = dataclasses.field(
- default=True,
- metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
- )
- cache_dir: Optional[str] = dataclasses.field(
- default=None,
- metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co."},
- )
-
-
-@dataclasses.dataclass
-class FTDataArguments:
- """Arguments pertaining to what data we are going to input our model for training and evaluation."""
-
- train_file: str = dataclasses.field(
- default=None, metadata={"help": "A csv or a json file containing the training data."}
- )
- eval_file: Optional[str] = dataclasses.field(
- default=None, metadata={"help": "A csv or a json file containing the validation data."}
- )
- test_file: Optional[str] = dataclasses.field(
- default=None, metadata={"help": "A csv or a json file containing the test data."}
- )
- infer_file: Optional[str] = dataclasses.field(
- default=None, metadata={"help": "A csv or a json file containing the data to predict on."}
- )
- task_name: Optional[str] = dataclasses.field(
- default=None,
- metadata={"help": "The name of the task to train on."},
- )
- label_list: Optional[List[str]] = dataclasses.field(
- default=None, metadata={"help": "The list of labels for the task."}
- )
-
- max_length: Optional[int] = dataclasses.field(
- default=128,
- metadata={
- "help": (
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- )
- },
- )
- pad_to_max_length: Optional[bool] = dataclasses.field(
- default=False,
- metadata={
- "help": (
- "Whether to pad all samples to `max_seq_length`. "
- "If False, will pad the samples dynamically when batching to the maximum length in the batch."
- )
- },
- )
-
-
-@dataclasses.dataclass
-class FTTrainingArguments:
- """Training arguments pertaining to the training loop itself."""
-
- output_dir: str = dataclasses.field(
- metadata={"help": "The output directory where the model predictions and checkpoints will be written."}
- )
- do_train: Optional[bool] = dataclasses.field(
- default=False,
- metadata={"help": "Whether to run training or not."},
- )
- do_eval: Optional[bool] = dataclasses.field(
- default=False,
- metadata={"help": "Whether to run evaluation on the validation set or not."},
- )
- do_predict: Optional[bool] = dataclasses.field(
- default=False,
- metadata={"help": "Whether to run inference on the inference set or not."},
- )
- seed: Optional[int] = dataclasses.field(
- default=42,
- metadata={"help": "Random seed that will be set at the beginning of training."},
- )
- per_device_train_batch_size: Optional[int] = dataclasses.field(
- default=8,
- metadata={"help": "The batch size per GPU/TPU core/CPU for training."},
- )
- per_device_eval_batch_size: Optional[int] = dataclasses.field(
- default=8,
- metadata={"help": "The batch size per GPU/TPU core/CPU for evaluation."},
- )
- weight_decay: Optional[float] = dataclasses.field(
- default=0.0,
- metadata={
- "help": (
- "The weight decay to apply (if not zero) to all layers except all bias and LayerNorm weights in"
- " [`AdamW`] optimizer."
- )
- },
- )
- learning_rate: Optional[float] = dataclasses.field(
- default=5e-5,
- metadata={"help": "The initial learning rate for [`AdamW`] optimizer."},
- )
- gradient_accumulation_steps: Optional[int] = dataclasses.field(
- default=1,
- metadata={
- "help": (
- "Number of updates steps to accumulate the gradients for, before performing a backward/update pass."
- )
- },
- )
- max_steps: Optional[int] = dataclasses.field(
- default=-1,
- metadata={
- "help": (
- "If set to a positive number, the total number of training steps to perform. Overrides"
- " `num_train_epochs`."
- )
- },
- )
- lr_scheduler_type: Optional[str] = dataclasses.field(
- default="linear", metadata={"help": "The scheduler type to use."}
- )
- warmup_steps: Optional[int] = dataclasses.field(
- default=1,
- metadata={
- "help": (
- "Number of steps used for a linear warmup from 0 to `learning_rate`. Overrides any effect of"
- " `warmup_ratio`."
- )
- },
- )
- eval_strategy: Optional[str] = dataclasses.field(
- default="no",
- metadata={
- "help": 'The evaluation strategy to adopt during training. Possible values are: ["no", "step", "epoch]'
- },
- )
- eval_steps: Optional[int] = dataclasses.field(
- default=1,
- metadata={"help": 'Number of update steps between two evaluations if `eval_strategy="steps"`.'},
- )
- eval_metric: Optional[str] = dataclasses.field(
- default="accuracy", metadata={"help": "The evaluation metric used for the task."}
- )
- keep_checkpoint_max: Optional[int] = dataclasses.field(
- default=1,
- metadata={"help": "The maximum number of best checkpoint files to keep."},
- )
- early_stopping_patience: Optional[int] = dataclasses.field(
- default=10,
- metadata={"help": "Number of evaluation calls with no improvement after which training will be stopped."},
- )
- early_stopping_threshold: Optional[float] = dataclasses.field(
- default=0.0,
- metadata={
- "help": "How much the specified evaluation metric must improve to satisfy early stopping conditions."
- },
- )
-
-
-def train(args, accelerator, model, tokenizer, train_dataloader, optimizer, lr_scheduler, eval_dataloader=None):
- """Train a model on the given training data."""
-
- total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
-
- logger.info("***** Running training *****")
- logger.info(" Num examples = %d", args.num_examples[Split.TRAIN.value])
- logger.info(" Instantaneous batch size per device = %d", args.per_device_train_batch_size)
- logger.info(" Total train batch size (w. parallel, distributed & accumulation) = %d", total_batch_size)
- logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)
- logger.info(" Total optimization steps = %d", args.max_steps)
-
- # Only show the progress bar once on each machine.
- progress_bar = tqdm(range(args.max_steps), disable=not accelerator.is_local_main_process)
-
- checkpoints = None
- eval_results = None
- best_checkpoint = None
- best_eval_result = None
- early_stopping_patience_counter = 0
- should_training_stop = False
- epoch = 0
- completed_steps = 0
- train_loss = 0.0
- model.zero_grad()
-
- for _ in range(args.num_train_epochs):
- epoch += 1
- model.train()
- for step, batch in enumerate(train_dataloader):
- outputs = model(**batch)
- loss = outputs.loss
- loss = loss / args.gradient_accumulation_steps
- accelerator.backward(loss)
- train_loss += loss.item()
-
- if step % args.gradient_accumulation_steps == 0 or step == len(train_dataloader) - 1:
- optimizer.step()
- lr_scheduler.step()
- optimizer.zero_grad()
- progress_bar.update(1)
- completed_steps += 1
-
- # Evaluate during training
- if (
- eval_dataloader is not None
- and args.eval_strategy == IntervalStrategy.STEPS.value
- and args.eval_steps > 0
- and completed_steps % args.eval_steps == 0
- ):
- accelerator.wait_for_everyone()
- new_checkpoint = f"checkpoint-{IntervalStrategy.STEPS.value}-{completed_steps}"
- new_eval_result = evaluate(args, accelerator, eval_dataloader, "eval", model, new_checkpoint)[
- args.eval_metric
- ]
- logger.info(
- "Evaluation result at step %d: %s = %f", completed_steps, args.eval_metric, new_eval_result
- )
- if checkpoints is None:
- checkpoints = np.array([new_checkpoint])
- eval_results = np.array([new_eval_result])
- best_checkpoint = new_checkpoint
- best_eval_result = new_eval_result
- else:
- if new_eval_result - best_eval_result > args.early_stopping_threshold:
- best_checkpoint = new_checkpoint
- best_eval_result = new_eval_result
- early_stopping_patience_counter = 0
- else:
- if new_eval_result == best_eval_result:
- best_checkpoint = new_checkpoint
- best_eval_result = new_eval_result
- early_stopping_patience_counter += 1
-
- if early_stopping_patience_counter >= args.early_stopping_patience:
- should_training_stop = True
-
- checkpoints = np.append(checkpoints, [new_checkpoint], axis=0)
- eval_results = np.append(eval_results, [new_eval_result], axis=0)
- sorted_ids = np.argsort(eval_results)
- eval_results = eval_results[sorted_ids]
- checkpoints = checkpoints[sorted_ids]
-
- if len(checkpoints) > args.keep_checkpoint_max:
- # Delete the current worst checkpoint
- checkpoint_to_remove, *checkpoints = checkpoints
- eval_results = eval_results[1:]
- if checkpoint_to_remove != new_checkpoint:
- if accelerator.is_main_process:
- shutil.rmtree(os.path.join(args.output_dir, checkpoint_to_remove), ignore_errors=True)
- accelerator.wait_for_everyone()
-
- if new_checkpoint in checkpoints:
- # Save model checkpoint
- checkpoint_output_dir = os.path.join(args.output_dir, new_checkpoint)
- if accelerator.is_main_process:
- if not os.path.exists(checkpoint_output_dir):
- os.makedirs(checkpoint_output_dir)
- accelerator.wait_for_everyone()
- unwrapped_model = accelerator.unwrap_model(model)
- unwrapped_model.save_pretrained(checkpoint_output_dir, save_function=accelerator.save)
- if accelerator.is_main_process:
- tokenizer.save_pretrained(checkpoint_output_dir)
- logger.info("Saving model checkpoint to %s", checkpoint_output_dir)
-
- if completed_steps >= args.max_steps:
- break
-
- if should_training_stop:
- break
-
- # Evaluate during training
- if eval_dataloader is not None and args.eval_strategy == IntervalStrategy.EPOCH.value:
- accelerator.wait_for_everyone()
- new_checkpoint = f"checkpoint-{IntervalStrategy.EPOCH.value}-{epoch}"
- new_eval_result = evaluate(args, accelerator, eval_dataloader, "eval", model, new_checkpoint)[
- args.eval_metric
- ]
- logger.info("Evaluation result at epoch %d: %s = %f", epoch, args.eval_metric, new_eval_result)
-
- if checkpoints is None:
- checkpoints = np.array([new_checkpoint])
- eval_results = np.array([new_eval_result])
- best_checkpoint = new_checkpoint
- best_eval_result = new_eval_result
- else:
- if new_eval_result - best_eval_result > args.early_stopping_threshold:
- best_checkpoint = new_checkpoint
- best_eval_result = new_eval_result
- early_stopping_patience_counter = 0
- else:
- if new_eval_result == best_eval_result:
- best_checkpoint = new_checkpoint
- best_eval_result = new_eval_result
- early_stopping_patience_counter += 1
-
- if early_stopping_patience_counter >= args.early_stopping_patience:
- should_training_stop = True
-
- checkpoints = np.append(checkpoints, [new_checkpoint], axis=0)
- eval_results = np.append(eval_results, [new_eval_result], axis=0)
- sorted_ids = np.argsort(eval_results)
- eval_results = eval_results[sorted_ids]
- checkpoints = checkpoints[sorted_ids]
-
- if len(checkpoints) > args.keep_checkpoint_max:
- # Delete the current worst checkpoint
- checkpoint_to_remove, *checkpoints = checkpoints
- eval_results = eval_results[1:]
- if checkpoint_to_remove != new_checkpoint:
- if accelerator.is_main_process:
- shutil.rmtree(os.path.join(args.output_dir, checkpoint_to_remove), ignore_errors=True)
- accelerator.wait_for_everyone()
-
- if new_checkpoint in checkpoints:
- # Save model checkpoint
- checkpoint_output_dir = os.path.join(args.output_dir, new_checkpoint)
- if accelerator.is_main_process:
- if not os.path.exists(checkpoint_output_dir):
- os.makedirs(checkpoint_output_dir)
- accelerator.wait_for_everyone()
- unwrapped_model = accelerator.unwrap_model(model)
- unwrapped_model.save_pretrained(checkpoint_output_dir, save_function=accelerator.save)
- if accelerator.is_main_process:
- tokenizer.save_pretrained(checkpoint_output_dir)
- logger.info("Saving model checkpoint to %s", checkpoint_output_dir)
-
- if completed_steps >= args.max_steps:
- break
-
- if should_training_stop:
- break
-
- if best_checkpoint is not None:
- # Save the best checkpoint
- logger.info("Best checkpoint: %s", best_checkpoint)
- logger.info("Best evaluation result: %s = %f", args.eval_metric, best_eval_result)
- best_checkpoint_output_dir = os.path.join(args.output_dir, best_checkpoint)
- if accelerator.is_main_process:
- shutil.move(best_checkpoint_output_dir, os.path.join(args.output_dir, "best-checkpoint"))
- shutil.rmtree(best_checkpoint_output_dir, ignore_errors=True)
- accelerator.wait_for_everyone()
-
- else:
- # Assume that the last checkpoint is the best checkpoint and save it
- checkpoint_output_dir = os.path.join(args.output_dir, "best-checkpoint")
- if not os.path.exists(checkpoint_output_dir):
- os.makedirs(checkpoint_output_dir)
-
- accelerator.wait_for_everyone()
- unwrapped_model = accelerator.unwrap_model(model)
- unwrapped_model.save_pretrained(checkpoint_output_dir, save_function=accelerator.save)
- if accelerator.is_main_process:
- tokenizer.save_pretrained(checkpoint_output_dir)
- logger.info("Saving model checkpoint to %s", checkpoint_output_dir)
- return completed_steps, train_loss / completed_steps
-
-
-def evaluate(args, accelerator, dataloader, eval_set, model, checkpoint, has_labels=True, write_to_file=True):
- """Evaluate a model checkpoint on the given evaluation data."""
-
- num_examples = args.num_examples[eval_set]
- eval_metric = None
- completed_steps = 0
- eval_loss = 0.0
- all_predictions = None
- all_references = None
- all_probabilities = None
-
- if has_labels:
- # Get the metric function
- eval_metric = load_metric(args.eval_metric)
-
- eval_results = {}
- model.eval()
- for _, batch in enumerate(dataloader):
- with torch.no_grad():
- outputs = model(**batch)
-
- eval_loss += outputs.loss.item()
- logits = outputs.logits
- predictions = logits.argmax(dim=-1) if not args.is_regression else logits.squeeze()
- predictions = accelerator.gather(predictions)
-
- if all_predictions is None:
- all_predictions = predictions.detach().cpu().numpy()
- else:
- all_predictions = np.append(all_predictions, predictions.detach().cpu().numpy(), axis=0)
-
- if not args.is_regression:
- probabilities = logits.softmax(dim=-1).max(dim=-1).values
- probabilities = accelerator.gather(probabilities)
- if all_probabilities is None:
- all_probabilities = probabilities.detach().cpu().numpy()
- else:
- all_probabilities = np.append(all_probabilities, probabilities.detach().cpu().numpy(), axis=0)
-
- if has_labels:
- references = batch["labels"]
- references = accelerator.gather(references)
- if all_references is None:
- all_references = references.detach().cpu().numpy()
- else:
- all_references = np.append(all_references, references.detach().cpu().numpy(), axis=0)
-
- eval_metric.add_batch(
- predictions=predictions,
- references=references,
- )
- completed_steps += 1
-
- if has_labels:
- eval_results.update(eval_metric.compute())
- eval_results["completed_steps"] = completed_steps
- eval_results["avg_eval_loss"] = eval_loss / completed_steps
-
- if write_to_file:
- accelerator.wait_for_everyone()
- if accelerator.is_main_process:
- results_file = os.path.join(args.output_dir, f"{eval_set}_results_{checkpoint}.json")
- with open(results_file, "w") as f:
- json.dump(eval_results, f, indent=4, sort_keys=True)
-
- if write_to_file:
- accelerator.wait_for_everyone()
- if accelerator.is_main_process:
- output_file = os.path.join(args.output_dir, f"{eval_set}_output_{checkpoint}.csv")
- if not args.is_regression:
- assert len(all_predictions) == len(all_probabilities)
- df = pd.DataFrame(list(zip(all_predictions, all_probabilities)), columns=["prediction", "probability"])
- else:
- df = pd.DataFrame(all_predictions, columns=["prediction"])
- df = df.head(num_examples)
- df.to_csv(output_file, header=True, index=False)
- return eval_results
-
-
-def load_from_pretrained(args, pretrained_model_name_or_path):
- """Load the pretrained model and tokenizer."""
-
- # In distributed training, the .from_pretrained methods guarantee that only
- # one local process can concurrently perform this procedure.
-
- config = AutoConfig.from_pretrained(
- pretrained_model_name_or_path,
- num_labels=args.num_labels if hasattr(args, "num_labels") else None,
- finetuning_task=args.task_name.lower(),
- cache_dir=args.cache_dir,
- )
- tokenizer = AutoTokenizer.from_pretrained(
- pretrained_model_name_or_path, use_fast=args.use_fast_tokenizer, cache_dir=args.cache_dir
- )
- model = AutoModelForSequenceClassification.from_pretrained(
- pretrained_model_name_or_path,
- from_tf=bool(".ckpt" in args.model_name_or_path),
- config=config,
- ignore_mismatched_sizes=True,
- cache_dir=args.cache_dir,
- )
- return config, tokenizer, model
-
-
-def finetune(accelerator, model_name_or_path, train_file, output_dir, **kwargs):
- """Fine-tuning a pre-trained model on a downstream task.
-
- Args:
- accelerator: An instance of an accelerator for distributed training (on
- multi-GPU, TPU) or mixed precision training.
- model_name_or_path: Path to pretrained model or model identifier from
- huggingface.co/models.
- train_file: A csv or a json file containing the training data.
- output_dir: The output directory where the model predictions and checkpoints
- will be written.
- **kwargs: Dictionary of key/value pairs with which to update the
- configuration object after loading. The values in kwargs of any keys which
- are configuration attributes will be used to override the loaded values.
- """
- # Make one log on every process with the configuration for debugging.
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- level=logging.INFO,
- )
- logger.info(accelerator.state)
-
- # Setup logging, we only want one process per machine to log things on the
- # screen. accelerator.is_local_main_process is only True for one process per
- # machine.
- logger.setLevel(logging.INFO if accelerator.is_local_main_process else logging.ERROR)
-
- model_args = FTModelArguments(model_name_or_path=model_name_or_path)
- data_args = FTDataArguments(train_file=train_file)
- training_args = FTTrainingArguments(output_dir=output_dir)
- args = argparse.Namespace()
-
- for arg_class in (model_args, data_args, training_args):
- for key, value in vars(arg_class).items():
- setattr(args, key, value)
-
- for key, value in kwargs.items():
- if hasattr(args, key):
- setattr(args, key, value)
-
- # Sanity checks
- data_files = {}
- args.data_file_extension = None
-
- # You need to provide the training data as we always run training
- args.do_train = True
- assert args.train_file is not None
- data_files[Split.TRAIN.value] = args.train_file
-
- if args.do_eval or args.eval_strategy != IntervalStrategy.NO.value:
- assert args.eval_file is not None
- data_files[Split.EVAL.value] = args.eval_file
-
- if args.do_eval and args.test_file is not None:
- data_files[Split.TEST.value] = args.test_file
-
- if args.do_predict:
- assert args.infer_file is not None
- data_files[Split.INFER.value] = args.infer_file
-
- for key in data_files:
- extension = data_files[key].split(".")[-1]
- assert extension in ["csv", "json"], f"`{key}_file` should be a csv or a json file."
- if args.data_file_extension is None:
- args.data_file_extension = extension
- else:
- assert extension == args.data_file_extension, f"`{key}_file` should be a {args.data_file_extension} file`."
-
- assert (
- args.eval_metric in datasets.list_metrics()
- ), f"{args.eval_metric} not in the list of supported metrics {datasets.list_metrics()}."
-
- # Handle the output directory creation
- if accelerator.is_main_process:
- if args.output_dir is not None:
- os.makedirs(args.output_dir, exist_ok=True)
- accelerator.wait_for_everyone()
-
- # If passed along, set the training seed now.
- if args.seed is not None:
- set_seed(args.seed)
-
- # You need to provide your CSV/JSON data files.
- #
- # For CSV/JSON files, this script will use as labels the column called 'label'
- # and as pair of sentences the sentences in columns called 'sentence1' and
- # 'sentence2' if these columns exist or the first two columns not named
- # 'label' if at least two columns are provided.
- #
- # If the CSVs/JSONs contain only one non-label column, the script does single
- # sentence classification on this single column.
- #
- # In distributed training, the load_dataset function guarantees that only one
- # local process can download the dataset.
-
- # Loading the dataset from local csv or json files.
- raw_datasets = load_dataset(args.data_file_extension, data_files=data_files)
-
- # Labels
- is_regression = raw_datasets[Split.TRAIN.value].features["label"].dtype in ["float32", "float64"]
- args.is_regression = is_regression
-
- if args.is_regression:
- label_list = None
- num_labels = 1
- else:
- label_list = args.label_list
- assert label_list is not None
- label_list.sort() # Let's sort it for determinism
- num_labels = len(label_list)
- args.num_labels = num_labels
-
- # Load pre-trained model
- config, tokenizer, model = load_from_pretrained(args, args.model_name_or_path)
-
- # Preprocessing the datasets
- non_label_column_names = [name for name in raw_datasets[Split.TRAIN.value].column_names if name != "label"]
- if "sentence1" in non_label_column_names and "sentence2" in non_label_column_names:
- sentence1_key, sentence2_key = "sentence1", "sentence2"
- else:
- if len(non_label_column_names) >= 2:
- sentence1_key, sentence2_key = non_label_column_names[:2]
- else:
- sentence1_key, sentence2_key = non_label_column_names[0], None
-
- label_to_id = {v: i for i, v in enumerate(label_list)}
- config.label2id = label_to_id
- config.id2label = {id: label for label, id in config.label2id.items()}
- padding = "max_length" if args.pad_to_max_length else False
-
- def preprocess_function(examples):
- # Tokenize the texts
- texts = (
- (examples[sentence1_key],) if sentence2_key is None else (examples[sentence1_key], examples[sentence2_key])
- )
- result = tokenizer(*texts, padding=padding, max_length=args.max_length, truncation=True)
-
- if "label" in examples:
- if label_to_id is not None:
- # Map labels to IDs (not necessary for GLUE tasks)
- result["labels"] = [label_to_id[l] for l in examples["label"]]
- else:
- # In all cases, rename the column to labels because the model will
- # expect that.
- result["labels"] = examples["label"]
- return result
-
- with accelerator.main_process_first():
- processed_datasets = raw_datasets.map(
- preprocess_function,
- batched=True,
- remove_columns=raw_datasets[Split.TRAIN.value].column_names,
- desc="Running tokenizer on dataset",
- )
-
- num_examples = {}
- splits = [s.value for s in Split]
- for split in splits:
- if split in processed_datasets:
- num_examples[split] = len(processed_datasets[split])
- args.num_examples = num_examples
-
- train_dataset = processed_datasets[Split.TRAIN.value]
- eval_dataset = processed_datasets[Split.EVAL.value] if Split.EVAL.value in processed_datasets else None
- test_dataset = processed_datasets[Split.TEST.value] if Split.TEST.value in processed_datasets else None
- infer_dataset = processed_datasets[Split.INFER.value] if Split.INFER.value in processed_datasets else None
-
- # Log a few random samples from the training set:
- for index in random.sample(range(len(train_dataset)), 3):
- logger.info("Sample %d of the training set: %s.", index, train_dataset[index])
-
- # DataLoaders creation:
- if args.pad_to_max_length:
- # If padding was already done ot max length, we use the default data
- # collator that will just convert everything to tensors.
- data_collator = default_data_collator
- else:
- # Otherwise, `DataCollatorWithPadding` will apply dynamic padding for us (by
- # padding to the maximum length of the samples passed). When using mixed
- # precision, we add `pad_to_multiple_of=8` to pad all tensors to multiple of
- # 8s, which will enable the use of Tensor Cores on NVIDIA hardware with
- # compute capability >= 7.5 (Volta).
- # For fp8, we pad to multiple of 16.
- if accelerator.mixed_precision == "fp8":
- pad_to_multiple_of = 16
- elif accelerator.mixed_precision != "no":
- pad_to_multiple_of = 8
- else:
- pad_to_multiple_of = None
- data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=pad_to_multiple_of)
-
- train_dataloader = DataLoader(
- train_dataset,
- batch_size=args.per_device_train_batch_size,
- shuffle=True,
- collate_fn=data_collator,
- )
- eval_dataloader, test_dataloader, infer_dataloader = None, None, None
-
- if eval_dataset is not None:
- eval_dataloader = DataLoader(
- eval_dataset, batch_size=args.per_device_eval_batch_size, collate_fn=data_collator
- )
-
- if test_dataset is not None:
- test_dataloader = DataLoader(
- test_dataset, batch_size=args.per_device_eval_batch_size, collate_fn=data_collator
- )
-
- if infer_dataset is not None:
- infer_dataloader = DataLoader(
- infer_dataset, batch_size=args.per_device_eval_batch_size, collate_fn=data_collator
- )
-
- # Optimizer
- # Split weights in two groups, one with weight decay and the other not.
- no_decay = ["bias", "LayerNorm.weight"]
- optimizer_grouped_parameters = [
- {
- "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
- "weight_decay": args.weight_decay,
- },
- {
- "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
- "weight_decay": 0.0,
- },
- ]
- optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
-
- # Prepare everything with our `accelerator`.
- model, optimizer, train_dataloader, eval_dataloader, test_dataloader, infer_dataloader = accelerator.prepare(
- model, optimizer, train_dataloader, eval_dataloader, test_dataloader, infer_dataloader
- )
-
- # Note -> the training dataloader needs to be prepared before we grab its
- # length below (cause its length will be shorter in multiprocess)
-
- # Scheduler and math around the number of training steps.
- num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
- if args.max_steps == -1:
- args.max_steps = args.num_train_epochs * num_update_steps_per_epoch
- else:
- args.num_train_epochs = math.ceil(args.max_steps / num_update_steps_per_epoch)
-
- lr_scheduler = get_scheduler(
- name=args.lr_scheduler_type,
- optimizer=optimizer,
- num_warmup_steps=args.warmup_steps,
- num_training_steps=args.max_steps,
- )
-
- # Train
- completed_steps, avg_train_loss = train(
- args, accelerator, model, tokenizer, train_dataloader, optimizer, lr_scheduler, eval_dataloader
- )
- accelerator.wait_for_everyone()
- logger.info("Training job completed: completed_steps = %d, avg_train_loss = %f", completed_steps, avg_train_loss)
-
- args.model_name_or_path = os.path.join(args.output_dir, "best-checkpoint")
- logger.info("Loading the best checkpoint: %s", args.model_name_or_path)
- config, tokenizer, model = load_from_pretrained(args, args.model_name_or_path)
- model = accelerator.prepare(model)
-
- if args.do_eval:
- # Evaluate
- if eval_dataloader is not None:
- logger.info("***** Running evaluation on the eval data using the best checkpoint *****")
- eval_results = evaluate(args, accelerator, eval_dataloader, Split.EVAL.value, model, "best-checkpoint")
- avg_eval_loss = eval_results["avg_eval_loss"]
- eval_metric = eval_results[args.eval_metric]
- logger.info("Evaluation job completed: avg_eval_loss = %f", avg_eval_loss)
- logger.info("Evaluation result for the best checkpoint: %s = %f", args.eval_metric, eval_metric)
-
- if test_dataloader is not None:
- logger.info("***** Running evaluation on the test data using the best checkpoint *****")
- eval_results = evaluate(args, accelerator, test_dataloader, Split.TEST.value, model, "best-checkpoint")
- avg_eval_loss = eval_results["avg_eval_loss"]
- eval_metric = eval_results[args.eval_metric]
- logger.info("Test job completed: avg_test_loss = %f", avg_eval_loss)
- logger.info("Test result for the best checkpoint: %s = %f", args.eval_metric, eval_metric)
-
- if args.do_predict:
- # Predict
- if infer_dataloader is not None:
- logger.info("***** Running inference using the best checkpoint *****")
- evaluate(
- args, accelerator, infer_dataloader, Split.INFER.value, model, "best-checkpoint", has_labels=False
- )
- logger.info("Inference job completed.")
-
- # Release all references to the internal objects stored and call the garbage
- # collector. You should call this method between two trainings with different
- # models/optimizers.
- accelerator.free_memory()
diff --git a/examples/research_projects/self-training-text-classification/requirements.txt b/examples/research_projects/self-training-text-classification/requirements.txt
deleted file mode 100644
index 25d66c8b6a4..00000000000
--- a/examples/research_projects/self-training-text-classification/requirements.txt
+++ /dev/null
@@ -1,7 +0,0 @@
-accelerate
-datasets >= 1.8.0
-protobuf
-scikit-learn
-scipy
-sentencepiece != 0.1.92
-torch >= 1.3
diff --git a/examples/research_projects/self-training-text-classification/run.sh b/examples/research_projects/self-training-text-classification/run.sh
deleted file mode 100755
index 34e91d7c127..00000000000
--- a/examples/research_projects/self-training-text-classification/run.sh
+++ /dev/null
@@ -1,81 +0,0 @@
-# Copyright 2022 The Google Research Authors.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-#!/bin/bash
-
-# Create a virtual environment
-conda deactivate
-conda update conda -y
-conda update anaconda -y
-pip install --upgrade pip
-python3 -m pip install --user virtualenv
-conda create -n strata python=3.9 -y
-conda activate strata
-# Install all necessary packages
-pip install transformers
-pip install -r requirements.txt
-
-# Download and prepare data
-WORK_DIR="/tmp/strata"
-rm -rf "${WORK_DIR}" && mkdir -p "${WORK_DIR}"
-wget https://storage.googleapis.com/gresearch/strata/demo.zip -P "${WORK_DIR}"
-DEMO_ZIP_FILE="${WORK_DIR}/demo.zip"
-unzip "${DEMO_ZIP_FILE}" -d "${WORK_DIR}" && rm "${DEMO_ZIP_FILE}"
-DATA_DIR="${WORK_DIR}/demo/scitail-8"
-OUTPUT_DIR="/tmp/output"
-rm -rf "${OUTPUT_DIR}" && mkdir -p "${OUTPUT_DIR}"
-
-# Specific hyperparameters
-MODEL_NAME_OR_PATH="bert-base-uncased"
-NUM_NODES=1
-NUM_TRAINERS=4
-LAUNCH_SCRIPT="torchrun --nnodes='${NUM_NODES}' --nproc_per_node='${NUM_TRAINERS}' python -c"
-MAX_SELFTRAIN_ITERATIONS=100
-TRAIN_FILE="train.csv"
-INFER_FILE="infer.csv"
-EVAL_FILE="eval_256.csv"
-MAX_STEPS=100000
-
-# Start self-training
-${LAUNCH_SCRIPT} "
-import os
-from selftraining import selftrain
-
-data_dir = '${DATA_DIR}'
-parameters_dict = {
- 'max_selftrain_iterations': ${MAX_SELFTRAIN_ITERATIONS},
- 'model_name_or_path': '${MODEL_NAME_OR_PATH}',
- 'output_dir': '${OUTPUT_DIR}',
- 'train_file': os.path.join(data_dir, '${TRAIN_FILE}'),
- 'infer_file': os.path.join(data_dir, '${INFER_FILE}'),
- 'eval_file': os.path.join(data_dir, '${EVAL_FILE}'),
- 'eval_strategy': 'steps',
- 'task_name': 'scitail',
- 'label_list': ['entails', 'neutral'],
- 'per_device_train_batch_size': 32,
- 'per_device_eval_batch_size': 8,
- 'max_length': 128,
- 'learning_rate': 2e-5,
- 'max_steps': ${MAX_STEPS},
- 'eval_steps': 1,
- 'early_stopping_patience': 50,
- 'overwrite_output_dir': True,
- 'do_filter_by_confidence': False,
- 'do_filter_by_val_performance': True,
- 'finetune_on_labeled_data': False,
- 'seed': 42,
-}
-
-selftrain(**parameters_dict)
-"
diff --git a/examples/research_projects/self-training-text-classification/selftraining.py b/examples/research_projects/self-training-text-classification/selftraining.py
deleted file mode 100644
index d741225b061..00000000000
--- a/examples/research_projects/self-training-text-classification/selftraining.py
+++ /dev/null
@@ -1,388 +0,0 @@
-# coding=utf-8
-# Copyright 2022 The Google Research Authors.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Self-training for sequence classification."""
-
-import argparse
-import dataclasses
-import json
-import logging
-import os
-import shutil
-from typing import List, Optional
-
-import datasets
-from accelerate import Accelerator
-from datasets import load_dataset
-from finetuning import finetune
-from tqdm.auto import tqdm
-
-import transformers
-from transformers import AutoConfig, set_seed
-from transformers.trainer_utils import IntervalStrategy
-
-
-logger = logging.getLogger(__name__)
-
-MODEL_BIN_FILE = "pytorch_model.bin"
-
-
-@dataclasses.dataclass
-class STModelArguments:
- """Arguments pertaining to which config/tokenizer/model we are going to fine-tune from."""
-
- model_name_or_path: str = dataclasses.field(
- metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models."}
- )
- cache_dir: Optional[str] = dataclasses.field(
- default=None,
- metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co."},
- )
-
-
-@dataclasses.dataclass
-class STDataArguments:
- """Arguments pertaining to what data we are going to input our model for training and evaluation."""
-
- train_file: str = dataclasses.field(metadata={"help": "A csv or a json file containing the training data."})
- infer_file: str = dataclasses.field(metadata={"help": "A csv or a json file containing the data to predict on."})
- eval_file: Optional[str] = dataclasses.field(
- default=None, metadata={"help": "A csv or a json file containing the validation data."}
- )
- task_name: Optional[str] = dataclasses.field(
- default=None,
- metadata={"help": "The name of the task to train on."},
- )
- label_list: Optional[List[str]] = dataclasses.field(
- default=None, metadata={"help": "The list of labels for the task."}
- )
-
-
-@dataclasses.dataclass
-class STTrainingArguments:
- """Training arguments pertaining to the training loop itself."""
-
- output_dir: str = dataclasses.field(
- metadata={"help": "The output directory where the model predictions and checkpoints will be written."}
- )
- eval_metric: Optional[str] = dataclasses.field(
- default="accuracy", metadata={"help": "The evaluation metric used for the task."}
- )
- eval_strategy: Optional[str] = dataclasses.field(
- default="no",
- metadata={
- "help": 'The evaluation strategy to adopt during training. Possible values are: ["no", "step", "epoch]'
- },
- )
- early_stopping_patience: Optional[int] = dataclasses.field(
- default=10,
- metadata={"help": "Number of evaluation calls with no improvement after which training will be stopped."},
- )
- early_stopping_threshold: Optional[float] = dataclasses.field(
- default=0.0,
- metadata={
- "help": "How much the specified evaluation metric must improve to satisfy early stopping conditions."
- },
- )
- do_filter_by_confidence: Optional[bool] = dataclasses.field(
- default=False,
- metadata={"help": "Whether to filter the pseudo-labeled data based on the confidence score."},
- )
- do_filter_by_val_performance: Optional[bool] = dataclasses.field(
- default=False,
- metadata={"help": "Whether to filter the pseudo-labeled data based on the validation performance."},
- )
- finetune_on_labeled_data: Optional[bool] = dataclasses.field(
- default=False,
- metadata={"help": "Whether to fine-tune on labeled data after pseudo training."},
- )
- confidence_threshold: Optional[float] = dataclasses.field(
- default=0.0,
- metadata={"help": "Confidence threshold for pseudo-labeled data filtering."},
- )
- max_selftrain_iterations: Optional[int] = dataclasses.field(
- default=100,
- metadata={"help": "Number of evaluation calls with no improvement after which training will be stopped."},
- )
- seed: Optional[int] = dataclasses.field(
- default=None,
- metadata={"help": "Random seed for initialization."},
- )
-
-
-def create_pseudo_labeled_data(args, infer_input, infer_output, eval_result, id2label, next_data_dir):
- """Create pseudeo labeled data for the next self-training iteration."""
-
- dataset = datasets.concatenate_datasets([infer_input, infer_output], axis=1)
-
- if args.do_filter_by_confidence:
- dataset = dataset.filter(lambda example: example["probability"] > args.confidence_threshold)
-
- if args.do_filter_by_val_performance:
- assert eval_result >= 0.0 and eval_result <= 1.0
- num_selected_rows = int(eval_result * len(dataset))
- print(num_selected_rows)
- dataset = dataset.sort("probability", reverse=True)
- dataset = dataset.select(range(num_selected_rows))
-
- dataset = dataset.remove_columns(["label", "probability"])
- dataset = dataset.rename_column("prediction", "label")
- dataset = dataset.map(lambda example: {"label": id2label[example["label"]]})
- dataset = dataset.shuffle(seed=args.seed)
-
- pseudo_labeled_data_file = os.path.join(next_data_dir, f"train_pseudo.{args.data_file_extension}")
- if args.data_file_extension == "csv":
- dataset.to_csv(pseudo_labeled_data_file, index=False)
- else:
- dataset.to_json(pseudo_labeled_data_file)
-
-
-def selftrain(model_name_or_path, train_file, infer_file, output_dir, **kwargs):
- """Self-training a pre-trained model on a downstream task.
-
- Args:
- model_name_or_path: Path to pretrained model or model identifier from
- huggingface.co/models.
- train_file: A csv or a json file containing the training data.
- infer_file: A csv or a json file containing the data to predict on.
- output_dir: The output directory where the model predictions and checkpoints
- will be written.
- **kwargs: Dictionary of key/value pairs with which to update the
- configuration object after loading. The values in kwargs of any keys which
- are configuration attributes will be used to override the loaded values.
- """
- # Initialize the accelerator. We will let the accelerator handle device
- # placement for us.
- accelerator = Accelerator()
- # Make one log on every process with the configuration for debugging.
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- level=logging.INFO,
- )
- logger.info(accelerator.state)
-
- # Setup logging, we only want one process per machine to log things on the
- # screen. accelerator.is_local_main_process is only True for one process per
- # machine.
- logger.setLevel(logging.INFO if accelerator.is_local_main_process else logging.ERROR)
-
- if accelerator.is_local_main_process:
- datasets.utils.logging.set_verbosity_warning()
- transformers.utils.logging.set_verbosity_info()
- else:
- datasets.utils.logging.set_verbosity_error()
- transformers.utils.logging.set_verbosity_error()
-
- model_args = STModelArguments(model_name_or_path=model_name_or_path)
- data_args = STDataArguments(train_file=train_file, infer_file=infer_file)
- training_args = STTrainingArguments(output_dir=output_dir)
- args = argparse.Namespace()
-
- for arg_class in (model_args, data_args, training_args):
- for key, value in vars(arg_class).items():
- setattr(args, key, value)
-
- for key, value in kwargs.items():
- if hasattr(args, key):
- setattr(args, key, value)
-
- # Sanity checks
- data_files = {}
- args.data_file_extension = None
-
- # You need to provide the training data and the data to predict on
- assert args.train_file is not None
- assert args.infer_file is not None
- data_files["train"] = args.train_file
- data_files["infer"] = args.infer_file
-
- if args.eval_strategy != IntervalStrategy.NO.value:
- assert args.eval_file is not None
- data_files["eval"] = args.eval_file
-
- for key in data_files:
- extension = data_files[key].split(".")[-1]
- assert extension in ["csv", "json"], f"`{key}_file` should be a csv or a json file."
- if args.data_file_extension is None:
- args.data_file_extension = extension
- else:
- assert extension == args.data_file_extension, f"`{key}_file` should be a {args.data_file_extension} file`."
-
- assert (
- args.eval_metric in datasets.list_metrics()
- ), f"{args.eval_metric} not in the list of supported metrics {datasets.list_metrics()}."
-
- # If passed along, set the training seed now.
- if args.seed is not None:
- set_seed(args.seed)
-
- logger.info("Creating the initial data directory for self-training...")
- data_dir_format = f"{args.output_dir}/self-train_iter-{{}}".format
- initial_data_dir = data_dir_format(0)
-
- if accelerator.is_main_process:
- if args.output_dir is not None:
- os.makedirs(args.output_dir, exist_ok=True)
- os.makedirs(initial_data_dir, exist_ok=True)
- accelerator.wait_for_everyone()
-
- best_iteration = None
- best_eval_result = None
- early_stopping_patience_counter = 0
- should_training_stop = False
- # Show the progress bar
- progress_bar = tqdm(range(args.max_selftrain_iterations), disable=not accelerator.is_local_main_process)
-
- # Self-train
- for iteration in range(0, int(args.max_selftrain_iterations)):
- current_data_dir = data_dir_format(iteration)
- assert os.path.exists(current_data_dir)
-
- # Stage 1: initial fine-tuning for iteration = 0 or pseudo-training for
- # iteration > 0
- current_output_dir = os.path.join(current_data_dir, "stage-1")
- arguments_dict = {
- "accelerator": accelerator,
- "model_name_or_path": args.model_name_or_path,
- "cache_dir": args.cache_dir,
- "do_train": True,
- "train_file": data_files["train"] if iteration == 0 else data_files["train_pseudo"],
- "do_eval": True if args.eval_file is not None else False,
- "eval_file": data_files["eval"],
- "do_predict": True,
- "infer_file": data_files["infer"],
- "task_name": args.task_name,
- "label_list": args.label_list,
- "output_dir": current_output_dir,
- "eval_metric": args.eval_metric,
- "eval_strategy": args.eval_strategy,
- "early_stopping_patience": args.early_stopping_patience,
- "early_stopping_threshold": args.early_stopping_threshold,
- "seed": args.seed,
- }
- # Add additional training arguments
- for key, value in kwargs.items():
- if key not in arguments_dict and not hasattr(training_args, key):
- arguments_dict.update({key: value})
-
- model_bin_file_path = os.path.join(current_output_dir, "best-checkpoint", MODEL_BIN_FILE)
- if os.path.exists(model_bin_file_path):
- logger.info(
- "Found existing model checkpoint at %s. Skipping self-training: iteration: %d, stage: 1.",
- model_bin_file_path,
- iteration,
- )
- else:
- logger.info("***** Running self-training: iteration: %d, stage: 1 *****", iteration)
- finetune(**arguments_dict)
- accelerator.wait_for_everyone()
- assert os.path.exists(model_bin_file_path)
- logger.info("Self-training job completed: iteration: %d, stage: 1.", iteration)
-
- if iteration > 0 and args.finetune_on_labeled_data:
- # Stage 2 (optional): fine-tuning on the original labeled data
- model_path = os.path.join(current_output_dir, "best-checkpoint")
- current_output_dir = os.path.join(current_data_dir, "stage-2")
- # Update arguments_dict
- arguments_dict["model_name_or_path"] = model_path
- arguments_dict["train_file"] = data_files["train"]
- arguments_dict["output_dir"] = current_output_dir
-
- model_bin_file_path = os.path.join(current_output_dir, "best-checkpoint", MODEL_BIN_FILE)
- if os.path.exists(model_bin_file_path):
- logger.info(
- "Found existing model checkpoint at %s. Skipping self-training: iteration: %d, stage: 2.",
- model_bin_file_path,
- iteration,
- )
- else:
- logger.info("***** Running self-training: iteration: %d, stage: 2 *****", iteration)
- finetune(**arguments_dict)
- accelerator.wait_for_everyone()
- assert os.path.exists(model_bin_file_path)
- logger.info("Self-training job completed: iteration: %d, stage: 2.", iteration)
-
- new_iteration = iteration
- next_data_dir = data_dir_format(iteration + 1)
-
- config = AutoConfig.from_pretrained(os.path.join(current_output_dir, "best-checkpoint"))
- id2label = config.id2label
- eval_results_file = os.path.join(current_output_dir, "eval_results_best-checkpoint.json")
- test_results_file = os.path.join(current_output_dir, "test_results_best-checkpoint.json")
- assert os.path.exists(eval_results_file)
-
- with open(eval_results_file, "r") as f:
- eval_result = float(json.load(f)[args.eval_metric])
- infer_output_file = os.path.join(current_output_dir, "infer_output_best-checkpoint.csv")
- assert os.path.exists(infer_output_file)
- # Loading the dataset from local csv or json files.
- infer_input = load_dataset(args.data_file_extension, data_files={"data": data_files["infer"]})["data"]
- infer_output = load_dataset("csv", data_files={"data": infer_output_file})["data"]
-
- if accelerator.is_main_process:
- os.makedirs(next_data_dir, exist_ok=True)
- shutil.copy(eval_results_file, os.path.join(output_dir, f"eval_results_iter-{iteration}.json"))
- if os.path.exists(test_results_file):
- shutil.copy(eval_results_file, os.path.join(output_dir, f"test_results_iter-{iteration}.json"))
- create_pseudo_labeled_data(args, infer_input, infer_output, eval_result, id2label, next_data_dir)
- accelerator.wait_for_everyone()
-
- data_files["train_pseudo"] = os.path.join(next_data_dir, f"train_pseudo.{args.data_file_extension}")
-
- if args.eval_strategy != IntervalStrategy.NO.value:
- new_eval_result = eval_result
-
- if best_iteration is None:
- best_iteration = new_iteration
- best_eval_result = new_eval_result
- else:
- if new_eval_result - best_eval_result > args.early_stopping_threshold:
- best_iteration = new_iteration
- best_eval_result = new_eval_result
- early_stopping_patience_counter = 0
- else:
- if new_eval_result == best_eval_result:
- best_iteration = new_iteration
- best_eval_result = new_eval_result
- early_stopping_patience_counter += 1
-
- if early_stopping_patience_counter >= args.early_stopping_patience:
- should_training_stop = True
-
- progress_bar.update(1)
-
- if should_training_stop:
- break
-
- if best_iteration is not None:
- # Save the best iteration
- logger.info("Best iteration: %d", best_iteration)
- logger.info("Best evaluation result: %s = %f", args.eval_metric, best_eval_result)
- accelerator.wait_for_everyone()
- if accelerator.is_main_process:
- shutil.copy(
- os.path.join(output_dir, f"eval_results_iter-{iteration}.json"),
- os.path.join(output_dir, "eval_results_best-iteration.json"),
- )
- else:
- # Assume that the last iteration is the best
- logger.info("Best iteration: %d", args.max_selftrain_iterations - 1)
- logger.info("Best evaluation result: %s = %f", args.eval_metric, eval_result)
- accelerator.wait_for_everyone()
- if accelerator.is_main_process:
- shutil.copy(
- os.path.join(output_dir, f"eval_results_iter-{args.max_selftrain_iterations - 1}.json"),
- os.path.join(output_dir, "eval_results_best-iteration.json"),
- )
diff --git a/examples/research_projects/seq2seq-distillation/README.md b/examples/research_projects/seq2seq-distillation/README.md
deleted file mode 100644
index ab79a652ed3..00000000000
--- a/examples/research_projects/seq2seq-distillation/README.md
+++ /dev/null
@@ -1,434 +0,0 @@
-## Sequence to Sequence Training and Evaluation
-
-This directory contains examples for finetuning and evaluating transformers on summarization and translation tasks.
-
-Author: Sam Shleifer (https://github.com/sshleifer)
-
-### Supported Architectures
-
-- `BartForConditionalGeneration` (and anything that inherits from it)
-- `MarianMTModel`
-- `PegasusForConditionalGeneration`
-- `MBartForConditionalGeneration`
-- `FSMTForConditionalGeneration`
-- `T5ForConditionalGeneration`
-
-# Note
-
-⚠️ This project should be run with pytorch-lightning==1.0.4 which has a potential security vulnerability
-
-## Datasets
-
-#### XSUM
-
-```bash
-cd examples/contrib/pytorch-lightning/seq2seq
-wget https://cdn-datasets.huggingface.co/summarization/xsum.tar.gz
-tar -xzvf xsum.tar.gz
-export XSUM_DIR=${PWD}/xsum
-```
-this should make a directory called `xsum/` with files like `test.source`.
-To use your own data, copy that files format. Each article to be summarized is on its own line.
-
-#### CNN/DailyMail
-
-```bash
-cd examples/contrib/pytorch-lightning/seq2seq
-wget https://cdn-datasets.huggingface.co/summarization/cnn_dm_v2.tgz
-tar -xzvf cnn_dm_v2.tgz # empty lines removed
-mv cnn_cln cnn_dm
-export CNN_DIR=${PWD}/cnn_dm
-```
-this should make a directory called `cnn_dm/` with 6 files.
-
-#### WMT16 English-Romanian Translation Data
-
-download with this command:
-```bash
-wget https://cdn-datasets.huggingface.co/translation/wmt_en_ro.tar.gz
-tar -xzvf wmt_en_ro.tar.gz
-export ENRO_DIR=${PWD}/wmt_en_ro
-```
-this should make a directory called `wmt_en_ro/` with 6 files.
-
-#### WMT English-German
-
-```bash
-wget https://cdn-datasets.huggingface.co/translation/wmt_en_de.tgz
-tar -xzvf wmt_en_de.tgz
-export DATA_DIR=${PWD}/wmt_en_de
-```
-
-#### FSMT datasets (wmt)
-
-Refer to the scripts starting with `eval_` under:
-https://github.com/huggingface/transformers/tree/main/scripts/fsmt
-
-#### Pegasus (multiple datasets)
-
-Multiple eval datasets are available for download from:
-https://github.com/stas00/porting/tree/master/datasets/pegasus
-
-
-#### Your Data
-
-If you are using your own data, it must be formatted as one directory with 6 files:
-```
-train.source
-train.target
-val.source
-val.target
-test.source
-test.target
-```
-The `.source` files are the input, the `.target` files are the desired output.
-
-### Potential issues
-
-- native AMP (`--fp16` and no apex) may lead to a huge memory leak and require 10x gpu memory. This has been fixed in pytorch-nightly and the minimal official version to have this fix will be pytorch-1.8. Until then if you have to use mixed precision please use AMP only with pytorch-nightly or NVIDIA's apex. Reference: https://github.com/huggingface/transformers/issues/8403
-
-
-### Tips and Tricks
-
-General Tips:
-- since you need to run from this folder, and likely need to modify code, the easiest workflow is fork transformers, clone your fork, and run `pip install -e .` before you get started.
-- try `--freeze_encoder` or `--freeze_embeds` for faster training/larger batch size. (3hr per epoch with bs=8, see the "xsum_shared_task" command below)
-- `fp16_opt_level=O1` (the default works best).
-- In addition to the pytorch-lightning .ckpt checkpoint, a transformers checkpoint will be saved.
-Load it with `BartForConditionalGeneration.from_pretrained(f'{output_dir}/best_tfmr)`.
-- At the moment, `--do_predict` does not work in a multi-gpu setting. You need to use `evaluate_checkpoint` or the `run_eval.py` code.
-- This warning can be safely ignored:
- > "Some weights of BartForConditionalGeneration were not initialized from the model checkpoint at facebook/bart-large-xsum and are newly initialized: ['final_logits_bias']"
-- Both finetuning and eval are 30% faster with `--fp16`. For that you need to [install apex](https://github.com/NVIDIA/apex#quick-start).
-- Read scripts before you run them!
-
-Summarization Tips:
-- (summ) 1 epoch at batch size 1 for bart-large takes 24 hours and requires 13GB GPU RAM with fp16 on an NVIDIA-V100.
-- If you want to run experiments on improving the summarization finetuning process, try the XSUM Shared Task (below). It's faster to train than CNNDM because the summaries are shorter.
-- For CNN/DailyMail, the default `val_max_target_length` and `test_max_target_length` will truncate the ground truth labels, resulting in slightly higher rouge scores. To get accurate rouge scores, you should rerun calculate_rouge on the `{output_dir}/test_generations.txt` file saved by `trainer.test()`
-- `--max_target_length=60 --val_max_target_length=60 --test_max_target_length=100 ` is a reasonable setting for XSUM.
-- `wandb` can be used by specifying `--logger_name wandb`. It is useful for reproducibility. Specify the environment variable `WANDB_PROJECT='hf_xsum'` to do the XSUM shared task.
-- If you are finetuning on your own dataset, start from `distilbart-cnn-12-6` if you want long summaries and `distilbart-xsum-12-6` if you want short summaries.
-(It rarely makes sense to start from `bart-large` unless you are a researching finetuning methods).
-
-**Update 2018-07-18**
-Datasets: `LegacySeq2SeqDataset` will be used for all tokenizers without a `prepare_seq2seq_batch` method. Otherwise, `Seq2SeqDataset` will be used.
-Future work/help wanted: A new dataset to support multilingual tasks.
-
-
-### Finetuning Scripts
-All finetuning bash scripts call finetune.py (or distillation.py) with reasonable command line arguments. They usually require extra command line arguments to work.
-
-To see all the possible command line options, run:
-
-```bash
-./finetune.py --help
-```
-
-### Finetuning Training Params
-
-To override the pretrained model's training params, you can pass them to `./finetune.sh`:
-
-```bash
-./finetune.sh \
- [...]
- --encoder_layerdrop 0.1 \
- --decoder_layerdrop 0.1 \
- --dropout 0.1 \
- --attention_dropout 0.1 \
-```
-
-### Summarization Finetuning
-Run/modify `finetune.sh`
-
-The following command should work on a 16GB GPU:
-```bash
-./finetune.sh \
- --data_dir $XSUM_DIR \
- --train_batch_size=1 \
- --eval_batch_size=1 \
- --output_dir=xsum_results \
- --num_train_epochs 6 \
- --model_name_or_path facebook/bart-large
-```
-
-There is a starter finetuning script for pegasus at `finetune_pegasus_xsum.sh`.
-
-### Translation Finetuning
-
-First, follow the wmt_en_ro download instructions.
-Then you can finetune mbart_cc25 on english-romanian with the following command.
-**Recommendation:** Read and potentially modify the fairly opinionated defaults in `train_mbart_cc25_enro.sh` script before running it.
-
-Best performing command:
-```bash
-# optionally
-export ENRO_DIR='wmt_en_ro' # Download instructions above
-# export WANDB_PROJECT="MT" # optional
-export MAX_LEN=128
-export BS=4
-./train_mbart_cc25_enro.sh --output_dir enro_finetune_baseline --label_smoothing 0.1 --fp16_opt_level=O1 --logger_name wandb --sortish_sampler
-```
-This should take < 6h/epoch on a 16GB v100 and achieve test BLEU above 26
-To get results in line with fairseq, you need to do some postprocessing. (see `romanian_postprocessing.md`)
-
-MultiGPU command
-(using 8 GPUS as an example)
-```bash
-export ENRO_DIR='wmt_en_ro' # Download instructions above
- # export WANDB_PROJECT="MT" # optional
-export MAX_LEN=128
-export BS=4
-./train_mbart_cc25_enro.sh --output_dir enro_finetune_baseline --gpus 8 --logger_name wandb
-```
-### Finetuning Outputs
-As you train, `output_dir` will be filled with files, that look kind of like this (comments are mine).
-Some of them are metrics, some of them are checkpoints, some of them are metadata. Here is a quick tour:
-
-```bash
-output_dir
-├── best_tfmr # this is a huggingface checkpoint generated by save_pretrained. It is the same model as the PL .ckpt file below
-│ ├── config.json
-│ ├── merges.txt
-│ ├── pytorch_model.bin
-│ ├── special_tokens_map.json
-│ ├── tokenizer_config.json
-│ └── vocab.json
-├── git_log.json # repo, branch, and commit hash
-├── val_avg_rouge2=0.1984-step_count=11.ckpt # this is a pytorch lightning checkpoint associated with the best val score. (it will be called BLEU for MT)
-├── metrics.json # new validation metrics will continually be appended to this
-├── student # this is a huggingface checkpoint generated by SummarizationDistiller. It is the student before it gets finetuned.
-│ ├── config.json
-│ └── pytorch_model.bin
-├── test_generations.txt
-# ^^ are the summaries or translations produced by your best checkpoint on the test data. Populated when training is done
-├── test_results.txt # a convenience file with the test set metrics. This data is also in metrics.json['test']
-├── hparams.pkl # the command line args passed after some light preprocessing. Should be saved fairly quickly.
-```
-After training, you can recover the best checkpoint by running
-```python
-from transformers import AutoModelForSeq2SeqLM
-model = AutoModelForSeq2SeqLM.from_pretrained(f'{output_dir}/best_tfmr')
-```
-
-### Converting pytorch-lightning checkpoints
-pytorch lightning ``-do_predict`` often fails, after you are done training, the best way to evaluate your model is to convert it.
-
-This should be done for you, with a file called `{save_dir}/best_tfmr`.
-
-If that file doesn't exist but you have a lightning `.ckpt` file, you can run
-```bash
-python convert_pl_checkpoint_to_hf.py PATH_TO_CKPT randomly_initialized_hf_model_path save_dir/best_tfmr
-```
-Then either `run_eval` or `run_distributed_eval` with `save_dir/best_tfmr` (see previous sections)
-
-
-# Experimental Features
-These features are harder to use and not always useful.
-
-### Dynamic Batch Size for MT
-`finetune.py` has a command line arg `--max_tokens_per_batch` that allows batches to be dynamically sized.
-This feature can only be used:
-- with fairseq installed
-- on 1 GPU
-- without sortish sampler
-- after calling `./save_len_file.py $tok $data_dir`
-
-For example,
-```bash
-./save_len_file.py Helsinki-NLP/opus-mt-en-ro wmt_en_ro
-./dynamic_bs_example.sh --max_tokens_per_batch=2000 --output_dir benchmark_dynamic_bs
-```
-splits `wmt_en_ro/train` into 11,197 uneven length batches and can finish 1 epoch in 8 minutes on a v100.
-
-For comparison,
-```bash
-./dynamic_bs_example.sh --sortish_sampler --train_batch_size 48
-```
-uses 12,723 batches of length 48 and takes slightly more time 9.5 minutes.
-
-The feature is still experimental, because:
-+ we can make it much more robust if we have memory mapped/preprocessed datasets.
-+ The speedup over sortish sampler is not that large at the moment.
-
-# DistilBART
-
-This section describes all code and artifacts from our [Paper](http://arxiv.org/abs/2010.13002)
-
-
-
-+ For the CNN/DailyMail dataset, (relatively longer, more extractive summaries), we found a simple technique that works, which we call "Shrink and Fine-tune", or SFT.
-you just copy alternating layers from `facebook/bart-large-cnn` and fine-tune more on the cnn/dm data. `sshleifer/distill-pegasus-cnn-16-4`, `sshleifer/distilbart-cnn-12-6` and all other checkpoints under `sshleifer` that start with `distilbart-cnn` were trained this way.
-+ For the XSUM dataset, training on pseudo-labels worked best for Pegasus (`sshleifer/distill-pegasus-16-4`), while training with KD worked best for `distilbart-xsum-12-6`
-+ For `sshleifer/dbart-xsum-12-3`
-+ We ran 100s experiments, and didn't want to document 100s of commands. If you want a command to replicate a figure from the paper that is not documented below, feel free to ask on the [forums](https://discuss.huggingface.co/t/seq2seq-distillation-methodology-questions/1270) and tag `@sshleifer`.
-+ You can see the performance tradeoffs of model sizes [here](https://docs.google.com/spreadsheets/d/1EkhDMwVO02m8jCD1cG3RoFPLicpcL1GQHTQjfvDYgIM/edit#gid=0).
-and more granular timing results [here](https://docs.google.com/spreadsheets/d/1EkhDMwVO02m8jCD1cG3RoFPLicpcL1GQHTQjfvDYgIM/edit#gid=1753259047&range=B2:I23).
-
-### Evaluation
-
-use [run_distributed_eval](./run_distributed_eval.py), with the following convenient alias
-```bash
-deval () {
- proc=$1
- m=$2
- dd=$3
- sd=$4
- shift
- shift
- shift
- shift
- python -m torch.distributed.launch --nproc_per_node=$proc run_distributed_eval.py \
- --model_name $m --save_dir $sd --data_dir $dd $@
-}
-```
-On a 1 GPU system, here are four commands (that assume `xsum`, `cnn_dm` are downloaded, cmd-F for those links in this file).
-
-`distilBART`:
-```bash
-deval 1 sshleifer/distilbart-xsum-12-3 xsum dbart_12_3_xsum_eval --fp16 # --help for more choices.
-deval 1 sshleifer/distilbart-cnn_dm-12-6 cnn_dm dbart_12_6_cnn_eval --fp16
-```
-
-`distill-pegasus`:
-```bash
-deval 1 sshleifer/distill-pegasus-cnn-16-4 cnn_dm dpx_cnn_eval
-deval 1 sshleifer/distill-pegasus-xsum-16-4 xsum dpx_xsum_eval
-```
-
-### Distillation
-+ For all of the following commands, you can get roughly equivalent result and faster run times by passing `--num_beams=4`. That's not what we did for the paper.
-+ Besides the KD section, you can also run commands with the built-in transformers trainer. See, for example, [builtin_trainer/train_distilbart_cnn.sh](./builtin_trainer/train_distilbart_cnn.sh).
-+ Large performance deviations (> 5X slower or more than 0.5 Rouge-2 worse), should be reported.
-+ Multi-gpu (controlled with `--gpus` should work, but might require more epochs).
-
-#### Recommended Workflow
-+ Get your dataset in the right format. (see 6 files above).
-+ Find a teacher model [Pegasus](https://huggingface.co/models?search=pegasus) (slower, better ROUGE) or `facebook/bart-large-xsum`/`facebook/bart-large-cnn` (faster, slightly lower.).
-Choose the checkpoint where the corresponding dataset is most similar (or identical to) your dataset.
-+ Follow the sections in order below. You can stop after SFT if you are satisfied, or move on to pseudo-labeling if you want more performance.
-+ student size: If you want a close to free 50% speedup, cut the decoder in half. If you want a larger speedup, cut it in 4.
-+ If your SFT run starts at a validation ROUGE-2 that is more than 10 pts below the teacher's validation ROUGE-2, you have a bug. Switching to a more expensive technique will not help. Try setting a breakpoint and looking at generation and truncation defaults/hyper-parameters, and share your experience on the forums!
-
-
-#### Initialization
-We use [make_student.py](./make_student.py) to copy alternating layers from the teacher, and save the resulting model to disk
-```bash
-python make_student.py facebook/bart-large-xsum --save_path dbart_xsum_12_3 -e 12 -d 3
-```
-or for `pegasus-xsum`
-```bash
-python make_student.py google/pegasus-xsum --save_path dpx_xsum_16_4 --e 16 --d 4
-```
-we now have an initialized student saved to `dbart_xsum_12_3`, which we will use for the following commands.
-+ Extension: To replicate more complicated initialize experiments in section 6.1, or try your own. Use the `create_student_by_copying_alternating_layers` function.
-
-#### Pegasus
-+ The following commands are written for BART and will require, at minimum, the following modifications
-+ reduce batch size, and increase gradient accumulation steps so that the product `gpus * batch size * gradient_accumulation_steps = 256`. We used `--learning-rate` = 1e-4 * gradient accumulation steps.
-+ don't use fp16
-+ `--tokenizer_name google/pegasus-large`
-
-### SFT (No Teacher Distillation)
-You don't need `distillation.py`, you can just run:
-
-```bash
-python finetune.py \
- --data_dir xsum \
- --freeze_encoder --freeze_embeds \
- --learning_rate=3e-4 \
- --do_train \
- --do_predict \
- --fp16 --fp16_opt_level=O1 \
- --val_check_interval 0.1 --n_val 1000 --eval_beams 2 --length_penalty=0.5 \
- --max_target_length=60 --val_max_target_length=60 --test_max_target_length=100 \
- --model_name_or_path dbart_xsum_12_3 \
- --train_batch_size=64 --eval_batch_size=64 \
- --sortish_sampler \
- --num_train_epochs=6 \
- --warmup_steps 500 \
- --output_dir distilbart_xsum_sft_12_3 --gpus 1
-```
-
-+ Note: The command that produced `sshleifer/distilbart-cnn-12-6` is at [train_distilbart_cnn.sh](./[train_distilbart_cnn.sh)
-
-```bash
-./train_distilbart_cnn.sh
-```
-
-+ Tip: You can get the same simple distillation logic by using `distillation.py --no_teacher ` followed by identical arguments as the ones in `train_distilbart_cnn.sh`.
-If you are using `wandb` and comparing the two distillation methods, using this entry point will make your logs consistent,
-because you will have the same hyper-parameters logged in every run.
-
-### Pseudo-Labeling
-+ You don't need `distillation.py`.
-+ Instructions to generate pseudo-labels and use pre-computed pseudo-labels can be found [here](./precomputed_pseudo_labels.md).
-Simply run `finetune.py` with one of those pseudo-label datasets as `--data_dir` (`DATA`, below).
-
-```bash
-python finetune.py \
- --teacher facebook/bart-large-xsum --data_dir DATA \
- --freeze_encoder --freeze_embeds \
- --learning_rate=3e-4 \
- --do_train \
- --do_predict \
- --fp16 --fp16_opt_level=O1 \
- --val_check_interval 0.1 --n_val 1000 --eval_beams 2 --length_penalty=0.5 \
- --max_target_length=60 --val_max_target_length=60 --test_max_target_length=100 \
- --model_name_or_path dbart_xsum_12_3 \
- --train_batch_size=32 --eval_batch_size=32 \
- --sortish_sampler \
- --num_train_epochs=5 \
- --warmup_steps 500 \
- --output_dir dbart_xsum_12_3_PL --gpus 1 --logger_name wandb
-```
-
-
-
-To combine datasets, as in Section 6.2, try something like:
-```bash
-curl -S https://cdn-datasets.huggingface.co/pseudo/xsum/bart_xsum_pl.tgz | tar -xvz -C .
-curl -S https://cdn-datasets.huggingface.co/pseudo/xsum/pegasus_xsum.tgz | tar -xvz -C .
-curl -S https://cdn-datasets.huggingface.co/summarization/xsum.tar.gz | tar -xvz -C .
-mkdir all_pl
-cat bart_xsum_pl/train.source pegasus_xsum/train.source xsum/train.source > all_pl/train.source
-cat bart_xsum_pl/train.target pegasus_xsum/train.target xsum/train.target > all_pl/train.target
-cp xsum/val* all_pl
-cp xsum/test* all_pl
-```
-then use `all_pl` as DATA in the command above.
-
-#### Direct Knowledge Distillation (KD)
-+ In this method, we use try to enforce that the student and teacher produce similar encoder_outputs, logits, and hidden_states using `SummarizationDistiller`.
-+ This method was used for `sshleifer/distilbart-xsum-12-6`, `6-6`, and `9-6` checkpoints were produced.
-+ You must use [`distillation.py`](./distillation.py). Note that this command initializes the student for you.
-
-The command that produced `sshleifer/distilbart-xsum-12-6` is at [./train_distilbart_xsum.sh](train_distilbart_xsum.sh)
-```bash
-./train_distilbart_xsum.sh --logger_name wandb --gpus 1
-```
-
-+ Expected ROUGE-2 between 21.3 and 21.6, run time ~13H.
-+ direct KD + Pegasus is VERY slow and works best with `--supervise_forward --normalize_hidden`.
-
-
-
-### Citation
-
-```bibtex
-@misc{shleifer2020pretrained,
- title={Pre-trained Summarization Distillation},
- author={Sam Shleifer and Alexander M. Rush},
- year={2020},
- eprint={2010.13002},
- archivePrefix={arXiv},
- primaryClass={cs.CL}
-}
-@article{Wolf2019HuggingFacesTS,
- title={HuggingFace's Transformers: State-of-the-art Natural Language Processing},
- author={Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush},
- journal={ArXiv},
- year={2019},
- volume={abs/1910.03771}
-}
-```
diff --git a/examples/research_projects/seq2seq-distillation/_test_bash_script.py b/examples/research_projects/seq2seq-distillation/_test_bash_script.py
deleted file mode 100644
index fa84a60c0c8..00000000000
--- a/examples/research_projects/seq2seq-distillation/_test_bash_script.py
+++ /dev/null
@@ -1,203 +0,0 @@
-#!/usr/bin/env python
-
-import argparse
-import os
-import sys
-from unittest.mock import patch
-
-import pytorch_lightning as pl
-import timeout_decorator
-import torch
-from distillation import SummarizationDistiller, distill_main
-from finetune import SummarizationModule, main
-
-from transformers import MarianMTModel
-from transformers.file_utils import cached_path
-from transformers.testing_utils import TestCasePlus, require_torch_gpu, slow
-from utils import load_json
-
-
-MARIAN_MODEL = "sshleifer/mar_enro_6_3_student"
-
-
-class TestMbartCc25Enro(TestCasePlus):
- def setUp(self):
- super().setUp()
-
- data_cached = cached_path(
- "https://cdn-datasets.huggingface.co/translation/wmt_en_ro-tr40k-va0.5k-te0.5k.tar.gz",
- extract_compressed_file=True,
- )
- self.data_dir = f"{data_cached}/wmt_en_ro-tr40k-va0.5k-te0.5k"
-
- @slow
- @require_torch_gpu
- def test_model_download(self):
- """This warms up the cache so that we can time the next test without including download time, which varies between machines."""
- MarianMTModel.from_pretrained(MARIAN_MODEL)
-
- # @timeout_decorator.timeout(1200)
- @slow
- @require_torch_gpu
- def test_train_mbart_cc25_enro_script(self):
- env_vars_to_replace = {
- "$MAX_LEN": 64,
- "$BS": 64,
- "$GAS": 1,
- "$ENRO_DIR": self.data_dir,
- "facebook/mbart-large-cc25": MARIAN_MODEL,
- # "val_check_interval=0.25": "val_check_interval=1.0",
- "--learning_rate=3e-5": "--learning_rate 3e-4",
- "--num_train_epochs 6": "--num_train_epochs 1",
- }
-
- # Clean up bash script
- bash_script = (self.test_file_dir / "train_mbart_cc25_enro.sh").open().read().split("finetune.py")[1].strip()
- bash_script = bash_script.replace("\\\n", "").strip().replace('"$@"', "")
- for k, v in env_vars_to_replace.items():
- bash_script = bash_script.replace(k, str(v))
- output_dir = self.get_auto_remove_tmp_dir()
-
- # bash_script = bash_script.replace("--fp16 ", "")
- args = f"""
- --output_dir {output_dir}
- --tokenizer_name Helsinki-NLP/opus-mt-en-ro
- --sortish_sampler
- --do_predict
- --gpus 1
- --freeze_encoder
- --n_train 40000
- --n_val 500
- --n_test 500
- --fp16_opt_level O1
- --num_sanity_val_steps 0
- --eval_beams 2
- """.split()
- # XXX: args.gpus > 1 : handle multi_gpu in the future
-
- testargs = ["finetune.py"] + bash_script.split() + args
- with patch.object(sys, "argv", testargs):
- parser = argparse.ArgumentParser()
- parser = pl.Trainer.add_argparse_args(parser)
- parser = SummarizationModule.add_model_specific_args(parser, os.getcwd())
- args = parser.parse_args()
- model = main(args)
-
- # Check metrics
- metrics = load_json(model.metrics_save_path)
- first_step_stats = metrics["val"][0]
- last_step_stats = metrics["val"][-1]
- self.assertEqual(len(metrics["val"]), (args.max_epochs / args.val_check_interval))
- assert isinstance(last_step_stats[f"val_avg_{model.val_metric}"], float)
-
- self.assertGreater(last_step_stats["val_avg_gen_time"], 0.01)
- # model hanging on generate. Maybe bad config was saved. (XXX: old comment/assert?)
- self.assertLessEqual(last_step_stats["val_avg_gen_time"], 1.0)
-
- # test learning requirements:
-
- # 1. BLEU improves over the course of training by more than 2 pts
- self.assertGreater(last_step_stats["val_avg_bleu"] - first_step_stats["val_avg_bleu"], 2)
-
- # 2. BLEU finishes above 17
- self.assertGreater(last_step_stats["val_avg_bleu"], 17)
-
- # 3. test BLEU and val BLEU within ~1.1 pt.
- self.assertLess(abs(metrics["val"][-1]["val_avg_bleu"] - metrics["test"][-1]["test_avg_bleu"]), 1.1)
-
- # check lightning ckpt can be loaded and has a reasonable statedict
- contents = os.listdir(output_dir)
- ckpt_path = [x for x in contents if x.endswith(".ckpt")][0]
- full_path = os.path.join(args.output_dir, ckpt_path)
- ckpt = torch.load(full_path, map_location="cpu")
- expected_key = "model.model.decoder.layers.0.encoder_attn_layer_norm.weight"
- assert expected_key in ckpt["state_dict"]
- assert ckpt["state_dict"]["model.model.decoder.layers.0.encoder_attn_layer_norm.weight"].dtype == torch.float32
-
- # TODO: turn on args.do_predict when PL bug fixed.
- if args.do_predict:
- contents = {os.path.basename(p) for p in contents}
- assert "test_generations.txt" in contents
- assert "test_results.txt" in contents
- # assert len(metrics["val"]) == desired_n_evals
- assert len(metrics["test"]) == 1
-
-
-class TestDistilMarianNoTeacher(TestCasePlus):
- @timeout_decorator.timeout(600)
- @slow
- @require_torch_gpu
- def test_opus_mt_distill_script(self):
- data_dir = f"{self.test_file_dir_str}/test_data/wmt_en_ro"
- env_vars_to_replace = {
- "--fp16_opt_level=O1": "",
- "$MAX_LEN": 128,
- "$BS": 16,
- "$GAS": 1,
- "$ENRO_DIR": data_dir,
- "$m": "sshleifer/student_marian_en_ro_6_1",
- "val_check_interval=0.25": "val_check_interval=1.0",
- }
-
- # Clean up bash script
- bash_script = (
- (self.test_file_dir / "distil_marian_no_teacher.sh").open().read().split("distillation.py")[1].strip()
- )
- bash_script = bash_script.replace("\\\n", "").strip().replace('"$@"', "")
- bash_script = bash_script.replace("--fp16 ", " ")
-
- for k, v in env_vars_to_replace.items():
- bash_script = bash_script.replace(k, str(v))
- output_dir = self.get_auto_remove_tmp_dir()
- bash_script = bash_script.replace("--fp16", "")
- epochs = 6
- testargs = (
- ["distillation.py"]
- + bash_script.split()
- + [
- f"--output_dir={output_dir}",
- "--gpus=1",
- "--learning_rate=1e-3",
- f"--num_train_epochs={epochs}",
- "--warmup_steps=10",
- "--val_check_interval=1.0",
- "--do_predict",
- ]
- )
- with patch.object(sys, "argv", testargs):
- parser = argparse.ArgumentParser()
- parser = pl.Trainer.add_argparse_args(parser)
- parser = SummarizationDistiller.add_model_specific_args(parser, os.getcwd())
- args = parser.parse_args()
- # assert args.gpus == gpus THIS BREAKS for multi_gpu
-
- model = distill_main(args)
-
- # Check metrics
- metrics = load_json(model.metrics_save_path)
- first_step_stats = metrics["val"][0]
- last_step_stats = metrics["val"][-1]
- assert len(metrics["val"]) >= (args.max_epochs / args.val_check_interval) # +1 accounts for val_sanity_check
-
- assert last_step_stats["val_avg_gen_time"] >= 0.01
-
- assert first_step_stats["val_avg_bleu"] < last_step_stats["val_avg_bleu"] # model learned nothing
- assert 1.0 >= last_step_stats["val_avg_gen_time"] # model hanging on generate. Maybe bad config was saved.
- assert isinstance(last_step_stats[f"val_avg_{model.val_metric}"], float)
-
- # check lightning ckpt can be loaded and has a reasonable statedict
- contents = os.listdir(output_dir)
- ckpt_path = [x for x in contents if x.endswith(".ckpt")][0]
- full_path = os.path.join(args.output_dir, ckpt_path)
- ckpt = torch.load(full_path, map_location="cpu")
- expected_key = "model.model.decoder.layers.0.encoder_attn_layer_norm.weight"
- assert expected_key in ckpt["state_dict"]
- assert ckpt["state_dict"]["model.model.decoder.layers.0.encoder_attn_layer_norm.weight"].dtype == torch.float32
-
- # TODO: turn on args.do_predict when PL bug fixed.
- if args.do_predict:
- contents = {os.path.basename(p) for p in contents}
- assert "test_generations.txt" in contents
- assert "test_results.txt" in contents
- # assert len(metrics["val"]) == desired_n_evals
- assert len(metrics["test"]) == 1
diff --git a/examples/research_projects/seq2seq-distillation/_test_make_student.py b/examples/research_projects/seq2seq-distillation/_test_make_student.py
deleted file mode 100644
index 73df66315cb..00000000000
--- a/examples/research_projects/seq2seq-distillation/_test_make_student.py
+++ /dev/null
@@ -1,40 +0,0 @@
-import tempfile
-import unittest
-
-from make_student import create_student_by_copying_alternating_layers
-
-from transformers import AutoConfig
-from transformers.file_utils import cached_property
-from transformers.testing_utils import require_torch
-
-
-TINY_BART = "sshleifer/bart-tiny-random"
-TINY_T5 = "patrickvonplaten/t5-tiny-random"
-
-
-@require_torch
-class MakeStudentTester(unittest.TestCase):
- @cached_property
- def teacher_config(self):
- return AutoConfig.from_pretrained(TINY_BART)
-
- def test_valid_t5(self):
- student, *_ = create_student_by_copying_alternating_layers(TINY_T5, tempfile.mkdtemp(), e=1, d=1)
- self.assertEqual(student.config.num_hidden_layers, 1)
-
- def test_asymmetric_t5(self):
- student, *_ = create_student_by_copying_alternating_layers(TINY_T5, tempfile.mkdtemp(), e=1, d=None)
-
- def test_same_decoder_small_encoder(self):
- student, *_ = create_student_by_copying_alternating_layers(TINY_BART, tempfile.mkdtemp(), e=1, d=None)
- self.assertEqual(student.config.encoder_layers, 1)
- self.assertEqual(student.config.decoder_layers, self.teacher_config.encoder_layers)
-
- def test_small_enc_small_dec(self):
- student, *_ = create_student_by_copying_alternating_layers(TINY_BART, tempfile.mkdtemp(), e=1, d=1)
- self.assertEqual(student.config.encoder_layers, 1)
- self.assertEqual(student.config.decoder_layers, 1)
-
- def test_raises_assert(self):
- with self.assertRaises(AssertionError):
- create_student_by_copying_alternating_layers(TINY_BART, tempfile.mkdtemp(), e=None, d=None)
diff --git a/examples/research_projects/seq2seq-distillation/_test_seq2seq_examples.py b/examples/research_projects/seq2seq-distillation/_test_seq2seq_examples.py
deleted file mode 100644
index 0ee4dd8afe1..00000000000
--- a/examples/research_projects/seq2seq-distillation/_test_seq2seq_examples.py
+++ /dev/null
@@ -1,444 +0,0 @@
-import argparse
-import logging
-import os
-import sys
-import tempfile
-from pathlib import Path
-
-import lightning_base
-import pytest
-import pytorch_lightning as pl
-import torch
-from convert_pl_checkpoint_to_hf import convert_pl_to_hf
-from distillation import distill_main
-from finetune import SummarizationModule, main
-from huggingface_hub import list_models
-from parameterized import parameterized
-from run_eval import generate_summaries_or_translations
-from torch import nn
-
-from transformers import AutoConfig, AutoModelForSeq2SeqLM
-from transformers.testing_utils import CaptureStderr, CaptureStdout, TestCasePlus, require_torch_gpu, slow
-from utils import label_smoothed_nll_loss, lmap, load_json
-
-
-logging.basicConfig(level=logging.DEBUG)
-
-logger = logging.getLogger()
-CUDA_AVAILABLE = torch.cuda.is_available()
-CHEAP_ARGS = {
- "max_tokens_per_batch": None,
- "supervise_forward": True,
- "normalize_hidden": True,
- "label_smoothing": 0.2,
- "eval_max_gen_length": None,
- "eval_beams": 1,
- "val_metric": "loss",
- "save_top_k": 1,
- "adafactor": True,
- "early_stopping_patience": 2,
- "logger_name": "default",
- "length_penalty": 0.5,
- "cache_dir": "",
- "task": "summarization",
- "num_workers": 2,
- "alpha_hid": 0,
- "freeze_embeds": True,
- "enc_only": False,
- "tgt_suffix": "",
- "resume_from_checkpoint": None,
- "sortish_sampler": True,
- "student_decoder_layers": 1,
- "val_check_interval": 1.0,
- "output_dir": "",
- "fp16": False, # TODO(SS): set this to CUDA_AVAILABLE if ci installs apex or start using native amp
- "no_teacher": False,
- "fp16_opt_level": "O1",
- "gpus": 1 if CUDA_AVAILABLE else 0,
- "n_tpu_cores": 0,
- "max_grad_norm": 1.0,
- "do_train": True,
- "do_predict": True,
- "accumulate_grad_batches": 1,
- "server_ip": "",
- "server_port": "",
- "seed": 42,
- "model_name_or_path": "sshleifer/bart-tiny-random",
- "config_name": "",
- "tokenizer_name": "facebook/bart-large",
- "do_lower_case": False,
- "learning_rate": 0.3,
- "lr_scheduler": "linear",
- "weight_decay": 0.0,
- "adam_epsilon": 1e-08,
- "warmup_steps": 0,
- "max_epochs": 1,
- "train_batch_size": 2,
- "eval_batch_size": 2,
- "max_source_length": 12,
- "max_target_length": 12,
- "val_max_target_length": 12,
- "test_max_target_length": 12,
- "fast_dev_run": False,
- "no_cache": False,
- "n_train": -1,
- "n_val": -1,
- "n_test": -1,
- "student_encoder_layers": 1,
- "freeze_encoder": False,
- "auto_scale_batch_size": False,
- "overwrite_output_dir": False,
- "student": None,
-}
-
-
-def _dump_articles(path: Path, articles: list):
- content = "\n".join(articles)
- Path(path).open("w").writelines(content)
-
-
-ARTICLES = [" Sam ate lunch today.", "Sams lunch ingredients."]
-SUMMARIES = ["A very interesting story about what I ate for lunch.", "Avocado, celery, turkey, coffee"]
-T5_TINY = "patrickvonplaten/t5-tiny-random"
-T5_TINIER = "sshleifer/t5-tinier-random"
-BART_TINY = "sshleifer/bart-tiny-random"
-MBART_TINY = "sshleifer/tiny-mbart"
-MARIAN_TINY = "sshleifer/tiny-marian-en-de"
-FSMT_TINY = "stas/tiny-wmt19-en-de"
-
-
-stream_handler = logging.StreamHandler(sys.stdout)
-logger.addHandler(stream_handler)
-logging.disable(logging.CRITICAL) # remove noisy download output from tracebacks
-
-
-def make_test_data_dir(tmp_dir):
- for split in ["train", "val", "test"]:
- _dump_articles(os.path.join(tmp_dir, f"{split}.source"), ARTICLES)
- _dump_articles(os.path.join(tmp_dir, f"{split}.target"), SUMMARIES)
- return tmp_dir
-
-
-class TestSummarizationDistiller(TestCasePlus):
- @classmethod
- def setUpClass(cls):
- logging.disable(logging.CRITICAL) # remove noisy download output from tracebacks
- return cls
-
- @slow
- @require_torch_gpu
- def test_hub_configs(self):
- """I put require_torch_gpu cause I only want this to run with self-scheduled."""
-
- model_list = list_models()
- org = "sshleifer"
- model_ids = [x.modelId for x in model_list if x.modelId.startswith(org)]
- allowed_to_be_broken = ["sshleifer/blenderbot-3B", "sshleifer/blenderbot-90M"]
- failures = []
- for m in model_ids:
- if m in allowed_to_be_broken:
- continue
- try:
- AutoConfig.from_pretrained(m)
- except Exception:
- failures.append(m)
- assert not failures, f"The following models could not be loaded through AutoConfig: {failures}"
-
- def test_distill_no_teacher(self):
- updates = {"student_encoder_layers": 2, "student_decoder_layers": 1, "no_teacher": True}
- self._test_distiller_cli(updates)
-
- def test_distill_checkpointing_with_teacher(self):
- updates = {
- "student_encoder_layers": 2,
- "student_decoder_layers": 1,
- "max_epochs": 4,
- "val_check_interval": 0.25,
- "alpha_hid": 2.0,
- "model_name_or_path": "IGNORE_THIS_IT_DOESNT_GET_USED",
- }
- model = self._test_distiller_cli(updates, check_contents=False)
-
- ckpts = list(Path(model.output_dir).glob("*.ckpt"))
- self.assertEqual(1, len(ckpts))
- transformer_ckpts = list(Path(model.output_dir).glob("**/*.bin"))
- self.assertEqual(len(transformer_ckpts), 2)
- examples = lmap(str.strip, Path(model.hparams.data_dir).joinpath("test.source").open().readlines())
- out_path = tempfile.mktemp() # XXX: not being cleaned up
- generate_summaries_or_translations(examples, out_path, str(model.output_dir / "best_tfmr"))
- self.assertTrue(Path(out_path).exists())
-
- out_path_new = self.get_auto_remove_tmp_dir()
- convert_pl_to_hf(ckpts[0], transformer_ckpts[0].parent, out_path_new)
- assert os.path.exists(os.path.join(out_path_new, "pytorch_model.bin"))
-
- def test_loss_fn(self):
- model = AutoModelForSeq2SeqLM.from_pretrained(BART_TINY)
- input_ids, mask = model.dummy_inputs["input_ids"], model.dummy_inputs["attention_mask"]
- target_ids = torch.tensor([[0, 4, 8, 2], [0, 8, 2, 1]], dtype=torch.long, device=model.device)
- decoder_input_ids = target_ids[:, :-1].contiguous() # Why this line?
- lm_labels = target_ids[:, 1:].clone() # why clone?
- model_computed_loss = model(
- input_ids, attention_mask=mask, decoder_input_ids=decoder_input_ids, labels=lm_labels, use_cache=False
- ).loss
-
- logits = model(input_ids, attention_mask=mask, decoder_input_ids=decoder_input_ids, use_cache=False).logits
-
- lprobs = nn.functional.log_softmax(logits, dim=-1)
- smoothed_loss, nll_loss = label_smoothed_nll_loss(
- lprobs, lm_labels, 0.1, ignore_index=model.config.pad_token_id
- )
- with self.assertRaises(AssertionError):
- # TODO: understand why this breaks
- self.assertEqual(nll_loss, model_computed_loss)
-
- def test_distill_mbart(self):
- updates = {
- "student_encoder_layers": 2,
- "student_decoder_layers": 1,
- "num_train_epochs": 4,
- "val_check_interval": 0.25,
- "alpha_hid": 2.0,
- "task": "translation",
- "model_name_or_path": "IGNORE_THIS_IT_DOESNT_GET_USED",
- "tokenizer_name": MBART_TINY,
- "teacher": MBART_TINY,
- "src_lang": "en_XX",
- "tgt_lang": "ro_RO",
- }
- model = self._test_distiller_cli(updates, check_contents=False)
- assert model.model.config.model_type == "mbart"
-
- ckpts = list(Path(model.output_dir).glob("*.ckpt"))
- self.assertEqual(1, len(ckpts))
- transformer_ckpts = list(Path(model.output_dir).glob("**/*.bin"))
- all_files = list(Path(model.output_dir).glob("best_tfmr/*"))
- assert len(all_files) > 2
- self.assertEqual(len(transformer_ckpts), 2)
-
- def test_distill_t5(self):
- updates = {
- "student_encoder_layers": 1,
- "student_decoder_layers": 1,
- "alpha_hid": 2.0,
- "teacher": T5_TINY,
- "model_name_or_path": T5_TINY,
- "tokenizer_name": T5_TINY,
- }
- self._test_distiller_cli(updates)
-
- def test_distill_different_base_models(self):
- updates = {
- "teacher": T5_TINY,
- "student": T5_TINIER,
- "model_name_or_path": T5_TINIER,
- "tokenizer_name": T5_TINIER,
- }
- self._test_distiller_cli(updates)
-
- def _test_distiller_cli(self, updates, check_contents=True):
- default_updates = {
- "label_smoothing": 0.0,
- "early_stopping_patience": -1,
- "train_batch_size": 1,
- "eval_batch_size": 2,
- "max_epochs": 2,
- "alpha_mlm": 0.2,
- "alpha_ce": 0.8,
- "do_predict": True,
- "model_name_or_path": "sshleifer/tinier_bart",
- "teacher": CHEAP_ARGS["model_name_or_path"],
- "val_check_interval": 0.5,
- }
- default_updates.update(updates)
- args_d: dict = CHEAP_ARGS.copy()
- tmp_dir = make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir())
- output_dir = self.get_auto_remove_tmp_dir()
-
- args_d.update(data_dir=tmp_dir, output_dir=output_dir, **default_updates)
- model = distill_main(argparse.Namespace(**args_d))
- if not check_contents:
- return model
- contents = os.listdir(output_dir)
- contents = {os.path.basename(p) for p in contents}
- ckpt_files = [p for p in contents if p.endswith("ckpt")]
- assert len(ckpt_files) > 0
-
- self.assertIn("test_generations.txt", contents)
- self.assertIn("test_results.txt", contents)
-
- metrics = load_json(model.metrics_save_path)
- last_step_stats = metrics["val"][-1]
- self.assertGreaterEqual(last_step_stats["val_avg_gen_time"], 0.01)
- self.assertGreaterEqual(1.0, last_step_stats["val_avg_gen_time"])
- self.assertIsInstance(last_step_stats[f"val_avg_{model.val_metric}"], float)
- desired_n_evals = int(args_d["max_epochs"] * (1 / args_d["val_check_interval"]) + 1)
- self.assertEqual(len(metrics["val"]), desired_n_evals)
- self.assertEqual(len(metrics["test"]), 1)
- return model
-
-
-class TestTheRest(TestCasePlus):
- @parameterized.expand(
- [T5_TINY, BART_TINY, MBART_TINY, MARIAN_TINY, FSMT_TINY],
- )
- def test_finetune(self, model):
- args_d: dict = CHEAP_ARGS.copy()
- task = "translation" if model in [MBART_TINY, MARIAN_TINY, FSMT_TINY] else "summarization"
- args_d["label_smoothing"] = 0.1 if task == "translation" else 0
-
- tmp_dir = make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir())
- output_dir = self.get_auto_remove_tmp_dir()
- args_d.update(
- data_dir=tmp_dir,
- model_name_or_path=model,
- tokenizer_name=None,
- train_batch_size=2,
- eval_batch_size=2,
- output_dir=output_dir,
- do_predict=True,
- task=task,
- src_lang="en_XX",
- tgt_lang="ro_RO",
- freeze_encoder=True,
- freeze_embeds=True,
- )
- assert "n_train" in args_d
- args = argparse.Namespace(**args_d)
- module = main(args)
-
- input_embeds = module.model.get_input_embeddings()
- assert not input_embeds.weight.requires_grad
- if model == T5_TINY:
- lm_head = module.model.lm_head
- assert not lm_head.weight.requires_grad
- assert (lm_head.weight == input_embeds.weight).all().item()
- elif model == FSMT_TINY:
- fsmt = module.model.model
- embed_pos = fsmt.decoder.embed_positions
- assert not embed_pos.weight.requires_grad
- assert not fsmt.decoder.embed_tokens.weight.requires_grad
- # check that embeds are not the same
- assert fsmt.decoder.embed_tokens != fsmt.encoder.embed_tokens
- else:
- bart = module.model.model
- embed_pos = bart.decoder.embed_positions
- assert not embed_pos.weight.requires_grad
- assert not bart.shared.weight.requires_grad
- # check that embeds are the same
- assert bart.decoder.embed_tokens == bart.encoder.embed_tokens
- assert bart.decoder.embed_tokens == bart.shared
-
- example_batch = load_json(module.output_dir / "text_batch.json")
- assert isinstance(example_batch, dict)
- assert len(example_batch) >= 4
-
- def test_finetune_extra_model_args(self):
- args_d: dict = CHEAP_ARGS.copy()
-
- task = "summarization"
- tmp_dir = make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir())
-
- args_d.update(
- data_dir=tmp_dir,
- tokenizer_name=None,
- train_batch_size=2,
- eval_batch_size=2,
- do_predict=False,
- task=task,
- src_lang="en_XX",
- tgt_lang="ro_RO",
- freeze_encoder=True,
- freeze_embeds=True,
- )
-
- # test models whose config includes the extra_model_args
- model = BART_TINY
- output_dir = self.get_auto_remove_tmp_dir()
- args_d1 = args_d.copy()
- args_d1.update(
- model_name_or_path=model,
- output_dir=output_dir,
- )
- extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "dropout", "attention_dropout")
- for p in extra_model_params:
- args_d1[p] = 0.5
- args = argparse.Namespace(**args_d1)
- model = main(args)
- for p in extra_model_params:
- assert getattr(model.config, p) == 0.5, f"failed to override the model config for param {p}"
-
- # test models whose config doesn't include the extra_model_args
- model = T5_TINY
- output_dir = self.get_auto_remove_tmp_dir()
- args_d2 = args_d.copy()
- args_d2.update(
- model_name_or_path=model,
- output_dir=output_dir,
- )
- unsupported_param = "encoder_layerdrop"
- args_d2[unsupported_param] = 0.5
- args = argparse.Namespace(**args_d2)
- with pytest.raises(Exception) as excinfo:
- model = main(args)
- assert str(excinfo.value) == f"model config doesn't have a `{unsupported_param}` attribute"
-
- def test_finetune_lr_schedulers(self):
- args_d: dict = CHEAP_ARGS.copy()
-
- task = "summarization"
- tmp_dir = make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir())
-
- model = BART_TINY
- output_dir = self.get_auto_remove_tmp_dir()
-
- args_d.update(
- data_dir=tmp_dir,
- model_name_or_path=model,
- output_dir=output_dir,
- tokenizer_name=None,
- train_batch_size=2,
- eval_batch_size=2,
- do_predict=False,
- task=task,
- src_lang="en_XX",
- tgt_lang="ro_RO",
- freeze_encoder=True,
- freeze_embeds=True,
- )
-
- # emulate finetune.py
- parser = argparse.ArgumentParser()
- parser = pl.Trainer.add_argparse_args(parser)
- parser = SummarizationModule.add_model_specific_args(parser, os.getcwd())
- args = {"--help": True}
-
- # --help test
- with pytest.raises(SystemExit) as excinfo:
- with CaptureStdout() as cs:
- args = parser.parse_args(args)
- assert False, "--help is expected to sys.exit"
- assert excinfo.type is SystemExit
- expected = lightning_base.arg_to_scheduler_metavar
- assert expected in cs.out, "--help is expected to list the supported schedulers"
-
- # --lr_scheduler=non_existing_scheduler test
- unsupported_param = "non_existing_scheduler"
- args = {f"--lr_scheduler={unsupported_param}"}
- with pytest.raises(SystemExit) as excinfo:
- with CaptureStderr() as cs:
- args = parser.parse_args(args)
- assert False, "invalid argument is expected to sys.exit"
- assert excinfo.type is SystemExit
- expected = f"invalid choice: '{unsupported_param}'"
- assert expected in cs.err, f"should have bailed on invalid choice of scheduler {unsupported_param}"
-
- # --lr_scheduler=existing_scheduler test
- supported_param = "cosine"
- args_d1 = args_d.copy()
- args_d1["lr_scheduler"] = supported_param
- args = argparse.Namespace(**args_d1)
- model = main(args)
- assert (
- getattr(model.hparams, "lr_scheduler") == supported_param
- ), f"lr_scheduler={supported_param} shouldn't fail"
diff --git a/examples/research_projects/seq2seq-distillation/_test_seq2seq_examples_multi_gpu.py b/examples/research_projects/seq2seq-distillation/_test_seq2seq_examples_multi_gpu.py
deleted file mode 100644
index 9eeb3b30d39..00000000000
--- a/examples/research_projects/seq2seq-distillation/_test_seq2seq_examples_multi_gpu.py
+++ /dev/null
@@ -1,163 +0,0 @@
-# as due to their complexity multi-gpu tests could impact other tests, and to aid debug we have those in a separate module.
-
-import os
-import sys
-from pathlib import Path
-
-import torch
-
-from transformers.testing_utils import TestCasePlus, execute_subprocess_async, require_torch_multi_gpu
-from utils import load_json
-
-
-CUDA_AVAILABLE = torch.cuda.is_available()
-ARTICLES = [" Sam ate lunch today.", "Sams lunch ingredients."]
-SUMMARIES = ["A very interesting story about what I ate for lunch.", "Avocado, celery, turkey, coffee"]
-CHEAP_ARGS = {
- "max_tokens_per_batch": None,
- "supervise_forward": True,
- "normalize_hidden": True,
- "label_smoothing": 0.2,
- "eval_max_gen_length": None,
- "eval_beams": 1,
- "val_metric": "loss",
- "save_top_k": 1,
- "adafactor": True,
- "early_stopping_patience": 2,
- "logger_name": "default",
- "length_penalty": 0.5,
- "cache_dir": "",
- "task": "summarization",
- "num_workers": 2,
- "alpha_hid": 0,
- "freeze_embeds": True,
- "enc_only": False,
- "tgt_suffix": "",
- "resume_from_checkpoint": None,
- "sortish_sampler": True,
- "student_decoder_layers": 1,
- "val_check_interval": 1.0,
- "output_dir": "",
- "fp16": False, # TODO(SS): set this to CUDA_AVAILABLE if ci installs apex or start using native amp
- "no_teacher": False,
- "fp16_opt_level": "O1",
- "gpus": 1 if CUDA_AVAILABLE else 0,
- "n_tpu_cores": 0,
- "max_grad_norm": 1.0,
- "do_train": True,
- "do_predict": True,
- "accumulate_grad_batches": 1,
- "server_ip": "",
- "server_port": "",
- "seed": 42,
- "model_name_or_path": "sshleifer/bart-tiny-random",
- "config_name": "",
- "tokenizer_name": "facebook/bart-large",
- "do_lower_case": False,
- "learning_rate": 0.3,
- "lr_scheduler": "linear",
- "weight_decay": 0.0,
- "adam_epsilon": 1e-08,
- "warmup_steps": 0,
- "max_epochs": 1,
- "train_batch_size": 2,
- "eval_batch_size": 2,
- "max_source_length": 12,
- "max_target_length": 12,
- "val_max_target_length": 12,
- "test_max_target_length": 12,
- "fast_dev_run": False,
- "no_cache": False,
- "n_train": -1,
- "n_val": -1,
- "n_test": -1,
- "student_encoder_layers": 1,
- "freeze_encoder": False,
- "auto_scale_batch_size": False,
- "overwrite_output_dir": False,
- "student": None,
-}
-
-
-def _dump_articles(path: Path, articles: list):
- content = "\n".join(articles)
- Path(path).open("w").writelines(content)
-
-
-def make_test_data_dir(tmp_dir):
- for split in ["train", "val", "test"]:
- _dump_articles(os.path.join(tmp_dir, f"{split}.source"), ARTICLES)
- _dump_articles(os.path.join(tmp_dir, f"{split}.target"), SUMMARIES)
- return tmp_dir
-
-
-class TestSummarizationDistillerMultiGPU(TestCasePlus):
- @classmethod
- def setUpClass(cls):
- return cls
-
- @require_torch_multi_gpu
- def test_multi_gpu(self):
- updates = {
- "no_teacher": True,
- "freeze_encoder": True,
- "gpus": 2,
- "overwrite_output_dir": True,
- "sortish_sampler": True,
- }
- self._test_distiller_cli_fork(updates, check_contents=False)
-
- def _test_distiller_cli_fork(self, updates, check_contents=True):
- default_updates = {
- "label_smoothing": 0.0,
- "early_stopping_patience": -1,
- "train_batch_size": 1,
- "eval_batch_size": 2,
- "max_epochs": 2,
- "alpha_mlm": 0.2,
- "alpha_ce": 0.8,
- "do_predict": True,
- "model_name_or_path": "sshleifer/tinier_bart",
- "teacher": CHEAP_ARGS["model_name_or_path"],
- "val_check_interval": 0.5,
- }
- default_updates.update(updates)
- args_d: dict = CHEAP_ARGS.copy()
- tmp_dir = make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir())
- output_dir = self.get_auto_remove_tmp_dir()
- args_d.update(data_dir=tmp_dir, output_dir=output_dir, **default_updates)
-
- def convert(k, v):
- if k in ["tgt_suffix", "server_ip", "server_port", "out", "n_tpu_cores"]:
- return ""
- if v is False or v is None:
- return ""
- if v is True: # or len(str(v))==0:
- return f"--{k}"
- return f"--{k}={v}"
-
- cli_args = [x for x in (convert(k, v) for k, v in args_d.items()) if len(x)]
- cmd = [sys.executable, f"{self.test_file_dir}/distillation.py"] + cli_args
- execute_subprocess_async(cmd, env=self.get_env())
-
- contents = os.listdir(output_dir)
- contents = {os.path.basename(p) for p in contents}
- ckpt_files = [p for p in contents if p.endswith("ckpt")]
- assert len(ckpt_files) > 0
-
- self.assertIn("test_generations.txt", contents)
- self.assertIn("test_results.txt", contents)
-
- # get the following from the module, (we don't have access to `model` here)
- metrics_save_path = os.path.join(output_dir, "metrics.json")
- val_metric = "rouge2"
-
- metrics = load_json(metrics_save_path)
- # {'test': [{'test_avg_loss': 10.63731575012207, 'test_avg_rouge1': 0.0, 'test_avg_rouge2': 0.0, 'test_avg_rougeL': 0.0, 'test_avg_gen_time': 0.1822289228439331, 'test_avg_gen_len': 142.0, 'step_count': 1}]}
- print(metrics)
- last_step_stats = metrics["val"][-1]
- self.assertGreaterEqual(last_step_stats["val_avg_gen_time"], 0.01)
- self.assertIsInstance(last_step_stats[f"val_avg_{val_metric}"], float)
- self.assertEqual(len(metrics["test"]), 1)
- desired_n_evals = int(args_d["max_epochs"] * (1 / args_d["val_check_interval"]) / 2 + 1)
- self.assertEqual(len(metrics["val"]), desired_n_evals)
diff --git a/examples/research_projects/seq2seq-distillation/callbacks.py b/examples/research_projects/seq2seq-distillation/callbacks.py
deleted file mode 100644
index 6f6ed5dd58a..00000000000
--- a/examples/research_projects/seq2seq-distillation/callbacks.py
+++ /dev/null
@@ -1,116 +0,0 @@
-import logging
-from pathlib import Path
-
-import numpy as np
-import pytorch_lightning as pl
-import torch
-from pytorch_lightning.callbacks import EarlyStopping, ModelCheckpoint
-from pytorch_lightning.utilities import rank_zero_only
-
-from utils import save_json
-
-
-def count_trainable_parameters(model):
- model_parameters = filter(lambda p: p.requires_grad, model.parameters())
- params = sum([np.prod(p.size()) for p in model_parameters])
- return params
-
-
-logger = logging.getLogger(__name__)
-
-
-class Seq2SeqLoggingCallback(pl.Callback):
- def on_batch_end(self, trainer, pl_module):
- lrs = {f"lr_group_{i}": param["lr"] for i, param in enumerate(pl_module.trainer.optimizers[0].param_groups)}
- pl_module.logger.log_metrics(lrs)
-
- @rank_zero_only
- def _write_logs(
- self, trainer: pl.Trainer, pl_module: pl.LightningModule, type_path: str, save_generations=True
- ) -> None:
- logger.info(f"***** {type_path} results at step {trainer.global_step:05d} *****")
- metrics = trainer.callback_metrics
- trainer.logger.log_metrics({k: v for k, v in metrics.items() if k not in ["log", "progress_bar", "preds"]})
- # Log results
- od = Path(pl_module.hparams.output_dir)
- if type_path == "test":
- results_file = od / "test_results.txt"
- generations_file = od / "test_generations.txt"
- else:
- # this never gets hit. I prefer not to save intermediate generations, and results are in metrics.json
- # If people want this it will be easy enough to add back.
- results_file = od / f"{type_path}_results/{trainer.global_step:05d}.txt"
- generations_file = od / f"{type_path}_generations/{trainer.global_step:05d}.txt"
- results_file.parent.mkdir(exist_ok=True)
- generations_file.parent.mkdir(exist_ok=True)
- with open(results_file, "a+") as writer:
- for key in sorted(metrics):
- if key in ["log", "progress_bar", "preds"]:
- continue
- val = metrics[key]
- if isinstance(val, torch.Tensor):
- val = val.item()
- msg = f"{key}: {val:.6f}\n"
- writer.write(msg)
-
- if not save_generations:
- return
-
- if "preds" in metrics:
- content = "\n".join(metrics["preds"])
- generations_file.open("w+").write(content)
-
- @rank_zero_only
- def on_train_start(self, trainer, pl_module):
- try:
- npars = pl_module.model.model.num_parameters()
- except AttributeError:
- npars = pl_module.model.num_parameters()
-
- n_trainable_pars = count_trainable_parameters(pl_module)
- # mp stands for million parameters
- trainer.logger.log_metrics({"n_params": npars, "mp": npars / 1e6, "grad_mp": n_trainable_pars / 1e6})
-
- @rank_zero_only
- def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
- save_json(pl_module.metrics, pl_module.metrics_save_path)
- return self._write_logs(trainer, pl_module, "test")
-
- @rank_zero_only
- def on_validation_end(self, trainer: pl.Trainer, pl_module):
- save_json(pl_module.metrics, pl_module.metrics_save_path)
- # Uncommenting this will save val generations
- # return self._write_logs(trainer, pl_module, "valid")
-
-
-def get_checkpoint_callback(output_dir, metric, save_top_k=1, lower_is_better=False):
- """Saves the best model by validation ROUGE2 score."""
- if metric == "rouge2":
- exp = "{val_avg_rouge2:.4f}-{step_count}"
- elif metric == "bleu":
- exp = "{val_avg_bleu:.4f}-{step_count}"
- elif metric == "loss":
- exp = "{val_avg_loss:.4f}-{step_count}"
- else:
- raise NotImplementedError(
- f"seq2seq callbacks only support rouge2, bleu and loss, got {metric}, You can make your own by adding to"
- " this function."
- )
-
- checkpoint_callback = ModelCheckpoint(
- dirpath=output_dir,
- filename=exp,
- monitor=f"val_{metric}",
- mode="min" if "loss" in metric else "max",
- save_top_k=save_top_k,
- )
- return checkpoint_callback
-
-
-def get_early_stopping_callback(metric, patience):
- return EarlyStopping(
- monitor=f"val_{metric}", # does this need avg?
- mode="min" if "loss" in metric else "max",
- patience=patience,
- verbose=True,
- )
diff --git a/examples/research_projects/seq2seq-distillation/convert_pl_checkpoint_to_hf.py b/examples/research_projects/seq2seq-distillation/convert_pl_checkpoint_to_hf.py
deleted file mode 100755
index 5f3c984f372..00000000000
--- a/examples/research_projects/seq2seq-distillation/convert_pl_checkpoint_to_hf.py
+++ /dev/null
@@ -1,74 +0,0 @@
-#!/usr/bin/env python
-
-import os
-from pathlib import Path
-from typing import Dict, List
-
-import fire
-import torch
-
-from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
-from transformers.utils.logging import get_logger
-
-
-logger = get_logger(__name__)
-
-
-def remove_prefix(text: str, prefix: str):
- if text.startswith(prefix):
- return text[len(prefix) :]
- return text # or whatever
-
-
-def sanitize(sd):
- return {remove_prefix(k, "model."): v for k, v in sd.items()}
-
-
-def average_state_dicts(state_dicts: List[Dict[str, torch.Tensor]]):
- new_sd = {}
- for k in state_dicts[0].keys():
- tensors = [sd[k] for sd in state_dicts]
- new_t = sum(tensors) / len(tensors)
- assert isinstance(new_t, torch.Tensor)
- new_sd[k] = new_t
- return new_sd
-
-
-def convert_pl_to_hf(pl_ckpt_path: str, hf_src_model_dir: str, save_path: str) -> None:
- """Cleanup a pytorch-lightning .ckpt file or experiment dir and save a huggingface model with that state dict.
- Silently allows extra pl keys (like teacher.) Puts all ckpt models into CPU RAM at once!
-
- Args:
- pl_ckpt_path (:obj:`str`): Path to a .ckpt file saved by pytorch_lightning or dir containing ckpt files.
- If a directory is passed, all .ckpt files inside it will be averaged!
- hf_src_model_dir (:obj:`str`): Path to a directory containing a correctly shaped checkpoint
- save_path (:obj:`str`): Directory to save the new model
-
- """
- hf_model = AutoModelForSeq2SeqLM.from_pretrained(hf_src_model_dir)
- if os.path.isfile(pl_ckpt_path):
- ckpt_files = [pl_ckpt_path]
- else:
- assert os.path.isdir(pl_ckpt_path)
- ckpt_files = list(Path(pl_ckpt_path).glob("*.ckpt"))
- assert ckpt_files, f"could not find any ckpt files inside the {pl_ckpt_path} directory"
-
- if len(ckpt_files) > 1:
- logger.info(f"averaging the weights of {ckpt_files}")
-
- state_dicts = [sanitize(torch.load(x, map_location="cpu")["state_dict"]) for x in ckpt_files]
- state_dict = average_state_dicts(state_dicts)
-
- missing, unexpected = hf_model.load_state_dict(state_dict, strict=False)
- assert not missing, f"missing keys: {missing}"
- hf_model.save_pretrained(save_path)
- try:
- tok = AutoTokenizer.from_pretrained(hf_src_model_dir)
- tok.save_pretrained(save_path)
- except Exception:
- pass
- # dont copy tokenizer if cant
-
-
-if __name__ == "__main__":
- fire.Fire(convert_pl_to_hf)
diff --git a/examples/research_projects/seq2seq-distillation/distil_marian_enro_teacher.sh b/examples/research_projects/seq2seq-distillation/distil_marian_enro_teacher.sh
deleted file mode 100755
index 5c938a71604..00000000000
--- a/examples/research_projects/seq2seq-distillation/distil_marian_enro_teacher.sh
+++ /dev/null
@@ -1,20 +0,0 @@
-#!/usr/bin/env bash
-export PYTHONPATH="../":"${PYTHONPATH}"
-export WANDB_PROJECT=dmar
-# export MAX_LEN=128
-python distillation.py \
- --learning_rate=3e-4 \
- --do_train \
- --fp16 \
- --val_check_interval 0.25 \
- --teacher Helsinki-NLP/opus-mt-en-ro \
- --max_source_length $MAX_LEN --max_target_length $MAX_LEN --val_max_target_length $MAX_LEN --test_max_target_length $MAX_LEN \
- --student_decoder_layers 3 --student_encoder_layers 6 \
- --freeze_encoder --freeze_embeds \
- --model_name_or_path IGNORED \
- --alpha_hid=3. \
- --train_batch_size=$BS --eval_batch_size=$BS \
- --tokenizer_name Helsinki-NLP/opus-mt-en-ro \
- --warmup_steps 500 --logger_name wandb \
- --fp16_opt_level O1 --task translation --normalize_hidden --num_sanity_val_steps=0 \
- "$@"
diff --git a/examples/research_projects/seq2seq-distillation/distil_marian_no_teacher.sh b/examples/research_projects/seq2seq-distillation/distil_marian_no_teacher.sh
deleted file mode 100755
index 4f0f53d7960..00000000000
--- a/examples/research_projects/seq2seq-distillation/distil_marian_no_teacher.sh
+++ /dev/null
@@ -1,18 +0,0 @@
-#!/usr/bin/env bash
-export PYTHONPATH="../":"${PYTHONPATH}"
-export WANDB_PROJECT=dmar
-export MAX_LEN=128
-python finetune.py \
- --learning_rate=3e-4 \
- --do_train \
- --do_predict \
- --fp16 \
- --val_check_interval 0.25 \
- --data_dir $ENRO_DIR \
- --max_source_length $MAX_LEN --max_target_length $MAX_LEN --val_max_target_length $MAX_LEN --test_max_target_length $MAX_LEN \
- --freeze_encoder --freeze_embeds \
- --train_batch_size=$BS --eval_batch_size=$BS \
- --tokenizer_name $m --model_name_or_path $m \
- --warmup_steps 500 --sortish_sampler --logger_name wandb \
- --gpus 1 --fp16_opt_level=O1 --task translation --num_sanity_val_steps=0 \
- "$@"
diff --git a/examples/research_projects/seq2seq-distillation/distillation.py b/examples/research_projects/seq2seq-distillation/distillation.py
deleted file mode 100755
index 323f62bf458..00000000000
--- a/examples/research_projects/seq2seq-distillation/distillation.py
+++ /dev/null
@@ -1,310 +0,0 @@
-#!/usr/bin/env python
-
-import argparse
-import gc
-import os
-import sys
-from pathlib import Path
-from typing import List # noqa: F401
-
-import pytorch_lightning as pl
-import torch
-from finetune import SummarizationModule, TranslationModule
-from finetune import main as ft_main
-from make_student import create_student_by_copying_alternating_layers, get_layers_to_supervise
-from torch import nn
-
-from transformers import AutoModelForSeq2SeqLM, MBartTokenizer, T5ForConditionalGeneration
-from transformers.models.bart.modeling_bart import shift_tokens_right
-from utils import calculate_bleu, check_output_dir, freeze_params, label_smoothed_nll_loss, use_task_specific_params
-
-
-# need the parent dir module
-sys.path.insert(2, str(Path(__file__).resolve().parents[1]))
-from lightning_base import generic_train # noqa
-
-
-class SummarizationDistiller(SummarizationModule):
- """Supports T5, Bart, Pegasus and other models that inherit from Bart."""
-
- loss_names = ["loss", "ce_loss", "mlm_loss", "hid_loss_enc", "hid_loss_dec"]
-
- def __init__(self, hparams):
- assert Path(hparams.data_dir).exists()
- self.output_dir = Path(hparams.output_dir)
- self.output_dir.mkdir(exist_ok=True)
-
- save_dir = self.output_dir.joinpath("student")
-
- hparams.model_name_or_path = str(save_dir) # Tell lightning we are training the student
- teacher = AutoModelForSeq2SeqLM.from_pretrained(hparams.teacher).eval()
- use_task_specific_params(teacher, hparams.task) # We copy good generation parameters to student by default
- if hparams.student is not None:
- student = AutoModelForSeq2SeqLM.from_pretrained(hparams.student)
- use_task_specific_params(student, hparams.task)
- e_layer_ids, d_layer_ids = None, None
- else:
- student, e_layer_ids, d_layer_ids = create_student_by_copying_alternating_layers(
- teacher, e=hparams.student_encoder_layers, d=hparams.student_decoder_layers, save_path=save_dir
- )
-
- if hparams.length_penalty != -1:
- student.config.length_penalty = hparams.length_penalty
- hparams.tokenizer_name = hparams.teacher # Use teacher's tokenizer
- super().__init__(hparams, model=student, config=student.config)
- assert student.config.model_type == teacher.config.model_type, (
- f"teacher, student model types should be the same, got {student.config.model_type} !="
- f" {teacher.config.model_type}"
- )
-
- if student.config.model_type == "t5":
- student_encoder_layers = len(student.get_encoder().block)
- student_decoder_layers = len(student.get_decoder().block)
- teacher_encoder_layers = len(teacher.get_encoder().block)
- teacher_decoder_layers = len(teacher.get_decoder().block)
- else:
- student_encoder_layers = student.config.encoder_layers
- student_decoder_layers = student.config.decoder_layers
- teacher_encoder_layers = teacher.config.encoder_layers
- teacher_decoder_layers = teacher.config.decoder_layers
-
- self.different_base_models = not (hparams.student is None or hparams.teacher == hparams.student)
- self.do_calc_hidden_loss = (not self.different_base_models) and hparams.alpha_hid > 0
- self.different_encoder = self.different_base_models or (student_encoder_layers != teacher_encoder_layers)
- # self.different_encoder determines whether we need to run the teacher encoder
- self.teacher = teacher
- freeze_params(self.teacher)
-
- if not self.different_encoder: # To save RAM, delete teacher encoder and freeze student encoder.
- try:
- del self.teacher.model.encoder
- except AttributeError: # T5
- del self.teacher.encoder
-
- if e_layer_ids is None:
- e_layer_ids = list(range(student_encoder_layers))
- if d_layer_ids is None:
- d_layer_ids = list(range(student_decoder_layers))
-
- self.e_layer_ids, self.d_layer_ids = e_layer_ids, d_layer_ids # type: List[int], List[int]
-
- if self.do_calc_hidden_loss: # Intermediate supervision: Decide which layers to supervise
- if hparams.supervise_forward:
- self.e_matches = get_layers_to_supervise(
- n_student=len(self.e_layer_ids), n_teacher=teacher_encoder_layers
- )
- self.d_matches = get_layers_to_supervise(
- n_student=len(self.d_layer_ids), n_teacher=teacher_decoder_layers
- )
- else: # student layer should emulate hidden states of the teacher layer it was copied from
- self.e_matches = self.e_layer_ids
- self.d_matches = self.d_layer_ids
- else:
- self.e_matches = None
- self.d_matches = None
-
- self.ce_loss_fct = nn.KLDivLoss(reduction="batchmean")
- self.temperature = 2.0
- self.alpha_mlm = hparams.alpha_mlm
- self.alpha_ce = hparams.alpha_ce
- self.alpha_hid = hparams.alpha_hid
- gc.collect()
- torch.cuda.empty_cache()
-
- def calc_ce_loss(self, mask, s_logits, t_logits):
- """Copy pasted from distillbert (transformers/examples/distillation/)"""
- # mask has False at padding_idx
- sel_mask = mask[:, :, None].expand_as(s_logits)
- vocab_size = s_logits.size(-1)
- s_logits_slct = torch.masked_select(s_logits, sel_mask) # (bs * seq_length * voc_size) modulo the 1s in mask
- t_logits_slct = torch.masked_select(t_logits, sel_mask) # (bs * seq_length * voc_size) modulo the 1s in mask
- s_logits_slct = s_logits_slct.view(-1, vocab_size) # (bs * seq_length, voc_size) modulo the 1s in mask
- t_logits_slct = t_logits_slct.view(-1, vocab_size) # (bs * seq_length, voc_size) modulo the 1s in mask
- assert t_logits_slct.size() == s_logits_slct.size()
- loss_ce = (
- self.ce_loss_fct(
- nn.functional.log_softmax(s_logits_slct / self.temperature, dim=-1),
- nn.functional.softmax(t_logits_slct / self.temperature, dim=-1),
- )
- * (self.temperature) ** 2
- )
- return loss_ce
-
- @staticmethod
- def add_model_specific_args(parser, root_dir):
- SummarizationModule.add_model_specific_args(parser, root_dir)
- add_distill_args(parser)
- return parser
-
- def _step(self, batch: dict) -> tuple:
- """Compute the loss for a batch"""
- pad_token_id = self.tokenizer.pad_token_id
- input_ids, src_mask, labels = batch["input_ids"], batch["attention_mask"], batch["labels"]
- if isinstance(self.model, T5ForConditionalGeneration):
- decoder_input_ids = self.model._shift_right(labels)
- else:
- decoder_input_ids = shift_tokens_right(labels, pad_token_id)
-
- # noinspection PyCallingNonCallable
- student_outputs = self(
- input_ids,
- attention_mask=src_mask,
- decoder_input_ids=decoder_input_ids,
- output_hidden_states=self.do_calc_hidden_loss,
- output_attentions=False,
- use_cache=False,
- )
- lm_logits = student_outputs["logits"]
-
- # Same cross entropy vs. label smoothing logic as finetune.py
- assert lm_logits.shape[-1] == self.model.config.vocab_size
- if self.hparams.label_smoothing == 0:
- # Same behavior as modeling_bart.py, besides ignoring pad_token_id
- loss_fct = nn.CrossEntropyLoss(ignore_index=pad_token_id)
- student_lm_loss = loss_fct(lm_logits.view(-1, lm_logits.shape[-1]), labels.view(-1))
- else:
- lprobs = nn.functional.log_softmax(lm_logits, dim=-1)
- student_lm_loss, _ = label_smoothed_nll_loss(
- lprobs, labels, self.hparams.label_smoothing, ignore_index=pad_token_id
- )
-
- def zero_tensor():
- return torch.tensor(0.0).type_as(student_lm_loss)
-
- teacher_enc_outputs = student_outputs[
- "encoder_last_hidden_state"
- ] # use this unless self.different_base_models
- hid_loss_enc, hid_loss_dec = zero_tensor(), zero_tensor()
- if self.different_encoder: # compute encoder hidden state loss
- all_teacher_encoder_outputs = self.teacher.get_encoder()(
- input_ids,
- attention_mask=src_mask,
- output_hidden_states=self.do_calc_hidden_loss,
- )
- if self.different_base_models:
- teacher_enc_outputs = all_teacher_encoder_outputs["last_hidden_state"]
- elif self.do_calc_hidden_loss:
- hid_loss_enc = self.calc_hidden_loss(
- src_mask,
- student_outputs["encoder_hidden_states"],
- all_teacher_encoder_outputs["hidden_states"],
- self.e_matches,
- normalize_hidden=self.hparams.normalize_hidden,
- )
-
- teacher_outputs = self.teacher(
- input_ids,
- attention_mask=src_mask,
- encoder_outputs=(teacher_enc_outputs,),
- decoder_input_ids=decoder_input_ids,
- output_hidden_states=self.do_calc_hidden_loss,
- use_cache=False, # since we are not passing labels, never let this default to True
- )
- dec_mask = decoder_input_ids.ne(pad_token_id)
- loss_ce = self.calc_ce_loss(dec_mask, lm_logits, teacher_outputs["logits"])
- if self.do_calc_hidden_loss: # Intermediate supervision of decoder hidden states
- hid_loss_dec = self.calc_hidden_loss(
- dec_mask,
- student_outputs["decoder_hidden_states"],
- teacher_outputs["decoder_hidden_states"],
- self.d_matches,
- normalize_hidden=self.hparams.normalize_hidden,
- )
-
- blended_loss = (
- self.alpha_ce * loss_ce
- + self.alpha_mlm * student_lm_loss
- + self.hparams.alpha_hid * (hid_loss_enc + hid_loss_dec)
- )
- return blended_loss, loss_ce, student_lm_loss, hid_loss_enc, hid_loss_dec
-
- @staticmethod
- def calc_hidden_loss(attention_mask, hidden_states, hidden_states_T, matches, normalize_hidden):
- """MSE(student_hid, teacher_hid[matches]). Called "Intermediate supervision" in paper. Inspired by TinyBERT."""
- msg = "expected list or tuple for hidden_states, got tensor of shape: "
- assert not isinstance(hidden_states, torch.Tensor), f"{msg}{hidden_states.shape}"
- assert not isinstance(hidden_states_T, torch.Tensor), f"{msg}{hidden_states_T.shape}"
- mask = attention_mask.to(hidden_states[0])
- valid_count = mask.sum() * hidden_states[0].size(-1)
- student_states = torch.stack([hidden_states[i] for i in range(len(matches))])
- teacher_states = torch.stack([hidden_states_T[j] for j in matches])
- assert student_states.shape == teacher_states.shape, f"{student_states.shape} != {teacher_states.shape}"
- if normalize_hidden:
- student_states = nn.functional.layer_norm(student_states, student_states.shape[1:])
- teacher_states = nn.functional.layer_norm(teacher_states, teacher_states.shape[1:])
- mse = nn.functional.mse_loss(student_states, teacher_states, reduction="none")
- masked_mse = (mse * mask.unsqueeze(0).unsqueeze(-1)).sum() / valid_count
- return masked_mse
-
-
-def add_distill_args(parser):
- # NOTE: if --student argument was specified and the teacher and student base models
- # are different, the models still have to have the same tokenizer, specified by
- # --tokenizer_name. So, for example, you can distill from t5_large to t5_small but not
- # from bart to t5. This s because if the tokenizers are different, the output space
- # for the two models is also different and their logits are not comparable.
- parser.add_argument("--teacher", type=str)
- parser.add_argument("--alpha_ce", default=0.8, type=float)
- parser.add_argument("--alpha_mlm", default=0.2, type=float)
- parser.add_argument("--alpha_hid", default=0.0, type=float, required=False)
- parser.add_argument("--student", type=str, required=False)
- parser.add_argument("--student_decoder_layers", default=12, type=int, required=False)
- parser.add_argument("--student_encoder_layers", default=12, type=int, required=False)
- parser.add_argument("--no_teacher", action="store_true", default=False)
- parser.add_argument("--length_penalty", type=float, default=-1)
- parser.add_argument("--supervise_forward", action="store_true", default=False)
- parser.add_argument("--normalize_hidden", action="store_true", default=False)
-
-
-class TranslationDistiller(SummarizationDistiller):
- """Supports T5, mBART, Marian, other models that inherit from Bart."""
-
- mode = "translation"
- metric_names = ["bleu"]
- default_val_metric = "bleu"
-
- def __init__(self, hparams, **kwargs):
- super().__init__(hparams, **kwargs)
- assert hparams.src_lang is not None
- assert hparams.tgt_lang is not None
- self.dataset_kwargs["src_lang"] = hparams.src_lang
- self.dataset_kwargs["tgt_lang"] = hparams.tgt_lang
- if self.model.config.decoder_start_token_id is None and isinstance(self.tokenizer, MBartTokenizer):
- self.decoder_start_token_id = self.tokenizer.lang_code_to_id[hparams.tgt_lang]
-
- def calc_generative_metrics(self, preds, target) -> dict:
- return calculate_bleu(preds, target)
-
- @staticmethod
- def add_model_specific_args(parser, root_dir):
- TranslationModule.add_model_specific_args(parser, root_dir)
- add_distill_args(parser)
- return parser
-
-
-def create_module(args):
- if args.no_teacher:
- module_cls = TranslationModule if "translation" in args.task else SummarizationModule
- else: # DISTILL WITH TEACHER
- module_cls = TranslationDistiller if "translation" in args.task else SummarizationDistiller
- args.setup_cls: str = module_cls.__name__
- print(f"using module {args.setup_cls}")
- model = module_cls(args)
- return model
-
-
-def distill_main(args):
- Path(args.output_dir).mkdir(exist_ok=True)
- check_output_dir(args, expected_items=3)
-
- model = create_module(args)
- return ft_main(args, model=model)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser = pl.Trainer.add_argparse_args(parser)
- parser = SummarizationDistiller.add_model_specific_args(parser, os.getcwd())
- args = parser.parse_args()
-
- distill_main(args)
diff --git a/examples/research_projects/seq2seq-distillation/dynamic_bs_example.sh b/examples/research_projects/seq2seq-distillation/dynamic_bs_example.sh
deleted file mode 100755
index cfe9e21f0f6..00000000000
--- a/examples/research_projects/seq2seq-distillation/dynamic_bs_example.sh
+++ /dev/null
@@ -1,17 +0,0 @@
-#!/usr/bin/env bash
-export PYTHONPATH="../":"${PYTHONPATH}"
-export WANDB_PROJECT=dmar
-export MAX_LEN=128
-export m=sshleifer/student_marian_en_ro_6_1
-python finetune.py \
- --learning_rate=3e-4 \
- --do_train \
- --fp16 \
- --data_dir wmt_en_ro \
- --max_source_length $MAX_LEN --max_target_length $MAX_LEN --val_max_target_length $MAX_LEN --test_max_target_length $MAX_LEN \
- --freeze_encoder --freeze_embeds \
- --train_batch_size=48 --eval_batch_size=64 \
- --tokenizer_name $m --model_name_or_path $m --num_train_epochs=1 \
- --warmup_steps 500 --logger_name wandb --gpus 1 \
- --fp16_opt_level=O1 --task translation \
- "$@"
diff --git a/examples/research_projects/seq2seq-distillation/finetune.py b/examples/research_projects/seq2seq-distillation/finetune.py
deleted file mode 100755
index ff889af81e3..00000000000
--- a/examples/research_projects/seq2seq-distillation/finetune.py
+++ /dev/null
@@ -1,454 +0,0 @@
-#!/usr/bin/env python
-
-import argparse
-import glob
-import logging
-import os
-import sys
-import time
-from collections import defaultdict
-from pathlib import Path
-from typing import Dict, List, Tuple
-
-import numpy as np
-import pytorch_lightning as pl
-import torch
-from callbacks import Seq2SeqLoggingCallback, get_checkpoint_callback, get_early_stopping_callback
-from torch import nn
-from torch.utils.data import DataLoader
-
-from transformers import MBartTokenizer, T5ForConditionalGeneration
-from transformers.models.bart.modeling_bart import shift_tokens_right
-from utils import (
- ROUGE_KEYS,
- LegacySeq2SeqDataset,
- Seq2SeqDataset,
- assert_all_frozen,
- calculate_bleu,
- calculate_rouge,
- check_output_dir,
- flatten_list,
- freeze_embeds,
- freeze_params,
- get_git_info,
- label_smoothed_nll_loss,
- lmap,
- pickle_save,
- save_git_info,
- save_json,
- use_task_specific_params,
-)
-
-
-# need the parent dir module
-sys.path.insert(2, str(Path(__file__).resolve().parents[1]))
-from lightning_base import BaseTransformer, add_generic_args, generic_train # noqa
-
-
-logger = logging.getLogger(__name__)
-
-
-class SummarizationModule(BaseTransformer):
- mode = "summarization"
- loss_names = ["loss"]
- metric_names = ROUGE_KEYS
- default_val_metric = "rouge2"
-
- def __init__(self, hparams, **kwargs):
- if hparams.sortish_sampler and hparams.gpus > 1:
- hparams.replace_sampler_ddp = False
- elif hparams.max_tokens_per_batch is not None:
- if hparams.gpus > 1:
- raise NotImplementedError("Dynamic Batch size does not work for multi-gpu training")
- if hparams.sortish_sampler:
- raise ValueError("--sortish_sampler and --max_tokens_per_batch may not be used simultaneously")
-
- super().__init__(hparams, num_labels=None, mode=self.mode, **kwargs)
- use_task_specific_params(self.model, "summarization")
- save_git_info(self.hparams.output_dir)
- self.metrics_save_path = Path(self.output_dir) / "metrics.json"
- self.hparams_save_path = Path(self.output_dir) / "hparams.pkl"
- pickle_save(self.hparams, self.hparams_save_path)
- self.step_count = 0
- self.metrics = defaultdict(list)
- self.model_type = self.config.model_type
- self.vocab_size = self.config.tgt_vocab_size if self.model_type == "fsmt" else self.config.vocab_size
-
- self.dataset_kwargs: dict = {
- "data_dir": self.hparams.data_dir,
- "max_source_length": self.hparams.max_source_length,
- "prefix": self.model.config.prefix or "",
- }
- n_observations_per_split = {
- "train": self.hparams.n_train,
- "val": self.hparams.n_val,
- "test": self.hparams.n_test,
- }
- self.n_obs = {k: v if v >= 0 else None for k, v in n_observations_per_split.items()}
-
- self.target_lens = {
- "train": self.hparams.max_target_length,
- "val": self.hparams.val_max_target_length,
- "test": self.hparams.test_max_target_length,
- }
- assert self.target_lens["train"] <= self.target_lens["val"], f"target_lens: {self.target_lens}"
- assert self.target_lens["train"] <= self.target_lens["test"], f"target_lens: {self.target_lens}"
- if self.hparams.freeze_embeds:
- freeze_embeds(self.model)
- if self.hparams.freeze_encoder:
- freeze_params(self.model.get_encoder())
- assert_all_frozen(self.model.get_encoder())
-
- self.hparams.git_sha = get_git_info()["repo_sha"]
- self.num_workers = hparams.num_workers
- self.decoder_start_token_id = None # default to config
- if self.model.config.decoder_start_token_id is None and isinstance(self.tokenizer, MBartTokenizer):
- self.decoder_start_token_id = self.tokenizer.lang_code_to_id[hparams.tgt_lang]
- self.model.config.decoder_start_token_id = self.decoder_start_token_id
- self.dataset_class = (
- Seq2SeqDataset if hasattr(self.tokenizer, "prepare_seq2seq_batch") else LegacySeq2SeqDataset
- )
- self.already_saved_batch = False
- self.eval_beams = self.model.config.num_beams if self.hparams.eval_beams is None else self.hparams.eval_beams
- if self.hparams.eval_max_gen_length is not None:
- self.eval_max_length = self.hparams.eval_max_gen_length
- else:
- self.eval_max_length = self.model.config.max_length
- self.val_metric = self.default_val_metric if self.hparams.val_metric is None else self.hparams.val_metric
-
- def save_readable_batch(self, batch: Dict[str, torch.Tensor]) -> Dict[str, List[str]]:
- """A debugging utility"""
- readable_batch = {
- k: self.tokenizer.batch_decode(v.tolist()) if "mask" not in k else v.shape for k, v in batch.items()
- }
- save_json(readable_batch, Path(self.output_dir) / "text_batch.json")
- save_json({k: v.tolist() for k, v in batch.items()}, Path(self.output_dir) / "tok_batch.json")
-
- self.already_saved_batch = True
- return readable_batch
-
- def forward(self, input_ids, **kwargs):
- return self.model(input_ids, **kwargs)
-
- def ids_to_clean_text(self, generated_ids: List[int]):
- gen_text = self.tokenizer.batch_decode(
- generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
- )
- return lmap(str.strip, gen_text)
-
- def _step(self, batch: dict) -> Tuple:
- pad_token_id = self.tokenizer.pad_token_id
- src_ids, src_mask = batch["input_ids"], batch["attention_mask"]
- tgt_ids = batch["labels"]
- if isinstance(self.model, T5ForConditionalGeneration):
- decoder_input_ids = self.model._shift_right(tgt_ids)
- else:
- decoder_input_ids = shift_tokens_right(tgt_ids, pad_token_id)
- if not self.already_saved_batch: # This would be slightly better if it only happened on rank zero
- batch["decoder_input_ids"] = decoder_input_ids
- self.save_readable_batch(batch)
-
- outputs = self(src_ids, attention_mask=src_mask, decoder_input_ids=decoder_input_ids, use_cache=False)
- lm_logits = outputs["logits"]
- if self.hparams.label_smoothing == 0:
- # Same behavior as modeling_bart.py, besides ignoring pad_token_id
- ce_loss_fct = nn.CrossEntropyLoss(ignore_index=pad_token_id)
-
- assert lm_logits.shape[-1] == self.vocab_size
- loss = ce_loss_fct(lm_logits.view(-1, lm_logits.shape[-1]), tgt_ids.view(-1))
- else:
- lprobs = nn.functional.log_softmax(lm_logits, dim=-1)
- loss, nll_loss = label_smoothed_nll_loss(
- lprobs, tgt_ids, self.hparams.label_smoothing, ignore_index=pad_token_id
- )
- return (loss,)
-
- @property
- def pad(self) -> int:
- return self.tokenizer.pad_token_id
-
- def training_step(self, batch, batch_idx) -> Dict:
- loss_tensors = self._step(batch)
-
- logs = dict(zip(self.loss_names, loss_tensors))
- # tokens per batch
- logs["tpb"] = batch["input_ids"].ne(self.pad).sum() + batch["labels"].ne(self.pad).sum()
- logs["bs"] = batch["input_ids"].shape[0]
- logs["src_pad_tok"] = batch["input_ids"].eq(self.pad).sum()
- logs["src_pad_frac"] = batch["input_ids"].eq(self.pad).float().mean()
- # TODO(SS): make a wandb summary metric for this
- return {"loss": loss_tensors[0], "log": logs}
-
- def validation_step(self, batch, batch_idx) -> Dict:
- return self._generative_step(batch)
-
- def validation_epoch_end(self, outputs, prefix="val") -> Dict:
- self.step_count += 1
- losses = {k: torch.stack([x[k] for x in outputs]).mean() for k in self.loss_names}
- loss = losses["loss"]
- generative_metrics = {
- k: np.array([x[k] for x in outputs]).mean() for k in self.metric_names + ["gen_time", "gen_len"]
- }
- metric_val = (
- generative_metrics[self.val_metric] if self.val_metric in generative_metrics else losses[self.val_metric]
- )
- metric_tensor: torch.FloatTensor = torch.tensor(metric_val).type_as(loss)
- generative_metrics.update({k: v.item() for k, v in losses.items()})
- losses.update(generative_metrics)
- all_metrics = {f"{prefix}_avg_{k}": x for k, x in losses.items()}
- all_metrics["step_count"] = self.step_count
- self.metrics[prefix].append(all_metrics) # callback writes this to self.metrics_save_path
- preds = flatten_list([x["preds"] for x in outputs])
- return {
- "log": all_metrics,
- "preds": preds,
- f"{prefix}_loss": loss,
- f"{prefix}_{self.val_metric}": metric_tensor,
- }
-
- def calc_generative_metrics(self, preds, target) -> Dict:
- return calculate_rouge(preds, target)
-
- def _generative_step(self, batch: dict) -> dict:
- t0 = time.time()
-
- # parser.add_argument('--eval_max_gen_length', type=int, default=None, help='never generate more than n tokens')
- generated_ids = self.model.generate(
- batch["input_ids"],
- attention_mask=batch["attention_mask"],
- use_cache=True,
- decoder_start_token_id=self.decoder_start_token_id,
- num_beams=self.eval_beams,
- max_length=self.eval_max_length,
- )
- gen_time = (time.time() - t0) / batch["input_ids"].shape[0]
- preds: List[str] = self.ids_to_clean_text(generated_ids)
- target: List[str] = self.ids_to_clean_text(batch["labels"])
- loss_tensors = self._step(batch)
- base_metrics = dict(zip(self.loss_names, loss_tensors))
- rouge: Dict = self.calc_generative_metrics(preds, target)
- summ_len = np.mean(lmap(len, generated_ids))
- base_metrics.update(gen_time=gen_time, gen_len=summ_len, preds=preds, target=target, **rouge)
- return base_metrics
-
- def test_step(self, batch, batch_idx):
- return self._generative_step(batch)
-
- def test_epoch_end(self, outputs):
- return self.validation_epoch_end(outputs, prefix="test")
-
- def get_dataset(self, type_path) -> Seq2SeqDataset:
- n_obs = self.n_obs[type_path]
- max_target_length = self.target_lens[type_path]
- dataset = self.dataset_class(
- self.tokenizer,
- type_path=type_path,
- n_obs=n_obs,
- max_target_length=max_target_length,
- **self.dataset_kwargs,
- )
- return dataset
-
- def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False) -> DataLoader:
- dataset = self.get_dataset(type_path)
-
- if self.hparams.sortish_sampler and type_path != "test" and type_path != "val":
- sampler = dataset.make_sortish_sampler(batch_size, distributed=self.hparams.gpus > 1)
- return DataLoader(
- dataset,
- batch_size=batch_size,
- collate_fn=dataset.collate_fn,
- shuffle=False,
- num_workers=self.num_workers,
- sampler=sampler,
- )
-
- elif self.hparams.max_tokens_per_batch is not None and type_path != "test" and type_path != "val":
- batch_sampler = dataset.make_dynamic_sampler(
- self.hparams.max_tokens_per_batch, distributed=self.hparams.gpus > 1
- )
- return DataLoader(
- dataset,
- batch_sampler=batch_sampler,
- collate_fn=dataset.collate_fn,
- # shuffle=False,
- num_workers=self.num_workers,
- # batch_size=None,
- )
- else:
- return DataLoader(
- dataset,
- batch_size=batch_size,
- collate_fn=dataset.collate_fn,
- shuffle=shuffle,
- num_workers=self.num_workers,
- sampler=None,
- )
-
- def train_dataloader(self) -> DataLoader:
- dataloader = self.get_dataloader("train", batch_size=self.hparams.train_batch_size, shuffle=True)
- return dataloader
-
- def val_dataloader(self) -> DataLoader:
- return self.get_dataloader("val", batch_size=self.hparams.eval_batch_size)
-
- def test_dataloader(self) -> DataLoader:
- return self.get_dataloader("test", batch_size=self.hparams.eval_batch_size)
-
- @staticmethod
- def add_model_specific_args(parser, root_dir):
- BaseTransformer.add_model_specific_args(parser, root_dir)
- add_generic_args(parser, root_dir)
- parser.add_argument(
- "--max_source_length",
- default=1024,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument(
- "--max_target_length",
- default=56,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument(
- "--val_max_target_length",
- default=142, # these defaults are optimized for CNNDM. For xsum, see README.md.
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument(
- "--test_max_target_length",
- default=142,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument("--freeze_encoder", action="store_true")
- parser.add_argument("--freeze_embeds", action="store_true")
- parser.add_argument("--sortish_sampler", action="store_true", default=False)
- parser.add_argument("--overwrite_output_dir", action="store_true", default=False)
- parser.add_argument("--max_tokens_per_batch", type=int, default=None)
- parser.add_argument("--logger_name", type=str, choices=["default", "wandb", "wandb_shared"], default="default")
- parser.add_argument("--n_train", type=int, default=-1, required=False, help="# examples. -1 means use all.")
- parser.add_argument("--n_val", type=int, default=500, required=False, help="# examples. -1 means use all.")
- parser.add_argument("--n_test", type=int, default=-1, required=False, help="# examples. -1 means use all.")
- parser.add_argument(
- "--task", type=str, default="summarization", required=False, help="# examples. -1 means use all."
- )
- parser.add_argument("--label_smoothing", type=float, default=0.0, required=False)
- parser.add_argument("--src_lang", type=str, default="", required=False)
- parser.add_argument("--tgt_lang", type=str, default="", required=False)
- parser.add_argument("--eval_beams", type=int, default=None, required=False)
- parser.add_argument(
- "--val_metric", type=str, default=None, required=False, choices=["bleu", "rouge2", "loss", None]
- )
- parser.add_argument("--eval_max_gen_length", type=int, default=None, help="never generate more than n tokens")
- parser.add_argument("--save_top_k", type=int, default=1, required=False, help="How many checkpoints to save")
- parser.add_argument(
- "--early_stopping_patience",
- type=int,
- default=-1,
- required=False,
- help=(
- "-1 means never early stop. early_stopping_patience is measured in validation checks, not epochs. So"
- " val_check_interval will effect it."
- ),
- )
- return parser
-
-
-class TranslationModule(SummarizationModule):
- mode = "translation"
- loss_names = ["loss"]
- metric_names = ["bleu"]
- default_val_metric = "bleu"
-
- def __init__(self, hparams, **kwargs):
- super().__init__(hparams, **kwargs)
- self.dataset_kwargs["src_lang"] = hparams.src_lang
- self.dataset_kwargs["tgt_lang"] = hparams.tgt_lang
-
- def calc_generative_metrics(self, preds, target) -> dict:
- return calculate_bleu(preds, target)
-
-
-def main(args, model=None) -> SummarizationModule:
- Path(args.output_dir).mkdir(exist_ok=True)
- check_output_dir(args, expected_items=3)
-
- if model is None:
- if "summarization" in args.task:
- model: SummarizationModule = SummarizationModule(args)
- else:
- model: SummarizationModule = TranslationModule(args)
- dataset = Path(args.data_dir).name
- if (
- args.logger_name == "default"
- or args.fast_dev_run
- or str(args.output_dir).startswith("/tmp")
- or str(args.output_dir).startswith("/var")
- ):
- logger = True # don't pollute wandb logs unnecessarily
- elif args.logger_name == "wandb":
- from pytorch_lightning.loggers import WandbLogger
-
- project = os.environ.get("WANDB_PROJECT", dataset)
- logger = WandbLogger(name=model.output_dir.name, project=project)
-
- elif args.logger_name == "wandb_shared":
- from pytorch_lightning.loggers import WandbLogger
-
- logger = WandbLogger(name=model.output_dir.name, project=f"hf_{dataset}")
-
- if args.early_stopping_patience >= 0:
- es_callback = get_early_stopping_callback(model.val_metric, args.early_stopping_patience)
- else:
- es_callback = False
-
- lower_is_better = args.val_metric == "loss"
- trainer: pl.Trainer = generic_train(
- model,
- args,
- logging_callback=Seq2SeqLoggingCallback(),
- checkpoint_callback=get_checkpoint_callback(
- args.output_dir, model.val_metric, args.save_top_k, lower_is_better
- ),
- early_stopping_callback=es_callback,
- logger=logger,
- )
- pickle_save(model.hparams, model.output_dir / "hparams.pkl")
- if not args.do_predict:
- return model
-
- model.hparams.test_checkpoint = ""
- checkpoints = sorted(glob.glob(os.path.join(args.output_dir, "*.ckpt"), recursive=True))
- if checkpoints:
- model.hparams.test_checkpoint = checkpoints[-1]
- trainer.resume_from_checkpoint = checkpoints[-1]
- trainer.logger.log_hyperparams(model.hparams)
-
- # test() without a model tests using the best checkpoint automatically
- trainer.test()
- return model
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser = pl.Trainer.add_argparse_args(parser)
- parser = SummarizationModule.add_model_specific_args(parser, os.getcwd())
-
- args = parser.parse_args()
-
- main(args)
diff --git a/examples/research_projects/seq2seq-distillation/finetune.sh b/examples/research_projects/seq2seq-distillation/finetune.sh
deleted file mode 100755
index 683c2d7752d..00000000000
--- a/examples/research_projects/seq2seq-distillation/finetune.sh
+++ /dev/null
@@ -1,11 +0,0 @@
-# the proper usage is documented in the README, you need to specify data_dir, output_dir and model_name_or_path
-# run ./finetune.sh --help to see all the possible options
-python finetune.py \
- --learning_rate=3e-5 \
- --fp16 \
- --gpus 1 \
- --do_train \
- --do_predict \
- --n_val 1000 \
- --val_check_interval 0.1 \
- "$@"
diff --git a/examples/research_projects/seq2seq-distillation/finetune_bart_tiny.sh b/examples/research_projects/seq2seq-distillation/finetune_bart_tiny.sh
deleted file mode 100755
index f0289b45ab5..00000000000
--- a/examples/research_projects/seq2seq-distillation/finetune_bart_tiny.sh
+++ /dev/null
@@ -1,32 +0,0 @@
-# Script for verifying that run_bart_sum can be invoked from its directory
-
-# Get tiny dataset with cnn_dm format (4 examples for train, val, test)
-wget https://cdn-datasets.huggingface.co/summarization/cnn_tiny.tgz
-tar -xzvf cnn_tiny.tgz
-rm cnn_tiny.tgz
-
-export OUTPUT_DIR_NAME=bart_utest_output
-export CURRENT_DIR=${PWD}
-export OUTPUT_DIR=${CURRENT_DIR}/${OUTPUT_DIR_NAME}
-
-# Make output directory if it doesn't exist
-mkdir -p $OUTPUT_DIR
-
-# Add parent directory to python path to access lightning_base.py and testing_utils.py
-export PYTHONPATH="../":"${PYTHONPATH}"
-python finetune.py \
---data_dir=cnn_tiny/ \
---model_name_or_path=sshleifer/bart-tiny-random \
---learning_rate=3e-5 \
---train_batch_size=2 \
---eval_batch_size=2 \
---output_dir=$OUTPUT_DIR \
---num_train_epochs=1 \
---gpus=0 \
---do_train "$@"
-
-rm -rf cnn_tiny
-rm -rf $OUTPUT_DIR
-
-
-
diff --git a/examples/research_projects/seq2seq-distillation/finetune_pegasus_xsum.sh b/examples/research_projects/seq2seq-distillation/finetune_pegasus_xsum.sh
deleted file mode 100755
index ec7ff98557c..00000000000
--- a/examples/research_projects/seq2seq-distillation/finetune_pegasus_xsum.sh
+++ /dev/null
@@ -1,14 +0,0 @@
-#!/usr/bin/env bash
-export PYTHONPATH="../":"${PYTHONPATH}"
-
-# From appendix C of paper https://arxiv.org/abs/1912.08777
-# Set --gradient_accumulation_steps so that effective batch size is 256 (2*128, 4*64, 8*32, 16*16)
-python finetune.py \
- --learning_rate=1e-4 \
- --do_train \
- --do_predict \
- --n_val 1000 \
- --val_check_interval 0.25 \
- --max_source_length 512 --max_target_length 56 \
- --freeze_embeds --label_smoothing 0.1 --adafactor --task summarization_xsum \
- "$@"
diff --git a/examples/research_projects/seq2seq-distillation/finetune_t5.sh b/examples/research_projects/seq2seq-distillation/finetune_t5.sh
deleted file mode 100755
index 504e9eb71e3..00000000000
--- a/examples/research_projects/seq2seq-distillation/finetune_t5.sh
+++ /dev/null
@@ -1,14 +0,0 @@
-# Add parent directory to python path to access lightning_base.py
-export PYTHONPATH="../":"${PYTHONPATH}"
-
-python finetune.py \
---data_dir=$CNN_DIR \
---learning_rate=3e-5 \
---train_batch_size=$BS \
---eval_batch_size=$BS \
---output_dir=$OUTPUT_DIR \
---max_source_length=512 \
---max_target_length=56 \
---val_check_interval=0.1 --n_val=200 \
---do_train --do_predict \
- "$@"
diff --git a/examples/research_projects/seq2seq-distillation/lightning_base.py b/examples/research_projects/seq2seq-distillation/lightning_base.py
deleted file mode 100644
index 640828bacd3..00000000000
--- a/examples/research_projects/seq2seq-distillation/lightning_base.py
+++ /dev/null
@@ -1,393 +0,0 @@
-import argparse
-import logging
-import os
-from pathlib import Path
-from typing import Any, Dict
-
-import pytorch_lightning as pl
-from pytorch_lightning.utilities import rank_zero_info
-
-from transformers import (
- AdamW,
- AutoConfig,
- AutoModel,
- AutoModelForPreTraining,
- AutoModelForQuestionAnswering,
- AutoModelForSeq2SeqLM,
- AutoModelForSequenceClassification,
- AutoModelForTokenClassification,
- AutoModelWithLMHead,
- AutoTokenizer,
- PretrainedConfig,
- PreTrainedTokenizer,
-)
-from transformers.optimization import (
- Adafactor,
- get_cosine_schedule_with_warmup,
- get_cosine_with_hard_restarts_schedule_with_warmup,
- get_linear_schedule_with_warmup,
- get_polynomial_decay_schedule_with_warmup,
-)
-from transformers.utils.versions import require_version
-
-
-logger = logging.getLogger(__name__)
-
-require_version("pytorch_lightning>=1.0.4")
-
-MODEL_MODES = {
- "base": AutoModel,
- "sequence-classification": AutoModelForSequenceClassification,
- "question-answering": AutoModelForQuestionAnswering,
- "pretraining": AutoModelForPreTraining,
- "token-classification": AutoModelForTokenClassification,
- "language-modeling": AutoModelWithLMHead,
- "summarization": AutoModelForSeq2SeqLM,
- "translation": AutoModelForSeq2SeqLM,
-}
-
-
-# update this and the import above to support new schedulers from transformers.optimization
-arg_to_scheduler = {
- "linear": get_linear_schedule_with_warmup,
- "cosine": get_cosine_schedule_with_warmup,
- "cosine_w_restarts": get_cosine_with_hard_restarts_schedule_with_warmup,
- "polynomial": get_polynomial_decay_schedule_with_warmup,
- # '': get_constant_schedule, # not supported for now
- # '': get_constant_schedule_with_warmup, # not supported for now
-}
-arg_to_scheduler_choices = sorted(arg_to_scheduler.keys())
-arg_to_scheduler_metavar = "{" + ", ".join(arg_to_scheduler_choices) + "}"
-
-
-class BaseTransformer(pl.LightningModule):
- def __init__(
- self,
- hparams: argparse.Namespace,
- num_labels=None,
- mode="base",
- config=None,
- tokenizer=None,
- model=None,
- **config_kwargs,
- ):
- """Initialize a model, tokenizer and config."""
- super().__init__()
- # TODO: move to self.save_hyperparameters()
- # self.save_hyperparameters()
- # can also expand arguments into trainer signature for easier reading
-
- self.save_hyperparameters(hparams)
- self.step_count = 0
- self.output_dir = Path(self.hparams.output_dir)
- cache_dir = self.hparams.cache_dir if self.hparams.cache_dir else None
- if config is None:
- self.config = AutoConfig.from_pretrained(
- self.hparams.config_name if self.hparams.config_name else self.hparams.model_name_or_path,
- **({"num_labels": num_labels} if num_labels is not None else {}),
- cache_dir=cache_dir,
- **config_kwargs,
- )
- else:
- self.config: PretrainedConfig = config
-
- extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "dropout", "attention_dropout")
- for p in extra_model_params:
- if getattr(self.hparams, p, None):
- assert hasattr(self.config, p), f"model config doesn't have a `{p}` attribute"
- setattr(self.config, p, getattr(self.hparams, p))
-
- if tokenizer is None:
- self.tokenizer = AutoTokenizer.from_pretrained(
- self.hparams.tokenizer_name if self.hparams.tokenizer_name else self.hparams.model_name_or_path,
- cache_dir=cache_dir,
- )
- else:
- self.tokenizer: PreTrainedTokenizer = tokenizer
- self.model_type = MODEL_MODES[mode]
- if model is None:
- self.model = self.model_type.from_pretrained(
- self.hparams.model_name_or_path,
- from_tf=bool(".ckpt" in self.hparams.model_name_or_path),
- config=self.config,
- cache_dir=cache_dir,
- )
- else:
- self.model = model
-
- def load_hf_checkpoint(self, *args, **kwargs):
- self.model = self.model_type.from_pretrained(*args, **kwargs)
-
- def get_lr_scheduler(self):
- get_schedule_func = arg_to_scheduler[self.hparams.lr_scheduler]
- scheduler = get_schedule_func(
- self.opt, num_warmup_steps=self.hparams.warmup_steps, num_training_steps=self.total_steps()
- )
- scheduler = {"scheduler": scheduler, "interval": "step", "frequency": 1}
- return scheduler
-
- def configure_optimizers(self):
- """Prepare optimizer and schedule (linear warmup and decay)"""
- model = self.model
- no_decay = ["bias", "LayerNorm.weight"]
- optimizer_grouped_parameters = [
- {
- "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
- "weight_decay": self.hparams.weight_decay,
- },
- {
- "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
- "weight_decay": 0.0,
- },
- ]
- if self.hparams.adafactor:
- optimizer = Adafactor(
- optimizer_grouped_parameters, lr=self.hparams.learning_rate, scale_parameter=False, relative_step=False
- )
-
- else:
- optimizer = AdamW(
- optimizer_grouped_parameters, lr=self.hparams.learning_rate, eps=self.hparams.adam_epsilon
- )
- self.opt = optimizer
-
- scheduler = self.get_lr_scheduler()
-
- return [optimizer], [scheduler]
-
- def test_step(self, batch, batch_nb):
- return self.validation_step(batch, batch_nb)
-
- def test_epoch_end(self, outputs):
- return self.validation_end(outputs)
-
- def total_steps(self) -> int:
- """The number of total training steps that will be run. Used for lr scheduler purposes."""
- num_devices = max(1, self.hparams.gpus) # TODO: consider num_tpu_cores
- effective_batch_size = self.hparams.train_batch_size * self.hparams.accumulate_grad_batches * num_devices
- return (self.dataset_size / effective_batch_size) * self.hparams.max_epochs
-
- def setup(self, mode):
- if mode == "test":
- self.dataset_size = len(self.test_dataloader().dataset)
- else:
- self.train_loader = self.get_dataloader("train", self.hparams.train_batch_size, shuffle=True)
- self.dataset_size = len(self.train_dataloader().dataset)
-
- def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False):
- raise NotImplementedError("You must implement this for your task")
-
- def train_dataloader(self):
- return self.train_loader
-
- def val_dataloader(self):
- return self.get_dataloader("dev", self.hparams.eval_batch_size, shuffle=False)
-
- def test_dataloader(self):
- return self.get_dataloader("test", self.hparams.eval_batch_size, shuffle=False)
-
- def _feature_file(self, mode):
- return os.path.join(
- self.hparams.data_dir,
- "cached_{}_{}_{}".format(
- mode,
- list(filter(None, self.hparams.model_name_or_path.split("/"))).pop(),
- str(self.hparams.max_seq_length),
- ),
- )
-
- @pl.utilities.rank_zero_only
- def on_save_checkpoint(self, checkpoint: Dict[str, Any]) -> None:
- save_path = self.output_dir.joinpath("best_tfmr")
- self.model.config.save_step = self.step_count
- self.model.save_pretrained(save_path)
- self.tokenizer.save_pretrained(save_path)
-
- @staticmethod
- def add_model_specific_args(parser, root_dir):
- parser.add_argument(
- "--model_name_or_path",
- default=None,
- type=str,
- required=True,
- help="Path to pretrained model or model identifier from huggingface.co/models",
- )
- parser.add_argument(
- "--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
- )
- parser.add_argument(
- "--tokenizer_name",
- default=None,
- type=str,
- help="Pretrained tokenizer name or path if not the same as model_name",
- )
- parser.add_argument(
- "--cache_dir",
- default="",
- type=str,
- help="Where do you want to store the pre-trained models downloaded from huggingface.co",
- )
- parser.add_argument(
- "--encoder_layerdrop",
- type=float,
- help="Encoder layer dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument(
- "--decoder_layerdrop",
- type=float,
- help="Decoder layer dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument(
- "--dropout",
- type=float,
- help="Dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument(
- "--attention_dropout",
- type=float,
- help="Attention dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
- parser.add_argument(
- "--lr_scheduler",
- default="linear",
- choices=arg_to_scheduler_choices,
- metavar=arg_to_scheduler_metavar,
- type=str,
- help="Learning rate scheduler",
- )
- parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
- parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
- parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
- parser.add_argument("--num_workers", default=4, type=int, help="kwarg passed to DataLoader")
- parser.add_argument("--num_train_epochs", dest="max_epochs", default=3, type=int)
- parser.add_argument("--train_batch_size", default=32, type=int)
- parser.add_argument("--eval_batch_size", default=32, type=int)
- parser.add_argument("--adafactor", action="store_true")
-
-
-class LoggingCallback(pl.Callback):
- def on_batch_end(self, trainer, pl_module):
- lr_scheduler = trainer.lr_schedulers[0]["scheduler"]
- lrs = {f"lr_group_{i}": lr for i, lr in enumerate(lr_scheduler.get_lr())}
- pl_module.logger.log_metrics(lrs)
-
- def on_validation_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
- rank_zero_info("***** Validation results *****")
- metrics = trainer.callback_metrics
- # Log results
- for key in sorted(metrics):
- if key not in ["log", "progress_bar"]:
- rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
-
- def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
- rank_zero_info("***** Test results *****")
- metrics = trainer.callback_metrics
- # Log and save results to file
- output_test_results_file = os.path.join(pl_module.hparams.output_dir, "test_results.txt")
- with open(output_test_results_file, "w") as writer:
- for key in sorted(metrics):
- if key not in ["log", "progress_bar"]:
- rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
- writer.write("{} = {}\n".format(key, str(metrics[key])))
-
-
-def add_generic_args(parser, root_dir) -> None:
- # To allow all pl args uncomment the following line
- # parser = pl.Trainer.add_argparse_args(parser)
- parser.add_argument(
- "--output_dir",
- default=None,
- type=str,
- required=True,
- help="The output directory where the model predictions and checkpoints will be written.",
- )
- parser.add_argument(
- "--fp16",
- action="store_true",
- help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
- )
-
- parser.add_argument(
- "--fp16_opt_level",
- type=str,
- default="O2",
- help=(
- "For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
- "See details at https://nvidia.github.io/apex/amp.html"
- ),
- )
- parser.add_argument("--n_tpu_cores", dest="tpu_cores", type=int)
- parser.add_argument("--max_grad_norm", dest="gradient_clip_val", default=1.0, type=float, help="Max gradient norm")
- parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
- parser.add_argument("--do_predict", action="store_true", help="Whether to run predictions on the test set.")
- parser.add_argument(
- "--gradient_accumulation_steps",
- dest="accumulate_grad_batches",
- type=int,
- default=1,
- help="Number of updates steps to accumulate before performing a backward/update pass.",
- )
- parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
- parser.add_argument(
- "--data_dir",
- default=None,
- type=str,
- required=True,
- help="The input data dir. Should contain the training files for the CoNLL-2003 NER task.",
- )
-
-
-def generic_train(
- model: BaseTransformer,
- args: argparse.Namespace,
- early_stopping_callback=None,
- logger=True, # can pass WandbLogger() here
- extra_callbacks=[],
- checkpoint_callback=None,
- logging_callback=None,
- **extra_train_kwargs,
-):
- pl.seed_everything(args.seed)
-
- # init model
- odir = Path(model.hparams.output_dir)
- odir.mkdir(exist_ok=True)
-
- # add custom checkpoints
- if checkpoint_callback is None:
- checkpoint_callback = pl.callbacks.ModelCheckpoint(
- filepath=args.output_dir, prefix="checkpoint", monitor="val_loss", mode="min", save_top_k=1
- )
- if early_stopping_callback:
- extra_callbacks.append(early_stopping_callback)
- if logging_callback is None:
- logging_callback = LoggingCallback()
-
- train_params = {}
-
- # TODO: remove with PyTorch 1.6 since pl uses native amp
- if args.fp16:
- train_params["precision"] = 16
- train_params["amp_level"] = args.fp16_opt_level
-
- if args.gpus > 1:
- train_params["distributed_backend"] = "ddp"
-
- train_params["accumulate_grad_batches"] = args.accumulate_grad_batches
- train_params["accelerator"] = extra_train_kwargs.get("accelerator", None)
- train_params["profiler"] = extra_train_kwargs.get("profiler", None)
-
- trainer = pl.Trainer.from_argparse_args(
- args,
- weights_summary=None,
- callbacks=[logging_callback] + extra_callbacks,
- logger=logger,
- checkpoint_callback=checkpoint_callback,
- **train_params,
- )
-
- if args.do_train:
- trainer.fit(model)
-
- return trainer
diff --git a/examples/research_projects/seq2seq-distillation/make_student.py b/examples/research_projects/seq2seq-distillation/make_student.py
deleted file mode 100644
index 83e014bf481..00000000000
--- a/examples/research_projects/seq2seq-distillation/make_student.py
+++ /dev/null
@@ -1,186 +0,0 @@
-import warnings
-from pathlib import Path
-from typing import List, Tuple, Union
-
-import fire
-from torch import nn
-
-from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, PreTrainedModel
-from transformers.utils import logging
-
-
-logger = logging.get_logger(__name__)
-
-
-def copy_layers(src_layers: nn.ModuleList, dest_layers: nn.ModuleList, layers_to_copy: List[int]) -> None:
- layers_to_copy = nn.ModuleList([src_layers[i] for i in layers_to_copy])
- assert len(dest_layers) == len(layers_to_copy), f"{len(dest_layers)} != {len(layers_to_copy)}"
- dest_layers.load_state_dict(layers_to_copy.state_dict())
-
-
-LAYERS_TO_COPY = {
- # maps num layers in teacher -> num_layers in student -> which teacher layers to copy.
- # 12: bart, 16: pegasus, 6: marian/Helsinki-NLP
- 12: {
- 1: [0], # This says that if the teacher has 12 layers and the student has 1, copy layer 0 of the teacher
- 2: [0, 6],
- 3: [0, 6, 11],
- 4: [0, 4, 8, 11],
- 6: [0, 2, 4, 7, 9, 11],
- 9: [0, 1, 2, 4, 5, 7, 9, 10, 11],
- 12: list(range(12)),
- },
- 16: { # maps num layers in student -> which teacher layers to copy
- 1: [0],
- 2: [0, 15],
- 3: [0, 8, 15],
- 4: [0, 5, 10, 15],
- 6: [0, 3, 6, 9, 12, 15],
- 8: [0, 2, 4, 6, 8, 10, 12, 15],
- 9: [0, 1, 3, 5, 7, 9, 11, 13, 15],
- 12: [0, 1, 2, 3, 4, 5, 6, 7, 9, 11, 13, 15],
- 16: list(range(16)),
- },
- 6: {1: [0], 2: [0, 5], 3: [0, 2, 5], 4: [0, 1, 3, 5], 6: list(range(6))},
-}
-LAYERS_TO_SUPERVISE = {
- # maps num layers in student -> which teacher layers to copy.
- 6: {1: [5], 2: [3, 5], 3: [1, 4, 5], 4: [1, 2, 4, 5]},
- 12: {1: [11], 2: [5, 11], 3: [3, 7, 11], 6: [1, 3, 5, 8, 10, 11]},
- 16: {1: [15], 4: [4, 9, 12, 15], 8: [1, 3, 5, 7, 9, 11, 13, 15]},
-}
-
-
-def pick_layers_to_copy(n_student, n_teacher):
- try:
- val = LAYERS_TO_COPY[n_teacher][n_student]
- return val
- except KeyError:
- if n_student != n_teacher:
- warnings.warn(
- f"no hardcoded layers to copy for teacher {n_teacher} -> student {n_student}, defaulting to first"
- f" {n_student}"
- )
- return list(range(n_student))
-
-
-def get_layers_to_supervise(n_student, n_teacher) -> List[int]:
- """Used or the --supervise_forward kwarg"""
- if n_student > n_teacher:
- raise ValueError(f"Cannot perform intermediate supervision for student {n_student} > teacher {n_teacher}")
- elif n_teacher == n_student:
- return list(range(n_teacher))
- elif n_student == 1:
- return [n_teacher - 1]
- else:
- return LAYERS_TO_SUPERVISE[n_teacher][n_student]
-
-
-def create_student_by_copying_alternating_layers(
- teacher: Union[str, PreTrainedModel],
- save_path: Union[str, Path] = "student",
- e: Union[int, None] = None,
- d: Union[int, None] = None,
- copy_first_teacher_layers=False,
- e_layers_to_copy=None,
- d_layers_to_copy=None,
- **extra_config_kwargs,
-) -> Tuple[PreTrainedModel, List[int], List[int]]:
- """Make a student by copying alternating layers from a teacher, save it to save_path.
- Args:
- teacher: str or PreTrainedModel if str, this will call AutoModelForSeq2SeqLM.from_pretrained(teacher) before
- copying layers
- save_path: where to save the student, defaults to student directory.
- e: how many Encoder layers should the student have, default is fully copy of teacher
- d: how many Decoder layers should the student have, default is fully copy of teacher
- copy_first_teacher_layers: [bool] dont copy alternating layers, just the first e/d.
- **extra_config_kwargs: extra kwargs to pass to the student, by default the teacher config is used.
-
- Returns:
- student: new, smaller model. (Also saves it to save_path)
- e_layers_to_copy: list of which teacher encoder layers were used
- d_layers_to_copy: list of which teacher decoder layers were used
- """
- _msg = "encoder_layers and decoder_layers cannot be both None-- you would just have an identical teacher."
- assert (e is not None) or (d is not None), _msg
- if isinstance(teacher, str):
- AutoTokenizer.from_pretrained(teacher).save_pretrained(save_path) # purely for convenience
- teacher = AutoModelForSeq2SeqLM.from_pretrained(teacher).eval()
- else:
- assert isinstance(teacher, PreTrainedModel), f"teacher must be a model or string got type {type(teacher)}"
- init_kwargs = teacher.config.to_diff_dict()
-
- try:
- teacher_e, teacher_d = teacher.config.encoder_layers, teacher.config.decoder_layers
- if e is None:
- e = teacher_e
- if d is None:
- d = teacher_d
- init_kwargs.update({"encoder_layers": e, "decoder_layers": d})
- except AttributeError: # T5
- if hasattr(teacher.config, "num_encoder_layers"):
- teacher_e, teacher_d = teacher.config.num_encoder_layers, teacher.config.num_decoder_layers
- else:
- teacher_e, teacher_d = teacher.config.num_layers, teacher.config.num_decoder_layers
- if e is None:
- e = teacher_e
- if d is None:
- d = teacher_d
- if hasattr(teacher.config, "num_encoder_layers"):
- init_kwargs.update({"num_encoder_layers": e, "num_decoder_layers": d})
- else:
- init_kwargs.update({"num_layers": e, "num_decoder_layers": d})
-
- # Kwargs to instantiate student: teacher kwargs with updated layer numbers + **extra_config_kwargs
- init_kwargs.update(extra_config_kwargs)
-
- # Copy weights
- student_cfg = teacher.config_class(**init_kwargs)
- student = AutoModelForSeq2SeqLM.from_config(student_cfg)
- # Start by copying the full teacher state dict this will copy the first N teacher layers to the student.
- info = student.load_state_dict(teacher.state_dict(), strict=False)
- assert info.missing_keys == [], info.missing_keys # every student key should have a teacher keys.
-
- if copy_first_teacher_layers: # Our copying is done. We just log and save
- e_layers_to_copy, d_layers_to_copy = list(range(e)), list(range(d))
- logger.info(
- f"Copied encoder layers {e_layers_to_copy} and decoder layers {d_layers_to_copy}. Saving them to"
- f" {save_path}"
- )
- student.save_pretrained(save_path)
- return student, e_layers_to_copy, d_layers_to_copy
-
- # Decide which layers of the teacher to copy. Not exactly alternating -- we try to keep first and last layer.
- if e_layers_to_copy is None:
- e_layers_to_copy: List[int] = pick_layers_to_copy(e, teacher_e)
- if d_layers_to_copy is None:
- d_layers_to_copy: List[int] = pick_layers_to_copy(d, teacher_d)
-
- try:
- if hasattr(
- teacher, "prophetnet"
- ): # For ProphetNet, student.model.encoder.layers is called student.prophetnet.encoder.layers
- copy_layers(teacher.prophetnet.encoder.layers, student.prophetnet.encoder.layers, e_layers_to_copy)
- copy_layers(teacher.prophetnet.decoder.layers, student.prophetnet.decoder.layers, d_layers_to_copy)
- else:
- copy_layers(teacher.model.encoder.layers, student.model.encoder.layers, e_layers_to_copy)
- copy_layers(teacher.model.decoder.layers, student.model.decoder.layers, d_layers_to_copy)
- except AttributeError: # For t5, student.model.encoder.layers is called student.encoder.block
- copy_layers(teacher.encoder.block, student.encoder.block, e_layers_to_copy)
- copy_layers(teacher.decoder.block, student.decoder.block, d_layers_to_copy)
- logger.info(
- f"Copied encoder layers {e_layers_to_copy} and decoder layers {d_layers_to_copy}. Saving them to {save_path}"
- )
- student.config.init_metadata = {
- "teacher_type": teacher.config.model_type,
- "copied_encoder_layers": e_layers_to_copy,
- "copied_decoder_layers": d_layers_to_copy,
- }
- student.save_pretrained(save_path)
- # Save information about copying for easier reproducibility
-
- return student, e_layers_to_copy, d_layers_to_copy
-
-
-if __name__ == "__main__":
- fire.Fire(create_student_by_copying_alternating_layers)
diff --git a/examples/research_projects/seq2seq-distillation/precomputed_pseudo_labels.md b/examples/research_projects/seq2seq-distillation/precomputed_pseudo_labels.md
deleted file mode 100644
index fb2713ccde8..00000000000
--- a/examples/research_projects/seq2seq-distillation/precomputed_pseudo_labels.md
+++ /dev/null
@@ -1,43 +0,0 @@
-### Saved Pseudo-Labels
-These are the generations of various large models on various large **training** sets. All in all they took about 200 GPU hours to produce.
-
-### Available Pseudo-labels
-| Dataset | Model | Link | Rouge Scores | Notes
-|---------|-----------------------------|----------------------------------------------------------------------------------------|--------------------|-------------------------------------------------------------------------------------------------------------
-| XSUM | `facebook/bart-large-xsum` | [download](https://cdn-datasets.huggingface.co/pseudo/xsum/bart_xsum_pl.tgz) | 49.8/28.0/42.5 |
-| XSUM | `google/pegasus-xsum` | [download](https://cdn-datasets.huggingface.co/pseudo/xsum/pegasus_xsum.tgz) | 53.3/32.7/46.5 |
-| XSUM | `facebook/bart-large-xsum` | [download](https://cdn-datasets.huggingface.co/pseudo/xsum/xsum_pl2_bart.tgz) | | Bart pseudolabels filtered to those with Rouge2 > 10.0 w GT.
-| CNN/DM | `sshleifer/pegasus-cnn-ft-v2` | [download](https://cdn-datasets.huggingface.co/pseudo/cnn_dm/pegasus_cnn_cnn_pls.tgz) | 47.316/26.65/44.56 | do not worry about the fact that train.source is one line shorter.
-| CNN/DM | `facebook/bart-large-cnn` | [download](https://cdn-datasets.huggingface.co/pseudo/cnn_dm/cnn_bart_pl.tgz) | | 5K (2%) are missing, there should be 282173
-| CNN/DM | `google/pegasus-xsum` | [download](https://cdn-datasets.huggingface.co/pseudo/cnn_dm/pegasus_xsum_on_cnn.tgz) | 21.5/6.76/25 | extra labels for xsum distillation Used max_source_length=512, (and all other pegasus-xsum configuration).
-| EN-RO | `Helsinki-NLP/opus-mt-en-ro` | [download](https://cdn-datasets.huggingface.co/pseudo/wmt_en_ro/opus_mt_en_ro.tgz) | |
-| EN-RO | `facebook/mbart-large-en-ro` | [download](https://cdn-datasets.huggingface.co/pseudo/wmt_en_ro/mbart_large_en_ro.tgz) | |
-
-
-(EN_RO = WMT 2016 English-Romanian).
-
-Example Download Command:
-```bash
-curl -S https://cdn-datasets.huggingface.co/pseudo/xsum/bart_xsum_pl.tgz | tar -xvz -C .
-```
-### Generating New Pseudolabels
-Here is the command I used to generate the pseudolabels in the second row of the table, after downloading XSUM from [here](https://cdn-datasets.huggingface.co/summarization/xsum.tar.gz).
-
-```bash
-python -m torch.distributed.launch --nproc_per_node=8 run_distributed_eval.py \
- --model_name google/pegasus-xsum \
- --save_dir pegasus_xsum \
- --data_dir xsum \
- --bs 8 --sync_timeout 60000 \
- --max_source_length 512 \
- --type_path train
-```
-
-+ These commands takes a while to run. For example, `pegasus_cnn_cnn_pls.tgz` took 8 hours on 8 GPUs.
-+ Pegasus does not work in fp16 :(, Bart, mBART and Marian do.
-+ Even if you have 1 GPU, `run_distributed_eval.py` is 10-20% faster than `run_eval.py` because it uses `SortishSampler` to minimize padding computation.
-
-### Contributions
-Feel free to contribute your own pseudolabels via PR. Add a row to this table with a new google drive link (or other command line downloadable link).
-
-
diff --git a/examples/research_projects/seq2seq-distillation/requirements.txt b/examples/research_projects/seq2seq-distillation/requirements.txt
deleted file mode 100644
index 533f6339ab0..00000000000
--- a/examples/research_projects/seq2seq-distillation/requirements.txt
+++ /dev/null
@@ -1,20 +0,0 @@
-tensorboard
-scikit-learn
-psutil
-sacrebleu
-rouge-score
-tensorflow_datasets
-pytorch-lightning
-matplotlib
-git-python==1.0.3
-faiss-cpu
-streamlit
-elasticsearch
-nltk
-pandas
-datasets >= 1.1.3
-fire
-pytest
-conllu
-sentencepiece != 0.1.92
-protobuf
diff --git a/examples/research_projects/seq2seq-distillation/run_eval.py b/examples/research_projects/seq2seq-distillation/run_eval.py
deleted file mode 100755
index 54ad6c6fb6b..00000000000
--- a/examples/research_projects/seq2seq-distillation/run_eval.py
+++ /dev/null
@@ -1,167 +0,0 @@
-#!/usr/bin/env python
-
-import argparse
-import datetime
-import json
-import time
-import warnings
-from logging import getLogger
-from pathlib import Path
-from typing import Dict, List
-
-import torch
-from tqdm import tqdm
-
-from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
-from utils import calculate_bleu, calculate_rouge, chunks, parse_numeric_n_bool_cl_kwargs, use_task_specific_params
-
-
-logger = getLogger(__name__)
-
-
-DEFAULT_DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
-
-
-def generate_summaries_or_translations(
- examples: List[str],
- out_file: str,
- model_name: str,
- batch_size: int = 8,
- device: str = DEFAULT_DEVICE,
- fp16=False,
- task="summarization",
- prefix=None,
- **generate_kwargs,
-) -> Dict:
- """Save model.generate results to , and return how long it took."""
- fout = Path(out_file).open("w", encoding="utf-8")
- model_name = str(model_name)
- model = AutoModelForSeq2SeqLM.from_pretrained(model_name).to(device)
- if fp16:
- model = model.half()
-
- tokenizer = AutoTokenizer.from_pretrained(model_name)
- logger.info(f"Inferred tokenizer type: {tokenizer.__class__}") # if this is wrong, check config.model_type.
-
- start_time = time.time()
- # update config with task specific params
- use_task_specific_params(model, task)
- if prefix is None:
- prefix = prefix or getattr(model.config, "prefix", "") or ""
- for examples_chunk in tqdm(list(chunks(examples, batch_size))):
- examples_chunk = [prefix + text for text in examples_chunk]
- batch = tokenizer(examples_chunk, return_tensors="pt", truncation=True, padding="longest").to(device)
- summaries = model.generate(
- input_ids=batch.input_ids,
- attention_mask=batch.attention_mask,
- **generate_kwargs,
- )
- dec = tokenizer.batch_decode(summaries, skip_special_tokens=True, clean_up_tokenization_spaces=False)
- for hypothesis in dec:
- fout.write(hypothesis + "\n")
- fout.flush()
- fout.close()
- runtime = int(time.time() - start_time) # seconds
- n_obs = len(examples)
- return {"n_obs": n_obs, "runtime": runtime, "seconds_per_sample": round(runtime / n_obs, 4)}
-
-
-def datetime_now():
- return datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
-
-
-def run_generate(verbose=True):
- """
-
- Takes input text, generates output, and then using reference calculates the BLEU scores.
-
- The results are saved to a file and returned to the caller, and printed out unless ``verbose=False`` is passed.
-
- Args:
- verbose (:obj:`bool`, `optional`, defaults to :obj:`True`): print results to stdout
-
- Returns:
- a tuple: ``(scores, params}``
- - ``scores``: a dict of scores data ``{'bleu': 39.6501, 'n_obs': 2000, 'runtime': 186, 'seconds_per_sample': 0.093}``
- - ``params``: a dict of custom params, e.g. ``{'num_beams': 5, 'length_penalty': 0.8}``
- """
-
- parser = argparse.ArgumentParser()
- parser.add_argument("model_name", type=str, help="like facebook/bart-large-cnn,t5-base, etc.")
- parser.add_argument("input_path", type=str, help="like cnn_dm/test.source")
- parser.add_argument("save_path", type=str, help="where to save summaries")
- parser.add_argument("--reference_path", type=str, required=False, help="like cnn_dm/test.target")
- parser.add_argument("--score_path", type=str, required=False, default="metrics.json", help="where to save metrics")
- parser.add_argument("--device", type=str, required=False, default=DEFAULT_DEVICE, help="cuda, cuda:1, cpu etc.")
- parser.add_argument(
- "--prefix", type=str, required=False, default=None, help="will be added to the beginning of src examples"
- )
- parser.add_argument("--task", type=str, default="summarization", help="used for task_specific_params + metrics")
- parser.add_argument("--bs", type=int, default=8, required=False, help="batch size")
- parser.add_argument(
- "--n_obs", type=int, default=-1, required=False, help="How many observations. Defaults to all."
- )
- parser.add_argument("--fp16", action="store_true")
- parser.add_argument("--dump-args", action="store_true", help="print the custom hparams with the results")
- parser.add_argument(
- "--info",
- nargs="?",
- type=str,
- const=datetime_now(),
- help=(
- "use in conjunction w/ --dump-args to print with the results whatever other info you'd like, e.g."
- " lang=en-ru. If no value is passed, the current datetime string will be used."
- ),
- )
- # Unspecified args like --num_beams=2 --decoder_start_token_id=4 are passed to model.generate
- args, rest = parser.parse_known_args()
- parsed_args = parse_numeric_n_bool_cl_kwargs(rest)
- if parsed_args and verbose:
- print(f"parsed the following generate kwargs: {parsed_args}")
- with open(args.input_path) as f:
- examples = [" " + x.rstrip() if "t5" in args.model_name else x.rstrip() for x in f.readlines()]
- if args.n_obs > 0:
- examples = examples[: args.n_obs]
- Path(args.save_path).parent.mkdir(exist_ok=True)
- if args.reference_path is None and Path(args.score_path).exists():
- warnings.warn(f"score_path {args.score_path} will be overwritten unless you type ctrl-c.")
- runtime_metrics = generate_summaries_or_translations(
- examples,
- args.save_path,
- args.model_name,
- batch_size=args.bs,
- device=args.device,
- fp16=args.fp16,
- task=args.task,
- prefix=args.prefix,
- **parsed_args,
- )
-
- if args.reference_path is None:
- return {}
-
- # Compute scores
- score_fn = calculate_bleu if "translation" in args.task else calculate_rouge
- output_lns = [x.rstrip() for x in open(args.save_path).readlines()]
- reference_lns = [x.rstrip() for x in open(args.reference_path).readlines()][: len(output_lns)]
- scores: dict = score_fn(output_lns, reference_lns)
- scores.update(runtime_metrics)
-
- if args.dump_args:
- scores.update(parsed_args)
- if args.info:
- scores["info"] = args.info
-
- if verbose:
- print(scores)
-
- if args.score_path is not None:
- json.dump(scores, open(args.score_path, "w"))
-
- return scores
-
-
-if __name__ == "__main__":
- # Usage for MT:
- # python run_eval.py MODEL_NAME $DATA_DIR/test.source $save_dir/test_translations.txt --reference_path $DATA_DIR/test.target --score_path $save_dir/test_bleu.json --task translation $@
- run_generate(verbose=True)
diff --git a/examples/research_projects/seq2seq-distillation/sentence_splitter.py b/examples/research_projects/seq2seq-distillation/sentence_splitter.py
deleted file mode 100644
index c5acec73928..00000000000
--- a/examples/research_projects/seq2seq-distillation/sentence_splitter.py
+++ /dev/null
@@ -1,22 +0,0 @@
-import re
-
-from filelock import FileLock
-
-
-try:
- import nltk
-
- NLTK_AVAILABLE = True
-except (ImportError, ModuleNotFoundError):
- NLTK_AVAILABLE = False
-
-if NLTK_AVAILABLE:
- with FileLock(".lock") as lock:
- nltk.download("punkt", quiet=True)
-
-
-def add_newline_to_end_of_each_sentence(x: str) -> str:
- """This was added to get rougeLsum scores matching published rougeL scores for BART and PEGASUS."""
- re.sub("", "", x) # remove pegasus newline char
- assert NLTK_AVAILABLE, "nltk must be installed to separate newlines between sentences. (pip install nltk)"
- return "\n".join(nltk.sent_tokenize(x))
diff --git a/examples/research_projects/seq2seq-distillation/train_distilbart_cnn.sh b/examples/research_projects/seq2seq-distillation/train_distilbart_cnn.sh
deleted file mode 100755
index 6a1bafbdc9c..00000000000
--- a/examples/research_projects/seq2seq-distillation/train_distilbart_cnn.sh
+++ /dev/null
@@ -1,24 +0,0 @@
-#!/usr/bin/env bash
-export PYTHONPATH="../":"${PYTHONPATH}"
-
-export BS=32
-export GAS=1
-
-python finetune.py \
- --learning_rate=3e-5 \
- --fp16 \
- --gpus 1 \
- --do_train \
- --do_predict \
- --val_check_interval 0.25 \
- --n_val 500 \
- --num_train_epochs 2 \
- --freeze_encoder --freeze_embeds --data_dir cnn_dm \
- --max_target_length 142 --val_max_target_length=142 \
- --train_batch_size=$BS --eval_batch_size=$BS --gradient_accumulation_steps=$GAS \
- --model_name_or_path sshleifer/student_cnn_12_6 \
- --tokenizer_name facebook/bart-large \
- --warmup_steps 500 \
- --output_dir distilbart-cnn-12-6 \
- "$@"
-
diff --git a/examples/research_projects/seq2seq-distillation/train_distilbart_xsum.sh b/examples/research_projects/seq2seq-distillation/train_distilbart_xsum.sh
deleted file mode 100755
index 86a3440fc0c..00000000000
--- a/examples/research_projects/seq2seq-distillation/train_distilbart_xsum.sh
+++ /dev/null
@@ -1,21 +0,0 @@
-#!/usr/bin/env bash
-export PYTHONPATH="../":"${PYTHONPATH}"
-python distillation.py \
- --teacher facebook/bart-large-xsum --data_dir xsum \
- --tokenizer_name facebook/bart-large-xsum \
- --student_decoder_layers 6 --student_encoder_layers 12 \
- --freeze_encoder --freeze_embeds \
- --learning_rate=3e-4 \
- --do_train \
- --do_predict \
- --fp16 --fp16_opt_level=O1 \
- --val_check_interval 0.1 --n_val 1000 --eval_beams 2 --length_penalty=0.5 \
- --max_target_length=60 --val_max_target_length=60 --test_max_target_length=100 \
- --model_name_or_path IGNORED \
- --alpha_hid=3. \
- --train_batch_size=16 --eval_batch_size=16 --gradient_accumulation_steps=2 \
- --sortish_sampler \
- --num_train_epochs=6 \
- --warmup_steps 500 \
- --output_dir distilbart_xsum_12_6 \
- "$@"
diff --git a/examples/research_projects/seq2seq-distillation/train_mbart_cc25_enro.sh b/examples/research_projects/seq2seq-distillation/train_mbart_cc25_enro.sh
deleted file mode 100755
index 54e7935ff60..00000000000
--- a/examples/research_projects/seq2seq-distillation/train_mbart_cc25_enro.sh
+++ /dev/null
@@ -1,18 +0,0 @@
-#!/usr/bin/env bash
-export PYTHONPATH="../":"${PYTHONPATH}"
-
-python finetune.py \
- --learning_rate=3e-5 \
- --fp16 \
- --do_train \
- --val_check_interval=0.25 \
- --adam_eps 1e-06 \
- --num_train_epochs 6 --src_lang en_XX --tgt_lang ro_RO \
- --data_dir $ENRO_DIR \
- --max_source_length $MAX_LEN --max_target_length $MAX_LEN --val_max_target_length $MAX_LEN --test_max_target_length $MAX_LEN \
- --train_batch_size=$BS --eval_batch_size=$BS \
- --task translation \
- --warmup_steps 500 \
- --freeze_embeds \
- --model_name_or_path=facebook/mbart-large-cc25 \
- "$@"
diff --git a/examples/research_projects/seq2seq-distillation/utils.py b/examples/research_projects/seq2seq-distillation/utils.py
deleted file mode 100644
index de666e0c249..00000000000
--- a/examples/research_projects/seq2seq-distillation/utils.py
+++ /dev/null
@@ -1,645 +0,0 @@
-import itertools
-import json
-import linecache
-import math
-import os
-import pickle
-import socket
-from logging import getLogger
-from pathlib import Path
-from typing import Callable, Dict, Iterable, List, Tuple, Union
-
-import git
-import numpy as np
-import torch
-import torch.distributed as dist
-from rouge_score import rouge_scorer, scoring
-from sacrebleu import corpus_bleu
-from sentence_splitter import add_newline_to_end_of_each_sentence
-from torch import nn
-from torch.utils.data import Dataset, Sampler
-
-from transformers import BartTokenizer, EvalPrediction, PreTrainedTokenizer, T5Tokenizer
-from transformers.file_utils import cached_property
-from transformers.models.bart.modeling_bart import shift_tokens_right
-
-
-try:
- from fairseq.data.data_utils import batch_by_size
-
- FAIRSEQ_AVAILABLE = True
-except (ImportError, ModuleNotFoundError):
- FAIRSEQ_AVAILABLE = False
-
-
-def label_smoothed_nll_loss(lprobs, target, epsilon, ignore_index=-100):
- """From fairseq"""
- if target.dim() == lprobs.dim() - 1:
- target = target.unsqueeze(-1)
- nll_loss = -lprobs.gather(dim=-1, index=target)
- smooth_loss = -lprobs.sum(dim=-1, keepdim=True)
- if ignore_index is not None:
- pad_mask = target.eq(ignore_index)
- nll_loss.masked_fill_(pad_mask, 0.0)
- smooth_loss.masked_fill_(pad_mask, 0.0)
- else:
- nll_loss = nll_loss.squeeze(-1)
- smooth_loss = smooth_loss.squeeze(-1)
-
- nll_loss = nll_loss.sum() # mean()? Scared to break other math.
- smooth_loss = smooth_loss.sum()
- eps_i = epsilon / lprobs.size(-1)
- loss = (1.0 - epsilon) * nll_loss + eps_i * smooth_loss
- return loss, nll_loss
-
-
-def lmap(f: Callable, x: Iterable) -> List:
- """list(map(f, x))"""
- return list(map(f, x))
-
-
-def calculate_bleu(output_lns, refs_lns, **kwargs) -> dict:
- """Uses sacrebleu's corpus_bleu implementation."""
- return {"bleu": round(corpus_bleu(output_lns, [refs_lns], **kwargs).score, 4)}
-
-
-def build_compute_metrics_fn(task_name: str, tokenizer: PreTrainedTokenizer) -> Callable[[EvalPrediction], Dict]:
- def non_pad_len(tokens: np.ndarray) -> int:
- return np.count_nonzero(tokens != tokenizer.pad_token_id)
-
- def decode_pred(pred: EvalPrediction) -> Tuple[List[str], List[str]]:
- pred_str = tokenizer.batch_decode(pred.predictions, skip_special_tokens=True)
- label_str = tokenizer.batch_decode(pred.label_ids, skip_special_tokens=True)
- pred_str = lmap(str.strip, pred_str)
- label_str = lmap(str.strip, label_str)
- return pred_str, label_str
-
- def summarization_metrics(pred: EvalPrediction) -> Dict:
- pred_str, label_str = decode_pred(pred)
- rouge: Dict = calculate_rouge(pred_str, label_str)
- summ_len = np.round(np.mean(lmap(non_pad_len, pred.predictions)), 1)
- rouge.update({"gen_len": summ_len})
- return rouge
-
- def translation_metrics(pred: EvalPrediction) -> Dict:
- pred_str, label_str = decode_pred(pred)
- bleu: Dict = calculate_bleu(pred_str, label_str)
- gen_len = np.round(np.mean(lmap(non_pad_len, pred.predictions)), 1)
- bleu.update({"gen_len": gen_len})
- return bleu
-
- compute_metrics_fn = summarization_metrics if "summarization" in task_name else translation_metrics
- return compute_metrics_fn
-
-
-def trim_batch(
- input_ids,
- pad_token_id,
- attention_mask=None,
-):
- """Remove columns that are populated exclusively by pad_token_id"""
- keep_column_mask = input_ids.ne(pad_token_id).any(dim=0)
- if attention_mask is None:
- return input_ids[:, keep_column_mask]
- else:
- return (input_ids[:, keep_column_mask], attention_mask[:, keep_column_mask])
-
-
-class AbstractSeq2SeqDataset(Dataset):
- def __init__(
- self,
- tokenizer,
- data_dir,
- max_source_length,
- max_target_length,
- type_path="train",
- n_obs=None,
- prefix="",
- **dataset_kwargs,
- ):
- super().__init__()
- self.src_file = Path(data_dir).joinpath(type_path + ".source")
- self.tgt_file = Path(data_dir).joinpath(type_path + ".target")
- self.len_file = Path(data_dir).joinpath(type_path + ".len")
- if os.path.exists(self.len_file):
- self.src_lens = pickle_load(self.len_file)
- self.used_char_len = False
- else:
- self.src_lens = self.get_char_lens(self.src_file)
- self.used_char_len = True
- self.max_source_length = max_source_length
- self.max_target_length = max_target_length
- assert min(self.src_lens) > 0, f"found empty line in {self.src_file}"
- self.tokenizer = tokenizer
- self.prefix = prefix if prefix is not None else ""
-
- if n_obs is not None:
- self.src_lens = self.src_lens[:n_obs]
- self.pad_token_id = self.tokenizer.pad_token_id
- self.dataset_kwargs = dataset_kwargs
- dataset_kwargs.update({"add_prefix_space": True} if isinstance(self.tokenizer, BartTokenizer) else {})
-
- def __len__(self):
- return len(self.src_lens)
-
- @staticmethod
- def get_char_lens(data_file):
- return [len(x) for x in Path(data_file).open().readlines()]
-
- @cached_property
- def tgt_lens(self):
- """Length in characters of target documents"""
- return self.get_char_lens(self.tgt_file)
-
- def make_sortish_sampler(self, batch_size, distributed=False, shuffle=True, **kwargs):
- if distributed:
- return DistributedSortishSampler(self, batch_size, shuffle=shuffle, **kwargs)
- else:
- return SortishSampler(self.src_lens, batch_size, shuffle=shuffle)
-
- def make_dynamic_sampler(self, max_tokens_per_batch=1024, **kwargs):
- assert FAIRSEQ_AVAILABLE, "Dynamic batch size requires `pip install fairseq`"
- assert not self.used_char_len, "You must call python make_len_file.py before calling make_dynamic_sampler"
- sorted_indices = list(self.make_sortish_sampler(1024, shuffle=False))
-
- def num_tokens_in_example(i):
- return min(self.src_lens[i], self.max_target_length)
-
- # call fairseq cython function
- batch_sampler: List[List[int]] = batch_by_size(
- sorted_indices,
- num_tokens_fn=num_tokens_in_example,
- max_tokens=max_tokens_per_batch,
- required_batch_size_multiple=64,
- )
- shuffled_batches = [batch_sampler[i] for i in np.random.permutation(range(len(batch_sampler)))]
- # move the largest batch to the front to OOM quickly (uses an approximation for padding)
- approximate_toks_per_batch = [max(self.src_lens[i] for i in batch) * len(batch) for batch in shuffled_batches]
- largest_batch_idx = np.argmax(approximate_toks_per_batch)
- shuffled_batches[0], shuffled_batches[largest_batch_idx] = (
- shuffled_batches[largest_batch_idx],
- shuffled_batches[0],
- )
- return shuffled_batches
-
- def __getitem__(self, item):
- raise NotImplementedError("You must implement this")
-
- def collate_fn(self, batch):
- raise NotImplementedError("You must implement this")
-
-
-class LegacySeq2SeqDataset(AbstractSeq2SeqDataset):
- def __getitem__(self, index) -> Dict[str, torch.Tensor]:
- """Call tokenizer on src and tgt_lines"""
- index = index + 1 # linecache starts at 1
- source_line = self.prefix + linecache.getline(str(self.src_file), index).rstrip("\n")
- tgt_line = linecache.getline(str(self.tgt_file), index).rstrip("\n")
- assert source_line, f"empty source line for index {index}"
- assert tgt_line, f"empty tgt line for index {index}"
- source_inputs = self.encode_line(self.tokenizer, source_line, self.max_source_length)
- target_inputs = self.encode_line(self.tokenizer, tgt_line, self.max_target_length)
-
- source_ids = source_inputs["input_ids"].squeeze()
- target_ids = target_inputs["input_ids"].squeeze()
- src_mask = source_inputs["attention_mask"].squeeze()
- return {
- "input_ids": source_ids,
- "attention_mask": src_mask,
- "labels": target_ids,
- }
-
- def encode_line(self, tokenizer, line, max_length, pad_to_max_length=True, return_tensors="pt"):
- """Only used by LegacyDataset"""
- return tokenizer(
- [line],
- max_length=max_length,
- padding="max_length" if pad_to_max_length else None,
- truncation=True,
- return_tensors=return_tensors,
- **self.dataset_kwargs,
- )
-
- def collate_fn(self, batch) -> Dict[str, torch.Tensor]:
- input_ids = torch.stack([x["input_ids"] for x in batch])
- masks = torch.stack([x["attention_mask"] for x in batch])
- target_ids = torch.stack([x["labels"] for x in batch])
- pad_token_id = self.pad_token_id
- y = trim_batch(target_ids, pad_token_id)
- source_ids, source_mask = trim_batch(input_ids, pad_token_id, attention_mask=masks)
- batch = {
- "input_ids": source_ids,
- "attention_mask": source_mask,
- "labels": y,
- }
- return batch
-
-
-class Seq2SeqDataset(AbstractSeq2SeqDataset):
- """A dataset that calls prepare_seq2seq_batch."""
-
- def __getitem__(self, index) -> Dict[str, str]:
- index = index + 1 # linecache starts at 1
- source_line = self.prefix + linecache.getline(str(self.src_file), index).rstrip("\n")
- tgt_line = linecache.getline(str(self.tgt_file), index).rstrip("\n")
- assert source_line, f"empty source line for index {index}"
- assert tgt_line, f"empty tgt line for index {index}"
- return {"tgt_texts": tgt_line, "src_texts": source_line, "id": index - 1}
-
- def collate_fn(self, batch) -> Dict[str, torch.Tensor]:
- """Call prepare_seq2seq_batch."""
- batch_encoding: Dict[str, torch.Tensor] = self.tokenizer.prepare_seq2seq_batch(
- [x["src_texts"] for x in batch],
- tgt_texts=[x["tgt_texts"] for x in batch],
- max_length=self.max_source_length,
- max_target_length=self.max_target_length,
- return_tensors="pt",
- **self.dataset_kwargs,
- ).data
- batch_encoding["ids"] = torch.tensor([x["id"] for x in batch])
- return batch_encoding
-
-
-class Seq2SeqDataCollator:
- def __init__(self, tokenizer, data_args, tpu_num_cores=None):
- self.tokenizer = tokenizer
- self.pad_token_id = tokenizer.pad_token_id
- assert (
- self.pad_token_id is not None
- ), f"pad_token_id is not defined for ({self.tokenizer.__class__.__name__}), it must be defined."
- self.data_args = data_args
- self.tpu_num_cores = tpu_num_cores
- self.dataset_kwargs = {"add_prefix_space": True} if isinstance(tokenizer, BartTokenizer) else {}
- if data_args.src_lang is not None:
- self.dataset_kwargs["src_lang"] = data_args.src_lang
- if data_args.tgt_lang is not None:
- self.dataset_kwargs["tgt_lang"] = data_args.tgt_lang
-
- def __call__(self, batch) -> Dict[str, torch.Tensor]:
- if hasattr(self.tokenizer, "prepare_seq2seq_batch"):
- batch = self._encode(batch)
- input_ids, attention_mask, labels = (
- batch["input_ids"],
- batch["attention_mask"],
- batch["labels"],
- )
- else:
- input_ids = torch.stack([x["input_ids"] for x in batch])
- attention_mask = torch.stack([x["attention_mask"] for x in batch])
- labels = torch.stack([x["labels"] for x in batch])
-
- labels = trim_batch(labels, self.pad_token_id)
- input_ids, attention_mask = trim_batch(input_ids, self.pad_token_id, attention_mask=attention_mask)
-
- if isinstance(self.tokenizer, T5Tokenizer):
- decoder_input_ids = self._shift_right_t5(labels)
- else:
- decoder_input_ids = shift_tokens_right(labels, self.pad_token_id)
-
- batch = {
- "input_ids": input_ids,
- "attention_mask": attention_mask,
- "decoder_input_ids": decoder_input_ids,
- "labels": labels,
- }
- return batch
-
- def _shift_right_t5(self, input_ids):
- # shift inputs to the right
- shifted_input_ids = input_ids.new_zeros(input_ids.shape)
- shifted_input_ids[..., 1:] = input_ids[..., :-1].clone()
- shifted_input_ids[..., 0] = self.pad_token_id
- return shifted_input_ids
-
- def _encode(self, batch) -> Dict[str, torch.Tensor]:
- batch_encoding = self.tokenizer.prepare_seq2seq_batch(
- [x["src_texts"] for x in batch],
- tgt_texts=[x["tgt_texts"] for x in batch],
- max_length=self.data_args.max_source_length,
- max_target_length=self.data_args.max_target_length,
- padding="max_length" if self.tpu_num_cores is not None else "longest", # TPU hack
- return_tensors="pt",
- **self.dataset_kwargs,
- )
- return batch_encoding.data
-
-
-class SortishSampler(Sampler):
- "Go through the text data by order of src length with a bit of randomness. From fastai repo."
-
- def __init__(self, data, batch_size, shuffle=True):
- self.data, self.bs, self.shuffle = data, batch_size, shuffle
-
- def __len__(self) -> int:
- return len(self.data)
-
- def __iter__(self):
- return iter(sortish_sampler_indices(self.data, self.bs, shuffle=self.shuffle))
-
-
-def sortish_sampler_indices(data: List, bs: int, shuffle=True) -> np.array:
- "Go through the text data by order of src length with a bit of randomness. From fastai repo."
- if not shuffle:
- return np.argsort(np.array(data) * -1)
-
- def key_fn(i):
- return data[i]
-
- idxs = np.random.permutation(len(data))
- sz = bs * 50
- ck_idx = [idxs[i : i + sz] for i in range(0, len(idxs), sz)]
- sort_idx = np.concatenate([sorted(s, key=key_fn, reverse=True) for s in ck_idx])
- sz = bs
- ck_idx = [sort_idx[i : i + sz] for i in range(0, len(sort_idx), sz)]
- max_ck = np.argmax([key_fn(ck[0]) for ck in ck_idx]) # find the chunk with the largest key,
- ck_idx[0], ck_idx[max_ck] = ck_idx[max_ck], ck_idx[0] # then make sure it goes first.
- sort_idx = np.concatenate(np.random.permutation(ck_idx[1:])) if len(ck_idx) > 1 else np.array([], dtype=int)
- sort_idx = np.concatenate((ck_idx[0], sort_idx))
- return sort_idx
-
-
-class DistributedSortishSampler(Sampler):
- """Copied from torch DistributedSampler"""
-
- def __init__(self, dataset, batch_size, num_replicas=None, rank=None, add_extra_examples=True, shuffle=True):
- if num_replicas is None:
- if not dist.is_available():
- raise RuntimeError("Requires distributed package to be available")
- num_replicas = dist.get_world_size()
- if rank is None:
- if not dist.is_available():
- raise RuntimeError("Requires distributed package to be available")
- rank = dist.get_rank()
- self.dataset = dataset
- self.num_replicas = num_replicas
- self.rank = rank
- self.epoch = 0
- if add_extra_examples:
- self.num_samples = int(math.ceil(len(self.dataset) * 1.0 / self.num_replicas))
- self.total_size = self.num_samples * self.num_replicas
- else:
- self.total_size = len(dataset)
- self.num_samples = len(self.available_indices)
- self.batch_size = batch_size
- self.add_extra_examples = add_extra_examples
- self.shuffle = shuffle
-
- def __iter__(self) -> Iterable:
- g = torch.Generator()
- g.manual_seed(self.epoch)
-
- sortish_data = [self.dataset.src_lens[i] for i in self.available_indices]
- sortish_indices = sortish_sampler_indices(sortish_data, self.batch_size, shuffle=self.shuffle)
- indices = [self.available_indices[i] for i in sortish_indices]
- assert len(indices) == self.num_samples
- return iter(indices)
-
- @cached_property
- def available_indices(self) -> np.array:
- indices = list(range(len(self.dataset)))
- # add extra samples to make it evenly divisible
- indices += indices[: (self.total_size - len(indices))]
- assert len(indices) == self.total_size
- # subsample
- available_indices = indices[self.rank : self.total_size : self.num_replicas]
- return available_indices
-
- def __len__(self):
- return self.num_samples
-
- def set_epoch(self, epoch):
- self.epoch = epoch
-
-
-logger = getLogger(__name__)
-
-
-def use_task_specific_params(model, task):
- """Update config with summarization specific params."""
- task_specific_params = model.config.task_specific_params
-
- if task_specific_params is not None:
- pars = task_specific_params.get(task, {})
- logger.info(f"using task specific params for {task}: {pars}")
- model.config.update(pars)
-
-
-def pickle_load(path):
- """pickle.load(path)"""
- with open(path, "rb") as f:
- return pickle.load(f)
-
-
-def pickle_save(obj, path):
- """pickle.dump(obj, path)"""
- with open(path, "wb") as f:
- return pickle.dump(obj, f)
-
-
-def flatten_list(summary_ids: List[List]):
- return list(itertools.chain.from_iterable(summary_ids))
-
-
-def save_git_info(folder_path: str) -> None:
- """Save git information to output_dir/git_log.json"""
- repo_infos = get_git_info()
- save_json(repo_infos, os.path.join(folder_path, "git_log.json"))
-
-
-def save_json(content, path, indent=4, **json_dump_kwargs):
- with open(path, "w") as f:
- json.dump(content, f, indent=indent, **json_dump_kwargs)
-
-
-def load_json(path):
- with open(path) as f:
- return json.load(f)
-
-
-def get_git_info():
- try:
- repo = git.Repo(search_parent_directories=True)
- repo_infos = {
- "repo_id": str(repo),
- "repo_sha": str(repo.head.object.hexsha),
- "repo_branch": str(repo.active_branch),
- "hostname": str(socket.gethostname()),
- }
- return repo_infos
- except TypeError:
- return {
- "repo_id": None,
- "repo_sha": None,
- "repo_branch": None,
- "hostname": None,
- }
-
-
-ROUGE_KEYS = ["rouge1", "rouge2", "rougeL", "rougeLsum"]
-
-
-def extract_rouge_mid_statistics(dct):
- new_dict = {}
- for k1, v1 in dct.items():
- mid = v1.mid
- new_dict[k1] = {stat: round(getattr(mid, stat), 4) for stat in ["precision", "recall", "fmeasure"]}
- return new_dict
-
-
-def calculate_rouge(
- pred_lns: List[str],
- tgt_lns: List[str],
- use_stemmer=True,
- rouge_keys=ROUGE_KEYS,
- return_precision_and_recall=False,
- bootstrap_aggregation=True,
- newline_sep=True,
-) -> Dict:
- """Calculate rouge using rouge_scorer package.
-
- Args:
- pred_lns: list of summaries generated by model
- tgt_lns: list of groundtruth summaries (e.g. contents of val.target)
- use_stemmer: Bool indicating whether Porter stemmer should be used to
- strip word suffixes to improve matching.
- rouge_keys: which metrics to compute, defaults to rouge1, rouge2, rougeL, rougeLsum
- return_precision_and_recall: (False) whether to also return precision and recall.
- bootstrap_aggregation: whether to do the typical bootstrap resampling of scores. Defaults to True, if False
- this function returns a collections.defaultdict[metric: list of values for each observation for each subscore]``
- newline_sep:(default=True) whether to add newline between sentences. This is essential for calculation rougeL
- on multi sentence summaries (CNN/DM dataset).
-
- Returns:
- Dict[score: value] if aggregate else defaultdict(list) keyed by rouge_keys
-
- """
- scorer = rouge_scorer.RougeScorer(rouge_keys, use_stemmer=use_stemmer)
- aggregator = scoring.BootstrapAggregator()
- for pred, tgt in zip(tgt_lns, pred_lns):
- # rougeLsum expects "\n" separated sentences within a summary
- if newline_sep:
- pred = add_newline_to_end_of_each_sentence(pred)
- tgt = add_newline_to_end_of_each_sentence(tgt)
- scores = scorer.score(pred, tgt)
- aggregator.add_scores(scores)
-
- if bootstrap_aggregation:
- result = aggregator.aggregate()
- if return_precision_and_recall:
- return extract_rouge_mid_statistics(result) # here we return dict
- else:
- return {k: round(v.mid.fmeasure * 100, 4) for k, v in result.items()}
-
- else:
- return aggregator._scores # here we return defaultdict(list)
-
-
-# Utilities for freezing parameters and checking whether they are frozen
-
-
-def freeze_params(model: nn.Module):
- """Set requires_grad=False for each of model.parameters()"""
- for par in model.parameters():
- par.requires_grad = False
-
-
-def freeze_embeds(model):
- """Freeze token embeddings and positional embeddings for bart, just token embeddings for t5."""
- model_type = model.config.model_type
-
- if model_type == "t5":
- freeze_params(model.shared)
- for d in [model.encoder, model.decoder]:
- freeze_params(d.embed_tokens)
- elif model_type == "fsmt":
- for d in [model.model.encoder, model.model.decoder]:
- freeze_params(d.embed_positions)
- freeze_params(d.embed_tokens)
- else:
- freeze_params(model.model.shared)
- for d in [model.model.encoder, model.model.decoder]:
- freeze_params(d.embed_positions)
- freeze_params(d.embed_tokens)
-
-
-def grad_status(model: nn.Module) -> Iterable:
- return (par.requires_grad for par in model.parameters())
-
-
-def any_requires_grad(model: nn.Module) -> bool:
- return any(grad_status(model))
-
-
-def assert_all_frozen(model):
- model_grads: List[bool] = list(grad_status(model))
- n_require_grad = sum(lmap(int, model_grads))
- npars = len(model_grads)
- assert not any(model_grads), f"{n_require_grad/npars:.1%} of {npars} weights require grad"
-
-
-def assert_not_all_frozen(model):
- model_grads: List[bool] = list(grad_status(model))
- npars = len(model_grads)
- assert any(model_grads), f"none of {npars} weights require grad"
-
-
-def parse_numeric_n_bool_cl_kwargs(unparsed_args: List[str]) -> Dict[str, Union[int, float, bool]]:
- """
- Parse an argv list of unspecified command line args to a dict.
- Assumes all values are either numeric or boolean in the form of true/false.
- """
- result = {}
- assert len(unparsed_args) % 2 == 0, f"got odd number of unparsed args: {unparsed_args}"
- num_pairs = len(unparsed_args) // 2
- for pair_num in range(num_pairs):
- i = 2 * pair_num
- assert unparsed_args[i].startswith("--")
- if unparsed_args[i + 1].lower() == "true":
- value = True
- elif unparsed_args[i + 1].lower() == "false":
- value = False
- else:
- try:
- value = int(unparsed_args[i + 1])
- except ValueError:
- value = float(unparsed_args[i + 1]) # this can raise another informative ValueError
-
- result[unparsed_args[i][2:]] = value
- return result
-
-
-def write_txt_file(ordered_tgt, path):
- f = Path(path).open("w")
- for ln in ordered_tgt:
- f.write(ln + "\n")
- f.flush()
-
-
-def chunks(lst, n):
- """Yield successive n-sized chunks from lst."""
- for i in range(0, len(lst), n):
- yield lst[i : i + n]
-
-
-def check_output_dir(args, expected_items=0):
- """
- Checks whether to bail out if output_dir already exists and has more than expected_items in it
-
- `args`: needs to have the following attributes of `args`:
- - output_dir
- - do_train
- - overwrite_output_dir
-
- `expected_items`: normally 0 (default) - i.e. empty dir, but in some cases a few files are expected (e.g. recovery from OOM)
- """
- if (
- os.path.exists(args.output_dir)
- and len(os.listdir(args.output_dir)) > expected_items
- and args.do_train
- and not args.overwrite_output_dir
- ):
- raise ValueError(
- f"Output directory ({args.output_dir}) already exists and "
- f"has {len(os.listdir(args.output_dir))} items in it (expected {expected_items} items). "
- "Use --overwrite_output_dir to overcome."
- )
diff --git a/examples/research_projects/synthid_text/README.md b/examples/research_projects/synthid_text/README.md
deleted file mode 100644
index 30ab9990373..00000000000
--- a/examples/research_projects/synthid_text/README.md
+++ /dev/null
@@ -1,34 +0,0 @@
-# SynthID Text
-
-This project showcases the use of SynthIDText for watermarking LLMs. The code shown in this repo also
-demostrates the training of the detector for detecting such watermarked text. This detector can be uploaded onto
-a private HF hub repo (private for security reasons) and can be initialized again through pretrained model loading also shown in this script.
-
-See our blog post: https://huggingface.co/blog/synthid-text
-
-
-## Python version
-
-User would need python 3.9 to run this example.
-
-## Installation and running
-
-Once you install transformers you would need to install requirements for this project through requirements.txt provided in this folder.
-
-```
-pip install -r requirements.txt
-```
-
-## To run the detector training
-
-```
-python detector_training.py --model_name=google/gemma-7b-it
-```
-
-Check the script for more parameters are are tunable and check out paper at link
-https://www.nature.com/articles/s41586-024-08025-4 for more information on these parameters.
-
-## Caveat
-
-Make sure to run the training of the detector and the detection on the same hardware
-CPU, GPU or TPU to get consistent results (we use detecterministic randomness which is hardware dependent).
diff --git a/examples/research_projects/synthid_text/detector_training.py b/examples/research_projects/synthid_text/detector_training.py
deleted file mode 100644
index 35d0ea22f42..00000000000
--- a/examples/research_projects/synthid_text/detector_training.py
+++ /dev/null
@@ -1,502 +0,0 @@
-# coding=utf-8
-# Copyright 2024 Google DeepMind.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import argparse
-import dataclasses
-import enum
-from typing import Any, Dict, List, Optional, Tuple, Union
-
-import numpy as np
-import torch
-
-from transformers import (
- AutoModelForCausalLM,
- AutoTokenizer,
- BayesianDetectorConfig,
- BayesianDetectorModel,
- SynthIDTextWatermarkDetector,
- SynthIDTextWatermarkingConfig,
- SynthIDTextWatermarkLogitsProcessor,
-)
-from utils import (
- get_tokenized_uwm_outputs,
- get_tokenized_wm_outputs,
- process_raw_model_outputs,
- update_fn_if_fpr_tpr,
- upload_model_to_hf,
-)
-
-
-@enum.unique
-class ValidationMetric(enum.Enum):
- """Direction along the z-axis."""
-
- TPR_AT_FPR = "tpr_at_fpr"
- CROSS_ENTROPY = "cross_entropy"
-
-
-@dataclasses.dataclass
-class TrainingArguments:
- """Training arguments pertaining to the training loop itself."""
-
- eval_metric: Optional[str] = dataclasses.field(
- default=ValidationMetric.TPR_AT_FPR, metadata={"help": "The evaluation metric used."}
- )
-
-
-def train_detector(
- detector: torch.nn.Module,
- g_values: torch.Tensor,
- mask: torch.Tensor,
- watermarked: torch.Tensor,
- epochs: int = 250,
- learning_rate: float = 1e-3,
- minibatch_size: int = 64,
- seed: int = 0,
- l2_weight: float = 0.0,
- shuffle: bool = True,
- g_values_val: Optional[torch.Tensor] = None,
- mask_val: Optional[torch.Tensor] = None,
- watermarked_val: Optional[torch.Tensor] = None,
- verbose: bool = False,
- validation_metric: ValidationMetric = ValidationMetric.TPR_AT_FPR,
-) -> Tuple[Dict[str, Any], float]:
- """Trains a Bayesian detector model.
-
- Args:
- g_values: g-values of shape [num_train, seq_len, watermarking_depth].
- mask: A binary array shape [num_train, seq_len] indicating which g-values
- should be used. g-values with mask value 0 are discarded.
- watermarked: A binary array of shape [num_train] indicating whether the
- example is watermarked (0: unwatermarked, 1: watermarked).
- epochs: Number of epochs to train for.
- learning_rate: Learning rate for optimizer.
- minibatch_size: Minibatch size for training. Note that a minibatch
- requires ~ 32 * minibatch_size * seq_len * watermarked_depth *
- watermarked_depth bits of memory.
- seed: Seed for parameter initialization.
- l2_weight: Weight to apply to L2 regularization for delta parameters.
- shuffle: Whether to shuffle before training.
- g_values_val: Validation g-values of shape [num_val, seq_len,
- watermarking_depth].
- mask_val: Validation mask of shape [num_val, seq_len].
- watermarked_val: Validation watermark labels of shape [num_val].
- verbose: Boolean indicating verbosity of training. If true, the loss will
- be printed. Defaulted to False.
- use_tpr_fpr_for_val: Whether to use TPR@FPR=1% as metric for validation.
- If false, use cross entropy loss.
-
- Returns:
- Tuple of
- training_history: Training history keyed by epoch number where the
- values are
- dictionaries containing the loss, validation loss, and model
- parameters,
- keyed by
- 'loss', 'val_loss', and 'params', respectively.
- min_val_loss: Minimum validation loss achieved during training.
- """
-
- # Set the random seed for reproducibility
- torch.manual_seed(seed)
-
- # Shuffle the data if required
- if shuffle:
- indices = torch.randperm(len(g_values))
- g_values = g_values[indices]
- mask = mask[indices]
- watermarked = watermarked[indices]
-
- # Initialize optimizer
- optimizer = torch.optim.Adam(detector.parameters(), lr=learning_rate)
- history = {}
- min_val_loss = float("inf")
-
- for epoch in range(epochs):
- losses = []
- detector.train()
- num_batches = len(g_values) // minibatch_size
- for i in range(0, len(g_values), minibatch_size):
- end = i + minibatch_size
- if end > len(g_values):
- break
- loss_batch_weight = l2_weight / num_batches
-
- optimizer.zero_grad()
- loss = detector(
- g_values=g_values[i:end],
- mask=mask[i:end],
- labels=watermarked[i:end],
- loss_batch_weight=loss_batch_weight,
- )[1]
- loss.backward()
- optimizer.step()
- losses.append(loss.item())
- train_loss = sum(losses) / len(losses)
-
- val_losses = []
- if g_values_val is not None:
- detector.eval()
- if validation_metric == ValidationMetric.TPR_AT_FPR:
- val_loss = update_fn_if_fpr_tpr(
- detector,
- g_values_val,
- mask_val,
- watermarked_val,
- minibatch_size=minibatch_size,
- )
- else:
- for i in range(0, len(g_values_val), minibatch_size):
- end = i + minibatch_size
- if end > len(g_values_val):
- break
- with torch.no_grad():
- v_loss = detector(
- g_values=g_values_val[i:end],
- mask=mask_val[i:end],
- labels=watermarked_val[i:end],
- loss_batch_weight=0,
- )[1]
- val_losses.append(v_loss.item())
- val_loss = sum(val_losses) / len(val_losses)
-
- # Store training history
- history[epoch + 1] = {"loss": train_loss, "val_loss": val_loss}
- if verbose:
- if val_loss is not None:
- print(f"Epoch {epoch}: loss {loss} (train), {val_loss} (val)")
- else:
- print(f"Epoch {epoch}: loss {loss} (train)")
-
- if val_loss is not None and val_loss < min_val_loss:
- min_val_loss = val_loss
- best_val_epoch = epoch
-
- if verbose:
- print(f"Best val Epoch: {best_val_epoch}, min_val_loss: {min_val_loss}")
-
- return history, min_val_loss
-
-
-def train_best_detector(
- tokenized_wm_outputs: Union[List[np.ndarray], np.ndarray],
- tokenized_uwm_outputs: Union[List[np.ndarray], np.ndarray],
- logits_processor: SynthIDTextWatermarkLogitsProcessor,
- tokenizer: Any,
- torch_device: torch.device,
- test_size: float = 0.3,
- pos_truncation_length: Optional[int] = 200,
- neg_truncation_length: Optional[int] = 100,
- max_padded_length: int = 2300,
- n_epochs: int = 50,
- learning_rate: float = 2.1e-2,
- l2_weights: np.ndarray = np.logspace(-3, -2, num=4),
- verbose: bool = False,
- validation_metric: ValidationMetric = ValidationMetric.TPR_AT_FPR,
-):
- """Train and return the best detector given range of hyperparameters.
-
- In practice, we have found that tuning pos_truncation_length,
- neg_truncation_length, n_epochs, learning_rate and l2_weights can help
- improve the performance of the detector. We reccommend tuning these
- parameters for your data.
- """
- l2_weights = list(l2_weights)
-
- (
- train_g_values,
- train_masks,
- train_labels,
- cv_g_values,
- cv_masks,
- cv_labels,
- ) = process_raw_model_outputs(
- logits_processor,
- tokenizer,
- pos_truncation_length,
- neg_truncation_length,
- max_padded_length,
- tokenized_wm_outputs,
- test_size,
- tokenized_uwm_outputs,
- torch_device,
- )
-
- best_detector = None
- lowest_loss = float("inf")
- val_losses = []
- for l2_weight in l2_weights:
- config = BayesianDetectorConfig(watermarking_depth=len(logits_processor.keys))
- detector = BayesianDetectorModel(config).to(torch_device)
- _, min_val_loss = train_detector(
- detector=detector,
- g_values=train_g_values,
- mask=train_masks,
- watermarked=train_labels,
- g_values_val=cv_g_values,
- mask_val=cv_masks,
- watermarked_val=cv_labels,
- learning_rate=learning_rate,
- l2_weight=l2_weight,
- epochs=n_epochs,
- verbose=verbose,
- validation_metric=validation_metric,
- )
- val_losses.append(min_val_loss)
- if min_val_loss < lowest_loss:
- lowest_loss = min_val_loss
- best_detector = detector
- return best_detector, lowest_loss
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "--model_name",
- type=str,
- default="google/gemma-2b-it",
- help=("LM model to train the detector for."),
- )
- parser.add_argument(
- "--temperature",
- type=float,
- default=1.0,
- help=("Temperature to sample from the model."),
- )
- parser.add_argument(
- "--top_k",
- type=int,
- default=40,
- help=("Top K for sampling."),
- )
- parser.add_argument(
- "--top_p",
- type=float,
- default=1.0,
- help=("Top P for sampling."),
- )
- parser.add_argument(
- "--num_negatives",
- type=int,
- default=10000,
- help=("Number of negatives for detector training."),
- )
- parser.add_argument(
- "--pos_batch_size",
- type=int,
- default=32,
- help=("Batch size of watermarked positives while sampling."),
- )
- parser.add_argument(
- "--num_pos_batch",
- type=int,
- default=313,
- help=("Number of positive batches for training."),
- )
- parser.add_argument(
- "--generation_length",
- type=int,
- default=512,
- help=("Generation length for sampling."),
- )
- parser.add_argument(
- "--save_model_to_hf_hub",
- action="store_true",
- help=("Whether to save the trained model HF hub. By default it will be a private repo."),
- )
- parser.add_argument(
- "--load_from_hf_hub",
- action="store_true",
- help=(
- "Whether to load trained detector model from HF Hub, make sure its the model trained on the same model "
- "we are loading in the script."
- ),
- )
- parser.add_argument(
- "--hf_hub_model_name",
- type=str,
- default=None,
- help=("HF hub model name for loading of saving the model."),
- )
- parser.add_argument(
- "--eval_detector_on_prompts",
- action="store_true",
- help=("Evaluate detector on a prompt and print probability of watermark."),
- )
-
- args = parser.parse_args()
- model_name = args.model_name
- temperature = args.temperature
- top_k = args.top_k
- top_p = args.top_p
- num_negatives = args.num_negatives
- pos_batch_size = args.pos_batch_size
- num_pos_batch = args.num_pos_batch
- if num_pos_batch < 10:
- raise ValueError("--num_pos_batch should be greater than 10.")
- generation_length = args.generation_length
- save_model_to_hf_hub = args.save_model_to_hf_hub
- load_from_hf_hub = args.load_from_hf_hub
- repo_name = args.hf_hub_model_name
- eval_detector_on_prompts = args.eval_detector_on_prompts
-
- NEG_BATCH_SIZE = 32
-
- # Truncate outputs to this length for training.
- POS_TRUNCATION_LENGTH = 200
- NEG_TRUNCATION_LENGTH = 100
- # Pad trucated outputs to this length for equal shape across all batches.
- MAX_PADDED_LENGTH = 1000
-
- DEVICE = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
- if DEVICE.type not in ("cuda", "tpu"):
- raise ValueError("We have found the training stable on GPU and TPU, we are working on" " a fix for CPUs")
-
- model = None
- if not load_from_hf_hub:
- # Change this to make your watermark unique. Check documentation in the paper to understand the
- # impact of these parameters.
- DEFAULT_WATERMARKING_CONFIG = {
- "ngram_len": 5, # This corresponds to H=4 context window size in the paper.
- "keys": [
- 654,
- 400,
- 836,
- 123,
- 340,
- 443,
- 597,
- 160,
- 57,
- 29,
- 590,
- 639,
- 13,
- 715,
- 468,
- 990,
- 966,
- 226,
- 324,
- 585,
- 118,
- 504,
- 421,
- 521,
- 129,
- 669,
- 732,
- 225,
- 90,
- 960,
- ],
- "sampling_table_size": 2**16,
- "sampling_table_seed": 0,
- "context_history_size": 1024,
- }
- watermark_config = SynthIDTextWatermarkingConfig(**DEFAULT_WATERMARKING_CONFIG)
-
- model = AutoModelForCausalLM.from_pretrained(model_name).to(DEVICE)
- tokenizer = AutoTokenizer.from_pretrained(model_name)
- tokenizer.pad_token = tokenizer.eos_token
-
- logits_processor = SynthIDTextWatermarkLogitsProcessor(**DEFAULT_WATERMARKING_CONFIG, device=DEVICE)
- tokenized_wm_outputs = get_tokenized_wm_outputs(
- model,
- tokenizer,
- watermark_config,
- num_pos_batch,
- pos_batch_size,
- temperature,
- generation_length,
- top_k,
- top_p,
- DEVICE,
- )
- tokenized_uwm_outputs = get_tokenized_uwm_outputs(num_negatives, NEG_BATCH_SIZE, tokenizer, DEVICE)
-
- best_detector, lowest_loss = train_best_detector(
- tokenized_wm_outputs=tokenized_wm_outputs,
- tokenized_uwm_outputs=tokenized_uwm_outputs,
- logits_processor=logits_processor,
- tokenizer=tokenizer,
- torch_device=DEVICE,
- test_size=0.3,
- pos_truncation_length=POS_TRUNCATION_LENGTH,
- neg_truncation_length=NEG_TRUNCATION_LENGTH,
- max_padded_length=MAX_PADDED_LENGTH,
- n_epochs=100,
- learning_rate=3e-3,
- l2_weights=[
- 0,
- ],
- verbose=True,
- validation_metric=ValidationMetric.TPR_AT_FPR,
- )
- else:
- if repo_name is None:
- raise ValueError("When loading from pretrained detector model name cannot be None.")
- best_detector = BayesianDetectorModel.from_pretrained(repo_name).to(DEVICE)
-
- best_detector.config.set_detector_information(
- model_name=model_name, watermarking_config=DEFAULT_WATERMARKING_CONFIG
- )
- if save_model_to_hf_hub:
- upload_model_to_hf(best_detector, repo_name)
-
- # Evaluate model response with the detector
- if eval_detector_on_prompts:
- model_name = best_detector.config.model_name
- watermark_config_dict = best_detector.config.watermarking_config
- logits_processor = SynthIDTextWatermarkLogitsProcessor(**watermark_config_dict, device=DEVICE)
- tokenizer = AutoTokenizer.from_pretrained(model_name)
- tokenizer.pad_token = tokenizer.eos_token
- synthid_text_detector = SynthIDTextWatermarkDetector(best_detector, logits_processor, tokenizer)
-
- if model is None:
- model = AutoModelForCausalLM.from_pretrained(model_name).to(DEVICE)
- watermarking_config = SynthIDTextWatermarkingConfig(**watermark_config_dict)
-
- prompts = ["Write a essay on cats."]
- inputs = tokenizer(
- prompts,
- return_tensors="pt",
- padding=True,
- ).to(DEVICE)
-
- _, inputs_len = inputs["input_ids"].shape
-
- outputs = model.generate(
- **inputs,
- watermarking_config=watermarking_config,
- do_sample=True,
- max_length=inputs_len + generation_length,
- temperature=temperature,
- top_k=40,
- top_p=1.0,
- )
- outputs = outputs[:, inputs_len:]
- result = synthid_text_detector(outputs)
-
- # You should set this based on expected fpr (false positive rate) and tpr (true positive rate).
- # Check our demo at HF Spaces for more info.
- upper_threshold = 0.95
- lower_threshold = 0.12
- if result[0][0] > upper_threshold:
- print("The text is watermarked.")
- elif lower_threshold < result[0][0] < upper_threshold:
- print("It is hard to determine if the text is watermarked or not.")
- else:
- print("The text is not watermarked.")
diff --git a/examples/research_projects/synthid_text/requirements.txt b/examples/research_projects/synthid_text/requirements.txt
deleted file mode 100644
index 9e40a93ee08..00000000000
--- a/examples/research_projects/synthid_text/requirements.txt
+++ /dev/null
@@ -1,5 +0,0 @@
-tensorflow-datasets>=4.9.3
-torch >= 1.3
-datasets
-scikit-learn
-tensorflow
diff --git a/examples/research_projects/synthid_text/utils.py b/examples/research_projects/synthid_text/utils.py
deleted file mode 100644
index abcb6ca2f28..00000000000
--- a/examples/research_projects/synthid_text/utils.py
+++ /dev/null
@@ -1,408 +0,0 @@
-# coding=utf-8
-# Copyright 2024 Google DeepMind.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import gc
-from typing import Any, List, Optional, Tuple
-
-import datasets
-import numpy as np
-import tensorflow as tf
-import tensorflow_datasets as tfds
-import torch
-import tqdm
-from huggingface_hub import HfApi, create_repo
-from huggingface_hub.utils import RepositoryNotFoundError
-from sklearn import model_selection
-
-import transformers
-
-
-def pad_to_len(
- arr: torch.Tensor,
- target_len: int,
- left_pad: bool,
- eos_token: int,
- device: torch.device,
-) -> torch.Tensor:
- """Pad or truncate array to given length."""
- if arr.shape[1] < target_len:
- shape_for_ones = list(arr.shape)
- shape_for_ones[1] = target_len - shape_for_ones[1]
- padded = (
- torch.ones(
- shape_for_ones,
- device=device,
- dtype=torch.long,
- )
- * eos_token
- )
- if not left_pad:
- arr = torch.concatenate((arr, padded), dim=1)
- else:
- arr = torch.concatenate((padded, arr), dim=1)
- else:
- arr = arr[:, :target_len]
- return arr
-
-
-def filter_and_truncate(
- outputs: torch.Tensor,
- truncation_length: Optional[int],
- eos_token_mask: torch.Tensor,
-) -> torch.Tensor:
- """Filter and truncate outputs to given length.
-
- Args:
- outputs: output tensor of shape [batch_size, output_len]
- truncation_length: Length to truncate the final output.
- eos_token_mask: EOS token mask of shape [batch_size, output_len]
-
- Returns:
- output tensor of shape [batch_size, truncation_length].
- """
- if truncation_length:
- outputs = outputs[:, :truncation_length]
- truncation_mask = torch.sum(eos_token_mask, dim=1) >= truncation_length
- return outputs[truncation_mask, :]
- return outputs
-
-
-def process_outputs_for_training(
- all_outputs: List[torch.Tensor],
- logits_processor: transformers.generation.SynthIDTextWatermarkLogitsProcessor,
- tokenizer: Any,
- pos_truncation_length: Optional[int],
- neg_truncation_length: Optional[int],
- max_length: int,
- is_cv: bool,
- is_pos: bool,
- torch_device: torch.device,
-) -> Tuple[List[torch.Tensor], List[torch.Tensor]]:
- """Process raw model outputs into format understandable by the detector.
-
- Args:
- all_outputs: sequence of outputs of shape [batch_size, output_len].
- logits_processor: logits processor used for watermarking.
- tokenizer: tokenizer used for the model.
- pos_truncation_length: Length to truncate wm outputs.
- neg_truncation_length: Length to truncate uwm outputs.
- max_length: Length to pad truncated outputs so that all processed entries.
- have same shape.
- is_cv: Process given outputs for cross validation.
- is_pos: Process given outputs for positives.
- torch_device: torch device to use.
-
- Returns:
- Tuple of
- all_masks: list of masks of shape [batch_size, max_length].
- all_g_values: list of g_values of shape [batch_size, max_length, depth].
- """
- all_masks = []
- all_g_values = []
- for outputs in tqdm.tqdm(all_outputs):
- # outputs is of shape [batch_size, output_len].
- # output_len can differ from batch to batch.
- eos_token_mask = logits_processor.compute_eos_token_mask(
- input_ids=outputs,
- eos_token_id=tokenizer.eos_token_id,
- )
- if is_pos or is_cv:
- # filter with length for positives for both train and CV.
- # We also filter for length when CV negatives are processed.
- outputs = filter_and_truncate(outputs, pos_truncation_length, eos_token_mask)
- elif not is_pos and not is_cv:
- outputs = filter_and_truncate(outputs, neg_truncation_length, eos_token_mask)
-
- # If no filtered outputs skip this batch.
- if outputs.shape[0] == 0:
- continue
-
- # All outputs are padded to max-length with eos-tokens.
- outputs = pad_to_len(outputs, max_length, False, tokenizer.eos_token_id, torch_device)
- # outputs shape [num_filtered_entries, max_length]
-
- eos_token_mask = logits_processor.compute_eos_token_mask(
- input_ids=outputs,
- eos_token_id=tokenizer.eos_token_id,
- )
-
- context_repetition_mask = logits_processor.compute_context_repetition_mask(
- input_ids=outputs,
- )
-
- # context_repetition_mask of shape [num_filtered_entries, max_length -
- # (ngram_len - 1)].
- context_repetition_mask = pad_to_len(context_repetition_mask, max_length, True, 0, torch_device)
- # We pad on left to get same max_length shape.
- # context_repetition_mask of shape [num_filtered_entries, max_length].
- combined_mask = context_repetition_mask * eos_token_mask
-
- g_values = logits_processor.compute_g_values(
- input_ids=outputs,
- )
-
- # g_values of shape [num_filtered_entries, max_length - (ngram_len - 1),
- # depth].
- g_values = pad_to_len(g_values, max_length, True, 0, torch_device)
-
- # We pad on left to get same max_length shape.
- # g_values of shape [num_filtered_entries, max_length, depth].
- all_masks.append(combined_mask)
- all_g_values.append(g_values)
- return all_masks, all_g_values
-
-
-def tpr_at_fpr(detector, detector_inputs, w_true, minibatch_size, target_fpr=0.01) -> torch.Tensor:
- """Calculates true positive rate (TPR) at false positive rate (FPR)=target_fpr."""
- positive_idxs = w_true == 1
- negative_idxs = w_true == 0
- num_samples = detector_inputs[0].size(0)
-
- w_preds = []
- for start in range(0, num_samples, minibatch_size):
- end = start + minibatch_size
- detector_inputs_ = (
- detector_inputs[0][start:end],
- detector_inputs[1][start:end],
- )
- with torch.no_grad():
- w_pred = detector(*detector_inputs_)[0]
- w_preds.append(w_pred)
-
- w_pred = torch.cat(w_preds, dim=0) # Concatenate predictions
- positive_scores = w_pred[positive_idxs]
- negative_scores = w_pred[negative_idxs]
-
- # Calculate the FPR threshold
- # Note: percentile -> quantile
- fpr_threshold = torch.quantile(negative_scores, 1 - target_fpr)
- # Note: need to switch to FP32 since torch.mean doesn't work with torch.bool
- return torch.mean((positive_scores >= fpr_threshold).to(dtype=torch.float32)).item() # TPR
-
-
-def update_fn_if_fpr_tpr(detector, g_values_val, mask_val, watermarked_val, minibatch_size):
- """Loss function for negative TPR@FPR=1% as the validation loss."""
- tpr_ = tpr_at_fpr(
- detector=detector,
- detector_inputs=(g_values_val, mask_val),
- w_true=watermarked_val,
- minibatch_size=minibatch_size,
- )
- return -tpr_
-
-
-def process_raw_model_outputs(
- logits_processor,
- tokenizer,
- pos_truncation_length,
- neg_truncation_length,
- max_padded_length,
- tokenized_wm_outputs,
- test_size,
- tokenized_uwm_outputs,
- torch_device,
-):
- # Split data into train and CV
- train_wm_outputs, cv_wm_outputs = model_selection.train_test_split(tokenized_wm_outputs, test_size=test_size)
-
- train_uwm_outputs, cv_uwm_outputs = model_selection.train_test_split(tokenized_uwm_outputs, test_size=test_size)
-
- process_kwargs = {
- "logits_processor": logits_processor,
- "tokenizer": tokenizer,
- "pos_truncation_length": pos_truncation_length,
- "neg_truncation_length": neg_truncation_length,
- "max_length": max_padded_length,
- "torch_device": torch_device,
- }
-
- # Process both train and CV data for training
- wm_masks_train, wm_g_values_train = process_outputs_for_training(
- [torch.tensor(outputs, device=torch_device, dtype=torch.long) for outputs in train_wm_outputs],
- is_pos=True,
- is_cv=False,
- **process_kwargs,
- )
- wm_masks_cv, wm_g_values_cv = process_outputs_for_training(
- [torch.tensor(outputs, device=torch_device, dtype=torch.long) for outputs in cv_wm_outputs],
- is_pos=True,
- is_cv=True,
- **process_kwargs,
- )
- uwm_masks_train, uwm_g_values_train = process_outputs_for_training(
- [torch.tensor(outputs, device=torch_device, dtype=torch.long) for outputs in train_uwm_outputs],
- is_pos=False,
- is_cv=False,
- **process_kwargs,
- )
- uwm_masks_cv, uwm_g_values_cv = process_outputs_for_training(
- [torch.tensor(outputs, device=torch_device, dtype=torch.long) for outputs in cv_uwm_outputs],
- is_pos=False,
- is_cv=True,
- **process_kwargs,
- )
-
- # We get list of data; here we concat all together to be passed to the detector.
- def pack(mask, g_values):
- mask = torch.cat(mask, dim=0)
- g = torch.cat(g_values, dim=0)
- return mask, g
-
- wm_masks_train, wm_g_values_train = pack(wm_masks_train, wm_g_values_train)
- # Note: Use float instead of bool. Otherwise, the entropy calculation doesn't work
- wm_labels_train = torch.ones((wm_masks_train.shape[0],), dtype=torch.float, device=torch_device)
-
- wm_masks_cv, wm_g_values_cv = pack(wm_masks_cv, wm_g_values_cv)
- wm_labels_cv = torch.ones((wm_masks_cv.shape[0],), dtype=torch.float, device=torch_device)
-
- uwm_masks_train, uwm_g_values_train = pack(uwm_masks_train, uwm_g_values_train)
- uwm_labels_train = torch.zeros((uwm_masks_train.shape[0],), dtype=torch.float, device=torch_device)
-
- uwm_masks_cv, uwm_g_values_cv = pack(uwm_masks_cv, uwm_g_values_cv)
- uwm_labels_cv = torch.zeros((uwm_masks_cv.shape[0],), dtype=torch.float, device=torch_device)
-
- # Concat pos and negatives data together.
- train_g_values = torch.cat((wm_g_values_train, uwm_g_values_train), dim=0).squeeze()
- train_labels = torch.cat((wm_labels_train, uwm_labels_train), axis=0).squeeze()
- train_masks = torch.cat((wm_masks_train, uwm_masks_train), axis=0).squeeze()
-
- cv_g_values = torch.cat((wm_g_values_cv, uwm_g_values_cv), axis=0).squeeze()
- cv_labels = torch.cat((wm_labels_cv, uwm_labels_cv), axis=0).squeeze()
- cv_masks = torch.cat((wm_masks_cv, uwm_masks_cv), axis=0).squeeze()
-
- # Shuffle data.
- shuffled_idx = torch.randperm(train_g_values.shape[0]) # Use torch for GPU compatibility
-
- train_g_values = train_g_values[shuffled_idx]
- train_labels = train_labels[shuffled_idx]
- train_masks = train_masks[shuffled_idx]
-
- # Shuffle the cross-validation data
- shuffled_idx_cv = torch.randperm(cv_g_values.shape[0]) # Use torch for GPU compatibility
- cv_g_values = cv_g_values[shuffled_idx_cv]
- cv_labels = cv_labels[shuffled_idx_cv]
- cv_masks = cv_masks[shuffled_idx_cv]
-
- # Del some variables so we free up GPU memory.
- del (
- wm_g_values_train,
- wm_labels_train,
- wm_masks_train,
- wm_g_values_cv,
- wm_labels_cv,
- wm_masks_cv,
- )
- gc.collect()
- torch.cuda.empty_cache()
-
- return train_g_values, train_masks, train_labels, cv_g_values, cv_masks, cv_labels
-
-
-def get_tokenized_uwm_outputs(num_negatives, neg_batch_size, tokenizer, device):
- dataset, info = tfds.load("wikipedia/20230601.en", split="train", with_info=True)
- dataset = dataset.take(num_negatives)
-
- # Convert the dataset to a DataFrame
- df = tfds.as_dataframe(dataset, info)
- ds = tf.data.Dataset.from_tensor_slices(dict(df))
- tf.random.set_seed(0)
- ds = ds.shuffle(buffer_size=10_000)
- ds = ds.batch(batch_size=neg_batch_size)
-
- tokenized_uwm_outputs = []
- # Pad to this length (on the right) for batching.
- padded_length = 1000
- for i, batch in tqdm.tqdm(enumerate(ds)):
- responses = [val.decode() for val in batch["text"].numpy()]
- inputs = tokenizer(
- responses,
- return_tensors="pt",
- padding=True,
- ).to(device)
- inputs = inputs["input_ids"].cpu().numpy()
- if inputs.shape[1] >= padded_length:
- inputs = inputs[:, :padded_length]
- else:
- inputs = np.concatenate(
- [inputs, np.ones((neg_batch_size, padded_length - inputs.shape[1])) * tokenizer.eos_token_id], axis=1
- )
- tokenized_uwm_outputs.append(inputs)
- if len(tokenized_uwm_outputs) * neg_batch_size > num_negatives:
- break
- return tokenized_uwm_outputs
-
-
-def get_tokenized_wm_outputs(
- model,
- tokenizer,
- watermark_config,
- num_pos_batches,
- pos_batch_size,
- temperature,
- max_output_len,
- top_k,
- top_p,
- device,
-):
- eli5_prompts = datasets.load_dataset("Pavithree/eli5")
-
- wm_outputs = []
-
- for batch_id in tqdm.tqdm(range(num_pos_batches)):
- prompts = eli5_prompts["train"]["title"][batch_id * pos_batch_size : (batch_id + 1) * pos_batch_size]
- prompts = [prompt.strip('"') for prompt in prompts]
- inputs = tokenizer(
- prompts,
- return_tensors="pt",
- padding=True,
- ).to(device)
- _, inputs_len = inputs["input_ids"].shape
-
- outputs = model.generate(
- **inputs,
- watermarking_config=watermark_config,
- do_sample=True,
- max_length=inputs_len + max_output_len,
- temperature=temperature,
- top_k=top_k,
- top_p=top_p,
- )
-
- wm_outputs.append(outputs[:, inputs_len:].cpu().detach())
-
- del outputs, inputs, prompts
- gc.collect()
-
- gc.collect()
- torch.cuda.empty_cache()
- return wm_outputs
-
-
-def upload_model_to_hf(model, hf_repo_name: str, private: bool = True):
- api = HfApi()
-
- # Check if the repository exists
- try:
- api.repo_info(repo_id=hf_repo_name, use_auth_token=True)
- print(f"Repository '{hf_repo_name}' already exists.")
- except RepositoryNotFoundError:
- # If the repository does not exist, create it
- print(f"Repository '{hf_repo_name}' not found. Creating it...")
- create_repo(repo_id=hf_repo_name, private=private, use_auth_token=True)
- print(f"Repository '{hf_repo_name}' created successfully.")
-
- # Push the model to the Hugging Face Hub
- print(f"Uploading model to Hugging Face repo '{hf_repo_name}'...")
- model.push_to_hub(repo_id=hf_repo_name, use_auth_token=True)
diff --git a/examples/research_projects/tapex/README.md b/examples/research_projects/tapex/README.md
deleted file mode 100644
index b98eb9b428d..00000000000
--- a/examples/research_projects/tapex/README.md
+++ /dev/null
@@ -1,288 +0,0 @@
-
-
-# Run Table Tasks with TAPEX
-
-TAPEX is a table pre-training approach for table-related tasks. By learning a neural SQL executor over a synthetic corpus based on generative language models (e.g., BART), it achieves state-of-the-art performance on several table-based question answering benchmarks and table-based fact verification benchmark. More details can be found in the original paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/pdf/2107.07653.pdf).
-
-> If you are also familiar with [fairseq](https://github.com/pytorch/fairseq), you may also find [the official implementation](https://github.com/microsoft/Table-Pretraining) useful, which leverages the framework.
-
-## Table Question Answering Tasks
-
-### What is Table Question Answering
-
-
-
-The task of Table Question Answering (TableQA) is to empower machines to answer users' questions over a given table. The resulting answer(s) can be a region in the table, or a number calculated by applying aggregation operators to a specific region.
-
-### What Questions Can be Answered
-
-Benefiting from the powerfulness of generative models, TAPEX can deal with almost all kinds of questions over tables (if there is training data). Below are some typical question and their answers taken from [WikiTableQuestion](https://nlp.stanford.edu/blog/wikitablequestions-a-complex-real-world-question-understanding-dataset).
-
-| Question | Answer |
-| :---: | :---: |
-| What is the years won for each team? | 2004, 2008, 2012 |
-| How long did Taiki Tsuchiya last? | 4:27 |
-| What is the total amount of matches drawn? | 1 |
-| Besides Tiger Woods, what other player won between 2007 and 2009? | Camilo Villegas |
-| What was the last Baekje Temple? | Uija |
-| What is the difference between White voters and Black voters in 1948? | 0 |
-| What is the average number of sailors for each country during the worlds qualification tournament? | 2 |
-
-
-### How to Fine-tune TAPEX on TableQA
-
-We provide a fine-tuning script of tapex for TableQA on the WikiSQL benchmark: [WikiSQL](https://github.com/salesforce/WikiSQL).
-This script is customized for tapex models, and can be easily adapted to other benchmarks such as WikiTableQuestion
-(only some tweaks in the function `preprocess_tableqa_function`).
-
-#### TAPEX-Base on WikiSQL
-
-Here is how to run the script on the WikiSQL with `tapex-base`:
-> The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 16GB and 1 GPU card. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly.
-
-```bash
-export EXP_NAME=wikisql_tapex_base
-
-python run_wikisql_with_tapex.py \
- --do_train \
- --do_eval \
- --output_dir $EXP_NAME \
- --model_name_or_path microsoft/tapex-base \
- --overwrite_output_dir \
- --per_device_train_batch_size 4 \
- --gradient_accumulation_steps 8 \
- --per_device_eval_batch_size 4 \
- --learning_rate 3e-5 \
- --logging_steps 10 \
- --eval_steps 1000 \
- --save_steps 1000 \
- --warmup_steps 1000 \
- --eval_strategy steps \
- --predict_with_generate \
- --num_beams 5 \
- --weight_decay 1e-2 \
- --label_smoothing_factor 0.1 \
- --max_steps 20000
-```
-
-#### TAPEX-Large on WikiSQL
-
-Here is how to run the script on the WikiSQL with `tapex-large`:
-> The default hyper-parameter may allow you to reproduce our reported tapex-large results within the memory budget of 16GB and 1 GPU card with fp16. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly. If you do not install apex or other mixed-precision-training libs, you could disable the `predict_with_generate` option to save GPU memory and manually evaluate the model once the fine-tuning finished. Or just pick up the last checkpoint, which usually performs good enough on the dataset.
-
-```bash
-export EXP_NAME=wikisql_tapex_large
-
-python run_wikisql_with_tapex.py \
- --do_train \
- --do_eval \
- --output_dir $EXP_NAME \
- --model_name_or_path microsoft/tapex-large \
- --overwrite_output_dir \
- --per_device_train_batch_size 1 \
- --gradient_accumulation_steps 32 \
- --per_device_eval_batch_size 4 \
- --learning_rate 3e-5 \
- --logging_steps 10 \
- --eval_steps 1000 \
- --save_steps 1000 \
- --warmup_steps 1000 \
- --eval_strategy steps \
- --predict_with_generate \
- --num_beams 5 \
- --weight_decay 1e-2 \
- --label_smoothing_factor 0.1 \
- --max_steps 20000 \
- --fp16
-```
-
-#### TAPEX-Base on WikiTableQuestions
-
-Here is how to run the script on the WikiTableQuestions with `tapex-base`:
-> The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 16GB and 1 GPU card. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly.
-
-```bash
-export EXP_NAME=wikitablequestions_tapex_base
-
-python run_wikitablequestions_with_tapex.py \
- --do_train \
- --do_eval \
- --output_dir $EXP_NAME \
- --model_name_or_path microsoft/tapex-base \
- --overwrite_output_dir \
- --per_device_train_batch_size 4 \
- --gradient_accumulation_steps 8 \
- --per_device_eval_batch_size 4 \
- --learning_rate 3e-5 \
- --logging_steps 10 \
- --eval_steps 1000 \
- --save_steps 1000 \
- --warmup_steps 1000 \
- --eval_strategy steps \
- --predict_with_generate \
- --num_beams 5 \
- --weight_decay 1e-2 \
- --label_smoothing_factor 0.1 \
- --max_steps 20000
-```
-
-#### TAPEX-Large on WikiTableQuestions
-
-Here is how to run the script on the WikiTableQuestions with `tapex-large`:
-> The default hyper-parameter may allow you to reproduce our reported tapex-large results within the memory budget of 16GB and 1 GPU card with fp16. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly. If you do not install apex or other mixed-precision-training libs, you could reduce the `per_device_train_batch_size` and `per_device_eval_batch_size` and have another try. Or you could disable the `predict_with_generate` option to save GPU memory and manually evaluate the model once the fine-tuning finished. Or just pick up the last checkpoint, which usually performs good enough on the dataset.
-
-```bash
-export EXP_NAME=wikitablequestions_tapex_large
-
-python run_wikitablequestions_with_tapex.py \
- --do_train \
- --do_eval \
- --output_dir $EXP_NAME \
- --model_name_or_path microsoft/tapex-large \
- --overwrite_output_dir \
- --per_device_train_batch_size 2 \
- --gradient_accumulation_steps 12 \
- --per_device_eval_batch_size 4 \
- --learning_rate 3e-5 \
- --logging_steps 10 \
- --eval_steps 1000 \
- --save_steps 1000 \
- --warmup_steps 1000 \
- --eval_strategy steps \
- --predict_with_generate \
- --num_beams 5 \
- --weight_decay 1e-2 \
- --label_smoothing_factor 0.1 \
- --max_steps 20000 \
- --fp16
-```
-
-### How to Evaluate TAPEX Fine-tuned Models on TableQA
-
-We provide fine-tuned model weights to reproduce our results. You can evaluate them using the following command:
-> You can also replace `microsoft/tapex-base-finetuned-wikisql` with your local directory to evaluate your fine-tuned models. Notice that if the model has a larger size, you should reduce `per_device_eval_batch_size` to fit the memory requirement.
-
-```bash
-export EXP_NAME=wikisql_tapex_base_eval
-
-python run_wikisql_with_tapex.py \
- --do_eval \
- --model_name_or_path microsoft/tapex-base-finetuned-wikisql \
- --output_dir $EXP_NAME \
- --per_device_eval_batch_size 4 \
- --predict_with_generate \
- --num_beams 5
-```
-
-## Table Fact Verification Tasks
-
-### What is Table Fact Verification
-
-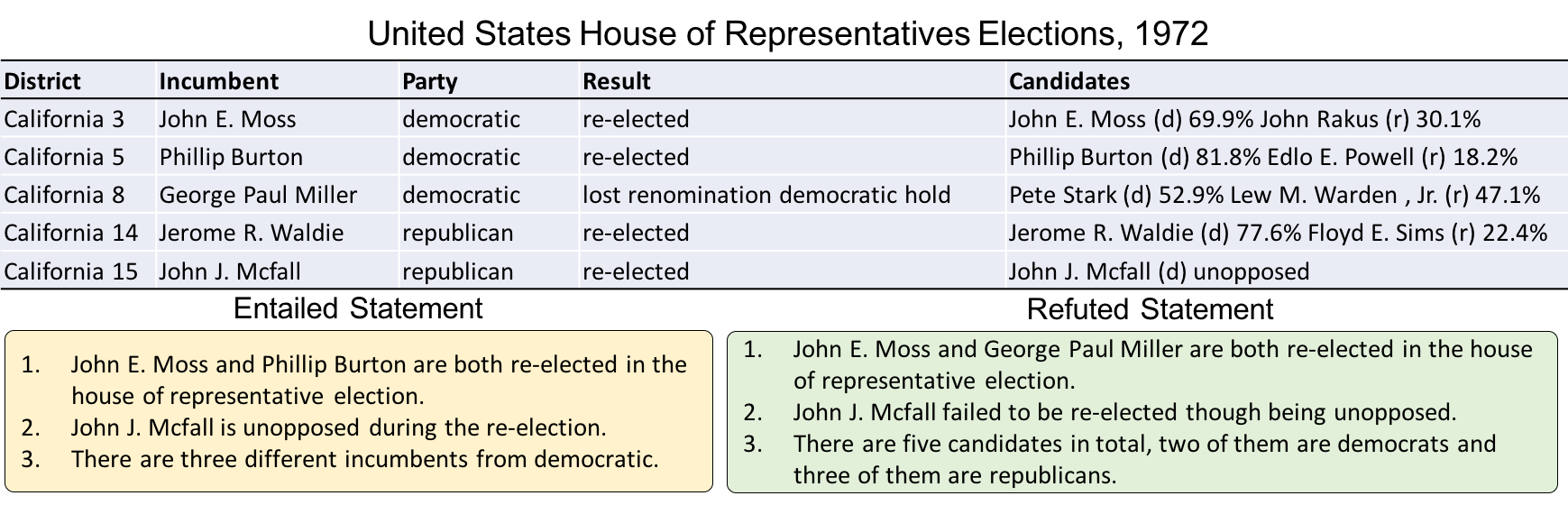
-
-The task of Table Fact Verification (TableFV) is to empower machines to justify if a statement follows facts in a given table. The result is a binary classification belonging to `1` (entailed) or `0` (refused).
-
-### How to Fine-tune TAPEX on TableFV
-
-#### TAPEX-Base on TabFact
-
-We provide a fine-tuning script of tapex for TableFV on the TabFact benchmark: [TabFact](https://github.com/wenhuchen/Table-Fact-Checking).
-
-Here is how to run the script on the TabFact:
-> The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 16GB and 1 GPU card. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly. Note that the `eval_accumulation_steps` is necessary, otherwise GPU memory leaks will occur during the evaluation.
-
-```bash
-export EXP_NAME=tabfact_tapex_base
-
-python run_tabfact_with_tapex.py \
- --do_train \
- --do_eval \
- --output_dir $EXP_NAME \
- --model_name_or_path microsoft/tapex-base \
- --overwrite_output_dir \
- --per_device_train_batch_size 3 \
- --gradient_accumulation_steps 16 \
- --per_device_eval_batch_size 12 \
- --eval_accumulation_steps 6 \
- --warm_steps 1000 \
- --logging_steps 10 \
- --learning_rate 3e-5 \
- --eval_steps 1000 \
- --save_steps 1000 \
- --eval_strategy steps \
- --weight_decay 1e-2 \
- --max_steps 30000 \
- --max_grad_norm 0.1
-```
-
-#### TAPEX-Large on TabFact
-
-Here is how to run the script on the TabFact:
-> The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 24GB and 1 GPU card. Sorry we cannot reduce the memory consumption since the model input in TabFact usually contains nearly ~1000 tokens. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly. Note that the `eval_accumulation_steps` is necessary, otherwise GPU memory leaks will occur during the evaluation.
-
-```bash
-export EXP_NAME=tabfact_tapex_large
-
-python run_tabfact_with_tapex.py \
- --do_train \
- --do_eval \
- --output_dir $EXP_NAME \
- --model_name_or_path microsoft/tapex-large \
- --overwrite_output_dir \
- --per_device_train_batch_size 2 \
- --gradient_accumulation_steps 18 \
- --per_device_eval_batch_size 4 \
- --eval_accumulation_steps 12 \
- --warm_steps 1000 \
- --logging_steps 10 \
- --learning_rate 3e-5 \
- --eval_steps 1000 \
- --save_steps 1000 \
- --eval_strategy steps \
- --weight_decay 1e-2 \
- --max_steps 30000 \
- --max_grad_norm 0.1
-```
-
-### How to Evaluate TAPEX Fine-tuned Models on TableFV
-
-We provide fine-tuned model weights to reproduce our results. You can evaluate them using the following command:
-> You can also replace `microsoft/tapex-base-finetuned-tabfact` with your local directory to evaluate your fine-tuned models. Notice that if the model has a larger size, you should reduce `per_device_eval_batch_size` to fit the memory requirement.
-
-```bash
-export EXP_NAME=tabfact_tapex_base_eval
-
-python run_tabfact_with_tapex.py \
- --do_eval \
- --model_name_or_path microsoft/tapex-base-finetuned-tabfact \
- --output_dir $EXP_NAME \
- --per_device_eval_batch_size 12 \
- --eval_accumulation_steps 6
-```
-
-## Reproduced Results
-
-We get the following results on the dev set of the benchmark with the previous commands:
-
-| Task | Model Size | Metric | Result |
-|:---:|:---:|:---:|:---:|
-| WikiSQL (Weak) | Base | Denotation Accuracy | 88.1 |
-| WikiSQL (Weak) | Large | Denotation Accuracy | 89.5 |
-| WikiTableQuestion | Base | Denotation Accuracy | 47.1 |
-| WikiTableQuestion | Large | Denotation Accuracy | 57.2 |
-| TabFact | Base | Accuracy | 78.7 |
-| TabFact | Large | Accuracy | 83.6 |
diff --git a/examples/research_projects/tapex/requirements.txt b/examples/research_projects/tapex/requirements.txt
deleted file mode 100644
index 2379012a9b2..00000000000
--- a/examples/research_projects/tapex/requirements.txt
+++ /dev/null
@@ -1,4 +0,0 @@
-numpy
-datasets
-pandas
-nltk
\ No newline at end of file
diff --git a/examples/research_projects/tapex/run_tabfact_with_tapex.py b/examples/research_projects/tapex/run_tabfact_with_tapex.py
deleted file mode 100644
index 5dcec10a084..00000000000
--- a/examples/research_projects/tapex/run_tabfact_with_tapex.py
+++ /dev/null
@@ -1,471 +0,0 @@
-#!/usr/bin/env python
-# coding=utf-8
-# Copyright 2022 The Microsoft and The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""
-Fine-tuning the library models for tapex on table-based fact verification tasks.
-Adapted from script: https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py
-"""
-
-import logging
-import os
-import random
-import sys
-from dataclasses import dataclass, field
-from typing import Optional
-
-import datasets
-import numpy as np
-import pandas as pd
-from datasets import load_dataset
-
-import transformers
-from transformers import (
- AutoConfig,
- BartForSequenceClassification,
- DataCollatorWithPadding,
- EvalPrediction,
- HfArgumentParser,
- TapexTokenizer,
- Trainer,
- TrainingArguments,
- default_data_collator,
- set_seed,
-)
-from transformers.trainer_utils import get_last_checkpoint
-from transformers.utils import check_min_version
-from transformers.utils.versions import require_version
-
-
-# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.17.0.dev0")
-
-require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/text-classification/requirements.txt")
-
-logger = logging.getLogger(__name__)
-
-
-@dataclass
-class DataTrainingArguments:
- """
- Arguments pertaining to what data we are going to input our model for training and eval.
-
- Using `HfArgumentParser` we can turn this class
- into argparse arguments to be able to specify them on
- the command line.
- """
-
- dataset_name: Optional[str] = field(
- default="tab_fact", metadata={"help": "The name of the dataset to use (via the datasets library)."}
- )
- dataset_config_name: Optional[str] = field(
- default="tab_fact",
- metadata={"help": "The configuration name of the dataset to use (via the datasets library)."},
- )
- max_seq_length: int = field(
- default=1024,
- metadata={
- "help": (
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- )
- },
- )
- overwrite_cache: bool = field(
- default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
- )
- pad_to_max_length: bool = field(
- default=False,
- metadata={
- "help": (
- "Whether to pad all samples to `max_seq_length`. "
- "If False, will pad the samples dynamically when batching to the maximum length in the batch."
- )
- },
- )
- max_train_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of training examples to this "
- "value if set."
- )
- },
- )
- max_eval_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
- "value if set."
- )
- },
- )
- max_predict_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of prediction examples to this "
- "value if set."
- )
- },
- )
- train_file: Optional[str] = field(
- default=None, metadata={"help": "A csv or a json file containing the training data."}
- )
- validation_file: Optional[str] = field(
- default=None, metadata={"help": "A csv or a json file containing the validation data."}
- )
- test_file: Optional[str] = field(default=None, metadata={"help": "A csv or a json file containing the test data."})
-
- def __post_init__(self):
- if self.dataset_name is not None:
- pass
- elif self.train_file is None or self.validation_file is None:
- raise ValueError("Need either a GLUE task, a training/validation file or a dataset name.")
- else:
- train_extension = self.train_file.split(".")[-1]
- assert train_extension in ["csv", "json"], "`train_file` should be a csv or a json file."
- validation_extension = self.validation_file.split(".")[-1]
- assert (
- validation_extension == train_extension
- ), "`validation_file` should have the same extension (csv or json) as `train_file`."
-
-
-@dataclass
-class ModelArguments:
- """
- Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
- """
-
- model_name_or_path: str = field(
- default=None, metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
- )
- config_name: Optional[str] = field(
- default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
- )
- tokenizer_name: Optional[str] = field(
- default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
- )
- cache_dir: Optional[str] = field(
- default=None,
- metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
- )
- use_fast_tokenizer: bool = field(
- default=True,
- metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
- )
- model_revision: str = field(
- default="main",
- metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
- )
- use_auth_token: bool = field(
- default=False,
- metadata={
- "help": (
- "Will use the token generated when running `huggingface-cli login` (necessary to use this script "
- "with private models)."
- )
- },
- )
-
-
-def main():
- # See all possible arguments in src/transformers/training_args.py
- # or by passing the --help flag to this script.
- # We now keep distinct sets of args, for a cleaner separation of concerns.
-
- parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
- if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
- # If we pass only one argument to the script and it's the path to a json file,
- # let's parse it to get our arguments.
- model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
- else:
- model_args, data_args, training_args = parser.parse_args_into_dataclasses()
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- handlers=[logging.StreamHandler(sys.stdout)],
- )
-
- log_level = training_args.get_process_log_level()
- logger.setLevel(log_level)
- datasets.utils.logging.set_verbosity(log_level)
- transformers.utils.logging.set_verbosity(log_level)
- transformers.utils.logging.enable_default_handler()
- transformers.utils.logging.enable_explicit_format()
-
- # Log on each process the small summary:
- logger.warning(
- f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
- + f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
- )
- logger.info(f"Training/evaluation parameters {training_args}")
-
- # Detecting last checkpoint.
- last_checkpoint = None
- if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
- last_checkpoint = get_last_checkpoint(training_args.output_dir)
- if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
- raise ValueError(
- f"Output directory ({training_args.output_dir}) already exists and is not empty. "
- "Use --overwrite_output_dir to overcome."
- )
- elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
- logger.info(
- f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
- "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
- )
-
- # Set seed before initializing model.
- set_seed(training_args.seed)
-
- # Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
- # or specify a GLUE benchmark task (the dataset will be downloaded automatically from the datasets Hub).
- #
- # For JSON files, this script will use the `question` column for the input question and `table` column for the corresponding table.
- #
- # If the CSVs/JSONs contain only one non-label column, the script does single sentence classification on this
- # single column. You can easily tweak this behavior (see below)
- #
- # In distributed training, the load_dataset function guarantee that only one local process can concurrently
- # download the dataset.
- if data_args.dataset_name is not None:
- # Downloading and loading a dataset from the hub.
- raw_datasets = load_dataset(
- data_args.dataset_name, data_args.dataset_config_name, cache_dir=model_args.cache_dir
- )
- else:
- # Loading a dataset from your local files.
- # CSV/JSON training and evaluation files are needed.
- data_files = {"train": data_args.train_file, "validation": data_args.validation_file}
-
- # Get the test dataset: you can provide your own CSV/JSON test file (see below)
- # when you use `do_predict` without specifying a GLUE benchmark task.
- if training_args.do_predict:
- if data_args.test_file is not None:
- train_extension = data_args.train_file.split(".")[-1]
- test_extension = data_args.test_file.split(".")[-1]
- assert (
- test_extension == train_extension
- ), "`test_file` should have the same extension (csv or json) as `train_file`."
- data_files["test"] = data_args.test_file
- else:
- raise ValueError("Need either a GLUE task or a test file for `do_predict`.")
-
- for key in data_files.keys():
- logger.info(f"load a local file for {key}: {data_files[key]}")
-
- if data_args.train_file.endswith(".csv"):
- # Loading a dataset from local csv files
- raw_datasets = load_dataset("csv", data_files=data_files, cache_dir=model_args.cache_dir)
- else:
- # Loading a dataset from local json files
- raw_datasets = load_dataset("json", data_files=data_files, cache_dir=model_args.cache_dir)
- # See more about loading any type of standard or custom dataset at
- # https://huggingface.co/docs/datasets/loading_datasets.
-
- # Labels
- label_list = raw_datasets["train"].features["label"].names
- num_labels = len(label_list)
-
- # Load pretrained model and tokenizer
- #
- # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
- # download model & vocab.
- config = AutoConfig.from_pretrained(
- model_args.config_name if model_args.config_name else model_args.model_name_or_path,
- num_labels=num_labels,
- cache_dir=model_args.cache_dir,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- )
- # load tapex tokenizer
- tokenizer = TapexTokenizer.from_pretrained(
- model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- use_fast=model_args.use_fast_tokenizer,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- add_prefix_space=True,
- )
- model = BartForSequenceClassification.from_pretrained(
- model_args.model_name_or_path,
- from_tf=bool(".ckpt" in model_args.model_name_or_path),
- config=config,
- cache_dir=model_args.cache_dir,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- )
-
- # Padding strategy
- if data_args.pad_to_max_length:
- padding = "max_length"
- else:
- # We will pad later, dynamically at batch creation, to the max sequence length in each batch
- padding = False
-
- # Some models have set the order of the labels to use, so let's make sure we do use it.
- model.config.label2id = {"Refused": 0, "Entailed": 1}
- model.config.id2label = {0: "Refused", 1: "Entailed"}
-
- if data_args.max_seq_length > tokenizer.model_max_length:
- logger.warning(
- f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the "
- f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
- )
- max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
-
- def preprocess_tabfact_function(examples):
- # Tokenize the texts
- def _convert_table_text_to_pandas(_table_text):
- """Runs the structured pandas table object for _table_text.
- An example _table_text can be: round#clubs remaining\nfirst round#156\n
- """
- _table_content = [_table_row.split("#") for _table_row in _table_text.strip("\n").split("\n")]
- _table_pd = pd.DataFrame.from_records(_table_content[1:], columns=_table_content[0])
- return _table_pd
-
- questions = examples["statement"]
- tables = list(map(_convert_table_text_to_pandas, examples["table_text"]))
- result = tokenizer(tables, questions, padding=padding, max_length=max_seq_length, truncation=True)
-
- result["label"] = examples["label"]
- return result
-
- with training_args.main_process_first(desc="dataset map pre-processing"):
- raw_datasets = raw_datasets.map(
- preprocess_tabfact_function,
- batched=True,
- load_from_cache_file=not data_args.overwrite_cache,
- desc="Running tokenizer on dataset",
- )
- if training_args.do_train:
- if "train" not in raw_datasets:
- raise ValueError("--do_train requires a train dataset")
- train_dataset = raw_datasets["train"]
- if data_args.max_train_samples is not None:
- train_dataset = train_dataset.select(range(data_args.max_train_samples))
-
- if training_args.do_eval:
- if "validation" not in raw_datasets and "validation_matched" not in raw_datasets:
- raise ValueError("--do_eval requires a validation dataset")
- eval_dataset = raw_datasets["validation"]
- if data_args.max_eval_samples is not None:
- eval_dataset = eval_dataset.select(range(data_args.max_eval_samples))
-
- if training_args.do_predict or data_args.test_file is not None:
- if "test" not in raw_datasets and "test_matched" not in raw_datasets:
- raise ValueError("--do_predict requires a test dataset")
- predict_dataset = raw_datasets["test"]
- if data_args.max_predict_samples is not None:
- predict_dataset = predict_dataset.select(range(data_args.max_predict_samples))
-
- # Log a few random samples from the training set:
- if training_args.do_train:
- for index in random.sample(range(len(train_dataset)), 3):
- logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
-
- # You can define your custom compute_metrics function. It takes an `EvalPrediction` object (a namedtuple with a
- # predictions and label_ids field) and has to return a dictionary string to float.
- def compute_metrics(p: EvalPrediction):
- preds = p.predictions[0] if isinstance(p.predictions, tuple) else p.predictions
- preds = np.argmax(preds, axis=1)
- return {"accuracy": (preds == p.label_ids).astype(np.float32).mean().item()}
-
- # Data collator will default to DataCollatorWithPadding, so we change it if we already did the padding.
- if data_args.pad_to_max_length:
- data_collator = default_data_collator
- elif training_args.fp16:
- data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=8)
- else:
- data_collator = None
-
- # Initialize our Trainer
- trainer = Trainer(
- model=model,
- args=training_args,
- train_dataset=train_dataset if training_args.do_train else None,
- eval_dataset=eval_dataset if training_args.do_eval else None,
- compute_metrics=compute_metrics,
- tokenizer=tokenizer,
- data_collator=data_collator,
- )
-
- # Training
- if training_args.do_train:
- checkpoint = None
- if training_args.resume_from_checkpoint is not None:
- checkpoint = training_args.resume_from_checkpoint
- elif last_checkpoint is not None:
- checkpoint = last_checkpoint
- train_result = trainer.train(resume_from_checkpoint=checkpoint)
- metrics = train_result.metrics
- max_train_samples = (
- data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
- )
- metrics["train_samples"] = min(max_train_samples, len(train_dataset))
-
- trainer.save_model() # Saves the tokenizer too for easy upload
-
- trainer.log_metrics("train", metrics)
- trainer.save_metrics("train", metrics)
- trainer.save_state()
-
- # Evaluation
- if training_args.do_eval:
- logger.info("*** Evaluate ***")
-
- metrics = trainer.evaluate(eval_dataset=eval_dataset)
- max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
- metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
-
- trainer.log_metrics("eval", metrics)
- trainer.save_metrics("eval", metrics)
-
- if training_args.do_predict:
- logger.info("*** Predict ***")
-
- # Removing the `label` columns because it contains -1 and Trainer won't like that.
- predict_dataset = predict_dataset.remove_columns("label")
- predictions = trainer.predict(predict_dataset, metric_key_prefix="predict").predictions
- predictions = np.argmax(predictions, axis=1)
-
- output_predict_file = os.path.join(training_args.output_dir, "predict_results_tabfact.txt")
- if trainer.is_world_process_zero():
- with open(output_predict_file, "w") as writer:
- logger.info("***** Predict Results *****")
- writer.write("index\tprediction\n")
- for index, item in enumerate(predictions):
- item = label_list[item]
- writer.write(f"{index}\t{item}\n")
-
- kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "text-classification"}
-
- if training_args.push_to_hub:
- trainer.push_to_hub(**kwargs)
- else:
- trainer.create_model_card(**kwargs)
-
-
-def _mp_fn(index):
- # For xla_spawn (TPUs)
- main()
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/tapex/run_wikisql_with_tapex.py b/examples/research_projects/tapex/run_wikisql_with_tapex.py
deleted file mode 100644
index 81e940a77c8..00000000000
--- a/examples/research_projects/tapex/run_wikisql_with_tapex.py
+++ /dev/null
@@ -1,649 +0,0 @@
-#!/usr/bin/env python
-# coding=utf-8
-# Copyright 2022 The Microsoft and The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""
-Fine-tuning the library models for tapex on table-based question answering tasks.
-Adapted from script: https://github.com/huggingface/transformers/blob/master/examples/pytorch/summarization/run_summarization.py
-"""
-
-import logging
-import os
-import sys
-from collections import defaultdict
-from copy import deepcopy
-from dataclasses import dataclass, field
-from functools import partial
-from typing import List, Optional
-
-import nltk # Here to have a nice missing dependency error message early on
-import numpy as np
-import pandas as pd
-from datasets import load_dataset
-from filelock import FileLock
-from wikisql_utils import _TYPE_CONVERTER, retrieve_wikisql_query_answer_tapas
-
-import transformers
-from transformers import (
- AutoConfig,
- BartForConditionalGeneration,
- DataCollatorForSeq2Seq,
- HfArgumentParser,
- Seq2SeqTrainer,
- Seq2SeqTrainingArguments,
- TapexTokenizer,
- set_seed,
-)
-from transformers.file_utils import is_offline_mode
-from transformers.trainer_utils import get_last_checkpoint, is_main_process
-from transformers.utils import check_min_version
-
-
-# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.17.0.dev0")
-
-logger = logging.getLogger(__name__)
-
-try:
- nltk.data.find("tokenizers/punkt")
-except (LookupError, OSError):
- if is_offline_mode():
- raise LookupError(
- "Offline mode: run this script without TRANSFORMERS_OFFLINE first to download nltk data files"
- )
- with FileLock(".lock") as lock:
- nltk.download("punkt", quiet=True)
-
-
-@dataclass
-class ModelArguments:
- """
- Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
- """
-
- model_name_or_path: str = field(
- metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"},
- )
- config_name: Optional[str] = field(
- default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
- )
- tokenizer_name: Optional[str] = field(
- default=None,
- metadata={
- "help": (
- "Pretrained tokenizer name or path if not the same as model_name. "
- "By default we use BART-large tokenizer for TAPEX-large."
- )
- },
- )
- cache_dir: Optional[str] = field(
- default=None,
- metadata={"help": "Where to store the pretrained models downloaded from huggingface.co"},
- )
- use_fast_tokenizer: bool = field(
- default=True,
- metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
- )
- model_revision: str = field(
- default="main",
- metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
- )
- use_auth_token: bool = field(
- default=False,
- metadata={
- "help": (
- "Will use the token generated when running `huggingface-cli login` (necessary to use this script "
- "with private models)."
- )
- },
- )
-
-
-@dataclass
-class DataTrainingArguments:
- """
- Arguments pertaining to what data we are going to input our model for training and eval.
- """
-
- dataset_name: Optional[str] = field(
- default="wikisql", metadata={"help": "The name of the dataset to use (via the datasets library)."}
- )
- dataset_config_name: Optional[str] = field(
- default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
- )
- train_file: Optional[str] = field(
- default=None, metadata={"help": "The input training data file (a jsonlines or csv file)."}
- )
- validation_file: Optional[str] = field(
- default=None,
- metadata={
- "help": (
- "An optional input evaluation data file to evaluate the metrics (rouge) on (a jsonlines or csv file)."
- )
- },
- )
- test_file: Optional[str] = field(
- default=None,
- metadata={
- "help": "An optional input test data file to evaluate the metrics (rouge) on (a jsonlines or csv file)."
- },
- )
- overwrite_cache: bool = field(
- default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
- )
- preprocessing_num_workers: Optional[int] = field(
- default=None,
- metadata={"help": "The number of processes to use for the preprocessing."},
- )
- max_source_length: Optional[int] = field(
- default=1024,
- metadata={
- "help": (
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- )
- },
- )
- max_target_length: Optional[int] = field(
- default=128,
- metadata={
- "help": (
- "The maximum total sequence length for target text after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- )
- },
- )
- val_max_target_length: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "The maximum total sequence length for validation target text after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded. Will default to `max_target_length`. "
- "This argument is also used to override the ``max_length`` param of ``model.generate``, which is used "
- "during ``evaluate`` and ``predict``."
- )
- },
- )
- pad_to_max_length: bool = field(
- default=False,
- metadata={
- "help": (
- "Whether to pad all samples to model maximum sentence length. "
- "If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
- "efficient on GPU but very bad for TPU."
- )
- },
- )
- max_train_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of training examples to this "
- "value if set."
- )
- },
- )
- max_eval_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
- "value if set."
- )
- },
- )
- max_predict_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of prediction examples to this "
- "value if set."
- )
- },
- )
- num_beams: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "Number of beams to use for evaluation. This argument will be passed to ``model.generate``, "
- "which is used during ``evaluate`` and ``predict``."
- )
- },
- )
- ignore_pad_token_for_loss: bool = field(
- default=True,
- metadata={
- "help": "Whether to ignore the tokens corresponding to padded labels in the loss computation or not."
- },
- )
-
- def __post_init__(self):
- if self.dataset_name is None and self.train_file is None and self.validation_file is None:
- raise ValueError("Need either a dataset name or a training/validation file.")
- else:
- if self.train_file is not None:
- extension = self.train_file.split(".")[-1]
- assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
- if self.validation_file is not None:
- extension = self.validation_file.split(".")[-1]
- assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
- if self.val_max_target_length is None:
- self.val_max_target_length = self.max_target_length
-
-
-def main():
- # See all possible arguments in src/transformers/training_args.py
- # or by passing the --help flag to this script.
- # We now keep distinct sets of args, for a cleaner separation of concerns.
-
- parser = HfArgumentParser((ModelArguments, DataTrainingArguments, Seq2SeqTrainingArguments))
- if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
- # If we pass only one argument to the script and it's the path to a json file,
- # let's parse it to get our arguments.
- model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
- else:
- model_args, data_args, training_args = parser.parse_args_into_dataclasses()
-
- # Detecting last checkpoint.
- last_checkpoint = None
- if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
- last_checkpoint = get_last_checkpoint(training_args.output_dir)
- if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
- raise ValueError(
- f"Output directory ({training_args.output_dir}) already exists and is not empty. "
- "Use --overwrite_output_dir to overcome."
- )
- elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
- logger.info(
- f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
- "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
- )
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- handlers=[logging.StreamHandler(sys.stdout)],
- )
- logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
-
- # Log on each process the small summary:
- logger.warning(
- f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
- + f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
- )
- # Set the verbosity to info of the Transformers logger (on main process only):
- if is_main_process(training_args.local_rank):
- transformers.utils.logging.set_verbosity_info()
- logger.info(f"Training/evaluation parameters {training_args}")
-
- # Set seed before initializing model.
- set_seed(training_args.seed)
-
- # Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
- # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
- # (the dataset will be downloaded automatically from the datasets Hub).
- #
- # For JSON files, this script will use the `question` column for the input question and `table` column for the corresponding table.
- #
- # In distributed training, the load_dataset function guarantee that only one local process can concurrently
- # download the dataset.
- if data_args.dataset_name is not None:
- # Downloading and loading a dataset from the hub.
- datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name, cache_dir=model_args.cache_dir)
- else:
- data_files = {}
- if data_args.train_file is not None:
- data_files["train"] = data_args.train_file
- extension = data_args.train_file.split(".")[-1]
- if data_args.validation_file is not None:
- data_files["validation"] = data_args.validation_file
- extension = data_args.validation_file.split(".")[-1]
- if data_args.test_file is not None:
- data_files["test"] = data_args.test_file
- extension = data_args.test_file.split(".")[-1]
- datasets = load_dataset(extension, data_files=data_files, cache_dir=model_args.cache_dir)
-
- # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
- # https://huggingface.co/docs/datasets/loading_datasets.
-
- # Load pretrained model and tokenizer
- #
- # Distributed training:
- # The .from_pretrained methods guarantee that only one local process can concurrently
- # download model & vocab.
-
- config = AutoConfig.from_pretrained(
- model_args.config_name if model_args.config_name else model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- )
-
- # IMPORTANT: the initial BART model's decoding is penalized by no_repeat_ngram_size, and thus
- # we should disable it here to avoid problematic generation
- config.no_repeat_ngram_size = 0
- config.max_length = 1024
- config.early_stopping = False
-
- # load tapex tokenizer
- tokenizer = TapexTokenizer.from_pretrained(
- model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- use_fast=model_args.use_fast_tokenizer,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- add_prefix_space=True,
- )
-
- # load Bart based Tapex model (default tapex-large)
- model = BartForConditionalGeneration.from_pretrained(
- model_args.model_name_or_path,
- from_tf=bool(".ckpt" in model_args.model_name_or_path),
- config=config,
- cache_dir=model_args.cache_dir,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- )
-
- if model.config.decoder_start_token_id is None:
- raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
-
- # Preprocessing the datasets.
- # We need to tokenize inputs and targets.
- if training_args.do_train:
- column_names = datasets["train"].column_names
- elif training_args.do_eval:
- column_names = datasets["validation"].column_names
- elif training_args.do_predict:
- column_names = datasets["test"].column_names
- else:
- logger.info("There is nothing to do. Please pass `do_train`, `do_eval` and/or `do_predict`.")
- return
-
- # Temporarily set max_target_length for training.
- max_target_length = data_args.max_target_length
- padding = "max_length" if data_args.pad_to_max_length else False
-
- if training_args.label_smoothing_factor > 0 and not hasattr(model, "prepare_decoder_input_ids_from_labels"):
- logger.warning(
- "label_smoothing is enabled but the `prepare_decoder_input_ids_from_labels` method is not defined for "
- f"`{model.__class__.__name__}`. This will lead to loss being calculated twice and will take up more memory"
- )
-
- def preprocess_tableqa_function(examples, is_training=False):
- """
- The is_training FLAG is used to identify if we could use the supervision
- to truncate the table content if it is required.
- """
-
- # this function is specific for WikiSQL since the util function need the data structure
- # to retrieve the WikiSQL answer for each question
- def _convert_table_types(_table):
- """Runs the type converter over the table cells."""
- ret_table = deepcopy(_table)
- types = ret_table["types"]
- ret_table["real_rows"] = ret_table["rows"]
- typed_rows = []
- for row in ret_table["rows"]:
- typed_row = []
- for column, cell_value in enumerate(row):
- typed_row.append(_TYPE_CONVERTER[types[column]](cell_value))
- typed_rows.append(typed_row)
- ret_table["rows"] = typed_rows
- return ret_table
-
- questions = [question.lower() for question in examples["question"]]
- example_tables = examples["table"]
- example_sqls = examples["sql"]
- tables = [
- pd.DataFrame.from_records(example_table["rows"], columns=example_table["header"])
- for example_table in example_tables
- ]
-
- # using tapas utils to obtain wikisql answer
- answers = []
- for example_sql, example_table in zip(example_sqls, example_tables):
- tapas_table = _convert_table_types(example_table)
- answer_list: List[str] = retrieve_wikisql_query_answer_tapas(tapas_table, example_sql)
- # you can choose other delimiters to split each answer
- answers.append(answer_list)
-
- # IMPORTANT: we cannot pass by answers during evaluation, answers passed during training are used to
- # truncate large tables in the train set!
- if is_training:
- model_inputs = tokenizer(
- table=tables,
- query=questions,
- answer=answers,
- max_length=data_args.max_source_length,
- padding=padding,
- truncation=True,
- )
- else:
- model_inputs = tokenizer(
- table=tables, query=questions, max_length=data_args.max_source_length, padding=padding, truncation=True
- )
-
- labels = tokenizer(
- answer=[", ".join(answer) for answer in answers],
- max_length=max_target_length,
- padding=padding,
- truncation=True,
- )
-
- # If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore
- # padding in the loss.
- if padding == "max_length" and data_args.ignore_pad_token_for_loss:
- labels["input_ids"] = [
- [(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]
- ]
-
- model_inputs["labels"] = labels["input_ids"]
-
- return model_inputs
-
- # in training, we can use the answer as extra information to truncate large tables
- preprocess_tableqa_function_training = partial(preprocess_tableqa_function, is_training=True)
-
- if training_args.do_train:
- if "train" not in datasets:
- raise ValueError("--do_train requires a train dataset")
- train_dataset = datasets["train"]
- if data_args.max_train_samples is not None:
- train_dataset = train_dataset.select(range(data_args.max_train_samples))
- train_dataset = train_dataset.map(
- preprocess_tableqa_function_training,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not data_args.overwrite_cache,
- )
-
- if training_args.do_eval:
- max_target_length = data_args.val_max_target_length
- if "validation" not in datasets:
- raise ValueError("--do_eval requires a validation dataset")
- eval_dataset = datasets["validation"]
- if data_args.max_eval_samples is not None:
- eval_dataset = eval_dataset.select(range(data_args.max_eval_samples))
- eval_dataset = eval_dataset.map(
- preprocess_tableqa_function,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not data_args.overwrite_cache,
- )
-
- if training_args.do_predict:
- max_target_length = data_args.val_max_target_length
- if "test" not in datasets:
- raise ValueError("--do_predict requires a test dataset")
- predict_dataset = datasets["test"]
- if data_args.max_predict_samples is not None:
- predict_dataset = predict_dataset.select(range(data_args.max_predict_samples))
- predict_dataset = predict_dataset.map(
- preprocess_tableqa_function,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not data_args.overwrite_cache,
- )
-
- # Data collator
- label_pad_token_id = -100 if data_args.ignore_pad_token_for_loss else tokenizer.pad_token_id
- data_collator = DataCollatorForSeq2Seq(
- tokenizer,
- model=model,
- label_pad_token_id=label_pad_token_id,
- pad_to_multiple_of=8 if training_args.fp16 else None,
- )
-
- def postprocess_text(preds, labels):
- preds = [pred.strip() for pred in preds]
- labels = [label.strip() for label in labels]
-
- return preds, labels
-
- def compute_metrics(eval_preds):
- preds, labels = eval_preds
- if isinstance(preds, tuple):
- preds = preds[0]
- decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
- if data_args.ignore_pad_token_for_loss:
- # Replace -100 in the labels as we can't decode them.
- labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
- decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
-
- # Some simple post-processing
- decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
-
- delimiter = ", "
-
- # define example evaluation
- def evaluate_example(predict_str: str, ground_str: str):
- predict_spans = predict_str.split(delimiter)
- ground_spans = ground_str.split(delimiter)
- predict_values = defaultdict(lambda: 0)
- ground_values = defaultdict(lambda: 0)
- for span in predict_spans:
- try:
- predict_values[float(span)] += 1
- except ValueError:
- predict_values[span.strip()] += 1
- for span in ground_spans:
- try:
- ground_values[float(span)] += 1
- except ValueError:
- ground_values[span.strip()] += 1
- is_correct = predict_values == ground_values
- return is_correct
-
- def get_denotation_accuracy(predictions: List[str], references: List[str]):
- assert len(predictions) == len(references)
- correct_num = 0
- for predict_str, ground_str in zip(predictions, references):
- is_correct = evaluate_example(predict_str.lower(), ground_str.lower())
- if is_correct:
- correct_num += 1
- return correct_num / len(predictions)
-
- accuracy = get_denotation_accuracy(decoded_preds, decoded_labels)
- result = {"denotation_accuracy": accuracy}
-
- return result
-
- # Initialize our Trainer
- trainer = Seq2SeqTrainer(
- model=model,
- args=training_args,
- train_dataset=train_dataset if training_args.do_train else None,
- eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
- data_collator=data_collator,
- compute_metrics=compute_metrics if training_args.predict_with_generate else None,
- )
-
- if training_args.do_train:
- checkpoint = None
- if training_args.resume_from_checkpoint is not None:
- checkpoint = training_args.resume_from_checkpoint
- elif last_checkpoint is not None:
- checkpoint = last_checkpoint
- train_result = trainer.train(resume_from_checkpoint=checkpoint)
- trainer.save_model() # Saves the tokenizer too for easy upload
-
- metrics = train_result.metrics
- max_train_samples = (
- data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
- )
- metrics["train_samples"] = min(max_train_samples, len(train_dataset))
-
- trainer.log_metrics("train", metrics)
- trainer.save_metrics("train", metrics)
- trainer.save_state()
-
- # Evaluation
- results = {}
- if training_args.do_eval:
- logger.info("*** Evaluate ***")
-
- metrics = trainer.evaluate(
- max_length=data_args.val_max_target_length, num_beams=data_args.num_beams, metric_key_prefix="eval"
- )
- max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
- metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
-
- trainer.log_metrics("eval", metrics)
- trainer.save_metrics("eval", metrics)
-
- if training_args.do_predict:
- logger.info("*** Predict ***")
-
- predict_results = trainer.predict(
- predict_dataset,
- metric_key_prefix="predict",
- max_length=data_args.val_max_target_length,
- num_beams=data_args.num_beams,
- )
- metrics = predict_results.metrics
- max_predict_samples = (
- data_args.max_predict_samples if data_args.max_predict_samples is not None else len(predict_dataset)
- )
- metrics["predict_samples"] = min(max_predict_samples, len(predict_dataset))
-
- trainer.log_metrics("predict", metrics)
- trainer.save_metrics("predict", metrics)
-
- if trainer.is_world_process_zero():
- if training_args.predict_with_generate:
- predictions = tokenizer.batch_decode(
- predict_results.predictions, skip_special_tokens=True, clean_up_tokenization_spaces=True
- )
- predictions = [pred.strip() for pred in predictions]
- output_prediction_file = os.path.join(training_args.output_dir, "tapex_predictions.txt")
- with open(output_prediction_file, "w") as writer:
- writer.write("\n".join(predictions))
-
- return results
-
-
-def _mp_fn(index):
- # For xla_spawn (TPUs)
- main()
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/tapex/run_wikitablequestions_with_tapex.py b/examples/research_projects/tapex/run_wikitablequestions_with_tapex.py
deleted file mode 100644
index 55350025cb3..00000000000
--- a/examples/research_projects/tapex/run_wikitablequestions_with_tapex.py
+++ /dev/null
@@ -1,625 +0,0 @@
-#!/usr/bin/env python
-# coding=utf-8
-# Copyright 2022 The Microsoft and The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""
-Fine-tuning the library models for tapex on table-based question answering tasks.
-Adapted from script: https://github.com/huggingface/transformers/blob/master/examples/pytorch/summarization/run_summarization.py
-"""
-
-import logging
-import os
-import sys
-from collections import defaultdict
-from dataclasses import dataclass, field
-from functools import partial
-from typing import List, Optional
-
-import nltk # Here to have a nice missing dependency error message early on
-import numpy as np
-import pandas as pd
-from datasets import load_dataset
-from filelock import FileLock
-
-import transformers
-from transformers import (
- AutoConfig,
- BartForConditionalGeneration,
- DataCollatorForSeq2Seq,
- HfArgumentParser,
- Seq2SeqTrainer,
- Seq2SeqTrainingArguments,
- TapexTokenizer,
- set_seed,
-)
-from transformers.file_utils import is_offline_mode
-from transformers.trainer_utils import get_last_checkpoint, is_main_process
-from transformers.utils import check_min_version
-
-
-# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.17.0.dev0")
-
-logger = logging.getLogger(__name__)
-
-try:
- nltk.data.find("tokenizers/punkt")
-except (LookupError, OSError):
- if is_offline_mode():
- raise LookupError(
- "Offline mode: run this script without TRANSFORMERS_OFFLINE first to download nltk data files"
- )
- with FileLock(".lock") as lock:
- nltk.download("punkt", quiet=True)
-
-
-@dataclass
-class ModelArguments:
- """
- Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
- """
-
- model_name_or_path: str = field(
- metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"},
- )
- config_name: Optional[str] = field(
- default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
- )
- tokenizer_name: Optional[str] = field(
- default=None,
- metadata={
- "help": (
- "Pretrained tokenizer name or path if not the same as model_name. "
- "By default we use BART-large tokenizer for TAPEX-large."
- )
- },
- )
- cache_dir: Optional[str] = field(
- default=None,
- metadata={"help": "Where to store the pretrained models downloaded from huggingface.co"},
- )
- use_fast_tokenizer: bool = field(
- default=True,
- metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
- )
- model_revision: str = field(
- default="main",
- metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
- )
- use_auth_token: bool = field(
- default=False,
- metadata={
- "help": (
- "Will use the token generated when running `huggingface-cli login` (necessary to use this script "
- "with private models)."
- )
- },
- )
-
-
-@dataclass
-class DataTrainingArguments:
- """
- Arguments pertaining to what data we are going to input our model for training and eval.
- """
-
- dataset_name: Optional[str] = field(
- default="wikitablequestions", metadata={"help": "The name of the dataset to use (via the datasets library)."}
- )
- dataset_config_name: Optional[str] = field(
- default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
- )
- train_file: Optional[str] = field(
- default=None, metadata={"help": "The input training data file (a jsonlines or csv file)."}
- )
- validation_file: Optional[str] = field(
- default=None,
- metadata={
- "help": (
- "An optional input evaluation data file to evaluate the metrics (rouge) on (a jsonlines or csv file)."
- )
- },
- )
- test_file: Optional[str] = field(
- default=None,
- metadata={
- "help": "An optional input test data file to evaluate the metrics (rouge) on (a jsonlines or csv file)."
- },
- )
- overwrite_cache: bool = field(
- default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
- )
- preprocessing_num_workers: Optional[int] = field(
- default=None,
- metadata={"help": "The number of processes to use for the preprocessing."},
- )
- max_source_length: Optional[int] = field(
- default=1024,
- metadata={
- "help": (
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- )
- },
- )
- max_target_length: Optional[int] = field(
- default=128,
- metadata={
- "help": (
- "The maximum total sequence length for target text after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- )
- },
- )
- val_max_target_length: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "The maximum total sequence length for validation target text after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded. Will default to `max_target_length`. "
- "This argument is also used to override the ``max_length`` param of ``model.generate``, which is used "
- "during ``evaluate`` and ``predict``."
- )
- },
- )
- pad_to_max_length: bool = field(
- default=False,
- metadata={
- "help": (
- "Whether to pad all samples to model maximum sentence length. "
- "If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
- "efficient on GPU but very bad for TPU."
- )
- },
- )
- max_train_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of training examples to this "
- "value if set."
- )
- },
- )
- max_eval_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
- "value if set."
- )
- },
- )
- max_predict_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of prediction examples to this "
- "value if set."
- )
- },
- )
- num_beams: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "Number of beams to use for evaluation. This argument will be passed to ``model.generate``, "
- "which is used during ``evaluate`` and ``predict``."
- )
- },
- )
- ignore_pad_token_for_loss: bool = field(
- default=True,
- metadata={
- "help": "Whether to ignore the tokens corresponding to padded labels in the loss computation or not."
- },
- )
-
- def __post_init__(self):
- if self.dataset_name is None and self.train_file is None and self.validation_file is None:
- raise ValueError("Need either a dataset name or a training/validation file.")
- else:
- if self.train_file is not None:
- extension = self.train_file.split(".")[-1]
- assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
- if self.validation_file is not None:
- extension = self.validation_file.split(".")[-1]
- assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
- if self.val_max_target_length is None:
- self.val_max_target_length = self.max_target_length
-
-
-def main():
- # See all possible arguments in src/transformers/training_args.py
- # or by passing the --help flag to this script.
- # We now keep distinct sets of args, for a cleaner separation of concerns.
-
- parser = HfArgumentParser((ModelArguments, DataTrainingArguments, Seq2SeqTrainingArguments))
- if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
- # If we pass only one argument to the script and it's the path to a json file,
- # let's parse it to get our arguments.
- model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
- else:
- model_args, data_args, training_args = parser.parse_args_into_dataclasses()
-
- # Detecting last checkpoint.
- last_checkpoint = None
- if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
- last_checkpoint = get_last_checkpoint(training_args.output_dir)
- if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
- raise ValueError(
- f"Output directory ({training_args.output_dir}) already exists and is not empty. "
- "Use --overwrite_output_dir to overcome."
- )
- elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
- logger.info(
- f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
- "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
- )
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- handlers=[logging.StreamHandler(sys.stdout)],
- )
- logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
-
- # Log on each process the small summary:
- logger.warning(
- f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
- + f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
- )
- # Set the verbosity to info of the Transformers logger (on main process only):
- if is_main_process(training_args.local_rank):
- transformers.utils.logging.set_verbosity_info()
- logger.info(f"Training/evaluation parameters {training_args}")
-
- # Set seed before initializing model.
- set_seed(training_args.seed)
-
- # Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
- # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
- # (the dataset will be downloaded automatically from the datasets Hub).
- #
- # For JSON files, this script will use the `question` column for the input question and `table` column for the corresponding table.
- #
- # In distributed training, the load_dataset function guarantee that only one local process can concurrently
- # download the dataset.
- if data_args.dataset_name is not None:
- # Downloading and loading a dataset from the hub.
- datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name, cache_dir=model_args.cache_dir)
- else:
- data_files = {}
- if data_args.train_file is not None:
- data_files["train"] = data_args.train_file
- extension = data_args.train_file.split(".")[-1]
- if data_args.validation_file is not None:
- data_files["validation"] = data_args.validation_file
- extension = data_args.validation_file.split(".")[-1]
- if data_args.test_file is not None:
- data_files["test"] = data_args.test_file
- extension = data_args.test_file.split(".")[-1]
- datasets = load_dataset(extension, data_files=data_files, cache_dir=model_args.cache_dir)
-
- # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
- # https://huggingface.co/docs/datasets/loading_datasets.
-
- # Load pretrained model and tokenizer
- #
- # Distributed training:
- # The .from_pretrained methods guarantee that only one local process can concurrently
- # download model & vocab.
-
- config = AutoConfig.from_pretrained(
- model_args.config_name if model_args.config_name else model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- )
-
- # IMPORTANT: the initial BART model's decoding is penalized by no_repeat_ngram_size, and thus
- # we should disable it here to avoid problematic generation
- config.no_repeat_ngram_size = 0
- config.max_length = 1024
- config.early_stopping = False
-
- # load tapex tokenizer
- tokenizer = TapexTokenizer.from_pretrained(
- model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- use_fast=model_args.use_fast_tokenizer,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- add_prefix_space=True,
- )
-
- # load Bart based Tapex model (default tapex-large)
- model = BartForConditionalGeneration.from_pretrained(
- model_args.model_name_or_path,
- from_tf=bool(".ckpt" in model_args.model_name_or_path),
- config=config,
- cache_dir=model_args.cache_dir,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- )
-
- if model.config.decoder_start_token_id is None:
- raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
-
- # Preprocessing the datasets.
- # We need to tokenize inputs and targets.
- if training_args.do_train:
- column_names = datasets["train"].column_names
- elif training_args.do_eval:
- column_names = datasets["validation"].column_names
- elif training_args.do_predict:
- column_names = datasets["test"].column_names
- else:
- logger.info("There is nothing to do. Please pass `do_train`, `do_eval` and/or `do_predict`.")
- return
-
- # Temporarily set max_target_length for training.
- max_target_length = data_args.max_target_length
- padding = "max_length" if data_args.pad_to_max_length else False
-
- if training_args.label_smoothing_factor > 0 and not hasattr(model, "prepare_decoder_input_ids_from_labels"):
- logger.warning(
- "label_smoothing is enabled but the `prepare_decoder_input_ids_from_labels` method is not defined for "
- f"`{model.__class__.__name__}`. This will lead to loss being calculated twice and will take up more memory"
- )
-
- def preprocess_tableqa_function(examples, is_training=False):
- """
- The is_training FLAG is used to identify if we could use the supervision
- to truncate the table content if it is required.
- """
-
- questions = [question.lower() for question in examples["question"]]
- example_tables = examples["table"]
- tables = [
- pd.DataFrame.from_records(example_table["rows"], columns=example_table["header"])
- for example_table in example_tables
- ]
-
- # using wikitablequestion's answer set
- answers = examples["answers"]
-
- # IMPORTANT: we cannot pass by answers during evaluation, answers passed during training are used to
- # truncate large tables in the train set!
- if is_training:
- model_inputs = tokenizer(
- table=tables,
- query=questions,
- answer=answers,
- max_length=data_args.max_source_length,
- padding=padding,
- truncation=True,
- )
- else:
- model_inputs = tokenizer(
- table=tables, query=questions, max_length=data_args.max_source_length, padding=padding, truncation=True
- )
-
- labels = tokenizer(
- answer=[", ".join(answer) for answer in answers],
- max_length=max_target_length,
- padding=padding,
- truncation=True,
- )
-
- # If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore
- # padding in the loss.
- if padding == "max_length" and data_args.ignore_pad_token_for_loss:
- labels["input_ids"] = [
- [(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]
- ]
-
- model_inputs["labels"] = labels["input_ids"]
-
- return model_inputs
-
- # in training, we can use the answer as extra information to truncate large tables
- preprocess_tableqa_function_training = partial(preprocess_tableqa_function, is_training=True)
-
- if training_args.do_train:
- if "train" not in datasets:
- raise ValueError("--do_train requires a train dataset")
- train_dataset = datasets["train"]
- if data_args.max_train_samples is not None:
- train_dataset = train_dataset.select(range(data_args.max_train_samples))
- train_dataset = train_dataset.map(
- preprocess_tableqa_function_training,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not data_args.overwrite_cache,
- )
-
- if training_args.do_eval:
- max_target_length = data_args.val_max_target_length
- if "validation" not in datasets:
- raise ValueError("--do_eval requires a validation dataset")
- eval_dataset = datasets["validation"]
- if data_args.max_eval_samples is not None:
- eval_dataset = eval_dataset.select(range(data_args.max_eval_samples))
- eval_dataset = eval_dataset.map(
- preprocess_tableqa_function,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not data_args.overwrite_cache,
- )
-
- if training_args.do_predict:
- max_target_length = data_args.val_max_target_length
- if "test" not in datasets:
- raise ValueError("--do_predict requires a test dataset")
- predict_dataset = datasets["test"]
- if data_args.max_predict_samples is not None:
- predict_dataset = predict_dataset.select(range(data_args.max_predict_samples))
- predict_dataset = predict_dataset.map(
- preprocess_tableqa_function,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not data_args.overwrite_cache,
- )
-
- # Data collator
- label_pad_token_id = -100 if data_args.ignore_pad_token_for_loss else tokenizer.pad_token_id
- data_collator = DataCollatorForSeq2Seq(
- tokenizer,
- model=model,
- label_pad_token_id=label_pad_token_id,
- pad_to_multiple_of=8 if training_args.fp16 else None,
- )
-
- def postprocess_text(preds, labels):
- preds = [pred.strip() for pred in preds]
- labels = [label.strip() for label in labels]
-
- return preds, labels
-
- def compute_metrics(eval_preds):
- preds, labels = eval_preds
- if isinstance(preds, tuple):
- preds = preds[0]
- decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
- if data_args.ignore_pad_token_for_loss:
- # Replace -100 in the labels as we can't decode them.
- labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
- decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
-
- # Some simple post-processing
- decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
-
- delimiter = ", "
-
- # define example evaluation
- def evaluate_example(predict_str: str, ground_str: str):
- predict_spans = predict_str.split(delimiter)
- ground_spans = ground_str.split(delimiter)
- predict_values = defaultdict(lambda: 0)
- ground_values = defaultdict(lambda: 0)
- for span in predict_spans:
- try:
- predict_values[float(span)] += 1
- except ValueError:
- predict_values[span.strip()] += 1
- for span in ground_spans:
- try:
- ground_values[float(span)] += 1
- except ValueError:
- ground_values[span.strip()] += 1
- _is_correct = predict_values == ground_values
- return _is_correct
-
- def get_denotation_accuracy(predictions: List[str], references: List[str]):
- assert len(predictions) == len(references)
- correct_num = 0
- for predict_str, ground_str in zip(predictions, references):
- is_correct = evaluate_example(predict_str.lower(), ground_str.lower())
- if is_correct:
- correct_num += 1
- return correct_num / len(predictions)
-
- accuracy = get_denotation_accuracy(decoded_preds, decoded_labels)
- result = {"denotation_accuracy": accuracy}
-
- return result
-
- # Initialize our Trainer
- trainer = Seq2SeqTrainer(
- model=model,
- args=training_args,
- train_dataset=train_dataset if training_args.do_train else None,
- eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
- data_collator=data_collator,
- compute_metrics=compute_metrics if training_args.predict_with_generate else None,
- )
-
- if training_args.do_train:
- checkpoint = None
- if training_args.resume_from_checkpoint is not None:
- checkpoint = training_args.resume_from_checkpoint
- elif last_checkpoint is not None:
- checkpoint = last_checkpoint
- train_result = trainer.train(resume_from_checkpoint=checkpoint)
- trainer.save_model() # Saves the tokenizer too for easy upload
-
- metrics = train_result.metrics
- max_train_samples = (
- data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
- )
- metrics["train_samples"] = min(max_train_samples, len(train_dataset))
-
- trainer.log_metrics("train", metrics)
- trainer.save_metrics("train", metrics)
- trainer.save_state()
-
- # Evaluation
- results = {}
- if training_args.do_eval:
- logger.info("*** Evaluate ***")
-
- metrics = trainer.evaluate(
- max_length=data_args.val_max_target_length, num_beams=data_args.num_beams, metric_key_prefix="eval"
- )
- max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
- metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
-
- trainer.log_metrics("eval", metrics)
- trainer.save_metrics("eval", metrics)
-
- if training_args.do_predict:
- logger.info("*** Predict ***")
-
- predict_results = trainer.predict(
- predict_dataset,
- metric_key_prefix="predict",
- max_length=data_args.val_max_target_length,
- num_beams=data_args.num_beams,
- )
- metrics = predict_results.metrics
- max_predict_samples = (
- data_args.max_predict_samples if data_args.max_predict_samples is not None else len(predict_dataset)
- )
- metrics["predict_samples"] = min(max_predict_samples, len(predict_dataset))
-
- trainer.log_metrics("predict", metrics)
- trainer.save_metrics("predict", metrics)
-
- if trainer.is_world_process_zero():
- if training_args.predict_with_generate:
- predictions = tokenizer.batch_decode(
- predict_results.predictions, skip_special_tokens=True, clean_up_tokenization_spaces=True
- )
- predictions = [pred.strip() for pred in predictions]
- output_prediction_file = os.path.join(training_args.output_dir, "tapex_predictions.txt")
- with open(output_prediction_file, "w") as writer:
- writer.write("\n".join(predictions))
-
- return results
-
-
-def _mp_fn(index):
- # For xla_spawn (TPUs)
- main()
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/tapex/wikisql_utils.py b/examples/research_projects/tapex/wikisql_utils.py
deleted file mode 100644
index 13d10e091a1..00000000000
--- a/examples/research_projects/tapex/wikisql_utils.py
+++ /dev/null
@@ -1,257 +0,0 @@
-# coding=utf-8
-# Copyright 2022 The Microsoft, The Google and The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import dataclasses
-import enum
-import functools
-import math
-import re
-
-# The following script is adapted from the script of TaPas.
-# Original: https://github.com/google-research/tapas/master/wikisql_utils.py
-from typing import Any, List
-
-
-EMPTY_ANSWER = "none"
-EMPTY_ANSWER_AGG = "none"
-
-
-def _split_thousands(delimiter, value):
- split = value.split(delimiter)
- return len(split) > 1 and any((len(x) == 3 for x in split))
-
-
-def convert_to_float(value):
- """Converts value to a float using a series of increasingly complex heuristics.
- Args:
- value: object that needs to be converted. Allowed types include
- float/int/strings.
- Returns:
- A float interpretation of value.
- Raises:
- ValueError if the float conversion of value fails.
- """
- if isinstance(value, float):
- return value
- if isinstance(value, int):
- return float(value)
- if not isinstance(value, str):
- raise TypeError("Argument value is not a string. Can't parse it as float")
- sanitized = value
-
- try:
- # Example: 1,000.7
- if "." in sanitized and "," in sanitized:
- return float(sanitized.replace(",", ""))
- # 1,000
- if "," in sanitized and _split_thousands(",", sanitized):
- return float(sanitized.replace(",", ""))
- # 5,5556
- if "," in sanitized and sanitized.count(",") == 1 and not _split_thousands(",", sanitized):
- return float(sanitized.replace(",", "."))
- # 0.0.0.1
- if sanitized.count(".") > 1:
- return float(sanitized.replace(".", ""))
- # 0,0,0,1
- if sanitized.count(",") > 1:
- return float(sanitized.replace(",", ""))
- return float(sanitized)
- except ValueError:
- # Avoid adding the sanitized value in the error message.
- raise ValueError("Unable to convert value to float")
-
-
-def _normalize_float(answer):
- if answer is None:
- return None
- try:
- value = convert_to_float(answer)
- if isinstance(value, float) and math.isnan(value):
- return None
- return value
- except ValueError:
- return answer.lower()
-
-
-_TYPE_CONVERTER = {
- "text": lambda x: x,
- "real": convert_to_float,
-}
-
-
-class _Aggregation(enum.Enum):
- """Aggregations as defined by WikiSQL. Indexes match the data."""
-
- NONE = 0
- MAX = 1
- MIN = 2
- COUNT = 3
- SUM = 4
- AVERAGE = 5
-
-
-class _Operator(enum.Enum):
- """The boolean operators used by WikiSQL. Indexes match the data."""
-
- EQUALS = 0
- GREATER = 1
- LESSER = 2
-
-
-@dataclasses.dataclass
-class _Condition:
- """Represents an SQL where clauses (e.g A = "a" or B > 5)."""
-
- column: str
- operator: _Operator
- cmp_value: Any
-
-
-_TOKENIZER = re.compile(r"\w+|[^\w\s]+", re.UNICODE | re.MULTILINE | re.DOTALL)
-
-
-def _normalize_for_match(x):
- return list(_TOKENIZER.findall(x.lower()))
-
-
-def _compare(operator, src, tgt):
- if operator == _Operator.EQUALS:
- return src == tgt
- elif operator == _Operator.GREATER:
- return src > tgt
- elif operator == _Operator.LESSER:
- return src < tgt
- raise ValueError(f"Unknown operator: {operator}")
-
-
-def _parse_value(table, column, cell_value):
- """Convert numeric values to floats and keeps everything else as string."""
- types = table["types"]
- return _TYPE_CONVERTER[types[column]](cell_value)
-
-
-def _is_string(x):
- return isinstance(x, str)
-
-
-def _respect_conditions(table, row, conditions):
- """True if 'row' satisfies all 'conditions'."""
- for cond in conditions:
- table_value = row[cond.column]
-
- cmp_value = _parse_value(table, cond.column, cond.cmp_value)
-
- if _is_string(table_value) and _is_string(cmp_value):
- table_value = _normalize_for_match(table_value)
- cmp_value = _normalize_for_match(cmp_value)
-
- if not isinstance(table_value, type(cmp_value)):
- raise TypeError("Type difference {} != {}".format(type(table_value), type(cmp_value)))
-
- if not _compare(cond.operator, table_value, cmp_value):
- return False
- return True
-
-
-def _get_float_answer(table, answer_coordinates, aggregation_op):
- """Applies operation to produce reference float answer."""
- if not answer_coordinates:
- if aggregation_op == _Aggregation.COUNT:
- return 0.0
- else:
- return EMPTY_ANSWER_AGG
-
- # Count can support non numeric answers.
- if aggregation_op == _Aggregation.COUNT:
- return float(len(answer_coordinates))
-
- # If we have just one answer, if float returns it or try a conversion.
- values = [table["rows"][i][j] for (i, j) in answer_coordinates]
- if len(answer_coordinates) == 1:
- try:
- return convert_to_float(values[0])
- except ValueError as e:
- if aggregation_op != _Aggregation.NONE:
- raise e
-
- if aggregation_op == _Aggregation.NONE:
- return None
-
- # Other aggregation only support numeric values. Bail out if we have strings.
- if not all((isinstance(v, (int, float)) for v in values)):
- return None
-
- if aggregation_op == _Aggregation.SUM:
- return float(sum(values))
- elif aggregation_op == _Aggregation.AVERAGE:
- return sum(values) / len(answer_coordinates)
- else:
- raise ValueError(f"Unknown aggregation: {aggregation_op}")
-
-
-def _get_answer_coordinates(table, sql_query):
- """Retrieves references coordinates by executing SQL."""
- # MAX and MIN are automatically supported by the model.
- aggregation_op_index = sql_query["agg"]
- if aggregation_op_index >= 3:
- aggregation_op = _Aggregation(aggregation_op_index)
- else:
- aggregation_op = _Aggregation.NONE
-
- target_column = sql_query["sel"]
- conditions = [
- _Condition(column, _Operator(operator), cmp_value)
- for column, operator, cmp_value in zip(
- sql_query["conds"]["column_index"], sql_query["conds"]["operator_index"], sql_query["conds"]["condition"]
- )
- ]
-
- indices = []
- for row in range(len(table["rows"])):
- if _respect_conditions(table, table["rows"][row], conditions):
- indices.append((row, target_column))
-
- if not indices:
- return [], aggregation_op
-
- if len(indices) == 1:
- return indices, aggregation_op
-
- # Parsing of MIN/MAX.
- if aggregation_op_index in (1, 2):
- operators = {2: min, 1: max}
- values = [(table["rows"][i][j], index) for index, (i, j) in enumerate(indices)]
- reduced = functools.reduce(operators[sql_query["agg"]], values)
-
- ret = [indices[reduced[1]]]
- return ret, _Aggregation.NONE
-
- return indices, aggregation_op
-
-
-def _get_answer_text(table, answer_coordinates, float_answer):
- if float_answer is not None:
- return [str(float_answer)]
- return [str(table["real_rows"][r][c]) for r, c in answer_coordinates]
-
-
-def retrieve_wikisql_query_answer_tapas(table, example) -> List:
- answer_coordinates, aggregation_op = _get_answer_coordinates(table, example)
- float_answer = _get_float_answer(table, answer_coordinates, aggregation_op)
- answer_text = _get_answer_text(table, answer_coordinates, float_answer)
- # keep the original data the same with TaPas
- if len(answer_text) == 0:
- answer_text = [EMPTY_ANSWER]
- return answer_text
diff --git a/examples/research_projects/token-healing/README.md b/examples/research_projects/token-healing/README.md
deleted file mode 100644
index f3594f32dc7..00000000000
--- a/examples/research_projects/token-healing/README.md
+++ /dev/null
@@ -1,40 +0,0 @@
-
-
-
-
-## What is token healing?
-
-Token healing rectifies the token boundary bias in greedy tokenization. It does this by trimming and regrowing the prompt to better align with the model's tokenizer, thus enhancing generation quality. The improvement is clearest with completion models.
-
-Example: given a completion prompt with a partial url ending with `:`, the model might have seen the expected completion `://` as a _single_ token in training. However, the prompt's tail token `:` tells it that the next token is not `//`, and so it looks for wrong completions. Such errors compound in auto-regressive language models.
-
-Debiasing token boundaries also addresses output sensitivity to prompts ending with whitespace.
-
-A more thorough explanation can be found on [The Art of Prompt Design: Prompt Boundaries and Token Healing | by Scott Lundberg](https://towardsdatascience.com/the-art-of-prompt-design-prompt-boundaries-and-token-healing-3b2448b0be38).
-
-## Usage
-
-```py
-prompt = 'The link is (back to top)
\n",
- "\n",
- "*Note: this notebook is compatible with `torch>=1.5.0` If you are using, `torch==1.4.0`, please refer to [this previous version of the notebook](https://github.com/huggingface/transformers/commit/b11386e158e86e62d4041eabd86d044cd1695737).*"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 1,
- "metadata": {},
- "outputs": [],
- "source": [
- "# Includes\n",
- "\n",
- "import json\n",
- "import os\n",
- "from collections import OrderedDict\n",
- "\n",
- "import h5py\n",
- "import numpy as np\n",
- "import torch\n",
- "from scipy import sparse\n",
- "from torch import nn\n",
- "\n",
- "from transformers import BertForQuestionAnswering\n",
- "\n",
- "\n",
- "os.chdir(\"../../\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Saving"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Dynamic quantization induces little or no loss of performance while significantly reducing the memory footprint."
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 2,
- "metadata": {},
- "outputs": [],
- "source": [
- "# Load fine-pruned model and quantize the model\n",
- "\n",
- "model = BertForQuestionAnswering.from_pretrained(\"huggingface/prunebert-base-uncased-6-finepruned-w-distil-squad\")\n",
- "model.to(\"cpu\")\n",
- "\n",
- "quantized_model = torch.quantization.quantize_dynamic(\n",
- " model=model,\n",
- " qconfig_spec={\n",
- " nn.Linear: torch.quantization.default_dynamic_qconfig,\n",
- " },\n",
- " dtype=torch.qint8,\n",
- ")\n",
- "# print(quantized_model)\n",
- "\n",
- "qtz_st = quantized_model.state_dict()"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 3,
- "metadata": {},
- "outputs": [],
- "source": [
- "# Saving the original (encoder + classifier) in the standard torch.save format\n",
- "\n",
- "dense_st = {\n",
- " name: param for name, param in model.state_dict().items() if \"embedding\" not in name and \"pooler\" not in name\n",
- "}\n",
- "torch.save(\n",
- " dense_st,\n",
- " \"dbg/dense_squad.pt\",\n",
- ")\n",
- "dense_mb_size = os.path.getsize(\"dbg/dense_squad.pt\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 4,
- "metadata": {
- "scrolled": true
- },
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Decompose quantization for bert.encoder.layer.0.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.0.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.0.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.0.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.0.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.0.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.1.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.1.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.1.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.1.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.1.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.1.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.2.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.2.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.2.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.2.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.2.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.2.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.3.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.3.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.3.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.3.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.3.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.3.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.4.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.4.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.4.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.4.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.4.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.4.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.5.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.5.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.5.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.5.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.5.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.5.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.6.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.6.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.6.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.6.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.6.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.6.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.7.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.7.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.7.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.7.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.7.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.7.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.8.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.8.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.8.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.8.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.8.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.8.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.9.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.9.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.9.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.9.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.9.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.9.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.10.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.10.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.10.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.10.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.10.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.10.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.11.attention.self.query._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.11.attention.self.key._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.11.attention.self.value._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.11.attention.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.11.intermediate.dense._packed_params.weight\n",
- "Decompose quantization for bert.encoder.layer.11.output.dense._packed_params.weight\n",
- "Decompose quantization for bert.pooler.dense._packed_params.weight\n",
- "Decompose quantization for qa_outputs._packed_params.weight\n"
- ]
- }
- ],
- "source": [
- "# Elementary representation: we decompose the quantized tensors into (scale, zero_point, int_repr).\n",
- "# See https://pytorch.org/docs/stable/quantization.html\n",
- "\n",
- "# We further leverage the fact that int_repr is sparse matrix to optimize the storage: we decompose int_repr into\n",
- "# its CSR representation (data, indptr, indices).\n",
- "\n",
- "elementary_qtz_st = {}\n",
- "for name, param in qtz_st.items():\n",
- " if \"dtype\" not in name and param.is_quantized:\n",
- " print(\"Decompose quantization for\", name)\n",
- " # We need to extract the scale, the zero_point and the int_repr for the quantized tensor and modules\n",
- " scale = param.q_scale() # torch.tensor(1,) - float32\n",
- " zero_point = param.q_zero_point() # torch.tensor(1,) - int32\n",
- " elementary_qtz_st[f\"{name}.scale\"] = scale\n",
- " elementary_qtz_st[f\"{name}.zero_point\"] = zero_point\n",
- "\n",
- " # We assume the int_repr is sparse and compute its CSR representation\n",
- " # Only the FCs in the encoder are actually sparse\n",
- " int_repr = param.int_repr() # torch.tensor(nb_rows, nb_columns) - int8\n",
- " int_repr_cs = sparse.csr_matrix(int_repr) # scipy.sparse.csr.csr_matrix\n",
- "\n",
- " elementary_qtz_st[f\"{name}.int_repr.data\"] = int_repr_cs.data # np.array int8\n",
- " elementary_qtz_st[f\"{name}.int_repr.indptr\"] = int_repr_cs.indptr # np.array int32\n",
- " assert max(int_repr_cs.indices) < 65535 # If not, we shall fall back to int32\n",
- " elementary_qtz_st[f\"{name}.int_repr.indices\"] = np.uint16(int_repr_cs.indices) # np.array uint16\n",
- " elementary_qtz_st[f\"{name}.int_repr.shape\"] = int_repr_cs.shape # tuple(int, int)\n",
- " else:\n",
- " elementary_qtz_st[name] = param"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 5,
- "metadata": {},
- "outputs": [],
- "source": [
- "# Create mapping from torch.dtype to string description (we could also used an int8 instead of string)\n",
- "str_2_dtype = {\"qint8\": torch.qint8}\n",
- "dtype_2_str = {torch.qint8: \"qint8\"}"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 6,
- "metadata": {
- "scrolled": true
- },
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Encoder Size (MB) - Sparse & Quantized - `torch.save`: 21.29\n"
- ]
- }
- ],
- "source": [
- "# Saving the pruned (encoder + classifier) in the standard torch.save format\n",
- "\n",
- "dense_optimized_st = {\n",
- " name: param for name, param in elementary_qtz_st.items() if \"embedding\" not in name and \"pooler\" not in name\n",
- "}\n",
- "torch.save(\n",
- " dense_optimized_st,\n",
- " \"dbg/dense_squad_optimized.pt\",\n",
- ")\n",
- "print(\n",
- " \"Encoder Size (MB) - Sparse & Quantized - `torch.save`:\",\n",
- " round(os.path.getsize(\"dbg/dense_squad_optimized.pt\") / 1e6, 2),\n",
- ")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 7,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Skip bert.embeddings.word_embeddings.weight\n",
- "Skip bert.embeddings.position_embeddings.weight\n",
- "Skip bert.embeddings.token_type_embeddings.weight\n",
- "Skip bert.embeddings.LayerNorm.weight\n",
- "Skip bert.embeddings.LayerNorm.bias\n",
- "Skip bert.pooler.dense.scale\n",
- "Skip bert.pooler.dense.zero_point\n",
- "Skip bert.pooler.dense._packed_params.weight.scale\n",
- "Skip bert.pooler.dense._packed_params.weight.zero_point\n",
- "Skip bert.pooler.dense._packed_params.weight.int_repr.data\n",
- "Skip bert.pooler.dense._packed_params.weight.int_repr.indptr\n",
- "Skip bert.pooler.dense._packed_params.weight.int_repr.indices\n",
- "Skip bert.pooler.dense._packed_params.weight.int_repr.shape\n",
- "Skip bert.pooler.dense._packed_params.bias\n",
- "Skip bert.pooler.dense._packed_params.dtype\n",
- "\n",
- "Encoder Size (MB) - Dense: 340.26\n",
- "Encoder Size (MB) - Sparse & Quantized: 11.28\n"
- ]
- }
- ],
- "source": [
- "# Save the decomposed state_dict with an HDF5 file\n",
- "# Saving only the encoder + QA Head\n",
- "\n",
- "with h5py.File(\"dbg/squad_sparse.h5\", \"w\") as hf:\n",
- " for name, param in elementary_qtz_st.items():\n",
- " if \"embedding\" in name:\n",
- " print(f\"Skip {name}\")\n",
- " continue\n",
- "\n",
- " if \"pooler\" in name:\n",
- " print(f\"Skip {name}\")\n",
- " continue\n",
- "\n",
- " if isinstance(param, torch.Tensor):\n",
- " if param.numel() == 1:\n",
- " # module scale\n",
- " # module zero_point\n",
- " hf.attrs[name] = param\n",
- " continue\n",
- "\n",
- " if param.requires_grad:\n",
- " # LayerNorm\n",
- " param = param.detach().numpy()\n",
- " hf.create_dataset(name, data=param, compression=\"gzip\", compression_opts=9)\n",
- "\n",
- " elif isinstance(param, (float, int, tuple)):\n",
- " # float - tensor _packed_params.weight.scale\n",
- " # int - tensor _packed_params.weight.zero_point\n",
- " # tuple - tensor _packed_params.weight.shape\n",
- " hf.attrs[name] = param\n",
- "\n",
- " elif isinstance(param, torch.dtype):\n",
- " # dtype - tensor _packed_params.dtype\n",
- " hf.attrs[name] = dtype_2_str[param]\n",
- "\n",
- " else:\n",
- " hf.create_dataset(name, data=param, compression=\"gzip\", compression_opts=9)\n",
- "\n",
- "\n",
- "with open(\"dbg/metadata.json\", \"w\") as f:\n",
- " f.write(json.dumps(qtz_st._metadata))\n",
- "\n",
- "size = os.path.getsize(\"dbg/squad_sparse.h5\") + os.path.getsize(\"dbg/metadata.json\")\n",
- "print(\"\")\n",
- "print(\"Encoder Size (MB) - Dense: \", round(dense_mb_size / 1e6, 2))\n",
- "print(\"Encoder Size (MB) - Sparse & Quantized:\", round(size / 1e6, 2))"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 8,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- "Size (MB): 99.41\n"
- ]
- }
- ],
- "source": [
- "# Save the decomposed state_dict to HDF5 storage\n",
- "# Save everything in the architecutre (embedding + encoder + QA Head)\n",
- "\n",
- "with h5py.File(\"dbg/squad_sparse_with_embs.h5\", \"w\") as hf:\n",
- " for name, param in elementary_qtz_st.items():\n",
- " # if \"embedding\" in name:\n",
- " # print(f\"Skip {name}\")\n",
- " # continue\n",
- "\n",
- " # if \"pooler\" in name:\n",
- " # print(f\"Skip {name}\")\n",
- " # continue\n",
- "\n",
- " if isinstance(param, torch.Tensor):\n",
- " if param.numel() == 1:\n",
- " # module scale\n",
- " # module zero_point\n",
- " hf.attrs[name] = param\n",
- " continue\n",
- "\n",
- " if param.requires_grad:\n",
- " # LayerNorm\n",
- " param = param.detach().numpy()\n",
- " hf.create_dataset(name, data=param, compression=\"gzip\", compression_opts=9)\n",
- "\n",
- " elif isinstance(param, (float, int, tuple)):\n",
- " # float - tensor _packed_params.weight.scale\n",
- " # int - tensor _packed_params.weight.zero_point\n",
- " # tuple - tensor _packed_params.weight.shape\n",
- " hf.attrs[name] = param\n",
- "\n",
- " elif isinstance(param, torch.dtype):\n",
- " # dtype - tensor _packed_params.dtype\n",
- " hf.attrs[name] = dtype_2_str[param]\n",
- "\n",
- " else:\n",
- " hf.create_dataset(name, data=param, compression=\"gzip\", compression_opts=9)\n",
- "\n",
- "\n",
- "with open(\"dbg/metadata.json\", \"w\") as f:\n",
- " f.write(json.dumps(qtz_st._metadata))\n",
- "\n",
- "size = os.path.getsize(\"dbg/squad_sparse_with_embs.h5\") + os.path.getsize(\"dbg/metadata.json\")\n",
- "print(\"\\nSize (MB):\", round(size / 1e6, 2))"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Loading"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 9,
- "metadata": {},
- "outputs": [],
- "source": [
- "# Reconstruct the elementary state dict\n",
- "\n",
- "reconstructed_elementary_qtz_st = {}\n",
- "\n",
- "hf = h5py.File(\"dbg/squad_sparse_with_embs.h5\", \"r\")\n",
- "\n",
- "for attr_name, attr_param in hf.attrs.items():\n",
- " if \"shape\" in attr_name:\n",
- " attr_param = tuple(attr_param)\n",
- " elif \".scale\" in attr_name:\n",
- " if \"_packed_params\" in attr_name:\n",
- " attr_param = float(attr_param)\n",
- " else:\n",
- " attr_param = torch.tensor(attr_param)\n",
- " elif \".zero_point\" in attr_name:\n",
- " if \"_packed_params\" in attr_name:\n",
- " attr_param = int(attr_param)\n",
- " else:\n",
- " attr_param = torch.tensor(attr_param)\n",
- " elif \".dtype\" in attr_name:\n",
- " attr_param = str_2_dtype[attr_param]\n",
- " reconstructed_elementary_qtz_st[attr_name] = attr_param\n",
- " # print(f\"Unpack {attr_name}\")\n",
- "\n",
- "# Get the tensors/arrays\n",
- "for data_name, data_param in hf.items():\n",
- " if \"LayerNorm\" in data_name or \"_packed_params.bias\" in data_name:\n",
- " reconstructed_elementary_qtz_st[data_name] = torch.from_numpy(np.array(data_param))\n",
- " elif \"embedding\" in data_name:\n",
- " reconstructed_elementary_qtz_st[data_name] = torch.from_numpy(np.array(data_param))\n",
- " else: # _packed_params.weight.int_repr.data, _packed_params.weight.int_repr.indices and _packed_params.weight.int_repr.indptr\n",
- " data_param = np.array(data_param)\n",
- " if \"indices\" in data_name:\n",
- " data_param = np.array(data_param, dtype=np.int32)\n",
- " reconstructed_elementary_qtz_st[data_name] = data_param\n",
- " # print(f\"Unpack {data_name}\")\n",
- "\n",
- "\n",
- "hf.close()"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 10,
- "metadata": {},
- "outputs": [],
- "source": [
- "# Sanity checks\n",
- "\n",
- "for name, param in reconstructed_elementary_qtz_st.items():\n",
- " assert name in elementary_qtz_st\n",
- "for name, param in elementary_qtz_st.items():\n",
- " assert name in reconstructed_elementary_qtz_st, name\n",
- "\n",
- "for name, param in reconstructed_elementary_qtz_st.items():\n",
- " assert isinstance(param, type(elementary_qtz_st[name])), name\n",
- " if isinstance(param, torch.Tensor):\n",
- " assert torch.all(torch.eq(param, elementary_qtz_st[name])), name\n",
- " elif isinstance(param, np.ndarray):\n",
- " assert (param == elementary_qtz_st[name]).all(), name\n",
- " else:\n",
- " assert param == elementary_qtz_st[name], name"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 11,
- "metadata": {},
- "outputs": [],
- "source": [
- "# Re-assemble the sparse int_repr from the CSR format\n",
- "\n",
- "reconstructed_qtz_st = {}\n",
- "\n",
- "for name, param in reconstructed_elementary_qtz_st.items():\n",
- " if \"weight.int_repr.indptr\" in name:\n",
- " prefix_ = name[:-16]\n",
- " data = reconstructed_elementary_qtz_st[f\"{prefix_}.int_repr.data\"]\n",
- " indptr = reconstructed_elementary_qtz_st[f\"{prefix_}.int_repr.indptr\"]\n",
- " indices = reconstructed_elementary_qtz_st[f\"{prefix_}.int_repr.indices\"]\n",
- " shape = reconstructed_elementary_qtz_st[f\"{prefix_}.int_repr.shape\"]\n",
- "\n",
- " int_repr = sparse.csr_matrix(arg1=(data, indices, indptr), shape=shape)\n",
- " int_repr = torch.tensor(int_repr.todense())\n",
- "\n",
- " scale = reconstructed_elementary_qtz_st[f\"{prefix_}.scale\"]\n",
- " zero_point = reconstructed_elementary_qtz_st[f\"{prefix_}.zero_point\"]\n",
- " weight = torch._make_per_tensor_quantized_tensor(int_repr, scale, zero_point)\n",
- "\n",
- " reconstructed_qtz_st[f\"{prefix_}\"] = weight\n",
- " elif (\n",
- " \"int_repr.data\" in name\n",
- " or \"int_repr.shape\" in name\n",
- " or \"int_repr.indices\" in name\n",
- " or \"weight.scale\" in name\n",
- " or \"weight.zero_point\" in name\n",
- " ):\n",
- " continue\n",
- " else:\n",
- " reconstructed_qtz_st[name] = param"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 12,
- "metadata": {},
- "outputs": [],
- "source": [
- "# Sanity checks\n",
- "\n",
- "for name, param in reconstructed_qtz_st.items():\n",
- " assert name in qtz_st\n",
- "for name, param in qtz_st.items():\n",
- " assert name in reconstructed_qtz_st, name\n",
- "\n",
- "for name, param in reconstructed_qtz_st.items():\n",
- " assert isinstance(param, type(qtz_st[name])), name\n",
- " if isinstance(param, torch.Tensor):\n",
- " assert torch.all(torch.eq(param, qtz_st[name])), name\n",
- " elif isinstance(param, np.ndarray):\n",
- " assert (param == qtz_st[name]).all(), name\n",
- " else:\n",
- " assert param == qtz_st[name], name"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Sanity checks"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 13,
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/plain": [
- ""
- ]
- },
- "execution_count": 13,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "# Load the re-constructed state dict into a model\n",
- "\n",
- "dummy_model = BertForQuestionAnswering.from_pretrained(\"bert-base-uncased\")\n",
- "dummy_model.to(\"cpu\")\n",
- "\n",
- "reconstructed_qtz_model = torch.quantization.quantize_dynamic(\n",
- " model=dummy_model,\n",
- " qconfig_spec=None,\n",
- " dtype=torch.qint8,\n",
- ")\n",
- "\n",
- "reconstructed_qtz_st = OrderedDict(reconstructed_qtz_st)\n",
- "with open(\"dbg/metadata.json\", \"r\") as read_file:\n",
- " metadata = json.loads(read_file.read())\n",
- "reconstructed_qtz_st._metadata = metadata\n",
- "\n",
- "reconstructed_qtz_model.load_state_dict(reconstructed_qtz_st)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 14,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Sanity check passed\n"
- ]
- }
- ],
- "source": [
- "# Sanity checks on the infernce\n",
- "\n",
- "N = 32\n",
- "\n",
- "for _ in range(25):\n",
- " inputs = torch.randint(low=0, high=30000, size=(N, 128))\n",
- " mask = torch.ones(size=(N, 128))\n",
- "\n",
- " y_reconstructed = reconstructed_qtz_model(input_ids=inputs, attention_mask=mask)[0]\n",
- " y = quantized_model(input_ids=inputs, attention_mask=mask)[0]\n",
- "\n",
- " assert torch.all(torch.eq(y, y_reconstructed))\n",
- "print(\"Sanity check passed\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": []
- }
- ],
- "metadata": {
- "kernelspec": {
- "display_name": "Python 3",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.6.8"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 4
-}
diff --git a/examples/research_projects/movement-pruning/bertarize.py b/examples/research_projects/movement-pruning/bertarize.py
deleted file mode 100644
index da7534f4a6f..00000000000
--- a/examples/research_projects/movement-pruning/bertarize.py
+++ /dev/null
@@ -1,136 +0,0 @@
-# Copyright 2020-present, the HuggingFace Inc. team.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-Once a model has been fine-pruned, the weights that are masked during the forward pass can be pruned once for all.
-For instance, once the a model from the :class:`~emmental.MaskedBertForSequenceClassification` is trained, it can be saved (and then loaded)
-as a standard :class:`~transformers.BertForSequenceClassification`.
-"""
-
-import argparse
-import os
-import shutil
-
-import torch
-from emmental.modules import MagnitudeBinarizer, ThresholdBinarizer, TopKBinarizer
-
-
-def main(args):
- pruning_method = args.pruning_method
- threshold = args.threshold
-
- model_name_or_path = args.model_name_or_path.rstrip("/")
- target_model_path = args.target_model_path
-
- print(f"Load fine-pruned model from {model_name_or_path}")
- model = torch.load(os.path.join(model_name_or_path, "pytorch_model.bin"))
- pruned_model = {}
-
- for name, tensor in model.items():
- if "embeddings" in name or "LayerNorm" in name or "pooler" in name:
- pruned_model[name] = tensor
- print(f"Copied layer {name}")
- elif "classifier" in name or "qa_output" in name:
- pruned_model[name] = tensor
- print(f"Copied layer {name}")
- elif "bias" in name:
- pruned_model[name] = tensor
- print(f"Copied layer {name}")
- else:
- if pruning_method == "magnitude":
- mask = MagnitudeBinarizer.apply(inputs=tensor, threshold=threshold)
- pruned_model[name] = tensor * mask
- print(f"Pruned layer {name}")
- elif pruning_method == "topK":
- if "mask_scores" in name:
- continue
- prefix_ = name[:-6]
- scores = model[f"{prefix_}mask_scores"]
- mask = TopKBinarizer.apply(scores, threshold)
- pruned_model[name] = tensor * mask
- print(f"Pruned layer {name}")
- elif pruning_method == "sigmoied_threshold":
- if "mask_scores" in name:
- continue
- prefix_ = name[:-6]
- scores = model[f"{prefix_}mask_scores"]
- mask = ThresholdBinarizer.apply(scores, threshold, True)
- pruned_model[name] = tensor * mask
- print(f"Pruned layer {name}")
- elif pruning_method == "l0":
- if "mask_scores" in name:
- continue
- prefix_ = name[:-6]
- scores = model[f"{prefix_}mask_scores"]
- l, r = -0.1, 1.1
- s = torch.sigmoid(scores)
- s_bar = s * (r - l) + l
- mask = s_bar.clamp(min=0.0, max=1.0)
- pruned_model[name] = tensor * mask
- print(f"Pruned layer {name}")
- else:
- raise ValueError("Unknown pruning method")
-
- if target_model_path is None:
- target_model_path = os.path.join(
- os.path.dirname(model_name_or_path), f"bertarized_{os.path.basename(model_name_or_path)}"
- )
-
- if not os.path.isdir(target_model_path):
- shutil.copytree(model_name_or_path, target_model_path)
- print(f"\nCreated folder {target_model_path}")
-
- torch.save(pruned_model, os.path.join(target_model_path, "pytorch_model.bin"))
- print("\nPruned model saved! See you later!")
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
-
- parser.add_argument(
- "--pruning_method",
- choices=["l0", "magnitude", "topK", "sigmoied_threshold"],
- type=str,
- required=True,
- help=(
- "Pruning Method (l0 = L0 regularization, magnitude = Magnitude pruning, topK = Movement pruning,"
- " sigmoied_threshold = Soft movement pruning)"
- ),
- )
- parser.add_argument(
- "--threshold",
- type=float,
- required=False,
- help=(
- "For `magnitude` and `topK`, it is the level of remaining weights (in %) in the fine-pruned model. "
- "For `sigmoied_threshold`, it is the threshold \tau against which the (sigmoied) scores are compared. "
- "Not needed for `l0`"
- ),
- )
- parser.add_argument(
- "--model_name_or_path",
- type=str,
- required=True,
- help="Folder containing the model that was previously fine-pruned",
- )
- parser.add_argument(
- "--target_model_path",
- default=None,
- type=str,
- required=False,
- help="Folder containing the model that was previously fine-pruned",
- )
-
- args = parser.parse_args()
-
- main(args)
diff --git a/examples/research_projects/movement-pruning/counts_parameters.py b/examples/research_projects/movement-pruning/counts_parameters.py
deleted file mode 100644
index c0ac53fb785..00000000000
--- a/examples/research_projects/movement-pruning/counts_parameters.py
+++ /dev/null
@@ -1,97 +0,0 @@
-# Copyright 2020-present, the HuggingFace Inc. team.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-Count remaining (non-zero) weights in the encoder (i.e. the transformer layers).
-Sparsity and remaining weights levels are equivalent: sparsity % = 100 - remaining weights %.
-"""
-
-import argparse
-import os
-
-import torch
-from emmental.modules import ThresholdBinarizer, TopKBinarizer
-
-
-def main(args):
- serialization_dir = args.serialization_dir
- pruning_method = args.pruning_method
- threshold = args.threshold
-
- st = torch.load(os.path.join(serialization_dir, "pytorch_model.bin"), map_location="cpu")
-
- remaining_count = 0 # Number of remaining (not pruned) params in the encoder
- encoder_count = 0 # Number of params in the encoder
-
- print("name".ljust(60, " "), "Remaining Weights %", "Remaining Weight")
- for name, param in st.items():
- if "encoder" not in name:
- continue
-
- if "mask_scores" in name:
- if pruning_method == "topK":
- mask_ones = TopKBinarizer.apply(param, threshold).sum().item()
- elif pruning_method == "sigmoied_threshold":
- mask_ones = ThresholdBinarizer.apply(param, threshold, True).sum().item()
- elif pruning_method == "l0":
- l, r = -0.1, 1.1
- s = torch.sigmoid(param)
- s_bar = s * (r - l) + l
- mask = s_bar.clamp(min=0.0, max=1.0)
- mask_ones = (mask > 0.0).sum().item()
- else:
- raise ValueError("Unknown pruning method")
- remaining_count += mask_ones
- print(name.ljust(60, " "), str(round(100 * mask_ones / param.numel(), 3)).ljust(20, " "), str(mask_ones))
- else:
- encoder_count += param.numel()
- if "bias" in name or "LayerNorm" in name:
- remaining_count += param.numel()
-
- print("")
- print("Remaining Weights (global) %: ", 100 * remaining_count / encoder_count)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
-
- parser.add_argument(
- "--pruning_method",
- choices=["l0", "topK", "sigmoied_threshold"],
- type=str,
- required=True,
- help=(
- "Pruning Method (l0 = L0 regularization, topK = Movement pruning, sigmoied_threshold = Soft movement"
- " pruning)"
- ),
- )
- parser.add_argument(
- "--threshold",
- type=float,
- required=False,
- help=(
- "For `topK`, it is the level of remaining weights (in %) in the fine-pruned model. "
- "For `sigmoied_threshold`, it is the threshold \tau against which the (sigmoied) scores are compared. "
- "Not needed for `l0`"
- ),
- )
- parser.add_argument(
- "--serialization_dir",
- type=str,
- required=True,
- help="Folder containing the model that was previously fine-pruned",
- )
-
- args = parser.parse_args()
-
- main(args)
diff --git a/examples/research_projects/movement-pruning/emmental/__init__.py b/examples/research_projects/movement-pruning/emmental/__init__.py
deleted file mode 100644
index 6646667ea88..00000000000
--- a/examples/research_projects/movement-pruning/emmental/__init__.py
+++ /dev/null
@@ -1,9 +0,0 @@
-from .configuration_bert_masked import MaskedBertConfig
-from .modeling_bert_masked import (
- MaskedBertForMultipleChoice,
- MaskedBertForQuestionAnswering,
- MaskedBertForSequenceClassification,
- MaskedBertForTokenClassification,
- MaskedBertModel,
-)
-from .modules import *
diff --git a/examples/research_projects/movement-pruning/emmental/configuration_bert_masked.py b/examples/research_projects/movement-pruning/emmental/configuration_bert_masked.py
deleted file mode 100644
index 9c7459f27a7..00000000000
--- a/examples/research_projects/movement-pruning/emmental/configuration_bert_masked.py
+++ /dev/null
@@ -1,70 +0,0 @@
-# coding=utf-8
-# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
-# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Masked BERT model configuration. It replicates the class `~transformers.BertConfig`
-and adapts it to the specificities of MaskedBert (`pruning_method`, `mask_init` and `mask_scale`."""
-
-import logging
-
-from transformers.configuration_utils import PretrainedConfig
-
-
-logger = logging.getLogger(__name__)
-
-
-class MaskedBertConfig(PretrainedConfig):
- """
- A class replicating the `~transformers.BertConfig` with additional parameters for pruning/masking configuration.
- """
-
- model_type = "masked_bert"
-
- def __init__(
- self,
- vocab_size=30522,
- hidden_size=768,
- num_hidden_layers=12,
- num_attention_heads=12,
- intermediate_size=3072,
- hidden_act="gelu",
- hidden_dropout_prob=0.1,
- attention_probs_dropout_prob=0.1,
- max_position_embeddings=512,
- type_vocab_size=2,
- initializer_range=0.02,
- layer_norm_eps=1e-12,
- pad_token_id=0,
- pruning_method="topK",
- mask_init="constant",
- mask_scale=0.0,
- **kwargs,
- ):
- super().__init__(pad_token_id=pad_token_id, **kwargs)
-
- self.vocab_size = vocab_size
- self.hidden_size = hidden_size
- self.num_hidden_layers = num_hidden_layers
- self.num_attention_heads = num_attention_heads
- self.hidden_act = hidden_act
- self.intermediate_size = intermediate_size
- self.hidden_dropout_prob = hidden_dropout_prob
- self.attention_probs_dropout_prob = attention_probs_dropout_prob
- self.max_position_embeddings = max_position_embeddings
- self.type_vocab_size = type_vocab_size
- self.initializer_range = initializer_range
- self.layer_norm_eps = layer_norm_eps
- self.pruning_method = pruning_method
- self.mask_init = mask_init
- self.mask_scale = mask_scale
diff --git a/examples/research_projects/movement-pruning/emmental/modeling_bert_masked.py b/examples/research_projects/movement-pruning/emmental/modeling_bert_masked.py
deleted file mode 100644
index 8c0b091c7de..00000000000
--- a/examples/research_projects/movement-pruning/emmental/modeling_bert_masked.py
+++ /dev/null
@@ -1,1019 +0,0 @@
-# coding=utf-8
-# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
-# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Masked Version of BERT. It replaces the `torch.nn.Linear` layers with
-:class:`~emmental.MaskedLinear` and add an additional parameters in the forward pass to
-compute the adaptive mask.
-Built on top of `transformers.models.bert.modeling_bert`"""
-
-import logging
-import math
-
-import torch
-from torch import nn
-from torch.nn import CrossEntropyLoss, MSELoss
-
-from emmental import MaskedBertConfig
-from emmental.modules import MaskedLinear
-from transformers.file_utils import add_start_docstrings, add_start_docstrings_to_model_forward
-from transformers.modeling_utils import PreTrainedModel, prune_linear_layer
-from transformers.models.bert.modeling_bert import ACT2FN, load_tf_weights_in_bert
-
-
-logger = logging.getLogger(__name__)
-
-
-class BertEmbeddings(nn.Module):
- """Construct the embeddings from word, position and token_type embeddings."""
-
- def __init__(self, config):
- super().__init__()
- self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=0)
- self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
- self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
-
- # self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
- # any TensorFlow checkpoint file
- self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
- self.dropout = nn.Dropout(config.hidden_dropout_prob)
-
- def forward(self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None):
- if input_ids is not None:
- input_shape = input_ids.size()
- else:
- input_shape = inputs_embeds.size()[:-1]
-
- seq_length = input_shape[1]
- device = input_ids.device if input_ids is not None else inputs_embeds.device
- if position_ids is None:
- position_ids = torch.arange(seq_length, dtype=torch.long, device=device)
- position_ids = position_ids.unsqueeze(0).expand(input_shape)
- if token_type_ids is None:
- token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
-
- if inputs_embeds is None:
- inputs_embeds = self.word_embeddings(input_ids)
- position_embeddings = self.position_embeddings(position_ids)
- token_type_embeddings = self.token_type_embeddings(token_type_ids)
-
- embeddings = inputs_embeds + position_embeddings + token_type_embeddings
- embeddings = self.LayerNorm(embeddings)
- embeddings = self.dropout(embeddings)
- return embeddings
-
-
-class BertSelfAttention(nn.Module):
- def __init__(self, config):
- super().__init__()
- if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
- raise ValueError(
- "The hidden size (%d) is not a multiple of the number of attention heads (%d)"
- % (config.hidden_size, config.num_attention_heads)
- )
- self.output_attentions = config.output_attentions
-
- self.num_attention_heads = config.num_attention_heads
- self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
- self.all_head_size = self.num_attention_heads * self.attention_head_size
-
- self.query = MaskedLinear(
- config.hidden_size,
- self.all_head_size,
- pruning_method=config.pruning_method,
- mask_init=config.mask_init,
- mask_scale=config.mask_scale,
- )
- self.key = MaskedLinear(
- config.hidden_size,
- self.all_head_size,
- pruning_method=config.pruning_method,
- mask_init=config.mask_init,
- mask_scale=config.mask_scale,
- )
- self.value = MaskedLinear(
- config.hidden_size,
- self.all_head_size,
- pruning_method=config.pruning_method,
- mask_init=config.mask_init,
- mask_scale=config.mask_scale,
- )
-
- self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
-
- def transpose_for_scores(self, x):
- new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
- return x.permute(0, 2, 1, 3)
-
- def forward(
- self,
- hidden_states,
- attention_mask=None,
- head_mask=None,
- encoder_hidden_states=None,
- encoder_attention_mask=None,
- threshold=None,
- ):
- mixed_query_layer = self.query(hidden_states, threshold=threshold)
-
- # If this is instantiated as a cross-attention module, the keys
- # and values come from an encoder; the attention mask needs to be
- # such that the encoder's padding tokens are not attended to.
- if encoder_hidden_states is not None:
- mixed_key_layer = self.key(encoder_hidden_states, threshold=threshold)
- mixed_value_layer = self.value(encoder_hidden_states, threshold=threshold)
- attention_mask = encoder_attention_mask
- else:
- mixed_key_layer = self.key(hidden_states, threshold=threshold)
- mixed_value_layer = self.value(hidden_states, threshold=threshold)
-
- query_layer = self.transpose_for_scores(mixed_query_layer)
- key_layer = self.transpose_for_scores(mixed_key_layer)
- value_layer = self.transpose_for_scores(mixed_value_layer)
-
- # Take the dot product between "query" and "key" to get the raw attention scores.
- attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
- attention_scores = attention_scores / math.sqrt(self.attention_head_size)
- if attention_mask is not None:
- # Apply the attention mask is (precomputed for all layers in BertModel forward() function)
- attention_scores = attention_scores + attention_mask
-
- # Normalize the attention scores to probabilities.
- attention_probs = nn.functional.softmax(attention_scores, dim=-1)
-
- # This is actually dropping out entire tokens to attend to, which might
- # seem a bit unusual, but is taken from the original Transformer paper.
- attention_probs = self.dropout(attention_probs)
-
- # Mask heads if we want to
- if head_mask is not None:
- attention_probs = attention_probs * head_mask
-
- context_layer = torch.matmul(attention_probs, value_layer)
-
- context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
- new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
- context_layer = context_layer.view(*new_context_layer_shape)
-
- outputs = (context_layer, attention_probs) if self.output_attentions else (context_layer,)
- return outputs
-
-
-class BertSelfOutput(nn.Module):
- def __init__(self, config):
- super().__init__()
- self.dense = MaskedLinear(
- config.hidden_size,
- config.hidden_size,
- pruning_method=config.pruning_method,
- mask_init=config.mask_init,
- mask_scale=config.mask_scale,
- )
- self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
- self.dropout = nn.Dropout(config.hidden_dropout_prob)
-
- def forward(self, hidden_states, input_tensor, threshold):
- hidden_states = self.dense(hidden_states, threshold=threshold)
- hidden_states = self.dropout(hidden_states)
- hidden_states = self.LayerNorm(hidden_states + input_tensor)
- return hidden_states
-
-
-class BertAttention(nn.Module):
- def __init__(self, config):
- super().__init__()
- self.self = BertSelfAttention(config)
- self.output = BertSelfOutput(config)
- self.pruned_heads = set()
-
- def prune_heads(self, heads):
- if len(heads) == 0:
- return
- mask = torch.ones(self.self.num_attention_heads, self.self.attention_head_size)
- heads = set(heads) - self.pruned_heads # Convert to set and remove already pruned heads
- for head in heads:
- # Compute how many pruned heads are before the head and move the index accordingly
- head = head - sum(1 if h < head else 0 for h in self.pruned_heads)
- mask[head] = 0
- mask = mask.view(-1).contiguous().eq(1)
- index = torch.arange(len(mask))[mask].long()
-
- # Prune linear layers
- self.self.query = prune_linear_layer(self.self.query, index)
- self.self.key = prune_linear_layer(self.self.key, index)
- self.self.value = prune_linear_layer(self.self.value, index)
- self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
-
- # Update hyper params and store pruned heads
- self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
- self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
- self.pruned_heads = self.pruned_heads.union(heads)
-
- def forward(
- self,
- hidden_states,
- attention_mask=None,
- head_mask=None,
- encoder_hidden_states=None,
- encoder_attention_mask=None,
- threshold=None,
- ):
- self_outputs = self.self(
- hidden_states,
- attention_mask,
- head_mask,
- encoder_hidden_states,
- encoder_attention_mask,
- threshold=threshold,
- )
- attention_output = self.output(self_outputs[0], hidden_states, threshold=threshold)
- outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
- return outputs
-
-
-class BertIntermediate(nn.Module):
- def __init__(self, config):
- super().__init__()
- self.dense = MaskedLinear(
- config.hidden_size,
- config.intermediate_size,
- pruning_method=config.pruning_method,
- mask_init=config.mask_init,
- mask_scale=config.mask_scale,
- )
- if isinstance(config.hidden_act, str):
- self.intermediate_act_fn = ACT2FN[config.hidden_act]
- else:
- self.intermediate_act_fn = config.hidden_act
-
- def forward(self, hidden_states, threshold):
- hidden_states = self.dense(hidden_states, threshold=threshold)
- hidden_states = self.intermediate_act_fn(hidden_states)
- return hidden_states
-
-
-class BertOutput(nn.Module):
- def __init__(self, config):
- super().__init__()
- self.dense = MaskedLinear(
- config.intermediate_size,
- config.hidden_size,
- pruning_method=config.pruning_method,
- mask_init=config.mask_init,
- mask_scale=config.mask_scale,
- )
- self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
- self.dropout = nn.Dropout(config.hidden_dropout_prob)
-
- def forward(self, hidden_states, input_tensor, threshold):
- hidden_states = self.dense(hidden_states, threshold=threshold)
- hidden_states = self.dropout(hidden_states)
- hidden_states = self.LayerNorm(hidden_states + input_tensor)
- return hidden_states
-
-
-class BertLayer(nn.Module):
- def __init__(self, config):
- super().__init__()
- self.attention = BertAttention(config)
- self.is_decoder = config.is_decoder
- if self.is_decoder:
- self.crossattention = BertAttention(config)
- self.intermediate = BertIntermediate(config)
- self.output = BertOutput(config)
-
- def forward(
- self,
- hidden_states,
- attention_mask=None,
- head_mask=None,
- encoder_hidden_states=None,
- encoder_attention_mask=None,
- threshold=None,
- ):
- self_attention_outputs = self.attention(hidden_states, attention_mask, head_mask, threshold=threshold)
- attention_output = self_attention_outputs[0]
- outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
-
- if self.is_decoder and encoder_hidden_states is not None:
- cross_attention_outputs = self.crossattention(
- attention_output, attention_mask, head_mask, encoder_hidden_states, encoder_attention_mask
- )
- attention_output = cross_attention_outputs[0]
- outputs = outputs + cross_attention_outputs[1:] # add cross attentions if we output attention weights
-
- intermediate_output = self.intermediate(attention_output, threshold=threshold)
- layer_output = self.output(intermediate_output, attention_output, threshold=threshold)
- outputs = (layer_output,) + outputs
- return outputs
-
-
-class BertEncoder(nn.Module):
- def __init__(self, config):
- super().__init__()
- self.output_attentions = config.output_attentions
- self.output_hidden_states = config.output_hidden_states
- self.layer = nn.ModuleList([BertLayer(config) for _ in range(config.num_hidden_layers)])
-
- def forward(
- self,
- hidden_states,
- attention_mask=None,
- head_mask=None,
- encoder_hidden_states=None,
- encoder_attention_mask=None,
- threshold=None,
- ):
- all_hidden_states = ()
- all_attentions = ()
- for i, layer_module in enumerate(self.layer):
- if self.output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- layer_outputs = layer_module(
- hidden_states,
- attention_mask,
- head_mask[i],
- encoder_hidden_states,
- encoder_attention_mask,
- threshold=threshold,
- )
- hidden_states = layer_outputs[0]
-
- if self.output_attentions:
- all_attentions = all_attentions + (layer_outputs[1],)
-
- # Add last layer
- if self.output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- outputs = (hidden_states,)
- if self.output_hidden_states:
- outputs = outputs + (all_hidden_states,)
- if self.output_attentions:
- outputs = outputs + (all_attentions,)
- return outputs # last-layer hidden state, (all hidden states), (all attentions)
-
-
-class BertPooler(nn.Module):
- def __init__(self, config):
- super().__init__()
- self.dense = nn.Linear(config.hidden_size, config.hidden_size)
- self.activation = nn.Tanh()
-
- def forward(self, hidden_states):
- # We "pool" the model by simply taking the hidden state corresponding
- # to the first token.
- first_token_tensor = hidden_states[:, 0]
- pooled_output = self.dense(first_token_tensor)
- pooled_output = self.activation(pooled_output)
- return pooled_output
-
-
-class MaskedBertPreTrainedModel(PreTrainedModel):
- """An abstract class to handle weights initialization and
- a simple interface for downloading and loading pretrained models.
- """
-
- config_class = MaskedBertConfig
- load_tf_weights = load_tf_weights_in_bert
- base_model_prefix = "bert"
-
- def _init_weights(self, module):
- """Initialize the weights"""
- if isinstance(module, (nn.Linear, nn.Embedding)):
- # Slightly different from the TF version which uses truncated_normal for initialization
- # cf https://github.com/pytorch/pytorch/pull/5617
- module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
- elif isinstance(module, nn.LayerNorm):
- module.bias.data.zero_()
- module.weight.data.fill_(1.0)
- if isinstance(module, nn.Linear) and module.bias is not None:
- module.bias.data.zero_()
-
-
-MASKED_BERT_START_DOCSTRING = r"""
- This model is a PyTorch `torch.nn.Module `_ sub-class.
- Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general
- usage and behavior.
-
- Parameters:
- config (:class:`~emmental.MaskedBertConfig`): Model configuration class with all the parameters of the model.
- Initializing with a config file does not load the weights associated with the model, only the configuration.
- Check out the :meth:`~transformers.PreTrainedModel.from_pretrained` method to load the model weights.
-"""
-
-MASKED_BERT_INPUTS_DOCSTRING = r"""
- Args:
- input_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`):
- Indices of input sequence tokens in the vocabulary.
-
- Indices can be obtained using :class:`transformers.BertTokenizer`.
- See :func:`transformers.PreTrainedTokenizer.encode` and
- :func:`transformers.PreTrainedTokenizer.__call__` for details.
-
- `What are input IDs? <../glossary.html#input-ids>`__
- attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
- Mask to avoid performing attention on padding token indices.
- Mask values selected in ``[0, 1]``:
- ``1`` for tokens that are NOT MASKED, ``0`` for MASKED tokens.
-
- `What are attention masks? <../glossary.html#attention-mask>`__
- token_type_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
- Segment token indices to indicate first and second portions of the inputs.
- Indices are selected in ``[0, 1]``: ``0`` corresponds to a `sentence A` token, ``1``
- corresponds to a `sentence B` token
-
- `What are token type IDs? <../glossary.html#token-type-ids>`_
- position_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
- Indices of positions of each input sequence tokens in the position embeddings.
- Selected in the range ``[0, config.max_position_embeddings - 1]``.
-
- `What are position IDs? <../glossary.html#position-ids>`_
- head_mask (:obj:`torch.FloatTensor` of shape :obj:`(num_heads,)` or :obj:`(num_layers, num_heads)`, `optional`):
- Mask to nullify selected heads of the self-attention modules.
- Mask values selected in ``[0, 1]``:
- :obj:`1` indicates the head is **not masked**, :obj:`0` indicates the head is **masked**.
- inputs_embeds (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
- Optionally, instead of passing :obj:`input_ids` you can choose to directly pass an embedded representation.
- This is useful if you want more control over how to convert `input_ids` indices into associated vectors
- than the model's internal embedding lookup matrix.
- encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
- Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention
- if the model is configured as a decoder.
- encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
- Mask to avoid performing attention on the padding token indices of the encoder input. This mask
- is used in the cross-attention if the model is configured as a decoder.
- Mask values selected in ``[0, 1]``:
- ``1`` for tokens that are NOT MASKED, ``0`` for MASKED tokens.
-"""
-
-
-@add_start_docstrings(
- "The bare Masked Bert Model transformer outputting raw hidden-states without any specific head on top.",
- MASKED_BERT_START_DOCSTRING,
-)
-class MaskedBertModel(MaskedBertPreTrainedModel):
- """
- The `MaskedBertModel` class replicates the :class:`~transformers.BertModel` class
- and adds specific inputs to compute the adaptive mask on the fly.
- Note that we freeze the embeddings modules from their pre-trained values.
- """
-
- def __init__(self, config):
- super().__init__(config)
- self.config = config
-
- self.embeddings = BertEmbeddings(config)
- self.embeddings.requires_grad_(requires_grad=False)
- self.encoder = BertEncoder(config)
- self.pooler = BertPooler(config)
-
- self.init_weights()
-
- def get_input_embeddings(self):
- return self.embeddings.word_embeddings
-
- def set_input_embeddings(self, value):
- self.embeddings.word_embeddings = value
-
- def _prune_heads(self, heads_to_prune):
- """Prunes heads of the model.
- heads_to_prune: dict of {layer_num: list of heads to prune in this layer}
- See base class PreTrainedModel
- """
- for layer, heads in heads_to_prune.items():
- self.encoder.layer[layer].attention.prune_heads(heads)
-
- @add_start_docstrings_to_model_forward(MASKED_BERT_INPUTS_DOCSTRING)
- def forward(
- self,
- input_ids=None,
- attention_mask=None,
- token_type_ids=None,
- position_ids=None,
- head_mask=None,
- inputs_embeds=None,
- encoder_hidden_states=None,
- encoder_attention_mask=None,
- threshold=None,
- ):
- r"""
- threshold (:obj:`float`):
- Threshold value (see :class:`~emmental.MaskedLinear`).
-
- Return:
- :obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~emmental.MaskedBertConfig`) and inputs:
- last_hidden_state (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`):
- Sequence of hidden-states at the output of the last layer of the model.
- pooler_output (:obj:`torch.FloatTensor`: of shape :obj:`(batch_size, hidden_size)`):
- Last layer hidden-state of the first token of the sequence (classification token)
- further processed by a Linear layer and a Tanh activation function. The Linear
- layer weights are trained from the next sentence prediction (classification)
- objective during pre-training.
-
- This output is usually *not* a good summary
- of the semantic content of the input, you're often better with averaging or pooling
- the sequence of hidden-states for the whole input sequence.
- hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
- Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
- of shape :obj:`(batch_size, sequence_length, hidden_size)`.
-
- Hidden-states of the model at the output of each layer plus the initial embedding outputs.
- attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
- Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
- :obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
-
- Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
- heads.
- """
-
- if input_ids is not None and inputs_embeds is not None:
- raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
- elif input_ids is not None:
- input_shape = input_ids.size()
- elif inputs_embeds is not None:
- input_shape = inputs_embeds.size()[:-1]
- else:
- raise ValueError("You have to specify either input_ids or inputs_embeds")
-
- device = input_ids.device if input_ids is not None else inputs_embeds.device
-
- if attention_mask is None:
- attention_mask = torch.ones(input_shape, device=device)
- if token_type_ids is None:
- token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
-
- # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
- # ourselves in which case we just need to make it broadcastable to all heads.
- if attention_mask.dim() == 3:
- extended_attention_mask = attention_mask[:, None, :, :]
- elif attention_mask.dim() == 2:
- # Provided a padding mask of dimensions [batch_size, seq_length]
- # - if the model is a decoder, apply a causal mask in addition to the padding mask
- # - if the model is an encoder, make the mask broadcastable to [batch_size, num_heads, seq_length, seq_length]
- if self.config.is_decoder:
- batch_size, seq_length = input_shape
- seq_ids = torch.arange(seq_length, device=device)
- causal_mask = seq_ids[None, None, :].repeat(batch_size, seq_length, 1) <= seq_ids[None, :, None]
- causal_mask = causal_mask.to(
- attention_mask.dtype
- ) # causal and attention masks must have same type with pytorch version < 1.3
- extended_attention_mask = causal_mask[:, None, :, :] * attention_mask[:, None, None, :]
- else:
- extended_attention_mask = attention_mask[:, None, None, :]
- else:
- raise ValueError(
- "Wrong shape for input_ids (shape {}) or attention_mask (shape {})".format(
- input_shape, attention_mask.shape
- )
- )
-
- # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
- # masked positions, this operation will create a tensor which is 0.0 for
- # positions we want to attend and -10000.0 for masked positions.
- # Since we are adding it to the raw scores before the softmax, this is
- # effectively the same as removing these entirely.
- extended_attention_mask = extended_attention_mask.to(dtype=next(self.parameters()).dtype) # fp16 compatibility
- extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
-
- # If a 2D ou 3D attention mask is provided for the cross-attention
- # we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
- if self.config.is_decoder and encoder_hidden_states is not None:
- encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
- encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
- if encoder_attention_mask is None:
- encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
-
- if encoder_attention_mask.dim() == 3:
- encoder_extended_attention_mask = encoder_attention_mask[:, None, :, :]
- elif encoder_attention_mask.dim() == 2:
- encoder_extended_attention_mask = encoder_attention_mask[:, None, None, :]
- else:
- raise ValueError(
- "Wrong shape for encoder_hidden_shape (shape {}) or encoder_attention_mask (shape {})".format(
- encoder_hidden_shape, encoder_attention_mask.shape
- )
- )
-
- encoder_extended_attention_mask = encoder_extended_attention_mask.to(
- dtype=next(self.parameters()).dtype
- ) # fp16 compatibility
- encoder_extended_attention_mask = (1.0 - encoder_extended_attention_mask) * -10000.0
- else:
- encoder_extended_attention_mask = None
-
- # Prepare head mask if needed
- # 1.0 in head_mask indicate we keep the head
- # attention_probs has shape bsz x n_heads x N x N
- # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
- # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
- if head_mask is not None:
- if head_mask.dim() == 1:
- head_mask = head_mask.unsqueeze(0).unsqueeze(0).unsqueeze(-1).unsqueeze(-1)
- head_mask = head_mask.expand(self.config.num_hidden_layers, -1, -1, -1, -1)
- elif head_mask.dim() == 2:
- head_mask = (
- head_mask.unsqueeze(1).unsqueeze(-1).unsqueeze(-1)
- ) # We can specify head_mask for each layer
- head_mask = head_mask.to(
- dtype=next(self.parameters()).dtype
- ) # switch to float if need + fp16 compatibility
- else:
- head_mask = [None] * self.config.num_hidden_layers
-
- embedding_output = self.embeddings(
- input_ids=input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds
- )
- encoder_outputs = self.encoder(
- embedding_output,
- attention_mask=extended_attention_mask,
- head_mask=head_mask,
- encoder_hidden_states=encoder_hidden_states,
- encoder_attention_mask=encoder_extended_attention_mask,
- threshold=threshold,
- )
- sequence_output = encoder_outputs[0]
- pooled_output = self.pooler(sequence_output)
-
- outputs = (
- sequence_output,
- pooled_output,
- ) + encoder_outputs[1:] # add hidden_states and attentions if they are here
- return outputs # sequence_output, pooled_output, (hidden_states), (attentions)
-
-
-@add_start_docstrings(
- """Masked Bert Model transformer with a sequence classification/regression head on top (a linear layer on top of
- the pooled output) e.g. for GLUE tasks. """,
- MASKED_BERT_START_DOCSTRING,
-)
-class MaskedBertForSequenceClassification(MaskedBertPreTrainedModel):
- def __init__(self, config):
- super().__init__(config)
- self.num_labels = config.num_labels
-
- self.bert = MaskedBertModel(config)
- self.dropout = nn.Dropout(config.hidden_dropout_prob)
- self.classifier = nn.Linear(config.hidden_size, self.config.num_labels)
-
- self.init_weights()
-
- @add_start_docstrings_to_model_forward(MASKED_BERT_INPUTS_DOCSTRING)
- def forward(
- self,
- input_ids=None,
- attention_mask=None,
- token_type_ids=None,
- position_ids=None,
- head_mask=None,
- inputs_embeds=None,
- labels=None,
- threshold=None,
- ):
- r"""
- labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
- Labels for computing the sequence classification/regression loss.
- Indices should be in :obj:`[0, ..., config.num_labels - 1]`.
- If :obj:`config.num_labels == 1` a regression loss is computed (Mean-Square loss),
- If :obj:`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
- threshold (:obj:`float`):
- Threshold value (see :class:`~emmental.MaskedLinear`).
-
- Returns:
- :obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~emmental.MaskedBertConfig`) and inputs:
- loss (:obj:`torch.FloatTensor` of shape :obj:`(1,)`, `optional`, returned when :obj:`label` is provided):
- Classification (or regression if config.num_labels==1) loss.
- logits (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, config.num_labels)`):
- Classification (or regression if config.num_labels==1) scores (before SoftMax).
- hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
- Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
- of shape :obj:`(batch_size, sequence_length, hidden_size)`.
-
- Hidden-states of the model at the output of each layer plus the initial embedding outputs.
- attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
- Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
- :obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
-
- Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
- heads.
- """
-
- outputs = self.bert(
- input_ids,
- attention_mask=attention_mask,
- token_type_ids=token_type_ids,
- position_ids=position_ids,
- head_mask=head_mask,
- inputs_embeds=inputs_embeds,
- threshold=threshold,
- )
-
- pooled_output = outputs[1]
-
- pooled_output = self.dropout(pooled_output)
- logits = self.classifier(pooled_output)
-
- outputs = (logits,) + outputs[2:] # add hidden states and attention if they are here
-
- if labels is not None:
- if self.num_labels == 1:
- # We are doing regression
- loss_fct = MSELoss()
- loss = loss_fct(logits.view(-1), labels.view(-1))
- else:
- loss_fct = CrossEntropyLoss()
- loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
- outputs = (loss,) + outputs
-
- return outputs # (loss), logits, (hidden_states), (attentions)
-
-
-@add_start_docstrings(
- """Masked Bert Model with a multiple choice classification head on top (a linear layer on top of
- the pooled output and a softmax) e.g. for RocStories/SWAG tasks. """,
- MASKED_BERT_START_DOCSTRING,
-)
-class MaskedBertForMultipleChoice(MaskedBertPreTrainedModel):
- def __init__(self, config):
- super().__init__(config)
-
- self.bert = MaskedBertModel(config)
- self.dropout = nn.Dropout(config.hidden_dropout_prob)
- self.classifier = nn.Linear(config.hidden_size, 1)
-
- self.init_weights()
-
- @add_start_docstrings_to_model_forward(MASKED_BERT_INPUTS_DOCSTRING)
- def forward(
- self,
- input_ids=None,
- attention_mask=None,
- token_type_ids=None,
- position_ids=None,
- head_mask=None,
- inputs_embeds=None,
- labels=None,
- threshold=None,
- ):
- r"""
- labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
- Labels for computing the multiple choice classification loss.
- Indices should be in ``[0, ..., num_choices]`` where `num_choices` is the size of the second dimension
- of the input tensors. (see `input_ids` above)
- threshold (:obj:`float`):
- Threshold value (see :class:`~emmental.MaskedLinear`).
-
- Returns:
- :obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~emmental.MaskedBertConfig`) and inputs:
- loss (:obj:`torch.FloatTensor` of shape `(1,)`, `optional`, returned when :obj:`labels` is provided):
- Classification loss.
- classification_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, num_choices)`):
- `num_choices` is the second dimension of the input tensors. (see `input_ids` above).
-
- Classification scores (before SoftMax).
- hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
- Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
- of shape :obj:`(batch_size, sequence_length, hidden_size)`.
-
- Hidden-states of the model at the output of each layer plus the initial embedding outputs.
- attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
- Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
- :obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
-
- Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
- heads.
-
- """
- num_choices = input_ids.shape[1]
-
- input_ids = input_ids.view(-1, input_ids.size(-1))
- attention_mask = attention_mask.view(-1, attention_mask.size(-1)) if attention_mask is not None else None
- token_type_ids = token_type_ids.view(-1, token_type_ids.size(-1)) if token_type_ids is not None else None
- position_ids = position_ids.view(-1, position_ids.size(-1)) if position_ids is not None else None
-
- outputs = self.bert(
- input_ids,
- attention_mask=attention_mask,
- token_type_ids=token_type_ids,
- position_ids=position_ids,
- head_mask=head_mask,
- inputs_embeds=inputs_embeds,
- threshold=threshold,
- )
-
- pooled_output = outputs[1]
-
- pooled_output = self.dropout(pooled_output)
- logits = self.classifier(pooled_output)
- reshaped_logits = logits.view(-1, num_choices)
-
- outputs = (reshaped_logits,) + outputs[2:] # add hidden states and attention if they are here
-
- if labels is not None:
- loss_fct = CrossEntropyLoss()
- loss = loss_fct(reshaped_logits, labels)
- outputs = (loss,) + outputs
-
- return outputs # (loss), reshaped_logits, (hidden_states), (attentions)
-
-
-@add_start_docstrings(
- """Masked Bert Model with a token classification head on top (a linear layer on top of
- the hidden-states output) e.g. for Named-Entity-Recognition (NER) tasks. """,
- MASKED_BERT_START_DOCSTRING,
-)
-class MaskedBertForTokenClassification(MaskedBertPreTrainedModel):
- def __init__(self, config):
- super().__init__(config)
- self.num_labels = config.num_labels
-
- self.bert = MaskedBertModel(config)
- self.dropout = nn.Dropout(config.hidden_dropout_prob)
- self.classifier = nn.Linear(config.hidden_size, config.num_labels)
-
- self.init_weights()
-
- @add_start_docstrings_to_model_forward(MASKED_BERT_INPUTS_DOCSTRING)
- def forward(
- self,
- input_ids=None,
- attention_mask=None,
- token_type_ids=None,
- position_ids=None,
- head_mask=None,
- inputs_embeds=None,
- labels=None,
- threshold=None,
- ):
- r"""
- labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
- Labels for computing the token classification loss.
- Indices should be in ``[0, ..., config.num_labels - 1]``.
- threshold (:obj:`float`):
- Threshold value (see :class:`~emmental.MaskedLinear`).
-
- Returns:
- :obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~emmental.MaskedBertConfig`) and inputs:
- loss (:obj:`torch.FloatTensor` of shape :obj:`(1,)`, `optional`, returned when ``labels`` is provided) :
- Classification loss.
- scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, config.num_labels)`)
- Classification scores (before SoftMax).
- hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
- Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
- of shape :obj:`(batch_size, sequence_length, hidden_size)`.
-
- Hidden-states of the model at the output of each layer plus the initial embedding outputs.
- attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
- Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
- :obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
-
- Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
- heads.
- """
-
- outputs = self.bert(
- input_ids,
- attention_mask=attention_mask,
- token_type_ids=token_type_ids,
- position_ids=position_ids,
- head_mask=head_mask,
- inputs_embeds=inputs_embeds,
- threshold=threshold,
- )
-
- sequence_output = outputs[0]
-
- sequence_output = self.dropout(sequence_output)
- logits = self.classifier(sequence_output)
-
- outputs = (logits,) + outputs[2:] # add hidden states and attention if they are here
- if labels is not None:
- loss_fct = CrossEntropyLoss()
- # Only keep active parts of the loss
- if attention_mask is not None:
- active_loss = attention_mask.view(-1) == 1
- active_logits = logits.view(-1, self.num_labels)
- active_labels = torch.where(
- active_loss, labels.view(-1), torch.tensor(loss_fct.ignore_index).type_as(labels)
- )
- loss = loss_fct(active_logits, active_labels)
- else:
- loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
- outputs = (loss,) + outputs
-
- return outputs # (loss), scores, (hidden_states), (attentions)
-
-
-@add_start_docstrings(
- """Masked Bert Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
- layers on top of the hidden-states output to compute `span start logits` and `span end logits`). """,
- MASKED_BERT_START_DOCSTRING,
-)
-class MaskedBertForQuestionAnswering(MaskedBertPreTrainedModel):
- def __init__(self, config):
- super().__init__(config)
- self.num_labels = config.num_labels
-
- self.bert = MaskedBertModel(config)
- self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels)
-
- self.init_weights()
-
- @add_start_docstrings_to_model_forward(MASKED_BERT_INPUTS_DOCSTRING)
- def forward(
- self,
- input_ids=None,
- attention_mask=None,
- token_type_ids=None,
- position_ids=None,
- head_mask=None,
- inputs_embeds=None,
- start_positions=None,
- end_positions=None,
- threshold=None,
- ):
- r"""
- start_positions (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
- Labels for position (index) of the start of the labelled span for computing the token classification loss.
- Positions are clamped to the length of the sequence (`sequence_length`).
- Position outside of the sequence are not taken into account for computing the loss.
- end_positions (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
- Labels for position (index) of the end of the labelled span for computing the token classification loss.
- Positions are clamped to the length of the sequence (`sequence_length`).
- Position outside of the sequence are not taken into account for computing the loss.
- threshold (:obj:`float`):
- Threshold value (see :class:`~emmental.MaskedLinear`).
-
- Returns:
- :obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~emmental.MaskedBertConfig`) and inputs:
- loss (:obj:`torch.FloatTensor` of shape :obj:`(1,)`, `optional`, returned when :obj:`labels` is provided):
- Total span extraction loss is the sum of a Cross-Entropy for the start and end positions.
- start_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length,)`):
- Span-start scores (before SoftMax).
- end_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length,)`):
- Span-end scores (before SoftMax).
- hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
- Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
- of shape :obj:`(batch_size, sequence_length, hidden_size)`.
-
- Hidden-states of the model at the output of each layer plus the initial embedding outputs.
- attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
- Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
- :obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
-
- Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
- heads.
- """
-
- outputs = self.bert(
- input_ids,
- attention_mask=attention_mask,
- token_type_ids=token_type_ids,
- position_ids=position_ids,
- head_mask=head_mask,
- inputs_embeds=inputs_embeds,
- threshold=threshold,
- )
-
- sequence_output = outputs[0]
-
- logits = self.qa_outputs(sequence_output)
- start_logits, end_logits = logits.split(1, dim=-1)
- start_logits = start_logits.squeeze(-1)
- end_logits = end_logits.squeeze(-1)
-
- outputs = (
- start_logits,
- end_logits,
- ) + outputs[2:]
- if start_positions is not None and end_positions is not None:
- # If we are on multi-GPU, split add a dimension
- if len(start_positions.size()) > 1:
- start_positions = start_positions.squeeze(-1)
- if len(end_positions.size()) > 1:
- end_positions = end_positions.squeeze(-1)
- # sometimes the start/end positions are outside our model inputs, we ignore these terms
- ignored_index = start_logits.size(1)
- start_positions.clamp_(0, ignored_index)
- end_positions.clamp_(0, ignored_index)
-
- loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
- start_loss = loss_fct(start_logits, start_positions)
- end_loss = loss_fct(end_logits, end_positions)
- total_loss = (start_loss + end_loss) / 2
- outputs = (total_loss,) + outputs
-
- return outputs # (loss), start_logits, end_logits, (hidden_states), (attentions)
diff --git a/examples/research_projects/movement-pruning/emmental/modules/__init__.py b/examples/research_projects/movement-pruning/emmental/modules/__init__.py
deleted file mode 100644
index 761a6343d6b..00000000000
--- a/examples/research_projects/movement-pruning/emmental/modules/__init__.py
+++ /dev/null
@@ -1,2 +0,0 @@
-from .binarizer import MagnitudeBinarizer, ThresholdBinarizer, TopKBinarizer
-from .masked_nn import MaskedLinear
diff --git a/examples/research_projects/movement-pruning/emmental/modules/binarizer.py b/examples/research_projects/movement-pruning/emmental/modules/binarizer.py
deleted file mode 100644
index c96975e3b37..00000000000
--- a/examples/research_projects/movement-pruning/emmental/modules/binarizer.py
+++ /dev/null
@@ -1,144 +0,0 @@
-# coding=utf-8
-# Copyright 2020-present, AllenAI Authors, University of Illinois Urbana-Champaign,
-# Intel Nervana Systems and the HuggingFace Inc. team.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-Binarizers take a (real value) matrix as input and produce a binary (values in {0,1}) mask of the same shape.
-"""
-
-import torch
-from torch import autograd
-
-
-class ThresholdBinarizer(autograd.Function):
- """
- Thresholdd binarizer.
- Computes a binary mask M from a real value matrix S such that `M_{i,j} = 1` if and only if `S_{i,j} > \tau`
- where `\tau` is a real value threshold.
-
- Implementation is inspired from:
- https://github.com/arunmallya/piggyback
- Piggyback: Adapting a Single Network to Multiple Tasks by Learning to Mask Weights
- Arun Mallya, Dillon Davis, Svetlana Lazebnik
- """
-
- @staticmethod
- def forward(ctx, inputs: torch.tensor, threshold: float, sigmoid: bool):
- """
- Args:
- inputs (`torch.FloatTensor`)
- The input matrix from which the binarizer computes the binary mask.
- threshold (`float`)
- The threshold value (in R).
- sigmoid (`bool`)
- If set to ``True``, we apply the sigmoid function to the `inputs` matrix before comparing to `threshold`.
- In this case, `threshold` should be a value between 0 and 1.
- Returns:
- mask (`torch.FloatTensor`)
- Binary matrix of the same size as `inputs` acting as a mask (1 - the associated weight is
- retained, 0 - the associated weight is pruned).
- """
- nb_elems = inputs.numel()
- nb_min = int(0.005 * nb_elems) + 1
- if sigmoid:
- mask = (torch.sigmoid(inputs) > threshold).type(inputs.type())
- else:
- mask = (inputs > threshold).type(inputs.type())
- if mask.sum() < nb_min:
- # We limit the pruning so that at least 0.5% (half a percent) of the weights are remaining
- k_threshold = inputs.flatten().kthvalue(max(nb_elems - nb_min, 1)).values
- mask = (inputs > k_threshold).type(inputs.type())
- return mask
-
- @staticmethod
- def backward(ctx, gradOutput):
- return gradOutput, None, None
-
-
-class TopKBinarizer(autograd.Function):
- """
- Top-k Binarizer.
- Computes a binary mask M from a real value matrix S such that `M_{i,j} = 1` if and only if `S_{i,j}`
- is among the k% highest values of S.
-
- Implementation is inspired from:
- https://github.com/allenai/hidden-networks
- What's hidden in a randomly weighted neural network?
- Vivek Ramanujan*, Mitchell Wortsman*, Aniruddha Kembhavi, Ali Farhadi, Mohammad Rastegari
- """
-
- @staticmethod
- def forward(ctx, inputs: torch.tensor, threshold: float):
- """
- Args:
- inputs (`torch.FloatTensor`)
- The input matrix from which the binarizer computes the binary mask.
- threshold (`float`)
- The percentage of weights to keep (the rest is pruned).
- `threshold` is a float between 0 and 1.
- Returns:
- mask (`torch.FloatTensor`)
- Binary matrix of the same size as `inputs` acting as a mask (1 - the associated weight is
- retained, 0 - the associated weight is pruned).
- """
- # Get the subnetwork by sorting the inputs and using the top threshold %
- mask = inputs.clone()
- _, idx = inputs.flatten().sort(descending=True)
- j = int(threshold * inputs.numel())
-
- # flat_out and mask access the same memory.
- flat_out = mask.flatten()
- flat_out[idx[j:]] = 0
- flat_out[idx[:j]] = 1
- return mask
-
- @staticmethod
- def backward(ctx, gradOutput):
- return gradOutput, None
-
-
-class MagnitudeBinarizer:
- """
- Magnitude Binarizer.
- Computes a binary mask M from a real value matrix S such that `M_{i,j} = 1` if and only if `S_{i,j}`
- is among the k% highest values of |S| (absolute value).
-
- Implementation is inspired from https://github.com/NervanaSystems/distiller/blob/2291fdcc2ea642a98d4e20629acb5a9e2e04b4e6/distiller/pruning/automated_gradual_pruner.py#L24
- """
-
- @staticmethod
- def apply(inputs: torch.tensor, threshold: float):
- """
- Args:
- inputs (`torch.FloatTensor`)
- The input matrix from which the binarizer computes the binary mask.
- This input marix is typically the weight matrix.
- threshold (`float`)
- The percentage of weights to keep (the rest is pruned).
- `threshold` is a float between 0 and 1.
- Returns:
- mask (`torch.FloatTensor`)
- Binary matrix of the same size as `inputs` acting as a mask (1 - the associated weight is
- retained, 0 - the associated weight is pruned).
- """
- # Get the subnetwork by sorting the inputs and using the top threshold %
- mask = inputs.clone()
- _, idx = inputs.abs().flatten().sort(descending=True)
- j = int(threshold * inputs.numel())
-
- # flat_out and mask access the same memory.
- flat_out = mask.flatten()
- flat_out[idx[j:]] = 0
- flat_out[idx[:j]] = 1
- return mask
diff --git a/examples/research_projects/movement-pruning/emmental/modules/masked_nn.py b/examples/research_projects/movement-pruning/emmental/modules/masked_nn.py
deleted file mode 100644
index e3c94836851..00000000000
--- a/examples/research_projects/movement-pruning/emmental/modules/masked_nn.py
+++ /dev/null
@@ -1,106 +0,0 @@
-# coding=utf-8
-# Copyright 2020-present, the HuggingFace Inc. team.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-Masked Linear module: A fully connected layer that computes an adaptive binary mask on the fly.
-The mask (binary or not) is computed at each forward pass and multiplied against
-the weight matrix to prune a portion of the weights.
-The pruned weight matrix is then multiplied against the inputs (and if necessary, the bias is added).
-"""
-
-import math
-
-import torch
-from torch import nn
-from torch.nn import init
-
-from .binarizer import MagnitudeBinarizer, ThresholdBinarizer, TopKBinarizer
-
-
-class MaskedLinear(nn.Linear):
- """
- Fully Connected layer with on the fly adaptive mask.
- If needed, a score matrix is created to store the importance of each associated weight.
- """
-
- def __init__(
- self,
- in_features: int,
- out_features: int,
- bias: bool = True,
- mask_init: str = "constant",
- mask_scale: float = 0.0,
- pruning_method: str = "topK",
- ):
- """
- Args:
- in_features (`int`)
- Size of each input sample
- out_features (`int`)
- Size of each output sample
- bias (`bool`)
- If set to ``False``, the layer will not learn an additive bias.
- Default: ``True``
- mask_init (`str`)
- The initialization method for the score matrix if a score matrix is needed.
- Choices: ["constant", "uniform", "kaiming"]
- Default: ``constant``
- mask_scale (`float`)
- The initialization parameter for the chosen initialization method `mask_init`.
- Default: ``0.``
- pruning_method (`str`)
- Method to compute the mask.
- Choices: ["topK", "threshold", "sigmoied_threshold", "magnitude", "l0"]
- Default: ``topK``
- """
- super(MaskedLinear, self).__init__(in_features=in_features, out_features=out_features, bias=bias)
- assert pruning_method in ["topK", "threshold", "sigmoied_threshold", "magnitude", "l0"]
- self.pruning_method = pruning_method
-
- if self.pruning_method in ["topK", "threshold", "sigmoied_threshold", "l0"]:
- self.mask_scale = mask_scale
- self.mask_init = mask_init
- self.mask_scores = nn.Parameter(torch.empty(self.weight.size()))
- self.init_mask()
-
- def init_mask(self):
- if self.mask_init == "constant":
- init.constant_(self.mask_scores, val=self.mask_scale)
- elif self.mask_init == "uniform":
- init.uniform_(self.mask_scores, a=-self.mask_scale, b=self.mask_scale)
- elif self.mask_init == "kaiming":
- init.kaiming_uniform_(self.mask_scores, a=math.sqrt(5))
-
- def forward(self, input: torch.tensor, threshold: float):
- # Get the mask
- if self.pruning_method == "topK":
- mask = TopKBinarizer.apply(self.mask_scores, threshold)
- elif self.pruning_method in ["threshold", "sigmoied_threshold"]:
- sig = "sigmoied" in self.pruning_method
- mask = ThresholdBinarizer.apply(self.mask_scores, threshold, sig)
- elif self.pruning_method == "magnitude":
- mask = MagnitudeBinarizer.apply(self.weight, threshold)
- elif self.pruning_method == "l0":
- l, r, b = -0.1, 1.1, 2 / 3
- if self.training:
- u = torch.zeros_like(self.mask_scores).uniform_().clamp(0.0001, 0.9999)
- s = torch.sigmoid((u.log() - (1 - u).log() + self.mask_scores) / b)
- else:
- s = torch.sigmoid(self.mask_scores)
- s_bar = s * (r - l) + l
- mask = s_bar.clamp(min=0.0, max=1.0)
- # Mask weights with computed mask
- weight_thresholded = mask * self.weight
- # Compute output (linear layer) with masked weights
- return nn.functional.linear(input, weight_thresholded, self.bias)
diff --git a/examples/research_projects/movement-pruning/masked_run_glue.py b/examples/research_projects/movement-pruning/masked_run_glue.py
deleted file mode 100644
index 4ddb4248357..00000000000
--- a/examples/research_projects/movement-pruning/masked_run_glue.py
+++ /dev/null
@@ -1,962 +0,0 @@
-# coding=utf-8
-# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
-# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Fine-pruning Masked BERT on sequence classification on GLUE."""
-
-import argparse
-import glob
-import json
-import logging
-import os
-import random
-
-import numpy as np
-import torch
-from emmental import MaskedBertConfig, MaskedBertForSequenceClassification
-from torch import nn
-from torch.utils.data import DataLoader, RandomSampler, SequentialSampler, TensorDataset
-from torch.utils.data.distributed import DistributedSampler
-from tqdm import tqdm, trange
-
-from transformers import (
- WEIGHTS_NAME,
- AdamW,
- BertConfig,
- BertForSequenceClassification,
- BertTokenizer,
- get_linear_schedule_with_warmup,
-)
-from transformers import glue_compute_metrics as compute_metrics
-from transformers import glue_convert_examples_to_features as convert_examples_to_features
-from transformers import glue_output_modes as output_modes
-from transformers import glue_processors as processors
-
-
-try:
- from torch.utils.tensorboard import SummaryWriter
-except ImportError:
- from tensorboardX import SummaryWriter
-
-
-logger = logging.getLogger(__name__)
-
-MODEL_CLASSES = {
- "bert": (BertConfig, BertForSequenceClassification, BertTokenizer),
- "masked_bert": (MaskedBertConfig, MaskedBertForSequenceClassification, BertTokenizer),
-}
-
-
-def set_seed(args):
- random.seed(args.seed)
- np.random.seed(args.seed)
- torch.manual_seed(args.seed)
- if args.n_gpu > 0:
- torch.cuda.manual_seed_all(args.seed)
-
-
-def schedule_threshold(
- step: int,
- total_step: int,
- warmup_steps: int,
- initial_threshold: float,
- final_threshold: float,
- initial_warmup: int,
- final_warmup: int,
- final_lambda: float,
-):
- if step <= initial_warmup * warmup_steps:
- threshold = initial_threshold
- elif step > (total_step - final_warmup * warmup_steps):
- threshold = final_threshold
- else:
- spars_warmup_steps = initial_warmup * warmup_steps
- spars_schedu_steps = (final_warmup + initial_warmup) * warmup_steps
- mul_coeff = 1 - (step - spars_warmup_steps) / (total_step - spars_schedu_steps)
- threshold = final_threshold + (initial_threshold - final_threshold) * (mul_coeff**3)
- regu_lambda = final_lambda * threshold / final_threshold
- return threshold, regu_lambda
-
-
-def regularization(model: nn.Module, mode: str):
- regu, counter = 0, 0
- for name, param in model.named_parameters():
- if "mask_scores" in name:
- if mode == "l1":
- regu += torch.norm(torch.sigmoid(param), p=1) / param.numel()
- elif mode == "l0":
- regu += torch.sigmoid(param - 2 / 3 * np.log(0.1 / 1.1)).sum() / param.numel()
- else:
- raise ValueError("Don't know this mode.")
- counter += 1
- return regu / counter
-
-
-def train(args, train_dataset, model, tokenizer, teacher=None):
- """Train the model"""
- if args.local_rank in [-1, 0]:
- tb_writer = SummaryWriter(log_dir=args.output_dir)
-
- args.train_batch_size = args.per_gpu_train_batch_size * max(1, args.n_gpu)
- train_sampler = RandomSampler(train_dataset) if args.local_rank == -1 else DistributedSampler(train_dataset)
- train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size)
-
- if args.max_steps > 0:
- t_total = args.max_steps
- args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
- else:
- t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
-
- # Prepare optimizer and schedule (linear warmup and decay)
- no_decay = ["bias", "LayerNorm.weight"]
- optimizer_grouped_parameters = [
- {
- "params": [p for n, p in model.named_parameters() if "mask_score" in n and p.requires_grad],
- "lr": args.mask_scores_learning_rate,
- },
- {
- "params": [
- p
- for n, p in model.named_parameters()
- if "mask_score" not in n and p.requires_grad and not any(nd in n for nd in no_decay)
- ],
- "lr": args.learning_rate,
- "weight_decay": args.weight_decay,
- },
- {
- "params": [
- p
- for n, p in model.named_parameters()
- if "mask_score" not in n and p.requires_grad and any(nd in n for nd in no_decay)
- ],
- "lr": args.learning_rate,
- "weight_decay": 0.0,
- },
- ]
-
- optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
- scheduler = get_linear_schedule_with_warmup(
- optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
- )
-
- # Check if saved optimizer or scheduler states exist
- if os.path.isfile(os.path.join(args.model_name_or_path, "optimizer.pt")) and os.path.isfile(
- os.path.join(args.model_name_or_path, "scheduler.pt")
- ):
- # Load in optimizer and scheduler states
- optimizer.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "optimizer.pt")))
- scheduler.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "scheduler.pt")))
-
- if args.fp16:
- try:
- from apex import amp
- except ImportError:
- raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
- model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
-
- # multi-gpu training (should be after apex fp16 initialization)
- if args.n_gpu > 1:
- model = nn.DataParallel(model)
-
- # Distributed training (should be after apex fp16 initialization)
- if args.local_rank != -1:
- model = nn.parallel.DistributedDataParallel(
- model,
- device_ids=[args.local_rank],
- output_device=args.local_rank,
- find_unused_parameters=True,
- )
-
- # Train!
- logger.info("***** Running training *****")
- logger.info(" Num examples = %d", len(train_dataset))
- logger.info(" Num Epochs = %d", args.num_train_epochs)
- logger.info(" Instantaneous batch size per GPU = %d", args.per_gpu_train_batch_size)
- logger.info(
- " Total train batch size (w. parallel, distributed & accumulation) = %d",
- args.train_batch_size
- * args.gradient_accumulation_steps
- * (torch.distributed.get_world_size() if args.local_rank != -1 else 1),
- )
- logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)
- logger.info(" Total optimization steps = %d", t_total)
- # Distillation
- if teacher is not None:
- logger.info(" Training with distillation")
-
- global_step = 0
- # Global TopK
- if args.global_topk:
- threshold_mem = None
- epochs_trained = 0
- steps_trained_in_current_epoch = 0
- # Check if continuing training from a checkpoint
- if os.path.exists(args.model_name_or_path):
- # set global_step to global_step of last saved checkpoint from model path
- try:
- global_step = int(args.model_name_or_path.split("-")[-1].split("/")[0])
- except ValueError:
- global_step = 0
- epochs_trained = global_step // (len(train_dataloader) // args.gradient_accumulation_steps)
- steps_trained_in_current_epoch = global_step % (len(train_dataloader) // args.gradient_accumulation_steps)
-
- logger.info(" Continuing training from checkpoint, will skip to saved global_step")
- logger.info(" Continuing training from epoch %d", epochs_trained)
- logger.info(" Continuing training from global step %d", global_step)
- logger.info(" Will skip the first %d steps in the first epoch", steps_trained_in_current_epoch)
-
- tr_loss, logging_loss = 0.0, 0.0
- model.zero_grad()
- train_iterator = trange(
- epochs_trained,
- int(args.num_train_epochs),
- desc="Epoch",
- disable=args.local_rank not in [-1, 0],
- )
- set_seed(args) # Added here for reproducibility
- for _ in train_iterator:
- epoch_iterator = tqdm(train_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])
- for step, batch in enumerate(epoch_iterator):
- # Skip past any already trained steps if resuming training
- if steps_trained_in_current_epoch > 0:
- steps_trained_in_current_epoch -= 1
- continue
-
- model.train()
- batch = tuple(t.to(args.device) for t in batch)
- threshold, regu_lambda = schedule_threshold(
- step=global_step,
- total_step=t_total,
- warmup_steps=args.warmup_steps,
- final_threshold=args.final_threshold,
- initial_threshold=args.initial_threshold,
- final_warmup=args.final_warmup,
- initial_warmup=args.initial_warmup,
- final_lambda=args.final_lambda,
- )
- # Global TopK
- if args.global_topk:
- if threshold == 1.0:
- threshold = -1e2 # Or an indefinitely low quantity
- else:
- if (threshold_mem is None) or (global_step % args.global_topk_frequency_compute == 0):
- # Sort all the values to get the global topK
- concat = torch.cat(
- [param.view(-1) for name, param in model.named_parameters() if "mask_scores" in name]
- )
- n = concat.numel()
- kth = max(n - (int(n * threshold) + 1), 1)
- threshold_mem = concat.kthvalue(kth).values.item()
- threshold = threshold_mem
- else:
- threshold = threshold_mem
- inputs = {"input_ids": batch[0], "attention_mask": batch[1], "labels": batch[3]}
- if args.model_type != "distilbert":
- inputs["token_type_ids"] = (
- batch[2] if args.model_type in ["bert", "masked_bert", "xlnet", "albert"] else None
- ) # XLM, DistilBERT, RoBERTa, and XLM-RoBERTa don't use segment_ids
-
- if "masked" in args.model_type:
- inputs["threshold"] = threshold
-
- outputs = model(**inputs)
- loss, logits_stu = outputs # model outputs are always tuple in transformers (see doc)
-
- # Distillation loss
- if teacher is not None:
- if "token_type_ids" not in inputs:
- inputs["token_type_ids"] = None if args.teacher_type == "xlm" else batch[2]
- with torch.no_grad():
- (logits_tea,) = teacher(
- input_ids=inputs["input_ids"],
- token_type_ids=inputs["token_type_ids"],
- attention_mask=inputs["attention_mask"],
- )
-
- loss_logits = nn.functional.kl_div(
- input=nn.functional.log_softmax(logits_stu / args.temperature, dim=-1),
- target=nn.functional.softmax(logits_tea / args.temperature, dim=-1),
- reduction="batchmean",
- ) * (args.temperature**2)
-
- loss = args.alpha_distil * loss_logits + args.alpha_ce * loss
-
- # Regularization
- if args.regularization is not None:
- regu_ = regularization(model=model, mode=args.regularization)
- loss = loss + regu_lambda * regu_
-
- if args.n_gpu > 1:
- loss = loss.mean() # mean() to average on multi-gpu parallel training
- if args.gradient_accumulation_steps > 1:
- loss = loss / args.gradient_accumulation_steps
-
- if args.fp16:
- with amp.scale_loss(loss, optimizer) as scaled_loss:
- scaled_loss.backward()
- else:
- loss.backward()
-
- tr_loss += loss.item()
- if (step + 1) % args.gradient_accumulation_steps == 0 or (
- # last step in epoch but step is always smaller than gradient_accumulation_steps
- len(epoch_iterator) <= args.gradient_accumulation_steps and (step + 1) == len(epoch_iterator)
- ):
- if args.fp16:
- nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
- else:
- nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
-
- if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
- tb_writer.add_scalar("threshold", threshold, global_step)
- for name, param in model.named_parameters():
- if not param.requires_grad:
- continue
- tb_writer.add_scalar("parameter_mean/" + name, param.data.mean(), global_step)
- tb_writer.add_scalar("parameter_std/" + name, param.data.std(), global_step)
- tb_writer.add_scalar("parameter_min/" + name, param.data.min(), global_step)
- tb_writer.add_scalar("parameter_max/" + name, param.data.max(), global_step)
- tb_writer.add_scalar("grad_mean/" + name, param.grad.data.mean(), global_step)
- tb_writer.add_scalar("grad_std/" + name, param.grad.data.std(), global_step)
- if args.regularization is not None and "mask_scores" in name:
- if args.regularization == "l1":
- perc = (torch.sigmoid(param) > threshold).sum().item() / param.numel()
- elif args.regularization == "l0":
- perc = (torch.sigmoid(param - 2 / 3 * np.log(0.1 / 1.1))).sum().item() / param.numel()
- tb_writer.add_scalar("retained_weights_perc/" + name, perc, global_step)
-
- optimizer.step()
- scheduler.step() # Update learning rate schedule
- model.zero_grad()
- global_step += 1
-
- if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
- logs = {}
- if (
- args.local_rank == -1 and args.evaluate_during_training
- ): # Only evaluate when single GPU otherwise metrics may not average well
- results = evaluate(args, model, tokenizer)
- for key, value in results.items():
- eval_key = "eval_{}".format(key)
- logs[eval_key] = value
-
- loss_scalar = (tr_loss - logging_loss) / args.logging_steps
- learning_rate_scalar = scheduler.get_lr()
- logs["learning_rate"] = learning_rate_scalar[0]
- if len(learning_rate_scalar) > 1:
- for idx, lr in enumerate(learning_rate_scalar[1:]):
- logs[f"learning_rate/{idx+1}"] = lr
- logs["loss"] = loss_scalar
- if teacher is not None:
- logs["loss/distil"] = loss_logits.item()
- if args.regularization is not None:
- logs["loss/regularization"] = regu_.item()
- if (teacher is not None) or (args.regularization is not None):
- if (teacher is not None) and (args.regularization is not None):
- logs["loss/instant_ce"] = (
- loss.item()
- - regu_lambda * logs["loss/regularization"]
- - args.alpha_distil * logs["loss/distil"]
- ) / args.alpha_ce
- elif teacher is not None:
- logs["loss/instant_ce"] = (
- loss.item() - args.alpha_distil * logs["loss/distil"]
- ) / args.alpha_ce
- else:
- logs["loss/instant_ce"] = loss.item() - regu_lambda * logs["loss/regularization"]
- logging_loss = tr_loss
-
- for key, value in logs.items():
- tb_writer.add_scalar(key, value, global_step)
- print(json.dumps({**logs, **{"step": global_step}}))
-
- if args.local_rank in [-1, 0] and args.save_steps > 0 and global_step % args.save_steps == 0:
- # Save model checkpoint
- output_dir = os.path.join(args.output_dir, "checkpoint-{}".format(global_step))
- if not os.path.exists(output_dir):
- os.makedirs(output_dir)
- model_to_save = (
- model.module if hasattr(model, "module") else model
- ) # Take care of distributed/parallel training
- model_to_save.save_pretrained(output_dir)
- tokenizer.save_pretrained(output_dir)
-
- torch.save(args, os.path.join(output_dir, "training_args.bin"))
- logger.info("Saving model checkpoint to %s", output_dir)
-
- torch.save(optimizer.state_dict(), os.path.join(output_dir, "optimizer.pt"))
- torch.save(scheduler.state_dict(), os.path.join(output_dir, "scheduler.pt"))
- logger.info("Saving optimizer and scheduler states to %s", output_dir)
-
- if args.max_steps > 0 and global_step > args.max_steps:
- epoch_iterator.close()
- break
- if args.max_steps > 0 and global_step > args.max_steps:
- train_iterator.close()
- break
-
- if args.local_rank in [-1, 0]:
- tb_writer.close()
-
- return global_step, tr_loss / global_step
-
-
-def evaluate(args, model, tokenizer, prefix=""):
- # Loop to handle MNLI double evaluation (matched, mis-matched)
- eval_task_names = ("mnli", "mnli-mm") if args.task_name == "mnli" else (args.task_name,)
- eval_outputs_dirs = (args.output_dir, args.output_dir + "/MM") if args.task_name == "mnli" else (args.output_dir,)
-
- results = {}
- for eval_task, eval_output_dir in zip(eval_task_names, eval_outputs_dirs):
- eval_dataset = load_and_cache_examples(args, eval_task, tokenizer, evaluate=True)
-
- if not os.path.exists(eval_output_dir) and args.local_rank in [-1, 0]:
- os.makedirs(eval_output_dir)
-
- args.eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)
- # Note that DistributedSampler samples randomly
- eval_sampler = SequentialSampler(eval_dataset)
- eval_dataloader = DataLoader(eval_dataset, sampler=eval_sampler, batch_size=args.eval_batch_size)
-
- # multi-gpu eval
- if args.n_gpu > 1 and not isinstance(model, nn.DataParallel):
- model = nn.DataParallel(model)
-
- # Eval!
- logger.info("***** Running evaluation {} *****".format(prefix))
- logger.info(" Num examples = %d", len(eval_dataset))
- logger.info(" Batch size = %d", args.eval_batch_size)
- eval_loss = 0.0
- nb_eval_steps = 0
- preds = None
- out_label_ids = None
-
- # Global TopK
- if args.global_topk:
- threshold_mem = None
-
- for batch in tqdm(eval_dataloader, desc="Evaluating"):
- model.eval()
- batch = tuple(t.to(args.device) for t in batch)
-
- with torch.no_grad():
- inputs = {"input_ids": batch[0], "attention_mask": batch[1], "labels": batch[3]}
- if args.model_type != "distilbert":
- inputs["token_type_ids"] = (
- batch[2] if args.model_type in ["bert", "masked_bert", "xlnet", "albert"] else None
- ) # XLM, DistilBERT, RoBERTa, and XLM-RoBERTa don't use segment_ids
- if "masked" in args.model_type:
- inputs["threshold"] = args.final_threshold
- if args.global_topk:
- if threshold_mem is None:
- concat = torch.cat(
- [param.view(-1) for name, param in model.named_parameters() if "mask_scores" in name]
- )
- n = concat.numel()
- kth = max(n - (int(n * args.final_threshold) + 1), 1)
- threshold_mem = concat.kthvalue(kth).values.item()
- inputs["threshold"] = threshold_mem
- outputs = model(**inputs)
- tmp_eval_loss, logits = outputs[:2]
-
- eval_loss += tmp_eval_loss.mean().item()
- nb_eval_steps += 1
- if preds is None:
- preds = logits.detach().cpu().numpy()
- out_label_ids = inputs["labels"].detach().cpu().numpy()
- else:
- preds = np.append(preds, logits.detach().cpu().numpy(), axis=0)
- out_label_ids = np.append(out_label_ids, inputs["labels"].detach().cpu().numpy(), axis=0)
-
- eval_loss = eval_loss / nb_eval_steps
- if args.output_mode == "classification":
- from scipy.special import softmax
-
- probs = softmax(preds, axis=-1)
- entropy = np.exp((-probs * np.log(probs)).sum(axis=-1).mean())
- preds = np.argmax(preds, axis=1)
- elif args.output_mode == "regression":
- preds = np.squeeze(preds)
- result = compute_metrics(eval_task, preds, out_label_ids)
- results.update(result)
- if entropy is not None:
- result["eval_avg_entropy"] = entropy
-
- output_eval_file = os.path.join(eval_output_dir, prefix, "eval_results.txt")
- with open(output_eval_file, "w") as writer:
- logger.info("***** Eval results {} *****".format(prefix))
- for key in sorted(result.keys()):
- logger.info(" %s = %s", key, str(result[key]))
- writer.write("%s = %s\n" % (key, str(result[key])))
-
- return results
-
-
-def load_and_cache_examples(args, task, tokenizer, evaluate=False):
- if args.local_rank not in [-1, 0] and not evaluate:
- torch.distributed.barrier() # Make sure only the first process in distributed training process the dataset, and the others will use the cache
-
- processor = processors[task]()
- output_mode = output_modes[task]
- # Load data features from cache or dataset file
- cached_features_file = os.path.join(
- args.data_dir,
- "cached_{}_{}_{}_{}".format(
- "dev" if evaluate else "train",
- list(filter(None, args.model_name_or_path.split("/"))).pop(),
- str(args.max_seq_length),
- str(task),
- ),
- )
- if os.path.exists(cached_features_file) and not args.overwrite_cache:
- logger.info("Loading features from cached file %s", cached_features_file)
- features = torch.load(cached_features_file)
- else:
- logger.info("Creating features from dataset file at %s", args.data_dir)
- label_list = processor.get_labels()
- if task in ["mnli", "mnli-mm"] and args.model_type in ["roberta", "xlmroberta"]:
- # HACK(label indices are swapped in RoBERTa pretrained model)
- label_list[1], label_list[2] = label_list[2], label_list[1]
- examples = (
- processor.get_dev_examples(args.data_dir) if evaluate else processor.get_train_examples(args.data_dir)
- )
- features = convert_examples_to_features(
- examples,
- tokenizer,
- max_length=args.max_seq_length,
- label_list=label_list,
- output_mode=output_mode,
- )
- if args.local_rank in [-1, 0]:
- logger.info("Saving features into cached file %s", cached_features_file)
- torch.save(features, cached_features_file)
-
- if args.local_rank == 0 and not evaluate:
- torch.distributed.barrier() # Make sure only the first process in distributed training process the dataset, and the others will use the cache
-
- # Convert to Tensors and build dataset
- all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
- all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
- all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
- if output_mode == "classification":
- all_labels = torch.tensor([f.label for f in features], dtype=torch.long)
- elif output_mode == "regression":
- all_labels = torch.tensor([f.label for f in features], dtype=torch.float)
-
- dataset = TensorDataset(all_input_ids, all_attention_mask, all_token_type_ids, all_labels)
- return dataset
-
-
-def main():
- parser = argparse.ArgumentParser()
-
- # Required parameters
- parser.add_argument(
- "--data_dir",
- default=None,
- type=str,
- required=True,
- help="The input data dir. Should contain the .tsv files (or other data files) for the task.",
- )
- parser.add_argument(
- "--model_type",
- default=None,
- type=str,
- required=True,
- help="Model type selected in the list: " + ", ".join(MODEL_CLASSES.keys()),
- )
- parser.add_argument(
- "--model_name_or_path",
- default=None,
- type=str,
- required=True,
- help="Path to pretrained model or model identifier from huggingface.co/models",
- )
- parser.add_argument(
- "--task_name",
- default=None,
- type=str,
- required=True,
- help="The name of the task to train selected in the list: " + ", ".join(processors.keys()),
- )
- parser.add_argument(
- "--output_dir",
- default=None,
- type=str,
- required=True,
- help="The output directory where the model predictions and checkpoints will be written.",
- )
- # Other parameters
- parser.add_argument(
- "--config_name",
- default="",
- type=str,
- help="Pretrained config name or path if not the same as model_name",
- )
- parser.add_argument(
- "--tokenizer_name",
- default="",
- type=str,
- help="Pretrained tokenizer name or path if not the same as model_name",
- )
- parser.add_argument(
- "--cache_dir",
- default="",
- type=str,
- help="Where do you want to store the pre-trained models downloaded from huggingface.co",
- )
- parser.add_argument(
- "--max_seq_length",
- default=128,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
- parser.add_argument("--do_eval", action="store_true", help="Whether to run eval on the dev set.")
- parser.add_argument(
- "--evaluate_during_training",
- action="store_true",
- help="Run evaluation during training at each logging step.",
- )
- parser.add_argument(
- "--do_lower_case",
- action="store_true",
- help="Set this flag if you are using an uncased model.",
- )
-
- parser.add_argument(
- "--per_gpu_train_batch_size",
- default=8,
- type=int,
- help="Batch size per GPU/CPU for training.",
- )
- parser.add_argument(
- "--per_gpu_eval_batch_size",
- default=8,
- type=int,
- help="Batch size per GPU/CPU for evaluation.",
- )
- parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
-
- # Pruning parameters
- parser.add_argument(
- "--mask_scores_learning_rate",
- default=1e-2,
- type=float,
- help="The Adam initial learning rate of the mask scores.",
- )
- parser.add_argument(
- "--initial_threshold", default=1.0, type=float, help="Initial value of the threshold (for scheduling)."
- )
- parser.add_argument(
- "--final_threshold", default=0.7, type=float, help="Final value of the threshold (for scheduling)."
- )
- parser.add_argument(
- "--initial_warmup",
- default=1,
- type=int,
- help=(
- "Run `initial_warmup` * `warmup_steps` steps of threshold warmup during which threshold stays "
- "at its `initial_threshold` value (sparsity schedule)."
- ),
- )
- parser.add_argument(
- "--final_warmup",
- default=2,
- type=int,
- help=(
- "Run `final_warmup` * `warmup_steps` steps of threshold cool-down during which threshold stays "
- "at its final_threshold value (sparsity schedule)."
- ),
- )
-
- parser.add_argument(
- "--pruning_method",
- default="topK",
- type=str,
- help=(
- "Pruning Method (l0 = L0 regularization, magnitude = Magnitude pruning, topK = Movement pruning,"
- " sigmoied_threshold = Soft movement pruning)."
- ),
- )
- parser.add_argument(
- "--mask_init",
- default="constant",
- type=str,
- help="Initialization method for the mask scores. Choices: constant, uniform, kaiming.",
- )
- parser.add_argument(
- "--mask_scale", default=0.0, type=float, help="Initialization parameter for the chosen initialization method."
- )
-
- parser.add_argument("--regularization", default=None, help="Add L0 or L1 regularization to the mask scores.")
- parser.add_argument(
- "--final_lambda",
- default=0.0,
- type=float,
- help="Regularization intensity (used in conjunction with `regularization`.",
- )
-
- parser.add_argument("--global_topk", action="store_true", help="Global TopK on the Scores.")
- parser.add_argument(
- "--global_topk_frequency_compute",
- default=25,
- type=int,
- help="Frequency at which we compute the TopK global threshold.",
- )
-
- # Distillation parameters (optional)
- parser.add_argument(
- "--teacher_type",
- default=None,
- type=str,
- help=(
- "Teacher type. Teacher tokenizer and student (model) tokenizer must output the same tokenization. Only for"
- " distillation."
- ),
- )
- parser.add_argument(
- "--teacher_name_or_path",
- default=None,
- type=str,
- help="Path to the already fine-tuned teacher model. Only for distillation.",
- )
- parser.add_argument(
- "--alpha_ce", default=0.5, type=float, help="Cross entropy loss linear weight. Only for distillation."
- )
- parser.add_argument(
- "--alpha_distil", default=0.5, type=float, help="Distillation loss linear weight. Only for distillation."
- )
- parser.add_argument(
- "--temperature", default=2.0, type=float, help="Distillation temperature. Only for distillation."
- )
-
- parser.add_argument(
- "--gradient_accumulation_steps",
- type=int,
- default=1,
- help="Number of updates steps to accumulate before performing a backward/update pass.",
- )
- parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
- parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
- parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
- parser.add_argument(
- "--num_train_epochs",
- default=3.0,
- type=float,
- help="Total number of training epochs to perform.",
- )
- parser.add_argument(
- "--max_steps",
- default=-1,
- type=int,
- help="If > 0: set total number of training steps to perform. Override num_train_epochs.",
- )
- parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
-
- parser.add_argument("--logging_steps", type=int, default=50, help="Log every X updates steps.")
- parser.add_argument("--save_steps", type=int, default=50, help="Save checkpoint every X updates steps.")
- parser.add_argument(
- "--eval_all_checkpoints",
- action="store_true",
- help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
- )
- parser.add_argument("--no_cuda", action="store_true", help="Avoid using CUDA when available")
- parser.add_argument(
- "--overwrite_output_dir",
- action="store_true",
- help="Overwrite the content of the output directory",
- )
- parser.add_argument(
- "--overwrite_cache",
- action="store_true",
- help="Overwrite the cached training and evaluation sets",
- )
- parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
-
- parser.add_argument(
- "--fp16",
- action="store_true",
- help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
- )
- parser.add_argument(
- "--fp16_opt_level",
- type=str,
- default="O1",
- help=(
- "For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
- "See details at https://nvidia.github.io/apex/amp.html"
- ),
- )
- parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
-
- args = parser.parse_args()
-
- # Regularization
- if args.regularization == "null":
- args.regularization = None
-
- if (
- os.path.exists(args.output_dir)
- and os.listdir(args.output_dir)
- and args.do_train
- and not args.overwrite_output_dir
- ):
- raise ValueError(
- f"Output directory ({args.output_dir}) already exists and is not empty. Use --overwrite_output_dir to"
- " overcome."
- )
-
- # Setup CUDA, GPU & distributed training
- if args.local_rank == -1 or args.no_cuda:
- device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
- args.n_gpu = 0 if args.no_cuda else torch.cuda.device_count()
- else: # Initializes the distributed backend which will take care of synchronizing nodes/GPUs
- torch.cuda.set_device(args.local_rank)
- device = torch.device("cuda", args.local_rank)
- torch.distributed.init_process_group(backend="nccl")
- args.n_gpu = 1
- args.device = device
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- level=logging.INFO if args.local_rank in [-1, 0] else logging.WARN,
- )
- logger.warning(
- "Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
- args.local_rank,
- device,
- args.n_gpu,
- bool(args.local_rank != -1),
- args.fp16,
- )
-
- # Set seed
- set_seed(args)
-
- # Prepare GLUE task
- args.task_name = args.task_name.lower()
- if args.task_name not in processors:
- raise ValueError("Task not found: %s" % (args.task_name))
- processor = processors[args.task_name]()
- args.output_mode = output_modes[args.task_name]
- label_list = processor.get_labels()
- num_labels = len(label_list)
-
- # Load pretrained model and tokenizer
- if args.local_rank not in [-1, 0]:
- torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab
-
- args.model_type = args.model_type.lower()
- config_class, model_class, tokenizer_class = MODEL_CLASSES[args.model_type]
- config = config_class.from_pretrained(
- args.config_name if args.config_name else args.model_name_or_path,
- num_labels=num_labels,
- finetuning_task=args.task_name,
- cache_dir=args.cache_dir if args.cache_dir else None,
- pruning_method=args.pruning_method,
- mask_init=args.mask_init,
- mask_scale=args.mask_scale,
- )
- tokenizer = tokenizer_class.from_pretrained(
- args.tokenizer_name if args.tokenizer_name else args.model_name_or_path,
- cache_dir=args.cache_dir if args.cache_dir else None,
- do_lower_case=args.do_lower_case,
- )
- model = model_class.from_pretrained(
- args.model_name_or_path,
- from_tf=bool(".ckpt" in args.model_name_or_path),
- config=config,
- cache_dir=args.cache_dir if args.cache_dir else None,
- )
-
- if args.teacher_type is not None:
- assert args.teacher_name_or_path is not None
- assert args.alpha_distil > 0.0
- assert args.alpha_distil + args.alpha_ce > 0.0
- teacher_config_class, teacher_model_class, _ = MODEL_CLASSES[args.teacher_type]
- teacher_config = teacher_config_class.from_pretrained(args.teacher_name_or_path)
- teacher = teacher_model_class.from_pretrained(
- args.teacher_name_or_path,
- from_tf=False,
- config=teacher_config,
- cache_dir=args.cache_dir if args.cache_dir else None,
- )
- teacher.to(args.device)
- else:
- teacher = None
-
- if args.local_rank == 0:
- torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab
-
- model.to(args.device)
-
- logger.info("Training/evaluation parameters %s", args)
-
- # Training
- if args.do_train:
- train_dataset = load_and_cache_examples(args, args.task_name, tokenizer, evaluate=False)
- global_step, tr_loss = train(args, train_dataset, model, tokenizer, teacher=teacher)
- logger.info(" global_step = %s, average loss = %s", global_step, tr_loss)
-
- # Saving best-practices: if you use defaults names for the model, you can reload it using from_pretrained()
- if args.do_train and (args.local_rank == -1 or torch.distributed.get_rank() == 0):
- logger.info("Saving model checkpoint to %s", args.output_dir)
- # Save a trained model, configuration and tokenizer using `save_pretrained()`.
- # They can then be reloaded using `from_pretrained()`
- model_to_save = (
- model.module if hasattr(model, "module") else model
- ) # Take care of distributed/parallel training
- model_to_save.save_pretrained(args.output_dir)
- tokenizer.save_pretrained(args.output_dir)
-
- # Good practice: save your training arguments together with the trained model
- torch.save(args, os.path.join(args.output_dir, "training_args.bin"))
-
- # Load a trained model and vocabulary that you have fine-tuned
- model = model_class.from_pretrained(args.output_dir)
- tokenizer = tokenizer_class.from_pretrained(args.output_dir, do_lower_case=args.do_lower_case)
- model.to(args.device)
-
- # Evaluation
- results = {}
- if args.do_eval and args.local_rank in [-1, 0]:
- tokenizer = tokenizer_class.from_pretrained(args.output_dir, do_lower_case=args.do_lower_case)
- checkpoints = [args.output_dir]
- if args.eval_all_checkpoints:
- checkpoints = [
- os.path.dirname(c) for c in sorted(glob.glob(args.output_dir + "/**/" + WEIGHTS_NAME, recursive=True))
- ]
-
- logger.info("Evaluate the following checkpoints: %s", checkpoints)
- for checkpoint in checkpoints:
- global_step = checkpoint.split("-")[-1] if len(checkpoints) > 1 else ""
- prefix = checkpoint.split("/")[-1] if checkpoint.find("checkpoint") != -1 else ""
-
- model = model_class.from_pretrained(checkpoint)
- model.to(args.device)
- result = evaluate(args, model, tokenizer, prefix=prefix)
- result = {k + "_{}".format(global_step): v for k, v in result.items()}
- results.update(result)
-
- return results
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/movement-pruning/masked_run_squad.py b/examples/research_projects/movement-pruning/masked_run_squad.py
deleted file mode 100644
index 7b1c2b32209..00000000000
--- a/examples/research_projects/movement-pruning/masked_run_squad.py
+++ /dev/null
@@ -1,1147 +0,0 @@
-# coding=utf-8
-# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
-# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Fine-pruning Masked BERT for question-answering on SQuAD."""
-
-import argparse
-import glob
-import logging
-import os
-import random
-import timeit
-
-import numpy as np
-import torch
-from emmental import MaskedBertConfig, MaskedBertForQuestionAnswering
-from torch import nn
-from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
-from torch.utils.data.distributed import DistributedSampler
-from tqdm import tqdm, trange
-
-from transformers import (
- WEIGHTS_NAME,
- AdamW,
- BertConfig,
- BertForQuestionAnswering,
- BertTokenizer,
- get_linear_schedule_with_warmup,
- squad_convert_examples_to_features,
-)
-from transformers.data.metrics.squad_metrics import (
- compute_predictions_log_probs,
- compute_predictions_logits,
- squad_evaluate,
-)
-from transformers.data.processors.squad import SquadResult, SquadV1Processor, SquadV2Processor
-
-
-try:
- from torch.utils.tensorboard import SummaryWriter
-except ImportError:
- from tensorboardX import SummaryWriter
-
-
-logger = logging.getLogger(__name__)
-
-MODEL_CLASSES = {
- "bert": (BertConfig, BertForQuestionAnswering, BertTokenizer),
- "masked_bert": (MaskedBertConfig, MaskedBertForQuestionAnswering, BertTokenizer),
-}
-
-
-def set_seed(args):
- random.seed(args.seed)
- np.random.seed(args.seed)
- torch.manual_seed(args.seed)
- if args.n_gpu > 0:
- torch.cuda.manual_seed_all(args.seed)
-
-
-def schedule_threshold(
- step: int,
- total_step: int,
- warmup_steps: int,
- initial_threshold: float,
- final_threshold: float,
- initial_warmup: int,
- final_warmup: int,
- final_lambda: float,
-):
- if step <= initial_warmup * warmup_steps:
- threshold = initial_threshold
- elif step > (total_step - final_warmup * warmup_steps):
- threshold = final_threshold
- else:
- spars_warmup_steps = initial_warmup * warmup_steps
- spars_schedu_steps = (final_warmup + initial_warmup) * warmup_steps
- mul_coeff = 1 - (step - spars_warmup_steps) / (total_step - spars_schedu_steps)
- threshold = final_threshold + (initial_threshold - final_threshold) * (mul_coeff**3)
- regu_lambda = final_lambda * threshold / final_threshold
- return threshold, regu_lambda
-
-
-def regularization(model: nn.Module, mode: str):
- regu, counter = 0, 0
- for name, param in model.named_parameters():
- if "mask_scores" in name:
- if mode == "l1":
- regu += torch.norm(torch.sigmoid(param), p=1) / param.numel()
- elif mode == "l0":
- regu += torch.sigmoid(param - 2 / 3 * np.log(0.1 / 1.1)).sum() / param.numel()
- else:
- raise ValueError("Don't know this mode.")
- counter += 1
- return regu / counter
-
-
-def to_list(tensor):
- return tensor.detach().cpu().tolist()
-
-
-def train(args, train_dataset, model, tokenizer, teacher=None):
- """Train the model"""
- if args.local_rank in [-1, 0]:
- tb_writer = SummaryWriter(log_dir=args.output_dir)
-
- args.train_batch_size = args.per_gpu_train_batch_size * max(1, args.n_gpu)
- train_sampler = RandomSampler(train_dataset) if args.local_rank == -1 else DistributedSampler(train_dataset)
- train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size)
-
- if args.max_steps > 0:
- t_total = args.max_steps
- args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
- else:
- t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
-
- # Prepare optimizer and schedule (linear warmup and decay)
- no_decay = ["bias", "LayerNorm.weight"]
- optimizer_grouped_parameters = [
- {
- "params": [p for n, p in model.named_parameters() if "mask_score" in n and p.requires_grad],
- "lr": args.mask_scores_learning_rate,
- },
- {
- "params": [
- p
- for n, p in model.named_parameters()
- if "mask_score" not in n and p.requires_grad and not any(nd in n for nd in no_decay)
- ],
- "lr": args.learning_rate,
- "weight_decay": args.weight_decay,
- },
- {
- "params": [
- p
- for n, p in model.named_parameters()
- if "mask_score" not in n and p.requires_grad and any(nd in n for nd in no_decay)
- ],
- "lr": args.learning_rate,
- "weight_decay": 0.0,
- },
- ]
-
- optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
- scheduler = get_linear_schedule_with_warmup(
- optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
- )
-
- # Check if saved optimizer or scheduler states exist
- if os.path.isfile(os.path.join(args.model_name_or_path, "optimizer.pt")) and os.path.isfile(
- os.path.join(args.model_name_or_path, "scheduler.pt")
- ):
- # Load in optimizer and scheduler states
- optimizer.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "optimizer.pt")))
- scheduler.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "scheduler.pt")))
-
- if args.fp16:
- try:
- from apex import amp
- except ImportError:
- raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
- model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
-
- # multi-gpu training (should be after apex fp16 initialization)
- if args.n_gpu > 1:
- model = nn.DataParallel(model)
-
- # Distributed training (should be after apex fp16 initialization)
- if args.local_rank != -1:
- model = nn.parallel.DistributedDataParallel(
- model,
- device_ids=[args.local_rank],
- output_device=args.local_rank,
- find_unused_parameters=True,
- )
-
- # Train!
- logger.info("***** Running training *****")
- logger.info(" Num examples = %d", len(train_dataset))
- logger.info(" Num Epochs = %d", args.num_train_epochs)
- logger.info(" Instantaneous batch size per GPU = %d", args.per_gpu_train_batch_size)
- logger.info(
- " Total train batch size (w. parallel, distributed & accumulation) = %d",
- args.train_batch_size
- * args.gradient_accumulation_steps
- * (torch.distributed.get_world_size() if args.local_rank != -1 else 1),
- )
- logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)
- logger.info(" Total optimization steps = %d", t_total)
- # Distillation
- if teacher is not None:
- logger.info(" Training with distillation")
-
- global_step = 1
- # Global TopK
- if args.global_topk:
- threshold_mem = None
- epochs_trained = 0
- steps_trained_in_current_epoch = 0
- # Check if continuing training from a checkpoint
- if os.path.exists(args.model_name_or_path):
- # set global_step to global_step of last saved checkpoint from model path
- try:
- checkpoint_suffix = args.model_name_or_path.split("-")[-1].split("/")[0]
- global_step = int(checkpoint_suffix)
- epochs_trained = global_step // (len(train_dataloader) // args.gradient_accumulation_steps)
- steps_trained_in_current_epoch = global_step % (len(train_dataloader) // args.gradient_accumulation_steps)
-
- logger.info(" Continuing training from checkpoint, will skip to saved global_step")
- logger.info(" Continuing training from epoch %d", epochs_trained)
- logger.info(" Continuing training from global step %d", global_step)
- logger.info(" Will skip the first %d steps in the first epoch", steps_trained_in_current_epoch)
- except ValueError:
- logger.info(" Starting fine-tuning.")
-
- tr_loss, logging_loss = 0.0, 0.0
- model.zero_grad()
- train_iterator = trange(
- epochs_trained, int(args.num_train_epochs), desc="Epoch", disable=args.local_rank not in [-1, 0]
- )
- # Added here for reproducibility
- set_seed(args)
-
- for _ in train_iterator:
- epoch_iterator = tqdm(train_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])
- for step, batch in enumerate(epoch_iterator):
- # Skip past any already trained steps if resuming training
- if steps_trained_in_current_epoch > 0:
- steps_trained_in_current_epoch -= 1
- continue
-
- model.train()
- batch = tuple(t.to(args.device) for t in batch)
- threshold, regu_lambda = schedule_threshold(
- step=global_step,
- total_step=t_total,
- warmup_steps=args.warmup_steps,
- final_threshold=args.final_threshold,
- initial_threshold=args.initial_threshold,
- final_warmup=args.final_warmup,
- initial_warmup=args.initial_warmup,
- final_lambda=args.final_lambda,
- )
- # Global TopK
- if args.global_topk:
- if threshold == 1.0:
- threshold = -1e2 # Or an indefinitely low quantity
- else:
- if (threshold_mem is None) or (global_step % args.global_topk_frequency_compute == 0):
- # Sort all the values to get the global topK
- concat = torch.cat(
- [param.view(-1) for name, param in model.named_parameters() if "mask_scores" in name]
- )
- n = concat.numel()
- kth = max(n - (int(n * threshold) + 1), 1)
- threshold_mem = concat.kthvalue(kth).values.item()
- threshold = threshold_mem
- else:
- threshold = threshold_mem
- inputs = {
- "input_ids": batch[0],
- "attention_mask": batch[1],
- "token_type_ids": batch[2],
- "start_positions": batch[3],
- "end_positions": batch[4],
- }
-
- if args.model_type in ["xlm", "roberta", "distilbert", "camembert"]:
- del inputs["token_type_ids"]
-
- if args.model_type in ["xlnet", "xlm"]:
- inputs.update({"cls_index": batch[5], "p_mask": batch[6]})
- if args.version_2_with_negative:
- inputs.update({"is_impossible": batch[7]})
- if hasattr(model, "config") and hasattr(model.config, "lang2id"):
- inputs.update(
- {"langs": (torch.ones(batch[0].shape, dtype=torch.int64) * args.lang_id).to(args.device)}
- )
-
- if "masked" in args.model_type:
- inputs["threshold"] = threshold
-
- outputs = model(**inputs)
- # model outputs are always tuple in transformers (see doc)
- loss, start_logits_stu, end_logits_stu = outputs
-
- # Distillation loss
- if teacher is not None:
- with torch.no_grad():
- start_logits_tea, end_logits_tea = teacher(
- input_ids=inputs["input_ids"],
- token_type_ids=inputs["token_type_ids"],
- attention_mask=inputs["attention_mask"],
- )
-
- loss_start = nn.functional.kl_div(
- input=nn.functional.log_softmax(start_logits_stu / args.temperature, dim=-1),
- target=nn.functional.softmax(start_logits_tea / args.temperature, dim=-1),
- reduction="batchmean",
- ) * (args.temperature**2)
- loss_end = nn.functional.kl_div(
- input=nn.functional.log_softmax(end_logits_stu / args.temperature, dim=-1),
- target=nn.functional.softmax(end_logits_tea / args.temperature, dim=-1),
- reduction="batchmean",
- ) * (args.temperature**2)
- loss_logits = (loss_start + loss_end) / 2.0
-
- loss = args.alpha_distil * loss_logits + args.alpha_ce * loss
-
- # Regularization
- if args.regularization is not None:
- regu_ = regularization(model=model, mode=args.regularization)
- loss = loss + regu_lambda * regu_
-
- if args.n_gpu > 1:
- loss = loss.mean() # mean() to average on multi-gpu parallel training
- if args.gradient_accumulation_steps > 1:
- loss = loss / args.gradient_accumulation_steps
-
- if args.fp16:
- with amp.scale_loss(loss, optimizer) as scaled_loss:
- scaled_loss.backward()
- else:
- loss.backward()
-
- tr_loss += loss.item()
- if (step + 1) % args.gradient_accumulation_steps == 0:
- if args.fp16:
- nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
- else:
- nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
-
- if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
- tb_writer.add_scalar("threshold", threshold, global_step)
- for name, param in model.named_parameters():
- if not param.requires_grad:
- continue
- tb_writer.add_scalar("parameter_mean/" + name, param.data.mean(), global_step)
- tb_writer.add_scalar("parameter_std/" + name, param.data.std(), global_step)
- tb_writer.add_scalar("parameter_min/" + name, param.data.min(), global_step)
- tb_writer.add_scalar("parameter_max/" + name, param.data.max(), global_step)
- if "pooler" in name:
- continue
- tb_writer.add_scalar("grad_mean/" + name, param.grad.data.mean(), global_step)
- tb_writer.add_scalar("grad_std/" + name, param.grad.data.std(), global_step)
- if args.regularization is not None and "mask_scores" in name:
- if args.regularization == "l1":
- perc = (torch.sigmoid(param) > threshold).sum().item() / param.numel()
- elif args.regularization == "l0":
- perc = (torch.sigmoid(param - 2 / 3 * np.log(0.1 / 1.1))).sum().item() / param.numel()
- tb_writer.add_scalar("retained_weights_perc/" + name, perc, global_step)
-
- optimizer.step()
- scheduler.step() # Update learning rate schedule
- model.zero_grad()
- global_step += 1
-
- # Log metrics
- if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
- # Only evaluate when single GPU otherwise metrics may not average well
- if args.local_rank == -1 and args.evaluate_during_training:
- results = evaluate(args, model, tokenizer)
- for key, value in results.items():
- tb_writer.add_scalar("eval_{}".format(key), value, global_step)
- learning_rate_scalar = scheduler.get_lr()
- tb_writer.add_scalar("lr", learning_rate_scalar[0], global_step)
- if len(learning_rate_scalar) > 1:
- for idx, lr in enumerate(learning_rate_scalar[1:]):
- tb_writer.add_scalar(f"lr/{idx+1}", lr, global_step)
- tb_writer.add_scalar("loss", (tr_loss - logging_loss) / args.logging_steps, global_step)
- if teacher is not None:
- tb_writer.add_scalar("loss/distil", loss_logits.item(), global_step)
- if args.regularization is not None:
- tb_writer.add_scalar("loss/regularization", regu_.item(), global_step)
- if (teacher is not None) or (args.regularization is not None):
- if (teacher is not None) and (args.regularization is not None):
- tb_writer.add_scalar(
- "loss/instant_ce",
- (loss.item() - regu_lambda * regu_.item() - args.alpha_distil * loss_logits.item())
- / args.alpha_ce,
- global_step,
- )
- elif teacher is not None:
- tb_writer.add_scalar(
- "loss/instant_ce",
- (loss.item() - args.alpha_distil * loss_logits.item()) / args.alpha_ce,
- global_step,
- )
- else:
- tb_writer.add_scalar(
- "loss/instant_ce", loss.item() - regu_lambda * regu_.item(), global_step
- )
- logging_loss = tr_loss
-
- # Save model checkpoint
- if args.local_rank in [-1, 0] and args.save_steps > 0 and global_step % args.save_steps == 0:
- output_dir = os.path.join(args.output_dir, "checkpoint-{}".format(global_step))
- if not os.path.exists(output_dir):
- os.makedirs(output_dir)
- # Take care of distributed/parallel training
- model_to_save = model.module if hasattr(model, "module") else model
- model_to_save.save_pretrained(output_dir)
- tokenizer.save_pretrained(output_dir)
-
- torch.save(args, os.path.join(output_dir, "training_args.bin"))
- logger.info("Saving model checkpoint to %s", output_dir)
-
- torch.save(optimizer.state_dict(), os.path.join(output_dir, "optimizer.pt"))
- torch.save(scheduler.state_dict(), os.path.join(output_dir, "scheduler.pt"))
- logger.info("Saving optimizer and scheduler states to %s", output_dir)
-
- if args.max_steps > 0 and global_step > args.max_steps:
- epoch_iterator.close()
- break
- if args.max_steps > 0 and global_step > args.max_steps:
- train_iterator.close()
- break
-
- if args.local_rank in [-1, 0]:
- tb_writer.close()
-
- return global_step, tr_loss / global_step
-
-
-def evaluate(args, model, tokenizer, prefix=""):
- dataset, examples, features = load_and_cache_examples(args, tokenizer, evaluate=True, output_examples=True)
-
- if not os.path.exists(args.output_dir) and args.local_rank in [-1, 0]:
- os.makedirs(args.output_dir)
-
- args.eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)
- # Note that DistributedSampler samples randomly
- eval_sampler = SequentialSampler(dataset)
- eval_dataloader = DataLoader(dataset, sampler=eval_sampler, batch_size=args.eval_batch_size)
-
- # multi-gpu eval
- if args.n_gpu > 1 and not isinstance(model, nn.DataParallel):
- model = nn.DataParallel(model)
-
- # Eval!
- logger.info("***** Running evaluation {} *****".format(prefix))
- logger.info(" Num examples = %d", len(dataset))
- logger.info(" Batch size = %d", args.eval_batch_size)
-
- all_results = []
- start_time = timeit.default_timer()
- # Global TopK
- if args.global_topk:
- threshold_mem = None
-
- for batch in tqdm(eval_dataloader, desc="Evaluating"):
- model.eval()
- batch = tuple(t.to(args.device) for t in batch)
-
- with torch.no_grad():
- inputs = {
- "input_ids": batch[0],
- "attention_mask": batch[1],
- "token_type_ids": batch[2],
- }
-
- if args.model_type in ["xlm", "roberta", "distilbert", "camembert"]:
- del inputs["token_type_ids"]
-
- example_indices = batch[3]
-
- # XLNet and XLM use more arguments for their predictions
- if args.model_type in ["xlnet", "xlm"]:
- inputs.update({"cls_index": batch[4], "p_mask": batch[5]})
- # for lang_id-sensitive xlm models
- if hasattr(model, "config") and hasattr(model.config, "lang2id"):
- inputs.update(
- {"langs": (torch.ones(batch[0].shape, dtype=torch.int64) * args.lang_id).to(args.device)}
- )
- if "masked" in args.model_type:
- inputs["threshold"] = args.final_threshold
- if args.global_topk:
- if threshold_mem is None:
- concat = torch.cat(
- [param.view(-1) for name, param in model.named_parameters() if "mask_scores" in name]
- )
- n = concat.numel()
- kth = max(n - (int(n * args.final_threshold) + 1), 1)
- threshold_mem = concat.kthvalue(kth).values.item()
- inputs["threshold"] = threshold_mem
- outputs = model(**inputs)
-
- for i, example_index in enumerate(example_indices):
- eval_feature = features[example_index.item()]
- unique_id = int(eval_feature.unique_id)
-
- output = [to_list(output[i]) for output in outputs]
-
- # Some models (XLNet, XLM) use 5 arguments for their predictions, while the other "simpler"
- # models only use two.
- if len(output) >= 5:
- start_logits = output[0]
- start_top_index = output[1]
- end_logits = output[2]
- end_top_index = output[3]
- cls_logits = output[4]
-
- result = SquadResult(
- unique_id,
- start_logits,
- end_logits,
- start_top_index=start_top_index,
- end_top_index=end_top_index,
- cls_logits=cls_logits,
- )
-
- else:
- start_logits, end_logits = output
- result = SquadResult(unique_id, start_logits, end_logits)
-
- all_results.append(result)
-
- evalTime = timeit.default_timer() - start_time
- logger.info(" Evaluation done in total %f secs (%f sec per example)", evalTime, evalTime / len(dataset))
-
- # Compute predictions
- output_prediction_file = os.path.join(args.output_dir, "predictions_{}.json".format(prefix))
- output_nbest_file = os.path.join(args.output_dir, "nbest_predictions_{}.json".format(prefix))
-
- if args.version_2_with_negative:
- output_null_log_odds_file = os.path.join(args.output_dir, "null_odds_{}.json".format(prefix))
- else:
- output_null_log_odds_file = None
-
- # XLNet and XLM use a more complex post-processing procedure
- if args.model_type in ["xlnet", "xlm"]:
- start_n_top = model.config.start_n_top if hasattr(model, "config") else model.module.config.start_n_top
- end_n_top = model.config.end_n_top if hasattr(model, "config") else model.module.config.end_n_top
-
- predictions = compute_predictions_log_probs(
- examples,
- features,
- all_results,
- args.n_best_size,
- args.max_answer_length,
- output_prediction_file,
- output_nbest_file,
- output_null_log_odds_file,
- start_n_top,
- end_n_top,
- args.version_2_with_negative,
- tokenizer,
- args.verbose_logging,
- )
- else:
- predictions = compute_predictions_logits(
- examples,
- features,
- all_results,
- args.n_best_size,
- args.max_answer_length,
- args.do_lower_case,
- output_prediction_file,
- output_nbest_file,
- output_null_log_odds_file,
- args.verbose_logging,
- args.version_2_with_negative,
- args.null_score_diff_threshold,
- tokenizer,
- )
-
- # Compute the F1 and exact scores.
- results = squad_evaluate(examples, predictions)
- return results
-
-
-def load_and_cache_examples(args, tokenizer, evaluate=False, output_examples=False):
- if args.local_rank not in [-1, 0] and not evaluate:
- # Make sure only the first process in distributed training process the dataset, and the others will use the cache
- torch.distributed.barrier()
-
- # Load data features from cache or dataset file
- input_dir = args.data_dir if args.data_dir else "."
- cached_features_file = os.path.join(
- input_dir,
- "cached_{}_{}_{}_{}".format(
- "dev" if evaluate else "train",
- args.tokenizer_name
- if args.tokenizer_name
- else list(filter(None, args.model_name_or_path.split("/"))).pop(),
- str(args.max_seq_length),
- list(filter(None, args.predict_file.split("/"))).pop()
- if evaluate
- else list(filter(None, args.train_file.split("/"))).pop(),
- ),
- )
-
- # Init features and dataset from cache if it exists
- if os.path.exists(cached_features_file) and not args.overwrite_cache:
- logger.info("Loading features from cached file %s", cached_features_file)
- features_and_dataset = torch.load(cached_features_file)
- features, dataset, examples = (
- features_and_dataset["features"],
- features_and_dataset["dataset"],
- features_and_dataset["examples"],
- )
- else:
- logger.info("Creating features from dataset file at %s", input_dir)
-
- if not args.data_dir and ((evaluate and not args.predict_file) or (not evaluate and not args.train_file)):
- try:
- import tensorflow_datasets as tfds
- except ImportError:
- raise ImportError("If not data_dir is specified, tensorflow_datasets needs to be installed.")
-
- if args.version_2_with_negative:
- logger.warning("tensorflow_datasets does not handle version 2 of SQuAD.")
-
- tfds_examples = tfds.load("squad")
- examples = SquadV1Processor().get_examples_from_dataset(tfds_examples, evaluate=evaluate)
- else:
- processor = SquadV2Processor() if args.version_2_with_negative else SquadV1Processor()
- if evaluate:
- examples = processor.get_dev_examples(args.data_dir, filename=args.predict_file)
- else:
- examples = processor.get_train_examples(args.data_dir, filename=args.train_file)
-
- features, dataset = squad_convert_examples_to_features(
- examples=examples,
- tokenizer=tokenizer,
- max_seq_length=args.max_seq_length,
- doc_stride=args.doc_stride,
- max_query_length=args.max_query_length,
- is_training=not evaluate,
- return_dataset="pt",
- threads=args.threads,
- )
-
- if args.local_rank in [-1, 0]:
- logger.info("Saving features into cached file %s", cached_features_file)
- torch.save({"features": features, "dataset": dataset, "examples": examples}, cached_features_file)
-
- if args.local_rank == 0 and not evaluate:
- # Make sure only the first process in distributed training process the dataset, and the others will use the cache
- torch.distributed.barrier()
-
- if output_examples:
- return dataset, examples, features
- return dataset
-
-
-def main():
- parser = argparse.ArgumentParser()
-
- # Required parameters
- parser.add_argument(
- "--model_type",
- default=None,
- type=str,
- required=True,
- help="Model type selected in the list: " + ", ".join(MODEL_CLASSES.keys()),
- )
- parser.add_argument(
- "--model_name_or_path",
- default=None,
- type=str,
- required=True,
- help="Path to pretrained model or model identifier from huggingface.co/models",
- )
- parser.add_argument(
- "--output_dir",
- default=None,
- type=str,
- required=True,
- help="The output directory where the model checkpoints and predictions will be written.",
- )
-
- # Other parameters
- parser.add_argument(
- "--data_dir",
- default=None,
- type=str,
- help="The input data dir. Should contain the .json files for the task."
- + "If no data dir or train/predict files are specified, will run with tensorflow_datasets.",
- )
- parser.add_argument(
- "--train_file",
- default=None,
- type=str,
- help="The input training file. If a data dir is specified, will look for the file there"
- + "If no data dir or train/predict files are specified, will run with tensorflow_datasets.",
- )
- parser.add_argument(
- "--predict_file",
- default=None,
- type=str,
- help="The input evaluation file. If a data dir is specified, will look for the file there"
- + "If no data dir or train/predict files are specified, will run with tensorflow_datasets.",
- )
- parser.add_argument(
- "--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
- )
- parser.add_argument(
- "--tokenizer_name",
- default="",
- type=str,
- help="Pretrained tokenizer name or path if not the same as model_name",
- )
- parser.add_argument(
- "--cache_dir",
- default="",
- type=str,
- help="Where do you want to store the pre-trained models downloaded from huggingface.co",
- )
-
- parser.add_argument(
- "--version_2_with_negative",
- action="store_true",
- help="If true, the SQuAD examples contain some that do not have an answer.",
- )
- parser.add_argument(
- "--null_score_diff_threshold",
- type=float,
- default=0.0,
- help="If null_score - best_non_null is greater than the threshold predict null.",
- )
-
- parser.add_argument(
- "--max_seq_length",
- default=384,
- type=int,
- help=(
- "The maximum total input sequence length after WordPiece tokenization. Sequences "
- "longer than this will be truncated, and sequences shorter than this will be padded."
- ),
- )
- parser.add_argument(
- "--doc_stride",
- default=128,
- type=int,
- help="When splitting up a long document into chunks, how much stride to take between chunks.",
- )
- parser.add_argument(
- "--max_query_length",
- default=64,
- type=int,
- help=(
- "The maximum number of tokens for the question. Questions longer than this will "
- "be truncated to this length."
- ),
- )
- parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
- parser.add_argument("--do_eval", action="store_true", help="Whether to run eval on the dev set.")
- parser.add_argument(
- "--evaluate_during_training", action="store_true", help="Run evaluation during training at each logging step."
- )
- parser.add_argument(
- "--do_lower_case", action="store_true", help="Set this flag if you are using an uncased model."
- )
-
- parser.add_argument("--per_gpu_train_batch_size", default=8, type=int, help="Batch size per GPU/CPU for training.")
- parser.add_argument(
- "--per_gpu_eval_batch_size", default=8, type=int, help="Batch size per GPU/CPU for evaluation."
- )
- parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
-
- # Pruning parameters
- parser.add_argument(
- "--mask_scores_learning_rate",
- default=1e-2,
- type=float,
- help="The Adam initial learning rate of the mask scores.",
- )
- parser.add_argument(
- "--initial_threshold", default=1.0, type=float, help="Initial value of the threshold (for scheduling)."
- )
- parser.add_argument(
- "--final_threshold", default=0.7, type=float, help="Final value of the threshold (for scheduling)."
- )
- parser.add_argument(
- "--initial_warmup",
- default=1,
- type=int,
- help=(
- "Run `initial_warmup` * `warmup_steps` steps of threshold warmup during which threshold stays "
- "at its `initial_threshold` value (sparsity schedule)."
- ),
- )
- parser.add_argument(
- "--final_warmup",
- default=2,
- type=int,
- help=(
- "Run `final_warmup` * `warmup_steps` steps of threshold cool-down during which threshold stays "
- "at its final_threshold value (sparsity schedule)."
- ),
- )
-
- parser.add_argument(
- "--pruning_method",
- default="topK",
- type=str,
- help=(
- "Pruning Method (l0 = L0 regularization, magnitude = Magnitude pruning, topK = Movement pruning,"
- " sigmoied_threshold = Soft movement pruning)."
- ),
- )
- parser.add_argument(
- "--mask_init",
- default="constant",
- type=str,
- help="Initialization method for the mask scores. Choices: constant, uniform, kaiming.",
- )
- parser.add_argument(
- "--mask_scale", default=0.0, type=float, help="Initialization parameter for the chosen initialization method."
- )
-
- parser.add_argument("--regularization", default=None, help="Add L0 or L1 regularization to the mask scores.")
- parser.add_argument(
- "--final_lambda",
- default=0.0,
- type=float,
- help="Regularization intensity (used in conjunction with `regularization`.",
- )
-
- parser.add_argument("--global_topk", action="store_true", help="Global TopK on the Scores.")
- parser.add_argument(
- "--global_topk_frequency_compute",
- default=25,
- type=int,
- help="Frequency at which we compute the TopK global threshold.",
- )
-
- # Distillation parameters (optional)
- parser.add_argument(
- "--teacher_type",
- default=None,
- type=str,
- help=(
- "Teacher type. Teacher tokenizer and student (model) tokenizer must output the same tokenization. Only for"
- " distillation."
- ),
- )
- parser.add_argument(
- "--teacher_name_or_path",
- default=None,
- type=str,
- help="Path to the already SQuAD fine-tuned teacher model. Only for distillation.",
- )
- parser.add_argument(
- "--alpha_ce", default=0.5, type=float, help="Cross entropy loss linear weight. Only for distillation."
- )
- parser.add_argument(
- "--alpha_distil", default=0.5, type=float, help="Distillation loss linear weight. Only for distillation."
- )
- parser.add_argument(
- "--temperature", default=2.0, type=float, help="Distillation temperature. Only for distillation."
- )
-
- parser.add_argument(
- "--gradient_accumulation_steps",
- type=int,
- default=1,
- help="Number of updates steps to accumulate before performing a backward/update pass.",
- )
- parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
- parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
- parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
- parser.add_argument(
- "--num_train_epochs",
- default=3.0,
- type=float,
- help="Total number of training epochs to perform.",
- )
- parser.add_argument(
- "--max_steps",
- default=-1,
- type=int,
- help="If > 0: set total number of training steps to perform. Override num_train_epochs.",
- )
- parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
- parser.add_argument(
- "--n_best_size",
- default=20,
- type=int,
- help="The total number of n-best predictions to generate in the nbest_predictions.json output file.",
- )
- parser.add_argument(
- "--max_answer_length",
- default=30,
- type=int,
- help=(
- "The maximum length of an answer that can be generated. This is needed because the start "
- "and end predictions are not conditioned on one another."
- ),
- )
- parser.add_argument(
- "--verbose_logging",
- action="store_true",
- help=(
- "If true, all of the warnings related to data processing will be printed. "
- "A number of warnings are expected for a normal SQuAD evaluation."
- ),
- )
- parser.add_argument(
- "--lang_id",
- default=0,
- type=int,
- help=(
- "language id of input for language-specific xlm models (see"
- " tokenization_xlm.PRETRAINED_INIT_CONFIGURATION)"
- ),
- )
-
- parser.add_argument("--logging_steps", type=int, default=500, help="Log every X updates steps.")
- parser.add_argument("--save_steps", type=int, default=500, help="Save checkpoint every X updates steps.")
- parser.add_argument(
- "--eval_all_checkpoints",
- action="store_true",
- help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
- )
- parser.add_argument("--no_cuda", action="store_true", help="Whether not to use CUDA when available")
- parser.add_argument(
- "--overwrite_output_dir", action="store_true", help="Overwrite the content of the output directory"
- )
- parser.add_argument(
- "--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
- )
- parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
-
- parser.add_argument("--local_rank", type=int, default=-1, help="local_rank for distributed training on gpus")
- parser.add_argument(
- "--fp16",
- action="store_true",
- help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
- )
- parser.add_argument(
- "--fp16_opt_level",
- type=str,
- default="O1",
- help=(
- "For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
- "See details at https://nvidia.github.io/apex/amp.html"
- ),
- )
- parser.add_argument("--server_ip", type=str, default="", help="Can be used for distant debugging.")
- parser.add_argument("--server_port", type=str, default="", help="Can be used for distant debugging.")
-
- parser.add_argument("--threads", type=int, default=1, help="multiple threads for converting example to features")
- args = parser.parse_args()
-
- # Regularization
- if args.regularization == "null":
- args.regularization = None
-
- if args.doc_stride >= args.max_seq_length - args.max_query_length:
- logger.warning(
- "WARNING - You've set a doc stride which may be superior to the document length in some "
- "examples. This could result in errors when building features from the examples. Please reduce the doc "
- "stride or increase the maximum length to ensure the features are correctly built."
- )
-
- if (
- os.path.exists(args.output_dir)
- and os.listdir(args.output_dir)
- and args.do_train
- and not args.overwrite_output_dir
- ):
- raise ValueError(
- "Output directory ({}) already exists and is not empty. Use --overwrite_output_dir to overcome.".format(
- args.output_dir
- )
- )
-
- # Setup distant debugging if needed
- if args.server_ip and args.server_port:
- # Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
- import ptvsd
-
- print("Waiting for debugger attach")
- ptvsd.enable_attach(address=(args.server_ip, args.server_port), redirect_output=True)
- ptvsd.wait_for_attach()
-
- # Setup CUDA, GPU & distributed training
- if args.local_rank == -1 or args.no_cuda:
- device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
- args.n_gpu = 0 if args.no_cuda else torch.cuda.device_count()
- else: # Initializes the distributed backend which will take care of synchronizing nodes/GPUs
- torch.cuda.set_device(args.local_rank)
- device = torch.device("cuda", args.local_rank)
- torch.distributed.init_process_group(backend="nccl")
- args.n_gpu = 1
- args.device = device
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- level=logging.INFO if args.local_rank in [-1, 0] else logging.WARN,
- )
- logger.warning(
- "Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
- args.local_rank,
- device,
- args.n_gpu,
- bool(args.local_rank != -1),
- args.fp16,
- )
-
- # Set seed
- set_seed(args)
-
- # Load pretrained model and tokenizer
- if args.local_rank not in [-1, 0]:
- # Make sure only the first process in distributed training will download model & vocab
- torch.distributed.barrier()
-
- args.model_type = args.model_type.lower()
- config_class, model_class, tokenizer_class = MODEL_CLASSES[args.model_type]
- config = config_class.from_pretrained(
- args.config_name if args.config_name else args.model_name_or_path,
- cache_dir=args.cache_dir if args.cache_dir else None,
- pruning_method=args.pruning_method,
- mask_init=args.mask_init,
- mask_scale=args.mask_scale,
- )
- tokenizer = tokenizer_class.from_pretrained(
- args.tokenizer_name if args.tokenizer_name else args.model_name_or_path,
- do_lower_case=args.do_lower_case,
- cache_dir=args.cache_dir if args.cache_dir else None,
- )
- model = model_class.from_pretrained(
- args.model_name_or_path,
- from_tf=bool(".ckpt" in args.model_name_or_path),
- config=config,
- cache_dir=args.cache_dir if args.cache_dir else None,
- )
-
- if args.teacher_type is not None:
- assert args.teacher_name_or_path is not None
- assert args.alpha_distil > 0.0
- assert args.alpha_distil + args.alpha_ce > 0.0
- teacher_config_class, teacher_model_class, _ = MODEL_CLASSES[args.teacher_type]
- teacher_config = teacher_config_class.from_pretrained(args.teacher_name_or_path)
- teacher = teacher_model_class.from_pretrained(
- args.teacher_name_or_path,
- from_tf=False,
- config=teacher_config,
- cache_dir=args.cache_dir if args.cache_dir else None,
- )
- teacher.to(args.device)
- else:
- teacher = None
-
- if args.local_rank == 0:
- # Make sure only the first process in distributed training will download model & vocab
- torch.distributed.barrier()
-
- model.to(args.device)
-
- logger.info("Training/evaluation parameters %s", args)
-
- # Before we do anything with models, we want to ensure that we get fp16 execution of torch.einsum if args.fp16 is set.
- # Otherwise it'll default to "promote" mode, and we'll get fp32 operations. Note that running `--fp16_opt_level="O2"` will
- # remove the need for this code, but it is still valid.
- if args.fp16:
- try:
- import apex
-
- apex.amp.register_half_function(torch, "einsum")
- except ImportError:
- raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
-
- # Training
- if args.do_train:
- train_dataset = load_and_cache_examples(args, tokenizer, evaluate=False, output_examples=False)
- global_step, tr_loss = train(args, train_dataset, model, tokenizer, teacher=teacher)
- logger.info(" global_step = %s, average loss = %s", global_step, tr_loss)
-
- # Save the trained model and the tokenizer
- if args.do_train and (args.local_rank == -1 or torch.distributed.get_rank() == 0):
- logger.info("Saving model checkpoint to %s", args.output_dir)
- # Save a trained model, configuration and tokenizer using `save_pretrained()`.
- # They can then be reloaded using `from_pretrained()`
- # Take care of distributed/parallel training
- model_to_save = model.module if hasattr(model, "module") else model
- model_to_save.save_pretrained(args.output_dir)
- tokenizer.save_pretrained(args.output_dir)
-
- # Good practice: save your training arguments together with the trained model
- torch.save(args, os.path.join(args.output_dir, "training_args.bin"))
-
- # Load a trained model and vocabulary that you have fine-tuned
- model = model_class.from_pretrained(args.output_dir) # , force_download=True)
- tokenizer = tokenizer_class.from_pretrained(args.output_dir, do_lower_case=args.do_lower_case)
- model.to(args.device)
-
- # Evaluation - we can ask to evaluate all the checkpoints (sub-directories) in a directory
- results = {}
- if args.do_eval and args.local_rank in [-1, 0]:
- if args.do_train:
- logger.info("Loading checkpoints saved during training for evaluation")
- checkpoints = [args.output_dir]
- if args.eval_all_checkpoints:
- checkpoints = [
- os.path.dirname(c)
- for c in sorted(glob.glob(args.output_dir + "/**/" + WEIGHTS_NAME, recursive=True))
- ]
-
- else:
- logger.info("Loading checkpoint %s for evaluation", args.model_name_or_path)
- checkpoints = [args.model_name_or_path]
-
- logger.info("Evaluate the following checkpoints: %s", checkpoints)
-
- for checkpoint in checkpoints:
- # Reload the model
- global_step = checkpoint.split("-")[-1] if len(checkpoints) > 1 else ""
- model = model_class.from_pretrained(checkpoint) # , force_download=True)
- model.to(args.device)
-
- # Evaluate
- result = evaluate(args, model, tokenizer, prefix=global_step)
-
- result = {k + ("_{}".format(global_step) if global_step else ""): v for k, v in result.items()}
- results.update(result)
-
- logger.info("Results: {}".format(results))
- predict_file = list(filter(None, args.predict_file.split("/"))).pop()
- if not os.path.exists(os.path.join(args.output_dir, predict_file)):
- os.makedirs(os.path.join(args.output_dir, predict_file))
- output_eval_file = os.path.join(args.output_dir, predict_file, "eval_results.txt")
- with open(output_eval_file, "w") as writer:
- for key in sorted(results.keys()):
- writer.write("%s = %s\n" % (key, str(results[key])))
-
- return results
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/movement-pruning/requirements.txt b/examples/research_projects/movement-pruning/requirements.txt
deleted file mode 100644
index b678a785bc3..00000000000
--- a/examples/research_projects/movement-pruning/requirements.txt
+++ /dev/null
@@ -1,6 +0,0 @@
-torch>=1.4.0
--e git+https://github.com/huggingface/transformers.git@352d5472b0c1dec0f420d606d16747d851b4bda8#egg=transformers
-knockknock>=0.1.8.1
-h5py>=2.10.0
-numpy>=1.18.2
-scipy>=1.4.1
diff --git a/examples/research_projects/onnx/summarization/README.md b/examples/research_projects/onnx/summarization/README.md
deleted file mode 100644
index c43b0450ea2..00000000000
--- a/examples/research_projects/onnx/summarization/README.md
+++ /dev/null
@@ -1,43 +0,0 @@
-
-
-# Bart + Beam Search to ONNX
-
-Author: [@fatcat-z](https://github.com/fatcat-z)
-
-This folder contains an example of exporting Bart + Beam Search generation (`BartForConditionalGeneration`) to ONNX.
-
-Beam Search contains a for-loop workflow, so we need to make them TorchScript-compatible for exporting to ONNX. This example shows how to make a Bart model be TorchScript-compatible by wrapping up it into a new model. In addition, some changes were made to the `beam_search()` function to make it TorchScript-compatible.
-
-
-## How to run the example
-
-To make sure you can successfully run the latest versions of the example scripts, you have to **install the library from source** and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
-
-```bash
-git clone https://github.com/huggingface/transformers
-cd transformers
-pip install '.[onnxruntime]'
-```
-Then cd in this example folder and run
-```bash
-pip install -r requirements.txt
-```
-
-Now you can run the example command below to get the example ONNX file:
-
-```bash
-python run_onnx_exporter.py --model_name_or_path facebook/bart-base
-```
diff --git a/examples/research_projects/onnx/summarization/bart_onnx/generation_onnx.py b/examples/research_projects/onnx/summarization/bart_onnx/generation_onnx.py
deleted file mode 100644
index 5c1b0da7000..00000000000
--- a/examples/research_projects/onnx/summarization/bart_onnx/generation_onnx.py
+++ /dev/null
@@ -1,755 +0,0 @@
-import copy
-import itertools
-from typing import List, Optional, Tuple
-
-import torch
-import torch.nn.functional as F
-
-from transformers import BartConfig
-from transformers.generation import GenerationMixin
-
-
-def _convert_past_list_to_tuple(past_key_values):
- """
- In Bart model, the type of past_key_values is tuple(tuple(torch.FloatTensor)) which is not
- TorchScript-compatible. To support this, we have to convert it during the export process.
- This function will convert past values from a list to tuple(tuple(torch.FloatTensor)) for
- the inner decoder.
-
- According to the definition of past_key_values, each inner tuple(torch.FloatTensor) has 4 tensors,
- so we convert every 4 elements in the list as a tuple(torch.FloatTensor).
- """
- count_of_each_inner_tuple = 4
- results = ()
- temp_result = ()
- count_n = len(past_key_values) // count_of_each_inner_tuple
- for idx in range(count_n):
- real_idx = idx * count_of_each_inner_tuple
- temp_result = tuple(past_key_values[real_idx : real_idx + count_of_each_inner_tuple])
- results += ((temp_result),)
-
- return results
-
-
-class EncoderForONNX(torch.nn.Module):
- def __init__(self, encoder):
- super().__init__()
- self.encoder = encoder
-
- def forward(self, input_ids, attention_mask):
- return self.encoder(
- input_ids=input_ids,
- attention_mask=attention_mask,
- return_dict=False,
- )
-
-
-class DecoderForONNX(torch.nn.Module):
- def __init__(self, decoder):
- super().__init__()
- self.decoder = decoder
-
- def forward(self, input_ids, encoder_state, attention_mask, past=None):
- all_results = None
- if past is not None:
- all_results = _convert_past_list_to_tuple(past)
- input_ids = input_ids[:, -1:]
-
- last_hidden_state, past_key_values = self.decoder(
- input_ids=input_ids,
- encoder_hidden_states=encoder_state,
- encoder_attention_mask=attention_mask,
- past_key_values=all_results,
- return_dict=False,
- )
-
- past_values = []
- for past in past_key_values:
- past_values = past_values + list(past)
- return last_hidden_state, past_values
-
-
-def _create_traced_encoder(encoder, input_ids, attention_mask):
- encoder_c = copy.deepcopy(encoder)
- encoder_for_onnx = EncoderForONNX(encoder_c)
-
- return torch.jit.trace(encoder_for_onnx, (input_ids, attention_mask))
-
-
-def _create_traced_decoder(decoder, input_ids, encoder_state, attention_mask, past=None):
- decoder_c = copy.deepcopy(decoder)
- decoder_for_onnx = DecoderForONNX(decoder_c)
- past_values = list(itertools.chain.from_iterable(past or ()))
-
- # Do this twice so we got 2 different decoders for further work.
- if past_values:
- return torch.jit.trace(decoder_for_onnx, (input_ids, encoder_state, attention_mask, past_values))
- else:
- return torch.jit.trace(decoder_for_onnx, (input_ids, encoder_state, attention_mask))
-
-
-class BartConfigTS(BartConfig, torch.nn.Module):
- """
- BartConfigTS is a TorchScript-compatible transformers.models.bart.configuration_bart.BartConfig.
- TorchScript only supports sub-classes of torch.nn.Module.
- """
-
- def __init__(self, config):
- BartConfig.__init__(self, config)
- torch.nn.Module.__init__(self)
-
-
-class MinLengthLogitsProcessorTS(torch.nn.Module):
- r"""
- :class:`transformers.LogitsProcessor` enforcing a min-length by setting EOS probability to 0.
-
- Args:
- min_length (:obj:`int`):
- The minimum length below which the score of :obj:`eos_token_id` is set to :obj:`-float("Inf")`.
- eos_token_id (:obj:`int`):
- The id of the `end-of-sequence` token.
- """
-
- def __init__(self, min_length: int, eos_token_id: int):
- super().__init__()
-
- if not isinstance(min_length, int) or min_length < 0:
- raise ValueError(f"`min_length` has to be a positive integer, but is {min_length}")
-
- if not isinstance(eos_token_id, int) or eos_token_id < 0:
- raise ValueError(f"`eos_token_id` has to be a positive integer, but is {eos_token_id}")
-
- self.min_length = min_length
- self.eos_token_id = eos_token_id
-
- def forward(self, input_ids, scores) -> torch.Tensor:
- cur_len = input_ids.shape[-1]
- if cur_len < self.min_length:
- scores[:, self.eos_token_id] = -float("inf")
- return scores
-
-
-class BARTGenerator(torch.nn.Module, GenerationMixin):
- def __init__(self, model):
- super().__init__()
- self.config = BartConfigTS(model.config)
- self.config.force_bos_token_to_be_generated = False
- self._trace_modules(model)
- self.logits_processor = MinLengthLogitsProcessorTS(self.config.min_length, self.config.eos_token_id)
- self.final_logits_weight = model.model.shared.weight
- self.final_logits_bias = model.final_logits_bias
- self.decoder_layers = model.config.decoder_layers
-
- def _trace_modules(self, model):
- input_ids = torch.tensor(
- [
- [
- 19,
- 669,
- 18,
- 420,
- 8,
- 664,
- 57,
- 42,
- 8,
- 664,
- 21,
- 3028,
- 195,
- 4445,
- 331,
- 1293,
- 34,
- 21,
- 10,
- 6174,
- 1100,
- 6,
- 69,
- 104,
- 42,
- 32,
- 2621,
- 1638,
- 144,
- 4,
- 6174,
- 558,
- 108,
- 4419,
- 1091,
- 28,
- 4,
- 1668,
- 9,
- 1509,
- 1621,
- 279,
- 35,
- 867,
- 2734,
- 85,
- 11,
- 2216,
- 2734,
- 85,
- 203,
- 2244,
- 7,
- 6,
- 15,
- 8102,
- 7,
- 57,
- 8629,
- 5,
- model.config.eos_token_id,
- ]
- ],
- device=model.device,
- dtype=torch.long,
- )
- attention_mask = torch.tensor(
- [[True] * input_ids.shape[-1]],
- device=model.device,
- dtype=torch.bool,
- )
- self.encoder = _create_traced_encoder(model.get_encoder(), input_ids, attention_mask)
- encoder_outputs = model.get_encoder()(input_ids, attention_mask=attention_mask, return_dict=True)
- decoder = model.model.decoder
- decoder_outputs = decoder(input_ids, attention_mask, encoder_outputs["last_hidden_state"], None, None, None)
- self.decoder_no_past = _create_traced_decoder(
- model.model.decoder, input_ids, encoder_outputs["last_hidden_state"], attention_mask
- )
- self.decoder_with_past = _create_traced_decoder(
- model.model.decoder, input_ids, encoder_outputs["last_hidden_state"], attention_mask, decoder_outputs[1]
- )
-
- def _encoder_forward(self, input_ids, attention_mask):
- return self.encoder(input_ids, attention_mask)[0]
-
- @staticmethod
- def _init_sequence_length_for_generation(
- input_ids: torch.LongTensor, max_length: int
- ) -> Tuple[torch.Tensor, torch.Tensor, int]:
- unfinished_sequences = torch.zeros(input_ids.shape[0], dtype=torch.long, device=input_ids.device) + 1
- sequence_lengths = torch.zeros(input_ids.shape[0], dtype=torch.long, device=input_ids.device) + max_length
-
- cur_len = input_ids.shape[-1]
- return sequence_lengths, unfinished_sequences, cur_len
-
- def _decoder_forward(self, input_ids, encoder_output, attention_mask, past: List[torch.Tensor]):
- # Update here to use different decoder for different values of past.
- if past is None or len(past) == 0:
- decoder_output, past = self.decoder_no_past(
- input_ids=input_ids, encoder_state=encoder_output, attention_mask=attention_mask
- )
- else:
- decoder_output, past = self.decoder_with_past(
- input_ids=input_ids, encoder_state=encoder_output, attention_mask=attention_mask, past=past
- )
-
- lm_logits = F.linear(decoder_output, self.final_logits_weight, bias=self.final_logits_bias)
-
- return lm_logits, past
-
- def greedy_search(
- self, input_ids, encoder_output, attention_mask, max_length, pad_token_id: int, eos_token_id: int
- ):
- # init sequence length tensors
- sequence_lengths, unfinished_sequences, cur_len = self._init_sequence_length_for_generation(
- input_ids, max_length
- )
-
- past: List[torch.Tensor] = []
- while cur_len < max_length:
- logits, past = self._decoder_forward(input_ids, encoder_output, attention_mask, past)
- next_token_logits = logits[:, -1, :]
-
- # pre-process distribution
- scores = self.logits_processor(input_ids, next_token_logits)
-
- # argmax
- next_tokens = torch.argmax(scores, dim=-1)
-
- # add code that transfomers next_tokens to tokens_to_add
- if eos_token_id is not None:
- assert pad_token_id is not None, "If eos_token_id is defined, make sure that pad_token_id is defined."
- next_tokens = next_tokens * unfinished_sequences + (pad_token_id) * (1 - unfinished_sequences)
-
- # add token and increase length by one
- input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
-
- # update sequence length
- if eos_token_id is not None:
- sequence_lengths, unfinished_sequences = self._update_seq_length_for_generation(
- sequence_lengths, unfinished_sequences, cur_len, next_tokens == eos_token_id
- )
-
- # stop when there is a in each sentence, or if we exceed the maximul length
- if unfinished_sequences.max() == 0:
- break
-
- # increase cur_len
- cur_len = cur_len + 1
-
- return input_ids
-
- def _prepare_decoder_input_ids_for_generation(
- self,
- input_ids: torch.LongTensor,
- decoder_start_token_id,
- bos_token_id: Optional[int] = None,
- ) -> torch.LongTensor:
- decoder_input_ids = (
- torch.ones((input_ids.shape[0], 1), dtype=input_ids.dtype, device=input_ids.device)
- * decoder_start_token_id
- )
- return decoder_input_ids
-
- def forward(self, input_ids, attention_mask, max_length, decoder_start_token_id):
- pad_token_id = self.config.pad_token_id
- bos_token_id = self.config.bos_token_id
- eos_token_id = self.config.eos_token_id
-
- # special case if pad_token_id is not defined
- if pad_token_id is None and eos_token_id is not None:
- # Setting `pad_token_id` to `eos_token_id`:{eos_token_id} for open-end generation.
- pad_token_id = eos_token_id
-
- encoder_output = self._encoder_forward(input_ids, attention_mask)
-
- input_ids = self._prepare_decoder_input_ids_for_generation(
- input_ids,
- decoder_start_token_id=decoder_start_token_id,
- bos_token_id=bos_token_id,
- )
-
- return self.greedy_search(
- input_ids,
- encoder_output,
- attention_mask,
- max_length=max_length,
- pad_token_id=pad_token_id,
- eos_token_id=eos_token_id,
- )
-
-
-# TorchScript compatible BeamSearchScorer
-class BeamSearchScorerTS(torch.nn.Module):
- def __init__(self):
- super().__init__()
- self.max_length: int = 200
- self.num_beams: int = 3
- self.batch_size: int = 1
- self.length_penalty: float = 1.0
- self.do_early_stopping: bool = True
- self.num_beam_hyps_to_keep: int = 1
- self.num_beam_groups: int = 1
- self.group_size: int = self.num_beams // self.num_beam_groups
- self._done = torch.zeros(self.batch_size, dtype=torch.bool)
- self._beam_hyps_count = torch.zeros(self.batch_size, dtype=torch.long)
- self._beam_hyps_worst_scores = torch.zeros(self.batch_size) + 1e9
- self._beam_hyps_max_length: int = self.max_length - 1
- self._beam_hyps: List[torch.Tensor] = [torch.zeros(2)] # placeholder for TorchScript compatibility
- self._beam_scores: List[torch.Tensor] = [torch.zeros(2)] # placeholder for TorchScript compatibility
-
- def is_done(self) -> torch.Tensor:
- return self._done.all()
-
- def init(
- self,
- batch_size: int,
- max_length: int,
- num_beams: int,
- device: torch.device,
- length_penalty: float = 1.0,
- do_early_stopping: bool = False,
- num_beam_hyps_to_keep: int = 1,
- num_beam_groups: int = 1,
- ):
- self.max_length = max_length
- self.num_beams = num_beams
- self.batch_size = batch_size
- self.length_penalty = length_penalty
- self.do_early_stopping = do_early_stopping
- self.num_beam_hyps_to_keep = num_beam_hyps_to_keep
- self.num_beam_groups = num_beam_groups
- self.group_size = self.num_beams // self.num_beam_groups
-
- # NOTE: TorchScript does not support List of Modules
- # Rewritten BeamHypotheses with tensors and list of tensors.
- self._done = torch.zeros(batch_size, dtype=torch.bool, device=device)
- self._beam_hyps_count = torch.zeros(batch_size, dtype=torch.long, device=device)
- self._beam_hyps_worst_scores = torch.zeros(batch_size, device=device) + 1e9
- self._beam_hyps = []
- self._beam_scores = []
-
- self._beam_hyps_max_length = max_length - 1 # ignoring bos_token
-
- if not isinstance(num_beams, int) or num_beams <= 1:
- raise ValueError(
- f"`num_beams` has to be an integer strictly greater than 1, but is {num_beams}. For `num_beams` == 1,"
- " one should make use of `greedy_search` instead."
- )
-
- if not isinstance(num_beam_groups, int) or (num_beam_groups > num_beams) or (num_beams % num_beam_groups != 0):
- raise ValueError(
- "`num_beam_groups` has to be an integer smaller or equal than `num_beams` and `num_beams` has to be"
- f" divisible by `num_beam_groups`, but is {num_beam_groups} with `num_beams` being {num_beams}."
- )
-
- def hypo_len(self, hypo_idx: int):
- """
- Number of hypotheses in the list.
- """
- return self._beam_hyps_count[hypo_idx]
-
- def hypo_add(self, hyp: torch.Tensor, sum_logprobs: float, hypo_idx: int):
- """
- Add a new hypothesis to the list.
- """
- score = sum_logprobs / (hyp.shape[-1] ** self.length_penalty)
- hyps_count = self.hypo_len(hypo_idx)
- if hyps_count < self.num_beams or score > self._beam_hyps_worst_scores[hypo_idx]:
- # NOTE: work around difference of torch.sum(empty_tensor) == 0, while error in onnx.
- # Bug: https://msdata.visualstudio.com/Vienna/_workitems/edit/1486599
- beam_idx = (
- torch.sum(self._beam_hyps_count[:hypo_idx]) if hypo_idx != 0 else torch.tensor(0, dtype=torch.long)
- )
- self._beam_scores.insert(beam_idx, torch.tensor([score]))
- self._beam_hyps.insert(beam_idx, hyp)
- if hyps_count + 1 > self.num_beams:
- sorted_next_scores, sorted_indices = torch.topk(
- torch.cat(self._beam_scores)[beam_idx : beam_idx + hyps_count + 1], hyps_count + 1, largest=False
- )
- del self._beam_hyps[int((sorted_indices[0] + beam_idx))]
- del self._beam_scores[int((sorted_indices[0] + beam_idx))]
- self._beam_hyps_worst_scores[hypo_idx] = sorted_next_scores[1]
- else:
- self._beam_hyps_worst_scores[hypo_idx] = min(score, self._beam_hyps_worst_scores[hypo_idx])
- self._beam_hyps_count[hypo_idx] = hyps_count + 1
-
- def hypo_is_done(self, hypo_idx: int, best_sum_logprobs: float, cur_len: int) -> bool:
- """
- If there are enough hypotheses and that none of the hypotheses being generated can become better than the worst
- one in the heap, then we are done with this sentence.
- """
- if self.hypo_len(hypo_idx) < self.num_beams:
- return False
- elif self.do_early_stopping:
- return True
- else:
- cur_score = best_sum_logprobs / cur_len**self.length_penalty
- ret = self._beam_hyps_worst_scores[hypo_idx].item() >= cur_score
- return ret
-
- def process(
- self,
- input_ids: torch.Tensor,
- next_scores: torch.Tensor,
- next_tokens: torch.Tensor,
- next_indices: torch.Tensor,
- pad_token_id: Optional[int] = None,
- eos_token_id: Optional[int] = None,
- ) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
- cur_len = input_ids.shape[-1]
- batch_size = len(self._beam_hyps_count)
- assert batch_size == (input_ids.shape[0] // self.group_size)
-
- device = input_ids.device
- next_beam_scores = torch.zeros((batch_size, self.group_size), dtype=next_scores.dtype, device=device)
- next_beam_tokens = torch.zeros((batch_size, self.group_size), dtype=next_tokens.dtype, device=device)
- next_beam_indices = torch.zeros((batch_size, self.group_size), dtype=next_indices.dtype, device=device)
-
- for batch_idx in range(batch_size):
- if self._done[batch_idx]:
- assert (
- self.hypo_len(batch_idx) >= self.num_beams
- ), "Batch can only be done if at least {} beams have been generated".format(self.num_beams)
- assert (
- eos_token_id is not None and pad_token_id is not None
- ), "generated beams >= num_beams -> eos_token_id and pad_token have to be defined"
- # pad the batch
- next_beam_scores[batch_idx, :] = 0
- next_beam_tokens[batch_idx, :] = pad_token_id
- next_beam_indices[batch_idx, :] = 0
- continue
-
- # next tokens for this sentence
- beam_idx = 0
- for beam_token_rank, (next_token, next_score, next_index) in enumerate(
- zip(next_tokens[batch_idx], next_scores[batch_idx], next_indices[batch_idx])
- ):
- batch_beam_idx = batch_idx * self.group_size + next_index
- # add to generated hypotheses if end of sentence
- if (eos_token_id is not None) and (next_token == eos_token_id):
- # if beam_token does not belong to top num_beams tokens, it should not be added
- is_beam_token_worse_than_top_num_beams = beam_token_rank >= self.group_size
- if is_beam_token_worse_than_top_num_beams:
- continue
- self.hypo_add(
- input_ids[batch_beam_idx].clone(),
- next_score.item(),
- batch_idx,
- )
- else:
- # add next predicted token since it is not eos_token
- next_beam_scores[batch_idx, beam_idx] = next_score
- next_beam_tokens[batch_idx, beam_idx] = next_token
- next_beam_indices[batch_idx, beam_idx] = batch_beam_idx
- beam_idx += 1
-
- # once the beam for next step is full, don't add more tokens to it.
- if beam_idx == self.group_size:
- break
-
- if beam_idx < self.group_size:
- raise ValueError(
- f"At most {self.group_size} tokens in {next_tokens[batch_idx]} can be equal to `eos_token_id:"
- f" {eos_token_id}`. Make sure {next_tokens[batch_idx]} are corrected."
- )
-
- # Check if we are done so that we can save a pad step if all(done)
- self._done[batch_idx] = self._done[batch_idx] or self.hypo_is_done(
- batch_idx,
- next_scores[batch_idx].max().item(),
- cur_len,
- )
-
- return next_beam_scores.view(-1), next_beam_tokens.view(-1), next_beam_indices.view(-1)
-
- def finalize(
- self,
- input_ids: torch.Tensor,
- final_beam_scores: torch.Tensor,
- final_beam_tokens: torch.Tensor,
- final_beam_indices: torch.Tensor,
- pad_token_id: int,
- eos_token_id: int,
- ) -> Tuple[torch.Tensor, torch.Tensor]:
- batch_size = len(self._beam_hyps_count)
-
- # finalize all open beam hypotheses and add to generated hypotheses
- for batch_idx in range(batch_size):
- if self._done[batch_idx]:
- continue
-
- # all open beam hypotheses are added to the beam hypothesis
- # beam hypothesis class automatically keeps the best beams
- for beam_id in range(self.num_beams):
- batch_beam_idx = batch_idx * self.num_beams + beam_id
- final_score = final_beam_scores[batch_beam_idx].item()
- final_tokens = input_ids[batch_beam_idx]
- self.hypo_add(final_tokens, final_score, batch_idx)
-
- # select the best hypotheses
- # NOTE: torch.Tensor.new_zeros() is not scriptable
- sent_lengths = torch.zeros(batch_size * self.num_beam_hyps_to_keep, dtype=torch.long)
- best = []
- best_scores = torch.zeros(
- batch_size * self.num_beam_hyps_to_keep, device=input_ids.device, dtype=torch.float32
- )
- # retrieve best hypotheses
- for i in range(batch_size):
- # NOTE: lambda is not scriptable
- batch_hypo_start = torch.sum(self._beam_hyps_count[:i]) if i > 0 else torch.tensor(0, dtype=torch.long)
- batch_hypo_end = torch.sum(self._beam_hyps_count[: i + 1])
- beam_scores = torch.cat(self._beam_scores)[batch_hypo_start:batch_hypo_end]
- sorted_next_scores, sorted_indices = torch.topk(beam_scores, len(beam_scores), largest=True)
- for j in range(self.num_beam_hyps_to_keep):
- best_score = beam_scores[sorted_indices[j]]
- best_hyp = self._beam_hyps[batch_hypo_start + sorted_indices[j]]
- sent_lengths[self.num_beam_hyps_to_keep * i + j] = len(best_hyp)
- # append to lists
- best.append(best_hyp)
- best_scores[i * self.num_beam_hyps_to_keep + j] = best_score
-
- # prepare for adding eos
- sent_max_len = min(sent_lengths.max() + 1, self.max_length)
- decoded = torch.zeros(batch_size * self.num_beam_hyps_to_keep, sent_max_len, dtype=torch.long)
- # shorter batches are padded if needed
- if sent_lengths.min() != sent_lengths.max():
- assert pad_token_id is not None, "`pad_token_id` has to be defined"
- decoded.fill_(pad_token_id)
-
- # fill with hypotheses and eos_token_id if the latter fits in
- for i, hypo in enumerate(best):
- decoded[i, : sent_lengths[i]] = hypo
- if sent_lengths[i] < self.max_length:
- decoded[i, sent_lengths[i]] = eos_token_id
-
- return decoded, best_scores
-
-
-class BARTBeamSearchGenerator(BARTGenerator):
- def __init__(self, model):
- super().__init__(model)
- self.beam_scorer = BeamSearchScorerTS()
- self.device = model.device
-
- @staticmethod
- def _expand_inputs_for_generation(
- input_ids: torch.Tensor,
- attention_mask: torch.Tensor,
- last_hidden_state: torch.Tensor,
- expand_size: int = 1,
- ) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
- expanded_return_idx = (
- torch.arange(input_ids.shape[0]).view(-1, 1).repeat(1, expand_size).view(-1).to(input_ids.device)
- )
- input_ids = input_ids.index_select(0, expanded_return_idx)
-
- attention_mask = attention_mask.index_select(0, expanded_return_idx)
-
- last_hidden_state = last_hidden_state.index_select(0, expanded_return_idx.to(last_hidden_state.device))
- return input_ids, attention_mask, last_hidden_state
-
- def adjust_logits_during_generation(self, logits, cur_len: int, max_length: int):
- if cur_len == 1 and self.config.force_bos_token_to_be_generated:
- logits = self._force_token_id_to_be_generated(logits, self.config.bos_token_id)
- elif cur_len == max_length - 1 and self.config.eos_token_id is not None:
- logits = self._force_token_id_to_be_generated(logits, self.config.eos_token_id)
- return logits
-
- @staticmethod
- def _force_token_id_to_be_generated(scores, token_id: int):
- """force one of token_ids to be generated by setting prob of all other tokens to 0 (logprob=-float("inf"))"""
- mask = torch.full_like(scores, 1, dtype=torch.bool)
- mask[:, token_id] = False
- return scores.masked_fill(mask, -float("inf"))
-
- def _reorder_cache(self, past: List[torch.Tensor], beam_idx):
- # if decoder past is not included in output
- # speedy decoding is disabled and no need to reorder
- reordered_decoder_past = []
- for state in past:
- reordered_decoder_past.append(state.index_select(0, beam_idx))
- return reordered_decoder_past
-
- def beam_search(
- self, input_ids, encoder_output, attention_mask, num_beams, max_length, pad_token_id: int, eos_token_id: int
- ):
- batch_size = self.beam_scorer.batch_size
-
- num_beams = self.beam_scorer.num_beams
- batch_beam_size, cur_len = input_ids.shape
-
- assert (
- num_beams * batch_size == batch_beam_size
- ), f"Batch dimension of `input_ids` should be {num_beams * batch_size}, but is {batch_beam_size}."
-
- beam_scores = torch.zeros((batch_size, num_beams), dtype=torch.float, device=input_ids.device)
- beam_scores[:, 1:] = -1e9
- beam_scores = beam_scores.view((batch_size * num_beams,))
- next_tokens = torch.zeros((batch_size, num_beams), dtype=torch.long, device=input_ids.device)
- next_indices = torch.zeros((batch_size, num_beams), dtype=torch.long, device=input_ids.device)
-
- past: List[torch.Tensor] = []
- while cur_len < max_length:
- logits, past = self._decoder_forward(input_ids, encoder_output, attention_mask, past)
- next_token_logits = logits[:, -1, :]
-
- # adjust tokens for Bart, *e.g.*
- next_token_logits = self.adjust_logits_during_generation(
- next_token_logits, cur_len=cur_len, max_length=max_length
- )
-
- next_token_scores = F.log_softmax(next_token_logits, dim=-1) # (batch_size * num_beams, vocab_size)
-
- # pre-process distribution
- next_token_scores = self.logits_processor(input_ids, next_token_scores)
- next_token_scores = next_token_scores + beam_scores[:, None].expand_as(next_token_scores)
-
- # reshape for beam search
- vocab_size = next_token_scores.shape[-1]
- next_token_scores = next_token_scores.view(batch_size, num_beams * vocab_size)
-
- next_token_scores, next_tokens = torch.topk(
- next_token_scores, 2 * num_beams, dim=1, largest=True, sorted=True
- )
-
- next_indices = next_tokens // vocab_size
- next_tokens = next_tokens % vocab_size
-
- beam_scores, beam_next_tokens, beam_idx = self.beam_scorer.process(
- input_ids,
- next_token_scores,
- next_tokens,
- next_indices,
- pad_token_id=pad_token_id,
- eos_token_id=eos_token_id,
- )
-
- input_ids = torch.cat([input_ids[beam_idx, :], beam_next_tokens.unsqueeze(-1)], dim=-1)
-
- cur_len = cur_len + 1
-
- if len(past) > 0:
- past = self._reorder_cache(past, beam_idx)
-
- if self.beam_scorer.is_done():
- break
-
- sequences, sequence_scores = self.beam_scorer.finalize(
- input_ids,
- beam_scores,
- next_tokens,
- next_indices,
- pad_token_id=pad_token_id,
- eos_token_id=eos_token_id,
- )
-
- return sequences
-
- def forward(self, input_ids, attention_mask, num_beams, max_length, decoder_start_token_id):
- pad_token_id = self.config.pad_token_id
- bos_token_id = self.config.bos_token_id
- eos_token_id = self.config.eos_token_id
-
- # special case if pad_token_id is not defined
- if pad_token_id is None and eos_token_id is not None:
- # logger.warning(f"Setting `pad_token_id` to `eos_token_id`:{eos_token_id} for open-end generation.")
- pad_token_id = eos_token_id
-
- encoder_output = self._encoder_forward(input_ids, attention_mask)
-
- input_ids = self._prepare_decoder_input_ids_for_generation(
- input_ids,
- decoder_start_token_id=decoder_start_token_id,
- bos_token_id=bos_token_id,
- )
-
- batch_size = input_ids.shape[0]
-
- length_penalty = self.config.length_penalty
- num_return_sequences = self.config.num_return_sequences
- early_stopping = True
-
- self.beam_scorer.init(
- batch_size=batch_size,
- max_length=max_length,
- num_beams=num_beams,
- device=self.device,
- length_penalty=length_penalty,
- do_early_stopping=early_stopping,
- num_beam_hyps_to_keep=num_return_sequences,
- )
-
- input_ids, attention_mask, encoder_output = self._expand_inputs_for_generation(
- input_ids,
- attention_mask,
- encoder_output,
- expand_size=num_beams,
- )
-
- return self.beam_search(
- input_ids=input_ids,
- encoder_output=encoder_output,
- attention_mask=attention_mask,
- num_beams=num_beams,
- max_length=max_length,
- pad_token_id=pad_token_id,
- eos_token_id=eos_token_id,
- )
diff --git a/examples/research_projects/onnx/summarization/bart_onnx/reduce_onnx_size.py b/examples/research_projects/onnx/summarization/bart_onnx/reduce_onnx_size.py
deleted file mode 100644
index 1df20e4504d..00000000000
--- a/examples/research_projects/onnx/summarization/bart_onnx/reduce_onnx_size.py
+++ /dev/null
@@ -1,121 +0,0 @@
-"""
-Code to remove duplicate initializers to reduce ONNX model size.
-"""
-
-import os
-
-import numpy
-import onnx
-
-
-def _is_equal_tensor_proto(a, b):
- name_a = a.name
- name_b = b.name
-
- a.name = ""
- b.name = ""
-
- res = a == b
-
- a.name = name_a
- b.name = name_b
-
- return res
-
-
-def _node_replace_input_with(node_proto, name, new_name):
- for i, input_name in enumerate(node_proto.input):
- if input_name == name:
- node_proto.input.insert(i, new_name)
- node_proto.input.pop(i + 1)
-
- if node_proto.op_type == "If":
- _graph_replace_input_with(node_proto.attribute[0].g, name, new_name)
- _graph_replace_input_with(node_proto.attribute[1].g, name, new_name)
- if node_proto.op_type == "Loop":
- _graph_replace_input_with(node_proto.attribute[0].g, name, new_name)
-
-
-def _graph_replace_input_with(graph_proto, name, new_name):
- for n in graph_proto.node:
- _node_replace_input_with(n, name, new_name)
-
-
-def _remove_dup_initializers_from_model(model, model_without_ext, ind_to_replace):
- inits_with_data = list(model.graph.initializer)
- inits = list(model_without_ext.graph.initializer)
- for i, ref_i in ind_to_replace:
- assert inits_with_data[i].name == inits[i].name
- assert inits_with_data[ref_i].name == inits[ref_i].name
- assert i > ref_i
-
- name_i = inits[i].name
- name_ref = inits[ref_i].name
-
- model_without_ext.graph.initializer.remove(inits[i])
-
- # for n in model.graph.node:
- _graph_replace_input_with(model_without_ext.graph, name_i, name_ref)
-
-
-def remove_dup_initializers(onnx_file_path):
- """
- Removes duplicate initializers from the model to reduce its size.
- Writes a new file in the same directory as onnx_file_path and returns the path to that file.
- """
-
- model_file_folder = os.path.dirname(onnx_file_path)
- model_file_name = os.path.basename(onnx_file_path)
-
- model = onnx.load(os.path.join(model_file_folder, model_file_name))
-
- inits = list(model.graph.initializer)
-
- dup_set = set()
- dup_map = {}
- ind_to_replace = []
-
- total_reduced_size = 0
-
- for i in range(len(inits)):
- if i in dup_set:
- continue
-
- for j in range(i + 1, len(inits)):
- if j in dup_set:
- continue
- if _is_equal_tensor_proto(inits[i], inits[j]):
- dup_set.add(i)
- dup_set.add(j)
-
- dtype = inits[j].data_type
- mem_size = numpy.prod(inits[j].dims)
- if dtype == 1:
- mem_size *= 4
- elif dtype == 6:
- mem_size *= 4
- elif dtype == 7 or dtype == 11:
- mem_size *= 8
- else:
- print("unexpected data type: ", dtype)
- total_reduced_size += mem_size
-
- name_i = inits[i].name
- name_j = inits[j].name
-
- if name_i in dup_map:
- dup_map[name_i].append(name_j)
- else:
- dup_map[name_i] = [name_j]
- ind_to_replace.append((j, i))
-
- print("total reduced size: ", total_reduced_size / 1024 / 1024 / 1024, "GB")
-
- ind_to_replace = sorted(ind_to_replace)
- _remove_dup_initializers_from_model(model, model, ind_to_replace)
-
- optimized_model_file_name = "optimized_" + model_file_name
- new_model = os.path.join(model_file_folder, optimized_model_file_name)
- onnx.save(model, new_model)
-
- return new_model
diff --git a/examples/research_projects/onnx/summarization/requirements.txt b/examples/research_projects/onnx/summarization/requirements.txt
deleted file mode 100644
index 21535650612..00000000000
--- a/examples/research_projects/onnx/summarization/requirements.txt
+++ /dev/null
@@ -1 +0,0 @@
-torch >= 1.10
\ No newline at end of file
diff --git a/examples/research_projects/onnx/summarization/run_onnx_exporter.py b/examples/research_projects/onnx/summarization/run_onnx_exporter.py
deleted file mode 100644
index fa826732701..00000000000
--- a/examples/research_projects/onnx/summarization/run_onnx_exporter.py
+++ /dev/null
@@ -1,206 +0,0 @@
-#!/usr/bin/env python
-# coding=utf-8
-# Copyright The HuggingFace Team and The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-""" """
-
-import argparse
-import logging
-import os
-import sys
-
-import numpy as np
-import onnxruntime
-import torch
-from bart_onnx.generation_onnx import BARTBeamSearchGenerator
-from bart_onnx.reduce_onnx_size import remove_dup_initializers
-
-import transformers
-from transformers import BartForConditionalGeneration, BartTokenizer
-
-
-logging.basicConfig(
- format="%(asctime)s | %(levelname)s | %(name)s | [%(filename)s:%(lineno)d] %(message)s",
- datefmt="%Y-%m-%d %H:%M:%S",
- level=os.environ.get("LOGLEVEL", "INFO").upper(),
- stream=sys.stdout,
-)
-
-logger = logging.getLogger(__name__)
-
-model_dict = {"facebook/bart-base": BartForConditionalGeneration}
-tokenizer_dict = {"facebook/bart-base": BartTokenizer}
-
-
-def parse_args():
- parser = argparse.ArgumentParser(description="Export Bart model + Beam Search to ONNX graph.")
- parser.add_argument(
- "--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
- )
- parser.add_argument(
- "--max_length",
- type=int,
- default=5,
- help="The maximum total input sequence length after tokenization.",
- )
- parser.add_argument(
- "--num_beams",
- type=int,
- default=None,
- help=(
- "Number of beams to use for evaluation. This argument will be "
- "passed to ``model.generate``, which is used during ``evaluate`` and ``predict``."
- ),
- )
- parser.add_argument(
- "--model_name_or_path",
- type=str,
- help="Path to pretrained model or model identifier from huggingface.co/models.",
- required=True,
- )
- parser.add_argument(
- "--config_name",
- type=str,
- default=None,
- help="Pretrained config name or path if not the same as model_name",
- )
- parser.add_argument(
- "--device",
- type=str,
- default="cpu",
- help="Device where the model will be run",
- )
- parser.add_argument("--output_file_path", type=str, default=None, help="Where to store the final ONNX file.")
-
- args = parser.parse_args()
-
- return args
-
-
-def load_model_tokenizer(model_name, device="cpu"):
- huggingface_model = model_dict[model_name].from_pretrained(model_name).to(device)
- tokenizer = tokenizer_dict[model_name].from_pretrained(model_name)
-
- if model_name in ["facebook/bart-base"]:
- huggingface_model.config.no_repeat_ngram_size = 0
- huggingface_model.config.forced_bos_token_id = None
- huggingface_model.config.min_length = 0
-
- return huggingface_model, tokenizer
-
-
-def export_and_validate_model(model, tokenizer, onnx_file_path, num_beams, max_length):
- model.eval()
-
- ort_sess = None
- bart_script_model = torch.jit.script(BARTBeamSearchGenerator(model))
-
- with torch.no_grad():
- ARTICLE_TO_SUMMARIZE = "My friends are cool but they eat too many carbs."
- inputs = tokenizer([ARTICLE_TO_SUMMARIZE], max_length=1024, return_tensors="pt").to(model.device)
-
- summary_ids = model.generate(
- inputs["input_ids"],
- attention_mask=inputs["attention_mask"],
- num_beams=num_beams,
- max_length=max_length,
- early_stopping=True,
- decoder_start_token_id=model.config.decoder_start_token_id,
- )
-
- torch.onnx.export(
- bart_script_model,
- (
- inputs["input_ids"],
- inputs["attention_mask"],
- num_beams,
- max_length,
- model.config.decoder_start_token_id,
- ),
- onnx_file_path,
- opset_version=14,
- input_names=["input_ids", "attention_mask", "num_beams", "max_length", "decoder_start_token_id"],
- output_names=["output_ids"],
- dynamic_axes={
- "input_ids": {0: "batch", 1: "seq"},
- "output_ids": {0: "batch", 1: "seq_out"},
- },
- example_outputs=summary_ids,
- )
-
- logger.info("Model exported to {}".format(onnx_file_path))
-
- new_onnx_file_path = remove_dup_initializers(os.path.abspath(onnx_file_path))
-
- logger.info("Deduplicated and optimized model written to {}".format(new_onnx_file_path))
-
- ort_sess = onnxruntime.InferenceSession(new_onnx_file_path)
- ort_out = ort_sess.run(
- None,
- {
- "input_ids": inputs["input_ids"].cpu().numpy(),
- "attention_mask": inputs["attention_mask"].cpu().numpy(),
- "num_beams": np.array(num_beams),
- "max_length": np.array(max_length),
- "decoder_start_token_id": np.array(model.config.decoder_start_token_id),
- },
- )
-
- np.testing.assert_allclose(summary_ids.cpu().numpy(), ort_out[0], rtol=1e-3, atol=1e-3)
-
- logger.info("Model outputs from torch and ONNX Runtime are similar.")
- logger.info("Success.")
-
-
-def main():
- args = parse_args()
- max_length = 5
- num_beams = 4
-
- # Make one log on every process with the configuration for debugging.
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- level=logging.INFO,
- )
-
- logger.setLevel(logging.INFO)
- transformers.utils.logging.set_verbosity_error()
-
- device = torch.device(args.device)
-
- model, tokenizer = load_model_tokenizer(args.model_name_or_path, device)
-
- if model.config.decoder_start_token_id is None:
- raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
-
- model.to(device)
-
- if args.max_length:
- max_length = args.max_length
-
- if args.num_beams:
- num_beams = args.num_beams
-
- if args.output_file_path:
- output_name = args.output_file_path
- else:
- output_name = "BART.onnx"
-
- logger.info("Exporting model to ONNX")
- export_and_validate_model(model, tokenizer, output_name, num_beams, max_length)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/performer/README.md b/examples/research_projects/performer/README.md
deleted file mode 100644
index fa847268b0c..00000000000
--- a/examples/research_projects/performer/README.md
+++ /dev/null
@@ -1,25 +0,0 @@
-# Performer fine-tuning
-
-Example authors: @TevenLeScao, @Patrickvonplaten
-
-Paper authors: Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, David Belanger, Lucy Colwell, Adrian Weller
-
-## Requirements
-
-`datasets`, `flax` and `jax`. `wandb` integration is built-in if you want to use it.
-
-## Examples
-
-`sanity_script.sh` will launch performer fine-tuning from the google-bert/bert-base-cased checkpoint on the Simple Wikipedia dataset (a small, easy-language English Wikipedia) from `datasets`.
-`full_script.sh` will launch performer fine-tuning from the google-bert/bert-large-cased checkpoint on the English Wikipedia dataset from `datasets`.
-
-Here are a few key arguments:
-- Remove the `--performer` argument to use a standard Bert model.
-
-- Add `--reinitialize` to start from a blank model rather than a Bert checkpoint.
-
-- You may change the Bert size by passing a different [checkpoint](https://huggingface.co/transformers/pretrained_models.html) to the `--model_name_or_path` argument.
-
-- Passing your user name to the `--wandb_user_name` argument will trigger weights and biases logging.
-
-- You can choose a dataset with `--dataset_name` and `--dataset_config`. Our [viewer](https://huggingface.co/datasets/viewer/) will help you find what you need.
\ No newline at end of file
diff --git a/examples/research_projects/performer/full_script.sh b/examples/research_projects/performer/full_script.sh
deleted file mode 100755
index 8634666f983..00000000000
--- a/examples/research_projects/performer/full_script.sh
+++ /dev/null
@@ -1 +0,0 @@
-TOKENIZERS_PARALLELISM=true python run_mlm_performer.py --output_dir experiments --dataset_name wikipedia --dataset_config_name 20200501.en --model_name_or_path bert-large-cased --tokenizer_name bert-large-cased --do_train --overwrite_output_dir --per_device_train_batch_size 4 --learning_rate 5e-4 --warmup_steps 100 --num_train_epochs 3 --performer
\ No newline at end of file
diff --git a/examples/research_projects/performer/modeling_flax_performer.py b/examples/research_projects/performer/modeling_flax_performer.py
deleted file mode 100644
index 7c2fde6ddbb..00000000000
--- a/examples/research_projects/performer/modeling_flax_performer.py
+++ /dev/null
@@ -1,551 +0,0 @@
-# coding=utf-8
-# Copyright 2018 The Google Flax Team Authors and The HuggingFace Inc. team.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-from typing import Callable, Dict, Tuple
-
-import flax.linen as nn
-import jax
-import jax.numpy as jnp
-import numpy as np
-from jax.random import PRNGKey
-from modeling_flax_performer_utils import make_fast_softmax_attention
-
-from transformers.file_utils import add_start_docstrings
-from transformers.modeling_flax_utils import ACT2FN
-from transformers.models.bert.configuration_bert import BertConfig
-from transformers.models.bert.modeling_flax_bert import FlaxBertOnlyMLMHead, FlaxBertPreTrainedModel
-from transformers.utils import logging
-
-
-logger = logging.get_logger(__name__)
-
-_CONFIG_FOR_DOC = "BertConfig"
-_TOKENIZER_FOR_DOC = "BertTokenizer"
-
-BERT_START_DOCSTRING = r"""
-
- This model inherits from :class:`~transformers.PreTrainedModel`. Check the superclass documentation for the generic
- methods the library implements for all its model (such as downloading or saving, resizing the input embeddings,
- pruning heads etc.)
-
- This model is also a PyTorch `torch.nn.Module `__
- subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to
- general usage and behavior.
-
- Parameters:
- config (:class:`~transformers.BertConfig`): Model configuration class with all the parameters of the model.
- Initializing with a config file does not load the weights associated with the model, only the
- configuration. Check out the :meth:`~transformers.PreTrainedModel.from_pretrained` method to load the model
- weights.
-"""
-
-BERT_INPUTS_DOCSTRING = r"""
- Args:
- input_ids (:obj:`torch.LongTensor` of shape :obj:`({0})`):
- Indices of input sequence tokens in the vocabulary.
-
- Indices can be obtained using :class:`~transformers.BertTokenizer`. See
- :meth:`transformers.PreTrainedTokenizer.encode` and :meth:`transformers.PreTrainedTokenizer.__call__` for
- details.
-
- `What are input IDs? <../glossary.html#input-ids>`__
- attention_mask (:obj:`torch.FloatTensor` of shape :obj:`({0})`, `optional`):
- Mask to avoid performing attention on padding token indices. Mask values selected in ``[0, 1]``:
-
- - 1 for tokens that are **not masked**,
- - 0 for tokens that are **masked**.
-
- `What are attention masks? <../glossary.html#attention-mask>`__
- token_type_ids (:obj:`torch.LongTensor` of shape :obj:`({0})`, `optional`):
- Segment token indices to indicate first and second portions of the inputs. Indices are selected in ``[0,
- 1]``:
-
- - 0 corresponds to a `sentence A` token,
- - 1 corresponds to a `sentence B` token.
-
- `What are token type IDs? <../glossary.html#token-type-ids>`_
- position_ids (:obj:`torch.LongTensor` of shape :obj:`({0})`, `optional`):
- Indices of positions of each input sequence tokens in the position embeddings. Selected in the range ``[0,
- config.max_position_embeddings - 1]``.
-
- `What are position IDs? <../glossary.html#position-ids>`_
- head_mask (:obj:`torch.FloatTensor` of shape :obj:`(num_heads,)` or :obj:`(num_layers, num_heads)`, `optional`):
- Mask to nullify selected heads of the self-attention modules. Mask values selected in ``[0, 1]``:
-
- - 1 indicates the head is **not masked**,
- - 0 indicates the head is **masked**.
-
- inputs_embeds (:obj:`torch.FloatTensor` of shape :obj:`({0}, hidden_size)`, `optional`):
- Optionally, instead of passing :obj:`input_ids` you can choose to directly pass an embedded representation.
- This is useful if you want more control over how to convert :obj:`input_ids` indices into associated
- vectors than the model's internal embedding lookup matrix.
- output_attentions (:obj:`bool`, `optional`):
- Whether or not to return the attentions tensors of all attention layers. See ``attentions`` under returned
- tensors for more detail.
- output_hidden_states (:obj:`bool`, `optional`):
- Whether or not to return the hidden states of all layers. See ``hidden_states`` under returned tensors for
- more detail.
- return_dict (:obj:`bool`, `optional`):
- Whether or not to return a :class:`~transformers.file_utils.ModelOutput` instead of a plain tuple.
-"""
-
-
-class FlaxPerformerLayerNorm(nn.Module):
- """
- Layer normalization (https://arxiv.org/abs/1607.06450). Operates on the last axis of the input data.
- """
-
- epsilon: float = 1e-6
- dtype: jnp.dtype = jnp.float32 # the dtype of the computation
- bias: bool = True # If True, bias (beta) is added.
- scale: bool = True # If True, multiply by scale (gamma). When the next layer is linear
- # (also e.g. nn.relu), this can be disabled since the scaling will be
- # done by the next layer.
- bias_init: jnp.ndarray = nn.initializers.zeros
- scale_init: jnp.ndarray = nn.initializers.ones
-
- @nn.compact
- def __call__(self, x):
- """
- Applies layer normalization on the input. It normalizes the activations of the layer for each given example in
- a batch independently, rather than across a batch like Batch Normalization. i.e. applies a transformation that
- maintains the mean activation within each example close to 0 and the activation standard deviation close to 1
-
- Args:
- x: the inputs
-
- Returns:
- Normalized inputs (the same shape as inputs).
- """
- features = x.shape[-1]
- mean = jnp.mean(x, axis=-1, keepdims=True)
- mean2 = jnp.mean(jax.lax.square(x), axis=-1, keepdims=True)
- var = mean2 - jax.lax.square(mean)
- mul = jax.lax.rsqrt(var + self.epsilon)
- if self.scale:
- mul = mul * jnp.asarray(self.param("gamma", self.scale_init, (features,)), self.dtype)
- y = (x - mean) * mul
- if self.bias:
- y = y + jnp.asarray(self.param("beta", self.bias_init, (features,)), self.dtype)
- return y
-
-
-class FlaxPerformerEmbedding(nn.Module):
- """
- Specify a new class for doing the embedding stuff as Flax's one use 'embedding' for the parameter name and PyTorch
- use 'weight'
- """
-
- vocab_size: int
- hidden_size: int
- emb_init: Callable[..., np.ndarray] = nn.initializers.normal(stddev=0.1)
-
- @nn.compact
- def __call__(self, inputs):
- embedding = self.param("weight", self.emb_init, (self.vocab_size, self.hidden_size))
- return jnp.take(embedding, inputs, axis=0)
-
-
-class FlaxPerformerEmbeddings(nn.Module):
- """Construct the embeddings from word, position and token_type embeddings."""
-
- vocab_size: int
- hidden_size: int
- type_vocab_size: int
- max_length: int
-
- @nn.compact
- def __call__(self, input_ids, token_type_ids, position_ids, attention_mask):
- # Embed
- w_emb = FlaxPerformerEmbedding(self.vocab_size, self.hidden_size, name="word_embeddings")(
- jnp.atleast_2d(input_ids.astype("i4"))
- )
- p_emb = FlaxPerformerEmbedding(self.max_length, self.hidden_size, name="position_embeddings")(
- jnp.atleast_2d(position_ids.astype("i4"))
- )
- t_emb = FlaxPerformerEmbedding(self.type_vocab_size, self.hidden_size, name="token_type_embeddings")(
- jnp.atleast_2d(token_type_ids.astype("i4"))
- )
-
- # Sum all embeddings
- summed_emb = w_emb + jnp.broadcast_to(p_emb, w_emb.shape) + t_emb
-
- # Layer Norm
- layer_norm = FlaxPerformerLayerNorm(name="layer_norm")(summed_emb)
-
- return layer_norm
-
-
-class FlaxPerformerAttention(nn.Module):
- num_heads: int
- head_size: int
-
- @nn.compact
- def __call__(self, hidden_state, attention_mask):
- single_head_dim = self.head_size // self.num_heads
- fast_softmax_attention = make_fast_softmax_attention(qkv_dim=single_head_dim)
- self_att = nn.attention.SelfAttention(
- num_heads=self.num_heads, qkv_features=self.head_size, name="self", attention_fn=fast_softmax_attention
- )(hidden_state, attention_mask)
-
- layer_norm = FlaxPerformerLayerNorm(name="layer_norm")(self_att + hidden_state)
- return layer_norm
-
-
-class FlaxPerformerIntermediate(nn.Module):
- output_size: int
- hidden_act: str = "gelu"
-
- @nn.compact
- def __call__(self, hidden_state):
- # TODO: Add ACT2FN reference to change activation function
- dense = nn.Dense(features=self.output_size, name="dense")(hidden_state)
- return ACT2FN[self.hidden_act](dense)
-
-
-class FlaxPerformerOutput(nn.Module):
- @nn.compact
- def __call__(self, intermediate_output, attention_output):
- hidden_state = nn.Dense(attention_output.shape[-1], name="dense")(intermediate_output)
- hidden_state = FlaxPerformerLayerNorm(name="layer_norm")(hidden_state + attention_output)
- return hidden_state
-
-
-class FlaxPerformerLayer(nn.Module):
- num_heads: int
- head_size: int
- intermediate_size: int
- hidden_act: str = "gelu"
-
- @nn.compact
- def __call__(self, hidden_state, attention_mask):
- attention = FlaxPerformerAttention(self.num_heads, self.head_size, name="attention")(
- hidden_state, attention_mask
- )
- intermediate = FlaxPerformerIntermediate(
- self.intermediate_size, name="intermediate", hidden_act=self.hidden_act
- )(attention)
- output = FlaxPerformerOutput(name="output")(intermediate, attention)
-
- return output
-
-
-class FlaxPerformerLayerCollection(nn.Module):
- """
- Stores N BertLayer(s)
- """
-
- num_layers: int
- num_heads: int
- head_size: int
- intermediate_size: int
- hidden_act: str = "gelu"
-
- @nn.compact
- def __call__(self, inputs, attention_mask):
- assert self.num_layers > 0, f"num_layers should be >= 1, got ({self.num_layers})"
-
- # Initialize input / output
- input_i = inputs
-
- # Forward over all encoders
- for i in range(self.num_layers):
- layer = FlaxPerformerLayer(
- self.num_heads, self.head_size, self.intermediate_size, hidden_act=self.hidden_act, name=f"{i}"
- )
- input_i = layer(input_i, attention_mask)
- return input_i
-
-
-class FlaxPerformerEncoder(nn.Module):
- num_layers: int
- num_heads: int
- head_size: int
- intermediate_size: int
- hidden_act: str = "gelu"
-
- @nn.compact
- def __call__(self, hidden_state, attention_mask):
- layer = FlaxPerformerLayerCollection(
- self.num_layers,
- self.num_heads,
- self.head_size,
- self.intermediate_size,
- name="layer",
- hidden_act=self.hidden_act,
- )(hidden_state, attention_mask)
- return layer
-
-
-class FlaxPerformerPooler(nn.Module):
- @nn.compact
- def __call__(self, hidden_state):
- cls_token = hidden_state[:, 0]
- out = nn.Dense(hidden_state.shape[-1], name="dense")(cls_token)
- return jax.lax.tanh(out)
-
-
-class FlaxPerformerModule(nn.Module):
- vocab_size: int
- hidden_size: int
- type_vocab_size: int
- max_length: int
- num_encoder_layers: int
- num_heads: int
- head_size: int
- intermediate_size: int
- hidden_act: str = "gelu"
- add_pooling_layer: bool = True
-
- @nn.compact
- def __call__(self, input_ids, token_type_ids, position_ids, attention_mask):
- # Embedding
- embeddings = FlaxPerformerEmbeddings(
- self.vocab_size, self.hidden_size, self.type_vocab_size, self.max_length, name="embeddings"
- )(input_ids, token_type_ids, position_ids, attention_mask)
-
- # N stacked encoding layers
- encoder = FlaxPerformerEncoder(
- self.num_encoder_layers,
- self.num_heads,
- self.head_size,
- self.intermediate_size,
- hidden_act=self.hidden_act,
- name="encoder",
- )(embeddings, attention_mask)
-
- if not self.add_pooling_layer:
- return encoder
-
- pooled = FlaxPerformerPooler(name="pooler")(encoder)
- return encoder, pooled
-
-
-@add_start_docstrings(
- "The bare Bert Model transformer outputting raw hidden-states without any specific head on top.",
- BERT_START_DOCSTRING,
-)
-class FlaxPerformerModel(FlaxBertPreTrainedModel):
- """
- The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
- cross-attention is added between the self-attention layers, following the architecture described in `Attention is
- all you need `__ by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
- Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
- """
-
- model_class = FlaxPerformerModule
- config_class = BertConfig
- base_model_prefix = "bert"
-
- @staticmethod
- def convert_from_pytorch(pt_state: Dict, config: BertConfig) -> Dict:
- jax_state = dict(pt_state)
-
- # Need to change some parameters name to match Flax names so that we don't have to fork any layer
- for key, tensor in pt_state.items():
- # Key parts
- key_parts = set(key.split("."))
-
- # Every dense layer has "kernel" parameters instead of "weight"
- if "dense.weight" in key:
- del jax_state[key]
- key = key.replace("weight", "kernel")
- jax_state[key] = tensor
-
- # SelfAttention needs also to replace "weight" by "kernel"
- if {"query", "key", "value"} & key_parts:
- # Flax SelfAttention decomposes the heads (num_head, size // num_heads)
- if "bias" in key:
- jax_state[key] = tensor.reshape((config.num_attention_heads, -1))
- elif "weight":
- del jax_state[key]
- key = key.replace("weight", "kernel")
- tensor = tensor.reshape((config.num_attention_heads, -1, config.hidden_size)).transpose((2, 0, 1))
- jax_state[key] = tensor
-
- # SelfAttention output is not a separate layer, remove one nesting
- if "attention.output.dense" in key:
- del jax_state[key]
- key = key.replace("attention.output.dense", "attention.self.out")
- jax_state[key] = tensor
-
- # SelfAttention output is not a separate layer, remove nesting on layer norm
- if "attention.output.LayerNorm" in key:
- del jax_state[key]
- key = key.replace("attention.output.LayerNorm", "attention.LayerNorm")
- jax_state[key] = tensor
-
- # There are some transposed parameters w.r.t their PyTorch counterpart
- if "intermediate.dense.kernel" in key or "output.dense.kernel" in key:
- jax_state[key] = tensor.T
-
- # Self Attention output projection needs to be transposed
- if "out.kernel" in key:
- jax_state[key] = tensor.reshape((config.hidden_size, config.num_attention_heads, -1)).transpose(
- 1, 2, 0
- )
-
- # Pooler needs to transpose its kernel
- if "pooler.dense.kernel" in key:
- jax_state[key] = tensor.T
-
- # Handle LayerNorm conversion
- if "LayerNorm" in key:
- del jax_state[key]
-
- # Replace LayerNorm by layer_norm
- new_key = key.replace("LayerNorm", "layer_norm")
-
- if "weight" in key:
- new_key = new_key.replace("weight", "gamma")
- elif "bias" in key:
- new_key = new_key.replace("bias", "beta")
-
- jax_state[new_key] = tensor
-
- return jax_state
-
- def __init__(
- self, config: BertConfig, input_shape: Tuple = (1, 1), seed: int = 0, dtype: jnp.dtype = jnp.float32, **kwargs
- ):
- module = FlaxPerformerModule(
- vocab_size=config.vocab_size,
- hidden_size=config.hidden_size,
- type_vocab_size=config.type_vocab_size,
- max_length=config.max_position_embeddings,
- num_encoder_layers=config.num_hidden_layers,
- num_heads=config.num_attention_heads,
- head_size=config.hidden_size,
- intermediate_size=config.intermediate_size,
- dropout_rate=config.hidden_dropout_prob,
- hidden_act=config.hidden_act,
- )
-
- super().__init__(config, module, input_shape=input_shape, seed=seed, dtype=dtype)
-
- @property
- def module(self) -> nn.Module:
- return self._module
-
- def __call__(
- self, input_ids, token_type_ids=None, position_ids=None, dropout_rng: PRNGKey = None, attention_mask=None
- ):
- input_ids, attention_mask, token_type_ids, position_ids = self._check_inputs(
- input_ids, attention_mask, token_type_ids, position_ids
- )
-
- # Handle any PRNG if needed
- rngs = {}
- if dropout_rng is not None:
- rngs["dropout"] = dropout_rng
-
- return self.module.apply(
- {"params": self.params},
- jnp.array(input_ids, dtype="i4"),
- jnp.array(token_type_ids, dtype="i4"),
- jnp.array(position_ids, dtype="i4"),
- jnp.array(attention_mask, dtype="i4"),
- rng=rngs,
- )
-
-
-class FlaxPerformerForMaskedLM(FlaxBertPreTrainedModel):
- def __init__(
- self, config: BertConfig, input_shape: Tuple = (1, 1), seed: int = 0, dtype: jnp.dtype = jnp.float32, **kwargs
- ):
- module = FlaxPerformerForMaskedLMModule(
- vocab_size=config.vocab_size,
- type_vocab_size=config.type_vocab_size,
- hidden_size=config.hidden_size,
- intermediate_size=config.intermediate_size,
- head_size=config.hidden_size,
- num_heads=config.num_attention_heads,
- num_encoder_layers=config.num_hidden_layers,
- max_length=config.max_position_embeddings,
- hidden_act=config.hidden_act,
- **kwargs,
- )
-
- super().__init__(config, module, input_shape=input_shape, seed=seed, dtype=dtype)
-
- def __call__(
- self,
- input_ids,
- attention_mask=None,
- token_type_ids=None,
- position_ids=None,
- params: dict = None,
- train: bool = False,
- dropout_rng: PRNGKey = None,
- ):
- input_ids, attention_mask, token_type_ids, position_ids = self._check_inputs(
- input_ids, attention_mask, token_type_ids, position_ids
- )
-
- # Handle any PRNG if needed
- rngs = {}
- if dropout_rng is not None:
- rngs["dropout"] = dropout_rng
-
- return self.module.apply(
- {"params": params or self.params},
- jnp.array(input_ids, dtype="i4"),
- jnp.array(attention_mask, dtype="i4"),
- jnp.array(token_type_ids, dtype="i4"),
- jnp.array(position_ids, dtype="i4"),
- not train,
- rngs=rngs,
- )
-
-
-class FlaxPerformerForMaskedLMModule(nn.Module):
- vocab_size: int
- hidden_size: int
- intermediate_size: int
- head_size: int
- num_heads: int
- num_encoder_layers: int
- type_vocab_size: int
- max_length: int
- hidden_act: str
- dropout_rate: float = 0.0
- dtype: jnp.dtype = jnp.float32
-
- @nn.compact
- def __call__(
- self, input_ids, attention_mask=None, token_type_ids=None, position_ids=None, deterministic: bool = True
- ):
- # Model
- encoder = FlaxPerformerModule(
- vocab_size=self.vocab_size,
- hidden_size=self.hidden_size,
- type_vocab_size=self.type_vocab_size,
- max_length=self.max_length,
- num_encoder_layers=self.num_encoder_layers,
- num_heads=self.num_heads,
- head_size=self.hidden_size,
- intermediate_size=self.intermediate_size,
- hidden_act=self.hidden_act,
- add_pooling_layer=False,
- name="bert",
- )(input_ids, attention_mask, token_type_ids, position_ids)
-
- # Compute the prediction scores
- encoder = nn.Dropout(rate=self.dropout_rate)(encoder, deterministic=deterministic)
- logits = FlaxBertOnlyMLMHead(
- vocab_size=self.vocab_size, hidden_act=self.hidden_act, name="cls", dtype=self.dtype
- )(encoder)
-
- return (logits,)
diff --git a/examples/research_projects/performer/modeling_flax_performer_utils.py b/examples/research_projects/performer/modeling_flax_performer_utils.py
deleted file mode 100644
index c5242509381..00000000000
--- a/examples/research_projects/performer/modeling_flax_performer_utils.py
+++ /dev/null
@@ -1,658 +0,0 @@
-# coding=utf-8
-# Copyright 2020 The Google Research Authors.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""
-IMPORTANT:
-
-This code was copied from
-https://github.com/google-research/google-research/blob/master/performer/fast_self_attention/fast_self_attention.py on
-6/11/2020. This is very new code, so it might be prone to change soon -> make sure to check the original code and
-update accordingly
-
-Core Fast Attention Module for Flax. Implementation of the approximate fast softmax and generalized attention mechanism
-leveraging structured random feature maps [RFM] techniques and low rank decomposition of the attention matrix.
-"""
-# pylint: disable=invalid-name, missing-function-docstring, line-too-long
-
-import abc
-import functools
-from collections.abc import Iterable # pylint: disable=g-importing-member
-
-import jax
-import jax.numpy as jnp
-import numpy as onp
-from absl import logging
-from jax import lax, random
-
-
-def nonnegative_softmax_kernel_feature_creator(
- data, projection_matrix, attention_dims_t, batch_dims_t, precision, is_query, normalize_data=True, eps=0.0001
-):
- """
- Constructs nonnegative kernel features for fast softmax attention
-
- Args:
- data: input for which features are computes
- projection_matrix: random matrix used to compute features
- attention_dims_t: tuple of attention dimensions
- batch_dims_t: tuple of batch dimensions
- precision: precision parameter
- is_query: predicate indicating whether input data corresponds to queries or
- keys
- normalize_data: predicate indicating whether data should be normalized,
- eps: numerical stabilizer
-
- Returns:
- Random features for fast softmax attention.
- """
- del attention_dims_t
- if normalize_data:
- # We have e^{qk^T/sqrt{d}} = e^{q_norm k_norm^T}, where
- # w_norm = w * data_normalizer for w in {q,k}.
- data_normalizer = 1.0 / (jnp.sqrt(jnp.sqrt(data.shape[-1])))
- else:
- data_normalizer = 1.0
- ratio = 1.0 / jnp.sqrt(projection_matrix.shape[0])
- data_mod_shape = data.shape[0 : len(batch_dims_t)] + projection_matrix.shape
- data_thick_random_matrix = jnp.zeros(data_mod_shape) + projection_matrix
-
- data_dash = lax.dot_general(
- data_normalizer * data,
- data_thick_random_matrix,
- (((data.ndim - 1,), (data_thick_random_matrix.ndim - 1,)), (batch_dims_t, batch_dims_t)),
- precision=precision,
- )
-
- diag_data = jnp.square(data)
- diag_data = jnp.sum(diag_data, axis=data.ndim - 1)
- diag_data = (diag_data / 2.0) * data_normalizer * data_normalizer
- diag_data = jnp.expand_dims(diag_data, axis=data.ndim - 1)
-
- if is_query:
- last_dims_t = (len(data_dash.shape) - 1,)
- data_dash = ratio * (
- jnp.exp(data_dash - diag_data - jnp.max(data_dash, axis=last_dims_t, keepdims=True)) + eps
- )
- else:
- data_dash = ratio * (jnp.exp(data_dash - diag_data - jnp.max(data_dash)) + eps)
-
- return data_dash
-
-
-def sincos_softmax_kernel_feature_creator(
- data, projection_matrix, attention_dims_t, batch_dims_t, precision, normalize_data=True
-):
- """
- Constructs kernel sin-cos features for fast softmax attention
-
- Args:
- data: input for which features are computes
- projection_matrix: random matrix used to compute features
- attention_dims_t: tuple of attention dimensions
- batch_dims_t: tuple of batch dimensions
- precision: precision parameter
- normalize_data: predicate indicating whether data should be normalized
-
- Returns:
- Random features for fast softmax attention.
- """
- if normalize_data:
- # We have: exp(qk^T/sqrt{d}) = exp(|q|^2/2sqrt{d}) * exp(|k|^2/2sqrt{d}) *
- # exp(-(|q*c-k*c|^2)/2), where c = 1.0 / sqrt{sqrt{d}}.
- data_normalizer = 1.0 / (jnp.sqrt(jnp.sqrt(data.shape[-1])))
- else:
- data_normalizer = 1.0
- ratio = 1.0 / jnp.sqrt(projection_matrix.shape[0])
- data_mod_shape = data.shape[0 : len(batch_dims_t)] + projection_matrix.shape
- data_thick_random_matrix = jnp.zeros(data_mod_shape) + projection_matrix
-
- data_dash = lax.dot_general(
- data_normalizer * data,
- data_thick_random_matrix,
- (((data.ndim - 1,), (data_thick_random_matrix.ndim - 1,)), (batch_dims_t, batch_dims_t)),
- precision=precision,
- )
- data_dash_cos = ratio * jnp.cos(data_dash)
- data_dash_sin = ratio * jnp.sin(data_dash)
- data_dash = jnp.concatenate((data_dash_cos, data_dash_sin), axis=-1)
-
- # Constructing D_data and data^{'}
- diag_data = jnp.square(data)
- diag_data = jnp.sum(diag_data, axis=data.ndim - 1)
- diag_data = (diag_data / 2.0) * data_normalizer * data_normalizer
- diag_data = jnp.expand_dims(diag_data, axis=data.ndim - 1)
- # Additional renormalization for numerical stability
- data_renormalizer = jnp.max(diag_data, attention_dims_t, keepdims=True)
- diag_data -= data_renormalizer
- diag_data = jnp.exp(diag_data)
- data_prime = data_dash * diag_data
- return data_prime
-
-
-def generalized_kernel_feature_creator(
- data, projection_matrix, batch_dims_t, precision, kernel_fn, kernel_epsilon, normalize_data
-):
- """
- Constructs kernel features for fast generalized attention
-
- Args:
- data: input for which features are computes
- projection_matrix: matrix used to compute features
- batch_dims_t: tuple of batch dimensions
- precision: precision parameter
- kernel_fn: kernel function used
- kernel_epsilon: additive positive term added to every feature for numerical
- stability
- normalize_data: predicate indicating whether data should be normalized
-
- Returns:
- Random features for fast generalized attention.
- """
- if normalize_data:
- data_normalizer = 1.0 / (jnp.sqrt(jnp.sqrt(data.shape[-1])))
- else:
- data_normalizer = 1.0
- if projection_matrix is None:
- return kernel_fn(data_normalizer * data) + kernel_epsilon
- else:
- data_mod_shape = data.shape[0 : len(batch_dims_t)] + projection_matrix.shape
- data_thick_random_matrix = jnp.zeros(data_mod_shape) + projection_matrix
- data_dash = lax.dot_general(
- data_normalizer * data,
- data_thick_random_matrix,
- (((data.ndim - 1,), (data_thick_random_matrix.ndim - 1,)), (batch_dims_t, batch_dims_t)),
- precision=precision,
- )
- data_prime = kernel_fn(data_dash) + kernel_epsilon
- return data_prime
-
-
-def make_fast_softmax_attention(
- qkv_dim,
- renormalize_attention=True,
- numerical_stabilizer=0.000001,
- nb_features=256,
- ortho_features=True,
- ortho_scaling=0.0,
- redraw_features=True,
- unidirectional=False,
- nonnegative_features=True,
- lax_scan_unroll=1,
-):
- """Construct a fast softmax attention method."""
- logging.info(
- "Fast softmax attention: %s features and orthogonal=%s, renormalize=%s",
- nb_features,
- ortho_features,
- renormalize_attention,
- )
- if ortho_features:
- matrix_creator = functools.partial(GaussianOrthogonalRandomMatrix, nb_features, qkv_dim, scaling=ortho_scaling)
- else:
- matrix_creator = functools.partial(GaussianUnstructuredRandomMatrix, nb_features, qkv_dim)
- if nonnegative_features:
-
- def kernel_feature_creator(
- data, projection_matrix, attention_dims_t, batch_dims_t, precision, is_query, normalize_data=True
- ):
- return nonnegative_softmax_kernel_feature_creator(
- data,
- projection_matrix,
- attention_dims_t,
- batch_dims_t,
- precision,
- is_query,
- normalize_data,
- numerical_stabilizer,
- )
-
- else:
-
- def kernel_feature_creator(
- data, projection_matrix, attention_dims_t, batch_dims_t, precision, is_query, normalize_data=True
- ):
- del is_query
- return sincos_softmax_kernel_feature_creator(
- data, projection_matrix, attention_dims_t, batch_dims_t, precision, normalize_data
- )
-
- attention_fn = FastAttentionviaLowRankDecomposition(
- matrix_creator,
- kernel_feature_creator,
- renormalize_attention=renormalize_attention,
- numerical_stabilizer=numerical_stabilizer,
- redraw_features=redraw_features,
- unidirectional=unidirectional,
- lax_scan_unroll=lax_scan_unroll,
- ).dot_product_attention
- return attention_fn
-
-
-def make_fast_generalized_attention(
- qkv_dim,
- renormalize_attention=True,
- numerical_stabilizer=0.0,
- nb_features=256,
- features_type="deterministic",
- kernel_fn=jax.nn.relu,
- kernel_epsilon=0.001,
- redraw_features=False,
- unidirectional=False,
- lax_scan_unroll=1,
-):
- """Construct a fast generalized attention method."""
- logging.info("Fast generalized attention.: %s features and renormalize=%s", nb_features, renormalize_attention)
- if features_type == "ortho":
- matrix_creator = functools.partial(GaussianOrthogonalRandomMatrix, nb_features, qkv_dim, scaling=False)
- elif features_type == "iid":
- matrix_creator = functools.partial(GaussianUnstructuredRandomMatrix, nb_features, qkv_dim)
- elif features_type == "deterministic":
- matrix_creator = None
- else:
- raise ValueError("Unknown feature value type")
-
- def kernel_feature_creator(
- data, projection_matrix, attention_dims_t, batch_dims_t, precision, is_query, normalize_data=False
- ):
- del attention_dims_t
- del is_query
- return generalized_kernel_feature_creator(
- data, projection_matrix, batch_dims_t, precision, kernel_fn, kernel_epsilon, normalize_data
- )
-
- attention_fn = FastAttentionviaLowRankDecomposition(
- matrix_creator,
- kernel_feature_creator,
- renormalize_attention=renormalize_attention,
- numerical_stabilizer=numerical_stabilizer,
- redraw_features=redraw_features,
- unidirectional=unidirectional,
- lax_scan_unroll=lax_scan_unroll,
- ).dot_product_attention
- return attention_fn
-
-
-class RandomMatrix:
- r"""
- Abstract class providing a method for constructing 2D random arrays. Class is responsible for constructing 2D
- random arrays.
- """
-
- __metaclass__ = abc.ABCMeta
-
- @abc.abstractmethod
- def get_2d_array(self):
- raise NotImplementedError("Abstract method")
-
-
-class GaussianUnstructuredRandomMatrix(RandomMatrix):
- def __init__(self, nb_rows, nb_columns, key):
- self.nb_rows = nb_rows
- self.nb_columns = nb_columns
- self.key = key
-
- def get_2d_array(self):
- return random.normal(self.key, (self.nb_rows, self.nb_columns))
-
-
-class GaussianOrthogonalRandomMatrix(RandomMatrix):
- r"""
- Class providing a method to create Gaussian orthogonal matrix. Class is responsible for constructing 2D Gaussian
- orthogonal arrays.
- """
-
- def __init__(self, nb_rows, nb_columns, key, scaling=0):
- self.nb_rows = nb_rows
- self.nb_columns = nb_columns
- self.key = key
- self.scaling = scaling
-
- def get_2d_array(self):
- nb_full_blocks = int(self.nb_rows / self.nb_columns)
- block_list = []
- rng = self.key
- for _ in range(nb_full_blocks):
- rng, rng_input = jax.random.split(rng)
- unstructured_block = random.normal(rng_input, (self.nb_columns, self.nb_columns))
- q, _ = jnp.linalg.qr(unstructured_block)
- q = jnp.transpose(q)
- block_list.append(q)
- remaining_rows = self.nb_rows - nb_full_blocks * self.nb_columns
- if remaining_rows > 0:
- rng, rng_input = jax.random.split(rng)
- unstructured_block = random.normal(rng_input, (self.nb_columns, self.nb_columns))
- q, _ = jnp.linalg.qr(unstructured_block)
- q = jnp.transpose(q)
- block_list.append(q[0:remaining_rows])
- final_matrix = jnp.vstack(block_list)
-
- if self.scaling == 0:
- multiplier = jnp.linalg.norm(random.normal(self.key, (self.nb_rows, self.nb_columns)), axis=1)
- elif self.scaling == 1:
- multiplier = jnp.sqrt(float(self.nb_columns)) * jnp.ones((self.nb_rows))
- else:
- raise ValueError("Scaling must be one of {0, 1}. Was %s" % self._scaling)
-
- return jnp.matmul(jnp.diag(multiplier), final_matrix)
-
-
-class FastAttention:
- r"""
- Abstract class providing a method for fast attention. Class is responsible for providing a method
- for fast approximate attention.
- """
-
- __metaclass__ = abc.ABCMeta
-
- @abc.abstractmethod
- def dot_product_attention(
- self,
- query,
- key,
- value,
- dtype=jnp.float32,
- bias=None,
- axis=None,
- broadcast_dropout=True,
- dropout_rng=None,
- dropout_rate=0.0,
- deterministic=False,
- precision=None,
- ):
- """
- Computes dot-product attention given query, key, and value. This is the core function for applying fast
- approximate dot-product attention. It calculates the attention weights given query and key and combines the
- values using the attention weights. This function supports multi-dimensional inputs
-
- Args:
- query: queries for calculating attention with shape of [batch_size, dim1,
- dim2, ..., dimN, num_heads, mem_channels].
- key: keys for calculating attention with shape of [batch_size, dim1, dim2,
- ..., dimN, num_heads, mem_channels].
- value: values to be used in attention with shape of [batch_size, dim1,
- dim2,..., dimN, num_heads, value_channels].
- dtype: the dtype of the computation (default: float32)
- bias: bias for the attention weights. This can be used for incorporating
- autoregressive mask, padding mask, proximity bias.
- axis: axises over which the attention is applied.
- broadcast_dropout: bool: use a broadcasted dropout along batch dims.
- dropout_rng: JAX PRNGKey: to be used for dropout.
- dropout_rate: dropout rate.
- deterministic: bool, deterministic or not (to apply dropout).
- precision: numerical precision of the computation see `jax.lax.Precision`
- for details
-
- Returns:
- Output of shape [bs, dim1, dim2, ..., dimN,, num_heads, value_channels].
- """
- raise NotImplementedError("Abstract method")
-
-
-def _numerator(z_slice_shape, precision, unroll=1):
- def fwd(qs, ks, vs):
- def body(p, qkv):
- (q, k, v) = qkv
- p += jnp.einsum("...m,...d->...md", k, v, precision=precision)
- X_slice = jnp.einsum("...m,...md->...d", q, p, precision=precision)
- return p, X_slice
-
- init_value = jnp.zeros(z_slice_shape)
- p, W = lax.scan(body, init_value, (qs, ks, vs), unroll=unroll)
- return W, (p, qs, ks, vs)
-
- def bwd(pqkv, W_ct):
- def body(carry, qkv_xct):
- p, p_ct = carry
- q, k, v, x_ct = qkv_xct
- q_ct = jnp.einsum("...d,...md->...m", x_ct, p, precision=precision)
- p_ct += jnp.einsum("...d,...m->...md", x_ct, q, precision=precision)
- k_ct = jnp.einsum("...md,...d->...m", p_ct, v, precision=precision)
- v_ct = jnp.einsum("...md,...m->...d", p_ct, k, precision=precision)
- p -= jnp.einsum("...m,...d->...md", k, v, precision=precision)
- return (p, p_ct), (q_ct, k_ct, v_ct)
-
- p, qs, ks, vs = pqkv
- _, (qs_ct, ks_ct, vs_ct) = lax.scan(
- body, (p, jnp.zeros_like(p)), (qs, ks, vs, W_ct), reverse=True, unroll=unroll
- )
- return qs_ct, ks_ct, vs_ct
-
- @jax.custom_vjp
- def _numerator_impl(qs, ks, vs):
- W, _ = fwd(qs, ks, vs)
- return W
-
- _numerator_impl.defvjp(fwd, bwd)
-
- return _numerator_impl
-
-
-def _denominator(t_slice_shape, precision, unroll=1):
- def fwd(qs, ks):
- def body(p, qk):
- q, k = qk
- p += k
- x = jnp.einsum("...m,...m->...", q, p, precision=precision)
- return p, x
-
- p = jnp.zeros(t_slice_shape)
- p, R = lax.scan(body, p, (qs, ks), unroll=unroll)
- return R, (qs, ks, p)
-
- def bwd(qkp, R_ct):
- def body(carry, qkx):
- p, p_ct = carry
- q, k, x_ct = qkx
- q_ct = jnp.einsum("...,...m->...m", x_ct, p, precision=precision)
- p_ct += jnp.einsum("...,...m->...m", x_ct, q, precision=precision)
- k_ct = p_ct
- p -= k
- return (p, p_ct), (q_ct, k_ct)
-
- qs, ks, p = qkp
- _, (qs_ct, ks_ct) = lax.scan(body, (p, jnp.zeros_like(p)), (qs, ks, R_ct), reverse=True, unroll=unroll)
- return (qs_ct, ks_ct)
-
- @jax.custom_vjp
- def _denominator_impl(qs, ks):
- R, _ = fwd(qs, ks)
- return R
-
- _denominator_impl.defvjp(fwd, bwd)
-
- return _denominator_impl
-
-
-class FastAttentionviaLowRankDecomposition(FastAttention):
- r"""
- Class providing a method for fast attention via low rank decomposition. Class is responsible for providing a method
- for fast dot-product attention with the use of low rank decomposition (e.g. with random
- feature maps).
- """
-
- def __init__(
- self,
- matrix_creator,
- kernel_feature_creator,
- renormalize_attention,
- numerical_stabilizer,
- redraw_features,
- unidirectional,
- lax_scan_unroll=1,
- ): # For optimal GPU performance, set to 16.
- rng = random.PRNGKey(0)
- self.matrix_creator = matrix_creator
- self.projection_matrix = self.draw_weights(rng)
- self.kernel_feature_creator = kernel_feature_creator
- self.renormalize_attention = renormalize_attention
- self.numerical_stabilizer = numerical_stabilizer
- self.redraw_features = redraw_features
- self.unidirectional = unidirectional
- self.lax_scan_unroll = lax_scan_unroll
-
- def draw_weights(self, key):
- if self.matrix_creator is None:
- return None
- matrixrng, _ = random.split(key)
- projection_matrix = self.matrix_creator(key=matrixrng).get_2d_array()
- return projection_matrix
-
- def dot_product_attention(
- self,
- query,
- key,
- value,
- dtype=jnp.float32,
- bias=None,
- axis=None,
- broadcast_dropout=True,
- dropout_rng=None,
- dropout_rate=0.0,
- deterministic=False,
- precision=None,
- ):
- assert key.shape[:-1] == value.shape[:-1]
- assert query.shape[0:1] == key.shape[0:1] and query.shape[-1] == key.shape[-1]
- if axis is None:
- axis = tuple(range(1, key.ndim - 2))
- if not isinstance(axis, Iterable):
- axis = (axis,)
- assert key.ndim == query.ndim
- assert key.ndim == value.ndim
- for ax in axis:
- if not (query.ndim >= 3 and 1 <= ax < query.ndim - 2):
- raise ValueError("Attention axis must be between the batch axis and the last-two axes.")
- n = key.ndim
-
- # Constructing projection tensor.
- if self.redraw_features:
- # TODO(kchoro): Get rid of the constant below.
- query_seed = lax.convert_element_type(jnp.ceil(jnp.sum(query) * 10000000.0), jnp.int32)
- rng = random.PRNGKey(query_seed)
- self.projection_matrix = self.draw_weights(rng)
-
- # batch_dims is , num_heads>
- batch_dims = tuple(onp.delete(range(n), axis + (n - 1,)))
- # q & k -> (bs, , num_heads, , channels)
- qk_perm = batch_dims + axis + (n - 1,)
- k_extra_perm = axis + batch_dims + (n - 1,)
- key_extra = key.transpose(k_extra_perm)
- key = key.transpose(qk_perm)
- query = query.transpose(qk_perm)
- # v -> (bs, , num_heads, , channels)
- v_perm = batch_dims + axis + (n - 1,)
- value = value.transpose(v_perm)
- batch_dims_t = tuple(range(len(batch_dims)))
- attention_dims_t = tuple(range(len(batch_dims), len(batch_dims) + len(axis)))
-
- # Constructing tensors Q^{'} and K^{'}.
- query_prime = self.kernel_feature_creator(
- query, self.projection_matrix, attention_dims_t, batch_dims_t, precision, True
- )
- key_prime = self.kernel_feature_creator(
- key, self.projection_matrix, attention_dims_t, batch_dims_t, precision, False
- )
-
- if self.unidirectional:
- index = attention_dims_t[0]
- z_slice_shape = key_prime.shape[0 : len(batch_dims_t)] + (key_prime.shape[-1],) + (value.shape[-1],)
-
- numerator_fn = _numerator(z_slice_shape, precision, self.lax_scan_unroll)
- W = numerator_fn(
- jnp.moveaxis(query_prime, index, 0), jnp.moveaxis(key_prime, index, 0), jnp.moveaxis(value, index, 0)
- )
-
- # Constructing W = (Q^{'}(K^{'})^{T})_{masked}V
- W = jnp.moveaxis(W, 0, index)
-
- if not self.renormalize_attention:
- # Unidirectional, not-normalized attention.
- perm_inv = _invert_perm(qk_perm)
- result = W.transpose(perm_inv)
- return result
- else:
- # Unidirectional, normalized attention.
- thick_all_ones = jnp.zeros(key.shape[0:-1]) + jnp.ones(key_extra.shape[0 : len(axis)])
-
- index = attention_dims_t[0]
- t_slice_shape = key_prime.shape[0 : len(batch_dims_t)] + (key_prime.shape[-1],)
- denominator_fn = _denominator(t_slice_shape, precision, self.lax_scan_unroll)
- R = denominator_fn(jnp.moveaxis(query_prime, index, 0), jnp.moveaxis(key_prime, index, 0))
-
- R = jnp.moveaxis(R, 0, index)
- else:
- contract_query = tuple(range(len(batch_dims) + len(axis), len(batch_dims) + len(axis) + 1))
- contract_z = tuple(range(len(batch_dims), len(batch_dims) + 1))
- # Constructing Z = (K^{'})^{T}V
- # Z (bs, , num_heads, channels_m, channels_v)
- Z = lax.dot_general(
- key_prime,
- value,
- ((attention_dims_t, attention_dims_t), (batch_dims_t, batch_dims_t)),
- precision=precision,
- )
- # Constructing W = Q^{'}Z = Q^{'}(K^{'})^{T}V
- # q (bs, , num_heads, , channels_m)
- # Z (bs, , num_heads, channels_m, channels_v)
- # W (bs, , num_heads, , channels_v)
- W = lax.dot_general(
- query_prime, Z, ((contract_query, contract_z), (batch_dims_t, batch_dims_t)), precision=precision
- )
- if not self.renormalize_attention:
- # Bidirectional, not-normalized attention.
- perm_inv = _invert_perm(qk_perm)
- result = W.transpose(perm_inv)
- return result
- else:
- # Bidirectional, normalized attention.
- thick_all_ones = jnp.zeros(key.shape[0:-1]) + jnp.ones(key_extra.shape[0 : len(axis)])
- contract_key = tuple(range(len(batch_dims), len(batch_dims) + len(axis)))
- contract_thick_all_ones = tuple(range(thick_all_ones.ndim - len(axis), thick_all_ones.ndim))
- # Construct T = (K^{'})^{T} 1_L
- # k (bs, , num_heads, , channels)
- T = lax.dot_general(
- key_prime,
- thick_all_ones,
- ((contract_key, contract_thick_all_ones), (batch_dims_t, batch_dims_t)),
- precision=precision,
- )
-
- # Construct partition function: R = Q^{'} T = Q^{'}(K^{'})^{T} 1_L
- # q_p (bs, , num_heads, , channs_m)
- # T (bs, , num_heads, channels_m)
- R = lax.dot_general(
- query_prime,
- T,
- (((query_prime.ndim - 1,), (T.ndim - 1,)), (batch_dims_t, range(0, len(T.shape) - 1))),
- precision=precision,
- )
-
- R = R + 2 * self.numerical_stabilizer * (jnp.abs(R) <= self.numerical_stabilizer)
- R = jnp.reciprocal(R)
- R = jnp.expand_dims(R, len(R.shape))
- # W (bs, , num_heads, , channels_v)
- # R (bs, , num_heads, , extra_channel)
- result = W * R
- # back to (bs, dim1, dim2, ..., dimN, num_heads, channels)
- perm_inv = _invert_perm(qk_perm)
- result = result.transpose(perm_inv)
- return result
-
-
-def _invert_perm(perm):
- perm_inv = [0] * len(perm)
- for i, j in enumerate(perm):
- perm_inv[j] = i
- return tuple(perm_inv)
diff --git a/examples/research_projects/performer/run_mlm_performer.py b/examples/research_projects/performer/run_mlm_performer.py
deleted file mode 100644
index 0332fe1575f..00000000000
--- a/examples/research_projects/performer/run_mlm_performer.py
+++ /dev/null
@@ -1,693 +0,0 @@
-# coding=utf-8
-# Copyright 2020 The HuggingFace Team All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-Fine-tuning the library models for masked language modeling (BERT, ALBERT, RoBERTa...) with whole word masking on a
-text file or a dataset.
-
-Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
-https://huggingface.co/models?filter=fill-mask
-"""
-
-import logging
-import os
-import sys
-from dataclasses import dataclass, field
-
-# You can also adapt this script on your own masked language modeling task. Pointers for this are left as comments.
-from pathlib import Path
-from typing import Dict, List, Optional, Tuple
-
-import jax
-import jax.numpy as jnp
-import numpy as np
-from datasets import load_dataset
-from flax import jax_utils
-from flax.optim import Adam
-from flax.training import common_utils
-from flax.training.common_utils import get_metrics
-from jax.nn import log_softmax
-from modeling_flax_performer import FlaxPerformerForMaskedLM
-from tqdm import tqdm
-
-from transformers import (
- MODEL_FOR_MASKED_LM_MAPPING,
- AutoTokenizer,
- BertConfig,
- FlaxBertForMaskedLM,
- HfArgumentParser,
- PreTrainedTokenizerBase,
- TensorType,
- TrainingArguments,
- is_tensorboard_available,
- set_seed,
-)
-
-
-# Cache the result
-has_tensorboard = is_tensorboard_available()
-if has_tensorboard:
- try:
- from flax.metrics.tensorboard import SummaryWriter
- except ImportError as ie:
- has_tensorboard = False
- print(f"Unable to display metrics through TensorBoard because some package are not installed: {ie}")
-
-else:
- print(
- "Unable to display metrics through TensorBoard because the package is not installed: "
- "Please run pip install tensorboard to enable."
- )
-
-MODEL_CONFIG_CLASSES = list(MODEL_FOR_MASKED_LM_MAPPING.keys())
-MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
-
-
-@dataclass
-class WandbArguments:
- """
- Arguments for logging
- """
-
- wandb_user_name: Optional[str] = field(
- default=None,
- metadata={"help": "The WandB user name for potential logging. If left None, no logging"},
- )
- wandb_project_name: Optional[str] = field(
- default="performer-experiments",
- metadata={"help": "The WandB project name for potential logging"},
- )
-
-
-@dataclass
-class ModelArguments:
- """
- Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
- """
-
- model_name_or_path: Optional[str] = field(
- default=None,
- metadata={
- "help": (
- "The model checkpoint for weights initialization. Don't set if you want to train a model from scratch."
- )
- },
- )
- performer: bool = field(
- default=False,
- metadata={"help": "Whether to use FAVOR+ attention"},
- )
- reinitialize: bool = field(
- default=False,
- metadata={"help": "Whether to use a blank model without pretraining"},
- )
- tokenizer_name: Optional[str] = field(
- default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
- )
- use_fast_tokenizer: bool = field(
- default=True,
- metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
- )
- cache_dir: Optional[str] = field(
- default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
- )
-
-
-@dataclass
-class DataTrainingArguments:
- """
- Arguments pertaining to what data we are going to input our model for training and eval.
- """
-
- dataset_name: Optional[str] = field(
- default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
- )
- dataset_config_name: Optional[str] = field(
- default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
- )
- train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
- validation_file: Optional[str] = field(
- default=None,
- metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
- )
- train_ref_file: Optional[str] = field(
- default=None,
- metadata={"help": "An optional input train ref data file for whole word masking in Chinese."},
- )
- validation_ref_file: Optional[str] = field(
- default=None,
- metadata={"help": "An optional input validation ref data file for whole word masking in Chinese."},
- )
- overwrite_cache: bool = field(
- default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
- )
- validation_split_percentage: Optional[int] = field(
- default=5,
- metadata={
- "help": "The percentage of the train set used as validation set in case there's no validation split"
- },
- )
- max_seq_length: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated. Default to the max input length of the model."
- )
- },
- )
- preprocessing_num_workers: Optional[int] = field(
- default=None,
- metadata={"help": "The number of processes to use for the preprocessing."},
- )
- mlm_probability: float = field(
- default=0.15, metadata={"help": "Ratio of tokens to mask for masked language modeling loss"}
- )
- pad_to_max_length: bool = field(
- default=False,
- metadata={
- "help": (
- "Whether to pad all samples to `max_seq_length`. "
- "If False, will pad the samples dynamically when batching to the maximum length in the batch."
- )
- },
- )
-
- def __post_init__(self):
- if self.dataset_name is None and self.train_file is None and self.validation_file is None:
- raise ValueError("Need either a dataset name or a training/validation file.")
- else:
- if self.train_file is not None:
- extension = self.train_file.split(".")[-1]
- assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, a json or a txt file."
- if self.validation_file is not None:
- extension = self.validation_file.split(".")[-1]
- assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, a json or a txt file."
-
-
-# Adapted from transformers/data/data_collator.py
-# Letting here for now, let's discuss where it should live
-@dataclass
-class FlaxDataCollatorForLanguageModeling:
- """
- Data collator used for language modeling. Inputs are dynamically padded to the maximum length of a batch if they
- are not all of the same length.
-
- Args:
- tokenizer (:class:`~transformers.PreTrainedTokenizer` or :class:`~transformers.PreTrainedTokenizerFast`):
- The tokenizer used for encoding the data.
- mlm (:obj:`bool`, `optional`, defaults to :obj:`True`):
- Whether or not to use masked language modeling. If set to :obj:`False`, the labels are the same as the
- inputs with the padding tokens ignored (by setting them to -100). Otherwise, the labels are -100 for
- non-masked tokens and the value to predict for the masked token.
- mlm_probability (:obj:`float`, `optional`, defaults to 0.15):
- The probability with which to (randomly) mask tokens in the input, when :obj:`mlm` is set to :obj:`True`.
-
- .. note::
-
- For best performance, this data collator should be used with a dataset having items that are dictionaries or
- BatchEncoding, with the :obj:`"special_tokens_mask"` key, as returned by a
- :class:`~transformers.PreTrainedTokenizer` or a :class:`~transformers.PreTrainedTokenizerFast` with the
- argument :obj:`return_special_tokens_mask=True`.
- """
-
- tokenizer: PreTrainedTokenizerBase
- mlm: bool = True
- mlm_probability: float = 0.15
-
- def __post_init__(self):
- if self.mlm and self.tokenizer.mask_token is None:
- raise ValueError(
- "This tokenizer does not have a mask token which is necessary for masked language modeling. "
- "You should pass `mlm=False` to train on causal language modeling instead."
- )
-
- def __call__(self, examples: List[Dict[str, np.ndarray]], pad_to_multiple_of: int) -> Dict[str, np.ndarray]:
- # Handle dict or lists with proper padding and conversion to tensor.
- batch = self.tokenizer.pad(examples, pad_to_multiple_of=pad_to_multiple_of, return_tensors=TensorType.NUMPY)
-
- # If special token mask has been preprocessed, pop it from the dict.
- special_tokens_mask = batch.pop("special_tokens_mask", None)
- if self.mlm:
- batch["input_ids"], batch["labels"] = self.mask_tokens(
- batch["input_ids"], special_tokens_mask=special_tokens_mask
- )
- else:
- labels = batch["input_ids"].copy()
- if self.tokenizer.pad_token_id is not None:
- labels[labels == self.tokenizer.pad_token_id] = -100
- batch["labels"] = labels
- return batch
-
- def mask_tokens(
- self, inputs: np.ndarray, special_tokens_mask: Optional[np.ndarray]
- ) -> Tuple[jnp.ndarray, jnp.ndarray]:
- """
- Prepare masked tokens inputs/labels for masked language modeling: 80% MASK, 10% random, 10% original.
- """
- labels = inputs.copy()
- # We sample a few tokens in each sequence for MLM training (with probability `self.mlm_probability`)
- probability_matrix = np.full(labels.shape, self.mlm_probability)
- special_tokens_mask = special_tokens_mask.astype("bool")
-
- probability_matrix[special_tokens_mask] = 0.0
- masked_indices = np.random.binomial(1, probability_matrix).astype("bool")
- labels[~masked_indices] = -100 # We only compute loss on masked tokens
-
- # 80% of the time, we replace masked input tokens with tokenizer.mask_token ([MASK])
- indices_replaced = np.random.binomial(1, np.full(labels.shape, 0.8)).astype("bool") & masked_indices
- inputs[indices_replaced] = self.tokenizer.convert_tokens_to_ids(self.tokenizer.mask_token)
-
- # 10% of the time, we replace masked input tokens with random word
- indices_random = np.random.binomial(1, np.full(labels.shape, 0.5)).astype("bool")
- indices_random &= masked_indices & ~indices_replaced
-
- random_words = np.random.randint(self.tokenizer.vocab_size, size=labels.shape, dtype="i4")
- inputs[indices_random] = random_words[indices_random]
-
- # The rest of the time (10% of the time) we keep the masked input tokens unchanged
- return inputs, labels
-
-
-def create_learning_rate_scheduler(
- factors="constant * linear_warmup * rsqrt_decay",
- base_learning_rate=0.5,
- warmup_steps=1000,
- decay_factor=0.5,
- steps_per_decay=20000,
- steps_per_cycle=100000,
-):
- """Creates learning rate schedule.
- Interprets factors in the factors string which can consist of:
- * constant: interpreted as the constant value,
- * linear_warmup: interpreted as linear warmup until warmup_steps,
- * rsqrt_decay: divide by square root of max(step, warmup_steps)
- * rsqrt_normalized_decay: divide by square root of max(step/warmup_steps, 1)
- * decay_every: Every k steps decay the learning rate by decay_factor.
- * cosine_decay: Cyclic cosine decay, uses steps_per_cycle parameter.
- Args:
- factors: string, factors separated by "*" that defines the schedule.
- base_learning_rate: float, the starting constant for the lr schedule.
- warmup_steps: int, how many steps to warm up for in the warmup schedule.
- decay_factor: float, the amount to decay the learning rate by.
- steps_per_decay: int, how often to decay the learning rate.
- steps_per_cycle: int, steps per cycle when using cosine decay.
- Returns:
- a function learning_rate(step): float -> {"learning_rate": float}, the
- step-dependent lr.
- """
- factors = [n.strip() for n in factors.split("*")]
-
- def step_fn(step):
- """Step to learning rate function."""
- ret = 1.0
- for name in factors:
- if name == "constant":
- ret *= base_learning_rate
- elif name == "linear_warmup":
- ret *= jnp.minimum(1.0, step / warmup_steps)
- elif name == "rsqrt_decay":
- ret /= jnp.sqrt(jnp.maximum(step, warmup_steps))
- elif name == "rsqrt_normalized_decay":
- ret *= jnp.sqrt(warmup_steps)
- ret /= jnp.sqrt(jnp.maximum(step, warmup_steps))
- elif name == "decay_every":
- ret *= decay_factor ** (step // steps_per_decay)
- elif name == "cosine_decay":
- progress = jnp.maximum(0.0, (step - warmup_steps) / float(steps_per_cycle))
- ret *= jnp.maximum(0.0, 0.5 * (1.0 + jnp.cos(jnp.pi * (progress % 1.0))))
- else:
- raise ValueError("Unknown factor %s." % name)
- return jnp.asarray(ret, dtype=jnp.float32)
-
- return step_fn
-
-
-def compute_metrics(logits, labels, weights, label_smoothing=0.0):
- """Compute summary metrics."""
- loss, normalizer = cross_entropy(logits, labels, weights, label_smoothing)
- acc, _ = accuracy(logits, labels, weights)
- metrics = {"loss": loss, "accuracy": acc, "normalizer": normalizer}
- metrics = jax.lax.psum(metrics, axis_name="batch")
- return metrics
-
-
-def accuracy(logits, targets, weights=None):
- """Compute weighted accuracy for log probs and targets.
- Args:
- logits: [batch, length, num_classes] float array.
- targets: categorical targets [batch, length] int array.
- weights: None or array of shape [batch, length]
- Returns:
- Tuple of scalar loss and batch normalizing factor.
- """
- if logits.ndim != targets.ndim + 1:
- raise ValueError(
- "Incorrect shapes. Got shape %s logits and %s targets" % (str(logits.shape), str(targets.shape))
- )
-
- loss = jnp.equal(jnp.argmax(logits, axis=-1), targets)
- loss *= weights
-
- return loss.sum(), weights.sum()
-
-
-def cross_entropy(logits, targets, weights=None, label_smoothing=0.0):
- """Compute cross entropy and entropy for log probs and targets.
- Args:
- logits: [batch, length, num_classes] float array.
- targets: categorical targets [batch, length] int array.
- weights: None or array of shape [batch, length]
- label_smoothing: label smoothing constant, used to determine the on and off values.
- Returns:
- Tuple of scalar loss and batch normalizing factor.
- """
- if logits.ndim != targets.ndim + 1:
- raise ValueError(
- "Incorrect shapes. Got shape %s logits and %s targets" % (str(logits.shape), str(targets.shape))
- )
-
- vocab_size = logits.shape[-1]
- confidence = 1.0 - label_smoothing
- low_confidence = (1.0 - confidence) / (vocab_size - 1)
- normalizing_constant = -(
- confidence * jnp.log(confidence) + (vocab_size - 1) * low_confidence * jnp.log(low_confidence + 1e-20)
- )
- soft_targets = common_utils.onehot(targets, vocab_size, on_value=confidence, off_value=low_confidence)
-
- loss = -jnp.sum(soft_targets * log_softmax(logits), axis=-1)
- loss = loss - normalizing_constant
-
- if weights is not None:
- loss = loss * weights
- normalizing_factor = weights.sum()
- else:
- normalizing_factor = np.prod(targets.shape)
-
- return loss.sum(), normalizing_factor
-
-
-def training_step(optimizer, batch, dropout_rng):
- dropout_rng, new_dropout_rng = jax.random.split(dropout_rng)
-
- def loss_fn(params):
- targets = batch.pop("labels")
-
- # Hide away tokens which doesn't participate in the optimization
- token_mask = jnp.where(targets > 0, 1.0, 0.0)
-
- logits = model(**batch, params=params, dropout_rng=dropout_rng, train=True)[0]
- loss, weight_sum = cross_entropy(logits, targets, token_mask)
- return loss / weight_sum
-
- step = optimizer.state.step
- lr = lr_scheduler_fn(step)
- grad_fn = jax.value_and_grad(loss_fn)
- loss, grad = grad_fn(optimizer.target)
- grad = jax.lax.pmean(grad, "batch")
- optimizer = optimizer.apply_gradient(grad, learning_rate=lr)
-
- return loss, optimizer, new_dropout_rng
-
-
-def eval_step(params, batch):
- """
- Calculate evaluation metrics on a batch.
- """
- targets = batch.pop("labels")
-
- # Hide away tokens which doesn't participate in the optimization
- token_mask = jnp.where(targets > 0, 1.0, 0.0)
- logits = model(**batch, params=params, train=False)[0]
-
- return compute_metrics(logits, targets, token_mask)
-
-
-def generate_batch_splits(samples_idx: np.ndarray, batch_size: int) -> np.ndarray:
- nb_samples = len(samples_idx)
- samples_to_remove = nb_samples % batch_size
-
- if samples_to_remove != 0:
- samples_idx = samples_idx[:-samples_to_remove]
- sections_split = nb_samples // batch_size
- batch_idx = np.split(samples_idx, sections_split)
- return batch_idx
-
-
-if __name__ == "__main__":
- # See all possible arguments in src/transformers/training_args.py
- # or by passing the --help flag to this script.
- # We now keep distinct sets of args, for a cleaner separation of concerns.
-
- parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments, WandbArguments))
- if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
- # If we pass only one argument to the script and it's the path to a json file,
- # let's parse it to get our arguments.
- model_args, data_args, training_args, wandb_args = parser.parse_json_file(
- json_file=os.path.abspath(sys.argv[1])
- )
- else:
- model_args, data_args, training_args, wandb_args = parser.parse_args_into_dataclasses()
-
- if (
- os.path.exists(training_args.output_dir)
- and os.listdir(training_args.output_dir)
- and training_args.do_train
- and not training_args.overwrite_output_dir
- ):
- raise ValueError(
- f"Output directory ({training_args.output_dir}) already exists and is not empty. "
- "Use --overwrite_output_dir to overcome."
- )
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- level="NOTSET",
- datefmt="[%X]",
- )
-
- # Log on each process the small summary:
- logger = logging.getLogger(__name__)
- logger.warning(
- f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
- + f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
- )
-
- # Set the verbosity to info of the Transformers logger (on main process only):
- logger.info("Training/evaluation parameters %s", training_args)
-
- # Set seed before initializing model.
- set_seed(training_args.seed)
-
- # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
- # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
- # (the dataset will be downloaded automatically from the datasets Hub).
- #
- # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
- # 'text' is found. You can easily tweak this behavior (see below).
- #
- # In distributed training, the load_dataset function guarantees that only one local process can concurrently
- # download the dataset.
- if data_args.dataset_name is not None:
- # Downloading and loading a dataset from the hub.
- datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name)
- if "validation" not in datasets.keys():
- datasets["validation"] = load_dataset(
- data_args.dataset_name,
- data_args.dataset_config_name,
- split=f"train[:{data_args.validation_split_percentage}%]",
- )
- datasets["train"] = load_dataset(
- data_args.dataset_name,
- data_args.dataset_config_name,
- split=f"train[{data_args.validation_split_percentage}%:]",
- )
- else:
- data_files = {}
- if data_args.train_file is not None:
- data_files["train"] = data_args.train_file
- extension = data_args.train_file.split(".")[-1]
- if data_args.validation_file is not None:
- data_files["validation"] = data_args.validation_file
- extension = data_args.validation_file.split(".")[-1]
- if extension == "txt":
- extension = "text"
- datasets = load_dataset(extension, data_files=data_files)
- # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
- # https://huggingface.co/docs/datasets/loading_datasets.
-
- # Load pretrained model and tokenizer
-
- # Distributed training:
- # The .from_pretrained methods guarantee that only one local process can concurrently
- # download model & vocab.
-
- rng = jax.random.PRNGKey(training_args.seed)
- dropout_rngs = jax.random.split(rng, jax.local_device_count())
-
- config = BertConfig.from_pretrained(model_args.model_name_or_path, cache_dir=model_args.cache_dir)
- lm_class = FlaxPerformerForMaskedLM if model_args.performer else FlaxBertForMaskedLM
- if model_args.reinitialize:
- model = lm_class(config=BertConfig.from_pretrained(model_args.model_name_or_path))
- else:
- model = lm_class.from_pretrained(
- model_args.model_name_or_path,
- dtype=jnp.float32,
- input_shape=(training_args.train_batch_size, config.max_position_embeddings),
- seed=training_args.seed,
- dropout_rate=0.1,
- )
-
- if model_args.tokenizer_name:
- tokenizer = AutoTokenizer.from_pretrained(
- model_args.tokenizer_name, cache_dir=model_args.cache_dir, use_fast=model_args.use_fast_tokenizer
- )
- elif model_args.model_name_or_path:
- tokenizer = AutoTokenizer.from_pretrained(
- model_args.model_name_or_path, cache_dir=model_args.cache_dir, use_fast=model_args.use_fast_tokenizer
- )
- else:
- raise ValueError(
- "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
- "You can do it from another script, save it, and load it from here, using --tokenizer_name."
- )
-
- # Preprocessing the datasets.
- # First we tokenize all the texts.
- if training_args.do_train:
- column_names = datasets["train"].column_names
- else:
- column_names = datasets["validation"].column_names
- text_column_name = "text" if "text" in column_names else column_names[0]
-
- padding = "max_length" if data_args.pad_to_max_length else False
-
- def tokenize_function(examples):
- # Remove empty lines
- examples = [line for line in examples if len(line) > 0 and not line.isspace()]
- return tokenizer(
- examples,
- return_special_tokens_mask=True,
- padding=padding,
- truncation=True,
- max_length=data_args.max_seq_length,
- )
-
- tokenized_datasets = datasets.map(
- tokenize_function,
- input_columns=[text_column_name],
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not data_args.overwrite_cache,
- )
-
- # Enable tensorboard only on the master node
- if has_tensorboard and jax.host_id() == 0:
- summary_writer = SummaryWriter(log_dir=Path(training_args.output_dir).joinpath("logs").as_posix())
-
- # Data collator
- # This one will take care of randomly masking the tokens.
- data_collator = FlaxDataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=data_args.mlm_probability)
-
- # Setup optimizer
- optimizer = Adam(
- learning_rate=training_args.learning_rate,
- weight_decay=training_args.weight_decay,
- beta1=training_args.adam_beta1,
- beta2=training_args.adam_beta2,
- ).create(model.params)
-
- # Create learning rate scheduler
- lr_scheduler_fn = create_learning_rate_scheduler(
- base_learning_rate=training_args.learning_rate, warmup_steps=max(training_args.warmup_steps, 1)
- )
-
- # Create parallel version of the training and evaluation steps
- p_training_step = jax.pmap(training_step, "batch", donate_argnums=(0,))
- p_eval_step = jax.pmap(eval_step, "batch", donate_argnums=(0,))
-
- # Replicate the optimizer on each device
- optimizer = jax_utils.replicate(optimizer)
-
- # Store some constant
- nb_epochs = int(training_args.num_train_epochs)
- batch_size = int(training_args.train_batch_size)
- eval_batch_size = int(training_args.eval_batch_size)
-
- if wandb_args.wandb_user_name is not None:
- import wandb
-
- wandb.init(project=wandb_args.wandb_project_name, entity=wandb_args.wandb_user_name)
-
- epochs = tqdm(range(nb_epochs), desc=f"Epoch ... (1/{nb_epochs})", position=0)
- for epoch in epochs:
- # ======================== Training ================================
- # Create sampling rng
- rng, training_rng, eval_rng = jax.random.split(rng, 3)
-
- # Generate an epoch by shuffling sampling indices from the train dataset
- nb_training_samples = len(tokenized_datasets["train"])
- # Avoid using jax.numpy here in case of TPU training
- training_samples_idx = np.random.permutation(np.arange(nb_training_samples))
- training_batch_idx = generate_batch_splits(training_samples_idx, batch_size)
-
- # Gather the indexes for creating the batch and do a training step
- for batch_idx in tqdm(training_batch_idx, desc="Training...", position=1):
- samples = [tokenized_datasets["train"][int(idx)] for idx in batch_idx]
- model_inputs = data_collator(samples, pad_to_multiple_of=16)
-
- # Model forward
- model_inputs = common_utils.shard(model_inputs.data)
- loss, optimizer, dropout_rngs = p_training_step(optimizer, model_inputs, dropout_rngs)
-
- if wandb_args.wandb_user_name is not None:
- wandb.log({"Training loss": np.array(loss).mean()})
-
- epochs.write(f"Loss: {loss}")
-
- # ======================== Evaluating ==============================
- nb_eval_samples = len(tokenized_datasets["validation"])
- # Avoid using jax.numpy here in case of TPU training
- eval_samples_idx = np.arange(nb_eval_samples)
- eval_batch_idx = generate_batch_splits(eval_samples_idx, eval_batch_size)
-
- eval_metrics = []
- for i, batch_idx in enumerate(tqdm(eval_batch_idx, desc="Evaluating ...", position=2)):
- samples = [tokenized_datasets["validation"][int(idx)] for idx in batch_idx]
- model_inputs = data_collator(samples, pad_to_multiple_of=16)
-
- # Model forward
- model_inputs = common_utils.shard(model_inputs.data)
- metrics = p_eval_step(optimizer.target, model_inputs)
- eval_metrics.append(metrics)
-
- eval_metrics_np = get_metrics(eval_metrics)
- eval_metrics_np = jax.tree_util.tree_map(jnp.sum, eval_metrics_np)
- eval_normalizer = eval_metrics_np.pop("normalizer")
- eval_summary = jax.tree_util.tree_map(lambda x: x / eval_normalizer, eval_metrics_np)
-
- # Update progress bar
- epochs.desc = (
- f"Epoch... ({epoch + 1}/{nb_epochs} | Loss: {eval_summary['loss']}, Acc: {eval_summary['accuracy']})"
- )
-
- if wandb_args.wandb_user_name is not None:
- wandb.log({"Eval loss": np.array(eval_summary["loss"]).mean()})
-
- # Save metrics
- if has_tensorboard and jax.host_id() == 0:
- for name, value in eval_summary.items():
- summary_writer.scalar(name, value, epoch)
diff --git a/examples/research_projects/performer/sanity_script.sh b/examples/research_projects/performer/sanity_script.sh
deleted file mode 100755
index b96cd7e643e..00000000000
--- a/examples/research_projects/performer/sanity_script.sh
+++ /dev/null
@@ -1 +0,0 @@
-TOKENIZERS_PARALLELISM=true python run_mlm_performer.py --output_dir experiments --dataset_name wikipedia --dataset_config_name 20200501.simple --model_name_or_path bert-base-cased --tokenizer_name bert-base-cased --do_train --overwrite_output_dir --per_device_train_batch_size 4 --learning_rate 5e-4 --warmup_steps 100 --num_train_epochs 3 --performer
\ No newline at end of file
diff --git a/examples/research_projects/pplm/README.md b/examples/research_projects/pplm/README.md
deleted file mode 100644
index f37ea8e96f2..00000000000
--- a/examples/research_projects/pplm/README.md
+++ /dev/null
@@ -1,56 +0,0 @@
-# Plug and Play Language Models: a Simple Approach to Controlled Text Generation
-
-Authors: [Sumanth Dathathri](https://dathath.github.io/), [Andrea Madotto](https://andreamad8.github.io/), Janice Lan, Jane Hung, Eric Frank, [Piero Molino](https://w4nderlu.st/), [Jason Yosinski](http://yosinski.com/), and [Rosanne Liu](http://www.rosanneliu.com/)
-
-This folder contains the original code used to run the Plug and Play Language Model (PPLM).
-
-Paper link: https://arxiv.org/abs/1912.02164
-
-Blog link: https://eng.uber.com/pplm
-
-Please check out the repo under uber-research for more information: https://github.com/uber-research/PPLM
-
-# Note
-
-⚠️ This project should be run with pytorch-lightning==1.0.4 which has a potential security vulnerability
-
-## Setup
-
-```bash
-git clone https://github.com/huggingface/transformers && cd transformers
-pip install .
-pip install nltk torchtext # additional requirements.
-cd examples/research_projects/pplm
-```
-
-## PPLM-BoW
-
-### Example command for bag-of-words control
-
-```bash
-python run_pplm.py -B military --cond_text "The potato" --length 50 --gamma 1.5 --num_iterations 3 --num_samples 10 --stepsize 0.03 --window_length 5 --kl_scale 0.01 --gm_scale 0.99 --colorama --sample
-```
-
-### Tuning hyperparameters for bag-of-words control
-
-1. Increase `--stepsize` to intensify topic control, and decrease its value to soften the control. `--stepsize 0` recovers the original uncontrolled GPT-2 model.
-
-2. If the language being generated is repetitive (For e.g. "science science experiment experiment"), there are several options to consider:
- a) Reduce the `--stepsize`
- b) Increase `--kl_scale` (the KL-loss coefficient) or decrease `--gm_scale` (the gm-scaling term)
- c) Add `--grad-length xx` where xx is an (integer <= length, e.g. `--grad-length 30`).
-
-
-## PPLM-Discrim
-
-### Example command for discriminator based sentiment control
-
-```bash
-python run_pplm.py -D sentiment --class_label 2 --cond_text "My dog died" --length 50 --gamma 1.0 --num_iterations 10 --num_samples 10 --stepsize 0.04 --kl_scale 0.01 --gm_scale 0.95 --sample
-```
-
-### Tuning hyperparameters for discriminator control
-
-1. Increase `--stepsize` to intensify topic control, and decrease its value to soften the control. `--stepsize 0` recovers the original uncontrolled GPT-2 model.
-
-2. Use `--class_label 3` for negative, and `--class_label 2` for positive
diff --git a/examples/research_projects/pplm/imgs/headfigure.png b/examples/research_projects/pplm/imgs/headfigure.png
deleted file mode 100644
index f4c11ad54d1..00000000000
Binary files a/examples/research_projects/pplm/imgs/headfigure.png and /dev/null differ
diff --git a/examples/research_projects/pplm/imgs/wooly.png b/examples/research_projects/pplm/imgs/wooly.png
deleted file mode 100644
index 190d3afd49f..00000000000
Binary files a/examples/research_projects/pplm/imgs/wooly.png and /dev/null differ
diff --git a/examples/research_projects/pplm/pplm_classification_head.py b/examples/research_projects/pplm/pplm_classification_head.py
deleted file mode 100644
index e26521fe391..00000000000
--- a/examples/research_projects/pplm/pplm_classification_head.py
+++ /dev/null
@@ -1,19 +0,0 @@
-from torch import nn
-
-
-class ClassificationHead(nn.Module):
- """Classification Head for transformer encoders"""
-
- def __init__(self, class_size, embed_size):
- super().__init__()
- self.class_size = class_size
- self.embed_size = embed_size
- # self.mlp1 = nn.Linear(embed_size, embed_size)
- # self.mlp2 = (nn.Linear(embed_size, class_size))
- self.mlp = nn.Linear(embed_size, class_size)
-
- def forward(self, hidden_state):
- # hidden_state = nn.functional.relu(self.mlp1(hidden_state))
- # hidden_state = self.mlp2(hidden_state)
- logits = self.mlp(hidden_state)
- return logits
diff --git a/examples/research_projects/pplm/requirements.txt b/examples/research_projects/pplm/requirements.txt
deleted file mode 100644
index 630d1b0f8f6..00000000000
--- a/examples/research_projects/pplm/requirements.txt
+++ /dev/null
@@ -1,22 +0,0 @@
-tensorboard
-scikit-learn
-seqeval
-psutil
-sacrebleu
-rouge-score
-tensorflow_datasets
-pytorch-lightning
-matplotlib
-git-python==1.0.3
-faiss-cpu
-streamlit
-elasticsearch
-nltk
-pandas
-datasets >= 1.1.3
-fire
-pytest
-conllu
-sentencepiece != 0.1.92
-protobuf
-transformers==4.48.0
diff --git a/examples/research_projects/pplm/run_pplm.py b/examples/research_projects/pplm/run_pplm.py
deleted file mode 100644
index cc49b7fa83c..00000000000
--- a/examples/research_projects/pplm/run_pplm.py
+++ /dev/null
@@ -1,823 +0,0 @@
-#! /usr/bin/env python3
-# coding=utf-8
-
-# Copyright (c) 2019 Uber Technologies, Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""
-Example command with bag of words:
-python run_pplm.py -B space --cond_text "The president" --length 100 --gamma 1.5 --num_iterations 3 --num_samples 10 --stepsize 0.01 --window_length 5 --kl_scale 0.01 --gm_scale 0.95
-
-Example command with discriminator:
-python run_pplm.py -D sentiment --class_label 3 --cond_text "The lake" --length 10 --gamma 1.0 --num_iterations 30 --num_samples 10 --stepsize 0.01 --kl_scale 0.01 --gm_scale 0.95
-"""
-
-import argparse
-import json
-from operator import add
-from typing import List, Optional, Tuple, Union
-
-import numpy as np
-import torch
-from pplm_classification_head import ClassificationHead
-from torch import nn
-from tqdm import trange
-
-from transformers import GPT2LMHeadModel, GPT2Tokenizer
-from transformers.file_utils import cached_path
-
-
-PPLM_BOW = 1
-PPLM_DISCRIM = 2
-PPLM_BOW_DISCRIM = 3
-SMALL_CONST = 1e-15
-BIG_CONST = 1e10
-
-BAG_OF_WORDS_ARCHIVE_MAP = {
- "legal": "https://s3.amazonaws.com/models.huggingface.co/bert/pplm/bow/legal.txt",
- "military": "https://s3.amazonaws.com/models.huggingface.co/bert/pplm/bow/military.txt",
- "politics": "https://s3.amazonaws.com/models.huggingface.co/bert/pplm/bow/politics.txt",
- "religion": "https://s3.amazonaws.com/models.huggingface.co/bert/pplm/bow/religion.txt",
- "science": "https://s3.amazonaws.com/models.huggingface.co/bert/pplm/bow/science.txt",
- "space": "https://s3.amazonaws.com/models.huggingface.co/bert/pplm/bow/space.txt",
- "technology": "https://s3.amazonaws.com/models.huggingface.co/bert/pplm/bow/technology.txt",
-}
-
-DISCRIMINATOR_MODELS_PARAMS = {
- "clickbait": {
- "url": "https://s3.amazonaws.com/models.huggingface.co/bert/pplm/discriminators/clickbait_classifier_head.pt",
- "class_size": 2,
- "embed_size": 1024,
- "class_vocab": {"non_clickbait": 0, "clickbait": 1},
- "default_class": 1,
- "pretrained_model": "openai-community/gpt2-medium",
- },
- "sentiment": {
- "url": "https://s3.amazonaws.com/models.huggingface.co/bert/pplm/discriminators/SST_classifier_head.pt",
- "class_size": 5,
- "embed_size": 1024,
- "class_vocab": {"very_positive": 2, "very_negative": 3},
- "default_class": 3,
- "pretrained_model": "openai-community/gpt2-medium",
- },
-}
-
-
-def top_k_filter(logits, k, probs=False):
- """
- Masks everything but the k top entries as -infinity (1e10).
- Used to mask logits such that e^-infinity -> 0 won't contribute to the
- sum of the denominator.
- """
- if k == 0:
- return logits
- else:
- values = torch.topk(logits, k)[0]
- batch_mins = values[:, -1].view(-1, 1).expand_as(logits)
- if probs:
- return torch.where(logits < batch_mins, torch.ones_like(logits) * 0.0, logits)
- return torch.where(logits < batch_mins, torch.ones_like(logits) * -BIG_CONST, logits)
-
-
-def perturb_past(
- past,
- model,
- last,
- unpert_past=None,
- unpert_logits=None,
- accumulated_hidden=None,
- grad_norms=None,
- stepsize=0.01,
- one_hot_bows_vectors=None,
- classifier=None,
- class_label=None,
- loss_type=0,
- num_iterations=3,
- horizon_length=1,
- window_length=0,
- decay=False,
- gamma=1.5,
- kl_scale=0.01,
- device="cuda",
-):
- # Generate inital perturbed past
- grad_accumulator = [(np.zeros(p.shape).astype("float32")) for p in past]
-
- if accumulated_hidden is None:
- accumulated_hidden = 0
-
- if decay:
- decay_mask = torch.arange(0.0, 1.0 + SMALL_CONST, 1.0 / (window_length))[1:]
- else:
- decay_mask = 1.0
-
- # TODO fix this comment (SUMANTH)
- # Generate a mask is gradient perturbated is based on a past window
- _, _, _, curr_length, _ = past[0].shape
-
- if curr_length > window_length and window_length > 0:
- ones_key_val_shape = tuple(past[0].shape[:-2]) + (window_length,) + tuple(past[0].shape[-1:])
-
- zeros_key_val_shape = tuple(past[0].shape[:-2]) + (curr_length - window_length,) + tuple(past[0].shape[-1:])
-
- ones_mask = torch.ones(ones_key_val_shape)
- ones_mask = decay_mask * ones_mask.permute(0, 1, 2, 4, 3)
- ones_mask = ones_mask.permute(0, 1, 2, 4, 3)
-
- window_mask = torch.cat((ones_mask, torch.zeros(zeros_key_val_shape)), dim=-2).to(device)
- else:
- window_mask = torch.ones_like(past[0]).to(device)
-
- # accumulate perturbations for num_iterations
- loss_per_iter = []
- new_accumulated_hidden = None
- for i in range(num_iterations):
- print("Iteration ", i + 1)
- curr_perturbation = [torch.from_numpy(p_).requires_grad_(True).to(device=device) for p_ in grad_accumulator]
- # make sure p_.grad is not None
- for p_ in curr_perturbation:
- p_.retain_grad()
-
- # Compute hidden using perturbed past
- perturbed_past = list(map(add, past, curr_perturbation))
- _, _, _, curr_length, _ = curr_perturbation[0].shape
- lm_output = model(last, past_key_values=perturbed_past)
- all_logits, all_hidden = lm_output["logits"], lm_output["hidden_states"]
- hidden = all_hidden[-1]
- new_accumulated_hidden = accumulated_hidden + torch.sum(hidden, dim=1).detach()
- # TODO: Check the layer-norm consistency of this with trained discriminator (Sumanth)
- logits = all_logits[:, -1, :]
- probs = nn.functional.softmax(logits, dim=-1)
-
- loss = 0.0
- loss_list = []
- if loss_type == PPLM_BOW or loss_type == PPLM_BOW_DISCRIM:
- for one_hot_bow in one_hot_bows_vectors:
- bow_logits = torch.mm(probs, torch.t(one_hot_bow))
- bow_loss = -torch.log(torch.sum(bow_logits))
- loss += bow_loss
- loss_list.append(bow_loss)
- print(" pplm_bow_loss:", loss.data.cpu().numpy())
-
- if loss_type == 2 or loss_type == 3:
- ce_loss = nn.CrossEntropyLoss()
- # TODO why we need to do this assignment and not just using unpert_past? (Sumanth)
- curr_unpert_past = unpert_past
- curr_probs = torch.unsqueeze(probs, dim=1)
- wte = model.resize_token_embeddings()
- for _ in range(horizon_length):
- inputs_embeds = torch.matmul(curr_probs, wte.weight.data)
- lm_output = model(past_key_values=curr_unpert_past, inputs_embeds=inputs_embeds)
- curr_all_logits, curr_unpert_past, curr_all_hidden = (
- lm_output["logits"],
- lm_output["past_key_values"],
- lm_output["hidden_states"],
- )
- curr_logits = curr_all_logits[:, -1, :]
- curr_probs = nn.functional.softmax(curr_logits, dim=-1)
- curr_probs = torch.unsqueeze(curr_probs, dim=1)
- curr_hidden = curr_all_hidden[-1]
- new_accumulated_hidden = new_accumulated_hidden + torch.sum(curr_hidden, dim=1)
-
- prediction = classifier(new_accumulated_hidden / (curr_length + 1 + horizon_length))
-
- label = torch.tensor(prediction.shape[0] * [class_label], device=device, dtype=torch.long)
- discrim_loss = ce_loss(prediction, label)
- print(" pplm_discrim_loss:", discrim_loss.data.cpu().numpy())
- loss += discrim_loss
- loss_list.append(discrim_loss)
-
- kl_loss = 0.0
- if kl_scale > 0.0:
- unpert_probs = nn.functional.softmax(unpert_logits[:, -1, :], dim=-1)
- unpert_probs = unpert_probs + SMALL_CONST * (unpert_probs <= SMALL_CONST).float().to(device).detach()
- correction = SMALL_CONST * (probs <= SMALL_CONST).float().to(device).detach()
- corrected_probs = probs + correction.detach()
- kl_loss = kl_scale * ((corrected_probs * (corrected_probs / unpert_probs).log()).sum())
- print(" kl_loss", kl_loss.data.cpu().numpy())
- loss += kl_loss
-
- loss_per_iter.append(loss.data.cpu().numpy())
- print(" pplm_loss", (loss - kl_loss).data.cpu().numpy())
-
- # compute gradients
- loss.backward()
-
- # calculate gradient norms
- if grad_norms is not None and loss_type == PPLM_BOW:
- grad_norms = [
- torch.max(grad_norms[index], torch.norm(p_.grad * window_mask))
- for index, p_ in enumerate(curr_perturbation)
- ]
- else:
- grad_norms = [
- (torch.norm(p_.grad * window_mask) + SMALL_CONST) for index, p_ in enumerate(curr_perturbation)
- ]
-
- # normalize gradients
- grad = [
- -stepsize * (p_.grad * window_mask / grad_norms[index] ** gamma).data.cpu().numpy()
- for index, p_ in enumerate(curr_perturbation)
- ]
-
- # accumulate gradient
- grad_accumulator = list(map(add, grad, grad_accumulator))
-
- # reset gradients, just to make sure
- for p_ in curr_perturbation:
- p_.grad.data.zero_()
-
- # removing past from the graph
- new_past = []
- for p_ in past:
- new_past.append(p_.detach())
- past = new_past
-
- # apply the accumulated perturbations to the past
- grad_accumulator = [torch.from_numpy(p_).requires_grad_(True).to(device=device) for p_ in grad_accumulator]
- pert_past = list(map(add, past, grad_accumulator))
-
- return pert_past, new_accumulated_hidden, grad_norms, loss_per_iter
-
-
-def get_classifier(
- name: Optional[str], class_label: Union[str, int], device: str
-) -> Tuple[Optional[ClassificationHead], Optional[int]]:
- if name is None:
- return None, None
-
- params = DISCRIMINATOR_MODELS_PARAMS[name]
- classifier = ClassificationHead(class_size=params["class_size"], embed_size=params["embed_size"]).to(device)
- if "url" in params:
- resolved_archive_file = cached_path(params["url"])
- elif "path" in params:
- resolved_archive_file = params["path"]
- else:
- raise ValueError("Either url or path have to be specified in the discriminator model parameters")
- classifier.load_state_dict(torch.load(resolved_archive_file, map_location=device))
- classifier.eval()
-
- if isinstance(class_label, str):
- if class_label in params["class_vocab"]:
- label_id = params["class_vocab"][class_label]
- else:
- label_id = params["default_class"]
- print("class_label {} not in class_vocab".format(class_label))
- print("available values are: {}".format(params["class_vocab"]))
- print("using default class {}".format(label_id))
-
- elif isinstance(class_label, int):
- if class_label in set(params["class_vocab"].values()):
- label_id = class_label
- else:
- label_id = params["default_class"]
- print("class_label {} not in class_vocab".format(class_label))
- print("available values are: {}".format(params["class_vocab"]))
- print("using default class {}".format(label_id))
-
- else:
- label_id = params["default_class"]
-
- return classifier, label_id
-
-
-def get_bag_of_words_indices(bag_of_words_ids_or_paths: List[str], tokenizer) -> List[List[List[int]]]:
- bow_indices = []
- for id_or_path in bag_of_words_ids_or_paths:
- if id_or_path in BAG_OF_WORDS_ARCHIVE_MAP:
- filepath = cached_path(BAG_OF_WORDS_ARCHIVE_MAP[id_or_path])
- else:
- filepath = id_or_path
- with open(filepath, "r") as f:
- words = f.read().strip().split("\n")
- bow_indices.append([tokenizer.encode(word.strip(), add_prefix_space=True) for word in words])
- return bow_indices
-
-
-def build_bows_one_hot_vectors(bow_indices, tokenizer, device="cuda"):
- if bow_indices is None:
- return None
-
- one_hot_bows_vectors = []
- for single_bow in bow_indices:
- single_bow = list(filter(lambda x: len(x) <= 1, single_bow))
- single_bow = torch.tensor(single_bow).to(device)
- num_words = single_bow.shape[0]
- one_hot_bow = torch.zeros(num_words, tokenizer.vocab_size).to(device)
- one_hot_bow.scatter_(1, single_bow, 1)
- one_hot_bows_vectors.append(one_hot_bow)
- return one_hot_bows_vectors
-
-
-def full_text_generation(
- model,
- tokenizer,
- context=None,
- num_samples=1,
- device="cuda",
- bag_of_words=None,
- discrim=None,
- class_label=None,
- length=100,
- stepsize=0.02,
- temperature=1.0,
- top_k=10,
- sample=False,
- num_iterations=3,
- grad_length=10000,
- horizon_length=1,
- window_length=0,
- decay=False,
- gamma=1.5,
- gm_scale=0.9,
- kl_scale=0.01,
- repetition_penalty=1.0,
- **kwargs,
-):
- classifier, class_id = get_classifier(discrim, class_label, device)
-
- bow_indices = []
- if bag_of_words:
- bow_indices = get_bag_of_words_indices(bag_of_words.split(";"), tokenizer)
-
- if bag_of_words and classifier:
- print("Both PPLM-BoW and PPLM-Discrim are on. This is not optimized.")
- loss_type = PPLM_BOW_DISCRIM
-
- elif bag_of_words:
- loss_type = PPLM_BOW
- print("Using PPLM-BoW")
-
- elif classifier is not None:
- loss_type = PPLM_DISCRIM
- print("Using PPLM-Discrim")
-
- else:
- raise Exception("Specify either a bag of words or a discriminator")
-
- unpert_gen_tok_text, _, _ = generate_text_pplm(
- model=model,
- tokenizer=tokenizer,
- context=context,
- device=device,
- length=length,
- sample=sample,
- perturb=False,
- repetition_penalty=repetition_penalty,
- )
- if device == "cuda":
- torch.cuda.empty_cache()
-
- pert_gen_tok_texts = []
- discrim_losses = []
- losses_in_time = []
-
- for i in range(num_samples):
- pert_gen_tok_text, discrim_loss, loss_in_time = generate_text_pplm(
- model=model,
- tokenizer=tokenizer,
- context=context,
- device=device,
- perturb=True,
- bow_indices=bow_indices,
- classifier=classifier,
- class_label=class_id,
- loss_type=loss_type,
- length=length,
- stepsize=stepsize,
- temperature=temperature,
- top_k=top_k,
- sample=sample,
- num_iterations=num_iterations,
- grad_length=grad_length,
- horizon_length=horizon_length,
- window_length=window_length,
- decay=decay,
- gamma=gamma,
- gm_scale=gm_scale,
- kl_scale=kl_scale,
- repetition_penalty=repetition_penalty,
- )
- pert_gen_tok_texts.append(pert_gen_tok_text)
- if classifier is not None:
- discrim_losses.append(discrim_loss.data.cpu().numpy())
- losses_in_time.append(loss_in_time)
-
- if device == "cuda":
- torch.cuda.empty_cache()
-
- return unpert_gen_tok_text, pert_gen_tok_texts, discrim_losses, losses_in_time
-
-
-def generate_text_pplm(
- model,
- tokenizer,
- context=None,
- past=None,
- device="cuda",
- perturb=True,
- bow_indices=None,
- classifier=None,
- class_label=None,
- loss_type=0,
- length=100,
- stepsize=0.02,
- temperature=1.0,
- top_k=10,
- sample=False,
- num_iterations=3,
- grad_length=10000,
- horizon_length=1,
- window_length=0,
- decay=False,
- gamma=1.5,
- gm_scale=0.9,
- kl_scale=0.01,
- repetition_penalty=1.0,
-):
- output_so_far = None
- if context:
- context_t = torch.tensor(context, device=device, dtype=torch.long)
- while len(context_t.shape) < 2:
- context_t = context_t.unsqueeze(0)
- output_so_far = context_t
-
- # collect one hot vectors for bags of words
- one_hot_bows_vectors = build_bows_one_hot_vectors(bow_indices, tokenizer, device)
-
- grad_norms = None
- last = None
- unpert_discrim_loss = 0
- loss_in_time = []
- for i in trange(length, ascii=True):
- # Get past/probs for current output, except for last word
- # Note that GPT takes 2 inputs: past + current_token
-
- # run model forward to obtain unperturbed
- if past is None and output_so_far is not None:
- last = output_so_far[:, -1:]
- if output_so_far.shape[1] > 1:
- past = model(output_so_far[:, :-1])["past_key_values"]
-
- lm_output = model(output_so_far)
- unpert_logits, unpert_past, unpert_all_hidden = (
- lm_output["logits"],
- lm_output["past_key_values"],
- lm_output["hidden_states"],
- )
- unpert_last_hidden = unpert_all_hidden[-1]
-
- # check if we are abowe grad max length
- if i >= grad_length:
- current_stepsize = stepsize * 0
- else:
- current_stepsize = stepsize
-
- # modify the past if necessary
- if not perturb or num_iterations == 0:
- pert_past = past
-
- else:
- accumulated_hidden = unpert_last_hidden[:, :-1, :]
- accumulated_hidden = torch.sum(accumulated_hidden, dim=1)
-
- if past is not None:
- pert_past, _, grad_norms, loss_this_iter = perturb_past(
- past,
- model,
- last,
- unpert_past=unpert_past,
- unpert_logits=unpert_logits,
- accumulated_hidden=accumulated_hidden,
- grad_norms=grad_norms,
- stepsize=current_stepsize,
- one_hot_bows_vectors=one_hot_bows_vectors,
- classifier=classifier,
- class_label=class_label,
- loss_type=loss_type,
- num_iterations=num_iterations,
- horizon_length=horizon_length,
- window_length=window_length,
- decay=decay,
- gamma=gamma,
- kl_scale=kl_scale,
- device=device,
- )
- loss_in_time.append(loss_this_iter)
- else:
- pert_past = past
-
- lm_output = model(last, past_key_values=pert_past)
- pert_logits, past = (
- lm_output["logits"],
- lm_output["past_key_values"],
- )
- pert_logits = pert_logits[:, -1, :] / temperature # + SMALL_CONST
-
- for token_idx in set(output_so_far[0].tolist()):
- if pert_logits[0, token_idx] < 0:
- pert_logits[0, token_idx] *= repetition_penalty
- else:
- pert_logits[0, token_idx] /= repetition_penalty
-
- pert_probs = nn.functional.softmax(pert_logits, dim=-1)
-
- if classifier is not None:
- ce_loss = nn.CrossEntropyLoss()
- prediction = classifier(torch.mean(unpert_last_hidden, dim=1))
- label = torch.tensor([class_label], device=device, dtype=torch.long)
- unpert_discrim_loss = ce_loss(prediction, label)
- print("unperturbed discrim loss", unpert_discrim_loss.data.cpu().numpy())
- else:
- unpert_discrim_loss = 0
-
- # Fuse the modified model and original model
- if perturb:
- unpert_probs = nn.functional.softmax(unpert_logits[:, -1, :], dim=-1)
-
- pert_probs = (pert_probs**gm_scale) * (unpert_probs ** (1 - gm_scale)) # + SMALL_CONST
- pert_probs = top_k_filter(pert_probs, k=top_k, probs=True) # + SMALL_CONST
-
- # rescale
- if torch.sum(pert_probs) <= 1:
- pert_probs = pert_probs / torch.sum(pert_probs)
-
- else:
- pert_logits = top_k_filter(pert_logits, k=top_k) # + SMALL_CONST
- pert_probs = nn.functional.softmax(pert_logits, dim=-1)
-
- # sample or greedy
- if sample:
- last = torch.multinomial(pert_probs, num_samples=1)
-
- else:
- _, last = torch.topk(pert_probs, k=1, dim=-1)
-
- # update context/output_so_far appending the new token
- output_so_far = last if output_so_far is None else torch.cat((output_so_far, last), dim=1)
-
- print(tokenizer.decode(output_so_far.tolist()[0]))
-
- return output_so_far, unpert_discrim_loss, loss_in_time
-
-
-def set_generic_model_params(discrim_weights, discrim_meta):
- if discrim_weights is None:
- raise ValueError("When using a generic discriminator, discrim_weights need to be specified")
- if discrim_meta is None:
- raise ValueError("When using a generic discriminator, discrim_meta need to be specified")
-
- with open(discrim_meta, "r") as discrim_meta_file:
- meta = json.load(discrim_meta_file)
- meta["path"] = discrim_weights
- DISCRIMINATOR_MODELS_PARAMS["generic"] = meta
-
-
-def run_pplm_example(
- pretrained_model="openai-community/gpt2-medium",
- cond_text="",
- uncond=False,
- num_samples=1,
- bag_of_words=None,
- discrim=None,
- discrim_weights=None,
- discrim_meta=None,
- class_label=-1,
- length=100,
- stepsize=0.02,
- temperature=1.0,
- top_k=10,
- sample=False,
- num_iterations=3,
- grad_length=10000,
- horizon_length=1,
- window_length=0,
- decay=False,
- gamma=1.5,
- gm_scale=0.9,
- kl_scale=0.01,
- seed=0,
- no_cuda=False,
- colorama=False,
- repetition_penalty=1.0,
-):
- # set Random seed
- torch.manual_seed(seed)
- np.random.seed(seed)
-
- # set the device
- device = "cuda" if torch.cuda.is_available() and not no_cuda else "cpu"
-
- if discrim == "generic":
- set_generic_model_params(discrim_weights, discrim_meta)
-
- if discrim is not None:
- pretrained_model = DISCRIMINATOR_MODELS_PARAMS[discrim]["pretrained_model"]
- print("discrim = {}, pretrained_model set to discriminator's = {}".format(discrim, pretrained_model))
-
- # load pretrained model
- model = GPT2LMHeadModel.from_pretrained(pretrained_model, output_hidden_states=True)
- model.to(device)
- model.eval()
-
- # load tokenizer
- tokenizer = GPT2Tokenizer.from_pretrained(pretrained_model)
-
- # Freeze GPT-2 weights
- for param in model.parameters():
- param.requires_grad = False
-
- # figure out conditioning text
- if uncond:
- tokenized_cond_text = tokenizer.encode([tokenizer.bos_token])
- else:
- raw_text = cond_text
- while not raw_text:
- print("Did you forget to add `--cond_text`? ")
- raw_text = input("Model prompt >>> ")
- tokenized_cond_text = tokenizer.encode(tokenizer.bos_token + raw_text)
-
- print("= Prefix of sentence =")
- print(tokenizer.decode(tokenized_cond_text))
- print()
-
- # generate unperturbed and perturbed texts
-
- # full_text_generation returns:
- # unpert_gen_tok_text, pert_gen_tok_texts, discrim_losses, losses_in_time
- unpert_gen_tok_text, pert_gen_tok_texts, _, _ = full_text_generation(
- model=model,
- tokenizer=tokenizer,
- context=tokenized_cond_text,
- device=device,
- num_samples=num_samples,
- bag_of_words=bag_of_words,
- discrim=discrim,
- class_label=class_label,
- length=length,
- stepsize=stepsize,
- temperature=temperature,
- top_k=top_k,
- sample=sample,
- num_iterations=num_iterations,
- grad_length=grad_length,
- horizon_length=horizon_length,
- window_length=window_length,
- decay=decay,
- gamma=gamma,
- gm_scale=gm_scale,
- kl_scale=kl_scale,
- repetition_penalty=repetition_penalty,
- )
-
- # untokenize unperturbed text
- unpert_gen_text = tokenizer.decode(unpert_gen_tok_text.tolist()[0])
-
- print("=" * 80)
- print("= Unperturbed generated text =")
- print(unpert_gen_text)
- print()
-
- generated_texts = []
-
- bow_word_ids = set()
- if bag_of_words and colorama:
- bow_indices = get_bag_of_words_indices(bag_of_words.split(";"), tokenizer)
- for single_bow_list in bow_indices:
- # filtering all words in the list composed of more than 1 token
- filtered = list(filter(lambda x: len(x) <= 1, single_bow_list))
- # w[0] because we are sure w has only 1 item because previous fitler
- bow_word_ids.update(w[0] for w in filtered)
-
- # iterate through the perturbed texts
- for i, pert_gen_tok_text in enumerate(pert_gen_tok_texts):
- try:
- # untokenize unperturbed text
- if colorama:
- import colorama
-
- pert_gen_text = ""
- for word_id in pert_gen_tok_text.tolist()[0]:
- if word_id in bow_word_ids:
- pert_gen_text += "{}{}{}".format(
- colorama.Fore.RED,
- tokenizer.decode([word_id]),
- colorama.Style.RESET_ALL,
- )
- else:
- pert_gen_text += tokenizer.decode([word_id])
- else:
- pert_gen_text = tokenizer.decode(pert_gen_tok_text.tolist()[0])
-
- print("= Perturbed generated text {} =".format(i + 1))
- print(pert_gen_text)
- print()
- except Exception as exc:
- print("Ignoring error while generating perturbed text:", exc)
-
- # keep the prefix, perturbed seq, original seq for each index
- generated_texts.append((tokenized_cond_text, pert_gen_tok_text, unpert_gen_tok_text))
-
- return
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "--pretrained_model",
- "-M",
- type=str,
- default="openai-community/gpt2-medium",
- help="pretrained model name or path to local checkpoint",
- )
- parser.add_argument("--cond_text", type=str, default="The lake", help="Prefix texts to condition on")
- parser.add_argument("--uncond", action="store_true", help="Generate from end-of-text as prefix")
- parser.add_argument(
- "--num_samples",
- type=int,
- default=1,
- help="Number of samples to generate from the modified latents",
- )
- parser.add_argument(
- "--bag_of_words",
- "-B",
- type=str,
- default=None,
- help=(
- "Bags of words used for PPLM-BoW. "
- "Either a BOW id (see list in code) or a filepath. "
- "Multiple BoWs separated by ;"
- ),
- )
- parser.add_argument(
- "--discrim",
- "-D",
- type=str,
- default=None,
- choices=("clickbait", "sentiment", "toxicity", "generic"),
- help="Discriminator to use",
- )
- parser.add_argument(
- "--discrim_weights",
- type=str,
- default=None,
- help="Weights for the generic discriminator",
- )
- parser.add_argument(
- "--discrim_meta",
- type=str,
- default=None,
- help="Meta information for the generic discriminator",
- )
- parser.add_argument(
- "--class_label",
- type=int,
- default=-1,
- help="Class label used for the discriminator",
- )
- parser.add_argument("--length", type=int, default=100)
- parser.add_argument("--stepsize", type=float, default=0.02)
- parser.add_argument("--temperature", type=float, default=1.0)
- parser.add_argument("--top_k", type=int, default=10)
- parser.add_argument("--sample", action="store_true", help="Generate from end-of-text as prefix")
- parser.add_argument("--num_iterations", type=int, default=3)
- parser.add_argument("--grad_length", type=int, default=10000)
- parser.add_argument(
- "--window_length",
- type=int,
- default=0,
- help="Length of past which is being optimized; 0 corresponds to infinite window length",
- )
- parser.add_argument(
- "--horizon_length",
- type=int,
- default=1,
- help="Length of future to optimize over",
- )
- parser.add_argument("--decay", action="store_true", help="whether to decay or not")
- parser.add_argument("--gamma", type=float, default=1.5)
- parser.add_argument("--gm_scale", type=float, default=0.9)
- parser.add_argument("--kl_scale", type=float, default=0.01)
- parser.add_argument("--seed", type=int, default=0)
- parser.add_argument("--no_cuda", action="store_true", help="no cuda")
- parser.add_argument("--colorama", action="store_true", help="colors keywords")
- parser.add_argument(
- "--repetition_penalty",
- type=float,
- default=1.0,
- help="Penalize repetition. More than 1.0 -> less repetition",
- )
-
- args = parser.parse_args()
- run_pplm_example(**vars(args))
diff --git a/examples/research_projects/pplm/run_pplm_discrim_train.py b/examples/research_projects/pplm/run_pplm_discrim_train.py
deleted file mode 100644
index 43ec5823e37..00000000000
--- a/examples/research_projects/pplm/run_pplm_discrim_train.py
+++ /dev/null
@@ -1,526 +0,0 @@
-#! /usr/bin/env python3
-# coding=utf-8
-
-# Copyright (c) 2019 Uber Technologies, Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import argparse
-import csv
-import json
-import math
-import time
-
-import numpy as np
-import torch
-import torch.optim as optim
-import torch.utils.data as data
-from nltk.tokenize.treebank import TreebankWordDetokenizer
-from pplm_classification_head import ClassificationHead
-from torch import nn
-from torchtext import data as torchtext_data
-from torchtext import datasets
-from tqdm import tqdm, trange
-
-from transformers import GPT2LMHeadModel, GPT2Tokenizer
-
-
-torch.manual_seed(0)
-np.random.seed(0)
-EPSILON = 1e-10
-example_sentence = "This is incredible! I love it, this is the best chicken I have ever had."
-max_length_seq = 100
-
-
-class Discriminator(nn.Module):
- """Transformer encoder followed by a Classification Head"""
-
- def __init__(self, class_size, pretrained_model="openai-community/gpt2-medium", cached_mode=False, device="cpu"):
- super().__init__()
- self.tokenizer = GPT2Tokenizer.from_pretrained(pretrained_model)
- self.encoder = GPT2LMHeadModel.from_pretrained(pretrained_model)
- self.embed_size = self.encoder.transformer.config.hidden_size
- self.classifier_head = ClassificationHead(class_size=class_size, embed_size=self.embed_size)
- self.cached_mode = cached_mode
- self.device = device
-
- def get_classifier(self):
- return self.classifier_head
-
- def train_custom(self):
- for param in self.encoder.parameters():
- param.requires_grad = False
- self.classifier_head.train()
-
- def avg_representation(self, x):
- mask = x.ne(0).unsqueeze(2).repeat(1, 1, self.embed_size).float().to(self.device).detach()
- hidden = self.encoder.transformer(x)["last_hidden_state"]
- masked_hidden = hidden * mask
- avg_hidden = torch.sum(masked_hidden, dim=1) / (torch.sum(mask, dim=1).detach() + EPSILON)
- return avg_hidden
-
- def forward(self, x):
- if self.cached_mode:
- avg_hidden = x.to(self.device)
- else:
- avg_hidden = self.avg_representation(x.to(self.device))
-
- logits = self.classifier_head(avg_hidden)
- probs = nn.functional.log_softmax(logits, dim=-1)
-
- return probs
-
-
-class Dataset(data.Dataset):
- def __init__(self, X, y):
- """Reads source and target sequences from txt files."""
- self.X = X
- self.y = y
-
- def __len__(self):
- return len(self.X)
-
- def __getitem__(self, index):
- """Returns one data pair (source and target)."""
- data = {}
- data["X"] = self.X[index]
- data["y"] = self.y[index]
- return data
-
-
-def collate_fn(data):
- def pad_sequences(sequences):
- lengths = [len(seq) for seq in sequences]
-
- padded_sequences = torch.zeros(len(sequences), max(lengths)).long() # padding value = 0
-
- for i, seq in enumerate(sequences):
- end = lengths[i]
- padded_sequences[i, :end] = seq[:end]
-
- return padded_sequences, lengths
-
- item_info = {}
- for key in data[0].keys():
- item_info[key] = [d[key] for d in data]
-
- x_batch, _ = pad_sequences(item_info["X"])
- y_batch = torch.tensor(item_info["y"], dtype=torch.long)
-
- return x_batch, y_batch
-
-
-def cached_collate_fn(data):
- item_info = {}
- for key in data[0].keys():
- item_info[key] = [d[key] for d in data]
-
- x_batch = torch.cat(item_info["X"], 0)
- y_batch = torch.tensor(item_info["y"], dtype=torch.long)
-
- return x_batch, y_batch
-
-
-def train_epoch(data_loader, discriminator, optimizer, epoch=0, log_interval=10, device="cpu"):
- samples_so_far = 0
- discriminator.train_custom()
- for batch_idx, (input_t, target_t) in enumerate(data_loader):
- input_t, target_t = input_t.to(device), target_t.to(device)
-
- optimizer.zero_grad()
-
- output_t = discriminator(input_t)
- loss = nn.functional.nll_loss(output_t, target_t)
- loss.backward(retain_graph=True)
- optimizer.step()
-
- samples_so_far += len(input_t)
-
- if batch_idx % log_interval == 0:
- print(
- "Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}".format(
- epoch + 1,
- samples_so_far,
- len(data_loader.dataset),
- 100 * samples_so_far / len(data_loader.dataset),
- loss.item(),
- )
- )
-
-
-def evaluate_performance(data_loader, discriminator, device="cpu"):
- discriminator.eval()
- test_loss = 0
- correct = 0
- with torch.no_grad():
- for input_t, target_t in data_loader:
- input_t, target_t = input_t.to(device), target_t.to(device)
- output_t = discriminator(input_t)
- # sum up batch loss
- test_loss += nn.functional.nll_loss(output_t, target_t, reduction="sum").item()
- # get the index of the max log-probability
- pred_t = output_t.argmax(dim=1, keepdim=True)
- correct += pred_t.eq(target_t.view_as(pred_t)).sum().item()
-
- test_loss /= len(data_loader.dataset)
-
- print(
- "Performance on test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)".format(
- test_loss, correct, len(data_loader.dataset), 100.0 * correct / len(data_loader.dataset)
- )
- )
-
-
-def predict(input_sentence, model, classes, cached=False, device="cpu"):
- input_t = model.tokenizer.encode(input_sentence)
- input_t = torch.tensor([input_t], dtype=torch.long, device=device)
- if cached:
- input_t = model.avg_representation(input_t)
-
- log_probs = model(input_t).data.cpu().numpy().flatten().tolist()
- print("Input sentence:", input_sentence)
- print(
- "Predictions:",
- ", ".join("{}: {:.4f}".format(c, math.exp(log_prob)) for c, log_prob in zip(classes, log_probs)),
- )
-
-
-def get_cached_data_loader(dataset, batch_size, discriminator, shuffle=False, device="cpu"):
- data_loader = torch.utils.data.DataLoader(dataset=dataset, batch_size=batch_size, collate_fn=collate_fn)
-
- xs = []
- ys = []
- for batch_idx, (x, y) in enumerate(tqdm(data_loader, ascii=True)):
- with torch.no_grad():
- x = x.to(device)
- avg_rep = discriminator.avg_representation(x).cpu().detach()
- avg_rep_list = torch.unbind(avg_rep.unsqueeze(1))
- xs += avg_rep_list
- ys += y.cpu().numpy().tolist()
-
- data_loader = torch.utils.data.DataLoader(
- dataset=Dataset(xs, ys), batch_size=batch_size, shuffle=shuffle, collate_fn=cached_collate_fn
- )
-
- return data_loader
-
-
-def train_discriminator(
- dataset,
- dataset_fp=None,
- pretrained_model="openai-community/gpt2-medium",
- epochs=10,
- batch_size=64,
- log_interval=10,
- save_model=False,
- cached=False,
- no_cuda=False,
-):
- device = "cuda" if torch.cuda.is_available() and not no_cuda else "cpu"
-
- print("Preprocessing {} dataset...".format(dataset))
- start = time.time()
-
- if dataset == "SST":
- idx2class = ["positive", "negative", "very positive", "very negative", "neutral"]
- class2idx = {c: i for i, c in enumerate(idx2class)}
-
- discriminator = Discriminator(
- class_size=len(idx2class), pretrained_model=pretrained_model, cached_mode=cached, device=device
- ).to(device)
-
- text = torchtext_data.Field()
- label = torchtext_data.Field(sequential=False)
- train_data, val_data, test_data = datasets.SST.splits(
- text,
- label,
- fine_grained=True,
- train_subtrees=True,
- )
-
- x = []
- y = []
- for i in trange(len(train_data), ascii=True):
- seq = TreebankWordDetokenizer().detokenize(vars(train_data[i])["text"])
- seq = discriminator.tokenizer.encode(seq)
- seq = torch.tensor([50256] + seq, device=device, dtype=torch.long)
- x.append(seq)
- y.append(class2idx[vars(train_data[i])["label"]])
- train_dataset = Dataset(x, y)
-
- test_x = []
- test_y = []
- for i in trange(len(test_data), ascii=True):
- seq = TreebankWordDetokenizer().detokenize(vars(test_data[i])["text"])
- seq = discriminator.tokenizer.encode(seq)
- seq = torch.tensor([50256] + seq, device=device, dtype=torch.long)
- test_x.append(seq)
- test_y.append(class2idx[vars(test_data[i])["label"]])
- test_dataset = Dataset(test_x, test_y)
-
- discriminator_meta = {
- "class_size": len(idx2class),
- "embed_size": discriminator.embed_size,
- "pretrained_model": pretrained_model,
- "class_vocab": class2idx,
- "default_class": 2,
- }
-
- elif dataset == "clickbait":
- idx2class = ["non_clickbait", "clickbait"]
- class2idx = {c: i for i, c in enumerate(idx2class)}
-
- discriminator = Discriminator(
- class_size=len(idx2class), pretrained_model=pretrained_model, cached_mode=cached, device=device
- ).to(device)
-
- with open("datasets/clickbait/clickbait_train_prefix.txt") as f:
- data = []
- for i, line in enumerate(f):
- try:
- data.append(eval(line))
- except Exception:
- print("Error evaluating line {}: {}".format(i, line))
- continue
- x = []
- y = []
- with open("datasets/clickbait/clickbait_train_prefix.txt") as f:
- for i, line in enumerate(tqdm(f, ascii=True)):
- try:
- d = eval(line)
- seq = discriminator.tokenizer.encode(d["text"])
-
- if len(seq) < max_length_seq:
- seq = torch.tensor([50256] + seq, device=device, dtype=torch.long)
- else:
- print("Line {} is longer than maximum length {}".format(i, max_length_seq))
- continue
- x.append(seq)
- y.append(d["label"])
- except Exception:
- print("Error evaluating / tokenizing line {}, skipping it".format(i))
- pass
-
- full_dataset = Dataset(x, y)
- train_size = int(0.9 * len(full_dataset))
- test_size = len(full_dataset) - train_size
- train_dataset, test_dataset = torch.utils.data.random_split(full_dataset, [train_size, test_size])
-
- discriminator_meta = {
- "class_size": len(idx2class),
- "embed_size": discriminator.embed_size,
- "pretrained_model": pretrained_model,
- "class_vocab": class2idx,
- "default_class": 1,
- }
-
- elif dataset == "toxic":
- idx2class = ["non_toxic", "toxic"]
- class2idx = {c: i for i, c in enumerate(idx2class)}
-
- discriminator = Discriminator(
- class_size=len(idx2class), pretrained_model=pretrained_model, cached_mode=cached, device=device
- ).to(device)
-
- x = []
- y = []
- with open("datasets/toxic/toxic_train.txt") as f:
- for i, line in enumerate(tqdm(f, ascii=True)):
- try:
- d = eval(line)
- seq = discriminator.tokenizer.encode(d["text"])
-
- if len(seq) < max_length_seq:
- seq = torch.tensor([50256] + seq, device=device, dtype=torch.long)
- else:
- print("Line {} is longer than maximum length {}".format(i, max_length_seq))
- continue
- x.append(seq)
- y.append(int(np.sum(d["label"]) > 0))
- except Exception:
- print("Error evaluating / tokenizing line {}, skipping it".format(i))
- pass
-
- full_dataset = Dataset(x, y)
- train_size = int(0.9 * len(full_dataset))
- test_size = len(full_dataset) - train_size
- train_dataset, test_dataset = torch.utils.data.random_split(full_dataset, [train_size, test_size])
-
- discriminator_meta = {
- "class_size": len(idx2class),
- "embed_size": discriminator.embed_size,
- "pretrained_model": pretrained_model,
- "class_vocab": class2idx,
- "default_class": 0,
- }
-
- else: # if dataset == "generic":
- # This assumes the input dataset is a TSV with the following structure:
- # class \t text
-
- if dataset_fp is None:
- raise ValueError("When generic dataset is selected, dataset_fp needs to be specified aswell.")
-
- classes = set()
- with open(dataset_fp) as f:
- csv_reader = csv.reader(f, delimiter="\t")
- for row in tqdm(csv_reader, ascii=True):
- if row:
- classes.add(row[0])
-
- idx2class = sorted(classes)
- class2idx = {c: i for i, c in enumerate(idx2class)}
-
- discriminator = Discriminator(
- class_size=len(idx2class), pretrained_model=pretrained_model, cached_mode=cached, device=device
- ).to(device)
-
- x = []
- y = []
- with open(dataset_fp) as f:
- csv_reader = csv.reader(f, delimiter="\t")
- for i, row in enumerate(tqdm(csv_reader, ascii=True)):
- if row:
- label = row[0]
- text = row[1]
-
- try:
- seq = discriminator.tokenizer.encode(text)
- if len(seq) < max_length_seq:
- seq = torch.tensor([50256] + seq, device=device, dtype=torch.long)
-
- else:
- print("Line {} is longer than maximum length {}".format(i, max_length_seq))
- continue
-
- x.append(seq)
- y.append(class2idx[label])
-
- except Exception:
- print("Error tokenizing line {}, skipping it".format(i))
- pass
-
- full_dataset = Dataset(x, y)
- train_size = int(0.9 * len(full_dataset))
- test_size = len(full_dataset) - train_size
- train_dataset, test_dataset = torch.utils.data.random_split(full_dataset, [train_size, test_size])
-
- discriminator_meta = {
- "class_size": len(idx2class),
- "embed_size": discriminator.embed_size,
- "pretrained_model": pretrained_model,
- "class_vocab": class2idx,
- "default_class": 0,
- }
-
- end = time.time()
- print("Preprocessed {} data points".format(len(train_dataset) + len(test_dataset)))
- print("Data preprocessing took: {:.3f}s".format(end - start))
-
- if cached:
- print("Building representation cache...")
-
- start = time.time()
-
- train_loader = get_cached_data_loader(train_dataset, batch_size, discriminator, shuffle=True, device=device)
-
- test_loader = get_cached_data_loader(test_dataset, batch_size, discriminator, device=device)
-
- end = time.time()
- print("Building representation cache took: {:.3f}s".format(end - start))
-
- else:
- train_loader = torch.utils.data.DataLoader(
- dataset=train_dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn
- )
- test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, collate_fn=collate_fn)
-
- if save_model:
- with open("{}_classifier_head_meta.json".format(dataset), "w") as meta_file:
- json.dump(discriminator_meta, meta_file)
-
- optimizer = optim.Adam(discriminator.parameters(), lr=0.0001)
-
- for epoch in range(epochs):
- start = time.time()
- print("\nEpoch", epoch + 1)
-
- train_epoch(
- discriminator=discriminator,
- data_loader=train_loader,
- optimizer=optimizer,
- epoch=epoch,
- log_interval=log_interval,
- device=device,
- )
- evaluate_performance(data_loader=test_loader, discriminator=discriminator, device=device)
-
- end = time.time()
- print("Epoch took: {:.3f}s".format(end - start))
-
- print("\nExample prediction")
- predict(example_sentence, discriminator, idx2class, cached=cached, device=device)
-
- if save_model:
- # torch.save(discriminator.state_dict(),
- # "{}_discriminator_{}.pt".format(
- # args.dataset, epoch + 1
- # ))
- torch.save(
- discriminator.get_classifier().state_dict(),
- "{}_classifier_head_epoch_{}.pt".format(dataset, epoch + 1),
- )
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser(description="Train a discriminator on top of GPT-2 representations")
- parser.add_argument(
- "--dataset",
- type=str,
- default="SST",
- choices=("SST", "clickbait", "toxic", "generic"),
- help=(
- "dataset to train the discriminator on. "
- "In case of generic, the dataset is expected "
- "to be a TSBV file with structure: class \\t text"
- ),
- )
- parser.add_argument(
- "--dataset_fp",
- type=str,
- default="",
- help="File path of the dataset to use. Needed only in case of generic datadset",
- )
- parser.add_argument(
- "--pretrained_model",
- type=str,
- default="openai-community/gpt2-medium",
- help="Pretrained model to use as encoder",
- )
- parser.add_argument("--epochs", type=int, default=10, metavar="N", help="Number of training epochs")
- parser.add_argument(
- "--batch_size", type=int, default=64, metavar="N", help="input batch size for training (default: 64)"
- )
- parser.add_argument(
- "--log_interval",
- type=int,
- default=10,
- metavar="N",
- help="how many batches to wait before logging training status",
- )
- parser.add_argument("--save_model", action="store_true", help="whether to save the model")
- parser.add_argument("--cached", action="store_true", help="whether to cache the input representations")
- parser.add_argument("--no_cuda", action="store_true", help="use to turn off cuda")
- args = parser.parse_args()
-
- train_discriminator(**(vars(args)))
diff --git a/examples/research_projects/quantization-qdqbert/Dockerfile b/examples/research_projects/quantization-qdqbert/Dockerfile
deleted file mode 100644
index e64c9f0e021..00000000000
--- a/examples/research_projects/quantization-qdqbert/Dockerfile
+++ /dev/null
@@ -1,34 +0,0 @@
-# coding=utf-8
-# Copyright 2021 NVIDIA Corporation. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-FROM nvcr.io/nvidia/pytorch:22.02-py3
-LABEL maintainer="Hugging Face"
-LABEL repository="transformers"
-
-RUN apt-get update
-RUN apt-get install sudo
-
-RUN python3 -m pip install --no-cache-dir --upgrade pip
-RUN python3 -m pip install --no-cache-dir --ignore-installed pycuda
-RUN python3 -m pip install --no-cache-dir \
- pytorch-quantization --extra-index-url https://pypi.ngc.nvidia.com
-RUN python3 -m pip install --no-cache-dir onnxruntime-gpu==1.11
-
-WORKDIR /workspace
-COPY . transformers/
-RUN cd transformers/ && \
- python3 -m pip install --no-cache-dir .
-
-RUN python3 -m pip install --no-cache-dir datasets \
- accelerate
diff --git a/examples/research_projects/quantization-qdqbert/README.md b/examples/research_projects/quantization-qdqbert/README.md
deleted file mode 100644
index 2cc2d5e5f98..00000000000
--- a/examples/research_projects/quantization-qdqbert/README.md
+++ /dev/null
@@ -1,200 +0,0 @@
-
-
-# Huggingface QDQBERT Quantization Example
-
-The QDQBERT model adds fake quantization (pair of QuantizeLinear/DequantizeLinear ops) to:
- * linear layer inputs and weights
- * matmul inputs
- * residual add inputs
-
-In this example, we use QDQBERT model to do quantization on SQuAD task, including Quantization Aware Training (QAT), Post Training Quantization (PTQ) and inferencing using TensorRT.
-
-Required:
-- [pytorch-quantization toolkit](https://github.com/NVIDIA/TensorRT/tree/master/tools/pytorch-quantization)
-- [TensorRT >= 8.2](https://developer.nvidia.com/tensorrt)
-- PyTorch >= 1.10.0
-
-## Setup the environment with Dockerfile
-
-Under the directory of `transformers/`, build the docker image:
-```bash
-docker build . -f examples/research_projects/quantization-qdqbert/Dockerfile -t bert_quantization:latest
-```
-
-Run the docker:
-```bash
-docker run --gpus all --privileged --rm -it --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 bert_quantization:latest
-```
-
-In the container:
-```bash
-cd transformers/examples/research_projects/quantization-qdqbert/
-```
-
-## Quantization Aware Training (QAT)
-
-Calibrate the pretrained model and finetune with quantization awared:
-
-```bash
-python3 run_quant_qa.py \
- --model_name_or_path google-bert/bert-base-uncased \
- --dataset_name squad \
- --max_seq_length 128 \
- --doc_stride 32 \
- --output_dir calib/google-bert/bert-base-uncased \
- --do_calib \
- --calibrator percentile \
- --percentile 99.99
-```
-
-```bash
-python3 run_quant_qa.py \
- --model_name_or_path calib/google-bert/bert-base-uncased \
- --dataset_name squad \
- --do_train \
- --do_eval \
- --per_device_train_batch_size 12 \
- --learning_rate 4e-5 \
- --num_train_epochs 2 \
- --max_seq_length 128 \
- --doc_stride 32 \
- --output_dir finetuned_int8/google-bert/bert-base-uncased \
- --tokenizer_name google-bert/bert-base-uncased \
- --save_steps 0
-```
-
-### Export QAT model to ONNX
-
-To export the QAT model finetuned above:
-
-```bash
-python3 run_quant_qa.py \
- --model_name_or_path finetuned_int8/google-bert/bert-base-uncased \
- --output_dir ./ \
- --save_onnx \
- --per_device_eval_batch_size 1 \
- --max_seq_length 128 \
- --doc_stride 32 \
- --dataset_name squad \
- --tokenizer_name google-bert/bert-base-uncased
-```
-
-Use `--recalibrate-weights` to calibrate the weight ranges according to the quantizer axis. Use `--quant-per-tensor` for per tensor quantization (default is per channel).
-Recalibrating will affect the accuracy of the model, but the change should be minimal (< 0.5 F1).
-
-### Benchmark the INT8 QAT ONNX model inference with TensorRT using dummy input
-
-```bash
-trtexec --onnx=model.onnx --explicitBatch --workspace=16384 --int8 --shapes=input_ids:64x128,attention_mask:64x128,token_type_ids:64x128 --verbose
-```
-
-### Benchmark the INT8 QAT ONNX model inference with [ONNX Runtime-TRT](https://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.html) using dummy input
-
-```bash
-python3 ort-infer-benchmark.py
-```
-
-### Evaluate the INT8 QAT ONNX model inference with TensorRT
-
-```bash
-python3 evaluate-hf-trt-qa.py \
- --onnx_model_path=./model.onnx \
- --output_dir ./ \
- --per_device_eval_batch_size 64 \
- --max_seq_length 128 \
- --doc_stride 32 \
- --dataset_name squad \
- --tokenizer_name google-bert/bert-base-uncased \
- --int8 \
- --seed 42
-```
-
-## Fine-tuning of FP32 model for comparison
-
-Finetune a fp32 precision model with [transformers/examples/pytorch/question-answering/](../../pytorch/question-answering/):
-
-```bash
-python3 ../../pytorch/question-answering/run_qa.py \
- --model_name_or_path google-bert/bert-base-uncased \
- --dataset_name squad \
- --per_device_train_batch_size 12 \
- --learning_rate 3e-5 \
- --num_train_epochs 2 \
- --max_seq_length 128 \
- --doc_stride 32 \
- --output_dir ./finetuned_fp32/google-bert/bert-base-uncased \
- --save_steps 0 \
- --do_train \
- --do_eval
-```
-
-## Post Training Quantization (PTQ)
-
-### PTQ by calibrating and evaluating the finetuned FP32 model above:
-
-```bash
-python3 run_quant_qa.py \
- --model_name_or_path ./finetuned_fp32/google-bert/bert-base-uncased \
- --dataset_name squad \
- --calibrator percentile \
- --percentile 99.99 \
- --max_seq_length 128 \
- --doc_stride 32 \
- --output_dir ./calib/google-bert/bert-base-uncased \
- --save_steps 0 \
- --do_calib \
- --do_eval
-```
-
-### Export the INT8 PTQ model to ONNX
-
-```bash
-python3 run_quant_qa.py \
- --model_name_or_path ./calib/google-bert/bert-base-uncased \
- --output_dir ./ \
- --save_onnx \
- --per_device_eval_batch_size 1 \
- --max_seq_length 128 \
- --doc_stride 32 \
- --dataset_name squad \
- --tokenizer_name google-bert/bert-base-uncased
-```
-
-### Evaluate the INT8 PTQ ONNX model inference with TensorRT
-
-```bash
-python3 evaluate-hf-trt-qa.py \
- --onnx_model_path=./model.onnx \
- --output_dir ./ \
- --per_device_eval_batch_size 64 \
- --max_seq_length 128 \
- --doc_stride 32 \
- --dataset_name squad \
- --tokenizer_name google-bert/bert-base-uncased \
- --int8 \
- --seed 42
-```
-
-### Quantization options
-
-Some useful options to support different implementations and optimizations. These should be specified for both calibration and finetuning.
-
-|argument|description|
-|--------|-----------|
-|`--quant-per-tensor`| quantize weights with one quantization range per tensor |
-|`--fuse-qkv` | use a single range (the max) for quantizing QKV weights and output activations |
-|`--clip-gelu N` | clip the output of GELU to a maximum of N when quantizing (e.g. 10) |
-|`--disable-dropout` | disable dropout for consistent activation ranges |
diff --git a/examples/research_projects/quantization-qdqbert/evaluate-hf-trt-qa.py b/examples/research_projects/quantization-qdqbert/evaluate-hf-trt-qa.py
deleted file mode 100755
index 7a8ea2109bc..00000000000
--- a/examples/research_projects/quantization-qdqbert/evaluate-hf-trt-qa.py
+++ /dev/null
@@ -1,457 +0,0 @@
-# coding=utf-8
-# Copyright 2021 NVIDIA Corporation. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Finetuning the library models for question-answering on SQuAD (DistilBERT, Bert, XLM, XLNet)."""
-
-import argparse
-import logging
-import os
-import time
-import timeit
-
-import datasets
-import numpy as np
-import pycuda.autoinit # noqa: F401
-import pycuda.driver as cuda
-import tensorrt as trt
-import torch
-from absl import logging as absl_logging
-from accelerate import Accelerator
-from datasets import load_dataset, load_metric
-from torch.utils.data import DataLoader
-from utils_qa import postprocess_qa_predictions
-
-import transformers
-from transformers import AutoTokenizer, EvalPrediction, default_data_collator, set_seed
-from transformers.trainer_pt_utils import nested_concat, nested_truncate
-
-
-TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
-absl_logger = absl_logging.get_absl_logger()
-absl_logger.setLevel(logging.WARNING)
-
-logger = logging.getLogger(__name__)
-
-parser = argparse.ArgumentParser()
-
-# Required parameters
-parser.add_argument(
- "--onnx_model_path",
- default=None,
- type=str,
- required=True,
- help="Path to ONNX model: ",
-)
-
-parser.add_argument(
- "--output_dir",
- default=None,
- type=str,
- required=True,
- help="The output directory where the model checkpoints and predictions will be written.",
-)
-
-# Other parameters
-
-parser.add_argument(
- "--tokenizer_name",
- default="",
- type=str,
- required=True,
- help="Pretrained tokenizer name or path if not the same as model_name",
-)
-
-parser.add_argument(
- "--version_2_with_negative",
- action="store_true",
- help="If true, the SQuAD examples contain some that do not have an answer.",
-)
-parser.add_argument(
- "--null_score_diff_threshold",
- type=float,
- default=0.0,
- help="If null_score - best_non_null is greater than the threshold predict null.",
-)
-
-parser.add_argument(
- "--max_seq_length",
- default=384,
- type=int,
- help=(
- "The maximum total input sequence length after WordPiece tokenization. Sequences "
- "longer than this will be truncated, and sequences shorter than this will be padded."
- ),
-)
-parser.add_argument(
- "--doc_stride",
- default=128,
- type=int,
- help="When splitting up a long document into chunks, how much stride to take between chunks.",
-)
-
-parser.add_argument("--per_device_eval_batch_size", default=8, type=int, help="Batch size per GPU/CPU for evaluation.")
-
-parser.add_argument(
- "--n_best_size",
- default=20,
- type=int,
- help="The total number of n-best predictions to generate in the nbest_predictions.json output file.",
-)
-parser.add_argument(
- "--max_answer_length",
- default=30,
- type=int,
- help=(
- "The maximum length of an answer that can be generated. This is needed because the start "
- "and end predictions are not conditioned on one another."
- ),
-)
-
-parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
-
-parser.add_argument(
- "--dataset_name",
- type=str,
- default=None,
- required=True,
- help="The name of the dataset to use (via the datasets library).",
-)
-parser.add_argument(
- "--dataset_config_name",
- type=str,
- default=None,
- help="The configuration name of the dataset to use (via the datasets library).",
-)
-parser.add_argument(
- "--preprocessing_num_workers", type=int, default=4, help="A csv or a json file containing the training data."
-)
-parser.add_argument("--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets")
-parser.add_argument(
- "--fp16",
- action="store_true",
- help="Whether to use 16-bit (mixed) precision instead of 32-bit",
-)
-parser.add_argument(
- "--int8",
- action="store_true",
- help="Whether to use INT8",
-)
-
-args = parser.parse_args()
-
-if args.tokenizer_name:
- tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name, use_fast=True)
-else:
- raise ValueError(
- "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
- "You can do it from another script, save it, and load it from here, using --tokenizer_name."
- )
-
-logger.info("Training/evaluation parameters %s", args)
-
-args.eval_batch_size = args.per_device_eval_batch_size
-
-INPUT_SHAPE = (args.eval_batch_size, args.max_seq_length)
-
-# TRT Engine properties
-STRICT_TYPES = True
-
-engine_name = "temp_engine/bert-fp32.engine"
-if args.fp16:
- engine_name = "temp_engine/bert-fp16.engine"
-if args.int8:
- engine_name = "temp_engine/bert-int8.engine"
-
-# import ONNX file
-if not os.path.exists("temp_engine"):
- os.makedirs("temp_engine")
-
-EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
-with trt.Builder(TRT_LOGGER) as builder, builder.create_network(EXPLICIT_BATCH) as network, trt.OnnxParser(
- network, TRT_LOGGER
-) as parser:
- with open(args.onnx_model_path, "rb") as model:
- if not parser.parse(model.read()):
- for error in range(parser.num_errors):
- print(parser.get_error(error))
-
- # Query input names and shapes from parsed TensorRT network
- network_inputs = [network.get_input(i) for i in range(network.num_inputs)]
- input_names = [_input.name for _input in network_inputs] # ex: ["actual_input1"]
-
- with builder.create_builder_config() as config:
- config.max_workspace_size = 1 << 50
- if STRICT_TYPES:
- config.set_flag(trt.BuilderFlag.STRICT_TYPES)
- if args.fp16:
- config.set_flag(trt.BuilderFlag.FP16)
- if args.int8:
- config.set_flag(trt.BuilderFlag.INT8)
- profile = builder.create_optimization_profile()
- config.add_optimization_profile(profile)
- for i in range(len(input_names)):
- profile.set_shape(input_names[i], INPUT_SHAPE, INPUT_SHAPE, INPUT_SHAPE)
- engine = builder.build_engine(network, config)
-
- # serialize_engine and store in file (can be directly loaded and deserialized):
- with open(engine_name, "wb") as f:
- f.write(engine.serialize())
-
-
-# run inference with TRT
-def model_infer(inputs, context, d_inputs, h_output0, h_output1, d_output0, d_output1, stream):
- input_ids = np.asarray(inputs["input_ids"], dtype=np.int32)
- attention_mask = np.asarray(inputs["attention_mask"], dtype=np.int32)
- token_type_ids = np.asarray(inputs["token_type_ids"], dtype=np.int32)
-
- # Copy inputs
- cuda.memcpy_htod_async(d_inputs[0], input_ids.ravel(), stream)
- cuda.memcpy_htod_async(d_inputs[1], attention_mask.ravel(), stream)
- cuda.memcpy_htod_async(d_inputs[2], token_type_ids.ravel(), stream)
- # start time
- start_time = time.time()
- # Run inference
- context.execute_async(
- bindings=[int(d_inp) for d_inp in d_inputs] + [int(d_output0), int(d_output1)], stream_handle=stream.handle
- )
- # Transfer predictions back from GPU
- cuda.memcpy_dtoh_async(h_output0, d_output0, stream)
- cuda.memcpy_dtoh_async(h_output1, d_output1, stream)
- # Synchronize the stream and take time
- stream.synchronize()
- # end time
- end_time = time.time()
- infer_time = end_time - start_time
- outputs = (h_output0, h_output1)
- # print(outputs)
- return outputs, infer_time
-
-
-# Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
-accelerator = Accelerator()
-# Make one log on every process with the configuration for debugging.
-logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- level=logging.INFO,
-)
-
-# Setup logging, we only want one process per machine to log things on the screen.
-# accelerator.is_local_main_process is only True for one process per machine.
-logger.setLevel(logging.INFO if accelerator.is_local_main_process else logging.ERROR)
-if accelerator.is_local_main_process:
- datasets.utils.logging.set_verbosity_warning()
- transformers.utils.logging.set_verbosity_info()
-else:
- datasets.utils.logging.set_verbosity_error()
- transformers.utils.logging.set_verbosity_error()
-
-# If passed along, set the training seed now.
-if args.seed is not None:
- set_seed(args.seed)
-
-# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
-# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
-# (the dataset will be downloaded automatically from the datasets Hub).
-#
-# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
-# 'text' is found. You can easily tweak this behavior (see below).
-if args.dataset_name is not None:
- # Downloading and loading a dataset from the hub.
- raw_datasets = load_dataset(args.dataset_name, args.dataset_config_name)
-else:
- raise ValueError("Evaluation requires a dataset name")
-# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
-# https://huggingface.co/docs/datasets/loading_datasets.
-
-# Preprocessing the datasets.
-# Preprocessing is slightly different for training and evaluation.
-
-column_names = raw_datasets["validation"].column_names
-
-question_column_name = "question" if "question" in column_names else column_names[0]
-context_column_name = "context" if "context" in column_names else column_names[1]
-answer_column_name = "answers" if "answers" in column_names else column_names[2]
-
-# Padding side determines if we do (question|context) or (context|question).
-pad_on_right = tokenizer.padding_side == "right"
-
-if args.max_seq_length > tokenizer.model_max_length:
- logger.warning(
- f"The max_seq_length passed ({args.max_seq_length}) is larger than the maximum length for the "
- f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
- )
-
-max_seq_length = min(args.max_seq_length, tokenizer.model_max_length)
-
-
-# Validation preprocessing
-def prepare_validation_features(examples):
- # Some of the questions have lots of whitespace on the left, which is not useful and will make the
- # truncation of the context fail (the tokenized question will take a lots of space). So we remove that
- # left whitespace
- examples[question_column_name] = [q.lstrip() for q in examples[question_column_name]]
-
- # Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
- # in one example possible giving several features when a context is long, each of those features having a
- # context that overlaps a bit the context of the previous feature.
- tokenized_examples = tokenizer(
- examples[question_column_name if pad_on_right else context_column_name],
- examples[context_column_name if pad_on_right else question_column_name],
- truncation="only_second" if pad_on_right else "only_first",
- max_length=max_seq_length,
- stride=args.doc_stride,
- return_overflowing_tokens=True,
- return_offsets_mapping=True,
- padding="max_length",
- )
-
- # Since one example might give us several features if it has a long context, we need a map from a feature to
- # its corresponding example. This key gives us just that.
- sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
-
- # For evaluation, we will need to convert our predictions to substrings of the context, so we keep the
- # corresponding example_id and we will store the offset mappings.
- tokenized_examples["example_id"] = []
-
- for i in range(len(tokenized_examples["input_ids"])):
- # Grab the sequence corresponding to that example (to know what is the context and what is the question).
- sequence_ids = tokenized_examples.sequence_ids(i)
- context_index = 1 if pad_on_right else 0
-
- # One example can give several spans, this is the index of the example containing this span of text.
- sample_index = sample_mapping[i]
- tokenized_examples["example_id"].append(examples["id"][sample_index])
-
- # Set to None the offset_mapping that are not part of the context so it's easy to determine if a token
- # position is part of the context or not.
- tokenized_examples["offset_mapping"][i] = [
- (o if sequence_ids[k] == context_index else None)
- for k, o in enumerate(tokenized_examples["offset_mapping"][i])
- ]
-
- return tokenized_examples
-
-
-eval_examples = raw_datasets["validation"]
-# Validation Feature Creation
-eval_dataset = eval_examples.map(
- prepare_validation_features,
- batched=True,
- num_proc=args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not args.overwrite_cache,
- desc="Running tokenizer on validation dataset",
-)
-
-data_collator = default_data_collator
-
-eval_dataset_for_model = eval_dataset.remove_columns(["example_id", "offset_mapping"])
-eval_dataloader = DataLoader(
- eval_dataset_for_model, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size
-)
-
-
-# Post-processing:
-def post_processing_function(examples, features, predictions, stage="eval"):
- # Post-processing: we match the start logits and end logits to answers in the original context.
- predictions = postprocess_qa_predictions(
- examples=examples,
- features=features,
- predictions=predictions,
- version_2_with_negative=args.version_2_with_negative,
- n_best_size=args.n_best_size,
- max_answer_length=args.max_answer_length,
- null_score_diff_threshold=args.null_score_diff_threshold,
- output_dir=args.output_dir,
- prefix=stage,
- )
- # Format the result to the format the metric expects.
- if args.version_2_with_negative:
- formatted_predictions = [
- {"id": k, "prediction_text": v, "no_answer_probability": 0.0} for k, v in predictions.items()
- ]
- else:
- formatted_predictions = [{"id": k, "prediction_text": v} for k, v in predictions.items()]
-
- references = [{"id": ex["id"], "answers": ex[answer_column_name]} for ex in examples]
- return EvalPrediction(predictions=formatted_predictions, label_ids=references)
-
-
-metric = load_metric("squad_v2" if args.version_2_with_negative else "squad")
-
-# Evaluation!
-logger.info("Loading ONNX model %s for evaluation", args.onnx_model_path)
-with open(engine_name, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime, runtime.deserialize_cuda_engine(
- f.read()
-) as engine, engine.create_execution_context() as context:
- # setup for TRT inferrence
- for i in range(len(input_names)):
- context.set_binding_shape(i, INPUT_SHAPE)
- assert context.all_binding_shapes_specified
-
- def binding_nbytes(binding):
- return trt.volume(engine.get_binding_shape(binding)) * engine.get_binding_dtype(binding).itemsize
-
- # Allocate device memory for inputs and outputs.
- d_inputs = [cuda.mem_alloc(binding_nbytes(binding)) for binding in engine if engine.binding_is_input(binding)]
-
- # Allocate output buffer
- h_output0 = cuda.pagelocked_empty(tuple(context.get_binding_shape(3)), dtype=np.float32)
- h_output1 = cuda.pagelocked_empty(tuple(context.get_binding_shape(4)), dtype=np.float32)
- d_output0 = cuda.mem_alloc(h_output0.nbytes)
- d_output1 = cuda.mem_alloc(h_output1.nbytes)
-
- # Create a stream in which to copy inputs/outputs and run inference.
- stream = cuda.Stream()
-
- # Evaluation
- logger.info("***** Running Evaluation *****")
- logger.info(f" Num examples = {len(eval_dataset)}")
- logger.info(f" Batch size = {args.per_device_eval_batch_size}")
-
- total_time = 0.0
- niter = 0
- start_time = timeit.default_timer()
-
- all_preds = None
- for step, batch in enumerate(eval_dataloader):
- outputs, infer_time = model_infer(batch, context, d_inputs, h_output0, h_output1, d_output0, d_output1, stream)
- total_time += infer_time
- niter += 1
-
- start_logits, end_logits = outputs
- start_logits = torch.tensor(start_logits)
- end_logits = torch.tensor(end_logits)
-
- # necessary to pad predictions and labels for being gathered
- start_logits = accelerator.pad_across_processes(start_logits, dim=1, pad_index=-100)
- end_logits = accelerator.pad_across_processes(end_logits, dim=1, pad_index=-100)
-
- logits = (accelerator.gather(start_logits).cpu().numpy(), accelerator.gather(end_logits).cpu().numpy())
- all_preds = logits if all_preds is None else nested_concat(all_preds, logits, padding_index=-100)
-
- if all_preds is not None:
- all_preds = nested_truncate(all_preds, len(eval_dataset))
-
- evalTime = timeit.default_timer() - start_time
- logger.info(" Evaluation done in total %f secs (%f sec per example)", evalTime, evalTime / len(eval_dataset))
- # Inference time from TRT
- logger.info("Average Inference Time = {:.3f} ms".format(total_time * 1000 / niter))
- logger.info("Total Inference Time = {:.3f} ms".format(total_time * 1000))
- logger.info("Total Number of Inference = %d", niter)
-
-prediction = post_processing_function(eval_examples, eval_dataset, all_preds)
-eval_metric = metric.compute(predictions=prediction.predictions, references=prediction.label_ids)
-logger.info(f"Evaluation metrics: {eval_metric}")
diff --git a/examples/research_projects/quantization-qdqbert/ort-infer-benchmark.py b/examples/research_projects/quantization-qdqbert/ort-infer-benchmark.py
deleted file mode 100644
index bb0436c1258..00000000000
--- a/examples/research_projects/quantization-qdqbert/ort-infer-benchmark.py
+++ /dev/null
@@ -1,50 +0,0 @@
-import os
-import time
-
-import numpy as np
-import onnxruntime as ort
-
-
-os.environ["ORT_TENSORRT_INT8_ENABLE"] = "1"
-os.environ["ORT_TENSORRT_INT8_USE_NATIVE_CALIBRATION_TABLE"] = "0"
-os.environ["ORT_TENSORRT_ENGINE_CACHE_ENABLE"] = "1"
-
-sess_opt = ort.SessionOptions()
-sess_opt.graph_optimization_level = ort.GraphOptimizationLevel.ORT_DISABLE_ALL
-print("Create inference session...")
-execution_provider = ["TensorrtExecutionProvider", "CUDAExecutionProvider"]
-sess = ort.InferenceSession("model.onnx", sess_options=sess_opt, providers=execution_provider)
-run_opt = ort.RunOptions()
-
-sequence = 128
-batch = 1
-input_ids = np.ones((batch, sequence), dtype=np.int64)
-attention_mask = np.ones((batch, sequence), dtype=np.int64)
-token_type_ids = np.ones((batch, sequence), dtype=np.int64)
-
-print("Warm up phase...")
-sess.run(
- None,
- {
- sess.get_inputs()[0].name: input_ids,
- sess.get_inputs()[1].name: attention_mask,
- sess.get_inputs()[2].name: token_type_ids,
- },
- run_options=run_opt,
-)
-
-print("Start inference...")
-start_time = time.time()
-max_iters = 2000
-predict = {}
-for iter in range(max_iters):
- predict = sess.run(
- None,
- {
- sess.get_inputs()[0].name: input_ids,
- sess.get_inputs()[1].name: attention_mask,
- sess.get_inputs()[2].name: token_type_ids,
- },
- run_options=run_opt,
- )
-print("Average Inference Time = {:.3f} ms".format((time.time() - start_time) * 1000 / max_iters))
diff --git a/examples/research_projects/quantization-qdqbert/quant_trainer.py b/examples/research_projects/quantization-qdqbert/quant_trainer.py
deleted file mode 100755
index 132aa284905..00000000000
--- a/examples/research_projects/quantization-qdqbert/quant_trainer.py
+++ /dev/null
@@ -1,305 +0,0 @@
-# coding=utf-8
-# Copyright 2021 NVIDIA Corporation. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Helper functions for training models with pytorch-quantization"""
-
-import logging
-import re
-
-import pytorch_quantization
-import pytorch_quantization.nn as quant_nn
-import torch
-from pytorch_quantization import calib
-from pytorch_quantization.tensor_quant import QuantDescriptor
-
-
-logger = logging.getLogger(__name__)
-
-name_width = 50 # max width of layer names
-qname_width = 70 # max width of quantizer names
-
-# ========================================== Quant Trainer API ==========================================
-
-
-def add_arguments(parser):
- """Add arguments to parser for functions defined in quant_trainer."""
-
- group = parser.add_argument_group("quant_trainer arguments")
- group.add_argument("--wprec", type=int, default=8, help="weight precision")
- group.add_argument("--aprec", type=int, default=8, help="activation precision")
- group.add_argument("--quant-per-tensor", action="store_true", help="per tensor weight scaling")
- group.add_argument("--quant-disable", action="store_true", help="disable all quantizers")
- group.add_argument("--quant-disable-embeddings", action="store_true", help="disable all embeddings quantizers")
- group.add_argument("--quant-disable-keyword", type=str, nargs="+", help="disable quantizers by keyword")
- group.add_argument("--quant-disable-layer-module", type=str, help="disable quantizers by keyword under layer.")
- group.add_argument("--quant-enable-layer-module", type=str, help="enable quantizers by keyword under layer")
- group.add_argument("--calibrator", default="max", help="which quantization range calibrator to use")
- group.add_argument("--percentile", default=None, type=float, help="percentile for PercentileCalibrator")
- group.add_argument("--fuse-qkv", action="store_true", help="use the same scale factor for qkv")
- group.add_argument("--clip-gelu", metavar="N", type=float, help="clip gelu output maximum value to N")
- group.add_argument(
- "--recalibrate-weights",
- action="store_true",
- help=(
- "recalibrate weight amaxes by taking the max of the weights."
- " amaxes will be computed with the current quantization granularity (axis)."
- ),
- )
-
-
-def set_default_quantizers(args):
- """Set default quantizers before creating the model."""
-
- if args.calibrator == "max":
- calib_method = "max"
- elif args.calibrator == "percentile":
- if args.percentile is None:
- raise ValueError("Specify --percentile when using percentile calibrator")
- calib_method = "histogram"
- elif args.calibrator == "mse":
- calib_method = "histogram"
- else:
- raise ValueError(f"Invalid calibrator {args.calibrator}")
-
- input_desc = QuantDescriptor(num_bits=args.aprec, calib_method=calib_method)
- weight_desc = QuantDescriptor(num_bits=args.wprec, axis=(None if args.quant_per_tensor else (0,)))
- quant_nn.QuantLinear.set_default_quant_desc_input(input_desc)
- quant_nn.QuantLinear.set_default_quant_desc_weight(weight_desc)
-
-
-def configure_model(model, args, calib=False, eval=False):
- """Function called before the training loop."""
-
- logger.info("Configuring Model for Quantization")
- logger.info(f"using quantization package {pytorch_quantization.__file__}")
-
- if not calib:
- if args.quant_disable_embeddings:
- set_quantizer_by_name(model, ["embeddings"], which="weight", _disabled=True)
-
- if args.quant_disable:
- set_quantizer_by_name(model, [""], _disabled=True)
-
- if args.quant_disable_keyword:
- set_quantizer_by_name(model, args.quant_disable_keyword, _disabled=True)
-
- if args.quant_disable_layer_module:
- set_quantizer_by_name(model, [r"layer.\d+." + args.quant_disable_layer_module], _disabled=True)
-
- if args.quant_enable_layer_module:
- set_quantizer_by_name(model, [r"layer.\d+." + args.quant_enable_layer_module], _disabled=False)
-
- if args.recalibrate_weights:
- recalibrate_weights(model)
-
- if args.fuse_qkv:
- fuse_qkv(model, args)
-
- if args.clip_gelu:
- clip_gelu(model, args.clip_gelu)
-
- # if args.local_rank in [-1, 0] and not calib:
- print_quant_summary(model)
-
-
-def enable_calibration(model):
- """Enable calibration of all *_input_quantizer modules in model."""
-
- logger.info("Enabling Calibration")
- for name, module in model.named_modules():
- if name.endswith("_quantizer"):
- if module._calibrator is not None:
- module.disable_quant()
- module.enable_calib()
- else:
- module.disable()
- logger.info(f"{name:80}: {module}")
-
-
-def finish_calibration(model, args):
- """Disable calibration and load amax for all "*_input_quantizer modules in model."""
-
- logger.info("Loading calibrated amax")
- for name, module in model.named_modules():
- if name.endswith("_quantizer"):
- if module._calibrator is not None:
- if isinstance(module._calibrator, calib.MaxCalibrator):
- module.load_calib_amax()
- else:
- module.load_calib_amax("percentile", percentile=args.percentile)
- module.enable_quant()
- module.disable_calib()
- else:
- module.enable()
- model.cuda()
- print_quant_summary(model)
-
-
-# ========================================== Helper Function ==========================================
-
-
-def fuse_qkv(model, args):
- """Adjust quantization ranges to match an implementation where the QKV projections are implemented with a single GEMM.
- Force the weight and output scale factors to match by taking the max of (Q,K,V).
- """
-
- def fuse3(qq, qk, qv):
- for mod in [qq, qk, qv]:
- if not hasattr(mod, "_amax"):
- print(" WARNING: NO AMAX BUFFER")
- return
- q = qq._amax.detach().item()
- k = qk._amax.detach().item()
- v = qv._amax.detach().item()
-
- amax = max(q, k, v)
- qq._amax.fill_(amax)
- qk._amax.fill_(amax)
- qv._amax.fill_(amax)
- logger.info(f" q={q:5.2f} k={k:5.2f} v={v:5.2f} -> {amax:5.2f}")
-
- for name, mod in model.named_modules():
- if name.endswith(".attention.self"):
- logger.info(f"FUSE_QKV: {name:{name_width}}")
- fuse3(mod.matmul_q_input_quantizer, mod.matmul_k_input_quantizer, mod.matmul_v_input_quantizer)
- if args.quant_per_tensor:
- fuse3(mod.query._weight_quantizer, mod.key._weight_quantizer, mod.value._weight_quantizer)
-
-
-def clip_gelu(model, maxval):
- """Clip activations generated by GELU to maxval when quantized.
- Implemented by adjusting the amax of the following input_quantizer.
- """
-
- for name, mod in model.named_modules():
- if name.endswith(".output.dense") and not name.endswith("attention.output.dense"):
- amax_init = mod._input_quantizer._amax.data.detach().item()
- mod._input_quantizer._amax.data.detach().clamp_(max=maxval)
- amax = mod._input_quantizer._amax.data.detach().item()
- logger.info(f"CLIP_GELU: {name:{name_width}} amax: {amax_init:5.2f} -> {amax:5.2f}")
-
-
-def expand_amax(model):
- """Expand per-tensor amax to be per channel, where each channel is assigned the per-tensor amax."""
-
- for name, mod in model.named_modules():
- if hasattr(mod, "_weight_quantizer") and mod._weight_quantizer.axis is not None:
- k = mod.weight.shape[0]
- amax = mod._weight_quantizer._amax.detach()
- mod._weight_quantizer._amax = torch.ones(k, dtype=amax.dtype, device=amax.device) * amax
- print(f"expanding {name} {amax} -> {mod._weight_quantizer._amax}")
-
-
-def recalibrate_weights(model):
- """Performs max calibration on the weights and updates amax."""
-
- for name, mod in model.named_modules():
- if hasattr(mod, "_weight_quantizer"):
- if not hasattr(mod.weight_quantizer, "_amax"):
- print("RECALIB: {name:{name_width}} WARNING: NO AMAX BUFFER")
- continue
-
- # determine which axes to reduce across
- # e.g. a 4D tensor quantized per axis 0 should reduce over (1,2,3)
- axis_set = set() if mod._weight_quantizer.axis is None else set(mod._weight_quantizer.axis)
- reduce_axis = set(range(len(mod.weight.size()))) - axis_set
- amax = pytorch_quantization.utils.reduce_amax(mod.weight, axis=reduce_axis, keepdims=True).detach()
- logger.info(f"RECALIB: {name:{name_width}} {mod._weight_quantizer._amax.flatten()} -> {amax.flatten()}")
- mod._weight_quantizer._amax = amax
-
-
-def print_model_summary(model, name_width=25, line_width=180, ignore=None):
- """Print model quantization configuration."""
-
- if ignore is None:
- ignore = []
- elif not isinstance(ignore, list):
- ignore = [ignore]
-
- name_width = 0
- for name, mod in model.named_modules():
- if not hasattr(mod, "weight"):
- continue
- name_width = max(name_width, len(name))
-
- for name, mod in model.named_modules():
- input_q = getattr(mod, "_input_quantizer", None)
- weight_q = getattr(mod, "_weight_quantizer", None)
- if not hasattr(mod, "weight"):
- continue
- if type(mod) in ignore:
- continue
- if [True for s in ignore if isinstance(s, str) and s in name]:
- continue
- act_str = f"Act:{input_q.extra_repr()}"
- wgt_str = f"Wgt:{weight_q.extra_repr()}"
- s = f"{name:{name_width}} {act_str} {wgt_str}"
- if len(s) <= line_width:
- logger.info(s)
- else:
- logger.info(f"{name:{name_width}} {act_str}")
- logger.info(f'{" ":{name_width}} {wgt_str}')
-
-
-def print_quant_summary(model):
- """Print summary of all quantizer modules in the model."""
-
- count = 0
- for name, mod in model.named_modules():
- if isinstance(mod, pytorch_quantization.nn.TensorQuantizer):
- print(f"{name:80} {mod}")
- count += 1
- print(f"{count} TensorQuantizers found in model")
-
-
-def set_quantizer(name, mod, quantizer, k, v):
- """Set attributes for mod.quantizer."""
-
- quantizer_mod = getattr(mod, quantizer, None)
- if quantizer_mod is not None:
- assert hasattr(quantizer_mod, k)
- setattr(quantizer_mod, k, v)
- else:
- logger.warning(f"{name} has no {quantizer}")
-
-
-def set_quantizers(name, mod, which="both", **kwargs):
- """Set quantizer attributes for mod."""
-
- s = f"Warning: changing {which} quantizers of {name:{qname_width}}"
- for k, v in kwargs.items():
- s += f" {k}={v}"
- if which in ["input", "both"]:
- set_quantizer(name, mod, "_input_quantizer", k, v)
- if which in ["weight", "both"]:
- set_quantizer(name, mod, "_weight_quantizer", k, v)
- logger.info(s)
-
-
-def set_quantizer_by_name(model, names, **kwargs):
- """Set quantizer attributes for layers where name contains a substring in names."""
-
- for name, mod in model.named_modules():
- if hasattr(mod, "_input_quantizer") or hasattr(mod, "_weight_quantizer"):
- for n in names:
- if re.search(n, name):
- set_quantizers(name, mod, **kwargs)
- elif name.endswith("_quantizer"):
- for n in names:
- if re.search(n, name):
- s = f"Warning: changing {name:{name_width}}"
- for k, v in kwargs.items():
- s += f" {k}={v}"
- setattr(mod, k, v)
- logger.info(s)
diff --git a/examples/research_projects/quantization-qdqbert/run_quant_qa.py b/examples/research_projects/quantization-qdqbert/run_quant_qa.py
deleted file mode 100755
index 770a36525b5..00000000000
--- a/examples/research_projects/quantization-qdqbert/run_quant_qa.py
+++ /dev/null
@@ -1,688 +0,0 @@
-#!/usr/bin/env python
-# coding=utf-8
-# Copyright 2020 The HuggingFace Team All rights reserved.
-# Copyright 2021 NVIDIA Corporation. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-Fine-tuning the library models for question answering.
-"""
-# You can also adapt this script on your own question answering task. Pointers for this are left as comments.
-
-import logging
-import os
-import sys
-from dataclasses import dataclass, field
-from typing import Optional
-
-import datasets
-import quant_trainer
-from datasets import load_dataset, load_metric
-from trainer_quant_qa import QuestionAnsweringTrainer
-from utils_qa import postprocess_qa_predictions
-
-import transformers
-from transformers import (
- AutoTokenizer,
- DataCollatorWithPadding,
- EvalPrediction,
- HfArgumentParser,
- PreTrainedTokenizerFast,
- QDQBertConfig,
- QDQBertForQuestionAnswering,
- TrainingArguments,
- default_data_collator,
- set_seed,
-)
-from transformers.trainer_utils import SchedulerType, get_last_checkpoint
-from transformers.utils import check_min_version
-from transformers.utils.versions import require_version
-
-
-# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.9.0")
-
-require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/question-answering/requirements.txt")
-
-logger = logging.getLogger(__name__)
-
-
-@dataclass
-class ModelArguments:
- """
- Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
- """
-
- model_name_or_path: str = field(
- metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
- )
- config_name: Optional[str] = field(
- default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
- )
- tokenizer_name: Optional[str] = field(
- default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
- )
- cache_dir: Optional[str] = field(
- default=None,
- metadata={"help": "Path to directory to store the pretrained models downloaded from huggingface.co"},
- )
- model_revision: str = field(
- default="main",
- metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
- )
- use_auth_token: bool = field(
- default=False,
- metadata={
- "help": (
- "Will use the token generated when running `huggingface-cli login` (necessary to use this script "
- "with private models)."
- )
- },
- )
- do_calib: bool = field(default=False, metadata={"help": "Whether to run calibration of quantization ranges."})
- num_calib_batch: int = field(
- default=4,
- metadata={"help": "Number of batches for calibration. 0 will disable calibration "},
- )
- save_onnx: bool = field(default=False, metadata={"help": "Whether to save model to onnx."})
-
-
-@dataclass
-class DataTrainingArguments:
- """
- Arguments pertaining to what data we are going to input our model for training and eval.
- """
-
- dataset_name: Optional[str] = field(
- default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
- )
- dataset_config_name: Optional[str] = field(
- default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
- )
- train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
- validation_file: Optional[str] = field(
- default=None,
- metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
- )
- test_file: Optional[str] = field(
- default=None,
- metadata={"help": "An optional input test data file to evaluate the perplexity on (a text file)."},
- )
- overwrite_cache: bool = field(
- default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
- )
- preprocessing_num_workers: Optional[int] = field(
- default=None,
- metadata={"help": "The number of processes to use for the preprocessing."},
- )
- max_seq_length: int = field(
- default=384,
- metadata={
- "help": (
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- )
- },
- )
- pad_to_max_length: bool = field(
- default=True,
- metadata={
- "help": (
- "Whether to pad all samples to `max_seq_length`. If False, will pad the samples dynamically when"
- " batching to the maximum length in the batch (which can be faster on GPU but will be slower on TPU)."
- )
- },
- )
- max_train_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of training examples to this "
- "value if set."
- )
- },
- )
- max_eval_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
- "value if set."
- )
- },
- )
- max_predict_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of prediction examples to this "
- "value if set."
- )
- },
- )
- version_2_with_negative: bool = field(
- default=False, metadata={"help": "If true, some of the examples do not have an answer."}
- )
- null_score_diff_threshold: float = field(
- default=0.0,
- metadata={
- "help": (
- "The threshold used to select the null answer: if the best answer has a score that is less than "
- "the score of the null answer minus this threshold, the null answer is selected for this example. "
- "Only useful when `version_2_with_negative=True`."
- )
- },
- )
- doc_stride: int = field(
- default=128,
- metadata={"help": "When splitting up a long document into chunks, how much stride to take between chunks."},
- )
- n_best_size: int = field(
- default=20,
- metadata={"help": "The total number of n-best predictions to generate when looking for an answer."},
- )
- max_answer_length: int = field(
- default=30,
- metadata={
- "help": (
- "The maximum length of an answer that can be generated. This is needed because the start "
- "and end predictions are not conditioned on one another."
- )
- },
- )
-
- def __post_init__(self):
- if (
- self.dataset_name is None
- and self.train_file is None
- and self.validation_file is None
- and self.test_file is None
- ):
- raise ValueError("Need either a dataset name or a training/validation file/test_file.")
- else:
- if self.train_file is not None:
- extension = self.train_file.split(".")[-1]
- assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
- if self.validation_file is not None:
- extension = self.validation_file.split(".")[-1]
- assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
- if self.test_file is not None:
- extension = self.test_file.split(".")[-1]
- assert extension in ["csv", "json"], "`test_file` should be a csv or a json file."
-
-
-def main():
- # See all possible arguments in src/transformers/training_args.py
- # or by passing the --help flag to this script.
- # We now keep distinct sets of args, for a cleaner separation of concerns.
-
- parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
- # quant_trainer arguments
- quant_trainer.add_arguments(parser)
-
- # if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
- # # If we pass only one argument to the script and it's the path to a json file,
- # # let's parse it to get our arguments.
- # model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
- # else:
-
- model_args, data_args, training_args, quant_trainer_args = parser.parse_args_into_dataclasses()
-
- # setup QAT training args for scheduler (default to use cosine annealing learning rate schedule)
- training_args.lr_scheduler_type = SchedulerType.COSINE
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- handlers=[logging.StreamHandler(sys.stdout)],
- )
-
- log_level = training_args.get_process_log_level()
- logger.setLevel(log_level)
- datasets.utils.logging.set_verbosity(log_level)
- transformers.utils.logging.set_verbosity(log_level)
- transformers.utils.logging.enable_default_handler()
- transformers.utils.logging.enable_explicit_format()
-
- # Log on each process the small summary:
- logger.warning(
- f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
- + f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
- )
- logger.info(f"Training/evaluation parameters {training_args}")
-
- # Detecting last checkpoint.
- last_checkpoint = None
- if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
- last_checkpoint = get_last_checkpoint(training_args.output_dir)
- if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
- raise ValueError(
- f"Output directory ({training_args.output_dir}) already exists and is not empty. "
- "Use --overwrite_output_dir to overcome."
- )
- elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
- logger.info(
- f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
- "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
- )
-
- # Set seed before initializing model.
- set_seed(training_args.seed)
-
- # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
- # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
- # (the dataset will be downloaded automatically from the datasets Hub).
- #
- # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
- # 'text' is found. You can easily tweak this behavior (see below).
- #
- # In distributed training, the load_dataset function guarantee that only one local process can concurrently
- # download the dataset.
- if data_args.dataset_name is not None:
- # Downloading and loading a dataset from the hub.
- raw_datasets = load_dataset(
- data_args.dataset_name, data_args.dataset_config_name, cache_dir=model_args.cache_dir
- )
- else:
- data_files = {}
- if data_args.train_file is not None:
- data_files["train"] = data_args.train_file
- extension = data_args.train_file.split(".")[-1]
-
- if data_args.validation_file is not None:
- data_files["validation"] = data_args.validation_file
- extension = data_args.validation_file.split(".")[-1]
- if data_args.test_file is not None:
- data_files["test"] = data_args.test_file
- extension = data_args.test_file.split(".")[-1]
- raw_datasets = load_dataset(extension, data_files=data_files, field="data", cache_dir=model_args.cache_dir)
- # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
- # https://huggingface.co/docs/datasets/loading_datasets.
-
- # set default quantization parameters before building model
- quant_trainer.set_default_quantizers(quant_trainer_args)
-
- # Load pretrained model and tokenizer
- #
- # Distributed training:
- # The .from_pretrained methods guarantee that only one local process can concurrently
- # download model & vocab.
- config = QDQBertConfig.from_pretrained(
- model_args.config_name if model_args.config_name else model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- )
- tokenizer = AutoTokenizer.from_pretrained(
- model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- use_fast=True,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- )
- model = QDQBertForQuestionAnswering.from_pretrained(
- model_args.model_name_or_path,
- from_tf=bool(".ckpt" in model_args.model_name_or_path),
- config=config,
- cache_dir=model_args.cache_dir,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- )
-
- # Tokenizer check: this script requires a fast tokenizer.
- if not isinstance(tokenizer, PreTrainedTokenizerFast):
- raise ValueError(
- "This example script only works for models that have a fast tokenizer. Checkout the big table of models at"
- " https://huggingface.co/transformers/index.html#supported-frameworks to find the model types that meet"
- " this requirement"
- )
-
- # Preprocessing the datasets.
- # Preprocessing is slightly different for training and evaluation.
- if training_args.do_train or model_args.do_calib:
- column_names = raw_datasets["train"].column_names
- elif training_args.do_eval or model_args.save_onnx:
- column_names = raw_datasets["validation"].column_names
- else:
- column_names = raw_datasets["test"].column_names
- question_column_name = "question" if "question" in column_names else column_names[0]
- context_column_name = "context" if "context" in column_names else column_names[1]
- answer_column_name = "answers" if "answers" in column_names else column_names[2]
-
- # Padding side determines if we do (question|context) or (context|question).
- pad_on_right = tokenizer.padding_side == "right"
-
- if data_args.max_seq_length > tokenizer.model_max_length:
- logger.warning(
- f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the "
- f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
- )
- max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
-
- # Training preprocessing
- def prepare_train_features(examples):
- # Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
- # in one example possible giving several features when a context is long, each of those features having a
- # context that overlaps a bit the context of the previous feature.
- tokenized_examples = tokenizer(
- examples[question_column_name if pad_on_right else context_column_name],
- examples[context_column_name if pad_on_right else question_column_name],
- truncation="only_second" if pad_on_right else "only_first",
- max_length=max_seq_length,
- stride=data_args.doc_stride,
- return_overflowing_tokens=True,
- return_offsets_mapping=True,
- padding="max_length" if data_args.pad_to_max_length else False,
- )
-
- # Since one example might give us several features if it has a long context, we need a map from a feature to
- # its corresponding example. This key gives us just that.
- sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
- # The offset mappings will give us a map from token to character position in the original context. This will
- # help us compute the start_positions and end_positions.
- offset_mapping = tokenized_examples.pop("offset_mapping")
-
- # Let's label those examples!
- tokenized_examples["start_positions"] = []
- tokenized_examples["end_positions"] = []
-
- for i, offsets in enumerate(offset_mapping):
- # We will label impossible answers with the index of the CLS token.
- input_ids = tokenized_examples["input_ids"][i]
- cls_index = input_ids.index(tokenizer.cls_token_id)
-
- # Grab the sequence corresponding to that example (to know what is the context and what is the question).
- sequence_ids = tokenized_examples.sequence_ids(i)
-
- # One example can give several spans, this is the index of the example containing this span of text.
- sample_index = sample_mapping[i]
- answers = examples[answer_column_name][sample_index]
- # If no answers are given, set the cls_index as answer.
- if len(answers["answer_start"]) == 0:
- tokenized_examples["start_positions"].append(cls_index)
- tokenized_examples["end_positions"].append(cls_index)
- else:
- # Start/end character index of the answer in the text.
- start_char = answers["answer_start"][0]
- end_char = start_char + len(answers["text"][0])
-
- # Start token index of the current span in the text.
- token_start_index = 0
- while sequence_ids[token_start_index] != (1 if pad_on_right else 0):
- token_start_index += 1
-
- # End token index of the current span in the text.
- token_end_index = len(input_ids) - 1
- while sequence_ids[token_end_index] != (1 if pad_on_right else 0):
- token_end_index -= 1
-
- # Detect if the answer is out of the span (in which case this feature is labeled with the CLS index).
- if not (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char):
- tokenized_examples["start_positions"].append(cls_index)
- tokenized_examples["end_positions"].append(cls_index)
- else:
- # Otherwise move the token_start_index and token_end_index to the two ends of the answer.
- # Note: we could go after the last offset if the answer is the last word (edge case).
- while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char:
- token_start_index += 1
- tokenized_examples["start_positions"].append(token_start_index - 1)
- while offsets[token_end_index][1] >= end_char:
- token_end_index -= 1
- tokenized_examples["end_positions"].append(token_end_index + 1)
-
- return tokenized_examples
-
- if training_args.do_train or model_args.do_calib:
- if "train" not in raw_datasets:
- raise ValueError("--do_train requires a train dataset")
- train_dataset = raw_datasets["train"]
- if data_args.max_train_samples is not None:
- # We will select sample from whole data if argument is specified
- max_train_samples = min(len(train_dataset), data_args.max_train_samples)
- train_dataset = train_dataset.select(range(max_train_samples))
- # Create train feature from dataset
- with training_args.main_process_first(desc="train dataset map pre-processing"):
- train_dataset = train_dataset.map(
- prepare_train_features,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not data_args.overwrite_cache,
- desc="Running tokenizer on train dataset",
- )
- if data_args.max_train_samples is not None:
- # Number of samples might increase during Feature Creation, We select only specified max samples
- max_train_samples = min(len(train_dataset), data_args.max_train_samples)
- train_dataset = train_dataset.select(range(max_train_samples))
-
- # Validation preprocessing
- def prepare_validation_features(examples):
- # Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
- # in one example possible giving several features when a context is long, each of those features having a
- # context that overlaps a bit the context of the previous feature.
- tokenized_examples = tokenizer(
- examples[question_column_name if pad_on_right else context_column_name],
- examples[context_column_name if pad_on_right else question_column_name],
- truncation="only_second" if pad_on_right else "only_first",
- max_length=max_seq_length,
- stride=data_args.doc_stride,
- return_overflowing_tokens=True,
- return_offsets_mapping=True,
- padding="max_length" if data_args.pad_to_max_length else False,
- )
-
- # Since one example might give us several features if it has a long context, we need a map from a feature to
- # its corresponding example. This key gives us just that.
- sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
-
- # For evaluation, we will need to convert our predictions to substrings of the context, so we keep the
- # corresponding example_id and we will store the offset mappings.
- tokenized_examples["example_id"] = []
-
- for i in range(len(tokenized_examples["input_ids"])):
- # Grab the sequence corresponding to that example (to know what is the context and what is the question).
- sequence_ids = tokenized_examples.sequence_ids(i)
- context_index = 1 if pad_on_right else 0
-
- # One example can give several spans, this is the index of the example containing this span of text.
- sample_index = sample_mapping[i]
- tokenized_examples["example_id"].append(examples["id"][sample_index])
-
- # Set to None the offset_mapping that are not part of the context so it's easy to determine if a token
- # position is part of the context or not.
- tokenized_examples["offset_mapping"][i] = [
- (o if sequence_ids[k] == context_index else None)
- for k, o in enumerate(tokenized_examples["offset_mapping"][i])
- ]
-
- return tokenized_examples
-
- if training_args.do_eval or model_args.save_onnx:
- if "validation" not in raw_datasets:
- raise ValueError("--do_eval requires a validation dataset")
- eval_examples = raw_datasets["validation"]
- if data_args.max_eval_samples is not None:
- # We will select sample from whole data
- max_eval_samples = min(len(eval_examples), data_args.max_eval_samples)
- eval_examples = eval_examples.select(range(max_eval_samples))
- # Validation Feature Creation
- with training_args.main_process_first(desc="validation dataset map pre-processing"):
- eval_dataset = eval_examples.map(
- prepare_validation_features,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not data_args.overwrite_cache,
- desc="Running tokenizer on validation dataset",
- )
- if data_args.max_eval_samples is not None:
- # During Feature creation dataset samples might increase, we will select required samples again
- max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
- eval_dataset = eval_dataset.select(range(max_eval_samples))
-
- if training_args.do_predict:
- if "test" not in raw_datasets:
- raise ValueError("--do_predict requires a test dataset")
- predict_examples = raw_datasets["test"]
- if data_args.max_predict_samples is not None:
- # We will select sample from whole data
- predict_examples = predict_examples.select(range(data_args.max_predict_samples))
- # Predict Feature Creation
- with training_args.main_process_first(desc="prediction dataset map pre-processing"):
- predict_dataset = predict_examples.map(
- prepare_validation_features,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not data_args.overwrite_cache,
- desc="Running tokenizer on prediction dataset",
- )
- if data_args.max_predict_samples is not None:
- # During Feature creation dataset samples might increase, we will select required samples again
- max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)
- predict_dataset = predict_dataset.select(range(max_predict_samples))
-
- # Data collator
- # We have already padded to max length if the corresponding flag is True, otherwise we need to pad in the data
- # collator.
- data_collator = (
- default_data_collator
- if data_args.pad_to_max_length
- else DataCollatorWithPadding(tokenizer, pad_to_multiple_of=8 if training_args.fp16 else None)
- )
-
- # Post-processing:
- def post_processing_function(examples, features, predictions, stage="eval"):
- # Post-processing: we match the start logits and end logits to answers in the original context.
- predictions = postprocess_qa_predictions(
- examples=examples,
- features=features,
- predictions=predictions,
- version_2_with_negative=data_args.version_2_with_negative,
- n_best_size=data_args.n_best_size,
- max_answer_length=data_args.max_answer_length,
- null_score_diff_threshold=data_args.null_score_diff_threshold,
- output_dir=training_args.output_dir,
- log_level=log_level,
- prefix=stage,
- )
- # Format the result to the format the metric expects.
- if data_args.version_2_with_negative:
- formatted_predictions = [
- {"id": k, "prediction_text": v, "no_answer_probability": 0.0} for k, v in predictions.items()
- ]
- else:
- formatted_predictions = [{"id": k, "prediction_text": v} for k, v in predictions.items()]
-
- references = [{"id": ex["id"], "answers": ex[answer_column_name]} for ex in examples]
- return EvalPrediction(predictions=formatted_predictions, label_ids=references)
-
- metric = load_metric("squad_v2" if data_args.version_2_with_negative else "squad")
-
- def compute_metrics(p: EvalPrediction):
- return metric.compute(predictions=p.predictions, references=p.label_ids)
-
- # Initialize our Trainer
- trainer = QuestionAnsweringTrainer(
- model=model,
- args=training_args,
- train_dataset=train_dataset if training_args.do_train or model_args.do_calib else None,
- eval_dataset=eval_dataset if training_args.do_eval or model_args.save_onnx else None,
- eval_examples=eval_examples if training_args.do_eval or model_args.save_onnx else None,
- tokenizer=tokenizer,
- data_collator=data_collator,
- post_process_function=post_processing_function,
- compute_metrics=compute_metrics,
- quant_trainer_args=quant_trainer_args,
- )
-
- # Calibration
- if model_args.do_calib:
- logger.info("*** Calibrate ***")
- results = trainer.calibrate()
- trainer.save_model()
-
- # Training
- if training_args.do_train:
- checkpoint = None
- if training_args.resume_from_checkpoint is not None:
- checkpoint = training_args.resume_from_checkpoint
- elif last_checkpoint is not None:
- checkpoint = last_checkpoint
-
- quant_trainer.configure_model(trainer.model, quant_trainer_args)
-
- train_result = trainer.train(resume_from_checkpoint=checkpoint)
- trainer.save_model() # Saves the tokenizer too for easy upload
-
- metrics = train_result.metrics
- max_train_samples = (
- data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
- )
- metrics["train_samples"] = min(max_train_samples, len(train_dataset))
-
- trainer.log_metrics("train", metrics)
- trainer.save_metrics("train", metrics)
- trainer.save_state()
-
- # Evaluation
- if training_args.do_eval:
- logger.info("*** Evaluate ***")
- quant_trainer.configure_model(trainer.model, quant_trainer_args, eval=True)
- metrics = trainer.evaluate()
-
- max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
- metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
-
- trainer.log_metrics("eval", metrics)
- trainer.save_metrics("eval", metrics)
-
- # Prediction
- if training_args.do_predict:
- logger.info("*** Predict ***")
- results = trainer.predict(predict_dataset, predict_examples)
- metrics = results.metrics
-
- max_predict_samples = (
- data_args.max_predict_samples if data_args.max_predict_samples is not None else len(predict_dataset)
- )
- metrics["predict_samples"] = min(max_predict_samples, len(predict_dataset))
-
- trainer.log_metrics("predict", metrics)
- trainer.save_metrics("predict", metrics)
-
- if training_args.push_to_hub:
- kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "question-answering"}
- if data_args.dataset_name is not None:
- kwargs["dataset_tags"] = data_args.dataset_name
- if data_args.dataset_config_name is not None:
- kwargs["dataset_args"] = data_args.dataset_config_name
- kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
- else:
- kwargs["dataset"] = data_args.dataset_name
-
- trainer.push_to_hub(**kwargs)
-
- if model_args.save_onnx:
- logger.info("Exporting model to onnx")
- results = trainer.save_onnx(output_dir=training_args.output_dir)
-
-
-def _mp_fn(index):
- # For xla_spawn (TPUs)
- main()
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/quantization-qdqbert/trainer_quant_qa.py b/examples/research_projects/quantization-qdqbert/trainer_quant_qa.py
deleted file mode 100644
index a56d875354d..00000000000
--- a/examples/research_projects/quantization-qdqbert/trainer_quant_qa.py
+++ /dev/null
@@ -1,212 +0,0 @@
-# coding=utf-8
-# Copyright 2020 The HuggingFace Team All rights reserved.
-# Copyright 2021 NVIDIA Corporation. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-A subclass of `Trainer` specific to Question-Answering tasks
-"""
-
-import logging
-import os
-
-import quant_trainer
-import torch
-from torch.utils.data import DataLoader
-
-from transformers import Trainer, is_torch_xla_available
-from transformers.trainer_utils import PredictionOutput
-
-
-logger = logging.getLogger(__name__)
-
-if is_torch_xla_available():
- import torch_xla.core.xla_model as xm
- import torch_xla.debug.metrics as met
-
-
-class QuestionAnsweringTrainer(Trainer):
- def __init__(self, *args, eval_examples=None, post_process_function=None, quant_trainer_args=None, **kwargs):
- super().__init__(*args, **kwargs)
- self.eval_examples = eval_examples
- self.post_process_function = post_process_function
- self.quant_trainer_args = quant_trainer_args
- self.calib_num = 128 # default number of calibration samples
-
- def get_calib_dataloader(self, calib_dataset=None):
- """
- Returns the calibration dataloader :class:`~torch.utils.data.DataLoader`.
-
- Args:
- calib_dataset (:obj:`torch.utils.data.Dataset`, `optional`)
- """
- if calib_dataset is None and self.calib_dataset is None:
- raise ValueError("Trainer: calibration requires an calib_dataset.")
- calib_dataset = calib_dataset if calib_dataset is not None else self.calib_dataset
-
- calib_dataset = self._remove_unused_columns(calib_dataset, description="Calibration")
-
- return DataLoader(
- calib_dataset,
- batch_size=self.args.eval_batch_size,
- collate_fn=self.data_collator,
- drop_last=self.args.dataloader_drop_last,
- num_workers=self.args.dataloader_num_workers,
- pin_memory=self.args.dataloader_pin_memory,
- shuffle=True,
- )
-
- def calibrate(self, calib_dataset=None):
- calib_dataset = self.train_dataset if calib_dataset is None else calib_dataset
- calib_dataloader = self.get_calib_dataloader(calib_dataset)
-
- model = self.model
- quant_trainer.configure_model(model, self.quant_trainer_args, calib=True)
- model.eval()
- quant_trainer.enable_calibration(model)
-
- logger.info("***** Running calibration *****")
- logger.info(f" Num examples = {self.calib_num}")
- logger.info(f" Batch size = {calib_dataloader.batch_size}")
-
- for step, inputs in enumerate(calib_dataloader):
- # Prediction step
- loss, logits, labels = self.prediction_step(model, inputs, prediction_loss_only=True)
- if (step + 1) * calib_dataloader.batch_size >= self.calib_num:
- break
-
- quant_trainer.finish_calibration(model, self.quant_trainer_args)
- self.model = model
-
- def evaluate(self, eval_dataset=None, eval_examples=None, ignore_keys=None, metric_key_prefix: str = "eval"):
- eval_dataset = self.eval_dataset if eval_dataset is None else eval_dataset
- eval_dataloader = self.get_eval_dataloader(eval_dataset)
- eval_examples = self.eval_examples if eval_examples is None else eval_examples
-
- # Temporarily disable metric computation, we will do it in the loop here.
- compute_metrics = self.compute_metrics
- self.compute_metrics = None
- eval_loop = self.prediction_loop if self.args.use_legacy_prediction_loop else self.evaluation_loop
- try:
- output = eval_loop(
- eval_dataloader,
- description="Evaluation",
- # No point gathering the predictions if there are no metrics, otherwise we defer to
- # self.args.prediction_loss_only
- prediction_loss_only=True if compute_metrics is None else None,
- ignore_keys=ignore_keys,
- )
- finally:
- self.compute_metrics = compute_metrics
-
- if self.post_process_function is not None and self.compute_metrics is not None:
- eval_preds = self.post_process_function(eval_examples, eval_dataset, output.predictions)
- metrics = self.compute_metrics(eval_preds)
-
- # Prefix all keys with metric_key_prefix + '_'
- for key in list(metrics.keys()):
- if not key.startswith(f"{metric_key_prefix}_"):
- metrics[f"{metric_key_prefix}_{key}"] = metrics.pop(key)
-
- self.log(metrics)
- else:
- metrics = {}
-
- if self.args.tpu_metrics_debug or self.args.debug:
- # tpu-comment: Logging debug metrics for PyTorch/XLA (compile, execute times, ops, etc.)
- xm.master_print(met.metrics_report())
-
- self.control = self.callback_handler.on_evaluate(self.args, self.state, self.control, metrics)
- return metrics
-
- def predict(self, predict_dataset, predict_examples, ignore_keys=None, metric_key_prefix: str = "test"):
- predict_dataloader = self.get_test_dataloader(predict_dataset)
-
- # Temporarily disable metric computation, we will do it in the loop here.
- compute_metrics = self.compute_metrics
- self.compute_metrics = None
- eval_loop = self.prediction_loop if self.args.use_legacy_prediction_loop else self.evaluation_loop
- try:
- output = eval_loop(
- predict_dataloader,
- description="Prediction",
- # No point gathering the predictions if there are no metrics, otherwise we defer to
- # self.args.prediction_loss_only
- prediction_loss_only=True if compute_metrics is None else None,
- ignore_keys=ignore_keys,
- )
- finally:
- self.compute_metrics = compute_metrics
-
- if self.post_process_function is None or self.compute_metrics is None:
- return output
-
- predictions = self.post_process_function(predict_examples, predict_dataset, output.predictions, "predict")
- metrics = self.compute_metrics(predictions)
-
- # Prefix all keys with metric_key_prefix + '_'
- for key in list(metrics.keys()):
- if not key.startswith(f"{metric_key_prefix}_"):
- metrics[f"{metric_key_prefix}_{key}"] = metrics.pop(key)
-
- return PredictionOutput(predictions=predictions.predictions, label_ids=predictions.label_ids, metrics=metrics)
-
- def save_onnx(self, output_dir="./"):
- eval_dataset = self.eval_dataset
- eval_dataloader = self.get_eval_dataloader(eval_dataset)
-
- batch = next(iter(eval_dataloader))
-
- # saving device - to make it consistent
- device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
-
- # convert to tuple
- input_tuple = tuple(v.to(device) for k, v in batch.items())
-
- logger.info("Converting model to be onnx compatible")
- from pytorch_quantization.nn import TensorQuantizer
-
- TensorQuantizer.use_fb_fake_quant = True
-
- model = self.model.to(device)
-
- model.eval()
- model.float()
-
- model_to_save = model.module if hasattr(model, "module") else model
- quant_trainer.configure_model(model_to_save, self.quant_trainer_args)
-
- output_model_file = os.path.join(output_dir, "model.onnx")
- logger.info(f"exporting model to {output_model_file}")
-
- axes = {0: "batch_size", 1: "seq_len"}
-
- torch.onnx.export(
- model_to_save,
- input_tuple,
- output_model_file,
- export_params=True,
- opset_version=13,
- do_constant_folding=True,
- input_names=["input_ids", "attention_mask", "token_type_ids"],
- output_names=["output_start_logits", "output_end_logits"],
- dynamic_axes={
- "input_ids": axes,
- "attention_mask": axes,
- "token_type_ids": axes,
- "output_start_logits": axes,
- "output_end_logits": axes,
- },
- verbose=True,
- )
- logger.info("onnx export finished")
diff --git a/examples/research_projects/quantization-qdqbert/utils_qa.py b/examples/research_projects/quantization-qdqbert/utils_qa.py
deleted file mode 100644
index e90d6c4747c..00000000000
--- a/examples/research_projects/quantization-qdqbert/utils_qa.py
+++ /dev/null
@@ -1,435 +0,0 @@
-# coding=utf-8
-# Copyright 2020 The HuggingFace Team All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-Post-processing utilities for question answering.
-"""
-
-import collections
-import json
-import logging
-import os
-from typing import Optional, Tuple
-
-import numpy as np
-from tqdm.auto import tqdm
-
-
-logger = logging.getLogger(__name__)
-
-
-def postprocess_qa_predictions(
- examples,
- features,
- predictions: Tuple[np.ndarray, np.ndarray],
- version_2_with_negative: bool = False,
- n_best_size: int = 20,
- max_answer_length: int = 30,
- null_score_diff_threshold: float = 0.0,
- output_dir: Optional[str] = None,
- prefix: Optional[str] = None,
- log_level: Optional[int] = logging.WARNING,
-):
- """
- Post-processes the predictions of a question-answering model to convert them to answers that are substrings of the
- original contexts. This is the base postprocessing functions for models that only return start and end logits.
-
- Args:
- examples: The non-preprocessed dataset (see the main script for more information).
- features: The processed dataset (see the main script for more information).
- predictions (:obj:`Tuple[np.ndarray, np.ndarray]`):
- The predictions of the model: two arrays containing the start logits and the end logits respectively. Its
- first dimension must match the number of elements of :obj:`features`.
- version_2_with_negative (:obj:`bool`, `optional`, defaults to :obj:`False`):
- Whether or not the underlying dataset contains examples with no answers.
- n_best_size (:obj:`int`, `optional`, defaults to 20):
- The total number of n-best predictions to generate when looking for an answer.
- max_answer_length (:obj:`int`, `optional`, defaults to 30):
- The maximum length of an answer that can be generated. This is needed because the start and end predictions
- are not conditioned on one another.
- null_score_diff_threshold (:obj:`float`, `optional`, defaults to 0):
- The threshold used to select the null answer: if the best answer has a score that is less than the score of
- the null answer minus this threshold, the null answer is selected for this example (note that the score of
- the null answer for an example giving several features is the minimum of the scores for the null answer on
- each feature: all features must be aligned on the fact they `want` to predict a null answer).
-
- Only useful when :obj:`version_2_with_negative` is :obj:`True`.
- output_dir (:obj:`str`, `optional`):
- If provided, the dictionaries of predictions, n_best predictions (with their scores and logits) and, if
- :obj:`version_2_with_negative=True`, the dictionary of the scores differences between best and null
- answers, are saved in `output_dir`.
- prefix (:obj:`str`, `optional`):
- If provided, the dictionaries mentioned above are saved with `prefix` added to their names.
- log_level (:obj:`int`, `optional`, defaults to ``logging.WARNING``):
- ``logging`` log level (e.g., ``logging.WARNING``)
- """
- if len(predictions) != 2:
- raise ValueError("`predictions` should be a tuple with two elements (start_logits, end_logits).")
- all_start_logits, all_end_logits = predictions
-
- if len(predictions[0]) != len(features):
- raise ValueError(f"Got {len(predictions[0])} predictions and {len(features)} features.")
-
- # Build a map example to its corresponding features.
- example_id_to_index = {k: i for i, k in enumerate(examples["id"])}
- features_per_example = collections.defaultdict(list)
- for i, feature in enumerate(features):
- features_per_example[example_id_to_index[feature["example_id"]]].append(i)
-
- # The dictionaries we have to fill.
- all_predictions = collections.OrderedDict()
- all_nbest_json = collections.OrderedDict()
- if version_2_with_negative:
- scores_diff_json = collections.OrderedDict()
-
- # Logging.
- logger.setLevel(log_level)
- logger.info(f"Post-processing {len(examples)} example predictions split into {len(features)} features.")
-
- # Let's loop over all the examples!
- for example_index, example in enumerate(tqdm(examples)):
- # Those are the indices of the features associated to the current example.
- feature_indices = features_per_example[example_index]
-
- min_null_prediction = None
- prelim_predictions = []
-
- # Looping through all the features associated to the current example.
- for feature_index in feature_indices:
- # We grab the predictions of the model for this feature.
- start_logits = all_start_logits[feature_index]
- end_logits = all_end_logits[feature_index]
- # This is what will allow us to map some the positions in our logits to span of texts in the original
- # context.
- offset_mapping = features[feature_index]["offset_mapping"]
- # Optional `token_is_max_context`, if provided we will remove answers that do not have the maximum context
- # available in the current feature.
- token_is_max_context = features[feature_index].get("token_is_max_context", None)
-
- # Update minimum null prediction.
- feature_null_score = start_logits[0] + end_logits[0]
- if min_null_prediction is None or min_null_prediction["score"] > feature_null_score:
- min_null_prediction = {
- "offsets": (0, 0),
- "score": feature_null_score,
- "start_logit": start_logits[0],
- "end_logit": end_logits[0],
- }
-
- # Go through all possibilities for the `n_best_size` greater start and end logits.
- start_indexes = np.argsort(start_logits)[-1 : -n_best_size - 1 : -1].tolist()
- end_indexes = np.argsort(end_logits)[-1 : -n_best_size - 1 : -1].tolist()
- for start_index in start_indexes:
- for end_index in end_indexes:
- # Don't consider out-of-scope answers, either because the indices are out of bounds or correspond
- # to part of the input_ids that are not in the context.
- if (
- start_index >= len(offset_mapping)
- or end_index >= len(offset_mapping)
- or offset_mapping[start_index] is None
- or len(offset_mapping[start_index]) < 2
- or offset_mapping[end_index] is None
- or len(offset_mapping[end_index]) < 2
- ):
- continue
- # Don't consider answers with a length that is either < 0 or > max_answer_length.
- if end_index < start_index or end_index - start_index + 1 > max_answer_length:
- continue
- # Don't consider answer that don't have the maximum context available (if such information is
- # provided).
- if token_is_max_context is not None and not token_is_max_context.get(str(start_index), False):
- continue
-
- prelim_predictions.append(
- {
- "offsets": (offset_mapping[start_index][0], offset_mapping[end_index][1]),
- "score": start_logits[start_index] + end_logits[end_index],
- "start_logit": start_logits[start_index],
- "end_logit": end_logits[end_index],
- }
- )
- if version_2_with_negative:
- # Add the minimum null prediction
- prelim_predictions.append(min_null_prediction)
- null_score = min_null_prediction["score"]
-
- # Only keep the best `n_best_size` predictions.
- predictions = sorted(prelim_predictions, key=lambda x: x["score"], reverse=True)[:n_best_size]
-
- # Add back the minimum null prediction if it was removed because of its low score.
- if version_2_with_negative and not any(p["offsets"] == (0, 0) for p in predictions):
- predictions.append(min_null_prediction)
-
- # Use the offsets to gather the answer text in the original context.
- context = example["context"]
- for pred in predictions:
- offsets = pred.pop("offsets")
- pred["text"] = context[offsets[0] : offsets[1]]
-
- # In the very rare edge case we have not a single non-null prediction, we create a fake prediction to avoid
- # failure.
- if len(predictions) == 0 or (len(predictions) == 1 and predictions[0]["text"] == ""):
- predictions.insert(0, {"text": "empty", "start_logit": 0.0, "end_logit": 0.0, "score": 0.0})
-
- # Compute the softmax of all scores (we do it with numpy to stay independent from torch/tf in this file, using
- # the LogSumExp trick).
- scores = np.array([pred.pop("score") for pred in predictions])
- exp_scores = np.exp(scores - np.max(scores))
- probs = exp_scores / exp_scores.sum()
-
- # Include the probabilities in our predictions.
- for prob, pred in zip(probs, predictions):
- pred["probability"] = prob
-
- # Pick the best prediction. If the null answer is not possible, this is easy.
- if not version_2_with_negative:
- all_predictions[example["id"]] = predictions[0]["text"]
- else:
- # Otherwise we first need to find the best non-empty prediction.
- i = 0
- while predictions[i]["text"] == "":
- i += 1
- best_non_null_pred = predictions[i]
-
- # Then we compare to the null prediction using the threshold.
- score_diff = null_score - best_non_null_pred["start_logit"] - best_non_null_pred["end_logit"]
- scores_diff_json[example["id"]] = float(score_diff) # To be JSON-serializable.
- if score_diff > null_score_diff_threshold:
- all_predictions[example["id"]] = ""
- else:
- all_predictions[example["id"]] = best_non_null_pred["text"]
-
- # Make `predictions` JSON-serializable by casting np.float back to float.
- all_nbest_json[example["id"]] = [
- {k: (float(v) if isinstance(v, (np.float16, np.float32, np.float64)) else v) for k, v in pred.items()}
- for pred in predictions
- ]
-
- # If we have an output_dir, let's save all those dicts.
- if output_dir is not None:
- if not os.path.isdir(output_dir):
- raise EnvironmentError(f"{output_dir} is not a directory.")
-
- prediction_file = os.path.join(
- output_dir, "predictions.json" if prefix is None else f"{prefix}_predictions.json"
- )
- nbest_file = os.path.join(
- output_dir, "nbest_predictions.json" if prefix is None else f"{prefix}_nbest_predictions.json"
- )
- if version_2_with_negative:
- null_odds_file = os.path.join(
- output_dir, "null_odds.json" if prefix is None else f"{prefix}_null_odds.json"
- )
-
- logger.info(f"Saving predictions to {prediction_file}.")
- with open(prediction_file, "w") as writer:
- writer.write(json.dumps(all_predictions, indent=4) + "\n")
- logger.info(f"Saving nbest_preds to {nbest_file}.")
- with open(nbest_file, "w") as writer:
- writer.write(json.dumps(all_nbest_json, indent=4) + "\n")
- if version_2_with_negative:
- logger.info(f"Saving null_odds to {null_odds_file}.")
- with open(null_odds_file, "w") as writer:
- writer.write(json.dumps(scores_diff_json, indent=4) + "\n")
-
- return all_predictions
-
-
-def postprocess_qa_predictions_with_beam_search(
- examples,
- features,
- predictions: Tuple[np.ndarray, np.ndarray],
- version_2_with_negative: bool = False,
- n_best_size: int = 20,
- max_answer_length: int = 30,
- start_n_top: int = 5,
- end_n_top: int = 5,
- output_dir: Optional[str] = None,
- prefix: Optional[str] = None,
- log_level: Optional[int] = logging.WARNING,
-):
- """
- Post-processes the predictions of a question-answering model with beam search to convert them to answers that are substrings of the
- original contexts. This is the postprocessing functions for models that return start and end logits, indices, as well as
- cls token predictions.
-
- Args:
- examples: The non-preprocessed dataset (see the main script for more information).
- features: The processed dataset (see the main script for more information).
- predictions (:obj:`Tuple[np.ndarray, np.ndarray]`):
- The predictions of the model: two arrays containing the start logits and the end logits respectively. Its
- first dimension must match the number of elements of :obj:`features`.
- version_2_with_negative (:obj:`bool`, `optional`, defaults to :obj:`False`):
- Whether or not the underlying dataset contains examples with no answers.
- n_best_size (:obj:`int`, `optional`, defaults to 20):
- The total number of n-best predictions to generate when looking for an answer.
- max_answer_length (:obj:`int`, `optional`, defaults to 30):
- The maximum length of an answer that can be generated. This is needed because the start and end predictions
- are not conditioned on one another.
- start_n_top (:obj:`int`, `optional`, defaults to 5):
- The number of top start logits too keep when searching for the :obj:`n_best_size` predictions.
- end_n_top (:obj:`int`, `optional`, defaults to 5):
- The number of top end logits too keep when searching for the :obj:`n_best_size` predictions.
- output_dir (:obj:`str`, `optional`):
- If provided, the dictionaries of predictions, n_best predictions (with their scores and logits) and, if
- :obj:`version_2_with_negative=True`, the dictionary of the scores differences between best and null
- answers, are saved in `output_dir`.
- prefix (:obj:`str`, `optional`):
- If provided, the dictionaries mentioned above are saved with `prefix` added to their names.
- log_level (:obj:`int`, `optional`, defaults to ``logging.WARNING``):
- ``logging`` log level (e.g., ``logging.WARNING``)
- """
- if len(predictions) != 5:
- raise ValueError("`predictions` should be a tuple with five elements.")
- start_top_log_probs, start_top_index, end_top_log_probs, end_top_index, cls_logits = predictions
-
- if len(predictions[0]) != len(features):
- raise ValueError(f"Got {len(predictions[0])} predictions and {len(features)} features.")
-
- # Build a map example to its corresponding features.
- example_id_to_index = {k: i for i, k in enumerate(examples["id"])}
- features_per_example = collections.defaultdict(list)
- for i, feature in enumerate(features):
- features_per_example[example_id_to_index[feature["example_id"]]].append(i)
-
- # The dictionaries we have to fill.
- all_predictions = collections.OrderedDict()
- all_nbest_json = collections.OrderedDict()
- scores_diff_json = collections.OrderedDict() if version_2_with_negative else None
-
- # Logging.
- logger.setLevel(log_level)
- logger.info(f"Post-processing {len(examples)} example predictions split into {len(features)} features.")
-
- # Let's loop over all the examples!
- for example_index, example in enumerate(tqdm(examples)):
- # Those are the indices of the features associated to the current example.
- feature_indices = features_per_example[example_index]
-
- min_null_score = None
- prelim_predictions = []
-
- # Looping through all the features associated to the current example.
- for feature_index in feature_indices:
- # We grab the predictions of the model for this feature.
- start_log_prob = start_top_log_probs[feature_index]
- start_indexes = start_top_index[feature_index]
- end_log_prob = end_top_log_probs[feature_index]
- end_indexes = end_top_index[feature_index]
- feature_null_score = cls_logits[feature_index]
- # This is what will allow us to map some the positions in our logits to span of texts in the original
- # context.
- offset_mapping = features[feature_index]["offset_mapping"]
- # Optional `token_is_max_context`, if provided we will remove answers that do not have the maximum context
- # available in the current feature.
- token_is_max_context = features[feature_index].get("token_is_max_context", None)
-
- # Update minimum null prediction
- if min_null_score is None or feature_null_score < min_null_score:
- min_null_score = feature_null_score
-
- # Go through all possibilities for the `n_start_top`/`n_end_top` greater start and end logits.
- for i in range(start_n_top):
- for j in range(end_n_top):
- start_index = int(start_indexes[i])
- j_index = i * end_n_top + j
- end_index = int(end_indexes[j_index])
- # Don't consider out-of-scope answers (last part of the test should be unnecessary because of the
- # p_mask but let's not take any risk)
- if (
- start_index >= len(offset_mapping)
- or end_index >= len(offset_mapping)
- or offset_mapping[start_index] is None
- or offset_mapping[end_index] is None
- ):
- continue
- # Don't consider answers with a length negative or > max_answer_length.
- if end_index < start_index or end_index - start_index + 1 > max_answer_length:
- continue
- # Don't consider answer that don't have the maximum context available (if such information is
- # provided).
- if token_is_max_context is not None and not token_is_max_context.get(str(start_index), False):
- continue
- prelim_predictions.append(
- {
- "offsets": (offset_mapping[start_index][0], offset_mapping[end_index][1]),
- "score": start_log_prob[i] + end_log_prob[j_index],
- "start_log_prob": start_log_prob[i],
- "end_log_prob": end_log_prob[j_index],
- }
- )
-
- # Only keep the best `n_best_size` predictions.
- predictions = sorted(prelim_predictions, key=lambda x: x["score"], reverse=True)[:n_best_size]
-
- # Use the offsets to gather the answer text in the original context.
- context = example["context"]
- for pred in predictions:
- offsets = pred.pop("offsets")
- pred["text"] = context[offsets[0] : offsets[1]]
-
- # In the very rare edge case we have not a single non-null prediction, we create a fake prediction to avoid
- # failure.
- if len(predictions) == 0:
- predictions.insert(0, {"text": "", "start_logit": -1e-6, "end_logit": -1e-6, "score": -2e-6})
-
- # Compute the softmax of all scores (we do it with numpy to stay independent from torch/tf in this file, using
- # the LogSumExp trick).
- scores = np.array([pred.pop("score") for pred in predictions])
- exp_scores = np.exp(scores - np.max(scores))
- probs = exp_scores / exp_scores.sum()
-
- # Include the probabilities in our predictions.
- for prob, pred in zip(probs, predictions):
- pred["probability"] = prob
-
- # Pick the best prediction and set the probability for the null answer.
- all_predictions[example["id"]] = predictions[0]["text"]
- if version_2_with_negative:
- scores_diff_json[example["id"]] = float(min_null_score)
-
- # Make `predictions` JSON-serializable by casting np.float back to float.
- all_nbest_json[example["id"]] = [
- {k: (float(v) if isinstance(v, (np.float16, np.float32, np.float64)) else v) for k, v in pred.items()}
- for pred in predictions
- ]
-
- # If we have an output_dir, let's save all those dicts.
- if output_dir is not None:
- if not os.path.isdir(output_dir):
- raise EnvironmentError(f"{output_dir} is not a directory.")
-
- prediction_file = os.path.join(
- output_dir, "predictions.json" if prefix is None else f"{prefix}_predictions.json"
- )
- nbest_file = os.path.join(
- output_dir, "nbest_predictions.json" if prefix is None else f"{prefix}_nbest_predictions.json"
- )
- if version_2_with_negative:
- null_odds_file = os.path.join(
- output_dir, "null_odds.json" if prefix is None else f"{prefix}_null_odds.json"
- )
-
- logger.info(f"Saving predictions to {prediction_file}.")
- with open(prediction_file, "w") as writer:
- writer.write(json.dumps(all_predictions, indent=4) + "\n")
- logger.info(f"Saving nbest_preds to {nbest_file}.")
- with open(nbest_file, "w") as writer:
- writer.write(json.dumps(all_nbest_json, indent=4) + "\n")
- if version_2_with_negative:
- logger.info(f"Saving null_odds to {null_odds_file}.")
- with open(null_odds_file, "w") as writer:
- writer.write(json.dumps(scores_diff_json, indent=4) + "\n")
-
- return all_predictions, scores_diff_json
diff --git a/examples/research_projects/rag-end2end-retriever/README.md b/examples/research_projects/rag-end2end-retriever/README.md
deleted file mode 100644
index 9aa0bc5dbcb..00000000000
--- a/examples/research_projects/rag-end2end-retriever/README.md
+++ /dev/null
@@ -1,56 +0,0 @@
-# End-to-End finetuning of RAG (including DPR retriever) for Question Answering.
-
-This finetuning script is actively maintained by [Shamane Siri](https://github.com/shamanez). Feel free to ask questions on the [Forum](https://discuss.huggingface.co/) or post an issue on [GitHub](https://github.com/huggingface/transformers/issues/new/choose) and tag @shamanez.
-
-Others that helped out: Patrick von Platen (@patrickvonplaten), Quentin Lhoest (@lhoestq), and Rivindu Weerasekera (@rivinduw)
-
-The original RAG implementation is able to train the question encoder and generator end-to-end.
-This extension enables complete end-to-end training of RAG including the context encoder in the retriever component.
-Please read the [accompanying blog post](https://shamanesiri.medium.com/how-to-finetune-the-entire-rag-architecture-including-dpr-retriever-4b4385322552) for details on this implementation.
-
-The original RAG code has also been modified to work with the latest versions of pytorch lightning (version 1.2.10) and RAY (version 1.3.0). All other implementation details remain the same as the [original RAG code](https://github.com/huggingface/transformers/tree/main/examples/research_projects/rag).
-Read more about RAG at https://arxiv.org/abs/2005.11401.
-
-This code can be modified to experiment with other research on retrieval augmented models which include training of the retriever (e.g. [REALM](https://arxiv.org/abs/2002.08909) and [MARGE](https://arxiv.org/abs/2006.15020)).
-
-To start training, use the bash script (finetune_rag_ray_end2end.sh) in this folder. This script also includes descriptions on each command-line argument used.
-
-# Latest Update
-
-⚠️ Updated the rag-end2end-retriever to be compatible with PL==1.6.4 and RAY==1.13.0 (latest versions to the date 2022-June-11)
-
-# Note
-
-⚠️ This project should be run with pytorch-lightning==1.3.1 which has a potential security vulnerability
-
-# Testing
-
-The following two bash scripts can be used to quickly test the implementation.
-1. sh ./test_run/test_finetune.sh script
- - Tests the full end-to-end fine-tuning ability with a dummy knowlendge-base and dummy training dataset (check test_dir directory).
- - Users can replace the dummy dataset and knowledge-base with their own to do their own finetuning.
- - Please read the comments in the test_finetune.sh file.
-2. sh ./test_run/test_rag_new_features.sh
- - Tests the newly added functions (set_context_encoder and set_context_encoder_tokenizer) related to modeling rag.
- - This is sufficient to check the model's ability to use the set functions correctly.
-
-
-
-# Comparison of end2end RAG (including DPR finetuning) VS original-RAG
-
-We conducted a simple experiment to investigate the effectiveness of this end2end training extension using the SQuAD dataset. Please execute the following steps to reproduce the results.
-
-- Create a knowledge-base using all the context passages in the SQuAD dataset with their respective titles.
-- Use the question-answer pairs as training data.
-- Train the system for 10 epochs.
-- Test the Exact Match (EM) score with the SQuAD dataset's validation set.
-- Training dataset, the knowledge-base, and hyperparameters used in experiments can be accessed from [here](https://drive.google.com/drive/folders/1qyzV-PaEARWvaU_jjpnU_NUS3U_dSjtG?usp=sharing).
-
-# Results
-
-- We train both models for 10 epochs.
-
-| Model Type | EM-Score|
-| --------------------| --------|
-| RAG-original | 28.12 |
-| RAG-end2end with DPR| 40.02 |
diff --git a/examples/research_projects/rag-end2end-retriever/callbacks_rag.py b/examples/research_projects/rag-end2end-retriever/callbacks_rag.py
deleted file mode 100644
index 09a30ff6d5c..00000000000
--- a/examples/research_projects/rag-end2end-retriever/callbacks_rag.py
+++ /dev/null
@@ -1,119 +0,0 @@
-import logging
-from pathlib import Path
-
-import numpy as np
-import pytorch_lightning as pl
-import torch
-from pytorch_lightning.callbacks import EarlyStopping, ModelCheckpoint
-from pytorch_lightning.utilities import rank_zero_only
-from utils_rag import save_json
-
-
-def count_trainable_parameters(model):
- model_parameters = filter(lambda p: p.requires_grad, model.parameters())
- params = sum([np.prod(p.size()) for p in model_parameters])
- return params
-
-
-logger = logging.getLogger(__name__)
-
-
-def get_checkpoint_callback(output_dir, metric):
- """Saves the best model by validation EM score."""
- if metric == "rouge2":
- exp = "{val_avg_rouge2:.4f}-{step_count}"
- elif metric == "bleu":
- exp = "{val_avg_bleu:.4f}-{step_count}"
- elif metric == "em":
- exp = "{val_avg_em:.4f}-{step_count}"
- elif metric == "loss":
- exp = "{val_avg_loss:.4f}-{step_count}"
- else:
- raise NotImplementedError(
- f"seq2seq callbacks only support rouge2 and bleu, got {metric}, You can make your own by adding to this"
- " function."
- )
-
- checkpoint_callback = ModelCheckpoint(
- dirpath=output_dir,
- filename=exp,
- monitor=f"val_{metric}",
- mode="max",
- save_top_k=1,
- every_n_epochs=1, # works only with PL > 1.3
- )
-
- return checkpoint_callback
-
-
-def get_early_stopping_callback(metric, patience):
- return EarlyStopping(
- monitor=f"val_{metric}", # does this need avg?
- mode="min" if "loss" in metric else "max",
- patience=patience,
- verbose=True,
- )
-
-
-class Seq2SeqLoggingCallback(pl.Callback):
- def on_batch_end(self, trainer, pl_module):
- lrs = {f"lr_group_{i}": param["lr"] for i, param in enumerate(pl_module.trainer.optimizers[0].param_groups)}
- pl_module.logger.log_metrics(lrs)
-
- @rank_zero_only
- def _write_logs(
- self, trainer: pl.Trainer, pl_module: pl.LightningModule, type_path: str, save_generations=True
- ) -> None:
- logger.info(f"***** {type_path} results at step {trainer.global_step:05d} *****")
- metrics = trainer.callback_metrics
- trainer.logger.log_metrics({k: v for k, v in metrics.items() if k not in ["log", "progress_bar", "preds"]})
- # Log results
- od = Path(pl_module.hparams.output_dir)
- if type_path == "test":
- results_file = od / "test_results.txt"
- generations_file = od / "test_generations.txt"
- else:
- # this never gets hit. I prefer not to save intermediate generations, and results are in metrics.json
- # If people want this it will be easy enough to add back.
- results_file = od / f"{type_path}_results/{trainer.global_step:05d}.txt"
- generations_file = od / f"{type_path}_generations/{trainer.global_step:05d}.txt"
- results_file.parent.mkdir(exist_ok=True)
- generations_file.parent.mkdir(exist_ok=True)
- with open(results_file, "a+") as writer:
- for key in sorted(metrics):
- if key in ["log", "progress_bar", "preds"]:
- continue
- val = metrics[key]
- if isinstance(val, torch.Tensor):
- val = val.item()
- msg = f"{key}: {val:.6f}\n"
- writer.write(msg)
-
- if not save_generations:
- return
-
- if "preds" in metrics:
- content = "\n".join(metrics["preds"])
- generations_file.open("w+").write(content)
-
- @rank_zero_only
- def on_train_start(self, trainer, pl_module):
- try:
- npars = pl_module.model.model.num_parameters()
- except AttributeError:
- npars = pl_module.model.num_parameters()
-
- n_trainable_pars = count_trainable_parameters(pl_module)
- # mp stands for million parameters
- trainer.logger.log_metrics({"n_params": npars, "mp": npars / 1e6, "grad_mp": n_trainable_pars / 1e6})
-
- @rank_zero_only
- def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
- save_json(pl_module.metrics, pl_module.metrics_save_path)
- return self._write_logs(trainer, pl_module, "test")
-
- @rank_zero_only
- def on_validation_end(self, trainer: pl.Trainer, pl_module):
- save_json(pl_module.metrics, pl_module.metrics_save_path)
- # Uncommenting this will save val generations
- # return self._write_logs(trainer, pl_module, "valid")
diff --git a/examples/research_projects/rag-end2end-retriever/distributed_ray_retriever.py b/examples/research_projects/rag-end2end-retriever/distributed_ray_retriever.py
deleted file mode 100644
index f97467292c2..00000000000
--- a/examples/research_projects/rag-end2end-retriever/distributed_ray_retriever.py
+++ /dev/null
@@ -1,185 +0,0 @@
-import logging
-import random
-
-import ray
-
-from transformers import RagConfig, RagRetriever, RagTokenizer
-from transformers.models.rag.retrieval_rag import CustomHFIndex
-
-
-logger = logging.getLogger(__name__)
-
-
-class RayRetriever:
- def __init__(self):
- self.initialized = False
-
- def create_rag_retriever(self, config, question_encoder_tokenizer, generator_tokenizer, index):
- if not self.initialized:
- self.retriever = RagRetriever(
- config,
- question_encoder_tokenizer=question_encoder_tokenizer,
- generator_tokenizer=generator_tokenizer,
- index=index,
- init_retrieval=False,
- )
- self.initialized = True
-
- def init_retrieval(self):
- self.retriever.index.init_index()
-
- def clear_object(self):
- # delete the old self.retriever object before assigning the new index
- del self.retriever
- self.initialized = False
-
- def retrieve(self, question_hidden_states, n_docs):
- doc_ids, retrieved_doc_embeds = self.retriever._main_retrieve(question_hidden_states, n_docs)
- doc_dicts = self.retriever.index.get_doc_dicts(doc_ids)
- return doc_ids, retrieved_doc_embeds, doc_dicts
-
-
-class RagRayDistributedRetriever(RagRetriever):
- """
- A distributed retriever built on top of the ``Ray`` API, a library
- for building distributed applications (https://docs.ray.io/en/master/).
- package. During training, all training workers initialize their own
- instance of a `RagRayDistributedRetriever`, and each instance of
- this distributed retriever shares a common set of Retrieval Ray
- Actors (https://docs.ray.io/en/master/walkthrough.html#remote
- -classes-actors) that load the index on separate processes. Ray
- handles the communication between the `RagRayDistributedRetriever`
- instances and the remote Ray actors. If training is done in a
- non-distributed setup, the index will simply be loaded in the same
- process as the training worker and Ray will not be used.
-
- Args:
- config (:class:`~transformers.RagConfig`):
- The configuration of the RAG model this Retriever is used with. Contains parameters indicating which ``Index`` to build.
- question_encoder_tokenizer (:class:`~transformers.PreTrainedTokenizer`):
- The tokenizer that was used to tokenize the question.
- It is used to decode the question and then use the generator_tokenizer.
- generator_tokenizer (:class:`~transformers.PreTrainedTokenizer`):
- The tokenizer used for the generator part of the RagModel.
- retrieval_workers (:obj:`List[ray.ActorClass(RayRetriever)]`): A list of already initialized `RayRetriever` actors.
- These actor classes run on remote processes and are responsible for performing the index lookup.
- index (:class:`~transformers.retrieval_rag.Index`, optional, defaults to the one defined by the configuration):
- If specified, use this index instead of the one built using the configuration
- """
-
- def __init__(self, config, question_encoder_tokenizer, generator_tokenizer, retrieval_workers, index=None):
- if index is not None and index.is_initialized() and len(retrieval_workers) > 0:
- raise ValueError(
- "When using Ray for distributed fine-tuning, "
- "you'll need to provide the paths instead, "
- "as the dataset and the index are loaded "
- "separately. More info in examples/rag/use_own_knowledge_dataset.py "
- )
-
- super().__init__(
- config,
- question_encoder_tokenizer=question_encoder_tokenizer,
- generator_tokenizer=generator_tokenizer,
- index=index,
- init_retrieval=False,
- )
-
- self.retrieval_workers = retrieval_workers
- self.question_encoder_tokenizer = question_encoder_tokenizer
- self.generator_tokenizer = generator_tokenizer
- if len(self.retrieval_workers) > 0:
- ray.get(
- [
- worker.create_rag_retriever.remote(config, question_encoder_tokenizer, generator_tokenizer, index)
- for worker in self.retrieval_workers
- ]
- )
-
- def init_retrieval(self):
- """
- Retriever initialization function, needs to be called from the
- training process. This function triggers retrieval initialization
- for all retrieval actors if using distributed setting, or loads
- index into current process if training is not distributed.
- """
- logger.info("initializing retrieval")
-
- if len(self.retrieval_workers) > 0:
- ray.get([worker.init_retrieval.remote() for worker in self.retrieval_workers])
- else:
- # Non-distributed training. Load index into this same process.
- self.index.init_index()
-
- def retrieve(self, question_hidden_states, n_docs):
- """
- Retrieves documents for specified ``question_hidden_states``. If
- running training with multiple workers, a random retrieval actor is
- selected to perform the index lookup and return the result.
-
- Args:
- question_hidden_states (:obj:`np.ndarray` of shape :obj:`(batch_size, vector_size)`):
- A batch of query vectors to retrieve with.
- n_docs (:obj:`int`):
- The number of docs retrieved per query.
-
- Output:
- retrieved_doc_embeds (:obj:`np.ndarray` of shape :obj:`(batch_size, n_docs, dim)`
- The retrieval embeddings of the retrieved docs per query.
- doc_ids (:obj:`np.ndarray` of shape :obj:`batch_size, n_docs`)
- The ids of the documents in the index
- doc_dicts (:obj:`List[dict]`):
- The retrieved_doc_embeds examples per query.
- """
- if len(self.retrieval_workers) > 0:
- # Select a random retrieval actor.
- random_worker = self.retrieval_workers[random.randint(0, len(self.retrieval_workers) - 1)]
- doc_ids, retrieved_doc_embeds, doc_dicts = ray.get(
- random_worker.retrieve.remote(question_hidden_states, n_docs)
- )
- else:
- doc_ids, retrieved_doc_embeds = self._main_retrieve(question_hidden_states, n_docs)
- doc_dicts = self.index.get_doc_dicts(doc_ids)
- return retrieved_doc_embeds, doc_ids, doc_dicts
-
- @classmethod
- def get_tokenizers(cls, retriever_name_or_path, indexed_dataset=None, **kwargs):
- return super(RagRayDistributedRetriever, cls).get_tokenizers(retriever_name_or_path, indexed_dataset, **kwargs)
-
- @classmethod
- def from_pretrained(cls, retriever_name_or_path, actor_handles, indexed_dataset=None, **kwargs):
- config = kwargs.pop("config", None) or RagConfig.from_pretrained(retriever_name_or_path, **kwargs)
- rag_tokenizer = RagTokenizer.from_pretrained(retriever_name_or_path, config=config)
- question_encoder_tokenizer = rag_tokenizer.question_encoder
- generator_tokenizer = rag_tokenizer.generator
-
- if indexed_dataset is not None:
- config.index_name = "custom"
- index = CustomHFIndex(config.retrieval_vector_size, indexed_dataset)
- else:
- index = cls._build_index(config)
-
- return cls(
- config,
- question_encoder_tokenizer=question_encoder_tokenizer,
- generator_tokenizer=generator_tokenizer,
- retrieval_workers=actor_handles,
- index=index,
- )
-
- def re_load(self):
- logger.info("re-loading the new dataset with embeddings")
- # access from the training loop
-
- ray.get([worker.clear_object.remote() for worker in self.retrieval_workers])
-
- # build the index object again
- index = self._build_index(self.config)
-
- ray.get(
- [
- worker.create_rag_retriever.remote(
- self.config, self.question_encoder_tokenizer, self.generator_tokenizer, index
- )
- for worker in self.retrieval_workers
- ]
- )
diff --git a/examples/research_projects/rag-end2end-retriever/eval_rag.py b/examples/research_projects/rag-end2end-retriever/eval_rag.py
deleted file mode 100644
index 55f4da56571..00000000000
--- a/examples/research_projects/rag-end2end-retriever/eval_rag.py
+++ /dev/null
@@ -1,320 +0,0 @@
-"""Evaluation script for RAG models."""
-
-import argparse
-import ast
-import logging
-import os
-import sys
-
-import pandas as pd
-import torch
-from tqdm import tqdm
-
-from transformers import BartForConditionalGeneration, RagRetriever, RagSequenceForGeneration, RagTokenForGeneration
-from transformers import logging as transformers_logging
-
-
-sys.path.append(os.path.join(os.getcwd())) # noqa: E402 # isort:skip
-from utils_rag import exact_match_score, f1_score # noqa: E402 # isort:skip
-
-
-logger = logging.getLogger(__name__)
-logging.basicConfig(level=logging.INFO)
-
-transformers_logging.set_verbosity_info()
-
-
-def infer_model_type(model_name_or_path):
- if "token" in model_name_or_path:
- return "rag_token"
- if "sequence" in model_name_or_path:
- return "rag_sequence"
- if "bart" in model_name_or_path:
- return "bart"
- return None
-
-
-def metric_max_over_ground_truths(metric_fn, prediction, ground_truths):
- return max(metric_fn(prediction, gt) for gt in ground_truths)
-
-
-def get_scores(args, preds_path, gold_data_path):
- hypos = [line.strip() for line in open(preds_path, "r").readlines()]
- answers = []
-
- if args.gold_data_mode == "qa":
- data = pd.read_csv(gold_data_path, sep="\t", header=None)
- for answer_list in data[1]:
- ground_truths = ast.literal_eval(answer_list)
- answers.append(ground_truths)
- else:
- references = [line.strip() for line in open(gold_data_path, "r").readlines()]
- answers = [[reference] for reference in references]
-
- f1 = em = total = 0
- for prediction, ground_truths in zip(hypos, answers):
- total += 1
- em += metric_max_over_ground_truths(exact_match_score, prediction, ground_truths)
- f1 += metric_max_over_ground_truths(f1_score, prediction, ground_truths)
-
- em = 100.0 * em / total
- f1 = 100.0 * f1 / total
-
- logger.info(f"F1: {f1:.2f}")
- logger.info(f"EM: {em:.2f}")
-
-
-def get_precision_at_k(args, preds_path, gold_data_path):
- k = args.k
- hypos = [line.strip() for line in open(preds_path, "r").readlines()]
- references = [line.strip() for line in open(gold_data_path, "r").readlines()]
-
- em = total = 0
- for hypo, reference in zip(hypos, references):
- hypo_provenance = set(hypo.split("\t")[:k])
- ref_provenance = set(reference.split("\t"))
- total += 1
- em += len(hypo_provenance & ref_provenance) / k
-
- em = 100.0 * em / total
- logger.info(f"Precision@{k}: {em: .2f}")
-
-
-def evaluate_batch_retrieval(args, rag_model, questions):
- def strip_title(title):
- if title.startswith('"'):
- title = title[1:]
- if title.endswith('"'):
- title = title[:-1]
- return title
-
- retriever_input_ids = rag_model.retriever.question_encoder_tokenizer.batch_encode_plus(
- questions,
- return_tensors="pt",
- padding=True,
- truncation=True,
- )["input_ids"].to(args.device)
-
- question_enc_outputs = rag_model.rag.question_encoder(retriever_input_ids)
- question_enc_pool_output = question_enc_outputs[0]
-
- result = rag_model.retriever(
- retriever_input_ids,
- question_enc_pool_output.cpu().detach().to(torch.float32).numpy(),
- prefix=rag_model.rag.generator.config.prefix,
- n_docs=rag_model.config.n_docs,
- return_tensors="pt",
- )
- all_docs = rag_model.retriever.index.get_doc_dicts(result.doc_ids)
- provenance_strings = []
- for docs in all_docs:
- provenance = [strip_title(title) for title in docs["title"]]
- provenance_strings.append("\t".join(provenance))
- return provenance_strings
-
-
-def evaluate_batch_e2e(args, rag_model, questions):
- with torch.no_grad():
- inputs_dict = rag_model.retriever.question_encoder_tokenizer.batch_encode_plus(
- questions, return_tensors="pt", padding=True, truncation=True
- )
-
- input_ids = inputs_dict.input_ids.to(args.device)
- attention_mask = inputs_dict.attention_mask.to(args.device)
- outputs = rag_model.generate( # rag_model overwrites generate
- input_ids,
- attention_mask=attention_mask,
- num_beams=args.num_beams,
- min_length=args.min_length,
- max_length=args.max_length,
- early_stopping=False,
- num_return_sequences=1,
- bad_words_ids=[[0, 0]], # BART likes to repeat BOS tokens, dont allow it to generate more than one
- )
- answers = rag_model.retriever.generator_tokenizer.batch_decode(outputs, skip_special_tokens=True)
-
- if args.print_predictions:
- for q, a in zip(questions, answers):
- logger.info("Q: {} - A: {}".format(q, a))
-
- return answers
-
-
-def get_args():
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "--model_type",
- choices=["rag_sequence", "rag_token", "bart"],
- type=str,
- help=(
- "RAG model type: rag_sequence, rag_token or bart, if none specified, the type is inferred from the"
- " model_name_or_path"
- ),
- )
- parser.add_argument(
- "--index_name",
- default=None,
- choices=["exact", "compressed", "legacy"],
- type=str,
- help="RAG model retriever type",
- )
- parser.add_argument(
- "--index_path",
- default=None,
- type=str,
- help="Path to the retrieval index",
- )
- parser.add_argument("--n_docs", default=5, type=int, help="Number of retrieved docs")
- parser.add_argument(
- "--model_name_or_path",
- default=None,
- type=str,
- required=True,
- help="Path to pretrained checkpoints or model identifier from huggingface.co/models",
- )
- parser.add_argument(
- "--eval_mode",
- choices=["e2e", "retrieval"],
- default="e2e",
- type=str,
- help=(
- "Evaluation mode, e2e calculates exact match and F1 of the downstream task, retrieval calculates"
- " precision@k."
- ),
- )
- parser.add_argument("--k", default=1, type=int, help="k for the precision@k calculation")
- parser.add_argument(
- "--evaluation_set",
- default=None,
- type=str,
- required=True,
- help="Path to a file containing evaluation samples",
- )
- parser.add_argument(
- "--gold_data_path",
- default=None,
- type=str,
- required=True,
- help="Path to a tab-separated file with gold samples",
- )
- parser.add_argument(
- "--gold_data_mode",
- default="qa",
- type=str,
- choices=["qa", "ans"],
- help=(
- "Format of the gold data file"
- "qa - a single line in the following format: question [tab] answer_list"
- "ans - a single line of the gold file contains the expected answer string"
- ),
- )
- parser.add_argument(
- "--predictions_path",
- type=str,
- default="predictions.txt",
- help="Name of the predictions file, to be stored in the checkpoints directory",
- )
- parser.add_argument(
- "--eval_all_checkpoints",
- action="store_true",
- help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
- )
- parser.add_argument(
- "--eval_batch_size",
- default=8,
- type=int,
- help="Batch size per GPU/CPU for evaluation.",
- )
- parser.add_argument(
- "--recalculate",
- help="Recalculate predictions even if the prediction file exists",
- action="store_true",
- )
- parser.add_argument(
- "--num_beams",
- default=4,
- type=int,
- help="Number of beams to be used when generating answers",
- )
- parser.add_argument("--min_length", default=1, type=int, help="Min length of the generated answers")
- parser.add_argument("--max_length", default=50, type=int, help="Max length of the generated answers")
-
- parser.add_argument(
- "--print_predictions",
- action="store_true",
- help="If True, prints predictions while evaluating.",
- )
- parser.add_argument(
- "--print_docs",
- action="store_true",
- help="If True, prints docs retried while generating.",
- )
- args = parser.parse_args()
- args.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
- return args
-
-
-def main(args):
- model_kwargs = {}
- if args.model_type is None:
- args.model_type = infer_model_type(args.model_name_or_path)
- assert args.model_type is not None
- if args.model_type.startswith("rag"):
- model_class = RagTokenForGeneration if args.model_type == "rag_token" else RagSequenceForGeneration
- model_kwargs["n_docs"] = args.n_docs
- if args.index_name is not None:
- model_kwargs["index_name"] = args.index_name
- if args.index_path is not None:
- model_kwargs["index_path"] = args.index_path
- else:
- model_class = BartForConditionalGeneration
-
- checkpoints = (
- [f.path for f in os.scandir(args.model_name_or_path) if f.is_dir()]
- if args.eval_all_checkpoints
- else [args.model_name_or_path]
- )
-
- logger.info("Evaluate the following checkpoints: %s", checkpoints)
-
- score_fn = get_scores if args.eval_mode == "e2e" else get_precision_at_k
- evaluate_batch_fn = evaluate_batch_e2e if args.eval_mode == "e2e" else evaluate_batch_retrieval
-
- for checkpoint in checkpoints:
- if os.path.exists(args.predictions_path) and (not args.recalculate):
- logger.info("Calculating metrics based on an existing predictions file: {}".format(args.predictions_path))
- score_fn(args, args.predictions_path, args.gold_data_path)
- continue
-
- logger.info("***** Running evaluation for {} *****".format(checkpoint))
- logger.info(" Batch size = %d", args.eval_batch_size)
- logger.info(" Predictions will be stored under {}".format(args.predictions_path))
-
- if args.model_type.startswith("rag"):
- retriever = RagRetriever.from_pretrained(checkpoint, **model_kwargs)
- model = model_class.from_pretrained(checkpoint, retriever=retriever, **model_kwargs)
- model.retriever.init_retrieval()
- else:
- model = model_class.from_pretrained(checkpoint, **model_kwargs)
- model.to(args.device)
-
- with open(args.evaluation_set, "r") as eval_file, open(args.predictions_path, "w") as preds_file:
- questions = []
- for line in tqdm(eval_file):
- questions.append(line.strip())
- if len(questions) == args.eval_batch_size:
- answers = evaluate_batch_fn(args, model, questions)
- preds_file.write("\n".join(answers) + "\n")
- preds_file.flush()
- questions = []
- if len(questions) > 0:
- answers = evaluate_batch_fn(args, model, questions)
- preds_file.write("\n".join(answers))
- preds_file.flush()
-
- score_fn(args, args.predictions_path, args.gold_data_path)
-
-
-if __name__ == "__main__":
- args = get_args()
- main(args)
diff --git a/examples/research_projects/rag-end2end-retriever/finetune_rag.py b/examples/research_projects/rag-end2end-retriever/finetune_rag.py
deleted file mode 100644
index 9bc2e5db6d5..00000000000
--- a/examples/research_projects/rag-end2end-retriever/finetune_rag.py
+++ /dev/null
@@ -1,815 +0,0 @@
-"""Finetuning script for RAG models. Adapted from examples.seq2seq.finetune.py"""
-
-import argparse
-import copy
-import json
-import logging
-import multiprocessing
-import os
-import random
-import shutil
-import sys
-import time
-from collections import defaultdict
-from pathlib import Path
-from typing import Any, Dict, List, Tuple
-
-import numpy as np
-import pytorch_lightning as pl
-import torch
-import torch.distributed as dist
-from datasets import concatenate_datasets, load_from_disk
-from torch.utils.data import DataLoader
-
-from transformers import (
- AutoConfig,
- AutoTokenizer,
- BartForConditionalGeneration,
- BatchEncoding,
- DPRConfig,
- DPRContextEncoder,
- DPRContextEncoderTokenizerFast,
- RagConfig,
- RagSequenceForGeneration,
- RagTokenForGeneration,
- RagTokenizer,
- T5ForConditionalGeneration,
-)
-from transformers import logging as transformers_logging
-from transformers.integrations import is_ray_available
-
-
-if is_ray_available():
- import ray
- from distributed_ray_retriever import RagRayDistributedRetriever, RayRetriever
-
-from glob import glob
-
-from callbacks_rag import Seq2SeqLoggingCallback, get_checkpoint_callback, get_early_stopping_callback
-from kb_encode_utils import add_index, embed_update
-from lightning_base import BaseTransformer, add_generic_args, generic_train
-from pynvml import nvmlDeviceGetCount, nvmlDeviceGetHandleByIndex, nvmlDeviceGetMemoryInfo, nvmlInit
-from utils_rag import (
- Seq2SeqDataset,
- calculate_exact_match,
- get_git_info,
- is_rag_model,
- lmap,
- pickle_save,
- save_git_info,
- save_json,
- set_extra_model_params,
-)
-
-
-logging.basicConfig(level=logging.INFO)
-logger = logging.getLogger(__name__)
-
-transformers_logging.set_verbosity_info()
-
-
-sys.path.insert(2, str(Path(__file__).resolve().parents[1]))
-isEmUpdateBusy = False
-isAddIndexBusy = False
-processes = []
-threadHandle_index = None
-
-
-class AttrDict(dict):
- def __init__(self, *args, **kwargs):
- super(AttrDict, self).__init__(*args, **kwargs)
- self.__dict__ = self
-
-
-class GenerativeQAModule(BaseTransformer):
- mode = "generative_qa"
- loss_names = ["loss"]
- metric_names = ["em"]
- val_metric = "em"
-
- def __init__(self, hparams, **kwargs):
- # when loading from a pytorch lightning checkpoint, hparams are passed as dict
- if isinstance(hparams, dict):
- hparams = AttrDict(hparams)
- if hparams.model_type == "rag_sequence":
- self.model_class = RagSequenceForGeneration
- elif hparams.model_type == "rag_token":
- self.model_class = RagTokenForGeneration
- elif hparams.model_type == "bart":
- self.model_class = BartForConditionalGeneration
- else:
- self.model_class = T5ForConditionalGeneration
- self.is_rag_model = is_rag_model(hparams.model_type)
-
- config_class = RagConfig if self.is_rag_model else AutoConfig
- config = config_class.from_pretrained(hparams.model_name_or_path)
-
- # set retriever parameters
- config.index_name = hparams.index_name or config.index_name
- config.passages_path = hparams.passages_path or config.passages_path
- config.index_path = hparams.index_path or config.index_path
- config.use_dummy_dataset = hparams.use_dummy_dataset
-
- # set extra_model_params for generator configs and load_model
- extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "attention_dropout", "dropout")
- if self.is_rag_model:
- if hparams.prefix is not None:
- config.generator.prefix = hparams.prefix
- config.label_smoothing = hparams.label_smoothing
- hparams, config.generator = set_extra_model_params(extra_model_params, hparams, config.generator)
- if hparams.distributed_retriever == "ray":
- # The Ray retriever needs the handles to the retriever actors.
- retriever = RagRayDistributedRetriever.from_pretrained(
- hparams.model_name_or_path, hparams.actor_handles, config=config
- )
-
- if hparams.end2end:
- ctx_encoder_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained(
- "facebook/dpr-ctx_encoder-multiset-base"
- )
- retriever.set_ctx_encoder_tokenizer(ctx_encoder_tokenizer)
- else:
- logger.info("please use RAY as the distributed retrieval method")
-
- model = self.model_class.from_pretrained(hparams.model_name_or_path, config=config, retriever=retriever)
- if hparams.end2end:
- ctx_encoder = DPRContextEncoder.from_pretrained(hparams.context_encoder_name)
- model.set_context_encoder_for_training(ctx_encoder)
- prefix = config.question_encoder.prefix
- else:
- if hparams.prefix is not None:
- config.prefix = hparams.prefix
- hparams, config = set_extra_model_params(extra_model_params, hparams, config)
- model = self.model_class.from_pretrained(hparams.model_name_or_path, config=config)
- prefix = config.prefix
-
- tokenizer = (
- RagTokenizer.from_pretrained(hparams.model_name_or_path)
- if self.is_rag_model
- else AutoTokenizer.from_pretrained(hparams.model_name_or_path)
- )
-
- self.config_dpr = DPRConfig.from_pretrained(hparams.context_encoder_name)
- self.custom_config = hparams
- self.context_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained(hparams.context_encoder_name)
-
- super().__init__(hparams, config=config, tokenizer=tokenizer, model=model)
-
- save_git_info(self.hparams.output_dir)
- self.output_dir = Path(self.hparams.output_dir)
- self.dpr_ctx_check_dir = str(Path(self.hparams.output_dir)) + "/dpr_ctx_checkpoint"
- self.metrics_save_path = Path(self.output_dir) / "metrics.json"
- self.hparams_save_path = Path(self.output_dir) / "hparams.pkl"
- pickle_save(self.hparams, self.hparams_save_path)
- self.step_count = 0
- self.metrics = defaultdict(list)
-
- self.dataset_kwargs: dict = {
- "data_dir": self.hparams.data_dir,
- "max_source_length": self.hparams.max_source_length,
- "prefix": prefix or "",
- }
- n_observations_per_split = {
- "train": self.hparams.n_train,
- "val": self.hparams.n_val,
- "test": self.hparams.n_test,
- }
- self.n_obs = {k: v if v >= 0 else None for k, v in n_observations_per_split.items()}
- self.target_lens = {
- "train": self.hparams.max_target_length,
- "val": self.hparams.val_max_target_length,
- "test": self.hparams.test_max_target_length,
- }
- assert self.target_lens["train"] <= self.target_lens["val"], f"target_lens: {self.target_lens}"
- assert self.target_lens["train"] <= self.target_lens["test"], f"target_lens: {self.target_lens}"
-
- self.hparams.git_sha = get_git_info()["repo_sha"]
- self.num_workers = hparams.num_workers
- self.distributed_port = self.hparams.distributed_port
-
- # For single GPU training, init_ddp_connection is not called.
- # So we need to initialize the retrievers here.
- if hparams.gpus <= 1:
- if hparams.distributed_retriever == "ray":
- self.model.retriever.init_retrieval()
- else:
- logger.info("please use RAY as the distributed retrieval method")
-
- self.distributed_retriever = hparams.distributed_retriever
-
- def forward(self, input_ids, **kwargs):
- return self.model(input_ids, **kwargs)
-
- def ids_to_clean_text(self, generated_ids: List[int]):
- gen_text = self.tokenizer.batch_decode(
- generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
- )
- return lmap(str.strip, gen_text)
-
- def _step(self, batch: dict) -> Tuple:
- source_ids, source_mask, target_ids = batch["input_ids"], batch["attention_mask"], batch["decoder_input_ids"]
-
- rag_kwargs = {}
- if isinstance(self.model, T5ForConditionalGeneration):
- decoder_input_ids = self.model._shift_right(target_ids)
- lm_labels = target_ids
- elif isinstance(self.model, BartForConditionalGeneration):
- decoder_input_ids = target_ids[:, :-1].contiguous()
- lm_labels = target_ids[:, 1:].clone()
- else:
- assert self.is_rag_model
- generator = self.model.rag.generator
- if isinstance(generator, T5ForConditionalGeneration):
- decoder_start_token_id = generator.config.decoder_start_token_id
- decoder_input_ids = (
- torch.cat(
- [torch.tensor([[decoder_start_token_id]] * target_ids.shape[0]).to(target_ids), target_ids],
- dim=1,
- )
- if target_ids.shape[0] < self.target_lens["train"]
- else generator._shift_right(target_ids)
- )
- elif isinstance(generator, BartForConditionalGeneration):
- decoder_input_ids = target_ids
- lm_labels = decoder_input_ids
- rag_kwargs["reduce_loss"] = True
-
- assert decoder_input_ids is not None
-
- outputs = self(
- source_ids,
- attention_mask=source_mask,
- decoder_input_ids=decoder_input_ids,
- use_cache=False,
- labels=lm_labels,
- **rag_kwargs,
- )
- loss = outputs["loss"]
- return (loss,)
-
- @property
- def pad(self) -> int:
- raise NotImplementedError("pad not implemented")
-
- def training_step(self, batch, batch_idx) -> Dict:
- global isEmUpdateBusy # use to check whether the entire embedding update process is finished or not
- global isAddIndexBusy # use to check whether the entire indexing process is finished or not
- global processes # use to keep threads embedding update processes
- global threadHandle_index # use to keep thread in embedding indexing processes
-
- if (self.trainer.global_rank == 0) and (self.custom_config.end2end):
- if (not batch_idx == 0) and (batch_idx % self.custom_config.indexing_freq == 0):
- free_gpu_list = []
- nvmlInit()
- deviceCount = nvmlDeviceGetCount()
-
- my_list = json.loads(self.custom_config.gpu_order)
-
- for i in range(deviceCount):
- handle = nvmlDeviceGetHandleByIndex(i)
- info = nvmlDeviceGetMemoryInfo(handle)
-
- if info.used / 1e6 < 15:
- position = my_list.index(i)
- free_gpu_list.append("cuda:" + str(position))
-
- if len(free_gpu_list) >= self.custom_config.index_gpus:
- has_free_gpus = True
-
- else:
- has_free_gpus = False
-
- if (not isEmUpdateBusy) and has_free_gpus:
- model_copy = type(self.model.rag.ctx_encoder)(
- self.config_dpr
- ) # get a new instance #this will be load in the CPU
- model_copy.load_state_dict(self.model.rag.ctx_encoder.state_dict()) # copy weights
-
- processes = []
-
- if len(free_gpu_list) > self.custom_config.index_gpus:
- cuda_devices = random.sample(free_gpu_list, self.custom_config.index_gpus)
- else:
- cuda_devices = free_gpu_list
-
- num_processes = len(cuda_devices)
-
- for rank in range(num_processes):
- logger.info("Iniitializing embedding calculation process rank{}".format(rank))
- device = cuda_devices[rank]
- p = multiprocessing.Process(
- target=embed_update,
- args=(
- copy.deepcopy(model_copy),
- num_processes,
- device,
- rank,
- self.custom_config.shard_dir,
- self.custom_config.csv_path,
- ),
- )
- processes.append(p)
-
- for p in processes:
- p.start()
-
- isEmUpdateBusy = True
-
- if isEmUpdateBusy and (not isAddIndexBusy):
- index_process_list = [processes[k].is_alive() for k in range(self.custom_config.index_gpus)]
- if (
- sum(index_process_list) == 0
- ): # If entire list is false, we can say all embedding calculation process has finished
- logger.info("Start adding the index")
- threadHandle_index = multiprocessing.Process(
- target=add_index,
- args=(
- self.custom_config.shard_dir,
- self.config.index_path,
- ),
- )
- threadHandle_index.start()
- isAddIndexBusy = True
-
- # check when index building has started
- if isAddIndexBusy:
- # check still the index_building process is happening
- if not threadHandle_index.is_alive():
- logger.info("Merging the dataset shards")
- saved_dataset_shards = []
-
- for address in glob(str(self.custom_config.shard_dir) + "/*/"):
- saved_dataset_shards.append(load_from_disk(address))
-
- concat = concatenate_datasets(saved_dataset_shards)
- concat.save_to_disk(self.config.passages_path) # here we update the main passage file on the disk
- logger.info("done updating the dataset")
-
- # To Do (@Aaron) : Useful in the future dynamic memory implementation.
- # if you load the index from the disk make sure to update the index file here, otherwise it is ok to update the index file from the worker.
- # logger.info("then updating the index")
- # shutil.copy(self.custom_config.temp_index, self.config.idex_path)
-
- logger.info("Loading new passages and iniitalzing new index")
- self.trainer.model.module.module.model.rag.retriever.re_load()
- self.trainer.model.module.module.model.rag.retriever.init_retrieval()
-
- isEmUpdateBusy = False
- isAddIndexBusy = False
- self.trainer.strategy.barrier("barrier")
-
- loss_tensors = self._step(batch)
-
- logs = dict(zip(self.loss_names, loss_tensors))
- # tokens per batch
- tgt_pad_token_id = (
- self.tokenizer.generator.pad_token_id
- if isinstance(self.tokenizer, RagTokenizer)
- else self.tokenizer.pad_token_id
- )
- src_pad_token_id = (
- self.tokenizer.question_encoder.pad_token_id
- if isinstance(self.tokenizer, RagTokenizer)
- else self.tokenizer.pad_token_id
- )
- logs["tpb"] = (
- batch["input_ids"].ne(src_pad_token_id).sum() + batch["decoder_input_ids"].ne(tgt_pad_token_id).sum()
- )
- self.log("loss", loss_tensors[0])
- return loss_tensors[0]
-
- def validation_step(self, batch, batch_idx) -> Dict:
- return self._generative_step(batch)
-
- def validation_epoch_end(self, outputs, prefix="val") -> Dict:
- self.step_count += 1
- losses = {k: torch.stack([x[k] for x in outputs]).mean() for k in self.loss_names}
- loss = losses["loss"]
- gen_metrics = {
- k: np.array([x[k] for x in outputs]).mean() for k in self.metric_names + ["gen_time", "gen_len"]
- }
- metrics_tensor: torch.FloatTensor = torch.tensor(gen_metrics[self.val_metric]).type_as(loss)
- gen_metrics.update({k: v.item() for k, v in losses.items()})
-
- # fix for https://github.com/PyTorchLightning/pytorch-lightning/issues/2424
- if dist.is_initialized():
- dist.all_reduce(metrics_tensor, op=dist.ReduceOp.SUM)
- metrics_tensor = metrics_tensor / dist.get_world_size()
- gen_metrics.update({self.val_metric: metrics_tensor.item()})
-
- losses.update(gen_metrics)
- metrics = {f"{prefix}_avg_{k}": x for k, x in losses.items()}
- metrics["step_count"] = self.step_count
- self.save_metrics(metrics, prefix) # writes to self.metrics_save_path
-
- log_dict = {
- f"{prefix}_avg_em": metrics[f"{prefix}_avg_em"],
- "step_count": metrics["step_count"],
- f"{prefix}_avg_loss": metrics[f"{prefix}_avg_loss"],
- f"{prefix}_loss": loss,
- f"{prefix}_em": metrics_tensor,
- }
- self.log_dict(log_dict)
-
- def save_metrics(self, latest_metrics, type_path) -> None:
- self.metrics[type_path].append(latest_metrics)
- save_json(self.metrics, self.metrics_save_path)
-
- def calc_generative_metrics(self, preds, target) -> Dict:
- return calculate_exact_match(preds, target)
-
- def _generative_step(self, batch: dict) -> dict:
- start_time = time.time()
- batch = BatchEncoding(batch).to(device=self.model.device)
- generated_ids = self.model.generate(
- batch["input_ids"],
- attention_mask=batch["attention_mask"],
- do_deduplication=False, # rag specific parameter
- use_cache=True,
- min_length=1,
- max_length=self.target_lens["val"],
- )
- gen_time = (time.time() - start_time) / batch["input_ids"].shape[0]
- preds: List[str] = self.ids_to_clean_text(generated_ids)
- target: List[str] = self.ids_to_clean_text(batch["decoder_input_ids"])
- # print(preds,target)
- loss_tensors = self._step(batch)
- base_metrics = dict(zip(self.loss_names, loss_tensors))
- gen_metrics: Dict = self.calc_generative_metrics(preds, target)
-
- summ_len = np.mean(lmap(len, generated_ids))
- base_metrics.update(gen_time=gen_time, gen_len=summ_len, preds=preds, target=target, **gen_metrics)
- return base_metrics
-
- def test_step(self, batch, batch_idx):
- return self._generative_step(batch)
-
- def test_epoch_end(self, outputs):
- return self.validation_epoch_end(outputs, prefix="test")
-
- def get_dataset(self, type_path) -> Seq2SeqDataset:
- n_obs = self.n_obs[type_path]
- max_target_length = self.target_lens[type_path]
- dataset = Seq2SeqDataset(
- self.tokenizer,
- type_path=type_path,
- n_obs=n_obs,
- max_target_length=max_target_length,
- **self.dataset_kwargs,
- )
- return dataset
-
- def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False) -> DataLoader:
- dataset = self.get_dataset(type_path)
-
- dataloader = DataLoader(
- dataset,
- batch_size=batch_size,
- collate_fn=dataset.collate_fn,
- shuffle=shuffle,
- num_workers=self.num_workers,
- )
- return dataloader
-
- def train_dataloader(self) -> DataLoader:
- dataloader = self.get_dataloader("train", batch_size=self.hparams.train_batch_size, shuffle=True)
- return dataloader
-
- def val_dataloader(self) -> DataLoader:
- return self.get_dataloader("val", batch_size=self.hparams.eval_batch_size)
-
- def test_dataloader(self) -> DataLoader:
- return self.get_dataloader("test", batch_size=self.hparams.eval_batch_size)
-
- @pl.utilities.rank_zero_only
- def on_save_checkpoint(self, checkpoint: Dict[str, Any]) -> None:
- save_path = self.output_dir.joinpath("checkpoint{}".format(self.step_count))
- self.model.config.save_step = self.step_count
- # self.model.save_pretrained(save_path)
- self.tokenizer.save_pretrained(save_path)
-
- if self.custom_config.end2end:
- modified_state_dict = self.model.state_dict()
- for key in self.model.state_dict().keys():
- if key.split(".")[1] == "ctx_encoder":
- del modified_state_dict[key]
- self.model.save_pretrained(save_directory=save_path, state_dict=modified_state_dict)
-
- save_path_dpr = os.path.join(self.dpr_ctx_check_dir, "checkpoint{}".format(self.step_count))
- self.model.rag.ctx_encoder.save_pretrained(save_path_dpr)
- self.context_tokenizer.save_pretrained(save_path_dpr)
-
- @staticmethod
- def add_model_specific_args(parser, root_dir):
- BaseTransformer.add_model_specific_args(parser, root_dir)
- add_generic_args(parser, root_dir)
- parser.add_argument(
- "--max_source_length",
- default=128,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument(
- "--max_target_length",
- default=25,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument(
- "--val_max_target_length",
- default=25,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument(
- "--test_max_target_length",
- default=25,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument("--logger_name", type=str, choices=["default", "wandb", "wandb_shared"], default="default")
- parser.add_argument("--n_train", type=int, default=-1, required=False, help="# examples. -1 means use all.")
- parser.add_argument("--n_val", type=int, default=-1, required=False, help="# examples. -1 means use all.")
- parser.add_argument("--n_test", type=int, default=-1, required=False, help="# examples. -1 means use all.")
- parser.add_argument("--label_smoothing", type=float, default=0.0, required=False)
- parser.add_argument(
- "--prefix",
- type=str,
- default=None,
- help="Prefix added at the beginning of each text, typically used with T5-based models.",
- )
- parser.add_argument(
- "--early_stopping_patience",
- type=int,
- default=-1,
- required=False,
- help=(
- "-1 means never early stop. early_stopping_patience is measured in validation checks, not epochs. So"
- " val_check_interval will effect it."
- ),
- )
- parser.add_argument(
- "--distributed-port", type=int, default=-1, required=False, help="Port number for distributed training."
- )
- parser.add_argument(
- "--model_type",
- choices=["rag_sequence", "rag_token", "bart", "t5"],
- type=str,
- help=(
- "RAG model type: sequence or token, if none specified, the type is inferred from the"
- " model_name_or_path"
- ),
- )
- parser.add_argument(
- "--context_encoder_name",
- default="facebook/dpr-ctx_encoder-multiset-base",
- type=str,
- help="Name of the pre-trained context encoder checkpoint from the DPR",
- )
- parser.add_argument(
- "--csv_path",
- default=str(Path(__file__).parent / "test_run" / "dummy-kb" / "my_knowledge_dataset.csv"),
- type=str,
- help="path of the raw KB csv",
- )
- parser.add_argument("--end2end", action="store_true", help="whether to train the system end2end or not")
- parser.add_argument("--index_gpus", type=int, help="how many GPUs used in re-encoding process")
- parser.add_argument(
- "--shard_dir",
- type=str,
- default=str(Path(__file__).parent / "test_run" / "kb-shards"),
- help="directory used to keep temporary shards during the re-encode process",
- )
-
- parser.add_argument(
- "--gpu_order",
- type=str,
- help=(
- "order of the GPU used during the fine-tuning. Used to finding free GPUs during the re-encode"
- " process. I do not have many GPUs :)"
- ),
- )
-
- parser.add_argument("--indexing_freq", type=int, help="frequency of re-encode process")
- return parser
-
- @staticmethod
- def add_retriever_specific_args(parser):
- parser.add_argument(
- "--index_name",
- type=str,
- default=None,
- help=(
- "Name of the index to use: 'hf' for a canonical dataset from the datasets library (default), 'custom'"
- " for a local index, or 'legacy' for the orignal one)"
- ),
- )
- parser.add_argument(
- "--passages_path",
- type=str,
- default=str(Path(__file__).parent / "test_run" / "dummy-kb" / "my_knowledge_dataset"),
- help=(
- "Path to the dataset of passages for custom index. More info about custom indexes in the RagRetriever"
- " documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
- ),
- )
- parser.add_argument(
- "--index_path",
- type=str,
- default=str(Path(__file__).parent / "test_run" / "dummy-kb" / "my_knowledge_dataset_hnsw_index.faiss"),
- help=(
- "Path to the faiss index for custom index. More info about custom indexes in the RagRetriever"
- " documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
- ),
- )
- parser.add_argument(
- "--distributed_retriever",
- choices=["ray", "pytorch"],
- type=str,
- default="ray",
- help=(
- "What implementation to use for distributed retriever? If "
- "pytorch is selected, the index is loaded on training "
- "worker 0, and torch.distributed is used to handle "
- "communication between training worker 0, and the other "
- "training workers. If ray is selected, the Ray library is "
- "used to create load the index on separate processes, "
- "and Ray handles the communication between the training "
- "workers and the retrieval actors."
- ),
- )
- parser.add_argument(
- "--use_dummy_dataset",
- type=bool,
- default=False,
- help=(
- "Whether to use the dummy version of the dataset index. More info about custom indexes in the"
- " RagRetriever documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
- ),
- )
- return parser
-
- @staticmethod
- def add_ray_specific_args(parser):
- # Ray cluster address.
- parser.add_argument(
- "--ray-address",
- default="auto",
- type=str,
- help=(
- "The address of the Ray cluster to connect to. If not "
- "specified, Ray will attempt to automatically detect the "
- "cluster. Has no effect if pytorch is used as the distributed "
- "retriever."
- ),
- )
- parser.add_argument(
- "--num_retrieval_workers",
- type=int,
- default=1,
- help=(
- "The number of retrieval actors to use when Ray is selected "
- "for the distributed retriever. Has no effect when "
- "distributed_retriever is set to pytorch."
- ),
- )
- return parser
-
-
-def main(args=None, model=None) -> GenerativeQAModule:
- parser = argparse.ArgumentParser()
- parser = pl.Trainer.add_argparse_args(parser)
- parser = GenerativeQAModule.add_model_specific_args(parser, os.getcwd())
- parser = GenerativeQAModule.add_retriever_specific_args(parser)
- args = args or parser.parse_args()
-
- Path(args.output_dir).mkdir(exist_ok=True)
- Path(args.output_dir + "/dpr_ctx_checkpoint").mkdir(
- exist_ok=True
- ) # save dpr_context encoder seprately for the future use
- print(args.shard_dir)
- if os.path.exists(args.shard_dir): # we do not need previous kb shards used in dataset re-conding and re-indexing
- shutil.rmtree(args.shard_dir)
- Path(args.shard_dir).mkdir(exist_ok=True)
-
- if os.path.exists(
- args.cache_dir
- ): # we do not need previous cache files used in dataset re-conding and re-indexing
- shutil.rmtree(args.cache_dir)
- Path(args.cache_dir).mkdir(exist_ok=True)
-
- named_actors = []
- if args.distributed_retriever == "ray" and args.gpus > 1:
- if not is_ray_available():
- raise RuntimeError("Please install Ray to use the Ray distributed retriever.")
- # Connect to an existing Ray cluster.
- try:
- ray.init(address=args.ray_address, namespace="rag")
- except (ConnectionError, ValueError):
- logger.warning(
- "Connection to Ray cluster failed. Make sure a Ray "
- "cluster is running by either using Ray's cluster "
- "launcher (`ray up`) or by manually starting Ray on "
- "each node via `ray start --head` for the head node "
- "and `ray start --address=':6379'` for "
- "additional nodes. See "
- "https://docs.ray.io/en/master/cluster/index.html "
- "for more info."
- )
- raise
-
- # Create Ray actors only for rank 0.
- if ("LOCAL_RANK" not in os.environ or os.environ["LOCAL_RANK"] == 0) and (
- "NODE_RANK" not in os.environ or os.environ["NODE_RANK"] == 0
- ):
- remote_cls = ray.remote(RayRetriever)
- named_actors = [
- remote_cls.options(name="retrieval_worker_{}".format(i)).remote()
- for i in range(args.num_retrieval_workers)
- ]
- else:
- logger.info(
- "Getting named actors for NODE_RANK {}, LOCAL_RANK {}".format(
- os.environ["NODE_RANK"], os.environ["LOCAL_RANK"]
- )
- )
- named_actors = [ray.get_actor("retrieval_worker_{}".format(i)) for i in range(args.num_retrieval_workers)]
- args.actor_handles = named_actors
- assert args.actor_handles == named_actors
-
- if model is None:
- model: GenerativeQAModule = GenerativeQAModule(args)
-
- dataset = Path(args.data_dir).name
- if (
- args.logger_name == "default"
- or args.fast_dev_run
- or str(args.output_dir).startswith("/tmp")
- or str(args.output_dir).startswith("/var")
- ):
- training_logger = True # don't pollute wandb logs unnecessarily
- elif args.logger_name == "wandb":
- from pytorch_lightning.loggers import WandbLogger
-
- project = os.environ.get("WANDB_PROJECT", dataset)
- training_logger = WandbLogger(name=model.output_dir.name, project=project)
-
- elif args.logger_name == "wandb_shared":
- from pytorch_lightning.loggers import WandbLogger
-
- training_logger = WandbLogger(name=model.output_dir.name, project=f"hf_{dataset}")
-
- es_callback = (
- get_early_stopping_callback(model.val_metric, args.early_stopping_patience)
- if args.early_stopping_patience >= 0
- else False
- )
-
- trainer: pl.Trainer = generic_train(
- model,
- args,
- logging_callback=Seq2SeqLoggingCallback(),
- checkpoint_callback=get_checkpoint_callback(args.output_dir, model.val_metric),
- early_stopping_callback=es_callback,
- logger=training_logger,
- profiler=pl.profiler.AdvancedProfiler() if args.profile else None,
- )
-
- pickle_save(model.hparams, model.output_dir / "hparams.pkl")
- if not args.do_predict:
- return model
-
- # test() without a model tests using the best checkpoint automatically
- trainer.test()
- return model
-
-
-if __name__ == "__main__":
- multiprocessing.set_start_method("spawn")
- parser = argparse.ArgumentParser()
- parser = pl.Trainer.add_argparse_args(parser)
- parser = GenerativeQAModule.add_model_specific_args(parser, os.getcwd())
- parser = GenerativeQAModule.add_retriever_specific_args(parser)
- parser = GenerativeQAModule.add_ray_specific_args(parser)
-
- # Pytorch Lightning Profiler
- parser.add_argument(
- "--profile",
- action="store_true",
- help="If True, use pytorch_lightning.profiler.AdvancedProfiler to profile the Trainer.",
- )
-
- args = parser.parse_args()
- main(args)
diff --git a/examples/research_projects/rag-end2end-retriever/finetune_rag_ray_end2end.sh b/examples/research_projects/rag-end2end-retriever/finetune_rag_ray_end2end.sh
deleted file mode 100755
index cef1a264c93..00000000000
--- a/examples/research_projects/rag-end2end-retriever/finetune_rag_ray_end2end.sh
+++ /dev/null
@@ -1,68 +0,0 @@
-# Sample script to finetune RAG using Ray for distributed retrieval.
-
-# Add parent directory to python path to access lightning_base.py
-export PYTHONPATH="../":"${PYTHONPATH}"
-
-#creates the custom knowlegebase
-python use_own_knowledge_dataset.py \
- --csv_path /DIR/SQUAD-KB/squad-kb.csv \
- --output_dir /DIR/SQUAD-KB
-
-# Start a single-node Ray cluster.
-ray start --head
-
-# A sample finetuning run, you need to specify data_dir, output_dir and model_name_or_path
-# run ./examples/rag/finetune_rag_ray.sh --help to see all the possible options
-
-
-
-python finetune_rag.py \
- --data_dir /DIR/squad-training-data \
- --output_dir /DIR/model_checkpoints \
- --model_name_or_path facebook/rag-token-base \
- --model_type rag_token \
- --fp16 \
- --gpus 2 \
- --profile \
- --do_train \
- --end2end \
- --do_predict \
- --n_val -1 \
- --train_batch_size 4 \
- --eval_batch_size 1 \
- --max_source_length 128 \
- --max_target_length 25 \
- --val_max_target_length 25 \
- --test_max_target_length 25 \
- --label_smoothing 0.1 \
- --dropout 0.1 \
- --attention_dropout 0.1 \
- --weight_decay 0.001 \
- --adam_epsilon 1e-08 \
- --max_grad_norm 0.1 \
- --lr_scheduler polynomial \
- --learning_rate 3e-05 \
- --num_train_epochs 10 \
- --warmup_steps 500 \
- --gradient_accumulation_steps 8 \
- --distributed_retriever ray \
- --num_retrieval_workers 4 \
- --passages_path /DIR/SQUAD-KB/my_knowledge_dataset \
- --index_path /DIR/SQUAD-KB/my_knowledge_dataset_hnsw_index.faiss \
- --index_name custom \
- --context_encoder_name facebook/dpr-ctx_encoder-multiset-base \
- --csv_path /DIR/SQUAD-KB/squad-kb.csv \
- --index_gpus 1 \
- --gpu_order [5,6,7,8,9,0,1,2,3,4] \
- --shard_dir ./test_dir/kb-shards \
- --indexing_freq 500
-
-
-
-# Stop the Ray cluster.
-ray stop
-
-
-#this script was used to test the SQuAD data.
-#change the dir paramater acording to your prefernece.
-#please use the same device ordere when running CUDA_VISIBLE_DEVICES=5,6,7,8,9,0,1,2,3,4 sh finetune_rag_ray_end2end.sh
\ No newline at end of file
diff --git a/examples/research_projects/rag-end2end-retriever/kb_encode_utils.py b/examples/research_projects/rag-end2end-retriever/kb_encode_utils.py
deleted file mode 100644
index 444c07b2bab..00000000000
--- a/examples/research_projects/rag-end2end-retriever/kb_encode_utils.py
+++ /dev/null
@@ -1,80 +0,0 @@
-import os
-from functools import partial
-from glob import glob
-
-import faiss
-from datasets import Features, Sequence, Value, concatenate_datasets, load_dataset, load_from_disk
-
-from transformers import DPRContextEncoder, DPRContextEncoderTokenizerFast
-
-
-def split_text(text, n=100, character=" "):
- """Split the text every ``n``-th occurrence of ``character``"""
- text = text.split(character)
- return [character.join(text[i : i + n]).strip() for i in range(0, len(text), n)]
-
-
-def split_documents(documents):
- """Split documents into passages"""
- titles, texts = [], []
- for title, text in zip(documents["title"], documents["text"]):
- if text is not None:
- for passage in split_text(text):
- titles.append(title if title is not None else "")
- texts.append(passage)
- return {"title": titles, "text": texts}
-
-
-def embed_update(ctx_encoder, total_processes, device, process_num, shard_dir, csv_path):
- kb_dataset = load_dataset(
- "csv", data_files=[csv_path], split="train", delimiter="\t", column_names=["title", "text"]
- )
- kb_dataset = kb_dataset.map(
- split_documents, batched=True, num_proc=1
- ) # if you want you can load already splitted csv.
- kb_list = [kb_dataset.shard(total_processes, i, contiguous=True) for i in range(total_processes)]
- data_shrad = kb_list[process_num]
-
- arrow_folder = "data_" + str(process_num)
- passages_path = os.path.join(shard_dir, arrow_folder)
-
- context_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained("facebook/dpr-ctx_encoder-multiset-base")
- ctx_encoder = ctx_encoder.to(device=device)
-
- def embed(
- documents: dict, ctx_encoder: DPRContextEncoder, ctx_tokenizer: DPRContextEncoderTokenizerFast, device
- ) -> dict:
- """Compute the DPR embeddings of document passages"""
- input_ids = ctx_tokenizer(
- documents["title"], documents["text"], truncation=True, padding="longest", return_tensors="pt"
- )["input_ids"]
- embeddings = ctx_encoder(input_ids.to(device=device), return_dict=True).pooler_output
- return {"embeddings": embeddings.detach().cpu().numpy()}
-
- new_features = Features(
- {"text": Value("string"), "title": Value("string"), "embeddings": Sequence(Value("float32"))}
- ) # optional, save as float32 instead of float64 to save space
-
- dataset = data_shrad.map(
- partial(embed, ctx_encoder=ctx_encoder, ctx_tokenizer=context_tokenizer, device=device),
- batched=True,
- batch_size=16,
- features=new_features,
- )
- dataset.save_to_disk(passages_path)
-
-
-def add_index(shard_dir, index_path):
- data_shard_list = []
-
- for shard_address in glob(str(shard_dir) + "/*/"):
- data_shard_list.append(load_from_disk(shard_address))
-
- concat = concatenate_datasets(data_shard_list)
- faiss.omp_set_num_threads(96)
-
- index = faiss.IndexHNSWFlat(768, 128, faiss.METRIC_INNER_PRODUCT)
- concat.add_faiss_index("embeddings", custom_index=index)
- concat.get_index("embeddings").save(
- index_path
- ) # since we load the index in to memory,we can directly update the index in the disk
diff --git a/examples/research_projects/rag-end2end-retriever/lightning_base.py b/examples/research_projects/rag-end2end-retriever/lightning_base.py
deleted file mode 100644
index c1a271e88d1..00000000000
--- a/examples/research_projects/rag-end2end-retriever/lightning_base.py
+++ /dev/null
@@ -1,414 +0,0 @@
-import argparse
-import logging
-import os
-from pathlib import Path
-from typing import Any, Dict
-
-import pytorch_lightning as pl
-from pytorch_lightning.utilities import rank_zero_info
-
-from transformers import (
- AdamW,
- AutoConfig,
- AutoModel,
- AutoModelForPreTraining,
- AutoModelForQuestionAnswering,
- AutoModelForSeq2SeqLM,
- AutoModelForSequenceClassification,
- AutoModelForTokenClassification,
- AutoModelWithLMHead,
- AutoTokenizer,
- PretrainedConfig,
- PreTrainedTokenizer,
-)
-from transformers.optimization import (
- Adafactor,
- get_cosine_schedule_with_warmup,
- get_cosine_with_hard_restarts_schedule_with_warmup,
- get_linear_schedule_with_warmup,
- get_polynomial_decay_schedule_with_warmup,
-)
-from transformers.utils.versions import require_version
-
-
-logger = logging.getLogger(__name__)
-
-require_version("pytorch_lightning>=1.0.4")
-
-MODEL_MODES = {
- "base": AutoModel,
- "sequence-classification": AutoModelForSequenceClassification,
- "question-answering": AutoModelForQuestionAnswering,
- "pretraining": AutoModelForPreTraining,
- "token-classification": AutoModelForTokenClassification,
- "language-modeling": AutoModelWithLMHead,
- "summarization": AutoModelForSeq2SeqLM,
- "translation": AutoModelForSeq2SeqLM,
-}
-
-
-# update this and the import above to support new schedulers from transformers.optimization
-arg_to_scheduler = {
- "linear": get_linear_schedule_with_warmup,
- "cosine": get_cosine_schedule_with_warmup,
- "cosine_w_restarts": get_cosine_with_hard_restarts_schedule_with_warmup,
- "polynomial": get_polynomial_decay_schedule_with_warmup,
- # '': get_constant_schedule, # not supported for now
- # '': get_constant_schedule_with_warmup, # not supported for now
-}
-arg_to_scheduler_choices = sorted(arg_to_scheduler.keys())
-arg_to_scheduler_metavar = "{" + ", ".join(arg_to_scheduler_choices) + "}"
-
-
-class BaseTransformer(pl.LightningModule):
- def __init__(
- self,
- hparams: argparse.Namespace,
- num_labels=None,
- mode="base",
- config=None,
- tokenizer=None,
- model=None,
- **config_kwargs,
- ):
- """Initialize a model, tokenizer and config."""
- super().__init__()
- # TODO: move to self.save_hyperparameters()
- # self.save_hyperparameters()
- # can also expand arguments into trainer signature for easier reading
-
- self.save_hyperparameters(hparams)
- self.step_count = 0
- self.output_dir = Path(self.hparams.output_dir)
- cache_dir = self.hparams.cache_dir if self.hparams.cache_dir else None
- if config is None:
- self.config = AutoConfig.from_pretrained(
- self.hparams.config_name if self.hparams.config_name else self.hparams.model_name_or_path,
- **({"num_labels": num_labels} if num_labels is not None else {}),
- cache_dir=cache_dir,
- **config_kwargs,
- )
- else:
- self.config: PretrainedConfig = config
-
- extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "dropout", "attention_dropout")
- for p in extra_model_params:
- if getattr(self.hparams, p, None):
- assert hasattr(self.config, p), f"model config doesn't have a `{p}` attribute"
- setattr(self.config, p, getattr(self.hparams, p))
-
- if tokenizer is None:
- self.tokenizer = AutoTokenizer.from_pretrained(
- self.hparams.tokenizer_name if self.hparams.tokenizer_name else self.hparams.model_name_or_path,
- cache_dir=cache_dir,
- )
- else:
- self.tokenizer: PreTrainedTokenizer = tokenizer
- self.model_type = MODEL_MODES[mode]
- if model is None:
- self.model = self.model_type.from_pretrained(
- self.hparams.model_name_or_path,
- from_tf=bool(".ckpt" in self.hparams.model_name_or_path),
- config=self.config,
- cache_dir=cache_dir,
- )
- else:
- self.model = model
-
- def load_hf_checkpoint(self, *args, **kwargs):
- self.model = self.model_type.from_pretrained(*args, **kwargs)
-
- def get_lr_scheduler(self):
- get_schedule_func = arg_to_scheduler[self.hparams.lr_scheduler]
- scheduler = get_schedule_func(
- self.opt, num_warmup_steps=self.hparams.warmup_steps, num_training_steps=self.total_steps()
- )
- scheduler = {"scheduler": scheduler, "interval": "step", "frequency": 1}
- return scheduler
-
- def configure_optimizers(self):
- """Prepare optimizer and schedule (linear warmup and decay)"""
- model = self.model
- no_decay = ["bias", "LayerNorm.weight"]
- optimizer_grouped_parameters = [
- {
- "params": [
- p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)
- ], # check this named parameters
- "weight_decay": self.hparams.weight_decay,
- },
- {
- "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
- "weight_decay": 0.0,
- },
- ]
- if self.hparams.adafactor:
- optimizer = Adafactor(
- optimizer_grouped_parameters, lr=self.hparams.learning_rate, scale_parameter=False, relative_step=False
- )
-
- else:
- optimizer = AdamW(
- optimizer_grouped_parameters, lr=self.hparams.learning_rate, eps=self.hparams.adam_epsilon
- )
- self.opt = optimizer
-
- scheduler = self.get_lr_scheduler()
-
- return [optimizer], [scheduler]
-
- def test_step(self, batch, batch_nb):
- return self.validation_step(batch, batch_nb)
-
- def test_epoch_end(self, outputs):
- return self.validation_end(outputs)
-
- def total_steps(self) -> int:
- """The number of total training steps that will be run. Used for lr scheduler purposes."""
- num_devices = max(1, self.hparams.gpus) # TODO: consider num_tpu_cores
- effective_batch_size = self.hparams.train_batch_size * self.hparams.accumulate_grad_batches * num_devices
- return (self.dataset_size / effective_batch_size) * self.hparams.max_epochs
-
- def setup(self, stage):
- if stage == "test":
- self.dataset_size = len(self.test_dataloader().dataset)
- else:
- self.train_loader = self.get_dataloader("train", self.hparams.train_batch_size, shuffle=True)
- self.dataset_size = len(self.train_dataloader().dataset)
-
- def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False):
- raise NotImplementedError("You must implement this for your task")
-
- def train_dataloader(self):
- return self.train_loader
-
- def val_dataloader(self):
- return self.get_dataloader("dev", self.hparams.eval_batch_size, shuffle=False)
-
- def test_dataloader(self):
- return self.get_dataloader("test", self.hparams.eval_batch_size, shuffle=False)
-
- def _feature_file(self, mode):
- return os.path.join(
- self.hparams.data_dir,
- "cached_{}_{}_{}".format(
- mode,
- list(filter(None, self.hparams.model_name_or_path.split("/"))).pop(),
- str(self.hparams.max_seq_length),
- ),
- )
-
- @pl.utilities.rank_zero_only
- def on_save_checkpoint(self, checkpoint: Dict[str, Any]) -> None:
- save_path = self.output_dir.joinpath("best_tfmr")
- self.model.config.save_step = self.step_count
- self.model.save_pretrained(save_path)
- self.tokenizer.save_pretrained(save_path)
-
- @staticmethod
- def add_model_specific_args(parser, root_dir):
- parser.add_argument(
- "--model_name_or_path",
- default=None,
- type=str,
- required=True,
- help="Path to pretrained model or model identifier from huggingface.co/models",
- )
- parser.add_argument(
- "--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
- )
- parser.add_argument(
- "--tokenizer_name",
- default=None,
- type=str,
- help="Pretrained tokenizer name or path if not the same as model_name",
- )
- parser.add_argument(
- "--cache_dir",
- default=str(Path(__file__).parent / "test_run" / "cache"),
- type=str,
- help="Where do you want to store the pre-trained models downloaded from huggingface.co",
- )
- parser.add_argument(
- "--encoder_layerdrop",
- type=float,
- help="Encoder layer dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument(
- "--decoder_layerdrop",
- type=float,
- help="Decoder layer dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument(
- "--dropout",
- type=float,
- help="Dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument(
- "--attention_dropout",
- type=float,
- help="Attention dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
- parser.add_argument(
- "--lr_scheduler",
- default="linear",
- choices=arg_to_scheduler_choices,
- metavar=arg_to_scheduler_metavar,
- type=str,
- help="Learning rate scheduler",
- )
- parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
- parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
- parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
- parser.add_argument("--num_workers", default=4, type=int, help="kwarg passed to DataLoader")
- parser.add_argument("--num_train_epochs", dest="max_epochs", default=3, type=int)
- parser.add_argument("--train_batch_size", default=32, type=int)
- parser.add_argument("--eval_batch_size", default=32, type=int)
- parser.add_argument("--adafactor", action="store_true")
-
-
-class InitCallback(pl.Callback):
- # this process can also be done with PL ddp plugging.
- # But still it is experimental (check original RAG, I updated that with pluggin (shamanez))
- def on_sanity_check_start(self, trainer, pl_module):
- if (
- trainer.is_global_zero and trainer.global_rank == 0
- ): # we initialize the retriever only on master worker with RAY. In new pytorch-lightning accelorators are removed.
- pl_module.model.rag.retriever.init_retrieval() # better to use hook functions.
-
-
-class CheckParamCallback(pl.Callback):
- # check whether new added model parameters are differentiable
- def on_after_backward(self, trainer, pl_module):
- # print(pl_module.model.rag)
- for name, param in pl_module.model.rag.named_parameters():
- if param.grad is None:
- print(name)
-
-
-class LoggingCallback(pl.Callback):
- def on_batch_end(self, trainer, pl_module):
- lr_scheduler = trainer.lr_schedulers[0]["scheduler"]
- lrs = {f"lr_group_{i}": lr for i, lr in enumerate(lr_scheduler.get_lr())}
- pl_module.logger.log_metrics(lrs)
-
- def on_validation_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
- rank_zero_info("***** Validation results *****")
- metrics = trainer.callback_metrics
- # Log results
- for key in sorted(metrics):
- if key not in ["log", "progress_bar"]:
- rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
-
- def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
- rank_zero_info("***** Test results *****")
- metrics = trainer.callback_metrics
- # Log and save results to file
- output_test_results_file = os.path.join(pl_module.hparams.output_dir, "test_results.txt")
- with open(output_test_results_file, "w") as writer:
- for key in sorted(metrics):
- if key not in ["log", "progress_bar"]:
- rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
- writer.write("{} = {}\n".format(key, str(metrics[key])))
-
-
-def add_generic_args(parser, root_dir) -> None:
- # To allow all pl args uncomment the following line
- # parser = pl.Trainer.add_argparse_args(parser)
- parser.add_argument(
- "--output_dir",
- default=str(Path(__file__).parent / "test_run" / "model_checkpoints"),
- type=str,
- help="The output directory where the model predictions and checkpoints will be written.",
- )
- parser.add_argument(
- "--fp16",
- action="store_true",
- help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
- )
-
- parser.add_argument(
- "--fp16_opt_level",
- type=str,
- default="O2",
- help=(
- "For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
- "See details at https://nvidia.github.io/apex/amp.html"
- ),
- )
- parser.add_argument("--n_tpu_cores", dest="tpu_cores", type=int)
- parser.add_argument("--max_grad_norm", dest="gradient_clip_val", default=1.0, type=float, help="Max gradient norm")
- parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
- parser.add_argument("--do_predict", action="store_true", help="Whether to run predictions on the test set.")
- parser.add_argument(
- "--gradient_accumulation_steps",
- dest="accumulate_grad_batches",
- type=int,
- default=1,
- help="Number of updates steps to accumulate before performing a backward/update pass.",
- )
- parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
- parser.add_argument(
- "--data_dir",
- default=str(Path(__file__).parent / "test_run" / "dummy-train-data"),
- type=str,
- help="The input data dir. Should contain the training files for the CoNLL-2003 NER task.",
- )
-
-
-def generic_train(
- model: BaseTransformer,
- args: argparse.Namespace,
- early_stopping_callback=None,
- logger=True, # can pass WandbLogger() here
- extra_callbacks=[],
- checkpoint_callback=None,
- logging_callback=None,
- **extra_train_kwargs,
-):
- pl.seed_everything(args.seed)
-
- # init model
- odir = Path(model.hparams.output_dir)
- odir.mkdir(exist_ok=True)
-
- # add custom checkpoints
- if checkpoint_callback is None:
- checkpoint_callback = pl.callbacks.ModelCheckpoint(
- filepath=args.output_dir, prefix="checkpoint", monitor="val_loss", mode="min", save_top_k=1
- )
- if early_stopping_callback:
- extra_callbacks.append(early_stopping_callback)
- if logging_callback is None:
- logging_callback = LoggingCallback()
-
- train_params = {}
-
- if args.fp16:
- train_params["precision"] = 16
-
- if args.gpus > 1:
- train_params["accelerator"] = "auto"
- train_params["strategy"] = "ddp"
-
- train_params["accumulate_grad_batches"] = args.accumulate_grad_batches
- train_params["profiler"] = None
- train_params["devices"] = "auto"
-
- trainer = pl.Trainer.from_argparse_args(
- args,
- weights_summary=None,
- callbacks=[logging_callback] + extra_callbacks + [InitCallback()] + [checkpoint_callback],
- logger=logger,
- val_check_interval=1,
- num_sanity_val_steps=2,
- **train_params,
- )
-
- if args.do_train:
- trainer.fit(model)
-
- else:
- print("RAG modeling tests with new set functions successfully executed!")
- return trainer
diff --git a/examples/research_projects/rag-end2end-retriever/requirements.txt b/examples/research_projects/rag-end2end-retriever/requirements.txt
deleted file mode 100644
index 32025229d07..00000000000
--- a/examples/research_projects/rag-end2end-retriever/requirements.txt
+++ /dev/null
@@ -1,7 +0,0 @@
-faiss-cpu >= 1.7.2
-datasets
-psutil >= 5.9.1
-torch >= 1.11.0
-pytorch-lightning == 1.6.4
-nvidia-ml-py3 == 7.352.0
-ray >= 1.13.0
\ No newline at end of file
diff --git a/examples/research_projects/rag-end2end-retriever/test_run/dummy-kb/my_knowledge_dataset.csv b/examples/research_projects/rag-end2end-retriever/test_run/dummy-kb/my_knowledge_dataset.csv
deleted file mode 100644
index 76da009a2f2..00000000000
--- a/examples/research_projects/rag-end2end-retriever/test_run/dummy-kb/my_knowledge_dataset.csv
+++ /dev/null
@@ -1,2 +0,0 @@
-Aaron Aaron Aaron ( or ; "Ahärôn") is a prophet, high priest, and the brother of Moses in the Abrahamic religions. Knowledge of Aaron, along with his brother Moses, comes exclusively from religious texts, such as the Bible and Quran. The Hebrew Bible relates that, unlike Moses, who grew up in the Egyptian royal court, Aaron and his elder sister Miriam remained with their kinsmen in the eastern border-land of Egypt (Goshen). When Moses first confronted the Egyptian king about the Israelites, Aaron served as his brother's spokesman ("prophet") to the Pharaoh. Part of the Law (Torah) that Moses received from God at Sinai granted Aaron the priesthood for himself and his male descendants, and he became the first High Priest of the Israelites. Aaron died before the Israelites crossed the North Jordan river and he was buried on Mount Hor (Numbers 33:39; Deuteronomy 10:6 says he died and was buried at Moserah). Aaron is also mentioned in the New Testament of the Bible. According to the Book of Exodus, Aaron first functioned as Moses' assistant. Because Moses complained that he could not speak well, God appointed Aaron as Moses' "prophet" (Exodus 4:10-17; 7:1). At the command of Moses, he let his rod turn into a snake. Then he stretched out his rod in order to bring on the first three plagues. After that, Moses tended to act and speak for himself. During the journey in the wilderness, Aaron was not always prominent or active. At the battle with Amalek, he was chosen with Hur to support the hand of Moses that held the "rod of God". When the revelation was given to Moses at biblical Mount Sinai, he headed the elders of Israel who accompanied Moses on the way to the summit.
-"Pokémon" Pokémon , also known as in Japan, is a media franchise managed by The Pokémon Company, a Japanese consortium between Nintendo, Game Freak, and Creatures. The franchise copyright is shared by all three companies, but Nintendo is the sole owner of the trademark. The franchise was created by Satoshi Tajiri in 1995, and is centered on fictional creatures called "Pokémon", which humans, known as Pokémon Trainers, catch and train to battle each other for sport. The English slogan for the franchise is "Gotta Catch 'Em All". Works within the franchise are set in the Pokémon universe. The franchise began as "Pokémon Red" and "Green" (released outside of Japan as "Pokémon Red" and "Blue"), a pair of video games for the original Game Boy that were developed by Game Freak and published by Nintendo in February 1996. "Pokémon" has since gone on to become the highest-grossing media franchise of all time, with over in revenue up until March 2017. The original video game series is the second best-selling video game franchise (behind Nintendo's "Mario" franchise) with more than 300million copies sold and over 800million mobile downloads. In addition, the "Pokémon" franchise includes the world's top-selling toy brand, the top-selling trading card game with over 25.7billion cards sold, an anime television series that has become the most successful video game adaptation with over 20 seasons and 1,000 episodes in 124 countries, as well as an anime film series, a , books, manga comics, music, and merchandise. The franchise is also represented in other Nintendo media, such as the "Super Smash Bros." series. In November 2005, 4Kids Entertainment, which had managed the non-game related licensing of "Pokémon", announced that it had agreed not to renew the "Pokémon" representation agreement. The Pokémon Company International oversees all "Pokémon" licensing outside Asia.
\ No newline at end of file
diff --git a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/test.source b/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/test.source
deleted file mode 100644
index 3d5cbc38039..00000000000
--- a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/test.source
+++ /dev/null
@@ -1,8 +0,0 @@
-What does Moses' rod turn into ?
-Who is Aron?
-Where did Moses grow up ?
-What happens at the command of the Moses ?
-Who manages the Pokémon ?
-Who owned the Pokémon trademark ?
-What else include in Pokémon franchise ?
-How many seasons in Pokémon animme series ?
diff --git a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/test.target b/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/test.target
deleted file mode 100644
index a3a6e04372c..00000000000
--- a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/test.target
+++ /dev/null
@@ -1,8 +0,0 @@
-to a snake
-Moses' assistant
-Egyptian royal court
-let his rod turn in to a snake
-The Pokémon Company
-Nintendo
-world's top-selling toy brand, the top-selling trading card game
-over 20 seasons
diff --git a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/train.source b/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/train.source
deleted file mode 100644
index 9f72c3e03a7..00000000000
--- a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/train.source
+++ /dev/null
@@ -1,48 +0,0 @@
-What does Moses' rod turn into ?
-Who is Aron?
-Where did Moses grow up ?
-What happens at the command of the Moses ?
-Who manages the Pokémon ?
-Who owned the Pokémon trademark ?
-What else include in Pokémon franchise ?
-How many seasons in Pokémon animme series ?
-What does Moses' rod turn into ?
-Who is Aron?
-Where did Moses grow up ?
-What happens at the command of the Moses ?
-Who manages the Pokémon ?
-Who owned the Pokémon trademark ?
-What else include in Pokémon franchise ?
-How many seasons in Pokémon animme series ?
-What does Moses' rod turn into ?
-Who is Aron?
-Where did Moses grow up ?
-What happens at the command of the Moses ?
-Who manages the Pokémon ?
-Who owned the Pokémon trademark ?
-What else include in Pokémon franchise ?
-How many seasons in Pokémon animme series ?
-What does Moses' rod turn into ?
-Who is Aron?
-Where did Moses grow up ?
-What happens at the command of the Moses ?
-Who manages the Pokémon ?
-Who owned the Pokémon trademark ?
-What else include in Pokémon franchise ?
-How many seasons in Pokémon animme series ?
-What does Moses' rod turn into ?
-Who is Aron?
-Where did Moses grow up ?
-What happens at the command of the Moses ?
-Who manages the Pokémon ?
-Who owned the Pokémon trademark ?
-What else include in Pokémon franchise ?
-How many seasons in Pokémon animme series ?
-What does Moses' rod turn into ?
-Who is Aron?
-Where did Moses grow up ?
-What happens at the command of the Moses ?
-Who manages the Pokémon ?
-Who owned the Pokémon trademark ?
-What else include in Pokémon franchise ?
-How many seasons in Pokémon animme series ?
\ No newline at end of file
diff --git a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/train.target b/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/train.target
deleted file mode 100644
index 3bda0caf2e3..00000000000
--- a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/train.target
+++ /dev/null
@@ -1,48 +0,0 @@
-to a snake
-Moses' assistant
-Egyptian royal court
-let his rod turn in to a snake
-The Pokémon Company
-Nintendo
-world's top-selling toy brand, the top-selling trading card game
-over 20 seasons
-to a snake
-Moses' assistant
-Egyptian royal court
-let his rod turn in to a snake
-The Pokémon Company
-Nintendo
-world's top-selling toy brand, the top-selling trading card game
-over 20 seasons
-to a snake
-Moses' assistant
-Egyptian royal court
-let his rod turn in to a snake
-The Pokémon Company
-Nintendo
-world's top-selling toy brand, the top-selling trading card game
-over 20 seasons
-to a snake
-Moses' assistant
-Egyptian royal court
-let his rod turn in to a snake
-The Pokémon Company
-Nintendo
-world's top-selling toy brand, the top-selling trading card game
-over 20 seasons
-to a snake
-Moses' assistant
-Egyptian royal court
-let his rod turn in to a snake
-The Pokémon Company
-Nintendo
-world's top-selling toy brand, the top-selling trading card game
-over 20 seasons
-to a snake
-Moses' assistant
-Egyptian royal court
-let his rod turn in to a snake
-The Pokémon Company
-Nintendo
-world's top-selling toy brand, the top-selling trading card game
-over 20 seasons
\ No newline at end of file
diff --git a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/val.source b/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/val.source
deleted file mode 100644
index a2c628e9ca0..00000000000
--- a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/val.source
+++ /dev/null
@@ -1,8 +0,0 @@
-What does Moses' rod turn into ?
-Who is Aron?
-Where did Moses grow up ?
-What happens at the command of the Moses ?
-Who manages the Pokémon ?
-Who owned the Pokémon trademark ?
-What else include in Pokémon franchise ?
-How many seasons in Pokémon animme series ?
\ No newline at end of file
diff --git a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/val.target b/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/val.target
deleted file mode 100644
index 57bfcf5270a..00000000000
--- a/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/val.target
+++ /dev/null
@@ -1,8 +0,0 @@
-to a snake
-Moses' assistant
-Egyptian royal court
-let his rod turn in to a snake
-The Pokémon Company
-Nintendo
-world's top-selling toy brand, the top-selling trading card game
-over 20 seasons
\ No newline at end of file
diff --git a/examples/research_projects/rag-end2end-retriever/test_run/test_finetune.sh b/examples/research_projects/rag-end2end-retriever/test_run/test_finetune.sh
deleted file mode 100755
index c44d110d200..00000000000
--- a/examples/research_projects/rag-end2end-retriever/test_run/test_finetune.sh
+++ /dev/null
@@ -1,57 +0,0 @@
-# Add parent directory to python path to access lightning_base.py
-export PYTHONPATH="../":"${PYTHONPATH}"
-
-#creates the custom knowlegebase
-python use_own_knowledge_dataset.py
-
-
-# Start a single-node Ray cluster.
-ray start --head
-
-# A sample finetuning run, you need to specify data_dir, output_dir and model_name_or_path
-# run ./examples/rag/finetune_rag_ray.sh --help to see all the possible options
-
-
-
-python finetune_rag.py \
- --model_name_or_path facebook/rag-token-base \
- --model_type rag_token \
- --fp16 \
- --gpus 2 \
- --profile \
- --do_train \
- --end2end \
- --do_predict \
- --n_val -1 \
- --train_batch_size 1 \
- --eval_batch_size 1 \
- --max_source_length 128 \
- --max_target_length 25 \
- --val_max_target_length 25 \
- --test_max_target_length 25 \
- --label_smoothing 0.1 \
- --dropout 0.1 \
- --attention_dropout 0.1 \
- --weight_decay 0.001 \
- --adam_epsilon 1e-08 \
- --max_grad_norm 0.1 \
- --lr_scheduler polynomial \
- --learning_rate 3e-05 \
- --num_train_epochs 10 \
- --warmup_steps 500 \
- --gradient_accumulation_steps 1 \
- --distributed_retriever ray \
- --num_retrieval_workers 4 \
- --index_name custom \
- --context_encoder_name facebook/dpr-ctx_encoder-multiset-base \
- --index_gpus 2 \
- --gpu_order [2,3,4,5,6,7,8,9,0,1] \
- --indexing_freq 5
-
-
-
-# Stop the Ray cluster.
-ray stop
-
-#CUDA_VISIBLE_DEVICES=2,3,4,5,6,7,8,9,0,1 sh ./test_run/test_finetune.sh
-#Make sure --gpu_order is same.
\ No newline at end of file
diff --git a/examples/research_projects/rag-end2end-retriever/test_run/test_rag_new_features.sh b/examples/research_projects/rag-end2end-retriever/test_run/test_rag_new_features.sh
deleted file mode 100755
index 6c667c09403..00000000000
--- a/examples/research_projects/rag-end2end-retriever/test_run/test_rag_new_features.sh
+++ /dev/null
@@ -1,16 +0,0 @@
-export PYTHONPATH="../":"${PYTHONPATH}"
-
-python use_own_knowledge_dataset.py
-
-ray start --head
-python finetune_rag.py \
- --model_name_or_path facebook/rag-token-base \
- --model_type rag_token \
- --context_encoder_name facebook/dpr-ctx_encoder-multiset-base \
- --fp16 \
- --gpus 1 \
- --profile \
- --end2end \
- --index_name custom
-
-ray stop
diff --git a/examples/research_projects/rag-end2end-retriever/use_own_knowledge_dataset.py b/examples/research_projects/rag-end2end-retriever/use_own_knowledge_dataset.py
deleted file mode 100644
index 20e0ea2d3cc..00000000000
--- a/examples/research_projects/rag-end2end-retriever/use_own_knowledge_dataset.py
+++ /dev/null
@@ -1,175 +0,0 @@
-import logging
-import os
-from dataclasses import dataclass, field
-from functools import partial
-from pathlib import Path
-from tempfile import TemporaryDirectory
-from typing import List, Optional
-
-import faiss
-import torch
-from datasets import Features, Sequence, Value, load_dataset
-
-from transformers import DPRContextEncoder, DPRContextEncoderTokenizerFast, HfArgumentParser
-
-
-logger = logging.getLogger(__name__)
-torch.set_grad_enabled(False)
-device = "cuda" if torch.cuda.is_available() else "cpu"
-
-
-def split_text(text: str, n=100, character=" ") -> List[str]:
- """Split the text every ``n``-th occurrence of ``character``"""
- text = text.split(character)
- return [character.join(text[i : i + n]).strip() for i in range(0, len(text), n)]
-
-
-def split_documents(documents: dict) -> dict:
- """Split documents into passages"""
- titles, texts = [], []
- for title, text in zip(documents["title"], documents["text"]):
- if text is not None:
- for passage in split_text(text):
- titles.append(title if title is not None else "")
- texts.append(passage)
- return {"title": titles, "text": texts}
-
-
-def embed(documents: dict, ctx_encoder: DPRContextEncoder, ctx_tokenizer: DPRContextEncoderTokenizerFast) -> dict:
- """Compute the DPR embeddings of document passages"""
- input_ids = ctx_tokenizer(
- documents["title"], documents["text"], truncation=True, padding="longest", return_tensors="pt"
- )["input_ids"]
- embeddings = ctx_encoder(input_ids.to(device=device), return_dict=True).pooler_output
- return {"embeddings": embeddings.detach().cpu().numpy()}
-
-
-def main(
- rag_example_args: "RagExampleArguments",
- processing_args: "ProcessingArguments",
- index_hnsw_args: "IndexHnswArguments",
-):
- ######################################
- logger.info("Step 1 - Create the dataset")
- ######################################
-
- # The dataset needed for RAG must have three columns:
- # - title (string): title of the document
- # - text (string): text of a passage of the document
- # - embeddings (array of dimension d): DPR representation of the passage
- # Let's say you have documents in tab-separated csv files with columns "title" and "text"
- assert os.path.isfile(rag_example_args.csv_path), "Please provide a valid path to a csv file"
-
- # You can load a Dataset object this way
- dataset = load_dataset(
- "csv", data_files=[rag_example_args.csv_path], split="train", delimiter="\t", column_names=["title", "text"]
- )
-
- # More info about loading csv files in the documentation: https://huggingface.co/docs/datasets/loading_datasets?highlight=csv#csv-files
-
- # Then split the documents into passages of 100 words
- dataset = dataset.map(split_documents, batched=True, num_proc=processing_args.num_proc)
-
- # And compute the embeddings
- ctx_encoder = DPRContextEncoder.from_pretrained(rag_example_args.dpr_ctx_encoder_model_name).to(device=device)
- ctx_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained(rag_example_args.dpr_ctx_encoder_model_name)
- new_features = Features(
- {"text": Value("string"), "title": Value("string"), "embeddings": Sequence(Value("float32"))}
- ) # optional, save as float32 instead of float64 to save space
- dataset = dataset.map(
- partial(embed, ctx_encoder=ctx_encoder, ctx_tokenizer=ctx_tokenizer),
- batched=True,
- batch_size=processing_args.batch_size,
- features=new_features,
- )
-
- # And finally save your dataset
- passages_path = os.path.join(rag_example_args.output_dir, "my_knowledge_dataset")
- dataset.save_to_disk(passages_path)
- # from datasets import load_from_disk
- # dataset = load_from_disk(passages_path) # to reload the dataset
-
- ######################################
- logger.info("Step 2 - Index the dataset")
- ######################################
-
- # Let's use the Faiss implementation of HNSW for fast approximate nearest neighbor search
- index = faiss.IndexHNSWFlat(index_hnsw_args.d, index_hnsw_args.m, faiss.METRIC_INNER_PRODUCT)
- dataset.add_faiss_index("embeddings", custom_index=index)
-
- # And save the index
- index_path = os.path.join(rag_example_args.output_dir, "my_knowledge_dataset_hnsw_index.faiss")
- dataset.get_index("embeddings").save(index_path)
- # dataset.load_faiss_index("embeddings", index_path) # to reload the index
-
-
-@dataclass
-class RagExampleArguments:
- csv_path: str = field(
- default=str(Path(__file__).parent / "test_run" / "dummy-kb" / "my_knowledge_dataset.csv"),
- metadata={"help": "Path to a tab-separated csv file with columns 'title' and 'text'"},
- )
- question: Optional[str] = field(
- default=None,
- metadata={"help": "Question that is passed as input to RAG. Default is 'What does Moses' rod turn into ?'."},
- )
- rag_model_name: str = field(
- default="facebook/rag-sequence-nq",
- metadata={"help": "The RAG model to use. Either 'facebook/rag-sequence-nq' or 'facebook/rag-token-nq'"},
- )
- dpr_ctx_encoder_model_name: str = field(
- default="facebook/dpr-ctx_encoder-multiset-base",
- metadata={
- "help": (
- "The DPR context encoder model to use. Either 'facebook/dpr-ctx_encoder-single-nq-base' or"
- " 'facebook/dpr-ctx_encoder-multiset-base'"
- )
- },
- )
- output_dir: Optional[str] = field(
- default=str(Path(__file__).parent / "test_run" / "dummy-kb"),
- metadata={"help": "Path to a directory where the dataset passages and the index will be saved"},
- )
-
-
-@dataclass
-class ProcessingArguments:
- num_proc: Optional[int] = field(
- default=None,
- metadata={
- "help": "The number of processes to use to split the documents into passages. Default is single process."
- },
- )
- batch_size: int = field(
- default=16,
- metadata={
- "help": "The batch size to use when computing the passages embeddings using the DPR context encoder."
- },
- )
-
-
-@dataclass
-class IndexHnswArguments:
- d: int = field(
- default=768,
- metadata={"help": "The dimension of the embeddings to pass to the HNSW Faiss index."},
- )
- m: int = field(
- default=128,
- metadata={
- "help": (
- "The number of bi-directional links created for every new element during the HNSW index construction."
- )
- },
- )
-
-
-if __name__ == "__main__":
- logging.basicConfig(level=logging.WARNING)
- logger.setLevel(logging.INFO)
-
- parser = HfArgumentParser((RagExampleArguments, ProcessingArguments, IndexHnswArguments))
- rag_example_args, processing_args, index_hnsw_args = parser.parse_args_into_dataclasses()
- with TemporaryDirectory() as tmp_dir:
- rag_example_args.output_dir = rag_example_args.output_dir or tmp_dir
- main(rag_example_args, processing_args, index_hnsw_args)
diff --git a/examples/research_projects/rag-end2end-retriever/utils_rag.py b/examples/research_projects/rag-end2end-retriever/utils_rag.py
deleted file mode 100644
index ec98c1d782e..00000000000
--- a/examples/research_projects/rag-end2end-retriever/utils_rag.py
+++ /dev/null
@@ -1,244 +0,0 @@
-import itertools
-import json
-import linecache
-import os
-import pickle
-import re
-import socket
-import string
-from collections import Counter
-from logging import getLogger
-from pathlib import Path
-from typing import Callable, Dict, Iterable, List
-
-import git
-import torch
-from torch.utils.data import Dataset
-
-from transformers import BartTokenizer, RagTokenizer, T5Tokenizer
-
-
-def encode_line(tokenizer, line, max_length, padding_side, pad_to_max_length=True, return_tensors="pt"):
- extra_kw = {"add_prefix_space": True} if isinstance(tokenizer, BartTokenizer) and not line.startswith(" ") else {}
- tokenizer.padding_side = padding_side
- return tokenizer(
- [line],
- max_length=max_length,
- padding="max_length" if pad_to_max_length else None,
- truncation=True,
- return_tensors=return_tensors,
- add_special_tokens=True,
- **extra_kw,
- )
-
-
-def trim_batch(
- input_ids,
- pad_token_id,
- attention_mask=None,
-):
- """Remove columns that are populated exclusively by pad_token_id"""
- keep_column_mask = input_ids.ne(pad_token_id).any(dim=0)
- if attention_mask is None:
- return input_ids[:, keep_column_mask]
- else:
- return (input_ids[:, keep_column_mask], attention_mask[:, keep_column_mask])
-
-
-class Seq2SeqDataset(Dataset):
- def __init__(
- self,
- tokenizer,
- data_dir,
- max_source_length,
- max_target_length,
- type_path="train",
- n_obs=None,
- src_lang=None,
- tgt_lang=None,
- prefix="",
- ):
- super().__init__()
- self.src_file = Path(data_dir).joinpath(type_path + ".source")
- self.tgt_file = Path(data_dir).joinpath(type_path + ".target")
- self.src_lens = self.get_char_lens(self.src_file)
- self.max_source_length = max_source_length
- self.max_target_length = max_target_length
- assert min(self.src_lens) > 0, f"found empty line in {self.src_file}"
- self.tokenizer = tokenizer
- self.prefix = prefix
- if n_obs is not None:
- self.src_lens = self.src_lens[:n_obs]
- self.src_lang = src_lang
- self.tgt_lang = tgt_lang
-
- def __len__(self):
- return len(self.src_lens)
-
- def __getitem__(self, index) -> Dict[str, torch.Tensor]:
- index = index + 1 # linecache starts at 1
- source_line = self.prefix + linecache.getline(str(self.src_file), index).rstrip("\n")
- tgt_line = linecache.getline(str(self.tgt_file), index).rstrip("\n")
- assert source_line, f"empty source line for index {index}"
- assert tgt_line, f"empty tgt line for index {index}"
-
- # Need to add eos token manually for T5
- if isinstance(self.tokenizer, T5Tokenizer):
- source_line += self.tokenizer.eos_token
- tgt_line += self.tokenizer.eos_token
-
- # Pad source and target to the right
- source_tokenizer = (
- self.tokenizer.question_encoder if isinstance(self.tokenizer, RagTokenizer) else self.tokenizer
- )
- target_tokenizer = self.tokenizer.generator if isinstance(self.tokenizer, RagTokenizer) else self.tokenizer
-
- source_inputs = encode_line(source_tokenizer, source_line, self.max_source_length, "right")
- target_inputs = encode_line(target_tokenizer, tgt_line, self.max_target_length, "right")
-
- source_ids = source_inputs["input_ids"].squeeze()
- target_ids = target_inputs["input_ids"].squeeze()
- src_mask = source_inputs["attention_mask"].squeeze()
- return {
- "input_ids": source_ids,
- "attention_mask": src_mask,
- "decoder_input_ids": target_ids,
- }
-
- @staticmethod
- def get_char_lens(data_file):
- return [len(x) for x in Path(data_file).open().readlines()]
-
- def collate_fn(self, batch) -> Dict[str, torch.Tensor]:
- input_ids = torch.stack([x["input_ids"] for x in batch])
- masks = torch.stack([x["attention_mask"] for x in batch])
- target_ids = torch.stack([x["decoder_input_ids"] for x in batch])
- tgt_pad_token_id = (
- self.tokenizer.generator.pad_token_id
- if isinstance(self.tokenizer, RagTokenizer)
- else self.tokenizer.pad_token_id
- )
- src_pad_token_id = (
- self.tokenizer.question_encoder.pad_token_id
- if isinstance(self.tokenizer, RagTokenizer)
- else self.tokenizer.pad_token_id
- )
- y = trim_batch(target_ids, tgt_pad_token_id)
- source_ids, source_mask = trim_batch(input_ids, src_pad_token_id, attention_mask=masks)
- batch = {
- "input_ids": source_ids,
- "attention_mask": source_mask,
- "decoder_input_ids": y,
- }
- return batch
-
-
-logger = getLogger(__name__)
-
-
-def flatten_list(summary_ids: List[List]):
- return list(itertools.chain.from_iterable(summary_ids))
-
-
-def save_git_info(folder_path: str) -> None:
- """Save git information to output_dir/git_log.json"""
- repo_infos = get_git_info()
- save_json(repo_infos, os.path.join(folder_path, "git_log.json"))
-
-
-def save_json(content, path, indent=4, **json_dump_kwargs):
- with open(path, "w") as f:
- json.dump(content, f, indent=indent, **json_dump_kwargs)
-
-
-def load_json(path):
- with open(path) as f:
- return json.load(f)
-
-
-def get_git_info():
- repo = git.Repo(search_parent_directories=True)
- repo_infos = {
- "repo_id": str(repo),
- "repo_sha": str(repo.head.object.hexsha),
- "repo_branch": str(repo.active_branch),
- "hostname": str(socket.gethostname()),
- }
- return repo_infos
-
-
-def lmap(f: Callable, x: Iterable) -> List:
- """list(map(f, x))"""
- return list(map(f, x))
-
-
-def pickle_save(obj, path):
- """pickle.dump(obj, path)"""
- with open(path, "wb") as f:
- return pickle.dump(obj, f)
-
-
-def normalize_answer(s):
- """Lower text and remove punctuation, articles and extra whitespace."""
-
- def remove_articles(text):
- return re.sub(r"\b(a|an|the)\b", " ", text)
-
- def white_space_fix(text):
- return " ".join(text.split())
-
- def remove_punc(text):
- exclude = set(string.punctuation)
- return "".join(ch for ch in text if ch not in exclude)
-
- def lower(text):
- return text.lower()
-
- return white_space_fix(remove_articles(remove_punc(lower(s))))
-
-
-def f1_score(prediction, ground_truth):
- prediction_tokens = normalize_answer(prediction).split()
- ground_truth_tokens = normalize_answer(ground_truth).split()
- common = Counter(prediction_tokens) & Counter(ground_truth_tokens)
- num_same = sum(common.values())
- if num_same == 0:
- return 0
- precision = 1.0 * num_same / len(prediction_tokens)
- recall = 1.0 * num_same / len(ground_truth_tokens)
- f1 = (2 * precision * recall) / (precision + recall)
- return f1
-
-
-def exact_match_score(prediction, ground_truth):
- return normalize_answer(prediction) == normalize_answer(ground_truth)
-
-
-def calculate_exact_match(output_lns: List[str], reference_lns: List[str]) -> Dict:
- assert len(output_lns) == len(reference_lns)
- em = 0
- for hypo, pred in zip(output_lns, reference_lns):
- em += exact_match_score(hypo, pred)
- if len(output_lns) > 0:
- em /= len(output_lns)
- return {"em": em}
-
-
-def is_rag_model(model_prefix):
- return model_prefix.startswith("rag")
-
-
-def set_extra_model_params(extra_params, hparams, config):
- equivalent_param = {p: p for p in extra_params}
- # T5 models don't have `dropout` param, they have `dropout_rate` instead
- equivalent_param["dropout"] = "dropout_rate"
- for p in extra_params:
- if getattr(hparams, p, None):
- if not hasattr(config, p) and not hasattr(config, equivalent_param[p]):
- logger.info("config doesn't have a `{}` attribute".format(p))
- delattr(hparams, p)
- continue
- set_p = p if hasattr(config, p) else equivalent_param[p]
- setattr(config, set_p, getattr(hparams, p))
- delattr(hparams, p)
- return hparams, config
diff --git a/examples/research_projects/rag/README.md b/examples/research_projects/rag/README.md
deleted file mode 100644
index 59aa46a8952..00000000000
--- a/examples/research_projects/rag/README.md
+++ /dev/null
@@ -1,203 +0,0 @@
-# Intro
-
-Authors: @patrickvonplaten and @lhoestq
-
-Aimed at tackling the knowledge-intensive NLP tasks (think tasks a human wouldn't be expected to solve without access to external knowledge sources), RAG models are seq2seq models with access to a retrieval mechanism providing relevant context documents at training and evaluation time.
-
-A RAG model encapsulates two core components: a question encoder and a generator.
-During a forward pass, we encode the input with the question encoder and pass it
-to the retriever to extract relevant context documents. The documents are then prepended to the input.
-Such contextualized inputs are passed to the generator.
-
-Read more about RAG at https://arxiv.org/abs/2005.11401.
-
-# Note
-
-⚠️ This project should be run with pytorch-lightning==1.3.1 which has a potential security vulnerability
-
-# Finetuning
-
-Our finetuning logic is based on scripts from [`examples/legacy/seq2seq`](https://github.com/huggingface/transformers/tree/main/examples/legacy/seq2seq). We accept training data in the same format as specified there - we expect a directory consisting of 6 text files:
-```bash
-train.source
-train.target
-val.source
-val.target
-test.source
-test.target
-```
-
-A sample finetuning command (run ` ./examples/research_projects/rag/finetune_rag.py --help` to list all available options):
-
-```bash
-python examples/research_projects/rag/finetune_rag.py \
- --data_dir $DATA_DIR \
- --output_dir $OUTPUT_DIR \
- --model_name_or_path $MODEL_NAME_OR_PATH \
- --model_type rag_sequence \
- --fp16 \
- --gpus 8
-```
-We publish two `base` models which can serve as a starting point for finetuning on downstream tasks (use them as `model_name_or_path`):
-- [`facebook/rag-sequence-base`](https://huggingface.co/facebook/rag-sequence-base) - a base for finetuning `RagSequenceForGeneration` models,
-- [`facebook/rag-token-base`](https://huggingface.co/facebook/rag-token-base) - a base for finetuning `RagTokenForGeneration` models.
-
-The `base` models initialize the question encoder with [`facebook/dpr-question_encoder-single-nq-base`](https://huggingface.co/facebook/dpr-question_encoder-single-nq-base) and the generator with [`facebook/bart-large`](https://huggingface.co/facebook/bart-large).
-
-If you would like to initialize finetuning with a base model using different question encoder and generator architectures, you can build it with a consolidation script, e.g.:
-```bash
-python examples/research_projects/rag/consolidate_rag_checkpoint.py \
- --model_type rag_sequence \
- --generator_name_or_path facebook/bart-large-cnn \
- --question_encoder_name_or_path facebook/dpr-question_encoder-single-nq-base \
- --dest path/to/checkpoint
-```
-You will then be able to pass `path/to/checkpoint` as `model_name_or_path` to the `finetune_rag.py` script.
-
-## Document Retrieval
-When running distributed fine-tuning, each training worker needs to retrieve contextual documents
-for its input by querying a index loaded into memory. RAG provides two implementations for document retrieval,
-one with [`torch.distributed`](https://pytorch.org/docs/stable/distributed.html) communication package and the other
-with [`Ray`](https://docs.ray.io/en/master/).
-
-This option can be configured with the `--distributed_retriever` flag which can either be set to `pytorch` or `ray`.
-By default this flag is set to `pytorch`.
-
-For the Pytorch implementation, only training worker 0 loads the index into CPU memory, and a gather/scatter pattern is used
-to collect the inputs from the other training workers and send back the corresponding document embeddings.
-
-For the Ray implementation, the index is loaded in *separate* process(es). The training workers randomly select which
-retriever worker to query. To use Ray for distributed retrieval, you have to set the `--distributed_retriever` arg to `ray`.
-To configure the number of retrieval workers (the number of processes that load the index), you can set the `num_retrieval_workers` flag.
-Also make sure to start the Ray cluster before running fine-tuning.
-
-```bash
-# Start a single-node Ray cluster.
-ray start --head
-
-python examples/research_projects/rag/finetune_rag.py \
- --data_dir $DATA_DIR \
- --output_dir $OUTPUT_DIR \
- --model_name_or_path $MODEL_NAME_OR_PATH \
- --model_type rag_sequence \
- --fp16 \
- --gpus 8
- --distributed_retriever ray \
- --num_retrieval_workers 4
-
-# Stop the ray cluster once fine-tuning has finished.
-ray stop
-```
-
-Using Ray can lead to retrieval speedups on multi-GPU settings since multiple processes load the index rather than
-just the rank 0 training worker. Using Ray also allows you to load the index on GPU since the index is loaded on a separate
-processes than the model, while with pytorch distributed retrieval, both are loaded in the same process potentially leading to GPU OOM.
-
-# Evaluation
-Our evaluation script enables two modes of evaluation (controlled by the `eval_mode` argument): `e2e` - end2end evaluation, returns EM (exact match) and F1 scores calculated for the downstream task and `retrieval` - which returns precision@k of the documents retrieved for provided inputs.
-
-The evaluation script expects paths to two files:
-- `evaluation_set` - a path to a file specifying the evaluation dataset, a single input per line.
-- `gold_data_path` - a path to a file containing ground truth answers for datapoints from the `evaluation_set`, a single output per line. Check below for expected formats of the gold data files.
-
-
-## Retrieval evaluation
-For `retrieval` evaluation, we expect a gold data file where each line will consist of a tab-separated list of document titles constituting positive contexts for respective datapoints from the `evaluation_set`. E.g. given a question `who sings does he love me with reba` in the `evaluation_set`, a respective ground truth line could look as follows:
-```
-Does He Love You Does He Love You Red Sandy Spika dress of Reba McEntire Greatest Hits Volume Two (Reba McEntire album) Shoot for the Moon (album)
-```
-
-We demonstrate how to evaluate retrieval against DPR evaluation data. You can download respective files from links listed [here](https://github.com/facebookresearch/DPR/blob/master/data/download_data.py#L39-L45).
-
-1. Download and unzip the gold data file. We use the `biencoder-nq-dev` from https://dl.fbaipublicfiles.com/dpr/data/retriever/biencoder-nq-dev.json.gz.
- ```bash
- wget https://dl.fbaipublicfiles.com/dpr/data/retriever/biencoder-nq-dev.json.gz && gzip -d biencoder-nq-dev.json.gz
- ```
-
-2. Parse the unziped file using the `parse_dpr_relevance_data.py`
- ```bash
- mkdir output # or wherever you want to save this
- python examples/research_projects/rag/parse_dpr_relevance_data.py \
- --src_path biencoder-nq-dev.json \
- --evaluation_set output/biencoder-nq-dev.questions \
- --gold_data_path output/biencoder-nq-dev.pages
- ```
-3. Run evaluation:
- ```bash
- python examples/research_projects/rag/eval_rag.py \
- --model_name_or_path facebook/rag-sequence-nq \
- --model_type rag_sequence \
- --evaluation_set output/biencoder-nq-dev.questions \
- --gold_data_path output/biencoder-nq-dev.pages \
- --predictions_path output/retrieval_preds.tsv \
- --eval_mode retrieval \
- --k 1
- ```
- ```bash
- # EXPLANATION
- python examples/research_projects/rag/eval_rag.py \
- --model_name_or_path facebook/rag-sequence-nq \ # model name or path of the model we're evaluating
- --model_type rag_sequence \ # RAG model type (rag_token or rag_sequence)
- --evaluation_set output/biencoder-nq-dev.questions \ # an input dataset for evaluation
- --gold_data_path poutput/biencoder-nq-dev.pages \ # a dataset containing ground truth answers for samples from the evaluation_set
- --predictions_path output/retrieval_preds.tsv \ # name of file where predictions will be stored
- --eval_mode retrieval \ # indicates whether we're performing retrieval evaluation or e2e evaluation
- --k 1 # parameter k for the precision@k metric
-
- ```
-## End-to-end evaluation
-
-We support two formats of the gold data file (controlled by the `gold_data_mode` parameter):
-- `qa` - where a single line has the following format: `input [tab] output_list`, e.g.:
-```
-who is the owner of reading football club ['Xiu Li Dai', 'Dai Yongge', 'Dai Xiuli', 'Yongge Dai']
-```
-- `ans` - where a single line contains a single expected answer, e.g.:
-```
-Xiu Li Dai
-```
-
-Predictions of the model for the samples from the `evaluation_set` will be saved under the path specified by the `predictions_path` parameter.
-If this path already exists, the script will use saved predictions to calculate metrics.
-Add `--recalculate` parameter to force the script to perform inference from scratch.
-
-An example e2e evaluation run could look as follows:
-```bash
-python examples/research_projects/rag/eval_rag.py \
- --model_name_or_path facebook/rag-sequence-nq \
- --model_type rag_sequence \
- --evaluation_set path/to/test.source \
- --gold_data_path path/to/gold_data \
- --predictions_path path/to/e2e_preds.txt \
- --eval_mode e2e \
- --gold_data_mode qa \
- --n_docs 5 \ # You can experiment with retrieving different number of documents at evaluation time
- --print_predictions \
- --recalculate \ # adding this parameter will force recalculating predictions even if predictions_path already exists
-```
-
-# Use your own knowledge source
-
-By default, RAG uses the English Wikipedia as a knowledge source, known as the 'wiki_dpr' dataset.
-With `use_custom_knowledge_dataset.py` you can build your own knowledge source, *e.g.* for RAG.
-
-For instance, if documents are serialized as tab-separated csv files with the columns "title" and "text", one can use `use_own_knowledge_dataset.py` as follows:
-```bash
-python examples/research_projects/rag/use_own_knowledge_dataset.py \
- --csv_path path/to/my_csv \
- --output_dir path/to/my_knowledge_dataset \
-```
-
-The created outputs in `path/to/my_knowledge_dataset` can then be used to finetune RAG as follows:
-```bash
-python examples/research_projects/rag/finetune_rag.py \
- --data_dir $DATA_DIR \
- --output_dir $OUTPUT_DIR \
- --model_name_or_path $MODEL_NAME_OR_PATH \
- --model_type rag_sequence \
- --fp16 \
- --gpus 8
- --index_name custom
- --passages_path path/to/data/my_knowledge_dataset
- --index_path path/to/my_knowledge_dataset_hnsw_index.faiss
-```
diff --git a/examples/research_projects/rag/__init__.py b/examples/research_projects/rag/__init__.py
deleted file mode 100644
index 3cee09bb7f5..00000000000
--- a/examples/research_projects/rag/__init__.py
+++ /dev/null
@@ -1,5 +0,0 @@
-import os
-import sys
-
-
-sys.path.insert(1, os.path.dirname(os.path.realpath(__file__)))
diff --git a/examples/research_projects/rag/_test_finetune_rag.py b/examples/research_projects/rag/_test_finetune_rag.py
deleted file mode 100644
index 0906295b301..00000000000
--- a/examples/research_projects/rag/_test_finetune_rag.py
+++ /dev/null
@@ -1,111 +0,0 @@
-import json
-import logging
-import os
-import sys
-from pathlib import Path
-
-import finetune_rag
-
-from transformers.file_utils import is_apex_available
-from transformers.testing_utils import (
- TestCasePlus,
- execute_subprocess_async,
- require_ray,
- require_torch_gpu,
- require_torch_multi_gpu,
-)
-
-
-logging.basicConfig(level=logging.DEBUG)
-logger = logging.getLogger()
-
-stream_handler = logging.StreamHandler(sys.stdout)
-logger.addHandler(stream_handler)
-
-
-class RagFinetuneExampleTests(TestCasePlus):
- def _create_dummy_data(self, data_dir):
- os.makedirs(data_dir, exist_ok=True)
- contents = {"source": "What is love ?", "target": "life"}
- n_lines = {"train": 12, "val": 2, "test": 2}
- for split in ["train", "test", "val"]:
- for field in ["source", "target"]:
- content = "\n".join([contents[field]] * n_lines[split])
- with open(os.path.join(data_dir, f"{split}.{field}"), "w") as f:
- f.write(content)
-
- def _run_finetune(self, gpus: int, distributed_retriever: str = "pytorch"):
- tmp_dir = self.get_auto_remove_tmp_dir()
- output_dir = os.path.join(tmp_dir, "output")
- data_dir = os.path.join(tmp_dir, "data")
- self._create_dummy_data(data_dir=data_dir)
-
- testargs = f"""
- --data_dir {data_dir} \
- --output_dir {output_dir} \
- --model_name_or_path facebook/rag-sequence-base \
- --model_type rag_sequence \
- --do_train \
- --do_predict \
- --n_val -1 \
- --val_check_interval 1.0 \
- --train_batch_size 2 \
- --eval_batch_size 1 \
- --max_source_length 25 \
- --max_target_length 25 \
- --val_max_target_length 25 \
- --test_max_target_length 25 \
- --label_smoothing 0.1 \
- --dropout 0.1 \
- --attention_dropout 0.1 \
- --weight_decay 0.001 \
- --adam_epsilon 1e-08 \
- --max_grad_norm 0.1 \
- --lr_scheduler polynomial \
- --learning_rate 3e-04 \
- --num_train_epochs 1 \
- --warmup_steps 4 \
- --gradient_accumulation_steps 1 \
- --distributed-port 8787 \
- --use_dummy_dataset 1 \
- --distributed_retriever {distributed_retriever} \
- """.split()
-
- if gpus > 0:
- testargs.append(f"--gpus={gpus}")
- if is_apex_available():
- testargs.append("--fp16")
- else:
- testargs.append("--gpus=0")
- testargs.append("--distributed_backend=ddp_cpu")
- testargs.append("--num_processes=2")
-
- cmd = [sys.executable, str(Path(finetune_rag.__file__).resolve())] + testargs
- execute_subprocess_async(cmd, env=self.get_env())
-
- metrics_save_path = os.path.join(output_dir, "metrics.json")
- with open(metrics_save_path) as f:
- result = json.load(f)
- return result
-
- @require_torch_gpu
- def test_finetune_gpu(self):
- result = self._run_finetune(gpus=1)
- self.assertGreaterEqual(result["test"][0]["test_avg_em"], 0.2)
-
- @require_torch_multi_gpu
- def test_finetune_multigpu(self):
- result = self._run_finetune(gpus=2)
- self.assertGreaterEqual(result["test"][0]["test_avg_em"], 0.2)
-
- @require_torch_gpu
- @require_ray
- def test_finetune_gpu_ray_retrieval(self):
- result = self._run_finetune(gpus=1, distributed_retriever="ray")
- self.assertGreaterEqual(result["test"][0]["test_avg_em"], 0.2)
-
- @require_torch_multi_gpu
- @require_ray
- def test_finetune_multigpu_ray_retrieval(self):
- result = self._run_finetune(gpus=1, distributed_retriever="ray")
- self.assertGreaterEqual(result["test"][0]["test_avg_em"], 0.2)
diff --git a/examples/research_projects/rag/callbacks_rag.py b/examples/research_projects/rag/callbacks_rag.py
deleted file mode 100644
index d75f97995bd..00000000000
--- a/examples/research_projects/rag/callbacks_rag.py
+++ /dev/null
@@ -1,116 +0,0 @@
-import logging
-from pathlib import Path
-
-import numpy as np
-import pytorch_lightning as pl
-import torch
-from pytorch_lightning.callbacks import EarlyStopping, ModelCheckpoint
-from pytorch_lightning.utilities import rank_zero_only
-from utils_rag import save_json
-
-
-def count_trainable_parameters(model):
- model_parameters = filter(lambda p: p.requires_grad, model.parameters())
- params = sum([np.prod(p.size()) for p in model_parameters])
- return params
-
-
-logger = logging.getLogger(__name__)
-
-
-def get_checkpoint_callback(output_dir, metric):
- """Saves the best model by validation EM score."""
- if metric == "rouge2":
- exp = "{val_avg_rouge2:.4f}-{step_count}"
- elif metric == "bleu":
- exp = "{val_avg_bleu:.4f}-{step_count}"
- elif metric == "em":
- exp = "{val_avg_em:.4f}-{step_count}"
- else:
- raise NotImplementedError(
- f"seq2seq callbacks only support rouge2 and bleu, got {metric}, You can make your own by adding to this"
- " function."
- )
-
- checkpoint_callback = ModelCheckpoint(
- dirpath=output_dir,
- filename=exp,
- monitor=f"val_{metric}",
- mode="max",
- save_top_k=3,
- every_n_epochs=1, # maybe save a checkpoint every time val is run, not just end of epoch.
- )
- return checkpoint_callback
-
-
-def get_early_stopping_callback(metric, patience):
- return EarlyStopping(
- monitor=f"val_{metric}", # does this need avg?
- mode="min" if "loss" in metric else "max",
- patience=patience,
- verbose=True,
- )
-
-
-class Seq2SeqLoggingCallback(pl.Callback):
- def on_batch_end(self, trainer, pl_module):
- lrs = {f"lr_group_{i}": param["lr"] for i, param in enumerate(pl_module.trainer.optimizers[0].param_groups)}
- pl_module.logger.log_metrics(lrs)
-
- @rank_zero_only
- def _write_logs(
- self, trainer: pl.Trainer, pl_module: pl.LightningModule, type_path: str, save_generations=True
- ) -> None:
- logger.info(f"***** {type_path} results at step {trainer.global_step:05d} *****")
- metrics = trainer.callback_metrics
- trainer.logger.log_metrics({k: v for k, v in metrics.items() if k not in ["log", "progress_bar", "preds"]})
- # Log results
- od = Path(pl_module.hparams.output_dir)
- if type_path == "test":
- results_file = od / "test_results.txt"
- generations_file = od / "test_generations.txt"
- else:
- # this never gets hit. I prefer not to save intermediate generations, and results are in metrics.json
- # If people want this it will be easy enough to add back.
- results_file = od / f"{type_path}_results/{trainer.global_step:05d}.txt"
- generations_file = od / f"{type_path}_generations/{trainer.global_step:05d}.txt"
- results_file.parent.mkdir(exist_ok=True)
- generations_file.parent.mkdir(exist_ok=True)
- with open(results_file, "a+") as writer:
- for key in sorted(metrics):
- if key in ["log", "progress_bar", "preds"]:
- continue
- val = metrics[key]
- if isinstance(val, torch.Tensor):
- val = val.item()
- msg = f"{key}: {val:.6f}\n"
- writer.write(msg)
-
- if not save_generations:
- return
-
- if "preds" in metrics:
- content = "\n".join(metrics["preds"])
- generations_file.open("w+").write(content)
-
- @rank_zero_only
- def on_train_start(self, trainer, pl_module):
- try:
- npars = pl_module.model.model.num_parameters()
- except AttributeError:
- npars = pl_module.model.num_parameters()
-
- n_trainable_pars = count_trainable_parameters(pl_module)
- # mp stands for million parameters
- trainer.logger.log_metrics({"n_params": npars, "mp": npars / 1e6, "grad_mp": n_trainable_pars / 1e6})
-
- @rank_zero_only
- def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
- save_json(pl_module.metrics, pl_module.metrics_save_path)
- return self._write_logs(trainer, pl_module, "test")
-
- @rank_zero_only
- def on_validation_end(self, trainer: pl.Trainer, pl_module):
- save_json(pl_module.metrics, pl_module.metrics_save_path)
- # Uncommenting this will save val generations
- # return self._write_logs(trainer, pl_module, "valid")
diff --git a/examples/research_projects/rag/consolidate_rag_checkpoint.py b/examples/research_projects/rag/consolidate_rag_checkpoint.py
deleted file mode 100644
index 6adae75fea9..00000000000
--- a/examples/research_projects/rag/consolidate_rag_checkpoint.py
+++ /dev/null
@@ -1,101 +0,0 @@
-"""
-A script creating a RAG checkpoint from a generator and a question encoder checkpoints.
-"""
-
-import argparse
-from pathlib import Path
-
-from transformers import AutoConfig, AutoTokenizer, RagConfig, RagSequenceForGeneration, RagTokenForGeneration
-
-
-def consolidate(
- model_type,
- generator_name_or_path: str,
- question_encoder_name_or_path: str,
- dest_dir: Path,
- config_name_or_path: str = None,
- generator_tokenizer_name_or_path: str = None,
- question_encoder_tokenizer_name_or_path: str = None,
-):
- if config_name_or_path is None:
- config_name_or_path = "facebook/rag-token-base" if model_type == "rag_token" else "facebook/rag-sequence-base"
-
- if generator_tokenizer_name_or_path is None:
- generator_tokenizer_name_or_path = generator_name_or_path
-
- if question_encoder_tokenizer_name_or_path is None:
- question_encoder_tokenizer_name_or_path = question_encoder_name_or_path
-
- model_class = RagTokenForGeneration if model_type == "rag_token" else RagSequenceForGeneration
-
- # Save model.
- rag_config = RagConfig.from_pretrained(config_name_or_path)
- gen_config = AutoConfig.from_pretrained(generator_name_or_path)
- question_encoder_config = AutoConfig.from_pretrained(question_encoder_name_or_path)
-
- rag_config.generator = gen_config
- rag_config.question_encoder = question_encoder_config
-
- rag_model = model_class.from_pretrained_question_encoder_generator(
- question_encoder_name_or_path, generator_name_or_path, config=rag_config
- )
- rag_model.save_pretrained(dest_dir)
-
- # Sanity check.
- model_class.from_pretrained(dest_dir)
-
- # Save tokenizers.
- gen_tokenizer = AutoTokenizer.from_pretrained(generator_tokenizer_name_or_path)
- gen_tokenizer.save_pretrained(dest_dir / "generator_tokenizer/")
- question_encoder_tokenizer = AutoTokenizer.from_pretrained(question_encoder_tokenizer_name_or_path)
- question_encoder_tokenizer.save_pretrained(dest_dir / "question_encoder_tokenizer/")
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "--model_type",
- choices=["rag_sequence", "rag_token"],
- required=True,
- type=str,
- help="RAG model type: rag_sequence, rag_token",
- )
- parser.add_argument("--dest", type=str, required=True, help="Path to the output checkpoint directory.")
- parser.add_argument("--generator_name_or_path", type=str, required=True, help="Generator model identifier")
- parser.add_argument(
- "--question_encoder_name_or_path", type=str, required=True, help="Question encoder model identifier"
- )
-
- parser.add_argument(
- "--generator_tokenizer_name_or_path",
- type=str,
- help="Generator tokenizer identifier, if not specified, resolves to ``generator_name_or_path``",
- )
- parser.add_argument(
- "--question_encoder_tokenizer_name_or_path",
- type=str,
- help="Question encoder tokenizer identifier, if not specified, resolves to ``question_encoder_name_or_path``",
- )
- parser.add_argument(
- "--config_name_or_path",
- type=str,
- help=(
- "Identifier of the model config to use, if not provided, resolves to a base config for a given"
- " ``model_type``"
- ),
- )
-
- args = parser.parse_args()
-
- dest_dir = Path(args.dest)
- dest_dir.mkdir(exist_ok=True)
-
- consolidate(
- args.model_type,
- args.generator_name_or_path,
- args.question_encoder_name_or_path,
- dest_dir,
- args.config_name_or_path,
- args.generator_tokenizer_name_or_path,
- args.question_encoder_tokenizer_name_or_path,
- )
diff --git a/examples/research_projects/rag/distributed_pytorch_retriever.py b/examples/research_projects/rag/distributed_pytorch_retriever.py
deleted file mode 100644
index b8c4b6fc3c5..00000000000
--- a/examples/research_projects/rag/distributed_pytorch_retriever.py
+++ /dev/null
@@ -1,138 +0,0 @@
-import logging
-import os
-from typing import List, Tuple
-
-import numpy as np
-import psutil
-import torch
-import torch.distributed as dist
-
-from transformers import RagRetriever
-
-
-logger = logging.getLogger(__name__)
-
-
-class RagPyTorchDistributedRetriever(RagRetriever):
- """
- A distributed retriever built on top of the ``torch.distributed`` communication package. During training all workers
- initialize their own instance of the retriever, however, only the main worker loads the index into memory. The index is stored
- in cpu memory. The index will also work well in a non-distributed setup.
-
- Args:
- config (:class:`~transformers.RagConfig`):
- The configuration of the RAG model this Retriever is used with. Contains parameters indicating which ``Index`` to build.
- question_encoder_tokenizer (:class:`~transformers.PreTrainedTokenizer`):
- The tokenizer that was used to tokenize the question.
- It is used to decode the question and then use the generator_tokenizer.
- generator_tokenizer (:class:`~transformers.PreTrainedTokenizer`):
- The tokenizer used for the generator part of the RagModel.
- index (:class:`~transformers.models.rag.retrieval_rag.Index`, optional, defaults to the one defined by the configuration):
- If specified, use this index instead of the one built using the configuration
- """
-
- def __init__(self, config, question_encoder_tokenizer, generator_tokenizer, index=None):
- super().__init__(
- config,
- question_encoder_tokenizer=question_encoder_tokenizer,
- generator_tokenizer=generator_tokenizer,
- index=index,
- init_retrieval=False,
- )
- self.process_group = None
-
- def init_retrieval(self, distributed_port: int):
- """
- Retriever initialization function, needs to be called from the training process. The function sets some common parameters
- and environment variables. On top of that, (only) the main process in the process group loads the index into memory.
-
- Args:
- distributed_port (:obj:`int`):
- The port on which the main communication of the training run is carried out. We set the port for retrieval-related
- communication as ``distributed_port + 1``.
- """
-
- logger.info("initializing retrieval")
-
- # initializing a separate process group for retrieval as the default
- # nccl backend doesn't support gather/scatter operations while gloo
- # is too slow to replace nccl for the core gpu communication
- if dist.is_initialized():
- logger.info("dist initialized")
- # needs to be set manually
- os.environ["GLOO_SOCKET_IFNAME"] = self._infer_socket_ifname()
- # avoid clash with the NCCL port
- os.environ["MASTER_PORT"] = str(distributed_port + 1)
- self.process_group = dist.new_group(ranks=None, backend="gloo")
-
- # initialize retriever only on the main worker
- if not dist.is_initialized() or self._is_main():
- logger.info("dist not initialized / main")
- self.index.init_index()
-
- # all processes wait until the retriever is initialized by the main process
- if dist.is_initialized():
- torch.distributed.barrier(group=self.process_group)
-
- def _is_main(self):
- return dist.get_rank(group=self.process_group) == 0
-
- def _scattered(self, scatter_list, target_shape, target_type=torch.float32):
- target_tensor = torch.empty(target_shape, dtype=target_type)
- dist.scatter(target_tensor, src=0, scatter_list=scatter_list, group=self.process_group)
- return target_tensor
-
- def _infer_socket_ifname(self):
- addrs = psutil.net_if_addrs()
- # a hacky way to deal with varying network interface names
- ifname = next((addr for addr in addrs if addr.startswith("e")), None)
- return ifname
-
- def retrieve(self, question_hidden_states: np.ndarray, n_docs: int) -> Tuple[np.ndarray, List[dict]]:
- """
- Retrieves documents for specified ``question_hidden_states``. The main process, which has the access to the index stored in memory, gathers queries
- from all the processes in the main training process group, performs the retrieval and scatters back the results.
-
- Args:
- question_hidden_states (:obj:`np.ndarray` of shape :obj:`(batch_size, vector_size)`):
- A batch of query vectors to retrieve with.
- n_docs (:obj:`int`):
- The number of docs retrieved per query.
-
- Output:
- retrieved_doc_embeds (:obj:`np.ndarray` of shape :obj:`(batch_size, n_docs, dim)`
- The retrieval embeddings of the retrieved docs per query.
- doc_ids (:obj:`np.ndarray` of shape :obj:`batch_size, n_docs`)
- The ids of the documents in the index
- doc_dicts (:obj:`List[dict]`):
- The retrieved_doc_embeds examples per query.
- """
-
- # single GPU training
- if not dist.is_initialized():
- doc_ids, retrieved_doc_embeds = self._main_retrieve(question_hidden_states, n_docs)
- return retrieved_doc_embeds, doc_ids, self.index.get_doc_dicts(doc_ids)
-
- # distributed training
- world_size = dist.get_world_size(group=self.process_group)
-
- # gather logic
- gather_list = None
- if self._is_main():
- gather_list = [torch.empty(question_hidden_states.shape, dtype=torch.float32) for _ in range(world_size)]
- dist.gather(torch.tensor(question_hidden_states), dst=0, gather_list=gather_list, group=self.process_group)
-
- # scatter logic
- n_queries = question_hidden_states.shape[0]
- scatter_ids = []
- scatter_vectors = []
- if self._is_main():
- assert len(gather_list) == world_size
- ids, vectors = self._main_retrieve(torch.cat(gather_list).numpy(), n_docs)
- ids, vectors = torch.tensor(ids), torch.tensor(vectors)
- scatter_ids = self._chunk_tensor(ids, n_queries)
- scatter_vectors = self._chunk_tensor(vectors, n_queries)
- doc_ids = self._scattered(scatter_ids, [n_queries, n_docs], target_type=torch.int64)
- retrieved_doc_embeds = self._scattered(scatter_vectors, [n_queries, n_docs, question_hidden_states.shape[1]])
-
- return retrieved_doc_embeds.numpy(), doc_ids.numpy(), self.index.get_doc_dicts(doc_ids)
diff --git a/examples/research_projects/rag/distributed_ray_retriever.py b/examples/research_projects/rag/distributed_ray_retriever.py
deleted file mode 100644
index dd5baaf7261..00000000000
--- a/examples/research_projects/rag/distributed_ray_retriever.py
+++ /dev/null
@@ -1,152 +0,0 @@
-import logging
-import random
-
-import ray
-
-from transformers import RagConfig, RagRetriever, RagTokenizer
-from transformers.models.rag.retrieval_rag import CustomHFIndex
-
-
-logger = logging.getLogger(__name__)
-
-
-class RayRetriever:
- def __init__(self):
- self.initialized = False
-
- def create_rag_retriever(self, config, question_encoder_tokenizer, generator_tokenizer, index):
- if not self.initialized:
- self.retriever = RagRetriever(
- config,
- question_encoder_tokenizer=question_encoder_tokenizer,
- generator_tokenizer=generator_tokenizer,
- index=index,
- init_retrieval=False,
- )
- self.initialized = True
-
- def init_retrieval(self):
- self.retriever.index.init_index()
-
- def retrieve(self, question_hidden_states, n_docs):
- doc_ids, retrieved_doc_embeds = self.retriever._main_retrieve(question_hidden_states, n_docs)
- return doc_ids, retrieved_doc_embeds
-
-
-class RagRayDistributedRetriever(RagRetriever):
- """
- A distributed retriever built on top of the ``Ray`` API, a library
- for building distributed applications (https://docs.ray.io/en/master/).
- package. During training, all training workers initialize their own
- instance of a `RagRayDistributedRetriever`, and each instance of
- this distributed retriever shares a common set of Retrieval Ray
- Actors (https://docs.ray.io/en/master/walkthrough.html#remote
- -classes-actors) that load the index on separate processes. Ray
- handles the communication between the `RagRayDistributedRetriever`
- instances and the remote Ray actors. If training is done in a
- non-distributed setup, the index will simply be loaded in the same
- process as the training worker and Ray will not be used.
-
- Args:
- config (:class:`~transformers.RagConfig`):
- The configuration of the RAG model this Retriever is used with. Contains parameters indicating which ``Index`` to build.
- question_encoder_tokenizer (:class:`~transformers.PreTrainedTokenizer`):
- The tokenizer that was used to tokenize the question.
- It is used to decode the question and then use the generator_tokenizer.
- generator_tokenizer (:class:`~transformers.PreTrainedTokenizer`):
- The tokenizer used for the generator part of the RagModel.
- retrieval_workers (:obj:`List[ray.ActorClass(RayRetriever)]`): A list of already initialized `RayRetriever` actors.
- These actor classes run on remote processes and are responsible for performing the index lookup.
- index (:class:`~transformers.retrieval_rag.Index`, optional, defaults to the one defined by the configuration):
- If specified, use this index instead of the one built using the configuration
- """
-
- def __init__(self, config, question_encoder_tokenizer, generator_tokenizer, retrieval_workers, index=None):
- if index is not None and index.is_initialized() and len(retrieval_workers) > 0:
- raise ValueError(
- "When using Ray for distributed fine-tuning, "
- "you'll need to provide the paths instead, "
- "as the dataset and the index are loaded "
- "separately. More info in examples/rag/use_own_knowledge_dataset.py "
- )
- super().__init__(
- config,
- question_encoder_tokenizer=question_encoder_tokenizer,
- generator_tokenizer=generator_tokenizer,
- index=index,
- init_retrieval=False,
- )
- self.retrieval_workers = retrieval_workers
- if len(self.retrieval_workers) > 0:
- ray.get(
- [
- worker.create_rag_retriever.remote(config, question_encoder_tokenizer, generator_tokenizer, index)
- for worker in self.retrieval_workers
- ]
- )
-
- def init_retrieval(self):
- """
- Retriever initialization function, needs to be called from the
- training process. This function triggers retrieval initialization
- for all retrieval actors if using distributed setting, or loads
- index into current process if training is not distributed.
- """
- logger.info("initializing retrieval")
-
- if len(self.retrieval_workers) > 0:
- ray.get([worker.init_retrieval.remote() for worker in self.retrieval_workers])
- else:
- # Non-distributed training. Load index into this same process.
- self.index.init_index()
-
- def retrieve(self, question_hidden_states, n_docs):
- """
- Retrieves documents for specified ``question_hidden_states``. If
- running training with multiple workers, a random retrieval actor is
- selected to perform the index lookup and return the result.
-
- Args:
- question_hidden_states (:obj:`np.ndarray` of shape :obj:`(batch_size, vector_size)`):
- A batch of query vectors to retrieve with.
- n_docs (:obj:`int`):
- The number of docs retrieved per query.
-
- Output:
- retrieved_doc_embeds (:obj:`np.ndarray` of shape :obj:`(batch_size, n_docs, dim)`
- The retrieval embeddings of the retrieved docs per query.
- doc_ids (:obj:`np.ndarray` of shape :obj:`batch_size, n_docs`)
- The ids of the documents in the index
- doc_dicts (:obj:`List[dict]`):
- The retrieved_doc_embeds examples per query.
- """
- if len(self.retrieval_workers) > 0:
- # Select a random retrieval actor.
- random_worker = self.retrieval_workers[random.randint(0, len(self.retrieval_workers) - 1)]
- doc_ids, retrieved_doc_embeds = ray.get(random_worker.retrieve.remote(question_hidden_states, n_docs))
- else:
- doc_ids, retrieved_doc_embeds = self._main_retrieve(question_hidden_states, n_docs)
- return retrieved_doc_embeds, doc_ids, self.index.get_doc_dicts(doc_ids)
-
- @classmethod
- def get_tokenizers(cls, retriever_name_or_path, indexed_dataset=None, **kwargs):
- return super(RagRayDistributedRetriever, cls).get_tokenizers(retriever_name_or_path, indexed_dataset, **kwargs)
-
- @classmethod
- def from_pretrained(cls, retriever_name_or_path, actor_handles, indexed_dataset=None, **kwargs):
- config = kwargs.pop("config", None) or RagConfig.from_pretrained(retriever_name_or_path, **kwargs)
- rag_tokenizer = RagTokenizer.from_pretrained(retriever_name_or_path, config=config)
- question_encoder_tokenizer = rag_tokenizer.question_encoder
- generator_tokenizer = rag_tokenizer.generator
- if indexed_dataset is not None:
- config.index_name = "custom"
- index = CustomHFIndex(config.retrieval_vector_size, indexed_dataset)
- else:
- index = cls._build_index(config)
- return cls(
- config,
- question_encoder_tokenizer=question_encoder_tokenizer,
- generator_tokenizer=generator_tokenizer,
- retrieval_workers=actor_handles,
- index=index,
- )
diff --git a/examples/research_projects/rag/eval_rag.py b/examples/research_projects/rag/eval_rag.py
deleted file mode 100644
index 55f4da56571..00000000000
--- a/examples/research_projects/rag/eval_rag.py
+++ /dev/null
@@ -1,320 +0,0 @@
-"""Evaluation script for RAG models."""
-
-import argparse
-import ast
-import logging
-import os
-import sys
-
-import pandas as pd
-import torch
-from tqdm import tqdm
-
-from transformers import BartForConditionalGeneration, RagRetriever, RagSequenceForGeneration, RagTokenForGeneration
-from transformers import logging as transformers_logging
-
-
-sys.path.append(os.path.join(os.getcwd())) # noqa: E402 # isort:skip
-from utils_rag import exact_match_score, f1_score # noqa: E402 # isort:skip
-
-
-logger = logging.getLogger(__name__)
-logging.basicConfig(level=logging.INFO)
-
-transformers_logging.set_verbosity_info()
-
-
-def infer_model_type(model_name_or_path):
- if "token" in model_name_or_path:
- return "rag_token"
- if "sequence" in model_name_or_path:
- return "rag_sequence"
- if "bart" in model_name_or_path:
- return "bart"
- return None
-
-
-def metric_max_over_ground_truths(metric_fn, prediction, ground_truths):
- return max(metric_fn(prediction, gt) for gt in ground_truths)
-
-
-def get_scores(args, preds_path, gold_data_path):
- hypos = [line.strip() for line in open(preds_path, "r").readlines()]
- answers = []
-
- if args.gold_data_mode == "qa":
- data = pd.read_csv(gold_data_path, sep="\t", header=None)
- for answer_list in data[1]:
- ground_truths = ast.literal_eval(answer_list)
- answers.append(ground_truths)
- else:
- references = [line.strip() for line in open(gold_data_path, "r").readlines()]
- answers = [[reference] for reference in references]
-
- f1 = em = total = 0
- for prediction, ground_truths in zip(hypos, answers):
- total += 1
- em += metric_max_over_ground_truths(exact_match_score, prediction, ground_truths)
- f1 += metric_max_over_ground_truths(f1_score, prediction, ground_truths)
-
- em = 100.0 * em / total
- f1 = 100.0 * f1 / total
-
- logger.info(f"F1: {f1:.2f}")
- logger.info(f"EM: {em:.2f}")
-
-
-def get_precision_at_k(args, preds_path, gold_data_path):
- k = args.k
- hypos = [line.strip() for line in open(preds_path, "r").readlines()]
- references = [line.strip() for line in open(gold_data_path, "r").readlines()]
-
- em = total = 0
- for hypo, reference in zip(hypos, references):
- hypo_provenance = set(hypo.split("\t")[:k])
- ref_provenance = set(reference.split("\t"))
- total += 1
- em += len(hypo_provenance & ref_provenance) / k
-
- em = 100.0 * em / total
- logger.info(f"Precision@{k}: {em: .2f}")
-
-
-def evaluate_batch_retrieval(args, rag_model, questions):
- def strip_title(title):
- if title.startswith('"'):
- title = title[1:]
- if title.endswith('"'):
- title = title[:-1]
- return title
-
- retriever_input_ids = rag_model.retriever.question_encoder_tokenizer.batch_encode_plus(
- questions,
- return_tensors="pt",
- padding=True,
- truncation=True,
- )["input_ids"].to(args.device)
-
- question_enc_outputs = rag_model.rag.question_encoder(retriever_input_ids)
- question_enc_pool_output = question_enc_outputs[0]
-
- result = rag_model.retriever(
- retriever_input_ids,
- question_enc_pool_output.cpu().detach().to(torch.float32).numpy(),
- prefix=rag_model.rag.generator.config.prefix,
- n_docs=rag_model.config.n_docs,
- return_tensors="pt",
- )
- all_docs = rag_model.retriever.index.get_doc_dicts(result.doc_ids)
- provenance_strings = []
- for docs in all_docs:
- provenance = [strip_title(title) for title in docs["title"]]
- provenance_strings.append("\t".join(provenance))
- return provenance_strings
-
-
-def evaluate_batch_e2e(args, rag_model, questions):
- with torch.no_grad():
- inputs_dict = rag_model.retriever.question_encoder_tokenizer.batch_encode_plus(
- questions, return_tensors="pt", padding=True, truncation=True
- )
-
- input_ids = inputs_dict.input_ids.to(args.device)
- attention_mask = inputs_dict.attention_mask.to(args.device)
- outputs = rag_model.generate( # rag_model overwrites generate
- input_ids,
- attention_mask=attention_mask,
- num_beams=args.num_beams,
- min_length=args.min_length,
- max_length=args.max_length,
- early_stopping=False,
- num_return_sequences=1,
- bad_words_ids=[[0, 0]], # BART likes to repeat BOS tokens, dont allow it to generate more than one
- )
- answers = rag_model.retriever.generator_tokenizer.batch_decode(outputs, skip_special_tokens=True)
-
- if args.print_predictions:
- for q, a in zip(questions, answers):
- logger.info("Q: {} - A: {}".format(q, a))
-
- return answers
-
-
-def get_args():
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "--model_type",
- choices=["rag_sequence", "rag_token", "bart"],
- type=str,
- help=(
- "RAG model type: rag_sequence, rag_token or bart, if none specified, the type is inferred from the"
- " model_name_or_path"
- ),
- )
- parser.add_argument(
- "--index_name",
- default=None,
- choices=["exact", "compressed", "legacy"],
- type=str,
- help="RAG model retriever type",
- )
- parser.add_argument(
- "--index_path",
- default=None,
- type=str,
- help="Path to the retrieval index",
- )
- parser.add_argument("--n_docs", default=5, type=int, help="Number of retrieved docs")
- parser.add_argument(
- "--model_name_or_path",
- default=None,
- type=str,
- required=True,
- help="Path to pretrained checkpoints or model identifier from huggingface.co/models",
- )
- parser.add_argument(
- "--eval_mode",
- choices=["e2e", "retrieval"],
- default="e2e",
- type=str,
- help=(
- "Evaluation mode, e2e calculates exact match and F1 of the downstream task, retrieval calculates"
- " precision@k."
- ),
- )
- parser.add_argument("--k", default=1, type=int, help="k for the precision@k calculation")
- parser.add_argument(
- "--evaluation_set",
- default=None,
- type=str,
- required=True,
- help="Path to a file containing evaluation samples",
- )
- parser.add_argument(
- "--gold_data_path",
- default=None,
- type=str,
- required=True,
- help="Path to a tab-separated file with gold samples",
- )
- parser.add_argument(
- "--gold_data_mode",
- default="qa",
- type=str,
- choices=["qa", "ans"],
- help=(
- "Format of the gold data file"
- "qa - a single line in the following format: question [tab] answer_list"
- "ans - a single line of the gold file contains the expected answer string"
- ),
- )
- parser.add_argument(
- "--predictions_path",
- type=str,
- default="predictions.txt",
- help="Name of the predictions file, to be stored in the checkpoints directory",
- )
- parser.add_argument(
- "--eval_all_checkpoints",
- action="store_true",
- help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
- )
- parser.add_argument(
- "--eval_batch_size",
- default=8,
- type=int,
- help="Batch size per GPU/CPU for evaluation.",
- )
- parser.add_argument(
- "--recalculate",
- help="Recalculate predictions even if the prediction file exists",
- action="store_true",
- )
- parser.add_argument(
- "--num_beams",
- default=4,
- type=int,
- help="Number of beams to be used when generating answers",
- )
- parser.add_argument("--min_length", default=1, type=int, help="Min length of the generated answers")
- parser.add_argument("--max_length", default=50, type=int, help="Max length of the generated answers")
-
- parser.add_argument(
- "--print_predictions",
- action="store_true",
- help="If True, prints predictions while evaluating.",
- )
- parser.add_argument(
- "--print_docs",
- action="store_true",
- help="If True, prints docs retried while generating.",
- )
- args = parser.parse_args()
- args.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
- return args
-
-
-def main(args):
- model_kwargs = {}
- if args.model_type is None:
- args.model_type = infer_model_type(args.model_name_or_path)
- assert args.model_type is not None
- if args.model_type.startswith("rag"):
- model_class = RagTokenForGeneration if args.model_type == "rag_token" else RagSequenceForGeneration
- model_kwargs["n_docs"] = args.n_docs
- if args.index_name is not None:
- model_kwargs["index_name"] = args.index_name
- if args.index_path is not None:
- model_kwargs["index_path"] = args.index_path
- else:
- model_class = BartForConditionalGeneration
-
- checkpoints = (
- [f.path for f in os.scandir(args.model_name_or_path) if f.is_dir()]
- if args.eval_all_checkpoints
- else [args.model_name_or_path]
- )
-
- logger.info("Evaluate the following checkpoints: %s", checkpoints)
-
- score_fn = get_scores if args.eval_mode == "e2e" else get_precision_at_k
- evaluate_batch_fn = evaluate_batch_e2e if args.eval_mode == "e2e" else evaluate_batch_retrieval
-
- for checkpoint in checkpoints:
- if os.path.exists(args.predictions_path) and (not args.recalculate):
- logger.info("Calculating metrics based on an existing predictions file: {}".format(args.predictions_path))
- score_fn(args, args.predictions_path, args.gold_data_path)
- continue
-
- logger.info("***** Running evaluation for {} *****".format(checkpoint))
- logger.info(" Batch size = %d", args.eval_batch_size)
- logger.info(" Predictions will be stored under {}".format(args.predictions_path))
-
- if args.model_type.startswith("rag"):
- retriever = RagRetriever.from_pretrained(checkpoint, **model_kwargs)
- model = model_class.from_pretrained(checkpoint, retriever=retriever, **model_kwargs)
- model.retriever.init_retrieval()
- else:
- model = model_class.from_pretrained(checkpoint, **model_kwargs)
- model.to(args.device)
-
- with open(args.evaluation_set, "r") as eval_file, open(args.predictions_path, "w") as preds_file:
- questions = []
- for line in tqdm(eval_file):
- questions.append(line.strip())
- if len(questions) == args.eval_batch_size:
- answers = evaluate_batch_fn(args, model, questions)
- preds_file.write("\n".join(answers) + "\n")
- preds_file.flush()
- questions = []
- if len(questions) > 0:
- answers = evaluate_batch_fn(args, model, questions)
- preds_file.write("\n".join(answers))
- preds_file.flush()
-
- score_fn(args, args.predictions_path, args.gold_data_path)
-
-
-if __name__ == "__main__":
- args = get_args()
- main(args)
diff --git a/examples/research_projects/rag/finetune_rag.py b/examples/research_projects/rag/finetune_rag.py
deleted file mode 100644
index af3acd4def6..00000000000
--- a/examples/research_projects/rag/finetune_rag.py
+++ /dev/null
@@ -1,649 +0,0 @@
-"""Finetuning script for RAG models. Adapted from examples.seq2seq.finetune.py"""
-
-import argparse
-import logging
-import os
-import sys
-import time
-from collections import defaultdict
-from pathlib import Path
-from typing import Any, Dict, List, Tuple
-
-import numpy as np
-import pytorch_lightning as pl
-import torch
-import torch.distributed as dist
-import torch.distributed as torch_distrib
-from pytorch_lightning.plugins.training_type import DDPPlugin
-from torch.utils.data import DataLoader
-
-from transformers import (
- AutoConfig,
- AutoTokenizer,
- BartForConditionalGeneration,
- BatchEncoding,
- RagConfig,
- RagSequenceForGeneration,
- RagTokenForGeneration,
- RagTokenizer,
- T5ForConditionalGeneration,
-)
-from transformers import logging as transformers_logging
-from transformers.integrations import is_ray_available
-
-
-if is_ray_available():
- import ray
- from distributed_ray_retriever import RagRayDistributedRetriever, RayRetriever
-
-from callbacks_rag import ( # noqa: E402 # isort:skipq
- get_checkpoint_callback,
- get_early_stopping_callback,
- Seq2SeqLoggingCallback,
-)
-
-from distributed_pytorch_retriever import RagPyTorchDistributedRetriever # noqa: E402 # isort:skip
-from utils_rag import ( # noqa: E402 # isort:skip
- calculate_exact_match,
- flatten_list,
- get_git_info,
- is_rag_model,
- lmap,
- pickle_save,
- save_git_info,
- save_json,
- set_extra_model_params,
- Seq2SeqDataset,
-)
-
-# need the parent dir module
-sys.path.insert(2, str(Path(__file__).resolve().parents[1]))
-from lightning_base import BaseTransformer, add_generic_args, generic_train # noqa
-
-
-logging.basicConfig(level=logging.INFO)
-logger = logging.getLogger(__name__)
-
-transformers_logging.set_verbosity_info()
-
-
-class AttrDict(dict):
- def __init__(self, *args, **kwargs):
- super(AttrDict, self).__init__(*args, **kwargs)
- self.__dict__ = self
-
-
-class CustomDDP(DDPPlugin):
- def init_ddp_connection(self, global_rank=None, world_size=None) -> None:
- module = self.model
- global_rank = global_rank if global_rank is not None else self.cluster_environment.global_rank()
- world_size = world_size if world_size is not None else self.cluster_environment.world_size()
- os.environ["MASTER_ADDR"] = self.cluster_environment.master_address()
- os.environ["MASTER_PORT"] = str(self.cluster_environment.master_port())
- if not torch.distributed.is_initialized():
- logger.info(f"initializing ddp: GLOBAL_RANK: {global_rank}, MEMBER: {global_rank + 1}/{world_size}")
- torch_distrib.init_process_group(self.torch_distributed_backend, rank=global_rank, world_size=world_size)
-
- if module.is_rag_model:
- self.distributed_port = module.hparams.distributed_port
- if module.distributed_retriever == "pytorch":
- module.model.rag.retriever.init_retrieval(self.distributed_port)
- elif module.distributed_retriever == "ray" and global_rank == 0:
- # For the Ray retriever, only initialize it once when global
- # rank is 0.
- module.model.rag.retriever.init_retrieval()
-
-
-class GenerativeQAModule(BaseTransformer):
- mode = "generative_qa"
- loss_names = ["loss"]
- metric_names = ["em"]
- val_metric = "em"
-
- def __init__(self, hparams, **kwargs):
- # when loading from a pytorch lightning checkpoint, hparams are passed as dict
- if isinstance(hparams, dict):
- hparams = AttrDict(hparams)
- if hparams.model_type == "rag_sequence":
- self.model_class = RagSequenceForGeneration
- elif hparams.model_type == "rag_token":
- self.model_class = RagTokenForGeneration
- elif hparams.model_type == "bart":
- self.model_class = BartForConditionalGeneration
- else:
- self.model_class = T5ForConditionalGeneration
- self.is_rag_model = is_rag_model(hparams.model_type)
-
- config_class = RagConfig if self.is_rag_model else AutoConfig
- config = config_class.from_pretrained(hparams.model_name_or_path)
-
- # set retriever parameters
- config.index_name = hparams.index_name or config.index_name
- config.passages_path = hparams.passages_path or config.passages_path
- config.index_path = hparams.index_path or config.index_path
- config.use_dummy_dataset = hparams.use_dummy_dataset
-
- # set extra_model_params for generator configs and load_model
- extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "attention_dropout", "dropout")
- if self.is_rag_model:
- if hparams.prefix is not None:
- config.generator.prefix = hparams.prefix
- config.label_smoothing = hparams.label_smoothing
- hparams, config.generator = set_extra_model_params(extra_model_params, hparams, config.generator)
- if hparams.distributed_retriever == "pytorch":
- retriever = RagPyTorchDistributedRetriever.from_pretrained(hparams.model_name_or_path, config=config)
- elif hparams.distributed_retriever == "ray":
- # The Ray retriever needs the handles to the retriever actors.
- retriever = RagRayDistributedRetriever.from_pretrained(
- hparams.model_name_or_path, hparams.actor_handles, config=config
- )
- model = self.model_class.from_pretrained(hparams.model_name_or_path, config=config, retriever=retriever)
- prefix = config.question_encoder.prefix
- else:
- if hparams.prefix is not None:
- config.prefix = hparams.prefix
- hparams, config = set_extra_model_params(extra_model_params, hparams, config)
- model = self.model_class.from_pretrained(hparams.model_name_or_path, config=config)
- prefix = config.prefix
-
- tokenizer = (
- RagTokenizer.from_pretrained(hparams.model_name_or_path)
- if self.is_rag_model
- else AutoTokenizer.from_pretrained(hparams.model_name_or_path)
- )
-
- super().__init__(hparams, config=config, tokenizer=tokenizer, model=model)
-
- save_git_info(self.hparams.output_dir)
- self.output_dir = Path(self.hparams.output_dir)
- self.metrics_save_path = Path(self.output_dir) / "metrics.json"
- self.hparams_save_path = Path(self.output_dir) / "hparams.pkl"
- pickle_save(self.hparams, self.hparams_save_path)
- self.step_count = 0
- self.metrics = defaultdict(list)
-
- self.dataset_kwargs: dict = {
- "data_dir": self.hparams.data_dir,
- "max_source_length": self.hparams.max_source_length,
- "prefix": prefix or "",
- }
- n_observations_per_split = {
- "train": self.hparams.n_train,
- "val": self.hparams.n_val,
- "test": self.hparams.n_test,
- }
- self.n_obs = {k: v if v >= 0 else None for k, v in n_observations_per_split.items()}
-
- self.target_lens = {
- "train": self.hparams.max_target_length,
- "val": self.hparams.val_max_target_length,
- "test": self.hparams.test_max_target_length,
- }
- assert self.target_lens["train"] <= self.target_lens["val"], f"target_lens: {self.target_lens}"
- assert self.target_lens["train"] <= self.target_lens["test"], f"target_lens: {self.target_lens}"
-
- self.hparams.git_sha = get_git_info()["repo_sha"]
- self.num_workers = hparams.num_workers
- self.distributed_port = self.hparams.distributed_port
-
- # For single GPU training, init_ddp_connection is not called.
- # So we need to initialize the retrievers here.
- if hparams.gpus <= 1:
- if hparams.distributed_retriever == "ray":
- self.model.retriever.init_retrieval()
- elif hparams.distributed_retriever == "pytorch":
- self.model.retriever.init_retrieval(self.distributed_port)
-
- self.distributed_retriever = hparams.distributed_retriever
-
- def forward(self, input_ids, **kwargs):
- return self.model(input_ids, **kwargs)
-
- def ids_to_clean_text(self, generated_ids: List[int]):
- gen_text = self.tokenizer.batch_decode(
- generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
- )
- return lmap(str.strip, gen_text)
-
- def _step(self, batch: dict) -> Tuple:
- source_ids, source_mask, target_ids = batch["input_ids"], batch["attention_mask"], batch["decoder_input_ids"]
-
- rag_kwargs = {}
- if isinstance(self.model, T5ForConditionalGeneration):
- decoder_input_ids = self.model._shift_right(target_ids)
- lm_labels = target_ids
- elif isinstance(self.model, BartForConditionalGeneration):
- decoder_input_ids = target_ids[:, :-1].contiguous()
- lm_labels = target_ids[:, 1:].clone()
- else:
- assert self.is_rag_model
- generator = self.model.rag.generator
- if isinstance(generator, T5ForConditionalGeneration):
- decoder_start_token_id = generator.config.decoder_start_token_id
- decoder_input_ids = (
- torch.cat(
- [torch.tensor([[decoder_start_token_id]] * target_ids.shape[0]).to(target_ids), target_ids],
- dim=1,
- )
- if target_ids.shape[0] < self.target_lens["train"]
- else generator._shift_right(target_ids)
- )
- elif isinstance(generator, BartForConditionalGeneration):
- decoder_input_ids = target_ids
- lm_labels = decoder_input_ids
- rag_kwargs["reduce_loss"] = True
-
- assert decoder_input_ids is not None
-
- outputs = self(
- source_ids,
- attention_mask=source_mask,
- decoder_input_ids=decoder_input_ids,
- use_cache=False,
- labels=lm_labels,
- **rag_kwargs,
- )
-
- loss = outputs["loss"]
- return (loss,)
-
- @property
- def pad(self) -> int:
- raise NotImplementedError("pad not implemented")
-
- def training_step(self, batch, batch_idx) -> Dict:
- loss_tensors = self._step(batch)
-
- logs = {name: loss.detach() for name, loss in zip(self.loss_names, loss_tensors)}
- # tokens per batch
- tgt_pad_token_id = (
- self.tokenizer.generator.pad_token_id
- if isinstance(self.tokenizer, RagTokenizer)
- else self.tokenizer.pad_token_id
- )
- src_pad_token_id = (
- self.tokenizer.question_encoder.pad_token_id
- if isinstance(self.tokenizer, RagTokenizer)
- else self.tokenizer.pad_token_id
- )
- logs["tpb"] = (
- batch["input_ids"].ne(src_pad_token_id).sum() + batch["decoder_input_ids"].ne(tgt_pad_token_id).sum()
- )
-
- return {"loss": loss_tensors[0], "log": logs}
-
- def validation_step(self, batch, batch_idx) -> Dict:
- return self._generative_step(batch)
-
- def validation_epoch_end(self, outputs, prefix="val") -> Dict:
- self.step_count += 1
- losses = {k: torch.stack([x[k] for x in outputs]).mean() for k in self.loss_names}
- loss = losses["loss"]
- gen_metrics = {
- k: np.array([x[k] for x in outputs]).mean() for k in self.metric_names + ["gen_time", "gen_len"]
- }
- metrics_tensor: torch.FloatTensor = torch.tensor(gen_metrics[self.val_metric]).type_as(loss)
- gen_metrics.update({k: v.item() for k, v in losses.items()})
-
- # fix for https://github.com/PyTorchLightning/pytorch-lightning/issues/2424
- if dist.is_initialized():
- dist.all_reduce(metrics_tensor, op=dist.ReduceOp.SUM)
- metrics_tensor = metrics_tensor / dist.get_world_size()
- gen_metrics.update({self.val_metric: metrics_tensor.item()})
-
- losses.update(gen_metrics)
- metrics = {f"{prefix}_avg_{k}": x for k, x in losses.items()}
- metrics["step_count"] = self.step_count
- self.save_metrics(metrics, prefix) # writes to self.metrics_save_path
- preds = flatten_list([x["preds"] for x in outputs])
- return {"log": metrics, "preds": preds, f"{prefix}_loss": loss, f"{prefix}_{self.val_metric}": metrics_tensor}
-
- def save_metrics(self, latest_metrics, type_path) -> None:
- self.metrics[type_path].append(latest_metrics)
- save_json(self.metrics, self.metrics_save_path)
-
- def calc_generative_metrics(self, preds, target) -> Dict:
- return calculate_exact_match(preds, target)
-
- def _generative_step(self, batch: dict) -> dict:
- start_time = time.time()
- batch = BatchEncoding(batch).to(device=self.model.device)
- generated_ids = self.model.generate(
- batch["input_ids"],
- attention_mask=batch["attention_mask"],
- do_deduplication=False, # rag specific parameter
- use_cache=True,
- min_length=1,
- max_length=self.target_lens["val"],
- )
-
- gen_time = (time.time() - start_time) / batch["input_ids"].shape[0]
- preds: List[str] = self.ids_to_clean_text(generated_ids)
- target: List[str] = self.ids_to_clean_text(batch["decoder_input_ids"])
- loss_tensors = self._step(batch)
- base_metrics = dict(zip(self.loss_names, loss_tensors))
- gen_metrics: Dict = self.calc_generative_metrics(preds, target)
-
- summ_len = np.mean(lmap(len, generated_ids))
- base_metrics.update(gen_time=gen_time, gen_len=summ_len, preds=preds, target=target, **gen_metrics)
- return base_metrics
-
- def test_step(self, batch, batch_idx):
- return self._generative_step(batch)
-
- def test_epoch_end(self, outputs):
- return self.validation_epoch_end(outputs, prefix="test")
-
- def get_dataset(self, type_path) -> Seq2SeqDataset:
- n_obs = self.n_obs[type_path]
- max_target_length = self.target_lens[type_path]
- dataset = Seq2SeqDataset(
- self.tokenizer,
- type_path=type_path,
- n_obs=n_obs,
- max_target_length=max_target_length,
- **self.dataset_kwargs,
- )
- return dataset
-
- def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False) -> DataLoader:
- dataset = self.get_dataset(type_path)
-
- dataloader = DataLoader(
- dataset,
- batch_size=batch_size,
- collate_fn=dataset.collate_fn,
- shuffle=shuffle,
- num_workers=self.num_workers,
- )
- return dataloader
-
- def train_dataloader(self) -> DataLoader:
- dataloader = self.get_dataloader("train", batch_size=self.hparams.train_batch_size, shuffle=True)
- return dataloader
-
- def val_dataloader(self) -> DataLoader:
- return self.get_dataloader("val", batch_size=self.hparams.eval_batch_size)
-
- def test_dataloader(self) -> DataLoader:
- return self.get_dataloader("test", batch_size=self.hparams.eval_batch_size)
-
- @pl.utilities.rank_zero_only
- def on_save_checkpoint(self, checkpoint: Dict[str, Any]) -> None:
- save_path = self.output_dir.joinpath("checkpoint{}".format(self.step_count))
- self.model.config.save_step = self.step_count
- self.model.save_pretrained(save_path)
- self.tokenizer.save_pretrained(save_path)
-
- @staticmethod
- def add_model_specific_args(parser, root_dir):
- BaseTransformer.add_model_specific_args(parser, root_dir)
- add_generic_args(parser, root_dir)
- parser.add_argument(
- "--max_source_length",
- default=128,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument(
- "--max_target_length",
- default=25,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument(
- "--val_max_target_length",
- default=25,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument(
- "--test_max_target_length",
- default=25,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument("--logger_name", type=str, choices=["default", "wandb", "wandb_shared"], default="default")
- parser.add_argument("--n_train", type=int, default=-1, required=False, help="# examples. -1 means use all.")
- parser.add_argument("--n_val", type=int, default=-1, required=False, help="# examples. -1 means use all.")
- parser.add_argument("--n_test", type=int, default=-1, required=False, help="# examples. -1 means use all.")
- parser.add_argument("--label_smoothing", type=float, default=0.0, required=False)
- parser.add_argument(
- "--prefix",
- type=str,
- default=None,
- help="Prefix added at the beginning of each text, typically used with T5-based models.",
- )
- parser.add_argument(
- "--early_stopping_patience",
- type=int,
- default=-1,
- required=False,
- help=(
- "-1 means never early stop. early_stopping_patience is measured in validation checks, not epochs. So"
- " val_check_interval will effect it."
- ),
- )
- parser.add_argument(
- "--distributed-port", type=int, default=-1, required=False, help="Port number for distributed training."
- )
- parser.add_argument(
- "--model_type",
- choices=["rag_sequence", "rag_token", "bart", "t5"],
- type=str,
- help=(
- "RAG model type: sequence or token, if none specified, the type is inferred from the"
- " model_name_or_path"
- ),
- )
- return parser
-
- @staticmethod
- def add_retriever_specific_args(parser):
- parser.add_argument(
- "--index_name",
- type=str,
- default=None,
- help=(
- "Name of the index to use: 'hf' for a canonical dataset from the datasets library (default), 'custom'"
- " for a local index, or 'legacy' for the original one)"
- ),
- )
- parser.add_argument(
- "--passages_path",
- type=str,
- default=None,
- help=(
- "Path to the dataset of passages for custom index. More info about custom indexes in the RagRetriever"
- " documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
- ),
- )
- parser.add_argument(
- "--index_path",
- type=str,
- default=None,
- help=(
- "Path to the faiss index for custom index. More info about custom indexes in the RagRetriever"
- " documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
- ),
- )
- parser.add_argument(
- "--distributed_retriever",
- choices=["ray", "pytorch"],
- type=str,
- default="pytorch",
- help=(
- "What implementation to use for distributed retriever? If "
- "pytorch is selected, the index is loaded on training "
- "worker 0, and torch.distributed is used to handle "
- "communication between training worker 0, and the other "
- "training workers. If ray is selected, the Ray library is "
- "used to create load the index on separate processes, "
- "and Ray handles the communication between the training "
- "workers and the retrieval actors."
- ),
- )
- parser.add_argument(
- "--use_dummy_dataset",
- type=bool,
- default=False,
- help=(
- "Whether to use the dummy version of the dataset index. More info about custom indexes in the"
- " RagRetriever documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
- ),
- )
- return parser
-
- @staticmethod
- def add_ray_specific_args(parser):
- # Ray cluster address.
- parser.add_argument(
- "--ray-address",
- default="auto",
- type=str,
- help=(
- "The address of the Ray cluster to connect to. If not "
- "specified, Ray will attempt to automatically detect the "
- "cluster. Has no effect if pytorch is used as the distributed "
- "retriever."
- ),
- )
- parser.add_argument(
- "--num_retrieval_workers",
- type=int,
- default=1,
- help=(
- "The number of retrieval actors to use when Ray is selected "
- "for the distributed retriever. Has no effect when "
- "distributed_retriever is set to pytorch."
- ),
- )
- return parser
-
-
-def main(args=None, model=None) -> GenerativeQAModule:
- parser = argparse.ArgumentParser()
- parser = pl.Trainer.add_argparse_args(parser)
- parser = GenerativeQAModule.add_model_specific_args(parser, os.getcwd())
- parser = GenerativeQAModule.add_retriever_specific_args(parser)
-
- args = args or parser.parse_args()
-
- Path(args.output_dir).mkdir(exist_ok=True)
-
- named_actors = []
- if args.distributed_retriever == "ray" and args.gpus > 1:
- if not is_ray_available():
- raise RuntimeError("Please install Ray to use the Ray distributed retriever.")
- # Connect to an existing Ray cluster.
- try:
- ray.init(address=args.ray_address, namespace="rag")
- except (ConnectionError, ValueError):
- logger.warning(
- "Connection to Ray cluster failed. Make sure a Ray "
- "cluster is running by either using Ray's cluster "
- "launcher (`ray up`) or by manually starting Ray on "
- "each node via `ray start --head` for the head node "
- "and `ray start --address=':6379'` for "
- "additional nodes. See "
- "https://docs.ray.io/en/master/cluster/index.html "
- "for more info."
- )
- raise
-
- # Create Ray actors only for rank 0.
- if ("LOCAL_RANK" not in os.environ or int(os.environ["LOCAL_RANK"]) == 0) and (
- "NODE_RANK" not in os.environ or int(os.environ["NODE_RANK"]) == 0
- ):
- remote_cls = ray.remote(RayRetriever)
- named_actors = [
- remote_cls.options(name="retrieval_worker_{}".format(i)).remote()
- for i in range(args.num_retrieval_workers)
- ]
- else:
- logger.info(
- "Getting named actors for NODE_RANK {}, LOCAL_RANK {}".format(
- os.environ["NODE_RANK"], os.environ["LOCAL_RANK"]
- )
- )
- named_actors = [ray.get_actor("retrieval_worker_{}".format(i)) for i in range(args.num_retrieval_workers)]
- args.actor_handles = named_actors
- assert args.actor_handles == named_actors
-
- if model is None:
- model: GenerativeQAModule = GenerativeQAModule(args)
-
- dataset = Path(args.data_dir).name
- if (
- args.logger_name == "default"
- or args.fast_dev_run
- or str(args.output_dir).startswith("/tmp")
- or str(args.output_dir).startswith("/var")
- ):
- training_logger = True # don't pollute wandb logs unnecessarily
- elif args.logger_name == "wandb":
- from pytorch_lightning.loggers import WandbLogger
-
- project = os.environ.get("WANDB_PROJECT", dataset)
- training_logger = WandbLogger(name=model.output_dir.name, project=project)
-
- elif args.logger_name == "wandb_shared":
- from pytorch_lightning.loggers import WandbLogger
-
- training_logger = WandbLogger(name=model.output_dir.name, project=f"hf_{dataset}")
-
- es_callback = (
- get_early_stopping_callback(model.val_metric, args.early_stopping_patience)
- if args.early_stopping_patience >= 0
- else False
- )
-
- trainer: pl.Trainer = generic_train(
- model,
- args,
- logging_callback=Seq2SeqLoggingCallback(),
- checkpoint_callback=get_checkpoint_callback(args.output_dir, model.val_metric),
- early_stopping_callback=es_callback,
- logger=training_logger,
- custom_ddp_plugin=CustomDDP() if args.gpus > 1 else None,
- profiler=pl.profiler.AdvancedProfiler() if args.profile else None,
- )
- pickle_save(model.hparams, model.output_dir / "hparams.pkl")
-
- if not args.do_predict:
- return model
-
- # test() without a model tests using the best checkpoint automatically
- trainer.test()
- return model
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser = pl.Trainer.add_argparse_args(parser)
- parser = GenerativeQAModule.add_model_specific_args(parser, os.getcwd())
- parser = GenerativeQAModule.add_retriever_specific_args(parser)
- parser = GenerativeQAModule.add_ray_specific_args(parser)
-
- # Pytorch Lightning Profiler
- parser.add_argument(
- "--profile",
- action="store_true",
- help="If True, use pytorch_lightning.profiler.AdvancedProfiler to profile the Trainer.",
- )
-
- args = parser.parse_args()
-
- main(args)
diff --git a/examples/research_projects/rag/finetune_rag.sh b/examples/research_projects/rag/finetune_rag.sh
deleted file mode 100755
index 8fd1fea3e54..00000000000
--- a/examples/research_projects/rag/finetune_rag.sh
+++ /dev/null
@@ -1,34 +0,0 @@
-# Add parent directory to python path to access lightning_base.py
-export PYTHONPATH="../":"${PYTHONPATH}"
-
-# A sample finetuning run, you need to specify data_dir, output_dir and model_name_or_path
-# run ./examples/rag/finetune_rag.sh --help to see all the possible options
-
-python examples/rag/finetune_rag.py \
- --data_dir $DATA_DIR \
- --output_dir $OUTPUT_DIR \
- --model_name_or_path $MODEL_NAME_OR_PATH \
- --model_type rag_sequence \
- --fp16 \
- --gpus 8 \
- --profile \
- --do_train \
- --do_predict \
- --n_val -1 \
- --train_batch_size 8 \
- --eval_batch_size 1 \
- --max_source_length 128 \
- --max_target_length 25 \
- --val_max_target_length 25 \
- --test_max_target_length 25 \
- --label_smoothing 0.1 \
- --dropout 0.1 \
- --attention_dropout 0.1 \
- --weight_decay 0.001 \
- --adam_epsilon 1e-08 \
- --max_grad_norm 0.1 \
- --lr_scheduler polynomial \
- --learning_rate 3e-05 \
- --num_train_epochs 100 \
- --warmup_steps 500 \
- --gradient_accumulation_steps 1 \
diff --git a/examples/research_projects/rag/finetune_rag_ray.sh b/examples/research_projects/rag/finetune_rag_ray.sh
deleted file mode 100755
index 7c8e7b97e77..00000000000
--- a/examples/research_projects/rag/finetune_rag_ray.sh
+++ /dev/null
@@ -1,44 +0,0 @@
-# Sample script to finetune RAG using Ray for distributed retrieval.
-
-# Add parent directory to python path to access lightning_base.py
-export PYTHONPATH="../":"${PYTHONPATH}"
-
-# Start a single-node Ray cluster.
-ray start --head
-
-# A sample finetuning run, you need to specify data_dir, output_dir and model_name_or_path
-# run ./examples/rag/finetune_rag_ray.sh --help to see all the possible options
-
-python examples/rag/finetune_rag.py \
- --data_dir $DATA_DIR \
- --output_dir $OUTPUT_DIR \
- --model_name_or_path $MODEL_NAME_OR_PATH \
- --model_type rag_sequence \
- --fp16 \
- --gpus 8 \
- --profile \
- --do_train \
- --do_predict \
- --n_val -1 \
- --train_batch_size 8 \
- --eval_batch_size 1 \
- --max_source_length 128 \
- --max_target_length 25 \
- --val_max_target_length 25 \
- --test_max_target_length 25 \
- --label_smoothing 0.1 \
- --dropout 0.1 \
- --attention_dropout 0.1 \
- --weight_decay 0.001 \
- --adam_epsilon 1e-08 \
- --max_grad_norm 0.1 \
- --lr_scheduler polynomial \
- --learning_rate 3e-05 \
- --num_train_epochs 100 \
- --warmup_steps 500 \
- --gradient_accumulation_steps 1 \
- --distributed_retriever ray \
- --num_retrieval_workers 4
-
-# Stop the Ray cluster.
-ray stop
diff --git a/examples/research_projects/rag/lightning_base.py b/examples/research_projects/rag/lightning_base.py
deleted file mode 100644
index 12099bc3aa1..00000000000
--- a/examples/research_projects/rag/lightning_base.py
+++ /dev/null
@@ -1,404 +0,0 @@
-import argparse
-import logging
-import os
-from pathlib import Path
-from typing import Any, Dict
-
-import pytorch_lightning as pl
-from pytorch_lightning.utilities import rank_zero_info
-
-from transformers import (
- AdamW,
- AutoConfig,
- AutoModel,
- AutoModelForPreTraining,
- AutoModelForQuestionAnswering,
- AutoModelForSeq2SeqLM,
- AutoModelForSequenceClassification,
- AutoModelForTokenClassification,
- AutoModelWithLMHead,
- AutoTokenizer,
- PretrainedConfig,
- PreTrainedTokenizer,
-)
-from transformers.optimization import (
- Adafactor,
- get_cosine_schedule_with_warmup,
- get_cosine_with_hard_restarts_schedule_with_warmup,
- get_linear_schedule_with_warmup,
- get_polynomial_decay_schedule_with_warmup,
-)
-from transformers.utils.versions import require_version
-
-
-logger = logging.getLogger(__name__)
-
-require_version("pytorch_lightning>=1.0.4")
-
-MODEL_MODES = {
- "base": AutoModel,
- "sequence-classification": AutoModelForSequenceClassification,
- "question-answering": AutoModelForQuestionAnswering,
- "pretraining": AutoModelForPreTraining,
- "token-classification": AutoModelForTokenClassification,
- "language-modeling": AutoModelWithLMHead,
- "summarization": AutoModelForSeq2SeqLM,
- "translation": AutoModelForSeq2SeqLM,
-}
-
-
-# update this and the import above to support new schedulers from transformers.optimization
-arg_to_scheduler = {
- "linear": get_linear_schedule_with_warmup,
- "cosine": get_cosine_schedule_with_warmup,
- "cosine_w_restarts": get_cosine_with_hard_restarts_schedule_with_warmup,
- "polynomial": get_polynomial_decay_schedule_with_warmup,
- # '': get_constant_schedule, # not supported for now
- # '': get_constant_schedule_with_warmup, # not supported for now
-}
-arg_to_scheduler_choices = sorted(arg_to_scheduler.keys())
-arg_to_scheduler_metavar = "{" + ", ".join(arg_to_scheduler_choices) + "}"
-
-
-class BaseTransformer(pl.LightningModule):
- def __init__(
- self,
- hparams: argparse.Namespace,
- num_labels=None,
- mode="base",
- config=None,
- tokenizer=None,
- model=None,
- **config_kwargs,
- ):
- """Initialize a model, tokenizer and config."""
- super().__init__()
- # TODO: move to self.save_hyperparameters()
- # self.save_hyperparameters()
- # can also expand arguments into trainer signature for easier reading
-
- self.save_hyperparameters(hparams)
- self.step_count = 0
- self.output_dir = Path(self.hparams.output_dir)
- cache_dir = self.hparams.cache_dir if self.hparams.cache_dir else None
- if config is None:
- self.config = AutoConfig.from_pretrained(
- self.hparams.config_name if self.hparams.config_name else self.hparams.model_name_or_path,
- **({"num_labels": num_labels} if num_labels is not None else {}),
- cache_dir=cache_dir,
- **config_kwargs,
- )
- else:
- self.config: PretrainedConfig = config
-
- extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "dropout", "attention_dropout")
- for p in extra_model_params:
- if getattr(self.hparams, p, None):
- assert hasattr(self.config, p), f"model config doesn't have a `{p}` attribute"
- setattr(self.config, p, getattr(self.hparams, p))
-
- if tokenizer is None:
- self.tokenizer = AutoTokenizer.from_pretrained(
- self.hparams.tokenizer_name if self.hparams.tokenizer_name else self.hparams.model_name_or_path,
- cache_dir=cache_dir,
- )
- else:
- self.tokenizer: PreTrainedTokenizer = tokenizer
- self.model_type = MODEL_MODES[mode]
- if model is None:
- self.model = self.model_type.from_pretrained(
- self.hparams.model_name_or_path,
- from_tf=bool(".ckpt" in self.hparams.model_name_or_path),
- config=self.config,
- cache_dir=cache_dir,
- )
- else:
- self.model = model
-
- def load_hf_checkpoint(self, *args, **kwargs):
- self.model = self.model_type.from_pretrained(*args, **kwargs)
-
- def get_lr_scheduler(self):
- get_schedule_func = arg_to_scheduler[self.hparams.lr_scheduler]
- scheduler = get_schedule_func(
- self.opt, num_warmup_steps=self.hparams.warmup_steps, num_training_steps=self.total_steps()
- )
- scheduler = {"scheduler": scheduler, "interval": "step", "frequency": 1}
- return scheduler
-
- def configure_optimizers(self):
- """Prepare optimizer and schedule (linear warmup and decay)"""
- model = self.model
- no_decay = ["bias", "LayerNorm.weight"]
- optimizer_grouped_parameters = [
- {
- "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
- "weight_decay": self.hparams.weight_decay,
- },
- {
- "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
- "weight_decay": 0.0,
- },
- ]
- if self.hparams.adafactor:
- optimizer = Adafactor(
- optimizer_grouped_parameters, lr=self.hparams.learning_rate, scale_parameter=False, relative_step=False
- )
-
- else:
- optimizer = AdamW(
- optimizer_grouped_parameters, lr=self.hparams.learning_rate, eps=self.hparams.adam_epsilon
- )
- self.opt = optimizer
-
- scheduler = self.get_lr_scheduler()
-
- return [optimizer], [scheduler]
-
- def test_step(self, batch, batch_nb):
- return self.validation_step(batch, batch_nb)
-
- def test_epoch_end(self, outputs):
- return self.validation_end(outputs)
-
- def total_steps(self) -> int:
- """The number of total training steps that will be run. Used for lr scheduler purposes."""
- num_devices = max(1, self.hparams.gpus) # TODO: consider num_tpu_cores
- effective_batch_size = self.hparams.train_batch_size * self.hparams.accumulate_grad_batches * num_devices
- return (self.dataset_size / effective_batch_size) * self.hparams.max_epochs
-
- def setup(self, stage):
- if stage == "test":
- self.dataset_size = len(self.test_dataloader().dataset)
- else:
- self.train_loader = self.get_dataloader("train", self.hparams.train_batch_size, shuffle=True)
- self.dataset_size = len(self.train_dataloader().dataset)
-
- def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False):
- raise NotImplementedError("You must implement this for your task")
-
- def train_dataloader(self):
- return self.train_loader
-
- def val_dataloader(self):
- return self.get_dataloader("dev", self.hparams.eval_batch_size, shuffle=False)
-
- def test_dataloader(self):
- return self.get_dataloader("test", self.hparams.eval_batch_size, shuffle=False)
-
- def _feature_file(self, mode):
- return os.path.join(
- self.hparams.data_dir,
- "cached_{}_{}_{}".format(
- mode,
- list(filter(None, self.hparams.model_name_or_path.split("/"))).pop(),
- str(self.hparams.max_seq_length),
- ),
- )
-
- @pl.utilities.rank_zero_only
- def on_save_checkpoint(self, checkpoint: Dict[str, Any]) -> None:
- save_path = self.output_dir.joinpath("best_tfmr")
- self.model.config.save_step = self.step_count
- self.model.save_pretrained(save_path)
- self.tokenizer.save_pretrained(save_path)
-
- @staticmethod
- def add_model_specific_args(parser, root_dir):
- parser.add_argument(
- "--model_name_or_path",
- default=None,
- type=str,
- required=True,
- help="Path to pretrained model or model identifier from huggingface.co/models",
- )
- parser.add_argument(
- "--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
- )
- parser.add_argument(
- "--tokenizer_name",
- default=None,
- type=str,
- help="Pretrained tokenizer name or path if not the same as model_name",
- )
- parser.add_argument(
- "--cache_dir",
- default="",
- type=str,
- help="Where do you want to store the pre-trained models downloaded from huggingface.co",
- )
- parser.add_argument(
- "--encoder_layerdrop",
- type=float,
- help="Encoder layer dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument(
- "--decoder_layerdrop",
- type=float,
- help="Decoder layer dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument(
- "--dropout",
- type=float,
- help="Dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument(
- "--attention_dropout",
- type=float,
- help="Attention dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
- parser.add_argument(
- "--lr_scheduler",
- default="linear",
- choices=arg_to_scheduler_choices,
- metavar=arg_to_scheduler_metavar,
- type=str,
- help="Learning rate scheduler",
- )
- parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
- parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
- parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
- parser.add_argument("--num_workers", default=4, type=int, help="kwarg passed to DataLoader")
- parser.add_argument("--num_train_epochs", dest="max_epochs", default=3, type=int)
- parser.add_argument("--train_batch_size", default=32, type=int)
- parser.add_argument("--eval_batch_size", default=32, type=int)
- parser.add_argument("--adafactor", action="store_true")
-
-
-class InitCallback(pl.Callback):
- # This method is better that using a custom DDP plugging with the latest pytorch-lightning (@shamanez)
- def on_sanity_check_start(self, trainer, pl_module):
- if (
- trainer.is_global_zero and trainer.global_rank == 0
- ): # we initialize the retriever only on master worker with RAY. In new pytorch-lightning accelorators are removed.
- pl_module.model.rag.retriever.init_retrieval() # better to use hook functions.
-
-
-class LoggingCallback(pl.Callback):
- def on_batch_end(self, trainer, pl_module):
- lr_scheduler = trainer.lr_schedulers[0]["scheduler"]
- lrs = {f"lr_group_{i}": lr for i, lr in enumerate(lr_scheduler.get_lr())}
- pl_module.logger.log_metrics(lrs)
-
- def on_validation_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
- rank_zero_info("***** Validation results *****")
- metrics = trainer.callback_metrics
- # Log results
- for key in sorted(metrics):
- if key not in ["log", "progress_bar"]:
- rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
-
- def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
- rank_zero_info("***** Test results *****")
- metrics = trainer.callback_metrics
- # Log and save results to file
- output_test_results_file = os.path.join(pl_module.hparams.output_dir, "test_results.txt")
- with open(output_test_results_file, "w") as writer:
- for key in sorted(metrics):
- if key not in ["log", "progress_bar"]:
- rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
- writer.write("{} = {}\n".format(key, str(metrics[key])))
-
-
-def add_generic_args(parser, root_dir) -> None:
- # To allow all pl args uncomment the following line
- # parser = pl.Trainer.add_argparse_args(parser)
- parser.add_argument(
- "--output_dir",
- default=None,
- type=str,
- required=True,
- help="The output directory where the model predictions and checkpoints will be written.",
- )
- parser.add_argument(
- "--fp16",
- action="store_true",
- help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
- )
-
- parser.add_argument(
- "--fp16_opt_level",
- type=str,
- default="O2",
- help=(
- "For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
- "See details at https://nvidia.github.io/apex/amp.html"
- ),
- )
- parser.add_argument("--n_tpu_cores", dest="tpu_cores", type=int)
- parser.add_argument("--max_grad_norm", dest="gradient_clip_val", default=1.0, type=float, help="Max gradient norm")
- parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
- parser.add_argument("--do_predict", action="store_true", help="Whether to run predictions on the test set.")
- parser.add_argument(
- "--gradient_accumulation_steps",
- dest="accumulate_grad_batches",
- type=int,
- default=1,
- help="Number of updates steps to accumulate before performing a backward/update pass.",
- )
- parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
- parser.add_argument(
- "--data_dir",
- default=None,
- type=str,
- required=True,
- help="The input data dir. Should contain the training files for the CoNLL-2003 NER task.",
- )
-
-
-def generic_train(
- model: BaseTransformer,
- args: argparse.Namespace,
- early_stopping_callback=None,
- logger=True, # can pass WandbLogger() here
- custom_ddp_plugin=None,
- extra_callbacks=[],
- checkpoint_callback=None,
- logging_callback=None,
- **extra_train_kwargs,
-):
- pl.seed_everything(args.seed)
-
- # init model
- odir = Path(model.hparams.output_dir)
- odir.mkdir(exist_ok=True)
-
- # add custom checkpoints
- if checkpoint_callback is None:
- checkpoint_callback = pl.callbacks.ModelCheckpoint(
- filepath=args.output_dir, prefix="checkpoint", monitor="val_loss", mode="min", save_top_k=1
- )
- if early_stopping_callback:
- extra_callbacks.append(early_stopping_callback)
- if logging_callback is None:
- logging_callback = LoggingCallback()
-
- train_params = {}
-
- # TODO: remove with PyTorch 1.6 since pl uses native amp
- if args.fp16:
- train_params["precision"] = 16
- # train_params["amp_level"] = args.fp16_opt_level
-
- if args.gpus > 1:
- train_params["accelerator"] = "auto" # "ddp"
- train_params["strategy"] = "ddp"
-
- train_params["accumulate_grad_batches"] = args.accumulate_grad_batches
- train_params["profiler"] = None # extra_train_kwargs.get("profiler", None) #get unwanted logs
- train_params["devices"] = "auto"
-
- trainer = pl.Trainer.from_argparse_args(
- args,
- weights_summary=None,
- callbacks=[logging_callback] + extra_callbacks + [checkpoint_callback] + [InitCallback()],
- # plugins=[custom_ddp_plugin],
- logger=logger,
- **train_params,
- )
-
- if args.do_train:
- trainer.fit(model)
-
- return trainer
diff --git a/examples/research_projects/rag/parse_dpr_relevance_data.py b/examples/research_projects/rag/parse_dpr_relevance_data.py
deleted file mode 100644
index 4d8a1e5f467..00000000000
--- a/examples/research_projects/rag/parse_dpr_relevance_data.py
+++ /dev/null
@@ -1,47 +0,0 @@
-"""
-This script reads DPR retriever training data and parses each datapoint. We save a line per datapoint.
-Each line consists of the query followed by a tab-separated list of Wikipedia page titles constituting
-positive contexts for a given query.
-"""
-
-import argparse
-import json
-
-from tqdm import tqdm
-
-
-def main():
- parser = argparse.ArgumentParser()
-
- # Required parameters
- parser.add_argument(
- "--src_path",
- type=str,
- default="biencoder-nq-dev.json",
- help="Path to raw DPR training data",
- )
- parser.add_argument(
- "--evaluation_set",
- type=str,
- help="where to store parsed evaluation_set file",
- )
- parser.add_argument(
- "--gold_data_path",
- type=str,
- help="where to store parsed gold_data_path file",
- )
- args = parser.parse_args()
-
- with open(args.src_path, "r") as src_file, open(args.evaluation_set, "w") as eval_file, open(
- args.gold_data_path, "w"
- ) as gold_file:
- dpr_records = json.load(src_file)
- for dpr_record in tqdm(dpr_records):
- question = dpr_record["question"]
- contexts = [context["title"] for context in dpr_record["positive_ctxs"]]
- eval_file.write(question + "\n")
- gold_file.write("\t".join(contexts) + "\n")
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/rag/requirements.txt b/examples/research_projects/rag/requirements.txt
deleted file mode 100644
index 5988d38de9e..00000000000
--- a/examples/research_projects/rag/requirements.txt
+++ /dev/null
@@ -1,8 +0,0 @@
-faiss-cpu >= 1.6.3
-datasets >= 1.0.1
-psutil >= 5.7.0
-torch >= 1.4.0
-ray >= 1.10.0
-pytorch-lightning >= 1.5.10, <=1.6.0
-transformers
-GitPython
\ No newline at end of file
diff --git a/examples/research_projects/rag/test_data/my_knowledge_dataset.csv b/examples/research_projects/rag/test_data/my_knowledge_dataset.csv
deleted file mode 100644
index 76da009a2f2..00000000000
--- a/examples/research_projects/rag/test_data/my_knowledge_dataset.csv
+++ /dev/null
@@ -1,2 +0,0 @@
-Aaron Aaron Aaron ( or ; "Ahärôn") is a prophet, high priest, and the brother of Moses in the Abrahamic religions. Knowledge of Aaron, along with his brother Moses, comes exclusively from religious texts, such as the Bible and Quran. The Hebrew Bible relates that, unlike Moses, who grew up in the Egyptian royal court, Aaron and his elder sister Miriam remained with their kinsmen in the eastern border-land of Egypt (Goshen). When Moses first confronted the Egyptian king about the Israelites, Aaron served as his brother's spokesman ("prophet") to the Pharaoh. Part of the Law (Torah) that Moses received from God at Sinai granted Aaron the priesthood for himself and his male descendants, and he became the first High Priest of the Israelites. Aaron died before the Israelites crossed the North Jordan river and he was buried on Mount Hor (Numbers 33:39; Deuteronomy 10:6 says he died and was buried at Moserah). Aaron is also mentioned in the New Testament of the Bible. According to the Book of Exodus, Aaron first functioned as Moses' assistant. Because Moses complained that he could not speak well, God appointed Aaron as Moses' "prophet" (Exodus 4:10-17; 7:1). At the command of Moses, he let his rod turn into a snake. Then he stretched out his rod in order to bring on the first three plagues. After that, Moses tended to act and speak for himself. During the journey in the wilderness, Aaron was not always prominent or active. At the battle with Amalek, he was chosen with Hur to support the hand of Moses that held the "rod of God". When the revelation was given to Moses at biblical Mount Sinai, he headed the elders of Israel who accompanied Moses on the way to the summit.
-"Pokémon" Pokémon , also known as in Japan, is a media franchise managed by The Pokémon Company, a Japanese consortium between Nintendo, Game Freak, and Creatures. The franchise copyright is shared by all three companies, but Nintendo is the sole owner of the trademark. The franchise was created by Satoshi Tajiri in 1995, and is centered on fictional creatures called "Pokémon", which humans, known as Pokémon Trainers, catch and train to battle each other for sport. The English slogan for the franchise is "Gotta Catch 'Em All". Works within the franchise are set in the Pokémon universe. The franchise began as "Pokémon Red" and "Green" (released outside of Japan as "Pokémon Red" and "Blue"), a pair of video games for the original Game Boy that were developed by Game Freak and published by Nintendo in February 1996. "Pokémon" has since gone on to become the highest-grossing media franchise of all time, with over in revenue up until March 2017. The original video game series is the second best-selling video game franchise (behind Nintendo's "Mario" franchise) with more than 300million copies sold and over 800million mobile downloads. In addition, the "Pokémon" franchise includes the world's top-selling toy brand, the top-selling trading card game with over 25.7billion cards sold, an anime television series that has become the most successful video game adaptation with over 20 seasons and 1,000 episodes in 124 countries, as well as an anime film series, a , books, manga comics, music, and merchandise. The franchise is also represented in other Nintendo media, such as the "Super Smash Bros." series. In November 2005, 4Kids Entertainment, which had managed the non-game related licensing of "Pokémon", announced that it had agreed not to renew the "Pokémon" representation agreement. The Pokémon Company International oversees all "Pokémon" licensing outside Asia.
\ No newline at end of file
diff --git a/examples/research_projects/rag/test_distributed_retriever.py b/examples/research_projects/rag/test_distributed_retriever.py
deleted file mode 100644
index 7e75e0a7a7e..00000000000
--- a/examples/research_projects/rag/test_distributed_retriever.py
+++ /dev/null
@@ -1,338 +0,0 @@
-import json
-import os
-import shutil
-import sys
-import tempfile
-import unittest
-from unittest import TestCase
-from unittest.mock import patch
-
-import faiss
-import numpy as np
-from datasets import Dataset
-
-from transformers import BartConfig, BartTokenizer, DPRConfig, DPRQuestionEncoderTokenizer, RagConfig
-from transformers.file_utils import is_datasets_available, is_faiss_available, is_psutil_available, is_torch_available
-from transformers.integrations import is_ray_available
-from transformers.models.bert.tokenization_bert import VOCAB_FILES_NAMES as DPR_VOCAB_FILES_NAMES
-from transformers.models.rag.retrieval_rag import CustomHFIndex, RagRetriever
-from transformers.models.roberta.tokenization_roberta import VOCAB_FILES_NAMES as BART_VOCAB_FILES_NAMES
-from transformers.testing_utils import require_ray
-
-
-sys.path.append(os.path.join(os.getcwd())) # noqa: E402 # noqa: E402 # isort:skip
-
-if is_torch_available():
- from distributed_pytorch_retriever import RagPyTorchDistributedRetriever # noqa: E402 # isort:skip
-else:
- RagPyTorchDistributedRetriever = None
-
-if is_ray_available():
- import ray # noqa: E402 # isort:skip
- from distributed_ray_retriever import RagRayDistributedRetriever, RayRetriever # noqa: E402 # isort:skip
-else:
- ray = None
- RagRayDistributedRetriever = None
- RayRetriever = None
-
-
-def require_distributed_retrieval(test_case):
- """
- Decorator marking a test that requires a set of dependencies necessary for pefrorm retrieval with
- :class:`~transformers.RagRetriever`.
-
- These tests are skipped when respective libraries are not installed.
-
- """
- if not (is_datasets_available() and is_faiss_available() and is_psutil_available()):
- test_case = unittest.skip("test requires Datasets, Faiss, psutil")(test_case)
- return test_case
-
-
-@require_distributed_retrieval
-class RagRetrieverTest(TestCase):
- def setUp(self):
- self.tmpdirname = tempfile.mkdtemp()
- self.retrieval_vector_size = 8
-
- # DPR tok
- vocab_tokens = [
- "[UNK]",
- "[CLS]",
- "[SEP]",
- "[PAD]",
- "[MASK]",
- "want",
- "##want",
- "##ed",
- "wa",
- "un",
- "runn",
- "##ing",
- ",",
- "low",
- "lowest",
- ]
- dpr_tokenizer_path = os.path.join(self.tmpdirname, "dpr_tokenizer")
- os.makedirs(dpr_tokenizer_path, exist_ok=True)
- self.vocab_file = os.path.join(dpr_tokenizer_path, DPR_VOCAB_FILES_NAMES["vocab_file"])
- with open(self.vocab_file, "w", encoding="utf-8") as vocab_writer:
- vocab_writer.write("".join([x + "\n" for x in vocab_tokens]))
-
- # BART tok
- vocab = [
- "l",
- "o",
- "w",
- "e",
- "r",
- "s",
- "t",
- "i",
- "d",
- "n",
- "\u0120",
- "\u0120l",
- "\u0120n",
- "\u0120lo",
- "\u0120low",
- "er",
- "\u0120lowest",
- "\u0120newer",
- "\u0120wider",
- "",
- ]
- vocab_tokens = dict(zip(vocab, range(len(vocab))))
- merges = ["#version: 0.2", "\u0120 l", "\u0120l o", "\u0120lo w", "e r", ""]
- self.special_tokens_map = {"unk_token": ""}
-
- bart_tokenizer_path = os.path.join(self.tmpdirname, "bart_tokenizer")
- os.makedirs(bart_tokenizer_path, exist_ok=True)
- self.vocab_file = os.path.join(bart_tokenizer_path, BART_VOCAB_FILES_NAMES["vocab_file"])
- self.merges_file = os.path.join(bart_tokenizer_path, BART_VOCAB_FILES_NAMES["merges_file"])
- with open(self.vocab_file, "w", encoding="utf-8") as fp:
- fp.write(json.dumps(vocab_tokens) + "\n")
- with open(self.merges_file, "w", encoding="utf-8") as fp:
- fp.write("\n".join(merges))
-
- def get_dpr_tokenizer(self) -> DPRQuestionEncoderTokenizer:
- return DPRQuestionEncoderTokenizer.from_pretrained(os.path.join(self.tmpdirname, "dpr_tokenizer"))
-
- def get_bart_tokenizer(self) -> BartTokenizer:
- return BartTokenizer.from_pretrained(os.path.join(self.tmpdirname, "bart_tokenizer"))
-
- def tearDown(self):
- shutil.rmtree(self.tmpdirname)
-
- def get_dummy_dataset(self):
- dataset = Dataset.from_dict(
- {
- "id": ["0", "1"],
- "text": ["foo", "bar"],
- "title": ["Foo", "Bar"],
- "embeddings": [np.ones(self.retrieval_vector_size), 2 * np.ones(self.retrieval_vector_size)],
- }
- )
- dataset.add_faiss_index("embeddings", string_factory="Flat", metric_type=faiss.METRIC_INNER_PRODUCT)
- return dataset
-
- def get_dummy_pytorch_distributed_retriever(
- self, init_retrieval: bool, port=12345
- ) -> RagPyTorchDistributedRetriever:
- dataset = self.get_dummy_dataset()
- config = RagConfig(
- retrieval_vector_size=self.retrieval_vector_size,
- question_encoder=DPRConfig().to_dict(),
- generator=BartConfig().to_dict(),
- )
- with patch("transformers.models.rag.retrieval_rag.load_dataset") as mock_load_dataset:
- mock_load_dataset.return_value = dataset
- retriever = RagPyTorchDistributedRetriever(
- config,
- question_encoder_tokenizer=self.get_dpr_tokenizer(),
- generator_tokenizer=self.get_bart_tokenizer(),
- )
- if init_retrieval:
- retriever.init_retrieval(port)
- return retriever
-
- def get_dummy_ray_distributed_retriever(self, init_retrieval: bool) -> RagRayDistributedRetriever:
- # Have to run in local mode because sys.path modifications at top of
- # file are not propogated to remote workers.
- # https://stackoverflow.com/questions/54338013/parallel-import-a-python-file-from-sibling-folder
- ray.init(local_mode=True)
- config = RagConfig(
- retrieval_vector_size=self.retrieval_vector_size,
- question_encoder=DPRConfig().to_dict(),
- generator=BartConfig().to_dict(),
- )
- remote_cls = ray.remote(RayRetriever)
- workers = [remote_cls.remote() for _ in range(1)]
- with patch("transformers.models.rag.retrieval_rag.load_dataset") as mock_load_dataset:
- mock_load_dataset.return_value = self.get_dummy_dataset()
- retriever = RagRayDistributedRetriever(
- config,
- question_encoder_tokenizer=self.get_dpr_tokenizer(),
- generator_tokenizer=self.get_bart_tokenizer(),
- retrieval_workers=workers,
- )
- if init_retrieval:
- retriever.init_retrieval()
- return retriever
-
- def get_dummy_custom_hf_index_pytorch_retriever(self, init_retrieval: bool, from_disk: bool, port=12345):
- dataset = self.get_dummy_dataset()
- config = RagConfig(
- retrieval_vector_size=self.retrieval_vector_size,
- question_encoder=DPRConfig().to_dict(),
- generator=BartConfig().to_dict(),
- index_name="custom",
- )
- if from_disk:
- config.passages_path = os.path.join(self.tmpdirname, "dataset")
- config.index_path = os.path.join(self.tmpdirname, "index.faiss")
- dataset.get_index("embeddings").save(os.path.join(self.tmpdirname, "index.faiss"))
- dataset.drop_index("embeddings")
- dataset.save_to_disk(os.path.join(self.tmpdirname, "dataset"))
- del dataset
- retriever = RagPyTorchDistributedRetriever(
- config,
- question_encoder_tokenizer=self.get_dpr_tokenizer(),
- generator_tokenizer=self.get_bart_tokenizer(),
- )
- else:
- retriever = RagPyTorchDistributedRetriever(
- config,
- question_encoder_tokenizer=self.get_dpr_tokenizer(),
- generator_tokenizer=self.get_bart_tokenizer(),
- index=CustomHFIndex(config.retrieval_vector_size, dataset),
- )
- if init_retrieval:
- retriever.init_retrieval(port)
- return retriever
-
- def get_dummy_custom_hf_index_ray_retriever(self, init_retrieval: bool, from_disk: bool):
- # Have to run in local mode because sys.path modifications at top of
- # file are not propogated to remote workers.
- # https://stackoverflow.com/questions/54338013/parallel-import-a-python-file-from-sibling-folder
- ray.init(local_mode=True)
- dataset = self.get_dummy_dataset()
- config = RagConfig(
- retrieval_vector_size=self.retrieval_vector_size,
- question_encoder=DPRConfig().to_dict(),
- generator=BartConfig().to_dict(),
- index_name="custom",
- )
- remote_cls = ray.remote(RayRetriever)
- workers = [remote_cls.remote() for _ in range(1)]
- if from_disk:
- config.passages_path = os.path.join(self.tmpdirname, "dataset")
- config.index_path = os.path.join(self.tmpdirname, "index.faiss")
- dataset.get_index("embeddings").save(os.path.join(self.tmpdirname, "index.faiss"))
- dataset.drop_index("embeddings")
- dataset.save_to_disk(os.path.join(self.tmpdirname, "dataset"))
- del dataset
- retriever = RagRayDistributedRetriever(
- config,
- question_encoder_tokenizer=self.get_dpr_tokenizer(),
- generator_tokenizer=self.get_bart_tokenizer(),
- retrieval_workers=workers,
- index=CustomHFIndex.load_from_disk(
- vector_size=config.retrieval_vector_size,
- dataset_path=config.passages_path,
- index_path=config.index_path,
- ),
- )
- else:
- retriever = RagRayDistributedRetriever(
- config,
- question_encoder_tokenizer=self.get_dpr_tokenizer(),
- generator_tokenizer=self.get_bart_tokenizer(),
- retrieval_workers=workers,
- index=CustomHFIndex(config.retrieval_vector_size, dataset),
- )
- if init_retrieval:
- retriever.init_retrieval()
- return retriever
-
- def distributed_retriever_check(self, retriever: RagRetriever, hidden_states: np.array, n_docs: int) -> None:
- retrieved_doc_embeds, doc_ids, doc_dicts = retriever.retrieve(hidden_states, n_docs=n_docs)
- self.assertEqual(retrieved_doc_embeds.shape, (2, n_docs, self.retrieval_vector_size))
- self.assertEqual(len(doc_dicts), 2)
- self.assertEqual(sorted(doc_dicts[0]), ["embeddings", "id", "text", "title"])
- self.assertEqual(len(doc_dicts[0]["id"]), n_docs)
- self.assertEqual(doc_dicts[0]["id"][0], "1") # max inner product is reached with second doc
- self.assertEqual(doc_dicts[1]["id"][0], "0") # max inner product is reached with first doc
- self.assertListEqual(doc_ids.tolist(), [[1], [0]])
-
- def test_pytorch_distributed_retriever_retrieve(self):
- n_docs = 1
- hidden_states = np.array(
- [np.ones(self.retrieval_vector_size), -np.ones(self.retrieval_vector_size)], dtype=np.float32
- )
-
- self.distributed_retriever_check(
- self.get_dummy_pytorch_distributed_retriever(init_retrieval=True), hidden_states, n_docs
- )
-
- def test_custom_hf_index_pytorch_retriever_retrieve(self):
- n_docs = 1
- hidden_states = np.array(
- [np.ones(self.retrieval_vector_size), -np.ones(self.retrieval_vector_size)], dtype=np.float32
- )
-
- self.distributed_retriever_check(
- self.get_dummy_custom_hf_index_pytorch_retriever(init_retrieval=True, from_disk=False),
- hidden_states,
- n_docs,
- )
-
- def test_custom_pytorch_distributed_retriever_retrieve_from_disk(self):
- n_docs = 1
- hidden_states = np.array(
- [np.ones(self.retrieval_vector_size), -np.ones(self.retrieval_vector_size)], dtype=np.float32
- )
-
- self.distributed_retriever_check(
- self.get_dummy_custom_hf_index_pytorch_retriever(init_retrieval=True, from_disk=True),
- hidden_states,
- n_docs,
- )
-
- @require_ray
- def test_ray_distributed_retriever_retrieve(self):
- n_docs = 1
- hidden_states = np.array(
- [np.ones(self.retrieval_vector_size), -np.ones(self.retrieval_vector_size)], dtype=np.float32
- )
-
- self.distributed_retriever_check(
- self.get_dummy_ray_distributed_retriever(init_retrieval=True), hidden_states, n_docs
- )
- ray.shutdown()
-
- @require_ray
- def test_custom_hf_index_ray_retriever_retrieve(self):
- n_docs = 1
- hidden_states = np.array(
- [np.ones(self.retrieval_vector_size), -np.ones(self.retrieval_vector_size)], dtype=np.float32
- )
- with self.assertRaises(ValueError):
- self.distributed_retriever_check(
- self.get_dummy_custom_hf_index_ray_retriever(init_retrieval=True, from_disk=False),
- hidden_states,
- n_docs,
- )
- ray.shutdown()
-
- @require_ray
- def test_custom_ray_distributed_retriever_retrieve_from_disk(self):
- n_docs = 1
- hidden_states = np.array(
- [np.ones(self.retrieval_vector_size), -np.ones(self.retrieval_vector_size)], dtype=np.float32
- )
-
- self.distributed_retriever_check(
- self.get_dummy_custom_hf_index_ray_retriever(init_retrieval=True, from_disk=True), hidden_states, n_docs
- )
- ray.shutdown()
diff --git a/examples/research_projects/rag/use_own_knowledge_dataset.py b/examples/research_projects/rag/use_own_knowledge_dataset.py
deleted file mode 100644
index d2ab6d07d5c..00000000000
--- a/examples/research_projects/rag/use_own_knowledge_dataset.py
+++ /dev/null
@@ -1,208 +0,0 @@
-import logging
-import os
-from dataclasses import dataclass, field
-from functools import partial
-from pathlib import Path
-from tempfile import TemporaryDirectory
-from typing import List, Optional
-
-import faiss
-import torch
-from datasets import Features, Sequence, Value, load_dataset
-
-from transformers import (
- DPRContextEncoder,
- DPRContextEncoderTokenizerFast,
- HfArgumentParser,
- RagRetriever,
- RagSequenceForGeneration,
- RagTokenizer,
-)
-
-
-logger = logging.getLogger(__name__)
-torch.set_grad_enabled(False)
-device = "cuda" if torch.cuda.is_available() else "cpu"
-
-
-def split_text(text: str, n=100, character=" ") -> List[str]:
- """Split the text every ``n``-th occurrence of ``character``"""
- text = text.split(character)
- return [character.join(text[i : i + n]).strip() for i in range(0, len(text), n)]
-
-
-def split_documents(documents: dict) -> dict:
- """Split documents into passages"""
- titles, texts = [], []
- for title, text in zip(documents["title"], documents["text"]):
- if text is not None:
- for passage in split_text(text):
- titles.append(title if title is not None else "")
- texts.append(passage)
- return {"title": titles, "text": texts}
-
-
-def embed(documents: dict, ctx_encoder: DPRContextEncoder, ctx_tokenizer: DPRContextEncoderTokenizerFast) -> dict:
- """Compute the DPR embeddings of document passages"""
- input_ids = ctx_tokenizer(
- documents["title"], documents["text"], truncation=True, padding="longest", return_tensors="pt"
- )["input_ids"]
- embeddings = ctx_encoder(input_ids.to(device=device), return_dict=True).pooler_output
- return {"embeddings": embeddings.detach().cpu().numpy()}
-
-
-def main(
- rag_example_args: "RagExampleArguments",
- processing_args: "ProcessingArguments",
- index_hnsw_args: "IndexHnswArguments",
-):
- ######################################
- logger.info("Step 1 - Create the dataset")
- ######################################
-
- # The dataset needed for RAG must have three columns:
- # - title (string): title of the document
- # - text (string): text of a passage of the document
- # - embeddings (array of dimension d): DPR representation of the passage
-
- # Let's say you have documents in tab-separated csv files with columns "title" and "text"
- assert os.path.isfile(rag_example_args.csv_path), "Please provide a valid path to a csv file"
-
- # You can load a Dataset object this way
- dataset = load_dataset(
- "csv", data_files=[rag_example_args.csv_path], split="train", delimiter="\t", column_names=["title", "text"]
- )
-
- # More info about loading csv files in the documentation: https://huggingface.co/docs/datasets/loading_datasets?highlight=csv#csv-files
-
- # Then split the documents into passages of 100 words
- dataset = dataset.map(split_documents, batched=True, num_proc=processing_args.num_proc)
-
- # And compute the embeddings
- ctx_encoder = DPRContextEncoder.from_pretrained(rag_example_args.dpr_ctx_encoder_model_name).to(device=device)
- ctx_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained(rag_example_args.dpr_ctx_encoder_model_name)
- new_features = Features(
- {"text": Value("string"), "title": Value("string"), "embeddings": Sequence(Value("float32"))}
- ) # optional, save as float32 instead of float64 to save space
- dataset = dataset.map(
- partial(embed, ctx_encoder=ctx_encoder, ctx_tokenizer=ctx_tokenizer),
- batched=True,
- batch_size=processing_args.batch_size,
- features=new_features,
- )
-
- # And finally save your dataset
- passages_path = os.path.join(rag_example_args.output_dir, "my_knowledge_dataset")
- dataset.save_to_disk(passages_path)
- # from datasets import load_from_disk
- # dataset = load_from_disk(passages_path) # to reload the dataset
-
- ######################################
- logger.info("Step 2 - Index the dataset")
- ######################################
-
- # Let's use the Faiss implementation of HNSW for fast approximate nearest neighbor search
- index = faiss.IndexHNSWFlat(index_hnsw_args.d, index_hnsw_args.m, faiss.METRIC_INNER_PRODUCT)
- dataset.add_faiss_index("embeddings", custom_index=index)
-
- # And save the index
- index_path = os.path.join(rag_example_args.output_dir, "my_knowledge_dataset_hnsw_index.faiss")
- dataset.get_index("embeddings").save(index_path)
- # dataset.load_faiss_index("embeddings", index_path) # to reload the index
-
- ######################################
- logger.info("Step 3 - Load RAG")
- ######################################
-
- # Easy way to load the model
- retriever = RagRetriever.from_pretrained(
- rag_example_args.rag_model_name, index_name="custom", indexed_dataset=dataset
- )
- model = RagSequenceForGeneration.from_pretrained(rag_example_args.rag_model_name, retriever=retriever)
- tokenizer = RagTokenizer.from_pretrained(rag_example_args.rag_model_name)
-
- # For distributed fine-tuning you'll need to provide the paths instead, as the dataset and the index are loaded separately.
- # retriever = RagRetriever.from_pretrained(rag_model_name, index_name="custom", passages_path=passages_path, index_path=index_path)
-
- ######################################
- logger.info("Step 4 - Have fun")
- ######################################
-
- question = rag_example_args.question or "What does Moses' rod turn into ?"
- input_ids = tokenizer.question_encoder(question, return_tensors="pt")["input_ids"]
- generated = model.generate(input_ids)
- generated_string = tokenizer.batch_decode(generated, skip_special_tokens=True)[0]
- logger.info("Q: " + question)
- logger.info("A: " + generated_string)
-
-
-@dataclass
-class RagExampleArguments:
- csv_path: str = field(
- default=str(Path(__file__).parent / "test_data" / "my_knowledge_dataset.csv"),
- metadata={"help": "Path to a tab-separated csv file with columns 'title' and 'text'"},
- )
- question: Optional[str] = field(
- default=None,
- metadata={"help": "Question that is passed as input to RAG. Default is 'What does Moses' rod turn into ?'."},
- )
- rag_model_name: str = field(
- default="facebook/rag-sequence-nq",
- metadata={"help": "The RAG model to use. Either 'facebook/rag-sequence-nq' or 'facebook/rag-token-nq'"},
- )
- dpr_ctx_encoder_model_name: str = field(
- default="facebook/dpr-ctx_encoder-multiset-base",
- metadata={
- "help": (
- "The DPR context encoder model to use. Either 'facebook/dpr-ctx_encoder-single-nq-base' or"
- " 'facebook/dpr-ctx_encoder-multiset-base'"
- )
- },
- )
- output_dir: Optional[str] = field(
- default=None,
- metadata={"help": "Path to a directory where the dataset passages and the index will be saved"},
- )
-
-
-@dataclass
-class ProcessingArguments:
- num_proc: Optional[int] = field(
- default=None,
- metadata={
- "help": "The number of processes to use to split the documents into passages. Default is single process."
- },
- )
- batch_size: int = field(
- default=16,
- metadata={
- "help": "The batch size to use when computing the passages embeddings using the DPR context encoder."
- },
- )
-
-
-@dataclass
-class IndexHnswArguments:
- d: int = field(
- default=768,
- metadata={"help": "The dimension of the embeddings to pass to the HNSW Faiss index."},
- )
- m: int = field(
- default=128,
- metadata={
- "help": (
- "The number of bi-directional links created for every new element during the HNSW index construction."
- )
- },
- )
-
-
-if __name__ == "__main__":
- logging.basicConfig(level=logging.WARNING)
- logger.setLevel(logging.INFO)
-
- parser = HfArgumentParser((RagExampleArguments, ProcessingArguments, IndexHnswArguments))
- rag_example_args, processing_args, index_hnsw_args = parser.parse_args_into_dataclasses()
- with TemporaryDirectory() as tmp_dir:
- rag_example_args.output_dir = rag_example_args.output_dir or tmp_dir
- main(rag_example_args, processing_args, index_hnsw_args)
diff --git a/examples/research_projects/rag/utils_rag.py b/examples/research_projects/rag/utils_rag.py
deleted file mode 100644
index ec98c1d782e..00000000000
--- a/examples/research_projects/rag/utils_rag.py
+++ /dev/null
@@ -1,244 +0,0 @@
-import itertools
-import json
-import linecache
-import os
-import pickle
-import re
-import socket
-import string
-from collections import Counter
-from logging import getLogger
-from pathlib import Path
-from typing import Callable, Dict, Iterable, List
-
-import git
-import torch
-from torch.utils.data import Dataset
-
-from transformers import BartTokenizer, RagTokenizer, T5Tokenizer
-
-
-def encode_line(tokenizer, line, max_length, padding_side, pad_to_max_length=True, return_tensors="pt"):
- extra_kw = {"add_prefix_space": True} if isinstance(tokenizer, BartTokenizer) and not line.startswith(" ") else {}
- tokenizer.padding_side = padding_side
- return tokenizer(
- [line],
- max_length=max_length,
- padding="max_length" if pad_to_max_length else None,
- truncation=True,
- return_tensors=return_tensors,
- add_special_tokens=True,
- **extra_kw,
- )
-
-
-def trim_batch(
- input_ids,
- pad_token_id,
- attention_mask=None,
-):
- """Remove columns that are populated exclusively by pad_token_id"""
- keep_column_mask = input_ids.ne(pad_token_id).any(dim=0)
- if attention_mask is None:
- return input_ids[:, keep_column_mask]
- else:
- return (input_ids[:, keep_column_mask], attention_mask[:, keep_column_mask])
-
-
-class Seq2SeqDataset(Dataset):
- def __init__(
- self,
- tokenizer,
- data_dir,
- max_source_length,
- max_target_length,
- type_path="train",
- n_obs=None,
- src_lang=None,
- tgt_lang=None,
- prefix="",
- ):
- super().__init__()
- self.src_file = Path(data_dir).joinpath(type_path + ".source")
- self.tgt_file = Path(data_dir).joinpath(type_path + ".target")
- self.src_lens = self.get_char_lens(self.src_file)
- self.max_source_length = max_source_length
- self.max_target_length = max_target_length
- assert min(self.src_lens) > 0, f"found empty line in {self.src_file}"
- self.tokenizer = tokenizer
- self.prefix = prefix
- if n_obs is not None:
- self.src_lens = self.src_lens[:n_obs]
- self.src_lang = src_lang
- self.tgt_lang = tgt_lang
-
- def __len__(self):
- return len(self.src_lens)
-
- def __getitem__(self, index) -> Dict[str, torch.Tensor]:
- index = index + 1 # linecache starts at 1
- source_line = self.prefix + linecache.getline(str(self.src_file), index).rstrip("\n")
- tgt_line = linecache.getline(str(self.tgt_file), index).rstrip("\n")
- assert source_line, f"empty source line for index {index}"
- assert tgt_line, f"empty tgt line for index {index}"
-
- # Need to add eos token manually for T5
- if isinstance(self.tokenizer, T5Tokenizer):
- source_line += self.tokenizer.eos_token
- tgt_line += self.tokenizer.eos_token
-
- # Pad source and target to the right
- source_tokenizer = (
- self.tokenizer.question_encoder if isinstance(self.tokenizer, RagTokenizer) else self.tokenizer
- )
- target_tokenizer = self.tokenizer.generator if isinstance(self.tokenizer, RagTokenizer) else self.tokenizer
-
- source_inputs = encode_line(source_tokenizer, source_line, self.max_source_length, "right")
- target_inputs = encode_line(target_tokenizer, tgt_line, self.max_target_length, "right")
-
- source_ids = source_inputs["input_ids"].squeeze()
- target_ids = target_inputs["input_ids"].squeeze()
- src_mask = source_inputs["attention_mask"].squeeze()
- return {
- "input_ids": source_ids,
- "attention_mask": src_mask,
- "decoder_input_ids": target_ids,
- }
-
- @staticmethod
- def get_char_lens(data_file):
- return [len(x) for x in Path(data_file).open().readlines()]
-
- def collate_fn(self, batch) -> Dict[str, torch.Tensor]:
- input_ids = torch.stack([x["input_ids"] for x in batch])
- masks = torch.stack([x["attention_mask"] for x in batch])
- target_ids = torch.stack([x["decoder_input_ids"] for x in batch])
- tgt_pad_token_id = (
- self.tokenizer.generator.pad_token_id
- if isinstance(self.tokenizer, RagTokenizer)
- else self.tokenizer.pad_token_id
- )
- src_pad_token_id = (
- self.tokenizer.question_encoder.pad_token_id
- if isinstance(self.tokenizer, RagTokenizer)
- else self.tokenizer.pad_token_id
- )
- y = trim_batch(target_ids, tgt_pad_token_id)
- source_ids, source_mask = trim_batch(input_ids, src_pad_token_id, attention_mask=masks)
- batch = {
- "input_ids": source_ids,
- "attention_mask": source_mask,
- "decoder_input_ids": y,
- }
- return batch
-
-
-logger = getLogger(__name__)
-
-
-def flatten_list(summary_ids: List[List]):
- return list(itertools.chain.from_iterable(summary_ids))
-
-
-def save_git_info(folder_path: str) -> None:
- """Save git information to output_dir/git_log.json"""
- repo_infos = get_git_info()
- save_json(repo_infos, os.path.join(folder_path, "git_log.json"))
-
-
-def save_json(content, path, indent=4, **json_dump_kwargs):
- with open(path, "w") as f:
- json.dump(content, f, indent=indent, **json_dump_kwargs)
-
-
-def load_json(path):
- with open(path) as f:
- return json.load(f)
-
-
-def get_git_info():
- repo = git.Repo(search_parent_directories=True)
- repo_infos = {
- "repo_id": str(repo),
- "repo_sha": str(repo.head.object.hexsha),
- "repo_branch": str(repo.active_branch),
- "hostname": str(socket.gethostname()),
- }
- return repo_infos
-
-
-def lmap(f: Callable, x: Iterable) -> List:
- """list(map(f, x))"""
- return list(map(f, x))
-
-
-def pickle_save(obj, path):
- """pickle.dump(obj, path)"""
- with open(path, "wb") as f:
- return pickle.dump(obj, f)
-
-
-def normalize_answer(s):
- """Lower text and remove punctuation, articles and extra whitespace."""
-
- def remove_articles(text):
- return re.sub(r"\b(a|an|the)\b", " ", text)
-
- def white_space_fix(text):
- return " ".join(text.split())
-
- def remove_punc(text):
- exclude = set(string.punctuation)
- return "".join(ch for ch in text if ch not in exclude)
-
- def lower(text):
- return text.lower()
-
- return white_space_fix(remove_articles(remove_punc(lower(s))))
-
-
-def f1_score(prediction, ground_truth):
- prediction_tokens = normalize_answer(prediction).split()
- ground_truth_tokens = normalize_answer(ground_truth).split()
- common = Counter(prediction_tokens) & Counter(ground_truth_tokens)
- num_same = sum(common.values())
- if num_same == 0:
- return 0
- precision = 1.0 * num_same / len(prediction_tokens)
- recall = 1.0 * num_same / len(ground_truth_tokens)
- f1 = (2 * precision * recall) / (precision + recall)
- return f1
-
-
-def exact_match_score(prediction, ground_truth):
- return normalize_answer(prediction) == normalize_answer(ground_truth)
-
-
-def calculate_exact_match(output_lns: List[str], reference_lns: List[str]) -> Dict:
- assert len(output_lns) == len(reference_lns)
- em = 0
- for hypo, pred in zip(output_lns, reference_lns):
- em += exact_match_score(hypo, pred)
- if len(output_lns) > 0:
- em /= len(output_lns)
- return {"em": em}
-
-
-def is_rag_model(model_prefix):
- return model_prefix.startswith("rag")
-
-
-def set_extra_model_params(extra_params, hparams, config):
- equivalent_param = {p: p for p in extra_params}
- # T5 models don't have `dropout` param, they have `dropout_rate` instead
- equivalent_param["dropout"] = "dropout_rate"
- for p in extra_params:
- if getattr(hparams, p, None):
- if not hasattr(config, p) and not hasattr(config, equivalent_param[p]):
- logger.info("config doesn't have a `{}` attribute".format(p))
- delattr(hparams, p)
- continue
- set_p = p if hasattr(config, p) else equivalent_param[p]
- setattr(config, set_p, getattr(hparams, p))
- delattr(hparams, p)
- return hparams, config
diff --git a/examples/research_projects/robust-speech-event/README.md b/examples/research_projects/robust-speech-event/README.md
deleted file mode 100644
index ca3c5cdecde..00000000000
--- a/examples/research_projects/robust-speech-event/README.md
+++ /dev/null
@@ -1,713 +0,0 @@
-# Robust Speech Challenge 🤗
-
-Welcome to the robust speech recognition challenge 🎙️ !
-
-The goal of this event is to build **robust**, **real-world** speech recognition (ASR) systems in as many languages as possible 🌏🌍🌎.
-If necessary and available, free access to a V100S 32 GB GPU will kindly be provided by the [OVHcloud team](https://www.ovhcloud.com/) 🚀.
-This document summarizes all the relevant information required for the speech community event 📋.
-
-To sign-up, please see [this forum post](https://discuss.huggingface.co/t/open-to-the-community-robust-speech-recognition-challenge/13614) 🤗. Please make sure to:
-- Read it in detail
-- Fill the google form
-- Join our Discord server in the #join-sprint channel.
-
-## Table of Contents
-
-- [TLDR;](#tldr)
-- [Important dates](#important-dates)
-- [How to install pytorch, transformers, datasets](#how-to-install-relevant-libraries)
-- [Data and Preprocessing](#data-and-preprocessing)
-- [How to fine-tune an acoustic model](#how-to-finetune-an-acoustic-model)
-- [How to fine-tune with OVH could](#how-to-finetune-with-ovh-cloud)
-- [How to combine n-gram language models with acoustic model](#how-to-combine-n-gram-with-acoustic-model)
-- [Evaluation](#evaluation)
-- [Prizes](#prizes)
-- [Communication and Problems](#communication-and-problems)
-- [Talks](#talks)
-- [General Tips & Tricks](#general-tips-and-tricks)
-
-## TLDR
-
-Participants are encouraged to leverage pre-trained speech recognition checkpoints,
-preferably [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53),
-to train a speech recognition system in a language of their choice.
-
-Speech recognition systems should be trained using **PyTorch**, **🤗 Transformers**, and, **🤗 Datasets**.
-For more information on how to install the above libraries, please read through
-[How to install pytorch, transformers, datasets](#how-to-install-relevant-libraries).
-
-Participants can make use of whatever data they think is useful to build a
-speech recognition system for **real-world** audio data -
-**except** the Common Voice `"test"` split of their chosen language.
-The section [Data and preprocessing](#data-and-preprocessing) explains
-in more detail what audio data can be used, how to find suitable audio data, and
-how the audio data can be processed.
-
-For training, it is recommended to use the [official training script](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py) or a modification thereof. A step-by-step guide on how to fine-tune
-an acoustic model for a speech recognition system can be found under [How to fine-tune an acoustic model](#how-to-finetune-an-acoustic-model).
-If possible it is encouraged to fine-tune the acoustic models on local GPU machines, but
-if those are not available, the OVH could team kindly provides a limited
-number of GPUs for the event. Simply fill out [this google form](https://forms.gle/GFZkMkKLiufi75g28) to get access to a GPU.
-For more information on how to train an acoustic model on one of OVH's GPU - see [How to fine-tune a speech recognition model with OVHcould](#how-to-fine-tune-with-ovh-cloud).
-
-The performance of speech recognition system can often significantly be improved by adding a
-language model for decoding. For more information on how to add a language model, please
-take a look at [How to combine n-gram language models with speech recognition models](#how-to-combine-n-gram-with-model).
-
-During the event, the speech recognition system will be evaluated on both the Common Voice `"test"` split
-of the participants' chosen language as well as the *real-world* `"dev"` data provided by
-the Hugging Face team.
-At the end of the robust speech recognition challenge, the speech recognition system will also be evaluated on the
-*real-world* `"test"` data provided by the Hugging Face team. Each participant should add an
-`eval.py` script to her/his model repository in a specific format that lets one easily
-evaluate the speech recognition system on both Common Voice's `"test"` data as well as the *real-world* audio
-data. Please read through the [Evaluation](#evaluation) section to make sure your evaluation script is in the correct format. Speech recognition systems
-with evaluation scripts in an incorrect format can sadly not be considered for the Challenge.
-
-At the end of the event, the best performing speech recognition system
-will receive a prize 🏆 - more information regarding the prizes can be found under [Prizes](#prizes).
-
-We believe that framing the event as a competition is more fun, but at the core, the event is about
-creating speech recognition systems in as many languages as possible as a community.
-This can be achieved by working together, helping each other to solve bugs, share important findings, etc...🤗
-
-**Note**:
-Please, read through the section on [Communication & Problems](#communication-and-problems) to make sure you
-know how to ask for help, etc...
-All important announcements will be made on discord. Please make sure that
-you've joined [this discord channel](https://discord.gg/SHr5wC7m)
-
-Also, please make sure that you have been added to the [Speech Event Organization](https://huggingface.co/speech-recognition-community-v2).
-You should have received an invite by email. If you didn't receive an invite, please contact the organizers, *e.g.* Anton, Patrick, or Omar directly on discord.
-
-## Important dates
-
-
-
-
-## Data and preprocessing
-
-In this section, we will quickly go over how to find suitable training data and
-how to preprocess it.
-
-To begin with, **all data except Common Voice's `"test"` data can be used as training data.**
-The exception includes all Common Voice versions as the test data split of later Common Voice versions often
-overlaps with the one of previous versions, *e.g.* the test data of Common Voice 7 in English is
-to a big part identical to the test data of Common Voice 6 in English:
-
-```python
-load_dataset("mozilla-foundation/common_voice_7_0", "en", split="test")
-```
-
-includes more or less the same data as
-
-```python
-load_dataset("mozilla-foundation/common_voice_6_1", "en", split="test")
-```
-
-However, we strongly encourage participants to make use of Common Voice's other splits, *e.g.* `"train"` and `"validation"`.
-For most languages, the Common Voice dataset offers already a decent amount of training data. It is usually
-always advantageous to collect additional data. To do so, the participants are in a first step encouraged to search the
-Hugging Face Hub for additional audio data, for example by selecting the category
-["speech-processing"](https://huggingface.co/datasets?task_categories=task_categories:speech-processing&sort=downloads).
-All datasets that are available on the Hub can be downloaded via the 🤗 Datasets library in the same way Common Voice is downloaded.
-If one wants to combine multiple datasets for training, it might make sense to take a look at
-the [`interleave_datasets`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=interleave#datasets.interleave_datasets) function.
-
-In addition, participants can also make use of their audio data. Here, please make sure that you **are allowed to use the audio data**. E.g., if audio data
-is taken from media platforms, such as YouTube, it should be verified that the media platform and the owner of the data have given her/his approval to use the audio
-data in the context of machine learning research. If you are not sure whether the data you want to use has the appropriate licensing, please contact the Hugging Face
-team on discord.
-
-Next, let's talk about preprocessing. Audio data and transcriptions have to be brought into the correct format when
-training the acoustic model (example shown in [How to fine-tune an acoustic model](#how-to-finetune-an-acoustic-model)).
-It is recommended that this is done by using 🤗 Datasets `.map()` function as shown
-[here](https://github.com/huggingface/transformers/blob/9a2dabae7002258e41419491c73dd43ad61b5de7/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py#L444). As can be
-see we can pass some characters that will be removed from the transcriptions, *e.g.*: `--chars_to_ignore , ? . ! - \; \: \" “ % ‘ ” � \`
-on the official ["Single GPU Example"](https://github.com/huggingface/transformers/tree/main/examples/pytorch/speech-recognition#single-gpu-ctc).
-The participants are free to modify this preprocessing by removing more characters or even replacing characters as
-it is done in the [official blog post](https://github.com/huggingface/transformers/blob/9a2dabae7002258e41419491c73dd43ad61b5de7/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py#L444).
-**However**, there are some rules regarding what characters are allowed to be removed/replaced and which are not.
-These rules are not this straightforward and therefore often have to be evaluated case-by-case.
-It is allowed (and recommended) to normalize the data to only have lower-case characters. It is also allowed (and recommended) to remove typographical
-symbols and punctuation marks. A list of such symbols can *e.g.* be found [here](https://en.wikipedia.org/wiki/List_of_typographical_symbols_and_punctuation_marks) - however here we already must be careful. We should **not** remove a symbol that would change the meaning of the words, *e.g.* in English,
-we should not remove the single quotation mark `'` since it would change the meaning of the word `"it's"` to `"its"` which would then be incorrect.
-So the golden rule here is to not remove any characters that could change the meaning of a word into another word. This is not always obvious and should
-be given some consideration. As another example, it is fine to remove the "Hyphen-minus" sign "`-`" since it doesn't change the
-meaning of a word to another one. *E.g.* "`fine-tuning`" would be changed to "`finetuning`" which has still the same meaning.
-
-Since those choices are not always obvious when in doubt feel free to ask on Discord or even better post your question on the forum, as was
-done, *e.g.* [here](https://discuss.huggingface.co/t/spanish-asr-fine-tuning-wav2vec2/4586).
-
-## How to install relevant libraries
-
-The following libraries are required to fine-tune a speech model with 🤗 Transformers and 🤗 Datasets in PyTorch.
-
-- [PyTorch](https://pytorch.org/)
-- [Transformers](https://github.com/huggingface/transformers)
-- [Datasets](https://github.com/huggingface/datasets)
-
-We recommend installing the above libraries in a [virtual environment](https://docs.python.org/3/library/venv.html).
-If you're unfamiliar with Python virtual environments, check out the [user guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/). Create a virtual environment with the version of Python you're going
-to use and activate it.
-
-You should be able to run the command:
-
-```bash
-python3 -m venv
-```
-
-You can activate your venv by running
-
-```bash
-source ~//bin/activate
-```
-
-To begin with please make sure you have PyTorch and CUDA correctly installed.
-The following command should return ``True``:
-
-```bash
-python -c "import torch; print(torch.cuda.is_available())"
-```
-
-If the above command doesn't print ``True``, in the first step, please follow the
-instructions [here](https://pytorch.org/) to install PyTorch with CUDA.
-
-We strongly recommend making use of the provided PyTorch examples scripts in [transformers/examples/pytorch/speech-recognition](https://github.com/huggingface/transformers/tree/main/examples/pytorch/speech-recognition) to train your speech recognition
-system.
-In all likelihood, you will adjust one of the example scripts, so we recommend forking and cloning the 🤗 Transformers repository as follows.
-
-1. Fork the [repository](https://github.com/huggingface/transformers) by
- clicking on the 'Fork' button on the repository's page. This creates a copy of the code
- under your GitHub user account.
-
-2. Clone your fork to your local disk, and add the base repository as a remote:
-
- ```bash
- $ git clone https://github.com//transformers.git
- $ cd transformers
- $ git remote add upstream https://github.com/huggingface/transformers.git
- ```
-
-3. Create a new branch to hold your development changes. This is especially useful to share code changes with your team:
-
- ```bash
- $ git checkout -b a-descriptive-name-for-my-project
- ```
-
-4. Set up a PyTorch environment by running the following command your virtual environment:
-
- ```bash
- $ pip install -e ".[torch-speech]"
- ```
-
- (If transformers was already installed in the virtual environment, remove
- it with `pip uninstall transformers` before reinstalling it in editable
- mode with the `-e` flag.)
-
- If you have already cloned that repo, you might need to `git pull` to get the most recent changes in the `transformers`
- library.
-
- Running this command will automatically install `torch` and the most relevant
- libraries required for fine-tuning a speech recognition system.
-
-Next, you should also install the 🤗 Datasets library. We strongly recommend installing the
-library from source to profit from the most current additions during the community week.
-
-Simply run the following steps:
-
-```bash
-$ cd ~/
-$ git clone https://github.com/huggingface/datasets.git
-$ cd datasets
-$ pip install -e ".[streaming]"
-```
-
-If you plan on contributing a specific dataset during
-the community week, please fork the datasets repository and follow the instructions
-[here](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-create-a-pull-request).
-
-To verify that all libraries are correctly installed, you can run the following command in a Python shell.
-It verifies that both `transformers` and `datasets` have been correclty installed.
-
-```python
-from transformers import AutoModelForCTC, AutoProcessor
-from datasets import load_dataset
-
-dummy_dataset = load_dataset("common_voice", "ab", split="test")
-
-model = AutoModelForCTC.from_pretrained("hf-internal-testing/tiny-random-wav2vec2")
-model.to("cuda")
-
-processor = AutoProcessor.from_pretrained("hf-internal-testing/tiny-random-wav2vec2")
-
-input_values = processor(dummy_dataset[0]["audio"]["array"], return_tensors="pt", sampling_rate=16_000).input_values
-input_values = input_values.to("cuda")
-
-logits = model(input_values).logits
-
-assert logits.shape[-1] == 32
-```
-
-## How to finetune an acoustic model
-
-In this section, we show you how to fine-tune a pre-trained [XLS-R Model](https://huggingface.co/docs/transformers/model_doc/xls_r) on the [Common Voice 7 dataset](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
-
-We recommend fine-tuning one of the following pre-trained XLS-R checkpoints:
-
-- [300M parameters version](https://huggingface.co/facebook/wav2vec2-xls-r-300m)
-- [1B parameters version](https://huggingface.co/facebook/wav2vec2-xls-r-1b)
-- [2B parameters version](https://huggingface.co/facebook/wav2vec2-xls-r-2b)
-
-To begin with, please note that to use the Common Voice dataset, you
-have to accept that **your email address** and **username** are shared with the
-mozilla-foundation. To get access to the dataset please click on "*Access repository*" [here](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
-
-Next, we recommended that you get familiar with the XLS-R model and its capabilities.
-In collaboration with [Fairseq's Wav2Vec2 team](https://github.com/pytorch/fairseq/tree/main/examples/wav2vec),
-we've written ["Fine-tuning XLS-R for Multi-Lingual ASR with 🤗 Transformers"](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) which gives an in-detail explanation of how XLS-R functions and how it can be fine-tuned.
-
-The blog can also be opened and directly fine-tuned in a google colab notebook.
-In this section, we will explain how to fine-tune the model on a local machine.
-
-1. **Log in**
-
-To begin with, you should check that you are correctly logged in and that you have `git-lfs` installed so that your fine-tuned model can automatically be uploaded.
-
-Run:
-
-```bash
-huggingface-cli login
-```
-
-to login. It is recommended to login with your access token that can be found under your hugging face profile (icon in the top right corner on [hf.co](http://hf.co/), then Settings -> Access Tokens -> User Access Tokens -> New Token (if haven't generated one already)
-
-You can then copy-paste this token to log in locally.
-
-2. **Create your model repository**
-
-First, let's make sure that `git-lfs` is correctly installed. To so, simply run:
-
-```bash
-git-lfs -v
-```
-
-The output should show something like `git-lfs/2.13.2 (GitHub; linux amd64; go 1.15.4)`. If your console states that the `git-lfs` command was not found, please make
-sure to install it [here](https://git-lfs.github.com/) or simply via:
-
-```bash
-sudo apt-get install git-lfs
-```
-
-Now you can create your model repository which will contain all relevant files to
-reproduce your training. You can either directly create the model repository on the
-Hub (Settings -> New Model) or via the CLI. Here we choose to use the CLI instead.
-
-Assuming that we want to call our model repository *xls-r-ab-test*, we can run the
-following command:
-
-```bash
-huggingface-cli repo create xls-r-ab-test
-```
-
-You can now see the model on the Hub, *e.g.* under https://huggingface.co/hf-test/xls-r-ab-test .
-
-Let's clone the repository so that we can define our training script inside.
-
-```bash
-git lfs install
-git clone https://huggingface.co/hf-test/xls-r-ab-test
-```
-
-3. **Add your training script and `run`-command to the repository**
-
-We encourage participants to add all relevant files for training directly to the
-directory so that everything is fully reproducible.
-
-Let's first copy-paste the official training script from our clone
-of `transformers` to our just created directory:
-
-```bash
-cp ~/transformers/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py ./
-```
-
-Next, we'll create a bash file to define the hyper-parameters and configurations
-for training. More detailed information on different settings (single-GPU vs. multi-GPU) can be found [here](https://github.com/huggingface/transformers/tree/main/examples/pytorch/speech-recognition#connectionist-temporal-classification).
-
-For demonstration purposes, we will use a dummy XLS-R model `model_name_or_path="hf-test/xls-r-dummy"` on the very low-resource language of "Abkhaz" of [Common Voice 7](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0): `dataset_config_name="ab"` for just a single epoch.
-
-Before starting to train, let's make sure we have installed all the required libraries. You might want to run:
-
-```bash
-pip install -r ~/transformers/examples/pytorch/speech-recognition/requirements.txt
-```
-
-Alright, finally we can define the training script. We'll simply use some
-dummy hyper-parameters and configurations for demonstration purposes.
-
-Note that we add the flag `--use_auth_token` so that datasets requiring access,
-such as [Common Voice 7](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0) can be downloaded. In addition, we add the `--push_to_hub` flag to make use of the
-[Trainers `push_to-hub` functionality](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#transformers.Trainer.push_to_hub) so that your model will be automatically uploaded to the Hub.
-
-Let's copy the following code snippet in a file called `run.sh`
-
-```bash
-echo '''python run_speech_recognition_ctc.py \
- --dataset_name="mozilla-foundation/common_voice_7_0" \
- --model_name_or_path="hf-test/xls-r-dummy" \
- --dataset_config_name="ab" \
- --output_dir="./" \
- --overwrite_output_dir \
- --max_steps="10" \
- --per_device_train_batch_size="2" \
- --learning_rate="3e-4" \
- --save_total_limit="1" \
- --eval_strategy="steps" \
- --text_column_name="sentence" \
- --length_column_name="input_length" \
- --save_steps="5" \
- --layerdrop="0.0" \
- --freeze_feature_encoder \
- --gradient_checkpointing \
- --fp16 \
- --group_by_length \
- --push_to_hub \
- --use_auth_token \
- --do_train --do_eval''' > run.sh
-```
-
-4. **Start training**
-
-Now all that is left to do is to start training the model by executing the
-run file.
-
-```bash
-bash run.sh
-```
-
-The training should not take more than a couple of minutes.
-During the training intermediate saved checkpoints are automatically uploaded to
-your model repository as can be seen [on this commit](https://huggingface.co/hf-test/xls-r-ab-test/commit/0eb19a0fca4d7d163997b59663d98cd856022aa6) .
-
-At the end of the training, the [Trainer](https://huggingface.co/docs/transformers/main/en/main_classes/trainer) automatically creates a nice model card and all
-relevant files are uploaded.
-
-5. **Tips for real model training**
-
-The above steps illustrate how a model can technically be fine-tuned.
-However as you can see on the model card [hf-test/xls-r-ab-test](https://huggingface.co/hf-test/xls-r-ab-test), our demonstration has a very poor performance which is
-not surprising given that we trained for just 10 steps on a randomly initialized
-model.
-
-For real model training, it is recommended to use one of the actual pre-trained XLS-R models:
-
-- [300M parameters version](https://huggingface.co/facebook/wav2vec2-xls-r-300m)
-- [1B parameters version](https://huggingface.co/facebook/wav2vec2-xls-r-1b)
-- [2B parameters version](https://huggingface.co/facebook/wav2vec2-xls-r-2b)
-
-Also, the hyper-parameters should be carefully chosen depending on the dataset.
-As an example, we will fine-tune the 300M parameters model on Swedish on a single
-TITAN RTX 24GB GPU.
-
-The model will be called `"xls-r-300m-sv"`.
-Following the above steps we first create the model:
-
-```bash
-huggingface-cli repo create xls-r-300m-sv
-```
-
-, clone it locally (assuming the `` is `hf-test`)
-
-```bash
-git clone hf-test/xls-r-300m-sv
-```
-
-, and, define the following hyperparameters for training
-
-```bash
-echo '''python run_speech_recognition_ctc.py \
- --dataset_name="mozilla-foundation/common_voice_7_0" \
- --model_name_or_path="facebook/wav2vec2-xls-r-300m" \
- --dataset_config_name="sv-SE" \
- --output_dir="./" \
- --overwrite_output_dir \
- --num_train_epochs="50" \
- --per_device_train_batch_size="8" \
- --per_device_eval_batch_size="8" \
- --gradient_accumulation_steps="4" \
- --learning_rate="7.5e-5" \
- --warmup_steps="2000" \
- --length_column_name="input_length" \
- --eval_strategy="steps" \
- --text_column_name="sentence" \
- --chars_to_ignore , ? . ! \- \; \: \" “ % ‘ ” � — ’ … – \
- --save_steps="500" \
- --eval_steps="500" \
- --logging_steps="100" \
- --layerdrop="0.0" \
- --activation_dropout="0.1" \
- --save_total_limit="3" \
- --freeze_feature_encoder \
- --feat_proj_dropout="0.0" \
- --mask_time_prob="0.75" \
- --mask_time_length="10" \
- --mask_feature_prob="0.25" \
- --mask_feature_length="64" \
- --gradient_checkpointing \
- --use_auth_token \
- --fp16 \
- --group_by_length \
- --do_train --do_eval \
- --push_to_hub''' > run.sh
-```
-
-The training takes *ca.* 7 hours and yields a reasonable test word
-error rate of 27% as can be seen on the automatically generated [model card](https://huggingface.co/hf-test/xls-r-300m-sv).
-
-The above-chosen hyperparameters probably work quite well on a range of different
-datasets and languages but are by no means optimal. It is up to you to find a good set of
-hyperparameters.
-
-
-## How to finetune with OVH cloud
-
-[](https://youtu.be/XkMnYocAEO0) For a more detailed guide on setting up OVHcloud please watch this video: https://youtu.be/XkMnYocAEO0
-
-### Creating an OVHCloud account
-*TIP*: If you haven't created a project on OVHcloud yet, make sure you've received your GPU voucher code *beforehand*,
-so that you can skip entering the credit card information.
-1. If you're a US citizen, create an account via [OVHcloud.CA](https://ovhcloud.ca/).
-If you're from anywhere else in the world, create an account via [OVHcloud.COM](https://ovhcloud.com/).
-2. Once logged in, click `Public Cloud` from the top menu and then click `Create your first OVH Public Cloud project`.
-Then enter a project name (e.g. "huggingface"), enter your voucher code, and click `Continue` -> `Create my project`.
-*Note: if you see a request for credit card details during the last step, and you can't skip it, then your voucher code
-is invalid. Please report it to the [#ovh-support](https://discord.gg/p4qqDV3M) channel on Discord.*
-
-### Setting up an AI notebook
-1. Go to the `Public Cloud` page and select `Project Management` -> `Users & Roles` from the menu on the left.
-2. Click `+ Add user`. Write a user description (e.g. `AI Trainer`), and select an `AI Training Operator` user role.
-Click `Confirm`.
-3. Write down the *username* and *password* (at the top of the screen) somewhere. They will be needed during step 7.
-4. Select `AI & Machine Learning` -> `AI Training` from the menu on the left.
-Click `+ Launch a new job` on the AI Training page.
-5. On the `Launch a new job` page:
- * In `1. Choose a region` select a region closest to you.
- * In `2. Enter the Docker image` select `Custom image` -> `baaastijn/ovh_huggingface`.
- * You can skip steps `3.` and `4.` if you will be using the Hugging Face Hub to store the models after training.
- * In `5. Configure your job` select **1** `GPU`.
- * Validate the info and Create the job.
-6. On the `AI Training Jobs` screen wait until the job's status changes from `Pending` to `Running`.
-7. Click `HTTP Access` from the Job's details page and log in with the AI training user you've created earlier.
-Once logged in, you can close the page and click `HTTP Access` to launch a JupyterLab notebook.
-8. Awesome, now you have a free GPU-enabled Jupyter instance!
-
-**Note**: If you're an experienced Docker user, feel free to create a custom docker image with all of the needed packages
-like the one in step 5. The Dockerfile for it is available here:
-[baaastijn/Dockerimages](https://github.com/baaastijn/Dockerimages/tree/main/Hugginface_challenge_speech).
-Once you've built your image, push it to https://hub.docker.com/ and select it during the OVHcloud job creation.
-
-For more quick tutorials about OVHcloud AI products, check out the showcase https://vimeo.com/showcase/8903300
-
-## How to combine n-gram with acoustic model
-
-Having trained a speech recognition model with CTC as shown in the section above,
-one can further improve the model's performance by adding an **n-gram language model**
-to the decoding process of the model. By doing so, we are replacing the naive greedy decoding
-with **n-gram-boosted** beam search decoding.
-
-N-gram language models can be built on CPU in just a few minutes. *N-gram-boosted* beam search decoding noticeably slows down the
-inference time, but also yields significant word error rates improvements - usually between 10-40 %.
-
-You can find an in-detail blog post on how to build an *n-gram* [here](https://huggingface.co/blog/wav2vec2-with-ngram).
-The blog post can be opened in a google colab and by adapting three lines of the example for your use case, one can directly
-create an *n-gram* in the google colab.
-The blog post gives in-detail instructions on how to build an n-gram and how to add it to your trained speech recognition model.
-
-- why one should add an *n-gram* to her/his speech recognition system,
-- how to build an *n-gram*, and,
-- how to add the built *n-gram* the speech recognition system for seamless decoding
-
-Our previously trained model - [xls-r-300m-sv](https://huggingface.co/hf-test/xls-r-300m-sv) - enjoys a 30% word error rate reduction after
-having added an n-gram. As shown in the example of the blog post, we strongly advise participants to upload all files required for combining
-the *n-gram* with a trained speech recognition model directly into the same model repository.
-
-## Evaluation
-
-Finally, we have arrived at the most fun part of the challenge - sitting back and
-watching the model transcribe audio. If possible, every participant should evaluate
-the speech recognition system on the test set of Common Voice 7 and
-ideally also on the real-world audio data (if available).
-For languages that have neither a Common Voice evaluation dataset nor a real world
-evaluation dataset, please contact the organizers on Discord so that we can work
-together to find some evaluation data.
-
-As a first step, one should copy the official `eval.py` script to her/his model
-repository. Let's use our previously trained [xls-r-300m-sv](https://huggingface.co/hf-test/xls-r-300m-sv) again as an example.
-
-Assuming that we have a clone of the model's repo under `~/xls-r-300m-sv`, we can
-copy the `eval.py` script to the repo.
-
-```bash
-cp ~/transformers/examples/research_projects/robust-speech-event/eval.py ~/xls-r-300m-sv
-```
-
-Next, we should adapt `eval.py` so that it fits our evaluation data. Here it is
-important to keep the `eval.py` file in the following format:
-
-- 1. The following input arguments should not be changed and keep their original functionality/meaning (being to load the model and dataset): `"--model_id"`, `"--dataset"`, `"--config"`, `"--split"`. We recommend to not change any of the code written under `if __name__ == "__main__":`.
-- 2. The function `def log_results(result: Dataset, args: Dict[str, str])` should also not be changed. The function expects the above names attached to the `args` object as well as a `datasets.Dataset` object, called `result` which includes all predictions and target transcriptions under the names `"predictions"` and `"targets"` respectively.
-- 3. All other code can be changed and adapted. Participants are especially invited to change the `def normalize_text(text: str) -> str:` function as this might be a very language and model-training specific function.
-- 4. **Important**: It is not allowed to "cheat" in any way when in comes to pre-and postprocessing. In short, "cheating" refers to any of the following:
- - a. Somehow giving the model access to the target transcriptions to improve performance. The model is not allowed to use the target transcriptions to generate its predictions.
- - b. Pre-processing the target transcriptions in a way that makes the target transcriptions lose their original meaning. This corresponds to what has already been said in [Data and Preprocessing](#data-and-preprocessing) and is somewhat of a grey zone. It means that one should not remove characters that would make a word to lose its meaning. E.g., it is not allowed to replace all `e` in English with `i` and simply make the model learn that `e` and `i` are the same letter for a better word error rate. This would destroy the meaning of words such as `fell -> fill`. However, it is totally fine to normalize (*e.g.* lowercase) all letters, remove punctuation. There can be a lot of language-specific exceptions and in case you are not sure whether your target transcription pre-processing is allowed, please ask on the Discord channel.
-
-Uff, that was a lot of text describing how to make sure your `eval.py` script
-is in the correct format. If you have any questions, please ask openly in Discord.
-
-Great, now that we have adapted the `eval.py` script, we can lean back and run the
-evaluation.
-First, one should evaluate the model on Common Voice 7's test data. This might
-already have been done for your acoustic model during training but in case you
-added an *n-gram* language model after having fine-tuned the acoustic model, you
-should now see a nice improvement.
-
-The command to evaluate our test model [xls-r-300m-sv](https://huggingface.co/hf-test/xls-r-300m-sv) on Common Voice 7's test data is the following:
-
-```bash
-cd xls-r-300m-sv
-./eval.py --model_id ./ --dataset mozilla-foundation/common_voice_7_0 --config sv-SE --split test --log_outputs
-```
-
-To log each of the model's predictions with the target transcriptions, you can just
-add the `--log_outputs` flag.
-
-Running this command should automatically create the file:
-`mozilla-foundation_common_voice_7_0_sv-SE_test_eval_results.txt` that contains
-both the word- and character error rate.
-
-In a few days, we will give everybody access to some real-world audio data for as many languages as possible.
-If your language has real-world audio data, it will most likely have audio input
-of multiple minutes. 🤗Transformer's [ASR pipeline](https://huggingface.co/docs/transformers/main/en/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline) supports audio chunking out-of-the-box. You only need to specify
-how song each audio chunk should be (`chunk_length_s`) and how much audio stride
-(`stride_length_s`) each chunk should use.
-For more information on the chunking works, please have a look at [this nice blog post](TODO: ).
-
-In the case of `xls-r-300m-sv`, the following command can be run:
-
-```bash
-cd xls-r-300m-sv
-./eval.py --model_id hf-test/xls-r-300m-sv --dataset --config sv --split validation --chunk_length_s 5.0 --stride_length_s 1.0 --log_outputs
-```
-
-Great, now you should have successfully evaluated your model. Finally, there is one
-**important** thing you should do so that your model is taken into account
-for the final evaluation. You should add two tags to your model, one being `robust-speech-event`, one being the ISO code of your chosen language, *e.g.* `"sv"` for the
-exemplary model we used above. You can find a list of all available languages and
-their ISO code [here](https://huggingface.co/languages).
-
-To add the tags, simply edit the README.md of your model repository and add
-
-```
-- "sv"
-- "robust-speech-event"
-```
-
-under `tags:` as done [here](https://huggingface.co/hf-test/xls-r-300m-sv/commit/a495fd70c96bb7d019729be9273a265c2557345e).
-
-To verify that you've added the tags correctly make sure that your model
-appears when clicking on [this link](https://huggingface.co/models?other=robust-speech-event).
-
-Great that's it! This should give you all the necessary information to evaluate
-your model. For the final evaluation, we will verify each evaluation result to
-determine the final score and thereby the winning models for each language.
-
-The final score is calculated as follows:
-
-```bash
-FINAL_SCORE = 1/3 * WER_Common_Voice_7_test + 1/3 * WER_REAL_AUDIO_DEV + 1/3 * WER_REAL_AUDIO_TEST
-```
-
-The dataset `WER_REAL_AUDIO_TEST` is hidden and will only be published
-at the end of the robust speech challenge.
-
-If there is no real audio data for your language the final score will be
-computed solely based on the Common Voice 7 test dataset. If there is also
-no Common Voice 7 test dataset for your language, we will see together how to
-score your model - if this is the case, please don't be discouraged. We are
-especially excited about speech recognition systems of such low-resource
-languages and will make sure that we'll decide on a good approach to evaluating
-your model.
-
-## Prizes
-
-TODO(Patrick, Omar, ...)
-
-## Communication and Problems
-
-If you encounter any problems or have any questions, you should use one of the following platforms
-depending on your type of problem. Hugging Face is an "open-source-first" organization meaning
-that we'll try to solve all problems in the most public and most transparent way possible so that everybody
-in the community profits.
-
-The following table summarizes what platform to use for which problem.
-
-- Problem/question/bug with the 🤗 Datasets library that you think is a general problem that also impacts other people, please open an [Issues on Datasets](https://github.com/huggingface/datasets/issues/new?assignees=&labels=bug&template=bug-report.md&title=) and ping @anton-l and @patrickvonplaten.
-- Problem/question/bug with the 🤗 Transformers library that you think is a general problem that also impacts other people, please open an [Issues on Transformers](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title=) and ping @anton-l and @patrickvonplaten.
-- Problem/question with a modified, customized training script that is less likely to impact other people, please post your problem/question [on the forum](https://discuss.huggingface.co/) and ping @anton-l and @patrickvonplaten.
-- Questions regarding access to the OVHcloud GPU, please ask in the Discord channel **#ovh-support**.
-- Other questions regarding the event, rules of the event, or if you are not sure where to post your question, please ask in the Discord channel **#sprint-discussions**.
-
-## Talks
-
-We are very excited to be hosting 2 days of talks from Kensho-Technologies, Mozilla's Common Voice, Meta AI Research and Hugging Face.
-
-### Thursday, January 20th
-
- Speaker | Topic | Time | Video |
-|-------------|---------------------------------|------------------------|------------------------|
-| Patrick von Platen, Hugging Face | Introduction to Robust Speech Challenge | 4h30pm - 5h00pm UTC | [](https://www.youtube.com/watch?v=X9e5Tto-Iuk)
-| Raymond Grossman and Jeremy Lopez, Kensho-Technologies | Pyctcdecode & Speech2text decoding | 5h30pm - 6h00pm UTC | [](https://www.youtube.com/watch?v=mp7fHMTnK9A)
-
-### Friday, January 21th
-
- Speaker | Topic | Time | Video |
-|-------------|---------------------------------|------------------------|------------------------|
-| Gabriel Habayeb, Mozilla Common Voice | Unlocking global speech with Mozilla Common Voice | 4h30pm - 5h00pm UTC | [](https://www.youtube.com/watch?v=Vvn984QmAVg)
-| Changhan Wang, Meta AI Research | XLS-R: Large-Scale Cross-lingual Speech Representation Learning on 128 Languages | 5h30pm - 6h00pm UTC | [](https://www.youtube.com/watch?v=ic_J7ZCROBM)
-
-### Talks & Speakers
-
-#### Patrick von Platen, Research Engineer, Hugging Face
-- Talk: Introduction to Robust Speech Challenge
-- Abstract: In this talk, Patrick outlines the Robust Speech Challenge and gives tips and tricks on how to train and evaluate speech recognition systems with 🤗 Transformers and 🤗 Datasets, and PyTorch.
-- Speaker info: Patrick von Platen is a research engineer at Hugging Face and one of the core maintainers of the popular Transformers library. He specializes in speech recognition, encoder-decoder models, and long-range sequence modeling. Before joining Hugging Face, Patrick researched speech recognition at Uber AI, Cambridge University, and RWTH Aachen University.
-
-#### Raymond Grossman, Jeremy Lopez, Machine Learning Engineer, Kensho Technologies
-- Talk: PyCTCDecode & Speech2text decoding
-- Abstract: PyCTCDecode is a fast and feature-rich CTC beam search decoder for speech recognition written in Python, providing n-gram (kenlm) language model support similar to PaddlePaddle's decoder, but incorporating many new features such as byte pair encoding and real-time decoding to support models like Nvidia's Conformer-CTC or Facebook's Wav2Vec2.
-- Speaker info :
- - Raymond works as a machine learning engineer at Kensho Technologies, specializing in speech and natural language domains. Before coming to Kensho, he studied mathematics at Princeton and was an avid Kaggler under the moniker @ToTrainThemIsMyCause.
- - Jeremy is a machine learning engineer at Kensho Technologies and has worked on a variety of different topics including search and speech recognition. Before working at Kensho, he earned a PhD in experimental particle physics at MIT and continued doing physics research as a postdoc at the University of Colorado Boulder.
-
-#### Gabriel Habayeb, Data Engineer, Common Voice @ Mozilla
-- Talk: Unlocking global speech with Mozilla Common Voice
-- Abstract: Hear from Common Voice Data Engineer Gabriel Habayeb (Mozilla Foundation) as he talks about how Common Voice makes it easy to crowdsource voice data in global languages, as well as getting key insights into the dataset itself, how we maintain quality, use metadata - and our plans for the future!
-- Speaker info: Gabriel is a software developer with the Common Voice team at the Mozilla Foundation with a focus on data engineering. Before joining the Foundation, he spent the last six years working across different industries, including education, enterprise and not-for-profit organizations.
-
-#### Changhan Wang, Main author of XLS-R and Research Engineer, Meta AI Research
-- Talk: XLS-R: Large-Scale Cross-lingual Speech Representation Learning on 128 Languages
-- Abstract: In this talk, Changhan will present XLS-R, a large-scale model for cross-lingual speech representation learning based on wav2vec 2.0. XLS-R has up to 2B parameters and was trained on nearly half a million hours of publicly available speech audio in 128 languages, an order of magnitude more public data than the largest known prior work. On the CoVoST-2 speech translation benchmark, XLS-R improves the previous state of the art by an average of 7.4 BLEU over 21 translation directions into English. For speech recognition, XLS-R improves over the best known prior work on BABEL, MLS, CommonVoice as well as VoxPopuli, lowering error rates by 14-34% relative on average. XLS-R also sets a new state of the art on VoxLingua107 language identification. The XLS-R team hopes to work together with the open-source community to improve speech processing tasks for many more languages of the world.
-
-## General Tips and Tricks
-
-- Memory efficient training:
-
-In case, you are getting out-of-memory errors on your GPU, we recommend to use
-[bitsandbytes](https://github.com/TimDettmers/bitsandbytes) to replace the
-native memory-intensive Adam optimizer with the one of `bitsandbytes`. You
-can simply run the script `./run_speech_recognition_ctc_bnb.py` provided in this
-folder that makes use of `bitsandbytes` instead of the official one.
-
-- Dataset streaming
-
-TODO(Patrick)
diff --git a/examples/research_projects/robust-speech-event/eval.py b/examples/research_projects/robust-speech-event/eval.py
deleted file mode 100755
index b6c89a6d49f..00000000000
--- a/examples/research_projects/robust-speech-event/eval.py
+++ /dev/null
@@ -1,136 +0,0 @@
-#!/usr/bin/env python3
-import argparse
-import re
-from typing import Dict
-
-import torch
-from datasets import Audio, Dataset, load_dataset, load_metric
-
-from transformers import AutoFeatureExtractor, pipeline
-
-
-def log_results(result: Dataset, args: Dict[str, str]):
- """DO NOT CHANGE. This function computes and logs the result metrics."""
-
- log_outputs = args.log_outputs
- dataset_id = "_".join(args.dataset.split("/") + [args.config, args.split])
-
- # load metric
- wer = load_metric("wer")
- cer = load_metric("cer")
-
- # compute metrics
- wer_result = wer.compute(references=result["target"], predictions=result["prediction"])
- cer_result = cer.compute(references=result["target"], predictions=result["prediction"])
-
- # print & log results
- result_str = f"WER: {wer_result}\nCER: {cer_result}"
- print(result_str)
-
- with open(f"{dataset_id}_eval_results.txt", "w") as f:
- f.write(result_str)
-
- # log all results in text file. Possibly interesting for analysis
- if log_outputs is not None:
- pred_file = f"log_{dataset_id}_predictions.txt"
- target_file = f"log_{dataset_id}_targets.txt"
-
- with open(pred_file, "w") as p, open(target_file, "w") as t:
- # mapping function to write output
- def write_to_file(batch, i):
- p.write(f"{i}" + "\n")
- p.write(batch["prediction"] + "\n")
- t.write(f"{i}" + "\n")
- t.write(batch["target"] + "\n")
-
- result.map(write_to_file, with_indices=True)
-
-
-def normalize_text(text: str) -> str:
- """DO ADAPT FOR YOUR USE CASE. this function normalizes the target text."""
-
- chars_to_ignore_regex = '[,?.!\-\;\:"“%‘”�—’…–]' # noqa: W605 IMPORTANT: this should correspond to the chars that were ignored during training
-
- text = re.sub(chars_to_ignore_regex, "", text.lower())
-
- # In addition, we can normalize the target text, e.g. removing new lines characters etc...
- # note that order is important here!
- token_sequences_to_ignore = ["\n\n", "\n", " ", " "]
-
- for t in token_sequences_to_ignore:
- text = " ".join(text.split(t))
-
- return text
-
-
-def main(args):
- # load dataset
- dataset = load_dataset(args.dataset, args.config, split=args.split, token=True)
-
- # for testing: only process the first two examples as a test
- # dataset = dataset.select(range(10))
-
- # load processor
- feature_extractor = AutoFeatureExtractor.from_pretrained(args.model_id)
- sampling_rate = feature_extractor.sampling_rate
-
- # resample audio
- dataset = dataset.cast_column("audio", Audio(sampling_rate=sampling_rate))
-
- # load eval pipeline
- if args.device is None:
- args.device = 0 if torch.cuda.is_available() else -1
- asr = pipeline("automatic-speech-recognition", model=args.model_id, device=args.device)
-
- # map function to decode audio
- def map_to_pred(batch):
- prediction = asr(
- batch["audio"]["array"], chunk_length_s=args.chunk_length_s, stride_length_s=args.stride_length_s
- )
-
- batch["prediction"] = prediction["text"]
- batch["target"] = normalize_text(batch["sentence"])
- return batch
-
- # run inference on all examples
- result = dataset.map(map_to_pred, remove_columns=dataset.column_names)
-
- # compute and log_results
- # do not change function below
- log_results(result, args)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
-
- parser.add_argument(
- "--model_id", type=str, required=True, help="Model identifier. Should be loadable with 🤗 Transformers"
- )
- parser.add_argument(
- "--dataset",
- type=str,
- required=True,
- help="Dataset name to evaluate the `model_id`. Should be loadable with 🤗 Datasets",
- )
- parser.add_argument(
- "--config", type=str, required=True, help="Config of the dataset. *E.g.* `'en'` for Common Voice"
- )
- parser.add_argument("--split", type=str, required=True, help="Split of the dataset. *E.g.* `'test'`")
- parser.add_argument(
- "--chunk_length_s", type=float, default=None, help="Chunk length in seconds. Defaults to 5 seconds."
- )
- parser.add_argument(
- "--stride_length_s", type=float, default=None, help="Stride of the audio chunks. Defaults to 1 second."
- )
- parser.add_argument(
- "--log_outputs", action="store_true", help="If defined, write outputs to log file for analysis."
- )
- parser.add_argument(
- "--device",
- type=int,
- default=None,
- help="The device to run the pipeline on. -1 for CPU (default), 0 for the first GPU and so on.",
- )
- args = parser.parse_args()
-
- main(args)
diff --git a/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_bnb.py b/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_bnb.py
deleted file mode 100755
index cb489ea28d6..00000000000
--- a/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_bnb.py
+++ /dev/null
@@ -1,779 +0,0 @@
-#!/usr/bin/env python
-# coding=utf-8
-# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-
-"""Fine-tuning a 🤗 Transformers CTC model for automatic speech recognition"""
-
-import functools
-import json
-import logging
-import os
-import re
-import sys
-import warnings
-from dataclasses import dataclass, field
-from typing import Dict, List, Optional, Union
-
-import bitsandbytes as bnb
-import datasets
-import numpy as np
-import torch
-from datasets import DatasetDict, load_dataset, load_metric
-
-import transformers
-from transformers import (
- AutoConfig,
- AutoFeatureExtractor,
- AutoModelForCTC,
- AutoProcessor,
- AutoTokenizer,
- HfArgumentParser,
- Trainer,
- TrainingArguments,
- Wav2Vec2Processor,
- set_seed,
-)
-from transformers.trainer_pt_utils import get_parameter_names
-from transformers.trainer_utils import get_last_checkpoint, is_main_process
-from transformers.utils import check_min_version
-from transformers.utils.versions import require_version
-
-
-# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.16.0.dev0")
-
-require_version("datasets>=1.13.3", "To fix: pip install -r examples/pytorch/text-classification/requirements.txt")
-
-
-logger = logging.getLogger(__name__)
-
-
-def list_field(default=None, metadata=None):
- return field(default_factory=lambda: default, metadata=metadata)
-
-
-@dataclass
-class ModelArguments:
- """
- Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
- """
-
- model_name_or_path: str = field(
- metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
- )
- tokenizer_name_or_path: Optional[str] = field(
- default=None,
- metadata={"help": "Path to pretrained tokenizer or tokenizer identifier from huggingface.co/models"},
- )
- cache_dir: Optional[str] = field(
- default=None,
- metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
- )
- freeze_feature_encoder: bool = field(
- default=True, metadata={"help": "Whether to freeze the feature encoder layers of the model."}
- )
- attention_dropout: float = field(
- default=0.0, metadata={"help": "The dropout ratio for the attention probabilities."}
- )
- activation_dropout: float = field(
- default=0.0, metadata={"help": "The dropout ratio for activations inside the fully connected layer."}
- )
- feat_proj_dropout: float = field(default=0.0, metadata={"help": "The dropout ratio for the projected features."})
- hidden_dropout: float = field(
- default=0.0,
- metadata={
- "help": "The dropout probability for all fully connected layers in the embeddings, encoder, and pooler."
- },
- )
- final_dropout: float = field(
- default=0.0,
- metadata={"help": "The dropout probability for the final projection layer."},
- )
- mask_time_prob: float = field(
- default=0.05,
- metadata={
- "help": (
- "Probability of each feature vector along the time axis to be chosen as the start of the vector "
- "span to be masked. Approximately ``mask_time_prob * sequence_length // mask_time_length`` feature "
- "vectors will be masked along the time axis."
- )
- },
- )
- mask_time_length: int = field(
- default=10,
- metadata={"help": "Length of vector span to mask along the time axis."},
- )
- mask_feature_prob: float = field(
- default=0.0,
- metadata={
- "help": (
- "Probability of each feature vector along the feature axis to be chosen as the start of the vectorspan"
- " to be masked. Approximately ``mask_feature_prob * sequence_length // mask_feature_length`` feature"
- " bins will be masked along the time axis."
- )
- },
- )
- mask_feature_length: int = field(
- default=10,
- metadata={"help": "Length of vector span to mask along the feature axis."},
- )
- layerdrop: float = field(default=0.0, metadata={"help": "The LayerDrop probability."})
- ctc_loss_reduction: Optional[str] = field(
- default="mean", metadata={"help": "The way the ctc loss should be reduced. Should be one of 'mean' or 'sum'."}
- )
-
-
-@dataclass
-class DataTrainingArguments:
- """
- Arguments pertaining to what data we are going to input our model for training and eval.
-
- Using `HfArgumentParser` we can turn this class
- into argparse arguments to be able to specify them on
- the command line.
- """
-
- dataset_name: str = field(
- metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
- )
- dataset_config_name: str = field(
- default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
- )
- train_split_name: str = field(
- default="train+validation",
- metadata={
- "help": "The name of the training data set split to use (via the datasets library). Defaults to 'train'"
- },
- )
- eval_split_name: str = field(
- default="test",
- metadata={
- "help": "The name of the training data set split to use (via the datasets library). Defaults to 'train'"
- },
- )
- audio_column_name: str = field(
- default="audio",
- metadata={"help": "The name of the dataset column containing the audio data. Defaults to 'audio'"},
- )
- text_column_name: str = field(
- default="text",
- metadata={"help": "The name of the dataset column containing the text data. Defaults to 'text'"},
- )
- overwrite_cache: bool = field(
- default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
- )
- preprocessing_num_workers: Optional[int] = field(
- default=None,
- metadata={"help": "The number of processes to use for the preprocessing."},
- )
- max_train_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of training examples to this "
- "value if set."
- )
- },
- )
- max_eval_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of validation examples to this "
- "value if set."
- )
- },
- )
- chars_to_ignore: Optional[List[str]] = list_field(
- default=None,
- metadata={"help": "A list of characters to remove from the transcripts."},
- )
- eval_metrics: List[str] = list_field(
- default=["wer"],
- metadata={"help": "A list of metrics the model should be evaluated on. E.g. `'wer cer'`"},
- )
- max_duration_in_seconds: float = field(
- default=20.0,
- metadata={
- "help": (
- "Filter audio files that are longer than `max_duration_in_seconds` seconds to"
- " 'max_duration_in_seconds`"
- )
- },
- )
- min_duration_in_seconds: float = field(
- default=0.0, metadata={"help": "Filter audio files that are shorter than `min_duration_in_seconds` seconds"}
- )
- preprocessing_only: bool = field(
- default=False,
- metadata={
- "help": (
- "Whether to only do data preprocessing and skip training. This is especially useful when data"
- " preprocessing errors out in distributed training due to timeout. In this case, one should run the"
- " preprocessing in a non-distributed setup with `preprocessing_only=True` so that the cached datasets"
- " can consequently be loaded in distributed training"
- )
- },
- )
- use_auth_token: bool = field(
- default=False,
- metadata={
- "help": (
- "If :obj:`True`, will use the token generated when running"
- ":obj:`huggingface-cli login` as HTTP bearer authorization for remote files."
- )
- },
- )
- unk_token: str = field(
- default="[UNK]",
- metadata={"help": "The unk token for the tokenizer"},
- )
- pad_token: str = field(
- default="[PAD]",
- metadata={"help": "The padding token for the tokenizer"},
- )
- word_delimiter_token: str = field(
- default="|",
- metadata={"help": "The word delimiter token for the tokenizer"},
- )
- phoneme_language: Optional[str] = field(
- default=None,
- metadata={
- "help": (
- "The target language that should be used be"
- " passed to the tokenizer for tokenization. Note that"
- " this is only relevant if the model classifies the"
- " input audio to a sequence of phoneme sequences."
- )
- },
- )
-
-
-@dataclass
-class DataCollatorCTCWithPadding:
- """
- Data collator that will dynamically pad the inputs received.
- Args:
- processor (:class:`~transformers.AutoProcessor`)
- The processor used for processing the data.
- padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
- Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
- among:
- * :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
- sequence if provided).
- * :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
- maximum acceptable input length for the model if that argument is not provided.
- * :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
- different lengths).
- max_length (:obj:`int`, `optional`):
- Maximum length of the ``input_values`` of the returned list and optionally padding length (see above).
- max_length_labels (:obj:`int`, `optional`):
- Maximum length of the ``labels`` returned list and optionally padding length (see above).
- pad_to_multiple_of (:obj:`int`, `optional`):
- If set will pad the sequence to a multiple of the provided value.
- This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
- 7.5 (Volta).
- """
-
- processor: AutoProcessor
- padding: Union[bool, str] = "longest"
- pad_to_multiple_of: Optional[int] = None
- pad_to_multiple_of_labels: Optional[int] = None
-
- def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
- # split inputs and labels since they have to be of different lengths and need
- # different padding methods
- input_features = [{"input_values": feature["input_values"]} for feature in features]
- label_features = [{"input_ids": feature["labels"]} for feature in features]
-
- batch = self.processor.pad(
- input_features,
- padding=self.padding,
- pad_to_multiple_of=self.pad_to_multiple_of,
- return_tensors="pt",
- )
-
- labels_batch = self.processor.pad(
- labels=label_features,
- padding=self.padding,
- pad_to_multiple_of=self.pad_to_multiple_of_labels,
- return_tensors="pt",
- )
-
- # replace padding with -100 to ignore loss correctly
- labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
-
- batch["labels"] = labels
-
- return batch
-
-
-def create_vocabulary_from_data(
- datasets: DatasetDict,
- word_delimiter_token: Optional[str] = None,
- unk_token: Optional[str] = None,
- pad_token: Optional[str] = None,
-):
- # Given training and test labels create vocabulary
- def extract_all_chars(batch):
- all_text = " ".join(batch["target_text"])
- vocab = list(set(all_text))
- return {"vocab": [vocab], "all_text": [all_text]}
-
- vocabs = datasets.map(
- extract_all_chars,
- batched=True,
- batch_size=-1,
- keep_in_memory=True,
- remove_columns=datasets["train"].column_names,
- )
-
- # take union of all unique characters in each dataset
- vocab_set = functools.reduce(
- lambda vocab_1, vocab_2: set(vocab_1["vocab"][0]) | set(vocab_2["vocab"][0]), vocabs.values()
- )
-
- vocab_dict = {v: k for k, v in enumerate(sorted(vocab_set))}
-
- # replace white space with delimiter token
- if word_delimiter_token is not None:
- vocab_dict[word_delimiter_token] = vocab_dict[" "]
- del vocab_dict[" "]
-
- # add unk and pad token
- if unk_token is not None:
- vocab_dict[unk_token] = len(vocab_dict)
-
- if pad_token is not None:
- vocab_dict[pad_token] = len(vocab_dict)
-
- return vocab_dict
-
-
-def main():
- # See all possible arguments in src/transformers/training_args.py
- # or by passing the --help flag to this script.
- # We now keep distinct sets of args, for a cleaner separation of concerns.
-
- parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
- if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
- # If we pass only one argument to the script and it's the path to a json file,
- # let's parse it to get our arguments.
- model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
- else:
- model_args, data_args, training_args = parser.parse_args_into_dataclasses()
-
- # Detecting last checkpoint.
- last_checkpoint = None
- if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
- last_checkpoint = get_last_checkpoint(training_args.output_dir)
- if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
- raise ValueError(
- f"Output directory ({training_args.output_dir}) already exists and is not empty. "
- "Use --overwrite_output_dir to overcome."
- )
- elif last_checkpoint is not None:
- logger.info(
- f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
- "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
- )
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- handlers=[logging.StreamHandler(sys.stdout)],
- )
- logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
-
- # Log on each process the small summary:
- logger.warning(
- f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
- f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
- )
- # Set the verbosity to info of the Transformers logger (on main process only):
- if is_main_process(training_args.local_rank):
- transformers.utils.logging.set_verbosity_info()
- logger.info("Training/evaluation parameters %s", training_args)
-
- # Set seed before initializing model.
- set_seed(training_args.seed)
-
- # 1. First, let's load the dataset
- raw_datasets = DatasetDict()
-
- if training_args.do_train:
- raw_datasets["train"] = load_dataset(
- data_args.dataset_name,
- data_args.dataset_config_name,
- split=data_args.train_split_name,
- token=data_args.use_auth_token,
- )
-
- if data_args.audio_column_name not in raw_datasets["train"].column_names:
- raise ValueError(
- f"--audio_column_name '{data_args.audio_column_name}' not found in dataset '{data_args.dataset_name}'."
- " Make sure to set `--audio_column_name` to the correct audio column - one of"
- f" {', '.join(raw_datasets['train'].column_names)}."
- )
-
- if data_args.text_column_name not in raw_datasets["train"].column_names:
- raise ValueError(
- f"--text_column_name {data_args.text_column_name} not found in dataset '{data_args.dataset_name}'. "
- "Make sure to set `--text_column_name` to the correct text column - one of "
- f"{', '.join(raw_datasets['train'].column_names)}."
- )
-
- if data_args.max_train_samples is not None:
- raw_datasets["train"] = raw_datasets["train"].select(range(data_args.max_train_samples))
-
- if training_args.do_eval:
- raw_datasets["eval"] = load_dataset(
- data_args.dataset_name,
- data_args.dataset_config_name,
- split=data_args.eval_split_name,
- token=data_args.use_auth_token,
- )
-
- if data_args.max_eval_samples is not None:
- raw_datasets["eval"] = raw_datasets["eval"].select(range(data_args.max_eval_samples))
-
- # 2. We remove some special characters from the datasets
- # that make training complicated and do not help in transcribing the speech
- # E.g. characters, such as `,` and `.` do not really have an acoustic characteristic
- # that could be easily picked up by the model
- chars_to_ignore_regex = (
- f'[{"".join(data_args.chars_to_ignore)}]' if data_args.chars_to_ignore is not None else None
- )
- text_column_name = data_args.text_column_name
-
- def remove_special_characters(batch):
- if chars_to_ignore_regex is not None:
- batch["target_text"] = re.sub(chars_to_ignore_regex, "", batch[text_column_name]).lower() + " "
- else:
- batch["target_text"] = batch[text_column_name].lower() + " "
- return batch
-
- with training_args.main_process_first(desc="dataset map special characters removal"):
- raw_datasets = raw_datasets.map(
- remove_special_characters,
- remove_columns=[text_column_name],
- desc="remove special characters from datasets",
- )
-
- # save special tokens for tokenizer
- word_delimiter_token = data_args.word_delimiter_token
- unk_token = data_args.unk_token
- pad_token = data_args.pad_token
-
- # 3. Next, let's load the config as we might need it to create
- # the tokenizer
- # load config
- config = AutoConfig.from_pretrained(
- model_args.model_name_or_path, cache_dir=model_args.cache_dir, token=data_args.use_auth_token
- )
-
- # 4. Next, if no tokenizer file is defined,
- # we create the vocabulary of the model by extracting all unique characters from
- # the training and evaluation datasets
- # We need to make sure that only first rank saves vocabulary
- # make sure all processes wait until vocab is created
- tokenizer_name_or_path = model_args.tokenizer_name_or_path
- tokenizer_kwargs = {}
- if tokenizer_name_or_path is None:
- # save vocab in training output dir
- tokenizer_name_or_path = training_args.output_dir
-
- vocab_file = os.path.join(tokenizer_name_or_path, "vocab.json")
-
- with training_args.main_process_first():
- if training_args.overwrite_output_dir and os.path.isfile(vocab_file):
- os.remove(vocab_file)
-
- with training_args.main_process_first(desc="dataset map vocabulary creation"):
- if not os.path.isfile(vocab_file):
- os.makedirs(tokenizer_name_or_path, exist_ok=True)
- vocab_dict = create_vocabulary_from_data(
- raw_datasets,
- word_delimiter_token=word_delimiter_token,
- unk_token=unk_token,
- pad_token=pad_token,
- )
-
- # save vocab dict to be loaded into tokenizer
- with open(vocab_file, "w") as file:
- json.dump(vocab_dict, file)
-
- # if tokenizer has just been created
- # it is defined by `tokenizer_class` if present in config else by `model_type`
- tokenizer_kwargs = {
- "config": config if config.tokenizer_class is not None else None,
- "tokenizer_type": config.model_type if config.tokenizer_class is None else None,
- "unk_token": unk_token,
- "pad_token": pad_token,
- "word_delimiter_token": word_delimiter_token,
- }
-
- # 5. Now we can instantiate the feature extractor, tokenizer and model
- # Note for distributed training, the .from_pretrained methods guarantee that only
- # one local process can concurrently download model & vocab.
-
- # load feature_extractor and tokenizer
- tokenizer = AutoTokenizer.from_pretrained(
- tokenizer_name_or_path,
- token=data_args.use_auth_token,
- **tokenizer_kwargs,
- )
- feature_extractor = AutoFeatureExtractor.from_pretrained(
- model_args.model_name_or_path, cache_dir=model_args.cache_dir, token=data_args.use_auth_token
- )
-
- # adapt config
- config.update(
- {
- "feat_proj_dropout": model_args.feat_proj_dropout,
- "attention_dropout": model_args.attention_dropout,
- "hidden_dropout": model_args.hidden_dropout,
- "final_dropout": model_args.final_dropout,
- "mask_time_prob": model_args.mask_time_prob,
- "mask_time_length": model_args.mask_time_length,
- "mask_feature_prob": model_args.mask_feature_prob,
- "mask_feature_length": model_args.mask_feature_length,
- "gradient_checkpointing": training_args.gradient_checkpointing,
- "layerdrop": model_args.layerdrop,
- "ctc_loss_reduction": model_args.ctc_loss_reduction,
- "pad_token_id": tokenizer.pad_token_id,
- "vocab_size": len(tokenizer),
- "activation_dropout": model_args.activation_dropout,
- }
- )
-
- # create model
- model = AutoModelForCTC.from_pretrained(
- model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- config=config,
- token=data_args.use_auth_token,
- )
-
- # freeze encoder
- if model_args.freeze_feature_encoder:
- model.freeze_feature_encoder()
-
- # 6. Now we preprocess the datasets including loading the audio, resampling and normalization
- # Thankfully, `datasets` takes care of automatically loading and resampling the audio,
- # so that we just need to set the correct target sampling rate and normalize the input
- # via the `feature_extractor`
-
- # make sure that dataset decodes audio with correct sampling rate
- dataset_sampling_rate = next(iter(raw_datasets.values())).features[data_args.audio_column_name].sampling_rate
- if dataset_sampling_rate != feature_extractor.sampling_rate:
- raw_datasets = raw_datasets.cast_column(
- data_args.audio_column_name, datasets.features.Audio(sampling_rate=feature_extractor.sampling_rate)
- )
-
- # derive max & min input length for sample rate & max duration
- max_input_length = data_args.max_duration_in_seconds * feature_extractor.sampling_rate
- min_input_length = data_args.min_duration_in_seconds * feature_extractor.sampling_rate
- audio_column_name = data_args.audio_column_name
- num_workers = data_args.preprocessing_num_workers
-
- # `phoneme_language` is only relevant if the model is fine-tuned on phoneme classification
- phoneme_language = data_args.phoneme_language
-
- # Preprocessing the datasets.
- # We need to read the audio files as arrays and tokenize the targets.
- def prepare_dataset(batch):
- # load audio
- sample = batch[audio_column_name]
-
- inputs = feature_extractor(sample["array"], sampling_rate=sample["sampling_rate"])
- batch["input_values"] = inputs.input_values[0]
- batch["input_length"] = len(batch["input_values"])
-
- # encode targets
- additional_kwargs = {}
- if phoneme_language is not None:
- additional_kwargs["phonemizer_lang"] = phoneme_language
-
- batch["labels"] = tokenizer(batch["target_text"], **additional_kwargs).input_ids
- return batch
-
- with training_args.main_process_first(desc="dataset map preprocessing"):
- vectorized_datasets = raw_datasets.map(
- prepare_dataset,
- remove_columns=next(iter(raw_datasets.values())).column_names,
- num_proc=num_workers,
- desc="preprocess datasets",
- )
-
- def is_audio_in_length_range(length):
- return length > min_input_length and length < max_input_length
-
- # filter data that is shorter than min_input_length
- vectorized_datasets = vectorized_datasets.filter(
- is_audio_in_length_range,
- num_proc=num_workers,
- input_columns=["input_length"],
- )
-
- # 7. Next, we can prepare the training.
- # Let's use word error rate (WER) as our evaluation metric,
- # instantiate a data collator and the trainer
-
- # Define evaluation metrics during training, *i.e.* word error rate, character error rate
- eval_metrics = {metric: load_metric(metric) for metric in data_args.eval_metrics}
-
- # for large datasets it is advised to run the preprocessing on a
- # single machine first with ``args.preprocessing_only`` since there will mostly likely
- # be a timeout when running the script in distributed mode.
- # In a second step ``args.preprocessing_only`` can then be set to `False` to load the
- # cached dataset
- if data_args.preprocessing_only:
- logger.info(f"Data preprocessing finished. Files cached at {vectorized_datasets.cache_files}")
- return
-
- def compute_metrics(pred):
- pred_logits = pred.predictions
- pred_ids = np.argmax(pred_logits, axis=-1)
-
- pred.label_ids[pred.label_ids == -100] = tokenizer.pad_token_id
-
- pred_str = tokenizer.batch_decode(pred_ids)
- # we do not want to group tokens when computing the metrics
- label_str = tokenizer.batch_decode(pred.label_ids, group_tokens=False)
-
- metrics = {k: v.compute(predictions=pred_str, references=label_str) for k, v in eval_metrics.items()}
-
- return metrics
-
- # Now save everything to be able to create a single processor later
- if is_main_process(training_args.local_rank):
- # save feature extractor, tokenizer and config
- feature_extractor.save_pretrained(training_args.output_dir)
- tokenizer.save_pretrained(training_args.output_dir)
- config.save_pretrained(training_args.output_dir)
-
- try:
- processor = AutoProcessor.from_pretrained(training_args.output_dir)
- except (OSError, KeyError):
- warnings.warn(
- "Loading a processor from a feature extractor config that does not"
- " include a `processor_class` attribute is deprecated and will be removed in v5. Please add the following "
- " attribute to your `preprocessor_config.json` file to suppress this warning: "
- " `'processor_class': 'Wav2Vec2Processor'`",
- FutureWarning,
- )
- processor = Wav2Vec2Processor.from_pretrained(training_args.output_dir)
-
- # Instantiate custom data collator
- data_collator = DataCollatorCTCWithPadding(processor=processor)
-
- decay_parameters = get_parameter_names(model, [torch.nn.LayerNorm], ["bias", "layernorm", "rmsnorm"])
- optimizer_grouped_parameters = [
- {
- "params": [p for n, p in model.named_parameters() if n in decay_parameters],
- "weight_decay": training_args.weight_decay,
- },
- {
- "params": [p for n, p in model.named_parameters() if n not in decay_parameters],
- "weight_decay": 0.0,
- },
- ]
- optimizer = bnb.optim.Adam8bit(
- params=optimizer_grouped_parameters,
- lr=training_args.learning_rate,
- betas=(training_args.adam_beta1, training_args.adam_beta2),
- eps=training_args.adam_epsilon,
- )
-
- optimizers = (optimizer, None)
-
- # Initialize Trainer
- trainer = Trainer(
- model=model,
- data_collator=data_collator,
- args=training_args,
- compute_metrics=compute_metrics,
- train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
- eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
- tokenizer=feature_extractor,
- optimizers=optimizers,
- )
-
- # 8. Finally, we can start training
-
- # Training
- if training_args.do_train:
- # use last checkpoint if exist
- if last_checkpoint is not None:
- checkpoint = last_checkpoint
- elif os.path.isdir(model_args.model_name_or_path):
- checkpoint = model_args.model_name_or_path
- else:
- checkpoint = None
-
- train_result = trainer.train(resume_from_checkpoint=checkpoint)
- trainer.save_model()
-
- metrics = train_result.metrics
- max_train_samples = (
- data_args.max_train_samples
- if data_args.max_train_samples is not None
- else len(vectorized_datasets["train"])
- )
- metrics["train_samples"] = min(max_train_samples, len(vectorized_datasets["train"]))
-
- trainer.log_metrics("train", metrics)
- trainer.save_metrics("train", metrics)
- trainer.save_state()
-
- # Evaluation
- results = {}
- if training_args.do_eval:
- logger.info("*** Evaluate ***")
- metrics = trainer.evaluate()
- max_eval_samples = (
- data_args.max_eval_samples if data_args.max_eval_samples is not None else len(vectorized_datasets["eval"])
- )
- metrics["eval_samples"] = min(max_eval_samples, len(vectorized_datasets["eval"]))
-
- trainer.log_metrics("eval", metrics)
- trainer.save_metrics("eval", metrics)
-
- # Write model card and (optionally) push to hub
- config_name = data_args.dataset_config_name if data_args.dataset_config_name is not None else "na"
- kwargs = {
- "finetuned_from": model_args.model_name_or_path,
- "tasks": "automatic-speech-recognition",
- "tags": ["automatic-speech-recognition", data_args.dataset_name],
- "dataset_args": (
- f"Config: {config_name}, Training split: {data_args.train_split_name}, Eval split:"
- f" {data_args.eval_split_name}"
- ),
- "dataset": f"{data_args.dataset_name.upper()} - {config_name.upper()}",
- }
- if "common_voice" in data_args.dataset_name:
- kwargs["language"] = config_name
-
- if training_args.push_to_hub:
- trainer.push_to_hub(**kwargs)
- else:
- trainer.create_model_card(**kwargs)
-
- return results
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_streaming.py b/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_streaming.py
deleted file mode 100644
index 37f91b9ef61..00000000000
--- a/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_streaming.py
+++ /dev/null
@@ -1,679 +0,0 @@
-#!/usr/bin/env python
-# coding=utf-8
-# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-
-"""Fine-tuning a 🤗 Transformers CTC model for automatic speech recognition in streaming mode"""
-
-import logging
-import os
-import re
-import sys
-import warnings
-from dataclasses import dataclass, field
-from typing import Dict, List, Optional, Union
-
-import datasets
-import numpy as np
-import torch
-from datasets import IterableDatasetDict, interleave_datasets, load_dataset, load_metric
-from torch.utils.data import IterableDataset
-
-import transformers
-from transformers import (
- AutoConfig,
- AutoFeatureExtractor,
- AutoModelForCTC,
- AutoProcessor,
- AutoTokenizer,
- HfArgumentParser,
- Trainer,
- TrainerCallback,
- TrainingArguments,
- Wav2Vec2Processor,
- set_seed,
-)
-from transformers.trainer_pt_utils import IterableDatasetShard
-from transformers.trainer_utils import get_last_checkpoint, is_main_process
-from transformers.utils import check_min_version
-from transformers.utils.versions import require_version
-
-
-# Will error if the minimal version of Transformers is not installed. Remove at your own risk.
-check_min_version("4.17.0.dev0")
-
-require_version("datasets>=1.18.2", "To fix: pip install 'datasets>=1.18.2'")
-
-
-logger = logging.getLogger(__name__)
-
-
-def list_field(default=None, metadata=None):
- return field(default_factory=lambda: default, metadata=metadata)
-
-
-@dataclass
-class ModelArguments:
- """
- Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
- """
-
- model_name_or_path: str = field(
- metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
- )
- tokenizer_name_or_path: Optional[str] = field(
- default=None,
- metadata={"help": "Path to pretrained tokenizer or tokenizer identifier from huggingface.co/models"},
- )
- cache_dir: Optional[str] = field(
- default=None,
- metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
- )
- freeze_feature_encoder: bool = field(
- default=True, metadata={"help": "Whether to freeze the feature encoder layers of the model."}
- )
- attention_dropout: float = field(
- default=0.0, metadata={"help": "The dropout ratio for the attention probabilities."}
- )
- activation_dropout: float = field(
- default=0.0, metadata={"help": "The dropout ratio for activations inside the fully connected layer."}
- )
- feat_proj_dropout: float = field(default=0.0, metadata={"help": "The dropout ratio for the projected features."})
- hidden_dropout: float = field(
- default=0.0,
- metadata={
- "help": "The dropout probability for all fully connected layers in the embeddings, encoder, and pooler."
- },
- )
- final_dropout: float = field(
- default=0.0,
- metadata={"help": "The dropout probability for the final projection layer."},
- )
- mask_time_prob: float = field(
- default=0.05,
- metadata={
- "help": (
- "Probability of each feature vector along the time axis to be chosen as the start of the vector "
- "span to be masked. Approximately ``mask_time_prob * sequence_length // mask_time_length`` feature "
- "vectors will be masked along the time axis."
- )
- },
- )
- mask_time_length: int = field(
- default=10,
- metadata={"help": "Length of vector span to mask along the time axis."},
- )
- mask_feature_prob: float = field(
- default=0.0,
- metadata={
- "help": (
- "Probability of each feature vector along the feature axis to be chosen as the start of the vectorspan"
- " to be masked. Approximately ``mask_feature_prob * sequence_length // mask_feature_length`` feature"
- " bins will be masked along the time axis."
- )
- },
- )
- mask_feature_length: int = field(
- default=10,
- metadata={"help": "Length of vector span to mask along the feature axis."},
- )
- layerdrop: float = field(default=0.0, metadata={"help": "The LayerDrop probability."})
- ctc_loss_reduction: Optional[str] = field(
- default="mean", metadata={"help": "The way the ctc loss should be reduced. Should be one of 'mean' or 'sum'."}
- )
-
-
-@dataclass
-class DataTrainingArguments:
- """
- Arguments pertaining to what data we are going to input our model for training and eval.
-
- Using `HfArgumentParser` we can turn this class
- into argparse arguments to be able to specify them on
- the command line.
- """
-
- dataset_name: str = field(
- metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
- )
- dataset_config_name: str = field(
- default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
- )
- train_split_name: str = field(
- default="train+validation",
- metadata={
- "help": (
- "The name of the training data set split to use (via the datasets library). Defaults to "
- "'train+validation'"
- )
- },
- )
- eval_split_name: str = field(
- default="test",
- metadata={
- "help": "The name of the training data set split to use (via the datasets library). Defaults to 'test'"
- },
- )
- audio_column_name: str = field(
- default="audio",
- metadata={"help": "The name of the dataset column containing the audio data. Defaults to 'audio'"},
- )
- text_column_name: str = field(
- default="text",
- metadata={"help": "The name of the dataset column containing the text data. Defaults to 'text'"},
- )
- overwrite_cache: bool = field(
- default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
- )
- preprocessing_num_workers: Optional[int] = field(
- default=None,
- metadata={"help": "The number of processes to use for the preprocessing."},
- )
- max_train_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of training examples to this "
- "value if set."
- )
- },
- )
- max_eval_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of validation examples to this "
- "value if set."
- )
- },
- )
- shuffle_buffer_size: Optional[int] = field(
- default=500,
- metadata={
- "help": (
- "The number of streamed examples to download before shuffling them. The large the buffer, "
- "the closer it is to real offline shuffling."
- )
- },
- )
- chars_to_ignore: Optional[List[str]] = list_field(
- default=None,
- metadata={"help": "A list of characters to remove from the transcripts."},
- )
- eval_metrics: List[str] = list_field(
- default=["wer"],
- metadata={"help": "A list of metrics the model should be evaluated on. E.g. `'wer cer'`"},
- )
- max_duration_in_seconds: float = field(
- default=20.0,
- metadata={"help": "Filter audio files that are longer than `max_duration_in_seconds` seconds."},
- )
- preprocessing_only: bool = field(
- default=False,
- metadata={
- "help": (
- "Whether to only do data preprocessing and skip training. This is especially useful when data"
- " preprocessing errors out in distributed training due to timeout. In this case, one should run the"
- " preprocessing in a non-distributed setup with `preprocessing_only=True` so that the cached datasets"
- " can consequently be loaded in distributed training"
- )
- },
- )
- use_auth_token: bool = field(
- default=False,
- metadata={
- "help": (
- "If :obj:`True`, will use the token generated when running"
- ":obj:`huggingface-cli login` as HTTP bearer authorization for remote files."
- )
- },
- )
- phoneme_language: Optional[str] = field(
- default=None,
- metadata={
- "help": (
- "The target language that should be used be"
- " passed to the tokenizer for tokenization. Note that"
- " this is only relevant if the model classifies the"
- " input audio to a sequence of phoneme sequences."
- )
- },
- )
-
-
-@dataclass
-class DataCollatorCTCWithPadding:
- """
- Data collator that will dynamically pad the inputs received.
- Args:
- processor (:class:`~transformers.AutoProcessor`)
- The processor used for processing the data.
- padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
- Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
- among:
- * :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
- sequence if provided).
- * :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
- maximum acceptable input length for the model if that argument is not provided.
- * :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
- different lengths).
- max_length (:obj:`int`, `optional`):
- Maximum length of the ``input_values`` of the returned list and optionally padding length (see above).
- max_length_labels (:obj:`int`, `optional`):
- Maximum length of the ``labels`` returned list and optionally padding length (see above).
- pad_to_multiple_of (:obj:`int`, `optional`):
- If set will pad the sequence to a multiple of the provided value.
- This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
- 7.5 (Volta).
- """
-
- processor: AutoProcessor
- padding: Union[bool, str] = "longest"
- max_length: Optional[int] = None
- pad_to_multiple_of: Optional[int] = None
- pad_to_multiple_of_labels: Optional[int] = None
-
- def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
- # split inputs and labels since they have to be of different lengths and need
- # different padding methods
- input_features = []
- label_features = []
- for feature in features:
- if self.max_length and feature["input_values"].shape[-1] > self.max_length:
- continue
- input_features.append({"input_values": feature["input_values"]})
- label_features.append({"input_ids": feature["labels"]})
-
- batch = self.processor.pad(
- input_features,
- padding=self.padding,
- pad_to_multiple_of=self.pad_to_multiple_of,
- return_tensors="pt",
- )
-
- labels_batch = self.processor.pad(
- labels=label_features,
- padding=self.padding,
- pad_to_multiple_of=self.pad_to_multiple_of_labels,
- return_tensors="pt",
- )
-
- # replace padding with -100 to ignore loss correctly
- labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
-
- batch["labels"] = labels
-
- return batch
-
-
-def main():
- # See all possible arguments in src/transformers/training_args.py
- # or by passing the --help flag to this script.
- # We now keep distinct sets of args, for a cleaner separation of concerns.
-
- parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
- if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
- # If we pass only one argument to the script and it's the path to a json file,
- # let's parse it to get our arguments.
- model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
- else:
- model_args, data_args, training_args = parser.parse_args_into_dataclasses()
-
- # Detecting last checkpoint.
- last_checkpoint = None
- if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
- last_checkpoint = get_last_checkpoint(training_args.output_dir)
- if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
- raise ValueError(
- f"Output directory ({training_args.output_dir}) already exists and is not empty. "
- "Use --overwrite_output_dir to overcome."
- )
- elif last_checkpoint is not None:
- logger.info(
- f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
- "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
- )
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- handlers=[logging.StreamHandler(sys.stdout)],
- )
- logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
-
- # Log on each process the small summary:
- logger.warning(
- f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
- f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
- )
- # Set the verbosity to info of the Transformers logger (on main process only):
- if is_main_process(training_args.local_rank):
- transformers.utils.logging.set_verbosity_info()
- logger.info("Training/evaluation parameters %s", training_args)
-
- # Set seed before initializing model.
- set_seed(training_args.seed)
-
- # 1. First, let's load the dataset
- raw_datasets = IterableDatasetDict()
- raw_column_names = {}
-
- def load_streaming_dataset(split, sampling_rate, **kwargs):
- if "+" in split:
- dataset_splits = [load_dataset(split=split_name, **kwargs) for split_name in split.split("+")]
- # `features` and `cast_column` won't be available after interleaving, so we'll use them here
- features = dataset_splits[0].features
- # make sure that the dataset decodes audio with a correct sampling rate
- dataset_splits = [
- dataset.cast_column(data_args.audio_column_name, datasets.features.Audio(sampling_rate=sampling_rate))
- for dataset in dataset_splits
- ]
-
- interleaved_dataset = interleave_datasets(dataset_splits)
- return interleaved_dataset, features
- else:
- dataset = load_dataset(split=split, **kwargs)
- features = dataset.features
- # make sure that the dataset decodes audio with a correct sampling rate
- dataset = dataset.cast_column(
- data_args.audio_column_name, datasets.features.Audio(sampling_rate=sampling_rate)
- )
- return dataset, features
-
- # `datasets` takes care of automatically loading and resampling the audio,
- # so we just need to set the correct target sampling rate and normalize the input
- # via the `feature_extractor`
- feature_extractor = AutoFeatureExtractor.from_pretrained(
- model_args.model_name_or_path, cache_dir=model_args.cache_dir, token=data_args.use_auth_token
- )
-
- if training_args.do_train:
- raw_datasets["train"], train_features = load_streaming_dataset(
- path=data_args.dataset_name,
- name=data_args.dataset_config_name,
- split=data_args.train_split_name,
- token=data_args.use_auth_token,
- streaming=True,
- sampling_rate=feature_extractor.sampling_rate,
- )
- raw_column_names["train"] = list(train_features.keys())
-
- if data_args.audio_column_name not in raw_column_names["train"]:
- raise ValueError(
- f"--audio_column_name '{data_args.audio_column_name}' not found in dataset '{data_args.dataset_name}'."
- " Make sure to set `--audio_column_name` to the correct audio column - one of"
- f" {', '.join(raw_column_names['train'])}."
- )
-
- if data_args.text_column_name not in raw_column_names["train"]:
- raise ValueError(
- f"--text_column_name {data_args.text_column_name} not found in dataset '{data_args.dataset_name}'. "
- "Make sure to set `--text_column_name` to the correct text column - one of "
- f"{', '.join(raw_column_names['train'])}."
- )
-
- if data_args.max_train_samples is not None:
- raw_datasets["train"] = raw_datasets["train"].take(range(data_args.max_train_samples))
-
- if training_args.do_eval:
- raw_datasets["eval"], eval_features = load_streaming_dataset(
- path=data_args.dataset_name,
- name=data_args.dataset_config_name,
- split=data_args.eval_split_name,
- token=data_args.use_auth_token,
- streaming=True,
- sampling_rate=feature_extractor.sampling_rate,
- )
- raw_column_names["eval"] = list(eval_features.keys())
-
- if data_args.max_eval_samples is not None:
- raw_datasets["eval"] = raw_datasets["eval"].take(range(data_args.max_eval_samples))
-
- # 2. We remove some special characters from the datasets
- # that make training complicated and do not help in transcribing the speech
- # E.g. characters, such as `,` and `.` do not really have an acoustic characteristic
- # that could be easily picked up by the model
- chars_to_ignore_regex = (
- f'[{"".join(data_args.chars_to_ignore)}]' if data_args.chars_to_ignore is not None else None
- )
- text_column_name = data_args.text_column_name
-
- def remove_special_characters(batch):
- if chars_to_ignore_regex is not None:
- batch["target_text"] = re.sub(chars_to_ignore_regex, "", batch[text_column_name]).lower() + " "
- else:
- batch["target_text"] = batch[text_column_name].lower() + " "
- return batch
-
- with training_args.main_process_first(desc="dataset map special characters removal"):
- for split, dataset in raw_datasets.items():
- raw_datasets[split] = dataset.map(
- remove_special_characters,
- ).remove_columns([text_column_name])
-
- # 3. Next, let's load the config as we might need it to create
- # the tokenizer
- config = AutoConfig.from_pretrained(
- model_args.model_name_or_path, cache_dir=model_args.cache_dir, token=data_args.use_auth_token
- )
-
- # 4. Now we can instantiate the tokenizer and model
- # Note for distributed training, the .from_pretrained methods guarantee that only
- # one local process can concurrently download model & vocab.
-
- tokenizer_name_or_path = model_args.tokenizer_name_or_path
- if tokenizer_name_or_path is None:
- raise ValueError(
- "Tokenizer has to be created before training in streaming mode. Please specify --tokenizer_name_or_path"
- )
- # load feature_extractor and tokenizer
- tokenizer = AutoTokenizer.from_pretrained(
- tokenizer_name_or_path,
- config=config,
- token=data_args.use_auth_token,
- )
-
- # adapt config
- config.update(
- {
- "feat_proj_dropout": model_args.feat_proj_dropout,
- "attention_dropout": model_args.attention_dropout,
- "hidden_dropout": model_args.hidden_dropout,
- "final_dropout": model_args.final_dropout,
- "mask_time_prob": model_args.mask_time_prob,
- "mask_time_length": model_args.mask_time_length,
- "mask_feature_prob": model_args.mask_feature_prob,
- "mask_feature_length": model_args.mask_feature_length,
- "gradient_checkpointing": training_args.gradient_checkpointing,
- "layerdrop": model_args.layerdrop,
- "ctc_loss_reduction": model_args.ctc_loss_reduction,
- "pad_token_id": tokenizer.pad_token_id,
- "vocab_size": len(tokenizer),
- "activation_dropout": model_args.activation_dropout,
- }
- )
-
- # create model
- model = AutoModelForCTC.from_pretrained(
- model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- config=config,
- token=data_args.use_auth_token,
- )
-
- # freeze encoder
- if model_args.freeze_feature_encoder:
- model.freeze_feature_encoder()
-
- # 5. Now we preprocess the datasets including loading the audio, resampling and normalization
- audio_column_name = data_args.audio_column_name
-
- # `phoneme_language` is only relevant if the model is fine-tuned on phoneme classification
- phoneme_language = data_args.phoneme_language
-
- # Preprocessing the datasets.
- # We need to read the audio files as arrays and tokenize the targets.
- def prepare_dataset(batch):
- # load audio
- sample = batch[audio_column_name]
-
- inputs = feature_extractor(sample["array"], sampling_rate=sample["sampling_rate"])
- batch["input_values"] = inputs.input_values[0]
- batch["input_length"] = len(batch["input_values"])
-
- # encode targets
- additional_kwargs = {}
- if phoneme_language is not None:
- additional_kwargs["phonemizer_lang"] = phoneme_language
-
- batch["labels"] = tokenizer(batch["target_text"], **additional_kwargs).input_ids
- return batch
-
- vectorized_datasets = IterableDatasetDict()
- with training_args.main_process_first(desc="dataset map preprocessing"):
- for split, dataset in raw_datasets.items():
- vectorized_datasets[split] = (
- dataset.map(prepare_dataset)
- .remove_columns(raw_column_names[split] + ["target_text"])
- .with_format("torch")
- )
- if split == "train":
- vectorized_datasets[split] = vectorized_datasets[split].shuffle(
- buffer_size=data_args.shuffle_buffer_size,
- seed=training_args.seed,
- )
-
- # 6. Next, we can prepare the training.
- # Let's use word error rate (WER) as our evaluation metric,
- # instantiate a data collator and the trainer
-
- # Define evaluation metrics during training, *i.e.* word error rate, character error rate
- eval_metrics = {metric: load_metric(metric) for metric in data_args.eval_metrics}
-
- def compute_metrics(pred):
- pred_logits = pred.predictions
- pred_ids = np.argmax(pred_logits, axis=-1)
-
- pred.label_ids[pred.label_ids == -100] = tokenizer.pad_token_id
-
- pred_str = tokenizer.batch_decode(pred_ids)
- # we do not want to group tokens when computing the metrics
- label_str = tokenizer.batch_decode(pred.label_ids, group_tokens=False)
-
- metrics = {k: v.compute(predictions=pred_str, references=label_str) for k, v in eval_metrics.items()}
-
- return metrics
-
- # Now save everything to be able to create a single processor later
- if is_main_process(training_args.local_rank):
- # save feature extractor, tokenizer and config
- feature_extractor.save_pretrained(training_args.output_dir)
- tokenizer.save_pretrained(training_args.output_dir)
- config.save_pretrained(training_args.output_dir)
-
- try:
- processor = AutoProcessor.from_pretrained(training_args.output_dir)
- except (OSError, KeyError):
- warnings.warn(
- "Loading a processor from a feature extractor config that does not"
- " include a `processor_class` attribute is deprecated and will be removed in v5. Please add the following "
- " attribute to your `preprocessor_config.json` file to suppress this warning: "
- " `'processor_class': 'Wav2Vec2Processor'`",
- FutureWarning,
- )
- processor = Wav2Vec2Processor.from_pretrained(training_args.output_dir)
-
- # Instantiate custom data collator
- max_input_length = data_args.max_duration_in_seconds * feature_extractor.sampling_rate
- data_collator = DataCollatorCTCWithPadding(processor=processor, max_length=max_input_length)
-
- # trainer callback to reinitialize and reshuffle the streamable datasets at the beginning of each epoch
- class ShuffleCallback(TrainerCallback):
- def on_epoch_begin(self, args, state, control, train_dataloader, **kwargs):
- if isinstance(train_dataloader.dataset, IterableDatasetShard):
- pass # set_epoch() is handled by the Trainer
- elif isinstance(train_dataloader.dataset, IterableDataset):
- train_dataloader.dataset.set_epoch(train_dataloader.dataset._epoch + 1)
-
- # Initialize Trainer
- trainer = Trainer(
- model=model,
- data_collator=data_collator,
- args=training_args,
- compute_metrics=compute_metrics,
- train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
- eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
- tokenizer=processor,
- callbacks=[ShuffleCallback()],
- )
-
- # 7. Finally, we can start training
-
- # Training
- if training_args.do_train:
- # use last checkpoint if exist
- if last_checkpoint is not None:
- checkpoint = last_checkpoint
- elif os.path.isdir(model_args.model_name_or_path):
- checkpoint = model_args.model_name_or_path
- else:
- checkpoint = None
-
- train_result = trainer.train(resume_from_checkpoint=checkpoint)
- trainer.save_model()
-
- metrics = train_result.metrics
- if data_args.max_train_samples:
- metrics["train_samples"] = data_args.max_train_samples
-
- trainer.log_metrics("train", metrics)
- trainer.save_metrics("train", metrics)
- trainer.save_state()
-
- # Evaluation
- results = {}
- if training_args.do_eval:
- logger.info("*** Evaluate ***")
- metrics = trainer.evaluate()
- if data_args.max_eval_samples:
- metrics["eval_samples"] = data_args.max_eval_samples
-
- trainer.log_metrics("eval", metrics)
- trainer.save_metrics("eval", metrics)
-
- # Write model card and (optionally) push to hub
- config_name = data_args.dataset_config_name if data_args.dataset_config_name is not None else "na"
- kwargs = {
- "finetuned_from": model_args.model_name_or_path,
- "tasks": "automatic-speech-recognition",
- "tags": ["automatic-speech-recognition", data_args.dataset_name],
- "dataset_args": (
- f"Config: {config_name}, Training split: {data_args.train_split_name}, Eval split:"
- f" {data_args.eval_split_name}"
- ),
- "dataset": f"{data_args.dataset_name.upper()} - {config_name.upper()}",
- }
- if "common_voice" in data_args.dataset_name:
- kwargs["language"] = config_name
-
- if training_args.push_to_hub:
- trainer.push_to_hub(**kwargs)
- else:
- trainer.create_model_card(**kwargs)
-
- return results
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/self-training-text-classification/README.md b/examples/research_projects/self-training-text-classification/README.md
deleted file mode 100644
index 062d5de7afd..00000000000
--- a/examples/research_projects/self-training-text-classification/README.md
+++ /dev/null
@@ -1,128 +0,0 @@
-# Self-training
-
-This is an implementation of the self-training algorithm (without task augmentation) in the [EMNLP 2021](https://2021.emnlp.org/) paper: [STraTA: Self-Training with Task Augmentation for Better Few-shot Learning](https://arxiv.org/abs/2109.06270). Please check out https://github.com/google-research/google-research/tree/master/STraTA for the original codebase.
-
-**Note**: The code can be used as a tool for automatic data labeling.
-
-## Table of Contents
-
- * [Installation](#installation)
- * [Self-training](#self-training)
- * [Running self-training with a base model](#running-self-training-with-a-base-model)
- * [Hyperparameters for self-training](#hyperparameters-for-self-training)
- * [Distributed training](#distributed-training)
- * [Demo](#demo)
- * [How to cite](#how-to-cite)
-
-## Installation
-This repository is tested on Python 3.8+, PyTorch 1.10+, and the 🤗 Transformers 4.16+.
-
-You should install all necessary Python packages in a [virtual environment](https://docs.python.org/3/library/venv.html). If you are unfamiliar with Python virtual environments, please check out the [user guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
-
-Below, we create a virtual environment with the [Anaconda Python distribution](https://www.anaconda.com/products/distribution) and activate it.
-```sh
-conda create -n strata python=3.9
-conda activate strata
-```
-Next, you need to install 🤗 Transformers. Please refer to [🤗 Transformers installation page](https://github.com/huggingface/transformers#installation) for a detailed guide.
-```sh
-pip install transformers
-```
-Finally, install all necessary Python packages for our self-training algorithm.
-
-```sh
-pip install -r STraTA/selftraining/requirements.txt
-```
-This will install PyTorch as a backend.
-
-## Self-training
-### Running self-training with a base model
-The following example code shows how to run our self-training algorithm with a base model (e.g., `BERT`) on the `SciTail` science entailment dataset, which has two classes `['entails', 'neutral']`. We assume that you have a data directory that includes some training data (e.g., `train.csv`), evaluation data (e.g., `eval.csv`), and unlabeled data (e.g., `infer.csv`).
-
-```python
-import os
-from selftraining import selftrain
-
-data_dir = '/path/to/your/data/dir'
-parameters_dict = {
- 'max_selftrain_iterations': 100,
- 'model_name_or_path': '/path/to/your/base/model', # could be the id of a model hosted by 🤗 Transformers
- 'output_dir': '/path/to/your/output/dir',
- 'train_file': os.path.join(data_dir, 'train.csv'),
- 'infer_file': os.path.join(data_dir, 'infer.csv'),
- 'eval_file': os.path.join(data_dir, 'eval.csv'),
- 'eval_strategy': 'steps',
- 'task_name': 'scitail',
- 'label_list': ['entails', 'neutral'],
- 'per_device_train_batch_size': 32,
- 'per_device_eval_batch_size': 8,
- 'max_length': 128,
- 'learning_rate': 2e-5,
- 'max_steps': 100000,
- 'eval_steps': 1,
- 'early_stopping_patience': 50,
- 'overwrite_output_dir': True,
- 'do_filter_by_confidence': False,
- # 'confidence_threshold': 0.3,
- 'do_filter_by_val_performance': True,
- 'finetune_on_labeled_data': False,
- 'seed': 42,
-}
-selftrain(**parameters_dict)
-```
-
-**Note**: We checkpoint periodically during self-training. In case of preemptions, just re-run the above script and self-training will resume from the latest iteration.
-
-### Hyperparameters for self-training
-If you have development data, you might want to tune some hyperparameters for self-training.
-Below are hyperparameters that could provide additional gains for your task.
-
- - `finetune_on_labeled_data`: If set to `True`, the resulting model from each self-training iteration is further fine-tuned on the original labeled data before the next self-training iteration. Intuitively, this would give the model a chance to "correct" ifself after being trained on pseudo-labeled data.
- - `do_filter_by_confidence`: If set to `True`, the pseudo-labeled data in each self-training iteration is filtered based on the model confidence. For instance, if `confidence_threshold` is set to `0.3`, pseudo-labeled examples with a confidence score less than or equal to `0.3` will be discarded. Note that `confidence_threshold` should be greater or equal to `1/num_labels`, where `num_labels` is the number of class labels. Filtering out the lowest-confidence pseudo-labeled examples could be helpful in some cases.
- - `do_filter_by_val_performance`: If set to `True`, the pseudo-labeled data in each self-training iteration is filtered based on the current validation performance. For instance, if your validation performance is 80% accuracy, you might want to get rid of 20% of the pseudo-labeled data with the lowest the confidence scores.
-
-### Distributed training
-We strongly recommend distributed training with multiple accelerators. To activate distributed training, please try one of the following methods:
-
-1. Run `accelerate config` and answer to the questions asked. This will save a `default_config.yaml` file in your cache folder for 🤗 Accelerate. Now, you can run your script with the following command:
-
-```sh
-accelerate launch your_script.py --args_to_your_script
-```
-
-2. Run your script with the following command:
-
-```sh
-python -m torch.distributed.launch --nnodes="{$NUM_NODES}" --nproc_per_node="{$NUM_TRAINERS}" --your_script.py --args_to_your_script
-```
-
-3. Run your script with the following command:
-
-```sh
-torchrun --nnodes="{$NUM_NODES}" --nproc_per_node="{$NUM_TRAINERS}" --your_script.py --args_to_your_script
-```
-
-## Demo
-Please check out `run.sh` to see how to perform our self-training algorithm with a `BERT` Base model on the SciTail science entailment dataset using 8 labeled examples per class. You can configure your training environment by specifying `NUM_NODES` and `NUM_TRAINERS` (number of processes per node). To launch the script, simply run `source run.sh`.
-
-## How to cite
-If you extend or use this code, please cite the [paper](https://arxiv.org/abs/2109.06270) where it was introduced:
-
-```bibtex
-@inproceedings{vu-etal-2021-strata,
- title = "{ST}ra{TA}: Self-Training with Task Augmentation for Better Few-shot Learning",
- author = "Vu, Tu and
- Luong, Minh-Thang and
- Le, Quoc and
- Simon, Grady and
- Iyyer, Mohit",
- booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
- month = nov,
- year = "2021",
- address = "Online and Punta Cana, Dominican Republic",
- publisher = "Association for Computational Linguistics",
- url = "https://aclanthology.org/2021.emnlp-main.462",
- doi = "10.18653/v1/2021.emnlp-main.462",
- pages = "5715--5731",
-}
-```
diff --git a/examples/research_projects/self-training-text-classification/finetuning.py b/examples/research_projects/self-training-text-classification/finetuning.py
deleted file mode 100644
index 4bf9eb28df2..00000000000
--- a/examples/research_projects/self-training-text-classification/finetuning.py
+++ /dev/null
@@ -1,818 +0,0 @@
-# coding=utf-8
-# Copyright 2022 The Google Research Authors.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Fine-tuning the library models for sequence classification."""
-
-import argparse
-import dataclasses
-import json
-import logging
-import math
-import os
-import random
-import shutil
-from typing import List, Optional
-
-import datasets
-import numpy as np
-import pandas as pd
-import torch
-from datasets import load_dataset, load_metric
-from torch.utils.data import DataLoader
-from tqdm.auto import tqdm
-
-from transformers import (
- AdamW,
- AutoConfig,
- AutoModelForSequenceClassification,
- AutoTokenizer,
- DataCollatorWithPadding,
- default_data_collator,
- get_scheduler,
- set_seed,
-)
-from transformers.file_utils import ExplicitEnum
-from transformers.trainer_utils import IntervalStrategy
-
-
-logger = logging.getLogger(__name__)
-
-
-class Split(ExplicitEnum):
- TRAIN = "train"
- EVAL = "eval"
- TEST = "test"
- INFER = "infer"
-
-
-@dataclasses.dataclass
-class FTModelArguments:
- """Arguments pertaining to which config/tokenizer/model we are going to fine-tune from."""
-
- model_name_or_path: str = dataclasses.field(
- metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models."}
- )
- use_fast_tokenizer: Optional[bool] = dataclasses.field(
- default=True,
- metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
- )
- cache_dir: Optional[str] = dataclasses.field(
- default=None,
- metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co."},
- )
-
-
-@dataclasses.dataclass
-class FTDataArguments:
- """Arguments pertaining to what data we are going to input our model for training and evaluation."""
-
- train_file: str = dataclasses.field(
- default=None, metadata={"help": "A csv or a json file containing the training data."}
- )
- eval_file: Optional[str] = dataclasses.field(
- default=None, metadata={"help": "A csv or a json file containing the validation data."}
- )
- test_file: Optional[str] = dataclasses.field(
- default=None, metadata={"help": "A csv or a json file containing the test data."}
- )
- infer_file: Optional[str] = dataclasses.field(
- default=None, metadata={"help": "A csv or a json file containing the data to predict on."}
- )
- task_name: Optional[str] = dataclasses.field(
- default=None,
- metadata={"help": "The name of the task to train on."},
- )
- label_list: Optional[List[str]] = dataclasses.field(
- default=None, metadata={"help": "The list of labels for the task."}
- )
-
- max_length: Optional[int] = dataclasses.field(
- default=128,
- metadata={
- "help": (
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- )
- },
- )
- pad_to_max_length: Optional[bool] = dataclasses.field(
- default=False,
- metadata={
- "help": (
- "Whether to pad all samples to `max_seq_length`. "
- "If False, will pad the samples dynamically when batching to the maximum length in the batch."
- )
- },
- )
-
-
-@dataclasses.dataclass
-class FTTrainingArguments:
- """Training arguments pertaining to the training loop itself."""
-
- output_dir: str = dataclasses.field(
- metadata={"help": "The output directory where the model predictions and checkpoints will be written."}
- )
- do_train: Optional[bool] = dataclasses.field(
- default=False,
- metadata={"help": "Whether to run training or not."},
- )
- do_eval: Optional[bool] = dataclasses.field(
- default=False,
- metadata={"help": "Whether to run evaluation on the validation set or not."},
- )
- do_predict: Optional[bool] = dataclasses.field(
- default=False,
- metadata={"help": "Whether to run inference on the inference set or not."},
- )
- seed: Optional[int] = dataclasses.field(
- default=42,
- metadata={"help": "Random seed that will be set at the beginning of training."},
- )
- per_device_train_batch_size: Optional[int] = dataclasses.field(
- default=8,
- metadata={"help": "The batch size per GPU/TPU core/CPU for training."},
- )
- per_device_eval_batch_size: Optional[int] = dataclasses.field(
- default=8,
- metadata={"help": "The batch size per GPU/TPU core/CPU for evaluation."},
- )
- weight_decay: Optional[float] = dataclasses.field(
- default=0.0,
- metadata={
- "help": (
- "The weight decay to apply (if not zero) to all layers except all bias and LayerNorm weights in"
- " [`AdamW`] optimizer."
- )
- },
- )
- learning_rate: Optional[float] = dataclasses.field(
- default=5e-5,
- metadata={"help": "The initial learning rate for [`AdamW`] optimizer."},
- )
- gradient_accumulation_steps: Optional[int] = dataclasses.field(
- default=1,
- metadata={
- "help": (
- "Number of updates steps to accumulate the gradients for, before performing a backward/update pass."
- )
- },
- )
- max_steps: Optional[int] = dataclasses.field(
- default=-1,
- metadata={
- "help": (
- "If set to a positive number, the total number of training steps to perform. Overrides"
- " `num_train_epochs`."
- )
- },
- )
- lr_scheduler_type: Optional[str] = dataclasses.field(
- default="linear", metadata={"help": "The scheduler type to use."}
- )
- warmup_steps: Optional[int] = dataclasses.field(
- default=1,
- metadata={
- "help": (
- "Number of steps used for a linear warmup from 0 to `learning_rate`. Overrides any effect of"
- " `warmup_ratio`."
- )
- },
- )
- eval_strategy: Optional[str] = dataclasses.field(
- default="no",
- metadata={
- "help": 'The evaluation strategy to adopt during training. Possible values are: ["no", "step", "epoch]'
- },
- )
- eval_steps: Optional[int] = dataclasses.field(
- default=1,
- metadata={"help": 'Number of update steps between two evaluations if `eval_strategy="steps"`.'},
- )
- eval_metric: Optional[str] = dataclasses.field(
- default="accuracy", metadata={"help": "The evaluation metric used for the task."}
- )
- keep_checkpoint_max: Optional[int] = dataclasses.field(
- default=1,
- metadata={"help": "The maximum number of best checkpoint files to keep."},
- )
- early_stopping_patience: Optional[int] = dataclasses.field(
- default=10,
- metadata={"help": "Number of evaluation calls with no improvement after which training will be stopped."},
- )
- early_stopping_threshold: Optional[float] = dataclasses.field(
- default=0.0,
- metadata={
- "help": "How much the specified evaluation metric must improve to satisfy early stopping conditions."
- },
- )
-
-
-def train(args, accelerator, model, tokenizer, train_dataloader, optimizer, lr_scheduler, eval_dataloader=None):
- """Train a model on the given training data."""
-
- total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
-
- logger.info("***** Running training *****")
- logger.info(" Num examples = %d", args.num_examples[Split.TRAIN.value])
- logger.info(" Instantaneous batch size per device = %d", args.per_device_train_batch_size)
- logger.info(" Total train batch size (w. parallel, distributed & accumulation) = %d", total_batch_size)
- logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)
- logger.info(" Total optimization steps = %d", args.max_steps)
-
- # Only show the progress bar once on each machine.
- progress_bar = tqdm(range(args.max_steps), disable=not accelerator.is_local_main_process)
-
- checkpoints = None
- eval_results = None
- best_checkpoint = None
- best_eval_result = None
- early_stopping_patience_counter = 0
- should_training_stop = False
- epoch = 0
- completed_steps = 0
- train_loss = 0.0
- model.zero_grad()
-
- for _ in range(args.num_train_epochs):
- epoch += 1
- model.train()
- for step, batch in enumerate(train_dataloader):
- outputs = model(**batch)
- loss = outputs.loss
- loss = loss / args.gradient_accumulation_steps
- accelerator.backward(loss)
- train_loss += loss.item()
-
- if step % args.gradient_accumulation_steps == 0 or step == len(train_dataloader) - 1:
- optimizer.step()
- lr_scheduler.step()
- optimizer.zero_grad()
- progress_bar.update(1)
- completed_steps += 1
-
- # Evaluate during training
- if (
- eval_dataloader is not None
- and args.eval_strategy == IntervalStrategy.STEPS.value
- and args.eval_steps > 0
- and completed_steps % args.eval_steps == 0
- ):
- accelerator.wait_for_everyone()
- new_checkpoint = f"checkpoint-{IntervalStrategy.STEPS.value}-{completed_steps}"
- new_eval_result = evaluate(args, accelerator, eval_dataloader, "eval", model, new_checkpoint)[
- args.eval_metric
- ]
- logger.info(
- "Evaluation result at step %d: %s = %f", completed_steps, args.eval_metric, new_eval_result
- )
- if checkpoints is None:
- checkpoints = np.array([new_checkpoint])
- eval_results = np.array([new_eval_result])
- best_checkpoint = new_checkpoint
- best_eval_result = new_eval_result
- else:
- if new_eval_result - best_eval_result > args.early_stopping_threshold:
- best_checkpoint = new_checkpoint
- best_eval_result = new_eval_result
- early_stopping_patience_counter = 0
- else:
- if new_eval_result == best_eval_result:
- best_checkpoint = new_checkpoint
- best_eval_result = new_eval_result
- early_stopping_patience_counter += 1
-
- if early_stopping_patience_counter >= args.early_stopping_patience:
- should_training_stop = True
-
- checkpoints = np.append(checkpoints, [new_checkpoint], axis=0)
- eval_results = np.append(eval_results, [new_eval_result], axis=0)
- sorted_ids = np.argsort(eval_results)
- eval_results = eval_results[sorted_ids]
- checkpoints = checkpoints[sorted_ids]
-
- if len(checkpoints) > args.keep_checkpoint_max:
- # Delete the current worst checkpoint
- checkpoint_to_remove, *checkpoints = checkpoints
- eval_results = eval_results[1:]
- if checkpoint_to_remove != new_checkpoint:
- if accelerator.is_main_process:
- shutil.rmtree(os.path.join(args.output_dir, checkpoint_to_remove), ignore_errors=True)
- accelerator.wait_for_everyone()
-
- if new_checkpoint in checkpoints:
- # Save model checkpoint
- checkpoint_output_dir = os.path.join(args.output_dir, new_checkpoint)
- if accelerator.is_main_process:
- if not os.path.exists(checkpoint_output_dir):
- os.makedirs(checkpoint_output_dir)
- accelerator.wait_for_everyone()
- unwrapped_model = accelerator.unwrap_model(model)
- unwrapped_model.save_pretrained(checkpoint_output_dir, save_function=accelerator.save)
- if accelerator.is_main_process:
- tokenizer.save_pretrained(checkpoint_output_dir)
- logger.info("Saving model checkpoint to %s", checkpoint_output_dir)
-
- if completed_steps >= args.max_steps:
- break
-
- if should_training_stop:
- break
-
- # Evaluate during training
- if eval_dataloader is not None and args.eval_strategy == IntervalStrategy.EPOCH.value:
- accelerator.wait_for_everyone()
- new_checkpoint = f"checkpoint-{IntervalStrategy.EPOCH.value}-{epoch}"
- new_eval_result = evaluate(args, accelerator, eval_dataloader, "eval", model, new_checkpoint)[
- args.eval_metric
- ]
- logger.info("Evaluation result at epoch %d: %s = %f", epoch, args.eval_metric, new_eval_result)
-
- if checkpoints is None:
- checkpoints = np.array([new_checkpoint])
- eval_results = np.array([new_eval_result])
- best_checkpoint = new_checkpoint
- best_eval_result = new_eval_result
- else:
- if new_eval_result - best_eval_result > args.early_stopping_threshold:
- best_checkpoint = new_checkpoint
- best_eval_result = new_eval_result
- early_stopping_patience_counter = 0
- else:
- if new_eval_result == best_eval_result:
- best_checkpoint = new_checkpoint
- best_eval_result = new_eval_result
- early_stopping_patience_counter += 1
-
- if early_stopping_patience_counter >= args.early_stopping_patience:
- should_training_stop = True
-
- checkpoints = np.append(checkpoints, [new_checkpoint], axis=0)
- eval_results = np.append(eval_results, [new_eval_result], axis=0)
- sorted_ids = np.argsort(eval_results)
- eval_results = eval_results[sorted_ids]
- checkpoints = checkpoints[sorted_ids]
-
- if len(checkpoints) > args.keep_checkpoint_max:
- # Delete the current worst checkpoint
- checkpoint_to_remove, *checkpoints = checkpoints
- eval_results = eval_results[1:]
- if checkpoint_to_remove != new_checkpoint:
- if accelerator.is_main_process:
- shutil.rmtree(os.path.join(args.output_dir, checkpoint_to_remove), ignore_errors=True)
- accelerator.wait_for_everyone()
-
- if new_checkpoint in checkpoints:
- # Save model checkpoint
- checkpoint_output_dir = os.path.join(args.output_dir, new_checkpoint)
- if accelerator.is_main_process:
- if not os.path.exists(checkpoint_output_dir):
- os.makedirs(checkpoint_output_dir)
- accelerator.wait_for_everyone()
- unwrapped_model = accelerator.unwrap_model(model)
- unwrapped_model.save_pretrained(checkpoint_output_dir, save_function=accelerator.save)
- if accelerator.is_main_process:
- tokenizer.save_pretrained(checkpoint_output_dir)
- logger.info("Saving model checkpoint to %s", checkpoint_output_dir)
-
- if completed_steps >= args.max_steps:
- break
-
- if should_training_stop:
- break
-
- if best_checkpoint is not None:
- # Save the best checkpoint
- logger.info("Best checkpoint: %s", best_checkpoint)
- logger.info("Best evaluation result: %s = %f", args.eval_metric, best_eval_result)
- best_checkpoint_output_dir = os.path.join(args.output_dir, best_checkpoint)
- if accelerator.is_main_process:
- shutil.move(best_checkpoint_output_dir, os.path.join(args.output_dir, "best-checkpoint"))
- shutil.rmtree(best_checkpoint_output_dir, ignore_errors=True)
- accelerator.wait_for_everyone()
-
- else:
- # Assume that the last checkpoint is the best checkpoint and save it
- checkpoint_output_dir = os.path.join(args.output_dir, "best-checkpoint")
- if not os.path.exists(checkpoint_output_dir):
- os.makedirs(checkpoint_output_dir)
-
- accelerator.wait_for_everyone()
- unwrapped_model = accelerator.unwrap_model(model)
- unwrapped_model.save_pretrained(checkpoint_output_dir, save_function=accelerator.save)
- if accelerator.is_main_process:
- tokenizer.save_pretrained(checkpoint_output_dir)
- logger.info("Saving model checkpoint to %s", checkpoint_output_dir)
- return completed_steps, train_loss / completed_steps
-
-
-def evaluate(args, accelerator, dataloader, eval_set, model, checkpoint, has_labels=True, write_to_file=True):
- """Evaluate a model checkpoint on the given evaluation data."""
-
- num_examples = args.num_examples[eval_set]
- eval_metric = None
- completed_steps = 0
- eval_loss = 0.0
- all_predictions = None
- all_references = None
- all_probabilities = None
-
- if has_labels:
- # Get the metric function
- eval_metric = load_metric(args.eval_metric)
-
- eval_results = {}
- model.eval()
- for _, batch in enumerate(dataloader):
- with torch.no_grad():
- outputs = model(**batch)
-
- eval_loss += outputs.loss.item()
- logits = outputs.logits
- predictions = logits.argmax(dim=-1) if not args.is_regression else logits.squeeze()
- predictions = accelerator.gather(predictions)
-
- if all_predictions is None:
- all_predictions = predictions.detach().cpu().numpy()
- else:
- all_predictions = np.append(all_predictions, predictions.detach().cpu().numpy(), axis=0)
-
- if not args.is_regression:
- probabilities = logits.softmax(dim=-1).max(dim=-1).values
- probabilities = accelerator.gather(probabilities)
- if all_probabilities is None:
- all_probabilities = probabilities.detach().cpu().numpy()
- else:
- all_probabilities = np.append(all_probabilities, probabilities.detach().cpu().numpy(), axis=0)
-
- if has_labels:
- references = batch["labels"]
- references = accelerator.gather(references)
- if all_references is None:
- all_references = references.detach().cpu().numpy()
- else:
- all_references = np.append(all_references, references.detach().cpu().numpy(), axis=0)
-
- eval_metric.add_batch(
- predictions=predictions,
- references=references,
- )
- completed_steps += 1
-
- if has_labels:
- eval_results.update(eval_metric.compute())
- eval_results["completed_steps"] = completed_steps
- eval_results["avg_eval_loss"] = eval_loss / completed_steps
-
- if write_to_file:
- accelerator.wait_for_everyone()
- if accelerator.is_main_process:
- results_file = os.path.join(args.output_dir, f"{eval_set}_results_{checkpoint}.json")
- with open(results_file, "w") as f:
- json.dump(eval_results, f, indent=4, sort_keys=True)
-
- if write_to_file:
- accelerator.wait_for_everyone()
- if accelerator.is_main_process:
- output_file = os.path.join(args.output_dir, f"{eval_set}_output_{checkpoint}.csv")
- if not args.is_regression:
- assert len(all_predictions) == len(all_probabilities)
- df = pd.DataFrame(list(zip(all_predictions, all_probabilities)), columns=["prediction", "probability"])
- else:
- df = pd.DataFrame(all_predictions, columns=["prediction"])
- df = df.head(num_examples)
- df.to_csv(output_file, header=True, index=False)
- return eval_results
-
-
-def load_from_pretrained(args, pretrained_model_name_or_path):
- """Load the pretrained model and tokenizer."""
-
- # In distributed training, the .from_pretrained methods guarantee that only
- # one local process can concurrently perform this procedure.
-
- config = AutoConfig.from_pretrained(
- pretrained_model_name_or_path,
- num_labels=args.num_labels if hasattr(args, "num_labels") else None,
- finetuning_task=args.task_name.lower(),
- cache_dir=args.cache_dir,
- )
- tokenizer = AutoTokenizer.from_pretrained(
- pretrained_model_name_or_path, use_fast=args.use_fast_tokenizer, cache_dir=args.cache_dir
- )
- model = AutoModelForSequenceClassification.from_pretrained(
- pretrained_model_name_or_path,
- from_tf=bool(".ckpt" in args.model_name_or_path),
- config=config,
- ignore_mismatched_sizes=True,
- cache_dir=args.cache_dir,
- )
- return config, tokenizer, model
-
-
-def finetune(accelerator, model_name_or_path, train_file, output_dir, **kwargs):
- """Fine-tuning a pre-trained model on a downstream task.
-
- Args:
- accelerator: An instance of an accelerator for distributed training (on
- multi-GPU, TPU) or mixed precision training.
- model_name_or_path: Path to pretrained model or model identifier from
- huggingface.co/models.
- train_file: A csv or a json file containing the training data.
- output_dir: The output directory where the model predictions and checkpoints
- will be written.
- **kwargs: Dictionary of key/value pairs with which to update the
- configuration object after loading. The values in kwargs of any keys which
- are configuration attributes will be used to override the loaded values.
- """
- # Make one log on every process with the configuration for debugging.
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- level=logging.INFO,
- )
- logger.info(accelerator.state)
-
- # Setup logging, we only want one process per machine to log things on the
- # screen. accelerator.is_local_main_process is only True for one process per
- # machine.
- logger.setLevel(logging.INFO if accelerator.is_local_main_process else logging.ERROR)
-
- model_args = FTModelArguments(model_name_or_path=model_name_or_path)
- data_args = FTDataArguments(train_file=train_file)
- training_args = FTTrainingArguments(output_dir=output_dir)
- args = argparse.Namespace()
-
- for arg_class in (model_args, data_args, training_args):
- for key, value in vars(arg_class).items():
- setattr(args, key, value)
-
- for key, value in kwargs.items():
- if hasattr(args, key):
- setattr(args, key, value)
-
- # Sanity checks
- data_files = {}
- args.data_file_extension = None
-
- # You need to provide the training data as we always run training
- args.do_train = True
- assert args.train_file is not None
- data_files[Split.TRAIN.value] = args.train_file
-
- if args.do_eval or args.eval_strategy != IntervalStrategy.NO.value:
- assert args.eval_file is not None
- data_files[Split.EVAL.value] = args.eval_file
-
- if args.do_eval and args.test_file is not None:
- data_files[Split.TEST.value] = args.test_file
-
- if args.do_predict:
- assert args.infer_file is not None
- data_files[Split.INFER.value] = args.infer_file
-
- for key in data_files:
- extension = data_files[key].split(".")[-1]
- assert extension in ["csv", "json"], f"`{key}_file` should be a csv or a json file."
- if args.data_file_extension is None:
- args.data_file_extension = extension
- else:
- assert extension == args.data_file_extension, f"`{key}_file` should be a {args.data_file_extension} file`."
-
- assert (
- args.eval_metric in datasets.list_metrics()
- ), f"{args.eval_metric} not in the list of supported metrics {datasets.list_metrics()}."
-
- # Handle the output directory creation
- if accelerator.is_main_process:
- if args.output_dir is not None:
- os.makedirs(args.output_dir, exist_ok=True)
- accelerator.wait_for_everyone()
-
- # If passed along, set the training seed now.
- if args.seed is not None:
- set_seed(args.seed)
-
- # You need to provide your CSV/JSON data files.
- #
- # For CSV/JSON files, this script will use as labels the column called 'label'
- # and as pair of sentences the sentences in columns called 'sentence1' and
- # 'sentence2' if these columns exist or the first two columns not named
- # 'label' if at least two columns are provided.
- #
- # If the CSVs/JSONs contain only one non-label column, the script does single
- # sentence classification on this single column.
- #
- # In distributed training, the load_dataset function guarantees that only one
- # local process can download the dataset.
-
- # Loading the dataset from local csv or json files.
- raw_datasets = load_dataset(args.data_file_extension, data_files=data_files)
-
- # Labels
- is_regression = raw_datasets[Split.TRAIN.value].features["label"].dtype in ["float32", "float64"]
- args.is_regression = is_regression
-
- if args.is_regression:
- label_list = None
- num_labels = 1
- else:
- label_list = args.label_list
- assert label_list is not None
- label_list.sort() # Let's sort it for determinism
- num_labels = len(label_list)
- args.num_labels = num_labels
-
- # Load pre-trained model
- config, tokenizer, model = load_from_pretrained(args, args.model_name_or_path)
-
- # Preprocessing the datasets
- non_label_column_names = [name for name in raw_datasets[Split.TRAIN.value].column_names if name != "label"]
- if "sentence1" in non_label_column_names and "sentence2" in non_label_column_names:
- sentence1_key, sentence2_key = "sentence1", "sentence2"
- else:
- if len(non_label_column_names) >= 2:
- sentence1_key, sentence2_key = non_label_column_names[:2]
- else:
- sentence1_key, sentence2_key = non_label_column_names[0], None
-
- label_to_id = {v: i for i, v in enumerate(label_list)}
- config.label2id = label_to_id
- config.id2label = {id: label for label, id in config.label2id.items()}
- padding = "max_length" if args.pad_to_max_length else False
-
- def preprocess_function(examples):
- # Tokenize the texts
- texts = (
- (examples[sentence1_key],) if sentence2_key is None else (examples[sentence1_key], examples[sentence2_key])
- )
- result = tokenizer(*texts, padding=padding, max_length=args.max_length, truncation=True)
-
- if "label" in examples:
- if label_to_id is not None:
- # Map labels to IDs (not necessary for GLUE tasks)
- result["labels"] = [label_to_id[l] for l in examples["label"]]
- else:
- # In all cases, rename the column to labels because the model will
- # expect that.
- result["labels"] = examples["label"]
- return result
-
- with accelerator.main_process_first():
- processed_datasets = raw_datasets.map(
- preprocess_function,
- batched=True,
- remove_columns=raw_datasets[Split.TRAIN.value].column_names,
- desc="Running tokenizer on dataset",
- )
-
- num_examples = {}
- splits = [s.value for s in Split]
- for split in splits:
- if split in processed_datasets:
- num_examples[split] = len(processed_datasets[split])
- args.num_examples = num_examples
-
- train_dataset = processed_datasets[Split.TRAIN.value]
- eval_dataset = processed_datasets[Split.EVAL.value] if Split.EVAL.value in processed_datasets else None
- test_dataset = processed_datasets[Split.TEST.value] if Split.TEST.value in processed_datasets else None
- infer_dataset = processed_datasets[Split.INFER.value] if Split.INFER.value in processed_datasets else None
-
- # Log a few random samples from the training set:
- for index in random.sample(range(len(train_dataset)), 3):
- logger.info("Sample %d of the training set: %s.", index, train_dataset[index])
-
- # DataLoaders creation:
- if args.pad_to_max_length:
- # If padding was already done ot max length, we use the default data
- # collator that will just convert everything to tensors.
- data_collator = default_data_collator
- else:
- # Otherwise, `DataCollatorWithPadding` will apply dynamic padding for us (by
- # padding to the maximum length of the samples passed). When using mixed
- # precision, we add `pad_to_multiple_of=8` to pad all tensors to multiple of
- # 8s, which will enable the use of Tensor Cores on NVIDIA hardware with
- # compute capability >= 7.5 (Volta).
- # For fp8, we pad to multiple of 16.
- if accelerator.mixed_precision == "fp8":
- pad_to_multiple_of = 16
- elif accelerator.mixed_precision != "no":
- pad_to_multiple_of = 8
- else:
- pad_to_multiple_of = None
- data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=pad_to_multiple_of)
-
- train_dataloader = DataLoader(
- train_dataset,
- batch_size=args.per_device_train_batch_size,
- shuffle=True,
- collate_fn=data_collator,
- )
- eval_dataloader, test_dataloader, infer_dataloader = None, None, None
-
- if eval_dataset is not None:
- eval_dataloader = DataLoader(
- eval_dataset, batch_size=args.per_device_eval_batch_size, collate_fn=data_collator
- )
-
- if test_dataset is not None:
- test_dataloader = DataLoader(
- test_dataset, batch_size=args.per_device_eval_batch_size, collate_fn=data_collator
- )
-
- if infer_dataset is not None:
- infer_dataloader = DataLoader(
- infer_dataset, batch_size=args.per_device_eval_batch_size, collate_fn=data_collator
- )
-
- # Optimizer
- # Split weights in two groups, one with weight decay and the other not.
- no_decay = ["bias", "LayerNorm.weight"]
- optimizer_grouped_parameters = [
- {
- "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
- "weight_decay": args.weight_decay,
- },
- {
- "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
- "weight_decay": 0.0,
- },
- ]
- optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
-
- # Prepare everything with our `accelerator`.
- model, optimizer, train_dataloader, eval_dataloader, test_dataloader, infer_dataloader = accelerator.prepare(
- model, optimizer, train_dataloader, eval_dataloader, test_dataloader, infer_dataloader
- )
-
- # Note -> the training dataloader needs to be prepared before we grab its
- # length below (cause its length will be shorter in multiprocess)
-
- # Scheduler and math around the number of training steps.
- num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
- if args.max_steps == -1:
- args.max_steps = args.num_train_epochs * num_update_steps_per_epoch
- else:
- args.num_train_epochs = math.ceil(args.max_steps / num_update_steps_per_epoch)
-
- lr_scheduler = get_scheduler(
- name=args.lr_scheduler_type,
- optimizer=optimizer,
- num_warmup_steps=args.warmup_steps,
- num_training_steps=args.max_steps,
- )
-
- # Train
- completed_steps, avg_train_loss = train(
- args, accelerator, model, tokenizer, train_dataloader, optimizer, lr_scheduler, eval_dataloader
- )
- accelerator.wait_for_everyone()
- logger.info("Training job completed: completed_steps = %d, avg_train_loss = %f", completed_steps, avg_train_loss)
-
- args.model_name_or_path = os.path.join(args.output_dir, "best-checkpoint")
- logger.info("Loading the best checkpoint: %s", args.model_name_or_path)
- config, tokenizer, model = load_from_pretrained(args, args.model_name_or_path)
- model = accelerator.prepare(model)
-
- if args.do_eval:
- # Evaluate
- if eval_dataloader is not None:
- logger.info("***** Running evaluation on the eval data using the best checkpoint *****")
- eval_results = evaluate(args, accelerator, eval_dataloader, Split.EVAL.value, model, "best-checkpoint")
- avg_eval_loss = eval_results["avg_eval_loss"]
- eval_metric = eval_results[args.eval_metric]
- logger.info("Evaluation job completed: avg_eval_loss = %f", avg_eval_loss)
- logger.info("Evaluation result for the best checkpoint: %s = %f", args.eval_metric, eval_metric)
-
- if test_dataloader is not None:
- logger.info("***** Running evaluation on the test data using the best checkpoint *****")
- eval_results = evaluate(args, accelerator, test_dataloader, Split.TEST.value, model, "best-checkpoint")
- avg_eval_loss = eval_results["avg_eval_loss"]
- eval_metric = eval_results[args.eval_metric]
- logger.info("Test job completed: avg_test_loss = %f", avg_eval_loss)
- logger.info("Test result for the best checkpoint: %s = %f", args.eval_metric, eval_metric)
-
- if args.do_predict:
- # Predict
- if infer_dataloader is not None:
- logger.info("***** Running inference using the best checkpoint *****")
- evaluate(
- args, accelerator, infer_dataloader, Split.INFER.value, model, "best-checkpoint", has_labels=False
- )
- logger.info("Inference job completed.")
-
- # Release all references to the internal objects stored and call the garbage
- # collector. You should call this method between two trainings with different
- # models/optimizers.
- accelerator.free_memory()
diff --git a/examples/research_projects/self-training-text-classification/requirements.txt b/examples/research_projects/self-training-text-classification/requirements.txt
deleted file mode 100644
index 25d66c8b6a4..00000000000
--- a/examples/research_projects/self-training-text-classification/requirements.txt
+++ /dev/null
@@ -1,7 +0,0 @@
-accelerate
-datasets >= 1.8.0
-protobuf
-scikit-learn
-scipy
-sentencepiece != 0.1.92
-torch >= 1.3
diff --git a/examples/research_projects/self-training-text-classification/run.sh b/examples/research_projects/self-training-text-classification/run.sh
deleted file mode 100755
index 34e91d7c127..00000000000
--- a/examples/research_projects/self-training-text-classification/run.sh
+++ /dev/null
@@ -1,81 +0,0 @@
-# Copyright 2022 The Google Research Authors.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-#!/bin/bash
-
-# Create a virtual environment
-conda deactivate
-conda update conda -y
-conda update anaconda -y
-pip install --upgrade pip
-python3 -m pip install --user virtualenv
-conda create -n strata python=3.9 -y
-conda activate strata
-# Install all necessary packages
-pip install transformers
-pip install -r requirements.txt
-
-# Download and prepare data
-WORK_DIR="/tmp/strata"
-rm -rf "${WORK_DIR}" && mkdir -p "${WORK_DIR}"
-wget https://storage.googleapis.com/gresearch/strata/demo.zip -P "${WORK_DIR}"
-DEMO_ZIP_FILE="${WORK_DIR}/demo.zip"
-unzip "${DEMO_ZIP_FILE}" -d "${WORK_DIR}" && rm "${DEMO_ZIP_FILE}"
-DATA_DIR="${WORK_DIR}/demo/scitail-8"
-OUTPUT_DIR="/tmp/output"
-rm -rf "${OUTPUT_DIR}" && mkdir -p "${OUTPUT_DIR}"
-
-# Specific hyperparameters
-MODEL_NAME_OR_PATH="bert-base-uncased"
-NUM_NODES=1
-NUM_TRAINERS=4
-LAUNCH_SCRIPT="torchrun --nnodes='${NUM_NODES}' --nproc_per_node='${NUM_TRAINERS}' python -c"
-MAX_SELFTRAIN_ITERATIONS=100
-TRAIN_FILE="train.csv"
-INFER_FILE="infer.csv"
-EVAL_FILE="eval_256.csv"
-MAX_STEPS=100000
-
-# Start self-training
-${LAUNCH_SCRIPT} "
-import os
-from selftraining import selftrain
-
-data_dir = '${DATA_DIR}'
-parameters_dict = {
- 'max_selftrain_iterations': ${MAX_SELFTRAIN_ITERATIONS},
- 'model_name_or_path': '${MODEL_NAME_OR_PATH}',
- 'output_dir': '${OUTPUT_DIR}',
- 'train_file': os.path.join(data_dir, '${TRAIN_FILE}'),
- 'infer_file': os.path.join(data_dir, '${INFER_FILE}'),
- 'eval_file': os.path.join(data_dir, '${EVAL_FILE}'),
- 'eval_strategy': 'steps',
- 'task_name': 'scitail',
- 'label_list': ['entails', 'neutral'],
- 'per_device_train_batch_size': 32,
- 'per_device_eval_batch_size': 8,
- 'max_length': 128,
- 'learning_rate': 2e-5,
- 'max_steps': ${MAX_STEPS},
- 'eval_steps': 1,
- 'early_stopping_patience': 50,
- 'overwrite_output_dir': True,
- 'do_filter_by_confidence': False,
- 'do_filter_by_val_performance': True,
- 'finetune_on_labeled_data': False,
- 'seed': 42,
-}
-
-selftrain(**parameters_dict)
-"
diff --git a/examples/research_projects/self-training-text-classification/selftraining.py b/examples/research_projects/self-training-text-classification/selftraining.py
deleted file mode 100644
index d741225b061..00000000000
--- a/examples/research_projects/self-training-text-classification/selftraining.py
+++ /dev/null
@@ -1,388 +0,0 @@
-# coding=utf-8
-# Copyright 2022 The Google Research Authors.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Self-training for sequence classification."""
-
-import argparse
-import dataclasses
-import json
-import logging
-import os
-import shutil
-from typing import List, Optional
-
-import datasets
-from accelerate import Accelerator
-from datasets import load_dataset
-from finetuning import finetune
-from tqdm.auto import tqdm
-
-import transformers
-from transformers import AutoConfig, set_seed
-from transformers.trainer_utils import IntervalStrategy
-
-
-logger = logging.getLogger(__name__)
-
-MODEL_BIN_FILE = "pytorch_model.bin"
-
-
-@dataclasses.dataclass
-class STModelArguments:
- """Arguments pertaining to which config/tokenizer/model we are going to fine-tune from."""
-
- model_name_or_path: str = dataclasses.field(
- metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models."}
- )
- cache_dir: Optional[str] = dataclasses.field(
- default=None,
- metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co."},
- )
-
-
-@dataclasses.dataclass
-class STDataArguments:
- """Arguments pertaining to what data we are going to input our model for training and evaluation."""
-
- train_file: str = dataclasses.field(metadata={"help": "A csv or a json file containing the training data."})
- infer_file: str = dataclasses.field(metadata={"help": "A csv or a json file containing the data to predict on."})
- eval_file: Optional[str] = dataclasses.field(
- default=None, metadata={"help": "A csv or a json file containing the validation data."}
- )
- task_name: Optional[str] = dataclasses.field(
- default=None,
- metadata={"help": "The name of the task to train on."},
- )
- label_list: Optional[List[str]] = dataclasses.field(
- default=None, metadata={"help": "The list of labels for the task."}
- )
-
-
-@dataclasses.dataclass
-class STTrainingArguments:
- """Training arguments pertaining to the training loop itself."""
-
- output_dir: str = dataclasses.field(
- metadata={"help": "The output directory where the model predictions and checkpoints will be written."}
- )
- eval_metric: Optional[str] = dataclasses.field(
- default="accuracy", metadata={"help": "The evaluation metric used for the task."}
- )
- eval_strategy: Optional[str] = dataclasses.field(
- default="no",
- metadata={
- "help": 'The evaluation strategy to adopt during training. Possible values are: ["no", "step", "epoch]'
- },
- )
- early_stopping_patience: Optional[int] = dataclasses.field(
- default=10,
- metadata={"help": "Number of evaluation calls with no improvement after which training will be stopped."},
- )
- early_stopping_threshold: Optional[float] = dataclasses.field(
- default=0.0,
- metadata={
- "help": "How much the specified evaluation metric must improve to satisfy early stopping conditions."
- },
- )
- do_filter_by_confidence: Optional[bool] = dataclasses.field(
- default=False,
- metadata={"help": "Whether to filter the pseudo-labeled data based on the confidence score."},
- )
- do_filter_by_val_performance: Optional[bool] = dataclasses.field(
- default=False,
- metadata={"help": "Whether to filter the pseudo-labeled data based on the validation performance."},
- )
- finetune_on_labeled_data: Optional[bool] = dataclasses.field(
- default=False,
- metadata={"help": "Whether to fine-tune on labeled data after pseudo training."},
- )
- confidence_threshold: Optional[float] = dataclasses.field(
- default=0.0,
- metadata={"help": "Confidence threshold for pseudo-labeled data filtering."},
- )
- max_selftrain_iterations: Optional[int] = dataclasses.field(
- default=100,
- metadata={"help": "Number of evaluation calls with no improvement after which training will be stopped."},
- )
- seed: Optional[int] = dataclasses.field(
- default=None,
- metadata={"help": "Random seed for initialization."},
- )
-
-
-def create_pseudo_labeled_data(args, infer_input, infer_output, eval_result, id2label, next_data_dir):
- """Create pseudeo labeled data for the next self-training iteration."""
-
- dataset = datasets.concatenate_datasets([infer_input, infer_output], axis=1)
-
- if args.do_filter_by_confidence:
- dataset = dataset.filter(lambda example: example["probability"] > args.confidence_threshold)
-
- if args.do_filter_by_val_performance:
- assert eval_result >= 0.0 and eval_result <= 1.0
- num_selected_rows = int(eval_result * len(dataset))
- print(num_selected_rows)
- dataset = dataset.sort("probability", reverse=True)
- dataset = dataset.select(range(num_selected_rows))
-
- dataset = dataset.remove_columns(["label", "probability"])
- dataset = dataset.rename_column("prediction", "label")
- dataset = dataset.map(lambda example: {"label": id2label[example["label"]]})
- dataset = dataset.shuffle(seed=args.seed)
-
- pseudo_labeled_data_file = os.path.join(next_data_dir, f"train_pseudo.{args.data_file_extension}")
- if args.data_file_extension == "csv":
- dataset.to_csv(pseudo_labeled_data_file, index=False)
- else:
- dataset.to_json(pseudo_labeled_data_file)
-
-
-def selftrain(model_name_or_path, train_file, infer_file, output_dir, **kwargs):
- """Self-training a pre-trained model on a downstream task.
-
- Args:
- model_name_or_path: Path to pretrained model or model identifier from
- huggingface.co/models.
- train_file: A csv or a json file containing the training data.
- infer_file: A csv or a json file containing the data to predict on.
- output_dir: The output directory where the model predictions and checkpoints
- will be written.
- **kwargs: Dictionary of key/value pairs with which to update the
- configuration object after loading. The values in kwargs of any keys which
- are configuration attributes will be used to override the loaded values.
- """
- # Initialize the accelerator. We will let the accelerator handle device
- # placement for us.
- accelerator = Accelerator()
- # Make one log on every process with the configuration for debugging.
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- level=logging.INFO,
- )
- logger.info(accelerator.state)
-
- # Setup logging, we only want one process per machine to log things on the
- # screen. accelerator.is_local_main_process is only True for one process per
- # machine.
- logger.setLevel(logging.INFO if accelerator.is_local_main_process else logging.ERROR)
-
- if accelerator.is_local_main_process:
- datasets.utils.logging.set_verbosity_warning()
- transformers.utils.logging.set_verbosity_info()
- else:
- datasets.utils.logging.set_verbosity_error()
- transformers.utils.logging.set_verbosity_error()
-
- model_args = STModelArguments(model_name_or_path=model_name_or_path)
- data_args = STDataArguments(train_file=train_file, infer_file=infer_file)
- training_args = STTrainingArguments(output_dir=output_dir)
- args = argparse.Namespace()
-
- for arg_class in (model_args, data_args, training_args):
- for key, value in vars(arg_class).items():
- setattr(args, key, value)
-
- for key, value in kwargs.items():
- if hasattr(args, key):
- setattr(args, key, value)
-
- # Sanity checks
- data_files = {}
- args.data_file_extension = None
-
- # You need to provide the training data and the data to predict on
- assert args.train_file is not None
- assert args.infer_file is not None
- data_files["train"] = args.train_file
- data_files["infer"] = args.infer_file
-
- if args.eval_strategy != IntervalStrategy.NO.value:
- assert args.eval_file is not None
- data_files["eval"] = args.eval_file
-
- for key in data_files:
- extension = data_files[key].split(".")[-1]
- assert extension in ["csv", "json"], f"`{key}_file` should be a csv or a json file."
- if args.data_file_extension is None:
- args.data_file_extension = extension
- else:
- assert extension == args.data_file_extension, f"`{key}_file` should be a {args.data_file_extension} file`."
-
- assert (
- args.eval_metric in datasets.list_metrics()
- ), f"{args.eval_metric} not in the list of supported metrics {datasets.list_metrics()}."
-
- # If passed along, set the training seed now.
- if args.seed is not None:
- set_seed(args.seed)
-
- logger.info("Creating the initial data directory for self-training...")
- data_dir_format = f"{args.output_dir}/self-train_iter-{{}}".format
- initial_data_dir = data_dir_format(0)
-
- if accelerator.is_main_process:
- if args.output_dir is not None:
- os.makedirs(args.output_dir, exist_ok=True)
- os.makedirs(initial_data_dir, exist_ok=True)
- accelerator.wait_for_everyone()
-
- best_iteration = None
- best_eval_result = None
- early_stopping_patience_counter = 0
- should_training_stop = False
- # Show the progress bar
- progress_bar = tqdm(range(args.max_selftrain_iterations), disable=not accelerator.is_local_main_process)
-
- # Self-train
- for iteration in range(0, int(args.max_selftrain_iterations)):
- current_data_dir = data_dir_format(iteration)
- assert os.path.exists(current_data_dir)
-
- # Stage 1: initial fine-tuning for iteration = 0 or pseudo-training for
- # iteration > 0
- current_output_dir = os.path.join(current_data_dir, "stage-1")
- arguments_dict = {
- "accelerator": accelerator,
- "model_name_or_path": args.model_name_or_path,
- "cache_dir": args.cache_dir,
- "do_train": True,
- "train_file": data_files["train"] if iteration == 0 else data_files["train_pseudo"],
- "do_eval": True if args.eval_file is not None else False,
- "eval_file": data_files["eval"],
- "do_predict": True,
- "infer_file": data_files["infer"],
- "task_name": args.task_name,
- "label_list": args.label_list,
- "output_dir": current_output_dir,
- "eval_metric": args.eval_metric,
- "eval_strategy": args.eval_strategy,
- "early_stopping_patience": args.early_stopping_patience,
- "early_stopping_threshold": args.early_stopping_threshold,
- "seed": args.seed,
- }
- # Add additional training arguments
- for key, value in kwargs.items():
- if key not in arguments_dict and not hasattr(training_args, key):
- arguments_dict.update({key: value})
-
- model_bin_file_path = os.path.join(current_output_dir, "best-checkpoint", MODEL_BIN_FILE)
- if os.path.exists(model_bin_file_path):
- logger.info(
- "Found existing model checkpoint at %s. Skipping self-training: iteration: %d, stage: 1.",
- model_bin_file_path,
- iteration,
- )
- else:
- logger.info("***** Running self-training: iteration: %d, stage: 1 *****", iteration)
- finetune(**arguments_dict)
- accelerator.wait_for_everyone()
- assert os.path.exists(model_bin_file_path)
- logger.info("Self-training job completed: iteration: %d, stage: 1.", iteration)
-
- if iteration > 0 and args.finetune_on_labeled_data:
- # Stage 2 (optional): fine-tuning on the original labeled data
- model_path = os.path.join(current_output_dir, "best-checkpoint")
- current_output_dir = os.path.join(current_data_dir, "stage-2")
- # Update arguments_dict
- arguments_dict["model_name_or_path"] = model_path
- arguments_dict["train_file"] = data_files["train"]
- arguments_dict["output_dir"] = current_output_dir
-
- model_bin_file_path = os.path.join(current_output_dir, "best-checkpoint", MODEL_BIN_FILE)
- if os.path.exists(model_bin_file_path):
- logger.info(
- "Found existing model checkpoint at %s. Skipping self-training: iteration: %d, stage: 2.",
- model_bin_file_path,
- iteration,
- )
- else:
- logger.info("***** Running self-training: iteration: %d, stage: 2 *****", iteration)
- finetune(**arguments_dict)
- accelerator.wait_for_everyone()
- assert os.path.exists(model_bin_file_path)
- logger.info("Self-training job completed: iteration: %d, stage: 2.", iteration)
-
- new_iteration = iteration
- next_data_dir = data_dir_format(iteration + 1)
-
- config = AutoConfig.from_pretrained(os.path.join(current_output_dir, "best-checkpoint"))
- id2label = config.id2label
- eval_results_file = os.path.join(current_output_dir, "eval_results_best-checkpoint.json")
- test_results_file = os.path.join(current_output_dir, "test_results_best-checkpoint.json")
- assert os.path.exists(eval_results_file)
-
- with open(eval_results_file, "r") as f:
- eval_result = float(json.load(f)[args.eval_metric])
- infer_output_file = os.path.join(current_output_dir, "infer_output_best-checkpoint.csv")
- assert os.path.exists(infer_output_file)
- # Loading the dataset from local csv or json files.
- infer_input = load_dataset(args.data_file_extension, data_files={"data": data_files["infer"]})["data"]
- infer_output = load_dataset("csv", data_files={"data": infer_output_file})["data"]
-
- if accelerator.is_main_process:
- os.makedirs(next_data_dir, exist_ok=True)
- shutil.copy(eval_results_file, os.path.join(output_dir, f"eval_results_iter-{iteration}.json"))
- if os.path.exists(test_results_file):
- shutil.copy(eval_results_file, os.path.join(output_dir, f"test_results_iter-{iteration}.json"))
- create_pseudo_labeled_data(args, infer_input, infer_output, eval_result, id2label, next_data_dir)
- accelerator.wait_for_everyone()
-
- data_files["train_pseudo"] = os.path.join(next_data_dir, f"train_pseudo.{args.data_file_extension}")
-
- if args.eval_strategy != IntervalStrategy.NO.value:
- new_eval_result = eval_result
-
- if best_iteration is None:
- best_iteration = new_iteration
- best_eval_result = new_eval_result
- else:
- if new_eval_result - best_eval_result > args.early_stopping_threshold:
- best_iteration = new_iteration
- best_eval_result = new_eval_result
- early_stopping_patience_counter = 0
- else:
- if new_eval_result == best_eval_result:
- best_iteration = new_iteration
- best_eval_result = new_eval_result
- early_stopping_patience_counter += 1
-
- if early_stopping_patience_counter >= args.early_stopping_patience:
- should_training_stop = True
-
- progress_bar.update(1)
-
- if should_training_stop:
- break
-
- if best_iteration is not None:
- # Save the best iteration
- logger.info("Best iteration: %d", best_iteration)
- logger.info("Best evaluation result: %s = %f", args.eval_metric, best_eval_result)
- accelerator.wait_for_everyone()
- if accelerator.is_main_process:
- shutil.copy(
- os.path.join(output_dir, f"eval_results_iter-{iteration}.json"),
- os.path.join(output_dir, "eval_results_best-iteration.json"),
- )
- else:
- # Assume that the last iteration is the best
- logger.info("Best iteration: %d", args.max_selftrain_iterations - 1)
- logger.info("Best evaluation result: %s = %f", args.eval_metric, eval_result)
- accelerator.wait_for_everyone()
- if accelerator.is_main_process:
- shutil.copy(
- os.path.join(output_dir, f"eval_results_iter-{args.max_selftrain_iterations - 1}.json"),
- os.path.join(output_dir, "eval_results_best-iteration.json"),
- )
diff --git a/examples/research_projects/seq2seq-distillation/README.md b/examples/research_projects/seq2seq-distillation/README.md
deleted file mode 100644
index ab79a652ed3..00000000000
--- a/examples/research_projects/seq2seq-distillation/README.md
+++ /dev/null
@@ -1,434 +0,0 @@
-## Sequence to Sequence Training and Evaluation
-
-This directory contains examples for finetuning and evaluating transformers on summarization and translation tasks.
-
-Author: Sam Shleifer (https://github.com/sshleifer)
-
-### Supported Architectures
-
-- `BartForConditionalGeneration` (and anything that inherits from it)
-- `MarianMTModel`
-- `PegasusForConditionalGeneration`
-- `MBartForConditionalGeneration`
-- `FSMTForConditionalGeneration`
-- `T5ForConditionalGeneration`
-
-# Note
-
-⚠️ This project should be run with pytorch-lightning==1.0.4 which has a potential security vulnerability
-
-## Datasets
-
-#### XSUM
-
-```bash
-cd examples/contrib/pytorch-lightning/seq2seq
-wget https://cdn-datasets.huggingface.co/summarization/xsum.tar.gz
-tar -xzvf xsum.tar.gz
-export XSUM_DIR=${PWD}/xsum
-```
-this should make a directory called `xsum/` with files like `test.source`.
-To use your own data, copy that files format. Each article to be summarized is on its own line.
-
-#### CNN/DailyMail
-
-```bash
-cd examples/contrib/pytorch-lightning/seq2seq
-wget https://cdn-datasets.huggingface.co/summarization/cnn_dm_v2.tgz
-tar -xzvf cnn_dm_v2.tgz # empty lines removed
-mv cnn_cln cnn_dm
-export CNN_DIR=${PWD}/cnn_dm
-```
-this should make a directory called `cnn_dm/` with 6 files.
-
-#### WMT16 English-Romanian Translation Data
-
-download with this command:
-```bash
-wget https://cdn-datasets.huggingface.co/translation/wmt_en_ro.tar.gz
-tar -xzvf wmt_en_ro.tar.gz
-export ENRO_DIR=${PWD}/wmt_en_ro
-```
-this should make a directory called `wmt_en_ro/` with 6 files.
-
-#### WMT English-German
-
-```bash
-wget https://cdn-datasets.huggingface.co/translation/wmt_en_de.tgz
-tar -xzvf wmt_en_de.tgz
-export DATA_DIR=${PWD}/wmt_en_de
-```
-
-#### FSMT datasets (wmt)
-
-Refer to the scripts starting with `eval_` under:
-https://github.com/huggingface/transformers/tree/main/scripts/fsmt
-
-#### Pegasus (multiple datasets)
-
-Multiple eval datasets are available for download from:
-https://github.com/stas00/porting/tree/master/datasets/pegasus
-
-
-#### Your Data
-
-If you are using your own data, it must be formatted as one directory with 6 files:
-```
-train.source
-train.target
-val.source
-val.target
-test.source
-test.target
-```
-The `.source` files are the input, the `.target` files are the desired output.
-
-### Potential issues
-
-- native AMP (`--fp16` and no apex) may lead to a huge memory leak and require 10x gpu memory. This has been fixed in pytorch-nightly and the minimal official version to have this fix will be pytorch-1.8. Until then if you have to use mixed precision please use AMP only with pytorch-nightly or NVIDIA's apex. Reference: https://github.com/huggingface/transformers/issues/8403
-
-
-### Tips and Tricks
-
-General Tips:
-- since you need to run from this folder, and likely need to modify code, the easiest workflow is fork transformers, clone your fork, and run `pip install -e .` before you get started.
-- try `--freeze_encoder` or `--freeze_embeds` for faster training/larger batch size. (3hr per epoch with bs=8, see the "xsum_shared_task" command below)
-- `fp16_opt_level=O1` (the default works best).
-- In addition to the pytorch-lightning .ckpt checkpoint, a transformers checkpoint will be saved.
-Load it with `BartForConditionalGeneration.from_pretrained(f'{output_dir}/best_tfmr)`.
-- At the moment, `--do_predict` does not work in a multi-gpu setting. You need to use `evaluate_checkpoint` or the `run_eval.py` code.
-- This warning can be safely ignored:
- > "Some weights of BartForConditionalGeneration were not initialized from the model checkpoint at facebook/bart-large-xsum and are newly initialized: ['final_logits_bias']"
-- Both finetuning and eval are 30% faster with `--fp16`. For that you need to [install apex](https://github.com/NVIDIA/apex#quick-start).
-- Read scripts before you run them!
-
-Summarization Tips:
-- (summ) 1 epoch at batch size 1 for bart-large takes 24 hours and requires 13GB GPU RAM with fp16 on an NVIDIA-V100.
-- If you want to run experiments on improving the summarization finetuning process, try the XSUM Shared Task (below). It's faster to train than CNNDM because the summaries are shorter.
-- For CNN/DailyMail, the default `val_max_target_length` and `test_max_target_length` will truncate the ground truth labels, resulting in slightly higher rouge scores. To get accurate rouge scores, you should rerun calculate_rouge on the `{output_dir}/test_generations.txt` file saved by `trainer.test()`
-- `--max_target_length=60 --val_max_target_length=60 --test_max_target_length=100 ` is a reasonable setting for XSUM.
-- `wandb` can be used by specifying `--logger_name wandb`. It is useful for reproducibility. Specify the environment variable `WANDB_PROJECT='hf_xsum'` to do the XSUM shared task.
-- If you are finetuning on your own dataset, start from `distilbart-cnn-12-6` if you want long summaries and `distilbart-xsum-12-6` if you want short summaries.
-(It rarely makes sense to start from `bart-large` unless you are a researching finetuning methods).
-
-**Update 2018-07-18**
-Datasets: `LegacySeq2SeqDataset` will be used for all tokenizers without a `prepare_seq2seq_batch` method. Otherwise, `Seq2SeqDataset` will be used.
-Future work/help wanted: A new dataset to support multilingual tasks.
-
-
-### Finetuning Scripts
-All finetuning bash scripts call finetune.py (or distillation.py) with reasonable command line arguments. They usually require extra command line arguments to work.
-
-To see all the possible command line options, run:
-
-```bash
-./finetune.py --help
-```
-
-### Finetuning Training Params
-
-To override the pretrained model's training params, you can pass them to `./finetune.sh`:
-
-```bash
-./finetune.sh \
- [...]
- --encoder_layerdrop 0.1 \
- --decoder_layerdrop 0.1 \
- --dropout 0.1 \
- --attention_dropout 0.1 \
-```
-
-### Summarization Finetuning
-Run/modify `finetune.sh`
-
-The following command should work on a 16GB GPU:
-```bash
-./finetune.sh \
- --data_dir $XSUM_DIR \
- --train_batch_size=1 \
- --eval_batch_size=1 \
- --output_dir=xsum_results \
- --num_train_epochs 6 \
- --model_name_or_path facebook/bart-large
-```
-
-There is a starter finetuning script for pegasus at `finetune_pegasus_xsum.sh`.
-
-### Translation Finetuning
-
-First, follow the wmt_en_ro download instructions.
-Then you can finetune mbart_cc25 on english-romanian with the following command.
-**Recommendation:** Read and potentially modify the fairly opinionated defaults in `train_mbart_cc25_enro.sh` script before running it.
-
-Best performing command:
-```bash
-# optionally
-export ENRO_DIR='wmt_en_ro' # Download instructions above
-# export WANDB_PROJECT="MT" # optional
-export MAX_LEN=128
-export BS=4
-./train_mbart_cc25_enro.sh --output_dir enro_finetune_baseline --label_smoothing 0.1 --fp16_opt_level=O1 --logger_name wandb --sortish_sampler
-```
-This should take < 6h/epoch on a 16GB v100 and achieve test BLEU above 26
-To get results in line with fairseq, you need to do some postprocessing. (see `romanian_postprocessing.md`)
-
-MultiGPU command
-(using 8 GPUS as an example)
-```bash
-export ENRO_DIR='wmt_en_ro' # Download instructions above
- # export WANDB_PROJECT="MT" # optional
-export MAX_LEN=128
-export BS=4
-./train_mbart_cc25_enro.sh --output_dir enro_finetune_baseline --gpus 8 --logger_name wandb
-```
-### Finetuning Outputs
-As you train, `output_dir` will be filled with files, that look kind of like this (comments are mine).
-Some of them are metrics, some of them are checkpoints, some of them are metadata. Here is a quick tour:
-
-```bash
-output_dir
-├── best_tfmr # this is a huggingface checkpoint generated by save_pretrained. It is the same model as the PL .ckpt file below
-│ ├── config.json
-│ ├── merges.txt
-│ ├── pytorch_model.bin
-│ ├── special_tokens_map.json
-│ ├── tokenizer_config.json
-│ └── vocab.json
-├── git_log.json # repo, branch, and commit hash
-├── val_avg_rouge2=0.1984-step_count=11.ckpt # this is a pytorch lightning checkpoint associated with the best val score. (it will be called BLEU for MT)
-├── metrics.json # new validation metrics will continually be appended to this
-├── student # this is a huggingface checkpoint generated by SummarizationDistiller. It is the student before it gets finetuned.
-│ ├── config.json
-│ └── pytorch_model.bin
-├── test_generations.txt
-# ^^ are the summaries or translations produced by your best checkpoint on the test data. Populated when training is done
-├── test_results.txt # a convenience file with the test set metrics. This data is also in metrics.json['test']
-├── hparams.pkl # the command line args passed after some light preprocessing. Should be saved fairly quickly.
-```
-After training, you can recover the best checkpoint by running
-```python
-from transformers import AutoModelForSeq2SeqLM
-model = AutoModelForSeq2SeqLM.from_pretrained(f'{output_dir}/best_tfmr')
-```
-
-### Converting pytorch-lightning checkpoints
-pytorch lightning ``-do_predict`` often fails, after you are done training, the best way to evaluate your model is to convert it.
-
-This should be done for you, with a file called `{save_dir}/best_tfmr`.
-
-If that file doesn't exist but you have a lightning `.ckpt` file, you can run
-```bash
-python convert_pl_checkpoint_to_hf.py PATH_TO_CKPT randomly_initialized_hf_model_path save_dir/best_tfmr
-```
-Then either `run_eval` or `run_distributed_eval` with `save_dir/best_tfmr` (see previous sections)
-
-
-# Experimental Features
-These features are harder to use and not always useful.
-
-### Dynamic Batch Size for MT
-`finetune.py` has a command line arg `--max_tokens_per_batch` that allows batches to be dynamically sized.
-This feature can only be used:
-- with fairseq installed
-- on 1 GPU
-- without sortish sampler
-- after calling `./save_len_file.py $tok $data_dir`
-
-For example,
-```bash
-./save_len_file.py Helsinki-NLP/opus-mt-en-ro wmt_en_ro
-./dynamic_bs_example.sh --max_tokens_per_batch=2000 --output_dir benchmark_dynamic_bs
-```
-splits `wmt_en_ro/train` into 11,197 uneven length batches and can finish 1 epoch in 8 minutes on a v100.
-
-For comparison,
-```bash
-./dynamic_bs_example.sh --sortish_sampler --train_batch_size 48
-```
-uses 12,723 batches of length 48 and takes slightly more time 9.5 minutes.
-
-The feature is still experimental, because:
-+ we can make it much more robust if we have memory mapped/preprocessed datasets.
-+ The speedup over sortish sampler is not that large at the moment.
-
-# DistilBART
-
-This section describes all code and artifacts from our [Paper](http://arxiv.org/abs/2010.13002)
-
-
-
-+ For the CNN/DailyMail dataset, (relatively longer, more extractive summaries), we found a simple technique that works, which we call "Shrink and Fine-tune", or SFT.
-you just copy alternating layers from `facebook/bart-large-cnn` and fine-tune more on the cnn/dm data. `sshleifer/distill-pegasus-cnn-16-4`, `sshleifer/distilbart-cnn-12-6` and all other checkpoints under `sshleifer` that start with `distilbart-cnn` were trained this way.
-+ For the XSUM dataset, training on pseudo-labels worked best for Pegasus (`sshleifer/distill-pegasus-16-4`), while training with KD worked best for `distilbart-xsum-12-6`
-+ For `sshleifer/dbart-xsum-12-3`
-+ We ran 100s experiments, and didn't want to document 100s of commands. If you want a command to replicate a figure from the paper that is not documented below, feel free to ask on the [forums](https://discuss.huggingface.co/t/seq2seq-distillation-methodology-questions/1270) and tag `@sshleifer`.
-+ You can see the performance tradeoffs of model sizes [here](https://docs.google.com/spreadsheets/d/1EkhDMwVO02m8jCD1cG3RoFPLicpcL1GQHTQjfvDYgIM/edit#gid=0).
-and more granular timing results [here](https://docs.google.com/spreadsheets/d/1EkhDMwVO02m8jCD1cG3RoFPLicpcL1GQHTQjfvDYgIM/edit#gid=1753259047&range=B2:I23).
-
-### Evaluation
-
-use [run_distributed_eval](./run_distributed_eval.py), with the following convenient alias
-```bash
-deval () {
- proc=$1
- m=$2
- dd=$3
- sd=$4
- shift
- shift
- shift
- shift
- python -m torch.distributed.launch --nproc_per_node=$proc run_distributed_eval.py \
- --model_name $m --save_dir $sd --data_dir $dd $@
-}
-```
-On a 1 GPU system, here are four commands (that assume `xsum`, `cnn_dm` are downloaded, cmd-F for those links in this file).
-
-`distilBART`:
-```bash
-deval 1 sshleifer/distilbart-xsum-12-3 xsum dbart_12_3_xsum_eval --fp16 # --help for more choices.
-deval 1 sshleifer/distilbart-cnn_dm-12-6 cnn_dm dbart_12_6_cnn_eval --fp16
-```
-
-`distill-pegasus`:
-```bash
-deval 1 sshleifer/distill-pegasus-cnn-16-4 cnn_dm dpx_cnn_eval
-deval 1 sshleifer/distill-pegasus-xsum-16-4 xsum dpx_xsum_eval
-```
-
-### Distillation
-+ For all of the following commands, you can get roughly equivalent result and faster run times by passing `--num_beams=4`. That's not what we did for the paper.
-+ Besides the KD section, you can also run commands with the built-in transformers trainer. See, for example, [builtin_trainer/train_distilbart_cnn.sh](./builtin_trainer/train_distilbart_cnn.sh).
-+ Large performance deviations (> 5X slower or more than 0.5 Rouge-2 worse), should be reported.
-+ Multi-gpu (controlled with `--gpus` should work, but might require more epochs).
-
-#### Recommended Workflow
-+ Get your dataset in the right format. (see 6 files above).
-+ Find a teacher model [Pegasus](https://huggingface.co/models?search=pegasus) (slower, better ROUGE) or `facebook/bart-large-xsum`/`facebook/bart-large-cnn` (faster, slightly lower.).
-Choose the checkpoint where the corresponding dataset is most similar (or identical to) your dataset.
-+ Follow the sections in order below. You can stop after SFT if you are satisfied, or move on to pseudo-labeling if you want more performance.
-+ student size: If you want a close to free 50% speedup, cut the decoder in half. If you want a larger speedup, cut it in 4.
-+ If your SFT run starts at a validation ROUGE-2 that is more than 10 pts below the teacher's validation ROUGE-2, you have a bug. Switching to a more expensive technique will not help. Try setting a breakpoint and looking at generation and truncation defaults/hyper-parameters, and share your experience on the forums!
-
-
-#### Initialization
-We use [make_student.py](./make_student.py) to copy alternating layers from the teacher, and save the resulting model to disk
-```bash
-python make_student.py facebook/bart-large-xsum --save_path dbart_xsum_12_3 -e 12 -d 3
-```
-or for `pegasus-xsum`
-```bash
-python make_student.py google/pegasus-xsum --save_path dpx_xsum_16_4 --e 16 --d 4
-```
-we now have an initialized student saved to `dbart_xsum_12_3`, which we will use for the following commands.
-+ Extension: To replicate more complicated initialize experiments in section 6.1, or try your own. Use the `create_student_by_copying_alternating_layers` function.
-
-#### Pegasus
-+ The following commands are written for BART and will require, at minimum, the following modifications
-+ reduce batch size, and increase gradient accumulation steps so that the product `gpus * batch size * gradient_accumulation_steps = 256`. We used `--learning-rate` = 1e-4 * gradient accumulation steps.
-+ don't use fp16
-+ `--tokenizer_name google/pegasus-large`
-
-### SFT (No Teacher Distillation)
-You don't need `distillation.py`, you can just run:
-
-```bash
-python finetune.py \
- --data_dir xsum \
- --freeze_encoder --freeze_embeds \
- --learning_rate=3e-4 \
- --do_train \
- --do_predict \
- --fp16 --fp16_opt_level=O1 \
- --val_check_interval 0.1 --n_val 1000 --eval_beams 2 --length_penalty=0.5 \
- --max_target_length=60 --val_max_target_length=60 --test_max_target_length=100 \
- --model_name_or_path dbart_xsum_12_3 \
- --train_batch_size=64 --eval_batch_size=64 \
- --sortish_sampler \
- --num_train_epochs=6 \
- --warmup_steps 500 \
- --output_dir distilbart_xsum_sft_12_3 --gpus 1
-```
-
-+ Note: The command that produced `sshleifer/distilbart-cnn-12-6` is at [train_distilbart_cnn.sh](./[train_distilbart_cnn.sh)
-
-```bash
-./train_distilbart_cnn.sh
-```
-
-+ Tip: You can get the same simple distillation logic by using `distillation.py --no_teacher ` followed by identical arguments as the ones in `train_distilbart_cnn.sh`.
-If you are using `wandb` and comparing the two distillation methods, using this entry point will make your logs consistent,
-because you will have the same hyper-parameters logged in every run.
-
-### Pseudo-Labeling
-+ You don't need `distillation.py`.
-+ Instructions to generate pseudo-labels and use pre-computed pseudo-labels can be found [here](./precomputed_pseudo_labels.md).
-Simply run `finetune.py` with one of those pseudo-label datasets as `--data_dir` (`DATA`, below).
-
-```bash
-python finetune.py \
- --teacher facebook/bart-large-xsum --data_dir DATA \
- --freeze_encoder --freeze_embeds \
- --learning_rate=3e-4 \
- --do_train \
- --do_predict \
- --fp16 --fp16_opt_level=O1 \
- --val_check_interval 0.1 --n_val 1000 --eval_beams 2 --length_penalty=0.5 \
- --max_target_length=60 --val_max_target_length=60 --test_max_target_length=100 \
- --model_name_or_path dbart_xsum_12_3 \
- --train_batch_size=32 --eval_batch_size=32 \
- --sortish_sampler \
- --num_train_epochs=5 \
- --warmup_steps 500 \
- --output_dir dbart_xsum_12_3_PL --gpus 1 --logger_name wandb
-```
-
-
-
-To combine datasets, as in Section 6.2, try something like:
-```bash
-curl -S https://cdn-datasets.huggingface.co/pseudo/xsum/bart_xsum_pl.tgz | tar -xvz -C .
-curl -S https://cdn-datasets.huggingface.co/pseudo/xsum/pegasus_xsum.tgz | tar -xvz -C .
-curl -S https://cdn-datasets.huggingface.co/summarization/xsum.tar.gz | tar -xvz -C .
-mkdir all_pl
-cat bart_xsum_pl/train.source pegasus_xsum/train.source xsum/train.source > all_pl/train.source
-cat bart_xsum_pl/train.target pegasus_xsum/train.target xsum/train.target > all_pl/train.target
-cp xsum/val* all_pl
-cp xsum/test* all_pl
-```
-then use `all_pl` as DATA in the command above.
-
-#### Direct Knowledge Distillation (KD)
-+ In this method, we use try to enforce that the student and teacher produce similar encoder_outputs, logits, and hidden_states using `SummarizationDistiller`.
-+ This method was used for `sshleifer/distilbart-xsum-12-6`, `6-6`, and `9-6` checkpoints were produced.
-+ You must use [`distillation.py`](./distillation.py). Note that this command initializes the student for you.
-
-The command that produced `sshleifer/distilbart-xsum-12-6` is at [./train_distilbart_xsum.sh](train_distilbart_xsum.sh)
-```bash
-./train_distilbart_xsum.sh --logger_name wandb --gpus 1
-```
-
-+ Expected ROUGE-2 between 21.3 and 21.6, run time ~13H.
-+ direct KD + Pegasus is VERY slow and works best with `--supervise_forward --normalize_hidden`.
-
-
-
-### Citation
-
-```bibtex
-@misc{shleifer2020pretrained,
- title={Pre-trained Summarization Distillation},
- author={Sam Shleifer and Alexander M. Rush},
- year={2020},
- eprint={2010.13002},
- archivePrefix={arXiv},
- primaryClass={cs.CL}
-}
-@article{Wolf2019HuggingFacesTS,
- title={HuggingFace's Transformers: State-of-the-art Natural Language Processing},
- author={Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush},
- journal={ArXiv},
- year={2019},
- volume={abs/1910.03771}
-}
-```
diff --git a/examples/research_projects/seq2seq-distillation/_test_bash_script.py b/examples/research_projects/seq2seq-distillation/_test_bash_script.py
deleted file mode 100644
index fa84a60c0c8..00000000000
--- a/examples/research_projects/seq2seq-distillation/_test_bash_script.py
+++ /dev/null
@@ -1,203 +0,0 @@
-#!/usr/bin/env python
-
-import argparse
-import os
-import sys
-from unittest.mock import patch
-
-import pytorch_lightning as pl
-import timeout_decorator
-import torch
-from distillation import SummarizationDistiller, distill_main
-from finetune import SummarizationModule, main
-
-from transformers import MarianMTModel
-from transformers.file_utils import cached_path
-from transformers.testing_utils import TestCasePlus, require_torch_gpu, slow
-from utils import load_json
-
-
-MARIAN_MODEL = "sshleifer/mar_enro_6_3_student"
-
-
-class TestMbartCc25Enro(TestCasePlus):
- def setUp(self):
- super().setUp()
-
- data_cached = cached_path(
- "https://cdn-datasets.huggingface.co/translation/wmt_en_ro-tr40k-va0.5k-te0.5k.tar.gz",
- extract_compressed_file=True,
- )
- self.data_dir = f"{data_cached}/wmt_en_ro-tr40k-va0.5k-te0.5k"
-
- @slow
- @require_torch_gpu
- def test_model_download(self):
- """This warms up the cache so that we can time the next test without including download time, which varies between machines."""
- MarianMTModel.from_pretrained(MARIAN_MODEL)
-
- # @timeout_decorator.timeout(1200)
- @slow
- @require_torch_gpu
- def test_train_mbart_cc25_enro_script(self):
- env_vars_to_replace = {
- "$MAX_LEN": 64,
- "$BS": 64,
- "$GAS": 1,
- "$ENRO_DIR": self.data_dir,
- "facebook/mbart-large-cc25": MARIAN_MODEL,
- # "val_check_interval=0.25": "val_check_interval=1.0",
- "--learning_rate=3e-5": "--learning_rate 3e-4",
- "--num_train_epochs 6": "--num_train_epochs 1",
- }
-
- # Clean up bash script
- bash_script = (self.test_file_dir / "train_mbart_cc25_enro.sh").open().read().split("finetune.py")[1].strip()
- bash_script = bash_script.replace("\\\n", "").strip().replace('"$@"', "")
- for k, v in env_vars_to_replace.items():
- bash_script = bash_script.replace(k, str(v))
- output_dir = self.get_auto_remove_tmp_dir()
-
- # bash_script = bash_script.replace("--fp16 ", "")
- args = f"""
- --output_dir {output_dir}
- --tokenizer_name Helsinki-NLP/opus-mt-en-ro
- --sortish_sampler
- --do_predict
- --gpus 1
- --freeze_encoder
- --n_train 40000
- --n_val 500
- --n_test 500
- --fp16_opt_level O1
- --num_sanity_val_steps 0
- --eval_beams 2
- """.split()
- # XXX: args.gpus > 1 : handle multi_gpu in the future
-
- testargs = ["finetune.py"] + bash_script.split() + args
- with patch.object(sys, "argv", testargs):
- parser = argparse.ArgumentParser()
- parser = pl.Trainer.add_argparse_args(parser)
- parser = SummarizationModule.add_model_specific_args(parser, os.getcwd())
- args = parser.parse_args()
- model = main(args)
-
- # Check metrics
- metrics = load_json(model.metrics_save_path)
- first_step_stats = metrics["val"][0]
- last_step_stats = metrics["val"][-1]
- self.assertEqual(len(metrics["val"]), (args.max_epochs / args.val_check_interval))
- assert isinstance(last_step_stats[f"val_avg_{model.val_metric}"], float)
-
- self.assertGreater(last_step_stats["val_avg_gen_time"], 0.01)
- # model hanging on generate. Maybe bad config was saved. (XXX: old comment/assert?)
- self.assertLessEqual(last_step_stats["val_avg_gen_time"], 1.0)
-
- # test learning requirements:
-
- # 1. BLEU improves over the course of training by more than 2 pts
- self.assertGreater(last_step_stats["val_avg_bleu"] - first_step_stats["val_avg_bleu"], 2)
-
- # 2. BLEU finishes above 17
- self.assertGreater(last_step_stats["val_avg_bleu"], 17)
-
- # 3. test BLEU and val BLEU within ~1.1 pt.
- self.assertLess(abs(metrics["val"][-1]["val_avg_bleu"] - metrics["test"][-1]["test_avg_bleu"]), 1.1)
-
- # check lightning ckpt can be loaded and has a reasonable statedict
- contents = os.listdir(output_dir)
- ckpt_path = [x for x in contents if x.endswith(".ckpt")][0]
- full_path = os.path.join(args.output_dir, ckpt_path)
- ckpt = torch.load(full_path, map_location="cpu")
- expected_key = "model.model.decoder.layers.0.encoder_attn_layer_norm.weight"
- assert expected_key in ckpt["state_dict"]
- assert ckpt["state_dict"]["model.model.decoder.layers.0.encoder_attn_layer_norm.weight"].dtype == torch.float32
-
- # TODO: turn on args.do_predict when PL bug fixed.
- if args.do_predict:
- contents = {os.path.basename(p) for p in contents}
- assert "test_generations.txt" in contents
- assert "test_results.txt" in contents
- # assert len(metrics["val"]) == desired_n_evals
- assert len(metrics["test"]) == 1
-
-
-class TestDistilMarianNoTeacher(TestCasePlus):
- @timeout_decorator.timeout(600)
- @slow
- @require_torch_gpu
- def test_opus_mt_distill_script(self):
- data_dir = f"{self.test_file_dir_str}/test_data/wmt_en_ro"
- env_vars_to_replace = {
- "--fp16_opt_level=O1": "",
- "$MAX_LEN": 128,
- "$BS": 16,
- "$GAS": 1,
- "$ENRO_DIR": data_dir,
- "$m": "sshleifer/student_marian_en_ro_6_1",
- "val_check_interval=0.25": "val_check_interval=1.0",
- }
-
- # Clean up bash script
- bash_script = (
- (self.test_file_dir / "distil_marian_no_teacher.sh").open().read().split("distillation.py")[1].strip()
- )
- bash_script = bash_script.replace("\\\n", "").strip().replace('"$@"', "")
- bash_script = bash_script.replace("--fp16 ", " ")
-
- for k, v in env_vars_to_replace.items():
- bash_script = bash_script.replace(k, str(v))
- output_dir = self.get_auto_remove_tmp_dir()
- bash_script = bash_script.replace("--fp16", "")
- epochs = 6
- testargs = (
- ["distillation.py"]
- + bash_script.split()
- + [
- f"--output_dir={output_dir}",
- "--gpus=1",
- "--learning_rate=1e-3",
- f"--num_train_epochs={epochs}",
- "--warmup_steps=10",
- "--val_check_interval=1.0",
- "--do_predict",
- ]
- )
- with patch.object(sys, "argv", testargs):
- parser = argparse.ArgumentParser()
- parser = pl.Trainer.add_argparse_args(parser)
- parser = SummarizationDistiller.add_model_specific_args(parser, os.getcwd())
- args = parser.parse_args()
- # assert args.gpus == gpus THIS BREAKS for multi_gpu
-
- model = distill_main(args)
-
- # Check metrics
- metrics = load_json(model.metrics_save_path)
- first_step_stats = metrics["val"][0]
- last_step_stats = metrics["val"][-1]
- assert len(metrics["val"]) >= (args.max_epochs / args.val_check_interval) # +1 accounts for val_sanity_check
-
- assert last_step_stats["val_avg_gen_time"] >= 0.01
-
- assert first_step_stats["val_avg_bleu"] < last_step_stats["val_avg_bleu"] # model learned nothing
- assert 1.0 >= last_step_stats["val_avg_gen_time"] # model hanging on generate. Maybe bad config was saved.
- assert isinstance(last_step_stats[f"val_avg_{model.val_metric}"], float)
-
- # check lightning ckpt can be loaded and has a reasonable statedict
- contents = os.listdir(output_dir)
- ckpt_path = [x for x in contents if x.endswith(".ckpt")][0]
- full_path = os.path.join(args.output_dir, ckpt_path)
- ckpt = torch.load(full_path, map_location="cpu")
- expected_key = "model.model.decoder.layers.0.encoder_attn_layer_norm.weight"
- assert expected_key in ckpt["state_dict"]
- assert ckpt["state_dict"]["model.model.decoder.layers.0.encoder_attn_layer_norm.weight"].dtype == torch.float32
-
- # TODO: turn on args.do_predict when PL bug fixed.
- if args.do_predict:
- contents = {os.path.basename(p) for p in contents}
- assert "test_generations.txt" in contents
- assert "test_results.txt" in contents
- # assert len(metrics["val"]) == desired_n_evals
- assert len(metrics["test"]) == 1
diff --git a/examples/research_projects/seq2seq-distillation/_test_make_student.py b/examples/research_projects/seq2seq-distillation/_test_make_student.py
deleted file mode 100644
index 73df66315cb..00000000000
--- a/examples/research_projects/seq2seq-distillation/_test_make_student.py
+++ /dev/null
@@ -1,40 +0,0 @@
-import tempfile
-import unittest
-
-from make_student import create_student_by_copying_alternating_layers
-
-from transformers import AutoConfig
-from transformers.file_utils import cached_property
-from transformers.testing_utils import require_torch
-
-
-TINY_BART = "sshleifer/bart-tiny-random"
-TINY_T5 = "patrickvonplaten/t5-tiny-random"
-
-
-@require_torch
-class MakeStudentTester(unittest.TestCase):
- @cached_property
- def teacher_config(self):
- return AutoConfig.from_pretrained(TINY_BART)
-
- def test_valid_t5(self):
- student, *_ = create_student_by_copying_alternating_layers(TINY_T5, tempfile.mkdtemp(), e=1, d=1)
- self.assertEqual(student.config.num_hidden_layers, 1)
-
- def test_asymmetric_t5(self):
- student, *_ = create_student_by_copying_alternating_layers(TINY_T5, tempfile.mkdtemp(), e=1, d=None)
-
- def test_same_decoder_small_encoder(self):
- student, *_ = create_student_by_copying_alternating_layers(TINY_BART, tempfile.mkdtemp(), e=1, d=None)
- self.assertEqual(student.config.encoder_layers, 1)
- self.assertEqual(student.config.decoder_layers, self.teacher_config.encoder_layers)
-
- def test_small_enc_small_dec(self):
- student, *_ = create_student_by_copying_alternating_layers(TINY_BART, tempfile.mkdtemp(), e=1, d=1)
- self.assertEqual(student.config.encoder_layers, 1)
- self.assertEqual(student.config.decoder_layers, 1)
-
- def test_raises_assert(self):
- with self.assertRaises(AssertionError):
- create_student_by_copying_alternating_layers(TINY_BART, tempfile.mkdtemp(), e=None, d=None)
diff --git a/examples/research_projects/seq2seq-distillation/_test_seq2seq_examples.py b/examples/research_projects/seq2seq-distillation/_test_seq2seq_examples.py
deleted file mode 100644
index 0ee4dd8afe1..00000000000
--- a/examples/research_projects/seq2seq-distillation/_test_seq2seq_examples.py
+++ /dev/null
@@ -1,444 +0,0 @@
-import argparse
-import logging
-import os
-import sys
-import tempfile
-from pathlib import Path
-
-import lightning_base
-import pytest
-import pytorch_lightning as pl
-import torch
-from convert_pl_checkpoint_to_hf import convert_pl_to_hf
-from distillation import distill_main
-from finetune import SummarizationModule, main
-from huggingface_hub import list_models
-from parameterized import parameterized
-from run_eval import generate_summaries_or_translations
-from torch import nn
-
-from transformers import AutoConfig, AutoModelForSeq2SeqLM
-from transformers.testing_utils import CaptureStderr, CaptureStdout, TestCasePlus, require_torch_gpu, slow
-from utils import label_smoothed_nll_loss, lmap, load_json
-
-
-logging.basicConfig(level=logging.DEBUG)
-
-logger = logging.getLogger()
-CUDA_AVAILABLE = torch.cuda.is_available()
-CHEAP_ARGS = {
- "max_tokens_per_batch": None,
- "supervise_forward": True,
- "normalize_hidden": True,
- "label_smoothing": 0.2,
- "eval_max_gen_length": None,
- "eval_beams": 1,
- "val_metric": "loss",
- "save_top_k": 1,
- "adafactor": True,
- "early_stopping_patience": 2,
- "logger_name": "default",
- "length_penalty": 0.5,
- "cache_dir": "",
- "task": "summarization",
- "num_workers": 2,
- "alpha_hid": 0,
- "freeze_embeds": True,
- "enc_only": False,
- "tgt_suffix": "",
- "resume_from_checkpoint": None,
- "sortish_sampler": True,
- "student_decoder_layers": 1,
- "val_check_interval": 1.0,
- "output_dir": "",
- "fp16": False, # TODO(SS): set this to CUDA_AVAILABLE if ci installs apex or start using native amp
- "no_teacher": False,
- "fp16_opt_level": "O1",
- "gpus": 1 if CUDA_AVAILABLE else 0,
- "n_tpu_cores": 0,
- "max_grad_norm": 1.0,
- "do_train": True,
- "do_predict": True,
- "accumulate_grad_batches": 1,
- "server_ip": "",
- "server_port": "",
- "seed": 42,
- "model_name_or_path": "sshleifer/bart-tiny-random",
- "config_name": "",
- "tokenizer_name": "facebook/bart-large",
- "do_lower_case": False,
- "learning_rate": 0.3,
- "lr_scheduler": "linear",
- "weight_decay": 0.0,
- "adam_epsilon": 1e-08,
- "warmup_steps": 0,
- "max_epochs": 1,
- "train_batch_size": 2,
- "eval_batch_size": 2,
- "max_source_length": 12,
- "max_target_length": 12,
- "val_max_target_length": 12,
- "test_max_target_length": 12,
- "fast_dev_run": False,
- "no_cache": False,
- "n_train": -1,
- "n_val": -1,
- "n_test": -1,
- "student_encoder_layers": 1,
- "freeze_encoder": False,
- "auto_scale_batch_size": False,
- "overwrite_output_dir": False,
- "student": None,
-}
-
-
-def _dump_articles(path: Path, articles: list):
- content = "\n".join(articles)
- Path(path).open("w").writelines(content)
-
-
-ARTICLES = [" Sam ate lunch today.", "Sams lunch ingredients."]
-SUMMARIES = ["A very interesting story about what I ate for lunch.", "Avocado, celery, turkey, coffee"]
-T5_TINY = "patrickvonplaten/t5-tiny-random"
-T5_TINIER = "sshleifer/t5-tinier-random"
-BART_TINY = "sshleifer/bart-tiny-random"
-MBART_TINY = "sshleifer/tiny-mbart"
-MARIAN_TINY = "sshleifer/tiny-marian-en-de"
-FSMT_TINY = "stas/tiny-wmt19-en-de"
-
-
-stream_handler = logging.StreamHandler(sys.stdout)
-logger.addHandler(stream_handler)
-logging.disable(logging.CRITICAL) # remove noisy download output from tracebacks
-
-
-def make_test_data_dir(tmp_dir):
- for split in ["train", "val", "test"]:
- _dump_articles(os.path.join(tmp_dir, f"{split}.source"), ARTICLES)
- _dump_articles(os.path.join(tmp_dir, f"{split}.target"), SUMMARIES)
- return tmp_dir
-
-
-class TestSummarizationDistiller(TestCasePlus):
- @classmethod
- def setUpClass(cls):
- logging.disable(logging.CRITICAL) # remove noisy download output from tracebacks
- return cls
-
- @slow
- @require_torch_gpu
- def test_hub_configs(self):
- """I put require_torch_gpu cause I only want this to run with self-scheduled."""
-
- model_list = list_models()
- org = "sshleifer"
- model_ids = [x.modelId for x in model_list if x.modelId.startswith(org)]
- allowed_to_be_broken = ["sshleifer/blenderbot-3B", "sshleifer/blenderbot-90M"]
- failures = []
- for m in model_ids:
- if m in allowed_to_be_broken:
- continue
- try:
- AutoConfig.from_pretrained(m)
- except Exception:
- failures.append(m)
- assert not failures, f"The following models could not be loaded through AutoConfig: {failures}"
-
- def test_distill_no_teacher(self):
- updates = {"student_encoder_layers": 2, "student_decoder_layers": 1, "no_teacher": True}
- self._test_distiller_cli(updates)
-
- def test_distill_checkpointing_with_teacher(self):
- updates = {
- "student_encoder_layers": 2,
- "student_decoder_layers": 1,
- "max_epochs": 4,
- "val_check_interval": 0.25,
- "alpha_hid": 2.0,
- "model_name_or_path": "IGNORE_THIS_IT_DOESNT_GET_USED",
- }
- model = self._test_distiller_cli(updates, check_contents=False)
-
- ckpts = list(Path(model.output_dir).glob("*.ckpt"))
- self.assertEqual(1, len(ckpts))
- transformer_ckpts = list(Path(model.output_dir).glob("**/*.bin"))
- self.assertEqual(len(transformer_ckpts), 2)
- examples = lmap(str.strip, Path(model.hparams.data_dir).joinpath("test.source").open().readlines())
- out_path = tempfile.mktemp() # XXX: not being cleaned up
- generate_summaries_or_translations(examples, out_path, str(model.output_dir / "best_tfmr"))
- self.assertTrue(Path(out_path).exists())
-
- out_path_new = self.get_auto_remove_tmp_dir()
- convert_pl_to_hf(ckpts[0], transformer_ckpts[0].parent, out_path_new)
- assert os.path.exists(os.path.join(out_path_new, "pytorch_model.bin"))
-
- def test_loss_fn(self):
- model = AutoModelForSeq2SeqLM.from_pretrained(BART_TINY)
- input_ids, mask = model.dummy_inputs["input_ids"], model.dummy_inputs["attention_mask"]
- target_ids = torch.tensor([[0, 4, 8, 2], [0, 8, 2, 1]], dtype=torch.long, device=model.device)
- decoder_input_ids = target_ids[:, :-1].contiguous() # Why this line?
- lm_labels = target_ids[:, 1:].clone() # why clone?
- model_computed_loss = model(
- input_ids, attention_mask=mask, decoder_input_ids=decoder_input_ids, labels=lm_labels, use_cache=False
- ).loss
-
- logits = model(input_ids, attention_mask=mask, decoder_input_ids=decoder_input_ids, use_cache=False).logits
-
- lprobs = nn.functional.log_softmax(logits, dim=-1)
- smoothed_loss, nll_loss = label_smoothed_nll_loss(
- lprobs, lm_labels, 0.1, ignore_index=model.config.pad_token_id
- )
- with self.assertRaises(AssertionError):
- # TODO: understand why this breaks
- self.assertEqual(nll_loss, model_computed_loss)
-
- def test_distill_mbart(self):
- updates = {
- "student_encoder_layers": 2,
- "student_decoder_layers": 1,
- "num_train_epochs": 4,
- "val_check_interval": 0.25,
- "alpha_hid": 2.0,
- "task": "translation",
- "model_name_or_path": "IGNORE_THIS_IT_DOESNT_GET_USED",
- "tokenizer_name": MBART_TINY,
- "teacher": MBART_TINY,
- "src_lang": "en_XX",
- "tgt_lang": "ro_RO",
- }
- model = self._test_distiller_cli(updates, check_contents=False)
- assert model.model.config.model_type == "mbart"
-
- ckpts = list(Path(model.output_dir).glob("*.ckpt"))
- self.assertEqual(1, len(ckpts))
- transformer_ckpts = list(Path(model.output_dir).glob("**/*.bin"))
- all_files = list(Path(model.output_dir).glob("best_tfmr/*"))
- assert len(all_files) > 2
- self.assertEqual(len(transformer_ckpts), 2)
-
- def test_distill_t5(self):
- updates = {
- "student_encoder_layers": 1,
- "student_decoder_layers": 1,
- "alpha_hid": 2.0,
- "teacher": T5_TINY,
- "model_name_or_path": T5_TINY,
- "tokenizer_name": T5_TINY,
- }
- self._test_distiller_cli(updates)
-
- def test_distill_different_base_models(self):
- updates = {
- "teacher": T5_TINY,
- "student": T5_TINIER,
- "model_name_or_path": T5_TINIER,
- "tokenizer_name": T5_TINIER,
- }
- self._test_distiller_cli(updates)
-
- def _test_distiller_cli(self, updates, check_contents=True):
- default_updates = {
- "label_smoothing": 0.0,
- "early_stopping_patience": -1,
- "train_batch_size": 1,
- "eval_batch_size": 2,
- "max_epochs": 2,
- "alpha_mlm": 0.2,
- "alpha_ce": 0.8,
- "do_predict": True,
- "model_name_or_path": "sshleifer/tinier_bart",
- "teacher": CHEAP_ARGS["model_name_or_path"],
- "val_check_interval": 0.5,
- }
- default_updates.update(updates)
- args_d: dict = CHEAP_ARGS.copy()
- tmp_dir = make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir())
- output_dir = self.get_auto_remove_tmp_dir()
-
- args_d.update(data_dir=tmp_dir, output_dir=output_dir, **default_updates)
- model = distill_main(argparse.Namespace(**args_d))
- if not check_contents:
- return model
- contents = os.listdir(output_dir)
- contents = {os.path.basename(p) for p in contents}
- ckpt_files = [p for p in contents if p.endswith("ckpt")]
- assert len(ckpt_files) > 0
-
- self.assertIn("test_generations.txt", contents)
- self.assertIn("test_results.txt", contents)
-
- metrics = load_json(model.metrics_save_path)
- last_step_stats = metrics["val"][-1]
- self.assertGreaterEqual(last_step_stats["val_avg_gen_time"], 0.01)
- self.assertGreaterEqual(1.0, last_step_stats["val_avg_gen_time"])
- self.assertIsInstance(last_step_stats[f"val_avg_{model.val_metric}"], float)
- desired_n_evals = int(args_d["max_epochs"] * (1 / args_d["val_check_interval"]) + 1)
- self.assertEqual(len(metrics["val"]), desired_n_evals)
- self.assertEqual(len(metrics["test"]), 1)
- return model
-
-
-class TestTheRest(TestCasePlus):
- @parameterized.expand(
- [T5_TINY, BART_TINY, MBART_TINY, MARIAN_TINY, FSMT_TINY],
- )
- def test_finetune(self, model):
- args_d: dict = CHEAP_ARGS.copy()
- task = "translation" if model in [MBART_TINY, MARIAN_TINY, FSMT_TINY] else "summarization"
- args_d["label_smoothing"] = 0.1 if task == "translation" else 0
-
- tmp_dir = make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir())
- output_dir = self.get_auto_remove_tmp_dir()
- args_d.update(
- data_dir=tmp_dir,
- model_name_or_path=model,
- tokenizer_name=None,
- train_batch_size=2,
- eval_batch_size=2,
- output_dir=output_dir,
- do_predict=True,
- task=task,
- src_lang="en_XX",
- tgt_lang="ro_RO",
- freeze_encoder=True,
- freeze_embeds=True,
- )
- assert "n_train" in args_d
- args = argparse.Namespace(**args_d)
- module = main(args)
-
- input_embeds = module.model.get_input_embeddings()
- assert not input_embeds.weight.requires_grad
- if model == T5_TINY:
- lm_head = module.model.lm_head
- assert not lm_head.weight.requires_grad
- assert (lm_head.weight == input_embeds.weight).all().item()
- elif model == FSMT_TINY:
- fsmt = module.model.model
- embed_pos = fsmt.decoder.embed_positions
- assert not embed_pos.weight.requires_grad
- assert not fsmt.decoder.embed_tokens.weight.requires_grad
- # check that embeds are not the same
- assert fsmt.decoder.embed_tokens != fsmt.encoder.embed_tokens
- else:
- bart = module.model.model
- embed_pos = bart.decoder.embed_positions
- assert not embed_pos.weight.requires_grad
- assert not bart.shared.weight.requires_grad
- # check that embeds are the same
- assert bart.decoder.embed_tokens == bart.encoder.embed_tokens
- assert bart.decoder.embed_tokens == bart.shared
-
- example_batch = load_json(module.output_dir / "text_batch.json")
- assert isinstance(example_batch, dict)
- assert len(example_batch) >= 4
-
- def test_finetune_extra_model_args(self):
- args_d: dict = CHEAP_ARGS.copy()
-
- task = "summarization"
- tmp_dir = make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir())
-
- args_d.update(
- data_dir=tmp_dir,
- tokenizer_name=None,
- train_batch_size=2,
- eval_batch_size=2,
- do_predict=False,
- task=task,
- src_lang="en_XX",
- tgt_lang="ro_RO",
- freeze_encoder=True,
- freeze_embeds=True,
- )
-
- # test models whose config includes the extra_model_args
- model = BART_TINY
- output_dir = self.get_auto_remove_tmp_dir()
- args_d1 = args_d.copy()
- args_d1.update(
- model_name_or_path=model,
- output_dir=output_dir,
- )
- extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "dropout", "attention_dropout")
- for p in extra_model_params:
- args_d1[p] = 0.5
- args = argparse.Namespace(**args_d1)
- model = main(args)
- for p in extra_model_params:
- assert getattr(model.config, p) == 0.5, f"failed to override the model config for param {p}"
-
- # test models whose config doesn't include the extra_model_args
- model = T5_TINY
- output_dir = self.get_auto_remove_tmp_dir()
- args_d2 = args_d.copy()
- args_d2.update(
- model_name_or_path=model,
- output_dir=output_dir,
- )
- unsupported_param = "encoder_layerdrop"
- args_d2[unsupported_param] = 0.5
- args = argparse.Namespace(**args_d2)
- with pytest.raises(Exception) as excinfo:
- model = main(args)
- assert str(excinfo.value) == f"model config doesn't have a `{unsupported_param}` attribute"
-
- def test_finetune_lr_schedulers(self):
- args_d: dict = CHEAP_ARGS.copy()
-
- task = "summarization"
- tmp_dir = make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir())
-
- model = BART_TINY
- output_dir = self.get_auto_remove_tmp_dir()
-
- args_d.update(
- data_dir=tmp_dir,
- model_name_or_path=model,
- output_dir=output_dir,
- tokenizer_name=None,
- train_batch_size=2,
- eval_batch_size=2,
- do_predict=False,
- task=task,
- src_lang="en_XX",
- tgt_lang="ro_RO",
- freeze_encoder=True,
- freeze_embeds=True,
- )
-
- # emulate finetune.py
- parser = argparse.ArgumentParser()
- parser = pl.Trainer.add_argparse_args(parser)
- parser = SummarizationModule.add_model_specific_args(parser, os.getcwd())
- args = {"--help": True}
-
- # --help test
- with pytest.raises(SystemExit) as excinfo:
- with CaptureStdout() as cs:
- args = parser.parse_args(args)
- assert False, "--help is expected to sys.exit"
- assert excinfo.type is SystemExit
- expected = lightning_base.arg_to_scheduler_metavar
- assert expected in cs.out, "--help is expected to list the supported schedulers"
-
- # --lr_scheduler=non_existing_scheduler test
- unsupported_param = "non_existing_scheduler"
- args = {f"--lr_scheduler={unsupported_param}"}
- with pytest.raises(SystemExit) as excinfo:
- with CaptureStderr() as cs:
- args = parser.parse_args(args)
- assert False, "invalid argument is expected to sys.exit"
- assert excinfo.type is SystemExit
- expected = f"invalid choice: '{unsupported_param}'"
- assert expected in cs.err, f"should have bailed on invalid choice of scheduler {unsupported_param}"
-
- # --lr_scheduler=existing_scheduler test
- supported_param = "cosine"
- args_d1 = args_d.copy()
- args_d1["lr_scheduler"] = supported_param
- args = argparse.Namespace(**args_d1)
- model = main(args)
- assert (
- getattr(model.hparams, "lr_scheduler") == supported_param
- ), f"lr_scheduler={supported_param} shouldn't fail"
diff --git a/examples/research_projects/seq2seq-distillation/_test_seq2seq_examples_multi_gpu.py b/examples/research_projects/seq2seq-distillation/_test_seq2seq_examples_multi_gpu.py
deleted file mode 100644
index 9eeb3b30d39..00000000000
--- a/examples/research_projects/seq2seq-distillation/_test_seq2seq_examples_multi_gpu.py
+++ /dev/null
@@ -1,163 +0,0 @@
-# as due to their complexity multi-gpu tests could impact other tests, and to aid debug we have those in a separate module.
-
-import os
-import sys
-from pathlib import Path
-
-import torch
-
-from transformers.testing_utils import TestCasePlus, execute_subprocess_async, require_torch_multi_gpu
-from utils import load_json
-
-
-CUDA_AVAILABLE = torch.cuda.is_available()
-ARTICLES = [" Sam ate lunch today.", "Sams lunch ingredients."]
-SUMMARIES = ["A very interesting story about what I ate for lunch.", "Avocado, celery, turkey, coffee"]
-CHEAP_ARGS = {
- "max_tokens_per_batch": None,
- "supervise_forward": True,
- "normalize_hidden": True,
- "label_smoothing": 0.2,
- "eval_max_gen_length": None,
- "eval_beams": 1,
- "val_metric": "loss",
- "save_top_k": 1,
- "adafactor": True,
- "early_stopping_patience": 2,
- "logger_name": "default",
- "length_penalty": 0.5,
- "cache_dir": "",
- "task": "summarization",
- "num_workers": 2,
- "alpha_hid": 0,
- "freeze_embeds": True,
- "enc_only": False,
- "tgt_suffix": "",
- "resume_from_checkpoint": None,
- "sortish_sampler": True,
- "student_decoder_layers": 1,
- "val_check_interval": 1.0,
- "output_dir": "",
- "fp16": False, # TODO(SS): set this to CUDA_AVAILABLE if ci installs apex or start using native amp
- "no_teacher": False,
- "fp16_opt_level": "O1",
- "gpus": 1 if CUDA_AVAILABLE else 0,
- "n_tpu_cores": 0,
- "max_grad_norm": 1.0,
- "do_train": True,
- "do_predict": True,
- "accumulate_grad_batches": 1,
- "server_ip": "",
- "server_port": "",
- "seed": 42,
- "model_name_or_path": "sshleifer/bart-tiny-random",
- "config_name": "",
- "tokenizer_name": "facebook/bart-large",
- "do_lower_case": False,
- "learning_rate": 0.3,
- "lr_scheduler": "linear",
- "weight_decay": 0.0,
- "adam_epsilon": 1e-08,
- "warmup_steps": 0,
- "max_epochs": 1,
- "train_batch_size": 2,
- "eval_batch_size": 2,
- "max_source_length": 12,
- "max_target_length": 12,
- "val_max_target_length": 12,
- "test_max_target_length": 12,
- "fast_dev_run": False,
- "no_cache": False,
- "n_train": -1,
- "n_val": -1,
- "n_test": -1,
- "student_encoder_layers": 1,
- "freeze_encoder": False,
- "auto_scale_batch_size": False,
- "overwrite_output_dir": False,
- "student": None,
-}
-
-
-def _dump_articles(path: Path, articles: list):
- content = "\n".join(articles)
- Path(path).open("w").writelines(content)
-
-
-def make_test_data_dir(tmp_dir):
- for split in ["train", "val", "test"]:
- _dump_articles(os.path.join(tmp_dir, f"{split}.source"), ARTICLES)
- _dump_articles(os.path.join(tmp_dir, f"{split}.target"), SUMMARIES)
- return tmp_dir
-
-
-class TestSummarizationDistillerMultiGPU(TestCasePlus):
- @classmethod
- def setUpClass(cls):
- return cls
-
- @require_torch_multi_gpu
- def test_multi_gpu(self):
- updates = {
- "no_teacher": True,
- "freeze_encoder": True,
- "gpus": 2,
- "overwrite_output_dir": True,
- "sortish_sampler": True,
- }
- self._test_distiller_cli_fork(updates, check_contents=False)
-
- def _test_distiller_cli_fork(self, updates, check_contents=True):
- default_updates = {
- "label_smoothing": 0.0,
- "early_stopping_patience": -1,
- "train_batch_size": 1,
- "eval_batch_size": 2,
- "max_epochs": 2,
- "alpha_mlm": 0.2,
- "alpha_ce": 0.8,
- "do_predict": True,
- "model_name_or_path": "sshleifer/tinier_bart",
- "teacher": CHEAP_ARGS["model_name_or_path"],
- "val_check_interval": 0.5,
- }
- default_updates.update(updates)
- args_d: dict = CHEAP_ARGS.copy()
- tmp_dir = make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir())
- output_dir = self.get_auto_remove_tmp_dir()
- args_d.update(data_dir=tmp_dir, output_dir=output_dir, **default_updates)
-
- def convert(k, v):
- if k in ["tgt_suffix", "server_ip", "server_port", "out", "n_tpu_cores"]:
- return ""
- if v is False or v is None:
- return ""
- if v is True: # or len(str(v))==0:
- return f"--{k}"
- return f"--{k}={v}"
-
- cli_args = [x for x in (convert(k, v) for k, v in args_d.items()) if len(x)]
- cmd = [sys.executable, f"{self.test_file_dir}/distillation.py"] + cli_args
- execute_subprocess_async(cmd, env=self.get_env())
-
- contents = os.listdir(output_dir)
- contents = {os.path.basename(p) for p in contents}
- ckpt_files = [p for p in contents if p.endswith("ckpt")]
- assert len(ckpt_files) > 0
-
- self.assertIn("test_generations.txt", contents)
- self.assertIn("test_results.txt", contents)
-
- # get the following from the module, (we don't have access to `model` here)
- metrics_save_path = os.path.join(output_dir, "metrics.json")
- val_metric = "rouge2"
-
- metrics = load_json(metrics_save_path)
- # {'test': [{'test_avg_loss': 10.63731575012207, 'test_avg_rouge1': 0.0, 'test_avg_rouge2': 0.0, 'test_avg_rougeL': 0.0, 'test_avg_gen_time': 0.1822289228439331, 'test_avg_gen_len': 142.0, 'step_count': 1}]}
- print(metrics)
- last_step_stats = metrics["val"][-1]
- self.assertGreaterEqual(last_step_stats["val_avg_gen_time"], 0.01)
- self.assertIsInstance(last_step_stats[f"val_avg_{val_metric}"], float)
- self.assertEqual(len(metrics["test"]), 1)
- desired_n_evals = int(args_d["max_epochs"] * (1 / args_d["val_check_interval"]) / 2 + 1)
- self.assertEqual(len(metrics["val"]), desired_n_evals)
diff --git a/examples/research_projects/seq2seq-distillation/callbacks.py b/examples/research_projects/seq2seq-distillation/callbacks.py
deleted file mode 100644
index 6f6ed5dd58a..00000000000
--- a/examples/research_projects/seq2seq-distillation/callbacks.py
+++ /dev/null
@@ -1,116 +0,0 @@
-import logging
-from pathlib import Path
-
-import numpy as np
-import pytorch_lightning as pl
-import torch
-from pytorch_lightning.callbacks import EarlyStopping, ModelCheckpoint
-from pytorch_lightning.utilities import rank_zero_only
-
-from utils import save_json
-
-
-def count_trainable_parameters(model):
- model_parameters = filter(lambda p: p.requires_grad, model.parameters())
- params = sum([np.prod(p.size()) for p in model_parameters])
- return params
-
-
-logger = logging.getLogger(__name__)
-
-
-class Seq2SeqLoggingCallback(pl.Callback):
- def on_batch_end(self, trainer, pl_module):
- lrs = {f"lr_group_{i}": param["lr"] for i, param in enumerate(pl_module.trainer.optimizers[0].param_groups)}
- pl_module.logger.log_metrics(lrs)
-
- @rank_zero_only
- def _write_logs(
- self, trainer: pl.Trainer, pl_module: pl.LightningModule, type_path: str, save_generations=True
- ) -> None:
- logger.info(f"***** {type_path} results at step {trainer.global_step:05d} *****")
- metrics = trainer.callback_metrics
- trainer.logger.log_metrics({k: v for k, v in metrics.items() if k not in ["log", "progress_bar", "preds"]})
- # Log results
- od = Path(pl_module.hparams.output_dir)
- if type_path == "test":
- results_file = od / "test_results.txt"
- generations_file = od / "test_generations.txt"
- else:
- # this never gets hit. I prefer not to save intermediate generations, and results are in metrics.json
- # If people want this it will be easy enough to add back.
- results_file = od / f"{type_path}_results/{trainer.global_step:05d}.txt"
- generations_file = od / f"{type_path}_generations/{trainer.global_step:05d}.txt"
- results_file.parent.mkdir(exist_ok=True)
- generations_file.parent.mkdir(exist_ok=True)
- with open(results_file, "a+") as writer:
- for key in sorted(metrics):
- if key in ["log", "progress_bar", "preds"]:
- continue
- val = metrics[key]
- if isinstance(val, torch.Tensor):
- val = val.item()
- msg = f"{key}: {val:.6f}\n"
- writer.write(msg)
-
- if not save_generations:
- return
-
- if "preds" in metrics:
- content = "\n".join(metrics["preds"])
- generations_file.open("w+").write(content)
-
- @rank_zero_only
- def on_train_start(self, trainer, pl_module):
- try:
- npars = pl_module.model.model.num_parameters()
- except AttributeError:
- npars = pl_module.model.num_parameters()
-
- n_trainable_pars = count_trainable_parameters(pl_module)
- # mp stands for million parameters
- trainer.logger.log_metrics({"n_params": npars, "mp": npars / 1e6, "grad_mp": n_trainable_pars / 1e6})
-
- @rank_zero_only
- def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
- save_json(pl_module.metrics, pl_module.metrics_save_path)
- return self._write_logs(trainer, pl_module, "test")
-
- @rank_zero_only
- def on_validation_end(self, trainer: pl.Trainer, pl_module):
- save_json(pl_module.metrics, pl_module.metrics_save_path)
- # Uncommenting this will save val generations
- # return self._write_logs(trainer, pl_module, "valid")
-
-
-def get_checkpoint_callback(output_dir, metric, save_top_k=1, lower_is_better=False):
- """Saves the best model by validation ROUGE2 score."""
- if metric == "rouge2":
- exp = "{val_avg_rouge2:.4f}-{step_count}"
- elif metric == "bleu":
- exp = "{val_avg_bleu:.4f}-{step_count}"
- elif metric == "loss":
- exp = "{val_avg_loss:.4f}-{step_count}"
- else:
- raise NotImplementedError(
- f"seq2seq callbacks only support rouge2, bleu and loss, got {metric}, You can make your own by adding to"
- " this function."
- )
-
- checkpoint_callback = ModelCheckpoint(
- dirpath=output_dir,
- filename=exp,
- monitor=f"val_{metric}",
- mode="min" if "loss" in metric else "max",
- save_top_k=save_top_k,
- )
- return checkpoint_callback
-
-
-def get_early_stopping_callback(metric, patience):
- return EarlyStopping(
- monitor=f"val_{metric}", # does this need avg?
- mode="min" if "loss" in metric else "max",
- patience=patience,
- verbose=True,
- )
diff --git a/examples/research_projects/seq2seq-distillation/convert_pl_checkpoint_to_hf.py b/examples/research_projects/seq2seq-distillation/convert_pl_checkpoint_to_hf.py
deleted file mode 100755
index 5f3c984f372..00000000000
--- a/examples/research_projects/seq2seq-distillation/convert_pl_checkpoint_to_hf.py
+++ /dev/null
@@ -1,74 +0,0 @@
-#!/usr/bin/env python
-
-import os
-from pathlib import Path
-from typing import Dict, List
-
-import fire
-import torch
-
-from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
-from transformers.utils.logging import get_logger
-
-
-logger = get_logger(__name__)
-
-
-def remove_prefix(text: str, prefix: str):
- if text.startswith(prefix):
- return text[len(prefix) :]
- return text # or whatever
-
-
-def sanitize(sd):
- return {remove_prefix(k, "model."): v for k, v in sd.items()}
-
-
-def average_state_dicts(state_dicts: List[Dict[str, torch.Tensor]]):
- new_sd = {}
- for k in state_dicts[0].keys():
- tensors = [sd[k] for sd in state_dicts]
- new_t = sum(tensors) / len(tensors)
- assert isinstance(new_t, torch.Tensor)
- new_sd[k] = new_t
- return new_sd
-
-
-def convert_pl_to_hf(pl_ckpt_path: str, hf_src_model_dir: str, save_path: str) -> None:
- """Cleanup a pytorch-lightning .ckpt file or experiment dir and save a huggingface model with that state dict.
- Silently allows extra pl keys (like teacher.) Puts all ckpt models into CPU RAM at once!
-
- Args:
- pl_ckpt_path (:obj:`str`): Path to a .ckpt file saved by pytorch_lightning or dir containing ckpt files.
- If a directory is passed, all .ckpt files inside it will be averaged!
- hf_src_model_dir (:obj:`str`): Path to a directory containing a correctly shaped checkpoint
- save_path (:obj:`str`): Directory to save the new model
-
- """
- hf_model = AutoModelForSeq2SeqLM.from_pretrained(hf_src_model_dir)
- if os.path.isfile(pl_ckpt_path):
- ckpt_files = [pl_ckpt_path]
- else:
- assert os.path.isdir(pl_ckpt_path)
- ckpt_files = list(Path(pl_ckpt_path).glob("*.ckpt"))
- assert ckpt_files, f"could not find any ckpt files inside the {pl_ckpt_path} directory"
-
- if len(ckpt_files) > 1:
- logger.info(f"averaging the weights of {ckpt_files}")
-
- state_dicts = [sanitize(torch.load(x, map_location="cpu")["state_dict"]) for x in ckpt_files]
- state_dict = average_state_dicts(state_dicts)
-
- missing, unexpected = hf_model.load_state_dict(state_dict, strict=False)
- assert not missing, f"missing keys: {missing}"
- hf_model.save_pretrained(save_path)
- try:
- tok = AutoTokenizer.from_pretrained(hf_src_model_dir)
- tok.save_pretrained(save_path)
- except Exception:
- pass
- # dont copy tokenizer if cant
-
-
-if __name__ == "__main__":
- fire.Fire(convert_pl_to_hf)
diff --git a/examples/research_projects/seq2seq-distillation/distil_marian_enro_teacher.sh b/examples/research_projects/seq2seq-distillation/distil_marian_enro_teacher.sh
deleted file mode 100755
index 5c938a71604..00000000000
--- a/examples/research_projects/seq2seq-distillation/distil_marian_enro_teacher.sh
+++ /dev/null
@@ -1,20 +0,0 @@
-#!/usr/bin/env bash
-export PYTHONPATH="../":"${PYTHONPATH}"
-export WANDB_PROJECT=dmar
-# export MAX_LEN=128
-python distillation.py \
- --learning_rate=3e-4 \
- --do_train \
- --fp16 \
- --val_check_interval 0.25 \
- --teacher Helsinki-NLP/opus-mt-en-ro \
- --max_source_length $MAX_LEN --max_target_length $MAX_LEN --val_max_target_length $MAX_LEN --test_max_target_length $MAX_LEN \
- --student_decoder_layers 3 --student_encoder_layers 6 \
- --freeze_encoder --freeze_embeds \
- --model_name_or_path IGNORED \
- --alpha_hid=3. \
- --train_batch_size=$BS --eval_batch_size=$BS \
- --tokenizer_name Helsinki-NLP/opus-mt-en-ro \
- --warmup_steps 500 --logger_name wandb \
- --fp16_opt_level O1 --task translation --normalize_hidden --num_sanity_val_steps=0 \
- "$@"
diff --git a/examples/research_projects/seq2seq-distillation/distil_marian_no_teacher.sh b/examples/research_projects/seq2seq-distillation/distil_marian_no_teacher.sh
deleted file mode 100755
index 4f0f53d7960..00000000000
--- a/examples/research_projects/seq2seq-distillation/distil_marian_no_teacher.sh
+++ /dev/null
@@ -1,18 +0,0 @@
-#!/usr/bin/env bash
-export PYTHONPATH="../":"${PYTHONPATH}"
-export WANDB_PROJECT=dmar
-export MAX_LEN=128
-python finetune.py \
- --learning_rate=3e-4 \
- --do_train \
- --do_predict \
- --fp16 \
- --val_check_interval 0.25 \
- --data_dir $ENRO_DIR \
- --max_source_length $MAX_LEN --max_target_length $MAX_LEN --val_max_target_length $MAX_LEN --test_max_target_length $MAX_LEN \
- --freeze_encoder --freeze_embeds \
- --train_batch_size=$BS --eval_batch_size=$BS \
- --tokenizer_name $m --model_name_or_path $m \
- --warmup_steps 500 --sortish_sampler --logger_name wandb \
- --gpus 1 --fp16_opt_level=O1 --task translation --num_sanity_val_steps=0 \
- "$@"
diff --git a/examples/research_projects/seq2seq-distillation/distillation.py b/examples/research_projects/seq2seq-distillation/distillation.py
deleted file mode 100755
index 323f62bf458..00000000000
--- a/examples/research_projects/seq2seq-distillation/distillation.py
+++ /dev/null
@@ -1,310 +0,0 @@
-#!/usr/bin/env python
-
-import argparse
-import gc
-import os
-import sys
-from pathlib import Path
-from typing import List # noqa: F401
-
-import pytorch_lightning as pl
-import torch
-from finetune import SummarizationModule, TranslationModule
-from finetune import main as ft_main
-from make_student import create_student_by_copying_alternating_layers, get_layers_to_supervise
-from torch import nn
-
-from transformers import AutoModelForSeq2SeqLM, MBartTokenizer, T5ForConditionalGeneration
-from transformers.models.bart.modeling_bart import shift_tokens_right
-from utils import calculate_bleu, check_output_dir, freeze_params, label_smoothed_nll_loss, use_task_specific_params
-
-
-# need the parent dir module
-sys.path.insert(2, str(Path(__file__).resolve().parents[1]))
-from lightning_base import generic_train # noqa
-
-
-class SummarizationDistiller(SummarizationModule):
- """Supports T5, Bart, Pegasus and other models that inherit from Bart."""
-
- loss_names = ["loss", "ce_loss", "mlm_loss", "hid_loss_enc", "hid_loss_dec"]
-
- def __init__(self, hparams):
- assert Path(hparams.data_dir).exists()
- self.output_dir = Path(hparams.output_dir)
- self.output_dir.mkdir(exist_ok=True)
-
- save_dir = self.output_dir.joinpath("student")
-
- hparams.model_name_or_path = str(save_dir) # Tell lightning we are training the student
- teacher = AutoModelForSeq2SeqLM.from_pretrained(hparams.teacher).eval()
- use_task_specific_params(teacher, hparams.task) # We copy good generation parameters to student by default
- if hparams.student is not None:
- student = AutoModelForSeq2SeqLM.from_pretrained(hparams.student)
- use_task_specific_params(student, hparams.task)
- e_layer_ids, d_layer_ids = None, None
- else:
- student, e_layer_ids, d_layer_ids = create_student_by_copying_alternating_layers(
- teacher, e=hparams.student_encoder_layers, d=hparams.student_decoder_layers, save_path=save_dir
- )
-
- if hparams.length_penalty != -1:
- student.config.length_penalty = hparams.length_penalty
- hparams.tokenizer_name = hparams.teacher # Use teacher's tokenizer
- super().__init__(hparams, model=student, config=student.config)
- assert student.config.model_type == teacher.config.model_type, (
- f"teacher, student model types should be the same, got {student.config.model_type} !="
- f" {teacher.config.model_type}"
- )
-
- if student.config.model_type == "t5":
- student_encoder_layers = len(student.get_encoder().block)
- student_decoder_layers = len(student.get_decoder().block)
- teacher_encoder_layers = len(teacher.get_encoder().block)
- teacher_decoder_layers = len(teacher.get_decoder().block)
- else:
- student_encoder_layers = student.config.encoder_layers
- student_decoder_layers = student.config.decoder_layers
- teacher_encoder_layers = teacher.config.encoder_layers
- teacher_decoder_layers = teacher.config.decoder_layers
-
- self.different_base_models = not (hparams.student is None or hparams.teacher == hparams.student)
- self.do_calc_hidden_loss = (not self.different_base_models) and hparams.alpha_hid > 0
- self.different_encoder = self.different_base_models or (student_encoder_layers != teacher_encoder_layers)
- # self.different_encoder determines whether we need to run the teacher encoder
- self.teacher = teacher
- freeze_params(self.teacher)
-
- if not self.different_encoder: # To save RAM, delete teacher encoder and freeze student encoder.
- try:
- del self.teacher.model.encoder
- except AttributeError: # T5
- del self.teacher.encoder
-
- if e_layer_ids is None:
- e_layer_ids = list(range(student_encoder_layers))
- if d_layer_ids is None:
- d_layer_ids = list(range(student_decoder_layers))
-
- self.e_layer_ids, self.d_layer_ids = e_layer_ids, d_layer_ids # type: List[int], List[int]
-
- if self.do_calc_hidden_loss: # Intermediate supervision: Decide which layers to supervise
- if hparams.supervise_forward:
- self.e_matches = get_layers_to_supervise(
- n_student=len(self.e_layer_ids), n_teacher=teacher_encoder_layers
- )
- self.d_matches = get_layers_to_supervise(
- n_student=len(self.d_layer_ids), n_teacher=teacher_decoder_layers
- )
- else: # student layer should emulate hidden states of the teacher layer it was copied from
- self.e_matches = self.e_layer_ids
- self.d_matches = self.d_layer_ids
- else:
- self.e_matches = None
- self.d_matches = None
-
- self.ce_loss_fct = nn.KLDivLoss(reduction="batchmean")
- self.temperature = 2.0
- self.alpha_mlm = hparams.alpha_mlm
- self.alpha_ce = hparams.alpha_ce
- self.alpha_hid = hparams.alpha_hid
- gc.collect()
- torch.cuda.empty_cache()
-
- def calc_ce_loss(self, mask, s_logits, t_logits):
- """Copy pasted from distillbert (transformers/examples/distillation/)"""
- # mask has False at padding_idx
- sel_mask = mask[:, :, None].expand_as(s_logits)
- vocab_size = s_logits.size(-1)
- s_logits_slct = torch.masked_select(s_logits, sel_mask) # (bs * seq_length * voc_size) modulo the 1s in mask
- t_logits_slct = torch.masked_select(t_logits, sel_mask) # (bs * seq_length * voc_size) modulo the 1s in mask
- s_logits_slct = s_logits_slct.view(-1, vocab_size) # (bs * seq_length, voc_size) modulo the 1s in mask
- t_logits_slct = t_logits_slct.view(-1, vocab_size) # (bs * seq_length, voc_size) modulo the 1s in mask
- assert t_logits_slct.size() == s_logits_slct.size()
- loss_ce = (
- self.ce_loss_fct(
- nn.functional.log_softmax(s_logits_slct / self.temperature, dim=-1),
- nn.functional.softmax(t_logits_slct / self.temperature, dim=-1),
- )
- * (self.temperature) ** 2
- )
- return loss_ce
-
- @staticmethod
- def add_model_specific_args(parser, root_dir):
- SummarizationModule.add_model_specific_args(parser, root_dir)
- add_distill_args(parser)
- return parser
-
- def _step(self, batch: dict) -> tuple:
- """Compute the loss for a batch"""
- pad_token_id = self.tokenizer.pad_token_id
- input_ids, src_mask, labels = batch["input_ids"], batch["attention_mask"], batch["labels"]
- if isinstance(self.model, T5ForConditionalGeneration):
- decoder_input_ids = self.model._shift_right(labels)
- else:
- decoder_input_ids = shift_tokens_right(labels, pad_token_id)
-
- # noinspection PyCallingNonCallable
- student_outputs = self(
- input_ids,
- attention_mask=src_mask,
- decoder_input_ids=decoder_input_ids,
- output_hidden_states=self.do_calc_hidden_loss,
- output_attentions=False,
- use_cache=False,
- )
- lm_logits = student_outputs["logits"]
-
- # Same cross entropy vs. label smoothing logic as finetune.py
- assert lm_logits.shape[-1] == self.model.config.vocab_size
- if self.hparams.label_smoothing == 0:
- # Same behavior as modeling_bart.py, besides ignoring pad_token_id
- loss_fct = nn.CrossEntropyLoss(ignore_index=pad_token_id)
- student_lm_loss = loss_fct(lm_logits.view(-1, lm_logits.shape[-1]), labels.view(-1))
- else:
- lprobs = nn.functional.log_softmax(lm_logits, dim=-1)
- student_lm_loss, _ = label_smoothed_nll_loss(
- lprobs, labels, self.hparams.label_smoothing, ignore_index=pad_token_id
- )
-
- def zero_tensor():
- return torch.tensor(0.0).type_as(student_lm_loss)
-
- teacher_enc_outputs = student_outputs[
- "encoder_last_hidden_state"
- ] # use this unless self.different_base_models
- hid_loss_enc, hid_loss_dec = zero_tensor(), zero_tensor()
- if self.different_encoder: # compute encoder hidden state loss
- all_teacher_encoder_outputs = self.teacher.get_encoder()(
- input_ids,
- attention_mask=src_mask,
- output_hidden_states=self.do_calc_hidden_loss,
- )
- if self.different_base_models:
- teacher_enc_outputs = all_teacher_encoder_outputs["last_hidden_state"]
- elif self.do_calc_hidden_loss:
- hid_loss_enc = self.calc_hidden_loss(
- src_mask,
- student_outputs["encoder_hidden_states"],
- all_teacher_encoder_outputs["hidden_states"],
- self.e_matches,
- normalize_hidden=self.hparams.normalize_hidden,
- )
-
- teacher_outputs = self.teacher(
- input_ids,
- attention_mask=src_mask,
- encoder_outputs=(teacher_enc_outputs,),
- decoder_input_ids=decoder_input_ids,
- output_hidden_states=self.do_calc_hidden_loss,
- use_cache=False, # since we are not passing labels, never let this default to True
- )
- dec_mask = decoder_input_ids.ne(pad_token_id)
- loss_ce = self.calc_ce_loss(dec_mask, lm_logits, teacher_outputs["logits"])
- if self.do_calc_hidden_loss: # Intermediate supervision of decoder hidden states
- hid_loss_dec = self.calc_hidden_loss(
- dec_mask,
- student_outputs["decoder_hidden_states"],
- teacher_outputs["decoder_hidden_states"],
- self.d_matches,
- normalize_hidden=self.hparams.normalize_hidden,
- )
-
- blended_loss = (
- self.alpha_ce * loss_ce
- + self.alpha_mlm * student_lm_loss
- + self.hparams.alpha_hid * (hid_loss_enc + hid_loss_dec)
- )
- return blended_loss, loss_ce, student_lm_loss, hid_loss_enc, hid_loss_dec
-
- @staticmethod
- def calc_hidden_loss(attention_mask, hidden_states, hidden_states_T, matches, normalize_hidden):
- """MSE(student_hid, teacher_hid[matches]). Called "Intermediate supervision" in paper. Inspired by TinyBERT."""
- msg = "expected list or tuple for hidden_states, got tensor of shape: "
- assert not isinstance(hidden_states, torch.Tensor), f"{msg}{hidden_states.shape}"
- assert not isinstance(hidden_states_T, torch.Tensor), f"{msg}{hidden_states_T.shape}"
- mask = attention_mask.to(hidden_states[0])
- valid_count = mask.sum() * hidden_states[0].size(-1)
- student_states = torch.stack([hidden_states[i] for i in range(len(matches))])
- teacher_states = torch.stack([hidden_states_T[j] for j in matches])
- assert student_states.shape == teacher_states.shape, f"{student_states.shape} != {teacher_states.shape}"
- if normalize_hidden:
- student_states = nn.functional.layer_norm(student_states, student_states.shape[1:])
- teacher_states = nn.functional.layer_norm(teacher_states, teacher_states.shape[1:])
- mse = nn.functional.mse_loss(student_states, teacher_states, reduction="none")
- masked_mse = (mse * mask.unsqueeze(0).unsqueeze(-1)).sum() / valid_count
- return masked_mse
-
-
-def add_distill_args(parser):
- # NOTE: if --student argument was specified and the teacher and student base models
- # are different, the models still have to have the same tokenizer, specified by
- # --tokenizer_name. So, for example, you can distill from t5_large to t5_small but not
- # from bart to t5. This s because if the tokenizers are different, the output space
- # for the two models is also different and their logits are not comparable.
- parser.add_argument("--teacher", type=str)
- parser.add_argument("--alpha_ce", default=0.8, type=float)
- parser.add_argument("--alpha_mlm", default=0.2, type=float)
- parser.add_argument("--alpha_hid", default=0.0, type=float, required=False)
- parser.add_argument("--student", type=str, required=False)
- parser.add_argument("--student_decoder_layers", default=12, type=int, required=False)
- parser.add_argument("--student_encoder_layers", default=12, type=int, required=False)
- parser.add_argument("--no_teacher", action="store_true", default=False)
- parser.add_argument("--length_penalty", type=float, default=-1)
- parser.add_argument("--supervise_forward", action="store_true", default=False)
- parser.add_argument("--normalize_hidden", action="store_true", default=False)
-
-
-class TranslationDistiller(SummarizationDistiller):
- """Supports T5, mBART, Marian, other models that inherit from Bart."""
-
- mode = "translation"
- metric_names = ["bleu"]
- default_val_metric = "bleu"
-
- def __init__(self, hparams, **kwargs):
- super().__init__(hparams, **kwargs)
- assert hparams.src_lang is not None
- assert hparams.tgt_lang is not None
- self.dataset_kwargs["src_lang"] = hparams.src_lang
- self.dataset_kwargs["tgt_lang"] = hparams.tgt_lang
- if self.model.config.decoder_start_token_id is None and isinstance(self.tokenizer, MBartTokenizer):
- self.decoder_start_token_id = self.tokenizer.lang_code_to_id[hparams.tgt_lang]
-
- def calc_generative_metrics(self, preds, target) -> dict:
- return calculate_bleu(preds, target)
-
- @staticmethod
- def add_model_specific_args(parser, root_dir):
- TranslationModule.add_model_specific_args(parser, root_dir)
- add_distill_args(parser)
- return parser
-
-
-def create_module(args):
- if args.no_teacher:
- module_cls = TranslationModule if "translation" in args.task else SummarizationModule
- else: # DISTILL WITH TEACHER
- module_cls = TranslationDistiller if "translation" in args.task else SummarizationDistiller
- args.setup_cls: str = module_cls.__name__
- print(f"using module {args.setup_cls}")
- model = module_cls(args)
- return model
-
-
-def distill_main(args):
- Path(args.output_dir).mkdir(exist_ok=True)
- check_output_dir(args, expected_items=3)
-
- model = create_module(args)
- return ft_main(args, model=model)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser = pl.Trainer.add_argparse_args(parser)
- parser = SummarizationDistiller.add_model_specific_args(parser, os.getcwd())
- args = parser.parse_args()
-
- distill_main(args)
diff --git a/examples/research_projects/seq2seq-distillation/dynamic_bs_example.sh b/examples/research_projects/seq2seq-distillation/dynamic_bs_example.sh
deleted file mode 100755
index cfe9e21f0f6..00000000000
--- a/examples/research_projects/seq2seq-distillation/dynamic_bs_example.sh
+++ /dev/null
@@ -1,17 +0,0 @@
-#!/usr/bin/env bash
-export PYTHONPATH="../":"${PYTHONPATH}"
-export WANDB_PROJECT=dmar
-export MAX_LEN=128
-export m=sshleifer/student_marian_en_ro_6_1
-python finetune.py \
- --learning_rate=3e-4 \
- --do_train \
- --fp16 \
- --data_dir wmt_en_ro \
- --max_source_length $MAX_LEN --max_target_length $MAX_LEN --val_max_target_length $MAX_LEN --test_max_target_length $MAX_LEN \
- --freeze_encoder --freeze_embeds \
- --train_batch_size=48 --eval_batch_size=64 \
- --tokenizer_name $m --model_name_or_path $m --num_train_epochs=1 \
- --warmup_steps 500 --logger_name wandb --gpus 1 \
- --fp16_opt_level=O1 --task translation \
- "$@"
diff --git a/examples/research_projects/seq2seq-distillation/finetune.py b/examples/research_projects/seq2seq-distillation/finetune.py
deleted file mode 100755
index ff889af81e3..00000000000
--- a/examples/research_projects/seq2seq-distillation/finetune.py
+++ /dev/null
@@ -1,454 +0,0 @@
-#!/usr/bin/env python
-
-import argparse
-import glob
-import logging
-import os
-import sys
-import time
-from collections import defaultdict
-from pathlib import Path
-from typing import Dict, List, Tuple
-
-import numpy as np
-import pytorch_lightning as pl
-import torch
-from callbacks import Seq2SeqLoggingCallback, get_checkpoint_callback, get_early_stopping_callback
-from torch import nn
-from torch.utils.data import DataLoader
-
-from transformers import MBartTokenizer, T5ForConditionalGeneration
-from transformers.models.bart.modeling_bart import shift_tokens_right
-from utils import (
- ROUGE_KEYS,
- LegacySeq2SeqDataset,
- Seq2SeqDataset,
- assert_all_frozen,
- calculate_bleu,
- calculate_rouge,
- check_output_dir,
- flatten_list,
- freeze_embeds,
- freeze_params,
- get_git_info,
- label_smoothed_nll_loss,
- lmap,
- pickle_save,
- save_git_info,
- save_json,
- use_task_specific_params,
-)
-
-
-# need the parent dir module
-sys.path.insert(2, str(Path(__file__).resolve().parents[1]))
-from lightning_base import BaseTransformer, add_generic_args, generic_train # noqa
-
-
-logger = logging.getLogger(__name__)
-
-
-class SummarizationModule(BaseTransformer):
- mode = "summarization"
- loss_names = ["loss"]
- metric_names = ROUGE_KEYS
- default_val_metric = "rouge2"
-
- def __init__(self, hparams, **kwargs):
- if hparams.sortish_sampler and hparams.gpus > 1:
- hparams.replace_sampler_ddp = False
- elif hparams.max_tokens_per_batch is not None:
- if hparams.gpus > 1:
- raise NotImplementedError("Dynamic Batch size does not work for multi-gpu training")
- if hparams.sortish_sampler:
- raise ValueError("--sortish_sampler and --max_tokens_per_batch may not be used simultaneously")
-
- super().__init__(hparams, num_labels=None, mode=self.mode, **kwargs)
- use_task_specific_params(self.model, "summarization")
- save_git_info(self.hparams.output_dir)
- self.metrics_save_path = Path(self.output_dir) / "metrics.json"
- self.hparams_save_path = Path(self.output_dir) / "hparams.pkl"
- pickle_save(self.hparams, self.hparams_save_path)
- self.step_count = 0
- self.metrics = defaultdict(list)
- self.model_type = self.config.model_type
- self.vocab_size = self.config.tgt_vocab_size if self.model_type == "fsmt" else self.config.vocab_size
-
- self.dataset_kwargs: dict = {
- "data_dir": self.hparams.data_dir,
- "max_source_length": self.hparams.max_source_length,
- "prefix": self.model.config.prefix or "",
- }
- n_observations_per_split = {
- "train": self.hparams.n_train,
- "val": self.hparams.n_val,
- "test": self.hparams.n_test,
- }
- self.n_obs = {k: v if v >= 0 else None for k, v in n_observations_per_split.items()}
-
- self.target_lens = {
- "train": self.hparams.max_target_length,
- "val": self.hparams.val_max_target_length,
- "test": self.hparams.test_max_target_length,
- }
- assert self.target_lens["train"] <= self.target_lens["val"], f"target_lens: {self.target_lens}"
- assert self.target_lens["train"] <= self.target_lens["test"], f"target_lens: {self.target_lens}"
- if self.hparams.freeze_embeds:
- freeze_embeds(self.model)
- if self.hparams.freeze_encoder:
- freeze_params(self.model.get_encoder())
- assert_all_frozen(self.model.get_encoder())
-
- self.hparams.git_sha = get_git_info()["repo_sha"]
- self.num_workers = hparams.num_workers
- self.decoder_start_token_id = None # default to config
- if self.model.config.decoder_start_token_id is None and isinstance(self.tokenizer, MBartTokenizer):
- self.decoder_start_token_id = self.tokenizer.lang_code_to_id[hparams.tgt_lang]
- self.model.config.decoder_start_token_id = self.decoder_start_token_id
- self.dataset_class = (
- Seq2SeqDataset if hasattr(self.tokenizer, "prepare_seq2seq_batch") else LegacySeq2SeqDataset
- )
- self.already_saved_batch = False
- self.eval_beams = self.model.config.num_beams if self.hparams.eval_beams is None else self.hparams.eval_beams
- if self.hparams.eval_max_gen_length is not None:
- self.eval_max_length = self.hparams.eval_max_gen_length
- else:
- self.eval_max_length = self.model.config.max_length
- self.val_metric = self.default_val_metric if self.hparams.val_metric is None else self.hparams.val_metric
-
- def save_readable_batch(self, batch: Dict[str, torch.Tensor]) -> Dict[str, List[str]]:
- """A debugging utility"""
- readable_batch = {
- k: self.tokenizer.batch_decode(v.tolist()) if "mask" not in k else v.shape for k, v in batch.items()
- }
- save_json(readable_batch, Path(self.output_dir) / "text_batch.json")
- save_json({k: v.tolist() for k, v in batch.items()}, Path(self.output_dir) / "tok_batch.json")
-
- self.already_saved_batch = True
- return readable_batch
-
- def forward(self, input_ids, **kwargs):
- return self.model(input_ids, **kwargs)
-
- def ids_to_clean_text(self, generated_ids: List[int]):
- gen_text = self.tokenizer.batch_decode(
- generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
- )
- return lmap(str.strip, gen_text)
-
- def _step(self, batch: dict) -> Tuple:
- pad_token_id = self.tokenizer.pad_token_id
- src_ids, src_mask = batch["input_ids"], batch["attention_mask"]
- tgt_ids = batch["labels"]
- if isinstance(self.model, T5ForConditionalGeneration):
- decoder_input_ids = self.model._shift_right(tgt_ids)
- else:
- decoder_input_ids = shift_tokens_right(tgt_ids, pad_token_id)
- if not self.already_saved_batch: # This would be slightly better if it only happened on rank zero
- batch["decoder_input_ids"] = decoder_input_ids
- self.save_readable_batch(batch)
-
- outputs = self(src_ids, attention_mask=src_mask, decoder_input_ids=decoder_input_ids, use_cache=False)
- lm_logits = outputs["logits"]
- if self.hparams.label_smoothing == 0:
- # Same behavior as modeling_bart.py, besides ignoring pad_token_id
- ce_loss_fct = nn.CrossEntropyLoss(ignore_index=pad_token_id)
-
- assert lm_logits.shape[-1] == self.vocab_size
- loss = ce_loss_fct(lm_logits.view(-1, lm_logits.shape[-1]), tgt_ids.view(-1))
- else:
- lprobs = nn.functional.log_softmax(lm_logits, dim=-1)
- loss, nll_loss = label_smoothed_nll_loss(
- lprobs, tgt_ids, self.hparams.label_smoothing, ignore_index=pad_token_id
- )
- return (loss,)
-
- @property
- def pad(self) -> int:
- return self.tokenizer.pad_token_id
-
- def training_step(self, batch, batch_idx) -> Dict:
- loss_tensors = self._step(batch)
-
- logs = dict(zip(self.loss_names, loss_tensors))
- # tokens per batch
- logs["tpb"] = batch["input_ids"].ne(self.pad).sum() + batch["labels"].ne(self.pad).sum()
- logs["bs"] = batch["input_ids"].shape[0]
- logs["src_pad_tok"] = batch["input_ids"].eq(self.pad).sum()
- logs["src_pad_frac"] = batch["input_ids"].eq(self.pad).float().mean()
- # TODO(SS): make a wandb summary metric for this
- return {"loss": loss_tensors[0], "log": logs}
-
- def validation_step(self, batch, batch_idx) -> Dict:
- return self._generative_step(batch)
-
- def validation_epoch_end(self, outputs, prefix="val") -> Dict:
- self.step_count += 1
- losses = {k: torch.stack([x[k] for x in outputs]).mean() for k in self.loss_names}
- loss = losses["loss"]
- generative_metrics = {
- k: np.array([x[k] for x in outputs]).mean() for k in self.metric_names + ["gen_time", "gen_len"]
- }
- metric_val = (
- generative_metrics[self.val_metric] if self.val_metric in generative_metrics else losses[self.val_metric]
- )
- metric_tensor: torch.FloatTensor = torch.tensor(metric_val).type_as(loss)
- generative_metrics.update({k: v.item() for k, v in losses.items()})
- losses.update(generative_metrics)
- all_metrics = {f"{prefix}_avg_{k}": x for k, x in losses.items()}
- all_metrics["step_count"] = self.step_count
- self.metrics[prefix].append(all_metrics) # callback writes this to self.metrics_save_path
- preds = flatten_list([x["preds"] for x in outputs])
- return {
- "log": all_metrics,
- "preds": preds,
- f"{prefix}_loss": loss,
- f"{prefix}_{self.val_metric}": metric_tensor,
- }
-
- def calc_generative_metrics(self, preds, target) -> Dict:
- return calculate_rouge(preds, target)
-
- def _generative_step(self, batch: dict) -> dict:
- t0 = time.time()
-
- # parser.add_argument('--eval_max_gen_length', type=int, default=None, help='never generate more than n tokens')
- generated_ids = self.model.generate(
- batch["input_ids"],
- attention_mask=batch["attention_mask"],
- use_cache=True,
- decoder_start_token_id=self.decoder_start_token_id,
- num_beams=self.eval_beams,
- max_length=self.eval_max_length,
- )
- gen_time = (time.time() - t0) / batch["input_ids"].shape[0]
- preds: List[str] = self.ids_to_clean_text(generated_ids)
- target: List[str] = self.ids_to_clean_text(batch["labels"])
- loss_tensors = self._step(batch)
- base_metrics = dict(zip(self.loss_names, loss_tensors))
- rouge: Dict = self.calc_generative_metrics(preds, target)
- summ_len = np.mean(lmap(len, generated_ids))
- base_metrics.update(gen_time=gen_time, gen_len=summ_len, preds=preds, target=target, **rouge)
- return base_metrics
-
- def test_step(self, batch, batch_idx):
- return self._generative_step(batch)
-
- def test_epoch_end(self, outputs):
- return self.validation_epoch_end(outputs, prefix="test")
-
- def get_dataset(self, type_path) -> Seq2SeqDataset:
- n_obs = self.n_obs[type_path]
- max_target_length = self.target_lens[type_path]
- dataset = self.dataset_class(
- self.tokenizer,
- type_path=type_path,
- n_obs=n_obs,
- max_target_length=max_target_length,
- **self.dataset_kwargs,
- )
- return dataset
-
- def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False) -> DataLoader:
- dataset = self.get_dataset(type_path)
-
- if self.hparams.sortish_sampler and type_path != "test" and type_path != "val":
- sampler = dataset.make_sortish_sampler(batch_size, distributed=self.hparams.gpus > 1)
- return DataLoader(
- dataset,
- batch_size=batch_size,
- collate_fn=dataset.collate_fn,
- shuffle=False,
- num_workers=self.num_workers,
- sampler=sampler,
- )
-
- elif self.hparams.max_tokens_per_batch is not None and type_path != "test" and type_path != "val":
- batch_sampler = dataset.make_dynamic_sampler(
- self.hparams.max_tokens_per_batch, distributed=self.hparams.gpus > 1
- )
- return DataLoader(
- dataset,
- batch_sampler=batch_sampler,
- collate_fn=dataset.collate_fn,
- # shuffle=False,
- num_workers=self.num_workers,
- # batch_size=None,
- )
- else:
- return DataLoader(
- dataset,
- batch_size=batch_size,
- collate_fn=dataset.collate_fn,
- shuffle=shuffle,
- num_workers=self.num_workers,
- sampler=None,
- )
-
- def train_dataloader(self) -> DataLoader:
- dataloader = self.get_dataloader("train", batch_size=self.hparams.train_batch_size, shuffle=True)
- return dataloader
-
- def val_dataloader(self) -> DataLoader:
- return self.get_dataloader("val", batch_size=self.hparams.eval_batch_size)
-
- def test_dataloader(self) -> DataLoader:
- return self.get_dataloader("test", batch_size=self.hparams.eval_batch_size)
-
- @staticmethod
- def add_model_specific_args(parser, root_dir):
- BaseTransformer.add_model_specific_args(parser, root_dir)
- add_generic_args(parser, root_dir)
- parser.add_argument(
- "--max_source_length",
- default=1024,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument(
- "--max_target_length",
- default=56,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument(
- "--val_max_target_length",
- default=142, # these defaults are optimized for CNNDM. For xsum, see README.md.
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument(
- "--test_max_target_length",
- default=142,
- type=int,
- help=(
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- ),
- )
- parser.add_argument("--freeze_encoder", action="store_true")
- parser.add_argument("--freeze_embeds", action="store_true")
- parser.add_argument("--sortish_sampler", action="store_true", default=False)
- parser.add_argument("--overwrite_output_dir", action="store_true", default=False)
- parser.add_argument("--max_tokens_per_batch", type=int, default=None)
- parser.add_argument("--logger_name", type=str, choices=["default", "wandb", "wandb_shared"], default="default")
- parser.add_argument("--n_train", type=int, default=-1, required=False, help="# examples. -1 means use all.")
- parser.add_argument("--n_val", type=int, default=500, required=False, help="# examples. -1 means use all.")
- parser.add_argument("--n_test", type=int, default=-1, required=False, help="# examples. -1 means use all.")
- parser.add_argument(
- "--task", type=str, default="summarization", required=False, help="# examples. -1 means use all."
- )
- parser.add_argument("--label_smoothing", type=float, default=0.0, required=False)
- parser.add_argument("--src_lang", type=str, default="", required=False)
- parser.add_argument("--tgt_lang", type=str, default="", required=False)
- parser.add_argument("--eval_beams", type=int, default=None, required=False)
- parser.add_argument(
- "--val_metric", type=str, default=None, required=False, choices=["bleu", "rouge2", "loss", None]
- )
- parser.add_argument("--eval_max_gen_length", type=int, default=None, help="never generate more than n tokens")
- parser.add_argument("--save_top_k", type=int, default=1, required=False, help="How many checkpoints to save")
- parser.add_argument(
- "--early_stopping_patience",
- type=int,
- default=-1,
- required=False,
- help=(
- "-1 means never early stop. early_stopping_patience is measured in validation checks, not epochs. So"
- " val_check_interval will effect it."
- ),
- )
- return parser
-
-
-class TranslationModule(SummarizationModule):
- mode = "translation"
- loss_names = ["loss"]
- metric_names = ["bleu"]
- default_val_metric = "bleu"
-
- def __init__(self, hparams, **kwargs):
- super().__init__(hparams, **kwargs)
- self.dataset_kwargs["src_lang"] = hparams.src_lang
- self.dataset_kwargs["tgt_lang"] = hparams.tgt_lang
-
- def calc_generative_metrics(self, preds, target) -> dict:
- return calculate_bleu(preds, target)
-
-
-def main(args, model=None) -> SummarizationModule:
- Path(args.output_dir).mkdir(exist_ok=True)
- check_output_dir(args, expected_items=3)
-
- if model is None:
- if "summarization" in args.task:
- model: SummarizationModule = SummarizationModule(args)
- else:
- model: SummarizationModule = TranslationModule(args)
- dataset = Path(args.data_dir).name
- if (
- args.logger_name == "default"
- or args.fast_dev_run
- or str(args.output_dir).startswith("/tmp")
- or str(args.output_dir).startswith("/var")
- ):
- logger = True # don't pollute wandb logs unnecessarily
- elif args.logger_name == "wandb":
- from pytorch_lightning.loggers import WandbLogger
-
- project = os.environ.get("WANDB_PROJECT", dataset)
- logger = WandbLogger(name=model.output_dir.name, project=project)
-
- elif args.logger_name == "wandb_shared":
- from pytorch_lightning.loggers import WandbLogger
-
- logger = WandbLogger(name=model.output_dir.name, project=f"hf_{dataset}")
-
- if args.early_stopping_patience >= 0:
- es_callback = get_early_stopping_callback(model.val_metric, args.early_stopping_patience)
- else:
- es_callback = False
-
- lower_is_better = args.val_metric == "loss"
- trainer: pl.Trainer = generic_train(
- model,
- args,
- logging_callback=Seq2SeqLoggingCallback(),
- checkpoint_callback=get_checkpoint_callback(
- args.output_dir, model.val_metric, args.save_top_k, lower_is_better
- ),
- early_stopping_callback=es_callback,
- logger=logger,
- )
- pickle_save(model.hparams, model.output_dir / "hparams.pkl")
- if not args.do_predict:
- return model
-
- model.hparams.test_checkpoint = ""
- checkpoints = sorted(glob.glob(os.path.join(args.output_dir, "*.ckpt"), recursive=True))
- if checkpoints:
- model.hparams.test_checkpoint = checkpoints[-1]
- trainer.resume_from_checkpoint = checkpoints[-1]
- trainer.logger.log_hyperparams(model.hparams)
-
- # test() without a model tests using the best checkpoint automatically
- trainer.test()
- return model
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser = pl.Trainer.add_argparse_args(parser)
- parser = SummarizationModule.add_model_specific_args(parser, os.getcwd())
-
- args = parser.parse_args()
-
- main(args)
diff --git a/examples/research_projects/seq2seq-distillation/finetune.sh b/examples/research_projects/seq2seq-distillation/finetune.sh
deleted file mode 100755
index 683c2d7752d..00000000000
--- a/examples/research_projects/seq2seq-distillation/finetune.sh
+++ /dev/null
@@ -1,11 +0,0 @@
-# the proper usage is documented in the README, you need to specify data_dir, output_dir and model_name_or_path
-# run ./finetune.sh --help to see all the possible options
-python finetune.py \
- --learning_rate=3e-5 \
- --fp16 \
- --gpus 1 \
- --do_train \
- --do_predict \
- --n_val 1000 \
- --val_check_interval 0.1 \
- "$@"
diff --git a/examples/research_projects/seq2seq-distillation/finetune_bart_tiny.sh b/examples/research_projects/seq2seq-distillation/finetune_bart_tiny.sh
deleted file mode 100755
index f0289b45ab5..00000000000
--- a/examples/research_projects/seq2seq-distillation/finetune_bart_tiny.sh
+++ /dev/null
@@ -1,32 +0,0 @@
-# Script for verifying that run_bart_sum can be invoked from its directory
-
-# Get tiny dataset with cnn_dm format (4 examples for train, val, test)
-wget https://cdn-datasets.huggingface.co/summarization/cnn_tiny.tgz
-tar -xzvf cnn_tiny.tgz
-rm cnn_tiny.tgz
-
-export OUTPUT_DIR_NAME=bart_utest_output
-export CURRENT_DIR=${PWD}
-export OUTPUT_DIR=${CURRENT_DIR}/${OUTPUT_DIR_NAME}
-
-# Make output directory if it doesn't exist
-mkdir -p $OUTPUT_DIR
-
-# Add parent directory to python path to access lightning_base.py and testing_utils.py
-export PYTHONPATH="../":"${PYTHONPATH}"
-python finetune.py \
---data_dir=cnn_tiny/ \
---model_name_or_path=sshleifer/bart-tiny-random \
---learning_rate=3e-5 \
---train_batch_size=2 \
---eval_batch_size=2 \
---output_dir=$OUTPUT_DIR \
---num_train_epochs=1 \
---gpus=0 \
---do_train "$@"
-
-rm -rf cnn_tiny
-rm -rf $OUTPUT_DIR
-
-
-
diff --git a/examples/research_projects/seq2seq-distillation/finetune_pegasus_xsum.sh b/examples/research_projects/seq2seq-distillation/finetune_pegasus_xsum.sh
deleted file mode 100755
index ec7ff98557c..00000000000
--- a/examples/research_projects/seq2seq-distillation/finetune_pegasus_xsum.sh
+++ /dev/null
@@ -1,14 +0,0 @@
-#!/usr/bin/env bash
-export PYTHONPATH="../":"${PYTHONPATH}"
-
-# From appendix C of paper https://arxiv.org/abs/1912.08777
-# Set --gradient_accumulation_steps so that effective batch size is 256 (2*128, 4*64, 8*32, 16*16)
-python finetune.py \
- --learning_rate=1e-4 \
- --do_train \
- --do_predict \
- --n_val 1000 \
- --val_check_interval 0.25 \
- --max_source_length 512 --max_target_length 56 \
- --freeze_embeds --label_smoothing 0.1 --adafactor --task summarization_xsum \
- "$@"
diff --git a/examples/research_projects/seq2seq-distillation/finetune_t5.sh b/examples/research_projects/seq2seq-distillation/finetune_t5.sh
deleted file mode 100755
index 504e9eb71e3..00000000000
--- a/examples/research_projects/seq2seq-distillation/finetune_t5.sh
+++ /dev/null
@@ -1,14 +0,0 @@
-# Add parent directory to python path to access lightning_base.py
-export PYTHONPATH="../":"${PYTHONPATH}"
-
-python finetune.py \
---data_dir=$CNN_DIR \
---learning_rate=3e-5 \
---train_batch_size=$BS \
---eval_batch_size=$BS \
---output_dir=$OUTPUT_DIR \
---max_source_length=512 \
---max_target_length=56 \
---val_check_interval=0.1 --n_val=200 \
---do_train --do_predict \
- "$@"
diff --git a/examples/research_projects/seq2seq-distillation/lightning_base.py b/examples/research_projects/seq2seq-distillation/lightning_base.py
deleted file mode 100644
index 640828bacd3..00000000000
--- a/examples/research_projects/seq2seq-distillation/lightning_base.py
+++ /dev/null
@@ -1,393 +0,0 @@
-import argparse
-import logging
-import os
-from pathlib import Path
-from typing import Any, Dict
-
-import pytorch_lightning as pl
-from pytorch_lightning.utilities import rank_zero_info
-
-from transformers import (
- AdamW,
- AutoConfig,
- AutoModel,
- AutoModelForPreTraining,
- AutoModelForQuestionAnswering,
- AutoModelForSeq2SeqLM,
- AutoModelForSequenceClassification,
- AutoModelForTokenClassification,
- AutoModelWithLMHead,
- AutoTokenizer,
- PretrainedConfig,
- PreTrainedTokenizer,
-)
-from transformers.optimization import (
- Adafactor,
- get_cosine_schedule_with_warmup,
- get_cosine_with_hard_restarts_schedule_with_warmup,
- get_linear_schedule_with_warmup,
- get_polynomial_decay_schedule_with_warmup,
-)
-from transformers.utils.versions import require_version
-
-
-logger = logging.getLogger(__name__)
-
-require_version("pytorch_lightning>=1.0.4")
-
-MODEL_MODES = {
- "base": AutoModel,
- "sequence-classification": AutoModelForSequenceClassification,
- "question-answering": AutoModelForQuestionAnswering,
- "pretraining": AutoModelForPreTraining,
- "token-classification": AutoModelForTokenClassification,
- "language-modeling": AutoModelWithLMHead,
- "summarization": AutoModelForSeq2SeqLM,
- "translation": AutoModelForSeq2SeqLM,
-}
-
-
-# update this and the import above to support new schedulers from transformers.optimization
-arg_to_scheduler = {
- "linear": get_linear_schedule_with_warmup,
- "cosine": get_cosine_schedule_with_warmup,
- "cosine_w_restarts": get_cosine_with_hard_restarts_schedule_with_warmup,
- "polynomial": get_polynomial_decay_schedule_with_warmup,
- # '': get_constant_schedule, # not supported for now
- # '': get_constant_schedule_with_warmup, # not supported for now
-}
-arg_to_scheduler_choices = sorted(arg_to_scheduler.keys())
-arg_to_scheduler_metavar = "{" + ", ".join(arg_to_scheduler_choices) + "}"
-
-
-class BaseTransformer(pl.LightningModule):
- def __init__(
- self,
- hparams: argparse.Namespace,
- num_labels=None,
- mode="base",
- config=None,
- tokenizer=None,
- model=None,
- **config_kwargs,
- ):
- """Initialize a model, tokenizer and config."""
- super().__init__()
- # TODO: move to self.save_hyperparameters()
- # self.save_hyperparameters()
- # can also expand arguments into trainer signature for easier reading
-
- self.save_hyperparameters(hparams)
- self.step_count = 0
- self.output_dir = Path(self.hparams.output_dir)
- cache_dir = self.hparams.cache_dir if self.hparams.cache_dir else None
- if config is None:
- self.config = AutoConfig.from_pretrained(
- self.hparams.config_name if self.hparams.config_name else self.hparams.model_name_or_path,
- **({"num_labels": num_labels} if num_labels is not None else {}),
- cache_dir=cache_dir,
- **config_kwargs,
- )
- else:
- self.config: PretrainedConfig = config
-
- extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "dropout", "attention_dropout")
- for p in extra_model_params:
- if getattr(self.hparams, p, None):
- assert hasattr(self.config, p), f"model config doesn't have a `{p}` attribute"
- setattr(self.config, p, getattr(self.hparams, p))
-
- if tokenizer is None:
- self.tokenizer = AutoTokenizer.from_pretrained(
- self.hparams.tokenizer_name if self.hparams.tokenizer_name else self.hparams.model_name_or_path,
- cache_dir=cache_dir,
- )
- else:
- self.tokenizer: PreTrainedTokenizer = tokenizer
- self.model_type = MODEL_MODES[mode]
- if model is None:
- self.model = self.model_type.from_pretrained(
- self.hparams.model_name_or_path,
- from_tf=bool(".ckpt" in self.hparams.model_name_or_path),
- config=self.config,
- cache_dir=cache_dir,
- )
- else:
- self.model = model
-
- def load_hf_checkpoint(self, *args, **kwargs):
- self.model = self.model_type.from_pretrained(*args, **kwargs)
-
- def get_lr_scheduler(self):
- get_schedule_func = arg_to_scheduler[self.hparams.lr_scheduler]
- scheduler = get_schedule_func(
- self.opt, num_warmup_steps=self.hparams.warmup_steps, num_training_steps=self.total_steps()
- )
- scheduler = {"scheduler": scheduler, "interval": "step", "frequency": 1}
- return scheduler
-
- def configure_optimizers(self):
- """Prepare optimizer and schedule (linear warmup and decay)"""
- model = self.model
- no_decay = ["bias", "LayerNorm.weight"]
- optimizer_grouped_parameters = [
- {
- "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
- "weight_decay": self.hparams.weight_decay,
- },
- {
- "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
- "weight_decay": 0.0,
- },
- ]
- if self.hparams.adafactor:
- optimizer = Adafactor(
- optimizer_grouped_parameters, lr=self.hparams.learning_rate, scale_parameter=False, relative_step=False
- )
-
- else:
- optimizer = AdamW(
- optimizer_grouped_parameters, lr=self.hparams.learning_rate, eps=self.hparams.adam_epsilon
- )
- self.opt = optimizer
-
- scheduler = self.get_lr_scheduler()
-
- return [optimizer], [scheduler]
-
- def test_step(self, batch, batch_nb):
- return self.validation_step(batch, batch_nb)
-
- def test_epoch_end(self, outputs):
- return self.validation_end(outputs)
-
- def total_steps(self) -> int:
- """The number of total training steps that will be run. Used for lr scheduler purposes."""
- num_devices = max(1, self.hparams.gpus) # TODO: consider num_tpu_cores
- effective_batch_size = self.hparams.train_batch_size * self.hparams.accumulate_grad_batches * num_devices
- return (self.dataset_size / effective_batch_size) * self.hparams.max_epochs
-
- def setup(self, mode):
- if mode == "test":
- self.dataset_size = len(self.test_dataloader().dataset)
- else:
- self.train_loader = self.get_dataloader("train", self.hparams.train_batch_size, shuffle=True)
- self.dataset_size = len(self.train_dataloader().dataset)
-
- def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False):
- raise NotImplementedError("You must implement this for your task")
-
- def train_dataloader(self):
- return self.train_loader
-
- def val_dataloader(self):
- return self.get_dataloader("dev", self.hparams.eval_batch_size, shuffle=False)
-
- def test_dataloader(self):
- return self.get_dataloader("test", self.hparams.eval_batch_size, shuffle=False)
-
- def _feature_file(self, mode):
- return os.path.join(
- self.hparams.data_dir,
- "cached_{}_{}_{}".format(
- mode,
- list(filter(None, self.hparams.model_name_or_path.split("/"))).pop(),
- str(self.hparams.max_seq_length),
- ),
- )
-
- @pl.utilities.rank_zero_only
- def on_save_checkpoint(self, checkpoint: Dict[str, Any]) -> None:
- save_path = self.output_dir.joinpath("best_tfmr")
- self.model.config.save_step = self.step_count
- self.model.save_pretrained(save_path)
- self.tokenizer.save_pretrained(save_path)
-
- @staticmethod
- def add_model_specific_args(parser, root_dir):
- parser.add_argument(
- "--model_name_or_path",
- default=None,
- type=str,
- required=True,
- help="Path to pretrained model or model identifier from huggingface.co/models",
- )
- parser.add_argument(
- "--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
- )
- parser.add_argument(
- "--tokenizer_name",
- default=None,
- type=str,
- help="Pretrained tokenizer name or path if not the same as model_name",
- )
- parser.add_argument(
- "--cache_dir",
- default="",
- type=str,
- help="Where do you want to store the pre-trained models downloaded from huggingface.co",
- )
- parser.add_argument(
- "--encoder_layerdrop",
- type=float,
- help="Encoder layer dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument(
- "--decoder_layerdrop",
- type=float,
- help="Decoder layer dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument(
- "--dropout",
- type=float,
- help="Dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument(
- "--attention_dropout",
- type=float,
- help="Attention dropout probability (Optional). Goes into model.config",
- )
- parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
- parser.add_argument(
- "--lr_scheduler",
- default="linear",
- choices=arg_to_scheduler_choices,
- metavar=arg_to_scheduler_metavar,
- type=str,
- help="Learning rate scheduler",
- )
- parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
- parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
- parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
- parser.add_argument("--num_workers", default=4, type=int, help="kwarg passed to DataLoader")
- parser.add_argument("--num_train_epochs", dest="max_epochs", default=3, type=int)
- parser.add_argument("--train_batch_size", default=32, type=int)
- parser.add_argument("--eval_batch_size", default=32, type=int)
- parser.add_argument("--adafactor", action="store_true")
-
-
-class LoggingCallback(pl.Callback):
- def on_batch_end(self, trainer, pl_module):
- lr_scheduler = trainer.lr_schedulers[0]["scheduler"]
- lrs = {f"lr_group_{i}": lr for i, lr in enumerate(lr_scheduler.get_lr())}
- pl_module.logger.log_metrics(lrs)
-
- def on_validation_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
- rank_zero_info("***** Validation results *****")
- metrics = trainer.callback_metrics
- # Log results
- for key in sorted(metrics):
- if key not in ["log", "progress_bar"]:
- rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
-
- def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
- rank_zero_info("***** Test results *****")
- metrics = trainer.callback_metrics
- # Log and save results to file
- output_test_results_file = os.path.join(pl_module.hparams.output_dir, "test_results.txt")
- with open(output_test_results_file, "w") as writer:
- for key in sorted(metrics):
- if key not in ["log", "progress_bar"]:
- rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
- writer.write("{} = {}\n".format(key, str(metrics[key])))
-
-
-def add_generic_args(parser, root_dir) -> None:
- # To allow all pl args uncomment the following line
- # parser = pl.Trainer.add_argparse_args(parser)
- parser.add_argument(
- "--output_dir",
- default=None,
- type=str,
- required=True,
- help="The output directory where the model predictions and checkpoints will be written.",
- )
- parser.add_argument(
- "--fp16",
- action="store_true",
- help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
- )
-
- parser.add_argument(
- "--fp16_opt_level",
- type=str,
- default="O2",
- help=(
- "For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
- "See details at https://nvidia.github.io/apex/amp.html"
- ),
- )
- parser.add_argument("--n_tpu_cores", dest="tpu_cores", type=int)
- parser.add_argument("--max_grad_norm", dest="gradient_clip_val", default=1.0, type=float, help="Max gradient norm")
- parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
- parser.add_argument("--do_predict", action="store_true", help="Whether to run predictions on the test set.")
- parser.add_argument(
- "--gradient_accumulation_steps",
- dest="accumulate_grad_batches",
- type=int,
- default=1,
- help="Number of updates steps to accumulate before performing a backward/update pass.",
- )
- parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
- parser.add_argument(
- "--data_dir",
- default=None,
- type=str,
- required=True,
- help="The input data dir. Should contain the training files for the CoNLL-2003 NER task.",
- )
-
-
-def generic_train(
- model: BaseTransformer,
- args: argparse.Namespace,
- early_stopping_callback=None,
- logger=True, # can pass WandbLogger() here
- extra_callbacks=[],
- checkpoint_callback=None,
- logging_callback=None,
- **extra_train_kwargs,
-):
- pl.seed_everything(args.seed)
-
- # init model
- odir = Path(model.hparams.output_dir)
- odir.mkdir(exist_ok=True)
-
- # add custom checkpoints
- if checkpoint_callback is None:
- checkpoint_callback = pl.callbacks.ModelCheckpoint(
- filepath=args.output_dir, prefix="checkpoint", monitor="val_loss", mode="min", save_top_k=1
- )
- if early_stopping_callback:
- extra_callbacks.append(early_stopping_callback)
- if logging_callback is None:
- logging_callback = LoggingCallback()
-
- train_params = {}
-
- # TODO: remove with PyTorch 1.6 since pl uses native amp
- if args.fp16:
- train_params["precision"] = 16
- train_params["amp_level"] = args.fp16_opt_level
-
- if args.gpus > 1:
- train_params["distributed_backend"] = "ddp"
-
- train_params["accumulate_grad_batches"] = args.accumulate_grad_batches
- train_params["accelerator"] = extra_train_kwargs.get("accelerator", None)
- train_params["profiler"] = extra_train_kwargs.get("profiler", None)
-
- trainer = pl.Trainer.from_argparse_args(
- args,
- weights_summary=None,
- callbacks=[logging_callback] + extra_callbacks,
- logger=logger,
- checkpoint_callback=checkpoint_callback,
- **train_params,
- )
-
- if args.do_train:
- trainer.fit(model)
-
- return trainer
diff --git a/examples/research_projects/seq2seq-distillation/make_student.py b/examples/research_projects/seq2seq-distillation/make_student.py
deleted file mode 100644
index 83e014bf481..00000000000
--- a/examples/research_projects/seq2seq-distillation/make_student.py
+++ /dev/null
@@ -1,186 +0,0 @@
-import warnings
-from pathlib import Path
-from typing import List, Tuple, Union
-
-import fire
-from torch import nn
-
-from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, PreTrainedModel
-from transformers.utils import logging
-
-
-logger = logging.get_logger(__name__)
-
-
-def copy_layers(src_layers: nn.ModuleList, dest_layers: nn.ModuleList, layers_to_copy: List[int]) -> None:
- layers_to_copy = nn.ModuleList([src_layers[i] for i in layers_to_copy])
- assert len(dest_layers) == len(layers_to_copy), f"{len(dest_layers)} != {len(layers_to_copy)}"
- dest_layers.load_state_dict(layers_to_copy.state_dict())
-
-
-LAYERS_TO_COPY = {
- # maps num layers in teacher -> num_layers in student -> which teacher layers to copy.
- # 12: bart, 16: pegasus, 6: marian/Helsinki-NLP
- 12: {
- 1: [0], # This says that if the teacher has 12 layers and the student has 1, copy layer 0 of the teacher
- 2: [0, 6],
- 3: [0, 6, 11],
- 4: [0, 4, 8, 11],
- 6: [0, 2, 4, 7, 9, 11],
- 9: [0, 1, 2, 4, 5, 7, 9, 10, 11],
- 12: list(range(12)),
- },
- 16: { # maps num layers in student -> which teacher layers to copy
- 1: [0],
- 2: [0, 15],
- 3: [0, 8, 15],
- 4: [0, 5, 10, 15],
- 6: [0, 3, 6, 9, 12, 15],
- 8: [0, 2, 4, 6, 8, 10, 12, 15],
- 9: [0, 1, 3, 5, 7, 9, 11, 13, 15],
- 12: [0, 1, 2, 3, 4, 5, 6, 7, 9, 11, 13, 15],
- 16: list(range(16)),
- },
- 6: {1: [0], 2: [0, 5], 3: [0, 2, 5], 4: [0, 1, 3, 5], 6: list(range(6))},
-}
-LAYERS_TO_SUPERVISE = {
- # maps num layers in student -> which teacher layers to copy.
- 6: {1: [5], 2: [3, 5], 3: [1, 4, 5], 4: [1, 2, 4, 5]},
- 12: {1: [11], 2: [5, 11], 3: [3, 7, 11], 6: [1, 3, 5, 8, 10, 11]},
- 16: {1: [15], 4: [4, 9, 12, 15], 8: [1, 3, 5, 7, 9, 11, 13, 15]},
-}
-
-
-def pick_layers_to_copy(n_student, n_teacher):
- try:
- val = LAYERS_TO_COPY[n_teacher][n_student]
- return val
- except KeyError:
- if n_student != n_teacher:
- warnings.warn(
- f"no hardcoded layers to copy for teacher {n_teacher} -> student {n_student}, defaulting to first"
- f" {n_student}"
- )
- return list(range(n_student))
-
-
-def get_layers_to_supervise(n_student, n_teacher) -> List[int]:
- """Used or the --supervise_forward kwarg"""
- if n_student > n_teacher:
- raise ValueError(f"Cannot perform intermediate supervision for student {n_student} > teacher {n_teacher}")
- elif n_teacher == n_student:
- return list(range(n_teacher))
- elif n_student == 1:
- return [n_teacher - 1]
- else:
- return LAYERS_TO_SUPERVISE[n_teacher][n_student]
-
-
-def create_student_by_copying_alternating_layers(
- teacher: Union[str, PreTrainedModel],
- save_path: Union[str, Path] = "student",
- e: Union[int, None] = None,
- d: Union[int, None] = None,
- copy_first_teacher_layers=False,
- e_layers_to_copy=None,
- d_layers_to_copy=None,
- **extra_config_kwargs,
-) -> Tuple[PreTrainedModel, List[int], List[int]]:
- """Make a student by copying alternating layers from a teacher, save it to save_path.
- Args:
- teacher: str or PreTrainedModel if str, this will call AutoModelForSeq2SeqLM.from_pretrained(teacher) before
- copying layers
- save_path: where to save the student, defaults to student directory.
- e: how many Encoder layers should the student have, default is fully copy of teacher
- d: how many Decoder layers should the student have, default is fully copy of teacher
- copy_first_teacher_layers: [bool] dont copy alternating layers, just the first e/d.
- **extra_config_kwargs: extra kwargs to pass to the student, by default the teacher config is used.
-
- Returns:
- student: new, smaller model. (Also saves it to save_path)
- e_layers_to_copy: list of which teacher encoder layers were used
- d_layers_to_copy: list of which teacher decoder layers were used
- """
- _msg = "encoder_layers and decoder_layers cannot be both None-- you would just have an identical teacher."
- assert (e is not None) or (d is not None), _msg
- if isinstance(teacher, str):
- AutoTokenizer.from_pretrained(teacher).save_pretrained(save_path) # purely for convenience
- teacher = AutoModelForSeq2SeqLM.from_pretrained(teacher).eval()
- else:
- assert isinstance(teacher, PreTrainedModel), f"teacher must be a model or string got type {type(teacher)}"
- init_kwargs = teacher.config.to_diff_dict()
-
- try:
- teacher_e, teacher_d = teacher.config.encoder_layers, teacher.config.decoder_layers
- if e is None:
- e = teacher_e
- if d is None:
- d = teacher_d
- init_kwargs.update({"encoder_layers": e, "decoder_layers": d})
- except AttributeError: # T5
- if hasattr(teacher.config, "num_encoder_layers"):
- teacher_e, teacher_d = teacher.config.num_encoder_layers, teacher.config.num_decoder_layers
- else:
- teacher_e, teacher_d = teacher.config.num_layers, teacher.config.num_decoder_layers
- if e is None:
- e = teacher_e
- if d is None:
- d = teacher_d
- if hasattr(teacher.config, "num_encoder_layers"):
- init_kwargs.update({"num_encoder_layers": e, "num_decoder_layers": d})
- else:
- init_kwargs.update({"num_layers": e, "num_decoder_layers": d})
-
- # Kwargs to instantiate student: teacher kwargs with updated layer numbers + **extra_config_kwargs
- init_kwargs.update(extra_config_kwargs)
-
- # Copy weights
- student_cfg = teacher.config_class(**init_kwargs)
- student = AutoModelForSeq2SeqLM.from_config(student_cfg)
- # Start by copying the full teacher state dict this will copy the first N teacher layers to the student.
- info = student.load_state_dict(teacher.state_dict(), strict=False)
- assert info.missing_keys == [], info.missing_keys # every student key should have a teacher keys.
-
- if copy_first_teacher_layers: # Our copying is done. We just log and save
- e_layers_to_copy, d_layers_to_copy = list(range(e)), list(range(d))
- logger.info(
- f"Copied encoder layers {e_layers_to_copy} and decoder layers {d_layers_to_copy}. Saving them to"
- f" {save_path}"
- )
- student.save_pretrained(save_path)
- return student, e_layers_to_copy, d_layers_to_copy
-
- # Decide which layers of the teacher to copy. Not exactly alternating -- we try to keep first and last layer.
- if e_layers_to_copy is None:
- e_layers_to_copy: List[int] = pick_layers_to_copy(e, teacher_e)
- if d_layers_to_copy is None:
- d_layers_to_copy: List[int] = pick_layers_to_copy(d, teacher_d)
-
- try:
- if hasattr(
- teacher, "prophetnet"
- ): # For ProphetNet, student.model.encoder.layers is called student.prophetnet.encoder.layers
- copy_layers(teacher.prophetnet.encoder.layers, student.prophetnet.encoder.layers, e_layers_to_copy)
- copy_layers(teacher.prophetnet.decoder.layers, student.prophetnet.decoder.layers, d_layers_to_copy)
- else:
- copy_layers(teacher.model.encoder.layers, student.model.encoder.layers, e_layers_to_copy)
- copy_layers(teacher.model.decoder.layers, student.model.decoder.layers, d_layers_to_copy)
- except AttributeError: # For t5, student.model.encoder.layers is called student.encoder.block
- copy_layers(teacher.encoder.block, student.encoder.block, e_layers_to_copy)
- copy_layers(teacher.decoder.block, student.decoder.block, d_layers_to_copy)
- logger.info(
- f"Copied encoder layers {e_layers_to_copy} and decoder layers {d_layers_to_copy}. Saving them to {save_path}"
- )
- student.config.init_metadata = {
- "teacher_type": teacher.config.model_type,
- "copied_encoder_layers": e_layers_to_copy,
- "copied_decoder_layers": d_layers_to_copy,
- }
- student.save_pretrained(save_path)
- # Save information about copying for easier reproducibility
-
- return student, e_layers_to_copy, d_layers_to_copy
-
-
-if __name__ == "__main__":
- fire.Fire(create_student_by_copying_alternating_layers)
diff --git a/examples/research_projects/seq2seq-distillation/precomputed_pseudo_labels.md b/examples/research_projects/seq2seq-distillation/precomputed_pseudo_labels.md
deleted file mode 100644
index fb2713ccde8..00000000000
--- a/examples/research_projects/seq2seq-distillation/precomputed_pseudo_labels.md
+++ /dev/null
@@ -1,43 +0,0 @@
-### Saved Pseudo-Labels
-These are the generations of various large models on various large **training** sets. All in all they took about 200 GPU hours to produce.
-
-### Available Pseudo-labels
-| Dataset | Model | Link | Rouge Scores | Notes
-|---------|-----------------------------|----------------------------------------------------------------------------------------|--------------------|-------------------------------------------------------------------------------------------------------------
-| XSUM | `facebook/bart-large-xsum` | [download](https://cdn-datasets.huggingface.co/pseudo/xsum/bart_xsum_pl.tgz) | 49.8/28.0/42.5 |
-| XSUM | `google/pegasus-xsum` | [download](https://cdn-datasets.huggingface.co/pseudo/xsum/pegasus_xsum.tgz) | 53.3/32.7/46.5 |
-| XSUM | `facebook/bart-large-xsum` | [download](https://cdn-datasets.huggingface.co/pseudo/xsum/xsum_pl2_bart.tgz) | | Bart pseudolabels filtered to those with Rouge2 > 10.0 w GT.
-| CNN/DM | `sshleifer/pegasus-cnn-ft-v2` | [download](https://cdn-datasets.huggingface.co/pseudo/cnn_dm/pegasus_cnn_cnn_pls.tgz) | 47.316/26.65/44.56 | do not worry about the fact that train.source is one line shorter.
-| CNN/DM | `facebook/bart-large-cnn` | [download](https://cdn-datasets.huggingface.co/pseudo/cnn_dm/cnn_bart_pl.tgz) | | 5K (2%) are missing, there should be 282173
-| CNN/DM | `google/pegasus-xsum` | [download](https://cdn-datasets.huggingface.co/pseudo/cnn_dm/pegasus_xsum_on_cnn.tgz) | 21.5/6.76/25 | extra labels for xsum distillation Used max_source_length=512, (and all other pegasus-xsum configuration).
-| EN-RO | `Helsinki-NLP/opus-mt-en-ro` | [download](https://cdn-datasets.huggingface.co/pseudo/wmt_en_ro/opus_mt_en_ro.tgz) | |
-| EN-RO | `facebook/mbart-large-en-ro` | [download](https://cdn-datasets.huggingface.co/pseudo/wmt_en_ro/mbart_large_en_ro.tgz) | |
-
-
-(EN_RO = WMT 2016 English-Romanian).
-
-Example Download Command:
-```bash
-curl -S https://cdn-datasets.huggingface.co/pseudo/xsum/bart_xsum_pl.tgz | tar -xvz -C .
-```
-### Generating New Pseudolabels
-Here is the command I used to generate the pseudolabels in the second row of the table, after downloading XSUM from [here](https://cdn-datasets.huggingface.co/summarization/xsum.tar.gz).
-
-```bash
-python -m torch.distributed.launch --nproc_per_node=8 run_distributed_eval.py \
- --model_name google/pegasus-xsum \
- --save_dir pegasus_xsum \
- --data_dir xsum \
- --bs 8 --sync_timeout 60000 \
- --max_source_length 512 \
- --type_path train
-```
-
-+ These commands takes a while to run. For example, `pegasus_cnn_cnn_pls.tgz` took 8 hours on 8 GPUs.
-+ Pegasus does not work in fp16 :(, Bart, mBART and Marian do.
-+ Even if you have 1 GPU, `run_distributed_eval.py` is 10-20% faster than `run_eval.py` because it uses `SortishSampler` to minimize padding computation.
-
-### Contributions
-Feel free to contribute your own pseudolabels via PR. Add a row to this table with a new google drive link (or other command line downloadable link).
-
-
diff --git a/examples/research_projects/seq2seq-distillation/requirements.txt b/examples/research_projects/seq2seq-distillation/requirements.txt
deleted file mode 100644
index 533f6339ab0..00000000000
--- a/examples/research_projects/seq2seq-distillation/requirements.txt
+++ /dev/null
@@ -1,20 +0,0 @@
-tensorboard
-scikit-learn
-psutil
-sacrebleu
-rouge-score
-tensorflow_datasets
-pytorch-lightning
-matplotlib
-git-python==1.0.3
-faiss-cpu
-streamlit
-elasticsearch
-nltk
-pandas
-datasets >= 1.1.3
-fire
-pytest
-conllu
-sentencepiece != 0.1.92
-protobuf
diff --git a/examples/research_projects/seq2seq-distillation/run_eval.py b/examples/research_projects/seq2seq-distillation/run_eval.py
deleted file mode 100755
index 54ad6c6fb6b..00000000000
--- a/examples/research_projects/seq2seq-distillation/run_eval.py
+++ /dev/null
@@ -1,167 +0,0 @@
-#!/usr/bin/env python
-
-import argparse
-import datetime
-import json
-import time
-import warnings
-from logging import getLogger
-from pathlib import Path
-from typing import Dict, List
-
-import torch
-from tqdm import tqdm
-
-from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
-from utils import calculate_bleu, calculate_rouge, chunks, parse_numeric_n_bool_cl_kwargs, use_task_specific_params
-
-
-logger = getLogger(__name__)
-
-
-DEFAULT_DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
-
-
-def generate_summaries_or_translations(
- examples: List[str],
- out_file: str,
- model_name: str,
- batch_size: int = 8,
- device: str = DEFAULT_DEVICE,
- fp16=False,
- task="summarization",
- prefix=None,
- **generate_kwargs,
-) -> Dict:
- """Save model.generate results to , and return how long it took."""
- fout = Path(out_file).open("w", encoding="utf-8")
- model_name = str(model_name)
- model = AutoModelForSeq2SeqLM.from_pretrained(model_name).to(device)
- if fp16:
- model = model.half()
-
- tokenizer = AutoTokenizer.from_pretrained(model_name)
- logger.info(f"Inferred tokenizer type: {tokenizer.__class__}") # if this is wrong, check config.model_type.
-
- start_time = time.time()
- # update config with task specific params
- use_task_specific_params(model, task)
- if prefix is None:
- prefix = prefix or getattr(model.config, "prefix", "") or ""
- for examples_chunk in tqdm(list(chunks(examples, batch_size))):
- examples_chunk = [prefix + text for text in examples_chunk]
- batch = tokenizer(examples_chunk, return_tensors="pt", truncation=True, padding="longest").to(device)
- summaries = model.generate(
- input_ids=batch.input_ids,
- attention_mask=batch.attention_mask,
- **generate_kwargs,
- )
- dec = tokenizer.batch_decode(summaries, skip_special_tokens=True, clean_up_tokenization_spaces=False)
- for hypothesis in dec:
- fout.write(hypothesis + "\n")
- fout.flush()
- fout.close()
- runtime = int(time.time() - start_time) # seconds
- n_obs = len(examples)
- return {"n_obs": n_obs, "runtime": runtime, "seconds_per_sample": round(runtime / n_obs, 4)}
-
-
-def datetime_now():
- return datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
-
-
-def run_generate(verbose=True):
- """
-
- Takes input text, generates output, and then using reference calculates the BLEU scores.
-
- The results are saved to a file and returned to the caller, and printed out unless ``verbose=False`` is passed.
-
- Args:
- verbose (:obj:`bool`, `optional`, defaults to :obj:`True`): print results to stdout
-
- Returns:
- a tuple: ``(scores, params}``
- - ``scores``: a dict of scores data ``{'bleu': 39.6501, 'n_obs': 2000, 'runtime': 186, 'seconds_per_sample': 0.093}``
- - ``params``: a dict of custom params, e.g. ``{'num_beams': 5, 'length_penalty': 0.8}``
- """
-
- parser = argparse.ArgumentParser()
- parser.add_argument("model_name", type=str, help="like facebook/bart-large-cnn,t5-base, etc.")
- parser.add_argument("input_path", type=str, help="like cnn_dm/test.source")
- parser.add_argument("save_path", type=str, help="where to save summaries")
- parser.add_argument("--reference_path", type=str, required=False, help="like cnn_dm/test.target")
- parser.add_argument("--score_path", type=str, required=False, default="metrics.json", help="where to save metrics")
- parser.add_argument("--device", type=str, required=False, default=DEFAULT_DEVICE, help="cuda, cuda:1, cpu etc.")
- parser.add_argument(
- "--prefix", type=str, required=False, default=None, help="will be added to the beginning of src examples"
- )
- parser.add_argument("--task", type=str, default="summarization", help="used for task_specific_params + metrics")
- parser.add_argument("--bs", type=int, default=8, required=False, help="batch size")
- parser.add_argument(
- "--n_obs", type=int, default=-1, required=False, help="How many observations. Defaults to all."
- )
- parser.add_argument("--fp16", action="store_true")
- parser.add_argument("--dump-args", action="store_true", help="print the custom hparams with the results")
- parser.add_argument(
- "--info",
- nargs="?",
- type=str,
- const=datetime_now(),
- help=(
- "use in conjunction w/ --dump-args to print with the results whatever other info you'd like, e.g."
- " lang=en-ru. If no value is passed, the current datetime string will be used."
- ),
- )
- # Unspecified args like --num_beams=2 --decoder_start_token_id=4 are passed to model.generate
- args, rest = parser.parse_known_args()
- parsed_args = parse_numeric_n_bool_cl_kwargs(rest)
- if parsed_args and verbose:
- print(f"parsed the following generate kwargs: {parsed_args}")
- with open(args.input_path) as f:
- examples = [" " + x.rstrip() if "t5" in args.model_name else x.rstrip() for x in f.readlines()]
- if args.n_obs > 0:
- examples = examples[: args.n_obs]
- Path(args.save_path).parent.mkdir(exist_ok=True)
- if args.reference_path is None and Path(args.score_path).exists():
- warnings.warn(f"score_path {args.score_path} will be overwritten unless you type ctrl-c.")
- runtime_metrics = generate_summaries_or_translations(
- examples,
- args.save_path,
- args.model_name,
- batch_size=args.bs,
- device=args.device,
- fp16=args.fp16,
- task=args.task,
- prefix=args.prefix,
- **parsed_args,
- )
-
- if args.reference_path is None:
- return {}
-
- # Compute scores
- score_fn = calculate_bleu if "translation" in args.task else calculate_rouge
- output_lns = [x.rstrip() for x in open(args.save_path).readlines()]
- reference_lns = [x.rstrip() for x in open(args.reference_path).readlines()][: len(output_lns)]
- scores: dict = score_fn(output_lns, reference_lns)
- scores.update(runtime_metrics)
-
- if args.dump_args:
- scores.update(parsed_args)
- if args.info:
- scores["info"] = args.info
-
- if verbose:
- print(scores)
-
- if args.score_path is not None:
- json.dump(scores, open(args.score_path, "w"))
-
- return scores
-
-
-if __name__ == "__main__":
- # Usage for MT:
- # python run_eval.py MODEL_NAME $DATA_DIR/test.source $save_dir/test_translations.txt --reference_path $DATA_DIR/test.target --score_path $save_dir/test_bleu.json --task translation $@
- run_generate(verbose=True)
diff --git a/examples/research_projects/seq2seq-distillation/sentence_splitter.py b/examples/research_projects/seq2seq-distillation/sentence_splitter.py
deleted file mode 100644
index c5acec73928..00000000000
--- a/examples/research_projects/seq2seq-distillation/sentence_splitter.py
+++ /dev/null
@@ -1,22 +0,0 @@
-import re
-
-from filelock import FileLock
-
-
-try:
- import nltk
-
- NLTK_AVAILABLE = True
-except (ImportError, ModuleNotFoundError):
- NLTK_AVAILABLE = False
-
-if NLTK_AVAILABLE:
- with FileLock(".lock") as lock:
- nltk.download("punkt", quiet=True)
-
-
-def add_newline_to_end_of_each_sentence(x: str) -> str:
- """This was added to get rougeLsum scores matching published rougeL scores for BART and PEGASUS."""
- re.sub("", "", x) # remove pegasus newline char
- assert NLTK_AVAILABLE, "nltk must be installed to separate newlines between sentences. (pip install nltk)"
- return "\n".join(nltk.sent_tokenize(x))
diff --git a/examples/research_projects/seq2seq-distillation/train_distilbart_cnn.sh b/examples/research_projects/seq2seq-distillation/train_distilbart_cnn.sh
deleted file mode 100755
index 6a1bafbdc9c..00000000000
--- a/examples/research_projects/seq2seq-distillation/train_distilbart_cnn.sh
+++ /dev/null
@@ -1,24 +0,0 @@
-#!/usr/bin/env bash
-export PYTHONPATH="../":"${PYTHONPATH}"
-
-export BS=32
-export GAS=1
-
-python finetune.py \
- --learning_rate=3e-5 \
- --fp16 \
- --gpus 1 \
- --do_train \
- --do_predict \
- --val_check_interval 0.25 \
- --n_val 500 \
- --num_train_epochs 2 \
- --freeze_encoder --freeze_embeds --data_dir cnn_dm \
- --max_target_length 142 --val_max_target_length=142 \
- --train_batch_size=$BS --eval_batch_size=$BS --gradient_accumulation_steps=$GAS \
- --model_name_or_path sshleifer/student_cnn_12_6 \
- --tokenizer_name facebook/bart-large \
- --warmup_steps 500 \
- --output_dir distilbart-cnn-12-6 \
- "$@"
-
diff --git a/examples/research_projects/seq2seq-distillation/train_distilbart_xsum.sh b/examples/research_projects/seq2seq-distillation/train_distilbart_xsum.sh
deleted file mode 100755
index 86a3440fc0c..00000000000
--- a/examples/research_projects/seq2seq-distillation/train_distilbart_xsum.sh
+++ /dev/null
@@ -1,21 +0,0 @@
-#!/usr/bin/env bash
-export PYTHONPATH="../":"${PYTHONPATH}"
-python distillation.py \
- --teacher facebook/bart-large-xsum --data_dir xsum \
- --tokenizer_name facebook/bart-large-xsum \
- --student_decoder_layers 6 --student_encoder_layers 12 \
- --freeze_encoder --freeze_embeds \
- --learning_rate=3e-4 \
- --do_train \
- --do_predict \
- --fp16 --fp16_opt_level=O1 \
- --val_check_interval 0.1 --n_val 1000 --eval_beams 2 --length_penalty=0.5 \
- --max_target_length=60 --val_max_target_length=60 --test_max_target_length=100 \
- --model_name_or_path IGNORED \
- --alpha_hid=3. \
- --train_batch_size=16 --eval_batch_size=16 --gradient_accumulation_steps=2 \
- --sortish_sampler \
- --num_train_epochs=6 \
- --warmup_steps 500 \
- --output_dir distilbart_xsum_12_6 \
- "$@"
diff --git a/examples/research_projects/seq2seq-distillation/train_mbart_cc25_enro.sh b/examples/research_projects/seq2seq-distillation/train_mbart_cc25_enro.sh
deleted file mode 100755
index 54e7935ff60..00000000000
--- a/examples/research_projects/seq2seq-distillation/train_mbart_cc25_enro.sh
+++ /dev/null
@@ -1,18 +0,0 @@
-#!/usr/bin/env bash
-export PYTHONPATH="../":"${PYTHONPATH}"
-
-python finetune.py \
- --learning_rate=3e-5 \
- --fp16 \
- --do_train \
- --val_check_interval=0.25 \
- --adam_eps 1e-06 \
- --num_train_epochs 6 --src_lang en_XX --tgt_lang ro_RO \
- --data_dir $ENRO_DIR \
- --max_source_length $MAX_LEN --max_target_length $MAX_LEN --val_max_target_length $MAX_LEN --test_max_target_length $MAX_LEN \
- --train_batch_size=$BS --eval_batch_size=$BS \
- --task translation \
- --warmup_steps 500 \
- --freeze_embeds \
- --model_name_or_path=facebook/mbart-large-cc25 \
- "$@"
diff --git a/examples/research_projects/seq2seq-distillation/utils.py b/examples/research_projects/seq2seq-distillation/utils.py
deleted file mode 100644
index de666e0c249..00000000000
--- a/examples/research_projects/seq2seq-distillation/utils.py
+++ /dev/null
@@ -1,645 +0,0 @@
-import itertools
-import json
-import linecache
-import math
-import os
-import pickle
-import socket
-from logging import getLogger
-from pathlib import Path
-from typing import Callable, Dict, Iterable, List, Tuple, Union
-
-import git
-import numpy as np
-import torch
-import torch.distributed as dist
-from rouge_score import rouge_scorer, scoring
-from sacrebleu import corpus_bleu
-from sentence_splitter import add_newline_to_end_of_each_sentence
-from torch import nn
-from torch.utils.data import Dataset, Sampler
-
-from transformers import BartTokenizer, EvalPrediction, PreTrainedTokenizer, T5Tokenizer
-from transformers.file_utils import cached_property
-from transformers.models.bart.modeling_bart import shift_tokens_right
-
-
-try:
- from fairseq.data.data_utils import batch_by_size
-
- FAIRSEQ_AVAILABLE = True
-except (ImportError, ModuleNotFoundError):
- FAIRSEQ_AVAILABLE = False
-
-
-def label_smoothed_nll_loss(lprobs, target, epsilon, ignore_index=-100):
- """From fairseq"""
- if target.dim() == lprobs.dim() - 1:
- target = target.unsqueeze(-1)
- nll_loss = -lprobs.gather(dim=-1, index=target)
- smooth_loss = -lprobs.sum(dim=-1, keepdim=True)
- if ignore_index is not None:
- pad_mask = target.eq(ignore_index)
- nll_loss.masked_fill_(pad_mask, 0.0)
- smooth_loss.masked_fill_(pad_mask, 0.0)
- else:
- nll_loss = nll_loss.squeeze(-1)
- smooth_loss = smooth_loss.squeeze(-1)
-
- nll_loss = nll_loss.sum() # mean()? Scared to break other math.
- smooth_loss = smooth_loss.sum()
- eps_i = epsilon / lprobs.size(-1)
- loss = (1.0 - epsilon) * nll_loss + eps_i * smooth_loss
- return loss, nll_loss
-
-
-def lmap(f: Callable, x: Iterable) -> List:
- """list(map(f, x))"""
- return list(map(f, x))
-
-
-def calculate_bleu(output_lns, refs_lns, **kwargs) -> dict:
- """Uses sacrebleu's corpus_bleu implementation."""
- return {"bleu": round(corpus_bleu(output_lns, [refs_lns], **kwargs).score, 4)}
-
-
-def build_compute_metrics_fn(task_name: str, tokenizer: PreTrainedTokenizer) -> Callable[[EvalPrediction], Dict]:
- def non_pad_len(tokens: np.ndarray) -> int:
- return np.count_nonzero(tokens != tokenizer.pad_token_id)
-
- def decode_pred(pred: EvalPrediction) -> Tuple[List[str], List[str]]:
- pred_str = tokenizer.batch_decode(pred.predictions, skip_special_tokens=True)
- label_str = tokenizer.batch_decode(pred.label_ids, skip_special_tokens=True)
- pred_str = lmap(str.strip, pred_str)
- label_str = lmap(str.strip, label_str)
- return pred_str, label_str
-
- def summarization_metrics(pred: EvalPrediction) -> Dict:
- pred_str, label_str = decode_pred(pred)
- rouge: Dict = calculate_rouge(pred_str, label_str)
- summ_len = np.round(np.mean(lmap(non_pad_len, pred.predictions)), 1)
- rouge.update({"gen_len": summ_len})
- return rouge
-
- def translation_metrics(pred: EvalPrediction) -> Dict:
- pred_str, label_str = decode_pred(pred)
- bleu: Dict = calculate_bleu(pred_str, label_str)
- gen_len = np.round(np.mean(lmap(non_pad_len, pred.predictions)), 1)
- bleu.update({"gen_len": gen_len})
- return bleu
-
- compute_metrics_fn = summarization_metrics if "summarization" in task_name else translation_metrics
- return compute_metrics_fn
-
-
-def trim_batch(
- input_ids,
- pad_token_id,
- attention_mask=None,
-):
- """Remove columns that are populated exclusively by pad_token_id"""
- keep_column_mask = input_ids.ne(pad_token_id).any(dim=0)
- if attention_mask is None:
- return input_ids[:, keep_column_mask]
- else:
- return (input_ids[:, keep_column_mask], attention_mask[:, keep_column_mask])
-
-
-class AbstractSeq2SeqDataset(Dataset):
- def __init__(
- self,
- tokenizer,
- data_dir,
- max_source_length,
- max_target_length,
- type_path="train",
- n_obs=None,
- prefix="",
- **dataset_kwargs,
- ):
- super().__init__()
- self.src_file = Path(data_dir).joinpath(type_path + ".source")
- self.tgt_file = Path(data_dir).joinpath(type_path + ".target")
- self.len_file = Path(data_dir).joinpath(type_path + ".len")
- if os.path.exists(self.len_file):
- self.src_lens = pickle_load(self.len_file)
- self.used_char_len = False
- else:
- self.src_lens = self.get_char_lens(self.src_file)
- self.used_char_len = True
- self.max_source_length = max_source_length
- self.max_target_length = max_target_length
- assert min(self.src_lens) > 0, f"found empty line in {self.src_file}"
- self.tokenizer = tokenizer
- self.prefix = prefix if prefix is not None else ""
-
- if n_obs is not None:
- self.src_lens = self.src_lens[:n_obs]
- self.pad_token_id = self.tokenizer.pad_token_id
- self.dataset_kwargs = dataset_kwargs
- dataset_kwargs.update({"add_prefix_space": True} if isinstance(self.tokenizer, BartTokenizer) else {})
-
- def __len__(self):
- return len(self.src_lens)
-
- @staticmethod
- def get_char_lens(data_file):
- return [len(x) for x in Path(data_file).open().readlines()]
-
- @cached_property
- def tgt_lens(self):
- """Length in characters of target documents"""
- return self.get_char_lens(self.tgt_file)
-
- def make_sortish_sampler(self, batch_size, distributed=False, shuffle=True, **kwargs):
- if distributed:
- return DistributedSortishSampler(self, batch_size, shuffle=shuffle, **kwargs)
- else:
- return SortishSampler(self.src_lens, batch_size, shuffle=shuffle)
-
- def make_dynamic_sampler(self, max_tokens_per_batch=1024, **kwargs):
- assert FAIRSEQ_AVAILABLE, "Dynamic batch size requires `pip install fairseq`"
- assert not self.used_char_len, "You must call python make_len_file.py before calling make_dynamic_sampler"
- sorted_indices = list(self.make_sortish_sampler(1024, shuffle=False))
-
- def num_tokens_in_example(i):
- return min(self.src_lens[i], self.max_target_length)
-
- # call fairseq cython function
- batch_sampler: List[List[int]] = batch_by_size(
- sorted_indices,
- num_tokens_fn=num_tokens_in_example,
- max_tokens=max_tokens_per_batch,
- required_batch_size_multiple=64,
- )
- shuffled_batches = [batch_sampler[i] for i in np.random.permutation(range(len(batch_sampler)))]
- # move the largest batch to the front to OOM quickly (uses an approximation for padding)
- approximate_toks_per_batch = [max(self.src_lens[i] for i in batch) * len(batch) for batch in shuffled_batches]
- largest_batch_idx = np.argmax(approximate_toks_per_batch)
- shuffled_batches[0], shuffled_batches[largest_batch_idx] = (
- shuffled_batches[largest_batch_idx],
- shuffled_batches[0],
- )
- return shuffled_batches
-
- def __getitem__(self, item):
- raise NotImplementedError("You must implement this")
-
- def collate_fn(self, batch):
- raise NotImplementedError("You must implement this")
-
-
-class LegacySeq2SeqDataset(AbstractSeq2SeqDataset):
- def __getitem__(self, index) -> Dict[str, torch.Tensor]:
- """Call tokenizer on src and tgt_lines"""
- index = index + 1 # linecache starts at 1
- source_line = self.prefix + linecache.getline(str(self.src_file), index).rstrip("\n")
- tgt_line = linecache.getline(str(self.tgt_file), index).rstrip("\n")
- assert source_line, f"empty source line for index {index}"
- assert tgt_line, f"empty tgt line for index {index}"
- source_inputs = self.encode_line(self.tokenizer, source_line, self.max_source_length)
- target_inputs = self.encode_line(self.tokenizer, tgt_line, self.max_target_length)
-
- source_ids = source_inputs["input_ids"].squeeze()
- target_ids = target_inputs["input_ids"].squeeze()
- src_mask = source_inputs["attention_mask"].squeeze()
- return {
- "input_ids": source_ids,
- "attention_mask": src_mask,
- "labels": target_ids,
- }
-
- def encode_line(self, tokenizer, line, max_length, pad_to_max_length=True, return_tensors="pt"):
- """Only used by LegacyDataset"""
- return tokenizer(
- [line],
- max_length=max_length,
- padding="max_length" if pad_to_max_length else None,
- truncation=True,
- return_tensors=return_tensors,
- **self.dataset_kwargs,
- )
-
- def collate_fn(self, batch) -> Dict[str, torch.Tensor]:
- input_ids = torch.stack([x["input_ids"] for x in batch])
- masks = torch.stack([x["attention_mask"] for x in batch])
- target_ids = torch.stack([x["labels"] for x in batch])
- pad_token_id = self.pad_token_id
- y = trim_batch(target_ids, pad_token_id)
- source_ids, source_mask = trim_batch(input_ids, pad_token_id, attention_mask=masks)
- batch = {
- "input_ids": source_ids,
- "attention_mask": source_mask,
- "labels": y,
- }
- return batch
-
-
-class Seq2SeqDataset(AbstractSeq2SeqDataset):
- """A dataset that calls prepare_seq2seq_batch."""
-
- def __getitem__(self, index) -> Dict[str, str]:
- index = index + 1 # linecache starts at 1
- source_line = self.prefix + linecache.getline(str(self.src_file), index).rstrip("\n")
- tgt_line = linecache.getline(str(self.tgt_file), index).rstrip("\n")
- assert source_line, f"empty source line for index {index}"
- assert tgt_line, f"empty tgt line for index {index}"
- return {"tgt_texts": tgt_line, "src_texts": source_line, "id": index - 1}
-
- def collate_fn(self, batch) -> Dict[str, torch.Tensor]:
- """Call prepare_seq2seq_batch."""
- batch_encoding: Dict[str, torch.Tensor] = self.tokenizer.prepare_seq2seq_batch(
- [x["src_texts"] for x in batch],
- tgt_texts=[x["tgt_texts"] for x in batch],
- max_length=self.max_source_length,
- max_target_length=self.max_target_length,
- return_tensors="pt",
- **self.dataset_kwargs,
- ).data
- batch_encoding["ids"] = torch.tensor([x["id"] for x in batch])
- return batch_encoding
-
-
-class Seq2SeqDataCollator:
- def __init__(self, tokenizer, data_args, tpu_num_cores=None):
- self.tokenizer = tokenizer
- self.pad_token_id = tokenizer.pad_token_id
- assert (
- self.pad_token_id is not None
- ), f"pad_token_id is not defined for ({self.tokenizer.__class__.__name__}), it must be defined."
- self.data_args = data_args
- self.tpu_num_cores = tpu_num_cores
- self.dataset_kwargs = {"add_prefix_space": True} if isinstance(tokenizer, BartTokenizer) else {}
- if data_args.src_lang is not None:
- self.dataset_kwargs["src_lang"] = data_args.src_lang
- if data_args.tgt_lang is not None:
- self.dataset_kwargs["tgt_lang"] = data_args.tgt_lang
-
- def __call__(self, batch) -> Dict[str, torch.Tensor]:
- if hasattr(self.tokenizer, "prepare_seq2seq_batch"):
- batch = self._encode(batch)
- input_ids, attention_mask, labels = (
- batch["input_ids"],
- batch["attention_mask"],
- batch["labels"],
- )
- else:
- input_ids = torch.stack([x["input_ids"] for x in batch])
- attention_mask = torch.stack([x["attention_mask"] for x in batch])
- labels = torch.stack([x["labels"] for x in batch])
-
- labels = trim_batch(labels, self.pad_token_id)
- input_ids, attention_mask = trim_batch(input_ids, self.pad_token_id, attention_mask=attention_mask)
-
- if isinstance(self.tokenizer, T5Tokenizer):
- decoder_input_ids = self._shift_right_t5(labels)
- else:
- decoder_input_ids = shift_tokens_right(labels, self.pad_token_id)
-
- batch = {
- "input_ids": input_ids,
- "attention_mask": attention_mask,
- "decoder_input_ids": decoder_input_ids,
- "labels": labels,
- }
- return batch
-
- def _shift_right_t5(self, input_ids):
- # shift inputs to the right
- shifted_input_ids = input_ids.new_zeros(input_ids.shape)
- shifted_input_ids[..., 1:] = input_ids[..., :-1].clone()
- shifted_input_ids[..., 0] = self.pad_token_id
- return shifted_input_ids
-
- def _encode(self, batch) -> Dict[str, torch.Tensor]:
- batch_encoding = self.tokenizer.prepare_seq2seq_batch(
- [x["src_texts"] for x in batch],
- tgt_texts=[x["tgt_texts"] for x in batch],
- max_length=self.data_args.max_source_length,
- max_target_length=self.data_args.max_target_length,
- padding="max_length" if self.tpu_num_cores is not None else "longest", # TPU hack
- return_tensors="pt",
- **self.dataset_kwargs,
- )
- return batch_encoding.data
-
-
-class SortishSampler(Sampler):
- "Go through the text data by order of src length with a bit of randomness. From fastai repo."
-
- def __init__(self, data, batch_size, shuffle=True):
- self.data, self.bs, self.shuffle = data, batch_size, shuffle
-
- def __len__(self) -> int:
- return len(self.data)
-
- def __iter__(self):
- return iter(sortish_sampler_indices(self.data, self.bs, shuffle=self.shuffle))
-
-
-def sortish_sampler_indices(data: List, bs: int, shuffle=True) -> np.array:
- "Go through the text data by order of src length with a bit of randomness. From fastai repo."
- if not shuffle:
- return np.argsort(np.array(data) * -1)
-
- def key_fn(i):
- return data[i]
-
- idxs = np.random.permutation(len(data))
- sz = bs * 50
- ck_idx = [idxs[i : i + sz] for i in range(0, len(idxs), sz)]
- sort_idx = np.concatenate([sorted(s, key=key_fn, reverse=True) for s in ck_idx])
- sz = bs
- ck_idx = [sort_idx[i : i + sz] for i in range(0, len(sort_idx), sz)]
- max_ck = np.argmax([key_fn(ck[0]) for ck in ck_idx]) # find the chunk with the largest key,
- ck_idx[0], ck_idx[max_ck] = ck_idx[max_ck], ck_idx[0] # then make sure it goes first.
- sort_idx = np.concatenate(np.random.permutation(ck_idx[1:])) if len(ck_idx) > 1 else np.array([], dtype=int)
- sort_idx = np.concatenate((ck_idx[0], sort_idx))
- return sort_idx
-
-
-class DistributedSortishSampler(Sampler):
- """Copied from torch DistributedSampler"""
-
- def __init__(self, dataset, batch_size, num_replicas=None, rank=None, add_extra_examples=True, shuffle=True):
- if num_replicas is None:
- if not dist.is_available():
- raise RuntimeError("Requires distributed package to be available")
- num_replicas = dist.get_world_size()
- if rank is None:
- if not dist.is_available():
- raise RuntimeError("Requires distributed package to be available")
- rank = dist.get_rank()
- self.dataset = dataset
- self.num_replicas = num_replicas
- self.rank = rank
- self.epoch = 0
- if add_extra_examples:
- self.num_samples = int(math.ceil(len(self.dataset) * 1.0 / self.num_replicas))
- self.total_size = self.num_samples * self.num_replicas
- else:
- self.total_size = len(dataset)
- self.num_samples = len(self.available_indices)
- self.batch_size = batch_size
- self.add_extra_examples = add_extra_examples
- self.shuffle = shuffle
-
- def __iter__(self) -> Iterable:
- g = torch.Generator()
- g.manual_seed(self.epoch)
-
- sortish_data = [self.dataset.src_lens[i] for i in self.available_indices]
- sortish_indices = sortish_sampler_indices(sortish_data, self.batch_size, shuffle=self.shuffle)
- indices = [self.available_indices[i] for i in sortish_indices]
- assert len(indices) == self.num_samples
- return iter(indices)
-
- @cached_property
- def available_indices(self) -> np.array:
- indices = list(range(len(self.dataset)))
- # add extra samples to make it evenly divisible
- indices += indices[: (self.total_size - len(indices))]
- assert len(indices) == self.total_size
- # subsample
- available_indices = indices[self.rank : self.total_size : self.num_replicas]
- return available_indices
-
- def __len__(self):
- return self.num_samples
-
- def set_epoch(self, epoch):
- self.epoch = epoch
-
-
-logger = getLogger(__name__)
-
-
-def use_task_specific_params(model, task):
- """Update config with summarization specific params."""
- task_specific_params = model.config.task_specific_params
-
- if task_specific_params is not None:
- pars = task_specific_params.get(task, {})
- logger.info(f"using task specific params for {task}: {pars}")
- model.config.update(pars)
-
-
-def pickle_load(path):
- """pickle.load(path)"""
- with open(path, "rb") as f:
- return pickle.load(f)
-
-
-def pickle_save(obj, path):
- """pickle.dump(obj, path)"""
- with open(path, "wb") as f:
- return pickle.dump(obj, f)
-
-
-def flatten_list(summary_ids: List[List]):
- return list(itertools.chain.from_iterable(summary_ids))
-
-
-def save_git_info(folder_path: str) -> None:
- """Save git information to output_dir/git_log.json"""
- repo_infos = get_git_info()
- save_json(repo_infos, os.path.join(folder_path, "git_log.json"))
-
-
-def save_json(content, path, indent=4, **json_dump_kwargs):
- with open(path, "w") as f:
- json.dump(content, f, indent=indent, **json_dump_kwargs)
-
-
-def load_json(path):
- with open(path) as f:
- return json.load(f)
-
-
-def get_git_info():
- try:
- repo = git.Repo(search_parent_directories=True)
- repo_infos = {
- "repo_id": str(repo),
- "repo_sha": str(repo.head.object.hexsha),
- "repo_branch": str(repo.active_branch),
- "hostname": str(socket.gethostname()),
- }
- return repo_infos
- except TypeError:
- return {
- "repo_id": None,
- "repo_sha": None,
- "repo_branch": None,
- "hostname": None,
- }
-
-
-ROUGE_KEYS = ["rouge1", "rouge2", "rougeL", "rougeLsum"]
-
-
-def extract_rouge_mid_statistics(dct):
- new_dict = {}
- for k1, v1 in dct.items():
- mid = v1.mid
- new_dict[k1] = {stat: round(getattr(mid, stat), 4) for stat in ["precision", "recall", "fmeasure"]}
- return new_dict
-
-
-def calculate_rouge(
- pred_lns: List[str],
- tgt_lns: List[str],
- use_stemmer=True,
- rouge_keys=ROUGE_KEYS,
- return_precision_and_recall=False,
- bootstrap_aggregation=True,
- newline_sep=True,
-) -> Dict:
- """Calculate rouge using rouge_scorer package.
-
- Args:
- pred_lns: list of summaries generated by model
- tgt_lns: list of groundtruth summaries (e.g. contents of val.target)
- use_stemmer: Bool indicating whether Porter stemmer should be used to
- strip word suffixes to improve matching.
- rouge_keys: which metrics to compute, defaults to rouge1, rouge2, rougeL, rougeLsum
- return_precision_and_recall: (False) whether to also return precision and recall.
- bootstrap_aggregation: whether to do the typical bootstrap resampling of scores. Defaults to True, if False
- this function returns a collections.defaultdict[metric: list of values for each observation for each subscore]``
- newline_sep:(default=True) whether to add newline between sentences. This is essential for calculation rougeL
- on multi sentence summaries (CNN/DM dataset).
-
- Returns:
- Dict[score: value] if aggregate else defaultdict(list) keyed by rouge_keys
-
- """
- scorer = rouge_scorer.RougeScorer(rouge_keys, use_stemmer=use_stemmer)
- aggregator = scoring.BootstrapAggregator()
- for pred, tgt in zip(tgt_lns, pred_lns):
- # rougeLsum expects "\n" separated sentences within a summary
- if newline_sep:
- pred = add_newline_to_end_of_each_sentence(pred)
- tgt = add_newline_to_end_of_each_sentence(tgt)
- scores = scorer.score(pred, tgt)
- aggregator.add_scores(scores)
-
- if bootstrap_aggregation:
- result = aggregator.aggregate()
- if return_precision_and_recall:
- return extract_rouge_mid_statistics(result) # here we return dict
- else:
- return {k: round(v.mid.fmeasure * 100, 4) for k, v in result.items()}
-
- else:
- return aggregator._scores # here we return defaultdict(list)
-
-
-# Utilities for freezing parameters and checking whether they are frozen
-
-
-def freeze_params(model: nn.Module):
- """Set requires_grad=False for each of model.parameters()"""
- for par in model.parameters():
- par.requires_grad = False
-
-
-def freeze_embeds(model):
- """Freeze token embeddings and positional embeddings for bart, just token embeddings for t5."""
- model_type = model.config.model_type
-
- if model_type == "t5":
- freeze_params(model.shared)
- for d in [model.encoder, model.decoder]:
- freeze_params(d.embed_tokens)
- elif model_type == "fsmt":
- for d in [model.model.encoder, model.model.decoder]:
- freeze_params(d.embed_positions)
- freeze_params(d.embed_tokens)
- else:
- freeze_params(model.model.shared)
- for d in [model.model.encoder, model.model.decoder]:
- freeze_params(d.embed_positions)
- freeze_params(d.embed_tokens)
-
-
-def grad_status(model: nn.Module) -> Iterable:
- return (par.requires_grad for par in model.parameters())
-
-
-def any_requires_grad(model: nn.Module) -> bool:
- return any(grad_status(model))
-
-
-def assert_all_frozen(model):
- model_grads: List[bool] = list(grad_status(model))
- n_require_grad = sum(lmap(int, model_grads))
- npars = len(model_grads)
- assert not any(model_grads), f"{n_require_grad/npars:.1%} of {npars} weights require grad"
-
-
-def assert_not_all_frozen(model):
- model_grads: List[bool] = list(grad_status(model))
- npars = len(model_grads)
- assert any(model_grads), f"none of {npars} weights require grad"
-
-
-def parse_numeric_n_bool_cl_kwargs(unparsed_args: List[str]) -> Dict[str, Union[int, float, bool]]:
- """
- Parse an argv list of unspecified command line args to a dict.
- Assumes all values are either numeric or boolean in the form of true/false.
- """
- result = {}
- assert len(unparsed_args) % 2 == 0, f"got odd number of unparsed args: {unparsed_args}"
- num_pairs = len(unparsed_args) // 2
- for pair_num in range(num_pairs):
- i = 2 * pair_num
- assert unparsed_args[i].startswith("--")
- if unparsed_args[i + 1].lower() == "true":
- value = True
- elif unparsed_args[i + 1].lower() == "false":
- value = False
- else:
- try:
- value = int(unparsed_args[i + 1])
- except ValueError:
- value = float(unparsed_args[i + 1]) # this can raise another informative ValueError
-
- result[unparsed_args[i][2:]] = value
- return result
-
-
-def write_txt_file(ordered_tgt, path):
- f = Path(path).open("w")
- for ln in ordered_tgt:
- f.write(ln + "\n")
- f.flush()
-
-
-def chunks(lst, n):
- """Yield successive n-sized chunks from lst."""
- for i in range(0, len(lst), n):
- yield lst[i : i + n]
-
-
-def check_output_dir(args, expected_items=0):
- """
- Checks whether to bail out if output_dir already exists and has more than expected_items in it
-
- `args`: needs to have the following attributes of `args`:
- - output_dir
- - do_train
- - overwrite_output_dir
-
- `expected_items`: normally 0 (default) - i.e. empty dir, but in some cases a few files are expected (e.g. recovery from OOM)
- """
- if (
- os.path.exists(args.output_dir)
- and len(os.listdir(args.output_dir)) > expected_items
- and args.do_train
- and not args.overwrite_output_dir
- ):
- raise ValueError(
- f"Output directory ({args.output_dir}) already exists and "
- f"has {len(os.listdir(args.output_dir))} items in it (expected {expected_items} items). "
- "Use --overwrite_output_dir to overcome."
- )
diff --git a/examples/research_projects/synthid_text/README.md b/examples/research_projects/synthid_text/README.md
deleted file mode 100644
index 30ab9990373..00000000000
--- a/examples/research_projects/synthid_text/README.md
+++ /dev/null
@@ -1,34 +0,0 @@
-# SynthID Text
-
-This project showcases the use of SynthIDText for watermarking LLMs. The code shown in this repo also
-demostrates the training of the detector for detecting such watermarked text. This detector can be uploaded onto
-a private HF hub repo (private for security reasons) and can be initialized again through pretrained model loading also shown in this script.
-
-See our blog post: https://huggingface.co/blog/synthid-text
-
-
-## Python version
-
-User would need python 3.9 to run this example.
-
-## Installation and running
-
-Once you install transformers you would need to install requirements for this project through requirements.txt provided in this folder.
-
-```
-pip install -r requirements.txt
-```
-
-## To run the detector training
-
-```
-python detector_training.py --model_name=google/gemma-7b-it
-```
-
-Check the script for more parameters are are tunable and check out paper at link
-https://www.nature.com/articles/s41586-024-08025-4 for more information on these parameters.
-
-## Caveat
-
-Make sure to run the training of the detector and the detection on the same hardware
-CPU, GPU or TPU to get consistent results (we use detecterministic randomness which is hardware dependent).
diff --git a/examples/research_projects/synthid_text/detector_training.py b/examples/research_projects/synthid_text/detector_training.py
deleted file mode 100644
index 35d0ea22f42..00000000000
--- a/examples/research_projects/synthid_text/detector_training.py
+++ /dev/null
@@ -1,502 +0,0 @@
-# coding=utf-8
-# Copyright 2024 Google DeepMind.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import argparse
-import dataclasses
-import enum
-from typing import Any, Dict, List, Optional, Tuple, Union
-
-import numpy as np
-import torch
-
-from transformers import (
- AutoModelForCausalLM,
- AutoTokenizer,
- BayesianDetectorConfig,
- BayesianDetectorModel,
- SynthIDTextWatermarkDetector,
- SynthIDTextWatermarkingConfig,
- SynthIDTextWatermarkLogitsProcessor,
-)
-from utils import (
- get_tokenized_uwm_outputs,
- get_tokenized_wm_outputs,
- process_raw_model_outputs,
- update_fn_if_fpr_tpr,
- upload_model_to_hf,
-)
-
-
-@enum.unique
-class ValidationMetric(enum.Enum):
- """Direction along the z-axis."""
-
- TPR_AT_FPR = "tpr_at_fpr"
- CROSS_ENTROPY = "cross_entropy"
-
-
-@dataclasses.dataclass
-class TrainingArguments:
- """Training arguments pertaining to the training loop itself."""
-
- eval_metric: Optional[str] = dataclasses.field(
- default=ValidationMetric.TPR_AT_FPR, metadata={"help": "The evaluation metric used."}
- )
-
-
-def train_detector(
- detector: torch.nn.Module,
- g_values: torch.Tensor,
- mask: torch.Tensor,
- watermarked: torch.Tensor,
- epochs: int = 250,
- learning_rate: float = 1e-3,
- minibatch_size: int = 64,
- seed: int = 0,
- l2_weight: float = 0.0,
- shuffle: bool = True,
- g_values_val: Optional[torch.Tensor] = None,
- mask_val: Optional[torch.Tensor] = None,
- watermarked_val: Optional[torch.Tensor] = None,
- verbose: bool = False,
- validation_metric: ValidationMetric = ValidationMetric.TPR_AT_FPR,
-) -> Tuple[Dict[str, Any], float]:
- """Trains a Bayesian detector model.
-
- Args:
- g_values: g-values of shape [num_train, seq_len, watermarking_depth].
- mask: A binary array shape [num_train, seq_len] indicating which g-values
- should be used. g-values with mask value 0 are discarded.
- watermarked: A binary array of shape [num_train] indicating whether the
- example is watermarked (0: unwatermarked, 1: watermarked).
- epochs: Number of epochs to train for.
- learning_rate: Learning rate for optimizer.
- minibatch_size: Minibatch size for training. Note that a minibatch
- requires ~ 32 * minibatch_size * seq_len * watermarked_depth *
- watermarked_depth bits of memory.
- seed: Seed for parameter initialization.
- l2_weight: Weight to apply to L2 regularization for delta parameters.
- shuffle: Whether to shuffle before training.
- g_values_val: Validation g-values of shape [num_val, seq_len,
- watermarking_depth].
- mask_val: Validation mask of shape [num_val, seq_len].
- watermarked_val: Validation watermark labels of shape [num_val].
- verbose: Boolean indicating verbosity of training. If true, the loss will
- be printed. Defaulted to False.
- use_tpr_fpr_for_val: Whether to use TPR@FPR=1% as metric for validation.
- If false, use cross entropy loss.
-
- Returns:
- Tuple of
- training_history: Training history keyed by epoch number where the
- values are
- dictionaries containing the loss, validation loss, and model
- parameters,
- keyed by
- 'loss', 'val_loss', and 'params', respectively.
- min_val_loss: Minimum validation loss achieved during training.
- """
-
- # Set the random seed for reproducibility
- torch.manual_seed(seed)
-
- # Shuffle the data if required
- if shuffle:
- indices = torch.randperm(len(g_values))
- g_values = g_values[indices]
- mask = mask[indices]
- watermarked = watermarked[indices]
-
- # Initialize optimizer
- optimizer = torch.optim.Adam(detector.parameters(), lr=learning_rate)
- history = {}
- min_val_loss = float("inf")
-
- for epoch in range(epochs):
- losses = []
- detector.train()
- num_batches = len(g_values) // minibatch_size
- for i in range(0, len(g_values), minibatch_size):
- end = i + minibatch_size
- if end > len(g_values):
- break
- loss_batch_weight = l2_weight / num_batches
-
- optimizer.zero_grad()
- loss = detector(
- g_values=g_values[i:end],
- mask=mask[i:end],
- labels=watermarked[i:end],
- loss_batch_weight=loss_batch_weight,
- )[1]
- loss.backward()
- optimizer.step()
- losses.append(loss.item())
- train_loss = sum(losses) / len(losses)
-
- val_losses = []
- if g_values_val is not None:
- detector.eval()
- if validation_metric == ValidationMetric.TPR_AT_FPR:
- val_loss = update_fn_if_fpr_tpr(
- detector,
- g_values_val,
- mask_val,
- watermarked_val,
- minibatch_size=minibatch_size,
- )
- else:
- for i in range(0, len(g_values_val), minibatch_size):
- end = i + minibatch_size
- if end > len(g_values_val):
- break
- with torch.no_grad():
- v_loss = detector(
- g_values=g_values_val[i:end],
- mask=mask_val[i:end],
- labels=watermarked_val[i:end],
- loss_batch_weight=0,
- )[1]
- val_losses.append(v_loss.item())
- val_loss = sum(val_losses) / len(val_losses)
-
- # Store training history
- history[epoch + 1] = {"loss": train_loss, "val_loss": val_loss}
- if verbose:
- if val_loss is not None:
- print(f"Epoch {epoch}: loss {loss} (train), {val_loss} (val)")
- else:
- print(f"Epoch {epoch}: loss {loss} (train)")
-
- if val_loss is not None and val_loss < min_val_loss:
- min_val_loss = val_loss
- best_val_epoch = epoch
-
- if verbose:
- print(f"Best val Epoch: {best_val_epoch}, min_val_loss: {min_val_loss}")
-
- return history, min_val_loss
-
-
-def train_best_detector(
- tokenized_wm_outputs: Union[List[np.ndarray], np.ndarray],
- tokenized_uwm_outputs: Union[List[np.ndarray], np.ndarray],
- logits_processor: SynthIDTextWatermarkLogitsProcessor,
- tokenizer: Any,
- torch_device: torch.device,
- test_size: float = 0.3,
- pos_truncation_length: Optional[int] = 200,
- neg_truncation_length: Optional[int] = 100,
- max_padded_length: int = 2300,
- n_epochs: int = 50,
- learning_rate: float = 2.1e-2,
- l2_weights: np.ndarray = np.logspace(-3, -2, num=4),
- verbose: bool = False,
- validation_metric: ValidationMetric = ValidationMetric.TPR_AT_FPR,
-):
- """Train and return the best detector given range of hyperparameters.
-
- In practice, we have found that tuning pos_truncation_length,
- neg_truncation_length, n_epochs, learning_rate and l2_weights can help
- improve the performance of the detector. We reccommend tuning these
- parameters for your data.
- """
- l2_weights = list(l2_weights)
-
- (
- train_g_values,
- train_masks,
- train_labels,
- cv_g_values,
- cv_masks,
- cv_labels,
- ) = process_raw_model_outputs(
- logits_processor,
- tokenizer,
- pos_truncation_length,
- neg_truncation_length,
- max_padded_length,
- tokenized_wm_outputs,
- test_size,
- tokenized_uwm_outputs,
- torch_device,
- )
-
- best_detector = None
- lowest_loss = float("inf")
- val_losses = []
- for l2_weight in l2_weights:
- config = BayesianDetectorConfig(watermarking_depth=len(logits_processor.keys))
- detector = BayesianDetectorModel(config).to(torch_device)
- _, min_val_loss = train_detector(
- detector=detector,
- g_values=train_g_values,
- mask=train_masks,
- watermarked=train_labels,
- g_values_val=cv_g_values,
- mask_val=cv_masks,
- watermarked_val=cv_labels,
- learning_rate=learning_rate,
- l2_weight=l2_weight,
- epochs=n_epochs,
- verbose=verbose,
- validation_metric=validation_metric,
- )
- val_losses.append(min_val_loss)
- if min_val_loss < lowest_loss:
- lowest_loss = min_val_loss
- best_detector = detector
- return best_detector, lowest_loss
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "--model_name",
- type=str,
- default="google/gemma-2b-it",
- help=("LM model to train the detector for."),
- )
- parser.add_argument(
- "--temperature",
- type=float,
- default=1.0,
- help=("Temperature to sample from the model."),
- )
- parser.add_argument(
- "--top_k",
- type=int,
- default=40,
- help=("Top K for sampling."),
- )
- parser.add_argument(
- "--top_p",
- type=float,
- default=1.0,
- help=("Top P for sampling."),
- )
- parser.add_argument(
- "--num_negatives",
- type=int,
- default=10000,
- help=("Number of negatives for detector training."),
- )
- parser.add_argument(
- "--pos_batch_size",
- type=int,
- default=32,
- help=("Batch size of watermarked positives while sampling."),
- )
- parser.add_argument(
- "--num_pos_batch",
- type=int,
- default=313,
- help=("Number of positive batches for training."),
- )
- parser.add_argument(
- "--generation_length",
- type=int,
- default=512,
- help=("Generation length for sampling."),
- )
- parser.add_argument(
- "--save_model_to_hf_hub",
- action="store_true",
- help=("Whether to save the trained model HF hub. By default it will be a private repo."),
- )
- parser.add_argument(
- "--load_from_hf_hub",
- action="store_true",
- help=(
- "Whether to load trained detector model from HF Hub, make sure its the model trained on the same model "
- "we are loading in the script."
- ),
- )
- parser.add_argument(
- "--hf_hub_model_name",
- type=str,
- default=None,
- help=("HF hub model name for loading of saving the model."),
- )
- parser.add_argument(
- "--eval_detector_on_prompts",
- action="store_true",
- help=("Evaluate detector on a prompt and print probability of watermark."),
- )
-
- args = parser.parse_args()
- model_name = args.model_name
- temperature = args.temperature
- top_k = args.top_k
- top_p = args.top_p
- num_negatives = args.num_negatives
- pos_batch_size = args.pos_batch_size
- num_pos_batch = args.num_pos_batch
- if num_pos_batch < 10:
- raise ValueError("--num_pos_batch should be greater than 10.")
- generation_length = args.generation_length
- save_model_to_hf_hub = args.save_model_to_hf_hub
- load_from_hf_hub = args.load_from_hf_hub
- repo_name = args.hf_hub_model_name
- eval_detector_on_prompts = args.eval_detector_on_prompts
-
- NEG_BATCH_SIZE = 32
-
- # Truncate outputs to this length for training.
- POS_TRUNCATION_LENGTH = 200
- NEG_TRUNCATION_LENGTH = 100
- # Pad trucated outputs to this length for equal shape across all batches.
- MAX_PADDED_LENGTH = 1000
-
- DEVICE = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
- if DEVICE.type not in ("cuda", "tpu"):
- raise ValueError("We have found the training stable on GPU and TPU, we are working on" " a fix for CPUs")
-
- model = None
- if not load_from_hf_hub:
- # Change this to make your watermark unique. Check documentation in the paper to understand the
- # impact of these parameters.
- DEFAULT_WATERMARKING_CONFIG = {
- "ngram_len": 5, # This corresponds to H=4 context window size in the paper.
- "keys": [
- 654,
- 400,
- 836,
- 123,
- 340,
- 443,
- 597,
- 160,
- 57,
- 29,
- 590,
- 639,
- 13,
- 715,
- 468,
- 990,
- 966,
- 226,
- 324,
- 585,
- 118,
- 504,
- 421,
- 521,
- 129,
- 669,
- 732,
- 225,
- 90,
- 960,
- ],
- "sampling_table_size": 2**16,
- "sampling_table_seed": 0,
- "context_history_size": 1024,
- }
- watermark_config = SynthIDTextWatermarkingConfig(**DEFAULT_WATERMARKING_CONFIG)
-
- model = AutoModelForCausalLM.from_pretrained(model_name).to(DEVICE)
- tokenizer = AutoTokenizer.from_pretrained(model_name)
- tokenizer.pad_token = tokenizer.eos_token
-
- logits_processor = SynthIDTextWatermarkLogitsProcessor(**DEFAULT_WATERMARKING_CONFIG, device=DEVICE)
- tokenized_wm_outputs = get_tokenized_wm_outputs(
- model,
- tokenizer,
- watermark_config,
- num_pos_batch,
- pos_batch_size,
- temperature,
- generation_length,
- top_k,
- top_p,
- DEVICE,
- )
- tokenized_uwm_outputs = get_tokenized_uwm_outputs(num_negatives, NEG_BATCH_SIZE, tokenizer, DEVICE)
-
- best_detector, lowest_loss = train_best_detector(
- tokenized_wm_outputs=tokenized_wm_outputs,
- tokenized_uwm_outputs=tokenized_uwm_outputs,
- logits_processor=logits_processor,
- tokenizer=tokenizer,
- torch_device=DEVICE,
- test_size=0.3,
- pos_truncation_length=POS_TRUNCATION_LENGTH,
- neg_truncation_length=NEG_TRUNCATION_LENGTH,
- max_padded_length=MAX_PADDED_LENGTH,
- n_epochs=100,
- learning_rate=3e-3,
- l2_weights=[
- 0,
- ],
- verbose=True,
- validation_metric=ValidationMetric.TPR_AT_FPR,
- )
- else:
- if repo_name is None:
- raise ValueError("When loading from pretrained detector model name cannot be None.")
- best_detector = BayesianDetectorModel.from_pretrained(repo_name).to(DEVICE)
-
- best_detector.config.set_detector_information(
- model_name=model_name, watermarking_config=DEFAULT_WATERMARKING_CONFIG
- )
- if save_model_to_hf_hub:
- upload_model_to_hf(best_detector, repo_name)
-
- # Evaluate model response with the detector
- if eval_detector_on_prompts:
- model_name = best_detector.config.model_name
- watermark_config_dict = best_detector.config.watermarking_config
- logits_processor = SynthIDTextWatermarkLogitsProcessor(**watermark_config_dict, device=DEVICE)
- tokenizer = AutoTokenizer.from_pretrained(model_name)
- tokenizer.pad_token = tokenizer.eos_token
- synthid_text_detector = SynthIDTextWatermarkDetector(best_detector, logits_processor, tokenizer)
-
- if model is None:
- model = AutoModelForCausalLM.from_pretrained(model_name).to(DEVICE)
- watermarking_config = SynthIDTextWatermarkingConfig(**watermark_config_dict)
-
- prompts = ["Write a essay on cats."]
- inputs = tokenizer(
- prompts,
- return_tensors="pt",
- padding=True,
- ).to(DEVICE)
-
- _, inputs_len = inputs["input_ids"].shape
-
- outputs = model.generate(
- **inputs,
- watermarking_config=watermarking_config,
- do_sample=True,
- max_length=inputs_len + generation_length,
- temperature=temperature,
- top_k=40,
- top_p=1.0,
- )
- outputs = outputs[:, inputs_len:]
- result = synthid_text_detector(outputs)
-
- # You should set this based on expected fpr (false positive rate) and tpr (true positive rate).
- # Check our demo at HF Spaces for more info.
- upper_threshold = 0.95
- lower_threshold = 0.12
- if result[0][0] > upper_threshold:
- print("The text is watermarked.")
- elif lower_threshold < result[0][0] < upper_threshold:
- print("It is hard to determine if the text is watermarked or not.")
- else:
- print("The text is not watermarked.")
diff --git a/examples/research_projects/synthid_text/requirements.txt b/examples/research_projects/synthid_text/requirements.txt
deleted file mode 100644
index 9e40a93ee08..00000000000
--- a/examples/research_projects/synthid_text/requirements.txt
+++ /dev/null
@@ -1,5 +0,0 @@
-tensorflow-datasets>=4.9.3
-torch >= 1.3
-datasets
-scikit-learn
-tensorflow
diff --git a/examples/research_projects/synthid_text/utils.py b/examples/research_projects/synthid_text/utils.py
deleted file mode 100644
index abcb6ca2f28..00000000000
--- a/examples/research_projects/synthid_text/utils.py
+++ /dev/null
@@ -1,408 +0,0 @@
-# coding=utf-8
-# Copyright 2024 Google DeepMind.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import gc
-from typing import Any, List, Optional, Tuple
-
-import datasets
-import numpy as np
-import tensorflow as tf
-import tensorflow_datasets as tfds
-import torch
-import tqdm
-from huggingface_hub import HfApi, create_repo
-from huggingface_hub.utils import RepositoryNotFoundError
-from sklearn import model_selection
-
-import transformers
-
-
-def pad_to_len(
- arr: torch.Tensor,
- target_len: int,
- left_pad: bool,
- eos_token: int,
- device: torch.device,
-) -> torch.Tensor:
- """Pad or truncate array to given length."""
- if arr.shape[1] < target_len:
- shape_for_ones = list(arr.shape)
- shape_for_ones[1] = target_len - shape_for_ones[1]
- padded = (
- torch.ones(
- shape_for_ones,
- device=device,
- dtype=torch.long,
- )
- * eos_token
- )
- if not left_pad:
- arr = torch.concatenate((arr, padded), dim=1)
- else:
- arr = torch.concatenate((padded, arr), dim=1)
- else:
- arr = arr[:, :target_len]
- return arr
-
-
-def filter_and_truncate(
- outputs: torch.Tensor,
- truncation_length: Optional[int],
- eos_token_mask: torch.Tensor,
-) -> torch.Tensor:
- """Filter and truncate outputs to given length.
-
- Args:
- outputs: output tensor of shape [batch_size, output_len]
- truncation_length: Length to truncate the final output.
- eos_token_mask: EOS token mask of shape [batch_size, output_len]
-
- Returns:
- output tensor of shape [batch_size, truncation_length].
- """
- if truncation_length:
- outputs = outputs[:, :truncation_length]
- truncation_mask = torch.sum(eos_token_mask, dim=1) >= truncation_length
- return outputs[truncation_mask, :]
- return outputs
-
-
-def process_outputs_for_training(
- all_outputs: List[torch.Tensor],
- logits_processor: transformers.generation.SynthIDTextWatermarkLogitsProcessor,
- tokenizer: Any,
- pos_truncation_length: Optional[int],
- neg_truncation_length: Optional[int],
- max_length: int,
- is_cv: bool,
- is_pos: bool,
- torch_device: torch.device,
-) -> Tuple[List[torch.Tensor], List[torch.Tensor]]:
- """Process raw model outputs into format understandable by the detector.
-
- Args:
- all_outputs: sequence of outputs of shape [batch_size, output_len].
- logits_processor: logits processor used for watermarking.
- tokenizer: tokenizer used for the model.
- pos_truncation_length: Length to truncate wm outputs.
- neg_truncation_length: Length to truncate uwm outputs.
- max_length: Length to pad truncated outputs so that all processed entries.
- have same shape.
- is_cv: Process given outputs for cross validation.
- is_pos: Process given outputs for positives.
- torch_device: torch device to use.
-
- Returns:
- Tuple of
- all_masks: list of masks of shape [batch_size, max_length].
- all_g_values: list of g_values of shape [batch_size, max_length, depth].
- """
- all_masks = []
- all_g_values = []
- for outputs in tqdm.tqdm(all_outputs):
- # outputs is of shape [batch_size, output_len].
- # output_len can differ from batch to batch.
- eos_token_mask = logits_processor.compute_eos_token_mask(
- input_ids=outputs,
- eos_token_id=tokenizer.eos_token_id,
- )
- if is_pos or is_cv:
- # filter with length for positives for both train and CV.
- # We also filter for length when CV negatives are processed.
- outputs = filter_and_truncate(outputs, pos_truncation_length, eos_token_mask)
- elif not is_pos and not is_cv:
- outputs = filter_and_truncate(outputs, neg_truncation_length, eos_token_mask)
-
- # If no filtered outputs skip this batch.
- if outputs.shape[0] == 0:
- continue
-
- # All outputs are padded to max-length with eos-tokens.
- outputs = pad_to_len(outputs, max_length, False, tokenizer.eos_token_id, torch_device)
- # outputs shape [num_filtered_entries, max_length]
-
- eos_token_mask = logits_processor.compute_eos_token_mask(
- input_ids=outputs,
- eos_token_id=tokenizer.eos_token_id,
- )
-
- context_repetition_mask = logits_processor.compute_context_repetition_mask(
- input_ids=outputs,
- )
-
- # context_repetition_mask of shape [num_filtered_entries, max_length -
- # (ngram_len - 1)].
- context_repetition_mask = pad_to_len(context_repetition_mask, max_length, True, 0, torch_device)
- # We pad on left to get same max_length shape.
- # context_repetition_mask of shape [num_filtered_entries, max_length].
- combined_mask = context_repetition_mask * eos_token_mask
-
- g_values = logits_processor.compute_g_values(
- input_ids=outputs,
- )
-
- # g_values of shape [num_filtered_entries, max_length - (ngram_len - 1),
- # depth].
- g_values = pad_to_len(g_values, max_length, True, 0, torch_device)
-
- # We pad on left to get same max_length shape.
- # g_values of shape [num_filtered_entries, max_length, depth].
- all_masks.append(combined_mask)
- all_g_values.append(g_values)
- return all_masks, all_g_values
-
-
-def tpr_at_fpr(detector, detector_inputs, w_true, minibatch_size, target_fpr=0.01) -> torch.Tensor:
- """Calculates true positive rate (TPR) at false positive rate (FPR)=target_fpr."""
- positive_idxs = w_true == 1
- negative_idxs = w_true == 0
- num_samples = detector_inputs[0].size(0)
-
- w_preds = []
- for start in range(0, num_samples, minibatch_size):
- end = start + minibatch_size
- detector_inputs_ = (
- detector_inputs[0][start:end],
- detector_inputs[1][start:end],
- )
- with torch.no_grad():
- w_pred = detector(*detector_inputs_)[0]
- w_preds.append(w_pred)
-
- w_pred = torch.cat(w_preds, dim=0) # Concatenate predictions
- positive_scores = w_pred[positive_idxs]
- negative_scores = w_pred[negative_idxs]
-
- # Calculate the FPR threshold
- # Note: percentile -> quantile
- fpr_threshold = torch.quantile(negative_scores, 1 - target_fpr)
- # Note: need to switch to FP32 since torch.mean doesn't work with torch.bool
- return torch.mean((positive_scores >= fpr_threshold).to(dtype=torch.float32)).item() # TPR
-
-
-def update_fn_if_fpr_tpr(detector, g_values_val, mask_val, watermarked_val, minibatch_size):
- """Loss function for negative TPR@FPR=1% as the validation loss."""
- tpr_ = tpr_at_fpr(
- detector=detector,
- detector_inputs=(g_values_val, mask_val),
- w_true=watermarked_val,
- minibatch_size=minibatch_size,
- )
- return -tpr_
-
-
-def process_raw_model_outputs(
- logits_processor,
- tokenizer,
- pos_truncation_length,
- neg_truncation_length,
- max_padded_length,
- tokenized_wm_outputs,
- test_size,
- tokenized_uwm_outputs,
- torch_device,
-):
- # Split data into train and CV
- train_wm_outputs, cv_wm_outputs = model_selection.train_test_split(tokenized_wm_outputs, test_size=test_size)
-
- train_uwm_outputs, cv_uwm_outputs = model_selection.train_test_split(tokenized_uwm_outputs, test_size=test_size)
-
- process_kwargs = {
- "logits_processor": logits_processor,
- "tokenizer": tokenizer,
- "pos_truncation_length": pos_truncation_length,
- "neg_truncation_length": neg_truncation_length,
- "max_length": max_padded_length,
- "torch_device": torch_device,
- }
-
- # Process both train and CV data for training
- wm_masks_train, wm_g_values_train = process_outputs_for_training(
- [torch.tensor(outputs, device=torch_device, dtype=torch.long) for outputs in train_wm_outputs],
- is_pos=True,
- is_cv=False,
- **process_kwargs,
- )
- wm_masks_cv, wm_g_values_cv = process_outputs_for_training(
- [torch.tensor(outputs, device=torch_device, dtype=torch.long) for outputs in cv_wm_outputs],
- is_pos=True,
- is_cv=True,
- **process_kwargs,
- )
- uwm_masks_train, uwm_g_values_train = process_outputs_for_training(
- [torch.tensor(outputs, device=torch_device, dtype=torch.long) for outputs in train_uwm_outputs],
- is_pos=False,
- is_cv=False,
- **process_kwargs,
- )
- uwm_masks_cv, uwm_g_values_cv = process_outputs_for_training(
- [torch.tensor(outputs, device=torch_device, dtype=torch.long) for outputs in cv_uwm_outputs],
- is_pos=False,
- is_cv=True,
- **process_kwargs,
- )
-
- # We get list of data; here we concat all together to be passed to the detector.
- def pack(mask, g_values):
- mask = torch.cat(mask, dim=0)
- g = torch.cat(g_values, dim=0)
- return mask, g
-
- wm_masks_train, wm_g_values_train = pack(wm_masks_train, wm_g_values_train)
- # Note: Use float instead of bool. Otherwise, the entropy calculation doesn't work
- wm_labels_train = torch.ones((wm_masks_train.shape[0],), dtype=torch.float, device=torch_device)
-
- wm_masks_cv, wm_g_values_cv = pack(wm_masks_cv, wm_g_values_cv)
- wm_labels_cv = torch.ones((wm_masks_cv.shape[0],), dtype=torch.float, device=torch_device)
-
- uwm_masks_train, uwm_g_values_train = pack(uwm_masks_train, uwm_g_values_train)
- uwm_labels_train = torch.zeros((uwm_masks_train.shape[0],), dtype=torch.float, device=torch_device)
-
- uwm_masks_cv, uwm_g_values_cv = pack(uwm_masks_cv, uwm_g_values_cv)
- uwm_labels_cv = torch.zeros((uwm_masks_cv.shape[0],), dtype=torch.float, device=torch_device)
-
- # Concat pos and negatives data together.
- train_g_values = torch.cat((wm_g_values_train, uwm_g_values_train), dim=0).squeeze()
- train_labels = torch.cat((wm_labels_train, uwm_labels_train), axis=0).squeeze()
- train_masks = torch.cat((wm_masks_train, uwm_masks_train), axis=0).squeeze()
-
- cv_g_values = torch.cat((wm_g_values_cv, uwm_g_values_cv), axis=0).squeeze()
- cv_labels = torch.cat((wm_labels_cv, uwm_labels_cv), axis=0).squeeze()
- cv_masks = torch.cat((wm_masks_cv, uwm_masks_cv), axis=0).squeeze()
-
- # Shuffle data.
- shuffled_idx = torch.randperm(train_g_values.shape[0]) # Use torch for GPU compatibility
-
- train_g_values = train_g_values[shuffled_idx]
- train_labels = train_labels[shuffled_idx]
- train_masks = train_masks[shuffled_idx]
-
- # Shuffle the cross-validation data
- shuffled_idx_cv = torch.randperm(cv_g_values.shape[0]) # Use torch for GPU compatibility
- cv_g_values = cv_g_values[shuffled_idx_cv]
- cv_labels = cv_labels[shuffled_idx_cv]
- cv_masks = cv_masks[shuffled_idx_cv]
-
- # Del some variables so we free up GPU memory.
- del (
- wm_g_values_train,
- wm_labels_train,
- wm_masks_train,
- wm_g_values_cv,
- wm_labels_cv,
- wm_masks_cv,
- )
- gc.collect()
- torch.cuda.empty_cache()
-
- return train_g_values, train_masks, train_labels, cv_g_values, cv_masks, cv_labels
-
-
-def get_tokenized_uwm_outputs(num_negatives, neg_batch_size, tokenizer, device):
- dataset, info = tfds.load("wikipedia/20230601.en", split="train", with_info=True)
- dataset = dataset.take(num_negatives)
-
- # Convert the dataset to a DataFrame
- df = tfds.as_dataframe(dataset, info)
- ds = tf.data.Dataset.from_tensor_slices(dict(df))
- tf.random.set_seed(0)
- ds = ds.shuffle(buffer_size=10_000)
- ds = ds.batch(batch_size=neg_batch_size)
-
- tokenized_uwm_outputs = []
- # Pad to this length (on the right) for batching.
- padded_length = 1000
- for i, batch in tqdm.tqdm(enumerate(ds)):
- responses = [val.decode() for val in batch["text"].numpy()]
- inputs = tokenizer(
- responses,
- return_tensors="pt",
- padding=True,
- ).to(device)
- inputs = inputs["input_ids"].cpu().numpy()
- if inputs.shape[1] >= padded_length:
- inputs = inputs[:, :padded_length]
- else:
- inputs = np.concatenate(
- [inputs, np.ones((neg_batch_size, padded_length - inputs.shape[1])) * tokenizer.eos_token_id], axis=1
- )
- tokenized_uwm_outputs.append(inputs)
- if len(tokenized_uwm_outputs) * neg_batch_size > num_negatives:
- break
- return tokenized_uwm_outputs
-
-
-def get_tokenized_wm_outputs(
- model,
- tokenizer,
- watermark_config,
- num_pos_batches,
- pos_batch_size,
- temperature,
- max_output_len,
- top_k,
- top_p,
- device,
-):
- eli5_prompts = datasets.load_dataset("Pavithree/eli5")
-
- wm_outputs = []
-
- for batch_id in tqdm.tqdm(range(num_pos_batches)):
- prompts = eli5_prompts["train"]["title"][batch_id * pos_batch_size : (batch_id + 1) * pos_batch_size]
- prompts = [prompt.strip('"') for prompt in prompts]
- inputs = tokenizer(
- prompts,
- return_tensors="pt",
- padding=True,
- ).to(device)
- _, inputs_len = inputs["input_ids"].shape
-
- outputs = model.generate(
- **inputs,
- watermarking_config=watermark_config,
- do_sample=True,
- max_length=inputs_len + max_output_len,
- temperature=temperature,
- top_k=top_k,
- top_p=top_p,
- )
-
- wm_outputs.append(outputs[:, inputs_len:].cpu().detach())
-
- del outputs, inputs, prompts
- gc.collect()
-
- gc.collect()
- torch.cuda.empty_cache()
- return wm_outputs
-
-
-def upload_model_to_hf(model, hf_repo_name: str, private: bool = True):
- api = HfApi()
-
- # Check if the repository exists
- try:
- api.repo_info(repo_id=hf_repo_name, use_auth_token=True)
- print(f"Repository '{hf_repo_name}' already exists.")
- except RepositoryNotFoundError:
- # If the repository does not exist, create it
- print(f"Repository '{hf_repo_name}' not found. Creating it...")
- create_repo(repo_id=hf_repo_name, private=private, use_auth_token=True)
- print(f"Repository '{hf_repo_name}' created successfully.")
-
- # Push the model to the Hugging Face Hub
- print(f"Uploading model to Hugging Face repo '{hf_repo_name}'...")
- model.push_to_hub(repo_id=hf_repo_name, use_auth_token=True)
diff --git a/examples/research_projects/tapex/README.md b/examples/research_projects/tapex/README.md
deleted file mode 100644
index b98eb9b428d..00000000000
--- a/examples/research_projects/tapex/README.md
+++ /dev/null
@@ -1,288 +0,0 @@
-
-
-# Run Table Tasks with TAPEX
-
-TAPEX is a table pre-training approach for table-related tasks. By learning a neural SQL executor over a synthetic corpus based on generative language models (e.g., BART), it achieves state-of-the-art performance on several table-based question answering benchmarks and table-based fact verification benchmark. More details can be found in the original paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/pdf/2107.07653.pdf).
-
-> If you are also familiar with [fairseq](https://github.com/pytorch/fairseq), you may also find [the official implementation](https://github.com/microsoft/Table-Pretraining) useful, which leverages the framework.
-
-## Table Question Answering Tasks
-
-### What is Table Question Answering
-
-
-
-The task of Table Question Answering (TableQA) is to empower machines to answer users' questions over a given table. The resulting answer(s) can be a region in the table, or a number calculated by applying aggregation operators to a specific region.
-
-### What Questions Can be Answered
-
-Benefiting from the powerfulness of generative models, TAPEX can deal with almost all kinds of questions over tables (if there is training data). Below are some typical question and their answers taken from [WikiTableQuestion](https://nlp.stanford.edu/blog/wikitablequestions-a-complex-real-world-question-understanding-dataset).
-
-| Question | Answer |
-| :---: | :---: |
-| What is the years won for each team? | 2004, 2008, 2012 |
-| How long did Taiki Tsuchiya last? | 4:27 |
-| What is the total amount of matches drawn? | 1 |
-| Besides Tiger Woods, what other player won between 2007 and 2009? | Camilo Villegas |
-| What was the last Baekje Temple? | Uija |
-| What is the difference between White voters and Black voters in 1948? | 0 |
-| What is the average number of sailors for each country during the worlds qualification tournament? | 2 |
-
-
-### How to Fine-tune TAPEX on TableQA
-
-We provide a fine-tuning script of tapex for TableQA on the WikiSQL benchmark: [WikiSQL](https://github.com/salesforce/WikiSQL).
-This script is customized for tapex models, and can be easily adapted to other benchmarks such as WikiTableQuestion
-(only some tweaks in the function `preprocess_tableqa_function`).
-
-#### TAPEX-Base on WikiSQL
-
-Here is how to run the script on the WikiSQL with `tapex-base`:
-> The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 16GB and 1 GPU card. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly.
-
-```bash
-export EXP_NAME=wikisql_tapex_base
-
-python run_wikisql_with_tapex.py \
- --do_train \
- --do_eval \
- --output_dir $EXP_NAME \
- --model_name_or_path microsoft/tapex-base \
- --overwrite_output_dir \
- --per_device_train_batch_size 4 \
- --gradient_accumulation_steps 8 \
- --per_device_eval_batch_size 4 \
- --learning_rate 3e-5 \
- --logging_steps 10 \
- --eval_steps 1000 \
- --save_steps 1000 \
- --warmup_steps 1000 \
- --eval_strategy steps \
- --predict_with_generate \
- --num_beams 5 \
- --weight_decay 1e-2 \
- --label_smoothing_factor 0.1 \
- --max_steps 20000
-```
-
-#### TAPEX-Large on WikiSQL
-
-Here is how to run the script on the WikiSQL with `tapex-large`:
-> The default hyper-parameter may allow you to reproduce our reported tapex-large results within the memory budget of 16GB and 1 GPU card with fp16. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly. If you do not install apex or other mixed-precision-training libs, you could disable the `predict_with_generate` option to save GPU memory and manually evaluate the model once the fine-tuning finished. Or just pick up the last checkpoint, which usually performs good enough on the dataset.
-
-```bash
-export EXP_NAME=wikisql_tapex_large
-
-python run_wikisql_with_tapex.py \
- --do_train \
- --do_eval \
- --output_dir $EXP_NAME \
- --model_name_or_path microsoft/tapex-large \
- --overwrite_output_dir \
- --per_device_train_batch_size 1 \
- --gradient_accumulation_steps 32 \
- --per_device_eval_batch_size 4 \
- --learning_rate 3e-5 \
- --logging_steps 10 \
- --eval_steps 1000 \
- --save_steps 1000 \
- --warmup_steps 1000 \
- --eval_strategy steps \
- --predict_with_generate \
- --num_beams 5 \
- --weight_decay 1e-2 \
- --label_smoothing_factor 0.1 \
- --max_steps 20000 \
- --fp16
-```
-
-#### TAPEX-Base on WikiTableQuestions
-
-Here is how to run the script on the WikiTableQuestions with `tapex-base`:
-> The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 16GB and 1 GPU card. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly.
-
-```bash
-export EXP_NAME=wikitablequestions_tapex_base
-
-python run_wikitablequestions_with_tapex.py \
- --do_train \
- --do_eval \
- --output_dir $EXP_NAME \
- --model_name_or_path microsoft/tapex-base \
- --overwrite_output_dir \
- --per_device_train_batch_size 4 \
- --gradient_accumulation_steps 8 \
- --per_device_eval_batch_size 4 \
- --learning_rate 3e-5 \
- --logging_steps 10 \
- --eval_steps 1000 \
- --save_steps 1000 \
- --warmup_steps 1000 \
- --eval_strategy steps \
- --predict_with_generate \
- --num_beams 5 \
- --weight_decay 1e-2 \
- --label_smoothing_factor 0.1 \
- --max_steps 20000
-```
-
-#### TAPEX-Large on WikiTableQuestions
-
-Here is how to run the script on the WikiTableQuestions with `tapex-large`:
-> The default hyper-parameter may allow you to reproduce our reported tapex-large results within the memory budget of 16GB and 1 GPU card with fp16. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly. If you do not install apex or other mixed-precision-training libs, you could reduce the `per_device_train_batch_size` and `per_device_eval_batch_size` and have another try. Or you could disable the `predict_with_generate` option to save GPU memory and manually evaluate the model once the fine-tuning finished. Or just pick up the last checkpoint, which usually performs good enough on the dataset.
-
-```bash
-export EXP_NAME=wikitablequestions_tapex_large
-
-python run_wikitablequestions_with_tapex.py \
- --do_train \
- --do_eval \
- --output_dir $EXP_NAME \
- --model_name_or_path microsoft/tapex-large \
- --overwrite_output_dir \
- --per_device_train_batch_size 2 \
- --gradient_accumulation_steps 12 \
- --per_device_eval_batch_size 4 \
- --learning_rate 3e-5 \
- --logging_steps 10 \
- --eval_steps 1000 \
- --save_steps 1000 \
- --warmup_steps 1000 \
- --eval_strategy steps \
- --predict_with_generate \
- --num_beams 5 \
- --weight_decay 1e-2 \
- --label_smoothing_factor 0.1 \
- --max_steps 20000 \
- --fp16
-```
-
-### How to Evaluate TAPEX Fine-tuned Models on TableQA
-
-We provide fine-tuned model weights to reproduce our results. You can evaluate them using the following command:
-> You can also replace `microsoft/tapex-base-finetuned-wikisql` with your local directory to evaluate your fine-tuned models. Notice that if the model has a larger size, you should reduce `per_device_eval_batch_size` to fit the memory requirement.
-
-```bash
-export EXP_NAME=wikisql_tapex_base_eval
-
-python run_wikisql_with_tapex.py \
- --do_eval \
- --model_name_or_path microsoft/tapex-base-finetuned-wikisql \
- --output_dir $EXP_NAME \
- --per_device_eval_batch_size 4 \
- --predict_with_generate \
- --num_beams 5
-```
-
-## Table Fact Verification Tasks
-
-### What is Table Fact Verification
-
-
-
-The task of Table Fact Verification (TableFV) is to empower machines to justify if a statement follows facts in a given table. The result is a binary classification belonging to `1` (entailed) or `0` (refused).
-
-### How to Fine-tune TAPEX on TableFV
-
-#### TAPEX-Base on TabFact
-
-We provide a fine-tuning script of tapex for TableFV on the TabFact benchmark: [TabFact](https://github.com/wenhuchen/Table-Fact-Checking).
-
-Here is how to run the script on the TabFact:
-> The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 16GB and 1 GPU card. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly. Note that the `eval_accumulation_steps` is necessary, otherwise GPU memory leaks will occur during the evaluation.
-
-```bash
-export EXP_NAME=tabfact_tapex_base
-
-python run_tabfact_with_tapex.py \
- --do_train \
- --do_eval \
- --output_dir $EXP_NAME \
- --model_name_or_path microsoft/tapex-base \
- --overwrite_output_dir \
- --per_device_train_batch_size 3 \
- --gradient_accumulation_steps 16 \
- --per_device_eval_batch_size 12 \
- --eval_accumulation_steps 6 \
- --warm_steps 1000 \
- --logging_steps 10 \
- --learning_rate 3e-5 \
- --eval_steps 1000 \
- --save_steps 1000 \
- --eval_strategy steps \
- --weight_decay 1e-2 \
- --max_steps 30000 \
- --max_grad_norm 0.1
-```
-
-#### TAPEX-Large on TabFact
-
-Here is how to run the script on the TabFact:
-> The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 24GB and 1 GPU card. Sorry we cannot reduce the memory consumption since the model input in TabFact usually contains nearly ~1000 tokens. If you have more GPU cards, you could reduce `gradient_accumulation_steps` accordingly. Note that the `eval_accumulation_steps` is necessary, otherwise GPU memory leaks will occur during the evaluation.
-
-```bash
-export EXP_NAME=tabfact_tapex_large
-
-python run_tabfact_with_tapex.py \
- --do_train \
- --do_eval \
- --output_dir $EXP_NAME \
- --model_name_or_path microsoft/tapex-large \
- --overwrite_output_dir \
- --per_device_train_batch_size 2 \
- --gradient_accumulation_steps 18 \
- --per_device_eval_batch_size 4 \
- --eval_accumulation_steps 12 \
- --warm_steps 1000 \
- --logging_steps 10 \
- --learning_rate 3e-5 \
- --eval_steps 1000 \
- --save_steps 1000 \
- --eval_strategy steps \
- --weight_decay 1e-2 \
- --max_steps 30000 \
- --max_grad_norm 0.1
-```
-
-### How to Evaluate TAPEX Fine-tuned Models on TableFV
-
-We provide fine-tuned model weights to reproduce our results. You can evaluate them using the following command:
-> You can also replace `microsoft/tapex-base-finetuned-tabfact` with your local directory to evaluate your fine-tuned models. Notice that if the model has a larger size, you should reduce `per_device_eval_batch_size` to fit the memory requirement.
-
-```bash
-export EXP_NAME=tabfact_tapex_base_eval
-
-python run_tabfact_with_tapex.py \
- --do_eval \
- --model_name_or_path microsoft/tapex-base-finetuned-tabfact \
- --output_dir $EXP_NAME \
- --per_device_eval_batch_size 12 \
- --eval_accumulation_steps 6
-```
-
-## Reproduced Results
-
-We get the following results on the dev set of the benchmark with the previous commands:
-
-| Task | Model Size | Metric | Result |
-|:---:|:---:|:---:|:---:|
-| WikiSQL (Weak) | Base | Denotation Accuracy | 88.1 |
-| WikiSQL (Weak) | Large | Denotation Accuracy | 89.5 |
-| WikiTableQuestion | Base | Denotation Accuracy | 47.1 |
-| WikiTableQuestion | Large | Denotation Accuracy | 57.2 |
-| TabFact | Base | Accuracy | 78.7 |
-| TabFact | Large | Accuracy | 83.6 |
diff --git a/examples/research_projects/tapex/requirements.txt b/examples/research_projects/tapex/requirements.txt
deleted file mode 100644
index 2379012a9b2..00000000000
--- a/examples/research_projects/tapex/requirements.txt
+++ /dev/null
@@ -1,4 +0,0 @@
-numpy
-datasets
-pandas
-nltk
\ No newline at end of file
diff --git a/examples/research_projects/tapex/run_tabfact_with_tapex.py b/examples/research_projects/tapex/run_tabfact_with_tapex.py
deleted file mode 100644
index 5dcec10a084..00000000000
--- a/examples/research_projects/tapex/run_tabfact_with_tapex.py
+++ /dev/null
@@ -1,471 +0,0 @@
-#!/usr/bin/env python
-# coding=utf-8
-# Copyright 2022 The Microsoft and The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""
-Fine-tuning the library models for tapex on table-based fact verification tasks.
-Adapted from script: https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py
-"""
-
-import logging
-import os
-import random
-import sys
-from dataclasses import dataclass, field
-from typing import Optional
-
-import datasets
-import numpy as np
-import pandas as pd
-from datasets import load_dataset
-
-import transformers
-from transformers import (
- AutoConfig,
- BartForSequenceClassification,
- DataCollatorWithPadding,
- EvalPrediction,
- HfArgumentParser,
- TapexTokenizer,
- Trainer,
- TrainingArguments,
- default_data_collator,
- set_seed,
-)
-from transformers.trainer_utils import get_last_checkpoint
-from transformers.utils import check_min_version
-from transformers.utils.versions import require_version
-
-
-# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.17.0.dev0")
-
-require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/text-classification/requirements.txt")
-
-logger = logging.getLogger(__name__)
-
-
-@dataclass
-class DataTrainingArguments:
- """
- Arguments pertaining to what data we are going to input our model for training and eval.
-
- Using `HfArgumentParser` we can turn this class
- into argparse arguments to be able to specify them on
- the command line.
- """
-
- dataset_name: Optional[str] = field(
- default="tab_fact", metadata={"help": "The name of the dataset to use (via the datasets library)."}
- )
- dataset_config_name: Optional[str] = field(
- default="tab_fact",
- metadata={"help": "The configuration name of the dataset to use (via the datasets library)."},
- )
- max_seq_length: int = field(
- default=1024,
- metadata={
- "help": (
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- )
- },
- )
- overwrite_cache: bool = field(
- default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
- )
- pad_to_max_length: bool = field(
- default=False,
- metadata={
- "help": (
- "Whether to pad all samples to `max_seq_length`. "
- "If False, will pad the samples dynamically when batching to the maximum length in the batch."
- )
- },
- )
- max_train_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of training examples to this "
- "value if set."
- )
- },
- )
- max_eval_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
- "value if set."
- )
- },
- )
- max_predict_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of prediction examples to this "
- "value if set."
- )
- },
- )
- train_file: Optional[str] = field(
- default=None, metadata={"help": "A csv or a json file containing the training data."}
- )
- validation_file: Optional[str] = field(
- default=None, metadata={"help": "A csv or a json file containing the validation data."}
- )
- test_file: Optional[str] = field(default=None, metadata={"help": "A csv or a json file containing the test data."})
-
- def __post_init__(self):
- if self.dataset_name is not None:
- pass
- elif self.train_file is None or self.validation_file is None:
- raise ValueError("Need either a GLUE task, a training/validation file or a dataset name.")
- else:
- train_extension = self.train_file.split(".")[-1]
- assert train_extension in ["csv", "json"], "`train_file` should be a csv or a json file."
- validation_extension = self.validation_file.split(".")[-1]
- assert (
- validation_extension == train_extension
- ), "`validation_file` should have the same extension (csv or json) as `train_file`."
-
-
-@dataclass
-class ModelArguments:
- """
- Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
- """
-
- model_name_or_path: str = field(
- default=None, metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
- )
- config_name: Optional[str] = field(
- default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
- )
- tokenizer_name: Optional[str] = field(
- default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
- )
- cache_dir: Optional[str] = field(
- default=None,
- metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
- )
- use_fast_tokenizer: bool = field(
- default=True,
- metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
- )
- model_revision: str = field(
- default="main",
- metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
- )
- use_auth_token: bool = field(
- default=False,
- metadata={
- "help": (
- "Will use the token generated when running `huggingface-cli login` (necessary to use this script "
- "with private models)."
- )
- },
- )
-
-
-def main():
- # See all possible arguments in src/transformers/training_args.py
- # or by passing the --help flag to this script.
- # We now keep distinct sets of args, for a cleaner separation of concerns.
-
- parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
- if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
- # If we pass only one argument to the script and it's the path to a json file,
- # let's parse it to get our arguments.
- model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
- else:
- model_args, data_args, training_args = parser.parse_args_into_dataclasses()
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- handlers=[logging.StreamHandler(sys.stdout)],
- )
-
- log_level = training_args.get_process_log_level()
- logger.setLevel(log_level)
- datasets.utils.logging.set_verbosity(log_level)
- transformers.utils.logging.set_verbosity(log_level)
- transformers.utils.logging.enable_default_handler()
- transformers.utils.logging.enable_explicit_format()
-
- # Log on each process the small summary:
- logger.warning(
- f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
- + f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
- )
- logger.info(f"Training/evaluation parameters {training_args}")
-
- # Detecting last checkpoint.
- last_checkpoint = None
- if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
- last_checkpoint = get_last_checkpoint(training_args.output_dir)
- if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
- raise ValueError(
- f"Output directory ({training_args.output_dir}) already exists and is not empty. "
- "Use --overwrite_output_dir to overcome."
- )
- elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
- logger.info(
- f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
- "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
- )
-
- # Set seed before initializing model.
- set_seed(training_args.seed)
-
- # Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
- # or specify a GLUE benchmark task (the dataset will be downloaded automatically from the datasets Hub).
- #
- # For JSON files, this script will use the `question` column for the input question and `table` column for the corresponding table.
- #
- # If the CSVs/JSONs contain only one non-label column, the script does single sentence classification on this
- # single column. You can easily tweak this behavior (see below)
- #
- # In distributed training, the load_dataset function guarantee that only one local process can concurrently
- # download the dataset.
- if data_args.dataset_name is not None:
- # Downloading and loading a dataset from the hub.
- raw_datasets = load_dataset(
- data_args.dataset_name, data_args.dataset_config_name, cache_dir=model_args.cache_dir
- )
- else:
- # Loading a dataset from your local files.
- # CSV/JSON training and evaluation files are needed.
- data_files = {"train": data_args.train_file, "validation": data_args.validation_file}
-
- # Get the test dataset: you can provide your own CSV/JSON test file (see below)
- # when you use `do_predict` without specifying a GLUE benchmark task.
- if training_args.do_predict:
- if data_args.test_file is not None:
- train_extension = data_args.train_file.split(".")[-1]
- test_extension = data_args.test_file.split(".")[-1]
- assert (
- test_extension == train_extension
- ), "`test_file` should have the same extension (csv or json) as `train_file`."
- data_files["test"] = data_args.test_file
- else:
- raise ValueError("Need either a GLUE task or a test file for `do_predict`.")
-
- for key in data_files.keys():
- logger.info(f"load a local file for {key}: {data_files[key]}")
-
- if data_args.train_file.endswith(".csv"):
- # Loading a dataset from local csv files
- raw_datasets = load_dataset("csv", data_files=data_files, cache_dir=model_args.cache_dir)
- else:
- # Loading a dataset from local json files
- raw_datasets = load_dataset("json", data_files=data_files, cache_dir=model_args.cache_dir)
- # See more about loading any type of standard or custom dataset at
- # https://huggingface.co/docs/datasets/loading_datasets.
-
- # Labels
- label_list = raw_datasets["train"].features["label"].names
- num_labels = len(label_list)
-
- # Load pretrained model and tokenizer
- #
- # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
- # download model & vocab.
- config = AutoConfig.from_pretrained(
- model_args.config_name if model_args.config_name else model_args.model_name_or_path,
- num_labels=num_labels,
- cache_dir=model_args.cache_dir,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- )
- # load tapex tokenizer
- tokenizer = TapexTokenizer.from_pretrained(
- model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- use_fast=model_args.use_fast_tokenizer,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- add_prefix_space=True,
- )
- model = BartForSequenceClassification.from_pretrained(
- model_args.model_name_or_path,
- from_tf=bool(".ckpt" in model_args.model_name_or_path),
- config=config,
- cache_dir=model_args.cache_dir,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- )
-
- # Padding strategy
- if data_args.pad_to_max_length:
- padding = "max_length"
- else:
- # We will pad later, dynamically at batch creation, to the max sequence length in each batch
- padding = False
-
- # Some models have set the order of the labels to use, so let's make sure we do use it.
- model.config.label2id = {"Refused": 0, "Entailed": 1}
- model.config.id2label = {0: "Refused", 1: "Entailed"}
-
- if data_args.max_seq_length > tokenizer.model_max_length:
- logger.warning(
- f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the "
- f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
- )
- max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
-
- def preprocess_tabfact_function(examples):
- # Tokenize the texts
- def _convert_table_text_to_pandas(_table_text):
- """Runs the structured pandas table object for _table_text.
- An example _table_text can be: round#clubs remaining\nfirst round#156\n
- """
- _table_content = [_table_row.split("#") for _table_row in _table_text.strip("\n").split("\n")]
- _table_pd = pd.DataFrame.from_records(_table_content[1:], columns=_table_content[0])
- return _table_pd
-
- questions = examples["statement"]
- tables = list(map(_convert_table_text_to_pandas, examples["table_text"]))
- result = tokenizer(tables, questions, padding=padding, max_length=max_seq_length, truncation=True)
-
- result["label"] = examples["label"]
- return result
-
- with training_args.main_process_first(desc="dataset map pre-processing"):
- raw_datasets = raw_datasets.map(
- preprocess_tabfact_function,
- batched=True,
- load_from_cache_file=not data_args.overwrite_cache,
- desc="Running tokenizer on dataset",
- )
- if training_args.do_train:
- if "train" not in raw_datasets:
- raise ValueError("--do_train requires a train dataset")
- train_dataset = raw_datasets["train"]
- if data_args.max_train_samples is not None:
- train_dataset = train_dataset.select(range(data_args.max_train_samples))
-
- if training_args.do_eval:
- if "validation" not in raw_datasets and "validation_matched" not in raw_datasets:
- raise ValueError("--do_eval requires a validation dataset")
- eval_dataset = raw_datasets["validation"]
- if data_args.max_eval_samples is not None:
- eval_dataset = eval_dataset.select(range(data_args.max_eval_samples))
-
- if training_args.do_predict or data_args.test_file is not None:
- if "test" not in raw_datasets and "test_matched" not in raw_datasets:
- raise ValueError("--do_predict requires a test dataset")
- predict_dataset = raw_datasets["test"]
- if data_args.max_predict_samples is not None:
- predict_dataset = predict_dataset.select(range(data_args.max_predict_samples))
-
- # Log a few random samples from the training set:
- if training_args.do_train:
- for index in random.sample(range(len(train_dataset)), 3):
- logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
-
- # You can define your custom compute_metrics function. It takes an `EvalPrediction` object (a namedtuple with a
- # predictions and label_ids field) and has to return a dictionary string to float.
- def compute_metrics(p: EvalPrediction):
- preds = p.predictions[0] if isinstance(p.predictions, tuple) else p.predictions
- preds = np.argmax(preds, axis=1)
- return {"accuracy": (preds == p.label_ids).astype(np.float32).mean().item()}
-
- # Data collator will default to DataCollatorWithPadding, so we change it if we already did the padding.
- if data_args.pad_to_max_length:
- data_collator = default_data_collator
- elif training_args.fp16:
- data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=8)
- else:
- data_collator = None
-
- # Initialize our Trainer
- trainer = Trainer(
- model=model,
- args=training_args,
- train_dataset=train_dataset if training_args.do_train else None,
- eval_dataset=eval_dataset if training_args.do_eval else None,
- compute_metrics=compute_metrics,
- tokenizer=tokenizer,
- data_collator=data_collator,
- )
-
- # Training
- if training_args.do_train:
- checkpoint = None
- if training_args.resume_from_checkpoint is not None:
- checkpoint = training_args.resume_from_checkpoint
- elif last_checkpoint is not None:
- checkpoint = last_checkpoint
- train_result = trainer.train(resume_from_checkpoint=checkpoint)
- metrics = train_result.metrics
- max_train_samples = (
- data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
- )
- metrics["train_samples"] = min(max_train_samples, len(train_dataset))
-
- trainer.save_model() # Saves the tokenizer too for easy upload
-
- trainer.log_metrics("train", metrics)
- trainer.save_metrics("train", metrics)
- trainer.save_state()
-
- # Evaluation
- if training_args.do_eval:
- logger.info("*** Evaluate ***")
-
- metrics = trainer.evaluate(eval_dataset=eval_dataset)
- max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
- metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
-
- trainer.log_metrics("eval", metrics)
- trainer.save_metrics("eval", metrics)
-
- if training_args.do_predict:
- logger.info("*** Predict ***")
-
- # Removing the `label` columns because it contains -1 and Trainer won't like that.
- predict_dataset = predict_dataset.remove_columns("label")
- predictions = trainer.predict(predict_dataset, metric_key_prefix="predict").predictions
- predictions = np.argmax(predictions, axis=1)
-
- output_predict_file = os.path.join(training_args.output_dir, "predict_results_tabfact.txt")
- if trainer.is_world_process_zero():
- with open(output_predict_file, "w") as writer:
- logger.info("***** Predict Results *****")
- writer.write("index\tprediction\n")
- for index, item in enumerate(predictions):
- item = label_list[item]
- writer.write(f"{index}\t{item}\n")
-
- kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "text-classification"}
-
- if training_args.push_to_hub:
- trainer.push_to_hub(**kwargs)
- else:
- trainer.create_model_card(**kwargs)
-
-
-def _mp_fn(index):
- # For xla_spawn (TPUs)
- main()
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/tapex/run_wikisql_with_tapex.py b/examples/research_projects/tapex/run_wikisql_with_tapex.py
deleted file mode 100644
index 81e940a77c8..00000000000
--- a/examples/research_projects/tapex/run_wikisql_with_tapex.py
+++ /dev/null
@@ -1,649 +0,0 @@
-#!/usr/bin/env python
-# coding=utf-8
-# Copyright 2022 The Microsoft and The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""
-Fine-tuning the library models for tapex on table-based question answering tasks.
-Adapted from script: https://github.com/huggingface/transformers/blob/master/examples/pytorch/summarization/run_summarization.py
-"""
-
-import logging
-import os
-import sys
-from collections import defaultdict
-from copy import deepcopy
-from dataclasses import dataclass, field
-from functools import partial
-from typing import List, Optional
-
-import nltk # Here to have a nice missing dependency error message early on
-import numpy as np
-import pandas as pd
-from datasets import load_dataset
-from filelock import FileLock
-from wikisql_utils import _TYPE_CONVERTER, retrieve_wikisql_query_answer_tapas
-
-import transformers
-from transformers import (
- AutoConfig,
- BartForConditionalGeneration,
- DataCollatorForSeq2Seq,
- HfArgumentParser,
- Seq2SeqTrainer,
- Seq2SeqTrainingArguments,
- TapexTokenizer,
- set_seed,
-)
-from transformers.file_utils import is_offline_mode
-from transformers.trainer_utils import get_last_checkpoint, is_main_process
-from transformers.utils import check_min_version
-
-
-# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.17.0.dev0")
-
-logger = logging.getLogger(__name__)
-
-try:
- nltk.data.find("tokenizers/punkt")
-except (LookupError, OSError):
- if is_offline_mode():
- raise LookupError(
- "Offline mode: run this script without TRANSFORMERS_OFFLINE first to download nltk data files"
- )
- with FileLock(".lock") as lock:
- nltk.download("punkt", quiet=True)
-
-
-@dataclass
-class ModelArguments:
- """
- Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
- """
-
- model_name_or_path: str = field(
- metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"},
- )
- config_name: Optional[str] = field(
- default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
- )
- tokenizer_name: Optional[str] = field(
- default=None,
- metadata={
- "help": (
- "Pretrained tokenizer name or path if not the same as model_name. "
- "By default we use BART-large tokenizer for TAPEX-large."
- )
- },
- )
- cache_dir: Optional[str] = field(
- default=None,
- metadata={"help": "Where to store the pretrained models downloaded from huggingface.co"},
- )
- use_fast_tokenizer: bool = field(
- default=True,
- metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
- )
- model_revision: str = field(
- default="main",
- metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
- )
- use_auth_token: bool = field(
- default=False,
- metadata={
- "help": (
- "Will use the token generated when running `huggingface-cli login` (necessary to use this script "
- "with private models)."
- )
- },
- )
-
-
-@dataclass
-class DataTrainingArguments:
- """
- Arguments pertaining to what data we are going to input our model for training and eval.
- """
-
- dataset_name: Optional[str] = field(
- default="wikisql", metadata={"help": "The name of the dataset to use (via the datasets library)."}
- )
- dataset_config_name: Optional[str] = field(
- default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
- )
- train_file: Optional[str] = field(
- default=None, metadata={"help": "The input training data file (a jsonlines or csv file)."}
- )
- validation_file: Optional[str] = field(
- default=None,
- metadata={
- "help": (
- "An optional input evaluation data file to evaluate the metrics (rouge) on (a jsonlines or csv file)."
- )
- },
- )
- test_file: Optional[str] = field(
- default=None,
- metadata={
- "help": "An optional input test data file to evaluate the metrics (rouge) on (a jsonlines or csv file)."
- },
- )
- overwrite_cache: bool = field(
- default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
- )
- preprocessing_num_workers: Optional[int] = field(
- default=None,
- metadata={"help": "The number of processes to use for the preprocessing."},
- )
- max_source_length: Optional[int] = field(
- default=1024,
- metadata={
- "help": (
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- )
- },
- )
- max_target_length: Optional[int] = field(
- default=128,
- metadata={
- "help": (
- "The maximum total sequence length for target text after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- )
- },
- )
- val_max_target_length: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "The maximum total sequence length for validation target text after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded. Will default to `max_target_length`. "
- "This argument is also used to override the ``max_length`` param of ``model.generate``, which is used "
- "during ``evaluate`` and ``predict``."
- )
- },
- )
- pad_to_max_length: bool = field(
- default=False,
- metadata={
- "help": (
- "Whether to pad all samples to model maximum sentence length. "
- "If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
- "efficient on GPU but very bad for TPU."
- )
- },
- )
- max_train_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of training examples to this "
- "value if set."
- )
- },
- )
- max_eval_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
- "value if set."
- )
- },
- )
- max_predict_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of prediction examples to this "
- "value if set."
- )
- },
- )
- num_beams: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "Number of beams to use for evaluation. This argument will be passed to ``model.generate``, "
- "which is used during ``evaluate`` and ``predict``."
- )
- },
- )
- ignore_pad_token_for_loss: bool = field(
- default=True,
- metadata={
- "help": "Whether to ignore the tokens corresponding to padded labels in the loss computation or not."
- },
- )
-
- def __post_init__(self):
- if self.dataset_name is None and self.train_file is None and self.validation_file is None:
- raise ValueError("Need either a dataset name or a training/validation file.")
- else:
- if self.train_file is not None:
- extension = self.train_file.split(".")[-1]
- assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
- if self.validation_file is not None:
- extension = self.validation_file.split(".")[-1]
- assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
- if self.val_max_target_length is None:
- self.val_max_target_length = self.max_target_length
-
-
-def main():
- # See all possible arguments in src/transformers/training_args.py
- # or by passing the --help flag to this script.
- # We now keep distinct sets of args, for a cleaner separation of concerns.
-
- parser = HfArgumentParser((ModelArguments, DataTrainingArguments, Seq2SeqTrainingArguments))
- if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
- # If we pass only one argument to the script and it's the path to a json file,
- # let's parse it to get our arguments.
- model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
- else:
- model_args, data_args, training_args = parser.parse_args_into_dataclasses()
-
- # Detecting last checkpoint.
- last_checkpoint = None
- if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
- last_checkpoint = get_last_checkpoint(training_args.output_dir)
- if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
- raise ValueError(
- f"Output directory ({training_args.output_dir}) already exists and is not empty. "
- "Use --overwrite_output_dir to overcome."
- )
- elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
- logger.info(
- f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
- "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
- )
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- handlers=[logging.StreamHandler(sys.stdout)],
- )
- logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
-
- # Log on each process the small summary:
- logger.warning(
- f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
- + f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
- )
- # Set the verbosity to info of the Transformers logger (on main process only):
- if is_main_process(training_args.local_rank):
- transformers.utils.logging.set_verbosity_info()
- logger.info(f"Training/evaluation parameters {training_args}")
-
- # Set seed before initializing model.
- set_seed(training_args.seed)
-
- # Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
- # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
- # (the dataset will be downloaded automatically from the datasets Hub).
- #
- # For JSON files, this script will use the `question` column for the input question and `table` column for the corresponding table.
- #
- # In distributed training, the load_dataset function guarantee that only one local process can concurrently
- # download the dataset.
- if data_args.dataset_name is not None:
- # Downloading and loading a dataset from the hub.
- datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name, cache_dir=model_args.cache_dir)
- else:
- data_files = {}
- if data_args.train_file is not None:
- data_files["train"] = data_args.train_file
- extension = data_args.train_file.split(".")[-1]
- if data_args.validation_file is not None:
- data_files["validation"] = data_args.validation_file
- extension = data_args.validation_file.split(".")[-1]
- if data_args.test_file is not None:
- data_files["test"] = data_args.test_file
- extension = data_args.test_file.split(".")[-1]
- datasets = load_dataset(extension, data_files=data_files, cache_dir=model_args.cache_dir)
-
- # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
- # https://huggingface.co/docs/datasets/loading_datasets.
-
- # Load pretrained model and tokenizer
- #
- # Distributed training:
- # The .from_pretrained methods guarantee that only one local process can concurrently
- # download model & vocab.
-
- config = AutoConfig.from_pretrained(
- model_args.config_name if model_args.config_name else model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- )
-
- # IMPORTANT: the initial BART model's decoding is penalized by no_repeat_ngram_size, and thus
- # we should disable it here to avoid problematic generation
- config.no_repeat_ngram_size = 0
- config.max_length = 1024
- config.early_stopping = False
-
- # load tapex tokenizer
- tokenizer = TapexTokenizer.from_pretrained(
- model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- use_fast=model_args.use_fast_tokenizer,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- add_prefix_space=True,
- )
-
- # load Bart based Tapex model (default tapex-large)
- model = BartForConditionalGeneration.from_pretrained(
- model_args.model_name_or_path,
- from_tf=bool(".ckpt" in model_args.model_name_or_path),
- config=config,
- cache_dir=model_args.cache_dir,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- )
-
- if model.config.decoder_start_token_id is None:
- raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
-
- # Preprocessing the datasets.
- # We need to tokenize inputs and targets.
- if training_args.do_train:
- column_names = datasets["train"].column_names
- elif training_args.do_eval:
- column_names = datasets["validation"].column_names
- elif training_args.do_predict:
- column_names = datasets["test"].column_names
- else:
- logger.info("There is nothing to do. Please pass `do_train`, `do_eval` and/or `do_predict`.")
- return
-
- # Temporarily set max_target_length for training.
- max_target_length = data_args.max_target_length
- padding = "max_length" if data_args.pad_to_max_length else False
-
- if training_args.label_smoothing_factor > 0 and not hasattr(model, "prepare_decoder_input_ids_from_labels"):
- logger.warning(
- "label_smoothing is enabled but the `prepare_decoder_input_ids_from_labels` method is not defined for "
- f"`{model.__class__.__name__}`. This will lead to loss being calculated twice and will take up more memory"
- )
-
- def preprocess_tableqa_function(examples, is_training=False):
- """
- The is_training FLAG is used to identify if we could use the supervision
- to truncate the table content if it is required.
- """
-
- # this function is specific for WikiSQL since the util function need the data structure
- # to retrieve the WikiSQL answer for each question
- def _convert_table_types(_table):
- """Runs the type converter over the table cells."""
- ret_table = deepcopy(_table)
- types = ret_table["types"]
- ret_table["real_rows"] = ret_table["rows"]
- typed_rows = []
- for row in ret_table["rows"]:
- typed_row = []
- for column, cell_value in enumerate(row):
- typed_row.append(_TYPE_CONVERTER[types[column]](cell_value))
- typed_rows.append(typed_row)
- ret_table["rows"] = typed_rows
- return ret_table
-
- questions = [question.lower() for question in examples["question"]]
- example_tables = examples["table"]
- example_sqls = examples["sql"]
- tables = [
- pd.DataFrame.from_records(example_table["rows"], columns=example_table["header"])
- for example_table in example_tables
- ]
-
- # using tapas utils to obtain wikisql answer
- answers = []
- for example_sql, example_table in zip(example_sqls, example_tables):
- tapas_table = _convert_table_types(example_table)
- answer_list: List[str] = retrieve_wikisql_query_answer_tapas(tapas_table, example_sql)
- # you can choose other delimiters to split each answer
- answers.append(answer_list)
-
- # IMPORTANT: we cannot pass by answers during evaluation, answers passed during training are used to
- # truncate large tables in the train set!
- if is_training:
- model_inputs = tokenizer(
- table=tables,
- query=questions,
- answer=answers,
- max_length=data_args.max_source_length,
- padding=padding,
- truncation=True,
- )
- else:
- model_inputs = tokenizer(
- table=tables, query=questions, max_length=data_args.max_source_length, padding=padding, truncation=True
- )
-
- labels = tokenizer(
- answer=[", ".join(answer) for answer in answers],
- max_length=max_target_length,
- padding=padding,
- truncation=True,
- )
-
- # If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore
- # padding in the loss.
- if padding == "max_length" and data_args.ignore_pad_token_for_loss:
- labels["input_ids"] = [
- [(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]
- ]
-
- model_inputs["labels"] = labels["input_ids"]
-
- return model_inputs
-
- # in training, we can use the answer as extra information to truncate large tables
- preprocess_tableqa_function_training = partial(preprocess_tableqa_function, is_training=True)
-
- if training_args.do_train:
- if "train" not in datasets:
- raise ValueError("--do_train requires a train dataset")
- train_dataset = datasets["train"]
- if data_args.max_train_samples is not None:
- train_dataset = train_dataset.select(range(data_args.max_train_samples))
- train_dataset = train_dataset.map(
- preprocess_tableqa_function_training,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not data_args.overwrite_cache,
- )
-
- if training_args.do_eval:
- max_target_length = data_args.val_max_target_length
- if "validation" not in datasets:
- raise ValueError("--do_eval requires a validation dataset")
- eval_dataset = datasets["validation"]
- if data_args.max_eval_samples is not None:
- eval_dataset = eval_dataset.select(range(data_args.max_eval_samples))
- eval_dataset = eval_dataset.map(
- preprocess_tableqa_function,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not data_args.overwrite_cache,
- )
-
- if training_args.do_predict:
- max_target_length = data_args.val_max_target_length
- if "test" not in datasets:
- raise ValueError("--do_predict requires a test dataset")
- predict_dataset = datasets["test"]
- if data_args.max_predict_samples is not None:
- predict_dataset = predict_dataset.select(range(data_args.max_predict_samples))
- predict_dataset = predict_dataset.map(
- preprocess_tableqa_function,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not data_args.overwrite_cache,
- )
-
- # Data collator
- label_pad_token_id = -100 if data_args.ignore_pad_token_for_loss else tokenizer.pad_token_id
- data_collator = DataCollatorForSeq2Seq(
- tokenizer,
- model=model,
- label_pad_token_id=label_pad_token_id,
- pad_to_multiple_of=8 if training_args.fp16 else None,
- )
-
- def postprocess_text(preds, labels):
- preds = [pred.strip() for pred in preds]
- labels = [label.strip() for label in labels]
-
- return preds, labels
-
- def compute_metrics(eval_preds):
- preds, labels = eval_preds
- if isinstance(preds, tuple):
- preds = preds[0]
- decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
- if data_args.ignore_pad_token_for_loss:
- # Replace -100 in the labels as we can't decode them.
- labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
- decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
-
- # Some simple post-processing
- decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
-
- delimiter = ", "
-
- # define example evaluation
- def evaluate_example(predict_str: str, ground_str: str):
- predict_spans = predict_str.split(delimiter)
- ground_spans = ground_str.split(delimiter)
- predict_values = defaultdict(lambda: 0)
- ground_values = defaultdict(lambda: 0)
- for span in predict_spans:
- try:
- predict_values[float(span)] += 1
- except ValueError:
- predict_values[span.strip()] += 1
- for span in ground_spans:
- try:
- ground_values[float(span)] += 1
- except ValueError:
- ground_values[span.strip()] += 1
- is_correct = predict_values == ground_values
- return is_correct
-
- def get_denotation_accuracy(predictions: List[str], references: List[str]):
- assert len(predictions) == len(references)
- correct_num = 0
- for predict_str, ground_str in zip(predictions, references):
- is_correct = evaluate_example(predict_str.lower(), ground_str.lower())
- if is_correct:
- correct_num += 1
- return correct_num / len(predictions)
-
- accuracy = get_denotation_accuracy(decoded_preds, decoded_labels)
- result = {"denotation_accuracy": accuracy}
-
- return result
-
- # Initialize our Trainer
- trainer = Seq2SeqTrainer(
- model=model,
- args=training_args,
- train_dataset=train_dataset if training_args.do_train else None,
- eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
- data_collator=data_collator,
- compute_metrics=compute_metrics if training_args.predict_with_generate else None,
- )
-
- if training_args.do_train:
- checkpoint = None
- if training_args.resume_from_checkpoint is not None:
- checkpoint = training_args.resume_from_checkpoint
- elif last_checkpoint is not None:
- checkpoint = last_checkpoint
- train_result = trainer.train(resume_from_checkpoint=checkpoint)
- trainer.save_model() # Saves the tokenizer too for easy upload
-
- metrics = train_result.metrics
- max_train_samples = (
- data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
- )
- metrics["train_samples"] = min(max_train_samples, len(train_dataset))
-
- trainer.log_metrics("train", metrics)
- trainer.save_metrics("train", metrics)
- trainer.save_state()
-
- # Evaluation
- results = {}
- if training_args.do_eval:
- logger.info("*** Evaluate ***")
-
- metrics = trainer.evaluate(
- max_length=data_args.val_max_target_length, num_beams=data_args.num_beams, metric_key_prefix="eval"
- )
- max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
- metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
-
- trainer.log_metrics("eval", metrics)
- trainer.save_metrics("eval", metrics)
-
- if training_args.do_predict:
- logger.info("*** Predict ***")
-
- predict_results = trainer.predict(
- predict_dataset,
- metric_key_prefix="predict",
- max_length=data_args.val_max_target_length,
- num_beams=data_args.num_beams,
- )
- metrics = predict_results.metrics
- max_predict_samples = (
- data_args.max_predict_samples if data_args.max_predict_samples is not None else len(predict_dataset)
- )
- metrics["predict_samples"] = min(max_predict_samples, len(predict_dataset))
-
- trainer.log_metrics("predict", metrics)
- trainer.save_metrics("predict", metrics)
-
- if trainer.is_world_process_zero():
- if training_args.predict_with_generate:
- predictions = tokenizer.batch_decode(
- predict_results.predictions, skip_special_tokens=True, clean_up_tokenization_spaces=True
- )
- predictions = [pred.strip() for pred in predictions]
- output_prediction_file = os.path.join(training_args.output_dir, "tapex_predictions.txt")
- with open(output_prediction_file, "w") as writer:
- writer.write("\n".join(predictions))
-
- return results
-
-
-def _mp_fn(index):
- # For xla_spawn (TPUs)
- main()
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/tapex/run_wikitablequestions_with_tapex.py b/examples/research_projects/tapex/run_wikitablequestions_with_tapex.py
deleted file mode 100644
index 55350025cb3..00000000000
--- a/examples/research_projects/tapex/run_wikitablequestions_with_tapex.py
+++ /dev/null
@@ -1,625 +0,0 @@
-#!/usr/bin/env python
-# coding=utf-8
-# Copyright 2022 The Microsoft and The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""
-Fine-tuning the library models for tapex on table-based question answering tasks.
-Adapted from script: https://github.com/huggingface/transformers/blob/master/examples/pytorch/summarization/run_summarization.py
-"""
-
-import logging
-import os
-import sys
-from collections import defaultdict
-from dataclasses import dataclass, field
-from functools import partial
-from typing import List, Optional
-
-import nltk # Here to have a nice missing dependency error message early on
-import numpy as np
-import pandas as pd
-from datasets import load_dataset
-from filelock import FileLock
-
-import transformers
-from transformers import (
- AutoConfig,
- BartForConditionalGeneration,
- DataCollatorForSeq2Seq,
- HfArgumentParser,
- Seq2SeqTrainer,
- Seq2SeqTrainingArguments,
- TapexTokenizer,
- set_seed,
-)
-from transformers.file_utils import is_offline_mode
-from transformers.trainer_utils import get_last_checkpoint, is_main_process
-from transformers.utils import check_min_version
-
-
-# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.17.0.dev0")
-
-logger = logging.getLogger(__name__)
-
-try:
- nltk.data.find("tokenizers/punkt")
-except (LookupError, OSError):
- if is_offline_mode():
- raise LookupError(
- "Offline mode: run this script without TRANSFORMERS_OFFLINE first to download nltk data files"
- )
- with FileLock(".lock") as lock:
- nltk.download("punkt", quiet=True)
-
-
-@dataclass
-class ModelArguments:
- """
- Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
- """
-
- model_name_or_path: str = field(
- metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"},
- )
- config_name: Optional[str] = field(
- default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
- )
- tokenizer_name: Optional[str] = field(
- default=None,
- metadata={
- "help": (
- "Pretrained tokenizer name or path if not the same as model_name. "
- "By default we use BART-large tokenizer for TAPEX-large."
- )
- },
- )
- cache_dir: Optional[str] = field(
- default=None,
- metadata={"help": "Where to store the pretrained models downloaded from huggingface.co"},
- )
- use_fast_tokenizer: bool = field(
- default=True,
- metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
- )
- model_revision: str = field(
- default="main",
- metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
- )
- use_auth_token: bool = field(
- default=False,
- metadata={
- "help": (
- "Will use the token generated when running `huggingface-cli login` (necessary to use this script "
- "with private models)."
- )
- },
- )
-
-
-@dataclass
-class DataTrainingArguments:
- """
- Arguments pertaining to what data we are going to input our model for training and eval.
- """
-
- dataset_name: Optional[str] = field(
- default="wikitablequestions", metadata={"help": "The name of the dataset to use (via the datasets library)."}
- )
- dataset_config_name: Optional[str] = field(
- default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
- )
- train_file: Optional[str] = field(
- default=None, metadata={"help": "The input training data file (a jsonlines or csv file)."}
- )
- validation_file: Optional[str] = field(
- default=None,
- metadata={
- "help": (
- "An optional input evaluation data file to evaluate the metrics (rouge) on (a jsonlines or csv file)."
- )
- },
- )
- test_file: Optional[str] = field(
- default=None,
- metadata={
- "help": "An optional input test data file to evaluate the metrics (rouge) on (a jsonlines or csv file)."
- },
- )
- overwrite_cache: bool = field(
- default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
- )
- preprocessing_num_workers: Optional[int] = field(
- default=None,
- metadata={"help": "The number of processes to use for the preprocessing."},
- )
- max_source_length: Optional[int] = field(
- default=1024,
- metadata={
- "help": (
- "The maximum total input sequence length after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- )
- },
- )
- max_target_length: Optional[int] = field(
- default=128,
- metadata={
- "help": (
- "The maximum total sequence length for target text after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded."
- )
- },
- )
- val_max_target_length: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "The maximum total sequence length for validation target text after tokenization. Sequences longer "
- "than this will be truncated, sequences shorter will be padded. Will default to `max_target_length`. "
- "This argument is also used to override the ``max_length`` param of ``model.generate``, which is used "
- "during ``evaluate`` and ``predict``."
- )
- },
- )
- pad_to_max_length: bool = field(
- default=False,
- metadata={
- "help": (
- "Whether to pad all samples to model maximum sentence length. "
- "If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
- "efficient on GPU but very bad for TPU."
- )
- },
- )
- max_train_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of training examples to this "
- "value if set."
- )
- },
- )
- max_eval_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
- "value if set."
- )
- },
- )
- max_predict_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of prediction examples to this "
- "value if set."
- )
- },
- )
- num_beams: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "Number of beams to use for evaluation. This argument will be passed to ``model.generate``, "
- "which is used during ``evaluate`` and ``predict``."
- )
- },
- )
- ignore_pad_token_for_loss: bool = field(
- default=True,
- metadata={
- "help": "Whether to ignore the tokens corresponding to padded labels in the loss computation or not."
- },
- )
-
- def __post_init__(self):
- if self.dataset_name is None and self.train_file is None and self.validation_file is None:
- raise ValueError("Need either a dataset name or a training/validation file.")
- else:
- if self.train_file is not None:
- extension = self.train_file.split(".")[-1]
- assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
- if self.validation_file is not None:
- extension = self.validation_file.split(".")[-1]
- assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
- if self.val_max_target_length is None:
- self.val_max_target_length = self.max_target_length
-
-
-def main():
- # See all possible arguments in src/transformers/training_args.py
- # or by passing the --help flag to this script.
- # We now keep distinct sets of args, for a cleaner separation of concerns.
-
- parser = HfArgumentParser((ModelArguments, DataTrainingArguments, Seq2SeqTrainingArguments))
- if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
- # If we pass only one argument to the script and it's the path to a json file,
- # let's parse it to get our arguments.
- model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
- else:
- model_args, data_args, training_args = parser.parse_args_into_dataclasses()
-
- # Detecting last checkpoint.
- last_checkpoint = None
- if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
- last_checkpoint = get_last_checkpoint(training_args.output_dir)
- if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
- raise ValueError(
- f"Output directory ({training_args.output_dir}) already exists and is not empty. "
- "Use --overwrite_output_dir to overcome."
- )
- elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
- logger.info(
- f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
- "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
- )
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- handlers=[logging.StreamHandler(sys.stdout)],
- )
- logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
-
- # Log on each process the small summary:
- logger.warning(
- f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
- + f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
- )
- # Set the verbosity to info of the Transformers logger (on main process only):
- if is_main_process(training_args.local_rank):
- transformers.utils.logging.set_verbosity_info()
- logger.info(f"Training/evaluation parameters {training_args}")
-
- # Set seed before initializing model.
- set_seed(training_args.seed)
-
- # Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
- # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
- # (the dataset will be downloaded automatically from the datasets Hub).
- #
- # For JSON files, this script will use the `question` column for the input question and `table` column for the corresponding table.
- #
- # In distributed training, the load_dataset function guarantee that only one local process can concurrently
- # download the dataset.
- if data_args.dataset_name is not None:
- # Downloading and loading a dataset from the hub.
- datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name, cache_dir=model_args.cache_dir)
- else:
- data_files = {}
- if data_args.train_file is not None:
- data_files["train"] = data_args.train_file
- extension = data_args.train_file.split(".")[-1]
- if data_args.validation_file is not None:
- data_files["validation"] = data_args.validation_file
- extension = data_args.validation_file.split(".")[-1]
- if data_args.test_file is not None:
- data_files["test"] = data_args.test_file
- extension = data_args.test_file.split(".")[-1]
- datasets = load_dataset(extension, data_files=data_files, cache_dir=model_args.cache_dir)
-
- # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
- # https://huggingface.co/docs/datasets/loading_datasets.
-
- # Load pretrained model and tokenizer
- #
- # Distributed training:
- # The .from_pretrained methods guarantee that only one local process can concurrently
- # download model & vocab.
-
- config = AutoConfig.from_pretrained(
- model_args.config_name if model_args.config_name else model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- )
-
- # IMPORTANT: the initial BART model's decoding is penalized by no_repeat_ngram_size, and thus
- # we should disable it here to avoid problematic generation
- config.no_repeat_ngram_size = 0
- config.max_length = 1024
- config.early_stopping = False
-
- # load tapex tokenizer
- tokenizer = TapexTokenizer.from_pretrained(
- model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- use_fast=model_args.use_fast_tokenizer,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- add_prefix_space=True,
- )
-
- # load Bart based Tapex model (default tapex-large)
- model = BartForConditionalGeneration.from_pretrained(
- model_args.model_name_or_path,
- from_tf=bool(".ckpt" in model_args.model_name_or_path),
- config=config,
- cache_dir=model_args.cache_dir,
- revision=model_args.model_revision,
- token=True if model_args.use_auth_token else None,
- )
-
- if model.config.decoder_start_token_id is None:
- raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
-
- # Preprocessing the datasets.
- # We need to tokenize inputs and targets.
- if training_args.do_train:
- column_names = datasets["train"].column_names
- elif training_args.do_eval:
- column_names = datasets["validation"].column_names
- elif training_args.do_predict:
- column_names = datasets["test"].column_names
- else:
- logger.info("There is nothing to do. Please pass `do_train`, `do_eval` and/or `do_predict`.")
- return
-
- # Temporarily set max_target_length for training.
- max_target_length = data_args.max_target_length
- padding = "max_length" if data_args.pad_to_max_length else False
-
- if training_args.label_smoothing_factor > 0 and not hasattr(model, "prepare_decoder_input_ids_from_labels"):
- logger.warning(
- "label_smoothing is enabled but the `prepare_decoder_input_ids_from_labels` method is not defined for "
- f"`{model.__class__.__name__}`. This will lead to loss being calculated twice and will take up more memory"
- )
-
- def preprocess_tableqa_function(examples, is_training=False):
- """
- The is_training FLAG is used to identify if we could use the supervision
- to truncate the table content if it is required.
- """
-
- questions = [question.lower() for question in examples["question"]]
- example_tables = examples["table"]
- tables = [
- pd.DataFrame.from_records(example_table["rows"], columns=example_table["header"])
- for example_table in example_tables
- ]
-
- # using wikitablequestion's answer set
- answers = examples["answers"]
-
- # IMPORTANT: we cannot pass by answers during evaluation, answers passed during training are used to
- # truncate large tables in the train set!
- if is_training:
- model_inputs = tokenizer(
- table=tables,
- query=questions,
- answer=answers,
- max_length=data_args.max_source_length,
- padding=padding,
- truncation=True,
- )
- else:
- model_inputs = tokenizer(
- table=tables, query=questions, max_length=data_args.max_source_length, padding=padding, truncation=True
- )
-
- labels = tokenizer(
- answer=[", ".join(answer) for answer in answers],
- max_length=max_target_length,
- padding=padding,
- truncation=True,
- )
-
- # If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore
- # padding in the loss.
- if padding == "max_length" and data_args.ignore_pad_token_for_loss:
- labels["input_ids"] = [
- [(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]
- ]
-
- model_inputs["labels"] = labels["input_ids"]
-
- return model_inputs
-
- # in training, we can use the answer as extra information to truncate large tables
- preprocess_tableqa_function_training = partial(preprocess_tableqa_function, is_training=True)
-
- if training_args.do_train:
- if "train" not in datasets:
- raise ValueError("--do_train requires a train dataset")
- train_dataset = datasets["train"]
- if data_args.max_train_samples is not None:
- train_dataset = train_dataset.select(range(data_args.max_train_samples))
- train_dataset = train_dataset.map(
- preprocess_tableqa_function_training,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not data_args.overwrite_cache,
- )
-
- if training_args.do_eval:
- max_target_length = data_args.val_max_target_length
- if "validation" not in datasets:
- raise ValueError("--do_eval requires a validation dataset")
- eval_dataset = datasets["validation"]
- if data_args.max_eval_samples is not None:
- eval_dataset = eval_dataset.select(range(data_args.max_eval_samples))
- eval_dataset = eval_dataset.map(
- preprocess_tableqa_function,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not data_args.overwrite_cache,
- )
-
- if training_args.do_predict:
- max_target_length = data_args.val_max_target_length
- if "test" not in datasets:
- raise ValueError("--do_predict requires a test dataset")
- predict_dataset = datasets["test"]
- if data_args.max_predict_samples is not None:
- predict_dataset = predict_dataset.select(range(data_args.max_predict_samples))
- predict_dataset = predict_dataset.map(
- preprocess_tableqa_function,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- remove_columns=column_names,
- load_from_cache_file=not data_args.overwrite_cache,
- )
-
- # Data collator
- label_pad_token_id = -100 if data_args.ignore_pad_token_for_loss else tokenizer.pad_token_id
- data_collator = DataCollatorForSeq2Seq(
- tokenizer,
- model=model,
- label_pad_token_id=label_pad_token_id,
- pad_to_multiple_of=8 if training_args.fp16 else None,
- )
-
- def postprocess_text(preds, labels):
- preds = [pred.strip() for pred in preds]
- labels = [label.strip() for label in labels]
-
- return preds, labels
-
- def compute_metrics(eval_preds):
- preds, labels = eval_preds
- if isinstance(preds, tuple):
- preds = preds[0]
- decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
- if data_args.ignore_pad_token_for_loss:
- # Replace -100 in the labels as we can't decode them.
- labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
- decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
-
- # Some simple post-processing
- decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
-
- delimiter = ", "
-
- # define example evaluation
- def evaluate_example(predict_str: str, ground_str: str):
- predict_spans = predict_str.split(delimiter)
- ground_spans = ground_str.split(delimiter)
- predict_values = defaultdict(lambda: 0)
- ground_values = defaultdict(lambda: 0)
- for span in predict_spans:
- try:
- predict_values[float(span)] += 1
- except ValueError:
- predict_values[span.strip()] += 1
- for span in ground_spans:
- try:
- ground_values[float(span)] += 1
- except ValueError:
- ground_values[span.strip()] += 1
- _is_correct = predict_values == ground_values
- return _is_correct
-
- def get_denotation_accuracy(predictions: List[str], references: List[str]):
- assert len(predictions) == len(references)
- correct_num = 0
- for predict_str, ground_str in zip(predictions, references):
- is_correct = evaluate_example(predict_str.lower(), ground_str.lower())
- if is_correct:
- correct_num += 1
- return correct_num / len(predictions)
-
- accuracy = get_denotation_accuracy(decoded_preds, decoded_labels)
- result = {"denotation_accuracy": accuracy}
-
- return result
-
- # Initialize our Trainer
- trainer = Seq2SeqTrainer(
- model=model,
- args=training_args,
- train_dataset=train_dataset if training_args.do_train else None,
- eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=tokenizer,
- data_collator=data_collator,
- compute_metrics=compute_metrics if training_args.predict_with_generate else None,
- )
-
- if training_args.do_train:
- checkpoint = None
- if training_args.resume_from_checkpoint is not None:
- checkpoint = training_args.resume_from_checkpoint
- elif last_checkpoint is not None:
- checkpoint = last_checkpoint
- train_result = trainer.train(resume_from_checkpoint=checkpoint)
- trainer.save_model() # Saves the tokenizer too for easy upload
-
- metrics = train_result.metrics
- max_train_samples = (
- data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
- )
- metrics["train_samples"] = min(max_train_samples, len(train_dataset))
-
- trainer.log_metrics("train", metrics)
- trainer.save_metrics("train", metrics)
- trainer.save_state()
-
- # Evaluation
- results = {}
- if training_args.do_eval:
- logger.info("*** Evaluate ***")
-
- metrics = trainer.evaluate(
- max_length=data_args.val_max_target_length, num_beams=data_args.num_beams, metric_key_prefix="eval"
- )
- max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
- metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
-
- trainer.log_metrics("eval", metrics)
- trainer.save_metrics("eval", metrics)
-
- if training_args.do_predict:
- logger.info("*** Predict ***")
-
- predict_results = trainer.predict(
- predict_dataset,
- metric_key_prefix="predict",
- max_length=data_args.val_max_target_length,
- num_beams=data_args.num_beams,
- )
- metrics = predict_results.metrics
- max_predict_samples = (
- data_args.max_predict_samples if data_args.max_predict_samples is not None else len(predict_dataset)
- )
- metrics["predict_samples"] = min(max_predict_samples, len(predict_dataset))
-
- trainer.log_metrics("predict", metrics)
- trainer.save_metrics("predict", metrics)
-
- if trainer.is_world_process_zero():
- if training_args.predict_with_generate:
- predictions = tokenizer.batch_decode(
- predict_results.predictions, skip_special_tokens=True, clean_up_tokenization_spaces=True
- )
- predictions = [pred.strip() for pred in predictions]
- output_prediction_file = os.path.join(training_args.output_dir, "tapex_predictions.txt")
- with open(output_prediction_file, "w") as writer:
- writer.write("\n".join(predictions))
-
- return results
-
-
-def _mp_fn(index):
- # For xla_spawn (TPUs)
- main()
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/tapex/wikisql_utils.py b/examples/research_projects/tapex/wikisql_utils.py
deleted file mode 100644
index 13d10e091a1..00000000000
--- a/examples/research_projects/tapex/wikisql_utils.py
+++ /dev/null
@@ -1,257 +0,0 @@
-# coding=utf-8
-# Copyright 2022 The Microsoft, The Google and The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import dataclasses
-import enum
-import functools
-import math
-import re
-
-# The following script is adapted from the script of TaPas.
-# Original: https://github.com/google-research/tapas/master/wikisql_utils.py
-from typing import Any, List
-
-
-EMPTY_ANSWER = "none"
-EMPTY_ANSWER_AGG = "none"
-
-
-def _split_thousands(delimiter, value):
- split = value.split(delimiter)
- return len(split) > 1 and any((len(x) == 3 for x in split))
-
-
-def convert_to_float(value):
- """Converts value to a float using a series of increasingly complex heuristics.
- Args:
- value: object that needs to be converted. Allowed types include
- float/int/strings.
- Returns:
- A float interpretation of value.
- Raises:
- ValueError if the float conversion of value fails.
- """
- if isinstance(value, float):
- return value
- if isinstance(value, int):
- return float(value)
- if not isinstance(value, str):
- raise TypeError("Argument value is not a string. Can't parse it as float")
- sanitized = value
-
- try:
- # Example: 1,000.7
- if "." in sanitized and "," in sanitized:
- return float(sanitized.replace(",", ""))
- # 1,000
- if "," in sanitized and _split_thousands(",", sanitized):
- return float(sanitized.replace(",", ""))
- # 5,5556
- if "," in sanitized and sanitized.count(",") == 1 and not _split_thousands(",", sanitized):
- return float(sanitized.replace(",", "."))
- # 0.0.0.1
- if sanitized.count(".") > 1:
- return float(sanitized.replace(".", ""))
- # 0,0,0,1
- if sanitized.count(",") > 1:
- return float(sanitized.replace(",", ""))
- return float(sanitized)
- except ValueError:
- # Avoid adding the sanitized value in the error message.
- raise ValueError("Unable to convert value to float")
-
-
-def _normalize_float(answer):
- if answer is None:
- return None
- try:
- value = convert_to_float(answer)
- if isinstance(value, float) and math.isnan(value):
- return None
- return value
- except ValueError:
- return answer.lower()
-
-
-_TYPE_CONVERTER = {
- "text": lambda x: x,
- "real": convert_to_float,
-}
-
-
-class _Aggregation(enum.Enum):
- """Aggregations as defined by WikiSQL. Indexes match the data."""
-
- NONE = 0
- MAX = 1
- MIN = 2
- COUNT = 3
- SUM = 4
- AVERAGE = 5
-
-
-class _Operator(enum.Enum):
- """The boolean operators used by WikiSQL. Indexes match the data."""
-
- EQUALS = 0
- GREATER = 1
- LESSER = 2
-
-
-@dataclasses.dataclass
-class _Condition:
- """Represents an SQL where clauses (e.g A = "a" or B > 5)."""
-
- column: str
- operator: _Operator
- cmp_value: Any
-
-
-_TOKENIZER = re.compile(r"\w+|[^\w\s]+", re.UNICODE | re.MULTILINE | re.DOTALL)
-
-
-def _normalize_for_match(x):
- return list(_TOKENIZER.findall(x.lower()))
-
-
-def _compare(operator, src, tgt):
- if operator == _Operator.EQUALS:
- return src == tgt
- elif operator == _Operator.GREATER:
- return src > tgt
- elif operator == _Operator.LESSER:
- return src < tgt
- raise ValueError(f"Unknown operator: {operator}")
-
-
-def _parse_value(table, column, cell_value):
- """Convert numeric values to floats and keeps everything else as string."""
- types = table["types"]
- return _TYPE_CONVERTER[types[column]](cell_value)
-
-
-def _is_string(x):
- return isinstance(x, str)
-
-
-def _respect_conditions(table, row, conditions):
- """True if 'row' satisfies all 'conditions'."""
- for cond in conditions:
- table_value = row[cond.column]
-
- cmp_value = _parse_value(table, cond.column, cond.cmp_value)
-
- if _is_string(table_value) and _is_string(cmp_value):
- table_value = _normalize_for_match(table_value)
- cmp_value = _normalize_for_match(cmp_value)
-
- if not isinstance(table_value, type(cmp_value)):
- raise TypeError("Type difference {} != {}".format(type(table_value), type(cmp_value)))
-
- if not _compare(cond.operator, table_value, cmp_value):
- return False
- return True
-
-
-def _get_float_answer(table, answer_coordinates, aggregation_op):
- """Applies operation to produce reference float answer."""
- if not answer_coordinates:
- if aggregation_op == _Aggregation.COUNT:
- return 0.0
- else:
- return EMPTY_ANSWER_AGG
-
- # Count can support non numeric answers.
- if aggregation_op == _Aggregation.COUNT:
- return float(len(answer_coordinates))
-
- # If we have just one answer, if float returns it or try a conversion.
- values = [table["rows"][i][j] for (i, j) in answer_coordinates]
- if len(answer_coordinates) == 1:
- try:
- return convert_to_float(values[0])
- except ValueError as e:
- if aggregation_op != _Aggregation.NONE:
- raise e
-
- if aggregation_op == _Aggregation.NONE:
- return None
-
- # Other aggregation only support numeric values. Bail out if we have strings.
- if not all((isinstance(v, (int, float)) for v in values)):
- return None
-
- if aggregation_op == _Aggregation.SUM:
- return float(sum(values))
- elif aggregation_op == _Aggregation.AVERAGE:
- return sum(values) / len(answer_coordinates)
- else:
- raise ValueError(f"Unknown aggregation: {aggregation_op}")
-
-
-def _get_answer_coordinates(table, sql_query):
- """Retrieves references coordinates by executing SQL."""
- # MAX and MIN are automatically supported by the model.
- aggregation_op_index = sql_query["agg"]
- if aggregation_op_index >= 3:
- aggregation_op = _Aggregation(aggregation_op_index)
- else:
- aggregation_op = _Aggregation.NONE
-
- target_column = sql_query["sel"]
- conditions = [
- _Condition(column, _Operator(operator), cmp_value)
- for column, operator, cmp_value in zip(
- sql_query["conds"]["column_index"], sql_query["conds"]["operator_index"], sql_query["conds"]["condition"]
- )
- ]
-
- indices = []
- for row in range(len(table["rows"])):
- if _respect_conditions(table, table["rows"][row], conditions):
- indices.append((row, target_column))
-
- if not indices:
- return [], aggregation_op
-
- if len(indices) == 1:
- return indices, aggregation_op
-
- # Parsing of MIN/MAX.
- if aggregation_op_index in (1, 2):
- operators = {2: min, 1: max}
- values = [(table["rows"][i][j], index) for index, (i, j) in enumerate(indices)]
- reduced = functools.reduce(operators[sql_query["agg"]], values)
-
- ret = [indices[reduced[1]]]
- return ret, _Aggregation.NONE
-
- return indices, aggregation_op
-
-
-def _get_answer_text(table, answer_coordinates, float_answer):
- if float_answer is not None:
- return [str(float_answer)]
- return [str(table["real_rows"][r][c]) for r, c in answer_coordinates]
-
-
-def retrieve_wikisql_query_answer_tapas(table, example) -> List:
- answer_coordinates, aggregation_op = _get_answer_coordinates(table, example)
- float_answer = _get_float_answer(table, answer_coordinates, aggregation_op)
- answer_text = _get_answer_text(table, answer_coordinates, float_answer)
- # keep the original data the same with TaPas
- if len(answer_text) == 0:
- answer_text = [EMPTY_ANSWER]
- return answer_text
diff --git a/examples/research_projects/token-healing/README.md b/examples/research_projects/token-healing/README.md
deleted file mode 100644
index f3594f32dc7..00000000000
--- a/examples/research_projects/token-healing/README.md
+++ /dev/null
@@ -1,40 +0,0 @@
-
-
-
-
-## What is token healing?
-
-Token healing rectifies the token boundary bias in greedy tokenization. It does this by trimming and regrowing the prompt to better align with the model's tokenizer, thus enhancing generation quality. The improvement is clearest with completion models.
-
-Example: given a completion prompt with a partial url ending with `:`, the model might have seen the expected completion `://` as a _single_ token in training. However, the prompt's tail token `:` tells it that the next token is not `//`, and so it looks for wrong completions. Such errors compound in auto-regressive language models.
-
-Debiasing token boundaries also addresses output sensitivity to prompts ending with whitespace.
-
-A more thorough explanation can be found on [The Art of Prompt Design: Prompt Boundaries and Token Healing | by Scott Lundberg](https://towardsdatascience.com/the-art-of-prompt-design-prompt-boundaries-and-token-healing-3b2448b0be38).
-
-## Usage
-
-```py
-prompt = 'The link is (back to top)
\ No newline at end of file
diff --git a/examples/research_projects/token-healing/run_token_healing.py b/examples/research_projects/token-healing/run_token_healing.py
deleted file mode 100644
index 2dd9148c1bc..00000000000
--- a/examples/research_projects/token-healing/run_token_healing.py
+++ /dev/null
@@ -1,62 +0,0 @@
-import argparse
-
-from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
-
-
-def generate(inputs, model, tokenizer, token_healing):
- input_ids = tokenizer(inputs, return_tensors="pt", padding=True, device_map="auto").input_ids
- generation_config = GenerationConfig(
- max_new_tokens=8,
- token_healing=token_healing,
- pad_token_id=model.config.pad_token_id,
- repetition_penalty=1.1,
- )
- output = model.generate(inputs=input_ids, generation_config=generation_config)
- return tokenizer.batch_decode(output, skip_special_tokens=True)
-
-
-def main():
- parser = argparse.ArgumentParser()
- parser.add_argument("--prompt", type=str)
- parser.add_argument("--model_name_or_path", type=str, default="TheBloke/deepseek-llm-7B-base-GPTQ")
- args = parser.parse_args()
-
- prompts = (
- [args.prompt]
- if args.prompt
- else [
- 'An example ["like this"] and another example [',
- 'The link is https
- "I read a book about ", # test trailing whitespace
- "I read a book about", # test nothing to heal
- ]
- )
-
- model_name_or_path = args.model_name_or_path
- completion_model = AutoModelForCausalLM.from_pretrained(
- model_name_or_path,
- device_map="auto",
- use_cache=True,
- )
- tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
-
- raw_output = generate(prompts, completion_model, tokenizer, token_healing=False)
- healed_output = generate(prompts, completion_model, tokenizer, token_healing=True)
-
- for p, a, b in zip(prompts, raw_output, healed_output):
- print(f"\nPrompt: {p}\nWithout healing:\n{a}\nWith healing:\n{b}")
-
- # You can also use token healing in isolation
- # This can be useful if you have other work to do before the generation
- # Or if you want to delegate generation to another process
- input_ids = tokenizer(prompts, return_tensors="pt", padding=True).input_ids.cuda()
- healed_ids = completion_model.heal_tokens(input_ids)
- healed_prompts = tokenizer.batch_decode(healed_ids, skip_special_tokens=True)
- print("\nhealed prompts:")
- for p in healed_prompts:
- print(p)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/visual_bert/README.md b/examples/research_projects/visual_bert/README.md
deleted file mode 100644
index ec197ce5f35..00000000000
--- a/examples/research_projects/visual_bert/README.md
+++ /dev/null
@@ -1,6 +0,0 @@
-# VisualBERT Demo
-
-This demo shows usage of VisualBERT VQA model and is adapted from LXMERT demo present [here](https://github.com/huggingface/transformers/blob/main/examples/research_projects/lxmert/demo.ipynb).
-1. make a virtualenv: ``virtualenv venv`` and activate ``source venv/bin/activate``
-2. install reqs: ``pip install -r ./requirements.txt``
-3. usage is as shown in demo.ipynb
diff --git a/examples/research_projects/visual_bert/demo.ipynb b/examples/research_projects/visual_bert/demo.ipynb
deleted file mode 100644
index 9f61beea8e2..00000000000
--- a/examples/research_projects/visual_bert/demo.ipynb
+++ /dev/null
@@ -1,255 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "code",
- "execution_count": 1,
- "metadata": {},
- "outputs": [],
- "source": [
- "# %pip install-r requirements.txt"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "**Note**: This demo is adapted from the LXMERT Demo present here: https://github.com/huggingface/transformers/tree/main/examples/research_projects/lxmert"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 2,
- "metadata": {},
- "outputs": [
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "2021-08-11 04:32:30.532299: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudart.so.11.0\n"
- ]
- }
- ],
- "source": [
- "import io\n",
- "\n",
- "import numpy as np\n",
- "import PIL.Image\n",
- "import torch\n",
- "from IPython.display import Image, display\n",
- "from modeling_frcnn import GeneralizedRCNN\n",
- "from processing_image import Preprocess\n",
- "from visualizing_image import SingleImageViz\n",
- "\n",
- "import utils\n",
- "from transformers import BertTokenizerFast, VisualBertForQuestionAnswering\n",
- "from utils import Config\n",
- "\n",
- "\n",
- "# URL = \"https://raw.githubusercontent.com/airsplay/py-bottom-up-attention/master/demo/data/images/input.jpg\"\n",
- "URL = \"https://vqa.cloudcv.org/media/test2014/COCO_test2014_000000262567.jpg\"\n",
- "OBJ_URL = \"https://raw.githubusercontent.com/airsplay/py-bottom-up-attention/master/demo/data/genome/1600-400-20/objects_vocab.txt\"\n",
- "ATTR_URL = \"https://raw.githubusercontent.com/airsplay/py-bottom-up-attention/master/demo/data/genome/1600-400-20/attributes_vocab.txt\"\n",
- "VQA_URL = \"https://dl.fbaipublicfiles.com/pythia/data/answers_vqa.txt\"\n",
- "\n",
- "\n",
- "# for visualizing output\n",
- "def showarray(a, fmt=\"jpeg\"):\n",
- " a = np.uint8(np.clip(a, 0, 255))\n",
- " f = io.BytesIO()\n",
- " PIL.Image.fromarray(a).save(f, fmt)\n",
- " display(Image(data=f.getvalue()))"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 3,
- "metadata": {},
- "outputs": [],
- "source": [
- "# load object, attribute, and answer labels\n",
- "\n",
- "objids = utils.get_data(OBJ_URL)\n",
- "attrids = utils.get_data(ATTR_URL)\n",
- "vqa_answers = utils.get_data(VQA_URL)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 4,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "loading configuration file cache\n",
- "loading weights file https://cdn.huggingface.co/unc-nlp/frcnn-vg-finetuned/pytorch_model.bin from cache at /home/crocoder/.cache/torch/transformers/57f6df6abe353be2773f2700159c65615babf39ab5b48114d2b49267672ae10f.77b59256a4cf8343ae0f923246a81489fc8d82f98d082edc2d2037c977c0d9d0\n",
- "All model checkpoint weights were used when initializing GeneralizedRCNN.\n",
- "\n",
- "All the weights of GeneralizedRCNN were initialized from the model checkpoint at unc-nlp/frcnn-vg-finetuned.\n",
- "If your task is similar to the task the model of the checkpoint was trained on, you can already use GeneralizedRCNN for predictions without further training.\n"
- ]
- }
- ],
- "source": [
- "# load models and model components\n",
- "frcnn_cfg = Config.from_pretrained(\"unc-nlp/frcnn-vg-finetuned\")\n",
- "\n",
- "frcnn = GeneralizedRCNN.from_pretrained(\"unc-nlp/frcnn-vg-finetuned\", config=frcnn_cfg)\n",
- "\n",
- "image_preprocess = Preprocess(frcnn_cfg)\n",
- "\n",
- "bert_tokenizer = BertTokenizerFast.from_pretrained(\"bert-base-uncased\")\n",
- "visualbert_vqa = VisualBertForQuestionAnswering.from_pretrained(\"uclanlp/visualbert-vqa\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 5,
- "metadata": {},
- "outputs": [
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "/home/crocoder/anaconda3/envs/transformers_env/lib/python3.8/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /pytorch/c10/core/TensorImpl.h:1156.)\n",
- " return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)\n"
- ]
- },
- {
- "data": {
- "image/jpeg": "/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAgGBgcGBQgHBwcJCQgKDBQNDAsLDBkSEw8UHRofHh0aHBwgJC4nICIsIxwcKDcpLDAxNDQ0Hyc5PTgyPC4zNDL/2wBDAQkJCQwLDBgNDRgyIRwhMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjL/wAARCAGPAlgDASIAAhEBAxEB/8QAHwAAAQUBAQEBAQEAAAAAAAAAAAECAwQFBgcICQoL/8QAtRAAAgEDAwIEAwUFBAQAAAF9AQIDAAQRBRIhMUEGE1FhByJxFDKBkaEII0KxwRVS0fAkM2JyggkKFhcYGRolJicoKSo0NTY3ODk6Q0RFRkdISUpTVFVWV1hZWmNkZWZnaGlqc3R1dnd4eXqDhIWGh4iJipKTlJWWl5iZmqKjpKWmp6ipqrKztLW2t7i5usLDxMXGx8jJytLT1NXW19jZ2uHi4+Tl5ufo6erx8vP09fb3+Pn6/8QAHwEAAwEBAQEBAQEBAQAAAAAAAAECAwQFBgcICQoL/8QAtREAAgECBAQDBAcFBAQAAQJ3AAECAxEEBSExBhJBUQdhcRMiMoEIFEKRobHBCSMzUvAVYnLRChYkNOEl8RcYGRomJygpKjU2Nzg5OkNERUZHSElKU1RVVldYWVpjZGVmZ2hpanN0dXZ3eHl6goOEhYaHiImKkpOUlZaXmJmaoqOkpaanqKmqsrO0tba3uLm6wsPExcbHyMnK0tPU1dbX2Nna4uPk5ebn6Onq8vP09fb3+Pn6/9oADAMBAAIRAxEAPwDI1SytpPEWqXl2ryIjQxLGhAJJjBySQccL6d6kttJsJFt0aI+Zc7jGQFwgBIGRjnke1Wm03UbnxdqBtJoFjkjQsko3A4VQMgqRnrWrB4Z1tYzGt3aBTn1yM9cHbkZ9q65y5XFPsv63JMePSNMKIGibebfzyQFxx1GMeg65p66Tp215jAfKFuJlUBd2d4XBOPrzitxPB+tHB+1WfEflfeb7vp92rtr4R1eOKUG5syxhEUfJIA3hsH5eR1/OoVRP+v8Aggec65olmZpp40wUhgaJcDgOXznjnpS3ek6ZZ6bdp9jZ5BcxrG+9VK5iJ5+UnGc5GRnjpjnrbzwTr8viBPL1KyR54AjBk3qQCSOCuOMcccVM/wANPEkpnMms2MhnwZN8W7JAIBGV4OCeRg81lzptuL/r7/Q0ukldHIT+GrC2uPJEkayrIIX2zxt5mTtbag+Zce+ffFc9r9pZCdra3V1RWWIySEEn5gM8AY47c/WvUW+GfiSQR7tYsCyEMH8n5yR0y23J/E1heJPhTrVvo93eNf2s7gqxVcgtlh6gDvSdr3QnNNWOR1i1tbi31eAWkEI067WKApEEKplwVYjljhQcnng1W8LNaR3sdrcBWt5ZB8n2SORpDwNu9jlO3K+tdi3w88capZ2zy/ZnQ7ZRzGN5xwX/ALxwcc56mpbf4beObTd9njsoyWLhgsO5GPUqeq/gRT5veuVzQOO0mJEguUura2WwhV/PZ4FMjMQdqh/vbs9ADjAJPGaytM0a3v5ri3AYzi3aSFV7soDYPr8ob9K9Hi+G/jqKxWyEVg8C7iFljgkILdTlgTn8e1V7P4VeNLC7iu7SOCG4i+4/moSOMdzipvqirwabMa18M2Gl+ItPuYHkeMajax27MR85EhEhPHQMnH1FUrXQ9Nury1ubJ7yANdSwSNvG/IUMGUgcA5PHOPU11q/DTx2iWiKYQLOXzoP3iHa+Qc8nnkDrTYPhf43ttghW3UJIZlG9DhyME9fSr512JvA5dtD0u/j0GzW3aCaS1aSSXzFAYK0pbIIHzHbwS3AwD0zWTrGj6fYxwTW/lnzMhoRdJOYyO5aPjkH0Heu2ufh/4t0uythc3VhaQwSfuJZZoUKk5O0OTnHLHbnHXis+68H6neFTPqvh8heix3dtGPyUjmh6rRBzRuUDZWm06SLSAW/9mC583yx5nmFBJu39ep24zj2zVPw7aWyxX1yy2cPlqipcXCeaiMW6FSGySAecHGD9a3z4Y1s2P2M67ovlY2/8f1vu25zt3bs7c84zilg8L6vbOzQ6v4fVXVVeM3VsUYDplScE8dcZ6nvRZ3TsNSiZrWyweJLqK2srKO33iSZ5oFdUiwCWBOdqnOQBzyAOan0LTtMuIbqRbUNE905j3k5VMDANZTXPiCO91G3XUNNcGfEvmiCRZGUkAgsDkDtjinWL6vZxsi3enfNIZGCyxgHOOMAjA47YqJtpe6XD2bl7y0/r/h/l5nT/ANk6f2s48bd1K2kadjC2cfBHPPeue/tHWgADf2Rx1Iki5Hp1/wDr0v8AaOtAhvttgQDkjzY+fQdai9Tuap0rp8pvtpOmqSDaRcdfmNOfRdOGALRAScZ5rATVdZzITdaf8x4zKny/Tn/GmLqWuBwWv7JgD0aWIA/kc0+apbdkNU01Zbb/ANev4HRJouncg2qHBxnmkTRdP3Ya1XJzj0rn/wC09b3vi9sVDdAJY8L9Of5099S1qQJtvNPQr3WWPJ/Mmi89NWJuKcvPy/L5nVaHoWmS65p8U1mrB7iMMp6EbhnpXsP/AAhPhv8A6BMH5t/jXzzBrOuRX9tcR39hA8UisGSSNsEEHJBJ9K6r/hP/ABVznxTYZ/3If/iKqE5xVrv73/mRWSlLmit/u+R65/whPhv/AKBMH5t/jR/whPhv/oEwfm3+NeRD4geKyAf+EnsAT2KQ5/8AQKP+FgeKv+hp0/8A74h/+Iq1Vm9m/vf+Zi4OLs0eu/8ACE+G/wDoEwfm3+NYfhzw1pD6trcTWS7IpwqKHYYGW9688X4h+K2/5mexH1SH/wCIrP0/xv4ltbu9li8QWaNNLl22xHccnkZX37VtTrP2U1JvW3fuP2M+bltqe6/8Iron/PiP+/j/AONL/wAIron/AD4j/v4/+NeM/wDCwvFe7H/CT2OPUJD/APE13Om61rV7Z2rDxfobTSxKxTzY92SuTwF61zpNuyQOLSTfU63/AIRXRP8AnxH/AH8f/Gs/XfDGjR+HtTkSyAZbSUg+Y3BCH3qh9o8Q/wDQz6P/AN9J/wDE1Be/29d2NxbSeJtIKSxNGwVkJIIIOPlqnTn/ACv7n/kZyaUWzlrPwno9zaw7LXD3axtCfMb5du3ze/TJb/vmm2XhvSbskNZQJHO0hhJklMgAzjGMrgf7VTQ+ENXVI/K8X6fEqAhFZ8FAc5HtnJ/OpY/CWtwxmOLxrpqRk52rJgZ9cVKpVGtn9z/yMaacoJqW6IPsFr/Z+3yuP7J2dT08/OPzrPtLZNP0TUbqwVortSiiSNjuVSGJwe3IWtT/AIQ3WNu3/hMdL27dmN4+7nOPpnnFRS+EdYsbae4g8YaajrExzC+1iMdART9lP+V/c/8AI15dGipdIItQkWFQjh8lUGNr9WAHb5s8VfvLuSfTLW5HneZFOR5s8m9i2AflOBwMdO2apaP4T1abSoZI/FmnRK7F9jvyGBPJ9+vPvWjL4T1yaVJZfGunPIhyjNLkr9D2o9lPs/uf+Qcu3kUtad5b6OSRiztbwlmPUny1q7a6ZbXFgk3lEvNEYowGP+uG4/qFUf8AAqS48J65d7ftPjXTptudvmS7sZ64zTE8H6xGECeMdLUI29Ar42t6j0PA5o9lU/lf3P8AyDlfKkmRalfWelxC3+xLcRHUBCAZWUD5QC3HOeM+nPSobK8gs76ALaLI5ub63JaQ8iKNSOmOu4/nVebwjd3GtrpVx4ltJXkiE8bxHIRlbLHqOdqtzVeXw3eTzaTNbeIIY3v7hriIkZ8shVDleeWLhh2ztHNS4SWjQvZu1rlrTrzTrqxtru4itoVuZZFdS85MSrjOzarAtg5wx54rO0fWWF9c7bb9/HaSTQYfJJC5BHHXbk+2K0bnw9qtnN5qeI7mOa5s7qS482LyHdo1JBZQ5/M9scVy+p6Fd2F/ZyQ6zBG4tYJQ6naykxqeD+PWlysrldndmtreuSra6XdXFo5nubbfIzPyf3jhSTjklQp+mK27rU2l0+6s4kkkuIbS3drc8QxAlPmRu7HcM8Dq3JxWNq/hzVYTrF5LrgMN5Iq2krE/6UhbIwc8jaBnr2FLoeh39wYNLu/FcUUq3Jiaxm8w+Wqjoq4xknIIOMbfejlYnB6eRvPezWVlZSwW0FxbWepIAYbqN94+XL/KSeT26gYzXQf8LEH/AEDB/wCBH/2NcV4d8J6jCdMmTURPHBfNK0kSHyYCu3DuDjIOM87ePXpUPh+x1O71J7KWe2c3MMkURKj5ZNpKEccfMAPoTQi4R5VY76Dx69zcRwQ6UGklcIi/aQMknAH3aRfHxabyv7MQPnHzXQUA/UristrYLqOnXtn9mSO51KCKNVQfKkUjB8cdWHkkn1JqlYwXV/cWU1xHZDGpPEVjhADRbQQp4+bB7nnnk0FG+3j90VGfSSqyDchM+AwyRkfLzyCPwpv/AAsMf9Awf+BH/wBjWFaQ6hd2/hpb17c6ekLpPItsnMoklKKWwOo2ZG4ZyT3zWZ4ls76KKyEZeK5/eea81glqHXjbhFLDj5ueM8daAO1/4Te4+y/av7El+zZ2+d5p2Z9M7MUWvjS6vmZbTQ5rhlGWEUhcge+ErmhBqvlreeen9mDRjAWx8vneWRt6dfNw2OvfFc/pWkavcaxa295cJHAxEspKYIhA3MwyP7oJFAHo58XXz3D2i+H7g3CDLxBmLqPUjZkdRWtoOojW7KW4aMWzRymIoW3HgA+g9f0rz/T21LVhrNxOsl0Li5idbOzYJIqguQd2xvlUYXG09RyMVtafbeJJrvV5LPVLPyjfyH7nU4X2PsOp6UAdwYI/+e60028f/Pda5Y2Xi7/oKWf/AHwP/iKYbLxb/wBBSz/74H/xFAHVG3j/AOfhKYbaP/n4T/P41yxsvFn/AEFLP/vgf/EUw2Xiz/oJ2f8A3wP/AIikBrapbxi+08eehzL+XIrRNrF/z8p/n8a4q8tfEa3FqJtQtmcv+7IQcHjr8v0qybPxV/0E7T/vgf8AxNZw+KXy/I0l8Mf66nUm0i/5+k/z+NMNpD/z9R/5/GuWNn4q/wCgnaf98D/4mmG08U/9BK0/74H/AMTWhmdSbOH/AJ+4/wDP40w2cJ/5fI/8/jXLGz8Uf9BK0/74H/xNRm08Tj/mI2v/AHwP/iaBnVNYwf8AP5H/AJ/GomsYP+f2P9P8a5g2nib/AKCNr/3wP/iaja08S/8AQRtf++B/8TSA6WaxhWMkXkZPoP8A9dMGnwFQTfRDI6cf41ysNzq1vr1vZX11HKsiFyEQDsfYelbxHApdTmX+8v8Awr82Wv7MgZgBfxEk4AAH+NFVoF/0uH/rov8AOiqOkx9OP/FU3X/XEf8AstddAelcfYHHiq7/AOuI/wDZa622PSurFfFH/DH8iEacXSrcdU4qux9BXOBQl/5GW0/65H/2atsCsWb/AJGW0/65H/2atsDis6e8vX/IuptH0/zFrJ8UD/im7z6L/wChCtisjxR/yLd59F/9CFaGZd0of8Siy/64R/8AoIq6Kp6T/wAgiy/64R/+girtABS0UuKBhijFFLQBwnxVtmvPDmn20eA0uoxqCegyj9a89XQdLkdtgYxopZ2KkEDIHA3c9R6V6P8AE+K7k8PWTWS5niv45ByBjCv6/hXKav4b1230q9mOlxRxi3cSASqQRjn+L+VdUW404+bYupjf8I7pwV5G4iCK4IBJIJx0z1z70TeHNPjEm0B2j2kj5gNpxg5z15HFVdQ8HWlm+oo+ryvHY3C20/l2fPJbaYx5nP3TnJGO2agPg9oLm5jv7wwqbs2UTxQeYHK7TvPzDauCvPJ56VHtvN/iOxiyeHLV9Yvbe1vC5hvvJlBiICb2IBU7vmwRg5xz69adpPh+0nvbb7US0JvPs7ooOSMEjncMdMVr2/gs3E2yW4EN7c3c0KRx224eZExA3sWGAT0IB56jvVrTPDUMtnDLqNuUQ6dLdxC3tk3RyCZl5+dd5wM8noQOABU80ea5pzytY56y8MR38Znt2u3gaXyo3W1LHcACS4ViFA3DnJz6VWutDtrGxSaaUi5dnQQqmRlW2nLZ4H4H+tbcfghpLRVG37TNDJdW9s8A27Vzwzh/ldgmcYYdMkVU1jwdJY2tnHETcXDwxTNGIVRIxIgcruL8kE44GCOc9qm8bWQOcm7sr6dpum/ZrH7VZ+cb25aHPmMDEo2jK4OCcsTzkcDis+LS1m1A2YwArMHck7VVc5b6AAmuvtvCkcdrBp39kxm5OnPfC9Mp3JOEMgULnbtwoXpnPOe1Yuh6DdQ6iv2iwsArAjzbuWQInfJ8lt3bHHrzQ5JpIFJp3K+pW+m2l9bm209Ht5LdHEU0jnJI6/KwOfxxUOuWdlb6mbe2tkh8pVWVUdiPMx82NxJ4OR17V1M3h2OPxZPC1pp8lkuwwTahJNsQYBJXyzuOc8Fh0AzVGDwgY/iDDCtmsmnjU1ULcBCWi80feHfI/OiUrpruCm00ygvhMP8AcnDFp0jT5cbo2Cnf14x5ice/WnNoun3Vjp0ccoSeSGYoBF/rdruRuOeMgADr07Cuk07wgYtfsLiJoby0S5a1nikgVAOCRgbjuU44Jwfl+6KybDwFe3ekG8jSZZ7aGRwptR5OFySPND/exk/dx2zTUoLYHUkzPt9I09rOaS+d+NPWdGhhGVzMF/vDcecc+vsKYPCjHTvtWy43eQbgEwN5ewDPL5xuwM4xjtnNbVr4NFlqGmx3LCe5YwCa2Nupi8tmVtpcvkkAjI247ZNVfEHg2azuZEaCE3LSORCqAeTHn5ATuxnHbHAxzngHNEHNsxNPtLIWN5e3Fqs4hMaLEzsFLMTydpB4CnuOtV9QsrWy1W4hhjPlERyorNnaHQPjPtux+Fdpp/g61S1s9Ol0pJJr6zknkumkIMUg37FChtpX5BnIJ+Y4IxXM6RpMsmp3Rn0WHUZNwRIpHZQGzgcIwJ4GMZo3g0CqNSuOu7bTF0y3u4Le2L+cFkihabYBjO19xzu6/dOOD6V3vhLStJn1PRd+nxxtNE0jqkkmMbDtHLH0z+VZFz4SsrNtSmXSIZ4oBbhbMzHyxM65kywYMQhDqOR1HXv0HhHwZInjeeSKGRNPjSKQfvFzEskJKr1ycZ2/hVRqtNtO1yG7pJnoP/COaF/z4j/v4/8AjTJfD+hpE7LZgMFJB8x+v51PeaPBaRLKkkhO8Dk9jUMZ/wBEl/H+VXKvV5W1Uf3v/MyqRXI/R/kxlroGjTW6vJZqXOcnzG9frVqPwvob9LFf+/j/AONNsz/oqfj/ADrStTWccTWSS5397Iw8V7GHovyKf/CJ6H/z4D/v4/8AjVXU/C2ippV462IDLA5B8x+u0+9dGOlVNW/5A99/17yf+gmn9Zrfzv72bWRzfhrwxo8/h60kksgzkNk+Y394+9a3/CJ6H/z4j/v4/wDjS+Ff+Ras/o3/AKEa2KFiay05397CyMX/AIRPRP8AnxH/AH8f/Gj/AIRPRP8AnxH/AH8f/Gtqin9Zrfzv72FkcjqXw28PanMJ5IriJlUJtil46k55B9aoH4TeG/W9/wC/o/8Aia77/lmfrTDUOtUerk/vHZHBn4T+G/W9/wC/o/8AiaafhP4c9b3/AL+j/wCJruzTan2s+7HZHC/8Kn8Oet5/39H/AMTWN4l+HOiaXp0c9s92HMyod0gPBB9vavUq5vxsP+JND/18r/Jq6cJOUq8Iyd1cUloVT8PtJ/5+L3/vtP8A4mj/AIV9pP8Az8Xv/faf/E11uKK4yjkv+FfaT/z8Xv8A32n/AMTSf8K+0n/n4vf++0/+JrraSgDkv+FfaT/z8Xv/AH2n/wATSf8ACv8ASv8An4vf++1/+JrraQ0Acl/wr/Sv+fi9/wC+1/8AiaT/AIV/pX/Pxe/99r/8TXWUUAcfJ4B0oH/j4vP++1/+JrW0nSLfRbR7a2eR0ZzITIQTkgDsB6VqSfeqI0AMNNNONMNADDTDTzTDSAytT/4/bD/rp/UVfNUNT/4/LD/rp/UVfNZQ+OXy/I0l8Mf66kZqM1I1RtWhAwjFMIp5phFAEZqNgKlNRsKQHN3vPjKx/wCuDf8As1bZFYl9/wAjlY/9cD/7NW6RkCjqcy/3l/4V+bEtx/pcP++v86Kdbj/Sof8AfX+dFUdJz9oyr4putxA/cjqf92uptp4v+eif99CvMtbsluvF13JLJ5cEFqjyMF3HkgAAZGTk+opttpdnIgle5ZIXl8qJjFyxwCSRu4AyPXrTxeI99Lsorr2Mue1z2KG5g4/fR/8AfQq5HdW//PeL/vsV4/BoEDeVHLMEnld41TYSAynHJzwPwNPh0S1maIpN+5dJG3shBBQZPGenT865PrS7r8SfaI9RluIP+EktG86PaIjzuGP4q2hd23/PxD/32K8NfRYGullikLQfZ2lUlcEkNtIIzx1B71fh0ewW2leffnyUkUquduWx/eGf/r0o4jlu/Pz8ip1NEey/a7b/AJ+If++xWV4nurdvDl2BPETheA4/vCvLz4eVbUymOTIjEv8Aq22bTz97PXFZuv6ZaWdnNGjF5Fxu+XAHI9+a0hiFOXLFp/eSppuyPb9Ku7YaRZA3EX+oT+Mf3RVz7Za/8/MP/fYrxSPSrFbT7OLcebFbJJ5u9sscKSCM4xz+lRWdpZGXbNFDtP8AFKz4H/fJpRrzlFyS2BTbV0e4/bLX/n5h/wC+xS/bLX/n5h/7+CvF4NOsRqb25s0eISMS0jOGVByejDsKqxadbXV4I0jEYkYhRknHoOv0FCryd7rRK41JnuX2y1/5+Yf++xS/bLX/AJ+Yf++xXicmhQRwCUkY8rzDweDkYXr6Mp/Gp77SLM3lw8O0FJgrIEwq5PGOefpgVP1rWyt+IvaanoXjW4gk0aERzRsftCnCsD2ar3iGeGbw9qMUUsckj27hUVgSTjoBXj2t6RafYIlj3C8kvWhXamFY8YH3vlHOeB3xU2o6HHZ2pmCSYD7DvjKc+2TyODXTHG80KcHZavvrsJTTZY1fVbyGK6lu7CVf7QnEz7IG4cbjgZPT5j61WPja4M8skmkPNvl89Ve2bEb4xkfN7Dg5HAqKfSbGaxsIXtw0l44Tzd7Ax5JUEDOOvJyDxXB2lwkU4aW2W5BGBGzMAT2+6Qf1rJVZScklt/m1+hSm3ex1mneMNRhvvNOmTSNb3LzRlomyzMxY7vx9MVbi8Y6hCsCDRHkjiga32OrgOjMWOcc9W7Y6CsSDTLM6pfu6wxJaWscs9vJI3lxyswUqSMtgZzgZOeKms1e0v7pfLhjR1jdBAzMhUgkFS2Tg9eeamnXlUfLFK4lUbdkag8aaosAjTQlDrG0UcpDl40bOVHbuRkgnnrVG88SaveSpI+lbSsSRDCt0RQo7dcAVY89v71IZ3/vVt+97L72V7w3/AITDXls/IGlRbxEYRcGJzIIz1XrjHJGcZwcZqtD4l1WFyW0O2lUoF2SRTYyP4uGByfrj2qyZ3/vVGbiT+9+lH73svxH7w0+L9ckupZ7nR7W4Z9oVZLeUCMKMALtYcYwMHPSqZ8UeJf7YTU2iLzrMJtpt2Ckg5xgduO1WmuZB/F+lRNdS/wB79KX73svxD3iR/G3iQXFvLFYQw+VKZmSO3k2yuRjLZY/kMAZ6VFD4z8RwWK2/2GN5Et5LZbh4JPMEbhgRw23I3Eg4z0zkcVE13MD9/wDQVG15P/f/AEFH73svxD3hzeLPEDJbNJYI91bmPF0YpA7hMbVYBtp4AGducd6p6h4i8RalAsdxHLvSRmWVY2DhTzsz3UHpnJHrjipGvZ/+en6CozfXH/PT9BRet2X4h7w+HxT4hg00Wgti8qRvDFdvE/mxRvncq4O3+JuSpI3HBFVtF8Q6no9/JcwaVHNIYDAwlE3UnmTKuCr4yMggAdADzTmv7j/np+gqtFeTrJKRJyTzwK3pRqulUbtol37iblctReINTt7m5ePSI/slyirJYsJ2i+Ugggl94ORnIbuR0OKgfWNbuL27v7ia5heZlZggKKAOAAOwAwAKkS+uCCTL+gp00rzaTOztkg4/lXM51I25kt/MG2tz6XikM/hSylJyTFGSfwqnGf8ARZPx/lT9HfzfAenv626H9aiT/j2k/H+VdX2GKp8MvR/kye0/49k/H+dadoe1ZVof9GT8f51p2ZrKOyJw/wDBh6L8jRHSquq/8ge+/wCveT/0E1aHSqurf8ge+/695P8A0E1RqUfCv/Is2f0b/wBCNbNY/hX/AJFmz+jf+hGtigBKKWigA/gP1phqT+A/WozQMaaaacRTaQCVzfjb/kCw/wDXyv8AJq6Wua8bf8gWH/r5X+TV1YL/AHiHr/mKWx0dFLRXKUNpD0p1NIoAQ02nUlADTSU41zHjjU9R0rRoJdLkZLiS5WP5Yw5IKscYIPoKBpXdjebqajNeVf8ACS+Lyqt9uyGUsp+zJggdSPl6DBpW8QeMEETS3jRxyEBXa2QA/T5eaB8vmeommGvNr3W/E1pHI39sK+25kgx9mjGduOenfPSmxax4snt1lGrW6s4Zo4miTdIF6kfJjsepGccUWDlPSDTDXmVr4g8UXcjKNVhRUUu7vEmFUd+EJ/KpjqnikSuG1i2WJY1kM5iXZtPT+DPPpjNKwcp2Wp/8flh/10/qKvNXlmo634mj1GC3lvVeZXGzZEhyTjBGF5zxipv7f8VsFIumIclVIt15I6gfL2qIxtKTLkvdSPSjUbGvP7zVfFNtGkovWeBo43Mv2ZQoLKDtztx3o+3+LJLee4huZHihKht1qoblS2cBTwMdc9x61dieU7w0w153JrniiOBJ5Lh1hf7sjW6hW+h281Laap4jvIzJ/atvCm8Rq0sajc57DCH8zx70WDlO8JppNeeprfiaS8FoLwecX2bTEgwc45+Wi41rXYpUSLV4Llm4/cwg4Ppyg/SlYLG9ff8AI5WOP+eB/wDZ63cHA+lcRA+qjxtb21/dRTTi1LqyAbQCCccAeprrvLvcD98mPp/9albUwjBfWG7r4V+bLcA/0qH/AH1/nRVRReRyK/mp8pB6f/Woq0jqVJvZnG6hBfSeMrn7LbpcRyWypJHIQFYcH1B64OQatW2m6zESq6VbtH5nmJGzgiNsYyPnz2HXPSr1v/yOFx/1xH8hXSRnDCniaUHPVbqP5HLGKd7nMwaR4h3wSfYkZoWZwTInzFjk5+ar2m6BrkRRXsU2RpNtzIhyzJjB+bpkCustm6VpwnisJUKclaw3CLVjzZtF19dZt4hpsQUwMggEi7SpyT/FnqM9e1aX/CPeImYltKhKGMRGPzVC7Qcjo+f1rrZD/wAVLaf9cj/7NW+tTCjTbenX+upU6cUlp0PChqstyoiGlyyyhdocAF9oHs+OAPToKz9a1N7q1uJHtJlZsZ+7jqP9quv0W3ggFnttjI89tNM0+4/KQHGAOmBgZzzk1U1ex06LQJFlkiEj2gmVwJTIX4IHA2bc/L/XtXSqUIu6Rx05ydn+n/BMm01i5nsYbdNOmeVoUjLoFLuoAwPvew7dqI9WCMxOlM4OMBiOMenz102m21qJ7CWyjjS2VhHuJcSKShIDg8Z4P3eKzNTgjtZ1giT5FUETE584H+IdgPQD8ean2NNKyX4lR5m7J/h/wTNOtzGSeQ2cxeYFWb5OATk4+b2xUUepvFIsi2lwGUhhynUf8Crq5mcxXFsc/YUsI5EX+EMQh3D3LEjPuRVXQYc3P2lWi82N1WNHkVTknluSM4Hp3IqlTgtEt/8Ahhpy5W7r7jHm1+4nimjaylCyyeYcbOPYfN06fkKRtdmaSZzYy5lcO33OCDnj5q34riWx164RvtDRvcEFLeYAMd3AOAQ3B6VTjgjbXzbXCoEadomCE7VJJGR7A8/hUKhSSso/1p/khJS8tr7f8E53WNdlazH+guH+0ecjkgGNz3XD+w65qxeaqbiI40142JyWXbyf++8flW14g0qzh0N5pI8PAqxPlj/ryU5PPYO3HT5Kuz6XZz3E1p5Jtlhu4rfztxJdWbBJzxnA3DGBWyo04xi0ur/QSlbVP8P+CcrLrVwmktFFZP5qIfKkbbmMkdR838wa5TTri80qW2vl0uJiqsqPLuw7d2BDD5hkDjGOO/NepQ6faXsKFrIwDzJIzCHb94FQtt5yc5ABx6jgVyiafZajZaOs9pHZQol9MIC0pjcpt6Y3Pt4ycZPDYx2zdGm76bg2/wCl/wAE5C01KVL+8kh022SKVfLmtwzskgznJLOWzkA8EdK0bfUpZLiWa5iEeVRESPG1VUYAHPpVqOz0BP7TvYIbe7EOnpOYYmnWFJjcLH8pfa5UqeRk8kgHgEZeuWtra6tCII/Jt57eCfywxby98aswBPJAJOM80KnCL5ktS1zN6P8AD/gmp/aUX91/0/xpP7Si/uv+n+NXvEUs8tv4jgus/ZbK+jjsFP3YhlwFT0BQZwOuAazfC97e2StdPeS2+jW8okuUB+W4b/nljo5YDGDkAZJrXS4J1HG919w86jF/df8AT/GtC1s5by2SeNkCPnAY88HFWPDcuNP0uASyQm9nuDHaxJmG54ACztngAj0bAOeOtc7pz/8AEviH1/maLxW6C1aV1GSXy/4JutpFz/fi/wC+j/hUbaPc/wDPSH/vo/4Vms+aiZqLw7fiHssR/wA/F/4D/wAE0m0W5P8Ay0h/76P+FRtod1/z0h/76P8AhWazVEWovDt+IvZ4j/n4v/Af+CaTaFdn/lpB/wB9H/CmHQbv/npB/wB9H/CswmmGlzQ7fiL2eI/5+L/wH/gmmdAu/wDnpB/30f8ACqkGiXMk06h4co2Dlj7+1UzUCffk+tdVFx9lU06Lr5i9nX6zX/gP/BNg+HrvPEkH/fR/wqwuh3X9mzQmSHcxyDuOO3tWDjPFXguzSZwP74/pXn1nGy06rr5ilTr9Zr/wH/gn0N4euFj8B2Fs4JkSAKSvIyDQkyi3cc9D/Ko/Ar+b8MbA+kLD9amjP+iv9D/Kum8eR6fiE6dfklea2f2fJ+YttcIIFBDVo2t7GvVX/KqVr/x7r/nvWnY9ayi4WWn4kUKeI9jG01svs/8ABLI1GHH3X/KquqahCdIvRtfmB+3+ya1R0qrqo/4k19/17yf+gmqvDt+Jr7PEfzr/AMB/4JkeF7+JPDdmpV+A3b/aNa/9ow/3ZPyql4U/5Fmz+jf+hmtqi8O34g6eIvpNf+A/8Epf2jD/AHZPy/8Ar0n9ow/3ZPyq7SUXh2/EXs8R/wA/F/4D/wAErC+iMDPtfAOOlRf2jD/dk/Kr/wDyzNRmi8e34lOnX6TX/gP/AASmdQi/uv8AlSfb4v7r/lVs0Urw7fiL2eI/5+L/AMB/4JT/ALQi/uyflXOeNL2N9HhAV/8Aj4XqPZq66ua8bf8AIFh/6+V/k1dWCcPrENOvf1B069tZr/wH/gmz9vi/uv8AlR9vi/uv+VW6SuW8O34h7PEf8/F/4D/wSp9vi/uv+VIb6L+6/wCVXDSGi8O34h7PEf8APxf+A/8ABKf26L+6/wCVJ9ui/uv+VWzSUXh2/Efs8R/z8X/gP/BKn22L+6/5VyXxB1JYNIsJ0Vt0N/HJyOuFY13GKxPE1vDcabGk8McqiYEB1DDODzzRePb8TSlTr86vNf8AgP8AwTzu71aw+y3UFvIzCJRFa/IRuVtu8+33T1/vUyW+0yOxligkQlzEy8SF+Dzuz8uevSvSW0XSv+gZZ/8Afhf8KjOjaX/0DbP/AL8L/hU3XYv953X3f8E8v1PULaeKUROWLXs0o+Uj5W24P6GpbW8tVjsrl5tslpGyeVtJMhyzLg4x1bBye3evQ59H0wQt/wAS2z/78L/hQuj6X5a/8S6z6f8APBf8KbS5boiFSXtXCXZP8TzPTZYbWdneaMM8LBGZCyxsTjDDHPGexHIq1cXlpdG4ga5RPMiiHnbGEe9PRQMhcHsO3QV6AdH0z/oG2f8A34X/AAph0jTP+gdaf9+F/wAKi50XPKdZull1a3lt2O2Py0RiME7FVQfxxmugutXsCl0sLnCxlrcbSPnk37x7Y39f9gV0eo6Vpy3liBp9qAZOcQrzyParp0jTf+gdaf8Aflf8KiMvekW7pJnAyajC7SAzEodOSBRg43gLx+YPtSXd3a3UV/GtwqeYYJEZlbDbI2UjgHnLd+Peu8Ok6b/0DrT/AL8r/hTDpOm9tPtf+/K/4VVyLnEanqVtcW1y1v8AZV+0BAUxL5gwQccnYMYxkdvSqdnLay2CW1xci3MVx524qzblIAIGAeflGM8c9a9AOk6cOmn2n/flf8KadK04f8w+1/78r/hRcLnB2+oxJr/9qOV2yXEjNFtyyq2eemD97pntU0mqW8L2rzTNqE8XmZnRihG4AKAWXJK4Y9OM8dK7M6Vp3/Pha/8Aflf8Kb/ZWnf8+Fr/AN+V/wAKLhc4yzubO58cacbMSgJYBG3tnkLjH3R09e9dyPuiucuLS2t/Gdl5FvFFmBvuIFz970rpOw+lL7RzL/eX/hX5sY3ANFDdD9KKuJ6NHZnN23PjCf8A64j+Qro1rnLb/kb5/wDriP5CujWtMR8a9I/kccOvqaFq/StWE9KxIGw1a1u3ArJFMY5/4qS0/wCuR/8AZq6BDXOsf+Kjtf8Arkf/AGauhjPFTT3l6/5FVNo+hxOn+BrpbRo49dmjj3nKLEQDx6b6q674JurPw3dKuuTGEAZhEZCnLDtvxXead/qG/wB4/wBKqeKf+RavPov/AKEK3qaSZxYR81CDfY5uz8E3t1p9lNL4guGYRKy7oySuVHQ76efh1IyIjayxRM7VMHC564+euu0n/kD2P/XvH/6CKu1B0WS2OHPw/uGtxbnXZDCDkRmE7QfpvxSN8OpGkEja05kGMMYOeOnO+u5paB2OKi8B3cO/yvEE8fmHL7YiNx9/n5qAfDYhgRq5BBzkW/8A9lXe0HPagLHlXi3wRPbaUrvrMkoluVLq0R+ZsN8x+bk9fzrXv/AFw1ntl12WRIwNitCSF+nz8Vs+OP8AkCQ5/wCflf5NW9ff8ecn4fzrrcV7Km+7f6E9Ti18B3Nx5MkuvTO6qNrNESV+h38V4/4u03UtP8WXMM2sXUslvJvilZmyuQOR83HQfkK+lYOIYj/sj+VeJfFy0+z+LY5wMC4hBz6kcf0rme7HZHmwk1G/urxrrVbqZ3AikaWRnLoGyFOTyAQDj1FSSWEs5Vprx5CqhFLgnCgYAHPQAYAqOzb/AEi6/wB//GrofikWkhssd9cRQRTapcyR2/8AqUdmIj/3QTx+FT291rNoJBba9fwiWQyyCOZ13uerHDck4HNR76XfQHLHsMiGoW8E0EOrXUcMxJljR2CyZ67gDz+NOt4/IgWLdu255xjvRu4ppagrREpamM1RlqaWoEOY1GTQTTCaQgJphpTSUCGmoE+/J9anNQp9+T611Uf4NX0X5kvdDgcEGrqfPpU/++P6VS+lXIjjSZv+ug/pXn1tl6oUuh738NH8z4Z2w/u+Yv8AKrsf/Hq/0/pWZ8KH8z4cqP7ssg/QVpR/8erD2P8AKun/AJdsVT4Zej/Iltf+PdfT/wCvWpY/erKtT+4StOxPz1lHZE4f+DD0X5GuvSquq/8AIGvv+veT/wBBNWl6VW1b/kD33/XvJ/6Cao1KXhT/AJFmz+jf+hmtmsbwp/yLNn9G/wDQzWzQAlBopKAF/wCWZplP/gP1qOgYhpKWkpAJXN+N/wDkCw/9fK/yaulrmvG//IFh/wCvlf5NXVgv94h6/wCZMtjo6KWkrlKENJmlNIaAEpKU0lACVk+If+PCP/rqP5GtbvWR4i/48Y/+ug/kaaLp/Gi21RmpGqNqkkr3H+pakX/Vr9BS3H+pamr/AKtfoKt/B8zmj/vT/wAK/NiGmGnmmVmdRl6l/wAflh/10/qKvGqOpf8AH5Y/9dP6irxrKHxS/roaS+GP9dRh71G1PI5phrQgafrTDTyaYaAGHFNOKccZppxQBzt9/wAjlY/9e5/9nreH3awb7/kc7H/rg3/s9bw4A+lLqcy/3l/4V+bGt90/SihuAfpRWsT0aOzPLdOvPEjpf6rctHEY7H7RGymPeeVC7k5YKQTgkDOODSPrnjaKKOQqh8xkQIuxnUv90MoO5c9sgZqFvEGlyW1/cfa5vPutMS1FuSnlo6iMEj5t3OzpgfU9r2p+L7K8DTQ3jRGeaN3jSC3XZh1YkOMOeR3x7mpk7vU5VBLp/X3klprnigS3aXd3ArQ2cs6eRJFJ8yY4O0tjr04NUp/GvjKxuBBNOscxAOzapIz0BA6H2PNXF8X6XZalFewy+dcpbTK0rxxIXYlSgKoxXjDc5yc1y+q39lJqv2qznOx8SbZGB2N1Kg55GfXB9fUpD5V2/r7zstV13xPp/m3MWsJPdWUiwXKeQqiMnP3TuO4AgjkL2wCKseHvFXi/XXaFNTnWbcAPKtFkRQf4nO8FV9wDXO6rrekSpqL2s7+bqtwksocpiIAsxC4bJ5Pfb0x71X0i80OxuzdXF7OXt5S0aIiYlXtk7/lPXONw+tJITS2aOs0PxL4w1O3uFh1OZZYS25ktFaBcDOWk38Zx/dNYU/jzxpqFlcxm5WWKOPzJFKr90Ec+/aoNI1TRIZor+ad0lhldzaoE8tgTkDcWzjsRtNUtE1TT7PVUe9kVrOVXhnVHGSjqVOMn3z+FU99yIQiopKJ0g8W/EOzRbcvsMSxLsAQkbx8gGDyT6CpZfF/xFinhhM6s8zFE8sxuCw6jKkgEdweneqsvjWykSwuQym5S+E8+XADIjsyD1z+8YfgKig8RaRYeRbxXUk8JlmaSSRkDKrxmPC4JHAJOeM+gpF8q7f195ePjH4iC6S3+0xlnjMiurxmMoM5beDtwMHnNXL7xV46gmtILe9DSPZrcTmRowiZZhneSFC8Lg55z15rFj8Q6TFEmni7kaA2ssLXBKeYGZ1cEDcRxsAxu9eRU6+KtKimWBLj9ybGOAyukMjB0cnO1iVOc9M/jxyByrt/X3lqPxb8R5GnUXEa+Q6pIZHjRVLAleWYDBAOD0PHqKrweO/Hs+rR6b9sEdy8wg2ugG1s45+hrN1PxHbXFnfRJd7pJJ7dkciOPKRxuvRDgdR07VDceILNfGbaxBIhiF2JwrMMkbs4ODQFl2/r7zX8T+LfEq6XDOmri+tDcGMl7dUKyKM9NzcEHg5zwcgVdsvGnijU7NlGukXnlySeQbZdmEBbBbdnJC5+6R71yur32jtplvplpdyGBrwzySuIyyjbtAA34OOeSRnPQVbsdS0W30GSIX8kF5OGE8ixRvleyKfMBAPBPHP0HOnM+Vai5VfY6WPxT4vbT1ZNcX7Z9kN2tuIF2+WATjduzu2jONuO2c1J4wk1Kfw5oer6tAsxngQhywPLKD7461y9l4mtrHQXiF80ty8D2yxtHGBGrAg/vMlyMHheBn6V6P4qgjv8A4N6SYnWSWGzt3Cqcn/VrWcrdXYcXGO8U/v8A0aPJINQszLNttI87uePr7VZ+3W3X7JH/AJ/CsS1hma5ucQyH5+cKeOtWxBcd4Jf++DUafzfijbnp/wDPtf8Ak3+Zofbrb/n0j/z+FL9utv8An0j/AM/hVD7Pcf8APCX/AL4NHkXHeCT/AL4NHu/zfig56f8Az7X/AJN/mXvt1v8A8+kf+fwo+3W3/PpH/n8Ko/Z7j/nhL/3waTyLj/nhL/3waPd/m/FBz0/+fa/8m/zL3262/wCfSP8Az+FSJJbXNtcEW6IUTIIH19qzvs1x/wA8JP8Avg1dsreYW12DDIMpxlTzwaNP5vxRE6kErqmvx7+pn/J/eNJiP+8acbW4H/LCT/vg0n2a4/54S/8AfBo93+f8Ub/WI/8APuP3P/MbiP8AvGkxH/eNP+zXH/PCX/vg0n2W4/54S/8AfBo93+f8UH1iP/PuP3P/ADGYi/vGoYxHvkyx61Y+y3H/ADwl/wC+DUEVvOZJQIZDg84U8V10Lexq+90XVfzESxEbr93H7n/mSrHGTwxqZONJm/3x/SmxQTqfmhkAx3U1KtvP/ZUw8mTO8YGw+1efOSvbm6oeJ5ZUYTUUm29vK3qe1/B1t/gKZf7tw4/8dFbEf/Hq30Nc98G5RB4UvYZz5ZFwSA/ynlfet5JEFs4LqDz3rs54+zepxVPhfo/yZNbf6hceh/nWlYZ8w1k280YhXMijr3rRsZ4RIcyoPqwrKM423Jw6/cw9F+RvL0qtqv8AyBr7/r3k/wDQTUiXVvj/AF8X/fYqtqtzbnR70CeP/j3k/jH901XPHujWxX8Kf8izZ/Rv/QzWzWD4VuYB4aswZowcNwWH941sfarf/nvF/wB9ijnj3HYlpDUf2q3/AOe8X/fYpPtVv/z3i/77FHPHuFib+A0ykFxCYmPnR4B67hURurf/AJ7xf99ijnj3AkNJUZuYP+e8X/fYpPtUH/PeL/vsUc8e6CxJXN+Nv+QND/18r/Jq3/tUH/PaP/vsVz3jVlfRIGVgwNyvIOezV1YGSeJhZ9f8yZbHTU2l4ppNc4xc02gmoJ7iO3jLucAUgJjSGqkF/FOuUYGpvNH94UDJc1j+Ij/ocf8A10H8jWoJFPQg1j+IHzar/wBdB/I00XT+NF9jUZpxNMJqSSC4/wBS1Iv+rX6CluP9U1NX/Vr9BVv4F6nLH/en/hX5saetNNOaoyazOszdS5vLH/rp/UVeNUNS/wCPyx/66f1FXiayh8Uv66Gkvhj/AF1GseKYaeaYeK0IGGmk89KeTUZoAQ/SmkUpFNoA52//AORysf8Ar3P/ALPW9/CKwb7/AJHKx/692/8AZ63uwHtS6nMv95f+FfmxG+6fpRQ2Ap+lFaxPRo7M8rsvC+lW7aik8vm3sWnLO0BjIWMsUIw+7lgG5GB16mtC5+H6WsZMiSxtHJGkzzQvHENxC5VyfmAJGeB6jNR2s2sz3E9oNMtDPLaLBLcZ/ePGu3aCd+3jaoyBk45zWhNZ6tdMJJtHtHuNwaSYv80hH94b9vPfABNedKniVJNve3bt+X49zBNale18GWX9pTWKWlzNM1rIY1uIjFluMFfnII96x5dD02O8FvEROBhTICwXd3xzyPfj6V1Pla8qLHb6bBbxLHIiJFJ93fjcwJcnPyjvjjpVW60bWr658+SxjWVgN7I6je394/N1PfGKqhCsp3qbW/H+u34g7dCDUPDeiCW/hgsPKfT5RH5nmuTMuWUlgTgHIBGMd6u6J4U0e6tkeTT45S9wI2Mtw6YXAPyYYbm9ue3HNWLi01+8u0gfTYFeYiWZkcBp2AbBY7sdz0xyc1q2eja/CoQaPbuiSmaJXlBETHHT5+eg4OelZKjWdFwW9+/l39df6sOVk0zmbLw9okum6iDp+ZYMMkrSuGA3quMZx0J7VSl8Mafc2V0IodskcLSqNzHdt5I6+gJ/Cu203QtfS2uVOjW85uGPmSSTYY8g44kA6jPSqs+geItEgOopp6EwEHEkiMpBOCCA2SDnFdbp1I+0stemvkvu1/O5z0ZKVOLuZX/CAWMRjg2q7loolbLAM7ZB/i4AKt+VNTwXo85je2O+Es4kdwylNq7icbjkYBx9O1dLaaL4qn03T2WyX92ROkglTcWPzc/N65P4mrH9geJleMw6TBCiMzeWkibWLDDZy56jjH5VzqniratX+X+XX8HubXickPBmjuBOm42nlNI0hDBhghSNu7rkr371afwRpNw8P2a2kaJbVZHaJXZ2JYgfLu6+vOOOtdGNA8Sh126RCsAjMfkCVdhUnJz8+euDnOeBTn0HxLI43aRAYvKERh81dpUHI/jzkeuaUqWJbuv0/wAt/PYLxOUk8D6RaidrsPEkTxqMK5Zg6lhwWGCMcj6/jBF4P0z+3F06WD/luImZXbpnBI5rq5PC3iJ4JYF0qKOOSRZNqTJwVBAxlz/eNEnhfxPJqDXwsAkxk8wFZo8Bs54+atYU69nzPdPto7K36iujhfEWg6N/YkV7a6eLZvtXlMqyuwI25B5J565/pWlbeFNF/s25lns90rQO8I81xtC/xdfXgfQ1q+KND1yPT7dp9Ht0t1uN3lLKNrsQc5w+e3YjFaw0TxhY2cixwyiPyygX7SuFB7gBuDWk6FZ4eKirO73fS60v/WmgXVzlbfwnoo0S4lms83RhWaP9642LvVeme+T17Y9a9Im0a3f4dJHBFtddOQock4IQetYVvoXjBNPa3EMrQyQiPDXK/KvB4+bjpj6E139haPHoVpZzrtkW1SJ1znBCgEUUqMuaftUnd6f09hSemh8n2V/dpcXWJSGL/N8o681c/tO8/wCex/75H+FQXNt9m13VbfGPLuWX8mNJsOa19jTf2V9wJssf2pe/89j/AN8j/Cl/tS8/57H/AL5H+FVtlL5Zpexp/wAq+4Lssf2pef8APc/98j/Cganef89z/wB8j/Cq+w1FdP8AZrd5du7bjjOO9Hsaf8q+4Ls0P7TvMcTH/vkf4Vbs9QuntrotKSVTI4HvXKf2q3UWrf8AfX/1qu2OrSeRdqLQnMefv4wAD7Ueypr7K+4malJWRo/2peH/AJbf+Oj/AAoOpXnUTH/vkf4VhxajLLII47NizdBu/wDrU+XUZoH2SWZyRkESAgj2IGDR7Kltyr7i7StzdDY/tS8/57f+Oj/CnwSX2qXcFlG3mSyuERcAZY8Dn8axzc3BhaZbZCgXccTqSB9Ovep9P1e90y9ttRhslkaCRZAolDe+GA5APSnCnSUk0kTWp1HTenQ3ZNLmfRrP7Hc2N5dT30sX2iF28tUSNWOdwGNvzEnHToSKzoNHvzM0kN9YSWbxPO14vmGNVRgGBGzfkFl429wenNJb+LxptnaSaRpElrHa3kkh33bPI3mR7GAYIuBtBwRyM9zzUc3ip5rm21GUa7JHFvjjL6yzTxv8pJV/LwoxxjHP4V0RkuVnN9Xl/L5/1qaFvp02oaJK1vJbTSxXoR7xSyxJF5e4sdwGBn1Ge3XiqOi7tRv5I5pl+zwJLNLJEvJjjQudue5C4GR3GRSt4+mc3kf9kqba8nWS4gaQlZUCBMN8v3iQG3jB3c4rJ0rVX0yWW/hsjJa7mgeCSQ5aORGUruCj+HIzjrg4rGdr/caexcqduXv+lzvNMtbS502G/thMtvcgkRyuGeNlYqQWAAboDnA647VdisLC50u6liS5jltog7SO4KMxIG0ADI6nHJ6Vy+j+KSYPstloNybK3j2RIJ9zKxLMWdtmDkn0HAA961LzxO39lx2CeHL1GjXcWjugyPIersBHyfbdwP10urNEPD+5dRNdbLTJNClvEguopVkSJC9wrq7HJbgIDgAevcU3TdEbUNhjZArSiIlmI2nBOTx0wD+RrBl8Q6g+k2kC6HKsUO9j+9yXdjy23bkcBR+FWdO8V6jp1pdR/wBgTSC6TapEvKHBGcBc/dZh261CkhxwrVO/L/wx0S+Gzx5jJGArs7Oxwiq20k8evAxmo7nw4ogud88UcKRBvPZmKEMDtxgE889uxq7NqfiG5unkl8HaoYZYBDJGscgJ+bcWB2cHdz0NQ3d9rb2lzFceDtV+xGFV2KrqyBAcHcUI/ibPHftV6EKl/d/r7ytpfhgx26x3TxRbJfLyznEhJyNpA6EYOeByOauz+G4nv7hImjhQ3LwwI7nLkHoOD6gZJH1qCx1XXLu0WSXwfqU0XmeZCIkkCrj5QudhyMKo7HjrV4ax4lzKD4W16NWmeZRAZI8bjnB+Q5H5UaCdJ3vYpp4a328cvmxBpY3kSIsd7BSwPbGflPU1DY6TaTefLP5nkwReYwRgC3zBQASDjlh2qyl74iSS0c+EdVYwRPHzFJ824uc/c/2/0qvZv4gtmlEnhLVZIpkMciCF1JGQeDsODkA9KV0X7FWegt9pdtbFBCXMM0aypvPzAHsfoQae+kadLYPcQC4iEcixkyuGD5z0wBgjGcc026k166Yn/hEdWRURY4VETnYB6/Jz39OT+FTXV3rMqwfZ/BuswmDHlqwZkHqceUCSe5zRcHRjZaGhF4cs7TVrArHcx/6fHEvnMMTLu++uAOOnr1HNel/2Laej/wDfVeWQalrn2+3dPCGrRqb2O5lMiu3IPb5BtHJ657c8V3H/AAlWq/8AQr3v5t/8RQ32IWFpyXvxu/68zWn0i1SCRwHyqkj5vauc8S2sf/CNWr5bJuB3/wB6rFx4p1Q28oPhi9AKEZy3p/u1zmveItQl8O20beH7qNRODvJOD97j7taYOpKONhroN4OgldQX9fM9FNhFj7z/AJ002UI/if8AOufbxXqg/wCZYvfzb/4moX8WamM58NXg9yT/APE1PtJ9w+pYf+Rf18y74k1Sw8M6NLqV2J3jVgiqnJZjnA6cdK8Ov/iXrk9+1zGsCx5wsBBK7fQ89feq/jrx3qHinUmhWOSHToGxHAGzuYdWbjk1xrXDd4WodSfcPqWH/kX9fM9Bh+LN0yZh09Fcdcvxn86WP4rap5wM9lC0XcIxDV5wJWV+Ijg08ztjJiIHrS9pPuH1LD/yI9/0vxVHf2Ud5bSbo3H3T1U9wa2ri5jvNMjlBOS4yM9ODXg3hnWDp90Y5GIt58Z/2T2NeoWl+REqZ43A0lUne1zSlg8OppqC/r5noot0I6t+dBt09W/Okhl3oGHcZqbPAp+0n3I+pYf+Rf18yrNAoiYgn86QQLsHXpUs/wDqmpF+4v0FU6k+TfqcyweH+stci+Ffm/MhMK+9MMS+pqdqjas/az7nV9Sw38i/r5mVqMYF3Y8nmT+oq8Yx71T1H/j8seP+Wn9RV81lCpPnlr2/I1ng8O4RXIuv5+pEUA7mmlR6mpG6UwnNa+1n3M/qWG/kX9fMZjDECkJ460v8RpvvRVd2n5IWCiowlFbKUvzEzTTnFKcfjSE1mdhzl9/yOVj/ANe7f+zVvgYUfSsC/wD+Rzsf+vdv/Zq3wflH0pdTlX+8v/CvzY1s4P0oob7p+lFaRPRo7M5HSv8AkYZP+uP+FdB0bFYGk/8AIxP/ANcf8K6Bxg5p1d4/4Y/+knLH4pepKpqZTVdDxUhkWMZd1UdMk4rNK+xdiaF/+J3bf9cz/WuqgbpXFxXcA1m3JnjwEPO8e9dRb39oMZuof+/gopQneWj37Py8iqkZWWnQ09NP7lv941B4o/5Fq8+i/wDoQpmnX9msRBuoB83eQf41F4mv7R/Dl2q3UDMQvAkBP3hXVUhLmej+44MFCX1eGnT/ADNjSf8AkDWP/XvH/wCgirlZelahZDSLINd24IgQEGQcfKPern9o2P8Az+W//f1f8ajkn2f3M6uWXYs0tVf7Rsf+f23/AO/q/wCNH9o2P/P7b/8Af1f8aXJPs/uYcsuxaFLVX+0bH/n9t/8Av6v+NH9o2P8Az+2//f1f8aOSfZ/cw5ZdjE8c/wDIEg/6+V/k1b99/wAeUn4fzrmPG19aSaNCsd1A5+0qcLID2at291GyazkAvLc9Okq+v1rscJexp6dX+hPLK70LsP8Ax7Rf7g/lStxg+lVYdRsRbxj7Zb/dH/LVfT60rajZEf8AH5b/APf1f8a5XCV9n9zHyy7HzV4mtPJ8d6+gGF+1uR/30azvI56V0ni8IfGWpToyssszcqcg8mskKAahpp6i23Kgt6d9mq8qr1qVYgRwKAM025qhq0ITTZSw4BXP/fQro/I46VQ1e3VtMmDDI4/mKAuYL7pLpCblRblsxbXHyjtgfw9hVpZAOUmxKYWUsZgxzzjLDFXIdJtDaxMYuSgP3j6fWp4dIszDcEw9F4+Y+/vWTpnU8a43dt33f9ehzFudt1IJHG51dN5bPJBHX+tJcr+6ghDIzRoSxDDA5JwD3/CtSW0skbb5ZLeikk1A1pD2tW/Fj/jVcutzNVvc5bf1uZ+5YtPKqwLyv8wB6KvT8yf0q7Zbo4JI3kh2lQVEZUsee+OcfWkNrCOtuw/E1Z0yOwjuWaaFmXYRgE9cj3pxjqjKtXapysr6W/r8zOs5JFsXWG4SKUyqfmcKSMHPJpxkt5JQI5hEn2qRgQQCBgYPtkjrQbSD/nn/AOPGoRZx5Pyjr6mqjTTjN37fmdCxLSUbbf18i20sZliYSr9o8l1DtKHKtnjLDjpnmm20wSzuftUyNKZUw5YOAdpwTjqBxUMVrCHO5OMf3jUiW0H9nyIY/wB4WGDuOMce9c0oW09DaeKfJGaWt3p9y1/zNfwZvZ9SVm3vlSSGznk9+9bw+6/1NV/htNoem3uoHWLOe4jdF8sQscggnOfmFdSdQ8JESY0u85Jx8x/+Lrfl0ucrq2g427/1+COdQ/IKmgb97W/9p8LQYjn0i/SQAEq2QeeRxv8ATFWEvPCVrctHcaNqCOhwyNkFT6Eb6hRClW/dRTXS2/e39fqexxn5RVfVf+QPff8AXvJ/6Ca5JPifoqgf6LqH/ftP/i6ZqnxH0o2F1bvZalHJJAcCSJR95cg/e6EEH6VoZHR+Ff8AkWbP6N/6Ga2a820H4jaRZaJbW8ltfF0DZKxpj7xP96tL/haGif8APrqH/ftP/i6AO2zSE1xB+KGi/wDPrqH/AH7T/wCLq3pfjvTdXuWgt4LtWVC5MiKBjIHZj60DOs3Dyz9aiL1nHWYPJb5JOvoP8a5m51GW8124hjvbmCNUDAJ9B2yPWolLlCx2hf3ppk965Dy5/wDoL3v/AHyf/iqryvKhw2rXw+qn/wCKqeeX8o7HY3Mv+jS/7h/lXK+JX/4pi0H/AE8D/wBmqq4naJsatdHKnsf/AIqsW4upZtMltXnkkMVwm0ufTfWuDnbHU3JWFJe6z0iWbAJrA8S6oNP8PajdZwY7d8H3IwP1NOm1VCDgNXCfES8nvNA+x27hPOkG8s2MqOcfmBSCx4+CSdxOd3J+pqGcYPQ/hWtHod2UGZIM/wC8f8Kf/YFyVw0kP/fR/wAKYHNyTtkALgZp29zC+/HtVy9iFnI9uVUzKwyQARgjNU5p5DEy+XEAfRBmkA9ZlCqCewrv/CmqvdwxrISSh27j/FXnCgkKOmfwrutDfyZoYgQQqjkdO1HUun8aPd7KTMSj2q+DWHp0gMMfPYVsI2etNmaFn/1TUi/6tfpRMf3TUi/6tfpTfwfM54/70/8ACvzY1qYae1MNZnWZmpf8flj/ANdP6irx6VR1H/j8sf8Arp/UVePWsofFL+uhrL4Y/wBdRhpn0p7fpTO9aGYz+LikPSlPDGk78HitKm69Ec2E+GX+KX5iU00pOaTtWZ1HO3//ACOdj/17t/7NW8PuisC//wCRzsf+vc/+zVvj7o57Uupyr/eX/hX5sa2Np+lFD/dP0orSJ6NHZnJaT/yMb/8AXH/Cuik6Gub0o/8AFRSf9cf8K0tb1T+ytNa68rzcMBt3bep9cGnUV3Ff3Y/+knNBNykl3ZeR6r6qwNmv/XQfyNcp/wAJpMI/N/sltpbaD53f/vmq1943eW3AbTWRVYMSZf8A7GtMMnGtFs6acHGabO2FjZDVYFMQ2lDn5j710NrpulsQDCuf99v8a82i8fxefBdnRsxY2DNz94kH/Zq4/jyUOGh0SUKeg88n/wBkqIVMQm7ye/cc3V016dz0yw0TTXjObYH5v77f41H4i0TTofD11JHbAOAuDvb+8PeuJsvihc2oMT6BIWznmcg/+gUa58UZbjQ7mJ9BeJGC5kNwSB8wP9yuidWs5O0n95x4aGJjSjGV7pa6no2l6Bpj6VZs1qCzQISd7ddo96uf8I9pP/PoP++2/wAa8wtfjG1lptsj6BMI0iVRI0xCnA/3Kt2/xjkul3QaKZB/s3Of/ZKl1ay3k/vN2qydm2vmeif8I7pP/PoP++2/xpf+Ed0n/n0H/fbf41wQ+LN4OvhuQ/8Abwf/AIinf8LbuO/hmX/wJP8A8RS9tW/mf3ivV7/j/wAE7v8A4R3Sf+fQf99t/jXM+OLO30fRoJ9PiEU73Kx5GWyNrHGDnuBWFcfGaSB0jPhe4d3DMFS4ycKMk/c6Ac/hWBq/xotdQlsRPoc8McF4krsJg5AUEHAwMnnPXtWdWvW5HaTv6ibrWvd/eReIRrEOj28k5kjlkuvKWFoAGPy5B6Z5z6VblfXPMNsY5fPIyIvs/wAxHqBtzWAPiPpVvBYI6T3Jiu5pHOGwqtHtVh0JOTkgEdOD3pJ/iLGsUEa2FtFA8UioWE5ikBZcqSfm6jPy9D9an6xW5Yrmel+rJ5qvd/ebt3f6hp+mrNNLJ9oM6262q24MjMVyABjOfaqlrJr2sTpFJKbMZJMbBVYAcksQOMAEmsyx8f6Bpwu4orW9JuJwwnPzPCDGASmewOVxnO09c1S034h2ttqDC4sZRA8ckTSI27AZSoYAgdyD9Kj2tZ3fPL72Pmq9394niEXdlNJNPMlzDLLvilgHyty6nqAQQQQQR/Sob6D7Dp8NzNqFuZZokmS1VZPM2t052bPf71VNU8TWV5YwabFG52l5WmIIG9nZtqjGSMbRk45z9as/2u0OkXVhqV7e3CPaolvaSRHED5Vgw3cLhc8r1B9DU1U5S5nJ39RSjKTuP1JBpKIJdStpLkpG5tolk3qHUOMkoF6EdGPWorW8vbnyxb29zL5r+XHsi3b34O0YHJ5HHvTZtZjl0K5sr7Ub3UGbyxaq6E/Z9p5ILfd+X5cLwc+1S+HfENlpGnXiOLv7SrCazYIDtkKPGe/HDhvqgrPkaju7+pPs5D4bnUbh4kgtrqR5siNUhyXx1xgc4qvdf2peCewhsbyW6UfPAkBLrgjOVAyK1r7xRo9xcXkFqLuC2msjBFJ5Y+Rmm85gQDnHJTI7YqrqniHTL7SbqwSa7ikaO0X7U8f+s8oMCGxk4+YY/wBxc47CT8/vYvZyK2li/vtkENtdOIgqzMkG7yh0y2On41ae11E3WpW9vHcSWtpI8U9ysHygKSMnGcdM1d/4STTNTvIRAdSjlGpLdKUiy8/yooOBn58qSB6ueatL4z0y4u4WttPLzwXs1xEJUlOQxDBgsbgE4HIYdB1xmlr5/eJ05NbHOC38uza6j07U5rULvNwsJEe3JGd3pkEZ9QaTTRaapNKgR7eKGMyzTyyEJGgIGTgEnkgYAJyRV+HxRo6yaYrR3ohttOuLZ0H3Q0nncY753rz9PSs7S9T0OC21G0mt7uNLyAR78g4KyK4zjnHy471XLo9X95Xs5CahBZafe/ZZppFJVZElA3xujAFWB64IPpn1q9aaTawxalqHm22rRWdmsoggaQKWaQL8/CthQSTtPYc1U1bVNAvJYQlrctHa20cCFjtL7RzgfUnr2/Kll1iygWJrPV9RikgKpbeUX/cr82SCWG3r90ZHXmqjG1nd/eKVN8pc8NaJpupXMdxd2WmCwvL1bRAZLverlQSkQUE5wQcvke9V9cl02y8IadYPp0TmO8vIkuN8m9Srpk/f25IwOQeOmDzU1r4gXzAr69q88k8haXypJAGUKcbiXGTnHGOMdav6HZx31vqNv5t4bOafc8DM21267mXdgnpyc9K1iouEry/HzNI0Jz+FEPhi4Nvp3h6PSopBHf6tJDfKvImA8rEcnqu1mODxyx7VgaLq+naB4hfULS3uJYLd5Qghl2vtKsoZW5xgHOfau1k0f+zbCWOxkubSOchZhFuRZFweGAbn8aLa3gtru3NneyQ/Z93liIlTGW67cNxnjOOtc0nC9ubt1N54KsqcXbq+3+YeH7qEa1HqZvtS83UdKLwTajK081tiRlGW6lTtbDAD73TitHxFGvmWzifzp2tFa4lKlS75b5iDzyu05PJ4J61EjLDqDXyahcLfMMNPk+YR/vbs1A9v+9l865mleVtxkaPJOfXmtbQ5X734mcsHWs/d/Ff5nQataQ3BvQbXypILOCZbnc2WJEYwR93BycYGeKtPpsd14kvWuYrZoZr8wq0jSh855CBAecEcsMVgb7maAW0moXc0anOxwSAfpu9Kt2yaixmaC9vlMhzKV3DefU/NzRFRk9JfiKOFrcik1p6r/MbdWkWn2EYFslzJM0qmZ2YeXtYqAoUgZ43HOeoqXxVapHpTXSqJpJbWBHfJAt8QJgY7luuTxjpznCLZajFHKkd1eIk2fMVQwD+ueeap31jeiyui1xc4eHY+VPzKBwDz0GBj6CtPYvv+Ivq8/wCmv8w8MS3lt4WtJLBiJ5L7y5Ng5ZcfKp9iS3HfFQ35a2167+wuVSK4fyTH1ChjjH4VFokF5a6ahtru5h3qQ3lAruGTwcHmniG7gCCK7uIxG5dNgI2scAkc8Hgc+1J0G+v4jWHm/wDh1/maWqahO8WlajD9rQ4kXzXuN07AEZO/aOMNgHHHPpW1pF40uuWt3tkjE2mEgzSb5XxLjc7YGTxwcdAK46Z9Ua7W7Oo3huVGFmJbeB/vZzT7G7vbPUZL25e4u5ZI9haQnceQepz6VMqF01d/eP6tP+mv8z1cXWbCVt3Rv8K5y3uv+KlumB6xD/2WqEOuSnw9dTNbvlZQMbuv3fasrStYmuNelMdnJI5j5RTzgY9q554Xb3n/AOBB9Xl/TR1Gu+Lbfw1Db+Yks91dNtht4VBdsdTz6cVjav49tE1G00+4tbmSK6AxPtAVWI5Xr1Hem6p58+qR6pJoU08tpCRboSwIckZOcegrnvEN5q3im1jt7fQ5tPa3YPCzpubefvHgCr+pf3n/AOBC+rT/AKa/zOtTUoIt0QV8fX/69c1qd7ELa5UZ5ulIH/fVQX93NZzQLLbPGjEIC5xk/lXP6tqIUyrxzKD1+v8AjVYPDcuYUld/eKeHkov/ADPSJ9WtSp3B8fX/AOvXn/jrUdHkgt/tlpcSgycbWxg4P+0KWXXFPp7fPXMeJZ4r+GAGVVKSZzuz2qfqf95/+BFfVp/01/mRpe+GkUD+z7of8D/+yqWLUPDn22BEsLkOXXB39Dn/AHq5uSJADi5QZ/z61JaQxnUrc/aUz5ifzHvVfU/7z/8AAifq0/6a/wAzotVvPDy6lKkthctJkZIfg8D/AGqzLu78PNbuIrC6WTsSTjr/AL1Qa1bxtrM3+kIDlcD8B71n3EZCyOXJ8vAwO5oeEt73M/8AwIiVGUVzPb1NqO58NrDGJNPui+wEkP3x/vVvaNf6LcTBbe0uFdRjLNnj/vquEDggEjJxXSeCVEms7DwCpOPXkUlho3vzP72FNe+j3rTJoZLWJ0RgCoxmtiI8cVhabGIoFTstbMJ4GKHhY/zS/wDAmZJE8ufKJPSgZ2DnjFDnMLUD7ij2pvCx5Pilv/MzCK/2lr+6vzYhFNNONNNYU48lZxTbVlu79WdS0Zmaj/x+WP8A10/qKvHpiqOoj/TLH/rp/UVeNbQ+KX9dDaXwx/rqRtzTT7089eaYeK0IIyPmNIenFKfvGkNaVN16I5cJ8Mv8UvzEpp9qd07U39azOs5y+/5HOx/69z/7NW+OMc9qwL7/AJHOx/692/8AZq3x90etLqcq/wB5f+FfmxrfdP0oofO059KK0iejR2ZxumnHiCT/AK4/4VL4lMcmmqk2PLM0YbPAxmq1i23XpT/0x/wpviEJc2HkOWCs4zg88Vo/jh6R/wDSTLDaV/mYeMpCLqNY8yt8oUDPyjHHHeq9xHvAX7LMzlSD/oy5HoQmSD3FST6VZoxAlm/76H+FR6i+g2EC2lvNcXV3jc+1l2j9K0o1OeoopHbDFKUkuXt2v+Q6NbO6tzbOsZMLhVUoFXftzyOgPPT14p1rqIeZra1hknlRXUvt2oHAOAT9eKytBFpqbPPqNnczorE+VBIqgL7Ajmuyv5/C6eEbjUNJmvWu48Rx2koVWDHpxt5HuK51iYSk7bozqVm3CSjt/wAHyOc1C3uWhgWS6aFkRmkiiOG25z168c1LNFpj6UZzErFYFCzyfNyMcAnvnOfzrKvtDV9TWRnlYGMEknvk+1TPotulm7bpQRjuPX6VUq8VNozw1S9Lm5dGlv5aLp9/ysdLBfQ2+nxGUmNVRRllIzx29fwqsJNIuJGu1RBLAd5kVNpPbn1HtVW10OzaCMmSYZUfxD0+lW10Gxx/rpv++l/wqViIpp9jRSalGSV7K2v/AA3f/gjX1GayZ4lzelIt6qBiRiW7dj8p+vFWIdatpi6IrmdApeEDLLkentxn0qM+HrBuPOmIPHLL/hWVqngW0jmxp16ySAZdWORu9AQKv6zBlyq9of8AA/Df+rGyk8F14gtYt6oBBeLI5GdgMDcnHbr+VUxpemK9+Z4IVSz8tUF0ZHWUMT+9Pl5OCAMYwPmHJ707fw9I0sCX9xc6dIAytcLysisMNtxgjIyCD1zW1aeFrWO6Q2viXUEMMZWJkXZsTOcA7+OTmuariIrmk9LEzqWSlyaGQukaNqVxJDZophhmWaWXawxbFSXPzAHCFeuATuFT6fb2Op2OiwzaUpS9mnRX3N/o6GT+HnHyg5O7OQPxqiLeKNNVmhnvJXuR9lF1O/LqSC5298lcZJ6Z471bg8PXcds1umt3UNuwKmCNyFIPUEZwfyrWV1CM29He3y3M1K7+Ehi06w8mC2bTVYy6dJdteZPyMoc4x93blQpyM5PXtT5tHto/D93LNZWUN3awwSkRmQv87KPnyNnIfPynIxViPws4sjZjXLlbZjkwhvkJ9SucVJJ4anktRav4gu2twuwRM5KBcg4xuxjIBx7Co51e9wtq3ylK9i0nTNR1uSDw/Gy6deCKOJpHPmAuQXPPQYwMY+8M5q3retW0HipbSfSIlj/0dXLgZQGNMg/QHH4Vz8Gm30Ot6jcWmp3Rvo5gGkViHdWySxOckZAz9auzaObi7uHlvJridZdjbYfNbaAAOrcDt+FTUqKE7N/1ocuIxEVJxa2/r9TY1fxBK1hqRvNLQmzvlt7dZFHAIk3BfQAKvA9R61L4c8QwXDWll5MVoXuCLmHySRPGdvdRjgZzuIAHNYMlpfXNssj6jd7bXcYHlUsEAPAVt3yngcDvSXlve21rPDb6rcGCRgblAxALED7wzyD61HtIv3SViIuoall4kuItOup5bRV0pd8cMAQYuHOcAL0wMglu3HcisnTLs6/LcaYunQrcTQMbciMD51w36hWH407TxqwsIILPWLyOBZWWSOORlRFODkgNjB+b9aw47LUG1GP+zJp0laRhBLHlDx1IIPGB+lWpx11B1o3s+m/9fkegW5srHWdIntbFFt7vUIYbXKjcqqSshz1zu2n8a5m1i0zV2s7s6aIBPcXEDxLI2CEiV1bk8H5ucYBwOBWVJHfWd1aWrXF/FFb/AOpkKOjJlgWdFJ45HbngV0E3hvV4/EtrpkcjWenfaZPsN0If3c3ytyhB/eFkVe5ySAaIu63Gq0Z200IY0s9Yl8OWM1lFGh01pmmVpdzBDMdhwW4Zl5wucnjsKwtaXTM2Z00QyyyhlljtVmMYYHjb5oDEkHkc8j3rt20S8s5tOsba8vUe5sbm4jsprJYmE0ecAQB2CucnpyfTmuU0qPUtc8QGHU7q5+2tBcRK1wCWimCuBF8x+Qk4AHHJHFWnZhKpFqxo3rSpDdaXNC8emRaLHOsTrhVlKId+OzeaSuevUVU8JRy6Xo2p38sV5Zw4iAu7eAmUBiSNvI+UgcncP4eucVFrulazZaLp+kzS3reVZvdXNptfFuQzEblzwcc8gYBFEMeoaZ4bk1hdTuIbm9mEEEiOQ5gjCAtuBzjJVQP9gjtSuthSqx6m5coujvqV+Le/t57nU0hD6fiNyhTIO4r3JOVAGSMcYqKw1i50C31uC6t2vrZNQa3F7HKqOko3YI6kggE4xjin3ml3+mHWNTGq3cNndJbrZXSAqLss6EKrB/mwm/Ppgg9ag8KLfy+A7w6ZpceoXX9rxDy3tlmITynydjZH1bqAc5HWrpScbruOVRTskNk8Q6w2mJfObo2TzNEsglGC6gEjGcjhhz05qpceJDqUTR3lo90zHOXIY11DadbTtZWOjywGxTXr5ULr5yYEcZCgH7/ooP3uPWi90SBLuxuotPWTU5NNneK0ubBLbzZ0kwu+3Viu4IWwv8RVeOeYajLVrsEqk5QUW9Fsefy6fcTwS6hZ288dtDKsUnzBiruGKjGc8hG9uPpWwniW6n1eERSPj5E+zu2S5z2966TSLOS803V49es4ra7F9ZNHZmEW8XneTcbEkUY2qeD25wCQCSOd8LzXcfxEBvbeKyuPMkTa6CMxTFHEfGAFw5X0Aq1U0sZ2crryNXUNWvrXVDbXVhc21ywBEMpZGIx1AIzU0t3qlvZC9uNKvUs8488hghOcY3bcdazvENrq9tpuhWcsM/8AakMt1MYNhMiQYQjI6gZWZvoSelamjHV10PUbi501LW2nsZGTU5FkxggERrlthLEbRxuBbPas2oXWhtQU40uVPSy7DI9fRrN7ldEuZreNgjzNcvsVj0BKgAE4PFaNxJZSQSA2zxFlI3LcMQPzzSXL2g8C6hBa6rZXFtb/AGZtgWVXaU7y5OUA3E8DnGEGT6517f25t5REWGVOAV56dDVOcV0KUJy+018kPg+yxQRoLsDrgu2AefWn3Fv5JXzZTHvGVJJAb6etcxNcym2QRqzAZ/h96hW+vmtjblZDHnIBB+U+1HNB9F95PLVX2n9y/wAjpmtkPP2n8c1EbFDz9p6+/wD9esGO4vgoK7sehU1Kl3dDkq2PTFTzQ7L7zRKp/O/uX+R2FvaoPCV7F5uVaYEv2H3aqeHdRg8N64t9LKjxrG6EFtudw9frVa21WVfBGoExkuLhcKRyRlO1Yi29tqtnqF07JbPHNAoefcAoZXyMAHOSo7Hp9aidSEbO23mTJSs7zf3L/I7y9+JE1xJ5VlLYRAnALnef51Xn8Y6tp96Yrm5sMgAmMxbTgj6/jXnQ0lv7QksnuLeG5SXylSQt87ZxwQCPxJApt9ZpFotvfG4X7TI8iNAyvu+UgcfLjjOTk+mKPrC5krLX1MHCS+2/uR6Bq2uWHiGCGMvAk4nSTKyZAI4xjtXNapZWst3JvvYo8Nxuxz+tY2mWVtLDZPefaA97cmCIxYAjxtG9gQcjLdBjoearW9jHceIRZ3rFIQXDMJAnIUnG5hgcjGTWlCtCOKjUt8N/6QPn5WuZ/cjYOk2bDi/h/If41TudFsyOdUgTHfA/xqnNZwW2qwxXFleQ2zqCFW4SVnzkZWQLtI/A9DVTVLP7Lql5aRBzHDO8aluSQGIGfypxq029F5/1qP8AeS05n9yGatpo0+6WEzh8qHztx6+/tUNko/tK2O8f61P5itnUfC+oSzBo/KYCaO3ABOWLdGHH3fmXJ/2hTR4cEtrpklvLbrcPHK7KWfM5SR8leMD5VGM7c+5qJ16aloyIN8quynq6j/hIJfnH30/kKgu2/d3CZ/iU/pWv/wAI/Hcy3MtzPDa7LFLmJh5hDEyqmXwrepGB6r71nyaHdC1klEsG8xef9ny3mGMfxDjHTJxnOOcVSrws1fqbqX7tx8/0M5cFR8w6V0vhZxb3TT8DYhwScVjabp8Elrd316lw0FvsURwkKzsxOOSDgYVj0PapbiwGn6xLApkkh2K6MRglGVWGffBFCqLn5bkwupI9b8LeMrjUoJESxa5eM8mNu35V08fiO8Vwv9i3G49tx/8Aia8g0PSreKWyuIWe3S6k8oxvcxzkggYPyAbTzjaea07PVLZZ9O1H7DfR25vfKYEb3XaVORgDrnp2IqVXjJpXM0mesx67fS/I2i3KKerEnA/8dp0mu368DQrpgOAwJ5/8drO0nxlpd/MbRLxWY/cLKy5+uQK6qO7tmiA+0RdP74rfmXJv1MYwl9af+FfmzFi1u+lmVG0W5jB6sSeP/HajfXb5ZGUaHcsASAQTz/47W011bZ/4+Iv++xTftVv/AM/EX/fYriTX1h6/ZX5s6VCXMcxeaxeyXNqzaPcIUfIUk/N09qtNrt//ANAO6/M//E1dvpY5byy8uRHxJztbOORWia0h8Utf6sazTUY6/wBXOeOu35/5gdz+Z/8AiaYddvv+gJc/mf8A4mugYUw1pqRZ9zEbV7wQiT+ybgsxwU5yP0qE65fd9EufzP8A8TW7/EaQ/rWlTdeiOXCJ8stftS/Mwv7bvv8AoC3P5n/4mk/tu+/6Atz+Z/8Aia28g0hOOazsdVn3OKn1O5m8X2RfTZoyIWGDn0b2rYk1u7jDZ0ifamcvk4wO/wB2or//AJHKxP8A07t/7NWtf/8AIMuf+uLf+gml1OVJ/WXr9lfmxtlefbrCO42bd4Py5zjBI/pRVfQv+QFb/Rv/AEI0VrDY9Kh8Jyts4XXJie0X+FVdZugI/vcBsntVa81GLTr67uJX2qkQH1zjgVy09/c6pcF5iUg/giz+prR/HD/DH/0kjCq9f5jr3VZr52jtTti6NL6/SoLa0RHOB1XknqadGoUAAAAdAKWQzgxpbBmlkcIqqMliegArOhNRqxk9rm1FKElJljSmk0+cNG3ynIIx1zV2HPzgnOT1xWf9g1dbtbYCJpSrMdk8TBAvXcwOFx33EVLHYa4000YRQYFV5HaSNUCt91txO0g+ucVj9TXNzaX/AK8jRStszfRm1PVI7aAxRSNEzAO/GFVmPb0BrMuNTj+yOMox4/j962dNutdttPaSXUBBZQaZLI0KvF8zuxUM6dTlW+ViPTB9cyz1P7T4YnW41CSHSYrZIHjQxuvnNkgiEgfPlWbduzgcHtWksPHmvZHLTlOMFG5f0a4/tGe2sofJEsi4UtJgcDPYH0pF1WIpuKIF/vGTioLzW9StNftEv9Y2m3nwsazK8KIUPzomP3YwRhfes3XpftcFhfpq0kmlb2t441tVRrfGCQE3YY8gk5BPftS+rw7Iv2k+52DyyW2lC+TTIymwSGSS5DMqE4D+WMMFJ4DEYPFUItU1DVMx209lCY8Es88UROfeQjJ+lZmrXrWtqmqW+rNKL/TxbiGW3SNwiBI1+UM3H7s88fd6mq0Gm6xZw6dqOnNayvLaNNILr7PIuQ7htqOCCAqqTgEjPan9Wj2QlOfc247LWNRkubZkLyxP5MvnTJHsc5AUbsAscHCjk4rM0+SawvpBcXDzRKpVoGIUqc+uM1Lqz39/IILbU0Z55U1CSS4kjjBZxgsGIAwD0HXmq0M2vP4xvr/iHbdObh5vLiUCQnIy2FyQW4HXtWU8JFxastRzqTlFK4+/1e1axjSKFAquMASdOD7VZm1mNrlUVAqkdpf/AK1Lq0t3/wAI9bNbXSzNHYPbP/q1VYhMQSDgcEo3OckvgdcU2LV7nUjdXGqarE+lWk8U0CLEknlpuwEVONgIIBXgHGcHFdUqadOMLLS/42J5533HjUk/vf8AkSrU0jQ2FteM6+XcM6oBKc5XGc8f7Qqje6zq9vqtrFfatFe3KymW0nKK2EeMGM8g4XJQhegwcVsXl5qunDTf7T1SWe7i81RPLbLgM2MssrAliMYBI9OmKz9hHXRA5z7nHhbW71O6kkkYEnosg/wqb7JY/wDPaT/v6P8ACuoh1W5tPFztFqLTSXWmruuJAnmS/vCwyR/ENowc5wo9K1NYW0uNQS48uGaSSCF5iACWfYu7J9cg5981VRJyv/WxMqjbOSvfDL6fbLcXSSJGWCn/AEhGKMRkBgOVJGSA2DxTLHw8NSB+yOHbdtEbXcSO59FVsFj9Aa9D1UWhTVZlmtphqF0skIVlLY3M25h/CRnHOOpqvocDWepLdJJp0SxyBJHlaEsoBBJXOSfYpnpUciI52cEvhppdPN8JEjt8uoaa9ijLFQCwCsQSRkdB3qlJ4ftX0Q33244IzsIB/ix1r1LTmTYY7mSyfSvMlYiYx+dz3A+/uOB049a3I1T/AIVE0QUZAORgY5npqKE5M8ftfBUFzDBuv3USqCAEGemcCrF38N7dBF5N9cMJI8gFRndk5/pXvsBWTwpYtydlvGeTyDtA4pbogT6XIc4+UZzz2rRxShfzOec5czV+i/M+fofhkLyyuGS7uHuLdwrARg8HHB96hg+F8txEsqXMxhb/AJa+UNoHrmvp1Nscz/3pSTlT1wMc/lTNqGBrcAZAGR/D+VTZG1z5wm+Et3JO5tzeNH/CTCDkY60aP8MoLxpEe9nYqSNsaqCSO3519KFtkeBnAHqa5JbK1t9UNxFEFklJLNk89fypxinJIyxFRwpSkuiPGE+EOqXE0iL9pZ4yA6+V93PSqFj8MLy+a7aNphFatiR9g9/8DX07G48yZ9oHzdeecVyfh9l8/wAQkqBmbkH3L1tSpxdKo2tkvzNeZ3R4vZ/DOO9gaeDUWkiVghdduAxGcflV+L4TyszI1zcBwGO4Acbc5yPwNes39lZaf4eiS0tIoA9wGbYgAJwatTTbL2KTCgmBznHXO6vPm2n80dFZWowkurf6Hkdl8KrW70prmWS8UhwgmR12591K/TvTp/hJLpBEst+WiLgFgoFd/Yata2ujFJriKJjPnaxA7CuQ8W+LlvruPTYZA8YnU706HntWskrGEptRfo/yZzV54V02O7ZZNZWM9lfbnp9aYfDulKg3awijsSy/N9KyvET3UuoSICzqpGNxzjgetVruOU21p93cE7/QVi4q8f66GuFm3h7vsjTl8P6cchNehx7lf8adLp0TRuR4htiQpO0KvPt96udaKX+Nhj2qaMhUO0rnHpWnJF7oXPLua8GmIYEY69bpnPyFVyOfrTjpkGc/8JHbD2Kr/jWKZdqAsAR7Cq84DruRuD2o5Idg55dzp4tOt88+IrVv+Ar/APFVZi0u0Y8a9asO4wP/AIquMgfa2D39KtENGVlQ7SOpH9aXs4dkNVJ9zuYtCim8NXsVvq8UkrTja6qDt+7xjPP/ANeuFvHu7e31DTyGkdriNjLjH+rDr0x33evGK7Hwq6totwwOB9q/9lWuO1O7c6pe7scTuAcf7Rp+yh2Ic5PdksXjGa2vZ5/sk6NJcicCG48vPAGxyFyy8dOOprLvNb+12Jgkt5FlWaSWKRZBhQ5BIZdvPTggjrVOdvmznk1WJLE1Cw9OLukQlY29J14wC1gntGuXguPNt2Em3ax28MMHcMqDgYPXnmobm6jXUSLu3uJOSZVEoQtkcY+U7cZ75z7VQsG/4mNsP+mqfzFXtVXzPEFwufT/ANBFbYWjCWMjDa43flbHvrkc11aBrSYWVqhVYVmHmHktkuUIzk/3en50zU9UXUNTmureCWATOZGR5BJhiSTghRxz0x+NaWlxWUPyyxK+04Ykcisa7QRanKiDChjjArNUoJ3SHqtbnU3XiS7s5oAbFv3dmYsEkZfjbJ07bE4/2etYNlr80V3pQ8gsbRHixu/1m9mOenGN/wClbOujdexqT/yyH8zWAiRpqdsB185P5iieHpRk0l/X9MzpLmgmXp9faK+NtcWkjRG0W0kRZAjH5xIGBKnHIHGDTbrxTcvp5sna+Vkh8hRHdlIiuMDdHt5OOOCAfSqOsf8AIxS/76fyFUr1c3Mhz6fyqvq9Nq9uptyp0+bz/Qt6dq/2aGe2uYHuLacLuVHCMGU5BDYPqRyD1q1Ffy6pqk00ltJuYrsRG+VI1GNvTJ4CjOR0PXPGREEA5Na+hf8AH24H/PM/zFCpR5uawQ+Jam5aR/arWO2tNPulsxOJZGL73kYAgAMFAAGT2z+Va+r3F2dMkeO3vIhbqZFkmZpGDYHJYjtgVn6FqJt7YJJKscUY6k4AqHXvFCX1hLZWm7bJw8zcAjuAKXsad07EK+5T8G3k0/ivTo5n3RtLhhgDIwa+ioNNsSBmAc/7R/xr538EWw/4SaynbOxWJU+pwa+iLa4DxqQea19nDk2W5zqpP601d/CvzZJLpFkDkQDH+8f8ai/sqy/54D/vo/41o7g8XuKZiuNQj9Yat9lfmzpVSfNuUV020jdXWHDKcg7j1/OrBqRqibiuhRS2RTbe5GTxUbVI3eoiRTAZ/FSGlP3uaQnpV1N16I5cJ8Mv8UvzG/hScdxSmkbmoOo52/8A+Rysf+vc/wDs9a1//wAgy5/64t/6CayL7P8AwmVj/wBe5/8AZq17/wD5Blz/ANcX/wDQTS6nKv8AeZf4V+bKmhf8gK3x6N/6EaKNC/5AUAx2b/0I0VcNj0MP8J4dez6helJvtAaSZNzeZtUDDY44AHQVWji1XzHUMoKAFiSoAB6HPTFWoLi38lDJGW8pShyoYZLZBwTz171Obi3uYrg7GRBHGpKqAeD6A4xUqV2teyN6NOm3dPXyfl/mUlh1LyJpGnRGiZVKttGcgnP6D659qltL3UtJ1Cy1CZVlSCdJDHkAnvg45XIzg057q3lSWNomVTs2Ecn5VIGefenNcQTOzCDMkzLuDjheQTjnn9KEkne/4A403pF/j6/8D8xYbyw06e5iSe+ktLy3aCV3hjWSE7lZcAOQ2CgzkrkE9Kmuddgm02exgaYI9vDbW7yIuW2OXZnAPGSxwBnHFV7pYTJPDb26l2lJO5OFAz7+/tTYpbWJY0eNZZY2LARRjaenBJPtWnMuXR/gQ4JT5b/1f/LX8DUn1axlW9mYXn22705LRkWNTEhXYNwbOSDs6Y4z3rL054E0+80y+a4FvO0c6zQxKzo6bgBsLDOQ7d+OKvTaFc3F2ip5nllfmZUAAP581Nc+GFS0DyT7RGuDhMliT1PPvVytzfF+DMKdnG7t95lajPb6lq8t5LLLBG8yARBFZlhAx1z94ADjGDzyKta/La3hhTS7m5+zQExxW0lssYiXudwdtzE8kkDP0wBauLCwtWhDq7MYlORGDke/PWp3ks4ZDG8DhlG0jyl6+vWs5TVtHv5M0jGDbUpWMrWS+pagHtsxWsUSQQpLgEIowM4zyep56k1tW99ZQW+lyk3BvbC0kgCBF8uRmaQgk5yAN/oc9OOpriazyvySHAIP7peffr/nFOle1jLRtHIGAA/1a8d89aamk9/wYKML3uOXULPzUM6kMtlFBHK1sk/lup+Y7HO0gjjJ5HpTtR1ex1Oa9jlkuILeSWOaJ4okdlKxhGVlyowcZBBGPTniCQw3EZWOCYqFwxW3U7ffOeKzLb7P5klttkeRiCNsQLZGe2fek6nuu7/BhKMdEnfQtXGt20nh220O4E3kQox82NRuWXzHZTjPzKVfBBxg8j3paReWkVpd2t48/wBnu1UeZFGCyMjAg7SwBHUYyOvtSXtuJbgxpbzrMWGIfI+bGPTOf0qJzAsiQvHJD5ahSGiAbOMkkZ9Sa0ck4xfN+DIdk3+BtwTW2q+J4HTzUSJYUt0KA5SNAAWOeD8oPGeSa7i/TTbqK6ykzG7nFxL5jHCkbunPP3j6cVyPh02CaxbyMJwu3adsCk8IR03V2n2jSnJDG7wDwBap/wDF1UJUmvenZ/4ZfoTUTUmo6r1K3hqz0LVPH1rbItxKLeE27pMnlrwGIIZXJPWvVD4Q0AShfsA+YEnM8n6fNXi+hXdpB4m1OdJbqKRSdhihUMOf94YrsU1qaaKSZNS1ciEAu20fKCcdPM55xTfsL61P/JZf5GVpPWx26+DvD5ZkNgABjgzyZ/nSDwjoDRsx08blJwPOfI/8erhf+EicPuGp6xk9TsH/AMXQPEDDIGp6wEPbYOf/ACJRbD/8/P8AyWX+QuWXb8Ud23hHw+Iw62Izxk+dJx/49UfiS1ttM8HXNpZoIoBjC7i3Vwep571xqatdyWzzLd641uh5cQ5VT7nfVDU9SvNS0ua2trjWrucgbYlh3Z+YZ4Dn+VFsP/z9/wDJZf5Byy7Hp1owHhm1jJAX7JEQv4LTpn3vpwJBKuMD04WvObLUrwW8FqJNcedIlV4BASwwBxjdnj6VfsJbvVLjy4L7Uo2jYBlmTaUJ9PmPp7U5OhyfxOvaX+RhOEuZu3RfmekmUtalw43gEFyOR60skwCpIrAAsNxA5NciuhayxZRq9/s6Yw2P50v9haw2V/ta/wAg+jf41HNhv+fv/ksv8jo9nPt+KOrupTHbSN7VhYBuICWx7fnWXd6JrAi2vrF8Nx7hv/iqqXGi6nCEjfU7vcRkOQcj9aqDw7mrVP8AyWX+RhioS9hO/byO72RRW8itP8zbuMetcro5ijl8Qfvek64yOvLVn6jpOrWtv+91m8jDHGXyP/Zq5O4ikiFwsersTKQXbOMnn3560vrGHp0ppTu3b7Mu9+qOhUptrT8Udp4p1uwt9Jhi+0JvVw23OOxrgdZ8ePeWbGzUosaiInPJ9cfnWHfWoDEyamkpz/FgkfrVT7BA1jKP7SgPzg71AwOnvXk1K8G/muj/AMjrr039Xp+r/NFK6leQ7y7ep3HFQRTq19bgsc+YvT6ip5dPtpX3y6tEgA+6cf41Z0/SrWS6ieLUrVwrr2yev+9XQ60Nv0f+Ry1IS9m/R/kytqkiJqs2TjJHX6Cpbu2SW3tnV+QvHOc9K0NR0SCTUpZP7QiUnGVYD0HvRJpluY4Qb+KPauASOD096ydaF4/5Pt6FYKD+rf8AbqMDywrYLEH1I4qGRIMksoDdiORXSJpVsw41WBvbA/xqq3hu1USu2oR5AJAA4/nWirw/pP8AyKdORjggRLmQYxwMVUkIOcMPqK6u28J2t7ZpL/aSqT1XA45+tQ3Pg23h5/tSMD3A/wAaHXhf/gP/ACF7OVjkF+/1GK04ZBsxlT6CtAeHLNTzqkOPoP8AGnx6HZwtn+1rfPuB/wDFUe3p/wBJ/wCQezkb/hSNBpEyk7d11n2+6tcDrYCapeAsAPPk6f7xr03w9pludCnKajEw+05yAPRfeuJ1DSLFr+6Y6zbAiZ/vY4O4/wC1Ve2glf8AR/5E8krnJSABRgk59RioM8mujl0ewkGDrlt9SB/8VUX/AAj9jjJ1y2A+g/8AiqX1in/Sf+QezkY9h/yErbH/AD1T+YrU1M+Xrdwcc/L1/wB0Voab4ctPtkLpq8EhV1bAA9f96na1pdqNTmk/tSAsSAU4yOB71rgq8Hj6dvyf+Qp05KLMia+YsHi2pIOvvUcsy3RVyhWQDDY6H3rVTQrAj/kNWx/Af/FVIuiWKjB1m2/DH/xVZfWIf0n/AJFezkT6yM6nHwf9SP5mqBtJG1C2cgbfNXp9a6y50W2uNViLanEuYwApA55PvSXOj2lleQo+qxbi6kIQB3+tXWrx9o1+j/yIw1P92mzktWgUa3KQBncv8hWVfw4ndvpXY6nptm2pyyHU4A2QdhxnoPesu/0y1NvJL/aUO/j5MDPX60lVXK/Xs/8AI7XGPsfn+hFPpE9tp6Xz2tsLdkDrvuI1kZd23IjJ3kZ7gYq7caDq+jTP9o01YnSTyJFimSRkc9FYISRnBxnr2zVyS80ybQvsF1dNcTm3CQpLaxj7M2/duWbdvx975MY5ro9aurHRfF2tXVo80t3NqayyRzKojTypd5AIOWywHUDAyOetedGtV5lG13r3117309TnSOFvNM1O0eCK5sYh50hiTFzGyq4xlWIJCMM8hsEVo6d4ble4nTVLVI4xZS3MLQTpKsu0HGGXKkZBBwa2WuNPuL23Ekpu7EXX2iS0Gl20AB2sFJMePMI3fxYB9Oa2odWFpLZTWscjS2lvcRq5sooVZ3wVPlodoA79T9aUqtZxSUdfn8hcpzFlpOrLqIjjg8h4UVmLXCRiIMDtBJICsf7pwfatuH/hIYrae4NzcwwwyPFIXuthDqMlcFgScHoOT2qW1ura3a7RYpYorqVLljJaxXRjkAYMoEh+ZTuyGyGHTnkmjq2rG5smikMrSm9luDI8aoGVlRRwpwD8p4HFaxqVW0nGyuu/z6mfIudvy8ja0y5vrmze6uNfvreASLEpV2cliCem4cADk+44NNurnWrS8ltZNVvTJE5jIE7nJBxxzWNo+rWP2RrC+eUJ54nR4ArEnBDKQSOoxz2x0NbK60s2qPqyRB5jcNJ5TDKDuOQQcg/y60k2q07ptW0/TX77lWNCaz1eO6s4Dr12TNE8kreY+Itm7ePvc42mqN3dahbJDNDrF7PbzglHd2RgQcEEbjg9O56irR1623WGNP8AKWKKWGYIzcrJvB27mPZs89/asq9vIJIYLS0ErQ2+475VCszMck4BOBwB1PSpozqqcee/X9f+BbyKaNW+i1iC3iuIL28eE20cz5uvmGQMkLnO0E4zj8ajuU1U6g1vaahcMFjibMt4EJLoGwNxGeScAUkmr2PlLKi3P2pbH7JsZV2ZKbS2c56E4GPfNKNY09p55pIX3skKxu1vHLgIgVl2ucDJA+bk8dKqFXEWva9r9P8Ag9O4NIrRf29L5rC7uUETmNzLdeX8w6qNzDJ9hzUt3/accMU0F9eMn2ZJ5Xe4ICliRgHI9OB160ahqun6pJcib7TChu5rmEpGrEiTGVYbhg/KOQT1NMvNYt73SbewlSVRbwjynUD/AFncEZ5UjHPUfpWzqYiTi3G3ddlZeev4W/PGkopO3d/mNsprye2murrWLyC3iZY9yMzsWbOABuHZSTzUF9dapYX01rJqNyzRsV3LM2G9COe9Nsbq1FjPY3vnLFJIkqvCoZlZQwxgkcEMe/YUs+pxyaw2prGDIs6ukEi5TaOgJyDngduatSqqpLTTp26W1++/bQ00sR6tbXlhq+kT3OrXHmTo6y4LEwbeo68n5uRxzkVpM11baw1mdRubmBrUyAyEjcGg3jK5PTPr2rI1fV7PULjSbU2YtniaR5pY97kKx52hn5PfnHIHPWtWS5srvWYprKS4bFoY2E0SpjZBsBGGbOdue2PeopSrc0faX+1fa2+mxk0vaO3ZfqdLof8AyArf6N/6EaKTQv8AkB2/0b/0I0V2w2OvD/CeR29vCbG6JhjyJePlHotMEEP/ADxj/wC+RXX+FPCJ1m1fzroRRSzH7oy3AH+FdXf+CdF0iwjkjheaUyhS8rZ4we1Y4WLc36/oVhpxVSz7nltppkl/J5dnYmd/SKLd/Kuq074YateMpuraCyiPUyAbsfSvYoIIbaMRwRJEg6Ki4FSitFBGTrPojhrf4WaIqol0XljXny0AQMf9ojk/TOK6Oy8K+H7CMJb6LYKB3aBWb8yM1r0tUZOTZQi0bSyvOm2fX/ngv+FZ/iLSNMTQLpk060VgFwRCoP3h7VtLKqIe59BWb4ilVvD90O+F/wDQhVT+JmND+HE5fUNJtPLiey0qznu/sttlGt0fEZD7mwR6hct29qfJpGl/b79o9NillW8KvHFYpcYjwMcEjaCd3zD06jvrnw1Za19knuZbhWWzjQCNgBgDPcH1p48A6V/z8Xv/AH2v/wATXPT95P1f5nRLQ5b+yLKTS7j7PpcdvEnmt5s1nGwcBjgeZ1VscYHU/WjXtL09I3a0sLVhlPtLGFd0bbRtA44U+o6nOewrqx4A0r/n4vf++1/+Jp3/AAr/AEn/AJ+L3/vtf/ia05dSbnD2mkx3UGktaWULeRfM10RGvyL8mGf/AGcBuvHX1rC1Pw8lzqi3NhpokWR3WONYuJADnAx1wPTnmvRtQ8CaXHeWKie8w8mDl19R/s1bufh9pPlY8+8OTj76/wDxNYVZKMJt9CqmkEzyHXNKuJ5NHig0CFbpISX0qGJ9wUOx+YbvM+bPTOQOlUPEduqX1mJLK2tJfsib7OJP+PcjI2Nkli2AG+Y5G4A9K0/FnhGLQr57UvMU3gxsSPmU59vwrAtdKjexnlSWZXjVmULjk7o19P8AaNdkoNUoyfn+g0uZ6HqFiuhZtC9rYQyXFuNT+WJVKxIEEij0H+u4/wBkVFpmo2N3ptvdrFatp0kMz3lyIxiKQF8At/AQAmF4znvmvKm8P3ks7rjLKQrbnQfMf4eep9utNh0S4MkKgMGlzs+72JB+nQ9aw+ZXI+x6Kt3Z2b314bS3GiNYJLFfJCuXuDt3L5nUtvLLszwBnHetu71WytrDVJJLYQ6UpgEFysSgSxNIo3Kw++MEEnnB446V5bJok0TJLDI/ltbrIxJTd7kL1x74pZNLu4oPOaaQJgE/dyAehI6gH3p/MXI10PVG1PTRrWn20mnXQjn1GKG3mexSOCRCTwHDHzQeDnnp71zV54u0ybw/a6iYvLLXUtuPKhVchVjYA4643detckdLvlaJRO7GVxGux0Ybj2JHQ/WlTS75pdnnvgEBsSR8E9v97g8dfahadQ9m30PRNP8AENtPZadqESznTYbScXUoUbImBk3K/PDMCuB3yMVzH9svqEZgtNHvr2R4hOtuYG/ex7gMgKQxXPdT29qwXs5W1eSxivJgBM0YZscAE8nj0FVdTg8qwW4ivpp4ZCU+ZApDDGQRz6g00wdNnqA1eK6e9sjZ3EtwLG2Emm2f+sT7vygncfkwMggnnnpkWLbxvYaT4i1Lzo7mQwGBmEaglcJkrnPLD7p9wa8xtdOaSCAf2hKtxJAZkiCAjaATjd64B7VY0+R4LS8lt9TuUeNA0gaBdpOcAA7vU+lGyIlSb0PW/wDhduioTjTtWcH/AGAP61H/AMLt0hWLDStVOexx/jXkceqaxOC0dzIwDqh4Xq2cfyqxbS6vLfNBPNKuPOT5dufMRC2Pzx+dPnZqqSfQ9Nn+NOkTEFtH1Q46DI4/Wlj+JNrrX76PTruJYhtw7cn9fevJ5brV0ZlldnxCZVKOhG0fxZGQQMHgVeD6xayiCK+Vy0av8jx8AqrHODwBnqeuM1UJ2kjDE0OajJJdDsdX+KdnqUIX7DcxEdCxyf51ysnie3lYkQyHPqo/xrmLu91G3cpcyYfAOPlYEHoQRwR7itCQ3VrFOI78tNalVuI/KAC54+U98Hg8CpbvuaKO9kSzX8V1KcxPkDptqtMxuNInCqY1DjAA+lWLFp7uHzJb54wZViQLCHJY+vTA/P6VbtfNuZXtJNSmR1LbiturIAoyTncPQ9qwnG7v5o2qXnRhHzf6GI+m3F3IoBUrj6H+da+meGjFPDKxdXVwQNowefXNO05bh4GlLMzhyAQAOwq7D4nvtPljtWnnYSOFIZsjk1vc5Kq9x+j/ACY68a3t9RlF0kr5xwuD2HvTLmLz4kaGOQJjOCmePzqteeIJY9YmDP0I6jOOBW5/wmD6XYh1udrSgHb1z/nNZveP9dB4P/dv+3Uc7b3ltG5jNvIXHBBUf41LdahbtbELbzx/KeAo5/Wur0TxFBrYkY2yROozvJ5Jqa7gN/ZyeXvQBGLMe/HatCkzhbHWVt0QIkuRwcDr+tW7vXo5Y8CGTP8AtIK6TTtBWWxhYSMrMDnnrya0I9PWOBhcBTj7uBSY0eXXN3EWD7JM55+UAUz7VDId5jkPoAK7m/0uIqSq4OeKypIVt4fLTjBwfrQBp+ErmGTw/cKIyo+04Ix/srXnGoyWv9r38cm9X+0PtYDj7x616loTLHoUrdzcgfoteVajdeTrl8+wMwuJME9vmNUSymbaSSdY40ZixwuB1rrNb8L6fpvhO1nJuv7VDHzsrmJgTwBzwQKytL8W3en6lBcAkLGeQp5xXW6r8RL/AF6NrO11CTyCPmhn43+2aBI86tZ3S8tnJbaJFzj2PSrOpTrNq87qGAOOv0Feq6HrV/e6RFpV7otlPbbgSXADZz98EDkii88L6TZzvfsvmPNIq7WGQnH/ANYVeDa+vUwl8LPIoElmbEMMjn0Vc1baCe3YC4t5Ez2ZSK+orGKztF8m3hijC8jYoGRWH400VNaslKKDNGcof6VmB5pFcWkOsRm5heSMxAEBc45PvTPEPkXl3bSWxnwsikB0Axz7Gusjt3tLjDIUJUbWP3SeeKoX/iJpJVtZ4dkokCup6deCKuq7TZOHTdNHmeszNDrcu5T95fr0FZt3dl3cBTg4rr9Zjil1SVhGAcjn8BWNf2i+VI468VHtPd+Z3Kh+5evX9C3ezousIsqsUNuFO0e5rp9M1a1vrhUCzK3/AC0GM8DuOayb5dlwp/uwh+Ovetzw/KtsiXqNuYHEi+3rWWFf7qJglaojvbTxTothAsNrZ3MaD+7EuT9TnmpT4003/nhd/wDfsf41v2l5BfWy3FvIHjYdQensaW4iE8DxEkB1KkjtWpCOUk8faISUH2jf6BF/+KqWPxtpckeFjuXA4I2KR/Osqbw5qFnfIygyQgk70PseoqPTrPVYtR3QxyhvMJLEYGM96t/B8zlT/wBpf+Ffmy/9v0C/vo2SyuIZ8nDpGF7Hrg1R0vxPH4c1WeGaO4kspZW+ZUHytn613qk8Z696R1SVGjcAqwwRXGn/ALQ/8K/NnRa8jIk8a6YeRBd4P/TMf41U/wCErsYWaRorkiU5XCD9efetXSdUR559LkkBmtzhSe4qeI/vZ/8Ae/xqqv8AEh8/yKXU55/GWnl8+Tdf98D/ABph8Yaf/wA8br/vgf410T/fFMJ5opWvL1/yLlsvQw28UWS263BiudjHAGwZ/n7VCfF+n/8APG6/74H+NdBnk0mfWumpuvRHFhPhl/il+Zz58X6f18m6/wC+B/jTT4usP+eN1/3wP8a6HOBwaYcc1B1nJJqMWqeK7SaFJFRYmU71xzhj/Wuiv/8AkGXP/XF//QTVlz8pqtf/APIMuf8Ari3/AKCaXU5V/vMv8K/NlXQ/+QFb49G/9CNFJoX/ACA7f6N/6EaKuGx6GH+Eg+Hv/HhD/wBdZP5V0viX/kGx/wDXZf5Gua+Hv/HhD/11k/lXS+Jf+QbH/wBdl/kajCfE/X9EZYb+N8zbFOpBVO51jTLKbybrUbSCUDOyWdVbH0JrVJvYzLwpcVmf8JHof/QZ07/wKT/Gl/4SPQ/+gzp3/gUn+NHLLsBZEJPK884xVLxFGqeHrsgc4X/0IUsXiPQwvOs6d1/5+k/xqtq2r6NqGlz2sWt6YryYwWukxwQfX2qpxlzPQyofw4mjpH/Htbf9e0f/AKCK1RXAQanPBII4/FOiqiIFXM6dAAB2q2ur3hPHizQ//AiP/CuejCST06s6JvVeh2wpwrjl1G8PXxhoI/7eY/8ACnf2vNHz/wAJfoLH2njP9K25JdjO50t7pz37RFJWjaMkggZ9P8Kgm0W8WMFtSm6+/wDjWEPEF9/D4s0FR7zx/wCFRXGs3siAv4v0NhnoLiMD+Vc2Kw96UnbW3mX7eSjyp/gih8TNHW00WG8kuTdSJKFw46DBPqa8nsNTGn2rSKmXfei8cZ3Rnn8AenNd3478SxNowtH8SaVesZAfKtGVyODySBXn2j3BS1b/AE+1T5zwzgdhXZVpJUYWT3ffyNadabev5IsQ6laxRNCgdI/M81GaCOVgSACPm+g5H5VJHdMNLuriVW3tIwgkIxkvw/6Dt0zU32s/9BOz/wC+1pDdn/oJ2f8A32tcvI+35m6m/wCrFH+07PzQ6rP9pS0+z7So2nKkE5znoemKfNqVs6zyKspmuEWN0OAqgFSSDnJztHYYzRHdY1KU/b7XO0fMXGD0q6JpnXK3tsw7EMP8KFTb6P8AH/IUZyf9IhbW7GN4fLicIl5HPgQom1FzleDljyOT19qzLfUrUQCK5Ew2T+chjAO7gZByRjoOefpWpI05HN3B+Y/wqo5l/wCe8X5im6cv5X+P+RfM3/SKX9rRprb3yxFo2mZ9p4JUk8fXBqO+vrI2cdrF5xgRmkZ3jG4scDG3OMfKO/c1bJkz/r4vzFVb0ubSTMqHp396Xs5fyv8AH/IG3Z/8D/MtaZrKQWccYklaby2RUMS7UBB6PndjnOMAZqv9ujGmy2yIfMMpeUnoQBhR+rfnV3RWf7VajzUxt6Z/2aspu3an+8Q/e79OtV7KXJez38/8jCdSSlbyXbqzG0vV4rCWZpYmYNH8m3HDghlP5irL+ILdpbZhDIBHbSJJ05laMpke3C/rUR3Y/wBbH+dRSuUGfMQmpVKb+y/x/wAjdycVv+QLrdtFZxxGJyy20sXAGMsxI/Dmr9hrNq8jXCLIGkt1gmVolYKVVACuThvu9CBWBK+8nJzXQ+HWZdLuTHIqNuPLdP4a2hh5XV4v8Thr4qUacmraHP6nq0d1cpsHmIiBFLQpFgZJxtXgdavXGuWdwt08MMouL1lM4cAKnO44OctlgOoGKyggLBsU1X2ueoz1pewl/K/x/wAi/bSOm0/VreziaNJbmICXeJIkG6VcfdYbuB+JHJ60RX8ax3zrGY3mO1AOiKTkj9APzqHT55J4lCTDaOMtxiurtUvEUA6haAn+9tP9KynSmn8L6d/8jWpUapQku77GJpd20Ni7CJziQ/MPoKa+oQzXcINrlzIo3Ee9aWoveopLXtpJnqFxn+Vc6gkS7idJkz5gPXpzVvDN/Zf4mU68lBrTZ9F5lnVBCNQmzbxs3HJ6nge1YOpzNKIwECrHkYByO3+FaWpyub6bzJ4ycjJXvxWTNMHXaTnPaiOGkrPlf4mVKtJ0Ypvouxd8PawLS+AlyIzgcGvV4tRhGnyhDuDRONy9vlOK8NfYCcI1dN4RuL66uza205UEHKSHqO9XKEo6tWGmetaJGJtOtZAD91gf++jVm6t90XlkkbsjNXNDs/s+kRQuQXTOcdOSTTruHdKoHY5qBnLRHz5Li2kx5sJ6ewrA1u3MF2uPuyrkfUVp3twlt40kYHAlHI/Co/EaGURlcfu2Bz9aQxNJ/wCQFP7XIP6LXkmrbn1m9UAkm4k4A/2jXtnh+zFxpF0mOfPz+gqt8PvCWg6h4k1Jr5DNeRTOTHNwo+Y8gd6pEs4fw58Ltf12ZGa1NvbjBZ5DjIPTFd/D+z8nkK02tskpOdscHb65617NZadaWMKx28e1R6sT/Oro6UmwPKYfhh/YkAew1S5ZEGWW5w2cemMYrlvE8ptNsUkyZZwdufY17T4jiuH0O7+ycT+UduBk18qa/wDb5vEk9vIsrS5HBBJ6CrwWuPp/11CXwM9cttZc3AKP/Dj61tw3V06Fi4ZeoBFcFpnh/XNH06KXVIhEpIGCfmH1rduteh0ywLu4bjjnk1i20y0k0S65qdvBaskmNxwpH1zg/mK4XUX83V7VyytJtQSYOcn/APViofEd1Lc6iMscFAf1NVrNT9phyc/Ov86utL32isLTtST8h+pqf7RlPuP5Cs69H+iyfh/MVq6kP+JhKfp/IVl32RZycen86lfC/U7F/Bfr+hf1VjHcbuP9QmPzNGkzs4mSLO1BvA9vT8qr6xKDJ5X8Xlqw9xzUOiTtBdSuBkeXk/mM1GF/hRORL3zrdH1e/wBO8uayuV6fvIm5BHY+46j8K7ew8c2cqhL+J7aTuy/Mh/wryOFrm3voltgTCi70z0KHGQfoeR+NaMmqOHYDBAOAQOtbtGCZ7PHqVndxZt7qKTP91qmQnHLDGPWvGNK1NX1SFSuCSeQMdjRceIHS6mQT3C4kYcSEd6pr3Pmc0X/tT/wr82e1b1B5ZR+NYeq+KbDTFdEk8+4GcRp2Pua850nWTPqsCNLM+SeGkJ7GqV7qkaX9woGMSt/OuRL/AGl/4V+bOm/vGkNTuo9UGoCRhLv3NtHUelemaZfR39ubmM8SYYj0rxk6oW3YzgDJPPSu68IzT/aYTGSLdoPnz/EcDFVV+OHz/IpHaMfnppNITk0n1pUt5+v6I0nsvQO5pD+tGaac9a6am69EcWE+GX+KX5gfWkOaOaac+pzUHUI/Q1XvsnTbn/ri/wDKp3PHpVa+4025548l/wCRqepyr/eZf4V+bK2hf8gO3+jf+hGik0P/AJAdufZv/QjRWkNj0MP8JF8Pf+PCH/rrJ/Kul8Tf8g2P/rsv8jXNfD0f6BD/ANdZP5V0viX/AJBsf/XZf5GownxP1/RGWG/jfM2xXm/im3s5fEeqyzqHlWCFFDQq4AIPTJ4Jx1xx2r0gc9K4DXNJ1bVPGV/b2FoJUeCJnJZVIK/Uj+9Xbh20ptdv1RkznrvQdOa8nkkVYIzN5aBFJGcegIwOR+dRL4Zs96xSgJNI7RxqMkEg45OeOeO9dYPC3iTe7zaZC4Z/M2tKmFb1Hz01dA16MjOnpJIrFlcyoSpPUj5qftbvd/iI5B9AsY7aGTaWklXeEAOAMkcnPtVy28PaYUto5LUM9wGO/e2U5IGOcdu9bJ8MeIpLePGnDEa7FxKmT1P973pE8OeLlt8vp9vAig7JZZk3Jnrj5gPzzSVVqWrJhZxVjmINN0yO8PmwRlMf8tHbA9zg5q9PpWmx3ipBYxSrIq7QXk2kn+7yDj61UvRb6Owe9hjusfJhJA+9s5/hbr249Kz5/E+szXCS2OlxReWNqea2QvpgZHrnr1rGniLRacups6UnsjVvtJ05buURW6pEh2/fbHHU8n1pdSstBTUrtI3RpI7gJJDEpAj3vtGMHHBOMcVxdxaazeHN3LI+f4Q4A/Q1qXF/qc9zJcDT7SKWWdZ5mi48xlOQDljx9MZ75NWsVe92P2DJrtdO/wBIMRMFvDL5BmaEuWk5+6u/7oAzk4PPSobPwtNc35iu70HEssL4U7EZdu09eQxYDtUEMmoxmcSWNvPFNJ5pjlPyhxnBGGB7nvg981d059cma+i8pXa6YTyOWUMGDZ45wATj8hWVTExUG5N29X/mVKm0tjIfw5ZxWbzXF00KxQxzSKsO5hvYgKBuGTjB5x1qtHoyW+p/2eZBIGkQJJgjKuFKnHbhhxV/VrnVLoXkk1vCv2woHCEAKF6BeeOg9arRLqGoyG7MSq42ICjAY2IqjqeuAK2qVf3UWm92NRfNsXdQ0/TntLyS1tPINncrDnzGbzFbfgtk/e+Ttgc9Kj0a0sLqQW9xYI0YBee5Mjhok9Rg7ePcHJOKtXcmpXa7XsLdFaUTTCM485/Vvm9zwMDk0sD3kFi9mdItJYnk8xt0jgk9gSsgyB2zWf1h81+Yfs3bYz9LtbG6+0xTaeixwwO8l55j7lbB2DGdvJwMYyfWtHTLO2bTYWaLJOe59TVaKa7FsdLbSrR1jy+8u4Ysf4jtcAkDgZHH51o2EclvYxxyDa4zkZz3NZzxFRJck3cujBXd0JJY2o6RA/8AAjVWSzgH/LP9TV92461UlJyeay+tYj+d/ezqUIdim1rD2T9TVO+t4ls5CF7DufWr7HnnNUr8k2cnPp/Ol9arvRzf3spwhZ6F3RYI/tVq2znb6n+7VlYIw2pfL13Z/Wq2i/8AHza8/wAP/stWVJDaj7Z/rWjxFb2fxvfuzlqwjzvTov8A0ox5I4Uz8owPc1mTupfAHFW7uXZGe5qjGm7LvnFVTxFfdzf3snE8t7JEW0tz0FdT4ahSWwulkXKbiev+7XNjqWOMDpXUeEZY1WaCVWYuC/HTHFdEMTWcleT+9nm4pJUZdNDlEDzfKicL3p7Wkg5YAj2rqIm0fy9gtZBwe/8A9ekH9lnzCLWXgDPzdf1qfrVf+d/ezo5UUNOls/L8tkbeP73H8q6NG09rcyGNTj0Y8frWWn9lqwdbaXkdc/8A16fHcaf9ilDxyxrvAJJ+nvXPUxNe/wDEe66s3qqPsKenV/oSXT2LKdigfVj/AI1lLbpJLAfLYKZQM9jzU01zo1uC0aTS56jd/wDXqO11vSY7iJfInVPMU5ZuBz161v8AWa/87+9nPUS5Xp0ZW1rS7iO+lZUUxggABuegrEkimBwUIIPHFejM+jXzNP58bc/d3+2PWnW/hmzv7xYFBeQ8jJOQPzpLF1rfG/vZyUq9KNOMZbpLo/8AI8zKPnJBq3ol1Jp2sxXUZIKMD9fUV3+s+GbHS4i15HsA6EkjJ/OsWG38PMEczIjDsZOf/Qq2lWlPDPnbfvLf0ZosRSvdfk/8j13StTjubKK4jx5brk+xqW7uFDRuCCrdTXA6Tqmn2StFBeoInGCPMBGfXrVqfV4FREW+UbTkfMP8a4nOJoq8H3+5/wCRianqMNxqouAcyeYB9BmtK5vY50YZycis25TRri4EzzRK4bcSr4yf++qT/iV4IF2o/wCB/wD2VTzo09tT8/uf+R3PhKSEaVdOxx/pHU/RaxbvUEs/EUur6U8SXcBIljznzFzg5p/h5LZNLmFvPvjM2Sd2ecD3rFa10ldSnk89RL5jbvn75570e0QlWpNu7f3P/INc+JviJb8XdhdPHE6geV1VT3r0v4c/EdPE6pplxFL9uij3PKej+pryu40/R3ODKm3OcB+//fVWtCu7Dw7qH2yxuEjlIw3zdR+Jo9pETqw6X+5/5H0bc4NnN/1zb+VcR4j02zj0G3vEt4xcSTqGk28kDd3qtpfjuLU7doFv7fzShBQlcnip9YkupdAthN/qPOBVscE/N7fWtMJJRxkJdjKeJpqLTv8Ac/8AI6u8s454yHRWQDoRXz38SNKm07xI58tUt5OYwh4/Lsa93aTVj1Q/98//AFq4jxtaWt/at/abIsqnKEnB/pWbtYunjKSe7+5/5Hluqrm+T/rkP5mmWo/0mH/fH866G/tNLNwvmyqGCDHzdufeolttJRgyzICpyPn/APr06rXtGa0cXSVJLX7n/kY+pf8AH/L+H8hWRqDYs5Pw/nXS3dnaz3Dyi+iUN2OPT61lapp9uthKwv4mIxwMeo96SkuX5m6xlL2XLd79pdvQz9eYpfQuvURL+PJpmmKHupiPuiEsPzFa+rabbTTxM+owxnyl+Vse/vUWmabbQmYrqUMh27cDHAyPessJL93FGX1mn7RLW/o/8ilJct5cYC4BjFVTubqKuDTLZbGFTrEHzMzZ456e9RjTbX/oMw/p/jXTzI4/rdLz+5/5E+iA/wBsW/ynqe3+yar3wP2+54P+tbt7mr+jWFumrQMurxOQT8oxzwfemXNhA17cH+2IgTKxxxxz9avmXJ8zmWKpfWW9fhXR935CaBu/ty24PVu3+yaqagx/tO66/wCuft7mtjRLGGPWLdhqschBb5Rjn5T71VvrCBtQuSdYiUmVjg445PvXIn/tDf8AdX5s6PrdLm6/c/8AIyWldbebG45UD9a9g8Kp5el2ZIwfJXt7V5tYaLb3VxFD/asUheRQFAHOOfWvW7SNYQFXoowKdWS54er/ACLjiqTu9fuf+RqZoz71ErkD7po3n+7SpPWXr/kaSxlKy327P/Ik7UhPJ60zccfdNG5v7proqSV16I48Li6SjK9/il0ff0HcnvzSE03ef7tJuPoajmR0/XKXn9z/AMgb7pHeq1//AMg25/64t/I1YJJHSq9//wAg254/5Yt/I0XuzOlUVSvKUduVdGur7oq6F/yBLf6N/wChGijQ/wDkCW/0b/0I0VpDY9PD/CO+HEDzafbbR1kk5rq/FFkItKiZ3/5bqP0Ncf8ACy8aex8iNsSQTODgc4K5/rXW+K42XSo5Z2wPOX5pGwOh9aWEXvP1/RGOHdq9vM6IS2sXES7yP7oz+tc5aXEreO9RKAJm3X37JVXVfiJ4X0gmP7a19OP+WVopf/x7p+teeXPxH1WbxBd3mkWcdkZYwmZ8Oyj5ecdM8V24eUVGp/hf5oy9nOVtD21o2KGSZzsHJaRsKP6VzOqfELwvpBaJtQF3Ov8AyxtPnOfQ46V45qV/qesvu1fVLi6/2Gc7B+HSq8ccMK4jRQK4nV7HRHDr7TPSvEvj7WNLnWy0m1t4w8Yk8+YbmXJIwB07elcBqWo6prDl9X1a6uc/8s95RP8AvlcCtrxdLs1eLP8Az7r/ADauYkYFuTU1ZPmY8JCKpRduhpsIYNBt1ijUDzDgAfWqQmJ7VZmb/iQ2/wD10P8AWs4N71x0Xo/VnbIsl89aA3NQB8mpFatSSYN7Vc0vUbW1vn8+XZ+7I+6Tzx6CqAPPWtbSLmG00HxBOFuluiYYhLBcCPCsG4+6TjI5GeRgcUp041ISUtrGNeTUdOpgX13DJAAjZO4Hoaj0e9gjtXDPj94f4T6CtzxJYaeda1C/1N71kn1P7JGlo6qUwqlnOQc/eGF4zzyKq2HhKztby20i9ubp72+v5rSGaBgI4iknlBmUglssDkAjA55rvlyujGPRN/oYqpPmvoN/tC2/56f+On/Cj+0Lb/np/wCOn/CqOqWen6fpGmMhvJL68thcMxlURx/vHXAXbk5C+ox7543NFht/K8Pac9rbyRaskzXU0kQaRT5jxja55TaEDcEZzzmsOWHmX7Wp5GOl7CNSlkL/AClQAdp9qsnULY/x/wDjp/wrndLvjaayJXdQmMMXt0uNoOMkRv8AKx+tdPqd3Z2PiK2uoFENldWiOZm06GXfxgusDHYpLKRgHjnHWly0/MUalRdis19bn/lp/wCOmq73UJ6P+ho8TLaw+JnMMMkNjKsMyquFLRsituAGQu7Jbb2zjtW7N4ItIA/m3d0fIuJpJtrAZtFEpRxx1Jgbnp8y8UuSHmX7aouxzhuI/wC8fyNVb2RZLV1Ukk4wMe9araDYi1a1E95/aS6YNR83evk4KCTy9uM/cP3t33uMd6fe+F7OWS+0uzubtNQsJIEmmmcGKUySJGdqgArhnGMk5AJ4oUIX6jdapboUdJuI4Z7dpHwFXng+lTfaoc33z/6zO3g89a3bDSdPvdKk0jTJb2IPr1rayS3bq2cR3A3jAGM8/Kc4wPmOeII/DOkTX0K/bZI4pBc+dDHqFvdSqI4mkVwY+ACQRtI4x1Oci+WHLbzMJzm5NvsvzOPlRXbnJA/WoZVJwiA49au69aW1tY6bf6c90kF7G5MVxKHZGRyp+YBQQeD0Fbc0UAt5NGFrbiBdAW/Fz5Q87zzCJi3mfexk7NuduO2eacVBdwqym+xyOx2lUbcItb/h+aK1ndpm25jIHBPcVieG9UFlqK/aZwkLjEkjWMV4V+iSkD8cg13dve6Tpuua9ZNEtk1xcQSWby6fFdiOIq5PyufkDb42+XJGMY4rWDipJo48RBzpSjLZnNWVncXEDyRRlgHxnIHvV6HTLxXJaE7SMH5h/jVX7Pe6dd6jp9xMRcW908cvlNhdynBwBjjI9KuNcSrlGmkwcYO48Uv3fZ/ga/vPIYumXYJUwnj/AGhzRdaXef2RMPs+5wwIG4c9Pejz5/PIM8nI4+c09rif+y5h50m4MP4j7VhUdK+z3XY3rKr9Xp6rd9/Iwx4f1KSMMbcLnryP8a3PDnge+vJlWaILDuw5bkgeop/heG+1vUEsYbktMDkh3PSvovQtBg03T44XjRnA5JGefqa3Xs+z/AwftF1X4nn1p8N9EtLq3uFmB2r+8XBwW9elbF5o9rZXf2+1lXIwpUKRkd+a75rW3xxBF/3wKq3VmkkLhIIskf3RRel2f4E2qd0efeMra31LwpdCJVklWMtGpXvj3rwoaLfMRm1A/wCBD/GvbPFusf2Vod1p7222Vo2Ak6HnPSvGYJ7lhk3Ex/4Ga2lKmsK9/iXbszejCo5dPxLFvot2o5gx+I/xqy2l3h/5Y/8Ajw/xpIpbgDHnS/8AfRqQSzn/AJbyf99GvP5qXZ/ejujGr0a+5lc6Ref88P8Ax4f40g0e85/cf+PD/GrBlnxzNL/32aBJPj/XS4/3jSvR7P8AAq1buvuZ1Hhizlt9FmSRNrG4zjPbC1zN3pl3/aVy6xcGZiDkep966zwyXbRJyzMT9o4JOT0WuUv5pxqN1iaQASt/EfU1bdKy0f4GUVV5nqvuYo066PWH/wAeH+NPXSpjyYf1FVBcXG7ieT/vs08XVwvJnf8A77NRej2f4FtVu6/E0bXR3W5jkaEZDDnI9a39Q1rWotOWwhO6BJQ6g444Pr9a5i2vpvtESmV8bhn5j60mtX0qzOomkGGHRj6VtgXS+u0+VO/yMa0ari72+5nf6j458QXdusSqsYxhimATXB6iNVvpiZjJJnuzgn+dVpr+fHE0nP8AtGqwubhjnz5f++zWbnTff8C406kdrfczZ1OwuXukKxkjYO49TWYylGKMMEHBrZmlk/tiBTIxUpyNxx3rKuR/pUv++f51rXjG7lHuY4WUuVRl2/VkDciqGoj/AEKT8P51oHGKo6gB9jk9eP51nH4Pmdr/AIT9f0DXh/pUX/XFf61T00stxJjoYzkflWzf21retHJ9vhTEYXGQf61HYaZbLcN/xMYWyhGBj29648PWjCMU/wAn/kZJbHN3HyR28Z42xDj6k1BketbsmlWrsCdUg4AHAH+NR/2Raf8AQUh/T/Guj61T8/uf+RyeyZX8Pkf25bc92/8AQTUF44XVLrPTzn/ma3dF0u1i1aB11KF2BPyjHPyn3qtfaVaNf3DHVIVJlYkHHHP1rT61T5Ou/Z/5HKqT+st/3V+bDw9/yH7X6t/6Cap6irNql2Auf3z9P941raFYxRa3bFdVikxuwgxz8p96c9jENVnc6pFkzOSvHHJ461yrEQ+sN/3V0fd+RrytSJvBVqZPEVqrj/VK0rA/gBXrMPUntXK6BaQQyC4V43kK7d4HJFdRCeT71pKpGdSHL59H29C4qxfU/LS5qND8lLVUt5+v6Iuey9B+flFJmg8DrSZxXVU3Xojiwnwy/wAUvzHdcU09aQ57Uhz6VB1BnDYNVr//AJB1z/1yf+RqxuBFV78j+zroEc+S/wDI0CexV0P/AJAlv9G/9CNFJoZ/4kluCOzf+hGiqhsb4f4TzPR/Ed14fkuJLKeWC4MnDooIwQB3qLUPEF1qcxl1G/vbok8ByAo/AVd1NiHvOeki/wAlqh5xZRk1z4WV5fP9DTDx/eadyOPUrOEfu4XH/AR/jUK6rF9tkfbJgr6D2qyZfeq6yf6W5z/D/hXXh/hqW/lf5omV7r1JP7XhJ+7J+Q/xpDq8P92T/vkf407zD60bznk1yNo0SZteK9etrnVInjSYAQKPmUep96wDqkJ/hk/If411Xjlsa1Dz/wAuy/8AoTVzW/j71VU+JmWFT9jG3YtS6xbnRbePZLkSEngY7+9URqkP92T8h/jWxM3/ABTtqc/8tT/7NWcG965qVrP1Z0yv3IhqkI/gk/IVINVt/wC5L+Q/xqVXx/FTw+e9ak69yIatAP4JfyH+NSw38zxXEMLlbe4Ks6FRklM457dT09akDcda6TRD+4T/AHW/nROXLRqS7L9Uc+Ivyr1OObxTrME09yl2pluJVlcvBG48wA4dQykKw7EYNTaLf67BYSRwXqBWld90ih3RmADMrFSyE9ypGadet+4Xn+IVcDAdDmuuppQhJdW/wsUqa53co3FlqF3HbpPPEy28XkxDptTcWxwOeWPX1q3bS63Zae1lb3kKwNuAygZk3DDbGK7kyODtIzUm/wBaN4Jrl5mackTOshqNpqP7k2O6OExgSW0bqyk5+YMhDHJ6tk8AdAKv/adba9e6kuLOWV0EeJreORAo6BUZCqgdsAVXjYf2nLz/AAj+lW94z14o5mTCEXczb601HUbuS7vLlJZ5MbnJPYYHbgAAAAdAKtzah4gl87zNRVhPaLZScD5oVxhfu+w56nnnk09nz3qEuPWi7L5IkTXetf2Z/Z/2yL7P5flfcXf5ec7N+3dtzztzj2qvqmoa3caWbee9jMS7MlUVXfZwm5woZ8dtxOKtM3HWqd+3+hSc+n86FKVxunGxoxat4i1M28UuoRAGZbvKRJGTMqtiQlVBLfMck8njOcCrxg8QTTPcC50+ORFkUNFbxxkh1Ktu2xjcSCRk5NYkDt9ni5H3B29qv2TE2110+5/jVxqK1pK5z1qLtzRdtunmVLjw/q1xaW1rJc2zQ2wYQrnG3ccnnbk8+tSyWPiN9K/ss39r9k2eX90bym7ds8zZv2buduce1QhuelIVJzxR7WK+z+Jbw039r8P+COsdN1yxunkhfSvnREZXtIpFwowDtaMgN/tYyTkkkmtTTIfEkepXNwb2xluJ2815Z4UlYMMYKlkJX8MdvSsUR4OQtXtDH+nysFOfLP8AStqNSEpJNficWOo1KdGU1LZdgg0i+Cyy3E8UkzyGRnLklicZJJHWp59KuXAYSRe/zH/CudQuFdSGw4446HtUmX+zhCrcNR7Sn2/Ev2FZfa/A3F0y5bHzxbhyPmP+FSPpdy2nShXiyzddx9vaufgRwxyrAgd6uwR+ZpMylXUFx29xXPUqU77dV1N61Ct7CneXV9PNeZLp+n6xpOsRX+n3MUUq4BIY8juOle++H/GiX0CQ3FnNHOqgHBDBjjrnivGtF8O2U8iu8mou56iCED9SDXrvhXT9PtQI7TcJR9/fMXf8fSuiM4Pp+JjUpTivi/D/AIJ1I1m3wNySA+mB/jTTq8BJwJf++R/jVmVLcmMSOpfPy5PJNIzqpaMEFh1welJuK6fiZKNT+b8P+CeafEq0Gr2SvAuHRTkvxxXl1toFwka5eL/vo/4V6j8UtTA04WUEqvLgmQJztGOhryuzidrWP92x684961lOH1V6faXXyZ00KVa/xdOxeXR5x/HH9Mn/AAqQaTN/ej/76P8AhVfyn/55n8qPJl4PlNj6Vw89Lt+J2ezr/wA34f8ABJzpE3ZovzP+FJ/ZE/TfF/30f8KgMUv/ADzP5UnkTHpE35Uc9Lt+InSr/wA34f8ABOu0C0e30maNypJnyMH2FczfaRPJe3DB4gGkYjn3+ldL4ailGiT5Q/8AHx6ey1yeoW0/9oXJ8o481v5mrc6Vlp+JnGlX5n734f8ABGnRrj+/F/30f8KYdGuefni/76P+FRG2uD/yyNQtaz94zUc9Lt+Jp7Kv/N+H/BL8OkXIuY23xYDA/ePr9KTVtIuZbpyHiALDqx9PpVS3tpxcxHZxvH86ZrdtN9qd9vG4d/atsFOm8bTstfUyq0q3K7y/D/glr+xbn/npF/30f8Kcui3AP34v++j/AIVRFrPnBUfnUv2SZe3X3rL2lLt+P/ANPZV/5vw/4JsS4/tmDn+D/Gsu5/4+ZsdnP86m0+KRb6PIHU9/Y1DdRyG6lwB989/etJ1FKnzeb/JGdKlKE+Tsl+bISOD61Sv/APjyk/D+Yq2UkA7fnVO/Vvsch4xx/OpjJcnzOtxfsnp1/Qqsv7iP/dH8qk01T9qb/cP9KljtjJbR/MB8o/lUthaFLhjvz8h/pUxkuYiMXoYrLmoiKvGz/wBs/lUbWo7sfyoUkZuLJtBH/E7t/q3/AKCap6iv/Eyuv+uz/wAzWpoduF1q3O49W/8AQTVS/t1/tG6JJ5lb+Zrbm/dr1/Q4VF/W5f4V+bDw4P8AioLT6t/6CasSQltXuMf893/9CNO8PQKNeteT1b/0E1pW9sG1G5Ocnzn/AJmuam74h/4V+bHUjaVzqdDbbGo6YFdXA3y+9cppqlAtdLbt2611shGmh+Q0oPpTFOYyfenA81z0t5+v6I1nsvQk/gpM0nRBSZOK6qm69EcWE+GX+KX5jskj6U08UdBkUmetZnUHSq1//wAg65/65P8AyNWP51Wvz/xLbr/rk38jTEyvoRzolv04Df8AoRopuh/8ga3Ps3/oRoqobG+H+E4a8MIup45ULBmB/QVXZLNQCIW6/wCe9O1EH7fKcen8hVZ2bbg56151Gnea1f3no0aMXJPXXzLPlWZ6QH/P41WjjthqMo8o7dgwPyp6M3YGoUJOoS9fuj+ldGFh7tXV/C+vmjKdGN4779y8I7PPMJ/z+NLstBx5B/z+NRjJ7Uq5yRiuPk8395r7CPd/eb/idIxqkYuVDv5C4I9MmsYJZ5/1JrovEgsZ9QjeaZ1YQqPlHbJ9qyBDpn/PxL+X/wBat6mHvJtS/wDJjzcPVhClGMozuuyY+WOD+yoMx5j3nA9OtVDHaD/ljWvImnjSYQbiQJvODj6+1U/L0zP/AB9S/l/9auelh20/e6vqdEq9NfZn9zKfl2qn/U04LbdoTVkppeMfaZPy/wDrUuzTNo/0mT8v/rVr9Wf83/kxPt6X8s/uZAotwf8AVVt6YqGFfKXbwev1rN26WMf6TJ+X/wBatjSRZbRsmcrtOCR7/SpqUHGhVfN9nv5owxFam4pKM9+qZzk1tbTIEMRAznP+TQLOMjHmS/8AfR/xq4P7Nx/x8yfl/wDWpynTgf8Aj5l/75/+tW0VWhHljPT1X+Ru6tBu7jP7pGa1rFn78v5n/Gnx2kR/5aS/mf8AGrrrpvU3Mv5f/Wpq/wBnZyLqX8v/AK1O9f8AnX3r/IOeh/JP7pGclpbnUZUBcOFyW3Hnp71bFjF/z0f8z/jRF/ZY1KVvtMpfYOCPp7VfB07acTyfl/8AWqZSr/zr71/kKnOg0/dnu+kjPNlFnBkf9f8AGl+xxN/y1f8AM/41dJ0/HNzJ+X/1qcBp4H/HzJ+X/wBap5q/86+9f5GnPQ/kqfdIofYYs/6x/wAz/jVPVbONdNmIdyQB3PqPetoHT8/8fUn5f/WqnrC2I0qcrcSFuMce49qalXvrNfev8gcqFtIz+6RFZ2KvZQEPJzGvc+n1q5BZBY5QHfkY6n/GpbD7CLG3zcSA+Wv8vpVtfsW19szEY59v0pc1e/xr71/kRVnQ5NIz6dJd0Zg08f8APVx/wI/4002Kg4M7f99H/GtLOn5BFw/5f/WpxGnnnzpP++f/AK1RzV/5196/yNueh/LU+6RmCxXbkTSEexP+NWLLTt0p8u4kU7T3P+NXl+wAcSyfl/8AWqzZ/ZDMdkjfdPb/AOtWlGVf2ivNfev8jmx1SisNNqM726qVuhhDT1I/18n/AH0f8aZ/Zqk/62T/AL6P+NbGLLb/AK1/y/8ArU0NZAYM8n/fP/1qy5sR/OvvX+R1c1D+Wp90jFuLCNE5kkPPqf8AGpjpzeSUS4dMnOTn/Grd79jEK7JpC27uP/rVYY2OOZpP++f/AK1JSr3+Naen+RtJ4dUoS5Z7vpLpbpcpR6ZKE/e6pOF/uLnn9auQPeQQ+VDq9zDH2SLIA/WpF+wsP9fJ+X/1qbixHPnyfl/9aupYzFraUfuj/kZSqYeW8J/+Ay/zFilvoJvPh1S587GPNZju/PPAqvJPqhlZhrV1luSdx5/Wp82P/PeT8v8A61MBsQf9fJ+X/wBam8bjH9uP3R/yBVMKv+Xc/wDwGX+ZjXdpctDMzahMxKknOeePrUNhYztZRkX0i5zwM+v1rbuzYG1m2zPny24x7fSq+m/Yv7OiLTOGAPGPc+1dCxGJeEk+aN+ZdI9n/dF9YoKovcnt2l/mUjYTg838v5H/ABqRrG4CZ/tGXH4/41oMbA8md/y/+tSl9PC4+0P+P/6q5PrGJ/mj90f/AJE0+s0f5J/+Ay/zMoWExB/0+X9f8aQWMx/5fpR+f+NaJfTz/wAvT/h/+qmeZpwz/pT/AJf/AFqpV8T/ADR+6P8A8iT9aofyT+6X+Zf0fSrp9MlZNVnUCXG0ZweB71z15Zzi6nDX0pxIwyc88/Wu10GSyOjzbLlmHn+nsPauWvp9J+23Aa/YN5jZH4/StniMRyrWP3R/+RMViKKk3yy+5/5mV9jl/wCfyT/P41DJbS5x9rk/z+NaZutFUHOoH/P4VCbrQc5Oon/P4UlXxPeP3R/+RG8VQ/kn90v8ylFbSmZB9qf7w5/yakvLFzO6vcu+CDyPb61Yiu9BNxHt1Fi24YHqc/SpLy+0JLyRZdQZXGMjHTj6VP1nFKqrSW3aPf0I+s0L3cZfc/8AMr4GelB4GMUh1Tw6D/yE2H/AT/hTX1bw3/0FH/75P/xNYfVp+X3mrzKl/LL/AMBZPYn/AE2P8f5Gq1yx+0y8/wAZ/nUtjqXh976JYdQleQ5wNh9D7VDc6r4cW5lD6hMHDkEBDwc/Suj6vP2KWm/fyOb+0aXtW7S2/lfcgc8VRvyPsUn4fzq4+qeHWGEv5yx+6PLPX8qp319of2KRPtc3n8fLsOOv09KcaElDpv3N3mFJ0npLe3wvsOgcC2j9do/lVi0Obhv901BDqPhwW0aveXIYIM4jPXH0qxZ32gyTsILq4Z9pyGQ9PypRw8lK+n3mUcxpNqNpf+AszWbioHcCrTXnh0/8vt1/3wf/AImmG58OH/l8uf8Avk//ABNNYeXdfeYPMqf8sv8AwFkuiNnWbfju3/oJqrft/wATC5/66t/M1atNR0CzuUnjupyyZwGU46Y/u1h3WppNfTuqEo0jMDnqCauUHGCXmY0q6qYmU0mlypaprqzb8PNnXbb6t/6Ca1LMk6lc5HHnvj8zWL4akMmu2+AAAW7/AOya6C0jA1K4zx+9f+Zrmpq2If8AhX5surNSlodJZjp71uW/QVj2YG0VsQ/dHuK6mJGkh/ck+9OByKijP7o/WnA9eawpby9f0RrPZehPn9360zPGaU42Aj1poP511VN16I4cJ8Mv8UvzHE8+9NzwBjFBoJqDqE6VXvj/AMS+6/65N/I1Pn2qvf8A/IPuf+uTfyNAnsV9D/5Atv8ARv8A0I0U3Qv+QPb/AI/+hGiqhsb4f4TyLXL9zrFx5VzmP5cbWyPuiqEc7XV1bw3ErtG0qgjPWuttrKxNtpCRhJHuYriWZZbOM7iqSAHzCSwwVGABg9eDxXNS6FNa29vKt20moeULsW6Q5VYwC+S+eu0ZxtxjvU4dqMotraxpJRhPdme8UIhmnF1II0k2KDGMkkE/3unFaWkeHp9Wt754DcvNbWyzpELclpi0sce1cHOP3mc+2Md6r3Wl3bR3FukeyWJkluIlhbCZwvBJPdwDkDk8VuaVdQWFz4jsr6++xS3WntZ+f9nkw0oniJDBdxAKq2cAcZwCcA9ntYNO369/+GMpSjYxrTRtTn1G4sIdL1GS7iQ+bB9mYyIPUryR9aZBp19dNMtnYXlwYF3SiKFnMYyR82BxyD1rrJb7Q57m4huJYpZNPsre2inu1uVhmZThyRFiTI+VUzjheccVdfU7DxJr0sGn3jwf8TpL2GQW82bgFRwu3JEgIYjfgfMfm9c5VFayIc+lzjYbK4u9ai0pUYXzyiDypMKVfOCGz0x3z0q1qukHS4baYXltdW1wXEdxb52lkxuX5lU5GQenQgjNXH1OCx+Keo6nLCz28eoTs8kQJby2dlLAdDw2feqt2bE6bpug2eoQXAjnuruW6WGZYlLxoqqAy7ycR8nbjLDnAzRzoXOu4tnpK6jpz3NtqNnJNFDJcPZ/OJBGmSzZ2bOAM43ZxVg6BKmnG6N3Zectst49pu/fLA2MSEbduMEHGc4OcYo0OWOw0G5SXxBM2n3FpOJNKiSdWklKEKW48vCtsbduJwMYqebU9Ne3m1NLrN/daKmnJYm3cOGWJYS5bGzZtjLDBzkgY70lUtcfMzHgQ3KBoE81TIsIKIGBkbO1eB944OB1ODV7TNFm1C4nhdHgaKO4IDQZLSRJvaPHHzfdz3G4cU3wVeW2krqRvVZQYY7uxAiZt13EcxdOn32GenNbt14l059TtZrS5kEk+m3rSP5Lg/b54yrqMe4jGenvQqmgXkc8dOmgubm1vLa5guoIvMaE23zryACwOCq89eeo45q7qXhfWdK1WLT57G4NxMoMKpA3735QTtBUE43AHA4NQ2+t2MukRJLO73SeHprWQeW+fN+2NKq5x02EHPQDjOeK0m1zSBql5ePNayw61pkUG2eK5AtpEEQYSeXtbafLYZjZvfjIJzqzuK/c5m8T7NcSw3K+TPG22SJ1CMh9CuOKta94auNLtJrg3lrLLBcLBdQ27EtbSMCQjggAdCPlyARjioPEmpfbtR+2RpZukEUMKS2iTiN9mMD98d5wBjJ7AVteIb7THg8RtY3Qlm1e+S4MTRSqbUeYXbzCRgtuYAbNwwCfam6qZXM2YVroDz6O+p3Os2dhbrP9nH2pJcu+3d8vlxtxjucU7QtIk1iJI7fUrMXspfy7R/MErhRn5SEKdj95hV7wvfvpV4BL4litbGO93XNjHFcML5BjOE2bGDDIw+33xTvCeo2+lzSXf9vNaabNI/2rSohOJJk5wgKjYcg4yzDGScUuaN/IV3fQwNOmhN0DcyJt2tksTjODjOOeuKtuixyS3IMbIkPmLGjnY/zBc8nPU/pWXa2rlYW8lX3kqgZG/eHPfB4544qwFvmbzREvl+SUEXltsK5JK9c9QTnOeKKc6ajaVt+39bGkFp1ND7QqzWrQuYxPsO1XIOCeR69qnhnlB3Pqr7c4z5p4Pp1rGeOaO8jubjKLFKqBFQgDbj5een86WGTFwqJEFRXLPl884xxxx7V0wlh3B3ste3TTy239OhnPmUtG/wCvmdVDOuzP9sSeo/ef/ZU69eNtPYf22ZC38PmgjqP9qsBJI5pI3Ikwm5QfMJPbvVhmjKOE8xCxz8jlecVpfC33/qy8tr3M7yel3/XzN+MpHaRga4PMVAPLE3IOOn3uMU2VpBIAmtPsOPmWXgj865hYijiQBS2TnJJyD61tw6a0lvCF2BSg2gk8ZH0rFVKbpyWl7u2mu6t07XuEmk1eT6E7TOp2jV5T6kSnAH51XknnjBC6pcED+ITHH86bLpcsSnBi3EEZ3HH8qgWwkaNkXywSMElif6VftKfJZqN7duvT7Pyf5lXj/M/6+ZYW4uyONVmP/bU/41Nb6leW16gOozspUk/vT/jWaNJuYVl8uWM71IAJPyn16fWqD/aRqIilCK/klfvcfXpV4Z4flTl8Xa3r5fMzrNOLTbt/Xmdyut7gv+luvfHmf/X6Uq622zL3TBu48wf41wCXErR7cr/q9mS3fdnPT8KsLLKXLo3DDDhZOQfbj/GoSwrVmvz8/L+kW35v+vmdZqOrtLAoW8bJYceZz/Oqk2qTnJ+2PwcH970/WuVnMrTEiXBGPvEk/wAqZPcPICEG3e258NnP044HJ9awSo++rLy+7S2nffyNnL3I6vr/AFudMupTMcfbJfXiakF9cPtAvJiXzjEprk1mnSOUDq4wDnO0Z+lLDeyQIRubf1B34X8Rj+tXQlRXKqiXW+nmtPPS/wB/kZya1s3/AF8z0bTbqN9NiaSdWc5yWkGfvGp2uIf+esf/AH8FebQXNysKqk6/TGe/0pxurwNzMqjuSuP6V5zjLyOlPD21lL7l/md9cXERgkAkQ5U/xj0qrazRC0jDSAEZ4Le9cUbq6IyLhPyH+FHn3xXIkLfRP/rV0JVPq7VlbmX5MX+zX+KX3L/M6PUJnNrKsDtu3gjaeaxXW8fDM1wcerEVJpf264uVjMqgk/xD/wCtW7/Z94V2GaLceQe38q4Ks+SXvWPRw1CnVg/ZuWl+3T5lfQmK2kiyHBD/AMZ5/WtNmT+9H+YqG0051ZxcyKc8qY6nNlAD96Q/lVqpTa3OOVGunpF/18zpvDk0EejTK00Kt9ozgsB2WvLNYs3fXL8xpuU3DkEcjG416LpWjvcafJJE6qgl2neec4HpXL32m3K39wFkhAEjD9fpVSnBJWZEKVRyaaOTOnzf88T+VH9nzZH7quiawuh1li/z+FN+wXeM+bFj/PtU+1Xc1+ry7GNZWEi31uxjwBIpJP1qzq9jJLq07ogZSRzkegrTh0+7aVMSw8sP5/Sn3enXa3Lq0sPGP5fSsnUj7RO/T9SfYSvaxzn9mzZ/1Y/MUv8AZs391f8AvoVtNY3QGTLF+X/1qjNnc9fNj/L/AOtWqqLuDoyXQg0exki1WB22BQTklh6Gq95YSNfXBGzBlYg7h61sabZTvqEQkdGXJyAPY+1QXVnci6m2ugXe2OOgz9K2517Ja9f0MfZP2r06fqZUdhIJFJaPgg/eovLFyZHDJjjvV37LdZ++n5f/AFqR7W4OVLpz/n0pKa5Pmb+zl7Nq3UorprGNW82PoOKuaXZmK7YtIn+rI6+4qysaLGoZMkAZOanso4mnIK/wnipjPUSpNNHPGwbuy0n2E92FaWFpp20cxm6Znmx/2x+VH2MD+P8ASrxxSZXFO5PIW/DSiLxDabmAUFsk8fwmuot5IxfXP7xMGVjnI9TXOeGIludehWQbky3H/ATXTR2EH2uYGPgSN3PTJqI29u/8K/NnI/jZ0Fg0ci/I6sR1wc1swgcZNc3oaBLi7RRgK4wPzro0HSt2Wi9Gf3DH3pVPpTIj/o7fWnKeKwo7z9f0RpPZehPn90tM4pSf3Y+tNrqqbr0Rw4T4Zf4pfmOHBHNJ7UZxjNIc9Kg6gycVXvm/4l9zn/nk38jVjPrVW+40+5/65P8AyNAnsV9D/wCQNbf8C/8AQjRSaGf+JRb/AEP/AKEaKqGxvh/hPGLnVr6wvLNfJhzZwyRxhsnIk3Zzg9fmOPwptvrl61p9mFtbGYWxthdbT5vlf3Ou3pxnGccZq5qWj3F5eGaJ4gpAGGYg/wAqrRaJdW7l3khIIxwx/wAKwwlalJwjJ6nViYcmMlBPS5XuPEl7PC0f2a1Weby1nuEU+ZOEIKhvmx1VScAZIGc1siwu9Stb/UZbaLfNOZZCMABmIYgZOcZNZtn4Yu5L2PdJAVBycMf8K762sC2iXkCFQVdcZPsldOGq0ZRm+bZX/FHA+Z7nJ3kt1dWxhOm2cbMVMssaAPLtGBnnA99oGTyafp2oatpK6gumg2aXybJEglZQq7s4HzfUZOTgn1rXOkz8/PH+f/1qjbSbgdHi/wC+j/hWH1ij/MiLye5DLFLo80kUuh2FwZogCZy2QpPQbHAHTr1rKsY7iwv1uo7G3dlDAJKoZPmBHTPPWuy8S2E8moRlXj/1Kjk+5rJj0u4Dhi8X/fR/wodeitHIfvaDJYbs2CPHpFlDC0bwqiAYG7OWyWJ3e5NZNudSSF7ZNKspHi3xx3DqPMRWJyB82D1OCQSM8EcV2k1rIdHhQMmQ5PXjvWLa2c73FyFeMENjk/WsqWIpNO8urLk5JqxmWk2sWgsQmlWD/YlkCGRFO/f/AH/m+bHb0wKhtbXV7UWDrpdo32OUyoZNp35IOG+bkcfqa6Y2xhAw0bN7tVeVbtiSDF+LH/CtPb0P5kTzzOOjjv8ATr6OUWluxAKtHKFZXBGCCM+h/wAK6iz8N61rkEdzDoNoIRD5cUcciqsYz1GXyTkn7xPWqi6XdvM88rQmQ9DuJwPbivRPBX2iz0bbOwJ+Ypg5zzSqV6SpTlF6pX/IyqVJxWnU4bVtL1JoYrGTw3p0ckcYRZI5DuAHfAk25Pckd6lGi65e2iM+h2SI0iGeZCgaTbxz8/HvtAz1Oa6Ai5a9e4d0LPnOea3A08OhRZ8suzH2HerVai7+8bxlOzPHdYtJdPvGka2iEkUocK2CCeuMA9KyJbqRZI9trAuN3yKv3iwwSef/AKwrtPF2j3F3rLSxyxqjxq6oxxz0PasKHQriQGRHhD9CzMfl+nFCq0XBy5trDjKaizJguLi0jSPyYneJi0bN1iY+mDjt3zzVmzkvo7eELFEsMEvmbpOASeMHnkcn8zWpHoU8DEg28h7b2OB+GKZPol/cfM00LlSDwxwP04rNV6L3kiY1Ki2Zly3ZVmhWHewn855HPVz7ela2kvqWpX5lECGBN0r4AAXGeRk81HPoFyuZpWh2s/3VYn+ldnoehzR208QlXdPJHGAp4C7gx7egrodWgqUZcy1v+guebe5q+GvBmtSWHmQWKeW7FlMcigEH/ebNbv8AwhPiAnmxJGc486P/AOKrvNKvLayso4Vjkwoxwo/xrQ/tm3/uS/8AfI/xqPb0LfEhe0qXueYN4L18NuNkfp50f+Nd3brJbaPaQSjbJHbojLnOCFAIq7PrEGOFk/75H+NY93qcbZwH/Kj6xRW0kJucrX6GRqsuc81zRuGjmO01r6hL5hOM/jWFJC5fOV/OpeKpfzIFFmpFPuGc15p9rN946vJs5GXRfYKMf0rvRvjhc5HCnv7VwGi6dPH4hBcxlpFkbg+uT6V1YPEUnUspdH+Ry42L9hP0MiOFSmTn8KniiCnncp7c1qxaRKcAmMAdwx/wqcaTKDkmP8T/APWrk+s0v5kdqRnK8oODK7ADocGs653t95nbJrfbTZoyGJj98Hqahm0S4J+/D+Z/wqPrFLmb5ux1VE3h4esv0Ob8sqOBg/WkDzZ+8T+Fbp0O4VcK8P4sf8KRtFugMB4QMep/wqvrFH+ZHI0YLPNgkuRjnoKYskwGfNP4jIrbOhXTJgvD0/vH/CkHh+5C5d4cD/aP+FDxFH+ZCszHmUJDFMsahpMgkDgY9qqsWbPJI+tdB/Y1yqSmRofLYcqGPy46EcVBHoVyybw0Iz0yx/wrqjiKX1ST5vtL8mKz5iPw8calGGzjJrr2K+euM9KwNK0S6hvUbzIevZj/AIVumzn80IXjyR614uKq05TTUj6DKZqMJJ9n+Q9mRXP86hZ0BJPWpP7Mue8sX5mmtpc//PWP/vr/AOtWCqU/5jZ1YnUeG3U6JNgn/j4/otcrfzKNQuf+urA/ma6vw3Yyx6LMGkQn7Rng+y1y1/pczX9ywkj5lbufU10SqU+RXZyxqL2kik8y44qIzjrnrVg6TL/z0i/M/wCFINIl7vH/AN9f/WqVVpdynUXcZbzr9pi4HLjv71JqUo+3SjGOR/IU+HS5I545C0ZCsCcN/wDWqvqTj7fLx6fyFKMoyq+7rp+oua7IXmHv+VMM2On8qaTkdBn1qNic9MV0JIG2XdOmJ1KEY9f5Gqt3K32uf/fb+dS6Z/yEYfx/kaq3h/0uf/ro3866LfuV6/oc137Z+i/MjEjbh6UOx3daaOoxSSffNC/hv1/Q3/5dv1GSOw71PpzE3THP8B/mKqyEgVPpmftLf7h/mKIbmH2iiSaaT2oOfWm80zFgelMc4UmlINMYElVz1NUkZzdkdH4Ojxq9u2OpP/oJrqkX/TZ/+ujfzrA8KR7dWtgPf/0E10iD/TJiP+erfzrNf7y/8K/NnH9ol0YZur3/AK6D+tb8fOAemawtIGLq9/66f1Nbafdya3Zoi7HzAw96cCKZGcwN9aBWNHefr+iLnsvQsZ/cr9aaPrR/yyX603POa6qm69EcWE+GX+KX5js570ZyKb0oyc1B1C7sj3qtfn/QLnH/ADyb+Rqfdg1Bf4+wXPp5TfyNAmVtDP8AxKLcfX/0I0Umh/8AIJtv+Bf+hGiqhsb4f4TxLVV/0z/gIqtZ/wCvb/dNXdUH+lE/7Iqnaf69v900YLeB2Yv/AJGE/wDEzW8E6e19rq4O1UxlvSvSb6zWG11CNBjLqTz7JXM/CSz+06xKD0DCvZbTSrS4169gkVfL2qSCM/wrXdh4/u5f4f1R5KfvfJnjMltJkgIx+gzVaS2mx/qZP++TXpGsaeuk6lLBJbP5LHMUoXhh6exriNX1bUba4zb22FBI2bCeK4xXG+LEddUiIRj+4Xt7msFJXJwBzXS+K9Xn+3xxmzkbMKnKqcHk+1Y0MN/dcjTLnB6EJQM0pGYeHbbc2P3h/wDZq597h90yxDJJ9cZ9q6a40HXL3QbaC2smSQSEkSsFwOef5VQ0/wAGancSTxSXEETRNh+S3PPTj2rChs/V/maVN16IwoZZ1DPdiNBj5UUgn8aqT+ZK3ySPg9Fr0ey+HPmY3STzDu20Io/XNdTpXgzTdJIkEIln9W5C10pNmLaOA0DwPc3CpdapI0EOAwiH3mHv6V3Ng0e+FEXbAFIRfYVd1JJJFWBSQ8jiNQPfr+maYlp5mqNDEp2xpsUD2rPEq2Gqen6oxqu9vU5+W2Vry4ubhAsKfvPr6CpZbh7rRbd24/eEge3NV9Thug/2BUldI2+Z9pO403V55tK8JxyrbSyT7yscaoT8xzyfaqVSGuq+9f5nVB6P0OJ8aSQzXsSxnMttAQ2O2TwP51y8lzPARskCqR09fwq6bDUp7eWaW0umllmyxMTdh9Peq72V4SWSynkPQYiY0KpDklqunVf5jXwsqiTewMuGJPfpVqKcyttkcYU4VDwo/Clj0i+MR3WNwGPP+pbj9K1tP06aa2PnaMWkQj70bAsPyrKNSHdfev8AMziK0aizRlKsu4D5cZFeq/Dm2gm1KeLA3Q7ZkHUdNv8A7NXmmsaNbQ20Ulpa3lvOWCvCcsvPcHA/Ku18D2Wr6F4b1vUisn2sNHGFwc7CRkDjn3rrlUh7GOq3fVeXmNtXZ7vBt8oFSCPUGlkk2isnw7m38P20chwQCRuPODzz+JNXZnUxFtwJ7DNY+1h3X3r/ADIKt3cZBrn76fg81Y1G7aIfLG0n+7WJcSPIu4I/PbBqXVh3X3r/ADKVjPvX3q2Oo/lWJICWyK1pUm35ET/98msjXVurOwla3t5Gc8AhCdoI61n7SHdfev8AMu6KupT+TpF22eRGa4nw0D/bMWc/6puv0roLpL648KTO1vOZGUKQYzknPpWL4etLuPWo1kglUmJsAofSuvB1Ie0eq2fVdvU5cb/AnbsJCY8Bt56+nWnrtZyCx570R6dd7Qfsswx3Mbf4VNHa3SMT9luGb3iOBXP7WHdfev8AM61YbuQk4GT1O7tSOFfndj29KsfZZwQ7Wsq9slDg002dyAf9Cnye4jNZqpDneq6dV/mdlRpYeHrL9DKkYqx5wuO9RlnIyTwegrSm0+6UFhaTt6fuz+tQC0v9xAs52OO8R/wqvaQ/mX3r/M5LopuONzZK/wAKg8sf8KhYFwHkIHoo7CtObTLuVjLHazktjKbDlPYcciqj6dej/lzuePWJv8KPaQ7r71/mJtFF8bSEyAfWnoizwhOPNQfJ/tDuKsPp15sLNaTqMZ/1Z/wpsVneBVeO0uD3DCMnmupVIfVXqviXVdn5kfaIdOcC+jPQbq6DzBtJ6Y96y/7PvF1CNls5wGIY/um4OPpWp9kucFTbSbjzjYa8fEyg5LVfee7lU1yyXk/yGGYHim+aM9P1p/2O6xj7JP8A9+zTGtLodLSf/v01ZKUO5o6i7nYeFZAdDnx/z8+vstcjqMg/tO66f65/5mt7wpqOp6ffRWkdkfJkdnYvC2Qdvr+Ap974n1yO/uEXTUKrIwB+zv0z9a35oOK1/r7zm57Tdrfecn5vzdaQuPeukHinXs/8gxP/AAHf/GnHxRr3/QMj/wDAd/8AGlzU/wCb+vvD2r8vvOZVx70oYZ710o8Ua/8A9AyP/wAB3/xpR4n1/wD6Bsf/AIDv/jRzU/5v6+8PaP8ApnMkgnHNNLAds11H/CTa9/0Do/8AwHf/ABpD4n17/oGR/wDgO/8AjRzU/wCb+vvB1H/TMLS2H9ow8ev8jVS7JN5Px/y0b+ddbZ+ItcmvI45dOjVGzkiBxjj60ybxJr6TyImnRFVYgH7O/TP1rfmh7Fe91/T1MOdus/Tv5nI8hhx3pJThjxXWf8JL4gyM6dF1/wCfd/8AGiTxNrwYj+zY/wDwHf8AxqVOHJ8S3/rqb875H69zi2O7gZFW9M3faWH+wf6V0h8Ta+B/yDY//AZ/8adB4h1q4kKTaeiKBkEQMOfzpwnC6s/6+8yUve/4JxBBB6U09O1dkfFHiD/oFx/+Az/400+KfEP/AEC4/wDwGf8Axo54fzL8P8zJyOMPWlhXfcqPSuvPinxF/wBAuP8A8Bn/AMatw+IvEAkOdMjxgf8ALu/+NaRnDuvvX+ZhVlpYh8MJjVID9f5GugVf9Ml9PMb+dWNE8Qau99EJrONE5yTCw7H3rUHiK8+0SjyrfhyPuH1+tZxcXXbT6L82YL4jG0ri7vh6yD+ZrZU96raRrVzHf6iwSLLy5OVPqfetxdeusD93Dzz90/410M0RBGcW7fWlBGc1fTW7kwE7Ic5/un/Gga3c4+5D/wB8n/GsaVry9f8AIufT0Kv/ACxX600H8q0v7ZuPKU7Iuv8AdP8AjTP7auf+ecX/AHyf8a6p7r0Rx4W3LK380vzKFJnjg1ojWbk5+SH/AL5P+NJ/bVxn7kX/AHyf8azOkzzyDVe9/wCQfc/9cm/ka2P7ZuP+ecX/AHyf8agu9cuUs528uHiNj90+n1oEzF0P/kE2/wCP/oRoq/p+u3M2iozJD8yMDhT6n3oqobG+H+E8K1Qf6R/wEVStP9e3+7Whqi5n/wCAis+1H+kMP9k0YLeB2Yv/AJGE/wDEz0/4Hwh7+8kPRWH8hXpGk3yP4w1KR22q7bVP935VxXPfC3ww+k+HXnIJvLoF2UdhjgflSs7QahqJwVZJF+o4SvRoOykn/L+qPHWsn6M9O8pHjCTBXB9QCDWddaFpdxnz7QjPR14qhoniGC5iMNzKqkD+I8N/9euiidSA0bHaR3rnlBMz2MKXwvaTziUSkEDaAQCKtRaOkOFfy2x6Ej+taYLKPl457Ck3EHmpUUNtmJPplnLO6OrhQM4DEVi+H4beLU9YWOJcCfAzz3auhuGL3khI7dq53RSRqesEf89/6tWFDZ+r/M0qdPRG8RvYIeAemKrywNH74p5lyMEVci/0mAFlIdeD7+9dBkczIVGvW5I+WKN5D9cGq81y9jDNcHiaUcewNbNxppXU/PZf3YTB9/aud1eTz7ltxG0HH6VSScZJrp/kTJXcfU5+bUruOQvJPtTBdjtHT8q5zxL4kv5/D9tcQzmMNMQvyqePm9R7U3xTqQeU2kR4AHmY/QVi64hfwdp2MZ+0N1/4HXIsPSSdor7jqglZ+hmDxNrbW5xeYAfk7F/wpYta1aM7Ybsqp6/Ip5/EVkxyeWjxvH8rDjHY+tX4YBJKq+Y+O+xc/wA6I4el7OS5V06AkuVmlDruqMT5t84UDP3E/wAK27C81u9VJPtqW8D/APLZkU8egGOTWLBp5muWjWFUjYDLTOMgZHv/AJzXUyWzW6IuxVjVeowB/wDqqI4Wjb4F9yM4pEes3cq2MaxTsQrgb3A3OeeTxx9BivU/h9cQXPh++m1CZHT7RtPm4UYGfSvIdU4sk2MrKXGPbg1ayVXa7M5HUZyAcV0zoUlRgnFbvovIpQTbPW9e8e6NoqbY4muHx8qoeK4TUvi1qrEfZbC2gQ8DcSxH61yUtyxLqflHGc81kXL7t3zHruJ9q53Qo/yL7kV7OKOhuPiV4jZzi4gXnoIRVM/ETxJnm5iP/bIVzbEM2M8fyqMEDOMmp+r0f5F9yDlR1sXxL1lWxNFA4/3cVpwfEaO5QR3cckRPcYYfyrz0rnPHtShGLn5eaX1aj/IvuQJLseh6x4hkk0SQ2N4rNkABVGR+GKxtC1PUZdcieaYlhG2CVA9fauehQ55OK2dEU/26mBwYmIz9K6sHh6PtH7q2fTyObGpKhNrsWTruoYA+1nPbCLj+VA1vUg4/0zKnr8i8fpWZjYp3kbfQVFGw2sM4A5zXN9Wo/wAi+5HTZdjaXXL2bMbzbl6jIH+FPj1+/cMTOeB2Vf8ACsiBV3/f4xk8c0xWjBYqG6Y61CoUuZrlXToddRL6vT06y/Q1pdevihxcMreyrz+lUz4h1QDAuiT3+Rfy6VRyxPO7GeCRUUgw3HfoKv6tR/kX3I5Womp/wkGqMOLk5HfYv+FMPiDWkP8Ax/cejIh/pWW7ngbWAHqMU0ox28bfrxS+rUf5V9wrJ9DVl8Rak8ZVpVIIwcKBUcOv6lFGkcU6qgzzsBI/Os3AAf5wR6CmgKQA3TrmupUKX1VrlXxLp5MXKuY0U8Q6sLpVN6Wy39xf8K0W1m/K+b9oO8cA7R/hXMrtN2m3ONwrVDYt3+teVXoUk1aK+49fLYxtLTo/yLzeINTA5uj/AN8L/hTD4i1MD/j6P/fC/wCFZjfWonPWpWHpfyr7iZRiuh0ugeINSl161je5JUlsjYv90+1UtR8SammqXaLdEATOB8i/3j7VW8Nn/iorT6t/6Caz9VP/ABN7z/ru/wD6Ea1WHpctuVfcYNR5tjRHiXVcf8fZ/wC+F/wpw8S6mcf6Uf8Avhf8KwckUoaj6tS/lX3B7vY3x4k1P/n7P/fC/wCFPHiPU8f8fR/74X/CueEhpwkNL6rS/lX3FJx7HQDxHqWP+Pon/gC/4UHxHqX/AD9H/vhf8KwhLR5lL6tS/lX3Fe52Om03XtRl1GJHuSVJPG1fQ+1RXXiDUkuplW6ICuw+4vr9KzdGkzqsPrk/yNQXj/6bcf8AXRv51q8PT9ilyrd9PIxSj7V6dP1NVfEOpsw/0ojn+4v+FJL4h1MOf9KOP9xf8Kx0b51xnrRO37xqlYalyP3Vv2Onlh7N6dTUPiPVev2o4/3F/wAKsWOuajPOyyXJZdhIGxf8K58tV3Sj/pTf7h/pRDD0k0+VfcZRUeZaEp8Rat/z9n/vhf8ACmnxHqv/AD9n/vhf8KzCaYTQsPS/lX3GbjHsan/CR6rkZvCOf7i/4VrprmpkKftJ6c/Iv+FcknzTIPfJroLRQV59a1jhqVvhX3I5qijzbHT2OrX7JzcE8/3R/hWrAzMS55LZJrBsE6dhmt6Djt2xVxpwh8KSJSSItLJ+13vr5n9TW2hz19Kw9L/4/L3/AK6dfxNbUbc5zVspF2M/6M3+9Qp4psR/0Z/rQvOMVhR3n6/oi57L0LJ/1Ax603PpQT/o6/U00nmuqpuvRHFhPhl/il+YoIFLTc0eg/KoOoUNkY71Wvv+PG5/65N/I1YzVa+P+gXH/XNv5GgT2Kuk/wDIDi/3W/maKTSj/wASOL/db+ZoqobG+H+E8m1Ejzj/ALtVdMiWW/JJ4UdPXmrGpDMx+gqvYEQXQkJ7c08D8UDrxf8Av8/8TPpPwpdohiQHDKR8p4ptzZW1/wCItTinGFJXJXqPlSqWi6l9usIZ4NKkmBUFJEJx+YFU01G7/t++R9PuzIwDlQM8YX2FenSg7TTXT9UeZGjNPW33r/Mk1Xw3Lp0263m82PqARhq6DQdSP2JI7nqvAccj8fSseTWZZ1W3l068Eij5cjkiqkOsfZLgt/Z90pP3gV4P4VgoNaXH9Vn3X3o9EQgx9cj1pjkbCa519da3kAWzuGBXPyjipF16eUYXTbk+23/61JQdtA+qzet195cP/H0/0rnNLcRajrJIz/pGMfi1aB1S4W4b/iVXecf3aw7LU1N/qOzTLveZsycd8msKVJpPVbsueHldarZdTrbODz8Ng4Na4SG1TLYJx0rmoNbuYIQq6XdAf7n/ANalbW7luX0u7Pttrf2ZH1WfdfejRv5mkjYjC8HFeY63dvDAxQZlZiFHp711eoeImt4y02n3QB4GR1rlLy/sZrYSyWU53Mcj8/eqjTevoRLDSTWq37nnOoRFGJY5YnLH1NTanEJfBdgGXOLhv/Z63b6TQ2P7ywuB/wAC/wDsqx9YvbG50mOys0kiWKTeN/Pr7n1rH2bVzpjQkk9vvRyiQxqfugGui0axWRt7sAOw9apWenNNJvyXVeoArfsRst9vkFhuIHFOMHyP5AqE+Vr9V/mJCj/2tJGwK5QA8fStOKNkbAB2dCr/ANKz4pSl/JlWY7QME8jpipvtMoHzIwbJJGamMJELDz/pr/ML2BZ1WN1wFbIwetZtxaQ52q8g7nn/AOtVqSc4AHBBLHJzVSS4G1skA7s59q0U6sVaL/IpYeXVL71/mUJrRARgv+NV5LRVXkt19e1W3/eAkyZz3qEdcb8t6Cj2tf8Am/FB9Xl2X3r/ADKbW6Ko5OSM8Ui265Oc8VcMJ6B0Bx0IpwVVGN4P8qXtq/8AN+KF9Wl2X3r/ADKJhXvmpFt42zgt781YVY1GcqcnvSkLwN6jvxS9tX/m/FD+rS7L71/mRLbJjqxI6Ctfw7Cv9pltzZWNsZ/Af1rOIXAAcetPTGMqcnHHtVKtW6v8UZ18HKpTcFZX81/majeHryT+OH8XOP5U0eGrzH+tt+vQOf8ACsraTnD4HelEe7+In6Cs3FdvxMlhMX/z8X3L/wCSNU6FcQDc7Q88cOf8KYvh67DDdJAR6Bj/AIVSjT96XJA4wM96g8ts/wCtHvWSiud6dup11MLi/q9NKa3l0Xl/eNUaBe7ifOg5P94/4UHw9ctwXgJHcMf8KyjsX7xQkcUEgqcOgyOwrXlXb8Tk+qYz+dfcv/kjR/4R68B/10BA7Fj/AIVCfDV85JM1uf8AgZ/wrN8lADiRen5U1Yk4/eA47etHKu34i+qYz+dfcv8A5I05fDd4sZbzIMKCT8x5/SmxeH7uaBXWW3CnsWPr9KzWjySxlHToaRIQwB3j6V0qK+rPT7S6+TF9Vxd7c6v6L/5I018MXyz7hLbcc/eP+FWDot6sbRb7fcxyDuOP5ViJGqXAbzVzjoau5U2zY29a8yvCN17vbqepl+GxcVK9RbS6Lt/iL/8Awjd6UH7y3zj++f8ACo38N35/5aW3/fR/wqSytRJZRNhWwME5xzT2ggX7xjH1cVqqUP5fxOJ0Mf8A8/F9y/8AkiTQvD1/Dr1pIz2+0Fs4Y5+6fas7UvDmovqt24ltcGZyMuf7x9q0tMS2OtWeyWLdvbADAn7prnNThT+17398n+vf/wBCPvRyR/l/ESw2MejqK/ov/kix/wAI1qX/AD2tf++z/hSf8IzqX/Pa1/77P+FZvkp/z3j/AC/+vR5C/wDPdPy/+vRyL+X8R/VcZ/z8X3L/AOSNL/hGdS/57Wv/AH0f8KP+EZ1P/nva/wDfR/wrN8hP+e6flR5Cf890/KjlX8v4h9Vxn/Pxfcv/AJI0v+EZ1P8A5723/fZ/wpP+EZ1P/n4tv++z/hWd5Ef/AD3SjyE/57p+VHLH+X8Q+qYz/n4vuX/yRvaT4d1GHU4ZHngKgnIDH0PtUN34a1F7ydluIAGkYj5z6/Sq2jQKNXgP2hTyePwNQXsC/brg/aAP3rfzNaOMfZrTr38jNYXGe0a9or27Lv8A4i5H4Z1LzEzcQYyP4z/hS3HhjUWnYi4gA/3z6fSsxYUDhvtAODmorghp2IbIqHyRjqvxNZUMXGnZ1Fv2X/yRp/8ACLaj3uIP++z/AIVc03w5fW9yzvNCQUI4c+3tXO4960NHAF4//XM/zFQnC+34kU6eI51eov8AwH/gk3/CKX//AD2t/wDvs/4Uf8Ipf/8APa3/AO+z/hWTgUhAANLmh2/EzdLE/wDPxf8AgP8AwTftfC96kmTLb8f7Z/wrdtPD92oBMkOM/wB4/wCFcTaA7xXSWQOwDNaXh2/Ew9niP+fi/wDAf+CddaaROi8vF+BP+FacenygffT86wLLiMHua042wOKV4dvxKVPE/wDPxf8AgP8AwR+lWshvL8ArxJjr7mthLWQd1/Oue0tsXl5/v/1Na8bfKaV4dvxH7PEdJr/wH/gmqkDi2YZXOfWkWBx3X86ij4tH+v8AhTV6GsqTheXu9e/oXOnibL94tv5f+CW3GyFQT3qPoaYTkg0ua0lLmY6FJ0otN3bbf3j80hOaT3pT9Kk1Aniq18f9BuB28pv5GrGflxVa+P8AoFz/ANcm/kaAZV0nH9ixeu1v5mio9KONFiI9G/maKqGx0Yf4Tyy6u3WQABenpUAunbghfyqO8b98P90VEjc0sLTjeLsdeKxdf6zKPM7XNiw8R6jpjZtpdq9052n8K6zw9410eXWXm1tZ7YSxhN8R3KDx14zjivOi1RnpXbheVRqJq/u/qjhni68rXm/6+R9N2uhaFrlotxp181ynUNFKrY/IZFVbrw1HbN+885/fcAf5c18522o3unSeZZ3UsD+sbEVuW3xO8WWQ2/2q86/3ZxuFc/JQeysH1vFfzv8Ar5Hut1pVjPcDe8ocIOMgf0qAaJZq37uSfPoGH+FYEPxH0+PWIbDWlFvI0atHcqPlySRg+nSu3W5D26zwmOWIjKyRkEGh0Y25rCWNxEdOd/18ira+HUnuSGE4GOSXAwPyrI0/wvBNqmrR+dIAk+Mhh6t7e1b8d5cPIX80xqRyTycVhaXqTR6rqypkK8/Lt16tWVClBp6dWOrjMRdPney/rY1H0DTraPMlxMAByzOOf0rFum0yMlYJJnP94uMfyqxcSPI5Z3Ln1NZM1qsrMU4bP4Vv7Gn2M/r+J/nf9fIq3Fok7szTO4/hGelU7mzQWSrluG/xqzNDJCQCcZ6EVOMzWimVeQfzq4UoWlZdP8jOeNxDcbze/wDn5HG6lAIkLDP41zrzSOMIoyzYHH511muESllXhRxVHSbKJSZZAMBSFGefrXO6ML7HTHHYj+d/18iaytYVtFYS8kc8cVFZIDGEViSSxIxwAAK0pUUPuf5Y0X8aq6cALdyUfJJC4HJ9a0VKCg1bsarGV2m+d/18ivGgOpyKeEVNxz6cUXDJvIBJHrmi6tYZpC5Lozjlcjp2rNltIlZsyMR0HvWHso9ifruJX2n/AF8ieR/m4IZR69qpyXJ3EKR+Peq7xRjcodj71CYkHckdhnqaTprsH17E/wAz+/8A4BO92/GAv5Un2mTrgD8DVfZFn7pJ74NXrDTWuZ49kMskRPz7OuPWl7OPYPr2J/mf9fIZGbmRZHWMBIxlmI6Vo6bp4v7a4uXuEit4QBuYfeY9AKu3WkWmm/bUuHl8huIxkbhg9TVSGyt7qBpLVZktYQTywOffpR7OPYX17E/zP+vkQXdpKl5HbWq+dJ5YaTaM7T159OKpPK0LbXT5h/eGK1rDQ7q5g3kBY3J2/vOvsTjGasx+GLaYYkEkbno6kPk/pRyR7C+vYn+Z/wBfI577R8v3VB7DFBuXjwAVJPoOlWNR0GexnAaK48sk7W2g5/Ks42vP3vx/xo9nHsP69if5n/XyLLXj4OCue4pPtj8cjFVvLj4CgsB601EUseMNR7OPYf17E/zP+vkW2uZWGQmc+oxUIUB8Ek+yjAFQopOck/TNNKqO5qox5dkZVcRVq253cfKw3jn8aUFAhL5Yk/dHSmGBtoOANx4GaQoi/KTubuR2p6mV32HPIrf8swB7dqZhRzk49KUxxKMnJOeMGo9iHoxBo1Bt9iQsdmS2PrULORxn9aTBUndz6UE8HPFdSv8AVX/iX5Mm75hY2Au1NaBf/RHPv6/Ss6MBp1BBAPrV/wAtRZvjON3+FeXX3R6uXylaWnSX5FJyrZ+UH61Xbbn7q/lVhkAGc1AwA6VaOaUp9jT8L4/4SS0+UDlu3+yap6oR/a97/wBd5P8A0I1f8L/8jHafVv8A0E1S1T/kL3v/AF3f/wBCNX0M7yvsU8ik3U7NFILy7DSaM07NIGzQF5dhM0U7NGeaAvLsX9EP/E4t/wAf/QTVa+P+n3H/AF1b+Zq1oh/4m9v+P/oJqtfH/T7n/rq38zWr/hL1/QzvL2j06fqVuaKdmkzWRpeXYMGtDRh/pb/9cz/MVQzxWho5/wBLf/rmf5iqje5UHLmWhnc01umKdupN2TihXuZScrbFq0X5veulsV6GuetogxHWt20sUYDJf8DVXZlr2OhteAPSr8bZFYUOnQN1aT8x/hVtNKt8Z3y/99D/AApaju+xd0w/6Ve/74/ma2UIzj1rlrHTIJLi5UvJhXwMEe/tWpHotscfPN/30P8ACnqF32OkjP8Aojn/AGqaprOh0i3/ALNlj3y7WYE/MM9vaoV0G0x/rJ/++h/hWFK95+v6I0m3ZadDaHX+dPzxWKNAtf8AnpP/AN9D/Cnf8I/adPMn/wC+h/hW2pF32NntRnpWOvh+0PHmT5/3h/hQfD9p/wA9J/8Avof4U9Qu+xrk1Wvj/oNx/wBcm/lVA+H7T/npP/30P8KY2g2vTzJ/++h/hS1Fr2JdKI/saIf7LfzNFTRQJa2ohQkqoOM9aKuOx1UNInjF6f36/wC6KjjbJ/CpbuGSSUMi5G0dxUcdvKpyU/UUYWSvFXN8TRqPEykou1+wzNGeKd9nm/ufqKd9nlx9z9RXZhY354vS8eunVHFKhV091/cV26VWkFXmtpSPun8xURspD/CfzFL6lP8Amj/4Eh+yqfyP7ma/jZS2uQAdTbL/ADau/wDg/wCJhGZvDt6/7uT95bMx6N3X8eK4/U7H+1r1Lp5ljZYxGAFJ6En+tLYaS1jcpcw3mJYzuVtp4rWnhZxeso2f95EujUa+B/cz364j2TMF7dvSuV05SdQ1Rl7Tf1aqFv4yvJIVWVrcyAYJ2Nz+tZ9n4mktby9dzB+9kzyjHufT61lTws6d02t31Qp0Kr2i9l0Z1z/vUynXuKrTnyISEGXPHSsBvFOWDLJACD2jeo38Sb9372BSe4jfj6Vt7CXdfejP6tW/lf3GjBM5nLzEFcHqOgplx5n2fCOWBP3u2KyDrFuGDSSxSEDABR8flT59btrq2WM3SQ88hImqoUJK+q27omeGraPle/Zla4hWU7Q3Q4/3j6U026tcsUXAVSfaka5smAH9oAYx0ieg3NoeP7TI57Qt/hWf1afdfejVU5r7L+5/5EszBzHG+1Qo3Nu7+lZ1oXWBnWQHLHqavG8stzsL5MvjcfJfmqNra29xaMsl2FG49Izmh0JKDu106o2jGfK/df3MglJZ2wOVHPPSov7OurjCxR4GMhm4BrYhstPhYsJkc5z80bVNMUm4N+qp/dWJqxdF/wA0f/AkQ4VP5H9z/wAjFXw1KRunmCgc5Wp49I05JYw0m92OApPU1dFtabdpvS31V/8AGhYbKNo2SaFNhyCIWzU+wf8ANH/wJC9nU/kf3P8AyJbTw1BZ3HnPG4kRsbXHGPp6Ulrd29vfNHpy/ZXVs55KuT1FTXl2bsENqrDIABEZyMUy1+zQKFW8UkHLP5R3Mfc9afsH/NH/AMCQezqfyP7n/kYustcXmqXXlqGMJ6N90e59q6VfDs1r4etrV5DIb2Tc0qDG0kdB7cVSRLGPYjyxSqrb9rxMQzerDufrW1a+I5oYXSO8hwZd4/ct8oxjA9qPq/8Aej/4Ehezq/yP7n/kVtUgh0vR00u3Ym8jhAhiH/LVmH3vzrl9N1X+y5zaX2551z5jhxtT6cc1saisV9qsd+b/AMqSPGwJG2B9Kxbrwxp0s5mOoyDJyRsJoeH/AL0f/AkHs6v8j+5/5Gj/AGzBqLiAyzmLPMm8At7dKp3/AIajG6S3eRUb5iXbdj+VXbCz0qz6eRKezSROSv05q2Tb7Cgu1IbqGjY/zpewf80f/AkV7Op/I/uf+Rx76O6LmNxJg8gHn8Kglt54k5hKp1zjmuznjsZ0CtJArgcOkDA1V+xQJjGo8D1iJo9g/wCaP/gSF7Op/I/uf+RxRDo3KsPrTCwD8fdHt1ruGsrOQYku42U9jAaqtoOk7TtuQrdmEbZFHsH/ADR/8CQ/Z1P5H9z/AMjkHZ2bcwKjtSDOeFy1dZ/wj9gG3DUnzjHMRNMfw9YsuDqTAZzxEeaPYP8Amj/4Eh8lT+R/c/8AI5YqC3LnPsOKaUOeoOPwzXT/APCNad/0E3/79Gkbw1pxx/xM3/79Gj2D/mj/AOBIXs6n8j+5/wCRy7A9wfqOlISAM4z9a6n/AIRnT+2pyY9PKNWE8K6G8Q83V5lfuBCf8K0naGHcbpu6ejT6MSo1G/hf3P8AyONWTE6M3A9avGZTZyEHgH/CumPhPw/kf8Tmfj/pif8ACkPhrRgfIXVJjE3LP5RyD9Me1eZVi5NWX5f5noYPmpqXMmtJdH29DjHlHY1Azgmu5Pg7QT/zGZ/+/J/wpv8Awhmg/wDQauP+/P8A9atVSn/L+X+ZxPEQfX8znvC7j/hI7Tr1b/0E1T1Vx/a97/13k/8AQjXcaZ4a0LTdRiu11edzHn5TERnII9Pesy90LQp764lOp3ALyM2PL6ZOf7tN05pfD/X3k+2hfc4/d7Ubq6n/AIR7Qf8AoKXH/fv/AOxo/wCEd0H/AKClx/37/wDsaXJP+V/18x+1h3OVzRkDiuq/4R7Qf+gpcf8Afv8A+xo/4R3Qf+gpcf8Afv8A+xo5J/yv+vmL2sO5yu7NJu9xXV/8I7oP/QUuP+/f/wBjR/wjug/9BS4/79//AGNHJP8Alf8AXzD2sO5iaG//ABOLf6t/6CarX7f8TC56f61v5murs9H0Kyu47hdSnYpngx9eMf3azbqz0B7uZzfXOWdicL7/AO7RUlyU0mnv28hQfNUbT6fqc8WpN5rc+w+H/wDn/uv++f8A7Gj7B4f/AOf+5/75/wDsaw9suz+5m3K+6+8ww5rS0Zibx8/88z/MVa+w+Hv+f65/75/+xq3p9toUVwzRXk5YoRyv0/2aqNVN7P7hwjaS1X3nMbjTo+Wrof7H0X/n7ufyH/xNSR6RooP/AB93P5f/AGNCrL+V/czOVOTKVkgytdHaDEeajt7HRkI/0uf8v/rVqxro6pj7XL/3yf8ACn7Zfyv7mL2UhIT/APXq1GwHH401H0cf8vcv/fJ/wqZZtIDZ+1Sf98n/AAo9sv5X9zH7ORBprf6TdZ/v/wCNbMZ9KzNKWya4uz5z7S+VOOo59q2IxZAD98/5f/Wpusl0f3MFSky3Cc2T/wC9/hTVPFJ51ulu0cchOTnkGo1lUH71TRu+Z23f+Q5xlorFkHpT+pquJk/vfpT/AD0z979K3syOWXYlzgZ96UnqPWofPjx979KQzJ/e/SiwckuxLnBFRs1M85P736UwzJu60WYcsuwO3yke1FRPIpU80VUTeimk7n//2Q==",
- "text/plain": [
- ""
- ]
- },
- "metadata": {},
- "output_type": "display_data"
- }
- ],
- "source": [
- "# image viz\n",
- "frcnn_visualizer = SingleImageViz(URL, id2obj=objids, id2attr=attrids)\n",
- "# run frcnn\n",
- "images, sizes, scales_yx = image_preprocess(URL)\n",
- "output_dict = frcnn(\n",
- " images,\n",
- " sizes,\n",
- " scales_yx=scales_yx,\n",
- " padding=\"max_detections\",\n",
- " max_detections=frcnn_cfg.max_detections,\n",
- " return_tensors=\"pt\",\n",
- ")\n",
- "# add boxes and labels to the image\n",
- "\n",
- "frcnn_visualizer.draw_boxes(\n",
- " output_dict.get(\"boxes\"),\n",
- " output_dict.pop(\"obj_ids\"),\n",
- " output_dict.pop(\"obj_probs\"),\n",
- " output_dict.pop(\"attr_ids\"),\n",
- " output_dict.pop(\"attr_probs\"),\n",
- ")\n",
- "showarray(frcnn_visualizer._get_buffer())"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 6,
- "metadata": {},
- "outputs": [],
- "source": [
- "# test_questions_for_url1 = [\n",
- "# \"Where is this scene?\",\n",
- "# \"what is the man riding?\",\n",
- "# \"What is the man wearing?\",\n",
- "# \"What is the color of the horse?\"\n",
- "# ]\n",
- "test_questions_for_url2 = [\n",
- " \"Where is the cat?\",\n",
- " \"What is near the disk?\",\n",
- " \"What is the color of the table?\",\n",
- " \"What is the color of the cat?\",\n",
- " \"What is the shape of the monitor?\",\n",
- "]\n",
- "\n",
- "# Very important that the boxes are normalized\n",
- "# normalized_boxes = output_dict.get(\"normalized_boxes\")\n",
- "features = output_dict.get(\"roi_features\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 7,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Question: ['Where is the cat?']\n",
- "prediction from VisualBert VQA: outside\n",
- "Question: ['What is near the disk?']\n",
- "prediction from VisualBert VQA: nothing\n",
- "Question: ['What is the color of the table?']\n",
- "prediction from VisualBert VQA: brown\n",
- "Question: ['What is the color of the cat?']\n",
- "prediction from VisualBert VQA: gray\n",
- "Question: ['What is the shape of the monitor?']\n",
- "prediction from VisualBert VQA: square\n"
- ]
- }
- ],
- "source": [
- "for test_question in test_questions_for_url2:\n",
- " test_question = [test_question]\n",
- "\n",
- " inputs = bert_tokenizer(\n",
- " test_question,\n",
- " padding=\"max_length\",\n",
- " max_length=20,\n",
- " truncation=True,\n",
- " return_token_type_ids=True,\n",
- " return_attention_mask=True,\n",
- " add_special_tokens=True,\n",
- " return_tensors=\"pt\",\n",
- " )\n",
- "\n",
- " output_vqa = visualbert_vqa(\n",
- " input_ids=inputs.input_ids,\n",
- " attention_mask=inputs.attention_mask,\n",
- " visual_embeds=features,\n",
- " visual_attention_mask=torch.ones(features.shape[:-1]),\n",
- " token_type_ids=inputs.token_type_ids,\n",
- " output_attentions=False,\n",
- " )\n",
- " # get prediction\n",
- " pred_vqa = output_vqa[\"logits\"].argmax(-1)\n",
- " print(\"Question:\", test_question)\n",
- " print(\"prediction from VisualBert VQA:\", vqa_answers[pred_vqa])"
- ]
- }
- ],
- "metadata": {
- "interpreter": {
- "hash": "f237d186bbb22b392353378fb98a8d08e33f23f14150c8880e3780871939e71d"
- },
- "kernelspec": {
- "display_name": "Python 3.8.0 64-bit ('transformers_env': conda)",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.8.0"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 4
-}
\ No newline at end of file
diff --git a/examples/research_projects/visual_bert/extracting_data.py b/examples/research_projects/visual_bert/extracting_data.py
deleted file mode 100644
index 6b1342c9b11..00000000000
--- a/examples/research_projects/visual_bert/extracting_data.py
+++ /dev/null
@@ -1,149 +0,0 @@
-import getopt
-import json
-import os
-
-# import numpy as np
-import sys
-from collections import OrderedDict
-
-import datasets
-import numpy as np
-import torch
-from modeling_frcnn import GeneralizedRCNN
-from processing_image import Preprocess
-
-from utils import Config
-
-
-"""
-USAGE:
-``python extracting_data.py -i -o .datasets ``
-"""
-
-
-TEST = False
-CONFIG = Config.from_pretrained("unc-nlp/frcnn-vg-finetuned")
-DEFAULT_SCHEMA = datasets.Features(
- OrderedDict(
- {
- "attr_ids": datasets.Sequence(length=CONFIG.MAX_DETECTIONS, feature=datasets.Value("float32")),
- "attr_probs": datasets.Sequence(length=CONFIG.MAX_DETECTIONS, feature=datasets.Value("float32")),
- "boxes": datasets.Array2D((CONFIG.MAX_DETECTIONS, 4), dtype="float32"),
- "img_id": datasets.Value("int32"),
- "obj_ids": datasets.Sequence(length=CONFIG.MAX_DETECTIONS, feature=datasets.Value("float32")),
- "obj_probs": datasets.Sequence(length=CONFIG.MAX_DETECTIONS, feature=datasets.Value("float32")),
- "roi_features": datasets.Array2D((CONFIG.MAX_DETECTIONS, 2048), dtype="float32"),
- "sizes": datasets.Sequence(length=2, feature=datasets.Value("float32")),
- "preds_per_image": datasets.Value(dtype="int32"),
- }
- )
-)
-
-
-class Extract:
- def __init__(self, argv=sys.argv[1:]):
- inputdir = None
- outputfile = None
- subset_list = None
- batch_size = 1
- opts, args = getopt.getopt(argv, "i:o:b:s", ["inputdir=", "outfile=", "batch_size=", "subset_list="])
- for opt, arg in opts:
- if opt in ("-i", "--inputdir"):
- inputdir = arg
- elif opt in ("-o", "--outfile"):
- outputfile = arg
- elif opt in ("-b", "--batch_size"):
- batch_size = int(arg)
- elif opt in ("-s", "--subset_list"):
- subset_list = arg
-
- assert inputdir is not None # and os.path.isdir(inputdir), f"{inputdir}"
- assert outputfile is not None and not os.path.isfile(outputfile), f"{outputfile}"
- if subset_list is not None:
- with open(os.path.realpath(subset_list)) as f:
- self.subset_list = {self._vqa_file_split()[0] for x in tryload(f)}
- else:
- self.subset_list = None
-
- self.config = CONFIG
- if torch.cuda.is_available():
- self.config.model.device = "cuda"
- self.inputdir = os.path.realpath(inputdir)
- self.outputfile = os.path.realpath(outputfile)
- self.preprocess = Preprocess(self.config)
- self.model = GeneralizedRCNN.from_pretrained("unc-nlp/frcnn-vg-finetuned", config=self.config)
- self.batch = batch_size if batch_size != 0 else 1
- self.schema = DEFAULT_SCHEMA
-
- def _vqa_file_split(self, file):
- img_id = int(file.split(".")[0].split("_")[-1])
- filepath = os.path.join(self.inputdir, file)
- return (img_id, filepath)
-
- @property
- def file_generator(self):
- batch = []
- for i, file in enumerate(os.listdir(self.inputdir)):
- if self.subset_list is not None and i not in self.subset_list:
- continue
- batch.append(self._vqa_file_split(file))
- if len(batch) == self.batch:
- temp = batch
- batch = []
- yield list(map(list, zip(*temp)))
-
- for i in range(1):
- yield list(map(list, zip(*batch)))
-
- def __call__(self):
- # make writer
- if not TEST:
- writer = datasets.ArrowWriter(features=self.schema, path=self.outputfile)
- # do file generator
- for i, (img_ids, filepaths) in enumerate(self.file_generator):
- images, sizes, scales_yx = self.preprocess(filepaths)
- output_dict = self.model(
- images,
- sizes,
- scales_yx=scales_yx,
- padding="max_detections",
- max_detections=self.config.MAX_DETECTIONS,
- pad_value=0,
- return_tensors="np",
- location="cpu",
- )
- output_dict["boxes"] = output_dict.pop("normalized_boxes")
- if not TEST:
- output_dict["img_id"] = np.array(img_ids)
- batch = self.schema.encode_batch(output_dict)
- writer.write_batch(batch)
- if TEST:
- break
- # finalizer the writer
- if not TEST:
- num_examples, num_bytes = writer.finalize()
- print(f"Success! You wrote {num_examples} entry(s) and {num_bytes >> 20} mb")
-
-
-def tryload(stream):
- try:
- data = json.load(stream)
- try:
- data = list(data.keys())
- except Exception:
- data = [d["img_id"] for d in data]
- except Exception:
- try:
- data = eval(stream.read())
- except Exception:
- data = stream.read().split("\n")
- return data
-
-
-if __name__ == "__main__":
- extract = Extract(sys.argv[1:])
- extract()
- if not TEST:
- dataset = datasets.Dataset.from_file(extract.outputfile)
- # wala!
- # print(np.array(dataset[0:2]["roi_features"]).shape)
diff --git a/examples/research_projects/visual_bert/modeling_frcnn.py b/examples/research_projects/visual_bert/modeling_frcnn.py
deleted file mode 100644
index c7c3bf376ce..00000000000
--- a/examples/research_projects/visual_bert/modeling_frcnn.py
+++ /dev/null
@@ -1,1920 +0,0 @@
-"""
-coding=utf-8
-Copyright 2018, Antonio Mendoza Hao Tan, Mohit Bansal
-Adapted From Facebook Inc, Detectron2 && Huggingface Co.
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.import copy
-"""
-
-import itertools
-import math
-import os
-from abc import ABCMeta, abstractmethod
-from collections import OrderedDict, namedtuple
-from typing import Dict, List, Tuple
-
-import numpy as np
-import torch
-from torch import nn
-from torch.nn.modules.batchnorm import BatchNorm2d
-from torchvision.ops import RoIPool
-from torchvision.ops.boxes import batched_nms, nms
-
-from utils import WEIGHTS_NAME, Config, cached_path, hf_bucket_url, is_remote_url, load_checkpoint
-
-
-# other:
-def norm_box(boxes, raw_sizes):
- if not isinstance(boxes, torch.Tensor):
- normalized_boxes = boxes.copy()
- else:
- normalized_boxes = boxes.clone()
- normalized_boxes[:, :, (0, 2)] /= raw_sizes[:, 1]
- normalized_boxes[:, :, (1, 3)] /= raw_sizes[:, 0]
- return normalized_boxes
-
-
-def pad_list_tensors(
- list_tensors,
- preds_per_image,
- max_detections=None,
- return_tensors=None,
- padding=None,
- pad_value=0,
- location=None,
-):
- """
- location will always be cpu for np tensors
- """
- if location is None:
- location = "cpu"
- assert return_tensors in {"pt", "np", None}
- assert padding in {"max_detections", "max_batch", None}
- new = []
- if padding is None:
- if return_tensors is None:
- return list_tensors
- elif return_tensors == "pt":
- if not isinstance(list_tensors, torch.Tensor):
- return torch.stack(list_tensors).to(location)
- else:
- return list_tensors.to(location)
- else:
- if not isinstance(list_tensors, list):
- return np.array(list_tensors.to(location))
- else:
- return list_tensors.to(location)
- if padding == "max_detections":
- assert max_detections is not None, "specify max number of detections per batch"
- elif padding == "max_batch":
- max_detections = max(preds_per_image)
- for i in range(len(list_tensors)):
- too_small = False
- tensor_i = list_tensors.pop(0)
- if tensor_i.ndim < 2:
- too_small = True
- tensor_i = tensor_i.unsqueeze(-1)
- assert isinstance(tensor_i, torch.Tensor)
- tensor_i = nn.functional.pad(
- input=tensor_i,
- pad=(0, 0, 0, max_detections - preds_per_image[i]),
- mode="constant",
- value=pad_value,
- )
- if too_small:
- tensor_i = tensor_i.squeeze(-1)
- if return_tensors is None:
- if location == "cpu":
- tensor_i = tensor_i.cpu()
- tensor_i = tensor_i.tolist()
- if return_tensors == "np":
- if location == "cpu":
- tensor_i = tensor_i.cpu()
- tensor_i = tensor_i.numpy()
- else:
- if location == "cpu":
- tensor_i = tensor_i.cpu()
- new.append(tensor_i)
- if return_tensors == "np":
- return np.stack(new, axis=0)
- elif return_tensors == "pt" and not isinstance(new, torch.Tensor):
- return torch.stack(new, dim=0)
- else:
- return list_tensors
-
-
-def do_nms(boxes, scores, image_shape, score_thresh, nms_thresh, mind, maxd):
- scores = scores[:, :-1]
- num_bbox_reg_classes = boxes.shape[1] // 4
- # Convert to Boxes to use the `clip` function ...
- boxes = boxes.reshape(-1, 4)
- _clip_box(boxes, image_shape)
- boxes = boxes.view(-1, num_bbox_reg_classes, 4) # R x C x 4
-
- # Select max scores
- max_scores, max_classes = scores.max(1) # R x C --> R
- num_objs = boxes.size(0)
- boxes = boxes.view(-1, 4)
- idxs = torch.arange(num_objs).to(boxes.device) * num_bbox_reg_classes + max_classes
- max_boxes = boxes[idxs] # Select max boxes according to the max scores.
-
- # Apply NMS
- keep = nms(max_boxes, max_scores, nms_thresh)
- keep = keep[:maxd]
- if keep.shape[-1] >= mind and keep.shape[-1] <= maxd:
- max_boxes, max_scores = max_boxes[keep], max_scores[keep]
- classes = max_classes[keep]
- return max_boxes, max_scores, classes, keep
- else:
- return None
-
-
-# Helper Functions
-def _clip_box(tensor, box_size: Tuple[int, int]):
- assert torch.isfinite(tensor).all(), "Box tensor contains infinite or NaN!"
- h, w = box_size
- tensor[:, 0].clamp_(min=0, max=w)
- tensor[:, 1].clamp_(min=0, max=h)
- tensor[:, 2].clamp_(min=0, max=w)
- tensor[:, 3].clamp_(min=0, max=h)
-
-
-def _nonempty_boxes(box, threshold: float = 0.0) -> torch.Tensor:
- widths = box[:, 2] - box[:, 0]
- heights = box[:, 3] - box[:, 1]
- keep = (widths > threshold) & (heights > threshold)
- return keep
-
-
-def get_norm(norm, out_channels):
- if isinstance(norm, str):
- if len(norm) == 0:
- return None
- norm = {
- "BN": BatchNorm2d,
- "GN": lambda channels: nn.GroupNorm(32, channels),
- "nnSyncBN": nn.SyncBatchNorm, # keep for debugging
- "": lambda x: x,
- }[norm]
- return norm(out_channels)
-
-
-def _create_grid_offsets(size: List[int], stride: int, offset: float, device):
- grid_height, grid_width = size
- shifts_x = torch.arange(
- offset * stride,
- grid_width * stride,
- step=stride,
- dtype=torch.float32,
- device=device,
- )
- shifts_y = torch.arange(
- offset * stride,
- grid_height * stride,
- step=stride,
- dtype=torch.float32,
- device=device,
- )
-
- shift_y, shift_x = torch.meshgrid(shifts_y, shifts_x)
- shift_x = shift_x.reshape(-1)
- shift_y = shift_y.reshape(-1)
- return shift_x, shift_y
-
-
-def build_backbone(cfg):
- input_shape = ShapeSpec(channels=len(cfg.MODEL.PIXEL_MEAN))
- norm = cfg.RESNETS.NORM
- stem = BasicStem(
- in_channels=input_shape.channels,
- out_channels=cfg.RESNETS.STEM_OUT_CHANNELS,
- norm=norm,
- caffe_maxpool=cfg.MODEL.MAX_POOL,
- )
- freeze_at = cfg.BACKBONE.FREEZE_AT
-
- if freeze_at >= 1:
- for p in stem.parameters():
- p.requires_grad = False
-
- out_features = cfg.RESNETS.OUT_FEATURES
- depth = cfg.RESNETS.DEPTH
- num_groups = cfg.RESNETS.NUM_GROUPS
- width_per_group = cfg.RESNETS.WIDTH_PER_GROUP
- bottleneck_channels = num_groups * width_per_group
- in_channels = cfg.RESNETS.STEM_OUT_CHANNELS
- out_channels = cfg.RESNETS.RES2_OUT_CHANNELS
- stride_in_1x1 = cfg.RESNETS.STRIDE_IN_1X1
- res5_dilation = cfg.RESNETS.RES5_DILATION
- assert res5_dilation in {1, 2}, "res5_dilation cannot be {}.".format(res5_dilation)
-
- num_blocks_per_stage = {50: [3, 4, 6, 3], 101: [3, 4, 23, 3], 152: [3, 8, 36, 3]}[depth]
-
- stages = []
- out_stage_idx = [{"res2": 2, "res3": 3, "res4": 4, "res5": 5}[f] for f in out_features]
- max_stage_idx = max(out_stage_idx)
- for idx, stage_idx in enumerate(range(2, max_stage_idx + 1)):
- dilation = res5_dilation if stage_idx == 5 else 1
- first_stride = 1 if idx == 0 or (stage_idx == 5 and dilation == 2) else 2
- stage_kargs = {
- "num_blocks": num_blocks_per_stage[idx],
- "first_stride": first_stride,
- "in_channels": in_channels,
- "bottleneck_channels": bottleneck_channels,
- "out_channels": out_channels,
- "num_groups": num_groups,
- "norm": norm,
- "stride_in_1x1": stride_in_1x1,
- "dilation": dilation,
- }
-
- stage_kargs["block_class"] = BottleneckBlock
- blocks = ResNet.make_stage(**stage_kargs)
- in_channels = out_channels
- out_channels *= 2
- bottleneck_channels *= 2
-
- if freeze_at >= stage_idx:
- for block in blocks:
- block.freeze()
- stages.append(blocks)
-
- return ResNet(stem, stages, out_features=out_features)
-
-
-def find_top_rpn_proposals(
- proposals,
- pred_objectness_logits,
- images,
- image_sizes,
- nms_thresh,
- pre_nms_topk,
- post_nms_topk,
- min_box_side_len,
- training,
-):
- """Args:
- proposals (list[Tensor]): (L, N, Hi*Wi*A, 4).
- pred_objectness_logits: tensors of length L.
- nms_thresh (float): IoU threshold to use for NMS
- pre_nms_topk (int): before nms
- post_nms_topk (int): after nms
- min_box_side_len (float): minimum proposal box side
- training (bool): True if proposals are to be used in training,
- Returns:
- results (List[Dict]): stores post_nms_topk object proposals for image i.
- """
- num_images = len(images)
- device = proposals[0].device
-
- # 1. Select top-k anchor for every level and every image
- topk_scores = [] # #lvl Tensor, each of shape N x topk
- topk_proposals = []
- level_ids = [] # #lvl Tensor, each of shape (topk,)
- batch_idx = torch.arange(num_images, device=device)
- for level_id, proposals_i, logits_i in zip(itertools.count(), proposals, pred_objectness_logits):
- Hi_Wi_A = logits_i.shape[1]
- num_proposals_i = min(pre_nms_topk, Hi_Wi_A)
-
- # sort is faster than topk (https://github.com/pytorch/pytorch/issues/22812)
- # topk_scores_i, topk_idx = logits_i.topk(num_proposals_i, dim=1)
- logits_i, idx = logits_i.sort(descending=True, dim=1)
- topk_scores_i = logits_i[batch_idx, :num_proposals_i]
- topk_idx = idx[batch_idx, :num_proposals_i]
-
- # each is N x topk
- topk_proposals_i = proposals_i[batch_idx[:, None], topk_idx] # N x topk x 4
-
- topk_proposals.append(topk_proposals_i)
- topk_scores.append(topk_scores_i)
- level_ids.append(torch.full((num_proposals_i,), level_id, dtype=torch.int64, device=device))
-
- # 2. Concat all levels together
- topk_scores = torch.cat(topk_scores, dim=1)
- topk_proposals = torch.cat(topk_proposals, dim=1)
- level_ids = torch.cat(level_ids, dim=0)
-
- # if I change to batched_nms, I wonder if this will make a difference
- # 3. For each image, run a per-level NMS, and choose topk results.
- results = []
- for n, image_size in enumerate(image_sizes):
- boxes = topk_proposals[n]
- scores_per_img = topk_scores[n]
- # I will have to take a look at the boxes clip method
- _clip_box(boxes, image_size)
- # filter empty boxes
- keep = _nonempty_boxes(boxes, threshold=min_box_side_len)
- lvl = level_ids
- if keep.sum().item() != len(boxes):
- boxes, scores_per_img, lvl = (
- boxes[keep],
- scores_per_img[keep],
- level_ids[keep],
- )
-
- keep = batched_nms(boxes, scores_per_img, lvl, nms_thresh)
- keep = keep[:post_nms_topk]
-
- res = (boxes[keep], scores_per_img[keep])
- results.append(res)
-
- # I wonder if it would be possible for me to pad all these things.
- return results
-
-
-def subsample_labels(labels, num_samples, positive_fraction, bg_label):
- """
- Returns:
- pos_idx, neg_idx (Tensor):
- 1D vector of indices. The total length of both is `num_samples` or fewer.
- """
- positive = torch.nonzero((labels != -1) & (labels != bg_label)).squeeze(1)
- negative = torch.nonzero(labels == bg_label).squeeze(1)
-
- num_pos = int(num_samples * positive_fraction)
- # protect against not enough positive examples
- num_pos = min(positive.numel(), num_pos)
- num_neg = num_samples - num_pos
- # protect against not enough negative examples
- num_neg = min(negative.numel(), num_neg)
-
- # randomly select positive and negative examples
- perm1 = torch.randperm(positive.numel(), device=positive.device)[:num_pos]
- perm2 = torch.randperm(negative.numel(), device=negative.device)[:num_neg]
-
- pos_idx = positive[perm1]
- neg_idx = negative[perm2]
- return pos_idx, neg_idx
-
-
-def add_ground_truth_to_proposals(gt_boxes, proposals):
- raise NotImplementedError()
-
-
-def add_ground_truth_to_proposals_single_image(gt_boxes, proposals):
- raise NotImplementedError()
-
-
-def _fmt_box_list(box_tensor, batch_index: int):
- repeated_index = torch.full(
- (len(box_tensor), 1),
- batch_index,
- dtype=box_tensor.dtype,
- device=box_tensor.device,
- )
- return torch.cat((repeated_index, box_tensor), dim=1)
-
-
-def convert_boxes_to_pooler_format(box_lists: List[torch.Tensor]):
- pooler_fmt_boxes = torch.cat(
- [_fmt_box_list(box_list, i) for i, box_list in enumerate(box_lists)],
- dim=0,
- )
- return pooler_fmt_boxes
-
-
-def assign_boxes_to_levels(
- box_lists: List[torch.Tensor],
- min_level: int,
- max_level: int,
- canonical_box_size: int,
- canonical_level: int,
-):
- box_sizes = torch.sqrt(torch.cat([boxes.area() for boxes in box_lists]))
- # Eqn.(1) in FPN paper
- level_assignments = torch.floor(canonical_level + torch.log2(box_sizes / canonical_box_size + 1e-8))
- # clamp level to (min, max), in case the box size is too large or too small
- # for the available feature maps
- level_assignments = torch.clamp(level_assignments, min=min_level, max=max_level)
- return level_assignments.to(torch.int64) - min_level
-
-
-# Helper Classes
-class _NewEmptyTensorOp(torch.autograd.Function):
- @staticmethod
- def forward(ctx, x, new_shape):
- ctx.shape = x.shape
- return x.new_empty(new_shape)
-
- @staticmethod
- def backward(ctx, grad):
- shape = ctx.shape
- return _NewEmptyTensorOp.apply(grad, shape), None
-
-
-class ShapeSpec(namedtuple("_ShapeSpec", ["channels", "height", "width", "stride"])):
- def __new__(cls, *, channels=None, height=None, width=None, stride=None):
- return super().__new__(cls, channels, height, width, stride)
-
-
-class Box2BoxTransform:
- """
- This R-CNN transformation scales the box's width and height
- by exp(dw), exp(dh) and shifts a box's center by the offset
- (dx * width, dy * height).
- """
-
- def __init__(self, weights: Tuple[float, float, float, float], scale_clamp: float = None):
- """
- Args:
- weights (4-element tuple): Scaling factors that are applied to the
- (dx, dy, dw, dh) deltas. In Fast R-CNN, these were originally set
- such that the deltas have unit variance; now they are treated as
- hyperparameters of the system.
- scale_clamp (float): When predicting deltas, the predicted box scaling
- factors (dw and dh) are clamped such that they are <= scale_clamp.
- """
- self.weights = weights
- if scale_clamp is not None:
- self.scale_clamp = scale_clamp
- else:
- """
- Value for clamping large dw and dh predictions.
- The heuristic is that we clamp such that dw and dh are no larger
- than what would transform a 16px box into a 1000px box
- (based on a small anchor, 16px, and a typical image size, 1000px).
- """
- self.scale_clamp = math.log(1000.0 / 16)
-
- def get_deltas(self, src_boxes, target_boxes):
- """
- Get box regression transformation deltas (dx, dy, dw, dh) that can be used
- to transform the `src_boxes` into the `target_boxes`. That is, the relation
- ``target_boxes == self.apply_deltas(deltas, src_boxes)`` is true (unless
- any delta is too large and is clamped).
- Args:
- src_boxes (Tensor): source boxes, e.g., object proposals
- target_boxes (Tensor): target of the transformation, e.g., ground-truth
- boxes.
- """
- assert isinstance(src_boxes, torch.Tensor), type(src_boxes)
- assert isinstance(target_boxes, torch.Tensor), type(target_boxes)
-
- src_widths = src_boxes[:, 2] - src_boxes[:, 0]
- src_heights = src_boxes[:, 3] - src_boxes[:, 1]
- src_ctr_x = src_boxes[:, 0] + 0.5 * src_widths
- src_ctr_y = src_boxes[:, 1] + 0.5 * src_heights
-
- target_widths = target_boxes[:, 2] - target_boxes[:, 0]
- target_heights = target_boxes[:, 3] - target_boxes[:, 1]
- target_ctr_x = target_boxes[:, 0] + 0.5 * target_widths
- target_ctr_y = target_boxes[:, 1] + 0.5 * target_heights
-
- wx, wy, ww, wh = self.weights
- dx = wx * (target_ctr_x - src_ctr_x) / src_widths
- dy = wy * (target_ctr_y - src_ctr_y) / src_heights
- dw = ww * torch.log(target_widths / src_widths)
- dh = wh * torch.log(target_heights / src_heights)
-
- deltas = torch.stack((dx, dy, dw, dh), dim=1)
- assert (src_widths > 0).all().item(), "Input boxes to Box2BoxTransform are not valid!"
- return deltas
-
- def apply_deltas(self, deltas, boxes):
- """
- Apply transformation `deltas` (dx, dy, dw, dh) to `boxes`.
- Args:
- deltas (Tensor): transformation deltas of shape (N, k*4), where k >= 1.
- deltas[i] represents k potentially different class-specific
- box transformations for the single box boxes[i].
- boxes (Tensor): boxes to transform, of shape (N, 4)
- """
- boxes = boxes.to(deltas.dtype)
-
- widths = boxes[:, 2] - boxes[:, 0]
- heights = boxes[:, 3] - boxes[:, 1]
- ctr_x = boxes[:, 0] + 0.5 * widths
- ctr_y = boxes[:, 1] + 0.5 * heights
-
- wx, wy, ww, wh = self.weights
- dx = deltas[:, 0::4] / wx
- dy = deltas[:, 1::4] / wy
- dw = deltas[:, 2::4] / ww
- dh = deltas[:, 3::4] / wh
-
- # Prevent sending too large values into torch.exp()
- dw = torch.clamp(dw, max=self.scale_clamp)
- dh = torch.clamp(dh, max=self.scale_clamp)
-
- pred_ctr_x = dx * widths[:, None] + ctr_x[:, None]
- pred_ctr_y = dy * heights[:, None] + ctr_y[:, None]
- pred_w = torch.exp(dw) * widths[:, None]
- pred_h = torch.exp(dh) * heights[:, None]
-
- pred_boxes = torch.zeros_like(deltas)
- pred_boxes[:, 0::4] = pred_ctr_x - 0.5 * pred_w # x1
- pred_boxes[:, 1::4] = pred_ctr_y - 0.5 * pred_h # y1
- pred_boxes[:, 2::4] = pred_ctr_x + 0.5 * pred_w # x2
- pred_boxes[:, 3::4] = pred_ctr_y + 0.5 * pred_h # y2
- return pred_boxes
-
-
-class Matcher:
- """
- This class assigns to each predicted "element" (e.g., a box) a ground-truth
- element. Each predicted element will have exactly zero or one matches; each
- ground-truth element may be matched to zero or more predicted elements.
- The matching is determined by the MxN match_quality_matrix, that characterizes
- how well each (ground-truth, prediction)-pair match each other. For example,
- if the elements are boxes, this matrix may contain box intersection-over-union
- overlap values.
- The matcher returns (a) a vector of length N containing the index of the
- ground-truth element m in [0, M) that matches to prediction n in [0, N).
- (b) a vector of length N containing the labels for each prediction.
- """
-
- def __init__(
- self,
- thresholds: List[float],
- labels: List[int],
- allow_low_quality_matches: bool = False,
- ):
- """
- Args:
- thresholds (list): a list of thresholds used to stratify predictions
- into levels.
- labels (list): a list of values to label predictions belonging at
- each level. A label can be one of {-1, 0, 1} signifying
- {ignore, negative class, positive class}, respectively.
- allow_low_quality_matches (bool): if True, produce additional matches or predictions with maximum match quality lower than high_threshold.
- For example, thresholds = [0.3, 0.5] labels = [0, -1, 1] All predictions with iou < 0.3 will be marked with 0 and
- thus will be considered as false positives while training. All predictions with 0.3 <= iou < 0.5 will be marked with -1 and
- thus will be ignored. All predictions with 0.5 <= iou will be marked with 1 and thus will be considered as true positives.
- """
- thresholds = thresholds[:]
- assert thresholds[0] > 0
- thresholds.insert(0, -float("inf"))
- thresholds.append(float("inf"))
- assert all(low <= high for (low, high) in zip(thresholds[:-1], thresholds[1:]))
- assert all(label_i in [-1, 0, 1] for label_i in labels)
- assert len(labels) == len(thresholds) - 1
- self.thresholds = thresholds
- self.labels = labels
- self.allow_low_quality_matches = allow_low_quality_matches
-
- def __call__(self, match_quality_matrix):
- """
- Args:
- match_quality_matrix (Tensor[float]): an MxN tensor, containing the pairwise quality between M ground-truth elements and N predicted
- elements. All elements must be >= 0 (due to the us of `torch.nonzero` for selecting indices in :meth:`set_low_quality_matches_`).
- Returns:
- matches (Tensor[int64]): a vector of length N, where matches[i] is a matched ground-truth index in [0, M)
- match_labels (Tensor[int8]): a vector of length N, where pred_labels[i] indicates true or false positive or ignored
- """
- assert match_quality_matrix.dim() == 2
- if match_quality_matrix.numel() == 0:
- default_matches = match_quality_matrix.new_full((match_quality_matrix.size(1),), 0, dtype=torch.int64)
- # When no gt boxes exist, we define IOU = 0 and therefore set labels
- # to `self.labels[0]`, which usually defaults to background class 0
- # To choose to ignore instead,
- # can make labels=[-1,0,-1,1] + set appropriate thresholds
- default_match_labels = match_quality_matrix.new_full(
- (match_quality_matrix.size(1),), self.labels[0], dtype=torch.int8
- )
- return default_matches, default_match_labels
-
- assert torch.all(match_quality_matrix >= 0)
-
- # match_quality_matrix is M (gt) x N (predicted)
- # Max over gt elements (dim 0) to find best gt candidate for each prediction
- matched_vals, matches = match_quality_matrix.max(dim=0)
-
- match_labels = matches.new_full(matches.size(), 1, dtype=torch.int8)
-
- for l, low, high in zip(self.labels, self.thresholds[:-1], self.thresholds[1:]):
- low_high = (matched_vals >= low) & (matched_vals < high)
- match_labels[low_high] = l
-
- if self.allow_low_quality_matches:
- self.set_low_quality_matches_(match_labels, match_quality_matrix)
-
- return matches, match_labels
-
- def set_low_quality_matches_(self, match_labels, match_quality_matrix):
- """
- Produce additional matches for predictions that have only low-quality matches.
- Specifically, for each ground-truth G find the set of predictions that have
- maximum overlap with it (including ties); for each prediction in that set, if
- it is unmatched, then match it to the ground-truth G.
- This function implements the RPN assignment case (i)
- in Sec. 3.1.2 of Faster R-CNN.
- """
- # For each gt, find the prediction with which it has highest quality
- highest_quality_foreach_gt, _ = match_quality_matrix.max(dim=1)
- # Find the highest quality match available, even if it is low, including ties.
- # Note that the matches qualities must be positive due to the use of
- # `torch.nonzero`.
- of_quality_inds = match_quality_matrix == highest_quality_foreach_gt[:, None]
- if of_quality_inds.dim() == 0:
- (_, pred_inds_with_highest_quality) = of_quality_inds.unsqueeze(0).nonzero().unbind(1)
- else:
- (_, pred_inds_with_highest_quality) = of_quality_inds.nonzero().unbind(1)
- match_labels[pred_inds_with_highest_quality] = 1
-
-
-class RPNOutputs:
- def __init__(
- self,
- box2box_transform,
- anchor_matcher,
- batch_size_per_image,
- positive_fraction,
- images,
- pred_objectness_logits,
- pred_anchor_deltas,
- anchors,
- boundary_threshold=0,
- gt_boxes=None,
- smooth_l1_beta=0.0,
- ):
- """
- Args:
- box2box_transform (Box2BoxTransform): :class:`Box2BoxTransform` instance for anchor-proposal transformations.
- anchor_matcher (Matcher): :class:`Matcher` instance for matching anchors to ground-truth boxes; used to determine training labels.
- batch_size_per_image (int): number of proposals to sample when training
- positive_fraction (float): target fraction of sampled proposals that should be positive
- images (ImageList): :class:`ImageList` instance representing N input images
- pred_objectness_logits (list[Tensor]): A list of L elements. Element i is a tensor of shape (N, A, Hi, W)
- pred_anchor_deltas (list[Tensor]): A list of L elements. Element i is a tensor of shape (N, A*4, Hi, Wi)
- anchors (list[torch.Tensor]): nested list of boxes. anchors[i][j] at (n, l) stores anchor array for feature map l
- boundary_threshold (int): if >= 0, then anchors that extend beyond the image boundary by more than boundary_thresh are not used in training.
- gt_boxes (list[Boxes], optional): A list of N elements.
- smooth_l1_beta (float): The transition point between L1 and L2 lossn. When set to 0, the loss becomes L1. When +inf, it is ignored
- """
- self.box2box_transform = box2box_transform
- self.anchor_matcher = anchor_matcher
- self.batch_size_per_image = batch_size_per_image
- self.positive_fraction = positive_fraction
- self.pred_objectness_logits = pred_objectness_logits
- self.pred_anchor_deltas = pred_anchor_deltas
-
- self.anchors = anchors
- self.gt_boxes = gt_boxes
- self.num_feature_maps = len(pred_objectness_logits)
- self.num_images = len(images)
- self.boundary_threshold = boundary_threshold
- self.smooth_l1_beta = smooth_l1_beta
-
- def _get_ground_truth(self):
- raise NotImplementedError()
-
- def predict_proposals(self):
- # pred_anchor_deltas: (L, N, ? Hi, Wi)
- # anchors:(N, L, -1, B)
- # here we loop over specific feature map, NOT images
- proposals = []
- anchors = self.anchors.transpose(0, 1)
- for anchors_i, pred_anchor_deltas_i in zip(anchors, self.pred_anchor_deltas):
- B = anchors_i.size(-1)
- N, _, Hi, Wi = pred_anchor_deltas_i.shape
- anchors_i = anchors_i.flatten(start_dim=0, end_dim=1)
- pred_anchor_deltas_i = pred_anchor_deltas_i.view(N, -1, B, Hi, Wi).permute(0, 3, 4, 1, 2).reshape(-1, B)
- proposals_i = self.box2box_transform.apply_deltas(pred_anchor_deltas_i, anchors_i)
- # Append feature map proposals with shape (N, Hi*Wi*A, B)
- proposals.append(proposals_i.view(N, -1, B))
- proposals = torch.stack(proposals)
- return proposals
-
- def predict_objectness_logits(self):
- """
- Returns:
- pred_objectness_logits (list[Tensor]) -> (N, Hi*Wi*A).
- """
- pred_objectness_logits = [
- # Reshape: (N, A, Hi, Wi) -> (N, Hi, Wi, A) -> (N, Hi*Wi*A)
- score.permute(0, 2, 3, 1).reshape(self.num_images, -1)
- for score in self.pred_objectness_logits
- ]
- return pred_objectness_logits
-
-
-# Main Classes
-class Conv2d(nn.Conv2d):
- def __init__(self, *args, **kwargs):
- norm = kwargs.pop("norm", None)
- activation = kwargs.pop("activation", None)
- super().__init__(*args, **kwargs)
-
- self.norm = norm
- self.activation = activation
-
- def forward(self, x):
- if x.numel() == 0 and self.training:
- assert not isinstance(self.norm, nn.SyncBatchNorm)
- if x.numel() == 0:
- assert not isinstance(self.norm, nn.GroupNorm)
- output_shape = [
- (i + 2 * p - (di * (k - 1) + 1)) // s + 1
- for i, p, di, k, s in zip(
- x.shape[-2:],
- self.padding,
- self.dilation,
- self.kernel_size,
- self.stride,
- )
- ]
- output_shape = [x.shape[0], self.weight.shape[0]] + output_shape
- empty = _NewEmptyTensorOp.apply(x, output_shape)
- if self.training:
- _dummy = sum(x.view(-1)[0] for x in self.parameters()) * 0.0
- return empty + _dummy
- else:
- return empty
-
- x = super().forward(x)
- if self.norm is not None:
- x = self.norm(x)
- if self.activation is not None:
- x = self.activation(x)
- return x
-
-
-class LastLevelMaxPool(nn.Module):
- """
- This module is used in the original FPN to generate a downsampled P6 feature from P5.
- """
-
- def __init__(self):
- super().__init__()
- self.num_levels = 1
- self.in_feature = "p5"
-
- def forward(self, x):
- return [nn.functional.max_pool2d(x, kernel_size=1, stride=2, padding=0)]
-
-
-class LastLevelP6P7(nn.Module):
- """
- This module is used in RetinaNet to generate extra layers, P6 and P7 from C5 feature.
- """
-
- def __init__(self, in_channels, out_channels):
- super().__init__()
- self.num_levels = 2
- self.in_feature = "res5"
- self.p6 = nn.Conv2d(in_channels, out_channels, 3, 2, 1)
- self.p7 = nn.Conv2d(out_channels, out_channels, 3, 2, 1)
-
- def forward(self, c5):
- p6 = self.p6(c5)
- p7 = self.p7(nn.functional.relu(p6))
- return [p6, p7]
-
-
-class BasicStem(nn.Module):
- def __init__(self, in_channels=3, out_channels=64, norm="BN", caffe_maxpool=False):
- super().__init__()
- self.conv1 = Conv2d(
- in_channels,
- out_channels,
- kernel_size=7,
- stride=2,
- padding=3,
- bias=False,
- norm=get_norm(norm, out_channels),
- )
- self.caffe_maxpool = caffe_maxpool
- # use pad 1 instead of pad zero
-
- def forward(self, x):
- x = self.conv1(x)
- x = nn.functional.relu_(x)
- if self.caffe_maxpool:
- x = nn.functional.max_pool2d(x, kernel_size=3, stride=2, padding=0, ceil_mode=True)
- else:
- x = nn.functional.max_pool2d(x, kernel_size=3, stride=2, padding=1)
- return x
-
- @property
- def out_channels(self):
- return self.conv1.out_channels
-
- @property
- def stride(self):
- return 4 # = stride 2 conv -> stride 2 max pool
-
-
-class ResNetBlockBase(nn.Module):
- def __init__(self, in_channels, out_channels, stride):
- super().__init__()
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.stride = stride
-
- def freeze(self):
- for p in self.parameters():
- p.requires_grad = False
- return self
-
-
-class BottleneckBlock(ResNetBlockBase):
- def __init__(
- self,
- in_channels,
- out_channels,
- bottleneck_channels,
- stride=1,
- num_groups=1,
- norm="BN",
- stride_in_1x1=False,
- dilation=1,
- ):
- super().__init__(in_channels, out_channels, stride)
-
- if in_channels != out_channels:
- self.shortcut = Conv2d(
- in_channels,
- out_channels,
- kernel_size=1,
- stride=stride,
- bias=False,
- norm=get_norm(norm, out_channels),
- )
- else:
- self.shortcut = None
-
- # The original MSRA ResNet models have stride in the first 1x1 conv
- # The subsequent fb.torch.resnet and Caffe2 ResNe[X]t implementations have
- # stride in the 3x3 conv
- stride_1x1, stride_3x3 = (stride, 1) if stride_in_1x1 else (1, stride)
-
- self.conv1 = Conv2d(
- in_channels,
- bottleneck_channels,
- kernel_size=1,
- stride=stride_1x1,
- bias=False,
- norm=get_norm(norm, bottleneck_channels),
- )
-
- self.conv2 = Conv2d(
- bottleneck_channels,
- bottleneck_channels,
- kernel_size=3,
- stride=stride_3x3,
- padding=1 * dilation,
- bias=False,
- groups=num_groups,
- dilation=dilation,
- norm=get_norm(norm, bottleneck_channels),
- )
-
- self.conv3 = Conv2d(
- bottleneck_channels,
- out_channels,
- kernel_size=1,
- bias=False,
- norm=get_norm(norm, out_channels),
- )
-
- def forward(self, x):
- out = self.conv1(x)
- out = nn.functional.relu_(out)
-
- out = self.conv2(out)
- out = nn.functional.relu_(out)
-
- out = self.conv3(out)
-
- if self.shortcut is not None:
- shortcut = self.shortcut(x)
- else:
- shortcut = x
-
- out += shortcut
- out = nn.functional.relu_(out)
- return out
-
-
-class Backbone(nn.Module, metaclass=ABCMeta):
- def __init__(self):
- super().__init__()
-
- @abstractmethod
- def forward(self):
- pass
-
- @property
- def size_divisibility(self):
- """
- Some backbones require the input height and width to be divisible by a specific integer. This is
- typically true for encoder / decoder type networks with lateral connection (e.g., FPN) for which feature maps need to match
- dimension in the "bottom up" and "top down" paths. Set to 0 if no specific input size divisibility is required.
- """
- return 0
-
- def output_shape(self):
- return {
- name: ShapeSpec(
- channels=self._out_feature_channels[name],
- stride=self._out_feature_strides[name],
- )
- for name in self._out_features
- }
-
- @property
- def out_features(self):
- """deprecated"""
- return self._out_features
-
- @property
- def out_feature_strides(self):
- """deprecated"""
- return {f: self._out_feature_strides[f] for f in self._out_features}
-
- @property
- def out_feature_channels(self):
- """deprecated"""
- return {f: self._out_feature_channels[f] for f in self._out_features}
-
-
-class ResNet(Backbone):
- def __init__(self, stem, stages, num_classes=None, out_features=None):
- """
- Args:
- stem (nn.Module): a stem module
- stages (list[list[ResNetBlock]]): several (typically 4) stages, each contains multiple :class:`ResNetBlockBase`.
- num_classes (None or int): if None, will not perform classification.
- out_features (list[str]): name of the layers whose outputs should be returned in forward. Can be anything in:
- "stem", "linear", or "res2" ... If None, will return the output of the last layer.
- """
- super(ResNet, self).__init__()
- self.stem = stem
- self.num_classes = num_classes
-
- current_stride = self.stem.stride
- self._out_feature_strides = {"stem": current_stride}
- self._out_feature_channels = {"stem": self.stem.out_channels}
-
- self.stages_and_names = []
- for i, blocks in enumerate(stages):
- for block in blocks:
- assert isinstance(block, ResNetBlockBase), block
- curr_channels = block.out_channels
- stage = nn.Sequential(*blocks)
- name = "res" + str(i + 2)
- self.add_module(name, stage)
- self.stages_and_names.append((stage, name))
- self._out_feature_strides[name] = current_stride = int(
- current_stride * np.prod([k.stride for k in blocks])
- )
- self._out_feature_channels[name] = blocks[-1].out_channels
-
- if num_classes is not None:
- self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
- self.linear = nn.Linear(curr_channels, num_classes)
-
- # Sec 5.1 in "Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour":
- # "The 1000-way fully-connected layer is initialized by
- # drawing weights from a zero-mean Gaussian with std of 0.01."
- nn.init.normal_(self.linear.weight, stddev=0.01)
- name = "linear"
-
- if out_features is None:
- out_features = [name]
- self._out_features = out_features
- assert len(self._out_features)
- children = [x[0] for x in self.named_children()]
- for out_feature in self._out_features:
- assert out_feature in children, "Available children: {}".format(", ".join(children))
-
- def forward(self, x):
- outputs = {}
- x = self.stem(x)
- if "stem" in self._out_features:
- outputs["stem"] = x
- for stage, name in self.stages_and_names:
- x = stage(x)
- if name in self._out_features:
- outputs[name] = x
- if self.num_classes is not None:
- x = self.avgpool(x)
- x = self.linear(x)
- if "linear" in self._out_features:
- outputs["linear"] = x
- return outputs
-
- def output_shape(self):
- return {
- name: ShapeSpec(
- channels=self._out_feature_channels[name],
- stride=self._out_feature_strides[name],
- )
- for name in self._out_features
- }
-
- @staticmethod
- def make_stage(
- block_class,
- num_blocks,
- first_stride=None,
- *,
- in_channels,
- out_channels,
- **kwargs,
- ):
- """
- Usually, layers that produce the same feature map spatial size
- are defined as one "stage".
- Under such definition, stride_per_block[1:] should all be 1.
- """
- if first_stride is not None:
- assert "stride" not in kwargs and "stride_per_block" not in kwargs
- kwargs["stride_per_block"] = [first_stride] + [1] * (num_blocks - 1)
- blocks = []
- for i in range(num_blocks):
- curr_kwargs = {}
- for k, v in kwargs.items():
- if k.endswith("_per_block"):
- assert (
- len(v) == num_blocks
- ), f"Argument '{k}' of make_stage should have the same length as num_blocks={num_blocks}."
- newk = k[: -len("_per_block")]
- assert newk not in kwargs, f"Cannot call make_stage with both {k} and {newk}!"
- curr_kwargs[newk] = v[i]
- else:
- curr_kwargs[k] = v
-
- blocks.append(block_class(in_channels=in_channels, out_channels=out_channels, **curr_kwargs))
- in_channels = out_channels
-
- return blocks
-
-
-class ROIPooler(nn.Module):
- """
- Region of interest feature map pooler that supports pooling from one or more
- feature maps.
- """
-
- def __init__(
- self,
- output_size,
- scales,
- sampling_ratio,
- canonical_box_size=224,
- canonical_level=4,
- ):
- super().__init__()
- # assumption that stride is a power of 2.
- min_level = -math.log2(scales[0])
- max_level = -math.log2(scales[-1])
-
- # a bunch of testing
- assert math.isclose(min_level, int(min_level)) and math.isclose(max_level, int(max_level))
- assert len(scales) == max_level - min_level + 1, "not pyramid"
- assert 0 < min_level and min_level <= max_level
- if isinstance(output_size, int):
- output_size = (output_size, output_size)
- assert len(output_size) == 2 and isinstance(output_size[0], int) and isinstance(output_size[1], int)
- if len(scales) > 1:
- assert min_level <= canonical_level and canonical_level <= max_level
- assert canonical_box_size > 0
-
- self.output_size = output_size
- self.min_level = int(min_level)
- self.max_level = int(max_level)
- self.level_poolers = nn.ModuleList(RoIPool(output_size, spatial_scale=scale) for scale in scales)
- self.canonical_level = canonical_level
- self.canonical_box_size = canonical_box_size
-
- def forward(self, feature_maps, boxes):
- """
- Args:
- feature_maps: List[torch.Tensor(N,C,W,H)]
- box_lists: list[torch.Tensor])
- Returns:
- A tensor of shape(N*B, Channels, output_size, output_size)
- """
- x = list(feature_maps.values())
- num_level_assignments = len(self.level_poolers)
- assert len(x) == num_level_assignments and len(boxes) == x[0].size(0)
-
- pooler_fmt_boxes = convert_boxes_to_pooler_format(boxes)
-
- if num_level_assignments == 1:
- return self.level_poolers[0](x[0], pooler_fmt_boxes)
-
- level_assignments = assign_boxes_to_levels(
- boxes,
- self.min_level,
- self.max_level,
- self.canonical_box_size,
- self.canonical_level,
- )
-
- num_boxes = len(pooler_fmt_boxes)
- num_channels = x[0].shape[1]
- output_size = self.output_size[0]
-
- dtype, device = x[0].dtype, x[0].device
- output = torch.zeros(
- (num_boxes, num_channels, output_size, output_size),
- dtype=dtype,
- device=device,
- )
-
- for level, (x_level, pooler) in enumerate(zip(x, self.level_poolers)):
- inds = torch.nonzero(level_assignments == level).squeeze(1)
- pooler_fmt_boxes_level = pooler_fmt_boxes[inds]
- output[inds] = pooler(x_level, pooler_fmt_boxes_level)
-
- return output
-
-
-class ROIOutputs:
- def __init__(self, cfg, training=False):
- self.smooth_l1_beta = cfg.ROI_BOX_HEAD.SMOOTH_L1_BETA
- self.box2box_transform = Box2BoxTransform(weights=cfg.ROI_BOX_HEAD.BBOX_REG_WEIGHTS)
- self.training = training
- self.score_thresh = cfg.ROI_HEADS.SCORE_THRESH_TEST
- self.min_detections = cfg.MIN_DETECTIONS
- self.max_detections = cfg.MAX_DETECTIONS
-
- nms_thresh = cfg.ROI_HEADS.NMS_THRESH_TEST
- if not isinstance(nms_thresh, list):
- nms_thresh = [nms_thresh]
- self.nms_thresh = nms_thresh
-
- def _predict_boxes(self, proposals, box_deltas, preds_per_image):
- num_pred = box_deltas.size(0)
- B = proposals[0].size(-1)
- K = box_deltas.size(-1) // B
- box_deltas = box_deltas.view(num_pred * K, B)
- proposals = torch.cat(proposals, dim=0).unsqueeze(-2).expand(num_pred, K, B)
- proposals = proposals.reshape(-1, B)
- boxes = self.box2box_transform.apply_deltas(box_deltas, proposals)
- return boxes.view(num_pred, K * B).split(preds_per_image, dim=0)
-
- def _predict_objs(self, obj_logits, preds_per_image):
- probs = nn.functional.softmax(obj_logits, dim=-1)
- probs = probs.split(preds_per_image, dim=0)
- return probs
-
- def _predict_attrs(self, attr_logits, preds_per_image):
- attr_logits = attr_logits[..., :-1].softmax(-1)
- attr_probs, attrs = attr_logits.max(-1)
- return attr_probs.split(preds_per_image, dim=0), attrs.split(preds_per_image, dim=0)
-
- @torch.no_grad()
- def inference(
- self,
- obj_logits,
- attr_logits,
- box_deltas,
- pred_boxes,
- features,
- sizes,
- scales=None,
- ):
- # only the pred boxes is the
- preds_per_image = [p.size(0) for p in pred_boxes]
- boxes_all = self._predict_boxes(pred_boxes, box_deltas, preds_per_image)
- obj_scores_all = self._predict_objs(obj_logits, preds_per_image) # list of length N
- attr_probs_all, attrs_all = self._predict_attrs(attr_logits, preds_per_image)
- features = features.split(preds_per_image, dim=0)
-
- # fun for each image too, also I can experiment and do multiple images
- final_results = []
- zipped = zip(boxes_all, obj_scores_all, attr_probs_all, attrs_all, sizes)
- for i, (boxes, obj_scores, attr_probs, attrs, size) in enumerate(zipped):
- for nms_t in self.nms_thresh:
- outputs = do_nms(
- boxes,
- obj_scores,
- size,
- self.score_thresh,
- nms_t,
- self.min_detections,
- self.max_detections,
- )
- if outputs is not None:
- max_boxes, max_scores, classes, ids = outputs
- break
-
- if scales is not None:
- scale_yx = scales[i]
- max_boxes[:, 0::2] *= scale_yx[1]
- max_boxes[:, 1::2] *= scale_yx[0]
-
- final_results.append(
- (
- max_boxes,
- classes,
- max_scores,
- attrs[ids],
- attr_probs[ids],
- features[i][ids],
- )
- )
- boxes, classes, class_probs, attrs, attr_probs, roi_features = map(list, zip(*final_results))
- return boxes, classes, class_probs, attrs, attr_probs, roi_features
-
- def training(self, obj_logits, attr_logits, box_deltas, pred_boxes, features, sizes):
- pass
-
- def __call__(
- self,
- obj_logits,
- attr_logits,
- box_deltas,
- pred_boxes,
- features,
- sizes,
- scales=None,
- ):
- if self.training:
- raise NotImplementedError()
- return self.inference(
- obj_logits,
- attr_logits,
- box_deltas,
- pred_boxes,
- features,
- sizes,
- scales=scales,
- )
-
-
-class Res5ROIHeads(nn.Module):
- """
- ROIHeads perform all per-region computation in an R-CNN.
- It contains logic of cropping the regions, extract per-region features
- (by the res-5 block in this case), and make per-region predictions.
- """
-
- def __init__(self, cfg, input_shape):
- super().__init__()
- self.batch_size_per_image = cfg.RPN.BATCH_SIZE_PER_IMAGE
- self.positive_sample_fraction = cfg.ROI_HEADS.POSITIVE_FRACTION
- self.in_features = cfg.ROI_HEADS.IN_FEATURES
- self.num_classes = cfg.ROI_HEADS.NUM_CLASSES
- self.proposal_append_gt = cfg.ROI_HEADS.PROPOSAL_APPEND_GT
- self.feature_strides = {k: v.stride for k, v in input_shape.items()}
- self.feature_channels = {k: v.channels for k, v in input_shape.items()}
- self.cls_agnostic_bbox_reg = cfg.ROI_BOX_HEAD.CLS_AGNOSTIC_BBOX_REG
- self.stage_channel_factor = 2**3 # res5 is 8x res2
- self.out_channels = cfg.RESNETS.RES2_OUT_CHANNELS * self.stage_channel_factor
-
- # self.proposal_matcher = Matcher(
- # cfg.ROI_HEADS.IOU_THRESHOLDS,
- # cfg.ROI_HEADS.IOU_LABELS,
- # allow_low_quality_matches=False,
- # )
-
- pooler_resolution = cfg.ROI_BOX_HEAD.POOLER_RESOLUTION
- pooler_scales = (1.0 / self.feature_strides[self.in_features[0]],)
- sampling_ratio = cfg.ROI_BOX_HEAD.POOLER_SAMPLING_RATIO
- res5_halve = cfg.ROI_BOX_HEAD.RES5HALVE
- use_attr = cfg.ROI_BOX_HEAD.ATTR
- num_attrs = cfg.ROI_BOX_HEAD.NUM_ATTRS
-
- self.pooler = ROIPooler(
- output_size=pooler_resolution,
- scales=pooler_scales,
- sampling_ratio=sampling_ratio,
- )
-
- self.res5 = self._build_res5_block(cfg)
- if not res5_halve:
- """
- Modifications for VG in RoI heads:
- 1. Change the stride of conv1 and shortcut in Res5.Block1 from 2 to 1
- 2. Modifying all conv2 with (padding: 1 --> 2) and (dilation: 1 --> 2)
- """
- self.res5[0].conv1.stride = (1, 1)
- self.res5[0].shortcut.stride = (1, 1)
- for i in range(3):
- self.res5[i].conv2.padding = (2, 2)
- self.res5[i].conv2.dilation = (2, 2)
-
- self.box_predictor = FastRCNNOutputLayers(
- self.out_channels,
- self.num_classes,
- self.cls_agnostic_bbox_reg,
- use_attr=use_attr,
- num_attrs=num_attrs,
- )
-
- def _build_res5_block(self, cfg):
- stage_channel_factor = self.stage_channel_factor # res5 is 8x res2
- num_groups = cfg.RESNETS.NUM_GROUPS
- width_per_group = cfg.RESNETS.WIDTH_PER_GROUP
- bottleneck_channels = num_groups * width_per_group * stage_channel_factor
- out_channels = self.out_channels
- stride_in_1x1 = cfg.RESNETS.STRIDE_IN_1X1
- norm = cfg.RESNETS.NORM
-
- blocks = ResNet.make_stage(
- BottleneckBlock,
- 3,
- first_stride=2,
- in_channels=out_channels // 2,
- bottleneck_channels=bottleneck_channels,
- out_channels=out_channels,
- num_groups=num_groups,
- norm=norm,
- stride_in_1x1=stride_in_1x1,
- )
- return nn.Sequential(*blocks)
-
- def _shared_roi_transform(self, features, boxes):
- x = self.pooler(features, boxes)
- return self.res5(x)
-
- def forward(self, features, proposal_boxes, gt_boxes=None):
- if self.training:
- """
- see https://github.com/airsplay/py-bottom-up-attention/\
- blob/master/detectron2/modeling/roi_heads/roi_heads.py
- """
- raise NotImplementedError()
-
- assert not proposal_boxes[0].requires_grad
- box_features = self._shared_roi_transform(features, proposal_boxes)
- feature_pooled = box_features.mean(dim=[2, 3]) # pooled to 1x1
- obj_logits, attr_logits, pred_proposal_deltas = self.box_predictor(feature_pooled)
- return obj_logits, attr_logits, pred_proposal_deltas, feature_pooled
-
-
-class AnchorGenerator(nn.Module):
- """
- For a set of image sizes and feature maps, computes a set of anchors.
- """
-
- def __init__(self, cfg, input_shape: List[ShapeSpec]):
- super().__init__()
- sizes = cfg.ANCHOR_GENERATOR.SIZES
- aspect_ratios = cfg.ANCHOR_GENERATOR.ASPECT_RATIOS
- self.strides = [x.stride for x in input_shape]
- self.offset = cfg.ANCHOR_GENERATOR.OFFSET
- assert 0.0 <= self.offset < 1.0, self.offset
-
- """
- sizes (list[list[int]]): sizes[i] is the list of anchor sizes for feat map i
- 1. given in absolute lengths in units of the input image;
- 2. they do not dynamically scale if the input image size changes.
- aspect_ratios (list[list[float]])
- strides (list[int]): stride of each input feature.
- """
-
- self.num_features = len(self.strides)
- self.cell_anchors = nn.ParameterList(self._calculate_anchors(sizes, aspect_ratios))
- self._spacial_feat_dim = 4
-
- def _calculate_anchors(self, sizes, aspect_ratios):
- # If one size (or aspect ratio) is specified and there are multiple feature
- # maps, then we "broadcast" anchors of that single size (or aspect ratio)
- if len(sizes) == 1:
- sizes *= self.num_features
- if len(aspect_ratios) == 1:
- aspect_ratios *= self.num_features
- assert self.num_features == len(sizes)
- assert self.num_features == len(aspect_ratios)
-
- cell_anchors = [self.generate_cell_anchors(s, a).float() for s, a in zip(sizes, aspect_ratios)]
-
- return cell_anchors
-
- @property
- def box_dim(self):
- return self._spacial_feat_dim
-
- @property
- def num_cell_anchors(self):
- """
- Returns:
- list[int]: Each int is the number of anchors at every pixel location, on that feature map.
- """
- return [len(cell_anchors) for cell_anchors in self.cell_anchors]
-
- def grid_anchors(self, grid_sizes):
- anchors = []
- for size, stride, base_anchors in zip(grid_sizes, self.strides, self.cell_anchors):
- shift_x, shift_y = _create_grid_offsets(size, stride, self.offset, base_anchors.device)
- shifts = torch.stack((shift_x, shift_y, shift_x, shift_y), dim=1)
-
- anchors.append((shifts.view(-1, 1, 4) + base_anchors.view(1, -1, 4)).reshape(-1, 4))
-
- return anchors
-
- def generate_cell_anchors(self, sizes=(32, 64, 128, 256, 512), aspect_ratios=(0.5, 1, 2)):
- """
- anchors are continuous geometric rectangles
- centered on one feature map point sample.
- We can later build the set of anchors
- for the entire feature map by tiling these tensors
- """
-
- anchors = []
- for size in sizes:
- area = size**2.0
- for aspect_ratio in aspect_ratios:
- w = math.sqrt(area / aspect_ratio)
- h = aspect_ratio * w
- x0, y0, x1, y1 = -w / 2.0, -h / 2.0, w / 2.0, h / 2.0
- anchors.append([x0, y0, x1, y1])
- return nn.Parameter(torch.tensor(anchors))
-
- def forward(self, features):
- """
- Args:
- features List[torch.Tensor]: list of feature maps on which to generate anchors.
- Returns:
- torch.Tensor: a list of #image elements.
- """
- num_images = features[0].size(0)
- grid_sizes = [feature_map.shape[-2:] for feature_map in features]
- anchors_over_all_feature_maps = self.grid_anchors(grid_sizes)
- anchors_over_all_feature_maps = torch.stack(anchors_over_all_feature_maps)
- return anchors_over_all_feature_maps.unsqueeze(0).repeat_interleave(num_images, dim=0)
-
-
-class RPNHead(nn.Module):
- """
- RPN classification and regression heads. Uses a 3x3 conv to produce a shared
- hidden state from which one 1x1 conv predicts objectness logits for each anchor
- and a second 1x1 conv predicts bounding-box deltas specifying how to deform
- each anchor into an object proposal.
- """
-
- def __init__(self, cfg, input_shape: List[ShapeSpec]):
- super().__init__()
-
- # Standard RPN is shared across levels:
- in_channels = [s.channels for s in input_shape]
- assert len(set(in_channels)) == 1, "Each level must have the same channel!"
- in_channels = in_channels[0]
-
- anchor_generator = AnchorGenerator(cfg, input_shape)
- num_cell_anchors = anchor_generator.num_cell_anchors
- box_dim = anchor_generator.box_dim
- assert len(set(num_cell_anchors)) == 1, "Each level must have the same number of cell anchors"
- num_cell_anchors = num_cell_anchors[0]
-
- if cfg.PROPOSAL_GENERATOR.HIDDEN_CHANNELS == -1:
- hid_channels = in_channels
- else:
- hid_channels = cfg.PROPOSAL_GENERATOR.HIDDEN_CHANNELS
- # Modifications for VG in RPN (modeling/proposal_generator/rpn.py)
- # Use hidden dim instead fo the same dim as Res4 (in_channels)
-
- # 3x3 conv for the hidden representation
- self.conv = nn.Conv2d(in_channels, hid_channels, kernel_size=3, stride=1, padding=1)
- # 1x1 conv for predicting objectness logits
- self.objectness_logits = nn.Conv2d(hid_channels, num_cell_anchors, kernel_size=1, stride=1)
- # 1x1 conv for predicting box2box transform deltas
- self.anchor_deltas = nn.Conv2d(hid_channels, num_cell_anchors * box_dim, kernel_size=1, stride=1)
-
- for layer in [self.conv, self.objectness_logits, self.anchor_deltas]:
- nn.init.normal_(layer.weight, std=0.01)
- nn.init.constant_(layer.bias, 0)
-
- def forward(self, features):
- """
- Args:
- features (list[Tensor]): list of feature maps
- """
- pred_objectness_logits = []
- pred_anchor_deltas = []
- for x in features:
- t = nn.functional.relu(self.conv(x))
- pred_objectness_logits.append(self.objectness_logits(t))
- pred_anchor_deltas.append(self.anchor_deltas(t))
- return pred_objectness_logits, pred_anchor_deltas
-
-
-class RPN(nn.Module):
- """
- Region Proposal Network, introduced by the Faster R-CNN paper.
- """
-
- def __init__(self, cfg, input_shape: Dict[str, ShapeSpec]):
- super().__init__()
-
- self.min_box_side_len = cfg.PROPOSAL_GENERATOR.MIN_SIZE
- self.in_features = cfg.RPN.IN_FEATURES
- self.nms_thresh = cfg.RPN.NMS_THRESH
- self.batch_size_per_image = cfg.RPN.BATCH_SIZE_PER_IMAGE
- self.positive_fraction = cfg.RPN.POSITIVE_FRACTION
- self.smooth_l1_beta = cfg.RPN.SMOOTH_L1_BETA
- self.loss_weight = cfg.RPN.LOSS_WEIGHT
-
- self.pre_nms_topk = {
- True: cfg.RPN.PRE_NMS_TOPK_TRAIN,
- False: cfg.RPN.PRE_NMS_TOPK_TEST,
- }
- self.post_nms_topk = {
- True: cfg.RPN.POST_NMS_TOPK_TRAIN,
- False: cfg.RPN.POST_NMS_TOPK_TEST,
- }
- self.boundary_threshold = cfg.RPN.BOUNDARY_THRESH
-
- self.anchor_generator = AnchorGenerator(cfg, [input_shape[f] for f in self.in_features])
- self.box2box_transform = Box2BoxTransform(weights=cfg.RPN.BBOX_REG_WEIGHTS)
- self.anchor_matcher = Matcher(
- cfg.RPN.IOU_THRESHOLDS,
- cfg.RPN.IOU_LABELS,
- allow_low_quality_matches=True,
- )
- self.rpn_head = RPNHead(cfg, [input_shape[f] for f in self.in_features])
-
- def training(self, images, image_shapes, features, gt_boxes):
- pass
-
- def inference(self, outputs, images, image_shapes, features, gt_boxes=None):
- outputs = find_top_rpn_proposals(
- outputs.predict_proposals(),
- outputs.predict_objectness_logits(),
- images,
- image_shapes,
- self.nms_thresh,
- self.pre_nms_topk[self.training],
- self.post_nms_topk[self.training],
- self.min_box_side_len,
- self.training,
- )
-
- results = []
- for img in outputs:
- im_boxes, img_box_logits = img
- img_box_logits, inds = img_box_logits.sort(descending=True)
- im_boxes = im_boxes[inds]
- results.append((im_boxes, img_box_logits))
-
- (proposal_boxes, logits) = tuple(map(list, zip(*results)))
- return proposal_boxes, logits
-
- def forward(self, images, image_shapes, features, gt_boxes=None):
- """
- Args:
- images (torch.Tensor): input images of length `N`
- features (dict[str: Tensor])
- gt_instances
- """
- # features is dict, key = block level, v = feature_map
- features = [features[f] for f in self.in_features]
- pred_objectness_logits, pred_anchor_deltas = self.rpn_head(features)
- anchors = self.anchor_generator(features)
- outputs = RPNOutputs(
- self.box2box_transform,
- self.anchor_matcher,
- self.batch_size_per_image,
- self.positive_fraction,
- images,
- pred_objectness_logits,
- pred_anchor_deltas,
- anchors,
- self.boundary_threshold,
- gt_boxes,
- self.smooth_l1_beta,
- )
- # For RPN-only models, the proposals are the final output
-
- if self.training:
- raise NotImplementedError()
- return self.training(outputs, images, image_shapes, features, gt_boxes)
- else:
- return self.inference(outputs, images, image_shapes, features, gt_boxes)
-
-
-class FastRCNNOutputLayers(nn.Module):
- """
- Two linear layers for predicting Fast R-CNN outputs:
- (1) proposal-to-detection box regression deltas
- (2) classification scores
- """
-
- def __init__(
- self,
- input_size,
- num_classes,
- cls_agnostic_bbox_reg,
- box_dim=4,
- use_attr=False,
- num_attrs=-1,
- ):
- """
- Args:
- input_size (int): channels, or (channels, height, width)
- num_classes (int)
- cls_agnostic_bbox_reg (bool)
- box_dim (int)
- """
- super().__init__()
-
- if not isinstance(input_size, int):
- input_size = np.prod(input_size)
-
- # (do + 1 for background class)
- self.cls_score = nn.Linear(input_size, num_classes + 1)
- num_bbox_reg_classes = 1 if cls_agnostic_bbox_reg else num_classes
- self.bbox_pred = nn.Linear(input_size, num_bbox_reg_classes * box_dim)
-
- self.use_attr = use_attr
- if use_attr:
- """
- Modifications for VG in RoI heads
- Embedding: {num_classes + 1} --> {input_size // 8}
- Linear: {input_size + input_size // 8} --> {input_size // 4}
- Linear: {input_size // 4} --> {num_attrs + 1}
- """
- self.cls_embedding = nn.Embedding(num_classes + 1, input_size // 8)
- self.fc_attr = nn.Linear(input_size + input_size // 8, input_size // 4)
- self.attr_score = nn.Linear(input_size // 4, num_attrs + 1)
-
- nn.init.normal_(self.cls_score.weight, std=0.01)
- nn.init.normal_(self.bbox_pred.weight, std=0.001)
- for item in [self.cls_score, self.bbox_pred]:
- nn.init.constant_(item.bias, 0)
-
- def forward(self, roi_features):
- if roi_features.dim() > 2:
- roi_features = torch.flatten(roi_features, start_dim=1)
- scores = self.cls_score(roi_features)
- proposal_deltas = self.bbox_pred(roi_features)
- if self.use_attr:
- _, max_class = scores.max(-1) # [b, c] --> [b]
- cls_emb = self.cls_embedding(max_class) # [b] --> [b, 256]
- roi_features = torch.cat([roi_features, cls_emb], -1) # [b, 2048] + [b, 256] --> [b, 2304]
- roi_features = self.fc_attr(roi_features)
- roi_features = nn.functional.relu(roi_features)
- attr_scores = self.attr_score(roi_features)
- return scores, attr_scores, proposal_deltas
- else:
- return scores, proposal_deltas
-
-
-class GeneralizedRCNN(nn.Module):
- def __init__(self, cfg):
- super().__init__()
-
- self.device = torch.device(cfg.MODEL.DEVICE)
- self.backbone = build_backbone(cfg)
- self.proposal_generator = RPN(cfg, self.backbone.output_shape())
- self.roi_heads = Res5ROIHeads(cfg, self.backbone.output_shape())
- self.roi_outputs = ROIOutputs(cfg)
- self.to(self.device)
-
- @classmethod
- def from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs):
- config = kwargs.pop("config", None)
- state_dict = kwargs.pop("state_dict", None)
- cache_dir = kwargs.pop("cache_dir", None)
- from_tf = kwargs.pop("from_tf", False)
- force_download = kwargs.pop("force_download", False)
- resume_download = kwargs.pop("resume_download", False)
- proxies = kwargs.pop("proxies", None)
- local_files_only = kwargs.pop("local_files_only", False)
- use_cdn = kwargs.pop("use_cdn", True)
-
- # Load config if we don't provide a configuration
- if not isinstance(config, Config):
- config_path = config if config is not None else pretrained_model_name_or_path
- # try:
- config = Config.from_pretrained(
- config_path,
- cache_dir=cache_dir,
- force_download=force_download,
- resume_download=resume_download,
- proxies=proxies,
- local_files_only=local_files_only,
- )
-
- # Load model
- if pretrained_model_name_or_path is not None:
- if os.path.isdir(pretrained_model_name_or_path):
- if os.path.isfile(os.path.join(pretrained_model_name_or_path, WEIGHTS_NAME)):
- # Load from a PyTorch checkpoint
- archive_file = os.path.join(pretrained_model_name_or_path, WEIGHTS_NAME)
- else:
- raise EnvironmentError(
- "Error no file named {} found in directory {} ".format(
- WEIGHTS_NAME,
- pretrained_model_name_or_path,
- )
- )
- elif os.path.isfile(pretrained_model_name_or_path) or is_remote_url(pretrained_model_name_or_path):
- archive_file = pretrained_model_name_or_path
- elif os.path.isfile(pretrained_model_name_or_path + ".index"):
- assert from_tf, "We found a TensorFlow checkpoint at {}, please set from_tf to True to load from this checkpoint".format(
- pretrained_model_name_or_path + ".index"
- )
- archive_file = pretrained_model_name_or_path + ".index"
- else:
- archive_file = hf_bucket_url(
- pretrained_model_name_or_path,
- filename=WEIGHTS_NAME,
- use_cdn=use_cdn,
- )
-
- try:
- # Load from URL or cache if already cached
- resolved_archive_file = cached_path(
- archive_file,
- cache_dir=cache_dir,
- force_download=force_download,
- proxies=proxies,
- resume_download=resume_download,
- local_files_only=local_files_only,
- )
- if resolved_archive_file is None:
- raise EnvironmentError
- except EnvironmentError:
- msg = f"Can't load weights for '{pretrained_model_name_or_path}'."
- raise EnvironmentError(msg)
-
- if resolved_archive_file == archive_file:
- print("loading weights file {}".format(archive_file))
- else:
- print("loading weights file {} from cache at {}".format(archive_file, resolved_archive_file))
- else:
- resolved_archive_file = None
-
- # Instantiate model.
- model = cls(config)
-
- if state_dict is None:
- try:
- try:
- state_dict = torch.load(resolved_archive_file, map_location="cpu")
- except Exception:
- state_dict = load_checkpoint(resolved_archive_file)
-
- except Exception:
- raise OSError(
- "Unable to load weights from pytorch checkpoint file. "
- "If you tried to load a PyTorch model from a TF 2.0 checkpoint, please set from_tf=True. "
- )
-
- missing_keys = []
- unexpected_keys = []
- error_msgs = []
-
- # Convert old format to new format if needed from a PyTorch state_dict
- old_keys = []
- new_keys = []
- for key in state_dict.keys():
- new_key = None
- if "gamma" in key:
- new_key = key.replace("gamma", "weight")
- if "beta" in key:
- new_key = key.replace("beta", "bias")
- if new_key:
- old_keys.append(key)
- new_keys.append(new_key)
- for old_key, new_key in zip(old_keys, new_keys):
- state_dict[new_key] = state_dict.pop(old_key)
-
- # copy state_dict so _load_from_state_dict can modify it
- metadata = getattr(state_dict, "_metadata", None)
- state_dict = state_dict.copy()
- if metadata is not None:
- state_dict._metadata = metadata
-
- model_to_load = model
- model_to_load.load_state_dict(state_dict)
-
- if model.__class__.__name__ != model_to_load.__class__.__name__:
- base_model_state_dict = model_to_load.state_dict().keys()
- head_model_state_dict_without_base_prefix = [
- key.split(cls.base_model_prefix + ".")[-1] for key in model.state_dict().keys()
- ]
- missing_keys.extend(head_model_state_dict_without_base_prefix - base_model_state_dict)
-
- if len(unexpected_keys) > 0:
- print(
- f"Some weights of the model checkpoint at {pretrained_model_name_or_path} were not used when"
- f" initializing {model.__class__.__name__}: {unexpected_keys}\n- This IS expected if you are"
- f" initializing {model.__class__.__name__} from the checkpoint of a model trained on another task or"
- " with another architecture (e.g. initializing a BertForSequenceClassification model from a"
- " BertForPreTraining model).\n- This IS NOT expected if you are initializing"
- f" {model.__class__.__name__} from the checkpoint of a model that you expect to be exactly identical"
- " (initializing a BertForSequenceClassification model from a BertForSequenceClassification model)."
- )
- else:
- print(f"All model checkpoint weights were used when initializing {model.__class__.__name__}.\n")
- if len(missing_keys) > 0:
- print(
- f"Some weights of {model.__class__.__name__} were not initialized from the model checkpoint at"
- f" {pretrained_model_name_or_path} and are newly initialized: {missing_keys}\nYou should probably"
- " TRAIN this model on a down-stream task to be able to use it for predictions and inference."
- )
- else:
- print(
- f"All the weights of {model.__class__.__name__} were initialized from the model checkpoint at"
- f" {pretrained_model_name_or_path}.\nIf your task is similar to the task the model of the checkpoint"
- f" was trained on, you can already use {model.__class__.__name__} for predictions without further"
- " training."
- )
- if len(error_msgs) > 0:
- raise RuntimeError(
- "Error(s) in loading state_dict for {}:\n\t{}".format(
- model.__class__.__name__, "\n\t".join(error_msgs)
- )
- )
- # Set model in evaluation mode to deactivate DropOut modules by default
- model.eval()
-
- return model
-
- def forward(
- self,
- images,
- image_shapes,
- gt_boxes=None,
- proposals=None,
- scales_yx=None,
- **kwargs,
- ):
- """
- kwargs:
- max_detections (int), return_tensors {"np", "pt", None}, padding {None,
- "max_detections"}, pad_value (int), location = {"cuda", "cpu"}
- """
- if self.training:
- raise NotImplementedError()
- return self.inference(
- images=images,
- image_shapes=image_shapes,
- gt_boxes=gt_boxes,
- proposals=proposals,
- scales_yx=scales_yx,
- **kwargs,
- )
-
- @torch.no_grad()
- def inference(
- self,
- images,
- image_shapes,
- gt_boxes=None,
- proposals=None,
- scales_yx=None,
- **kwargs,
- ):
- # run images through backbone
- original_sizes = image_shapes * scales_yx
- features = self.backbone(images)
-
- # generate proposals if none are available
- if proposals is None:
- proposal_boxes, _ = self.proposal_generator(images, image_shapes, features, gt_boxes)
- else:
- assert proposals is not None
-
- # pool object features from either gt_boxes, or from proposals
- obj_logits, attr_logits, box_deltas, feature_pooled = self.roi_heads(features, proposal_boxes, gt_boxes)
-
- # prepare FRCNN Outputs and select top proposals
- boxes, classes, class_probs, attrs, attr_probs, roi_features = self.roi_outputs(
- obj_logits=obj_logits,
- attr_logits=attr_logits,
- box_deltas=box_deltas,
- pred_boxes=proposal_boxes,
- features=feature_pooled,
- sizes=image_shapes,
- scales=scales_yx,
- )
-
- # will we pad???
- subset_kwargs = {
- "max_detections": kwargs.get("max_detections", None),
- "return_tensors": kwargs.get("return_tensors", None),
- "pad_value": kwargs.get("pad_value", 0),
- "padding": kwargs.get("padding", None),
- }
- preds_per_image = torch.tensor([p.size(0) for p in boxes])
- boxes = pad_list_tensors(boxes, preds_per_image, **subset_kwargs)
- classes = pad_list_tensors(classes, preds_per_image, **subset_kwargs)
- class_probs = pad_list_tensors(class_probs, preds_per_image, **subset_kwargs)
- attrs = pad_list_tensors(attrs, preds_per_image, **subset_kwargs)
- attr_probs = pad_list_tensors(attr_probs, preds_per_image, **subset_kwargs)
- roi_features = pad_list_tensors(roi_features, preds_per_image, **subset_kwargs)
- subset_kwargs["padding"] = None
- preds_per_image = pad_list_tensors(preds_per_image, None, **subset_kwargs)
- sizes = pad_list_tensors(image_shapes, None, **subset_kwargs)
- normalized_boxes = norm_box(boxes, original_sizes)
- return OrderedDict(
- {
- "obj_ids": classes,
- "obj_probs": class_probs,
- "attr_ids": attrs,
- "attr_probs": attr_probs,
- "boxes": boxes,
- "sizes": sizes,
- "preds_per_image": preds_per_image,
- "roi_features": roi_features,
- "normalized_boxes": normalized_boxes,
- }
- )
diff --git a/examples/research_projects/visual_bert/processing_image.py b/examples/research_projects/visual_bert/processing_image.py
deleted file mode 100644
index 65f8f6cd377..00000000000
--- a/examples/research_projects/visual_bert/processing_image.py
+++ /dev/null
@@ -1,151 +0,0 @@
-"""
-coding=utf-8
-Copyright 2018, Antonio Mendoza Hao Tan, Mohit Bansal
-Adapted From Facebook Inc, Detectron2
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.import copy
-"""
-
-import sys
-from typing import Tuple
-
-import numpy as np
-import torch
-from PIL import Image
-from torch import nn
-
-from transformers.image_utils import PILImageResampling
-from utils import img_tensorize
-
-
-class ResizeShortestEdge:
- def __init__(self, short_edge_length, max_size=sys.maxsize):
- """
- Args:
- short_edge_length (list[min, max])
- max_size (int): maximum allowed longest edge length.
- """
- self.interp_method = "bilinear"
- self.max_size = max_size
- self.short_edge_length = short_edge_length
-
- def __call__(self, imgs):
- img_augs = []
- for img in imgs:
- h, w = img.shape[:2]
- # later: provide list and randomly choose index for resize
- size = np.random.randint(self.short_edge_length[0], self.short_edge_length[1] + 1)
- if size == 0:
- return img
- scale = size * 1.0 / min(h, w)
- if h < w:
- newh, neww = size, scale * w
- else:
- newh, neww = scale * h, size
- if max(newh, neww) > self.max_size:
- scale = self.max_size * 1.0 / max(newh, neww)
- newh = newh * scale
- neww = neww * scale
- neww = int(neww + 0.5)
- newh = int(newh + 0.5)
-
- if img.dtype == np.uint8:
- pil_image = Image.fromarray(img)
- pil_image = pil_image.resize((neww, newh), PILImageResampling.BILINEAR)
- img = np.asarray(pil_image)
- else:
- img = img.permute(2, 0, 1).unsqueeze(0) # 3, 0, 1) # hw(c) -> nchw
- img = nn.functional.interpolate(
- img, (newh, neww), mode=self.interp_method, align_corners=False
- ).squeeze(0)
- img_augs.append(img)
-
- return img_augs
-
-
-class Preprocess:
- def __init__(self, cfg):
- self.aug = ResizeShortestEdge([cfg.INPUT.MIN_SIZE_TEST, cfg.INPUT.MIN_SIZE_TEST], cfg.INPUT.MAX_SIZE_TEST)
- self.input_format = cfg.INPUT.FORMAT
- self.size_divisibility = cfg.SIZE_DIVISIBILITY
- self.pad_value = cfg.PAD_VALUE
- self.max_image_size = cfg.INPUT.MAX_SIZE_TEST
- self.device = cfg.MODEL.DEVICE
- self.pixel_std = torch.tensor(cfg.MODEL.PIXEL_STD).to(self.device).view(len(cfg.MODEL.PIXEL_STD), 1, 1)
- self.pixel_mean = torch.tensor(cfg.MODEL.PIXEL_MEAN).to(self.device).view(len(cfg.MODEL.PIXEL_STD), 1, 1)
- self.normalizer = lambda x: (x - self.pixel_mean) / self.pixel_std
-
- def pad(self, images):
- max_size = tuple(max(s) for s in zip(*[img.shape for img in images]))
- image_sizes = [im.shape[-2:] for im in images]
- images = [
- nn.functional.pad(
- im,
- [0, max_size[-1] - size[1], 0, max_size[-2] - size[0]],
- value=self.pad_value,
- )
- for size, im in zip(image_sizes, images)
- ]
-
- return torch.stack(images), torch.tensor(image_sizes)
-
- def __call__(self, images, single_image=False):
- with torch.no_grad():
- if not isinstance(images, list):
- images = [images]
- if single_image:
- assert len(images) == 1
- for i in range(len(images)):
- if isinstance(images[i], torch.Tensor):
- images.insert(i, images.pop(i).to(self.device).float())
- elif not isinstance(images[i], torch.Tensor):
- images.insert(
- i,
- torch.as_tensor(img_tensorize(images.pop(i), input_format=self.input_format))
- .to(self.device)
- .float(),
- )
- # resize smallest edge
- raw_sizes = torch.tensor([im.shape[:2] for im in images])
- images = self.aug(images)
- # transpose images and convert to torch tensors
- # images = [torch.as_tensor(i.astype("float32")).permute(2, 0, 1).to(self.device) for i in images]
- # now normalize before pad to avoid useless arithmetic
- images = [self.normalizer(x) for x in images]
- # now pad them to do the following operations
- images, sizes = self.pad(images)
- # Normalize
-
- if self.size_divisibility > 0:
- raise NotImplementedError()
- # pad
- scales_yx = torch.true_divide(raw_sizes, sizes)
- if single_image:
- return images[0], sizes[0], scales_yx[0]
- else:
- return images, sizes, scales_yx
-
-
-def _scale_box(boxes, scale_yx):
- boxes[:, 0::2] *= scale_yx[:, 1]
- boxes[:, 1::2] *= scale_yx[:, 0]
- return boxes
-
-
-def _clip_box(tensor, box_size: Tuple[int, int]):
- assert torch.isfinite(tensor).all(), "Box tensor contains infinite or NaN!"
- h, w = box_size
- tensor[:, 0].clamp_(min=0, max=w)
- tensor[:, 1].clamp_(min=0, max=h)
- tensor[:, 2].clamp_(min=0, max=w)
- tensor[:, 3].clamp_(min=0, max=h)
diff --git a/examples/research_projects/visual_bert/requirements.txt b/examples/research_projects/visual_bert/requirements.txt
deleted file mode 100644
index e2778663a53..00000000000
--- a/examples/research_projects/visual_bert/requirements.txt
+++ /dev/null
@@ -1,98 +0,0 @@
-appdirs==1.4.3
-argon2-cffi==20.1.0
-async-generator==1.10
-attrs==20.2.0
-backcall==0.2.0
-CacheControl==0.12.6
-certifi==2024.7.4
-cffi==1.14.2
-chardet==3.0.4
-click==7.1.2
-colorama==0.4.3
-contextlib2==0.6.0
-cycler==0.10.0
-datasets==1.0.0
-decorator==4.4.2
-defusedxml==0.6.0
-dill==0.3.2
-distlib==0.3.0
-distro==1.4.0
-entrypoints==0.3
-filelock==3.0.12
-future==0.18.3
-html5lib==1.0.1
-idna==3.7
-ipaddr==2.2.0
-ipykernel==5.3.4
-ipython
-ipython-genutils==0.2.0
-ipywidgets==7.5.1
-jedi==0.17.2
-Jinja2>=2.11.3
-joblib==1.2.0
-jsonschema==3.2.0
-jupyter==1.0.0
-jupyter-client==6.1.7
-jupyter-console==6.2.0
-jupyter-core==4.11.2
-jupyterlab-pygments==0.1.1
-kiwisolver==1.2.0
-lockfile==0.12.2
-MarkupSafe==1.1.1
-matplotlib==3.3.1
-mistune==2.0.3
-msgpack==0.6.2
-nbclient==0.5.0
-nbconvert==6.5.1
-nbformat==5.0.7
-nest-asyncio==1.4.0
-notebook==6.4.12
-numpy==1.22.0
-opencv-python==4.8.1.78
-packaging==20.3
-pandas==1.1.2
-pandocfilters==1.4.2
-parso==0.7.1
-pep517==0.8.2
-pexpect==4.8.0
-pickleshare==0.7.5
-Pillow>=8.1.1
-progress==1.5
-prometheus-client==0.8.0
-prompt-toolkit==3.0.7
-ptyprocess==0.6.0
-pyaml==20.4.0
-pyarrow==15.0.0
-pycparser==2.20
-Pygments>=2.7.4
-pyparsing==2.4.6
-pyrsistent==0.16.0
-python-dateutil==2.8.1
-pytoml==0.1.21
-pytz==2020.1
-PyYAML>=5.4
-pyzmq==19.0.2
-qtconsole==4.7.7
-QtPy==1.9.0
-regex==2020.7.14
-requests==2.32.2
-retrying==1.3.3
-sacremoses==0.0.43
-Send2Trash==1.5.0
-sentencepiece==0.1.91
-six==1.14.0
-terminado==0.8.3
-testpath==0.4.4
-tokenizers==0.8.1rc2
-torch==2.2.0
-torchvision==0.7.0
-tornado==6.4.2
-tqdm==4.66.3
-traitlets
-git+https://github.com/huggingface/transformers.git
-urllib3==1.26.19
-wcwidth==0.2.5
-webencodings==0.5.1
-wget==3.2
-widgetsnbextension==3.5.1
-xxhash==2.0.0
diff --git a/examples/research_projects/visual_bert/utils.py b/examples/research_projects/visual_bert/utils.py
deleted file mode 100644
index 995fbd2c19a..00000000000
--- a/examples/research_projects/visual_bert/utils.py
+++ /dev/null
@@ -1,554 +0,0 @@
-"""
-coding=utf-8
-Copyright 2018, Antonio Mendoza Hao Tan, Mohit Bansal, Huggingface team :)
-Adapted From Facebook Inc, Detectron2
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.import copy
-"""
-
-import copy
-import fnmatch
-import json
-import os
-import pickle as pkl
-import shutil
-import sys
-import tarfile
-import tempfile
-from collections import OrderedDict
-from contextlib import contextmanager
-from functools import partial
-from io import BytesIO
-from pathlib import Path
-from urllib.parse import urlparse
-from zipfile import ZipFile, is_zipfile
-
-import cv2
-import numpy as np
-import requests
-import wget
-from filelock import FileLock
-from huggingface_hub.utils import insecure_hashlib
-from PIL import Image
-from tqdm.auto import tqdm
-from yaml import Loader, dump, load
-
-
-try:
- import torch
-
- _torch_available = True
-except ImportError:
- _torch_available = False
-
-
-try:
- from torch.hub import _get_torch_home
-
- torch_cache_home = _get_torch_home()
-except ImportError:
- torch_cache_home = os.path.expanduser(
- os.getenv("TORCH_HOME", os.path.join(os.getenv("XDG_CACHE_HOME", "~/.cache"), "torch"))
- )
-
-default_cache_path = os.path.join(torch_cache_home, "transformers")
-
-CLOUDFRONT_DISTRIB_PREFIX = "https://cdn.huggingface.co"
-S3_BUCKET_PREFIX = "https://s3.amazonaws.com/models.huggingface.co/bert"
-PATH = "/".join(str(Path(__file__).resolve()).split("/")[:-1])
-CONFIG = os.path.join(PATH, "config.yaml")
-ATTRIBUTES = os.path.join(PATH, "attributes.txt")
-OBJECTS = os.path.join(PATH, "objects.txt")
-PYTORCH_PRETRAINED_BERT_CACHE = os.getenv("PYTORCH_PRETRAINED_BERT_CACHE", default_cache_path)
-PYTORCH_TRANSFORMERS_CACHE = os.getenv("PYTORCH_TRANSFORMERS_CACHE", PYTORCH_PRETRAINED_BERT_CACHE)
-TRANSFORMERS_CACHE = os.getenv("TRANSFORMERS_CACHE", PYTORCH_TRANSFORMERS_CACHE)
-WEIGHTS_NAME = "pytorch_model.bin"
-CONFIG_NAME = "config.yaml"
-
-
-def load_labels(objs=OBJECTS, attrs=ATTRIBUTES):
- vg_classes = []
- with open(objs) as f:
- for object in f.readlines():
- vg_classes.append(object.split(",")[0].lower().strip())
-
- vg_attrs = []
- with open(attrs) as f:
- for object in f.readlines():
- vg_attrs.append(object.split(",")[0].lower().strip())
- return vg_classes, vg_attrs
-
-
-def load_checkpoint(ckp):
- r = OrderedDict()
- with open(ckp, "rb") as f:
- ckp = pkl.load(f)["model"]
- for k in copy.deepcopy(list(ckp.keys())):
- v = ckp.pop(k)
- if isinstance(v, np.ndarray):
- v = torch.tensor(v)
- else:
- assert isinstance(v, torch.tensor), type(v)
- r[k] = v
- return r
-
-
-class Config:
- _pointer = {}
-
- def __init__(self, dictionary: dict, name: str = "root", level=0):
- self._name = name
- self._level = level
- d = {}
- for k, v in dictionary.items():
- if v is None:
- raise ValueError()
- k = copy.deepcopy(k)
- v = copy.deepcopy(v)
- if isinstance(v, dict):
- v = Config(v, name=k, level=level + 1)
- d[k] = v
- setattr(self, k, v)
-
- self._pointer = d
-
- def __repr__(self):
- return str(list((self._pointer.keys())))
-
- def __setattr__(self, key, val):
- self.__dict__[key] = val
- self.__dict__[key.upper()] = val
- levels = key.split(".")
- last_level = len(levels) - 1
- pointer = self._pointer
- if len(levels) > 1:
- for i, l in enumerate(levels):
- if hasattr(self, l) and isinstance(getattr(self, l), Config):
- setattr(getattr(self, l), ".".join(levels[i:]), val)
- if l == last_level:
- pointer[l] = val
- else:
- pointer = pointer[l]
-
- def to_dict(self):
- return self._pointer
-
- def dump_yaml(self, data, file_name):
- with open(f"{file_name}", "w") as stream:
- dump(data, stream)
-
- def dump_json(self, data, file_name):
- with open(f"{file_name}", "w") as stream:
- json.dump(data, stream)
-
- @staticmethod
- def load_yaml(config):
- with open(config) as stream:
- data = load(stream, Loader=Loader)
- return data
-
- def __str__(self):
- t = " "
- if self._name != "root":
- r = f"{t * (self._level-1)}{self._name}:\n"
- else:
- r = ""
- level = self._level
- for i, (k, v) in enumerate(self._pointer.items()):
- if isinstance(v, Config):
- r += f"{t * (self._level)}{v}\n"
- self._level += 1
- else:
- r += f"{t * (self._level)}{k}: {v} ({type(v).__name__})\n"
- self._level = level
- return r[:-1]
-
- @classmethod
- def from_pretrained(cls, pretrained_model_name_or_path: str, **kwargs):
- config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
- return cls(config_dict)
-
- @classmethod
- def get_config_dict(cls, pretrained_model_name_or_path: str, **kwargs):
- cache_dir = kwargs.pop("cache_dir", None)
- force_download = kwargs.pop("force_download", False)
- resume_download = kwargs.pop("resume_download", False)
- proxies = kwargs.pop("proxies", None)
- local_files_only = kwargs.pop("local_files_only", False)
-
- if os.path.isdir(pretrained_model_name_or_path):
- config_file = os.path.join(pretrained_model_name_or_path, CONFIG_NAME)
- elif os.path.isfile(pretrained_model_name_or_path) or is_remote_url(pretrained_model_name_or_path):
- config_file = pretrained_model_name_or_path
- else:
- config_file = hf_bucket_url(pretrained_model_name_or_path, filename=CONFIG_NAME, use_cdn=False)
-
- try:
- # Load from URL or cache if already cached
- resolved_config_file = cached_path(
- config_file,
- cache_dir=cache_dir,
- force_download=force_download,
- proxies=proxies,
- resume_download=resume_download,
- local_files_only=local_files_only,
- )
- # Load config dict
- if resolved_config_file is None:
- raise EnvironmentError
-
- config_file = Config.load_yaml(resolved_config_file)
-
- except EnvironmentError:
- msg = "Can't load config for"
- raise EnvironmentError(msg)
-
- if resolved_config_file == config_file:
- print("loading configuration file from path")
- else:
- print("loading configuration file cache")
-
- return Config.load_yaml(resolved_config_file), kwargs
-
-
-# quick compare tensors
-def compare(in_tensor):
- out_tensor = torch.load("dump.pt", map_location=in_tensor.device)
- n1 = in_tensor.numpy()
- n2 = out_tensor.numpy()[0]
- print(n1.shape, n1[0, 0, :5])
- print(n2.shape, n2[0, 0, :5])
- assert np.allclose(n1, n2, rtol=0.01, atol=0.1), (
- f"{sum([1 for x in np.isclose(n1, n2, rtol=0.01, atol=0.1).flatten() if x is False])/len(n1.flatten())*100:.4f} %"
- " element-wise mismatch"
- )
- raise Exception("tensors are all good")
-
- # Hugging face functions below
-
-
-def is_remote_url(url_or_filename):
- parsed = urlparse(url_or_filename)
- return parsed.scheme in ("http", "https")
-
-
-def hf_bucket_url(model_id: str, filename: str, use_cdn=True) -> str:
- endpoint = CLOUDFRONT_DISTRIB_PREFIX if use_cdn else S3_BUCKET_PREFIX
- legacy_format = "/" not in model_id
- if legacy_format:
- return f"{endpoint}/{model_id}-{filename}"
- else:
- return f"{endpoint}/{model_id}/{filename}"
-
-
-def http_get(
- url,
- temp_file,
- proxies=None,
- resume_size=0,
- user_agent=None,
-):
- ua = "python/{}".format(sys.version.split()[0])
- if _torch_available:
- ua += "; torch/{}".format(torch.__version__)
- if isinstance(user_agent, dict):
- ua += "; " + "; ".join("{}/{}".format(k, v) for k, v in user_agent.items())
- elif isinstance(user_agent, str):
- ua += "; " + user_agent
- headers = {"user-agent": ua}
- if resume_size > 0:
- headers["Range"] = "bytes=%d-" % (resume_size,)
- response = requests.get(url, stream=True, proxies=proxies, headers=headers)
- if response.status_code == 416: # Range not satisfiable
- return
- content_length = response.headers.get("Content-Length")
- total = resume_size + int(content_length) if content_length is not None else None
- progress = tqdm(
- unit="B",
- unit_scale=True,
- total=total,
- initial=resume_size,
- desc="Downloading",
- )
- for chunk in response.iter_content(chunk_size=1024):
- if chunk: # filter out keep-alive new chunks
- progress.update(len(chunk))
- temp_file.write(chunk)
- progress.close()
-
-
-def get_from_cache(
- url,
- cache_dir=None,
- force_download=False,
- proxies=None,
- etag_timeout=10,
- resume_download=False,
- user_agent=None,
- local_files_only=False,
-):
- if cache_dir is None:
- cache_dir = TRANSFORMERS_CACHE
- if isinstance(cache_dir, Path):
- cache_dir = str(cache_dir)
-
- os.makedirs(cache_dir, exist_ok=True)
-
- etag = None
- if not local_files_only:
- try:
- response = requests.head(url, allow_redirects=True, proxies=proxies, timeout=etag_timeout)
- if response.status_code == 200:
- etag = response.headers.get("ETag")
- except (EnvironmentError, requests.exceptions.Timeout):
- # etag is already None
- pass
-
- filename = url_to_filename(url, etag)
-
- # get cache path to put the file
- cache_path = os.path.join(cache_dir, filename)
-
- # etag is None = we don't have a connection, or url doesn't exist, or is otherwise inaccessible.
- # try to get the last downloaded one
- if etag is None:
- if os.path.exists(cache_path):
- return cache_path
- else:
- matching_files = [
- file
- for file in fnmatch.filter(os.listdir(cache_dir), filename + ".*")
- if not file.endswith(".json") and not file.endswith(".lock")
- ]
- if len(matching_files) > 0:
- return os.path.join(cache_dir, matching_files[-1])
- else:
- # If files cannot be found and local_files_only=True,
- # the models might've been found if local_files_only=False
- # Notify the user about that
- if local_files_only:
- raise ValueError(
- "Cannot find the requested files in the cached path and outgoing traffic has been"
- " disabled. To enable model look-ups and downloads online, set 'local_files_only'"
- " to False."
- )
- return None
-
- # From now on, etag is not None.
- if os.path.exists(cache_path) and not force_download:
- return cache_path
-
- # Prevent parallel downloads of the same file with a lock.
- lock_path = cache_path + ".lock"
- with FileLock(lock_path):
- # If the download just completed while the lock was activated.
- if os.path.exists(cache_path) and not force_download:
- # Even if returning early like here, the lock will be released.
- return cache_path
-
- if resume_download:
- incomplete_path = cache_path + ".incomplete"
-
- @contextmanager
- def _resumable_file_manager():
- with open(incomplete_path, "a+b") as f:
- yield f
-
- temp_file_manager = _resumable_file_manager
- if os.path.exists(incomplete_path):
- resume_size = os.stat(incomplete_path).st_size
- else:
- resume_size = 0
- else:
- temp_file_manager = partial(tempfile.NamedTemporaryFile, dir=cache_dir, delete=False)
- resume_size = 0
-
- # Download to temporary file, then copy to cache dir once finished.
- # Otherwise you get corrupt cache entries if the download gets interrupted.
- with temp_file_manager() as temp_file:
- print(
- "%s not found in cache or force_download set to True, downloading to %s",
- url,
- temp_file.name,
- )
-
- http_get(
- url,
- temp_file,
- proxies=proxies,
- resume_size=resume_size,
- user_agent=user_agent,
- )
-
- os.replace(temp_file.name, cache_path)
-
- meta = {"url": url, "etag": etag}
- meta_path = cache_path + ".json"
- with open(meta_path, "w") as meta_file:
- json.dump(meta, meta_file)
-
- return cache_path
-
-
-def url_to_filename(url, etag=None):
- url_bytes = url.encode("utf-8")
- url_hash = insecure_hashlib.sha256(url_bytes)
- filename = url_hash.hexdigest()
-
- if etag:
- etag_bytes = etag.encode("utf-8")
- etag_hash = insecure_hashlib.sha256(etag_bytes)
- filename += "." + etag_hash.hexdigest()
-
- if url.endswith(".h5"):
- filename += ".h5"
-
- return filename
-
-
-def cached_path(
- url_or_filename,
- cache_dir=None,
- force_download=False,
- proxies=None,
- resume_download=False,
- user_agent=None,
- extract_compressed_file=False,
- force_extract=False,
- local_files_only=False,
-):
- if cache_dir is None:
- cache_dir = TRANSFORMERS_CACHE
- if isinstance(url_or_filename, Path):
- url_or_filename = str(url_or_filename)
- if isinstance(cache_dir, Path):
- cache_dir = str(cache_dir)
-
- if is_remote_url(url_or_filename):
- # URL, so get it from the cache (downloading if necessary)
- output_path = get_from_cache(
- url_or_filename,
- cache_dir=cache_dir,
- force_download=force_download,
- proxies=proxies,
- resume_download=resume_download,
- user_agent=user_agent,
- local_files_only=local_files_only,
- )
- elif os.path.exists(url_or_filename):
- # File, and it exists.
- output_path = url_or_filename
- elif urlparse(url_or_filename).scheme == "":
- # File, but it doesn't exist.
- raise EnvironmentError("file {} not found".format(url_or_filename))
- else:
- # Something unknown
- raise ValueError("unable to parse {} as a URL or as a local path".format(url_or_filename))
-
- if extract_compressed_file:
- if not is_zipfile(output_path) and not tarfile.is_tarfile(output_path):
- return output_path
-
- # Path where we extract compressed archives
- # We avoid '.' in dir name and add "-extracted" at the end: "./model.zip" => "./model-zip-extracted/"
- output_dir, output_file = os.path.split(output_path)
- output_extract_dir_name = output_file.replace(".", "-") + "-extracted"
- output_path_extracted = os.path.join(output_dir, output_extract_dir_name)
-
- if os.path.isdir(output_path_extracted) and os.listdir(output_path_extracted) and not force_extract:
- return output_path_extracted
-
- # Prevent parallel extractions
- lock_path = output_path + ".lock"
- with FileLock(lock_path):
- shutil.rmtree(output_path_extracted, ignore_errors=True)
- os.makedirs(output_path_extracted)
- if is_zipfile(output_path):
- with ZipFile(output_path, "r") as zip_file:
- zip_file.extractall(output_path_extracted)
- zip_file.close()
- elif tarfile.is_tarfile(output_path):
- tar_file = tarfile.open(output_path)
- tar_file.extractall(output_path_extracted)
- tar_file.close()
- else:
- raise EnvironmentError("Archive format of {} could not be identified".format(output_path))
-
- return output_path_extracted
-
- return output_path
-
-
-def get_data(query, delim=","):
- assert isinstance(query, str)
- if os.path.isfile(query):
- with open(query) as f:
- data = eval(f.read())
- else:
- req = requests.get(query)
- try:
- data = requests.json()
- except Exception:
- data = req.content.decode()
- assert data is not None, "could not connect"
- try:
- data = eval(data)
- except Exception:
- data = data.split("\n")
- req.close()
- return data
-
-
-def get_image_from_url(url):
- response = requests.get(url)
- img = np.array(Image.open(BytesIO(response.content)))
- return img
-
-
-# to load legacy frcnn checkpoint from detectron
-def load_frcnn_pkl_from_url(url):
- fn = url.split("/")[-1]
- if fn not in os.listdir(os.getcwd()):
- wget.download(url)
- with open(fn, "rb") as stream:
- weights = pkl.load(stream)
- model = weights.pop("model")
- new = {}
- for k, v in model.items():
- new[k] = torch.from_numpy(v)
- if "running_var" in k:
- zero = torch.tensor([0])
- k2 = k.replace("running_var", "num_batches_tracked")
- new[k2] = zero
- return new
-
-
-def get_demo_path():
- print(f"{os.path.abspath(os.path.join(PATH, os.pardir))}/demo.ipynb")
-
-
-def img_tensorize(im, input_format="RGB"):
- assert isinstance(im, str)
- if os.path.isfile(im):
- img = cv2.imread(im)
- else:
- img = get_image_from_url(im)
- assert img is not None, f"could not connect to: {im}"
- img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
- if input_format == "RGB":
- img = img[:, :, ::-1]
- return img
-
-
-def chunk(images, batch=1):
- return (images[i : i + batch] for i in range(0, len(images), batch))
diff --git a/examples/research_projects/visual_bert/visualizing_image.py b/examples/research_projects/visual_bert/visualizing_image.py
deleted file mode 100644
index dcfd8426ff4..00000000000
--- a/examples/research_projects/visual_bert/visualizing_image.py
+++ /dev/null
@@ -1,500 +0,0 @@
-"""
-coding=utf-8
-Copyright 2018, Antonio Mendoza Hao Tan, Mohit Bansal
-Adapted From Facebook Inc, Detectron2
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.import copy
-"""
-
-import colorsys
-import io
-
-import cv2
-import matplotlib as mpl
-import matplotlib.colors as mplc
-import matplotlib.figure as mplfigure
-import numpy as np
-import torch
-from matplotlib.backends.backend_agg import FigureCanvasAgg
-
-from utils import img_tensorize
-
-
-_SMALL_OBJ = 1000
-
-
-class SingleImageViz:
- def __init__(
- self,
- img,
- scale=1.2,
- edgecolor="g",
- alpha=0.5,
- linestyle="-",
- saveas="test_out.jpg",
- rgb=True,
- pynb=False,
- id2obj=None,
- id2attr=None,
- pad=0.7,
- ):
- """
- img: an RGB image of shape (H, W, 3).
- """
- if isinstance(img, torch.Tensor):
- img = img.numpy().astype("np.uint8")
- if isinstance(img, str):
- img = img_tensorize(img)
- assert isinstance(img, np.ndarray)
-
- width, height = img.shape[1], img.shape[0]
- fig = mplfigure.Figure(frameon=False)
- dpi = fig.get_dpi()
- width_in = (width * scale + 1e-2) / dpi
- height_in = (height * scale + 1e-2) / dpi
- fig.set_size_inches(width_in, height_in)
- ax = fig.add_axes([0.0, 0.0, 1.0, 1.0])
- ax.axis("off")
- ax.set_xlim(0.0, width)
- ax.set_ylim(height)
-
- self.saveas = saveas
- self.rgb = rgb
- self.pynb = pynb
- self.img = img
- self.edgecolor = edgecolor
- self.alpha = 0.5
- self.linestyle = linestyle
- self.font_size = int(np.sqrt(min(height, width)) * scale // 3)
- self.width = width
- self.height = height
- self.scale = scale
- self.fig = fig
- self.ax = ax
- self.pad = pad
- self.id2obj = id2obj
- self.id2attr = id2attr
- self.canvas = FigureCanvasAgg(fig)
-
- def add_box(self, box, color=None):
- if color is None:
- color = self.edgecolor
- (x0, y0, x1, y1) = box
- width = x1 - x0
- height = y1 - y0
- self.ax.add_patch(
- mpl.patches.Rectangle(
- (x0, y0),
- width,
- height,
- fill=False,
- edgecolor=color,
- linewidth=self.font_size // 3,
- alpha=self.alpha,
- linestyle=self.linestyle,
- )
- )
-
- def draw_boxes(self, boxes, obj_ids=None, obj_scores=None, attr_ids=None, attr_scores=None):
- if len(boxes.shape) > 2:
- boxes = boxes[0]
- if len(obj_ids.shape) > 1:
- obj_ids = obj_ids[0]
- if len(obj_scores.shape) > 1:
- obj_scores = obj_scores[0]
- if len(attr_ids.shape) > 1:
- attr_ids = attr_ids[0]
- if len(attr_scores.shape) > 1:
- attr_scores = attr_scores[0]
- if isinstance(boxes, torch.Tensor):
- boxes = boxes.numpy()
- if isinstance(boxes, list):
- boxes = np.array(boxes)
- assert isinstance(boxes, np.ndarray)
- areas = np.prod(boxes[:, 2:] - boxes[:, :2], axis=1)
- sorted_idxs = np.argsort(-areas).tolist()
- boxes = boxes[sorted_idxs] if boxes is not None else None
- obj_ids = obj_ids[sorted_idxs] if obj_ids is not None else None
- obj_scores = obj_scores[sorted_idxs] if obj_scores is not None else None
- attr_ids = attr_ids[sorted_idxs] if attr_ids is not None else None
- attr_scores = attr_scores[sorted_idxs] if attr_scores is not None else None
-
- assigned_colors = [self._random_color(maximum=1) for _ in range(len(boxes))]
- assigned_colors = [assigned_colors[idx] for idx in sorted_idxs]
- if obj_ids is not None:
- labels = self._create_text_labels_attr(obj_ids, obj_scores, attr_ids, attr_scores)
- for i in range(len(boxes)):
- color = assigned_colors[i]
- self.add_box(boxes[i], color)
- self.draw_labels(labels[i], boxes[i], color)
-
- def draw_labels(self, label, box, color):
- x0, y0, x1, y1 = box
- text_pos = (x0, y0)
- instance_area = (y1 - y0) * (x1 - x0)
- small = _SMALL_OBJ * self.scale
- if instance_area < small or y1 - y0 < 40 * self.scale:
- if y1 >= self.height - 5:
- text_pos = (x1, y0)
- else:
- text_pos = (x0, y1)
-
- height_ratio = (y1 - y0) / np.sqrt(self.height * self.width)
- lighter_color = self._change_color_brightness(color, brightness_factor=0.7)
- font_size = np.clip((height_ratio - 0.02) / 0.08 + 1, 1.2, 2)
- font_size *= 0.75 * self.font_size
-
- self.draw_text(
- text=label,
- position=text_pos,
- color=lighter_color,
- )
-
- def draw_text(
- self,
- text,
- position,
- color="g",
- ha="left",
- ):
- rotation = 0
- font_size = self.font_size
- color = np.maximum(list(mplc.to_rgb(color)), 0.2)
- color[np.argmax(color)] = max(0.8, np.max(color))
- bbox = {
- "facecolor": "black",
- "alpha": self.alpha,
- "pad": self.pad,
- "edgecolor": "none",
- }
- x, y = position
- self.ax.text(
- x,
- y,
- text,
- size=font_size * self.scale,
- family="sans-serif",
- bbox=bbox,
- verticalalignment="top",
- horizontalalignment=ha,
- color=color,
- zorder=10,
- rotation=rotation,
- )
-
- def save(self, saveas=None):
- if saveas is None:
- saveas = self.saveas
- if saveas.lower().endswith(".jpg") or saveas.lower().endswith(".png"):
- cv2.imwrite(
- saveas,
- self._get_buffer()[:, :, ::-1],
- )
- else:
- self.fig.savefig(saveas)
-
- def _create_text_labels_attr(self, classes, scores, attr_classes, attr_scores):
- labels = [self.id2obj[i] for i in classes]
- attr_labels = [self.id2attr[i] for i in attr_classes]
- labels = [
- f"{label} {score:.2f} {attr} {attr_score:.2f}"
- for label, score, attr, attr_score in zip(labels, scores, attr_labels, attr_scores)
- ]
- return labels
-
- def _create_text_labels(self, classes, scores):
- labels = [self.id2obj[i] for i in classes]
- if scores is not None:
- if labels is None:
- labels = ["{:.0f}%".format(s * 100) for s in scores]
- else:
- labels = ["{} {:.0f}%".format(li, s * 100) for li, s in zip(labels, scores)]
- return labels
-
- def _random_color(self, maximum=255):
- idx = np.random.randint(0, len(_COLORS))
- ret = _COLORS[idx] * maximum
- if not self.rgb:
- ret = ret[::-1]
- return ret
-
- def _get_buffer(self):
- if not self.pynb:
- s, (width, height) = self.canvas.print_to_buffer()
- if (width, height) != (self.width, self.height):
- img = cv2.resize(self.img, (width, height))
- else:
- img = self.img
- else:
- buf = io.BytesIO() # works for cairo backend
- self.canvas.print_rgba(buf)
- width, height = self.width, self.height
- s = buf.getvalue()
- img = self.img
-
- buffer = np.frombuffer(s, dtype="uint8")
- img_rgba = buffer.reshape(height, width, 4)
- rgb, alpha = np.split(img_rgba, [3], axis=2)
-
- try:
- import numexpr as ne # fuse them with numexpr
-
- visualized_image = ne.evaluate("img * (1 - alpha / 255.0) + rgb * (alpha / 255.0)")
- except ImportError:
- alpha = alpha.astype("float32") / 255.0
- visualized_image = img * (1 - alpha) + rgb * alpha
-
- return visualized_image.astype("uint8")
-
- def _change_color_brightness(self, color, brightness_factor):
- assert brightness_factor >= -1.0 and brightness_factor <= 1.0
- color = mplc.to_rgb(color)
- polygon_color = colorsys.rgb_to_hls(*mplc.to_rgb(color))
- modified_lightness = polygon_color[1] + (brightness_factor * polygon_color[1])
- modified_lightness = 0.0 if modified_lightness < 0.0 else modified_lightness
- modified_lightness = 1.0 if modified_lightness > 1.0 else modified_lightness
- modified_color = colorsys.hls_to_rgb(polygon_color[0], modified_lightness, polygon_color[2])
- return modified_color
-
-
-# Color map
-_COLORS = (
- np.array(
- [
- 0.000,
- 0.447,
- 0.741,
- 0.850,
- 0.325,
- 0.098,
- 0.929,
- 0.694,
- 0.125,
- 0.494,
- 0.184,
- 0.556,
- 0.466,
- 0.674,
- 0.188,
- 0.301,
- 0.745,
- 0.933,
- 0.635,
- 0.078,
- 0.184,
- 0.300,
- 0.300,
- 0.300,
- 0.600,
- 0.600,
- 0.600,
- 1.000,
- 0.000,
- 0.000,
- 1.000,
- 0.500,
- 0.000,
- 0.749,
- 0.749,
- 0.000,
- 0.000,
- 1.000,
- 0.000,
- 0.000,
- 0.000,
- 1.000,
- 0.667,
- 0.000,
- 1.000,
- 0.333,
- 0.333,
- 0.000,
- 0.333,
- 0.667,
- 0.000,
- 0.333,
- 1.000,
- 0.000,
- 0.667,
- 0.333,
- 0.000,
- 0.667,
- 0.667,
- 0.000,
- 0.667,
- 1.000,
- 0.000,
- 1.000,
- 0.333,
- 0.000,
- 1.000,
- 0.667,
- 0.000,
- 1.000,
- 1.000,
- 0.000,
- 0.000,
- 0.333,
- 0.500,
- 0.000,
- 0.667,
- 0.500,
- 0.000,
- 1.000,
- 0.500,
- 0.333,
- 0.000,
- 0.500,
- 0.333,
- 0.333,
- 0.500,
- 0.333,
- 0.667,
- 0.500,
- 0.333,
- 1.000,
- 0.500,
- 0.667,
- 0.000,
- 0.500,
- 0.667,
- 0.333,
- 0.500,
- 0.667,
- 0.667,
- 0.500,
- 0.667,
- 1.000,
- 0.500,
- 1.000,
- 0.000,
- 0.500,
- 1.000,
- 0.333,
- 0.500,
- 1.000,
- 0.667,
- 0.500,
- 1.000,
- 1.000,
- 0.500,
- 0.000,
- 0.333,
- 1.000,
- 0.000,
- 0.667,
- 1.000,
- 0.000,
- 1.000,
- 1.000,
- 0.333,
- 0.000,
- 1.000,
- 0.333,
- 0.333,
- 1.000,
- 0.333,
- 0.667,
- 1.000,
- 0.333,
- 1.000,
- 1.000,
- 0.667,
- 0.000,
- 1.000,
- 0.667,
- 0.333,
- 1.000,
- 0.667,
- 0.667,
- 1.000,
- 0.667,
- 1.000,
- 1.000,
- 1.000,
- 0.000,
- 1.000,
- 1.000,
- 0.333,
- 1.000,
- 1.000,
- 0.667,
- 1.000,
- 0.333,
- 0.000,
- 0.000,
- 0.500,
- 0.000,
- 0.000,
- 0.667,
- 0.000,
- 0.000,
- 0.833,
- 0.000,
- 0.000,
- 1.000,
- 0.000,
- 0.000,
- 0.000,
- 0.167,
- 0.000,
- 0.000,
- 0.333,
- 0.000,
- 0.000,
- 0.500,
- 0.000,
- 0.000,
- 0.667,
- 0.000,
- 0.000,
- 0.833,
- 0.000,
- 0.000,
- 1.000,
- 0.000,
- 0.000,
- 0.000,
- 0.167,
- 0.000,
- 0.000,
- 0.333,
- 0.000,
- 0.000,
- 0.500,
- 0.000,
- 0.000,
- 0.667,
- 0.000,
- 0.000,
- 0.833,
- 0.000,
- 0.000,
- 1.000,
- 0.000,
- 0.000,
- 0.000,
- 0.143,
- 0.143,
- 0.143,
- 0.857,
- 0.857,
- 0.857,
- 1.000,
- 1.000,
- 1.000,
- ]
- )
- .astype(np.float32)
- .reshape(-1, 3)
-)
diff --git a/examples/research_projects/vqgan-clip/README.md b/examples/research_projects/vqgan-clip/README.md
deleted file mode 100644
index a74bf9209b0..00000000000
--- a/examples/research_projects/vqgan-clip/README.md
+++ /dev/null
@@ -1,70 +0,0 @@
-# Simple VQGAN CLIP
-
-Author: @ErwannMillon
-
-This is a very simple VQGAN-CLIP implementation that was built as a part of the Face Editor project . This simplified version allows you to generate or edit images using text with just three lines of code. For a more full featured implementation with masking, more advanced losses, and a full GUI, check out the Face Editor project.
-
-By default this uses a CelebA checkpoint (for generating/editing faces), but also has an imagenet checkpoint that can be loaded by specifying vqgan_config and vqgan_checkpoint when instantiating VQGAN_CLIP.
-
-Learning rate and iterations can be set by modifying vqgan_clip.lr and vqgan_clip.iterations .
-
-You can edit images by passing `image_path` to the generate function.
-See the generate function's docstring to learn more about how to format prompts.
-
-## Usage
-The easiest way to test this out is by using the Colab demo
-
-To install locally:
-- Clone this repo
-- Install git-lfs (ubuntu: sudo apt-get install git-lfs , MacOS: brew install git-lfs)
-
-In the root of the repo run:
-
-```bash
-conda create -n vqganclip python=3.8
-conda activate vqganclip
-git-lfs install
-git clone https://huggingface.co/datasets/erwann/face_editor_model_ckpt model_checkpoints
-pip install -r requirements.txt
-```
-
-### Generate new images
-```python
-from VQGAN_CLIP import VQGAN_CLIP
-vqgan_clip = VQGAN_CLIP()
-vqgan_clip.generate("a picture of a smiling woman")
-```
-
-### Edit an image
-To get a test image, run
-`git clone https://huggingface.co/datasets/erwann/vqgan-clip-pic test_images`
-
-To edit:
-```python
-from VQGAN_CLIP import VQGAN_CLIP
-vqgan_clip = VQGAN_CLIP()
-
-vqgan_clip.lr = .07
-vqgan_clip.iterations = 15
-vqgan_clip.generate(
- pos_prompts= ["a picture of a beautiful asian woman", "a picture of a woman from Japan"],
- neg_prompts=["a picture of an Indian person", "a picture of a white person"],
- image_path="./test_images/face.jpeg",
- show_intermediate=True,
- save_intermediate=True,
-)
-```
-
-### Make an animation from the most recent generation
-`vqgan_clip.make_animation()`
-
-## Features:
-- Positive and negative prompts
-- Multiple prompts
-- Prompt Weights
-- Creating GIF animations of the transformations
-- Wandb logging
-
-
-
diff --git a/examples/research_projects/vqgan-clip/VQGAN_CLIP.py b/examples/research_projects/vqgan-clip/VQGAN_CLIP.py
deleted file mode 100644
index 1bfbc4cd5c3..00000000000
--- a/examples/research_projects/vqgan-clip/VQGAN_CLIP.py
+++ /dev/null
@@ -1,268 +0,0 @@
-import os
-from glob import glob
-
-import imageio
-import torch
-import torchvision
-import wandb
-from img_processing import custom_to_pil, loop_post_process, preprocess, preprocess_vqgan
-from loaders import load_vqgan
-from PIL import Image
-from torch import nn
-
-from transformers import CLIPModel, CLIPTokenizerFast
-from utils import get_device, get_timestamp, show_pil
-
-
-class ProcessorGradientFlow:
- """
- This wraps the huggingface CLIP processor to allow backprop through the image processing step.
- The original processor forces conversion to PIL images, which is faster for image processing but breaks gradient flow.
- We call the original processor to get the text embeddings, but use our own image processing to keep images as torch tensors.
- """
-
- def __init__(self, device: str = "cpu", clip_model: str = "openai/clip-vit-large-patch14") -> None:
- self.device = device
- self.tokenizer = CLIPTokenizerFast.from_pretrained(clip_model)
- self.image_mean = [0.48145466, 0.4578275, 0.40821073]
- self.image_std = [0.26862954, 0.26130258, 0.27577711]
- self.normalize = torchvision.transforms.Normalize(self.image_mean, self.image_std)
- self.resize = torchvision.transforms.Resize(224)
- self.center_crop = torchvision.transforms.CenterCrop(224)
-
- def preprocess_img(self, images):
- images = self.resize(images)
- images = self.center_crop(images)
- images = self.normalize(images)
- return images
-
- def __call__(self, text=None, images=None, **kwargs):
- encoding = self.tokenizer(text=text, **kwargs)
- encoding["pixel_values"] = self.preprocess_img(images)
- encoding = {key: value.to(self.device) for (key, value) in encoding.items()}
- return encoding
-
-
-class VQGAN_CLIP(nn.Module):
- def __init__(
- self,
- iterations=10,
- lr=0.01,
- vqgan=None,
- vqgan_config=None,
- vqgan_checkpoint=None,
- clip=None,
- clip_preprocessor=None,
- device=None,
- log=False,
- save_vector=True,
- return_val="image",
- quantize=True,
- save_intermediate=False,
- show_intermediate=False,
- make_grid=False,
- ) -> None:
- """
- Instantiate a VQGAN_CLIP model. If you want to use a custom VQGAN model, pass it as vqgan.
- """
- super().__init__()
- self.latent = None
- self.device = device if device else get_device()
- if vqgan:
- self.vqgan = vqgan
- else:
- self.vqgan = load_vqgan(self.device, conf_path=vqgan_config, ckpt_path=vqgan_checkpoint)
- self.vqgan.eval()
- if clip:
- self.clip = clip
- else:
- self.clip = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
- self.clip.to(self.device)
- self.clip_preprocessor = ProcessorGradientFlow(device=self.device)
-
- self.iterations = iterations
- self.lr = lr
- self.log = log
- self.make_grid = make_grid
- self.return_val = return_val
- self.quantize = quantize
- self.latent_dim = self.vqgan.decoder.z_shape
-
- def make_animation(self, input_path=None, output_path=None, total_duration=5, extend_frames=True):
- """
- Make an animation from the intermediate images saved during generation.
- By default, uses the images from the most recent generation created by the generate function.
- If you want to use images from a different generation, pass the path to the folder containing the images as input_path.
- """
- images = []
- if output_path is None:
- output_path = "./animation.gif"
- if input_path is None:
- input_path = self.save_path
- paths = sorted(glob(input_path + "/*"))
- if not len(paths):
- raise ValueError(
- "No images found in save path, aborting (did you pass save_intermediate=True to the generate"
- " function?)"
- )
- if len(paths) == 1:
- print("Only one image found in save path, (did you pass save_intermediate=True to the generate function?)")
- frame_duration = total_duration / len(paths)
- durations = [frame_duration] * len(paths)
- if extend_frames:
- durations[0] = 1.5
- durations[-1] = 3
- for file_name in paths:
- if file_name.endswith(".png"):
- images.append(imageio.imread(file_name))
- imageio.mimsave(output_path, images, duration=durations)
- print(f"gif saved to {output_path}")
-
- def _get_latent(self, path=None, img=None):
- if not (path or img):
- raise ValueError("Input either path or tensor")
- if img is not None:
- raise NotImplementedError
- x = preprocess(Image.open(path), target_image_size=256).to(self.device)
- x_processed = preprocess_vqgan(x)
- z, *_ = self.vqgan.encode(x_processed)
- return z
-
- def _add_vector(self, transform_vector):
- """Add a vector transform to the base latent and returns the resulting image."""
- base_latent = self.latent.detach().requires_grad_()
- trans_latent = base_latent + transform_vector
- if self.quantize:
- z_q, *_ = self.vqgan.quantize(trans_latent)
- else:
- z_q = trans_latent
- return self.vqgan.decode(z_q)
-
- def _get_clip_similarity(self, prompts, image, weights=None):
- clip_inputs = self.clip_preprocessor(text=prompts, images=image, return_tensors="pt", padding=True)
- clip_outputs = self.clip(**clip_inputs)
- similarity_logits = clip_outputs.logits_per_image
- if weights is not None:
- similarity_logits = similarity_logits * weights
- return similarity_logits.sum()
-
- def _get_clip_loss(self, pos_prompts, neg_prompts, image):
- pos_logits = self._get_clip_similarity(pos_prompts["prompts"], image, weights=(1 / pos_prompts["weights"]))
- if neg_prompts:
- neg_logits = self._get_clip_similarity(neg_prompts["prompts"], image, weights=neg_prompts["weights"])
- else:
- neg_logits = torch.tensor([1], device=self.device)
- loss = -torch.log(pos_logits) + torch.log(neg_logits)
- return loss
-
- def _optimize_CLIP(self, original_img, pos_prompts, neg_prompts):
- vector = torch.randn_like(self.latent, requires_grad=True, device=self.device)
- optim = torch.optim.Adam([vector], lr=self.lr)
-
- for i in range(self.iterations):
- optim.zero_grad()
- transformed_img = self._add_vector(vector)
- processed_img = loop_post_process(transformed_img)
- clip_loss = self._get_CLIP_loss(pos_prompts, neg_prompts, processed_img)
- print("CLIP loss", clip_loss)
- if self.log:
- wandb.log({"CLIP Loss": clip_loss})
- clip_loss.backward(retain_graph=True)
- optim.step()
- if self.return_val == "image":
- yield custom_to_pil(transformed_img[0])
- else:
- yield vector
-
- def _init_logging(self, positive_prompts, negative_prompts, image_path):
- wandb.init(reinit=True, project="face-editor")
- wandb.config.update({"Positive Prompts": positive_prompts})
- wandb.config.update({"Negative Prompts": negative_prompts})
- wandb.config.update({"lr": self.lr, "iterations": self.iterations})
- if image_path:
- image = Image.open(image_path)
- image = image.resize((256, 256))
- wandb.log("Original Image", wandb.Image(image))
-
- def process_prompts(self, prompts):
- if not prompts:
- return []
- processed_prompts = []
- weights = []
- if isinstance(prompts, str):
- prompts = [prompt.strip() for prompt in prompts.split("|")]
- for prompt in prompts:
- if isinstance(prompt, (tuple, list)):
- processed_prompt = prompt[0]
- weight = float(prompt[1])
- elif ":" in prompt:
- processed_prompt, weight = prompt.split(":")
- weight = float(weight)
- else:
- processed_prompt = prompt
- weight = 1.0
- processed_prompts.append(processed_prompt)
- weights.append(weight)
- return {
- "prompts": processed_prompts,
- "weights": torch.tensor(weights, device=self.device),
- }
-
- def generate(
- self,
- pos_prompts,
- neg_prompts=None,
- image_path=None,
- show_intermediate=True,
- save_intermediate=False,
- show_final=True,
- save_final=True,
- save_path=None,
- ):
- """Generate an image from the given prompts.
- If image_path is provided, the image is used as a starting point for the optimization.
- If image_path is not provided, a random latent vector is used as a starting point.
- You must provide at least one positive prompt, and optionally provide negative prompts.
- Prompts must be formatted in one of the following ways:
- - A single prompt as a string, e.g "A smiling woman"
- - A set of prompts separated by pipes: "A smiling woman | a woman with brown hair"
- - A set of prompts and their weights separated by colons: "A smiling woman:1 | a woman with brown hair: 3" (default weight is 1)
- - A list of prompts, e.g ["A smiling woman", "a woman with brown hair"]
- - A list of prompts and weights, e.g [("A smiling woman", 1), ("a woman with brown hair", 3)]
- """
- if image_path:
- self.latent = self._get_latent(image_path)
- else:
- self.latent = torch.randn(self.latent_dim, device=self.device)
- if self.log:
- self._init_logging(pos_prompts, neg_prompts, image_path)
-
- assert pos_prompts, "You must provide at least one positive prompt."
- pos_prompts = self.process_prompts(pos_prompts)
- neg_prompts = self.process_prompts(neg_prompts)
- if save_final and save_path is None:
- save_path = os.path.join("./outputs/", "_".join(pos_prompts["prompts"]))
- if not os.path.exists(save_path):
- os.makedirs(save_path)
- else:
- save_path = save_path + "_" + get_timestamp()
- os.makedirs(save_path)
- self.save_path = save_path
-
- original_img = self.vqgan.decode(self.latent)[0]
- if show_intermediate:
- print("Original Image")
- show_pil(custom_to_pil(original_img))
-
- original_img = loop_post_process(original_img)
- for iter, transformed_img in enumerate(self._optimize_CLIP(original_img, pos_prompts, neg_prompts)):
- if show_intermediate:
- show_pil(transformed_img)
- if save_intermediate:
- transformed_img.save(os.path.join(self.save_path, f"iter_{iter:03d}.png"))
- if self.log:
- wandb.log({"Image": wandb.Image(transformed_img)})
- if show_final:
- show_pil(transformed_img)
- if save_final:
- transformed_img.save(os.path.join(self.save_path, f"iter_{iter:03d}_final.png"))
diff --git a/examples/research_projects/vqgan-clip/img_processing.py b/examples/research_projects/vqgan-clip/img_processing.py
deleted file mode 100644
index 221ebd86dae..00000000000
--- a/examples/research_projects/vqgan-clip/img_processing.py
+++ /dev/null
@@ -1,50 +0,0 @@
-import numpy as np
-import PIL
-import torch
-import torchvision.transforms as T
-import torchvision.transforms.functional as TF
-from PIL import Image
-
-
-def preprocess(img, target_image_size=256):
- s = min(img.size)
-
- if s < target_image_size:
- raise ValueError(f"min dim for image {s} < {target_image_size}")
-
- r = target_image_size / s
- s = (round(r * img.size[1]), round(r * img.size[0]))
- img = TF.resize(img, s, interpolation=PIL.Image.LANCZOS)
- img = TF.center_crop(img, output_size=2 * [target_image_size])
- img = torch.unsqueeze(T.ToTensor()(img), 0)
- return img
-
-
-def preprocess_vqgan(x):
- x = 2.0 * x - 1.0
- return x
-
-
-def custom_to_pil(x, process=True, mode="RGB"):
- x = x.detach().cpu()
- if process:
- x = post_process_tensor(x)
- x = x.numpy()
- if process:
- x = (255 * x).astype(np.uint8)
- x = Image.fromarray(x)
- if not x.mode == mode:
- x = x.convert(mode)
- return x
-
-
-def post_process_tensor(x):
- x = torch.clamp(x, -1.0, 1.0)
- x = (x + 1.0) / 2.0
- x = x.permute(1, 2, 0)
- return x
-
-
-def loop_post_process(x):
- x = post_process_tensor(x.squeeze())
- return x.permute(2, 0, 1).unsqueeze(0)
diff --git a/examples/research_projects/vqgan-clip/loaders.py b/examples/research_projects/vqgan-clip/loaders.py
deleted file mode 100644
index 88513bcb691..00000000000
--- a/examples/research_projects/vqgan-clip/loaders.py
+++ /dev/null
@@ -1,74 +0,0 @@
-import importlib
-
-import torch
-import yaml
-from omegaconf import OmegaConf
-from taming.models.vqgan import VQModel
-
-
-def load_config(config_path, display=False):
- config = OmegaConf.load(config_path)
- if display:
- print(yaml.dump(OmegaConf.to_container(config)))
- return config
-
-
-def load_vqgan(device, conf_path=None, ckpt_path=None):
- if conf_path is None:
- conf_path = "./model_checkpoints/vqgan_only.yaml"
- config = load_config(conf_path, display=False)
- model = VQModel(**config.model.params)
- if ckpt_path is None:
- ckpt_path = "./model_checkpoints/vqgan_only.pt"
- sd = torch.load(ckpt_path, map_location=device)
- if ".ckpt" in ckpt_path:
- sd = sd["state_dict"]
- model.load_state_dict(sd, strict=True)
- model.to(device)
- del sd
- return model
-
-
-def reconstruct_with_vqgan(x, model):
- z, _, [_, _, indices] = model.encode(x)
- print(f"VQGAN --- {model.__class__.__name__}: latent shape: {z.shape[2:]}")
- xrec = model.decode(z)
- return xrec
-
-
-def get_obj_from_str(string, reload=False):
- module, cls = string.rsplit(".", 1)
- if reload:
- module_imp = importlib.import_module(module)
- importlib.reload(module_imp)
- return getattr(importlib.import_module(module, package=None), cls)
-
-
-def instantiate_from_config(config):
- if "target" not in config:
- raise KeyError("Expected key `target` to instantiate.")
- return get_obj_from_str(config["target"])(**config.get("params", {}))
-
-
-def load_model_from_config(config, sd, gpu=True, eval_mode=True):
- model = instantiate_from_config(config)
- if sd is not None:
- model.load_state_dict(sd)
- if gpu:
- model.cuda()
- if eval_mode:
- model.eval()
- return {"model": model}
-
-
-def load_model(config, ckpt, gpu, eval_mode):
- # load the specified checkpoint
- if ckpt:
- pl_sd = torch.load(ckpt, map_location="cpu")
- global_step = pl_sd["global_step"]
- print(f"loaded model from global step {global_step}.")
- else:
- pl_sd = {"state_dict": None}
- global_step = None
- model = load_model_from_config(config.model, pl_sd["state_dict"], gpu=gpu, eval_mode=eval_mode)["model"]
- return model, global_step
diff --git a/examples/research_projects/vqgan-clip/requirements.txt b/examples/research_projects/vqgan-clip/requirements.txt
deleted file mode 100644
index 19761632422..00000000000
--- a/examples/research_projects/vqgan-clip/requirements.txt
+++ /dev/null
@@ -1,27 +0,0 @@
-einops
-gradio
-icecream
-imageio
-lpips
-matplotlib
-more_itertools
-numpy
-omegaconf
-opencv_python_headless
-Pillow
-pudb
-pytorch_lightning
-PyYAML
-requests
-scikit_image
-scipy
-setuptools
-streamlit
-taming-transformers
-torch
-torchvision
-tqdm
-transformers==4.48.0
-tokenizers==0.13.2
-typing_extensions
-wandb
diff --git a/examples/research_projects/vqgan-clip/utils.py b/examples/research_projects/vqgan-clip/utils.py
deleted file mode 100644
index 7db45fcbb52..00000000000
--- a/examples/research_projects/vqgan-clip/utils.py
+++ /dev/null
@@ -1,35 +0,0 @@
-from datetime import datetime
-
-import matplotlib.pyplot as plt
-import torch
-
-
-def freeze_module(module):
- for param in module.parameters():
- param.requires_grad = False
-
-
-def get_device():
- device = "cuda" if torch.cuda.is_available() else "cpu"
- if torch.backends.mps.is_available() and torch.backends.mps.is_built():
- device = "mps"
- if device == "mps":
- print(
- "WARNING: MPS currently doesn't seem to work, and messes up backpropagation without any visible torch"
- " errors. I recommend using CUDA on a colab notebook or CPU instead if you're facing inexplicable issues"
- " with generations."
- )
- return device
-
-
-def show_pil(img):
- fig = plt.imshow(img)
- fig.axes.get_xaxis().set_visible(False)
- fig.axes.get_yaxis().set_visible(False)
- plt.show()
-
-
-def get_timestamp():
- current_time = datetime.now()
- timestamp = current_time.strftime("%H:%M:%S")
- return timestamp
diff --git a/examples/research_projects/wav2vec2/FINE_TUNE_XLSR_WAV2VEC2.md b/examples/research_projects/wav2vec2/FINE_TUNE_XLSR_WAV2VEC2.md
deleted file mode 100644
index 7a580a36132..00000000000
--- a/examples/research_projects/wav2vec2/FINE_TUNE_XLSR_WAV2VEC2.md
+++ /dev/null
@@ -1,516 +0,0 @@
-# Fine-Tuning week of XLSR-Wav2Vec2 on 60 languages 🌍
-
-Welcome to the fine-tuning week! The goal of this week is to have state-of-the-art automatic speech recognition (ASR) models in as many languages as possible. The fine-tuning week ends on Friday, the 26th March at midnight PST time.
-
-Participants are encouraged to fine-tune the pretrained [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) checkpoint on one or more of the 60 languages of [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets).
-Furthermore, it is very much appreciated if participants fine-tune XLSR-Wav2Vec2 on a language that is not included in the Common Voice dataset.
-
-All fine-tuned models uploaded until Friday, the 26th March midnight PST, will be taken into account for competition, and the best model per language will be awarded a prize if the best model performs reasonably well.
-The testing data to evaluate the models will be the official [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets) *`test data`* of version 6.1. Again, participants are very much encouraged to fine-tune XLSR-Wav2Vec2 on languages that are not found in the Common Voice dataset since those languages are even more likely to be underrepresented in the speech community.
-Each model fine-tuned on a language not found in Common Voice, will be evaluated by the Hugging Face team after Friday, the 26th March at midnight PST, and if the model performs reasonably well, the model receives a prize as well.
-For more information on which data can be used for training, how the models are evaluated exactly, and what type of data preprocessing can be used, please see ["Training and Evaluation Rules"](#training-and-evaluation-rules).
-
-**Please keep in mind:**
-The spirit of the fine-tuning week is to provide state-of-the-art speech recognition in as many languages as possible to the community!
-So while we encourage healthy competition between people/groups of the same language so that better results are obtained, it is extremely important that we help each other and share our insights with the whole team/community.
-What matters in the end is what has been achieved by the team as a whole during the fine-tuning week.
-That being said, we strongly encourage people to share tips & tricks on the forum or Slack, help each other when team members encounter bugs, and work in groups.
-To make it easier to share and help, forum threads have been created under the name {language} ASR: Fine-Tuning Wav2Vec2, e.g. here.
-It is very much possible that prizes will be given to groups of people instead of individuals. Also, don't hesitate to ask questions, propose improvements to the organization, to the material given to participants, etc...🤗
-
-## Table of Contents
-
-- [Organization of the fine tuning week](#organization-of-the-fine-tuning-week)
-- [How to fine tune XLSR Wav2Vec2](#how-to-fine-tune-xlsr-wav2vec2)
- - [Google colab setup](#google-colab-setup)
- - [Local machine](#local-machine)
-- [How to upload my trained checkpoint](#how-to-upload-my-trained-checkpoint)
- - [How to create the README](#how-to-create-the-readme)
-- [How to evaluate my trained checkpoint](#how-to-evaluate-my-trained-checkpoint)
-- [Rules of training and evaluation](#rules-of-training-and-evaluation)
-- [Tips and tricks](#tips-and-tricks)
- - [How to combine multiple datasests into one](#how-to-combine-multiple-datasets-into-one)
- - [How to effectively preprocess the data](#how-to-effectively-preprocess-the-data)
- - [How to efficiently preproces the data](#how-to-do-efficiently-load-datasets-with-limited-ram-and-hard-drive-space)
- - [How to do hyperparameter tuning](#how-to-do-hyperparameter-tuning)
- - [How to preprocess and evaluate character based languages](#how-to-preprocess-and-evaluate-character-based-languages)
-- [Further reading material](#further-reading-material)
-- [FAQ](#faq)
-
-## Organization of the fine tuning week
-
-The week officially starts on 22.03.2021 and ends on 29.03.2021, but you are more than welcome to start fine-tuning models before the start date.
-General questions you might have, general problems you encounter, and general tips can be shared directly on the Slack channel (see [this post](https://discuss.huggingface.co/t/open-to-the-community-xlsr-wav2vec2-fine-tuning-week-for-low-resource-languages/4467) on how to be added to Slack).
-More language-specific questions or specific bugs should be posted on the [forum](https://discuss.huggingface.co/) (feel free to use already existing language-specific threads, *e.g.* [this one](https://discuss.huggingface.co/t/arabic-asr-fine-tuning-wav2vec2/4608) or open a new one if there is no thread for your language yet) or directly on [github](https://github.com/huggingface/transformers) if you think some code or document needs correction/improvement.
-Starting on Monday, the 22.03.2021, the Hugging Face team will try to provide an overview of currently trained models along with their evaluation results.
-All the necessary information on:
-
-- How to fine-tune the XLSR model
-- How to upload the model
-- How to share your evaluation results & training/eval script
-- What are the training/evaluation rules
-
-can be found in the sections below. If something is still unclear, feel free to drop a message in the Slack channel.
-
-## How to fine tune XLSR Wav2Vec2
-
-This chapter gives an in-detail explanation of how to fine-tune [Facebook's multi-lingual Wav2vec2](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on any language of the [Common Voice dataset](https://commonvoice.mozilla.org/en/datasets).
-
-Two possible setups can be used to fine-tune Wav2Vec2. The easiest setup is to simply use [google colab](https://colab.research.google.com/). It is possible to train the full model in a *free* google colab, but it is recommended to use google colab pro since it is more stable.
-
-The other option is to run a script locally. While this can be more difficult to set up, it also means that you have more control over the training run and probably access to better GPUs than you would have in a google colab.
-For small datasets, it is usually totally sufficient to train your model
-in a google colab. For larger and thus more memory-intensive datasets, it is probably
-better to fine-tune the model locally.
-
-For each option, we explain in detail how to fine-tune XLSR-Wav2Vec2 in the following.
-
-### Google colab setup
-
-**Note**: Instead of reading the following section, you can simply watch [this](https://www.youtube.com/watch?v=UynYn2C3tI0&ab_channel=PatrickvonPlaten) video, where Patrick explains how to adapt the google colab for your specific language.
-
-**1.**: If you plan on training XLSR-Wav2Vec2 in a google colab, you should first make sure to have a valid gmail account. You can sign up for a gmail account [here](https://accounts.google.com/signup/v2/webcreateaccount?hl=en&flowName=GlifWebSignIn&flowEntry=SignUp).
-Having successfully signed up for gmail, you can now sign in to your account to make sure you are logged in when opening new tabs in your browser.
-
-**2.**: Next, head over to the official [Fine-Tune XLSR-Wav2Vec2 with 🤗 Transformes](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_Tune_XLSR_Wav2Vec2_on_Turkish_ASR_with_%F0%9F%A4%97_Transformers.ipynb) google colab. The first thing you should do is to make a copy of it - click `->File->Save a copy in Drive`. This should save a copy of the google colab in your google drive.
-
-**3.**: Now it is highly recommended to carefully read the google colab without running the cells yet.
-You should get an understanding of the model is trained and what you will have to change when training the model in a different language.
-Having done so, you can again head over to [Common Voice](https://commonvoice.mozilla.org/en/datasets) and pick a language you want to fine-tune [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on. Make sure you remember the language code (For each language, you can find it under the field "*Version*". It corresponds to **all characters before the first underscore**. *E.g.* for Greek it is *el*, while for Irish it is *ga-IE*.
-
-**4.**: Now you should replace the language code used for the demo of this colab, being *tr* for Turkish with the language code corresponding to the language you just chose in the **second** cell of the google colab. This will load the correct data for your language.
-
-**5.**: It is time to start running the google colab! Make sure that you have selected "GPU" as your runtime environment and you can start running the cells one-by-one. Make sure you attentively read the text between the cells to understand what is happening and to eventually correct the cells to improve the fine-tuning script for your language. Things you might want to improve/change:
-
- - Data loading. It is very much recommended to use more than just the official training data of the Common Voice dataset. If you find more data on the internet, feel free to use it! Check out the section ["How to combined multiple datasets into one"](#how-to-combine-multiple-datasets-into-one)
-
-- Data Processing. You should adapt the data processing to your specific language. In data processing, you should make the data more uniform so that it will be easier for the model to learn how to classify speech in your data. Here it can be really helpful to be proficient in the language to know what can be done to simplify the language without changing the meaning.
-Data processing methods include, but are not limited to:
- - Normalizing your data. Make sure all characters are lower-cased.
- - Remove typographical symbols and punctuation marks. See a list [here](https://en.wikipedia.org/wiki/List_of_typographical_symbols_and_punctuation_marks). Be careful to not remove punctuation marks that can change the meaning of the sentence. *E.g.* you should not remove the single quotation mark `'` in English, as it would change the words `"it's"` to `"its"` which is a different word and has thus a different meaning. For more tips on data processing see ["How to effectively preprocess the data"](#how-to-effectively-preprocess-the-data")
-
-- Hyperparameter Tuning. Depending on the size of the data you should probably change the hyperparameters of the google colab. You can change any parameter you like. For more tips and tricks see ["How to do hyperparameter tuning for my language"](#how-to-do-hyperparameter-tuning-for-my-language)
-
-When running the google colab make sure that you uncomment the cell corresponding to mounting your google drive to the colab. This cell looks as follows:
-
-```python
-# from google.colab import drive
-# drive.mount('/content/gdrive/')
-```
-
-Uncomment it, run it, and follow the instructions to mount your google drive. This way you can be sure that the model parameters and created tokenizer & feature extractor files are saved in **your** google drive.
-
-Also, make sure that you uncomment the cells corresponding to save the preprocessing files and trained model weights to your drive. Otherwise, you might lose a trained model if you google crashes. You should change the name of your model from `wav2vec2-large-xlsr-turkish-demo` to `wav2vec2-large-xlsr-{your_favorite_name}`.
-
-Those cells correspond to:
-
-```python
-# processor.save_pretrained("/content/gdrive/MyDrive/wav2vec2-large-xlsr-turkish-demo")
-```
-
-and the line:
-
-```python
- output_dir="/content/gdrive/MyDrive/wav2vec2-large-xlsr-turkish-demo",
-```
-
-further below (which should already be uncommented).
-
-Having finished the training you should find the following files/folders under the folder `wav2vec2-large-xlsr-{your_favorite_name}` in your google drive:
-
-- `preprocessor_config.json` - the parameters of the feature extractor
-- `special_tokens_map.json` - the special token map of the tokenizer
-- `tokenizer_config.json` - the parameters of the tokenizer
-- `vocab.json` - the vocabulary of the tokenizer
-- `checkpoint-{...}/` - the saved checkpoints saved during training. Each checkpoint should contain the files: `config.json`, `optimizer.pt`, `pytorch_model.bin`, `scheduler.pt`, `training_args.bin`. The files `config.json` and `pytorch_model.bin` define your model.
-
-If you are happy with your training results it is time to upload your model!
-Download the following files to your local computer: **`preprocessor_config.json`, `special_tokens_map.json`, `tokenizer_config.json`, `vocab.json`, `config.json`, `pytorch_model.bin`**. Those files fully define a XLSR-Wav2Vec2 model checkpoint.
-
-Awesome you have successfully trained a XLSR-Wav2Vec2 model 😎. Now you can jump to the section ["How to upload my trained checkpoint"](#how-to-upload-my-trained-checkpoint)
-
-### Local machine
-
-We have provided `run_common_voice.py` script to run fine-tuning on local machine. The script is similar to the colab but allows you to launch training using command line, save and continue training from previous checkpoints and launch training on multiple GPUs.
-For bigger datasets, we recommend to train Wav2Vec2 locally instead of in a google colab.
-
-1. To begin with, we should clone transformers localy and install all the required packages.
-
-First, you need to clone the `transformers` repo with:
-
-```bash
-$ git clone https://github.com/huggingface/transformers.git
-```
-
-Second, head over to the `examples/research_projects/wav2vec2` directory, where the `run_common_voice.py` script is located.
-
-```bash
-$ cd transformers/examples/research_projects/wav2vec2
-```
-
-Third, install the required packages. The
-packages are listed in the `requirements.txt` file and can be installed with
-
-```bash
-$ pip install -r requirements.txt
-```
-
- **Note**: Installing the latest version of `torchaudio` will also upgrade `torch` to it's latest stable version. If you are using specific version of `torch` then make sure
- to use the correct `torchaudio` version compatible with your version of `torch`. By default the `requirements.txt` will install the latest version of `torchaudio`.
-
-2. Next, take a look at the `run_common_voice.py` script to get an understanding of how it works. In short the script does the following:
-
- - Load the given common voice dataset
- - Create vocab for the language
- - Load the model with given hyperparameters
- - Pre-process the dataset to input into the model
- - Run training
- - Run evaluation
-
-3. The following examples show how you can launch fine-tuning for the common voice dataset.
-Here we will run the script on the *Turkish* Common Voice dataset for demonstration purposes.
-
- **To lanuch fine-tuninig on a single GPU:**
-
- ```bash
- python run_common_voice.py \
- --model_name_or_path="facebook/wav2vec2-large-xlsr-53" \
- --dataset_config_name="tr" \ # use this argument to specify the language code
- --output_dir=./wav2vec2-large-xlsr-turkish-demo \
- --overwrite_output_dir \
- --num_train_epochs="5" \
- --per_device_train_batch_size="16" \
- --learning_rate="3e-4" \
- --warmup_steps="500" \
- --eval_strategy="steps" \
- --save_steps="400" \
- --eval_steps="400" \
- --logging_steps="400" \
- --save_total_limit="3" \
- --freeze_feature_extractor \
- --feat_proj_dropout="0.0" \
- --layerdrop="0.1" \
- --gradient_checkpointing \
- --fp16 \
- --group_by_length \
- --do_train --do_eval
- ```
-
- **To lanuch fine-tuninig on multiple GPUs:**
-
- ```bash
- python -m torch.distributed.launch \
- --nproc_per_node 4 run_common_voice.py \
- --model_name_or_path="facebook/wav2vec2-large-xlsr-53" \
- --dataset_config_name="tr" \ # use this argument to specify the language code
- --output_dir=./wav2vec2-large-xlsr-turkish-demo \
- --overwrite_output_dir \
- --num_train_epochs="5" \
- --per_device_train_batch_size="16" \
- --learning_rate="3e-4" \
- --warmup_steps="500" \
- --eval_strategy="steps" \
- --save_steps="400" \
- --eval_steps="400" \
- --logging_steps="400" \
- --save_total_limit="3" \
- --freeze_feature_extractor \
- --feat_proj_dropout="0.0" \
- --layerdrop="0.1" \
- --gradient_checkpointing \
- --fp16 \
- --group_by_length \
- --do_train --do_eval
- ```
-
- The above command will launch the training on 4 GPUs. Use the `--nproc_per_node` option to specify the number of GPUs.
-
- Once the training is finished, the model and checkpoints will be saved under the directory specified by the `--output_dir` argument.
-
-4. The script also allows you to resume training from the last saved checkpoint. To resume training from last saved checkpoint remove the `--overwrite_output_dir` option and run the same command again. And to continue training from a specific checkpoint, keep the `--overwrite_output_dir`
-option and pass the path of the checkpoint as `--model_name_or_path`.
-
-As the script is based on the `Trainer` API, refer to the [Trainer docs](https://huggingface.co/transformers/main_classes/trainer.html) for more information about ``Trainer`` and ``TrainingArguments``.
-
-[OVH cloud](https://www.ovh.com/world/) has generously offered free compute for this sprint. Please refer to [this video](https://www.youtube.com/watch?v=2hlkWAESMk8&ab_channel=Databuzzword) to get started with OVH.
-
-
-## How to upload my trained checkpoint
-
-To upload your trained checkpoint, you have to create a new model repository on the 🤗 model hub, from this page: https://huggingface.co/new
-
-> You can also follow the more in-depth instructions [here](https://huggingface.co/transformers/model_sharing.html) if needed.
-
-Having created your model repository on the hub, you should clone it locally:
-
-```bash
-git lfs install
-
-git clone https://huggingface.co/username/your-model-name
-```
-
-Then and add the following files that fully define a XLSR-Wav2Vec2 checkpoint into the repository. You should have added the following files.
-
-- `preprocessor_config.json`
-- `special_tokens_map.json`
-- `tokenizer_config.json`
-- `vocab.json`
-- `config.json`
-- `pytorch_model.bin`
-
-Having added the above files, you should run the following to push files to your model repository.
-```bash
-git add . && git commit -m "Add model files" && git push
-```
-
-The next **very important** step is to create the model card. For people to use your fine-tuned
-model it is important to understand:
-
-- What kind of model is it?
-- What is your model useful for?
-- What data was your model trained on?
-- How well does your model perform?
-
-All these questions should be answered in a model card which is the first thing people see when
-visiting your model on the hub under `https://huggingface.co/{your_username}/{your_modelname}`.
-
-**Note**:
-It is extremely important that you add this model card or else we cannot find your model and thus cannot take the model into
-account for the final evaluation.
-
-### How to create the readme
-
-The model card is written in markdown (`.md`) and should be added by simply clicking on the "Add model card" button which is found on the top right corner.
-You are encouraged to copy-paste the following template into your model card.
-
-**Make sure that** instead of copying the output of the markdown file you copy the **raw** version of the following part.
-
-To get the raw version of this file, simply click on the "`raw`" button on the top right corner of this file next to "`blame`" and copy everything below the marker.
-Make sure that you read and consequently remove all #TODO: statements from the model card.
-
-<======================Copy **raw** version from here=========================
----
-language: {lang_id} #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
-datasets:
-- common_voice #TODO: remove if you did not use the common voice dataset
-- TODO: add more datasets if you have used additional datasets. Make sure to use the exact same
-dataset name as the one found [here](https://huggingface.co/datasets). If the dataset can not be found in the official datasets, just give it a new name
-metrics:
-- wer
-tags:
-- audio
-- automatic-speech-recognition
-- speech
-- xlsr-fine-tuning-week
-license: apache-2.0
-model-index:
-- name: {human_readable_name} #TODO: replace {human_readable_name} with a name of your model as it should appear on the leaderboard. It could be something like `Elgeish XLSR Wav2Vec2 Large 53`
- results:
- - task:
- name: Speech Recognition
- type: automatic-speech-recognition
- dataset:
- name: Common Voice {lang_id} #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
- type: common_voice
- args: {lang_id} #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
- metrics:
- - name: Test WER
- type: wer
- value: {wer_result_on_test} #TODO (IMPORTANT): replace {wer_result_on_test} with the WER error rate you achieved on the common_voice test set. It should be in the format XX.XX (don't add the % sign here). **Please** remember to fill out this value after you evaluated your model, so that your model appears on the leaderboard. If you fill out this model card before evaluating your model, please remember to edit the model card afterward to fill in your value
----
-
-# Wav2Vec2-Large-XLSR-53-{language} #TODO: replace language with your {language}, *e.g.* French
-
-Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on {language} using the [Common Voice](https://huggingface.co/datasets/common_voice), ... and ... dataset{s}. #TODO: replace {language} with your language, *e.g.* French and eventually add more datasets that were used and eventually remove common voice if model was not trained on common voice
-When using this model, make sure that your speech input is sampled at 16kHz.
-
-## Usage
-
-The model can be used directly (without a language model) as follows:
-
-```python
-import torch
-import torchaudio
-from datasets import load_dataset
-from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
-
-test_dataset = load_dataset("common_voice", "{lang_id}", split="test[:2%]") #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
-
-processor = Wav2Vec2Processor.from_pretrained("{model_id}") #TODO: replace {model_id} with your model id. The model id consists of {your_username}/{your_modelname}, *e.g.* `elgeish/wav2vec2-large-xlsr-53-arabic`
-model = Wav2Vec2ForCTC.from_pretrained("{model_id}") #TODO: replace {model_id} with your model id. The model id consists of {your_username}/{your_modelname}, *e.g.* `elgeish/wav2vec2-large-xlsr-53-arabic`
-
-resampler = torchaudio.transforms.Resample(48_000, 16_000)
-
-# Preprocessing the datasets.
-# We need to read the aduio files as arrays
-def speech_file_to_array_fn(batch):
- speech_array, sampling_rate = torchaudio.load(batch["path"])
- batch["speech"] = resampler(speech_array).squeeze().numpy()
- return batch
-
-test_dataset = test_dataset.map(speech_file_to_array_fn)
-inputs = processor(test_dataset[:2]["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
-
-with torch.no_grad():
- logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
-
-predicted_ids = torch.argmax(logits, dim=-1)
-
-print("Prediction:", processor.batch_decode(predicted_ids))
-print("Reference:", test_dataset[:2]["sentence"])
-```
-
-
-## Evaluation
-
-The model can be evaluated as follows on the {language} test data of Common Voice. # TODO: replace #TODO: replace language with your {language}, *e.g.* French
-
-
-```python
-import torch
-import torchaudio
-from datasets import load_dataset, load_metric
-from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
-import re
-
-test_dataset = load_dataset("common_voice", "{lang_id}", split="test") #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
-wer = load_metric("wer")
-
-processor = Wav2Vec2Processor.from_pretrained("{model_id}") #TODO: replace {model_id} with your model id. The model id consists of {your_username}/{your_modelname}, *e.g.* `elgeish/wav2vec2-large-xlsr-53-arabic`
-model = Wav2Vec2ForCTC.from_pretrained("{model_id}") #TODO: replace {model_id} with your model id. The model id consists of {your_username}/{your_modelname}, *e.g.* `elgeish/wav2vec2-large-xlsr-53-arabic`
-model.to("cuda")
-
-chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“]' # TODO: adapt this list to include all special characters you removed from the data
-resampler = torchaudio.transforms.Resample(48_000, 16_000)
-
-# Preprocessing the datasets.
-# We need to read the aduio files as arrays
-def speech_file_to_array_fn(batch):
- batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
- speech_array, sampling_rate = torchaudio.load(batch["path"])
- batch["speech"] = resampler(speech_array).squeeze().numpy()
- return batch
-
-test_dataset = test_dataset.map(speech_file_to_array_fn)
-
-# Preprocessing the datasets.
-# We need to read the aduio files as arrays
-def evaluate(batch):
- inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
-
- with torch.no_grad():
- logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
-
- pred_ids = torch.argmax(logits, dim=-1)
- batch["pred_strings"] = processor.batch_decode(pred_ids)
- return batch
-
-result = test_dataset.map(evaluate, batched=True, batch_size=8)
-
-print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
-```
-
-**Test Result**: XX.XX % # TODO: write output of print here. IMPORTANT: Please remember to also replace {wer_result_on_test} at the top of with this value here. tags.
-
-
-## Training
-
-The Common Voice `train`, `validation`, and ... datasets were used for training as well as ... and ... # TODO: adapt to state all the datasets that were used for training.
-
-The script used for training can be found [here](...) # TODO: fill in a link to your training script here. If you trained your model in a colab, simply fill in the link here. If you trained the model locally, it would be great if you could upload the training script on github and paste the link here.
-
-=======================To here===============================>
-
-Your model in then available under *huggingface.co/{your_username}/{your_chosen_xlsr-large_model_name}* for everybody to use 🎉.
-
-## How to evaluate my trained checkpoint
-
-Having uploaded your model, you should now evaluate your model in a final step. This should be as simple as
-copying the evaluation code of your model card into a python script and running it. Make sure to note
-the final result on the model card **both** under the YAML tags at the very top **and** below your evaluation code under "Test Results".
-
-## Rules of training and evaluation
-
-In this section, we will quickly go over what data is allowed to be used as training
-data, what kind of data preprocessing is allowed be used, and how the model should be evaluated.
-
-To make it very simple regarding the first point: **All data except the official common voice `test` data set can be used as training data**. For models trained in a language that is not included in Common Voice, the author of the model is responsible to
-leave a reasonable amount of data for evaluation.
-
-Second, the rules regarding the preprocessing are not that as straight-forward. It is allowed (and recommended) to
-normalize the data to only have lower-case characters. It is also allowed (and recommended) to remove typographical
-symbols and punctuation marks. A list of such symbols can *e.g.* be fonud [here](https://en.wikipedia.org/wiki/List_of_typographical_symbols_and_punctuation_marks) - however here we already must be careful. We should **not** remove a symbol that
-would change the meaning of the words, *e.g.* in English, we should not remove the single quotation mark `'` since it
-would change the meaning of the word `"it's"` to `"its"` which would then be incorrect. So the golden rule here is to
-not remove any characters that could change the meaning of a word into another word. This is not always obvious and should
-be given some consideration. As another example, it is fine to remove the "Hypen-minus" sign "`-`" since it doesn't change the
-meaninng of a word to another one. *E.g.* "`fine-tuning`" would be changed to "`finetuning`" which has still the same meaning.
-
-Since those choices are not always obvious when in doubt feel free to ask on Slack or even better post on the forum, as was
-done, *e.g.* [here](https://discuss.huggingface.co/t/spanish-asr-fine-tuning-wav2vec2/4586).
-
-## Tips and tricks
-
-This section summarizes a couple of tips and tricks across various topics. It will continously be updated during the week.
-
-### How to combine multiple datasets into one
-
-Check out [this](https://discuss.huggingface.co/t/how-to-combine-local-data-files-with-an-official-dataset/4685) post.
-
-### How to effectively preprocess the data
-
-
-### How to do efficiently load datasets with limited ram and hard drive space
-
-Check out [this](https://discuss.huggingface.co/t/german-asr-fine-tuning-wav2vec2/4558/8?u=patrickvonplaten) post.
-
-
-### How to do hyperparameter tuning
-
-
-### How to preprocess and evaluate character based languages
-
-
-## Further reading material
-
-It is recommended that take some time to read up on how Wav2vec2 works in theory.
-Getting a better understanding of the theory and the inner mechanisms of the model often helps when fine-tuning the model.
-
-**However**, if you don't like reading blog posts/papers, don't worry - it is by no means necessary to go through the theory to fine-tune Wav2Vec2 on your language of choice.
-
-If you are interested in learning more about the model though, here are a couple of resources that are important to better understand Wav2Vec2:
-
-- [Facebook's Wav2Vec2 blog post](https://ai.facebook.com/blog/wav2vec-state-of-the-art-speech-recognition-through-self-supervision/)
-- [Official Wav2Vec2 paper](https://arxiv.org/abs/2006.11477)
-- [Official XLSR Wav2vec2 paper](https://arxiv.org/pdf/2006.13979.pdf)
-- [Hugging Face Blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2)
-- [How does CTC (Connectionist Temporal Classification) work](https://distill.pub/2017/ctc/)
-
-It helps to have a good understanding of the following points:
-
-- How was XLSR-Wav2Vec2 pretrained? -> Feature vectors were masked and had to be predicted by the model; very similar in spirit to masked language model of BERT.
-
-- What parts of XLSR-Wav2Vec2 are responsible for what? What is the feature extractor part used for? -> extract feature vectors from the 1D raw audio waveform; What is the transformer part doing? -> mapping feature vectors to contextualized feature vectors; ...
-
-- What part of the model needs to be fine-tuned? -> The pretrained model **does not** include a language head to classify the contextualized features to letters. This is randomly initialized when loading the pretrained checkpoint and has to be fine-tuned. Also, note that the authors recommend to **not** further fine-tune the feature extractor.
-
-- What data was used to XLSR-Wav2Vec2? The checkpoint we will use for further fine-tuning was pretrained on **53** languages.
-
-- What languages are considered to be similar by XLSR-Wav2Vec2? In the official [XLSR Wav2Vec2 paper](https://arxiv.org/pdf/2006.13979.pdf), the authors show nicely which languages share a common contextualized latent space. It might be useful for you to extend your training data with data of other languages that are considered to be very similar by the model (or you).
-
-
-## FAQ
-
-- Can a participant fine-tune models for more than one language?
-Yes! A participant can fine-tune models in as many languages she/he likes
-- Can a participant use extra data (apart from the common voice data)?
-Yes! All data except the official common voice `test data` can be used for training.
-If a participant wants to train a model on a language that is not part of Common Voice (which
-is very much encouraged!), the participant should make sure that some test data is held out to
-make sure the model is not overfitting.
-- Can we fine-tune for high-resource languages?
-Yes! While we do not really recommend people to fine-tune models in English since there are
-already so many fine-tuned speech recognition models in English. However, it is very much
-appreciated if participants want to fine-tune models in other "high-resource" languages, such
-as French, Spanish, or German. For such cases, one probably needs to train locally and apply
-might have to apply tricks such as lazy data loading (check the ["Lazy data loading"](#how-to-do-lazy-data-loading) section for more details).
diff --git a/examples/research_projects/wav2vec2/README.md b/examples/research_projects/wav2vec2/README.md
deleted file mode 100644
index 88f62778a3a..00000000000
--- a/examples/research_projects/wav2vec2/README.md
+++ /dev/null
@@ -1,249 +0,0 @@
-**NOTE**: This example is outdated and is not longer actively maintained. Please
-follow the new instructions of fine-tuning Wav2Vec2 [here](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-recognition/README.md)
-
-## Fine-tuning Wav2Vec2
-
-The `run_asr.py` script allows one to fine-tune pretrained Wav2Vec2 models that can be found [here](https://huggingface.co/models?search=facebook/wav2vec2).
-
-This finetuning script can also be run as a google colab [TODO: here]( ).
-
-### Fine-Tuning with TIMIT
-Let's take a look at the [script](./finetune_base_timit_asr.sh) used to fine-tune [wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base)
-with the [TIMIT dataset](https://huggingface.co/datasets/timit_asr):
-
-```bash
-#!/usr/bin/env bash
-python run_asr.py \
---output_dir="./wav2vec2-base-timit-asr" \
---num_train_epochs="30" \
---per_device_train_batch_size="20" \
---per_device_eval_batch_size="20" \
---eval_strategy="steps" \
---save_steps="500" \
---eval_steps="100" \
---logging_steps="50" \
---learning_rate="5e-4" \
---warmup_steps="3000" \
---model_name_or_path="facebook/wav2vec2-base" \
---fp16 \
---dataset_name="timit_asr" \
---train_split_name="train" \
---validation_split_name="test" \
---orthography="timit" \
---preprocessing_num_workers="$(nproc)" \
---group_by_length \
---freeze_feature_extractor \
---verbose_logging \
-```
-
-The resulting model and inference examples can be found [here](https://huggingface.co/elgeish/wav2vec2-base-timit-asr).
-Some of the arguments above may look unfamiliar, let's break down what's going on:
-
-`--orthography="timit"` applies certain text preprocessing rules, for tokenization and normalization, to clean up the dataset.
-In this case, we use the following instance of `Orthography`:
-
-```python
-Orthography(
- do_lower_case=True,
- # break compounds like "quarter-century-old" and replace pauses "--"
- translation_table=str.maketrans({"-": " "}),
-)
-```
-
-The instance above is used as follows:
-* creates a tokenizer with `do_lower_case=True` (ignores casing for input and lowercases output when decoding)
-* replaces `"-"` with `" "` to break compounds like `"quarter-century-old"` and to clean up suspended hyphens
-* cleans up consecutive whitespaces (replaces them with a single space: `" "`)
-* removes characters not in vocabulary (lacking respective sound units)
-
-`--verbose_logging` logs text preprocessing updates and when evaluating, using the validation split every `eval_steps`,
-logs references and predictions.
-
-### Fine-Tuning with Arabic Speech Corpus
-
-Other datasets, like the [Arabic Speech Corpus dataset](https://huggingface.co/datasets/arabic_speech_corpus),
-require more work! Let's take a look at the [script](./finetune_large_xlsr_53_arabic_speech_corpus.sh)
-used to fine-tune [wav2vec2-large-xlsr-53](https://huggingface.co/elgeish/wav2vec2-large-xlsr-53-arabic):
-
-```bash
-#!/usr/bin/env bash
-python run_asr.py \
---output_dir="./wav2vec2-large-xlsr-53-arabic-speech-corpus" \
---num_train_epochs="50" \
---per_device_train_batch_size="1" \
---per_device_eval_batch_size="1" \
---gradient_accumulation_steps="8" \
---eval_strategy="steps" \
---save_steps="500" \
---eval_steps="100" \
---logging_steps="50" \
---learning_rate="5e-4" \
---warmup_steps="3000" \
---model_name_or_path="elgeish/wav2vec2-large-xlsr-53-arabic" \
---fp16 \
---dataset_name="arabic_speech_corpus" \
---train_split_name="train" \
---validation_split_name="test" \
---max_duration_in_seconds="15" \
---orthography="buckwalter" \
---preprocessing_num_workers="$(nproc)" \
---group_by_length \
---freeze_feature_extractor \
---target_feature_extractor_sampling_rate \
---verbose_logging \
-```
-
-First, let's understand how this dataset represents Arabic text; it uses a format called
-[Buckwalter transliteration](https://en.wikipedia.org/wiki/Buckwalter_transliteration).
-We use the [lang-trans](https://github.com/kariminf/lang-trans) package to convert back to Arabic when logging.
-The Buckwalter format only includes ASCII characters, some of which are non-alpha (e.g., `">"` maps to `"أ"`).
-
-`--orthography="buckwalter"` applies certain text preprocessing rules, for tokenization and normalization, to clean up the dataset. In this case, we use the following instance of `Orthography`:
-
-```python
-Orthography(
- vocab_file=pathlib.Path(__file__).parent.joinpath("vocab/buckwalter.json"),
- word_delimiter_token="/", # "|" is Arabic letter alef with madda above
- words_to_remove={"sil"}, # fixing "sil" in arabic_speech_corpus dataset
- untransliterator=arabic.buckwalter.untransliterate,
- translation_table=str.maketrans(translation_table = {
- "-": " ", # sometimes used to represent pauses
- "^": "v", # fixing "tha" in arabic_speech_corpus dataset
- }),
-)
-```
-
-The instance above is used as follows:
-* creates a tokenizer with Buckwalter vocabulary and `word_delimiter_token="/"`
-* replaces `"-"` with `" "` to clean up hyphens and fixes the orthography for `"ث"`
-* removes words used as indicators (in this case, `"sil"` is used for silence)
-* cleans up consecutive whitespaces (replaces them with a single space: `" "`)
-* removes characters not in vocabulary (lacking respective sound units)
-
-`--verbose_logging` logs text preprocessing updates and when evaluating, using the validation split every `eval_steps`,
-logs references and predictions. Using the Buckwalter format, text is also logged in Arabic abjad.
-
-`--target_feature_extractor_sampling_rate` resamples audio to target feature extractor's sampling rate (16kHz).
-
-`--max_duration_in_seconds="15"` filters out examples whose audio is longer than the specified limit,
-which helps with capping GPU memory usage.
-
-
-### DeepSpeed Integration
-
-To learn how to deploy Deepspeed Integration please refer to [this guide](https://huggingface.co/transformers/main/main_classes/deepspeed.html#deepspeed-trainer-integration).
-
-But to get started quickly all you need is to install:
-```bash
-pip install deepspeed
-```
-and then use the default configuration files in this directory:
-
-* `ds_config_wav2vec2_zero2.json`
-* `ds_config_wav2vec2_zero3.json`
-
-Here are examples of how you can use DeepSpeed:
-
-(edit the value for `--num_gpus` to match the number of GPUs you have)
-
-ZeRO-2:
-
-```bash
-PYTHONPATH=../../../src deepspeed --num_gpus 2 \
-run_asr.py \
---output_dir=output_dir --num_train_epochs=2 --per_device_train_batch_size=2 \
---per_device_eval_batch_size=2 --eval_strategy=steps --save_steps=500 --eval_steps=100 \
---logging_steps=5 --learning_rate=5e-4 --warmup_steps=3000 \
---model_name_or_path=patrickvonplaten/wav2vec2_tiny_random_robust \
---dataset_name=hf-internal-testing/librispeech_asr_dummy --dataset_config_name=clean \
---train_split_name=validation --validation_split_name=validation --orthography=timit \
---preprocessing_num_workers=1 --group_by_length --freeze_feature_extractor --verbose_logging \
---deepspeed ds_config_wav2vec2_zero2.json
-```
-
-For ZeRO-2 with more than 1 gpu you need to use (which is already in the example configuration file):
-```json
- "zero_optimization": {
- ...
- "find_unused_parameters": true,
- ...
- }
-```
-
-ZeRO-3:
-
-```bash
-PYTHONPATH=../../../src deepspeed --num_gpus 2 \
-run_asr.py \
---output_dir=output_dir --num_train_epochs=2 --per_device_train_batch_size=2 \
---per_device_eval_batch_size=2 --eval_strategy=steps --save_steps=500 --eval_steps=100 \
---logging_steps=5 --learning_rate=5e-4 --warmup_steps=3000 \
---model_name_or_path=patrickvonplaten/wav2vec2_tiny_random_robust \
---dataset_name=hf-internal-testing/librispeech_asr_dummy --dataset_config_name=clean \
---train_split_name=validation --validation_split_name=validation --orthography=timit \
---preprocessing_num_workers=1 --group_by_length --freeze_feature_extractor --verbose_logging \
---deepspeed ds_config_wav2vec2_zero3.json
-```
-
-### Pretraining Wav2Vec2
-
-The `run_pretrain.py` script allows one to pretrain a Wav2Vec2 model from scratch using Wav2Vec2's contrastive loss objective (see official [paper](https://arxiv.org/abs/2006.11477) for more information).
-It is recommended to pre-train Wav2Vec2 with Trainer + Deepspeed (please refer to [this guide](https://huggingface.co/transformers/main/main_classes/deepspeed.html#deepspeed-trainer-integration) for more information).
-
-Here is an example of how you can use DeepSpeed ZeRO-2 to pretrain a small Wav2Vec2 model:
-
-```bash
-PYTHONPATH=../../../src deepspeed --num_gpus 4 run_pretrain.py \
---output_dir="./wav2vec2-base-libri-100h" \
---num_train_epochs="3" \
---per_device_train_batch_size="32" \
---per_device_eval_batch_size="32" \
---gradient_accumulation_steps="2" \
---save_total_limit="3" \
---save_steps="500" \
---logging_steps="10" \
---learning_rate="5e-4" \
---weight_decay="0.01" \
---warmup_steps="3000" \
---model_name_or_path="patrickvonplaten/wav2vec2-base-libri-100h" \
---dataset_name="librispeech_asr" \
---dataset_config_name="clean" \
---train_split_name="train.100" \
---preprocessing_num_workers="4" \
---max_duration_in_seconds="10.0" \
---group_by_length \
---verbose_logging \
---fp16 \
---deepspeed ds_config_wav2vec2_zero2.json \
-```
-
-
-### Forced Alignment
-
-Character level forced alignment for audio and text pairs with wav2vec2 models finetuned on ASR task for a specific language.
-Inspired by [this](https://pytorch.org/tutorials/intermediate/forced_alignment_with_torchaudio_tutorial.html) Pytorch tutorial.
-
-#### Input Formats
-
- Input format in script.txt Input format in wavs directroy
- 0000 sentence1 0000.wav
- 0001 sentence2 0001.wav
-
-#### Output Format
-
-Output directory will contain 0000.txt and 0001.txt. Each file will have format like below
-
- char score start_ms end_ms
- h 0.25 1440 1520
-
-#### Run command
-
-```bash
-python alignment.py \
---model_name="arijitx/wav2vec2-xls-r-300m-bengali" \
---wav_dir="./wavs"
---text_file="script.txt" \
---input_wavs_sr=48000 \
---output_dir="./out_alignment" \
---cuda
-```
diff --git a/examples/research_projects/wav2vec2/alignment.py b/examples/research_projects/wav2vec2/alignment.py
deleted file mode 100644
index 55b477f5ee9..00000000000
--- a/examples/research_projects/wav2vec2/alignment.py
+++ /dev/null
@@ -1,223 +0,0 @@
-# Parts of the code are adapted from the snippets provided in the TorchAudio Wav2Vec forced alignment tutorial.
-# The full tutorial can be found here: https://pytorch.org/audio/stable/tutorials/forced_alignment_tutorial.html
-
-import argparse
-import os
-from dataclasses import dataclass
-
-import torch
-import torchaudio
-from tqdm import tqdm
-
-from transformers import AutoConfig, AutoModelForCTC, AutoProcessor
-
-
-class Wav2Vec2Aligner:
- def __init__(self, model_name, input_wavs_sr, cuda):
- self.cuda = cuda
- self.config = AutoConfig.from_pretrained(model_name)
- self.model = AutoModelForCTC.from_pretrained(model_name)
- self.model.eval()
- if self.cuda:
- self.model.to(device="cuda")
- self.processor = AutoProcessor.from_pretrained(model_name)
- self.resampler = torchaudio.transforms.Resample(input_wavs_sr, 16_000)
- blank_id = 0
- vocab = list(self.processor.tokenizer.get_vocab().keys())
- for i in range(len(vocab)):
- if vocab[i] == "[PAD]" or vocab[i] == "":
- blank_id = i
- print("Blank Token id [PAD]/", blank_id)
- self.blank_id = blank_id
-
- def speech_file_to_array_fn(self, wav_path):
- speech_array, sampling_rate = torchaudio.load(wav_path)
- speech = self.resampler(speech_array).squeeze().numpy()
- return speech
-
- def align_single_sample(self, item):
- blank_id = self.blank_id
- transcript = "|".join(item["sent"].split(" "))
- if not os.path.isfile(item["wav_path"]):
- print(item["wav_path"], "not found in wavs directory")
-
- speech_array = self.speech_file_to_array_fn(item["wav_path"])
- inputs = self.processor(speech_array, sampling_rate=16_000, return_tensors="pt", padding=True)
- if self.cuda:
- inputs = inputs.to(device="cuda")
-
- with torch.no_grad():
- logits = self.model(inputs.input_values).logits
-
- # get the emission probability at frame level
- emissions = torch.log_softmax(logits, dim=-1)
- emission = emissions[0].cpu().detach()
-
- # get labels from vocab
- labels = ([""] + list(self.processor.tokenizer.get_vocab().keys()))[
- :-1
- ] # logits don't align with the tokenizer's vocab
-
- dictionary = {c: i for i, c in enumerate(labels)}
- tokens = []
- for c in transcript:
- if c in dictionary:
- tokens.append(dictionary[c])
-
- def get_trellis(emission, tokens, blank_id=0):
- """
- Build a trellis matrix of shape (num_frames + 1, num_tokens + 1)
- that represents the probabilities of each source token being at a certain time step
- """
- num_frames = emission.size(0)
- num_tokens = len(tokens)
-
- # Trellis has extra diemsions for both time axis and tokens.
- # The extra dim for tokens represents (start-of-sentence)
- # The extra dim for time axis is for simplification of the code.
- trellis = torch.full((num_frames + 1, num_tokens + 1), -float("inf"))
- trellis[:, 0] = 0
- for t in range(num_frames):
- trellis[t + 1, 1:] = torch.maximum(
- # Score for staying at the same token
- trellis[t, 1:] + emission[t, blank_id],
- # Score for changing to the next token
- trellis[t, :-1] + emission[t, tokens],
- )
- return trellis
-
- trellis = get_trellis(emission, tokens, blank_id)
-
- @dataclass
- class Point:
- token_index: int
- time_index: int
- score: float
-
- def backtrack(trellis, emission, tokens, blank_id=0):
- """
- Walk backwards from the last (sentence_token, time_step) pair to build the optimal sequence alignment path
- """
- # Note:
- # j and t are indices for trellis, which has extra dimensions
- # for time and tokens at the beginning.
- # When referring to time frame index `T` in trellis,
- # the corresponding index in emission is `T-1`.
- # Similarly, when referring to token index `J` in trellis,
- # the corresponding index in transcript is `J-1`.
- j = trellis.size(1) - 1
- t_start = torch.argmax(trellis[:, j]).item()
-
- path = []
- for t in range(t_start, 0, -1):
- # 1. Figure out if the current position was stay or change
- # Note (again):
- # `emission[J-1]` is the emission at time frame `J` of trellis dimension.
- # Score for token staying the same from time frame J-1 to T.
- stayed = trellis[t - 1, j] + emission[t - 1, blank_id]
- # Score for token changing from C-1 at T-1 to J at T.
- changed = trellis[t - 1, j - 1] + emission[t - 1, tokens[j - 1]]
-
- # 2. Store the path with frame-wise probability.
- prob = emission[t - 1, tokens[j - 1] if changed > stayed else 0].exp().item()
- # Return token index and time index in non-trellis coordinate.
- path.append(Point(j - 1, t - 1, prob))
-
- # 3. Update the token
- if changed > stayed:
- j -= 1
- if j == 0:
- break
- else:
- raise ValueError("Failed to align")
- return path[::-1]
-
- path = backtrack(trellis, emission, tokens, blank_id)
-
- @dataclass
- class Segment:
- label: str
- start: int
- end: int
- score: float
-
- def __repr__(self):
- return f"{self.label}\t{self.score:4.2f}\t{self.start*20:5d}\t{self.end*20:5d}"
-
- @property
- def length(self):
- return self.end - self.start
-
- def merge_repeats(path):
- """
- Merge repeated tokens into a single segment. Note: this shouldn't affect repeated characters from the
- original sentences (e.g. `ll` in `hello`)
- """
- i1, i2 = 0, 0
- segments = []
- while i1 < len(path):
- while i2 < len(path) and path[i1].token_index == path[i2].token_index:
- i2 += 1
- score = sum(path[k].score for k in range(i1, i2)) / (i2 - i1)
- segments.append(
- Segment(
- transcript[path[i1].token_index],
- path[i1].time_index,
- path[i2 - 1].time_index + 1,
- score,
- )
- )
- i1 = i2
- return segments
-
- segments = merge_repeats(path)
- with open(item["out_path"], "w") as out_align:
- for seg in segments:
- out_align.write(str(seg) + "\n")
-
- def align_data(self, wav_dir, text_file, output_dir):
- if not os.path.exists(output_dir):
- os.makedirs(output_dir)
-
- # load text file
- lines = open(text_file, encoding="utf8").readlines()
-
- items = []
- for line in lines:
- if len(line.strip().split("\t")) != 2:
- print("Script must be in format: 00001 this is my sentence")
- exit()
-
- wav_name, sentence = line.strip().split("\t")
- wav_path = os.path.join(wav_dir, wav_name + ".wav")
- out_path = os.path.join(output_dir, wav_name + ".txt")
-
- items.append({"sent": sentence, "wav_path": wav_path, "out_path": out_path})
- print("Number of samples found in script file", len(items))
-
- for item in tqdm(items):
- self.align_single_sample(item)
-
-
-def main():
- parser = argparse.ArgumentParser()
-
- parser.add_argument(
- "--model_name", type=str, default="arijitx/wav2vec2-xls-r-300m-bengali", help="wav2vec model name"
- )
- parser.add_argument("--wav_dir", type=str, default="./wavs", help="directory containing wavs")
- parser.add_argument("--text_file", type=str, default="script.txt", help="file containing text")
- parser.add_argument("--input_wavs_sr", type=int, default=16000, help="sampling rate of input audios")
- parser.add_argument(
- "--output_dir", type=str, default="./out_alignment", help="output directory containing the alignment files"
- )
- parser.add_argument("--cuda", action="store_true")
-
- args = parser.parse_args()
-
- aligner = Wav2Vec2Aligner(args.model_name, args.input_wavs_sr, args.cuda)
- aligner.align_data(args.wav_dir, args.text_file, args.output_dir)
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/wav2vec2/ds_config_wav2vec2_zero2.json b/examples/research_projects/wav2vec2/ds_config_wav2vec2_zero2.json
deleted file mode 100644
index 6745e9917a3..00000000000
--- a/examples/research_projects/wav2vec2/ds_config_wav2vec2_zero2.json
+++ /dev/null
@@ -1,51 +0,0 @@
-{
- "fp16": {
- "enabled": "auto",
- "loss_scale": 0,
- "loss_scale_window": 1000,
- "initial_scale_power": 16,
- "hysteresis": 2,
- "min_loss_scale": 1
- },
-
- "optimizer": {
- "type": "AdamW",
- "params": {
- "lr": "auto",
- "betas": "auto",
- "eps": "auto",
- "weight_decay": "auto"
- }
- },
-
- "scheduler": {
- "type": "WarmupLR",
- "params": {
- "warmup_min_lr": "auto",
- "warmup_max_lr": "auto",
- "warmup_num_steps": "auto"
- }
- },
-
- "zero_optimization": {
- "stage": 2,
- "offload_optimizer": {
- "device": "cpu",
- "pin_memory": true
- },
- "find_unused_parameters": true,
- "allgather_partitions": true,
- "allgather_bucket_size": 2e8,
- "overlap_comm": true,
- "reduce_scatter": true,
- "reduce_bucket_size": 2e8,
- "contiguous_gradients": true
- },
-
- "gradient_accumulation_steps": "auto",
- "gradient_clipping": "auto",
- "steps_per_print": 2000,
- "train_batch_size": "auto",
- "train_micro_batch_size_per_gpu": "auto",
- "wall_clock_breakdown": false
-}
diff --git a/examples/research_projects/wav2vec2/ds_config_wav2vec2_zero3.json b/examples/research_projects/wav2vec2/ds_config_wav2vec2_zero3.json
deleted file mode 100644
index 1beb972ba89..00000000000
--- a/examples/research_projects/wav2vec2/ds_config_wav2vec2_zero3.json
+++ /dev/null
@@ -1,57 +0,0 @@
-{
- "fp16": {
- "enabled": "auto",
- "loss_scale": 0,
- "loss_scale_window": 1000,
- "initial_scale_power": 16,
- "hysteresis": 2,
- "min_loss_scale": 1
- },
-
- "optimizer": {
- "type": "AdamW",
- "params": {
- "lr": "auto",
- "betas": "auto",
- "eps": "auto",
- "weight_decay": "auto"
- }
- },
-
- "scheduler": {
- "type": "WarmupLR",
- "params": {
- "warmup_min_lr": "auto",
- "warmup_max_lr": "auto",
- "warmup_num_steps": "auto"
- }
- },
-
- "zero_optimization": {
- "stage": 3,
- "offload_optimizer": {
- "device": "cpu",
- "pin_memory": true
- },
- "offload_param": {
- "device": "cpu",
- "pin_memory": true
- },
- "overlap_comm": true,
- "contiguous_gradients": true,
- "sub_group_size": 1e9,
- "reduce_bucket_size": "auto",
- "stage3_prefetch_bucket_size": "auto",
- "stage3_param_persistence_threshold": "auto",
- "stage3_max_live_parameters": 1e9,
- "stage3_max_reuse_distance": 1e9,
- "stage3_gather_16bit_weights_on_model_save": true
- },
-
- "gradient_accumulation_steps": "auto",
- "gradient_clipping": "auto",
- "steps_per_print": 2000,
- "train_batch_size": "auto",
- "train_micro_batch_size_per_gpu": "auto",
- "wall_clock_breakdown": false
-}
diff --git a/examples/research_projects/wav2vec2/finetune_base_100.sh b/examples/research_projects/wav2vec2/finetune_base_100.sh
deleted file mode 100755
index 254b0afef3d..00000000000
--- a/examples/research_projects/wav2vec2/finetune_base_100.sh
+++ /dev/null
@@ -1,21 +0,0 @@
-#!/usr/bin/env bash
-python run_asr.py \
---output_dir="./wav2vec2-base-100h" \
---num_train_epochs="30" \
---per_device_train_batch_size="32" \
---per_device_eval_batch_size="32" \
---eval_strategy="steps" \
---save_total_limit="3" \
---save_steps="500" \
---eval_steps="100" \
---logging_steps="50" \
---learning_rate="5e-4" \
---warmup_steps="3000" \
---model_name_or_path="facebook/wav2vec2-base" \
---fp16 \
---dataset_name="librispeech_asr" \
---dataset_config_name="clean" \
---train_split_name="train.100" \
---preprocessing_num_workers="32" \
---group_by_length \
---freeze_feature_extractor
diff --git a/examples/research_projects/wav2vec2/finetune_base_timit_asr.sh b/examples/research_projects/wav2vec2/finetune_base_timit_asr.sh
deleted file mode 100755
index 508cb532b0f..00000000000
--- a/examples/research_projects/wav2vec2/finetune_base_timit_asr.sh
+++ /dev/null
@@ -1,22 +0,0 @@
-#!/usr/bin/env bash
-python run_asr.py \
---output_dir="./wav2vec2-base-timit-asr" \
---num_train_epochs="30" \
---per_device_train_batch_size="20" \
---per_device_eval_batch_size="20" \
---eval_strategy="steps" \
---save_steps="500" \
---eval_steps="100" \
---logging_steps="50" \
---learning_rate="5e-4" \
---warmup_steps="3000" \
---model_name_or_path="facebook/wav2vec2-base" \
---fp16 \
---dataset_name="timit_asr" \
---train_split_name="train" \
---validation_split_name="test" \
---orthography="timit" \
---preprocessing_num_workers="$(nproc)" \
---group_by_length \
---freeze_feature_extractor \
---verbose_logging \
diff --git a/examples/research_projects/wav2vec2/finetune_large_lv60_100.sh b/examples/research_projects/wav2vec2/finetune_large_lv60_100.sh
deleted file mode 100755
index 6956b093e72..00000000000
--- a/examples/research_projects/wav2vec2/finetune_large_lv60_100.sh
+++ /dev/null
@@ -1,21 +0,0 @@
-#!/usr/bin/env bash
-python run_asr.py \
---output_dir="./wav2vec2-large-lv60-100h" \
---num_train_epochs="30" \
---per_device_train_batch_size="16" \
---per_device_eval_batch_size="16" \
---eval_strategy="steps" \
---save_total_limit="3" \
---save_steps="500" \
---eval_steps="100" \
---logging_steps="50" \
---learning_rate="5e-4" \
---warmup_steps="3000" \
---model_name_or_path="facebook/wav2vec2-large-lv60" \
---fp16 \
---dataset_name="librispeech_asr" \
---dataset_config_name="clean" \
---train_split_name="train.100" \
---preprocessing_num_workers="32" \
---group_by_length \
---freeze_feature_extractor
diff --git a/examples/research_projects/wav2vec2/finetune_large_lv60_timit_asr.sh b/examples/research_projects/wav2vec2/finetune_large_lv60_timit_asr.sh
deleted file mode 100755
index fa02e71ea82..00000000000
--- a/examples/research_projects/wav2vec2/finetune_large_lv60_timit_asr.sh
+++ /dev/null
@@ -1,23 +0,0 @@
-#!/usr/bin/env bash
-python run_asr.py \
---output_dir="./wav2vec2-large-lv60-timit-asr" \
---num_train_epochs="30" \
---per_device_train_batch_size="2" \
---per_device_eval_batch_size="2" \
---gradient_accumulation_steps="4" \
---eval_strategy="steps" \
---save_steps="500" \
---eval_steps="100" \
---logging_steps="50" \
---learning_rate="5e-4" \
---warmup_steps="3000" \
---model_name_or_path="facebook/wav2vec2-large-lv60" \
---fp16 \
---dataset_name="timit_asr" \
---train_split_name="train" \
---validation_split_name="test" \
---orthography="timit" \
---preprocessing_num_workers="$(nproc)" \
---group_by_length \
---freeze_feature_extractor \
---verbose_logging \
diff --git a/examples/research_projects/wav2vec2/finetune_large_xlsr_53_arabic_speech_corpus.sh b/examples/research_projects/wav2vec2/finetune_large_xlsr_53_arabic_speech_corpus.sh
deleted file mode 100755
index e90bc8caa6c..00000000000
--- a/examples/research_projects/wav2vec2/finetune_large_xlsr_53_arabic_speech_corpus.sh
+++ /dev/null
@@ -1,25 +0,0 @@
-#!/usr/bin/env bash
-python run_asr.py \
---output_dir="./wav2vec2-large-xlsr-53-arabic-speech-corpus" \
---num_train_epochs="50" \
---per_device_train_batch_size="1" \
---per_device_eval_batch_size="1" \
---gradient_accumulation_steps="8" \
---eval_strategy="steps" \
---save_steps="500" \
---eval_steps="100" \
---logging_steps="50" \
---learning_rate="5e-4" \
---warmup_steps="3000" \
---model_name_or_path="elgeish/wav2vec2-large-xlsr-53-arabic" \
---fp16 \
---dataset_name="arabic_speech_corpus" \
---train_split_name="train" \
---validation_split_name="test" \
---max_duration_in_seconds="15" \
---orthography="buckwalter" \
---preprocessing_num_workers="$(nproc)" \
---group_by_length \
---freeze_feature_extractor \
---target_feature_extractor_sampling_rate \
---verbose_logging \
diff --git a/examples/research_projects/wav2vec2/finetune_wav2vec2_xlsr_turkish.sh b/examples/research_projects/wav2vec2/finetune_wav2vec2_xlsr_turkish.sh
deleted file mode 100644
index 70da0e0a0d1..00000000000
--- a/examples/research_projects/wav2vec2/finetune_wav2vec2_xlsr_turkish.sh
+++ /dev/null
@@ -1,22 +0,0 @@
-#!/usr/bin/env bash
-python run_common_voice.py \
- --model_name_or_path="facebook/wav2vec2-large-xlsr-53" \
- --dataset_config_name="tr" \
- --output_dir=./wav2vec2-large-xlsr-turkish-demo \
- --overwrite_output_dir \
- --num_train_epochs="5" \
- --per_device_train_batch_size="16" \
- --eval_strategy="steps" \
- --learning_rate="3e-4" \
- --warmup_steps="500" \
- --fp16 \
- --freeze_feature_extractor \
- --save_steps="400" \
- --eval_steps="400" \
- --save_total_limit="3" \
- --logging_steps="400" \
- --group_by_length \
- --feat_proj_dropout="0.0" \
- --layerdrop="0.1" \
- --gradient_checkpointing \
- --do_train --do_eval
diff --git a/examples/research_projects/wav2vec2/requirements.txt b/examples/research_projects/wav2vec2/requirements.txt
deleted file mode 100644
index 26b553c1392..00000000000
--- a/examples/research_projects/wav2vec2/requirements.txt
+++ /dev/null
@@ -1,7 +0,0 @@
-transformers
-datasets
-torch>=1.5.0
-torchaudio
-jiwer==2.2.0
-lang-trans==0.6.0
-librosa==0.8.0
diff --git a/examples/research_projects/wav2vec2/run_alignment.sh b/examples/research_projects/wav2vec2/run_alignment.sh
deleted file mode 100644
index 95bfe02cf03..00000000000
--- a/examples/research_projects/wav2vec2/run_alignment.sh
+++ /dev/null
@@ -1,8 +0,0 @@
-#!/usr/bin/env bash
-python alignment.py \
---model_name="arijitx/wav2vec2-xls-r-300m-bengali" \
---wav_dir="./wavs" \
---text_file="script.txt" \
---input_wavs_sr=48000 \
---output_dir="./out_alignment" \
---cuda
diff --git a/examples/research_projects/wav2vec2/run_asr.py b/examples/research_projects/wav2vec2/run_asr.py
deleted file mode 100755
index 796d271583b..00000000000
--- a/examples/research_projects/wav2vec2/run_asr.py
+++ /dev/null
@@ -1,480 +0,0 @@
-#!/usr/bin/env python3
-import logging
-import pathlib
-import re
-import sys
-from dataclasses import dataclass, field
-from typing import Any, Callable, Dict, List, Optional, Set, Union
-
-import datasets
-import librosa
-import numpy as np
-import torch
-from lang_trans import arabic
-from packaging import version
-from torch import nn
-
-from transformers import (
- HfArgumentParser,
- Trainer,
- TrainingArguments,
- Wav2Vec2CTCTokenizer,
- Wav2Vec2FeatureExtractor,
- Wav2Vec2ForCTC,
- Wav2Vec2Processor,
- is_apex_available,
- trainer_utils,
-)
-
-
-if is_apex_available():
- from apex import amp
-
-if version.parse(version.parse(torch.__version__).base_version) >= version.parse("1.6"):
- _is_native_amp_available = True
- from torch.cuda.amp import autocast
-
-
-logger = logging.getLogger(__name__)
-
-
-@dataclass
-class ModelArguments:
- """
- Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
- """
-
- model_name_or_path: str = field(
- metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
- )
- cache_dir: Optional[str] = field(
- default=None,
- metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
- )
- freeze_feature_extractor: Optional[bool] = field(
- default=True, metadata={"help": "Whether to freeze the feature extractor layers of the model."}
- )
- verbose_logging: Optional[bool] = field(
- default=False,
- metadata={"help": "Whether to log verbose messages or not."},
- )
-
-
-def configure_logger(model_args: ModelArguments, training_args: TrainingArguments):
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- handlers=[logging.StreamHandler(sys.stdout)],
- )
- logging_level = logging.WARNING
- if model_args.verbose_logging:
- logging_level = logging.DEBUG
- elif trainer_utils.is_main_process(training_args.local_rank):
- logging_level = logging.INFO
- logger.setLevel(logging_level)
-
-
-@dataclass
-class DataTrainingArguments:
- """
- Arguments pertaining to what data we are going to input our model for training and eval.
-
- Using `HfArgumentParser` we can turn this class
- into argparse arguments to be able to specify them on
- the command line.
- """
-
- dataset_name: str = field(
- default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
- )
- dataset_config_name: Optional[str] = field(
- default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
- )
- train_split_name: Optional[str] = field(
- default="train",
- metadata={
- "help": "The name of the training data set split to use (via the datasets library). Defaults to 'train'"
- },
- )
- validation_split_name: Optional[str] = field(
- default="validation",
- metadata={
- "help": (
- "The name of the validation data set split to use (via the datasets library). Defaults to 'validation'"
- )
- },
- )
- target_text_column: Optional[str] = field(
- default="text",
- metadata={"help": "Column in the dataset that contains label (target text). Defaults to 'text'"},
- )
- speech_file_column: Optional[str] = field(
- default="file",
- metadata={"help": "Column in the dataset that contains speech file path. Defaults to 'file'"},
- )
- target_feature_extractor_sampling_rate: Optional[bool] = field(
- default=False,
- metadata={"help": "Resample loaded audio to target feature extractor's sampling rate or not."},
- )
- max_duration_in_seconds: Optional[float] = field(
- default=None,
- metadata={"help": "Filters out examples longer than specified. Defaults to no filtering."},
- )
- orthography: Optional[str] = field(
- default="librispeech",
- metadata={
- "help": (
- "Orthography used for normalization and tokenization: 'librispeech' (default), 'timit', or"
- " 'buckwalter'."
- )
- },
- )
- overwrite_cache: bool = field(
- default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
- )
- preprocessing_num_workers: Optional[int] = field(
- default=None,
- metadata={"help": "The number of processes to use for the preprocessing."},
- )
-
-
-@dataclass
-class Orthography:
- """
- Orthography scheme used for text normalization and tokenization.
-
- Args:
- do_lower_case (:obj:`bool`, `optional`, defaults to :obj:`False`):
- Whether or not to accept lowercase input and lowercase the output when decoding.
- vocab_file (:obj:`str`, `optional`):
- File containing the vocabulary.
- word_delimiter_token (:obj:`str`, `optional`, defaults to :obj:`"|"`):
- The token used for delimiting words; it needs to be in the vocabulary.
- translation_table (:obj:`Dict[str, str]`, `optional`, defaults to :obj:`{}`):
- Table to use with `str.translate()` when preprocessing text (e.g., "-" -> " ").
- words_to_remove (:obj:`Set[str]`, `optional`, defaults to :obj:`set()`):
- Words to remove when preprocessing text (e.g., "sil").
- untransliterator (:obj:`Callable[[str], str]`, `optional`):
- Function that untransliterates text back into native writing system.
- """
-
- do_lower_case: bool = False
- vocab_file: Optional[str] = None
- word_delimiter_token: Optional[str] = "|"
- translation_table: Optional[Dict[str, str]] = field(default_factory=dict)
- words_to_remove: Optional[Set[str]] = field(default_factory=set)
- untransliterator: Optional[Callable[[str], str]] = None
-
- @classmethod
- def from_name(cls, name: str):
- if name == "librispeech":
- return cls()
- if name == "timit":
- return cls(
- do_lower_case=True,
- # break compounds like "quarter-century-old" and replace pauses "--"
- translation_table=str.maketrans({"-": " "}),
- )
- if name == "buckwalter":
- translation_table = {
- "-": " ", # sometimes used to represent pauses
- "^": "v", # fixing "tha" in arabic_speech_corpus dataset
- }
- return cls(
- vocab_file=pathlib.Path(__file__).parent.joinpath("vocab/buckwalter.json"),
- word_delimiter_token="/", # "|" is Arabic letter alef with madda above
- translation_table=str.maketrans(translation_table),
- words_to_remove={"sil"}, # fixing "sil" in arabic_speech_corpus dataset
- untransliterator=arabic.buckwalter.untransliterate,
- )
- raise ValueError(f"Unsupported orthography: '{name}'.")
-
- def preprocess_for_training(self, text: str) -> str:
- # TODO(elgeish) return a pipeline (e.g., from jiwer) instead? Or rely on branch predictor as is
- if len(self.translation_table) > 0:
- text = text.translate(self.translation_table)
- if len(self.words_to_remove) == 0:
- text = " ".join(text.split()) # clean up whitespaces
- else:
- text = " ".join(w for w in text.split() if w not in self.words_to_remove) # and clean up whilespaces
- return text
-
- def create_processor(self, model_args: ModelArguments) -> Wav2Vec2Processor:
- feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained(
- model_args.model_name_or_path, cache_dir=model_args.cache_dir
- )
- if self.vocab_file:
- tokenizer = Wav2Vec2CTCTokenizer(
- self.vocab_file,
- cache_dir=model_args.cache_dir,
- do_lower_case=self.do_lower_case,
- word_delimiter_token=self.word_delimiter_token,
- )
- else:
- tokenizer = Wav2Vec2CTCTokenizer.from_pretrained(
- model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- do_lower_case=self.do_lower_case,
- word_delimiter_token=self.word_delimiter_token,
- )
- return Wav2Vec2Processor(feature_extractor, tokenizer)
-
-
-@dataclass
-class DataCollatorCTCWithPadding:
- """
- Data collator that will dynamically pad the inputs received.
- Args:
- processor (:class:`~transformers.Wav2Vec2Processor`)
- The processor used for processing the data.
- padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
- Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
- among:
- * :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
- sequence if provided).
- * :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
- maximum acceptable input length for the model if that argument is not provided.
- * :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
- different lengths).
- max_length (:obj:`int`, `optional`):
- Maximum length of the ``input_values`` of the returned list and optionally padding length (see above).
- max_length_labels (:obj:`int`, `optional`):
- Maximum length of the ``labels`` returned list and optionally padding length (see above).
- pad_to_multiple_of (:obj:`int`, `optional`):
- If set will pad the sequence to a multiple of the provided value.
- This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
- 7.5 (Volta).
- """
-
- processor: Wav2Vec2Processor
- padding: Union[bool, str] = True
- max_length: Optional[int] = None
- max_length_labels: Optional[int] = None
- pad_to_multiple_of: Optional[int] = None
- pad_to_multiple_of_labels: Optional[int] = None
-
- def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
- # split inputs and labels since they have to be of different lengths and need
- # different padding methods
- input_features = [{"input_values": feature["input_values"]} for feature in features]
- label_features = [{"input_ids": feature["labels"]} for feature in features]
-
- batch = self.processor.pad(
- input_features,
- padding=self.padding,
- max_length=self.max_length,
- pad_to_multiple_of=self.pad_to_multiple_of,
- return_tensors="pt",
- )
- labels_batch = self.processor.pad(
- labels=label_features,
- padding=self.padding,
- max_length=self.max_length_labels,
- pad_to_multiple_of=self.pad_to_multiple_of_labels,
- return_tensors="pt",
- )
-
- # replace padding with -100 to ignore loss correctly
- labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
-
- batch["labels"] = labels
-
- return batch
-
-
-class CTCTrainer(Trainer):
- def training_step(self, model: nn.Module, inputs: Dict[str, Union[torch.Tensor, Any]]) -> torch.Tensor:
- """
- Perform a training step on a batch of inputs.
-
- Subclass and override to inject custom behavior.
-
- Args:
- model (:obj:`nn.Module`):
- The model to train.
- inputs (:obj:`Dict[str, Union[torch.Tensor, Any]]`):
- The inputs and targets of the model.
-
- The dictionary will be unpacked before being fed to the model. Most models expect the targets under the
- argument :obj:`labels`. Check your model's documentation for all accepted arguments.
-
- Return:
- :obj:`torch.Tensor`: The tensor with training loss on this batch.
- """
-
- model.train()
- inputs = self._prepare_inputs(inputs)
-
- if self.use_amp:
- with autocast():
- loss = self.compute_loss(model, inputs)
- else:
- loss = self.compute_loss(model, inputs)
-
- if self.args.n_gpu > 1:
- if model.module.config.ctc_loss_reduction == "mean":
- loss = loss.mean()
- elif model.module.config.ctc_loss_reduction == "sum":
- loss = loss.sum() / (inputs["labels"] >= 0).sum()
- else:
- raise ValueError(f"{model.config.ctc_loss_reduction} is not valid. Choose one of ['mean', 'sum']")
-
- if self.args.gradient_accumulation_steps > 1:
- loss = loss / self.args.gradient_accumulation_steps
-
- if self.use_amp:
- self.scaler.scale(loss).backward()
- elif self.use_apex:
- with amp.scale_loss(loss, self.optimizer) as scaled_loss:
- scaled_loss.backward()
- elif self.deepspeed:
- self.deepspeed.backward(loss)
- else:
- loss.backward()
-
- return loss.detach()
-
-
-def main():
- # See all possible arguments in src/transformers/training_args.py
- # or by passing the --help flag to this script.
- # We now keep distinct sets of args, for a cleaner separation of concerns.
-
- parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
-
- model_args, data_args, training_args = parser.parse_args_into_dataclasses()
- configure_logger(model_args, training_args)
-
- orthography = Orthography.from_name(data_args.orthography.lower())
- processor = orthography.create_processor(model_args)
- model = Wav2Vec2ForCTC.from_pretrained(
- model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- gradient_checkpointing=training_args.gradient_checkpointing,
- vocab_size=len(processor.tokenizer),
- )
-
- train_dataset = datasets.load_dataset(
- data_args.dataset_name, data_args.dataset_config_name, split=data_args.train_split_name
- )
- val_dataset = datasets.load_dataset(
- data_args.dataset_name, data_args.dataset_config_name, split=data_args.validation_split_name
- )
-
- wer_metric = datasets.load_metric("wer")
- target_sr = processor.feature_extractor.sampling_rate if data_args.target_feature_extractor_sampling_rate else None
- vocabulary_chars_str = "".join(t for t in processor.tokenizer.get_vocab().keys() if len(t) == 1)
- vocabulary_text_cleaner = re.compile( # remove characters not in vocabulary
- rf"[^\s{re.escape(vocabulary_chars_str)}]", # allow space in addition to chars in vocabulary
- flags=re.IGNORECASE if processor.tokenizer.do_lower_case else 0,
- )
- text_updates = []
-
- def prepare_example(example): # TODO(elgeish) make use of multiprocessing?
- example["speech"], example["sampling_rate"] = librosa.load(example[data_args.speech_file_column], sr=target_sr)
- if data_args.max_duration_in_seconds is not None:
- example["duration_in_seconds"] = len(example["speech"]) / example["sampling_rate"]
- # Normalize and clean up text; order matters!
- updated_text = orthography.preprocess_for_training(example[data_args.target_text_column])
- updated_text = vocabulary_text_cleaner.sub("", updated_text)
- if updated_text != example[data_args.target_text_column]:
- text_updates.append((example[data_args.target_text_column], updated_text))
- example[data_args.target_text_column] = updated_text
- return example
-
- train_dataset = train_dataset.map(prepare_example, remove_columns=[data_args.speech_file_column])
- val_dataset = val_dataset.map(prepare_example, remove_columns=[data_args.speech_file_column])
-
- if data_args.max_duration_in_seconds is not None:
-
- def filter_by_max_duration(example):
- return example["duration_in_seconds"] <= data_args.max_duration_in_seconds
-
- old_train_size = len(train_dataset)
- old_val_size = len(val_dataset)
- train_dataset = train_dataset.filter(filter_by_max_duration, remove_columns=["duration_in_seconds"])
- val_dataset = val_dataset.filter(filter_by_max_duration, remove_columns=["duration_in_seconds"])
- if len(train_dataset) > old_train_size:
- logger.warning(
- f"Filtered out {len(train_dataset) - old_train_size} train example(s) longer than"
- f" {data_args.max_duration_in_seconds} second(s)."
- )
- if len(val_dataset) > old_val_size:
- logger.warning(
- f"Filtered out {len(val_dataset) - old_val_size} validation example(s) longer than"
- f" {data_args.max_duration_in_seconds} second(s)."
- )
- logger.info(f"Split sizes: {len(train_dataset)} train and {len(val_dataset)} validation.")
-
- logger.warning(f"Updated {len(text_updates)} transcript(s) using '{data_args.orthography}' orthography rules.")
- if logger.isEnabledFor(logging.DEBUG):
- for original_text, updated_text in text_updates:
- logger.debug(f'Updated text: "{original_text}" -> "{updated_text}"')
- text_updates = None
-
- def prepare_dataset(batch):
- # check that all files have the correct sampling rate
- assert (
- len(set(batch["sampling_rate"])) == 1
- ), f"Make sure all inputs have the same sampling rate of {processor.feature_extractor.sampling_rate}."
-
- processed_batch = processor(
- audio=batch["speech"], text=batch[data_args.target_text_column], sampling_rate=batch["sampling_rate"][0]
- )
- batch.update(processed_batch)
- return batch
-
- train_dataset = train_dataset.map(
- prepare_dataset,
- batch_size=training_args.per_device_train_batch_size,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- )
- val_dataset = val_dataset.map(
- prepare_dataset,
- batch_size=training_args.per_device_train_batch_size,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- )
-
- data_collator = DataCollatorCTCWithPadding(processor=processor, padding=True)
-
- def compute_metrics(pred):
- pred_logits = pred.predictions
- pred_ids = np.argmax(pred_logits, axis=-1)
-
- pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
-
- pred_str = processor.batch_decode(pred_ids)
- # we do not want to group tokens when computing the metrics
- label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
- if logger.isEnabledFor(logging.DEBUG):
- for reference, predicted in zip(label_str, pred_str):
- logger.debug(f'reference: "{reference}"')
- logger.debug(f'predicted: "{predicted}"')
- if orthography.untransliterator is not None:
- logger.debug(f'reference (untransliterated): "{orthography.untransliterator(reference)}"')
- logger.debug(f'predicted (untransliterated): "{orthography.untransliterator(predicted)}"')
-
- wer = wer_metric.compute(predictions=pred_str, references=label_str)
-
- return {"wer": wer}
-
- if model_args.freeze_feature_extractor:
- model.freeze_feature_extractor()
-
- trainer = CTCTrainer(
- model=model,
- data_collator=data_collator,
- args=training_args,
- compute_metrics=compute_metrics,
- train_dataset=train_dataset,
- eval_dataset=val_dataset,
- tokenizer=processor.feature_extractor,
- )
-
- trainer.train()
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/wav2vec2/run_common_voice.py b/examples/research_projects/wav2vec2/run_common_voice.py
deleted file mode 100644
index 09a8458ca2a..00000000000
--- a/examples/research_projects/wav2vec2/run_common_voice.py
+++ /dev/null
@@ -1,513 +0,0 @@
-#!/usr/bin/env python3
-import json
-import logging
-import os
-import re
-import sys
-from dataclasses import dataclass, field
-from typing import Any, Dict, List, Optional, Union
-
-import datasets
-import numpy as np
-import torch
-import torchaudio
-from packaging import version
-from torch import nn
-
-import transformers
-from transformers import (
- HfArgumentParser,
- Trainer,
- TrainingArguments,
- Wav2Vec2CTCTokenizer,
- Wav2Vec2FeatureExtractor,
- Wav2Vec2ForCTC,
- Wav2Vec2Processor,
- is_apex_available,
- set_seed,
-)
-from transformers.trainer_utils import get_last_checkpoint, is_main_process
-
-
-if is_apex_available():
- from apex import amp
-
-
-if version.parse(version.parse(torch.__version__).base_version) >= version.parse("1.6"):
- _is_native_amp_available = True
- from torch.cuda.amp import autocast
-
-logger = logging.getLogger(__name__)
-
-
-def list_field(default=None, metadata=None):
- return field(default_factory=lambda: default, metadata=metadata)
-
-
-@dataclass
-class ModelArguments:
- """
- Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
- """
-
- model_name_or_path: str = field(
- metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
- )
- cache_dir: Optional[str] = field(
- default=None,
- metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
- )
- freeze_feature_extractor: Optional[bool] = field(
- default=True, metadata={"help": "Whether to freeze the feature extractor layers of the model."}
- )
- attention_dropout: Optional[float] = field(
- default=0.1, metadata={"help": "The dropout ratio for the attention probabilities."}
- )
- activation_dropout: Optional[float] = field(
- default=0.1, metadata={"help": "The dropout ratio for activations inside the fully connected layer."}
- )
- hidden_dropout: Optional[float] = field(
- default=0.1,
- metadata={
- "help": "The dropout probability for all fully connected layers in the embeddings, encoder, and pooler."
- },
- )
- feat_proj_dropout: Optional[float] = field(
- default=0.1,
- metadata={"help": "The dropout probability for all 1D convolutional layers in feature extractor."},
- )
- mask_time_prob: Optional[float] = field(
- default=0.05,
- metadata={
- "help": (
- "Propability of each feature vector along the time axis to be chosen as the start of the vector "
- "span to be masked. Approximately ``mask_time_prob * sequence_length // mask_time_length`` feature "
- "vectors will be masked along the time axis. This is only relevant if ``apply_spec_augment is True``."
- )
- },
- )
- layerdrop: Optional[float] = field(default=0.0, metadata={"help": "The LayerDrop probability."})
-
-
-@dataclass
-class DataTrainingArguments:
- """
- Arguments pertaining to what data we are going to input our model for training and eval.
-
- Using `HfArgumentParser` we can turn this class
- into argparse arguments to be able to specify them on
- the command line.
- """
-
- dataset_config_name: Optional[str] = field(
- default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
- )
- train_split_name: Optional[str] = field(
- default="train+validation",
- metadata={
- "help": "The name of the training data set split to use (via the datasets library). Defaults to 'train'"
- },
- )
- overwrite_cache: bool = field(
- default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
- )
- preprocessing_num_workers: Optional[int] = field(
- default=None,
- metadata={"help": "The number of processes to use for the preprocessing."},
- )
- max_train_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of training examples to this "
- "value if set."
- )
- },
- )
- max_val_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of validation examples to this "
- "value if set."
- )
- },
- )
- chars_to_ignore: List[str] = list_field(
- default=[",", "?", ".", "!", "-", ";", ":", '""', "%", "'", '"', "�"],
- metadata={"help": "A list of characters to remove from the transcripts."},
- )
-
-
-@dataclass
-class DataCollatorCTCWithPadding:
- """
- Data collator that will dynamically pad the inputs received.
- Args:
- processor (:class:`~transformers.Wav2Vec2Processor`)
- The processor used for processing the data.
- padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
- Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
- among:
- * :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
- sequence if provided).
- * :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
- maximum acceptable input length for the model if that argument is not provided.
- * :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
- different lengths).
- max_length (:obj:`int`, `optional`):
- Maximum length of the ``input_values`` of the returned list and optionally padding length (see above).
- max_length_labels (:obj:`int`, `optional`):
- Maximum length of the ``labels`` returned list and optionally padding length (see above).
- pad_to_multiple_of (:obj:`int`, `optional`):
- If set will pad the sequence to a multiple of the provided value.
- This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
- 7.5 (Volta).
- """
-
- processor: Wav2Vec2Processor
- padding: Union[bool, str] = True
- max_length: Optional[int] = None
- max_length_labels: Optional[int] = None
- pad_to_multiple_of: Optional[int] = None
- pad_to_multiple_of_labels: Optional[int] = None
-
- def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
- # split inputs and labels since they have to be of different lengths and need
- # different padding methods
- input_features = [{"input_values": feature["input_values"]} for feature in features]
- label_features = [{"input_ids": feature["labels"]} for feature in features]
-
- batch = self.processor.pad(
- input_features,
- padding=self.padding,
- max_length=self.max_length,
- pad_to_multiple_of=self.pad_to_multiple_of,
- return_tensors="pt",
- )
- labels_batch = self.processor.pad(
- labels=label_features,
- padding=self.padding,
- max_length=self.max_length_labels,
- pad_to_multiple_of=self.pad_to_multiple_of_labels,
- return_tensors="pt",
- )
-
- # replace padding with -100 to ignore loss correctly
- labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
-
- batch["labels"] = labels
-
- return batch
-
-
-class CTCTrainer(Trainer):
- def training_step(self, model: nn.Module, inputs: Dict[str, Union[torch.Tensor, Any]]) -> torch.Tensor:
- """
- Perform a training step on a batch of inputs.
-
- Subclass and override to inject custom behavior.
-
- Args:
- model (:obj:`nn.Module`):
- The model to train.
- inputs (:obj:`Dict[str, Union[torch.Tensor, Any]]`):
- The inputs and targets of the model.
-
- The dictionary will be unpacked before being fed to the model. Most models expect the targets under the
- argument :obj:`labels`. Check your model's documentation for all accepted arguments.
-
- Return:
- :obj:`torch.Tensor`: The tensor with training loss on this batch.
- """
-
- model.train()
- inputs = self._prepare_inputs(inputs)
-
- if self.use_amp:
- with autocast():
- loss = self.compute_loss(model, inputs)
- else:
- loss = self.compute_loss(model, inputs)
-
- if self.args.n_gpu > 1:
- if model.module.config.ctc_loss_reduction == "mean":
- loss = loss.mean()
- elif model.module.config.ctc_loss_reduction == "sum":
- loss = loss.sum() / (inputs["labels"] >= 0).sum()
- else:
- raise ValueError(f"{model.config.ctc_loss_reduction} is not valid. Choose one of ['mean', 'sum']")
-
- if self.args.gradient_accumulation_steps > 1:
- loss = loss / self.args.gradient_accumulation_steps
-
- if self.use_amp:
- self.scaler.scale(loss).backward()
- elif self.use_apex:
- with amp.scale_loss(loss, self.optimizer) as scaled_loss:
- scaled_loss.backward()
- elif self.deepspeed:
- self.deepspeed.backward(loss)
- else:
- loss.backward()
-
- return loss.detach()
-
-
-def main():
- # See all possible arguments in src/transformers/training_args.py
- # or by passing the --help flag to this script.
- # We now keep distinct sets of args, for a cleaner separation of concerns.
-
- parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
- if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
- # If we pass only one argument to the script and it's the path to a json file,
- # let's parse it to get our arguments.
- model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
- else:
- model_args, data_args, training_args = parser.parse_args_into_dataclasses()
-
- # Detecting last checkpoint.
- last_checkpoint = None
- if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
- last_checkpoint = get_last_checkpoint(training_args.output_dir)
- if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
- raise ValueError(
- f"Output directory ({training_args.output_dir}) already exists and is not empty. "
- "Use --overwrite_output_dir to overcome."
- )
- elif last_checkpoint is not None:
- logger.info(
- f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
- "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
- )
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- handlers=[logging.StreamHandler(sys.stdout)],
- )
- logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
-
- # Log on each process the small summary:
- logger.warning(
- f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
- + f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
- )
- # Set the verbosity to info of the Transformers logger (on main process only):
- if is_main_process(training_args.local_rank):
- transformers.utils.logging.set_verbosity_info()
- logger.info("Training/evaluation parameters %s", training_args)
-
- # Set seed before initializing model.
- set_seed(training_args.seed)
-
- # Get the datasets:
- train_dataset = datasets.load_dataset(
- "common_voice", data_args.dataset_config_name, split=data_args.train_split_name
- )
- eval_dataset = datasets.load_dataset("common_voice", data_args.dataset_config_name, split="test")
-
- # Create and save tokenizer
- chars_to_ignore_regex = f'[{"".join(data_args.chars_to_ignore)}]'
-
- def remove_special_characters(batch):
- batch["text"] = re.sub(chars_to_ignore_regex, "", batch["sentence"]).lower() + " "
- return batch
-
- train_dataset = train_dataset.map(remove_special_characters, remove_columns=["sentence"])
- eval_dataset = eval_dataset.map(remove_special_characters, remove_columns=["sentence"])
-
- def extract_all_chars(batch):
- all_text = " ".join(batch["text"])
- vocab = list(set(all_text))
- return {"vocab": [vocab], "all_text": [all_text]}
-
- vocab_train = train_dataset.map(
- extract_all_chars,
- batched=True,
- batch_size=-1,
- keep_in_memory=True,
- remove_columns=train_dataset.column_names,
- )
- vocab_test = train_dataset.map(
- extract_all_chars,
- batched=True,
- batch_size=-1,
- keep_in_memory=True,
- remove_columns=eval_dataset.column_names,
- )
-
- vocab_list = list(set(vocab_train["vocab"][0]) | set(vocab_test["vocab"][0]))
- vocab_dict = {v: k for k, v in enumerate(vocab_list)}
- vocab_dict["|"] = vocab_dict[" "]
- del vocab_dict[" "]
- vocab_dict["[UNK]"] = len(vocab_dict)
- vocab_dict["[PAD]"] = len(vocab_dict)
-
- with open("vocab.json", "w") as vocab_file:
- json.dump(vocab_dict, vocab_file)
-
- # Load pretrained model and tokenizer
- #
- # Distributed training:
- # The .from_pretrained methods guarantee that only one local process can concurrently
- # download model & vocab.
- tokenizer = Wav2Vec2CTCTokenizer(
- "vocab.json",
- unk_token="[UNK]",
- pad_token="[PAD]",
- word_delimiter_token="|",
- )
- feature_extractor = Wav2Vec2FeatureExtractor(
- feature_size=1, sampling_rate=16_000, padding_value=0.0, do_normalize=True, return_attention_mask=True
- )
- processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
- model = Wav2Vec2ForCTC.from_pretrained(
- model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- activation_dropout=model_args.activation_dropout,
- attention_dropout=model_args.attention_dropout,
- hidden_dropout=model_args.hidden_dropout,
- feat_proj_dropout=model_args.feat_proj_dropout,
- mask_time_prob=model_args.mask_time_prob,
- gradient_checkpointing=training_args.gradient_checkpointing,
- layerdrop=model_args.layerdrop,
- ctc_loss_reduction="mean",
- pad_token_id=processor.tokenizer.pad_token_id,
- vocab_size=len(processor.tokenizer),
- )
-
- if data_args.max_train_samples is not None:
- max_train_samples = min(len(train_dataset), data_args.max_train_samples)
- train_dataset = train_dataset.select(range(max_train_samples))
-
- if data_args.max_val_samples is not None:
- eval_dataset = eval_dataset.select(range(data_args.max_val_samples))
-
- resampler = torchaudio.transforms.Resample(48_000, 16_000)
-
- # Preprocessing the datasets.
- # We need to read the aduio files as arrays and tokenize the targets.
- def speech_file_to_array_fn(batch):
- speech_array, sampling_rate = torchaudio.load(batch["path"])
- batch["speech"] = resampler(speech_array).squeeze().numpy()
- batch["sampling_rate"] = 16_000
- batch["target_text"] = batch["text"]
- return batch
-
- train_dataset = train_dataset.map(
- speech_file_to_array_fn,
- remove_columns=train_dataset.column_names,
- num_proc=data_args.preprocessing_num_workers,
- )
- eval_dataset = eval_dataset.map(
- speech_file_to_array_fn,
- remove_columns=eval_dataset.column_names,
- num_proc=data_args.preprocessing_num_workers,
- )
-
- def prepare_dataset(batch):
- # check that all files have the correct sampling rate
- assert (
- len(set(batch["sampling_rate"])) == 1
- ), f"Make sure all inputs have the same sampling rate of {processor.feature_extractor.sampling_rate}."
-
- processed_batch = processor(
- audio=batch["speech"], text=batch["target_text"], sampling_rate=batch["sampling_rate"][0]
- )
- batch.update(processed_batch)
- return batch
-
- train_dataset = train_dataset.map(
- prepare_dataset,
- remove_columns=train_dataset.column_names,
- batch_size=training_args.per_device_train_batch_size,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- )
- eval_dataset = eval_dataset.map(
- prepare_dataset,
- remove_columns=eval_dataset.column_names,
- batch_size=training_args.per_device_train_batch_size,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- )
-
- # Metric
- wer_metric = datasets.load_metric("wer")
-
- def compute_metrics(pred):
- pred_logits = pred.predictions
- pred_ids = np.argmax(pred_logits, axis=-1)
-
- pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
-
- pred_str = processor.batch_decode(pred_ids)
- # we do not want to group tokens when computing the metrics
- label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
-
- wer = wer_metric.compute(predictions=pred_str, references=label_str)
-
- return {"wer": wer}
-
- if model_args.freeze_feature_extractor:
- model.freeze_feature_extractor()
-
- # Data collator
- data_collator = DataCollatorCTCWithPadding(processor=processor, padding=True)
-
- # Initialize our Trainer
- trainer = CTCTrainer(
- model=model,
- data_collator=data_collator,
- args=training_args,
- compute_metrics=compute_metrics,
- train_dataset=train_dataset if training_args.do_train else None,
- eval_dataset=eval_dataset if training_args.do_eval else None,
- tokenizer=processor.feature_extractor,
- )
-
- # Training
- if training_args.do_train:
- if last_checkpoint is not None:
- checkpoint = last_checkpoint
- elif os.path.isdir(model_args.model_name_or_path):
- checkpoint = model_args.model_name_or_path
- else:
- checkpoint = None
-
- # Save the feature_extractor and the tokenizer
- if is_main_process(training_args.local_rank):
- processor.save_pretrained(training_args.output_dir)
-
- train_result = trainer.train(resume_from_checkpoint=checkpoint)
- trainer.save_model()
-
- metrics = train_result.metrics
- max_train_samples = (
- data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
- )
- metrics["train_samples"] = min(max_train_samples, len(train_dataset))
-
- trainer.log_metrics("train", metrics)
- trainer.save_metrics("train", metrics)
- trainer.save_state()
-
- # Evaluation
- results = {}
- if training_args.do_eval:
- logger.info("*** Evaluate ***")
- metrics = trainer.evaluate()
- max_val_samples = data_args.max_val_samples if data_args.max_val_samples is not None else len(eval_dataset)
- metrics["eval_samples"] = min(max_val_samples, len(eval_dataset))
-
- trainer.log_metrics("eval", metrics)
- trainer.save_metrics("eval", metrics)
-
- return results
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/wav2vec2/run_pretrain.py b/examples/research_projects/wav2vec2/run_pretrain.py
deleted file mode 100755
index 00ef4edb37e..00000000000
--- a/examples/research_projects/wav2vec2/run_pretrain.py
+++ /dev/null
@@ -1,396 +0,0 @@
-#!/usr/bin/env python3
-import logging
-import sys
-from dataclasses import dataclass, field
-from typing import Any, Dict, List, Optional, Union
-
-import librosa
-import torch
-from datasets import DatasetDict, load_dataset
-from packaging import version
-from torch import nn
-
-from transformers import (
- HfArgumentParser,
- Trainer,
- TrainingArguments,
- Wav2Vec2Config,
- Wav2Vec2FeatureExtractor,
- Wav2Vec2ForPreTraining,
- is_apex_available,
- trainer_utils,
-)
-from transformers.models.wav2vec2.modeling_wav2vec2 import _compute_mask_indices
-
-
-if is_apex_available():
- from apex import amp
-
-if version.parse(version.parse(torch.__version__).base_version) >= version.parse("1.6"):
- _is_native_amp_available = True
- from torch.cuda.amp import autocast
-
-
-logger = logging.getLogger(__name__)
-
-
-@dataclass
-class ModelArguments:
- """
- Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
- """
-
- model_name_or_path: str = field(
- metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
- )
- cache_dir: Optional[str] = field(
- default=None,
- metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
- )
- freeze_feature_extractor: Optional[bool] = field(
- default=True, metadata={"help": "Whether to freeze the feature extractor layers of the model."}
- )
- verbose_logging: Optional[bool] = field(
- default=False,
- metadata={"help": "Whether to log verbose messages or not."},
- )
- max_gumbel_temperature: Optional[float] = field(
- default=2.0, metadata={"help": "Maximum temperature for gumbel softmax."}
- )
- min_gumbel_temperature: Optional[float] = field(
- default=0.5, metadata={"help": "Minimum temperature for gumbel softmax."}
- )
- gumbel_temperature_decay: Optional[float] = field(
- default=0.999995, metadata={"help": "Decay of gumbel temperature during training."}
- )
-
-
-def configure_logger(model_args: ModelArguments, training_args: TrainingArguments):
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- handlers=[logging.StreamHandler(sys.stdout)],
- )
- logging_level = logging.WARNING
- if model_args.verbose_logging:
- logging_level = logging.DEBUG
- elif trainer_utils.is_main_process(training_args.local_rank):
- logging_level = logging.INFO
- logger.setLevel(logging_level)
-
-
-@dataclass
-class DataTrainingArguments:
- """
- Arguments pertaining to what data we are going to input our model for training and eval.
-
- Using `HfArgumentParser` we can turn this class
- into argparse arguments to be able to specify them on
- the command line.
- """
-
- dataset_name: str = field(
- default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
- )
- dataset_config_name: Optional[str] = field(
- default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
- )
- train_split_name: Optional[str] = field(
- default="train",
- metadata={
- "help": "The name of the training data set split to use (via the datasets library). Defaults to 'train'"
- },
- )
- validation_split_name: Optional[str] = field(
- default="validation",
- metadata={
- "help": (
- "The name of the validation data set split to use (via the datasets library). Defaults to 'validation'"
- )
- },
- )
- speech_file_column: Optional[str] = field(
- default="file",
- metadata={"help": "Column in the dataset that contains speech file path. Defaults to 'file'"},
- )
- overwrite_cache: bool = field(
- default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
- )
- validation_split_percentage: Optional[int] = field(
- default=1,
- metadata={
- "help": "The percentage of the train set used as validation set in case there's no validation split"
- },
- )
- preprocessing_num_workers: Optional[int] = field(
- default=None,
- metadata={"help": "The number of processes to use for the preprocessing."},
- )
- max_duration_in_seconds: Optional[float] = field(
- default=20.0, metadata={"help": "Filter audio files that are longer than `max_duration_in_seconds` seconds"}
- )
-
-
-@dataclass
-class DataCollatorForWav2Vec2Pretraining:
- """
- Data collator that will dynamically pad the inputs received and prepare masked indices
- for self-supervised pretraining.
-
- Args:
- model (:class:`~transformers.Wav2Vec2ForPreTraining`):
- The Wav2Vec2 model used for pretraining. The data collator needs to have access
- to config and ``_get_feat_extract_output_lengths`` function for correct padding.
- feature_extractor (:class:`~transformers.Wav2Vec2FeatureExtractor`):
- The processor used for processing the data.
- padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
- Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
- among:
- * :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
- sequence if provided).
- * :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
- maximum acceptable input length for the model if that argument is not provided.
- * :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
- different lengths).
- max_length (:obj:`int`, `optional`):
- Maximum length of the ``input_values`` of the returned list and optionally padding length (see above).
- pad_to_multiple_of (:obj:`int`, `optional`):
- If set will pad the sequence to a multiple of the provided value.
- This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
- 7.5 (Volta).
- """
-
- model: Wav2Vec2ForPreTraining
- feature_extractor: Wav2Vec2FeatureExtractor
- padding: Union[bool, str] = "longest"
- pad_to_multiple_of: Optional[int] = None
- max_length: Optional[int] = None
-
- def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
- # reformat list to dict and set to pytorch format
- batch = self.feature_extractor.pad(
- features,
- max_length=self.max_length,
- padding=self.padding,
- pad_to_multiple_of=self.pad_to_multiple_of,
- return_tensors="pt",
- )
- mask_indices_seq_length = self.model._get_feat_extract_output_lengths(batch["input_values"].shape[-1])
-
- batch_size = batch["input_values"].shape[0]
-
- # make sure that no loss is computed on padded inputs
- if batch["attention_mask"] is not None:
- # compute real output lengths according to convolution formula
- output_lengths = self.model._get_feat_extract_output_lengths(batch["attention_mask"].sum(-1)).to(
- torch.long
- )
-
- attention_mask = torch.zeros(
- (batch_size, mask_indices_seq_length), dtype=torch.long, device=batch["input_values"].device
- )
-
- # these two operations makes sure that all values
- # before the output lengths indices are attended to
- attention_mask[
- (torch.arange(attention_mask.shape[0], device=batch["input_values"].device), output_lengths - 1)
- ] = 1
- attention_mask = attention_mask.flip([-1]).cumsum(-1).flip([-1]).bool()
-
- # sample randomly masked indices
- batch["mask_time_indices"] = _compute_mask_indices(
- (batch_size, mask_indices_seq_length),
- self.model.config.mask_time_prob,
- self.model.config.mask_time_length,
- attention_mask=attention_mask,
- min_masks=2,
- )
-
- return batch
-
-
-class Wav2Vec2PreTrainer(Trainer):
- """
- Subclassed :class:`~transformers.Trainer` for Wav2Vec2-like pretraining. Trainer can decay gumbel softmax temperature during training.
- """
-
- def __init__(self, *args, max_gumbel_temp=1, min_gumbel_temp=0, gumbel_temp_decay=1.0, **kwargs):
- super().__init__(*args, **kwargs)
- self.num_update_step = 0
- self.max_gumbel_temp = max_gumbel_temp
- self.min_gumbel_temp = min_gumbel_temp
- self.gumbel_temp_decay = gumbel_temp_decay
-
- def training_step(self, model: nn.Module, inputs: Dict[str, Union[torch.Tensor, Any]]) -> torch.Tensor:
- """
- Perform a training step on a batch of inputs.
-
- Subclass and override to inject custom behavior.
-
- Args:
- model (:obj:`nn.Module`):
- The model to train.
- inputs (:obj:`Dict[str, Union[torch.Tensor, Any]]`):
- The inputs and targets of the model.
-
- The dictionary will be unpacked before being fed to the model. Most models expect the targets under the
- argument :obj:`labels`. Check your model's documentation for all accepted arguments.
-
- Return:
- :obj:`torch.Tensor`: The tensor with training loss on this batch.
- """
-
- model.train()
- inputs = self._prepare_inputs(inputs)
-
- if self.use_amp:
- with autocast():
- loss = self.compute_loss(model, inputs)
- else:
- loss = self.compute_loss(model, inputs)
-
- if self.args.n_gpu > 1 or self.deepspeed:
- if model.module.config.ctc_loss_reduction == "mean":
- loss = loss.mean()
- elif model.module.config.ctc_loss_reduction == "sum":
- loss = loss.sum() / (inputs["mask_time_indices"]).sum()
- else:
- raise ValueError(f"{model.config.ctc_loss_reduction} is not valid. Choose one of ['mean', 'sum']")
-
- if self.args.gradient_accumulation_steps > 1:
- loss = loss / self.args.gradient_accumulation_steps
-
- if self.use_amp:
- self.scaler.scale(loss).backward()
- elif self.use_apex:
- with amp.scale_loss(loss, self.optimizer) as scaled_loss:
- scaled_loss.backward()
- elif self.deepspeed:
- self.deepspeed.backward(loss)
- else:
- loss.backward()
-
- self.num_update_step += 1
- # make sure gumbel softmax temperature is decayed
- if self.args.n_gpu > 1 or self.deepspeed:
- model.module.set_gumbel_temperature(
- max(self.max_gumbel_temp * self.gumbel_temp_decay**self.num_update_step, self.min_gumbel_temp)
- )
- else:
- model.set_gumbel_temperature(
- max(self.max_gumbel_temp * self.gumbel_temp_decay**self.num_update_step, self.min_gumbel_temp)
- )
-
- return loss.detach()
-
-
-def main():
- # See all possible arguments in src/transformers/training_args.py
- # or by passing the --help flag to this script.
- # We now keep distinct sets of args, for a cleaner separation of concerns.
-
- parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
-
- model_args, data_args, training_args = parser.parse_args_into_dataclasses()
- configure_logger(model_args, training_args)
-
- # Downloading and loading a dataset from the hub.
- datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name, cache_dir=model_args.cache_dir)
-
- if "validation" not in datasets.keys():
- # make sure only "validation" and "train" keys remain"
- datasets = DatasetDict()
- datasets["validation"] = load_dataset(
- data_args.dataset_name,
- data_args.dataset_config_name,
- split=f"{data_args.train_split_name}[:{data_args.validation_split_percentage}%]",
- cache_dir=model_args.cache_dir,
- )
- datasets["train"] = load_dataset(
- data_args.dataset_name,
- data_args.dataset_config_name,
- split=f"{data_args.train_split_name}[{data_args.validation_split_percentage}%:]",
- cache_dir=model_args.cache_dir,
- )
- else:
- # make sure only "validation" and "train" keys remain"
- datasets = DatasetDict()
- datasets["validation"] = load_dataset(
- data_args.dataset_name,
- data_args.dataset_config_name,
- split="validation",
- cache_dir=model_args.cache_dir,
- )
- datasets["train"] = load_dataset(
- data_args.dataset_name,
- data_args.dataset_config_name,
- split=f"{data_args.train_split_name}",
- cache_dir=model_args.cache_dir,
- )
-
- # only normalized-inputs-training is supported
- feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained(
- model_args.model_name_or_path, cache_dir=model_args.cache_dir, do_normalize=True
- )
-
- def prepare_dataset(batch):
- # check that all files have the correct sampling rate
- batch["speech"], _ = librosa.load(batch[data_args.speech_file_column], sr=feature_extractor.sampling_rate)
- return batch
-
- # load audio files into numpy arrays
- vectorized_datasets = datasets.map(
- prepare_dataset, num_proc=data_args.preprocessing_num_workers, remove_columns=datasets["train"].column_names
- )
-
- # filter audio files that are too long
- vectorized_datasets = vectorized_datasets.filter(
- lambda data: len(data["speech"]) < int(data_args.max_duration_in_seconds * feature_extractor.sampling_rate)
- )
-
- def normalize(batch):
- return feature_extractor(batch["speech"], sampling_rate=feature_extractor.sampling_rate)
-
- # normalize and transform to `BatchFeatures`
- vectorized_datasets = vectorized_datasets.map(
- normalize,
- batched=True,
- num_proc=data_args.preprocessing_num_workers,
- load_from_cache_file=not data_args.overwrite_cache,
- remove_columns=vectorized_datasets["train"].column_names,
- )
-
- # pretraining is only supported for "newer" stable layer norm architecture
- # apply_spec_augment has to be True, mask_feature_prob has to be 0.0
- config = Wav2Vec2Config.from_pretrained(
- model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- gradient_checkpointing=training_args.gradient_checkpointing,
- )
-
- if not config.do_stable_layer_norm or config.feat_extract_norm != "layer":
- raise ValueError(
- "PreTraining is only supported for ``config.do_stable_layer_norm=True`` and"
- " ``config.feat_extract_norm='layer'"
- )
-
- model = Wav2Vec2ForPreTraining(config)
-
- data_collator = DataCollatorForWav2Vec2Pretraining(model=model, feature_extractor=feature_extractor)
-
- trainer = Wav2Vec2PreTrainer(
- model=model,
- data_collator=data_collator,
- args=training_args,
- train_dataset=vectorized_datasets["train"],
- eval_dataset=vectorized_datasets["validation"],
- tokenizer=feature_extractor,
- max_gumbel_temp=model_args.max_gumbel_temperature,
- min_gumbel_temp=model_args.min_gumbel_temperature,
- gumbel_temp_decay=model_args.gumbel_temperature_decay,
- )
- trainer.train()
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/wav2vec2/test_wav2vec2_deepspeed.py b/examples/research_projects/wav2vec2/test_wav2vec2_deepspeed.py
deleted file mode 100644
index 8fb2df71112..00000000000
--- a/examples/research_projects/wav2vec2/test_wav2vec2_deepspeed.py
+++ /dev/null
@@ -1,199 +0,0 @@
-# Copyright 2020 The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-
-# XXX: we want transformers master here - in the absense of conftest manipulating sys.path:
-# hack it in for now:
-import sys
-from pathlib import Path
-
-
-git_repo_path = Path(__file__).resolve().parents[3] / "src"
-sys.path.insert(1, str(git_repo_path))
-
-import dataclasses # noqa
-import io # noqa
-import itertools # noqa
-import json # noqa
-import os # noqa
-import unittest # noqa
-from copy import deepcopy # noqa
-
-from parameterized import parameterized # noqa
-from transformers import TrainingArguments, is_torch_available # noqa
-from transformers.integrations.deepspeed import is_deepspeed_available # noqa
-from transformers.file_utils import WEIGHTS_NAME # noqa
-from transformers.testing_utils import ( # noqa
- CaptureLogger,
- ExtendSysPath,
- TestCasePlus,
- execute_subprocess_async,
- get_gpu_count,
- mockenv_context,
- require_deepspeed,
- require_torch_gpu,
- require_torch_multi_gpu,
- slow,
-)
-from transformers.trainer_utils import set_seed # noqa
-
-
-set_seed(42)
-
-models = {"base": "patrickvonplaten/wav2vec2_tiny_random", "robust": "patrickvonplaten/wav2vec2_tiny_random_robust"}
-
-ZERO2 = "zero2"
-ZERO3 = "zero3"
-stages = [ZERO2, ZERO3]
-
-
-def custom_name_func(func, param_num, param):
- # customize the test name generator function as we want both params to appear in the sub-test
- # name, as by default it shows only the first param
- param_based_name = parameterized.to_safe_name("_".join(str(x) for x in param.args))
- return f"{func.__name__}_{param_based_name}"
-
-
-# Cartesian-product of zero stages with models to test
-params = list(itertools.product(stages, models.keys()))
-
-
-@slow
-@require_deepspeed
-@require_torch_gpu
-class TestDeepSpeedWav2Vec2(TestCasePlus):
- @parameterized.expand(params, name_func=custom_name_func)
- def test_fp32_non_distributed(self, stage, model):
- self.run_and_check(
- stage=stage,
- model=model,
- distributed=False,
- fp16=False,
- )
-
- @require_torch_multi_gpu
- @parameterized.expand(params, name_func=custom_name_func)
- def test_fp32_distributed(self, stage, model):
- self.run_and_check(
- stage=stage,
- model=model,
- distributed=True,
- fp16=False,
- )
-
- @parameterized.expand(params, name_func=custom_name_func)
- def test_fp16_non_distributed(self, stage, model):
- self.run_and_check(
- stage=stage,
- model=model,
- distributed=False,
- fp16=True,
- )
-
- @require_torch_multi_gpu
- @parameterized.expand(params, name_func=custom_name_func)
- def test_fp16_distributed(self, stage, model):
- self.run_and_check(
- stage=stage,
- model=model,
- distributed=True,
- fp16=True,
- )
-
- def do_checks(self, output_dir):
- # XXX: run_asr is premature and doesn't save any results
- # so all we check for now is that the process didn't fail
- pass
-
- # XXX: need to do better validation beyond just that the run was successful
- def run_and_check(
- self,
- stage: str,
- model: str,
- eval_steps: int = 10,
- distributed: bool = True,
- quality_checks: bool = True,
- fp16: bool = True,
- ):
- model_name = models[model]
-
- output_dir = self.run_trainer(
- stage=stage,
- model_name=model_name,
- eval_steps=eval_steps,
- num_train_epochs=1,
- distributed=distributed,
- fp16=fp16,
- )
-
- self.do_checks(output_dir)
-
- return output_dir
-
- def run_trainer(
- self,
- stage: str,
- model_name: str,
- eval_steps: int = 10,
- num_train_epochs: int = 1,
- distributed: bool = True,
- fp16: bool = True,
- ):
- output_dir = self.get_auto_remove_tmp_dir("./xxx", after=False)
- args = f"""
- --model_name_or_path {model_name}
- --dataset_name hf-internal-testing/librispeech_asr_dummy
- --dataset_config_name clean
- --train_split_name validation
- --validation_split_name validation
- --output_dir {output_dir}
- --num_train_epochs {str(num_train_epochs)}
- --per_device_train_batch_size 2
- --per_device_eval_batch_size 2
- --eval_strategy steps
- --learning_rate 5e-4
- --warmup_steps 8
- --orthography timit
- --preprocessing_num_workers 1
- --group_by_length
- --freeze_feature_extractor
- --report_to none
- --save_steps 0
- --eval_steps {eval_steps}
- --report_to none
- """.split()
-
- if fp16:
- args.extend(["--fp16"])
-
- # currently ds_config_wav2vec2_zero.json requires "zero_optimization.find_unused_parameters": true,
- # hence the separate config files
- ds_args = f"--deepspeed {self.test_file_dir_str}/ds_config_wav2vec2_{stage}.json".split()
- script = [f"{self.examples_dir_str}/research_projects/wav2vec2/run_asr.py"]
- launcher = self.get_launcher(distributed)
-
- cmd = launcher + script + args + ds_args
- # keep for quick debug
- # print(" ".join([f"\nPYTHONPATH={self.src_dir_str}"] +cmd)); die
- execute_subprocess_async(cmd, env=self.get_env())
-
- return output_dir
-
- def get_launcher(self, distributed=False):
- # 1. explicitly set --num_nodes=1 just in case these tests end up run on a multi-node setup
- # - it won't be able to handle that
- # 2. for now testing with just 2 gpus max (since some quality tests may give different
- # results with mode gpus because we use very little data)
- num_gpus = min(2, get_gpu_count()) if distributed else 1
- return f"deepspeed --num_nodes 1 --num_gpus {num_gpus}".split()
diff --git a/examples/research_projects/wav2vec2/vocab/buckwalter.json b/examples/research_projects/wav2vec2/vocab/buckwalter.json
deleted file mode 100644
index 3f98fc2d521..00000000000
--- a/examples/research_projects/wav2vec2/vocab/buckwalter.json
+++ /dev/null
@@ -1,58 +0,0 @@
-{
- "": 0,
- "": 1,
- "": 2,
- "": 3,
- "/": 4,
- "'": 5,
- "|": 6,
- ">": 7,
- "&": 8,
- "<": 9,
- "}": 10,
- "A": 11,
- "b": 12,
- "p": 13,
- "t": 14,
- "v": 15,
- "j": 16,
- "H": 17,
- "x": 18,
- "d": 19,
- "*": 20,
- "r": 21,
- "z": 22,
- "s": 23,
- "$": 24,
- "S": 25,
- "D": 26,
- "T": 27,
- "Z": 28,
- "E": 29,
- "g": 30,
- "_": 31,
- "f": 32,
- "q": 33,
- "k": 34,
- "l": 35,
- "m": 36,
- "n": 37,
- "h": 38,
- "w": 39,
- "Y": 40,
- "y": 41,
- "F": 42,
- "N": 43,
- "K": 44,
- "a": 45,
- "u": 46,
- "i": 47,
- "~": 48,
- "o": 49,
- "`": 50,
- "{": 51,
- "P": 52,
- "J": 53,
- "V": 54,
- "G": 55
-}
\ No newline at end of file
diff --git a/examples/research_projects/xtreme-s/README.md b/examples/research_projects/xtreme-s/README.md
deleted file mode 100644
index 5314ba9880a..00000000000
--- a/examples/research_projects/xtreme-s/README.md
+++ /dev/null
@@ -1,160 +0,0 @@
-
-
-# XTREME-S benchmark examples
-
-*Maintainers: [Anton Lozhkov](https://github.com/anton-l) and [Patrick von Platen](https://github.com/patrickvonplaten)*
-
-The Cross-lingual TRansfer Evaluation of Multilingual Encoders for Speech (XTREME-S) benchmark is a benchmark designed to evaluate speech representations across languages, tasks, domains and data regimes. It covers XX typologically diverse languages and seven downstream tasks grouped in four families: speech recognition, translation, classification and retrieval.
-
-XTREME-S covers speech recognition with Fleurs, Multilingual LibriSpeech (MLS) and VoxPopuli, speech translation with CoVoST-2, speech classification with LangID (Fleurs) and intent classification (MInds-14) and finally speech(-text) retrieval with Fleurs. Each of the tasks covers a subset of the 102 languages included in XTREME-S (shown here with their ISO 3166-1 codes): afr, amh, ara, asm, ast, azj, bel, ben, bos, cat, ceb, ces, cmn, cym, dan, deu, ell, eng, spa, est, fas, ful, fin, tgl, fra, gle, glg, guj, hau, heb, hin, hrv, hun, hye, ind, ibo, isl, ita, jpn, jav, kat, kam, kea, kaz, khm, kan, kor, ckb, kir, ltz, lug, lin, lao, lit, luo, lav, mri, mkd, mal, mon, mar, msa, mlt, mya, nob, npi, nld, nso, nya, oci, orm, ory, pan, pol, pus, por, ron, rus, bul, snd, slk, slv, sna, som, srp, swe, swh, tam, tel, tgk, tha, tur, ukr, umb, urd, uzb, vie, wol, xho, yor, yue and zul.
-
-Paper: [XTREME-S: Evaluating Cross-lingual Speech Representations](https://arxiv.org/abs/2203.10752)
-
-Dataset: [https://huggingface.co/datasets/google/xtreme_s](https://huggingface.co/datasets/google/xtreme_s)
-
-## Fine-tuning for the XTREME-S tasks
-
-Based on the [`run_xtreme_s.py`](https://github.com/huggingface/transformers/blob/main/examples/research_projects/xtreme-s/run_xtreme_s.py) script.
-
-This script can fine-tune any of the pretrained speech models on the [hub](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition) on the [XTREME-S dataset](https://huggingface.co/datasets/google/xtreme_s) tasks.
-
-XTREME-S is made up of 7 different tasks. Here is how to run the script on each of them:
-
-```bash
-export TASK_NAME=mls.all
-
-python run_xtreme_s.py \
- --model_name_or_path="facebook/wav2vec2-xls-r-300m" \
- --task="${TASK_NAME}" \
- --output_dir="xtreme_s_xlsr_${TASK_NAME}" \
- --num_train_epochs=100 \
- --per_device_train_batch_size=32 \
- --learning_rate="3e-4" \
- --target_column_name="transcription" \
- --save_steps=500 \
- --eval_steps=500 \
- --gradient_checkpointing \
- --fp16 \
- --group_by_length \
- --do_train \
- --do_eval \
- --do_predict \
- --push_to_hub
-```
-
-where `TASK_NAME` can be one of: `mls, voxpopuli, covost2, fleurs-asr, fleurs-lang_id, minds14`.
-
-We get the following results on the test set of the benchmark's datasets.
-The corresponding training commands for each dataset are given in the sections below:
-
-| Task | Dataset | Result | Fine-tuned model & logs | Training time | GPUs |
-|-----------------------|-----------|-----------------------|--------------------------------------------------------------------|---------------|--------|
-| Speech Recognition | MLS | 30.33 WER | [here](https://huggingface.co/anton-l/xtreme_s_xlsr_300m_mls/) | 18:47:25 | 8xV100 |
-| Speech Recognition | VoxPopuli | - | - | - | - |
-| Speech Recognition | FLEURS | - | - | - | - |
-| Speech Translation | CoVoST-2 | - | - | - | - |
-| Speech Classification | Minds-14 | 90.15 F1 / 90.33 Acc. | [here](https://huggingface.co/anton-l/xtreme_s_xlsr_300m_minds14/) | 2:54:21 | 2xA100 |
-| Speech Classification | FLEURS | - | - | - | - |
-| Speech Retrieval | FLEURS | - | - | - | - |
-
-### Speech Recognition with MLS
-
-The following command shows how to fine-tune the [XLS-R](https://huggingface.co/docs/transformers/main/model_doc/xls_r) model on [XTREME-S MLS](https://huggingface.co/datasets/google/xtreme_s#multilingual-librispeech-mls) using 8 GPUs in half-precision.
-
-```bash
-python -m torch.distributed.launch \
- --nproc_per_node=8 \
- run_xtreme_s.py \
- --task="mls" \
- --language="all" \
- --model_name_or_path="facebook/wav2vec2-xls-r-300m" \
- --output_dir="xtreme_s_xlsr_300m_mls" \
- --overwrite_output_dir \
- --num_train_epochs=100 \
- --per_device_train_batch_size=4 \
- --per_device_eval_batch_size=1 \
- --gradient_accumulation_steps=2 \
- --learning_rate="3e-4" \
- --warmup_steps=3000 \
- --eval_strategy="steps" \
- --max_duration_in_seconds=20 \
- --save_steps=500 \
- --eval_steps=500 \
- --logging_steps=1 \
- --layerdrop=0.0 \
- --mask_time_prob=0.3 \
- --mask_time_length=10 \
- --mask_feature_prob=0.1 \
- --mask_feature_length=64 \
- --freeze_feature_encoder \
- --gradient_checkpointing \
- --fp16 \
- --group_by_length \
- --do_train \
- --do_eval \
- --do_predict \
- --metric_for_best_model="wer" \
- --greater_is_better=False \
- --load_best_model_at_end \
- --push_to_hub
-```
-
-On 8 V100 GPUs, this script should run in ~19 hours and yield a cross-entropy loss of **0.6215** and word error rate of **30.33**
-
-### Speech Classification with Minds-14
-
-The following command shows how to fine-tune the [XLS-R](https://huggingface.co/docs/transformers/main/model_doc/xls_r) model on [XTREME-S MLS](https://huggingface.co/datasets/google/xtreme_s#intent-classification---minds-14) using 2 GPUs in half-precision.
-
-```bash
-python -m torch.distributed.launch \
- --nproc_per_node=2 \
- run_xtreme_s.py \
- --task="minds14" \
- --language="all" \
- --model_name_or_path="facebook/wav2vec2-xls-r-300m" \
- --output_dir="xtreme_s_xlsr_300m_minds14" \
- --overwrite_output_dir \
- --num_train_epochs=50 \
- --per_device_train_batch_size=32 \
- --per_device_eval_batch_size=8 \
- --gradient_accumulation_steps=1 \
- --learning_rate="3e-4" \
- --warmup_steps=1500 \
- --eval_strategy="steps" \
- --max_duration_in_seconds=30 \
- --save_steps=200 \
- --eval_steps=200 \
- --logging_steps=1 \
- --layerdrop=0.0 \
- --mask_time_prob=0.3 \
- --mask_time_length=10 \
- --mask_feature_prob=0.1 \
- --mask_feature_length=64 \
- --freeze_feature_encoder \
- --gradient_checkpointing \
- --fp16 \
- --group_by_length \
- --do_train \
- --do_eval \
- --do_predict \
- --metric_for_best_model="f1" \
- --greater_is_better=True \
- --load_best_model_at_end \
- --push_to_hub
-```
-
-On 2 A100 GPUs, this script should run in ~5 hours and yield a cross-entropy loss of **0.4119** and F1 score of **90.15**
diff --git a/examples/research_projects/xtreme-s/requirements.txt b/examples/research_projects/xtreme-s/requirements.txt
deleted file mode 100644
index 219959a4b26..00000000000
--- a/examples/research_projects/xtreme-s/requirements.txt
+++ /dev/null
@@ -1,5 +0,0 @@
-datasets >= 1.18.0
-torch >= 1.5
-torchaudio
-librosa
-jiwer
diff --git a/examples/research_projects/xtreme-s/run_xtreme_s.py b/examples/research_projects/xtreme-s/run_xtreme_s.py
deleted file mode 100644
index a467b3c6eb8..00000000000
--- a/examples/research_projects/xtreme-s/run_xtreme_s.py
+++ /dev/null
@@ -1,949 +0,0 @@
-#!/usr/bin/env python
-# coding=utf-8
-# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-
-"""Fine-tuning a 🤗 Transformers pretrained speech model on the XTREME-S benchmark tasks"""
-
-import json
-import logging
-import os
-import re
-import sys
-from collections import OrderedDict, defaultdict
-from dataclasses import dataclass, field
-from typing import Dict, List, Optional, Union
-
-import datasets
-import numpy as np
-import torch
-from datasets import DatasetDict, load_dataset, load_metric
-
-import transformers
-from transformers import (
- AutoConfig,
- AutoFeatureExtractor,
- AutoModelForAudioClassification,
- AutoModelForCTC,
- AutoModelForSpeechSeq2Seq,
- AutoProcessor,
- AutoTokenizer,
- HfArgumentParser,
- Seq2SeqTrainer,
- Seq2SeqTrainingArguments,
- Trainer,
- set_seed,
-)
-from transformers.trainer_utils import get_last_checkpoint, is_main_process
-from transformers.utils import check_min_version
-from transformers.utils.versions import require_version
-
-
-# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.18.0.dev0")
-
-require_version("datasets>=1.18.0", "To fix: pip install -r examples/pytorch/speech-recognition/requirements.txt")
-
-
-logger = logging.getLogger(__name__)
-
-
-def list_field(default=None, metadata=None):
- return field(default_factory=lambda: default, metadata=metadata)
-
-
-TASK_TO_TARGET_COLUMN_NAME = {
- "fleurs-asr": "transcription",
- "fleurs-lang_id": "lang_id",
- "mls": "transcription",
- "voxpopuli": "transcription",
- "covost2": "translation",
- "minds14": "intent_class",
- "babel": "transcription",
-}
-
-
-@dataclass
-class ModelArguments:
- """
- Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
- """
-
- model_name_or_path: str = field(
- metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
- )
- tokenizer_name_or_path: Optional[str] = field(
- default=None,
- metadata={"help": "Path to pretrained tokenizer or tokenizer identifier from huggingface.co/models"},
- )
- cache_dir: Optional[str] = field(
- default=None,
- metadata={
- "help": "Where do you want to store the pretrained models and datasets downloaded from huggingface.co"
- },
- )
- freeze_feature_encoder: bool = field(
- default=True, metadata={"help": "Whether to freeze the feature encoder layers of the model."}
- )
- attention_dropout: float = field(
- default=0.0, metadata={"help": "The dropout ratio for the attention probabilities."}
- )
- activation_dropout: float = field(
- default=0.0, metadata={"help": "The dropout ratio for activations inside the fully connected layer."}
- )
- feat_proj_dropout: float = field(default=0.0, metadata={"help": "The dropout ratio for the projected features."})
- hidden_dropout: float = field(
- default=0.0,
- metadata={
- "help": "The dropout probability for all fully connected layers in the embeddings, encoder, and pooler."
- },
- )
- final_dropout: float = field(
- default=0.0,
- metadata={"help": "The dropout probability for the final projection layer."},
- )
- mask_time_prob: float = field(
- default=0.05,
- metadata={
- "help": (
- "Probability of each feature vector along the time axis to be chosen as the start of the vector "
- "span to be masked. Approximately ``mask_time_prob * sequence_length // mask_time_length`` feature "
- "vectors will be masked along the time axis."
- )
- },
- )
- mask_time_length: int = field(
- default=10,
- metadata={"help": "Length of vector span to mask along the time axis."},
- )
- mask_feature_prob: float = field(
- default=0.0,
- metadata={
- "help": (
- "Probability of each feature vector along the feature axis to be chosen as the start of the vectorspan"
- " to be masked. Approximately ``mask_feature_prob * sequence_length // mask_feature_length`` feature"
- " bins will be masked along the time axis."
- )
- },
- )
- mask_feature_length: int = field(
- default=10,
- metadata={"help": "Length of vector span to mask along the feature axis."},
- )
- layerdrop: float = field(default=0.0, metadata={"help": "The LayerDrop probability."})
- ctc_zero_infinity: bool = field(
- default=False,
- metadata={"help": "Whether to zero infinite losses and the associated gradients of `torch.nn.CTCLoss`."},
- )
- ctc_loss_reduction: Optional[str] = field(
- default="mean", metadata={"help": "The way the ctc loss should be reduced. Should be one of 'mean' or 'sum'."}
- )
-
-
-@dataclass
-class DataTrainingArguments:
- """
- Arguments pertaining to what data we are going to input our model for training and eval.
-
- Using `HfArgumentParser` we can turn this class
- into argparse arguments to be able to specify them on
- the command line.
- """
-
- dataset_name: str = field(
- default="google/xtreme_s",
- metadata={"help": "The name of the dataset to use (via the datasets library). Defaults to 'google/xtreme_s'"},
- )
- task: str = field(
- default=None,
- metadata={
- "help": (
- "The task name of the benchmark to use (via the datasets library). Should be on of: "
- "'fleurs-asr', 'mls', 'voxpopuli', 'covost2', 'minds14', 'fleurs-lang_id', 'babel'."
- )
- },
- )
- language: str = field(
- default="all",
- metadata={"help": "The language id as defined in the datasets config name or `all` for all languages."},
- )
- language_group: str = field(
- default=None,
- metadata={
- "help": (
- "The language group to select a subset of languages to train on. "
- "This option is only used the 'fleurs-asr' task. Should be one of: "
- "'western_european_we', 'eastern_european_ee', 'central_asia_middle_north_african_cmn', "
- "'sub_saharan_african_ssa', 'south_asian_sa', 'south_east_asian_sea', 'chinese_japanase_korean_cjk'."
- )
- },
- )
- train_split_name: str = field(
- default="train",
- metadata={
- "help": "The name of the training dataset split to use (via the datasets library). Defaults to 'train'"
- },
- )
- eval_split_name: str = field(
- default="validation",
- metadata={
- "help": (
- "The name of the evaluation dataset split to use (via the datasets library). Defaults to 'validation'"
- )
- },
- )
- predict_split_name: str = field(
- default="test",
- metadata={
- "help": "The name of the prediction dataset split to use (via the datasets library). Defaults to 'test'"
- },
- )
- audio_column_name: str = field(
- default="audio",
- metadata={"help": "The name of the dataset column containing the audio data. Defaults to 'audio'"},
- )
- target_column_name: str = field(
- default=None,
- metadata={
- "help": (
- "The name of the dataset column containing the target data (transcription/translation/label). If None,"
- " the name will be inferred from the task. Defaults to None."
- )
- },
- )
- overwrite_cache: bool = field(
- default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
- )
- preprocessing_num_workers: Optional[int] = field(
- default=None,
- metadata={"help": "The number of processes to use for the preprocessing."},
- )
- max_train_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of training examples to this "
- "value if set."
- )
- },
- )
- max_eval_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of validation examples to this "
- "value if set."
- )
- },
- )
- max_predict_samples: Optional[int] = field(
- default=None,
- metadata={
- "help": (
- "For debugging purposes or quicker training, truncate the number of prediction examples to this "
- "value if set."
- )
- },
- )
- chars_to_ignore: Optional[List[str]] = list_field(
- default=', ? . ! - ; : " “ % ‘ ” �'.split(" "),
- metadata={"help": "A list of characters to remove from the transcripts."},
- )
- max_duration_in_seconds: float = field(
- default=30.0,
- metadata={
- "help": (
- "Filter audio files that are longer than `max_duration_in_seconds` seconds to"
- " 'max_duration_in_seconds`"
- )
- },
- )
- min_duration_in_seconds: float = field(
- default=0.0, metadata={"help": "Filter audio files that are shorter than `min_duration_in_seconds` seconds"}
- )
- preprocessing_only: bool = field(
- default=False,
- metadata={
- "help": (
- "Whether to only do data preprocessing and skip training. This is especially useful when data"
- " preprocessing errors out in distributed training due to timeout. In this case, one should run the"
- " preprocessing in a non-distributed setup with `preprocessing_only=True` so that the cached datasets"
- " can consequently be loaded in distributed training"
- )
- },
- )
- use_auth_token: bool = field(
- default=False,
- metadata={
- "help": (
- "If :obj:`True`, will use the token generated when running"
- ":obj:`huggingface-cli login` as HTTP bearer authorization for remote files."
- )
- },
- )
- unk_token: str = field(
- default="[UNK]",
- metadata={"help": "The unk token for the tokenizer"},
- )
- pad_token: str = field(
- default="[PAD]",
- metadata={"help": "The padding token for the tokenizer"},
- )
- word_delimiter_token: str = field(
- default="|",
- metadata={"help": "The word delimiter token for the tokenizer"},
- )
- phoneme_language: Optional[str] = field(
- default=None,
- metadata={
- "help": (
- "The target language that should be used be"
- " passed to the tokenizer for tokenization. Note that"
- " this is only relevant if the model classifies the"
- " input audio to a sequence of phoneme sequences."
- )
- },
- )
- per_lang_metrics: bool = field(
- default=True,
- metadata={
- "help": (
- "If `True`, compute the test metrics separately for each language, and average the results. "
- "If `False` compute the average test metrics in a single pass for all languages at once."
- )
- },
- )
-
-
-@dataclass
-class SpeechDataCollatorWithPadding:
- processor: AutoProcessor
- decoder_start_token_id: Optional[int] = None
- padding: Union[bool, str] = "longest"
- pad_labels: Optional[int] = True
- pad_to_multiple_of: Optional[int] = None
- pad_to_multiple_of_labels: Optional[int] = None
-
- def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
- # split inputs and labels since they have to be of different lengths and need
- # different padding methods
- input_features = [{"input_values": feature["input_values"]} for feature in features]
-
- batch = self.processor.pad(
- input_features,
- padding=self.padding,
- pad_to_multiple_of=self.pad_to_multiple_of,
- return_tensors="pt",
- )
-
- if self.pad_labels:
- label_features = [{"input_ids": feature["labels"]} for feature in features]
- labels_batch = self.processor.pad(
- labels=label_features,
- padding=self.padding,
- pad_to_multiple_of=self.pad_to_multiple_of_labels,
- return_tensors="pt",
- )
-
- # replace padding with -100 to ignore loss correctly
- labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
-
- # if bos token is appended in previous tokenization step,
- # cut bos token here as it's append later anyways
- if (
- self.decoder_start_token_id is not None
- and (labels[:, 0] == self.decoder_start_token_id).all().cpu().item()
- ):
- labels = labels[:, 1:]
-
- batch["labels"] = labels
- else:
- batch["labels"] = torch.tensor([feature["labels"] for feature in features])
-
- return batch
-
-
-def create_vocabulary_from_data(
- datasets: DatasetDict,
- word_delimiter_token: Optional[str] = None,
- unk_token: Optional[str] = None,
- pad_token: Optional[str] = None,
-):
- # Given training and test labels create vocabulary
- def extract_all_chars(batch):
- all_text = " ".join(batch["target_text"])
- vocab = list(set(all_text))
- return {"vocab": [vocab], "all_text": [all_text]}
-
- vocabs = datasets.map(
- extract_all_chars,
- batched=True,
- batch_size=-1,
- keep_in_memory=True,
- remove_columns=datasets["train"].column_names,
- )
-
- # take union of all unique characters in each dataset
- vocab_set = (
- (set(vocabs["train"]["vocab"][0]) if "train" in vocabs else set())
- | (set(vocabs["eval"]["vocab"][0]) if "eval" in vocabs else set())
- | (set(vocabs["predict"]["vocab"][0]) if "predict" in vocabs else set())
- )
-
- vocab_dict = {v: k for k, v in enumerate(sorted(vocab_set))}
-
- # replace white space with delimiter token
- if word_delimiter_token is not None:
- vocab_dict[word_delimiter_token] = vocab_dict[" "]
- del vocab_dict[" "]
-
- # add unk and pad token
- if unk_token is not None:
- vocab_dict[unk_token] = len(vocab_dict)
-
- if pad_token is not None:
- vocab_dict[pad_token] = len(vocab_dict)
-
- return vocab_dict
-
-
-def main():
- # See all possible arguments in src/transformers/training_args.py
- # or by passing the --help flag to this script.
- # We now keep distinct sets of args, for a cleaner separation of concerns.
-
- parser = HfArgumentParser((ModelArguments, DataTrainingArguments, Seq2SeqTrainingArguments))
- if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
- # If we pass only one argument to the script and it's the path to a json file,
- # let's parse it to get our arguments.
- model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
- else:
- model_args, data_args, training_args = parser.parse_args_into_dataclasses()
-
- # Detecting last checkpoint.
- last_checkpoint = None
- if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
- last_checkpoint = get_last_checkpoint(training_args.output_dir)
- if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
- raise ValueError(
- f"Output directory ({training_args.output_dir}) already exists and is not empty. "
- "Use --overwrite_output_dir to overcome."
- )
- elif last_checkpoint is not None:
- logger.info(
- f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
- "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
- )
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- handlers=[logging.StreamHandler(sys.stdout)],
- )
- logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
-
- # Log on each process the small summary:
- logger.warning(
- f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
- f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
- )
- # Set the verbosity to info of the Transformers logger (on main process only):
- if is_main_process(training_args.local_rank):
- transformers.utils.logging.set_verbosity_info()
- logger.info("Training/evaluation parameters %s", training_args)
-
- # Set seed before initializing model.
- set_seed(training_args.seed)
-
- # 1. First, let's load the dataset
- raw_datasets = DatasetDict()
- task_name = data_args.task
- lang_id = data_args.language
-
- if task_name is None:
- raise ValueError(
- "Set --task should be set to '' (e.g. 'fleurs-asr', 'mls', 'covost2', 'minds14') "
- )
- if lang_id is None:
- raise ValueError(
- "Set --language should be set to the language id of the sub dataset "
- "config to be used (e.g. 'pl', 'en.tr', 'fr-FR') or 'all'"
- " for multi-lingual fine-tuning."
- )
- if data_args.language_group is not None:
- if data_args.task != "fleurs-asr":
- raise ValueError("--language_group should only be used with --task=fleurs-asr")
- if data_args.language != "all":
- raise ValueError("--language_group should only be used with --language=all")
-
- if data_args.target_column_name is None:
- target_column_name = TASK_TO_TARGET_COLUMN_NAME[task_name]
- else:
- target_column_name = data_args.target_column_name
-
- # here we differentiate between tasks with text as the target and classification tasks
- is_text_target = target_column_name in ("transcription", "translation")
-
- config_name = ".".join([task_name.split("-")[0], lang_id])
-
- if training_args.do_train:
- raw_datasets["train"] = load_dataset(
- data_args.dataset_name,
- config_name,
- split=data_args.train_split_name,
- token=data_args.use_auth_token,
- cache_dir=model_args.cache_dir,
- )
-
- if data_args.audio_column_name not in raw_datasets["train"].column_names:
- raise ValueError(
- f"--audio_column_name '{data_args.audio_column_name}' not found in dataset '{data_args.dataset_name}'."
- " Make sure to set `--audio_column_name` to the correct audio column - one of"
- f" {', '.join(raw_datasets['train'].column_names)}."
- )
-
- if target_column_name not in raw_datasets["train"].column_names:
- raise ValueError(
- f"--target_column_name {target_column_name} not found in dataset '{data_args.dataset_name}'. "
- "Make sure to set `--target_column_name` to the correct text column - one of "
- f"{', '.join(raw_datasets['train'].column_names)}."
- )
-
- if data_args.max_train_samples is not None:
- raw_datasets["train"] = raw_datasets["train"].select(range(data_args.max_train_samples))
-
- if training_args.do_eval:
- raw_datasets["eval"] = load_dataset(
- data_args.dataset_name,
- config_name,
- split=data_args.eval_split_name,
- token=data_args.use_auth_token,
- cache_dir=model_args.cache_dir,
- )
-
- if data_args.max_eval_samples is not None:
- raw_datasets["eval"] = raw_datasets["eval"].select(range(data_args.max_eval_samples))
-
- if training_args.do_predict:
- raw_datasets["predict"] = load_dataset(
- data_args.dataset_name,
- config_name,
- split=data_args.predict_split_name,
- token=data_args.use_auth_token,
- cache_dir=model_args.cache_dir,
- )
-
- if data_args.max_predict_samples is not None:
- raw_datasets["predict"] = raw_datasets["predict"].select(range(data_args.max_predict_samples))
-
- lang_list = next(iter(raw_datasets.values())).features["lang_id"].names
- if not is_text_target:
- label_list = next(iter(raw_datasets.values())).features[target_column_name].names
- num_labels = len(label_list)
-
- num_workers = data_args.preprocessing_num_workers
-
- lang_group = data_args.language_group
- if lang_group is not None:
- with training_args.main_process_first(desc="language group filter"):
- lang_group_id = next(iter(raw_datasets.values())).features["lang_group_id"].str2int(lang_group)
- raw_datasets = raw_datasets.filter(
- lambda lang_group: lang_group == lang_group_id,
- num_proc=num_workers,
- input_columns=["lang_group_id"],
- )
-
- # 2. We remove some special characters from the datasets
- # that make training complicated and do not help in transcribing the speech
- # E.g. characters, such as `,` and `.` do not really have an acoustic characteristic
- # that could be easily picked up by the model
- chars_to_ignore_regex = (
- f'[{"".join(data_args.chars_to_ignore)}]' if data_args.chars_to_ignore is not None else None
- )
-
- def remove_special_characters(batch):
- if chars_to_ignore_regex is not None:
- batch["target_text"] = re.sub(chars_to_ignore_regex, "", batch[target_column_name]).lower() + " "
- else:
- batch["target_text"] = batch[target_column_name].lower() + " "
- return batch
-
- if is_text_target:
- with training_args.main_process_first(desc="dataset map special characters removal"):
- raw_datasets = raw_datasets.map(
- remove_special_characters,
- remove_columns=[target_column_name],
- desc="remove special characters from datasets",
- )
-
- # save special tokens for tokenizer
- word_delimiter_token = data_args.word_delimiter_token
- unk_token = data_args.unk_token
- pad_token = data_args.pad_token
-
- # 3. Next, let's load the config as we might need it to create
- # the tokenizer
- config = AutoConfig.from_pretrained(
- model_args.model_name_or_path, cache_dir=model_args.cache_dir, token=data_args.use_auth_token
- )
-
- if is_text_target:
- # 4. (Optional, for ASR and translation) If no tokenizer file is defined,
- # we create the vocabulary of the model by extracting all unique characters from
- # the training and evaluation datasets
- # We need to make sure that only first rank saves vocabulary
- # make sure all processes wait until vocab is created
- tokenizer_name_or_path = model_args.tokenizer_name_or_path
- tokenizer_kwargs = {}
- if tokenizer_name_or_path is None:
- # save vocab in training output dir
- tokenizer_name_or_path = training_args.output_dir
-
- vocab_file = os.path.join(tokenizer_name_or_path, "vocab.json")
-
- with training_args.main_process_first():
- if training_args.overwrite_output_dir and os.path.isfile(vocab_file):
- os.remove(vocab_file)
-
- with training_args.main_process_first(desc="dataset map vocabulary creation"):
- if not os.path.isfile(vocab_file):
- os.makedirs(tokenizer_name_or_path, exist_ok=True)
- vocab_dict = create_vocabulary_from_data(
- raw_datasets,
- word_delimiter_token=word_delimiter_token,
- unk_token=unk_token,
- pad_token=pad_token,
- )
-
- # save vocab dict to be loaded into tokenizer
- with open(vocab_file, "w") as file:
- json.dump(vocab_dict, file)
-
- # if tokenizer has just been created
- # it is defined by `tokenizer_class` if present in config else by `model_type`
- if not config.is_encoder_decoder:
- tokenizer_kwargs = {
- "config": config if config.tokenizer_class is not None else None,
- "tokenizer_type": config.model_type if config.tokenizer_class is None else None,
- "unk_token": unk_token,
- "pad_token": pad_token,
- "word_delimiter_token": word_delimiter_token,
- }
- else:
- tokenizer_kwargs = {}
-
- # 5. Now we can instantiate the feature extractor, tokenizer and model
- # Note for distributed training, the .from_pretrained methods guarantee that only
- # one local process can concurrently download model & vocab.
-
- # load feature_extractor and tokenizer
- if is_text_target:
- tokenizer = AutoTokenizer.from_pretrained(
- tokenizer_name_or_path,
- token=data_args.use_auth_token,
- **tokenizer_kwargs,
- )
- feature_extractor = AutoFeatureExtractor.from_pretrained(
- model_args.model_name_or_path, cache_dir=model_args.cache_dir, token=data_args.use_auth_token
- )
-
- # adapt config
- # (speech translation requires pre-configured seq2seq models)
- if task_name != "covost2":
- config.update(
- {
- "feat_proj_dropout": model_args.feat_proj_dropout,
- "attention_dropout": model_args.attention_dropout,
- "hidden_dropout": model_args.hidden_dropout,
- "final_dropout": model_args.final_dropout,
- "mask_time_prob": model_args.mask_time_prob,
- "mask_time_length": model_args.mask_time_length,
- "mask_feature_prob": model_args.mask_feature_prob,
- "mask_feature_length": model_args.mask_feature_length,
- "gradient_checkpointing": training_args.gradient_checkpointing,
- "layerdrop": model_args.layerdrop,
- "ctc_zero_infinity": model_args.ctc_zero_infinity,
- "ctc_loss_reduction": model_args.ctc_loss_reduction,
- "activation_dropout": model_args.activation_dropout,
- }
- )
- if training_args.do_train:
- if is_text_target:
- config.pad_token_id = tokenizer.pad_token_id
- config.vocab_size = len(tokenizer)
- else:
- label_to_id = {v: i for i, v in enumerate(label_list)}
- config.label2id = label_to_id
- config.id2label = {id: label for label, id in label_to_id.items()}
- config.num_labels = num_labels
-
- # create model
- if target_column_name == "transcription":
- model = AutoModelForCTC.from_pretrained(
- model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- config=config,
- token=data_args.use_auth_token,
- )
- elif config.is_encoder_decoder:
- model = AutoModelForSpeechSeq2Seq.from_pretrained(
- model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- config=config,
- token=data_args.use_auth_token,
- )
- if model.config.decoder_start_token_id is None:
- raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
- else:
- model = AutoModelForAudioClassification.from_pretrained(
- model_args.model_name_or_path,
- cache_dir=model_args.cache_dir,
- config=config,
- token=data_args.use_auth_token,
- )
-
- # freeze encoder
- if model_args.freeze_feature_encoder:
- model.freeze_feature_encoder()
-
- # 6. Now we preprocess the datasets including loading the audio, resampling and normalization
- # Thankfully, `datasets` takes care of automatically loading and resampling the audio,
- # so that we just need to set the correct target sampling rate and normalize the input
- # via the `feature_extractor`
-
- # make sure that dataset decodes audio with correct sampling rate
- dataset_sampling_rate = next(iter(raw_datasets.values())).features[data_args.audio_column_name].sampling_rate
- if dataset_sampling_rate != feature_extractor.sampling_rate:
- raw_datasets = raw_datasets.cast_column(
- data_args.audio_column_name, datasets.features.Audio(sampling_rate=feature_extractor.sampling_rate)
- )
-
- # derive max & min input length for sample rate & max duration
- max_input_length = data_args.max_duration_in_seconds * feature_extractor.sampling_rate
- min_input_length = data_args.min_duration_in_seconds * feature_extractor.sampling_rate
- audio_column_name = data_args.audio_column_name
-
- # `phoneme_language` is only relevant if the model is fine-tuned on phoneme classification
- phoneme_language = data_args.phoneme_language
-
- # Preprocessing the datasets.
- # We need to read the audio files as arrays and tokenize the targets.
- def prepare_dataset(batch):
- # load audio
- sample = batch[audio_column_name]
-
- inputs = feature_extractor(sample["array"], sampling_rate=sample["sampling_rate"])
- batch["input_values"] = inputs.input_values[0]
- batch["length"] = len(batch["input_values"])
-
- # encode targets
- additional_kwargs = {}
- if phoneme_language is not None:
- additional_kwargs["phonemizer_lang"] = phoneme_language
-
- if is_text_target:
- batch["labels"] = tokenizer(batch["target_text"], **additional_kwargs).input_ids
- else:
- batch["labels"] = batch[target_column_name]
-
- batch["lang"] = batch["lang_id"]
-
- return batch
-
- with training_args.main_process_first(desc="dataset map preprocessing"):
- vectorized_datasets = raw_datasets.map(
- prepare_dataset,
- remove_columns=next(iter(raw_datasets.values())).column_names,
- num_proc=num_workers,
- desc="preprocess datasets",
- )
-
- if training_args.do_train:
-
- def is_audio_in_length_range(length):
- return length > min_input_length and length < max_input_length
-
- # filter data that is shorter than min_input_length
- vectorized_datasets["train"] = vectorized_datasets["train"].filter(
- is_audio_in_length_range,
- num_proc=num_workers,
- input_columns=["length"],
- )
-
- # 7. Next, we can prepare for the training step.
- # Let's use the appropriate XTREME-S evaluation metric,
- # instantiate a data collator and the trainer
-
- # Define evaluation metrics during training, *i.e.* word error rate, character error rate
- eval_metric = load_metric("xtreme_s", task_name)
-
- # for large datasets it is advised to run the preprocessing on a
- # single machine first with ``args.preprocessing_only`` since there will mostly likely
- # be a timeout when running the script in distributed mode.
- # In a second step ``args.preprocessing_only`` can then be set to `False` to load the
- # cached dataset
- if data_args.preprocessing_only:
- logger.info(f"Data preprocessing finished. Files cached at {vectorized_datasets.cache_files}")
- return
-
- def asr_logits_argmax(logits, labels):
- return logits.argmax(dim=-1)
-
- def compute_asr_metric(pred):
- pred.label_ids[pred.label_ids == -100] = tokenizer.pad_token_id
-
- pred_str = tokenizer.batch_decode(pred.predictions)
- # we do not want to group tokens when computing the metrics
- label_str = tokenizer.batch_decode(pred.label_ids, group_tokens=False)
-
- metric = eval_metric.compute(predictions=pred_str, references=label_str)
- return metric
-
- def compute_classification_metric(pred):
- pred_ids = np.argmax(pred.predictions, axis=1)
- metric = eval_metric.compute(predictions=pred_ids, references=pred.label_ids)
- return metric
-
- # Now save everything to be able to create a single processor later
- if is_main_process(training_args.local_rank):
- # save feature extractor, tokenizer and config
- feature_extractor.save_pretrained(training_args.output_dir)
- if is_text_target:
- tokenizer.save_pretrained(training_args.output_dir)
- config.save_pretrained(training_args.output_dir)
- # wait until configs are saved in the main process before loading the processor
- if training_args.local_rank != -1:
- torch.distributed.barrier()
-
- if is_text_target:
- processor = AutoProcessor.from_pretrained(training_args.output_dir)
- else:
- processor = AutoFeatureExtractor.from_pretrained(training_args.output_dir)
-
- # Instantiate custom data collator
- data_collator = SpeechDataCollatorWithPadding(processor=processor, pad_labels=is_text_target)
-
- # Initialize Trainer
- if target_column_name == "translation":
- trainer = Seq2SeqTrainer(
- model=model,
- data_collator=data_collator,
- args=training_args,
- preprocess_logits_for_metrics=asr_logits_argmax if training_args.predict_with_generate else None,
- compute_metrics=compute_asr_metric if training_args.predict_with_generate else None,
- train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
- eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
- tokenizer=feature_extractor,
- )
- else:
- trainer = Trainer(
- model=model,
- data_collator=data_collator,
- args=training_args,
- preprocess_logits_for_metrics=asr_logits_argmax if is_text_target else None,
- compute_metrics=compute_asr_metric if is_text_target else compute_classification_metric,
- train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
- eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
- tokenizer=feature_extractor,
- )
-
- # 8. Finally, we can start training
-
- # Training
- if training_args.do_train:
- # use last checkpoint if exist
- if last_checkpoint is not None:
- checkpoint = last_checkpoint
- elif os.path.isdir(model_args.model_name_or_path):
- checkpoint = model_args.model_name_or_path
- else:
- checkpoint = None
-
- train_result = trainer.train(resume_from_checkpoint=checkpoint)
- trainer.save_model()
-
- metrics = train_result.metrics
- max_train_samples = (
- data_args.max_train_samples
- if data_args.max_train_samples is not None
- else len(vectorized_datasets["train"])
- )
- metrics["train_samples"] = min(max_train_samples, len(vectorized_datasets["train"]))
-
- trainer.log_metrics("train", metrics)
- trainer.save_metrics("train", metrics)
- trainer.save_state()
-
- # Evaluation on the test set
- results = {}
- if training_args.do_predict:
- logger.info(f"*** Evaluating on the `{data_args.predict_split_name}` set ***")
- if data_args.per_lang_metrics:
- # separate the `test` dataset into language-specific subsets and compute metrics for each of them
- metrics = {}
- average_metrics = defaultdict(list)
- for lang_id in range(len(lang_list)):
- lang_name = lang_list[lang_id]
- with training_args.main_process_first(desc="per-language dataset filter"):
- lang_dataset = vectorized_datasets["predict"].filter(
- lambda lang: lang == lang_id,
- num_proc=num_workers,
- input_columns=["lang"],
- )
- lang_metrics = trainer.evaluate(lang_dataset)
- redundant_metrics = ["eval_runtime", "eval_samples_per_second", "eval_steps_per_second", "eval_epoch"]
- for metric_name, value in lang_metrics.items():
- average_metrics[metric_name].append(value)
- if metric_name not in redundant_metrics:
- metrics[f"{metric_name}_{lang_name}"] = value
- for metric_name, value in average_metrics.items():
- metrics[metric_name] = np.mean(value)
- else:
- metrics = trainer.evaluate(vectorized_datasets["predict"])
- max_predict_samples = (
- data_args.max_predict_samples
- if data_args.max_predict_samples is not None
- else len(vectorized_datasets["predict"])
- )
- metrics["predict_samples"] = min(max_predict_samples, len(vectorized_datasets["predict"]))
-
- # make sure that the `predict` metrics end up in the log history for the model card
- trainer.log(OrderedDict(sorted(metrics.items())))
-
- trainer.log_metrics("predict", metrics)
- trainer.save_metrics("predict", metrics)
-
- # Write model card and (optionally) push to hub
- kwargs = {
- "finetuned_from": model_args.model_name_or_path,
- "tasks": task_name,
- "tags": [task_name, data_args.dataset_name],
- "dataset_args": (
- f"Config: {config_name}, Training split: {data_args.train_split_name}, Eval split:"
- f" {data_args.eval_split_name}, Predict split: {data_args.predict_split_name}"
- ),
- "dataset": f"{data_args.dataset_name.upper()} - {config_name.upper()}",
- "language": data_args.language,
- }
-
- if training_args.push_to_hub:
- trainer.push_to_hub(**kwargs)
- else:
- trainer.create_model_card(**kwargs)
-
- return results
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/research_projects/zero-shot-distillation/README.md b/examples/research_projects/zero-shot-distillation/README.md
deleted file mode 100644
index 14b6a8ea07f..00000000000
--- a/examples/research_projects/zero-shot-distillation/README.md
+++ /dev/null
@@ -1,155 +0,0 @@
-# Zero-shot classifier distillation
-
-Author: @joeddav
-
-This script provides a way to improve the speed and memory performance of a zero-shot classifier by training a more
-efficient student model from the zero-shot teacher's predictions over an unlabeled dataset.
-
-The zero-shot classification pipeline uses a model pre-trained on natural language inference (NLI) to determine the
-compatibility of a set of candidate class names with a given sequence. This serves as a convenient out-of-the-box
-classifier without the need for labeled training data. However, for a given sequence, the method requires each
-possible label to be fed through the large NLI model separately. Thus for `N` sequences and `K` classes, a total of
-`N*K` forward passes through the model are required. This requirement slows inference considerably, particularly as
-`K` grows.
-
-Given (1) an unlabeled corpus and (2) a set of candidate class names, the provided script trains a student model
-with a standard classification head with `K` output dimensions. The resulting student model can then be used for
-classifying novel text instances with a significant boost in speed and memory performance while retaining similar
-classification performance to the original zero-shot model
-
-### Usage
-
-A teacher NLI model can be distilled to a more efficient student model by running [`distill_classifier.py`](https://github.com/huggingface/transformers/blob/main/examples/research_projects/zero-shot-distillation/distill_classifier.py):
-
-```bash
-python distill_classifier.py \
---data_file \
---class_names_file \
---output_dir
-```
-
-`` should be a text file with a single unlabeled example per line. `` is a text file with one class name per line.
-
-Other optional arguments include:
-
-- `--teacher_name_or_path` (default: `roberta-large-mnli`): The name or path of the NLI teacher model.
-- `--student_name_or_path` (default: `distillbert-base-uncased`): The name or path of the student model which will
-be fine-tuned to copy the teacher predictions.
-- `--hypothesis_template` (default `"This example is {}."`): The template used to turn each label into an NLI-style
-hypothesis when generating teacher predictions. This template must include a `{}` or similar syntax for the
-candidate label to be inserted into the template. For example, the default template is `"This example is {}."` With
-the candidate label `sports`, this would be fed into the model like `[CLS] sequence to classify [SEP] This example
-is sports . [SEP]`.
-- `--multi_class`: Whether or not multiple candidate labels can be true. By default, the scores are normalized such
-that the sum of the label likelihoods for each sequence is 1. If `--multi_class` is passed, the labels are
-considered independent and probabilities are normalized for each candidate by doing a softmax of the entailment
-score vs. the contradiction score. This is sometimes called "multi-class multi-label" classification.
-- `--temperature` (default: `1.0`): The temperature applied to the softmax of the teacher model predictions. A
-higher temperature results in a student with smoother (lower confidence) predictions than the teacher while a value
-`<1` resultings in a higher-confidence, peaked distribution. The default `1.0` is equivalent to no smoothing.
-- `--teacher_batch_size` (default: `32`): The batch size used for generating a single set of teacher predictions.
-Does not affect training. Use `--per_device_train_batch_size` to change the training batch size.
-
-Any of the arguments in the 🤗 Trainer's
-[`TrainingArguments`](https://huggingface.co/transformers/main_classes/trainer.html?#trainingarguments) can also be
-modified, such as `--learning_rate`, `--fp16`, `--no_cuda`, `--warmup_steps`, etc. Run `python distill_classifier.py
--h` for a full list of available arguments or consult the [Trainer
-documentation](https://huggingface.co/transformers/main_classes/trainer.html#trainingarguments).
-
-> **Note**: Distributed and TPU training are not currently supported. Single-node multi-GPU is supported, however,
-and will run automatically if multiple GPUs are available.
-
-### Example: Topic classification
-
-> A full colab demo notebook of this example can be found [here](https://colab.research.google.com/drive/1mjBjd0cR8G57ZpsnFCS3ngGyo5nCa9ya?usp=sharing).
-
-Let's say we're interested in classifying news articles into one of four topic categories: "the world", "sports",
-"business", or "science/tech". We have an unlabeled dataset, [AG's News](https://huggingface.co/datasets/ag_news),
-which corresponds to this problem (in reality AG's News is annotated, but we will pretend it is not for the sake of
-example).
-
-We can use an NLI model like `roberta-large-mnli` for zero-shot classification like so:
-
-```python
->>> class_names = ["the world", "sports", "business", "science/tech"]
->>> hypothesis_template = "This text is about {}."
->>> sequence = "A new moon has been discovered in Jupiter's orbit"
-
->>> zero_shot_classifier = pipeline("zero-shot-classification", model="roberta-large-mnli")
->>> zero_shot_classifier(sequence, class_names, hypothesis_template=hypothesis_template)
-{'sequence': "A new moon has been discovered in Jupiter's orbit",
- 'labels': ['science/tech', 'the world', 'business', 'sports'],
- 'scores': [0.7035840153694153, 0.18744826316833496, 0.06027870625257492, 0.04868902638554573]}
-```
-
-Unfortunately, inference is slow since each of our 4 class names must be fed through the large model for every
-sequence to be classified. But with our unlabeled data we can distill the model to a small distilbert classifier to
-make future inference much faster.
-
-To run the script, we will need to put each training example (text only) from AG's News on its own line in
-`agnews/train_unlabeled.txt`, and each of the four class names in the newline-separated `agnews/class_names.txt`.
-Then we can run distillation with the following command:
-
-```bash
-python distill_classifier.py \
---data_file ./agnews/unlabeled.txt \
---class_names_files ./agnews/class_names.txt \
---teacher_name_or_path roberta-large-mnli \
---hypothesis_template "This text is about {}." \
---output_dir ./agnews/distilled
-```
-
-The script will generate a set of soft zero-shot predictions from `roberta-large-mnli` for each example in
-`agnews/unlabeled.txt`. It will then train a student distilbert classifier on the teacher predictions and
-save the resulting model in `./agnews/distilled`.
-
-The resulting model can then be loaded and used like any other pre-trained classifier:
-
-```python
-from transformers import AutoModelForSequenceClassification, AutoTokenizer
-model = AutoModelForSequenceClassification.from_pretrained("./agnews/distilled")
-tokenizer = AutoTokenizer.from_pretrained("./agnews/distilled")
-```
-
-and even used trivially with a `TextClassificationPipeline`:
-
-```python
->>> distilled_classifier = TextClassificationPipeline(model=model, tokenizer=tokenizer, return_all_scores=True)
->>> distilled_classifier(sequence)
-[[{'label': 'the world', 'score': 0.14899294078350067},
- {'label': 'sports', 'score': 0.03205857425928116},
- {'label': 'business', 'score': 0.05943061783909798},
- {'label': 'science/tech', 'score': 0.7595179080963135}]]
-```
-
-> Tip: pass `device=0` when constructing a pipeline to run on a GPU
-
-As we can see, the results of the student closely resemble that of the trainer despite never having seen this
-example during training. Now let's do a quick & dirty speed comparison simulating 16K examples with a batch size of
-16:
-
-```python
-for _ in range(1000):
- zero_shot_classifier([sequence] * 16, class_names)
-# runs in 1m 23s on a single V100 GPU
-```
-
-```python
-%%time
-for _ in range(1000):
- distilled_classifier([sequence] * 16)
-# runs in 10.3s on a single V100 GPU
-```
-
-As we can see, the distilled student model runs an order of magnitude faster than its teacher NLI model. This is
-also a seeting where we only have `K=4` possible labels. The higher the number of classes for a given task, the more
-drastic the speedup will be, since the zero-shot teacher's complexity scales linearly with the number of classes.
-
-Since we secretly have access to ground truth labels for AG's news, we can evaluate the accuracy of each model. The
-original zero-shot model `roberta-large-mnli` gets an accuracy of 69.3% on the held-out test set. After training a
-student on the unlabeled training set, the distilled model gets a similar score of 70.4%.
-
-Lastly, you can share the distilled model with the community and/or use it with our inference API by [uploading it
-to the 🤗 Hub](https://huggingface.co/transformers/model_sharing.html). We've uploaded the distilled model from this
-example at
-[joeddav/distilbert-base-uncased-agnews-student](https://huggingface.co/joeddav/distilbert-base-uncased-agnews-student).
diff --git a/examples/research_projects/zero-shot-distillation/distill_classifier.py b/examples/research_projects/zero-shot-distillation/distill_classifier.py
deleted file mode 100644
index 56181208477..00000000000
--- a/examples/research_projects/zero-shot-distillation/distill_classifier.py
+++ /dev/null
@@ -1,338 +0,0 @@
-import logging
-import os
-import sys
-from dataclasses import dataclass, field
-from typing import List, Optional
-
-import torch
-from datasets import Dataset
-from torch import nn
-from tqdm.auto import tqdm
-
-from transformers import (
- AutoModelForSequenceClassification,
- AutoTokenizer,
- HfArgumentParser,
- Trainer,
- TrainingArguments,
- set_seed,
- utils,
-)
-from transformers.trainer_utils import get_last_checkpoint, is_main_process
-
-
-DESCRIPTION = """
-Distills an NLI-based zero-shot classifier to a smaller, more efficient model with a fixed set of candidate class
-names. Useful for speeding up zero-shot classification in cases where labeled training data is not available, but
-when only a single fixed set of classes is needed. Takes a teacher NLI model, student classifier model, unlabeled
-dataset, and set of K possible class names. Yields a single classifier with K outputs corresponding to the provided
-class names.
-"""
-
-logger = logging.getLogger(__name__)
-
-
-@dataclass
-class TeacherModelArguments:
- teacher_name_or_path: Optional[str] = field(
- default="roberta-large-mnli", metadata={"help": "The NLI/zero-shot teacher model to be distilled."}
- )
- hypothesis_template: Optional[str] = field(
- default="This example is {}.",
- metadata={
- "help": (
- "Template used to turn class names into mock hypotheses for teacher NLI model. Must include {{}} "
- "where class name is inserted."
- )
- },
- )
- teacher_batch_size: Optional[int] = field(
- default=32, metadata={"help": "Batch size for generating teacher predictions."}
- )
- multi_label: Optional[bool] = field(
- default=False,
- metadata={
- "help": (
- "Allow multiple classes to be true rather than forcing them to sum to 1 (sometimes called "
- "multi-class multi-label classification)."
- )
- },
- )
- temperature: Optional[float] = field(
- default=1.0, metadata={"help": "Temperature applied to teacher softmax for distillation."}
- )
-
-
-@dataclass
-class StudentModelArguments:
- student_name_or_path: Optional[str] = field(
- default="distilbert-base-uncased", metadata={"help": "The NLI/zero-shot teacher model to be distilled."}
- )
-
-
-@dataclass
-class DataTrainingArguments:
- data_file: str = field(metadata={"help": "Text file with one unlabeled instance per line."})
- class_names_file: str = field(metadata={"help": "Text file with one class name per line."})
- use_fast_tokenizer: bool = field(
- default=True,
- metadata={"help": "Whether to use one of the fast tokenizer (backed by the Rust tokenizers library) or not."},
- )
-
-
-@dataclass
-class DistillTrainingArguments(TrainingArguments):
- output_dir: Optional[str] = field(
- default=None,
- metadata={"help": "The output directory where the model predictions and checkpoints will be written."},
- )
- per_device_train_batch_size: int = field(
- default=32, metadata={"help": "Batch size per GPU/TPU core/CPU for training."}
- )
- per_device_eval_batch_size: int = field(
- default=128, metadata={"help": "Batch size per GPU/TPU core/CPU for evaluation."}
- )
- num_train_epochs: float = field(default=1.0, metadata={"help": "Total number of training epochs to perform."})
- do_train: bool = field(default=True, metadata={"help": "Whether to run training of student model."})
- do_eval: bool = field(
- default=True,
- metadata={
- "help": (
- "Whether to evaluate the agreement of the final student predictions and the teacher predictions "
- "after training."
- )
- },
- )
- save_total_limit: Optional[int] = field(
- default=0,
- metadata={
- "help": (
- "Limit the total amount of checkpoints. "
- "Deletes the older checkpoints in the output_dir. Default is 0 (no checkpoints)."
- )
- },
- )
-
-
-class DistillationTrainer(Trainer):
- def compute_loss(self, model, inputs, return_outputs=False):
- target_p = inputs["labels"]
- outputs = model(inputs["input_ids"], attention_mask=inputs["attention_mask"])
- logits = outputs[0]
-
- loss = -torch.sum(target_p * logits.log_softmax(dim=-1), axis=-1).mean()
-
- if return_outputs:
- return loss, outputs
-
- return loss
-
-
-def read_lines(path):
- lines = []
- with open(path, "r") as f:
- for line in f:
- line = line.strip()
- if len(line) > 0:
- lines.append(line)
- return lines
-
-
-def get_premise_hypothesis_pairs(examples, class_names, hypothesis_template):
- premises = []
- hypotheses = []
- for example in examples:
- for name in class_names:
- premises.append(example)
- hypotheses.append(hypothesis_template.format(name))
- return premises, hypotheses
-
-
-def get_entailment_id(config):
- for label, ind in config.label2id.items():
- if label.lower().startswith("entail"):
- return ind
- logger.warning("Could not identify entailment dimension from teacher config label2id. Setting to -1.")
- return -1
-
-
-def get_teacher_predictions(
- model_path: str,
- examples: List[str],
- class_names: List[str],
- hypothesis_template: str,
- batch_size: int,
- temperature: float,
- multi_label: bool,
- use_fast_tokenizer: bool,
- no_cuda: bool,
- fp16: bool,
-):
- """
- Gets predictions by the same method as the zero-shot pipeline but with DataParallel & more efficient batching
- """
- model = AutoModelForSequenceClassification.from_pretrained(model_path)
- model_config = model.config
- if not no_cuda and torch.cuda.is_available():
- model = nn.DataParallel(model.cuda())
- batch_size *= len(model.device_ids)
- tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=use_fast_tokenizer)
-
- premises, hypotheses = get_premise_hypothesis_pairs(examples, class_names, hypothesis_template)
- logits = []
-
- for i in tqdm(range(0, len(premises), batch_size)):
- batch_premises = premises[i : i + batch_size]
- batch_hypotheses = hypotheses[i : i + batch_size]
-
- encodings = tokenizer(
- batch_premises,
- batch_hypotheses,
- padding=True,
- truncation="only_first",
- return_tensors="pt",
- )
-
- with torch.cuda.amp.autocast(enabled=fp16):
- with torch.no_grad():
- outputs = model(**encodings)
- logits.append(outputs.logits.detach().cpu().float())
-
- entail_id = get_entailment_id(model_config)
- contr_id = -1 if entail_id == 0 else 0
- logits = torch.cat(logits, dim=0) # N*K x 3
- nli_logits = logits.reshape(len(examples), len(class_names), -1)[..., [contr_id, entail_id]] # N x K x 2
-
- if multi_label:
- # softmax over (contr, entail) logits for each class independently
- nli_prob = (nli_logits / temperature).softmax(-1)
- else:
- # softmax over entail logits across classes s.t. class probabilities sum to 1.
- nli_prob = (nli_logits / temperature).softmax(1)
-
- return nli_prob[..., 1] # N x K
-
-
-def main():
- parser = HfArgumentParser(
- (DataTrainingArguments, TeacherModelArguments, StudentModelArguments, DistillTrainingArguments),
- description=DESCRIPTION,
- )
-
- if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
- # If we pass only one argument to the script and it's the path to a json file,
- # let's parse it to get our arguments.
- data_args, teacher_args, student_args, training_args = parser.parse_json_file(
- json_file=os.path.abspath(sys.argv[1])
- )
- else:
- data_args, teacher_args, student_args, training_args = parser.parse_args_into_dataclasses()
-
- # Detecting last checkpoint.
- last_checkpoint = None
- if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
- last_checkpoint = get_last_checkpoint(training_args.output_dir)
- if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
- raise ValueError(
- f"Output directory ({training_args.output_dir}) already exists and is not empty. "
- "Use --overwrite_output_dir to overcome."
- )
- elif last_checkpoint is not None:
- logger.info(
- f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
- "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
- )
-
- # Setup logging
- logging.basicConfig(
- format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
- datefmt="%m/%d/%Y %H:%M:%S",
- handlers=[logging.StreamHandler(sys.stdout)],
- )
- logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
-
- # Log on each process the small summary:
- logger.warning(
- f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
- + f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
- )
- # Set the verbosity to info of the Transformers logger (on main process only):
- if is_main_process(training_args.local_rank):
- utils.logging.set_verbosity_info()
- utils.logging.enable_default_handler()
- utils.logging.enable_explicit_format()
-
- if training_args.local_rank != -1:
- raise ValueError("Distributed training is not currently supported.")
- if training_args.tpu_num_cores is not None:
- raise ValueError("TPU acceleration is not currently supported.")
-
- logger.info(f"Training/evaluation parameters {training_args}")
-
- # Set seed before initializing model.
- set_seed(training_args.seed)
-
- # 1. read in data
- examples = read_lines(data_args.data_file)
- class_names = read_lines(data_args.class_names_file)
-
- # 2. get teacher predictions and load into dataset
- logger.info("Generating predictions from zero-shot teacher model")
- teacher_soft_preds = get_teacher_predictions(
- teacher_args.teacher_name_or_path,
- examples,
- class_names,
- teacher_args.hypothesis_template,
- teacher_args.teacher_batch_size,
- teacher_args.temperature,
- teacher_args.multi_label,
- data_args.use_fast_tokenizer,
- training_args.no_cuda,
- training_args.fp16,
- )
- dataset = Dataset.from_dict(
- {
- "text": examples,
- "labels": teacher_soft_preds,
- }
- )
-
- # 3. create student
- logger.info("Initializing student model")
- model = AutoModelForSequenceClassification.from_pretrained(
- student_args.student_name_or_path, num_labels=len(class_names)
- )
- tokenizer = AutoTokenizer.from_pretrained(student_args.student_name_or_path, use_fast=data_args.use_fast_tokenizer)
- model.config.id2label = dict(enumerate(class_names))
- model.config.label2id = {label: i for i, label in enumerate(class_names)}
-
- # 4. train student on teacher predictions
- dataset = dataset.map(tokenizer, input_columns="text")
- dataset.set_format("torch")
-
- def compute_metrics(p, return_outputs=False):
- preds = p.predictions.argmax(-1)
- proxy_labels = p.label_ids.argmax(-1) # "label_ids" are actually distributions
- return {"agreement": (preds == proxy_labels).mean().item()}
-
- trainer = DistillationTrainer(
- model=model,
- tokenizer=tokenizer,
- args=training_args,
- train_dataset=dataset,
- compute_metrics=compute_metrics,
- )
-
- if training_args.do_train:
- logger.info("Training student model on teacher predictions")
- trainer.train()
-
- if training_args.do_eval:
- agreement = trainer.evaluate(eval_dataset=dataset)["eval_agreement"]
- logger.info(f"Agreement of student and teacher predictions: {agreement * 100:0.2f}%")
-
- trainer.save_model()
-
-
-if __name__ == "__main__":
- main()
diff --git a/src/transformers/generation/watermarking.py b/src/transformers/generation/watermarking.py
index da90c03dd0d..1c728a287b8 100644
--- a/src/transformers/generation/watermarking.py
+++ b/src/transformers/generation/watermarking.py
@@ -490,7 +490,7 @@ class SynthIDTextWatermarkDetector:
Parameters:
detector_module ([`BayesianDetectorModel`]):
Bayesian detector module object initialized with parameters.
- Check examples/research_projects/synthid_text/detector_training.py for usage.
+ Check https://github.com/huggingface/transformers-research-projects/tree/main/synthid_text for usage.
logits_processor (`SynthIDTextWatermarkLogitsProcessor`):
The logits processor used for watermarking.
tokenizer (`Any`):
@@ -502,7 +502,7 @@ class SynthIDTextWatermarkDetector:
... AutoTokenizer, BayesianDetectorModel, SynthIDTextWatermarkLogitsProcessor, SynthIDTextWatermarkDetector
... )
- >>> # Load the detector. See examples/research_projects/synthid_text for training a detector.
+ >>> # Load the detector. See https://github.com/huggingface/transformers-research-projects/tree/main/synthid_text for training a detector.
>>> detector_model = BayesianDetectorModel.from_pretrained("joaogante/dummy_synthid_detector")
>>> logits_processor = SynthIDTextWatermarkLogitsProcessor(
... **detector_model.config.watermarking_config, device="cpu"
diff --git a/utils/release.py b/utils/release.py
index d5b74602e68..e4e79cec158 100644
--- a/utils/release.py
+++ b/utils/release.py
@@ -95,8 +95,6 @@ def update_version_in_examples(version: str):
"""
for folder, directories, fnames in os.walk(PATH_TO_EXAMPLES):
# Removing some of the folders with non-actively maintained examples from the walk
- if "research_projects" in directories:
- directories.remove("research_projects")
if "legacy" in directories:
directories.remove("legacy")
for fname in fnames:
 -
-